
Abstract
The composite effect, originally demonstrated for faces, has recently been shown to suggest holistic processing of words. The effect is associated with reading fluency in Latin script, but not in nonalphabetic Chinese script, suggesting that script properties influence its relationship with reading expertise. We measured the composite effect for Arabic, a visually complex alphabetic script that offers a useful contrast against Latin and Chinese. Arabic-English bilinguals (
Introduction
The composite effect—first shown for faces, and then for other expertly recognized objects—is evidence for the processing of object features as interconnected wholes rather than as separate parts, also termed holistic processing (Boggan et al., 2012; Bukach et al., 2010; Cheung et al., 2008; Diamond & Carey, 1986; Farah et al., 1998; Feizabadi et al., 2021; Gauthier & Tarr, 2002; Jacques & Rossion, 2009; Kuefner et al., 2010; Richler et al., 2012). For example, recognizing the top half of a familiar face is difficult when it is paired with an unfamiliar bottom half, suggesting the two halves are not processed independently (Cheung et al., 2008). Printed words also elicit the effect, where words are split into their left and right halves, and readers struggle to recognize that the left halves of two words are identical if the right halves differ (Ventura et al., 2017, 2020b; Wong et al., 2012, 2011, see Anstis (2005) for a variation in which words were split top/bottom). This effect, termed the word composite or composite word effect, is thought to signify holistic word recognition, albeit at a later or more abstract stage of processing than that shown for faces (Ventura et al., 2017, 2020b). For Latin script, the word composite effect is consistent with phenomena such as the word superiority effect and letter transposition effects, which suggest whole-word recognition in fluent readers (Cattell, 1886; Reicher, 1969; Schoonbaert & Grainger, 2004; Wheeler, 1970). The goal of the work reported here was to examine the role of reading ability in holistic processing of Arabic words. Like Latin, Arabic is an alphabetic script, but it differs in other properties including visual complexity, word morphology, and omission of vowel sounds in writing. As we discuss below, such differences make it a useful comparison point for understanding which script properties underpin the association between reading fluency and the recognition processes revealed by composite effects.
With few exceptions (Brady et al., 2021), composite effects for Latin-script words are linked to expertise or reading fluency (Ventura et al., 2020b; Wong et al., 2011). For instance, the effect is stronger in native English readers than in second-language English readers (Wong et al., 2011), and for Portuguese words, it correlates with an independent measure of reading fluency, the word frequency effect (Ventura et al., 2020b). In contrast, composite effects for Chinese characters tend to be stronger in novices than in experts (Hsiao & Cottrell, 2009, but see Wong et al., 2012), and more pronounced in dyslexic than in typical readers (Tso et al., 2021, 2020). This suggests that the holistic process shown by this measure is not a universal aspect of reading expertise. Logographic scripts like Chinese may involve distinct perceptual and cognitive processes compared to alphabetic scripts (e.g., Tan et al., 2005; Tso, 2014). However, Chinese script is visually more complex than Latin (e.g., more within-character convolutions, Pelli et al., 2006), which may introduce differences in recognition strategies between scripts. Arabic is useful in this context because, like Latin, it is an alphabetic script, but it is as visually complex and inefficient to read as Chinese (Pelli et al., 2006). At minimum, Arabic provides a test of whether reading expertise elicits the composite effect across alphabetic script types.
The cursive nature of Arabic script offers additional insight into composite effects more broadly. Arabic letters typically are connected within words and their shapes vary by position. Hence, Arabic script is more configurational, and potentially Gestalt-like, than Latin script, where letter shape remains constant in printed text. Some evidence suggests that Gestalt properties alone can produce composite effects: untrained observers showed the composite effect for abstract line patterns with features like connectedness and closure, suggesting that holistic processing depends more on object properties than on observer expertise (Zhao et al., 2016). If so, non-Arabic readers may show composite effects for Arabic words.
In this experiment, we measured the composite effect for Arabic and English words in two groups: bilingual Arabic-English readers, and English-only readers. If reading ability drives the composite effect regardless of script complexity, it should appear for Arabic words only in bilinguals and for English words in both groups. This would suggest that visual complexity plays little role in the differences observed between Latin and Chinese scripts, and that expertise drives the effect generally for alphabetic scripts. If configurational features are the main factor, the composite effect should emerge in both groups—regardless of reading ability—and be larger for Arabic words than English words.
To measure the composite effect, we used the complete design, in which the effect is defined as an interaction between congruency and alignment in two successively presented objects (Richler & Gauthier, 2014) or words (Wong et al., 2011). Congruency refers to whether the two halves of the words yield the same response (e.g., legend-legend or legend-attack, see Figure 1; note that word halves comprise the left and right halves, rather than top and bottom. We discuss the implications of this method later). Alignment refers to whether the halves are visually offset, reducing the impact of congruency. Hence, the composite effect is the reduction in the congruency effect when the words are misaligned, or the decrease in whole-word interference in part recognition—a defining aspect of holistic processing. Our interest was in the four-way interaction of group, script-type, congruency and alignment, which would reveal whether the composite effect is specific to scripts that observers can read.
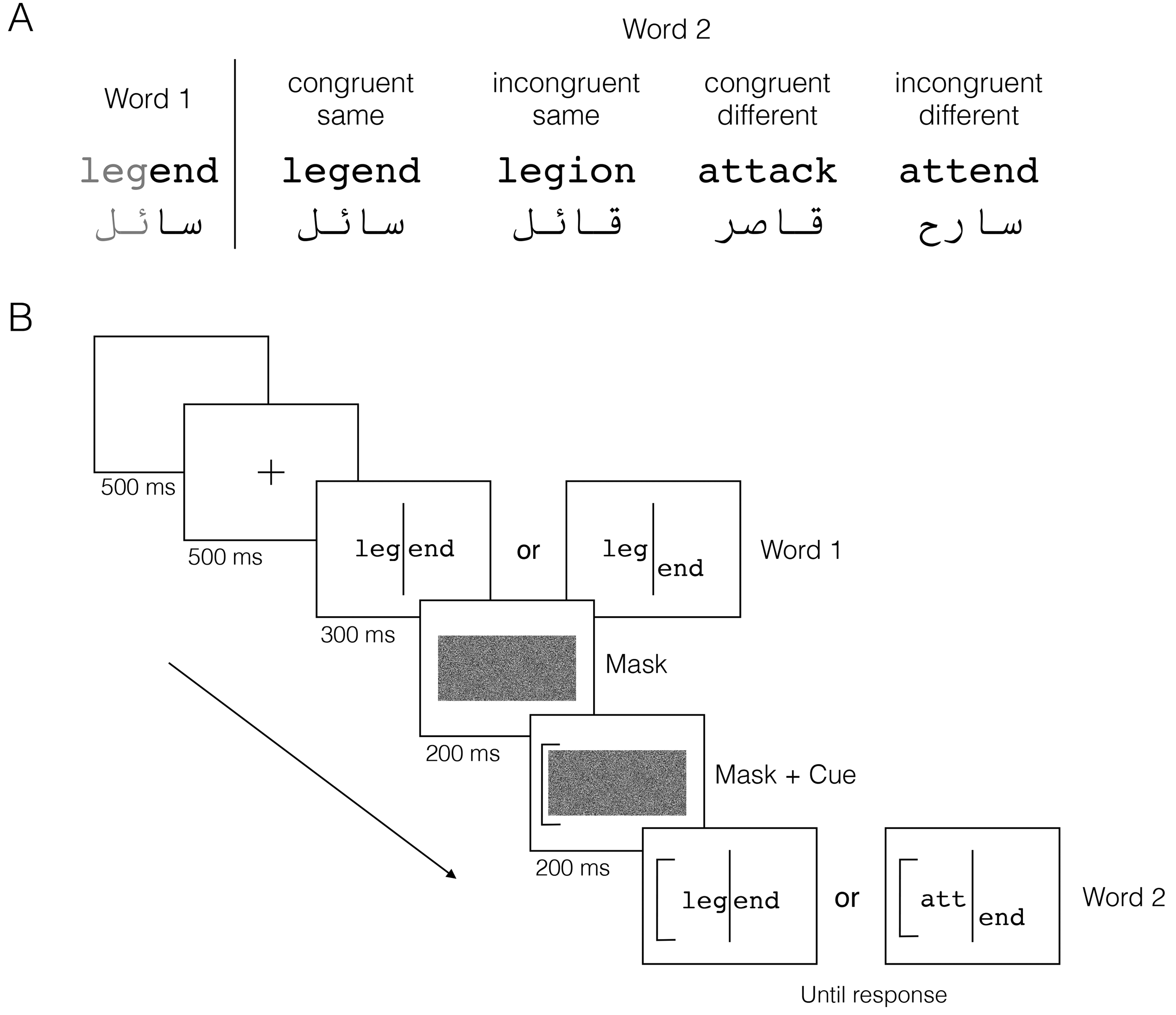
(A) Examples of the English and Arabic word stimuli used in the word composite task. The target half (left) is shown in light gray, not shaded in the experiment. (B) Schematic diagram of the task in the aligned (congruent-same; left) and misaligned (incongruent-different; right) conditions.
Methods
Design
The experimental design was a 2 (congruency: congruent vs. incongruent, within subjects)
Ethics Statement
All procedures of the experiment were approved by the Institutional Review Board for the Protection of Human Participants in Research and Research Related Activities (IRB) at the American University of Beirut, and the Ethics Board at McMaster University, Canada. All experiments were performed in accordance with relevant guidelines and regulations. Informed consent was obtained from all subjects before they participated in the study.
Subjects
The final sample comprised 22 monolingual English readers (mean age = 19.4 years; six males) and 24 bilingual Arabic-English readers (mean age = 19.6 years; 13 males), drawn from an initial pool of 26 monolingual and 30 bilingual subjects. This sample size is similar to previous studies examining between-group variations in the composite effect (e.g., Hsiao & Cottrell, 2009; Wong et al., 2011). Monolingual subjects were native English-speaking undergraduate students at McMaster University, Canada, with no experience in reading, writing, or speaking Arabic. Bilingual subjects were undergraduate students at the American University of Beirut, whose native language was Arabic, and who had received formal education in both English and Arabic. Bilingual subjects completed a self-report proficiency measure (scale: 0–4) assessing reading, writing, and speaking abilities in both languages. To be included, they needed an average score above 2 in each language (mean Arabic rating = 4.4, SD = 0.8; English = 4.1, SD = 0.8; mean difference between languages = 0.3, SD = 1). Four bilingual subjects were excluded due to low Arabic proficiency, and data from one subject were missing or not saved correctly. Additionally, four monolinguals and one bilingual subject were excluded from analyses for performing at chance level (below 60% correct) across stimulus conditions in one or both languages. All subjects had normal or corrected-to-normal vision, assessed using the Early Treatment of Diabetic Retinopathy Study (ETDRS) acuity chart. Subjects received either course credit or monetary compensation for their time.
Task
In the word composite task, participants judge whether the first or last few letters of two successively presented words are the same or different (Figure 1). For the English words in Figure 1, the target halves—the left halves or first three letters—are indicated by a cue (a square bracket) next to the second word. Participants must determine whether the cued halves match across the two presentations. Congruent pairs are those where both halves either match or differ, yielding a common response (same or different). Thus, congruent-same pairs are identical words (e.g., legend-legend), and congruent-different pairs have no letters in common at each letter position (e.g., legend-attack). Incongruent pairs contain conflicting information between the target and irrelevant halves: incongruent-same pairs have identical target halves but different irrelevant halves (e.g., legend-legion). Incongruent-different pairs have differing target halves but identical irrelevant halves (e.g., legend-attend). The congruency effect is the difference in accuracy or response time between congruent and incongruent conditions, reflecting interference from the irrelevant halves. A composite effect exists if the congruency effect is reduced when the word halves are misaligned (offset from each other). In a complete design, the composite effect is a 2 (congruency)
Stimuli
For each script, six sets of four words (common nouns and verbs) were used to generate word pairs for the congruent-same, incongruent-same, congruent-different, and incongruent-different conditions (see Supplemental Table 1). Within each set, these conditions were created by manipulating the correspondence between the left and right halves of the words, as described above. English words were six letters long and Arabic words were four letters long. Shorter words were used for Arabic because the stimulus conditions were more difficult to generate with longer words. Each script contained 24 words, all of which met the four conditions when either the first or second half was cued. Congruent-same and congruent-different pairs remained unchanged regardless of which half was cued. For example, legend-legend (congruent-same) and legend-attack (incongruent-different) were valid for both cued halves. Incongruent-same and incongruent-different pairs were swapped depending on the cued half. For example, legend-legion (incongruent-same) and legend-attend (incongruent-different) were used when the left half was cued, and legend-attend (incongruent-same) and legend-legion (incongruent-different) were used when the right half were cued.
Stimuli were presented using PsychoPy3, Version 3.1.5 (Peirce, 2008) on monitors with a 60 Hz frame rate and a resolution of 1024
Procedure
Subjects were seated at an adjustable chin rest 114 cm from the monitor. Each trial began with a blank screen (500 ms), followed by a fixation point (500 ms), and a centrally presented word (300 ms). The word was then replaced by a mask (200 ms), after which a cue (a square bracket) appeared on either the left or right side of the fixation point for 200 ms. Immediately after the mask disappeared, a second word appeared alongside the cue, and both remained on the screen until the participant had responded. Participants were instructed to report whether the cued halves of the words were the same or different, responding via keypress. Auditory feedback was provided: a high-pitched tone for correct responses and a low-pitched tone for incorrect responses. Each session lasted approximately 40 min and included trials with both Arabic and English words. The session was divided into four randomized blocks: English aligned, English misaligned, Arabic aligned, and Arabic misaligned. The congruency conditions were randomized within the block, and word pair order was randomized within each trial. Monolingual participants tested in Canada completed 288 trials per block (6 sets
The first 10 trials for every subject were treated as practice trials and were excluded from the analyses. Additionally, trials with response times shorter than 100 ms or longer than 3 s were removed (accounting for 2% of all trials). Two dependent measures were analyzed: sensitivity (
d′ = z(p(“same” | same))- z(p(“same” | different)) (1)
Additionally,
Results
As noted earlier, the composite effect is shown by a significant 2
Response time analyses were conducted on the raw data from correct trials only (38,756 trials across 46 subjects).
Sensitivity (
)
Figure 2A shows
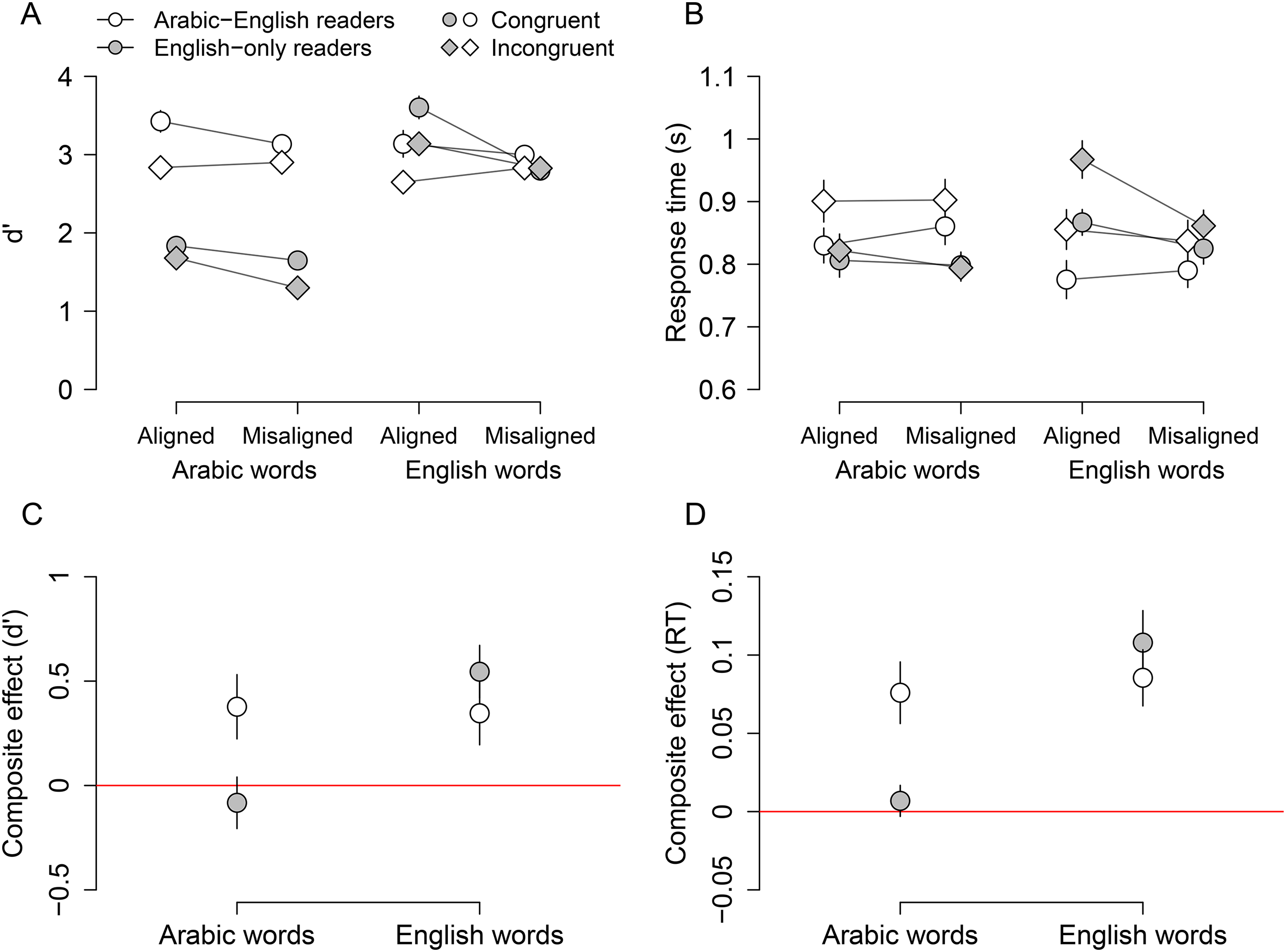
Performance on the word composite task. (A, B)
The omnibus mixed-effects model revealed significant main effects of group,
In summary, a composite effect was observed for Arabic words in bilingual readers but not in English-only readers. For English words, a composite effect was found in both groups. The size of the composite effect did not differ between Arabic and English words for the bilingual readers.
Response Time
Figure 2B presents mean response times across the eight stimulus conditions for the two groups. The congruency effect is evident, with faster response times in congruent than incongruent conditions. Similar to
A linear mixed-effects model (identical in formulation to that used for
In summary, the response time results indicate a composite effect for Arabic words that was clearer for Arabic-English readers than English-only readers (for whom there was no significant effect of congruency). The composite effect for English words was observed in both groups. This pattern of results closely mirrors the findings for
Discussion
The word composite task is a same/different perceptual judgement of word halves that does not require reading ability. However, the word composite effect—a reduction in perceptual interference when word halves are misaligned—here depended on reading ability. Specifically, Arabic-English bilingual readers, but not English-only readers, showed a composite effect for Arabic words, despite both groups performing above chance on the task. Hence, the composite effect for words relies on familiarity with the letters, or the ability to read the script. To the extent that composite effects for words provide evidence for holistic word recognition, these results support holistic processing as a marker of word recognition skill for alphabetic scripts (Ventura et al., 2017, 2020b; Wong et al., 2012, 2011). Broader mechanisms associated with familiarity or expertise (e.g., attentional factors) also were evident, where English readers performed better overall with English words than with Arabic words. Such factors can only account for the results to the extent that they reduce the congruency effect specifically (rather than performance in both congruency conditions) under misalignment for that script (i.e., account for the interaction effect in addition to any main effects of language or alignment). Word or letter alignment-related accounts alone (e.g., reduced crowding under misalignment) also do not explain the results.
These results provide the first evidence of a composite effect for Arabic words, extending findings from other languages and scripts (Hsiao & Cottrell, 2009; Ventura et al., 2017; Wong et al., 2012, 2011). The results are consistent with the patterns observed in fluent readers of Latin-script languages (Ventura et al., 2020b; Wong et al., 2011), but contrast with findings from novice readers of Chinese characters (Hsiao & Cottrell, 2009; Tso, 2014; Tso et al., 2022, 2021). Given that Chinese and Arabic characters are similarly complex (as measured by perimetric complexity; Pelli et al., 2006), this difference in expertise effects may stem from the nature of the writing system itself. One explanation is that logographic scripts involve more analytical than holistic perceptual processing (Liu et al., 2022; Tan et al., 2001; Tien et al., 2023; Wang et al., 2019). This would imply that the mechanisms of reading expertise are less universal across variations in script than previously assumed (Rueckl et al., 2015). Alternatively, measures of letter complexity may overlook graphemic subtleties (e.g., variability in stroke orientation and position), which might better predict perceptual strategies across different scripts. Another possibility is that expertise-dependent composite effects in Chinese script may emerge under different stimulus conditions—for instance when compound characters rather than individual Chinese characters are used, or when words are split left-right rather than top-bottom (as by Wong et al., 2012, see further on this point below). Future work should examine the stimulus manipulations that produce expertise-dependent composite effects across writing systems.
Among Arabic-English bilingual readers—who on average were equally proficient in both scripts—the size of the composite effect did not differ between Arabic and English words. This suggests that given sufficient reading ability, the composite effect is not influenced by graphemic differences in alphabetic scripts. Furthermore, the connectedness or cursive nature of Arabic letters (a Gestalt-like property) did not elicit composite effects in nonreaders, in contrast to findings for abstract line patterns (Zhao et al., 2016). Hence, the effect appears not to be tied to the visual properties of the word form, and consistent with other studies may be rooted in higher-level lexical representations. Indeed, for Latin script, the effect is reduced or absent for pseudowords and is insensitive to variations in surface visual properties such as font or case (e.g., Ventura et al., 2020a, 2017; Wong et al., 2011). Additionally, the effect has been shown to depend on the phonological properties of the words, such that it is more robust for words with shallow orthography (consistent grapheme-phoneme mapping), than for words with ambiguous pronunciation (Ventura et al., 2019). These findings further suggest that the composite effect or the holistic process it suggests is influenced by linguistic properties beyond visual appearance. Follow-up experiments should probe the degree to which reading ability or lexical knowledge is required: for instance, is the effect obtained in readers simply familiar with the letters, or in sublexical readers who can sound out words without lexical or semantic knowledge?
The absence of letter form effects and the dominance of higher-order lexical effects in prior studies may be attributable to the specific manipulation used in the word composite task—splitting words left/right, rather than top/bottom as typically is done in face composite tasks. Left–right splitting preserves letter identity, potentially shifting the locus to higher-level representations and reducing word form-related effects. If words were split differently, composite effects might emerge for pseudowords and nonreaders as well. Incidentally, an early study found that readers failed to recognize when the upper halves of different words were identical while the lower halves differed (e.g., bag vs. hoe), suggesting that this type of holistic processing extends to word form under certain conditions (Anstis, 2005). However, that study did not test nonreaders or pseudowords, leaving open the question of whether the effect relied on reading ability. In general, it is conceivable that variations in the composite task or stimulus manipulations differentially invoke lexical knowledge or sensitivity to word form.
Word and face recognition typically are framed as distinct processes—one part-based and hierarchical (letter-by-letter recognition: McClelland, 1981; Rumelhart & McClelland, 1982), and the other holistic, sensitive to subtle configurational differences within a fixed arrangement of features (eyes over nose over mouth). Neural evidence supports this distinction, with words preferentially engaging left-lateralized regions of the ventral occipitotemporal cortex (Bouhali et al., 2014; Dehaene et al., 2005; Puce et al., 1996; Purcell et al., 2011; Wimmer et al., 2016), while faces are predominantly processed in the right fusiform gyrus and associated regions (Puce et al., 1996; Rossion et al., 2003; Yovel et al., 2008). From this perspective, composite effects for words—typically associated with holistic face perception—run against the grain.
A different view, however, acknowledges part-based and holistic mechanisms for both words and faces (Martelli et al., 2005; Pelli et al., 2003). By this account, feature recognition precedes holistic processing for faces and words alike, reconciling traditional models of reading and object recognition with composite-like effects (Barnhart & Goldinger, 2013). Familiarity or expertise enhances recognition and elicits effects associated with holistic processing, as seen here with Arabic words. Yet, familiarity does not eliminate the ability to recognize individual parts—readers clearly succeed at part-based judgements regardless of alignment–and the composite effect provides no evidence that it does.
Supplemental Material
sj-pdf-1-pec-10.1177_03010066251364208 - Supplemental material for Reading ability underlies the composite effect for Arabic words
Supplemental material, sj-pdf-1-pec-10.1177_03010066251364208 for Reading ability underlies the composite effect for Arabic words by Rayan Kouzy and Zahra Hussain in Perception
Footnotes
Acknowledgments
We thank Patrick J. Bennett and Hailey Wright for support with collecting data from the English-only readers (McMaster University, Canada), Riwa Safa for help with constructing the English word list, and Julien Besle for feedback on the work.
Author Contribution(s)
Declaration of Competing Interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by a University Research Board (URB) grant awarded to Zahra Hussain at the American University of Beirut.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.