
Abstract
Viewing multiple images of a newly encountered face improves recognition of that identity in new instances. Studies examining face learning have presented high-variability (HV) images that incorporate changes that occur from moment-to-moment (e.g., head orientation and expression) and over time (e.g., lighting, hairstyle, and health). We examined whether low-variability (LV) images (i.e., images that incorporate only moment-to-moment changes) also promote generalisation of learning such that novel instances are recognised. Participants viewed a single image, six LV images, or six HV images of a target identity before being asked to recognise novel images of that identity in a face matching task (training stimuli remained visible) or a memory task (training stimuli were removed). In Experiment 1 (n = 71), participants indicated which image(s) in 8-image arrays belonged to the target identity. In Experiment 2 (n = 73), participants indicated whether sequentially presented images belonged to the target identity. Relative to the single-image condition, sensitivity to identity improved and response biases were less conservative in the HV condition; we found no evidence of generalisation of learning in the LV condition regardless of testing protocol. Our findings suggest that day-to-day variability in appearance plays an essential role in acquiring expertise with a novel face.
Recognizing facial identity is a ubiquitous task in daily life and inherently challenging. Images of two different people can be very similar, and images of the same person can vary significantly in appearance (e.g., due to changes in lighting, viewpoint, expression, makeup, health, and age) (Bindemann & Sandford, 2011; Jenkins et al., 2011; Laurence et al., 2016). The accuracy of face recognition varies as a function of familiarity. In many applied settings, employees (e.g., passport officers, clerks selling age-restricted goods) are required to match a single photograph to a live person (or a second photograph) with whom they are wholly unfamiliar. In such settings, recognition is error prone. Research participants and passport officers make errors even when images are taken only moments apart or incorporate systematic changes in lighting or expression (Duchaine & Nakayama, 2006; Megreya et al., 2013; Nordt & Weigelt, 2017; White et al., 2014).
In contrast, most people recognize familiar faces with ease, despite natural within-person variability in appearance (Jenkins et al., 2011), even when images are of poor quality (Burton et al., 1999), have been distorted (Hole et al., 2002), or when the face is disguised (Noyes & Jenkins, 2019). Recognizing highly familiar faces (e.g., friends, family, and actors) allows people to navigate social interactions or follow the plot of a movie. The effect of familiarity can be indexed by event-related potentials (ERPs). Both the N250 and the sustained familiarity effect (400–600 ms after stimulus presentation) are larger when participants view personally familiar as compared to wholly unfamiliar faces (Wiese et al., 2019).
In other settings, we might attempt to recognize a face that is neither wholly unfamiliar nor highly familiar. Such faces might have been encountered only once or only in a single setting. For example, people might need to recognize their waiter in a restaurant, someone with whom they briefly interacted at a party, their lecturer, or the perpetrator of a crime they witnessed. These lesser-known faces might be challenging to recognize for several reasons including short exposure time, sparse social representation, or minimal exposure to within-person variability in appearance (Devue et al., 2019; Ritchie & Burton, 2017; Schwartz & Yovel, 2019; Shoham et al., 2021). This middling level of familiarity is evident in ERPs. Wiese et al. (2019) reported comparable differences between the amplitude of the N250 for lecturer or celebrity faces as compared to unfamiliar faces, and a weaker sustained familiarity effect for lecturer and celebrity faces as compared to personally familiar faces.
In the current study we examined whether people recognize new instances of a person's face after a single encounter (i.e., after viewing moment-to-moment changes in head orientation, facial expression and facial speech but in the absence of variability in capture conditions, such as lighting, and changes in appearance that occur over time, such as hairstyle, make-up and health.) Understanding the process by which a newly encountered face becomes familiar is important, both for models of face recognition and in applied settings. Raviv et al. (2022) note that learning has been defined in two different ways. The first definition refers only to the ability to recognize items from a training phase (e.g., a child learning that their family pet is labelled “dog”). Traditional approaches to studying face recognition have adopted this definition of learning by presenting the same (or nearly identical) image of to-be-learned identities at study and test. For example, studies have shown that viewing the same face image from multiple viewpoints facilitates recognition of the face from those viewpoints (Hill et al., 1997; Troje & Bülthoff, 1996; Wallraven et al., 2002). The second definition defines learning as the ability to generalize from items presented during a training phase to new instances (e.g., a child learning that poodles, spaniels, and Australian shepherds are all dogs). We adopt this definition in the current study as it better captures how we recognize faces in daily life (see Burton, 2013 for a review). Familiarity allows perceivers to generalize beyond previous experience with a face (e.g., photos presented during a study phase; previous encounters with a live person) such that new instances of that face are recognised.
Exposure to within-person variability in appearance plays a key role in face learning. Viewing multiple images of an identity improves performance on memory tasks in which participants must decide whether test images belong to a previously learned identity (Baker & Mondloch, 2019; Matthews & Mondloch, 2018b; Murphy et al., 2015; Zhou et al., 2022), and on line-up tasks—at least on target-present trials (Dowsett et al., 2016; Matthews & Mondloch, 2018a). However, the evidence for whether variability helps with face matching tasks in which participants must decide whether two or more test images belong to the same person or two different people is mixed (see Matthews & Mondloch, 2018b; White et al., 2014; but see Menon et al., 2015; Ritchie et al., 2021, 2020). Whereas learning tasks require memory, matching tasks present all the images simultaneously with no memory requirement. Ritchie et al. (2021) demonstrated that memory demands may be key to a role for variability. When an array of images showing within-person variability was displayed prior to a test image, variability aided performance. When the array and test image were presented simultaneously, variability led to a shift in response bias with no improvement in accuracy. The authors argued that tasks requiring memory force participants to abstract a representation of the person from the variable images in order to compare a subsequent image to that representation. This evidence aligns with theoretical models which suggest that exposure to within-person variability in appearance allows the perceiver to form a representation that contains multiples instances of a person's appearance and/or an average of all encountered instances—a representation that allows generalisation to new instances (Burton et al., 2005, 2016; Kramer et al., 2015; Young & Burton, 2017).
The above findings are consistent with evidence from other domains in which exposure to variability during learning (i.e., the process of building a representation) leads to generalization. For example, viewing dangerous items from multiple categories (e.g., guns, knives) improves the ability to detect novel dangerous items in luggage (Gonzalez & Madhavan, 2011). Similar results have been reported for texture discrimination, language learning, and motor skills and concept formation (Hussain et al., 2012; Watson et al., 2014; see Raviv et al., 2022 for a theoretical review). Exposure to high variability (e.g., multiple speakers in a word learning task) may initially impair learning, but ultimately improves the ability to generalize (e.g., to recognize a newly learned word when pronounced by novel speakers). Across domains, variability has been characterised in different ways. One type of variability defined by Raviv et al. is heterogeneity. Heterogeneity refers to how variable examples are during learning (i.e., during training). In the case of face learning, heterogeneity refers to variability in the appearance of a to-be-learned face during the learning/study phase. Controlling for numerosity (another type of variability, i.e., the number of images of the to-be-learned face presented during learning), heterogeneity might benefit recognition because it provides greater coverage of the identity's appearance, allowing generalisation to previously unseen exemplars. In the current study, we examined the role of heterogeneity in face learning.
Studies that use multiple images to aid in learning almost always incorporate images that were captured on different days—images that serve as a proxy for high variability images (e.g., Andrews et al., 2015; Dowsett et al., 2016; Matthews & Mondloch, 2018a; White et al., 2014). Such images capture changes that occur over time (e.g., changes in hairstyle, makeup, age, weight, health), changes in capture conditions (e.g., camera lens, lighting, context), and changes that occur from moment to moment (e.g., different facial expressions, viewpoints). Of course, the degree of variability captured by such images will vary across identities. Watching the nightly news will provide less variable input from the anchor, who sits at the same desk portraying a similar appearance from night to night, than the reporter, who appears in a wide range of conditions. Nonetheless, images captured on different days can capture variability not available in a single encounter. In the current study, we examined whether adults benefit from images that were captured on the same day, under the same lighting conditions and with the same camera—images we will refer to as low-variability (LV) images. LV images capture moment-to-moment changes (e.g., changes in expression and viewpoint), but not changes that occur over time.
Ritchie and Burton (2017) examined the role of heterogeneity in face learning by directly comparing participants’ performance on a memory task after learning from either 10 images captured on different days (high variability) or 10 images captured all on the same day (low variability). Participants were more accurate on a name verification task in the high- as compared to the LV condition. These results suggest that exposure to images captured on a single encounter promotes less generalisation of learning than images captured on different encounters. However, Ritchie and Burton did not include a control group, so it is unclear whether viewing LV images provided any benefit. In a second experiment, participants completed a matching task after learning the identities from either high-variability (HV) or LV images. Performance in these two conditions was compared with a control group who had not viewed any learning images. Learning from HV images resulted in more accurate performance on match trials (i.e., those that included two images of the same person) than learning from LV images but learning from LV images produced no benefit over the control group.
Two additional studies suggest that exposure to low variability in appearance might not facilitate generalisation of learning, even when test stimuli were captured on the same day as stimuli presented in the learning phase, requiring minimal generalisation. Chen and Liu (2009) examined face learning from viewing systemic changes in viewpoints and emotional expressions captured on a single day. Training participants on multiple different poses of an identity led to better recognition of that identity across different expressions, but training on several expressions did not improve recognition across poses. Likewise, Lander and Bruce (2003) found no advantage for viewing multiple images extracted from a single video over viewing a single image, even when participants were tested with novel images of the learned identities taken on the same day (see also Matthews et al., 2007).
Results from one study suggest that exposure to low variability in appearance might be sufficient to facilitate adults’ learning of a newly encountered face in novel instances (Baker et al., 2017). Baker and colleagues compared learning after viewing 10 images extracted from a video filmed across 3 days (high variability) vs. a single day (low variability). Adults showed evidence of learning in both the HV and LV conditions relative to a no-training control group, with no difference between the HV and LV conditions. It is noteworthy that a reference photo of the target was provided to participants while they completed the old/new recognition task. The reference image was taken from a different source; thus, even in the LV condition, participants had exposure to between-day variability in appearance, albeit minimal. It is possible that the reference photo helped participants decide if the test images belonged to the identity, perhaps by alerting perceivers to potential variability in appearance.
One previous study reported no evidence that high variability in training stimuli facilitates generalisation of face learning. Honig et al. (2022) showed participants three images of a to-be-learned face previously judged as very similar to one another (low variability) or very dissimilar (high variability). In a subsequent face matching task, there was no benefit of viewing HV images during the study phase. Indeed, an advantage was observed for viewing LV images when test images were similar to those images. Honig et al. conclude that any benefit of highly variable images is attributable to their similarity to test images; the odds of a test image being similar to any study image are higher if study images are highly variable. It is noteworthy that Honig et al. only presented three learning images; as noted by Raviv et al. (2022), variability can hinder learning initially, but benefit generalisation as learning proceeds. Further, in the field of face recognition, the very essence of familiarity is the ability to recognize instances that are very dissimilar to previous encounters (e.g., when a neighbour is sick, after aging, when a colleague changes their hair or make-up). Nonetheless, further examination of how variability shapes face learning is needed.
In the current study, we examined the extent to which viewing different images from a single encounter leads to face learning, and whether the ability to benefit from viewing images from a single versus multiple encounter(s) depends on whether the task requires face matching versus face memory. In each of two experiments, participants learned one identity in each of three conditions: six HV images (captured across six days), six LV images (captured on a single day) and a single image. We included a single-image condition to allow us to examine whether viewing LV images provides any significant benefit over viewing only one image. After each learning phase, participants completed a task in which they needed to recognise novel images of the learned identity intermixed with images of other people. All test images were taken on different days than the study images, allowing us to examine generalisation of learning. In Experiment 1, participants were asked to select all the images of the target from four 8-image arrays; in Experiment 2, participants were asked to decide whether sequentially presented images belonged to the target. Based on an abundance of previous research, we expected better performance in the HV condition as compared to the control condition. Our key question was whether there was any evidence of generalisation of learning in the LV condition. If exposure to LV images is sufficient to facilitate learning, we would expect to see a benefit of viewing LV images relative to only viewing a single image. If exposure to LV images is not sufficient to facilitate learning, we would expect to see comparable performance in the LV and control conditions. The HV condition was included to determine whether any learning observed in the LV condition matched that observed in the HV condition.
In both experiments, we manipulated whether the images remained visible (face matching condition) or were removed (face memory condition) while participants completed the test phase. Some studies have suggested that the benefit of exposure to variability is only present in tasks requiring memory in which the training stimuli are removed from view before participants are asked to provide a response (e.g., Menon et al., 2015; Ritchie et al., 2021; Sandford & Ritchie, 2021). Whereas simultaneous tasks allow the perceiver to perceptually match images, sequential tasks require the perceiver to form a robust representation of each identity in memory and use that representation to recognise identities when the images are no longer visible. Extracting a robust mental representation of the variability in appearance might be necessary for learning—in which case any benefit of viewing HV or LV images might only be seen in the memory condition.
Experiment 1
Method
Each participant learned three identities, one in each of three learning conditions: a 1-image condition, a LV condition, and a HV condition. To assess generalisation of learning, participants completed a line-up task in which they were asked to select all the images of a target identity from each of four 8-image arrays. Half of the participants completed a matching task (i.e., the training stimuli remained visible during the recognition task) and half completed a memory task (i.e., the training stimuli were not visible during the recognition task).
Participants
The sample comprised 71 young adults (57 female; Mage = 19.59 years, SD = 2.99, range = 17–37) recruited through the online psychology research pool at Brock University in Canada. One additional participant was excluded for experimenter error. A power analysis using GPower software (Version 3.1.9.4; Faul et al., 2007) indicated that this sample was sufficient to detect a medium effect for any interactions with 99% power (α = .05). All participants provided written informed consent and were compensated with research participant credit.
Materials
Images from Ritchie and Burton's (2017) study were used in this task. Three female White Australian celebrities served as target identities. We confirmed that all participants were unfamiliar with these identities. All images were cropped to 400 by 300 pixels (72 ppi), and any background information was removed. All images were presented in colour.
Training Stimuli
We created two sets of training stimuli for each target identity, each of which comprised six images. The two sets differed in heterogeneity (see Figure 1). Images for the HV condition were obtained through Google Search. For each identity, we selected six images that were captured on different days and met the following criteria: the face was at least 150 pixels in height, was shown from a mostly frontal view and was free from occlusions. These unconstrained images included changes in appearance from day-to-day (e.g., lighting, hair style, and makeup) and moment-to-moment (e.g., facial expression and viewpoint). Images for the LV condition were taken from an interview of each target identity that was obtained through Google Video Search. For each celebrity we selected six still images captured from a single video. Like the HV images, the LV images captured moment-to-moment changes in head orientation and facial expressions; they also included variability in appearance associated with facial speech. Unlike the HV images, the LV images did not include day-to-day changes in appearance (e.g., changes in hairstyle, health, and make-up). The quality of the HV and LV images was comparable. For the 1-image control condition, a single image was selected from the six HV images; the selection of this image was counterbalanced across participants. All training images were printed on cards measuring 5.5 cm in height and backgrounds were removed.

An example of the training stimuli used in the high-variability condition (top row) and the low-variability condition (bottom row). All of these images depict the same person. Copyright restrictions prevent publication of the actual images used.
Recognition Task Stimuli
Ten additional images of each target were used as test stimuli in the recognition task; all were taken on a different day from each other and from the training stimuli. The 10 target images were intermixed with images of 10 similar-looking distractors (i.e., similar age, hair colour, and face shape). We presented one image of each distractor; distractor images were selected using the same criteria as for target images. These 20 test images were used for our main analyses.
We also included control stimuli. Specifically, we captured four new images from the video used to create the LV training stimuli. We used these LV control stimuli to verify that participants in the LV condition recognised new same-day images. This was important to establish that participants had attended to the learning images and that any errors on test stimuli reflected poor sensitivity to identity when tested with images that required generalizing beyond the type of variability encountered during learning. Eight other images were used as exclusion criteria; they were designed to verify that participants paid attention and understood the task. These attention checks included four images identical to those presented in the training phase and four images of a dissimilar looking identity (i.e., different age, hair colour, and face shape). In the LV and HV conditions, attention check images of the learned identity were randomly selected from those shown during learning; in the 1-image condition, the same previously viewed learning image was shown four times. To pass the attention checks, participants needed to correctly identify at least three of the four previously viewed images in each condition and correctly reject all four dissimilar distractor images in each condition.
Procedure
All procedures received clearance from the research ethics board at Brock University. Each participant learned three identities, one in each of three conditions. The assignment of target identities to condition and the order in which the conditions were presented was counterbalanced across participants. The procedure was adapted from Matthews et al. (2018). In the learning phase, participants were read a short story about a target identity that embarks on an adventure. Participants viewed the six HV images in the HV condition, and the six LV images in the low variability condition. Each of the six pages in the storybook contained a new image of the target attached to the page with Velcro. Before moving to the next page, participants detached the photo and placed it on a cardboard stand. Participants were told they would need these photos to perform a later task. In the 1-image condition, participants viewed only one of the six HV images. The selection of this image was counterbalanced across participants. Participants moved the single image through each page of the story book and placed it on a cardboard stand at the end of the story. At the end of each story, participants were asked to take a moment to look at the images they collected before proceeding to the recognition task.
The recognition task was presented to participants on an Apple iPad (2048 by 1536 pixel display; 264 ppi). Participants were presented with four 8-image arrays. Arrays were presented sequentially. Each array contained two attention checks (a previously viewed training image and a dissimilar distractor), a LV control stimulus (a novel image captured from the same video as the LV training stimuli) and five test stimuli. Test stimuli comprised novel images of the target identity and images of a similar-looking distractor. Participants were explicitly told that the number of images of the target identity could vary across arrays; in fact, the number of target images ranged from one to four (e.g., one image of the target and four images of the distractor, two images of the target and three images of the distractor). This was done to reduce response bias (e.g., prevent participants from always selecting the one best image from each line-up). The images within each array were randomly selected and remained the same for all participants. The position of each image within the array and the order in which the four arrays were presented were randomised across participants. For each array, participants were asked to select all the images of the target identity before tapping a button to proceed to the next array. Participants were not given a time limit for making their selection(s).
Half of the participants (n = 34) performed the face matching version of the recognition task, and the other half of participants (n = 35) performed the face memory version. In the matching condition, the images collected during the learning phase remained visible during the recognition task. In the memory condition, the learning images were removed before participants did the task. Once the recognition task was complete, participants were introduced to the next target identity and the procedure was repeated.
Results and Discussion
Primary Analyses
Our primary analyses included the 20 test stimuli (10 novel images of the target identity; 10 images of the distractor) to examine the effects of variability in training images and task structure (matching vs. memory) on sensitivity to facial identity. We defined a hit as selecting an image of the target identity and a false alarm as selecting an image of the distractor; across the four trials, a maximum of 10 hits and 10 false alarms were possible. We conducted separate 2 (Task: Matching/Memory) by 3 (Variability: 1-image/Low/High) mixed ANOVAs for d′ and criterion. Higher d′ values indicate greater sensitivity to identity, and higher criterion values indicate a more conservative response bias (i.e., fewer hits and fewer false alarms). 1 All tests were two-tailed. We used the Bonferroni correction to correct for multiple comparisons when analysing pairwise comparisons. In addition to traditional frequentist hypothesis testing, we included Bayes factors using JASP Version 0.14.01 (JASP Team, 2020), which allowed us to quantify the extent to which the data support the alternative hypothesis (BF10). For reference, BF > 10 indicates decisive evidence for the alternative hypothesis; BF10 > 3 indicates substantial evidence and BF10 > 1 indicates anecdotal evidence. BF10 < .33 and BF10 < .1 indicate substantial and anecdotal evidence for the null hypothesis, respectively (Wetzels et al., 2011). The data and analysis syntax are available at: https://osf.io/mh97y/?view_only=0a3c20b10aec4737ad5d1097f0a6f5b5.
d′
The analysis of d′ revealed no significant main effect of task, F(1, 69) = 0.59, p = .444, ηp2 = .01, BF10 = 0.24 and no interaction between task and variability, F(2, 138) = 0.10, p = .901, ηp2 < .01, BF10 = 0.10. There was a main effect of variability, F(2, 138) = 21.95, p < .001, ηp2 = .24, BF10 = 2.042 × 106. Consistent with previous studies, pairwise comparisons revealed that participants were more sensitive to identity in the HV condition (M = 2.10, SE = 0.10) than in both the LV (M = 1.39, SE = 0.11), p < .001, BF10 = 1.270 × 106, and the 1-image conditions (M = 1.56, SE = 0.12), p < .001, BF10 = 1.381 × 103. As shown in Figure 2A, there was no difference in sensitivity between the low variability and 1-image conditions, p = .391, BF10 = 0.40. This novel finding suggests that only exposure to high variability in appearance facilitated learning. Viewing 10 different images of an identity taken within a single encounter conferred no benefit on subsequent recognition—an effect that did not differ in the matching vs. memory versions of the task.
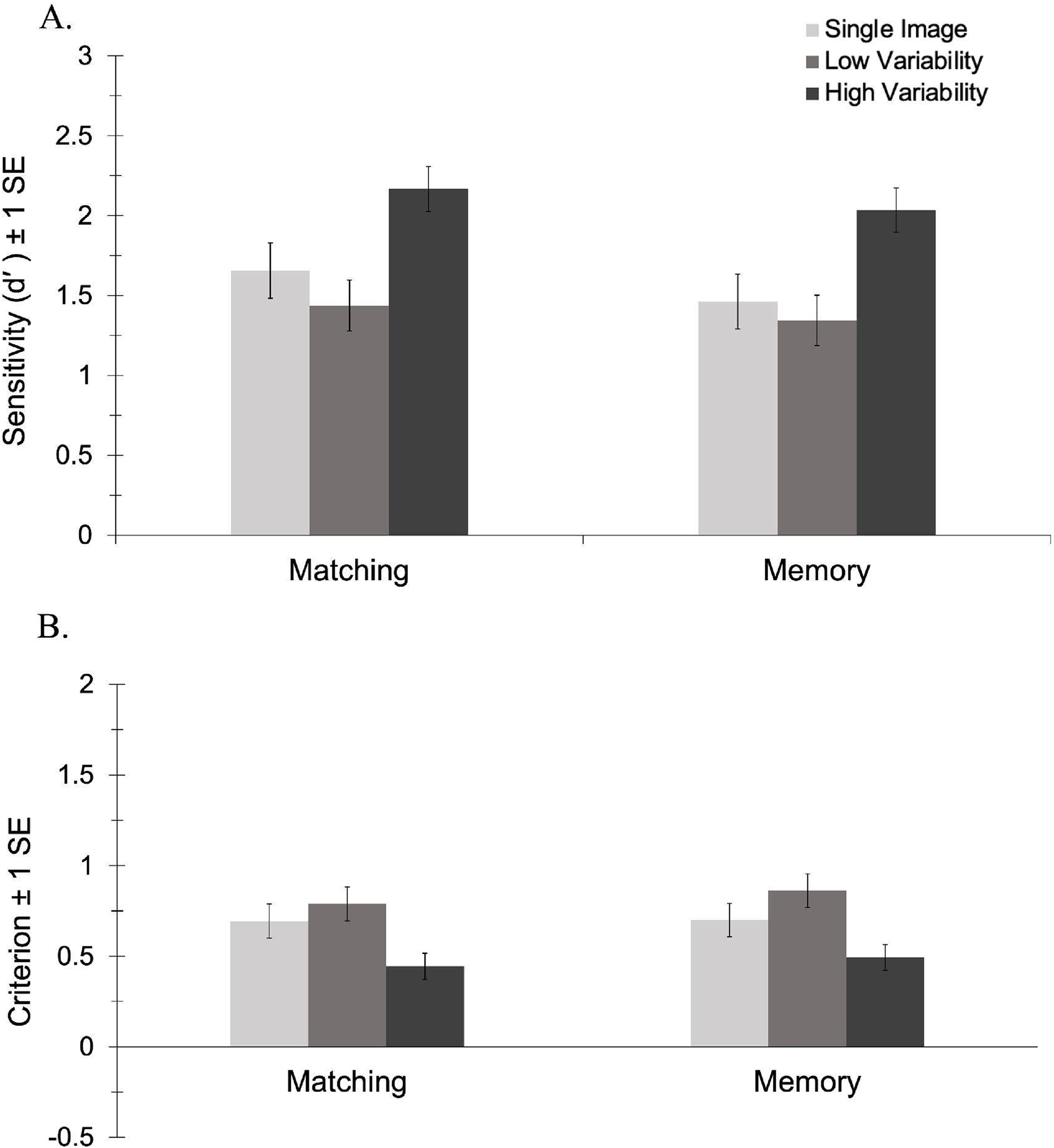
Sensitivity (A) and criterion (B) by variability for the matching and memory conditions in Experiment 1.
Criterion
The analysis of criterion revealed no significant main effect of task, F(1, 69) = 0.17, p = .682, ηp2 < .01, BF10 = 0.25 and no interaction between task and variability, F(2, 138) = 0.19, p = .827, ηp2 < .01, BF10 = 0.11. There was a main effect of variability, F(2, 138) = 20.38, p < .001, ηp2 = .23, BF10 = 5.768 × 105. Pairwise comparisons revealed that participants had a less conservative response bias in the HV condition (M = 0.47, SE = 0.05) than in both the LV (M = 0.83, SE = 0.07), p < .001, BF10 = 5.901 × 106, and the 1-image conditions (M = 0.70, SE = 0.07), p < .001, BF10 = 145.16. As shown in Figure 2B, there was no difference in criterion between the low variability and 1-image conditions, p = .109, BF10 = 1.14. This novel finding suggests that exposure to high, but not low, variability in appearance shifts perceivers’ decision boundary such that more novel images are perceived as belonging to the newly learned identity.
Low Variability Control Images
We conducted a 2 (Task: Matching/Memory) by 3 (Variability: 1-image/Low/High) mixed ANOVA with the number of recognised new low variability images as the dependent variable. The analysis revealed no significant main effect of task, F(1, 69) = 0.00, p = .999, ηp2 < .01, BF10 = 0.15, and no interaction between task and variability, F(2, 138) = 0.01, p = .988, ηp2 < .01, BF10 = 0.06. There was a main effect of variability, F(2, 138) = 47.54, p < .001, ηp2 = .41, BF10 = 3.00 × 1015. Pairwise comparisons confirmed that participants in the LV condition recognised more LV images (M = 3.99, SE = 0.01) than participants in both the HV (M = 2.90, SE = 0.17) p < .001, BF10 = 1.55 × 106, and 1-image conditions (M = 2.14, SE = 0.20) p < .001, BF10 = 3.51 × 1011. Participants also recognised more LV images in the HV condition than in the 1-image condition, p = .002, BF10 = 50.77. This suggests that participants were attending to LV images; nonetheless, these images only facilitated recognition of the identity in new images that were captured on the same day as the trained images. It is noteworthy that facilitation of recognition of images taken on the same day occurred despite background information being removed during the study phase.
Our results reveal that only exposure to HV images led to generalisation of learning, such that participants’ sensitivity to identity in novel images increased. Viewing high-variability images led participants to adopt a less conservative response bias relative to viewing a single image. Viewing LV images only provided a benefit for new images that were taken from the same encounter as the learned images, suggesting that exposure to changes in appearance that occur over time is necessary to facilitate recognition of novel images taken on different days (i.e., generalisation of learning).
In Experiment 1, we used a line-up paradigm in the test phase. In this type of task, participants can make relative judgements about the images (i.e., compare to the other test images in the line-up when deciding if an image belongs to the target). In Baker et al. (2017), in which evidence of learning from low-variability images was reported, participants completed a Yes/No task in which they viewed images individually and were asked to decide whether each image belonged to the target. This type of test involves a more absolute judgement about each image than the line-up task (i.e., participants had to decide if each image was an image of the target without comparing it to any other test images). To examine whether this difference in testing protocols might have contributed to our finding no evidence of learning in the LV condition, we changed our testing task in Experiment 2 to mimic Baker et al.'s task. Participants completed the same learning protocol but instead of the test images being presented in a line-up, each image was presented sequentially.
Experiment 2
Method
Participants
The sample comprised 73 young adults (54 females; Mage = 19.87 years, SD = 3.46, Range = 17–38) recruited through the online psychology research pool at Brock University in Canada. Six additional participants were excluded (five for experimenter error and one for failing attention checks). A power analysis using GPower software (Faul et al., 2007) indicated that this sample was sufficient to detect a medium effect for any interactions with 99% power (α = .05). All participants provided written informed consent and were compensated with research participant credit.
Materials and Procedure
The materials and procedure were identical to Experiment 1, except for the presentation of images in the recognition task. Here, images were presented one at a time on the screen in a randomised order (32 trials). Participants were asked to decide whether each image depicted the target identity. Participants responded by pressing a button on the touch screen of the iPad. There was no time limit for viewing each image. As in Experiment 1, half of the participants (n = 36) performed a matching version of the recognition task where the training images remained visible, and the other half of participants (n = 37) performed a memory version where the training images were taken away before the recognition task.
Results and Discussion
All analyses were identical to those in Experiment 1. When Mauchly's test of sphericity indicated that the assumption of sphericity was violated, the degrees of freedom were adjusted using the Greenhouse–Geisser correction. The data and analysis syntax are available at: https://osf.io/mh97y/?view_only = 0a3c20b10aec4737ad5d1097f0a6f5b5.
d′
The analysis of d′ revealed a significant main effect of task, F(1, 71) = 5.70, p = .20, ηp2 = .07, BF10 = 2.24. Participants were more sensitive to identity in the matching task (M = 2.03, SE = 0.11) than in the memory task (M = 1.67, SE = 0.11). There was a main effect of variability, F(2, 142) = 27.06, p < .001, ηp2 = .28, BF10 = 7.908 × 107. As predicted, pairwise comparisons revealed that participants were more sensitive to identity in the HV condition (M = 2.14, SE = 0.10) than in both the LV (M = 1.41, SE = 0.12), p < .001, BF10 = 5.381 × 107, and the 1-image conditions (M = 1.61, SE = 0.12), p < .001, BF10 = 1.656 × 104. There was no significant difference between the low variability and 1-image conditions, p = .277, BF10 = 0.52. As shown in Figure 3A, there was no interaction between task and variability, F(2, 138) = 1.16, p = .317, ηp2 = .02, BF10 = 0.64. This suggests that the effect of variability does not differ as a function of task. As in Experiment 1, only exposure to high variability in appearance facilitated learning and this effect did not differ in the matching vs. memory versions of the task.
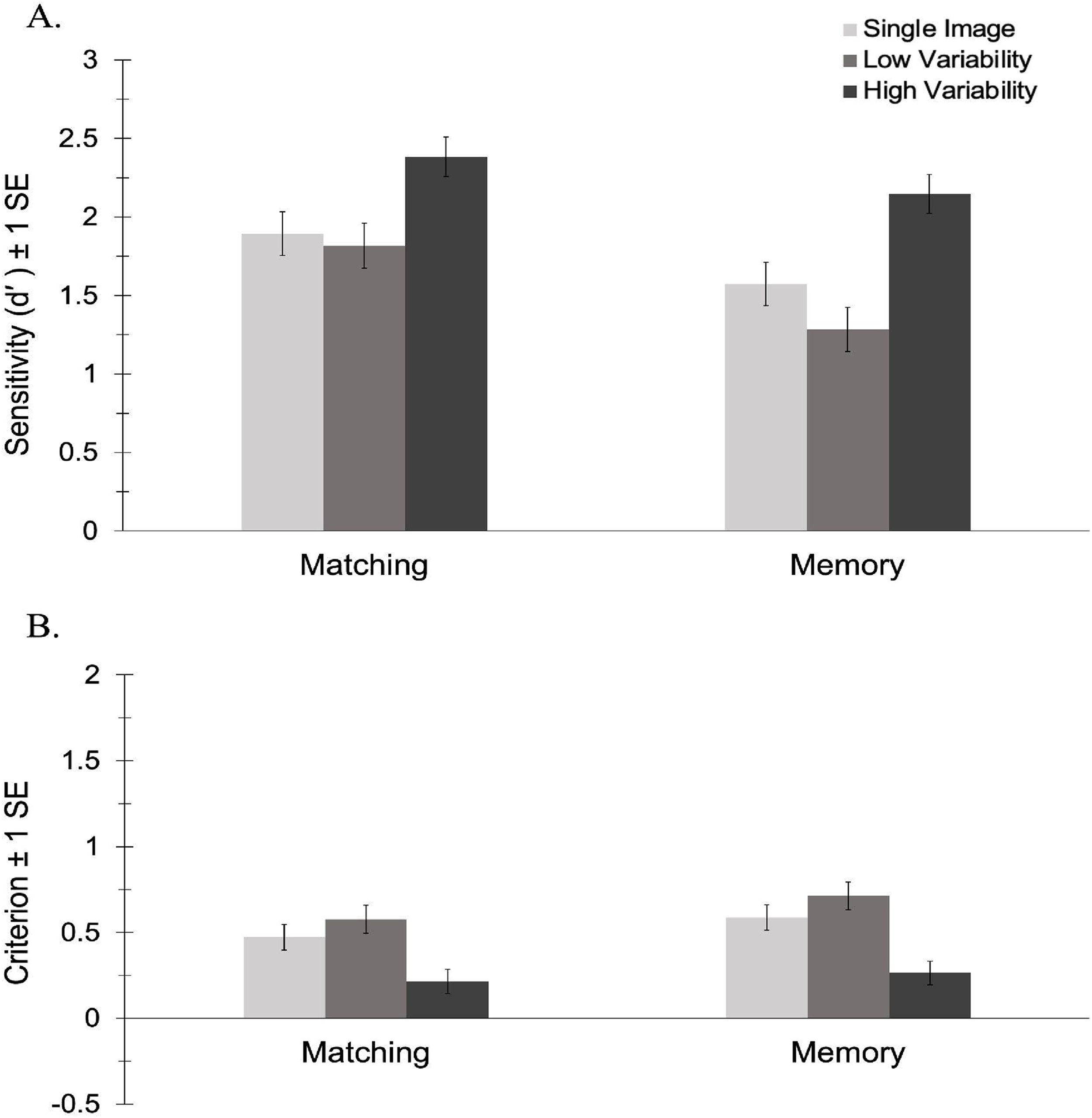
Sensitivity (A) and criterion (B) by variability for the matching and memory conditions in Experiment 2.
Criterion
The analysis of criterion revealed no significant main effect of task, F(1, 71) = 1.40, p = .241, ηp2 = .02, BF10 = 0.37, and no interaction between task and variability, F(1.81, 128.58) = 0.34, p = .694, ηp2 = .01, BF10 = 0.14. There was a main effect of variability, F(1.81, 128.58) = 28.57, p < .001, ηp2 = .29, BF10 = 2.451 × 108. Pairwise comparisons revealed that participants had a less conservative response bias in the HV condition (M = 0.24, SE = 0.05) than in both the LV (M = 0.65, SE = 0.06), p < .001, BF10 = 1.367 × 106, and the 1-image condition (M = 0.53, SE = 0.05), p < .001, BF10 = 3.970 × 105 As shown in Figure 3B, there was no significant difference in criterion between the low variability and 1-image conditions, p = .118, BF10 = 1.05—a pattern that mimics the results of Experiment 1.
Low Variability Control Images
A 2 (Task: Matching/Memory) by 3 (Variability: 1-image/Low/High) mixed ANOVA, with the number of LV control images recognised as the outcome, revealed no significant main effect of task F(1, 71) = 0.531, p = .469, ηp2 = .01, BF10 = 0.18 and no interaction between task and variability, F (1.68, 119.31) = 1.84, p = .302, ηp2 = .02, BF10 = 0.17. There was a main effect of variability, F (1.68, 119.31) = 33.77, p < .001, ηp2 = .32, BF10 = 1.584 × 1011. Pairwise comparisons revealed that participants in the LV condition recognised more LV control images (M = 3.99, SE = 0.01) than did participants in both the HV (M = 3.11, SE = 0.15) p < .001, BF10 = 1.022 × 105, and 1-image conditions (M = 2.44, SE = 0.19) p < .001, BF10 = 2.185 × 109. Participants in the HV condition recognised more LV control images than did participants in the 1-image condition, p = .011, BF10 = 7.86. As in Experiment 1, this suggests that exposure to LV images facilitates learning for new images taken from the same encounter but does not allow generalisation of learning for new images outside that range of variability.
The results of Experiment 2 demonstrate that exposure to images captured on different days increased sensitivity to the target identity and led participants to adopt a less conservative response bias; exposure to images captured on a single day did not. Indeed, any numerical differences in the LV condition relative to the single-image condition were in the opposite direction. Viewing LV images during learning improved recognition of other images taken on the same day, relative to viewing either a single image or six images taken on different days. Collectively, the results of Experiments 1 and 2 suggest that in both a Line-up and Yes/No task, regardless of whether the learning images were taken away or displayed during test, only exposure to high variability in appearance facilitated generalisation of learning to novel images taken on different days.
General Discussion
Several studies have demonstrated that exposure to within-person variability facilitates face learning, such that increased sensitivity to identity generalizes to new images taken on different days. Abundant research has provided evidence of learning after participants view multiple images of a target identity that incorporate variability in appearance over time (Andrews et al., 2015; Dowsett et al., 2016; Matthews & Mondloch, 2018a; Ritchie & Burton, 2017; White et al., 2014). In the current study, we investigated whether adults also show evidence of generalisation when viewing images that were captured from a single encounter. We compared participants’ face learning after viewing either a single image, six LV images or six HV images in both a matching and a memory task using two different testing paradigms. Across all these conditions, we found no evidence of generalisation after viewing LV images. Only exposure to HV images increased sensitivity for the target identity in novel instances and shifted response bias.
Our findings of a benefit of viewing high vs. low variability are consistent with Ritchie and Burton (2017), but the original study did not include the single image control condition that we included here. We have extended the Ritchie and Burton (2017) finding to show that, in fact, generalisation of learning does not occur through viewing a set of images captured in a single encounter. The only advantage for viewing such low variability images in Ritchie and Burton's study was in faster response times when test images showed new images from the same LV set as the learning images, a pattern akin to that reported by Honig et al. (2022). This shows that participants paid attention to low variability images and so rules out a simple attention-based explanation for the lack of generalisation when tested with HV images. Our findings complement and extend Lander and Bruce (2003) who found no learning advantage for viewing multiple images extracted from a single video over viewing a single image.
Participants showed a low variability advantage with test images taken from the same encounter. This finding suggests that similarity between learning and test images may play a role in face learning. Evidence for the importance of similarity was shown by Sandford and Ritchie (2021) who used HV and LV images in a face matching task. Highest accuracy was found for conditions using LV target images paired with probe images from the same LV set. Likewise, Honig et al. (2022) report the best performance when participants viewed three highly similar images during the study phase and saw very similar images at test. Neither of these conditions require broad generalisation of learning. Nonetheless, to the extent that people are biased to recognize faces when their appearance resembles that in previous encounters, then experiencing high variability in a face's appearance will allow for better recognition in daily life. In the words of Raviv et al. (2022), exposure to heterogeneity turns the problem of extrapolation into one of interpolation (see also Hasson et al., 2020).
In contrast with Baker et al. (2017), we found no evidence of improved sensitivity after viewing LV images relative to viewing a single image. One difference between our study and Baker et al.'s (Experiment 2) was the number of LV images shown; whereas in our study participants viewed six images, in their study participants viewed ten. It is possible that perceivers require more images (an increase in numerosity) to show significant evidence of learning when variability during the study phase is low. However, both Experiments 1 and 2 of the current study revealed a numerical decrease in sensitivity in the LV vs. single-image condition, suggesting not even a hint of improvement from viewing six LV images. This is consistent with over-fitting that occurs across domains when training sets are very specific, precluding generalisation (Raviv et al., 2022). Another difference between the studies was in the images visible to participants at test. In our study, the LV study images were either visible at test (matching task) or removed (memory); no other reference images were visible to participants. In Baker et al.'s study, participants were shown low-variability images during learning but a reference image that was taken on another day remained visible to participants as they completed the recognition task. Thus, their participants got to view several images of how the identity appeared across one encounter plus a single image of how she appeared in a different encounter. That exposure might have added enough variability to facilitate recognition of the identity in novel images, perhaps by expanding the range of variability anticipated as belonging to the same identity (see Raviv et al., 2022).
A recent study showed that learning a new face in a single live social interaction lasting as little as 5 min does lead to learning (Popva & Wiese, 2023). Such interactions differ from static images in two key ways: They provide rich visual information and are accompanied by biographical information which could help learning. Here we strictly examined whether generalisation of learning occurs when learning is based on viewing static images taken from a single, as compared to multiple, encounters.
Across both experiments, we found a benefit of viewing HV images in the matching and memory versions of our task. Sensitivity was higher in the matching than in the memory task in Experiment 2, but there was no interaction with variability condition in either study. These findings contrast with the results of Ritchie et al. (2021) who tested the utility of exposure to variability in matching tasks where an array of HV or LV images were presented either simultaneously (no memory) or sequentially (requiring memory) with the target image. An overall variability benefit was found only in the sequential task. The authors argued the sequential task requires participants to abstract a representation of the identity and hold that in memory in order to compare to the target image and that this abstraction requirement, which is not present in the simultaneous task, is key to learning faces from variable images. In the present study, we found a variability advantage in both our matching and memory tasks. The difference between our matching task results and those of the simultaneous matching task in Ritchie et al. (2021) may lie in the difference in presentation of training stimuli during the learning phase. In our matching task, images were presented one at a time (i.e., over time) and remained on display during the subsequent recognition test, whereas Ritchie et al. (2021) presented the images in an array simultaneously with the test image. Our sequential presentation of the training images over time may have encouraged the formation of a representation more than matching studies that present multiple training images all at once.
Our data provide novel insights about the process by which a newly encountered face becomes familiar. Face identification is inherently challenging; it requires discriminating match vs. mismatched pairs in a noisy environment where photos of the same person can look very different, and photos of different people can look very similar. Sensitivity to identity might be improved by increasing the perceptual distance between identities and/or by decreasing the perceptual distance between different images of the same identity. Although norm-based coding models emphasize the role of between-identity distance in performance (Leopold et al., 2001; Rhodes & Jeffery, 2006; Valentine, 1991), other evidence suggests that better recognition of familiar (vs. unfamiliar) faces is attributable to a shift in perceived within-identity similarity. White et al. (2022) asked participants to rate the similarity of identity-specific prototypes paired with sex-matched averages (between-identity similarity), and of individual images paired with the same-identity prototype (within-identity similarity). Only within-identity ratings differed as a function of familiarity, such that individual images were rated more similar to the same-identity average when faces were familiar. Baker and Mondloch (2023) examined face recognition as learning unfolds (after participants viewed one, three, six, or nine images of a target identity). Using a Dual Process Signal Detection Model, they provided evidence that learning is associated with an increase in both recollection old (a threshold process reflecting high confident hits) and recollection new (a threshold process reflecting high confidence correct rejections). Their findings suggest that perceptual distances both within and between identities play a role in face learning. The findings of the current study suggest that exposure to high variability in appearance is key to one or both of these processes.
Exposure to high within-person variability in appearance also influenced participants’ response bias; in both experiments, participants were less conservative in the HV condition than in the LV and 1-image control condition. Such a finding provides evidence that face learning involves accepting more images as having sufficient likeness to a target identity to warrant a match response, consistent with increased within-identity similarity. Although not significant, we discovered a numerical difference between the LV and 1-image condition, such that participants tended to be more conservative in the LV condition. Future research should explore this pattern, as it suggests that encountering a face only once constrains the range of variability accepted. Changes in criterion across conditions align with recent calls to conceptualize face recognition not just as a perceptual problem, but also as a decision-making problem (Baker et al., 2023; Bindemann & Burton, 2021).
The importance of exposure to within-person variability in appearance is attributable to the idiosyncratic nature of within-person variability in appearance. Principal Components Analysis of within-person variability reveals that the way in which any given face changes in appearance varies across individuals (Burton et al., 2016); thus, learning one face provides only minimal transfer of learning to the next (but see Strathie et al., 2022). Exposure to idiosyncratic variability (e.g., open-mouth smiles) improves recognition (Mileva & Burton, 2018) and influences perceived similarity. For example, which photos of celebrities are judged as being a good likeness varies across perceivers as a function of which movies each perceiver has seen and degree of familiarity with an identity predicts the likeness ratings given to all photos (Ritchie et al., 2018). Given that perceived within-person variability is idiosyncratic and drives the effect of familiarity on recognition, it is not surprising that between-day variability in appearance—variability that incorporates idiosyncratic variability, is key to face learning. Future research should examine which aspects of between-day variability in appearance (e.g., changes in lighting, camera lens, make-up, and hairstyle) are key to the process by which a face becomes familiar. Evidence from a learning study using the stimuli from Ritchie and Burton (2017) but with the external facial features masked also reported better recognition in the HV versus LV condition (Robins et al., 2018), suggesting that variability in the appearance of internal features is key.
Our findings do not exclude a role for exposure time or sparse social representations (Devue et al., 2019; Schwartz & Yovel, 2019; Shoham et al., 2021; Wiese et al., 2019) contributing to people's fragile representations of lesser-known faces, but they provide compelling evidence that exposure to how a face varies over time is key to face learning. Recognizing a waiter, a new acquaintance, a lecturer, or the perpetrator of a crime is challenging, at least in part, because such individuals have been encountered only once (or, in the case of a lecturer, in a single setting with minimal change in appearance)—an effect that might be enhanced for categories of faces with which the perceiver has minimal experience (e.g., other-race/age faces) or for poor face matchers. Future research should examine the extent to which the benefit of high variability is attributable to building a more representative average (i.e., an average that minimizes errors in identification) versus storing instances that capture a wider range of variability in appearance and the relative contributions of an increase in perceived similarity among images of a learned identity versus an increase in perceived differences between a learned identity and other faces.
Conclusion
Viewing six images of a newly encountered face promotes face learning, but only when the training images were captured on different days (i.e., incorporate variability in lighting, camera, hairstyle, make-up, health, etc.). Images captured during a single encounter do not promote generalisation of learning, despite incorporating changes in head orientation and facial expression. Our findings have implications in applied settings (e.g., for eye-witness testimony that relies on a single encounter; for use of photos on ID cards or unlocking cell phones) and for models of how humans develop expertise with a novel object.
Footnotes
Acknowledgements
We thank members from the Face Perception lab for their assistance in collecting data for this study. This research was funded by a Natural Sciences and Engineering Research Council of Canada (NSERC) Discovery Grant (RGPIN-2016-04281) awarded to Catherine Mondloch and an Economic and Social Research Council (ESRC) New Investigator Grant (ES/R005788/2) awarded to Sarah Laurence.
Author contribution(s)
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Economic and Social Research Council, Natural Sciences and Engineering Research Council of Canada (grant numbers ES/R005788/2 and RGPIN-2016-04281).