
Abstract
For unfamiliar faces, deciding whether two photographs depict the same person or not can be difficult. One way to substantially improve accuracy is to defer to the ‘wisdom of crowds’ by aggregating responses across multiple individuals. However, there are several methods available for doing this. Here, we investigated performance in three tests of unfamiliar face matching. In all cases, we found that going with the option chosen by the majority of people provided the best approach. No benefit was found by weighting an option's popularity using average confidence, while choosing the ‘surprisingly popular’ option resulted in a sizeable decrease in accuracy. Therefore, rather than incorporating metacognitive judgements, we endorse a simple majority vote for this particular task.
Deciding whether photographs depict the same person or not can be challenging, particularly when the faces are unfamiliar. In this context, we have little knowledge of how those faces might vary across time, viewing conditions, and so on (since much of this variation is idiosyncratic; Burton et al., 2016), and we are forced to rely on the limited information provided by the images themselves, resulting in errors (Burton, 2013). Neither training (Towler et al., 2019) nor experience (White et al., 2014) appear to improve accuracy. Instead, we might defer to the ‘wisdom of crowds’ to increase performance (Galton, 1907). But how do we get the best from our crowd?
In a typical face matching task, two face photographs are presented side-by-side. Since the answer is either ‘the same person’ or ‘two different people’, the simplest method of aggregating the group's responses is to choose the answer voted for by the majority. This approach produces substantial improvements in performance over individuals (White et al., 2013). However, the majority vote may not be the best solution. For instance, its success relies on minimising idiosyncratic biases, which is hampered if individuals confer before answering. Indeed, social collaboration in dyads does not improve performance when compared with response averaging over non-social pairings (Jeckeln et al., 2018). Equally, for complex decisions where, on average, voters’ judgements are no more likely to be right than wrong, the majority vote may be of little value.
Common alternatives often take advantage of people's metacognitive abilities. For instance, we can use the average confidence given to each of the two options to weight their popularities – a confidence-weighted solution. Let us suppose 30% of the crowd choose ‘the same person’ and their mean confidence is 4.5. For the remaining 70% who choose ‘two different people’, their mean confidence is 1.5. As a result, the former option would be selected (0.30 × 4.5 = 1.35) over the latter (0.70 × 1.5 = 1.05). If those answering correctly are more confident in their answer, this approach can counteract the majority of people responding incorrectly. By incorporating confidence ratings during aggregation, previous research has produced performance improvements over simple majority voting for other perceptual tasks (e.g., Juni & Eckstein, 2017; Saha Roy et al., 2021).
Similarly, in situations where people who are correct, but in the minority, know that their response is rare, a better solution might be to choose the ‘surprisingly popular’ option instead (Prelec et al., 2017). Suppose that 30% of the crowd choose ‘the same person’ while estimating, on average, that 15% of others would also respond in this way. For the remaining 70% who choose ‘two different people’, their mean estimate for others choosing that response is 90%. Consequently, the crowd has estimated that only 11.5% of people would choose ‘the same person’: 0.30 × 0.15 + 0.70×(1–0.90) = 0.115. In reality, that answer was given by 30% of people, making it ‘surprisingly popular’ (since 30% is larger than the crowd's estimate of 11.5%) and therefore the response selected. This solution relies on a well-informed subset of people who have access to the correct information and are aware that this information is not common knowledge. Such an approach has recently been shown to outperform the majority vote when participants were asked to detect AI-synthesised faces (Kramer & Cartledge, 2024), as well as in tasks unrelated to face perception (e.g., in predicting the outcomes of sports competitions and political elections – Rutchick et al., 2020).
To compare these approaches, we asked participants to complete either the Glasgow (40 trials; Burton et al., 2010), Kent (40 trials; Fysh & Bindemann, 2018), or Models Face Matching Test (120 trials; Dowsett & Burton, 2015). 1 On each trial, we collected a binary response (same person vs. different people), a confidence rating (1–5 scale), and an estimate of the percentage of other participants that they thought agreed with their answer (0–100% slider). Individual performance on these tests was as follows: Glasgow (M = 86.3%, SD = 9.2%), Kent (M = 68.4%, SD = 10.0%), and Models (M = 64.1%, SD = 10.7%).
To investigate crowd performance, we randomly generated 1,000 unique crowds for each crowd size, 2 and then for each trial, we considered the crowd's responses and determined the majority vote, the confidence-weighted solution, and the surprisingly popular answer. 3 Following this, we calculated the crowd's accuracy across all trials for each of the three methods. As Figure 1 illustrates, the majority vote performed similarly to, or outperformed, the confidence-weighted solution for all three tests. Further, the ‘surprisingly popular’ method performed substantially worse than these other two methods. Finally, we see that most of the benefits in using crowd wisdom were achieved once the crowd was approximately 10–15 in size, where performance began to level out.
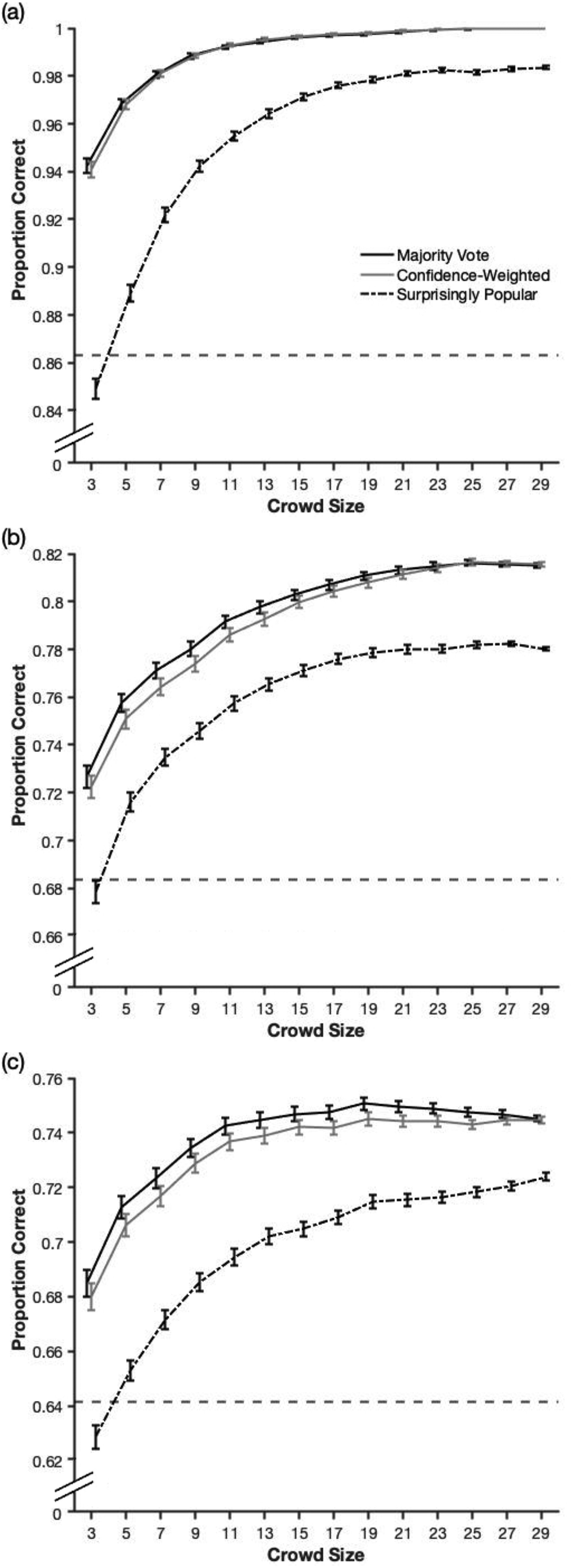
A comparison of the three aggregation methods for the (a) Glasgow, (b) Kent, and (c) Models Face Matching Test. The horizontal dashed lines depict average individual performance. Error bars represent 95% confidence intervals. The use of different y-axis limits reflects the differences in difficulty across these three tests.
Overall, our results demonstrate that a simple majority vote outperforms methods that utilise metacognitive measures, and this is clearest for smaller and likely more feasible crowd sizes. In applied settings, perhaps only a handful of individuals (e.g., passport issuing officers) might reasonably be asked to provide additional opinions which could be aggregated. A further advantage of the majority vote is that it requires no additional information from its users (i.e., regarding confidence judgements or estimates of others’ perceptions).
While other tasks may allow individuals to realise that they are correct but in the minority (e.g., in knowing that Harrisburg, rather than Philadelphia, is the capital of Pennsylvania), this does not seem to be the case here. The benefit of the ‘surprisingly popular’ method comes from its reliance on a well-informed subgroup of participants who can both answer correctly and accurately assess public perception. These two abilities may simply be unrelated for tests of face matching, although it would certainly be interesting to investigate whether high-performing individuals (e.g., ‘super-recognisers’; Bobak et al., 2016) also have a good sense of when the average person might answer incorrectly.
Similarly, using confidence-weighting relies on correct participants being more confident than incorrect ones. Previous research on face matching has shown that higher levels of metacognitive sensitivity (i.e., assigning higher confidence to correct in comparison with incorrect responses) can only be found in better performers rather than across all people (Kramer et al., 2022; Kramer & McIntosh, 2024). As such, there may be a limit to the utility of confidence judgements during aggregation when these are given by the entire group. Future research might therefore consider how the confidence judgements of better performers could be more heavily weighted during this process.
Taken together, these findings may have practical significance in contexts where particularly difficult comparisons are encountered and/or when crowdsourcing is a feasible option (i.e., where decisions are made by multiple online users). The increase in performance through using crowds might also represent a simpler alternative to identifying and recruiting particularly accurate individuals. Finally, we identify possible limitations with the use of metacognitive abilities, at least across the whole sample, when seeking to improve crowd performance.
Footnotes
Author contribution(s)
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.