
Abstract
Perceiving facial attractiveness is an important behaviour across psychological science due to these judgments having real-world consequences. However, there is little consensus on the measurement of this behaviour, and practices differ widely. Research typically asks participants to provide ratings of attractiveness across a multitude of different response scales, with little consideration of the psychometric properties of these scales. Here, we make psychometric comparisons across nine different response scales. Specifically, we analysed the psychometric properties of a binary response, a 0–100 scale, a visual analogue scale, and a set of Likert scales (1–3, 1–5, 1–7, 1–8, 1–9, 1–10) as tools to measure attractiveness, calculating a range of commonly used statistics for each. While certain properties suggested researchers might choose to favour the 1–5, 1–7 and 1–8 scales, we generally found little evidence of an advantage for one scale over any other. Taken together, our investigation provides consideration of currently used techniques for measuring facial attractiveness and makes recommendations for researchers in this field.
First impressions based on facial appearance are formed rapidly (Willis & Todorov, 2006), without awareness (Olson & Marshuetz, 2005), and are mandatory (Ritchie et al., 2017). The nature of these impressions can have a substantial impact on how we subsequently behave towards others. For instance, individuals who appear less trustworthy may receive harsher criminal sentences (Wilson & Rule, 2015) while those who are perceived to be more competent have a greater likelihood of success in political elections (Ballew & Todorov, 2007). Attractiveness in particular plays an influential role in our first impressions, with the ‘halo effect’ (Dion et al., 1972) describing how socially desirable traits are applied indiscriminately to attractive people. As a result, being attractive comes with numerous benefits. For example, attractive people are given more help (Benson et al., 1976), earn higher wages (Pfeifer, 2012) and enjoy more frequent hiring opportunities (López Bóo et al., 2013). It also follows that attractiveness influences mating success (Rhodes et al., 2005). Given the significance of perceived attractiveness on a variety of real-world outcomes, it is unsurprising that researchers have been investigating these perceptions for many years. This, of course, then begs the question: how should perceived attractiveness be measured?
One approach is to measure perceptions of attractiveness implicitly, focussing on behavioural or physiological responses that are outside of conscious awareness. For instance, we tend to look longer and more often at attractive faces (e.g., Leder et al., 2016a, 2016b), they cause our pupils to constrict (Liao et al., 2021), and they capture our attention when presented outside foveal vision (Sui & Liu, 2009). Attractive faces also attract hand movements during mouse tracking paradigms (Faust et al., 2019) and we lean more towards them during passive viewing (Kramer et al., 2020). Finally, both brain activity (e.g., Ueno et al., 2014; Winston et al., 2007) and skin conductance (McDonald et al., 2008) have been shown to reflect our perceptions of facial attractiveness. Although these techniques might be considered more direct measures of our perceptions in the sense that we are typically unaware of our responses, they often require additional equipment, logistical considerations, and expertise.
Perhaps the simplest way to measure attractiveness perceptions, and certainly the most prevalent in the literature, is to ask participants directly. This is often achieved by using a rating scale. Although typically presented in the form of a Likert scale (e.g., Kramer et al., 2013), this explicit judgement might also be represented as a visual analogue scale (VAS; e.g., Dourado et al., 2021; Hofmans & Theuns, 2008) or a binary choice (e.g., Taubert et al., 2016). For researchers who opt for a Likert scale, a decision must still be made as to the range of options available, for instance: 1–3 (e.g., Cooper et al., 2006; Ma, Xu, et al., 2015), 1–5 (e.g., Langlois & Roggman, 1990), 1–7 (e.g., Ma, Correll, et al., 2015; Penton-Voak et al., 2001; Rhodes et al., 2005; Sutherland et al., 2013), 1–8 (e.g., Pegors et al., 2015), 1–9 (e.g., Oosterhof & Todorov, 2008), or 1–10 (e.g., Kampe et al., 2001; Kramer et al., 2013). Other scales used in research have included −5 to +5 (e.g., Skrinda et al., 2014) and 0–100 (e.g., Kramer & Jones, 2022; Orghian & Hidalgo, 2020), although this list is far from exhaustive. The appeal of such scales is their ease of use, allowing them to be employed with children (e.g., Ma, Xu, et al., 2015) and those with intellectual disabilities (Donnachie et al., 2021). Rating scales are also well-suited for use with online data collection (e.g., Kramer & Pustelnik, 2021), which is not the case for many of the more direct measures of perception mentioned earlier. It is worth noting that other methods may provide more reliable measures of facial attractiveness perceptions (e.g., best-worst scaling; Burton et al., 2019, 2021) but, as yet, this has not impacted the widespread use of rating scales.
While little has been done in considering whether different scales affect outcomes for attractiveness perceptions, psychometricians have been comparing the use of scale types more generally for several decades (for a review, see Cox, 1980). To determine the optimum number of response categories, one must account for possible advantages and disadvantages. For instance, short scales with few response options may be too coarse when attempting to capture raters’ discriminative powers. In contrast, too many response options may go beyond the raters’ discriminative abilities while adding superfluous choices. Initially, researchers argued that 3-point scales were sufficient when measuring participants’ opinions with respect to reliability and validity considerations (e.g., concerning agreement with statements regarding values – Jacoby & Matell, 1971). However, others noted that the motivation for data collection is key – if the aim is to average responses across participants then 2- or 3-point scales are sufficient, while 5- to 7-point scales are required if the focus is to investigate individual behaviour (as demonstrated through the use of simulations; Lehmann & Hulbert, 1972). Although there are typically high correlations between ratings provided using different lengths of scale (e.g., when considering the quality of a recent service provider – Colman et al., 1997; when considering treatment goals following surgery – Lange et al., 2020), those with more response options tend to produce data more closely resembling a normal distribution (e.g., for a self-esteem questionnaire – Leung, 2011). In general, it seems that larger numbers of responses have the effect of improving both reliability and validity (for a survey measuring life satisfaction – Alwin, 1997; for measuring the quality of a service provider – Preston & Colman, 2000), although beyond seven options, this improvement is minimal (with simulated data – Lozano et al., 2008).
Investigations into how participants use response scales have revealed several different response styles that might be displayed. For instance, some people may tend to choose the most extreme responses while others may favour the more positive options of the scale (e.g., when considering agreement with attitudinal statements covering various topics – Baumgartner & Steenkamp, 2001). Through considering a survey measuring impulsive purchasing and comparing response scales ranging from four to nine points, alongside the use of eye tracking techniques, Chen et al. (2015) found that only the 6-point scale suffered from greater attention to the positive options, while the longer scales (7–9 points) showed evidence of participants attending more to the extreme responses. Further, the 5- and 7-point scales required the least cognitive effort (i.e., the shortest response times). Finally, evidence suggested that the inclusion of middle points (e.g., a 5- rather than 4-point scale) was beneficial in that their presence shifted response proportions away from the remaining options (with the assumption that utilised options provide additional information), with the added advantage of decreasing extreme response styles (Weijters et al., 2010). Interestingly, as the number of response options increased, the effect of removing the middle point decreased. Chen and colleagues concluded that, weighing up these advantages and disadvantages, their 5-point scale was optimal.
Another available option to researchers is the VAS, where participants can select any location along a line to represent their response. The idea is that VAS is more sensitive as a measure because of its small gradations, and responses using this type of scale have been shown to be linear (e.g., when measuring job satisfaction or the attractiveness of faces – Hofmans & Theuns, 2008). However, evidence suggests that VAS responses are strongly correlated with those produced using Likert scales, while users tend to prefer the latter due to their ease and simplicity (e.g., when measuring facial pleasantness – Dourado et al., 2021). Further, VAS may not provide any psychometric advantages beyond scales incorporating six or more response options (e.g., with personality questionnaires – Simms et al., 2019).
Considering further the notion that participants show preferences for some scales over others, Preston and Colman (2000) investigated lengths of scale ranging from 2 to 11 response options when participants were asked about the quality of a service provider. Participants judged the 5-, 7- and 10-point scales as the easiest to use. However, those rated as the quickest to use were those with the fewest options: 2-point, 3-point and 4-point scales. Finally, when considering which scales allowed the participants to express their feelings adequately, participants preferred the longest scales (9–11 response options). Overall, the researchers suggested that the most preferred scale length was 10 points, closely followed by the 7-point and 9-point scales.
While psychometricians have long debated the different characteristics of these various scales, researchers within the field of face perception have yet to give it consideration. As is clear from the literature, research on this topic spans a wide range of disciplines but there remains little overlap with considerations of facial attractiveness at present (e.g., Dourado et al., 2021). We therefore take the first steps in exploring the psychometrics of the various response scales used when judging facial attractiveness by investigating a variety of scale properties, including several measures of inter-rater agreement and within-person consistency, as well as quantifying shared versus private taste, all of which may vary depending on the number of available responses. We also focus on scale use, examining how often different response options are chosen, as well as face-level outcomes, by comparing how the attractiveness assigned to each face differs across response scales.
Method
Participants
A sample of 567 volunteers (362 women, 193 men, 10 nonbinary, 1 nonconforming, 1 preferred not to say; age M = 30.5 years, SD = 15.4 years; self-reported ethnicity: 3% Black, 4% Asian, 90% White, 3% Mixed or Other or preferred not to say) provided written, informed consent online before taking part, and received an onscreen debriefing upon completion of the experiment. Participants were recruited via student researchers as part of their ‘research skills’ module. This study was approved by the University of Lincoln's ethics committee (ref. 10146) and was carried out in accordance with the provisions of the World Medical Association Declaration of Helsinki.
The data from an additional 73 participants were excluded because these individuals either responded incorrectly to one or more attention checks (see below for details) or provided the same response for all images within a block. As such, we could be confident in the quality of our remaining data.
Stimuli
From a larger set of facial photographs featured in the Chicago face database (Ma, Correll, et al., 2015), we considered only the White models (93 men and 90 women). This allowed us to focus on response method while avoiding the additional influence on ratings due to the presentation of face sequences varying in ethnicity (e.g., Kramer et al., 2013). All individuals wore grey t-shirts and were photographed in colour, front-on, and posed with a neutral expression at a fixed distance from the camera.
Norming data for these images were provided alongside the database and included attractiveness ratings, given using a Likert scale (1 = not at all, 7 = extremely). From these 183 models, we selected a final set of 20 women (attractiveness M = 3.42, SD = 1.01) and 20 men (attractiveness M = 3.01, SD = 0.71) who evenly spanned the full range of attractiveness values represented by the initial set of images.
Procedure
The experiment was carried out using the Gorilla online testing platform (Anwyl-Irvine et al., 2020). Information was collected regarding the participant's age, gender and ethnicity. Participants were prevented from using mobile phones (via settings available in Gorilla) to ensure that images were viewed at an acceptable size onscreen.
Each participant judged all 40 images, presented in a random order, with the question ‘How attractive is this face?’ appearing at the top of the screen. Upon completion of this first block, participants were instructed onscreen that they were halfway through the task, and that they would see all of the faces again. At this point, participants were presented with all 40 images in a random order and again judged the attractiveness of the images. Both blocks were presented within the same condition (see below), and so judgements always followed the same response requirements for a given participant.
Participants were randomly assigned to one of ten conditions in which the available response requirements differed. Six of these conditions were Likert scales (1–3, 1–5, 1–7, 1–8, 1–9, 1–10), with labels displayed alongside the lowest (‘unattractive’) and highest (‘attractive’) values. The seventh condition required a binary response (unattractive/attractive), with only these two options (and no values) presented.
The eighth condition featured a 0–100 (i.e., 101-point) scale, where participants moved a slider along a line to select their response. The current position of the slider (a value from 0 to 100) was displayed onscreen, allowing participants to alter and refine their choice as needed before submitting their response. Labels were displayed alongside the left (‘unattractive’) and right (‘attractive’) endpoints of the line. Closely resembling this condition, the ninth condition was a VAS. The only difference between the 0–100 and the VAS conditions was that the latter did not display a value indicating the slider's position. As such, participants made their response based solely on the slider's visual position along the line. (Again, participants could alter and refine their choice before submission.) For both of these conditions, the line was initially presented without a slider, which then appeared as a result of the participant's first selection along the line (and could then be altered). As such, participants were not able to skip through trials by relying simply on the slider's default position (since there was no such position).
Finally, we included a ‘text response’ condition. Here, in addition to the question ‘How attractive is this face?’, participants were provided with the prompt ‘Describe your impressions of the attractiveness of this face’ and given a textbox in which to type their response. There was no limit placed on the length of response that could be entered. Participants completed only one block for this condition, given the longer time taken in comparison with simply rating the faces, and also that within-person agreement was not a consideration. For all ten conditions, responses were self-paced with no time limit.
In each block of images across all conditions, we also included an attention check within the randomly ordered presentation of faces, given that attentiveness is a common concern when collecting data online (Hauser & Schwarz, 2016). Each of these trials instructed the participant to respond with the lowest or highest option available for that condition. For instance, the text ‘Attention Check: Please respond with “9” for this face’ replaced the internal features of a face (not included in the 40 test faces) that was displayed onscreen. Across the two blocks, one attention check required the lowest response option available (e.g., ‘1’) and the other required the highest (e.g., ‘9’). For the attention check included in the single block for the ‘text response’ condition, participants were required to enter the word ‘house’ into the textbox as their response.
Results
The data from the 32 participants who completed the ‘text response’ condition will be the focus of a separate manuscript and will not be considered further here. The sample included in the following analyses therefore comprised 535 participants, with their trial-level response data available at https://osf.io/s8qp4/.
The measures of inter-rater agreement and within-person consistency presented here were, for the most part, also those investigated by Kramer et al. (2018). More information on each of these measures can be found in their article. In all cases below, Spearman's rank correlation coefficient was used as the measure of association. Following Kramer and colleagues, we have provided confidence intervals to illustrate the precision of our measures. For both measures of intraclass correlation, IBM SPSS Statistics v28 provided values for the 95% confidence intervals. However, for the remaining measures, there is no established method for obtaining interval estimates. We therefore used a bootstrapping procedure in MATLAB, over 10,000 samples with replacement, to estimate standard errors, and subsequently, confidence intervals.
We considered the binary response condition separately (see below) since our measures of inter-rater agreement and within-person consistency could not be calculated for this type of response.
Inter-Rater Agreement
Despite these criticisms, we calculated this measure for our scales to allow for comparison with each other, as well as with previous literature. As Table 1 illustrates, Cronbach's α was high for all scales and showed little variation.
A summary of measures for eight conditions regarding inter-rater agreement.
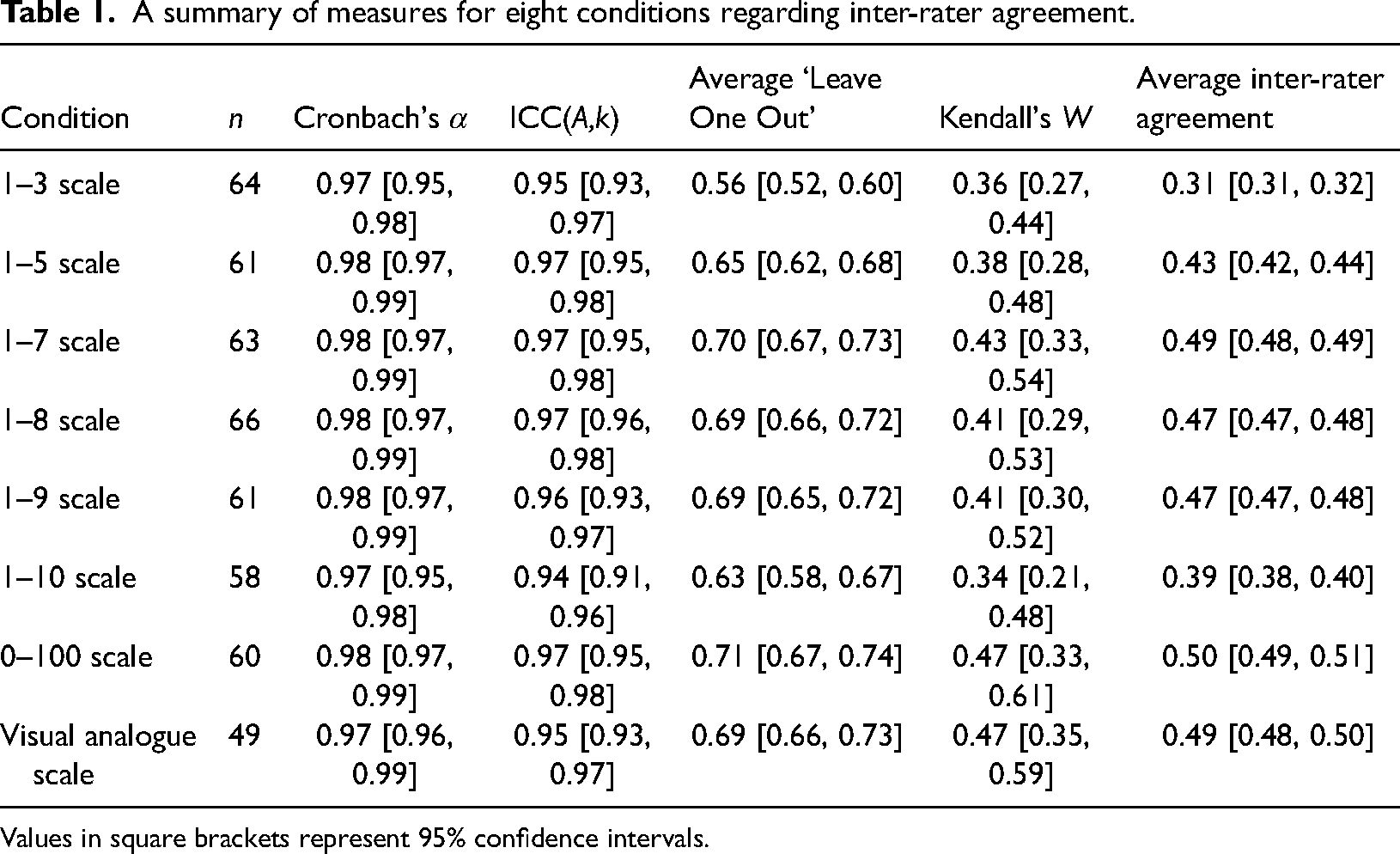
Values in square brackets represent 95% confidence intervals.
Within-Person Consistency and Shared/Private Taste
To quantify within-person consistency (i.e., test-retest reliability), we correlated each rater's responses given during the first block with those from the second block. These correlations were then averaged (using Fisher's transformations as above). For all scales, consistency was high, although it appears to decrease for scales with fewer response options (see Table 2). It is interesting to note that these high within-person correlations (0.72–0.79), alongside the substantially lower values for the average inter-rater agreement (0.31–0.50), suggest that private taste features heavily in these perceptions. While raters agreed strongly with themselves, their agreement with others was far lower.
A summary of measures for eight conditions regarding within-person consistency and shared/private taste.
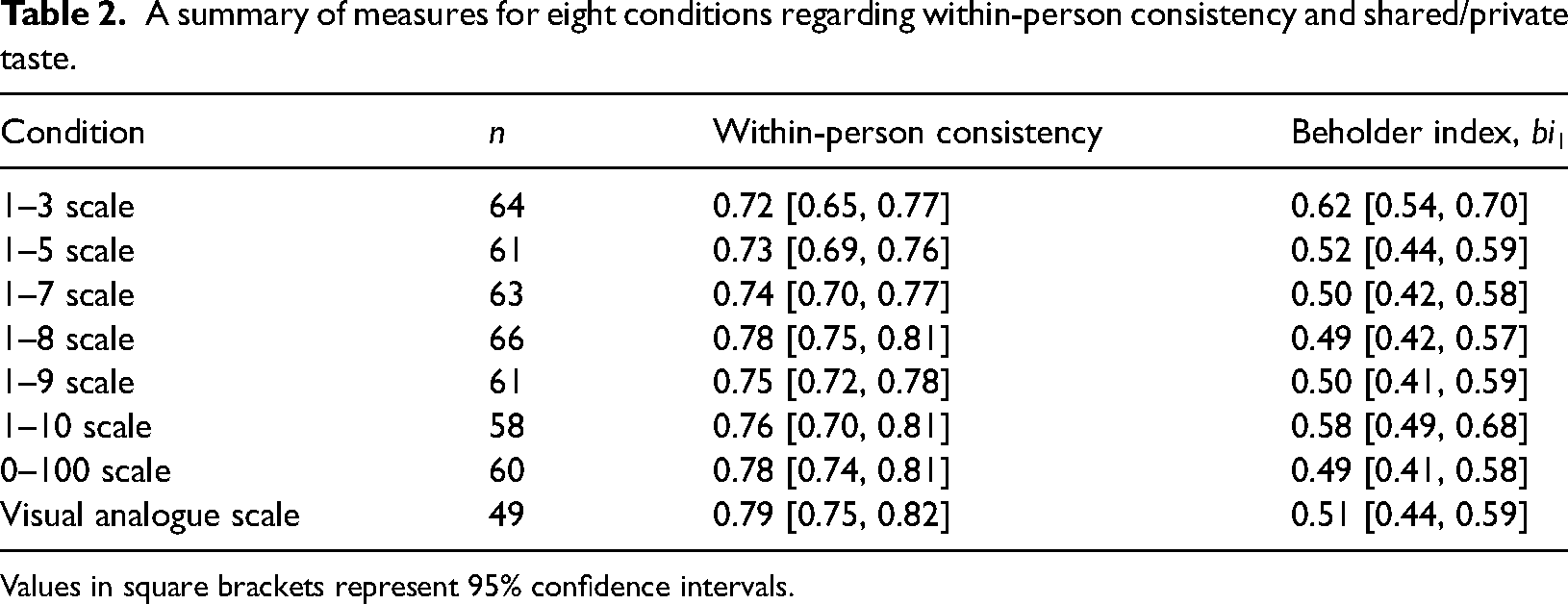
Values in square brackets represent 95% confidence intervals.
With the goal of quantifying the contributions of shared versus private taste, Hönekopp (2006) proposed a measure which represented the proportion of meaningful variance stable across time that arises from private taste – the beholder index, bi. By asking participants to rate the set of faces twice, one can differentiate between the observed variance attributed to participants, stimuli, time and their interactions. Here, we calculated bi1 (the version of this index where absolute rater-score differences are assumed to be meaningless), with higher values representing greater contributions of private taste, and found that values were generally similar across scales, although somewhat higher for the 1–3 and 1–10 scales (see Table 2). A value of 0.50 represents equal contributions of shared and private taste, which was typically shown here.
Decomposing Variability Using Multilevel Models
Another way to consider how rating scales may differ in terms of their use is to decompose the variability in attractiveness ratings using multilevel models (following Hehman et al., 2017). This approach utilises the fact that multiple ratings were made by each participant and multiple ratings were given to each face. Since participants rated each face twice, a cross-classified model can estimate four sources of variability: (1) perceiver ICC – representing consistent differences between participants; (2) target ICC – accounting for consensually agreed-upon elements of attractiveness; (3) interaction ICC – quantifying personal/private taste; and (4) residual – measuring within-person consistency.
We used hierarchical Bayesian models to estimate these variance components. For each rating scale separately, these models fit a grand intercept parameter, a residual standard deviation (i.e., error), and the standard deviations of three normal distributions with means of zero that the individual random effects were drawn from, for participants, faces, and the interaction between the two, respectively. By squaring these four standard deviations (the residual and three random effects), we obtained the total variance, and the contribution of each source was then obtained by dividing the variance estimate by the total. Note that, despite using Bayesian inference, we simply took the mean of the posterior distribution of these values to aid clarity, as well as comparison with previous work.
The results of this analysis are shown in Figure 1. Overall, we found that the response scales were relatively similar in terms of their decomposition. However, our results suggest that private taste (interaction ICC) perhaps played a smaller role for the 1–7 and 1–9 scales, and a larger role for the 1–3 scale (with this latter result aligning with the bi1 findings above). Inspection of the residual indicates that within-person consistency was lower (i.e., producing a larger residual) for scales with fewer response options (aligning with the pattern suggested in Table 2). Finally, we note that there were greater differences between participants (perceiver ICC) when using the 1–9 and 1–10 scales, which perhaps represents a disadvantage of using these particular scales.
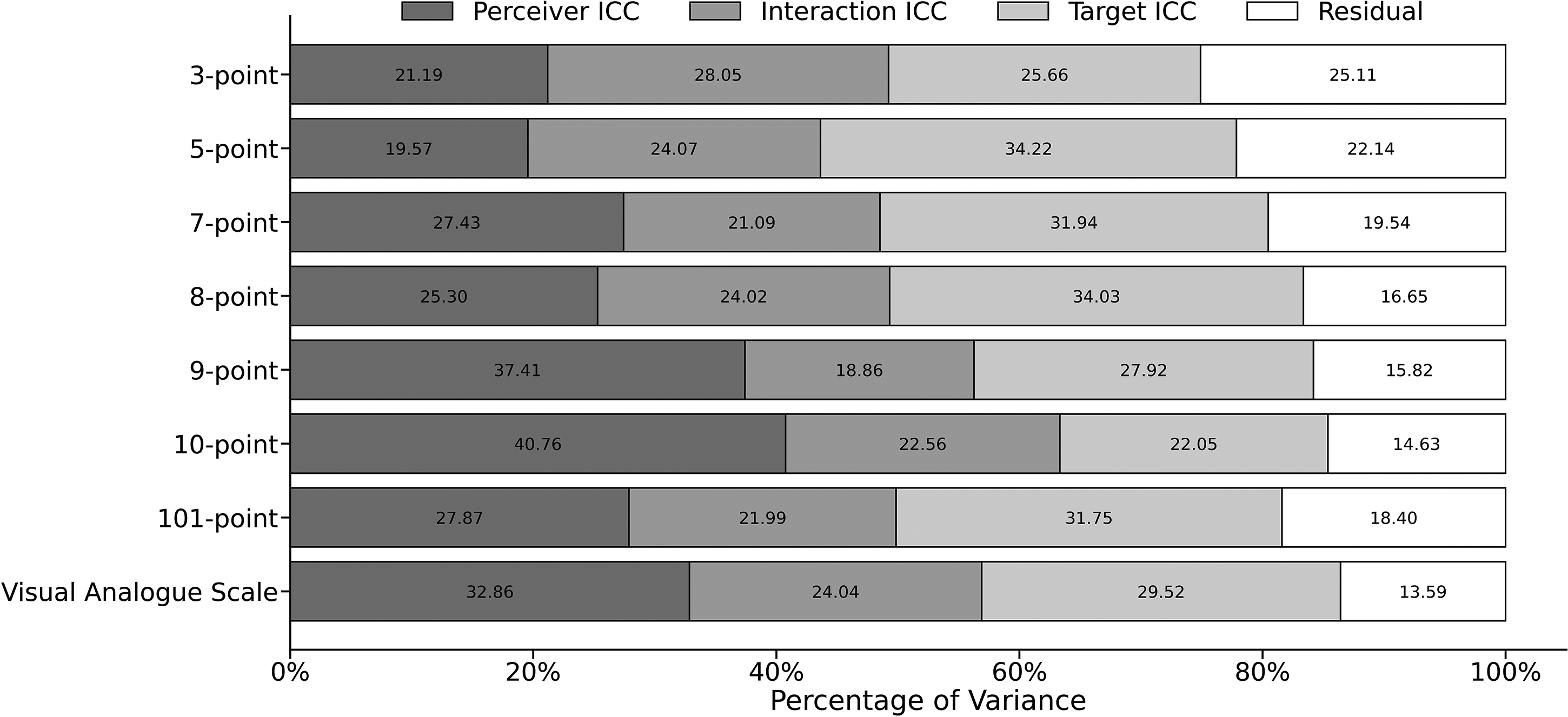
Relative contributions of between participant (perceiver ICC), between face (target ICC), between participant×face combinations (interaction ICC), and the residual, separately for each response scale.
Binary Response
Fifty-three participants completed the binary scale condition, where responses were limited to two response options: ‘unattractive’ or ‘attractive’. Typical measures of inter-rater agreement and within-person consistency could not be calculated here, given the binary nature of the data. As such, to quantify inter-rater agreement, we calculated a version of the average inter-rater agreement described above. However, rather than calculating the correlation between every possible pair of raters, we calculated the proportion of responses that were the same for these pairs. The average proportion was 0.66, 95% CI [0.65, 0.66], denoting that 66% of responses were identical for a given pair of raters (on average).
In order to quantify within-person consistency, we calculated the proportion of responses that were the same when comparing each rater's first and second blocks. The average proportion across all raters was 0.89, 95% CI [0.87, 0.91]. In other words, on average, participants repeated 89% of their responses across the two blocks.
Scale Use and Simple Equating
As a final step, we explored the frequency of scale use across each scale, simply by calculating the frequency of responses across both faces and raters. These frequencies are shown in Figure 2. To check if scale use was relatively consistent between scales, we estimated a simple linear association between each scale and the VAS, as the VAS is an unconstrained, continuous measure with no feedback on the response values. We averaged the responses in each scale for each face, and then carried out a series of regressions, predicting VAS scores from each scale separately. The slope from each regression indicates the amount of change in a scale that leads to a one-unit increase in the VAS. We used Bayesian estimation (with flat priors on the predictor) and recovered the posterior of the predictor. These are shown in Figure 3. If responses are used consistently between rating scales, a straightforward hypothesis is that the continuous response was simply divided between the available categories. For example, the 101-point scale mapped to the 1–3 point scale would mean that faces scoring below approximately 33 on the VAS would be given a 1, between 33 and 66 a 2, and so on. Regressing the 1–3 scale onto the VAS would then yield the amount that the VAS changes with a one-unit change in the 1–3 scale. As can be seen in Figure 3, the 1–5, 1–7, 1–8 and 101-point scale posterior estimates captured this naïve equating hypothesis – the equal division point was within the posterior estimate. However, the binary, 1–3, 1–9 and 1–10 scales showed an upward bias, such that the coefficient was greater than the simple division point.
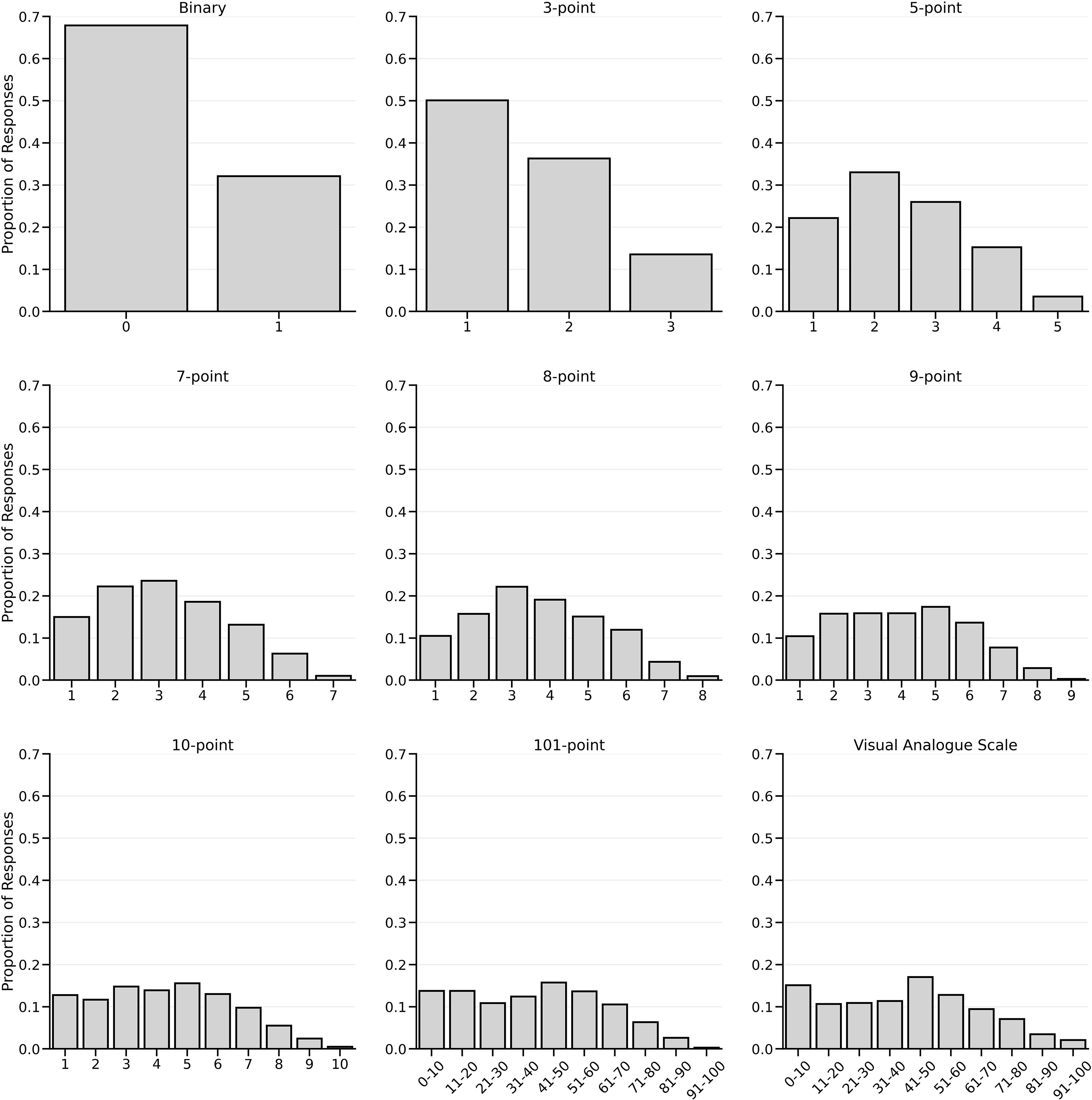
Histograms displaying the proportion of responses for each response option for each scale. The 101-point and VAS scales are binned within decile ranges for clarity.
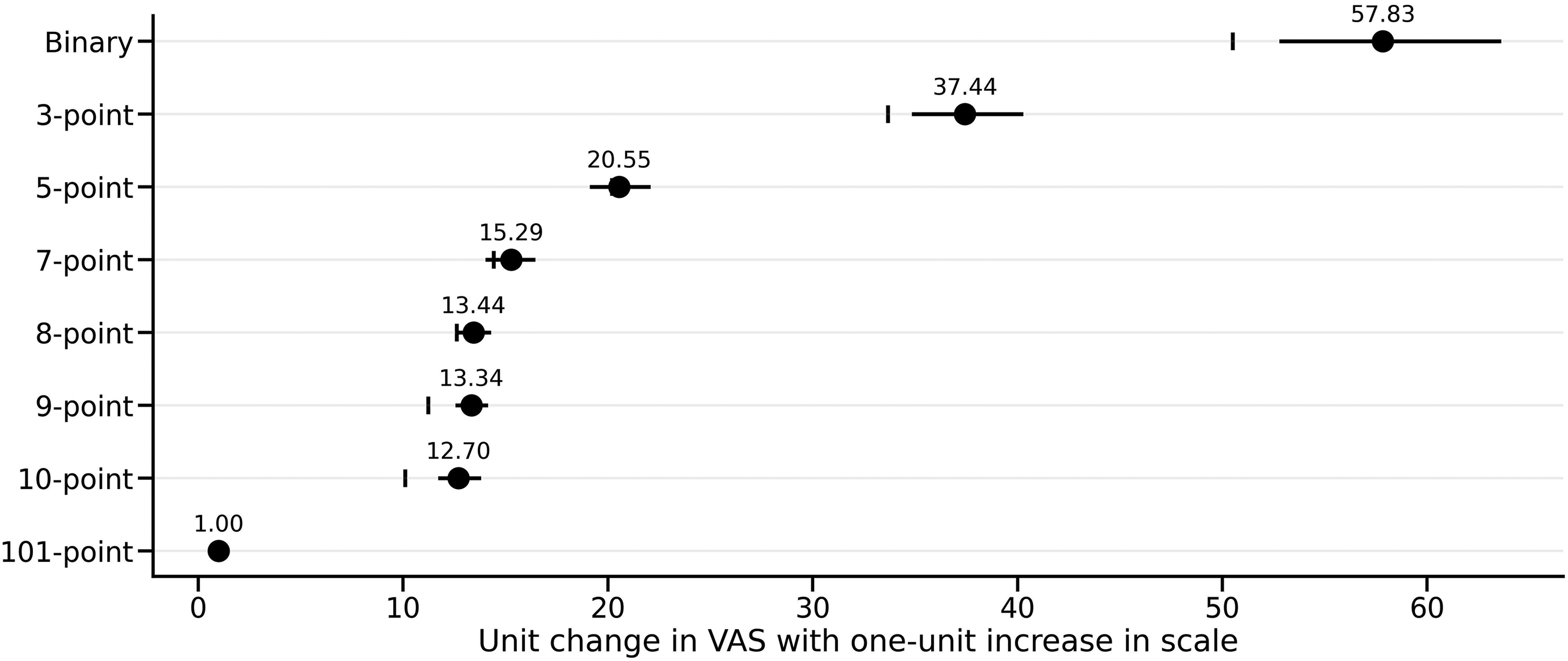
The coefficient and 95% credible interval resulting from a regression of each scale on to the VAS, with the vertical lines indicating the simple division of the VAS range into the number of responses available for the scale in question.
Discussion
In this study, we explored a range of questions relating to the psychometric properties of commonly used response scales for attractiveness perception. Our results provided little evidence of differences between the response scales investigated. As Tables 1 and 2 illustrate, considering measures of both inter-rater agreement and within-person consistency, values were similar across the scales. Perhaps the only noticeable result was that the 1–3 scale appeared to demonstrate lower inter-rater agreement, and correspondingly higher private taste, than the other scales. In addition, response scales with fewer options seemed to result in lower within-person consistency (see Figure 1 and Table 2). As such, we might recommend that small numbers of response options should be avoided if inter-rater agreement and within-person consistency are important for a particular study's outcomes.
Our regression analyses (see Figure 3) also provided evidence that the binary, 1–3, 1–9 and 1–10 scales did not seem to equate to a simple division of the VAS responses. That is, for these four response types, participant usage did not correspond to the division of the VAS into equally-sized categories (e.g., ten categories of approximately ten units each for the equivalent of the 1–10 scale). Therefore, researchers might avoid these response types in favour of using the 1–5, 1–7 and 1–8 scales since their use was more indicative of equally-sized, and perhaps more interpretable, scale units.
This recommendation, perhaps simply by chance, aligns with the literature in this field since the 1–7 scale in particular has been widely used over the years (e.g., Ma, Correll, et al., 2015; Penton-Voak et al., 2001; Rhodes et al., 2005; Sutherland et al., 2013). However, reassuringly, we found no substantial evidence for researchers to avoid any of the response scales investigated here. Until now, the common practice for measuring perceptions of facial attractiveness has been to select a scale based simply on researcher intuitions – for instance, does a 5-point scale feel sufficiently sensitive for the question being considered? While our findings suggest small benefits in the use of certain response scales, our overall conclusion is that, for the most part, the importance of choosing one scale over another is only minimal.
Given that the current measures of inter-rater agreement were also calculated in previous work for attractiveness ratings of unfamiliar faces (Kramer et al., 2018), we might consider these values side-by-side for our 1–7 scale (the length of scale used in their work). These were as follows (ours/theirs): Cronbach's α: 0.98/0.93; ICC(A,k): 0.97/0.91; average ‘leave one out’: 0.70/0.76; Kendall's W: 0.43/0.63; average inter-rater agreement: 0.49/0.61. For the two versions of intraclass correlation coefficient, our values were higher, but as mentioned earlier, this may simply have been due to our larger sample size. For the remaining three measures, we obtained lower values of agreement. Kramer et al. (2018) presented unfamiliar celebrity images that were obtained through Google's image search and were therefore unconstrained in appearance with regard to facial expression, background, clothing, lighting, etc. In contrast, our Chicago face database images featured identities posing front-on, wearing the same t-shirt, displaying neutral expressions, in front of the same background, and with the same camera set-up. Therefore, it is likely that the lower inter-rater agreement found here was the result of our using a more homogeneous set of stimuli, which resulted in a larger contribution of private taste (Hönekopp, 2006).
Indeed, we can also directly compare our measures of within-person consistency and shared/private taste with those obtained by Kramer et al. (2018), again for the 1–7 scale. These were as follows (ours/theirs): within-person consistency: 0.74/0.78; bi1: 0.50/0.31. As suggested above, we found a substantially greater contribution of private taste in our data, most likely due to the use of a more homogeneous set of stimuli.
Finally, our values for decomposing variability can also be compared with those obtained by Hehman et al. (2017) (Analysis 3), who used a 1–7 scale and presented findings relating to a combined ‘youthful/attractiveness’ dimension. These were as follows (ours/theirs): perceiver ICC: 0.27/0.13; interaction ICC: 0.21/0.34; target ICC: 0.32/0.32; residual: 0.20/0.21. Interestingly, both sets of data were obtained using images of men and women taken from the Chicago face database (Ma, Correll, et al., 2015), and so it is unclear as to why we found larger differences between participants (perceiver ICC) and a smaller role of private taste (interaction ICC). This may be the result of those researchers combining youthfulness ratings with perceptions of attractiveness, or that we selected our stimuli to evenly span the full range of attractiveness values (based on available norming data). As such, larger differences between faces would be expected to result in private taste featuring less prominently (Hönekopp, 2006).
In general, across our different response scales, we found that private taste explained approximately half of the variance in attractiveness judgements. Although likely to be somewhat dependent on the specific set of face images featured, this finding is in broad agreement with previous work investigating facial attractiveness (e.g., Hönekopp, 2006; Kramer et al., 2018; Leder et al., 2016a, 2016b). In contrast, other types of stimuli have shown a substantially larger influence of private (in comparison with shared) taste on preference judgements (abstract artworks – Leder et al., 2016a, 2016b; architecture – Vessel et al., 2018), perhaps because these categories were artefacts of human culture rather than naturally occurring domains (Vessel et al., 2018). Further work will likely consider additional stimulus categories when tackling this question, and our findings suggest that the method of collecting participants’ preferences will have little influence on outcomes.
In the current work, we focussed on the perception of facial attractiveness since this is perhaps the most common trait investigated by researchers. However, there are several other traits that have played an influential role in face perception research (e.g., dominance and trustworthiness – Oosterhof & Todorov, 2008) and it would be interesting to consider whether response methods differed in their psychometric properties for such traits. Although we have no reason to believe that participants use the various response scales differently across different traits, this remains an empirical question for future studies to answer.
To conclude, we have provided a comprehensive investigation of the psychometric attributes associated with methods of measuring perceived facial attractiveness. For decades, studies have utilised response scales where participants have explicitly rated face images. However, none have considered the properties associated with these scales. Our study is the first to do so, and has demonstrated that scale choice (we imagine many researchers will be pleased to learn) will likely have little effect on experimental outcomes.
Footnotes
Acknowledgements
The authors thank our Research Skills III students for collecting the data, and Abi Davis for her input during the project's conceptualisation.
Author Contribution(s)
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.