
Abstract
First impressions based on facial appearance affect our behaviour towards others. Since the same face will appear different across images, over time, and so on, our impressions may not be equally weighted across exposures but are instead disproportionately influenced by earlier or later instances. Here, we followed up on previous work which identified an anchoring effect, whereby higher attractiveness ratings were given to a person after viewing naturally varying images of their face presented in descending (high-to-low), rather than ascending (low-to-high), order of attractiveness of these images. In Experiment 1 (n = 301), we compared these ‘descending’ and ‘ascending’ conditions for unfamiliar identities by presenting six-image sequences. Although we found higher attractiveness ratings for the ‘descending’ condition, this small effect equated to only 0.22 points on a 1–7 response scale. In Experiment 2 (n = 307), we presented these six-image sequences in a random order and found no difference in attractiveness ratings given to these randomly ordered sequences when compared with those resulting from both our ‘descending’ and ‘ascending’ conditions. Further, we failed to detect an influence of the earlier images in these random sequences on attractiveness ratings. Taken together, we found no compelling evidence that anchoring could have an effect on real-world impression formation.
Facial first impressions are known to affect real-world outcomes. For example, we apply socially desirable traits indiscriminately to people we judge to be attractive (the ‘halo effect’; Dion et al., 1972). The consequences for such a bias include their receiving more help (Benson et al., 1976), earning higher wages (Pfeifer, 2012), and benefitting from more frequent hiring opportunities (López Bóo et al., 2013). Researchers have shown that forming these first impressions appears to be an automatic process (e.g., Olson & Marshuetz, 2005; Ritchie et al., 2017; Willis & Todorov, 2006), and the resulting biases can persist despite attempts to educate and instruct participants regarding their presence (e.g., Jaeger et al., 2020; Wetzel et al., 1981). If our initial impressions are both unavoidable and influential, then it is important to consider how pervasive they might be when presented with additional information. In other words, do our initial perceptions of a face, based on early exposures, remain unchanged despite information provided by later exposures?
Differences in facial attractiveness between people (an example of ‘between-person variability’) have been the focus of much research over the years, with studies exploring influences such as symmetry, averageness, and sexual dimorphism (e.g., Jones & Jaeger, 2019). However, only recently have researchers begun to investigate how the same face can vary in attractiveness across instances (an example of ‘within-person variability’). While more limited modifications to the same face may have little effect on attractiveness in comparison with sizable between-person differences (e.g., the application of makeup; Jones & Kramer, 2015, 2016), the combination of several changes resulting from differences in expression, age, viewing angle, and lighting, for example, can produce large variations in within-person attractiveness (Jenkins et al., 2011). Given that we can recognise familiar faces despite this variation in attractiveness (and appearance more generally) across instances of the same face, it remains unclear as to how we tolerate such within-person variability.
One possibility is that we create a summary of the different instances by simply calculating their average. Termed ‘ensemble encoding’, this process of internal averaging has been demonstrated for a variety of face properties, including attractiveness (Luo & Zhou, 2018; Ritchie et al., 2017), trustworthiness (Marini et al., 2023), emotional expression (Haberman et al., 2009), gaze direction (Sweeny & Whitney, 2014), gender (Haberman & Whitney, 2007), and identity (e.g., de Fockert & Wolfenstein, 2009; Koca & Oriet, 2023; Kramer et al., 2015; Neumann et al., 2013). However, it is worth noting that the majority of these studies presented a set of images simultaneously, rather than sequentially, and featured images of several identities rather than multiple images of a single face (cf. Koca & Oriet, 2023; Kramer et al., 2015; Ritchie et al., 2017). As such, for at least some of these studies, it is difficult to determine how their results might apply to the real-world exposure of a single face over time and multiple instances.
Averaging across instances should result in a robust internal representation of a particular face (e.g., Burton et al., 2005; Ritchie et al., 2018; Robertson et al., 2015). However, we might predict that more recent exposures are more heavily weighted during averaging since these will be more representative of a face's current appearance, and therefore more useful/relevant for recognition or other judgements. In terms of lower-level mechanisms, earlier information could also be lost or considered less reliable (more noisy) due to memory or attentional limitations. This recency effect has indeed been identified by Hubert-Wallander and Boynton (2015), who demonstrated that the perceived average expression resulting from the sequential presentation of faces was more influenced by the later items in the sequence. Evidence of recency effects is also common in studies using simpler, non-face stimuli (e.g., Tong et al., 2019; Yashiro et al., 2020).
In contrast, an average representation might give more weight to earlier instances if it is important to decide quickly, and the first few exposures provide sufficient information. The contribution of additional exposures when refining the representation may also be small relative to the information gained from the first few exposures (i.e., diminishing returns). This primacy effect could then be explained as the costs of time and cognitive resources needed to incorporate later instances outweighing any additional accuracy that these might contribute. To date, studies showing a primacy effect have tended to use non-face stimuli (e.g., dot location—Hubert-Wallander & Boynton, 2015; lists of adjectives—Sullivan, 2019).
Interestingly, a recent study by Goller et al. (2018) appeared to provide evidence of a primacy effect in facial attractiveness judgements. On each trial, participants were shown a sequence of six different images of the same face, either in descending or ascending order of attractiveness (pre-rated by a separate sample). They were then instructed to rate the attractiveness of the person, and since the same six images were presented in both cases, any differences in responding were assumed to be due to the presentation order. In other words, when forming an impression of attractiveness, did people place any more weight on the earlier or later images in the sequence? The results demonstrated that higher ratings were given for the descending presentation order, with the researchers concluding that “early items dominate impression formation” (p. 1050).
However, we believe that the procedure used in the study meant such an interpretation was unwarranted. Importantly, participants in both presentation conditions were shown the same, novel ‘test image’ (pre-rated as the image with the median attractiveness rating) before giving their responses. As a result, the sequence length became seven images, with a larger attractiveness contrast between the final two images—this median image was always preceded by either the least or most attractive image. Recent research has demonstrated that because of ‘sequential effects’ (also termed ‘serial dependence’), impressions of the test image would be contrasted with the previous image (Kramer & Pustelnik, 2021). This would cause the test image to appear more attractive when preceded by the least attractive image (in the descending condition) and to appear less attractive when preceded by the most attractive image (in the ascending condition). If the participant was calculating an internal average as a summary, for the descending condition, this could result in an increase for the overall impression of attractiveness. Or, if the participant simply rated the final (test) image, then a higher rating would be given because the image appeared more attractive when contrasted away from the one immediately preceding it.
Goller et al. (2018) acknowledged the possibility of a contrast effect, which motivated their second experiment. This followed the same design as the first except that participants provided an attractiveness rating of the person after every image in the sequence. Here, the results replicated their first experiment, with a higher final rating in the descending condition. In addition, the researchers found that the six initial images were each rated more attractive in this condition than the six initial images in the ascending sequence. Their explanation was couched in terms of an ‘anchoring effect’ (primacy), whereby the first image influenced ratings of all subsequent images. In other words, rating a highly attractive image at the start of the sequence provided an anchor, pulling subsequent ratings upwards as a result, with this also producing an increase in the final rating given after the test image. However, this reasoning could also be applied to each rating, since we know that sequential effects can produce an anchoring or assimilation to the previous rating and not just the first one given (e.g., Kramer et al., 2013). It is certainly possible that their data revealed both assimilation (for the initial six images) and contrast (following the test image) since the former may result from greater perceived similarity between two consecutive images (attractiveness increments were initially smaller), while the latter can arise when the current image is perceived to be sufficiently dissimilar (the step from the sixth image to the test image was larger). Although perceived similarity provides a potential explanation for why both types of bias may have arisen (Mussweiler, 2003), debate continues as to when assimilation versus contrast should be expected (e.g., Chang et al., 2017; Huang et al., 2018; Kramer & Jones, 2020; Pegors et al., 2015; Xia et al., 2016).
Of course, in considering whether each response was pulled towards or contrasted away from the previous rating, we are no longer investigating ensemble encoding and overall impression formation. Instead, the focus has necessarily shifted to the ratings given to particular images and their influence on subsequent ratings. While Goller et al. (2018) instructed participants to rate ‘the attractiveness of this person’ for each response, it seems more likely that participants were rating the attractiveness of each image, especially in the second experiment in which a response was required after each of the seven images. In fact, if participants were truly giving an updated impression of the person with each response, then we could simply compare ratings given after the sixth image (before viewing the test image). At that point in the sequence, all participants had been presented with the same six images, either in ascending or descending order of attractiveness, with ratings in the ascending condition (M = 4.88) clearly higher than in the descending condition (M = 3.91; see Figure 2a of Goller et al., 2018). We would, therefore, conclude that later images (recency) were more influential than earlier ones (primacy), in opposition to the interpretation given by the researchers themselves.
Thus, the aim of the current research was to address this question of primacy versus recency in impression formation by using the general design of Goller et al. (2018). Crucially, however, we chose to present only a six-image sequence (with attractiveness ascending or descending) and then collect a single rating of attractiveness afterwards, without including a test image. Further, we made our instruction to rate the person, rather than the image, more explicit for our participants to better measure overall impressions rather than those of specific images (which are influenced by sequential effects, as discussed earlier). Finally, we investigated impression formation when the six-image sequences were randomly ordered rather than arranged to systematically increase/decrease in attractiveness.
Experiment 1
This experiment replicated the design of Goller et al.’s (2018) Experiment 1 with two notable differences. First, we did not present a test image prior to collecting participants’ attractiveness ratings in order to remove the possibility that contrasting this image with the sixth (final) sequence image might influence responses. Second, we chose to focus on first impressions of previously unfamiliar identities. As such, we presented only identities likely to be unfamiliar to our participants and excluded attractiveness ratings given to identities with which participants demonstrated any prior familiarity.
Method
Participants
A sample of 301 participants living in the UK (196 women, 102 men, three nonbinary; age M = 30.4 years, SD = 17.1 years; 89% self-reported ethnicity as White) gave informed, onscreen consent before taking part in the experiment and were provided with an onscreen debriefing upon completion. Participants were recruited by word of mouth (e.g., through asking friends and family, and sharing the experiment's weblink on social media).
Both this experiment and Experiment 2 were approved by the University of Lincoln's research ethics committee (#2023_14600) and were carried out in accordance with the provisions of the World Medical Association Declaration of Helsinki.
An a priori power analysis was conducted using G*Power 3.1 (Faul et al., 2007). The analysis of focus utilises an independent samples t-test, comparing participants’ mean ratings in the ‘ascending’ versus ‘descending’ conditions (for details, see below). Thus, to achieve 95% power to detect a medium-sized effect (Cohen's d = 0.5) at an alpha of .05, a total sample size of 210 was required (with 105 participants in each condition).
To detect the large effect size reported by Goller et al. (2018) for this comparison (Cohen's d = 1.39), we would require a total sample size of only 30 participants (with 95% power and an alpha of .05). However, this reported value of Cohen's d appeared to disagree with their other reported effect size (η2p = 0.12) in terms of magnitude, as well as the value we calculated using their reported conditions’ means and standard deviations, assuming equal numbers of participants in the two conditions (Cohen's d = 0.71). As such, given this confusion, we chose the more conservative option of recruiting at least 210 participants.
Stimuli
We compiled a list of 30 celebrities (of national, rather than international, fame) who were likely to be unknown to participants living in the UK and Canada. These individuals (50% women, 50% men) were from Australia, Germany, Spain, Belgium, and France (for further details, see the Supplementary materials). For each celebrity, we collected 16 different photographs using Google Images searches, with each photograph depicting the celebrity facing roughly front-on and with their face free from occlusions. All images were subsequently cropped to contain only the head and neck, and in some cases, the top of the shoulders, and were resized to 380 × 570 pixels. Image backgrounds were not removed.
Prior to the main experiment, attractiveness ratings were collected for these images using the Gorilla online testing platform (Anwyl-Irvine et al., 2020). First, the 30 identities were randomly divided into two sets of 15 identities (Set A: eight men, seven women; Set B: seven men, eight women). Next, 71 participants (48 women; age M = 24.7 years, SD = 8.45 years) were recruited using the University of Regina's Sona Systems platform, as well as through word of mouth. There was no overlap between this sample and the participants who completed the main experiment below. This experiment was approved by the University of Regina's research ethics board (#285).
After consent was obtained, participants provided demographic information. Each participant was then presented with all images associated with each identity from only one of the two sets (i.e., 16 images × 15 identities = 240 images), with set assignment counterbalanced across participants (Set A: n = 36, Set B: n = 35). Images were blocked by identity during presentation, with the order of the 16 images of each identity randomised for each participant. The presentation order of the identities was also randomised for each participant. At the start of each block (identity), participants were provided with onscreen instructions: “You are about to see 16 photographs of the same person. Please judge how attractive you think each particular photo is of the person”. Each image was then presented, one at a time, and participants were asked “how attractive is this particular photo of the person?” Responses were given using a Likert scale ranging from 1 (not attractive) to 7 (very attractive) and were self-paced, with each image remaining onscreen until a response was provided.
Finally, upon completion of all 15 blocks, participants were presented with a ‘familiarity check’. A list of the names of the 15 identities corresponding with the set assigned to that participant was displayed onscreen. For each identity, participants rated their familiarity with the celebrity using a Likert scale ranging from 0 (unknown) to 4 (well known).
Participants were prevented from using mobile phones (via settings available in Gorilla) to complete this ratings experiment, as well as the main experiment below, to ensure that images were viewed at an acceptable size onscreen.
For any identity receiving either a rating higher than 0 in terms of familiarity or identical attractiveness ratings for all 16 images, that identity's image ratings were discarded for that participant. This resulted in the exclusion of 13.0% of attractiveness ratings. We then considered the interrater agreement for each identity (Cronbach's α) and chose to exclude three identities whose values (0.54, 0.63, 0.67) fell below the generally accepted minimum of 0.70 (e.g., McKinley et al., 1997). Since participants in this task disagreed on the attractiveness of these images, we could not be confident of a sufficiently strong manipulation of sequence order in the main experiment for these three identities.
For the remaining 27 identities’ attractiveness ratings, those given to each image were averaged across participants. For each identity, we then ordered the 16 images by mean attractiveness and selected six images that were evenly spread across the full range from least to most attractive (i.e., images 1, 4, 7, 10, 13, and 16). The average range of attractiveness spanned by these six images (i.e., the attractiveness of the most minus least attractive image) was 1.75 units (SD = 0.39 units) on the 1–7 scale.
Procedure
The main experiment was completed using the Gorilla online testing platform (Anwyl-Irvine et al., 2020). After consent was obtained, participants provided demographic information. Each participant was then presented with the six selected images (see above) associated with each of the 27 identities. Images were blocked by identity during presentation, with the order of the six images representing the experimental manipulation. The images were presented either in ascending (from least to most attractive) or descending order (from most to least attractive). Assignment to the ascending (n = 148) or descending condition (n = 153) was counterbalanced across participants. All identities were presented within the same condition for a given participant.
The presentation order of the identities was randomised for each participant (cf. Goller et al., 2018). At the start of each block (identity), participants were provided with onscreen instructions: “You are about to see 6 photographs of the same person. Afterwards, please judge how attractive you think the person is”. Each image in the sequence was then presented for 2 s (see Goller et al., 2018), with an interstimulus interval of 1 s (blank screen). 1 After the sixth (final) image disappeared from the screen, participants were asked, “How attractive is this person?” Responses were given using a Likert scale ranging from 1 (not attractive) to 7 (very attractive) and were self-paced (see Figure 1).
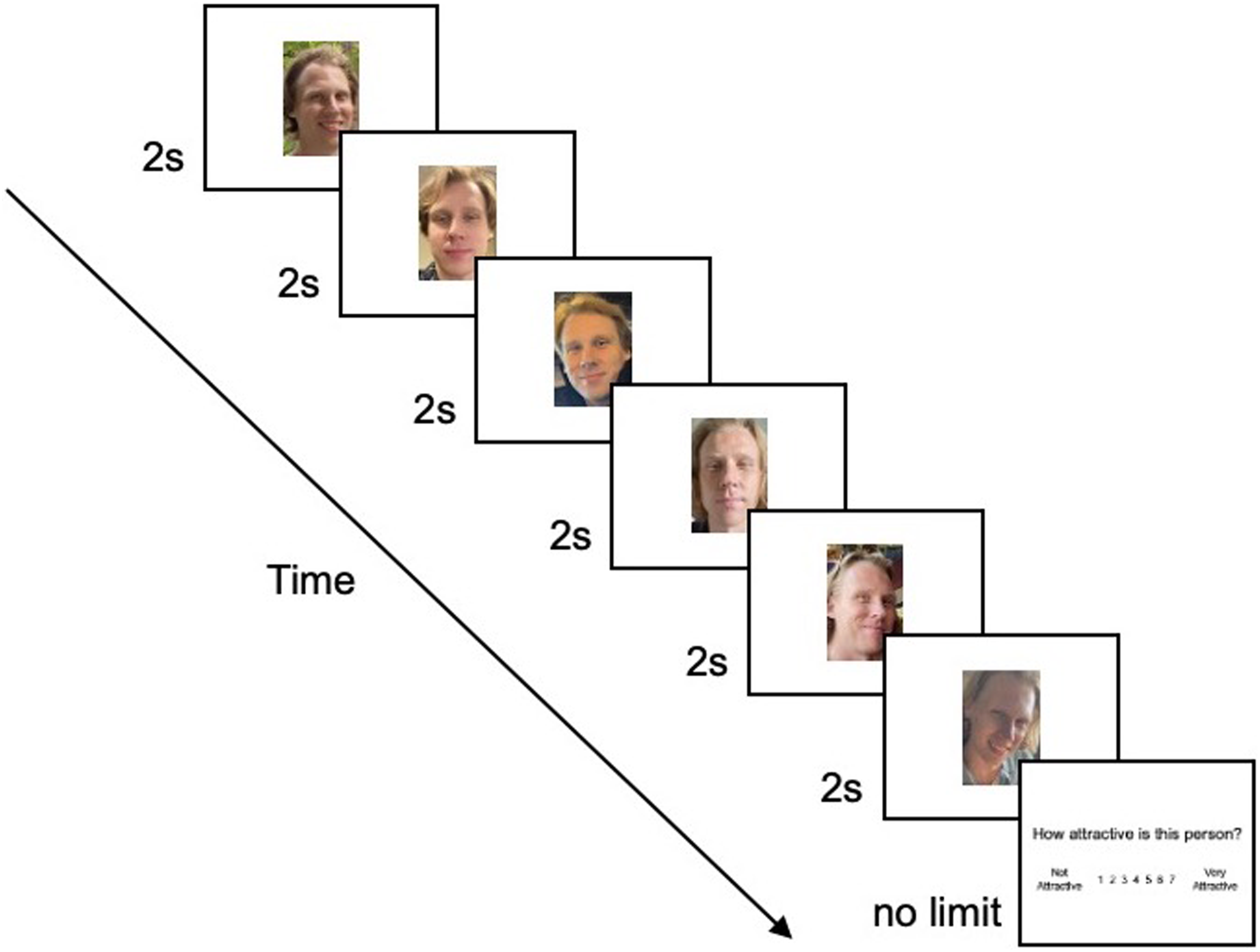
An illustration of the trial sequence. Each image was displayed for 2 s, with an interstimulus interval of 1 s (not shown here). Finally, participants provided an attractiveness rating for the person. (Copyright restrictions prevent publication of the original images used in these experiments. Images shown here feature an identity who did not appear in the experiments. He has given permission for his images to be reproduced here.)
Finally, upon completion of all 27 blocks, participants were presented with a ‘familiarity check’. A list of the names of the 27 identities was displayed onscreen. For each identity, participants rated their familiarity with the celebrity using a Likert scale ranging from 0 (unknown) to 4 (well known).
Results
No participants provided the same attractiveness rating for all 27 identities, and therefore no data were excluded for this reason.
Participant-Level Analysis
First, we excluded participants who gave a familiarity rating higher than 0 to any of the identities (n = 21) since we were interested in the impression formation of previously unfamiliar faces. However, since familiarity was assessed by presenting the names of the identities, we acknowledge that participants could have recognised the faces but not their names. Reassuringly, Goller et al. (2018) found no influence of familiarity in their work.
For participants who demonstrated no prior familiarity, the mean attractiveness rating across the remaining trials (identities) could not be used since this may have been strongly influenced by which identities were excluded. For instance, if a highly attractive identity was rated as familiar and therefore excluded, this would lower the resulting mean of the remaining ratings for reasons unrelated to the condition in which the sequences were seen. As such, data from these participants were excluded from analysis.
Next, for each remaining participant (n = 280), we calculated their mean attractiveness rating across all trials, and compared these for the ‘ascending’ versus ‘descending’ conditions using an independent samples t-test. We found that higher attractiveness ratings were given in the ‘descending’ (M = 4.03, SD = 0.91) in comparison with the ‘ascending’ condition (M = 3.81, SD = 0.85), t(278) = 2.11, p = .036, Cohen's d = 0.25 (see Figure 2).
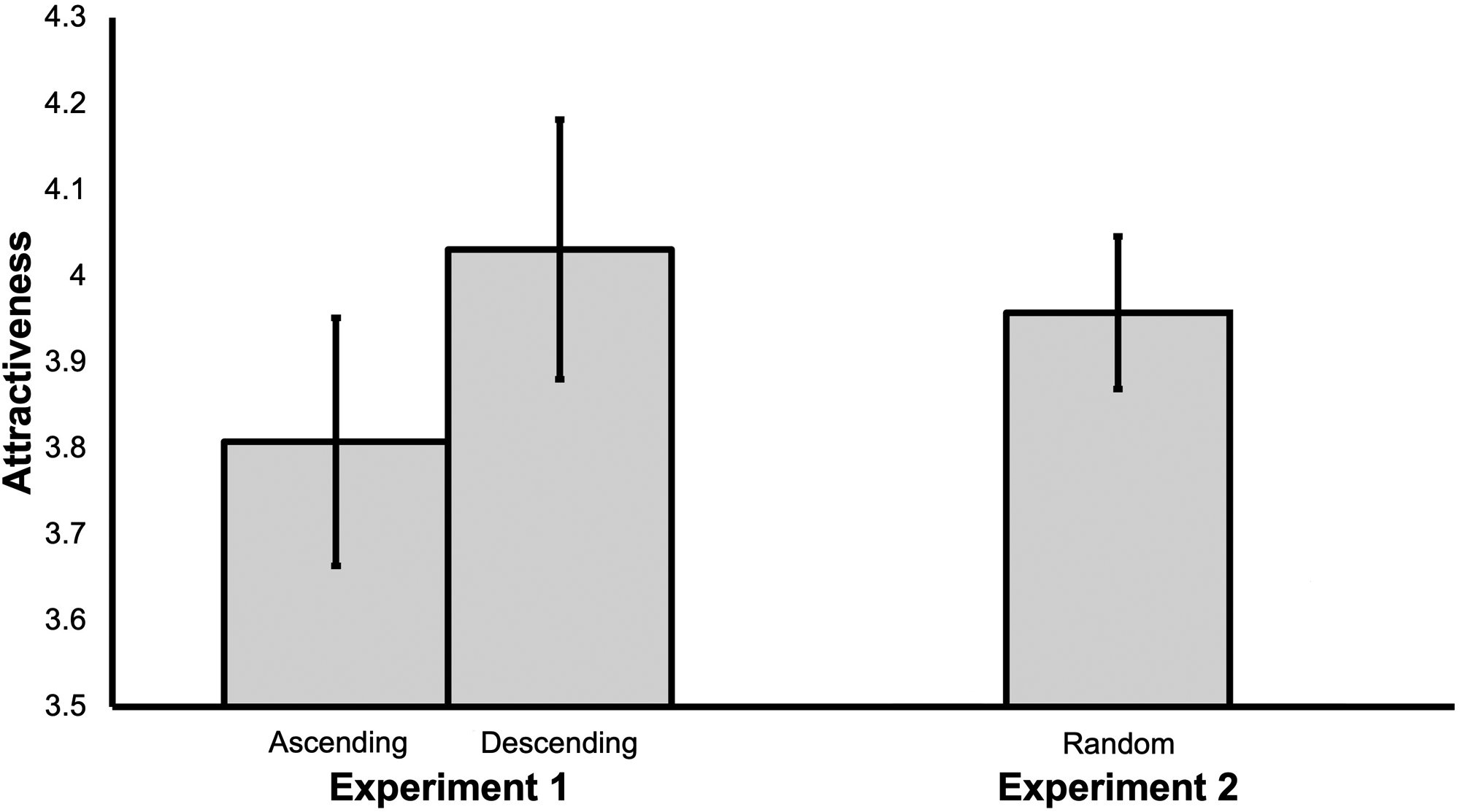
The participant-level results for Experiments 1 and 2. Error bars represent 95% confidence intervals.
Trial-Level Analysis
Given that all participants provided ratings for all identities, we analysed the trial-level data using a linear mixed-effects model with crossed random effects of participants and identities, where the latter equated to trials (since each trial collected a response on a different identity). Therefore, participants and identities variance were considered at Level 2 and residual variance at Level 1. In terms of the data set, each participant by identity observation was the unit of analysis, with each row of data indicating the response given by that participant to that identity (an attractiveness rating), along with the identity condition (ascending/descending). Participants’ attractiveness responses were excluded for identities for whom they had subsequently indicated a familiarity higher than 0, resulting in the loss of less than 1% of the data. (Note that these participants’ remaining responses were still included—an advantage of this type of analysis.)
Statistical analysis was carried out in R using a linear mixed-effects model (lme4 package—Bates et al., 2015). For significance reports, degrees of freedom were estimated using Satterthwaite's method (lmerTest package—Kuznetsova et al., 2017). The fixed effects were the intercept and the effect of identity condition. Only the intercept varied randomly across participants, whereas the intercept and the slope of the identity condition varied randomly across identities. Models using more complex random effects structures were identified as singular (Barr et al., 2013). We found a significant effect of identity condition, β = 0.22, SE = 0.10, t(287) = 2.08, p = .038, such that when identities were viewed in the ‘descending’ condition, they received higher attractiveness ratings. However, the outcome of a Bayesian analysis and subsequent Region of Practical Equivalence (ROPE; Kruschke, 2015) procedure was unclear, failing to find evidence in favour of, or against, the null hypotheses (60.42% in ROPE; for more information, see the Supplemental material).
Finally, Figure 3 illustrates the identity-level differences in the effect of identity condition. The gain in attractiveness for the ‘descending’ condition in comparison with the ‘ascending’ condition ranged from 0.57 to −0.22 on our 1–7 response scale.
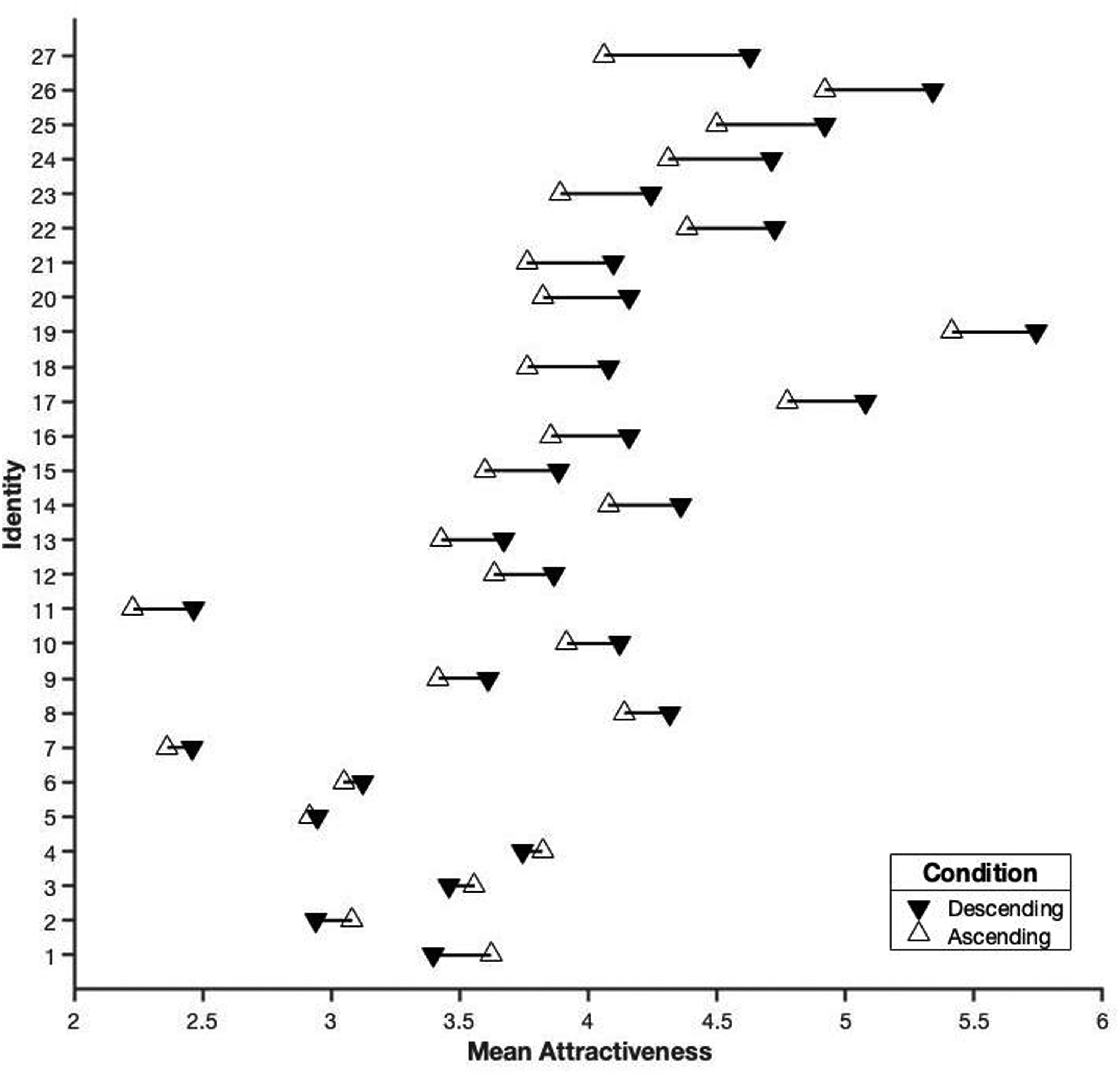
The difference in mean attractiveness rating for the two conditions, shown for each of the 27 identities separately. Identities are ordered from highest (top) to lowest (bottom) gain in attractiveness when presented in the ‘descending’ condition.
Discussion
In this first experiment, our aim was to replicate Goller et al.’s (2018) Experiment 1. However, we made several changes to their design in order to provide more conclusive results. By asking participants for attractiveness ratings of the person after the six-image sequence had finished, and with no seventh (test) image provided onscreen, we hoped to target participants’ formed impressions more directly without the potential influence of an additional image onscreen. We also focussed on entirely new ‘first impressions’ by excluding any responses given to previously familiar identities. In addition, we randomised the presentation order of the identities to avoid potential carryover effects from the previous sequence/identity seen or response given. (It was unclear why Goller et al. did not do this.) Finally, we considered the interrater agreement in our pre-experiment stimulus ratings and excluded any identities which failed to meet generally acceptable levels. (Again, there was no mention of this step in their experiment.)
With these alterations, we found the same pattern of results as Goller et al. (2018)—identities in the ‘descending’ condition received higher attractiveness ratings, suggesting an anchoring or primacy effect. Importantly, however, the key difference was in the size of this effect. While their results found a mean difference between conditions of 0.42 (giving a Cohen's d of 0.71, based on our calculations), our mean difference (0.22) and effect size (Cohen's d = 0.25) demonstrated a much smaller effect. Along with the above-mentioned alterations to the design, our sample (n = 280 for the t-test) was substantially larger than the sample used in their study (n = 38) and, as such, we believe their results may have overestimated the influence of this anchoring effect.
It is also worth highlighting that the average difference between the attractiveness values of the highest and lowest images in the six-image sequences was 1.75 scale units, providing an upper limit of sorts on an anchoring effect. In other words, if participants formed their impressions based solely on the first image they saw, we would have found a difference of around this magnitude between our two presentation conditions. Therefore, our finding of a 0.22 scale unit difference illustrates just how small this anchoring bias was shown to be.
Experiment 2
Earlier images were more influential than later ones when forming impressions of attractiveness in our first experiment. However, the effect was small. It is also crucial to remember that this effect represents the largest that could be found since we directly compared ‘descending’ versus ‘ascending’ image sequences. In the real-world, it is difficult to imagine a situation in which our exposure to a person would follow either of these orders. At best, one might choose to present one's most attractive self for a first meeting (or in the first image seen of an online dating profile), with subsequent encounters/images decreasing in attractiveness. However, it is unclear as to why someone would have a reason to start with their least attractive self and then systematically increase their attractiveness over time or across images (unless perhaps the aim was to disadvantage someone else).
For this reason, our second experiment investigated whether any influence of the earliest image(s) could be detected when image sequences were presented in a random order, representing a more realistic real-world exposure to a new person. If an anchoring or primacy effect is present then we should be able to see its influence on attractiveness ratings as the first image(s) in the sequence vary across trials and participants.
Method
Participants
Following the power analysis of Experiment 1, we aimed to recruit at least 105 participants for this experiment. However, in anticipation of carrying out finer-grained analyses based on the first few images in the sequence, we recruited as many participants as possible within the time available. A sample of 307 participants living in the UK (183 women, 120 men, two nonbinary, two preferred not to say; age M = 32.1 years, SD = 18.0 years; 93% self-reported ethnicity as White) gave informed, onscreen consent before taking part in the experiment and were provided with an onscreen debriefing upon completion. Participants were again recruited by word of mouth (e.g., through asking friends and family, and sharing the experiment's weblink on social media). There was no overlap between these participants and the sample featured in Experiment 1.
Stimuli
The same 27 identities, with six images per identity, were used here as in Experiment 1.
Procedure
The experiment was completed using the Gorilla online testing platform (Anwyl-Irvine et al., 2020), following the same procedure as Experiment 1. The only difference was that, for each identity's six-image sequence, the presentation order of these images was randomised for each participant.
Results
No participants provided the same attractiveness rating for all 27 identities and therefore no data were excluded for this reason.
Participant-Level Analysis
As in Experiment 1, we first excluded participants who gave a familiarity rating higher than 0 to any of the identities (n = 18). Next, for each remaining participant (n = 289), we calculated their mean attractiveness rating across all trials, and then compared these with the values produced by the participants in the ‘descending’ condition from Experiment 1 (n = 143) using an independent samples t-test. Equal variances were not assumed, given a statistically significant Levene's test (p = .013). We found no difference in attractiveness ratings for the ‘descending’ (M = 4.03, SD = 0.91) in comparison with the ‘random’ condition (M = 3.96, SD = 0.77), t(244) = 0.83, p = .409, Cohen's d = 0.09 (see Figure 2).
We also compared our participants with those in the ‘ascending’ condition from Experiment 1 (n = 137) using an independent samples t-test (equal variances assumed). We found no difference in attractiveness ratings for the ‘ascending’ (M = 3.81, SD = 0.85) in comparison with the ‘random’ condition, t(424) = 1.82, p = .070, Cohen's d = 0.19 (see Figure 2).
Trial-Level Analysis
As in Experiment 1, we analysed the trial-level data using a linear mixed-effects model with crossed random effects of participants and identities. Again, participants’ attractiveness responses were excluded for identities for whom they had subsequently indicated a familiarity higher than 0, resulting in the loss of less than 1% of the data.
In our first model, the fixed effects were the intercept and the rank of the first image presented in the sequence (from one to six, where one was the most attractive image). Only the intercept varied randomly across participants and identities. Models using more complex random effects structures were identified as singular (Barr et al., 2013). We found no significant effect of the first image's rank, β < 0.01, SE < 0.01, t(7930) = 1.31, p = .190, suggesting that the attractiveness of the first image in the sequence had no influence on the attractiveness given to the identity. This finding of a null effect was supported by an equivalent analysis using the Bayesian ROPE procedure (100% in ROPE; for more information, see the Supplemental material).
Since the results of Experiment 1 suggested that earlier images (i.e., the first three of the six) had a greater influence on impression formation than later images, we also considered a second model. If the initial impression is anchored not to the first image seen but to the first few, the average attractiveness rank of these first few images should predict subsequent ratings. Here, the fixed effects were the intercept and the average rank of the first three images presented in the sequence. Again, a lower value represented more attractive images. Only the intercept varied randomly across participants and identities. Models using more complex random effects structures were identified as singular (Barr et al., 2013). We found no significant effect of the average rank of the first three images, β < 0.01, SE = 0.02, t(7931) = 0.55, p = .582. Again, this finding of a null effect was supported by an equivalent analysis using the Bayesian ROPE procedure (100% in ROPE; for more information, see the Supplemental material).
Discussion
For the (small) effect of anchoring found in Experiment 1 to demonstrate any real-world outcomes in terms of perception or behaviour, the ‘descending’ condition would need to result in different first impressions to those produced by random sequences of images (i.e., ones not sorted for attractiveness, representing a notional ‘baseline’). Here, we found that there was no increase in the attractiveness rating given to a person following a ‘descending’ order of image presentation in comparison with randomly ordered images. In addition, there was no decrease in attractiveness rating resulting from an ‘ascending’ presentation in comparison with our ‘random’ condition.
Initial impressions are formed on the basis of minimal information (e.g., Zebrowitz, 2017) and from as little as a single face photograph visible for 100 ms (Willis & Todorov, 2006). Thus, even viewing an additional five images of the person, as in the present study, affords an opportunity to update the impression gleaned from the initial encounter. If the initial impression persists, it should not much matter as to whether subsequent images are presented in descending order by attractiveness or randomly. However, for images presented in random orders, we failed to detect any influence of the earlier images in the sequence on impression formation, with our Bayesian approach providing strong evidence of no effect.
Reassuringly, the mean attractiveness ratings (across all identities) for the ‘random’ condition (M = 3.96) in this experiment fell between the Experiment 1 values for the ‘descending’ (M = 4.03) and ‘ascending’ (M = 3.81) conditions, as we would expect. However, it is clear that the increase in ratings produced by ordering the images from highest to lowest attractiveness is negligible in comparison with simply presenting the images in a random order.
General Discussion
While we know that first impressions based on the faces of strangers are formed quickly (e.g., Willis & Todorov, 2006), it is less clear how these impressions may change with the incorporation of additional exposures or information. Previous work has supported an anchoring or primacy effect, whereby the initial images in a sequence provided an anchor for participants’ impressions of attractiveness (Goller et al., 2018). As a result, the later images in the sequence played a lesser role in the overall impression formed.
In our first experiment, using a similar experimental design to Goller et al. (2018), we replicated their finding of an anchoring effect. However, the size of this effect was smaller than the previous authors had shown. When comparing the two most extreme contexts for impression formation—viewing the images in descending versus ascending order of attractiveness—we found that the former resulted in attractiveness ratings that were only, on average, 0.22 scale points higher on a 1–7 scale. Indeed, a comparison of this descending condition with one in which the images were simply presented in a random order (Experiment 2) showed no difference between these two conditions. Further, we failed to detect a significant influence of the first image's attractiveness, or the average attractiveness of the first three images, on resulting impressions. Therefore, we argue that any anchoring effect is small and likely plays no measurable role in impression formation, at least within the experimental paradigm used here. However, researchers may still want to consider our results when making decisions regarding order and carryover effects when designing their experiments if these are likely to influence potential outcomes.
Ironically, Goller et al. (2018) were motivated by Asch (1946), who presented a list of character descriptions to explore impression formation. List A began with positive items, with these becoming more negative as the list progressed (e.g., intelligent, industrious, impulsive, critical, stubborn, envious), while List B was simply these same items in reverse order. Asch found a strong effect of anchoring, resulting in more positive impressions when presented with List A. However, recent attempts to replicate these findings identified a smaller effect (Sullivan, 2019), and we mirror this pattern in the current work by replicating the anchoring effect identified by Goller et al. (2018) while showing that it too is smaller than previously thought.
Primacy and recency effects were initially established in relation to memory, where participants better recalled the early and late items in a list of words in comparison with those appearing in the middle of a list (e.g., Glanzer & Cunitz, 1966; Waugh & Norman, 1965). In the current work, we found that primacy did not consistently influence impression formation, where it is thought that an internal representation of a face is produced in order to summarise the information experienced so far regarding its appearance. It may be possible that an ensemble encoding of the face is simply an unweighted average of all exposures (e.g., Kramer et al., 2015), while the recollection of particular instances could still show serial-position effects. Indeed, Kramer et al. (2015) provided evidence that participants formed an internal average when viewing multiple images of the same face, while also demonstrating good memory for exemplars from the set. As such, further research should investigate the presence of primacy and/or recency effects relating to the storage and recognition of instances within a sequence, which may be evident despite the lack of a higher weighting given to early or late instances when forming overall impressions.
Intuitively, we argue that it makes little sense to place more weight on early instances when forming a facial representation. Presumably, that representation is consulted during recognition, as well as trait judgements, and people's faces can change dramatically over time (i.e., due to aging and other alterations). As such, if anything, it would be more logical to depend more heavily on more recent exposures since these represent one's ‘best guess’ at how the person currently appears. Indeed, only in our very recent evolutionary history have we been able to create accurate external representations of faces (i.e., via drawings, paintings, photographs, etc.). Prior to this, the only way to access how a person's face used to look was through our (fading) memories. Therefore, it is difficult to imagine, for instance, giving higher weighting to the memory of your friend's face from ten years ago, compared with seeing her face yesterday, if the goal was to represent them in a way that provided some utility. However, we acknowledge that many cognitive biases may not adhere to a logical or rational approach (e.g., stereotypes) and so what is true of representing faces for the purpose of recognising them may not be true for the processes involved in impression formation. Moreover, while there may be no reason to remember what a person looks like after our first encounter with them if we do not anticipate encountering them again, it may be adaptive from an evolutionary perspective to assess whether they are attractive or trustworthy.
Of course, we know that recognition can still succeed even after a long period without any exposure to a person's face, where there have been few or no opportunities to update the representation of their identity. To establish a mental representation of someone that is sufficient to allow them to be identified on a subsequent occasion, exposure to a range of their within-person variability is required (Burton et al., 2011). Assuming that the first few encounters with a person are sufficient to consolidate a representation of their identity that achieves this goal (e.g., Corpuz & Oriet, 2022), additional encounters might not be helpful in refining this representation much further if their appearance shows little variability across these instances. This raises the possibility that while something like an anchoring effect may not contribute much to impression formation, the first few exposures may contribute disproportionately to establishing a representation that supports face recognition.
In the current work, we focussed on impression formation with regard to attractiveness judgements. However, the judgements we make in our everyday lives involve a wide variety of social traits, although these may be underpinned by only two or three fundamental dimensions (e.g., Jones & Kramer, 2021; Oosterhof & Todorov, 2008; Sutherland et al., 2013). It is possible that the time course describing how our impressions are formed differs across traits (Bar et al., 2006; South Palomares & Young, 2018). In contrast, if the same internal representation (once formed) is consulted when requiring judgements for all traits then we would predict that any primacy or recency effect in the formation of this representation would be the same no matter the trait under consideration. Of course, this remains an empirical question that future studies might seek to answer.
To summarise, the current work demonstrated that whether anchoring influences the formation of first impressions of attractiveness is highly dependent on the nature of successive encounters. Viewing images in descending, in comparison with ascending, order of attractiveness produced a statistically significant increase in ratings. However, the size of the effect was small. Moreover, when compared with images presented in a random order, we found no attractiveness benefits associated with the descending order. Further, we failed to detect a significant influence of the earliest images’ attractiveness on overall judgements during this random order viewing. This suggests that initial encounters with an image may anchor impressions only in the specific case where subsequent encounters (exposures) systematically increase or decrease in attractiveness over time—conditions we have argued are unlikely to be observed in the real world.
Supplemental Material
sj-docx-1-pec-10.1177_03010066241284956 - Supplemental material for Anchoring has little effect when forming first impressions of facial attractiveness
Supplemental material, sj-docx-1-pec-10.1177_03010066241284956 for Anchoring has little effect when forming first impressions of facial attractiveness by Robin S. S. Kramer, Yaren Koca, Michael O. Mireku and Chris Oriet in Perception
Footnotes
Acknowledgements
The authors thank our Research Skills III students for collecting the data.
Author Contribution(s)
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.