
Abstract
The sintering technology of iron and steel enterprises in China has reached a certain level. However, due to serious resource and environmental issues, how to achieve the greening of the sintering process, the intelligence of the equipment, the high quality of the products and the acceleration of the digital transformation based on intelligent decision-making and control are still key issues to be solved by the iron and steel industry. Based on the historical data of massive sintering production, this study establishes a big data platform for the whole sintering process to realise the reasonable storage and effective organisation of massive data. A sinter quality cascade prediction system, including the sinter bed permeability prediction model, burning through point (BTP) prediction model and sinter quality prediction model and a detailed software structure design are given for the application of the system. The development and application of the system are beneficial for realising the important development goals of low pollution, high yield and high quality in sinter production.
Introduction
In recent years, the sintering production technology of Chinese iron and steel enterprises has been improved, and the sintering equipment has been developed towards large-scale automation, which is conducive to improving the quality index of sintering production, reducing the energy consumption of the process, reducing the pollution emission, adapting to the demand of large-scale blast furnace (BF) and effectively improving the social and economic benefits of production.
However, due to the serious resource, energy and environmental problems, how to further realise the green sintering process, intelligent equipment, high-quality products and accelerate the digital and intelligent transformation of sintering production are the key issues to be solved in the current steel industry. Big data technology realises data information collection, data value extraction and data law mining through the comprehensive use of massive data storage technology, real-time data processing technology, high-speed data transmission technology and data analysis technology. The steel industry has a huge amount of data, while the rapid development of the Internet of Things, cloud computing, big data and other technologies has laid the technical foundation for the transformation of steel enterprises to informatisation and intelligence. Big data in the steel industry has become an important driver of innovation in the industry and is conducive to the establishment of a sustainable production model with high value and low energy consumption in the steel industry. 1
How to improve the digital and intelligent level of sintering production and optimise the predictive effect of sintering production quality have become the main research direction of sintering production scholars.
The sinter production process is complex, and the time lag and low accuracy of sinter ore chemical composition detection make it difficult to achieve precise control in sinter production. Therefore, it is important to predict the chemical composition of sinter ore in advance to improve its quality of sinter ore.2–7 Song et al. 8 proposed a method to automatically detect jittered segments and replace jittered segments based on sliding windows to solve the noise data in the monitoring results of sintering equipment. The online component monitoring model based on deep neural network (DNN) and the advanced component forecasting model based on long short-term memory (LSTM) artificial neural network were constructed. And the optimised network parameters and structures of each model were obtained. The online component monitoring model based on DNN and the advanced component forecasting model based on LSTM are shown to have better prediction performance through a large number of test results. This shows that the DNN is more suitable for online monitoring and advanced prediction of sinter composition.
The permeability of the sintered material layer is an important measurement to guide the sintering production, which directly affects the vertical sintering speed and the sintered mineral quality index. Xu 9 established a time series permeability prediction model and a process parameter permeability prediction model using a neural network and a particle swarm optimisation algorithm, respectively. And a fuzzy classifier was used to effectively fuse the two prediction models, which reduced the real-time state fluctuation rate of sinter permeability by about 60%. Lei et al. 10 developed a comprehensive permeability prediction model for the Pb–Zn sintering process based on the improved grey system theory. The burning through point (BTP) reflects the vertical burning speed of the mixture on the sintering machine, which directly affects the production quality index of the sintered ore. However, due to the lag and complexity of sintering production, the penultimate or third airbox position can only be determined as the BTP based on operational experience, and there is no instrumentation to directly detect the BTP. Wang et al. 11 developed a prediction model for BTP using an extreme learning machine and an improved AdaBoost RS algorithm and achieved good application results.
The stability of sinter ore quality is an important objective of sinter production. Early prediction of sinter quality index parameters can effectively control the fluctuation of sinter quality and suggest operational guidance. Yi and Shao 12 proposed a BP neural network algorithm to drive the quantity term and variable learning rate, established a sinter quality prediction model and verified the accuracy and effectiveness of the model application, and the model prediction accuracy reached more than 81.25%. Li et al. 13 used an online sequential limit learning machine (OS-ELM) to predict the FeO content and rolling strength in each group of sinter, and the verification results showed that the OS-ELM model is more accurate than the conventional back-propagation (BP) model.
The sinter production index prediction model plays a guiding role in the actual production. It can effectively help the field staff to stabilise sinter production and improve the production quality index of sinter production, which is of great significance in promoting the development of sinter production technology and improving the economic efficiency of enterprises. Due to the complexity of the sintering production mechanism, a large number of influencing factors and a large amount of data, the current forecasting model still has shortcomings. The database of the model is mostly offline data with limited information, the algorithm is single and the prediction parameters are based on local variables, which limit the accuracy and generalisability. The sintering process involves many factors, and the current prediction model is too simplified to comprehensively consider all the factors that affect the quality index of sintered production and to differentiate and analyse the quality index of different sintering machines and different sintering lines. In response to the above problems, this paper proposes an intelligent cascade prediction system for sinter ore quality. Firstly, the sintering data platform is established by using big data technology to realise data collection, storage and integration. Secondly, the raw sintering production data is processed by using feature engineering to obtain clean data for the prediction model. Thirdly, the prediction models of sintering layer permeability, BTP and sintering quality index are established. Finally, the intelligent cascade prediction system of sintering ore quality is established by using big data technology to realise the prediction of sintering production results.
Establishment and development of an intelligent cascade prediction system for sintered ore quality
In recent years, big data technology has been developed and applied in the production of BF ironmaking in China, and BF ironmaking has gradually developed towards green and intelligent. As an important part of BF iron production, the sintering process is bound to undergo a digital and intelligent transformation. The application of modern big data technology has enabled the development of an intelligent control system for sintering that serves the site. After continuous iteration and optimisation, the automation of sintering production is finally realised.
Based on the sintering data platform, the sinter quality intelligent cascade prediction system selects algorithms, such as integrated learning and deep learning to establish and develop three prediction models for sinter layer permeability, BTP and sinter quality indexes. The system can predict production results in advance and achieve rolling optimisation of production parameters so that each sintering process can operate in the best condition and achieve stabilisation and improvement of sinter quality indices.
Sintering data collection and integration
The study collected full process production data for a 360-m2 sinter at a steel plant in 2022. And the data were extracted and integrated into SQL Server and Oracle databases. Combined with the theoretical knowledge of sintering, these data can be divided into five parts: raw material parameters from the batching system, mix composition parameters from the composition testing department, sintering machine operation parameters from the sintering operating system, sintering machine status parameters from the equipment monitoring system and sinter ore quality parameters from the quality testing department. Sintering data was collected as shown in Table 1.
Sintering data collection.

Establishment of sintering data platform
Efficient distributed information transfer technology is used to collect data from the entire sintering production process and provide automated data backup, disaster recovery and load balancing to ensure data integrity and security. We use advanced big data technologies such as Hadoop and Spark to standardise the data format, eliminate abnormal data, fill in missing data, normalise the difference in magnitude and align the data time sequence, and integrate the data with process theory to improve the efficiency of data analysis and mining in response to the problems of abnormal data, missing data, large differences in distribution and inconsistent frequency in sintering production data.
Relying on high-performance computing technology and using big data technologies such as machine learning algorithms, it completes the docking, integration and operation of multi-source data to realise the deployment and management of sintering whole process data. Combined with the process experience, the data from different databases are effectively organised, and the scientific data model framework is designed for the data at different levels, themes and application scenarios. The report generation and download of core parameters and the visualisation of data analysis results are realised, and the sintering big data platform with reasonable storage, parallel processing and client interaction is constructed (Figure 1).
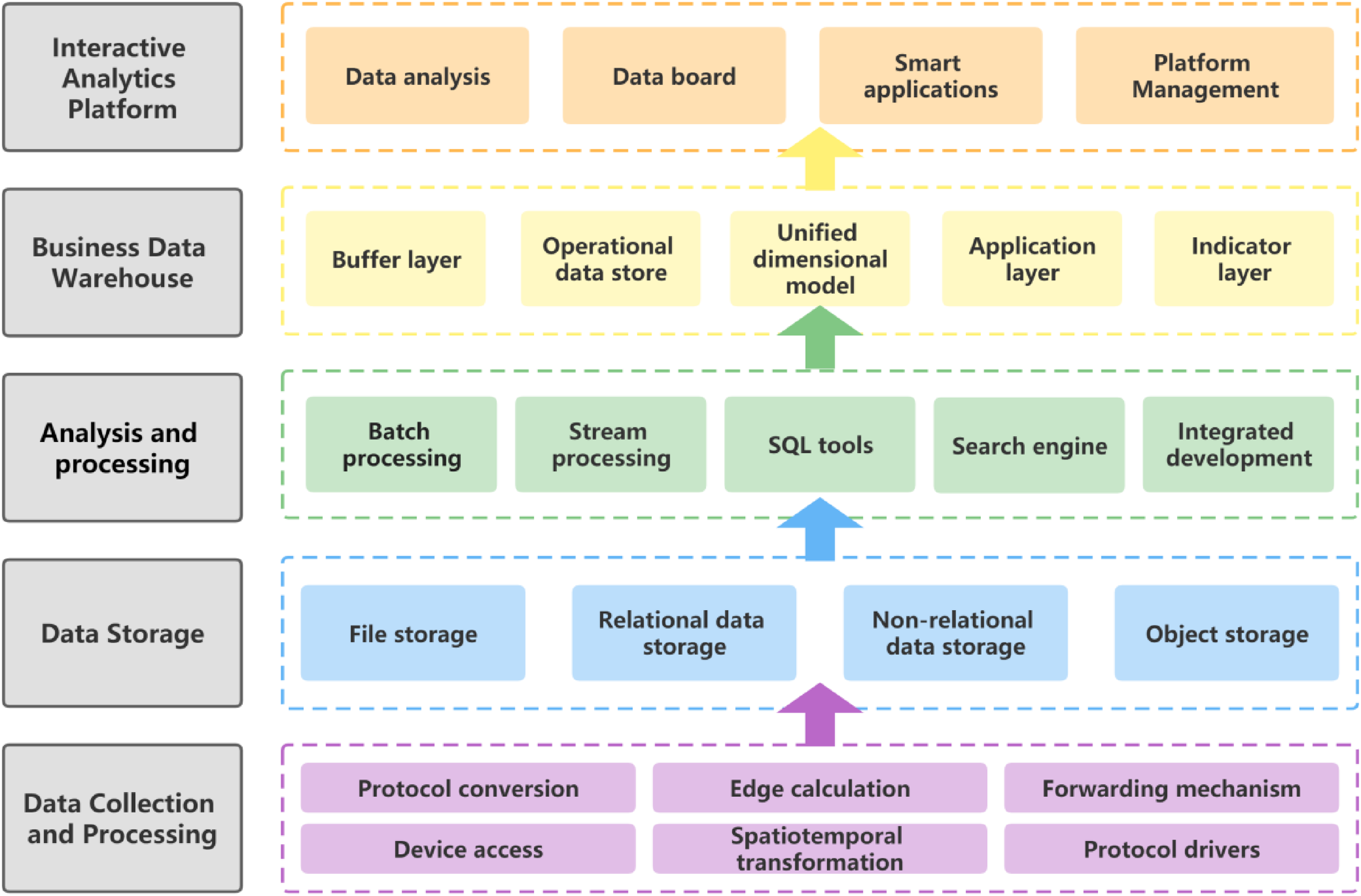
The architecture of the sintering data platform.
As a typical process industry, the sintering process has the characteristics of multi-process continuous production, strong heredity between processes and non-linear influencing factors. The data is characterised by high throughput, strong coupling, time variation and heterogeneity. All sintering data are classified according to the data source, data type, data structure, etc. At the same time, the data is sorted based on the interface characteristics of different data generation and storage. The reliable information acquisition device, protocol conversion platform and edge processing system are adopted to realise the acquisition, transmission and edge calculation control feedback of sintering data. Data collection collects various types of data from different data sources in real-time or promptly and sends the data to the storage system or intermediate data system for further processing. The existing sintering system has L1, L2 and L3 multi-level control system, and the equipment system is complex. In addition, there are differences in communication protocols, hardware types and network architectures between electrical control systems of various processes from different manufacturers. By defining the data conversion protocol, data acquisition and forwarding mechanism, device access, edge computing, spatiotemporal transformation and protocol driving, the limitations of hardware gateways, diverse data systems and inconsistent data structures are overcome, the unified interface acquisition and data island of the system is realised.
Using virtualisation, distributed storage, parallel computing, load scheduling and other technologies, it covers compute resources, storage resources, network resources and other infrastructure services. It provides high-performance computing, storage, network and other infrastructure for operating functions, building capabilities and delivering services.
The data warehouse is a core component. Through the integration of big data, the mathematical model of the smelting mechanism, expert experience, knowledge base and other multidisciplinary technologies, the valuable expert experience is consolidated in various ways and applied to the actual production and operation process. The high frequency buffer layer stores data from the sintering production system for a short period of time (3 days). The operational data store retains raw data on ironmaking production for the whole lifecycle. The unified dimensional model enables the storage of all integrated reorganisation data in ironmaking. The application layer enables personalised data storage based on the data requirements of independent smart applications. The indicator layer is geared towards the key process indicators in the production process, enabling indicator data to be extracted in the most convenient way for the most efficient analysis of key data.
According to the specific intelligent requirements of different scenes in the sintering production process, the data interactive analysis platform is designed to develop customised intelligent ironmaking applications to realise modularisation, plate formalisation and generalisation. As a result, it accelerates the reuse and innovation of BF ironmaking industrial knowledge. It provides industrial innovation applications, a developer community, an application store, application secondary development integration and other functions.
Data pre-processing
The sintering data platform can satisfy the collection and storage of data for the whole process of the sintering production line. The different sources and transmission methods of production data determine the data quality problems of the raw data. To address the quality of data, the sintering data platform uses data integration, standardisation and outlier processing to complete the pre-processing of data. For different types of sintering raw data stored in different data locations, the platform uses time as the primary key and integrates the data stored in different tables according to the process attributes by using the metallurgical process principle. It realises the data management of the whole process. Use box plots, linear interpolation, Lagrange interpolation, K-means clustering and other methods to realise the processing of various data quality problems.
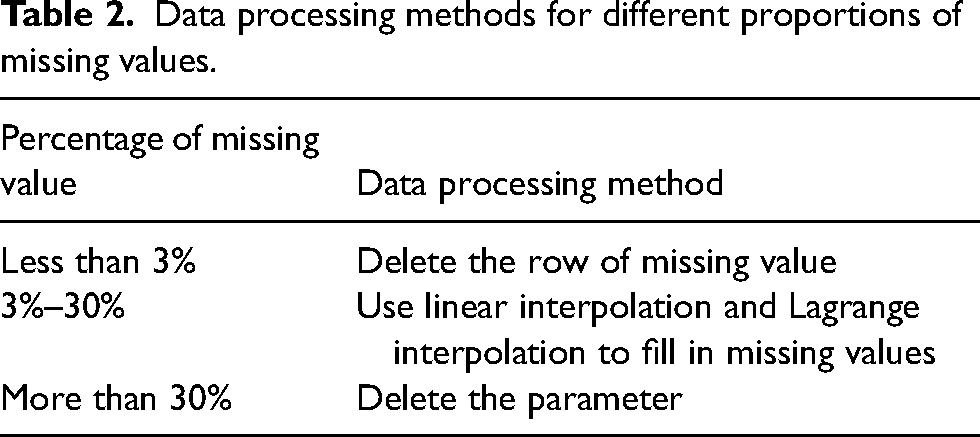
In the process of removing outliers, the values of duplicate records at the same time point in the dataset are first deleted. Then, based on the experience of the sintering plant, the approximate normal range of some parameters is determined, and the values that do not correspond to the actual production are eliminated. Different percentages of missing values are rectified utilising the specific approach presented in Table 2 during the process of missing value imputation.
Data processing methods for different proportions of missing values.
The sintering data platform can satisfy the collection and storage of data for the whole process of the sintering production line. The different sources and transmission methods of production data determine the data quality problems of the raw data. The Z-score normalisation method is applicable in situations where certain maximum and minimum data values may not have any practical significance. It can be utilised to detect unusual production situations, such as probable sintering stoppages. Therefore, standardisation using Z-score can eliminate the unwanted effects of different magnitudes.
The formula for Z-score standardisation is shown in Equations (1) and (2).
Standard deviation formula:

Sintering production forecasting models development
Data sources
A total of 104 parameters pertaining to the sintering production process were chosen and categorised by data type and specific process based on the resources available on the sintering data platform. Some of the parameter names are shown in Table 3.
Sintering process parameters.
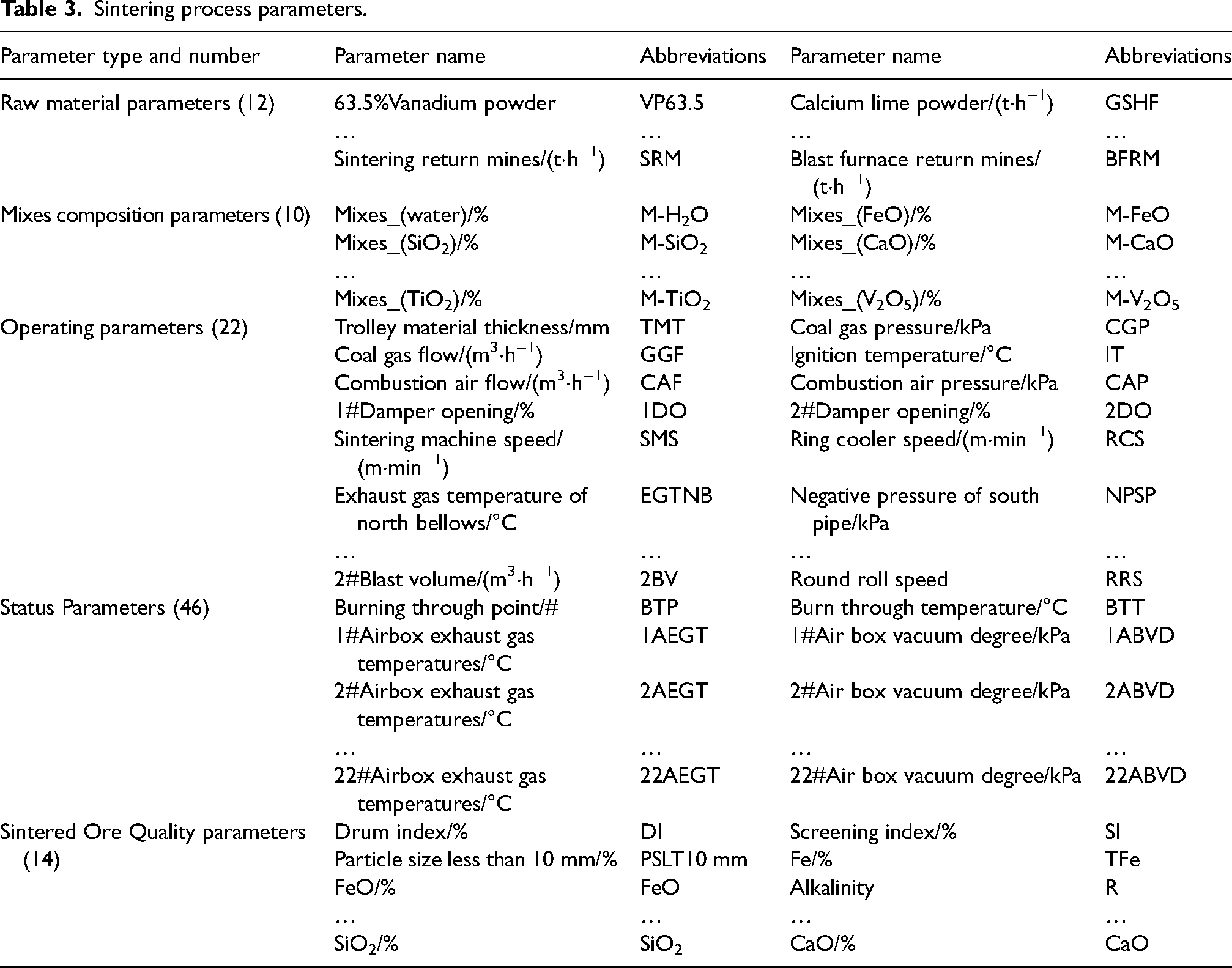
The sintering raw material parameters in Table 3 indicate the number of raw materials used in different periods, and the sintering mix parameters indicate the actual content of chemical components in the mix after the raw materials are fully mixed in different periods. The sinter operation parameter indicates the process of sinter production controlled by the site personnel, and the sinter status parameter indicates the operating status and working condition of the sinter. The sinter quality parameters represent the physical and chemical properties of the sinter ore.
Feature engineering
Based on the data pre-processed in the above section, the feature engineering work of the sinter production prediction model is realised by using different screening methods of the prediction model feature parameters. For all the sintering parameters, the redundant parameters among the characteristic parameters are first eliminated using Pearson correlation analysis and maximum mutual information coefficient (MIC) analysis. The Pearson correlation coefficient is a classical approach to feature selection and is a statistical indicator to study the degree of correlation between variables. The definition is given in Equation (3).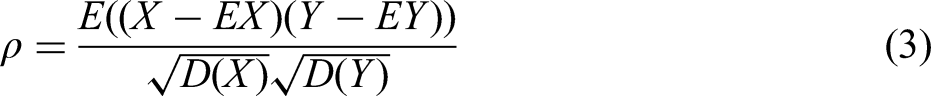
The MIC calculation formula is as follows.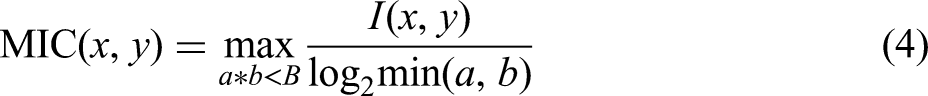
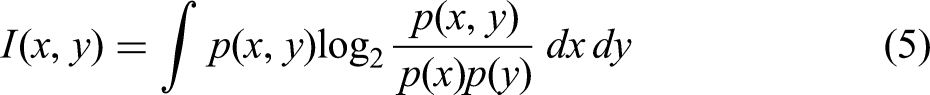
The feature parameters of the prediction model are selected using the gradient boosting decision tree (GBDT)-based feature selection method. That is, in the process of generating and pruning the CART tree, the Gini index of the tree is used to select the feature that contributes most to the target variable. From a macro perspective, the contribution value of the feature K is determined by calculating the average value (

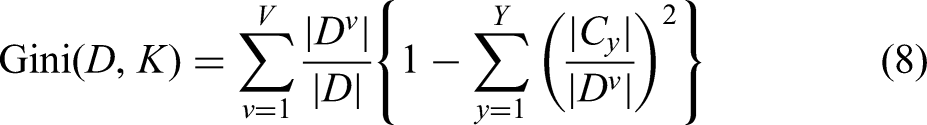
The specific method is to use the Gradient Boosting Regulator module in the Scikit-Learn library and package the model in a select from model instance, and gradually select the most valuable features for the model prediction in the instance.
Prediction model
Deep neural network algorithm
DNN acquire a number of functions through network learning and then non-linearly combine these functions and map them to neural networks of more complex functions. The central idea is to find out the form of distribution of data features by combining low-level features to form high-level features. DNN fulfils the performance requirements for modelling non-linear systems and can adeptly fit non-linear systems that are arduous to articulate mathematically.
The process of DNN training is as follows. At first, establish the overall count of layers l and the number of nodes
Gradient boosting decision tree
GBDT algorithm is an integrated learning model that uses a boosting method. The main concept is to consistently enhance the model by iteratively fitting the residuals. With each iteration, the output of the learner is combined with the output of the previous model, which gradually approaches the target. The algorithm provides several benefits, including flexible handling of diverse data types, greater prediction accuracy and robustness against outliers.
The general description of the learning process of the GBDT algorithm learning algorithm is as follows. The algorithm passes through multiple iterations, generating a weak classifier in each round. Before each iteration, calculate the first-order derivatives
AdaBoost regression model
AdaBoost is one of the best boosting algorithms, which trains different classifiers (weak classifiers) for the same training set, and then ensembles these weak classifiers to form a stronger final classifier (strong classifiers). AdaBoost has a high detection rate, a low generalisation error rate, does not require parameter tuning and is not prone to over-adaptation.
The AdaBoost algorithm flow is as follows.
Initialise the weights of each sample. Train a weak classifier for each feature, calculate the error rate of the weak classifier corresponding to all features, select the best weak classifier and adjust the weights. Through multiple rounds of continuous training, multiple optimal weak classifiers are obtained and combined into a strong classifier, and new classifiers are generated by adjusting the weights until the training error rate is 0 or reaches a specified value. Output prediction results.
Model prediction results and analysis
Owing to the continuous nature of sintering production, it is not feasible to use a random data division scheme. Therefore, to ensure the capture of parametric cycle features, the pre-processed dataset (January–December 2022) must be split into training and test sets in a 9:1 chronological order utilising the leave-out method. Mean absolute error (MAE), mean squared error (MSE) and R2 (R-squared) coefficients of determination were utilised to evaluate the predictive efficiency of the model.
Sintered material layer permeability prediction model
Sinter production is imperative to produce high-quality sinter ore for BF smelting, and its stability primarily relies on the permeability of the sinter layer. To ensure adequate air permeability during the sintering process, it is crucial to create a predictive model for the sinter layer's air permeability, which can be monitored and anticipated. After the feature selection method to screen the important feature parameters, a total of 18 important feature parameters such as IT, M-CaO, CGP, NPSP, M-FeO, EGTNB, CAP, M-H2O, 1ABVD, 2BV, M-V2O5, 1BV, RRS, SMS, CAF, 2DO, 1AEGT and EGTSB were selected for the sintered material layer permeability prediction model. DNN was employed to develop a model for predicting layer permeability. The model was then subjected to comparative analysis using a random forest model and a support vector machine model to determine its efficacy. The model prediction results are shown in Table 4 and Figure 2.
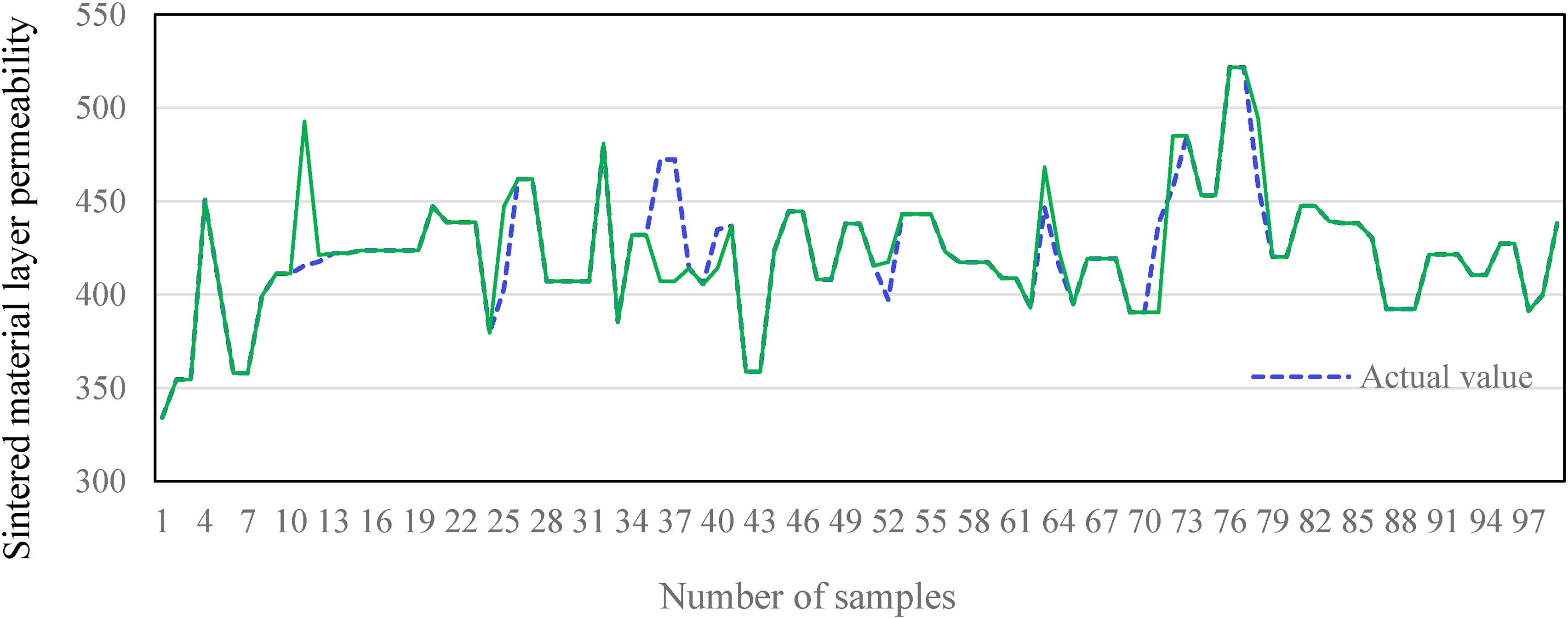
Comparison of the predicted and actual values of DNN.
Prediction and evaluation results of different models.
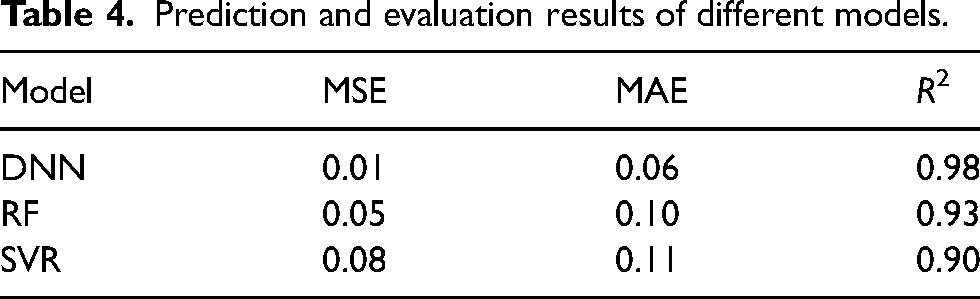
The predicted values of permeability using DNN compared to other models have a good fit with the true values. The evaluation criteria for the model, including an R2 of 0.98, MSE of 0.01 and MAE of 0.06, are indicative of excellent predictive performance and are appropriate for permeability forecasting in the sintered raw material layer. This model can be utilised in the field to aid the operator in accurately assessing the permeability of the material layer. This allows for advanced parameter control and adjustment, preventing production losses due to accidents.
BTP prediction model
The location of BTP directly affects the quality of sinter production. However, due to the complexity and dynamic time-varying nature of sintering production process, there is poor accuracy and significant latency in monitoring the end point of sintering, making it difficult to determine the status of the BTP. Therefore, the intrinsic principles and characteristics affecting the change in BTP are extracted from the sintering history data to establish the prediction model for the BTP to attain a precise prediction.
A total of 18 important feature parameters, such as IT, M-CaO, CGP, NPSP, M-FeO, DI, VP63.5, RCS, M-V2O5, M-H2O, CAP, 21AEGT, 1AEGST, SMS, 1ABVD, 22ABVD, 2DO and EGTNB were selected for the BTP prediction model. And GBDT algorithm was employed to construct the BTP prediction model, while random forest and PB neural network models were chosen to conduct comparative validation. The prediction results of GBDT algorithm with other models is shown in Table 5, and the comparison of the GBDT predicted and actual BTP values is shown in Figure 3.
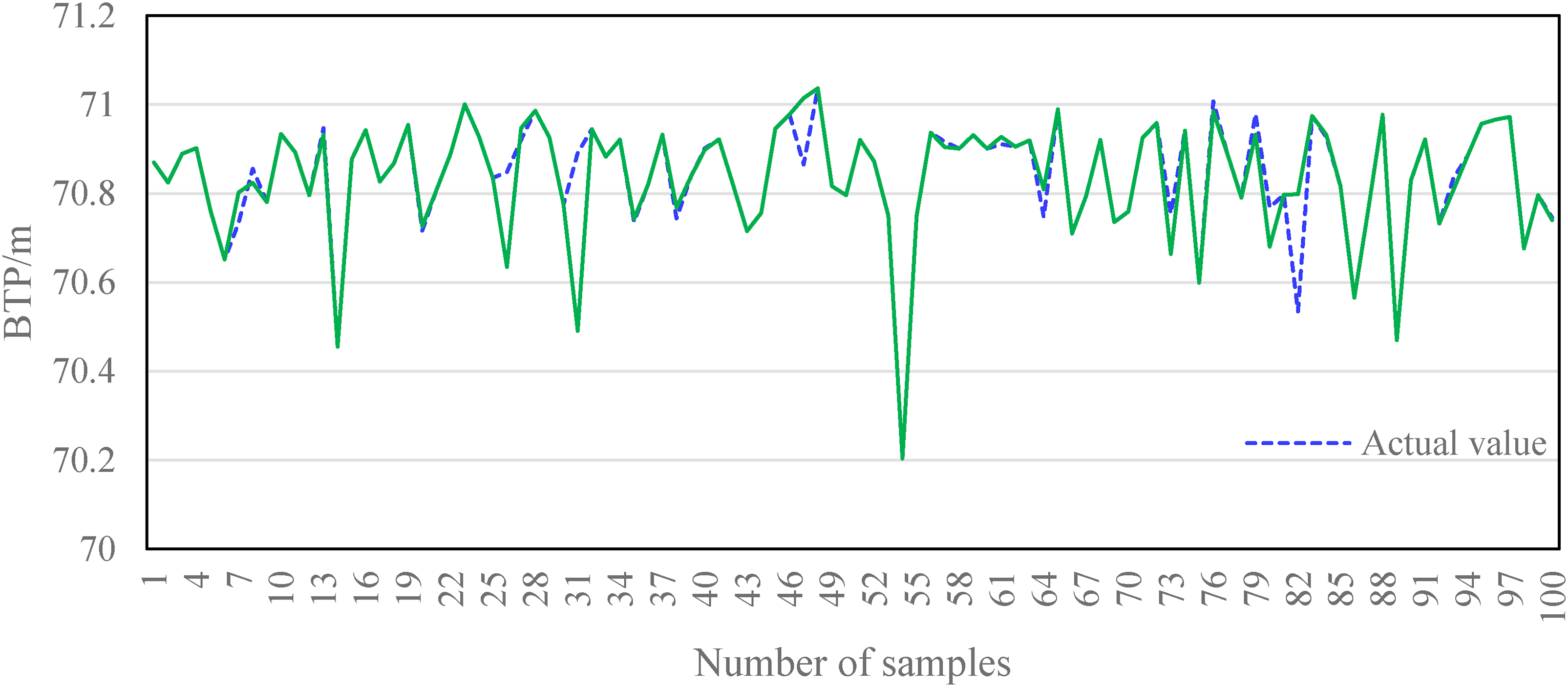
Comparison of the predicted value and actual value of BTP.
Prediction results of GBDT algorithm with other models.
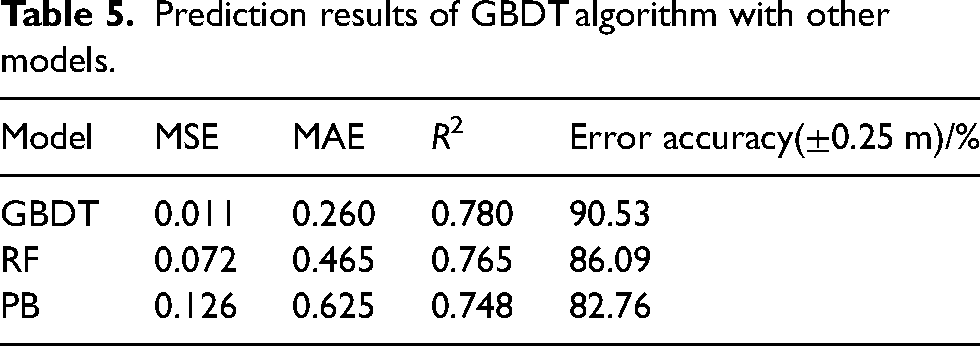
As evidenced by Table 5 and Figure 3, the BTP prediction model using the GBDT algorithm accurately forecasts values that align with actual results, achieving favourable prediction outcomes. The evaluation indexes for the model are 0.780 for R2, 0.11 for MSE, 0.26 for MAE, with an accuracy of error within 0.25 m reaching 90.53%. This model is implemented at the real site and has a beneficial impact on the operator's ability to determine the status of BTP.
Sintered mineral quality index forecasting model
To overcome the time lag in sinter ore quality testing, a cascade prediction model of the sintered mineral quality index is established for the production data of the whole sintering process. It combines the output results of the above sintering permeability prediction model and the sintering integrated final state prediction model and determines the key parameters affecting the sintered mineral quality based on mechanism analysis. A comprehensive mixing and sintering process to the whole process of sintered products, and accurate prediction of parameters such as sintered ore drum index and sieve index, facilitate the field operator to control the trend of the sintered mineral quality index in time.
After screening the important characteristic parameters, a total of 12 characteristic parameters were selected for the sinter drum index prediction model. These parameters include BTP, M-FeO, CAF, M-H2O, CAP, 21AEGT, SMS, M-V2O5, the average value of EGT, the average value of DO, the average value of BV and air permeability of the material layer. A total of 18 characteristic parameters were selected for the screening index prediction model, which are BTP, RRS, SMS, M-H2O, 9ABVD, 21AEGT, 1AEGT, 1ABVD, M-FeO, CAP, 3ABVD, CAF, M-V2O5, 2AEGT, average value of EGT, the average value of DO, the average value of BV and air permeability of the material layer. AdaBoost regression model was used to predict the model for sinter drum index and sinter screening index, respectively, and GBDT and RF models were selected for comparison to verify the effectiveness of the prediction model. The model prediction results are shown in Table 6, Figures 4 and 5.
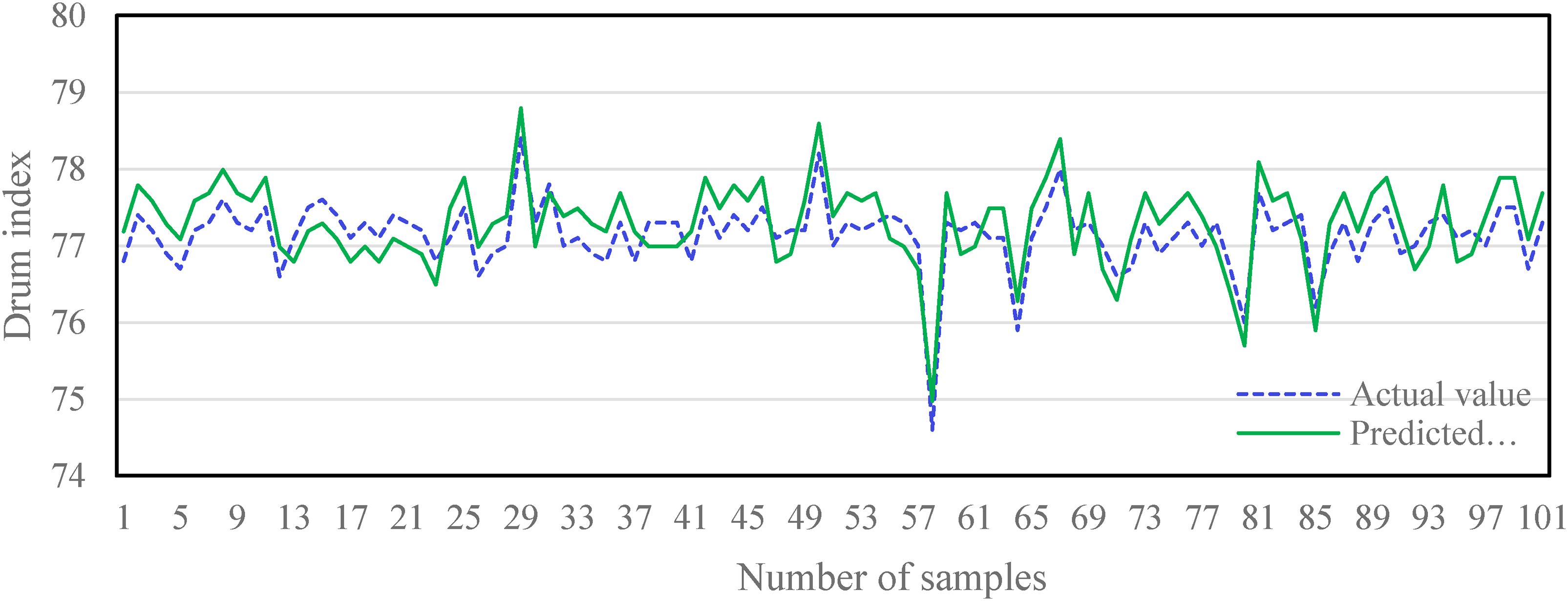
Simulation results of sinter drum index prediction model.
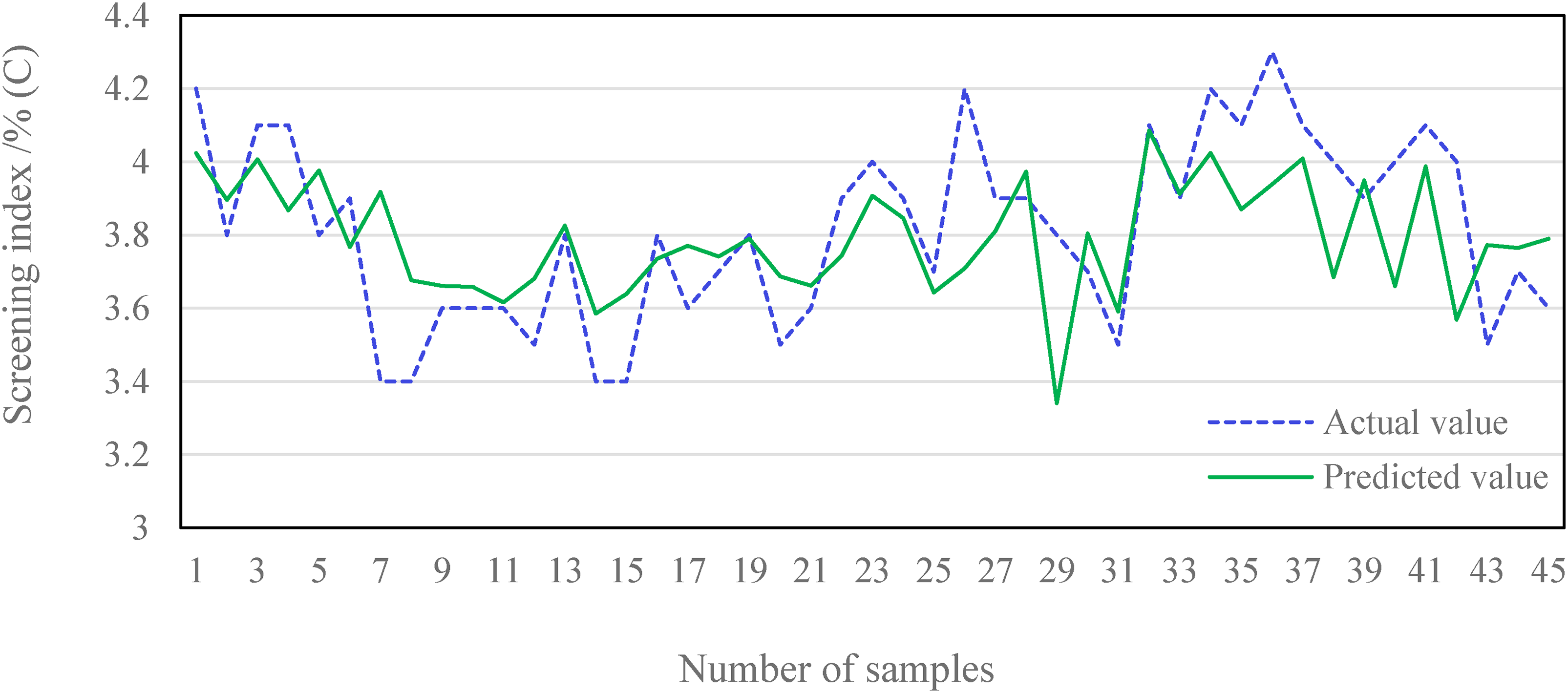
Simulation results of sinter screening index prediction model.
Prediction results of AdaBoost model with other models.
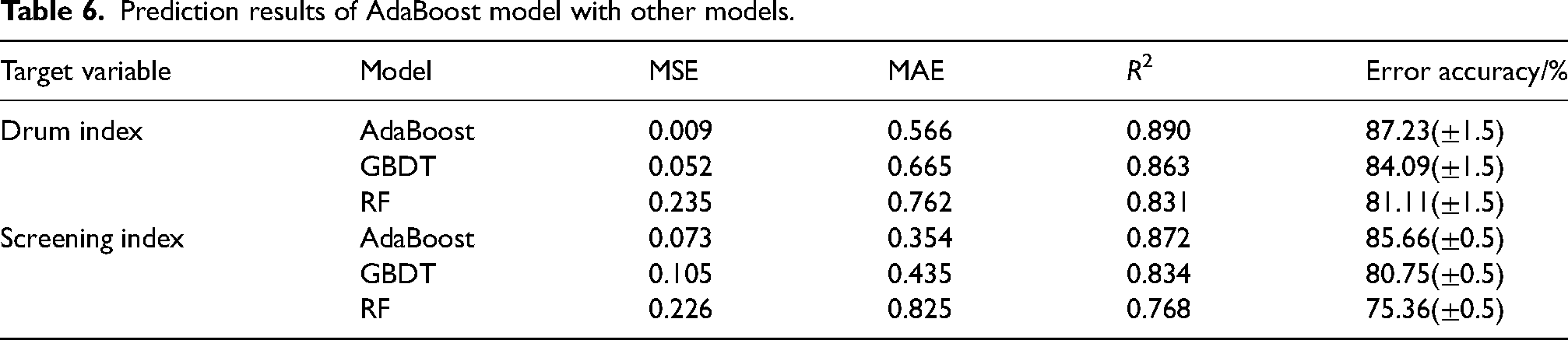
As can be seen from Table 6 and Figures 4 and 5, the evaluation indexes of sinter drum index and sieve index using AdaBoost model are higher than other models. R2 is 0.89 and 0.872. MSE is 0.009 and 0.073. MAE is 0.566 and 0.354. It is worth noting that the prediction errors of the AdaBoost model for the sinter ore drum indexes are over 85%, which meets the actual production requirements of sintering. With the application of this model in the actual field, the operators can grasp the trend of sinter quality indexes in time, which plays a positive role in improving the quality of sintered ore.
Development of intelligent sinter quality prediction system
System structure
By establishing a sinter layer permeability prediction model, a sinter end state prediction model, and a sinter ore quality prediction model, an intelligent cascade sinter ore quality prediction system is jointly established to realise the prediction of production results, optimise production parameters and achieve the purpose of stabilising and improving the sinter mineral quality index.
The software structure of the sinter quality intelligent cascade prediction system is divided into a data communication layer, a parameter prediction layer and a decision control layer. According to the functions, it is mainly divided into the sinter data warehouse module, the sinter layer permeability prediction module, the BTP prediction module and the sinter quality cascade prediction module. The structure is shown in Figure 6.
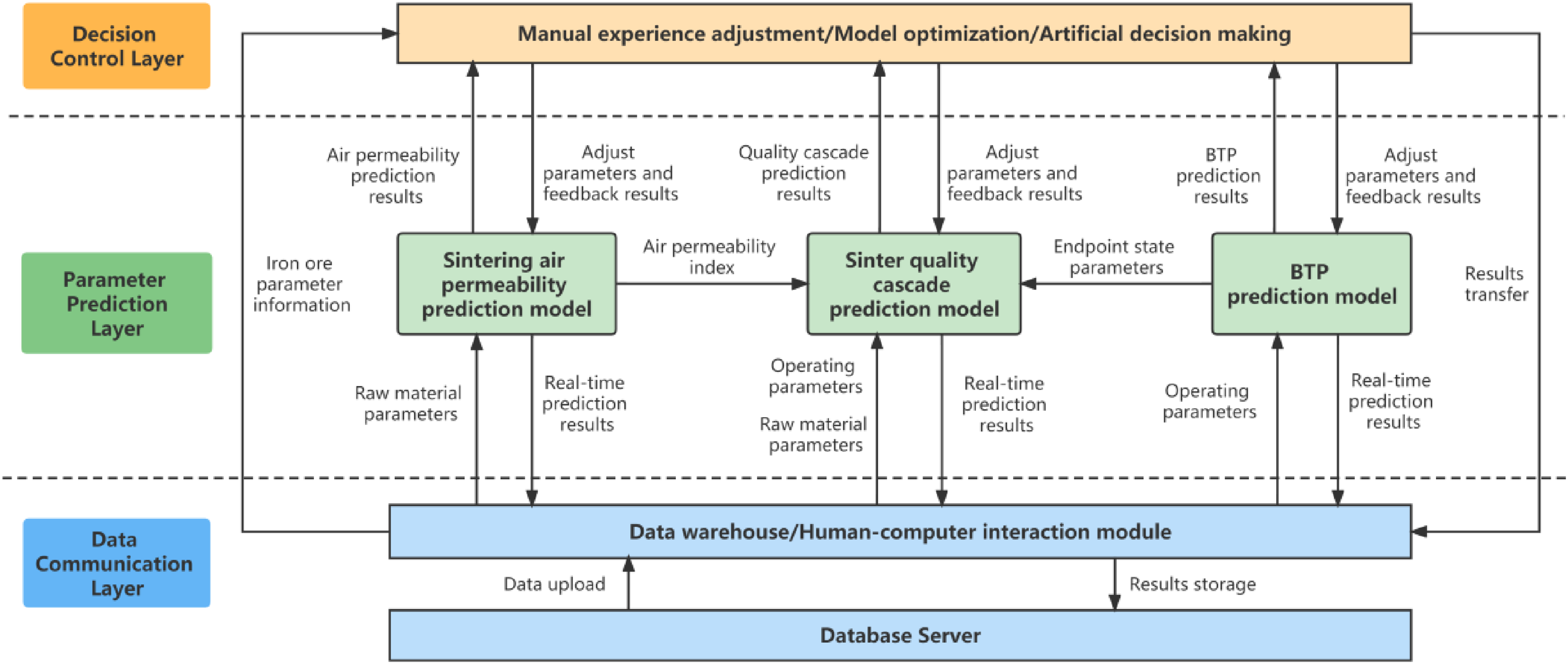
The software structure of the sinter intelligent cascade forecasting system.
The sintering data warehouse module mainly realises the storage and retrieval of relevant parameters in the forecasting and optimisation system and reads the data required for model operation from the database via SQL statements.
In operational settings, predictive systems are often consolidated as autonomous components. To attain optimal productivity and minimise response time of the prediction service during high concurrency intervals, it is imperative to utilise multi-core servers. The prediction algorithms are merged into the Python Flask Web framework, enabling the system to offer prediction services to other systems via http calls. Due to cost considerations, the deployment of this predictive system across multiple machines using Kubernetes (k8s) enables full utilisation of the server's resources. HPA (horizontal pod autoscaling) is utilised to adjust the scaling of services. KubeSphere tools are employed to enhance the management of k8s clusters. The KubeSphere platform provides a graphical user interface and command line interface designed to enable easy deployment, management and monitoring of applications. Users can effortlessly design, update and extend applications using KubeSphere.
System functions
Sinter layer permeability prediction module
The sintered layer permeability prediction module is based on real-time data of raw material parameters, equipment parameters and process parameters, which indirectly reflect parameters that are difficult to monitor online in real-time through operational and status parameters. This module can control the sintering production and optimise the mix performance in time. At the same time, the material layer permeability adjustment and optimisation model is established, and the parameters such as moisture, particle size and carbon allocation of the mixture are monitored and warned in real-time. As shown in Figure 7, the sintered material layer permeability prediction module shows the exponential trends of the mixture layer permeability for different raw material ratios and the real-time data monitoring of mixture moisture, particle size and carbon allocation, respectively.
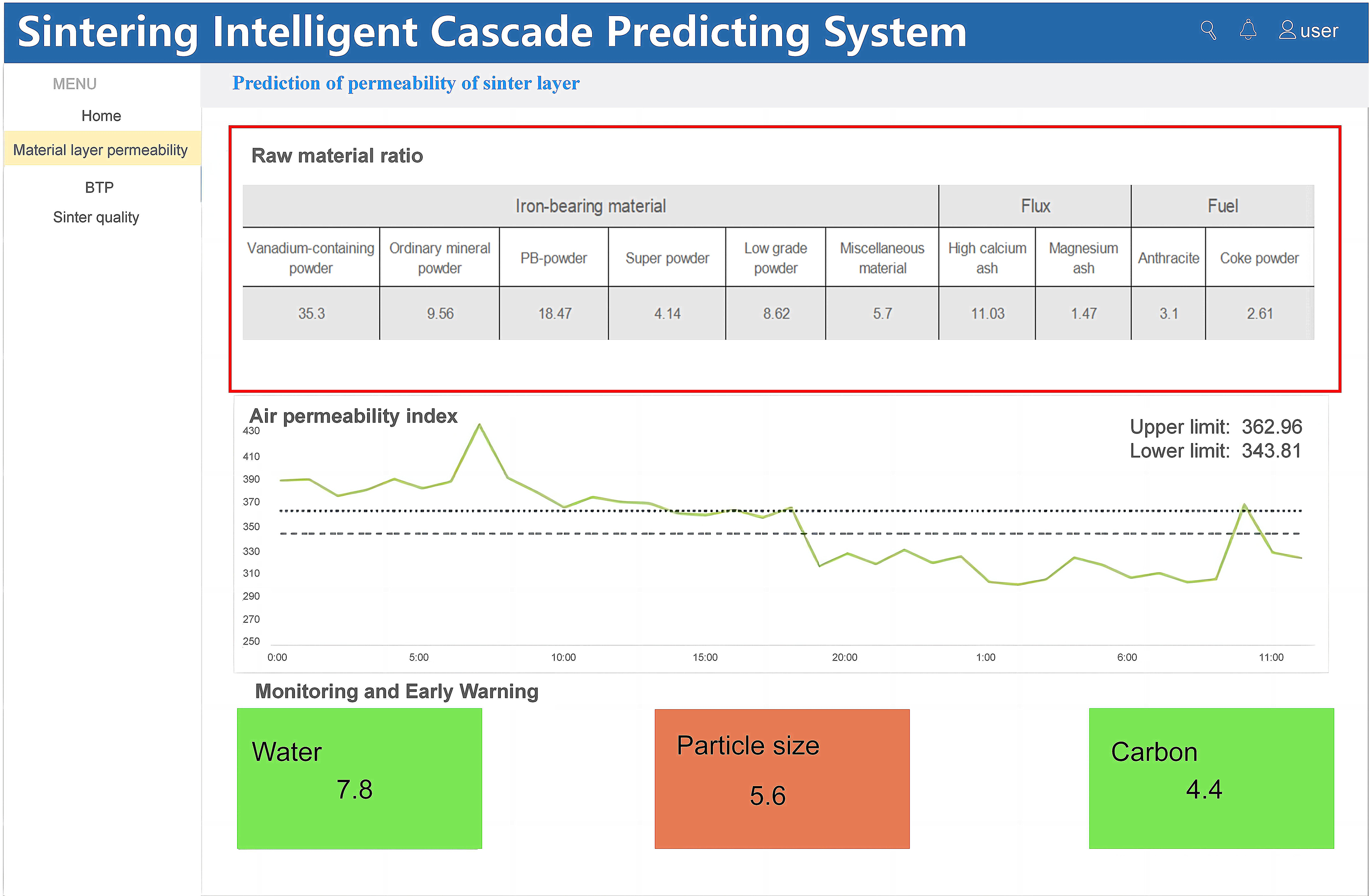
Prediction module of permeability sintering material layer.
The BTP prediction module
The BTP prediction module calculates the current BTP position in real-time based on the exhaust gas temperature detection value of the blast box and the length of the bogie. The BTP prediction model, using the online parameters of the sintering machine as input, can predict the change in the BTP position after 15 min. The real-time results of the BTP position with the predicted value assist the field operator in analysing and adjusting the fluctuation of the BTP position. As shown in Figure 8, the BTP position prediction module displays the graphs of real-time data and predicted data of BTP position and end temperature, as well as the histogram of real-time data of blast box exhausted gas temperature, which provides a comprehensive evaluation of the BTP state and gives the parameter criteria of past state, current state and target state.
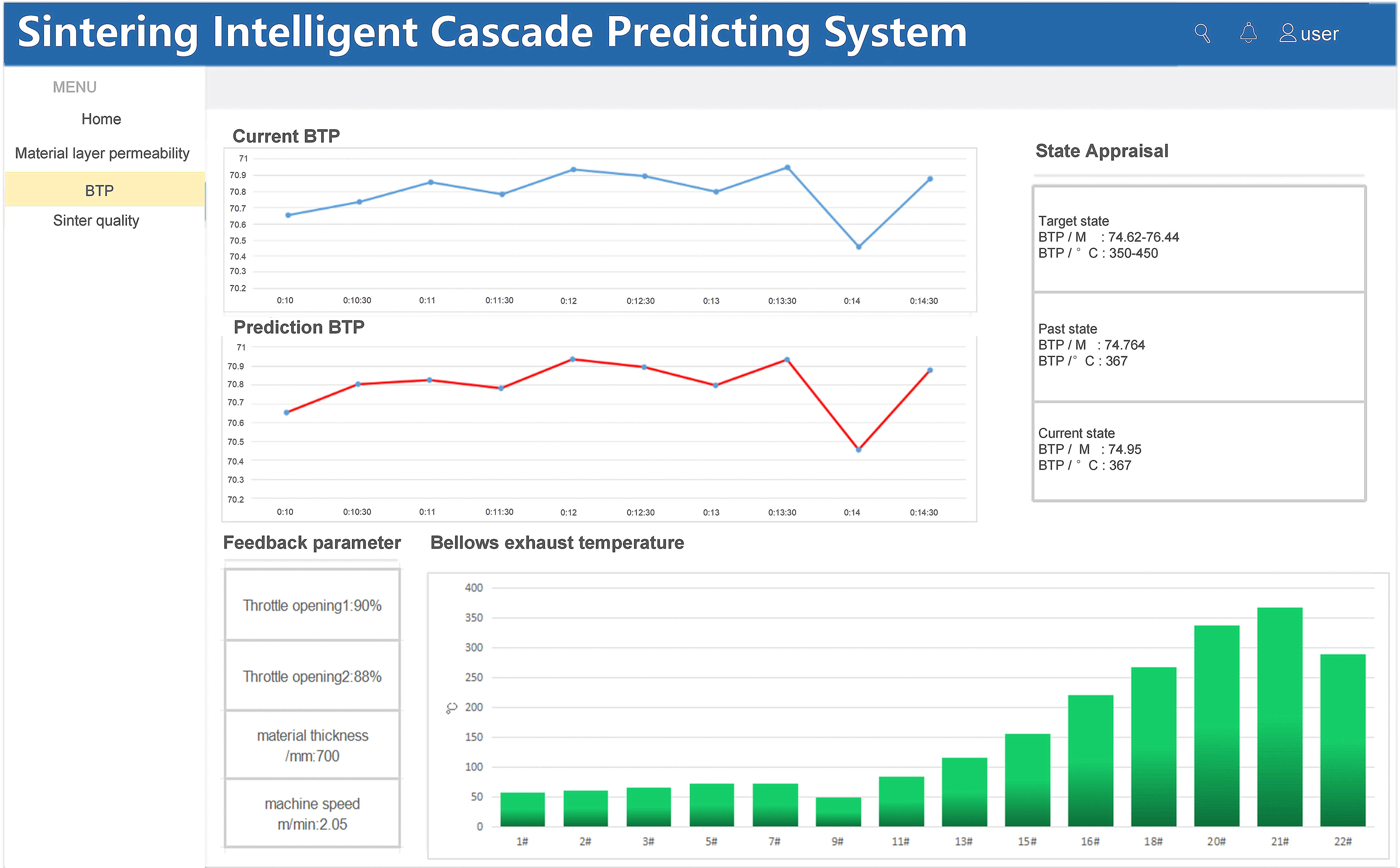
Prediction module of BTP.
Sintering quality cascade prediction module
The sintering quality cascade prediction module provides real-time monitoring and advanced prediction of sinter quality indicators. The prediction model uses the mixture properties, sintering process operating parameters and status parameters as inputs to calculate the quality index of sinter ore at the end of the sinter machine in real-time and assists the site operator in determining abnormalities in sinter ore properties in advance. As shown in Figure 9, the intelligent cascade sinter quality prediction module displays the real-time graphs of the predicted parameters of the drum index and screening index, which represent the quality of the sinter ore.
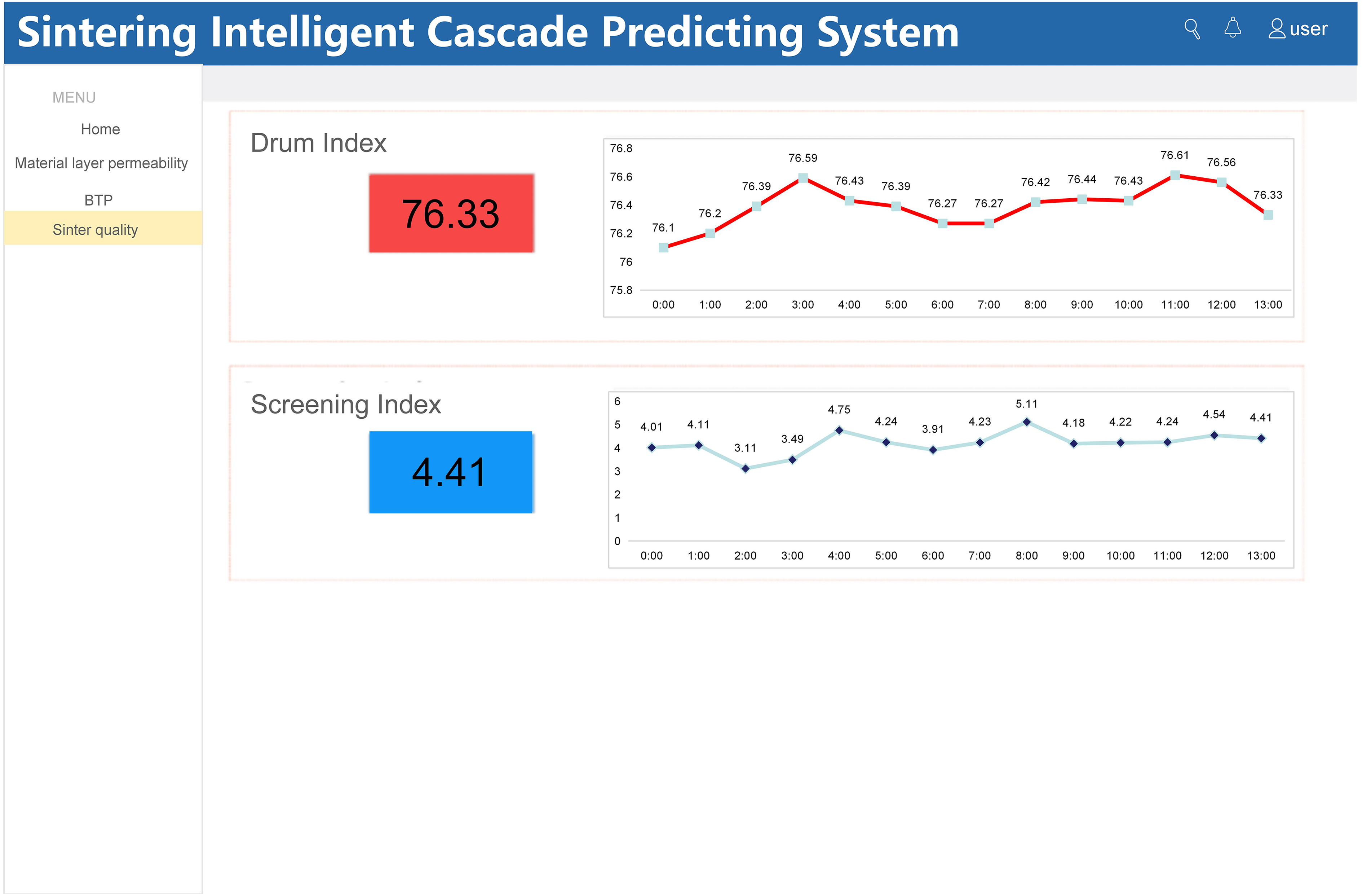
Prediction module of sinter ore production and quality index.
Since implementing the sintering process parameter forecasting and optimisation system, significant improvements have been observed in sintering batching optimisation, chemical composition control and sinter ore quality indexes. After using the system for 3 months, the average sinter TFe stabilisation rate increased by nearly 1.03%, the CaO/SiO2 stabilisation rate increased by about 3.1% and the drum index and sieve index of the sinter increased by about 0.18% and 4.2%, respectively. Sintered solid fuel consumption has been reduced by 5 kg/t. After the sinter quality intelligent cascade prediction system is applied to the sintering site, it can display the key indicators of concern in sinter production in real-time, providing more effective and favourable data support to the site operators. The application of the system can make the composition index of sintered ore more stable, which provides a theoretical research basis and an important guarantee to achieve the important goals of low energy, high production and high quality of sinter production.
Conclusion
A method of establishing an intelligent cascade prediction system of sintered ore quality is proposed to provide a perfect data warehouse for the development of the system by establishing a sintering big data platform. Based on the mechanism analysis, the key parameters affecting the sinter quality index are determined by establishing the sinter permeability model and the BTP model. The cascade prediction model of the sinter quality index is established to provide more effective data support to the field operators and to realise the production stability of the sinter quality.
The detailed software structure design is given for the application of the intelligent cascade prediction system of sinter quality. The system can make the composition index more stable, effectively improve the quality and output index of sinter production and conducive to realising the important development goal of low pollution, high yield and high quality of sinter production. The development of the system reflects the rapid development of digitalisation and intelligence in the steel industry and provides a solid theoretical and practical basis for the realisation of green manufacturing in the steel industry.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship and/or publication of this article: By Hebei Basic Research Projects of Higher Education Institutions (NO. JQN2020032), National Nature Science Foundation of China (NO. 52004096), Hebei Province High-end iron and Steel Metallurgical Joint Research Fund Project (NO. E2020209208).