
Abstract
According to the central-peripheral dichotomy (CPD), feedback from higher to lower cortical areas along the visual pathway to aid recognition is weaker in the more peripheral visual field. Metacontrast masking is predominantly a reduced visibility of a brief target by a brief and spatially adjacent mask when the mask succeeds rather than precedes or coincides with the target. If this masking works mainly by interfering with the feedback mechanisms for target recognition, then, by the CPD, this masking should be weaker at more peripheral visual locations. We extended the metacontrast masking at fovea by
Enns and Di Lollo to visual field eccentricities 1
Introduction
The central-peripheral dichotomy (CPD) (Zhaoping, 2017, 2019) is a recent proposal motivated mainly by the following two observations. One is the presence of an attentional bottleneck for visual recognition and the other is an increasing level of experimental support to the V1 saliency hypothesis (V1SH) that a saliency map is created in the primary visual cortex (V1) to guide attention or gaze shifts exogenously (Li, 2002), see review in Zhaoping (2014). The attentional bottleneck means that, due to limited brain resources, only a tiny fraction of all visual input information is selected for deep processing or visual recognition. This selection is often via gaze shifts to the selected location or object, and V1SH implies that the selection should start by V1’s output (Zhaoping, 2019). Accordingly, visual information from V1 to higher visual areas along the visual pathway is impoverished, giving ambiguous information about visual objects to be recognized. To aid object recognition in ambiguous or challenging situations (such as brief viewing durations, noisy inputs, or partially occluded objects), feedback from higher to lower visual cortical areas could query for additional information using analysis by synthesis as part of a perceptual decision-making process. This feedback query works as follows: first, the higher visual areas synthesize the would-be sensory signals according to the initial perceptual hypotheses about the sensory scene; then, the synthesized signals are fed back and compared with the ongoing sensory signals in early visual areas to update the hypotheses to arrive at an ultimate perceptual outcome. The CPD states that this feedback is mainly directed to the central fovea, which is typically centered on the object selected by attention to be recognized (Zhaoping, 2017, 2019). Hence, peripheral vision relies mainly or only on feedforward visual inputs for recognition, making it more vulnerable than central vision to visual illusions that could arise from impoverished and misleading visual inputs. The CPD is consistent with the observations that many visual illusions, including the rotating snake illusion (Hisakata and Murakami, 2008), the Hermann grid illusion (Schiller and Carvey, 2005), the furrow illusion (Anstis, 2012), the curved ball illusion (Shapiro et al., 2010), and the reversed Phi motion illusion (Anstis, 1970), tend to be stronger or only occur in the peripheral visual field. Knowledge of V1’s neural properties has also enabled the CPD to predict two new illusions, reversed-depth in contrast-reversed random-dot stereograms (Zhaoping and Ackermann, 2018) and filt tilt illusions (Zhaoping, 2020), that are subsequently confirmed experimentally to typically occur only in the peripheral but not central visual field.
The CPD also suggests that, if an illusion or phenomenon is associated with top-down feedback for recognition, then it should be stronger foveally (Zhaoping, 2019). This paper applies this prediction to metacontrast masking. Metacontrast masking is predominantly a reduction in the visibility of a brief target by a brief and spatially adjacent mask when the mask succeeds rather than precedes or coincides with the target, and the strongest masking occurs when the mask appears around 40–100 ms after the target appears (Kahneman, 1968; Enns and Di Lollo, 1997; Breitmeyer and Öğmen, 2006). It has been controversial whether predominantly feedforward or feedback mechanisms for visual recognition are interfered with by metacontrast masking. The masking effect is dramatically weakened by slightly increasing the distance between the target’s contour and the mask’s contour, supporting the idea that the masking works by inhibition of the neurons responding to the target by nearby neurons responding to the mask along the feedforward route (Breitmeyer and Öğmen, 2006; Macknik and Martinez-Conde, 2007). However, neurophysiological recording from monkey V1 (Bridgeman, 1980) and also from V2 (von der Heydt, 2022) and visual evoked potentials at scalp (Jeffreys and Musselwhite, 1986) showed that, very soon after the target’s onset, early cortical responses to masked and unmasked targets are similar. These observations suggest that masking had a limited effect on early visual cortical responses, consistent with the idea that masking interfered with the feedback processes to perceive the target.
In comparison to metacontrast masking, pattern masking and object substitution masking (OSM) are less controversially believed to interrupt, respectively, feedforward and feedback mechanisms for target recognition (Enns and Di Lollo, 2000). Pattern masking occurs when the target contours and mask contours overlap spatially, whereas OSM is often examplified by the four-dot masking (Enns and Di Lollo, 2000) in which the mask comprises four dots surrounding but sufficiently away from the target. OSM is typically observed by a common onset for the target and the mask, and the masking effect is typically weak unless the mask’s offset is delayed after the target’s offset and when an observer’s attention is not properly focused on the target at the beginning of the target’s presentation because the observer is uncertain about the target’s location before its appearance (Enns and Di Lollo, 2000). The mechanisms behind OSM have been proposed as follows (Enns and Di Lollo, 2000; Di Lollo et al., 2000): an initial feedforward processing of visual input along the visual pathway (including V1 and higher brain areas) generates initial perceptual hypotheses about the visual inputs—the target and the mask—in higher brain areas; these hypotheses require comparison with the high-resolution sensory information in V1 via subsequent feedback to V1; when the feedback signals arrive at V1 there is a mismatch between the initial hypotheses and the on-going V1 activities signalling information about the trailing mask alone; this mismatch causes the initial hypotheses to be substituted by new hypotheses about the mask alone, thus generating the masking effect. This OSM proposal is supported by experimental data. Event-related potentials from human scalp suggests that the target triggers a shift of attention to it, however, by the time attention is shifted to the target only the mask remains visible (Woodman and Luck, 2003). Data from functional magnetic resonance imaging (Weidner et al., 2006) indeed show that V1 and some higher brain areas that are plausibly involved in perceptual hypothesis processing have higher neural activities when the masking is effective, presumably to process the mismatch.
There are some similarities between metacontrast masking and OSM (Goodhew et al., 2013). In particular, both types of masking are unlike pattern masking such that the mask and target contours do not spatially overlap each other and that the masking effect is substantial by a trailing rather than a preceding mask. Furthermore, the early visual cortical responses do not seem to distinguish between masked and unmasked situations (Bridgeman, 1980; Jeffreys and Musselwhite, 1986; von der Heydt, 2022; Woodman and Luck, 2003) in both metacontrast masking and OSM. One could then ask whether metacontrast masking also interferes with the feedback mechanisms. However, notable differences between metacontrast masking and OSM are apparent. Metacontrast masking works only when the mask’s contour is very close to the target’s contour, while OSM is insensitive to the distance between these contours (Enns and Di Lollo, 1997). Visual crowding (Levi, 2008; Whitney and Levi, 2011), the deficit in identifying a target in visual periphery when this target is surrounded by flankers, can be reduced when the flankers are masked by metacontrast masking but not by OSM masking, suggesting that metacontrast masking but not OSM may act earlier than crowding (Chakravarthi and Cavanagh, 2009) in the stages of visual processing.
This paper uses the CPD to ask whether metacontrast masking also involves disrupting the feedback mechanisms for target recognition. If the answer is yes, the CPD would predict that this masking should be weaker at more peripheral visual locations. To test this prediction, we adapt the metacontrast masking stimulus from Enns and Di Lollo (1997) for visual locations at three different visual eccentricities, 1
In anticipation, we found that at all three eccentricities, target discrimination performance as a function of SOA followed a U-shaped curve that depressed mainly at positive, small, SOAs, as is characteristic of metacontrast masking for central vision. However, larger eccentricities yielded better task performance and a faster recovery of the target discrimination performance with increasing SOA, as predicted by the CPD if metacontrast masking mainly interrupts the feedback mechanisms.
Materials and Method
A total of 30 observers (experimental subjects, 12 male) with normal or corrected vision participated in the experiment whose results are reported in the figures of this paper. All except one of them were naive to the purpose of the experiment. Their minimum, maximum, and average ages were 20, 36, and 26.7 years old, respectively. One of the authors was always present with each participant throughout an experimental session. The target and mask stimuli were adapted from that of Enns and Di Lollo (1997). The target was a black solid diamond (a square with each of its sides tilted
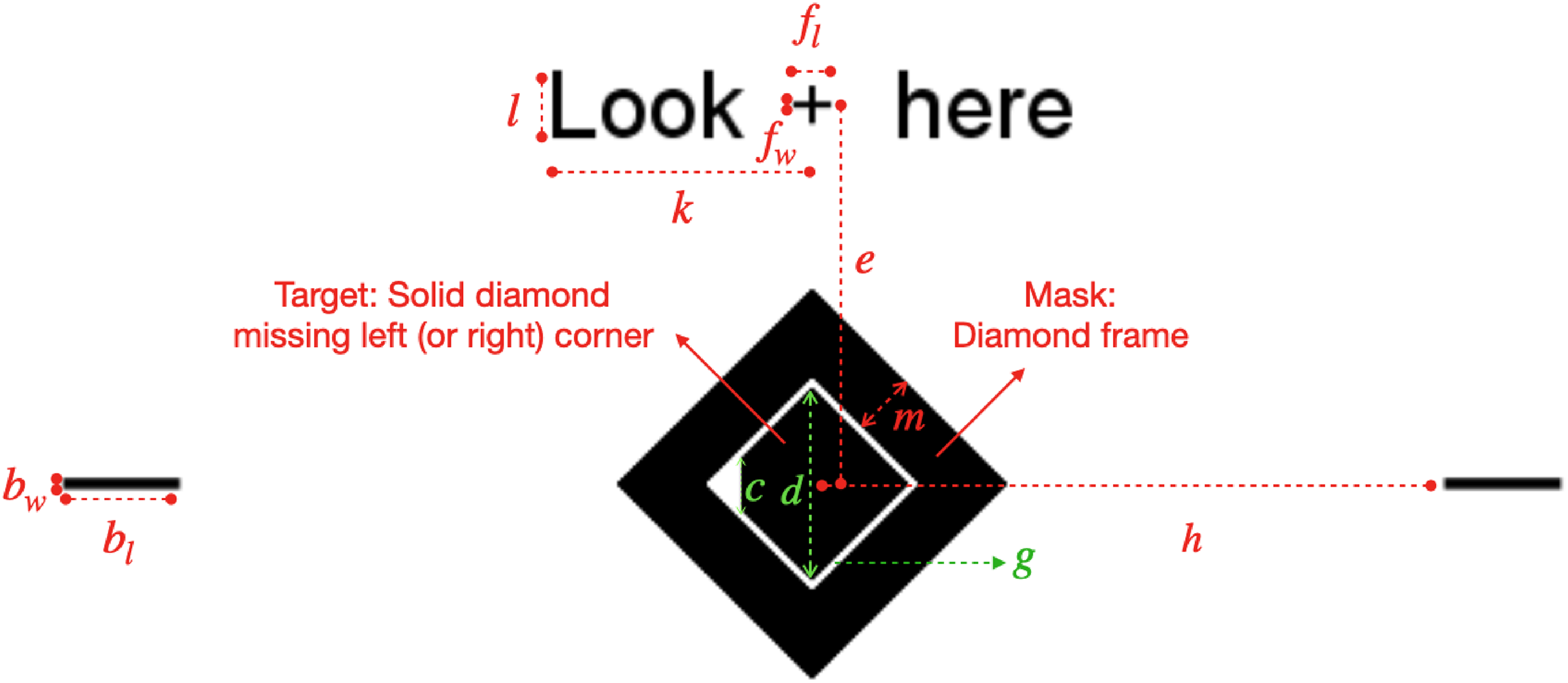
The spatial positioning of the experimental stimuli, and the notations for various sizes and spatial extents. The target diamond missing its left or right corner, the mask surrounding the target, the fixation cross, the horizontal bars, and the text string “Look here” are all black on a white background. All the colored markings and colored texts indicate the positions and sizes of various stimulus components, and are not part of the stimuli. Participants’ task was to report whether the target diamond missed a left or right corner. “Look here” appeared only at the beginning of each trial to prompt subject to fixate on the cross. The fixation cross and the horizontal bars were displayed on the screen throughout each trial to anchor the target diamond’s center location horizontally and vertically. The fixation cross was at the same location on the display throughout an experimental session, while the eccentricity
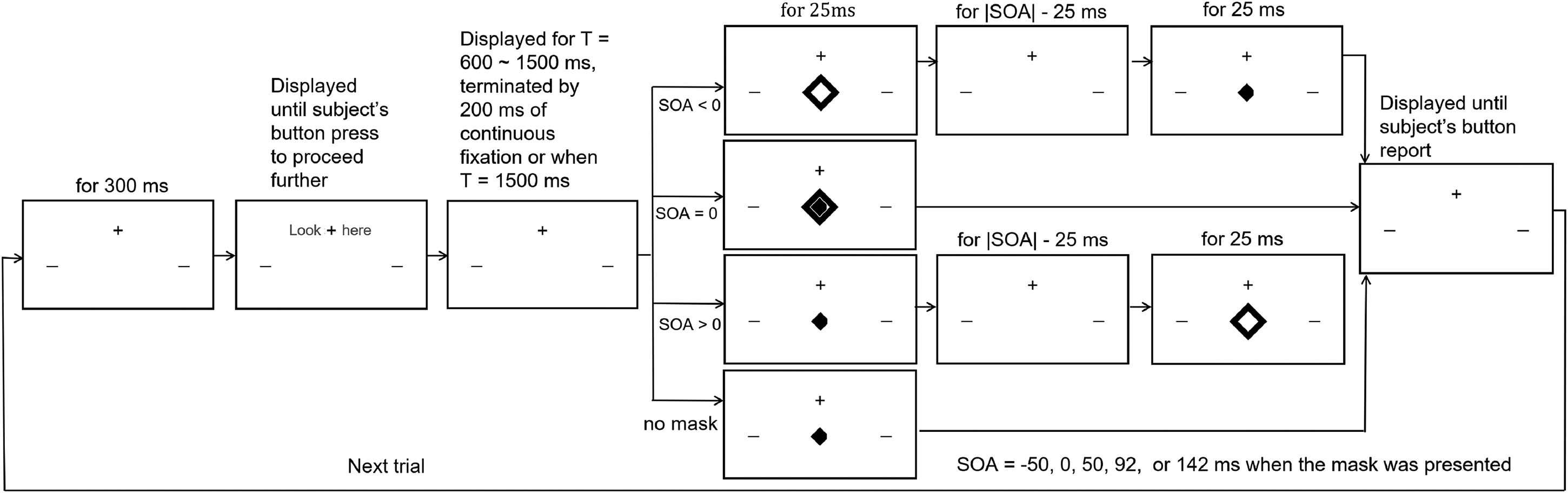
Temporal sequence of events in an experimental trial. For illustrative purposes, the sizes of stimulus elements drawn here are not scaled exactly as in the experiment. There were 18 possible conditions made from combinations of six possible target-mask situations (five stimulus onset asynchrony (SOAs) and one no-mask situation) and three possible eccentricities
Experimental Equipment
The visual stimuli were displayed using a VIEWPixx/EGG display screen from VPixx Technology at 120 Hz frame rate. The eye tracker was CRS LiveTrack Lightning which sampled at 50 Hz. The experiment was conducted in a dimly lit small room, with the white background (with luminance 100
Procedure
Each observer sat in front of the display with a viewing distance of 64 cm maintained by a chin stand. At the beginning of each experimental session, a fixation cross appeared near the center of the display and stayed on the display throughout the session. At the start of each trial, two horizontal bars appeared below the fixation cross (see Figures 1 and 2). They had the same displacement vertically from the fixation cross. Their center of mass was below the fixation cross to coincide with the center location of the upcoming target and mask at eccentricity
Sizes of Various Stimulus Components
In the image containing the target and the mask for
There was a large variability across subjects in their task performance accuracies, such that the standard deviation of the accuracies, which are by definition (see later) within
Care was taken so that the scale factors were not too large to obscure any possible masking effects (at larger eccentricities) for positive SOA values less than
In detail, the sizes of the various components of the target, mask, and contextual elements are completely specified by the quantities named in Figure 1, and listed in Table 1.
Spatial extent of the stimuli in degrees (for

Data Analysis
To obtain our results, we exclude all trials in which the subjects did not fixate properly (see Materials and method). These excluded trials are called invalid trials, and the other trials are valid trials. Among our
We define accuracy
Gender difference has been found in backward masked vernier tasks (Shaqiri et al., 2018) using data from hundreds of subjects. Perhaps partly because we used fewer subjects, we found no significant gender difference in any of our masked conditions after corrections for multiple comparisons. However, in our no mask condition at
Results
The Strongest Masking was Backward Masking at 50 ms SOA at All Three Eccentricities
Averaged across observers, the masking behavior at our smallest eccentricity
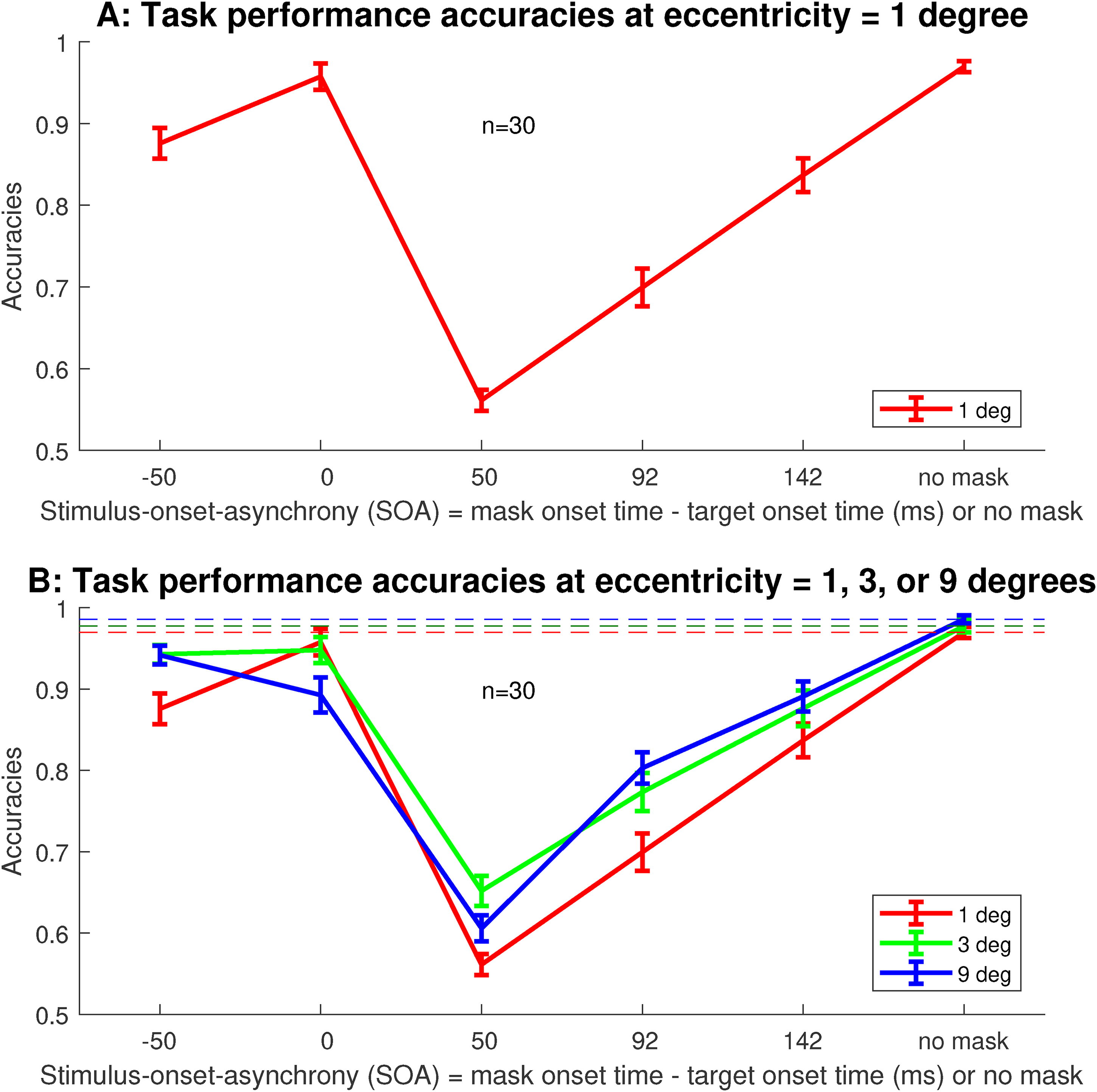
Performance accuracies for target discrimination averaged across
Figure 3B plots the task accuracies at all the three eccentricities,
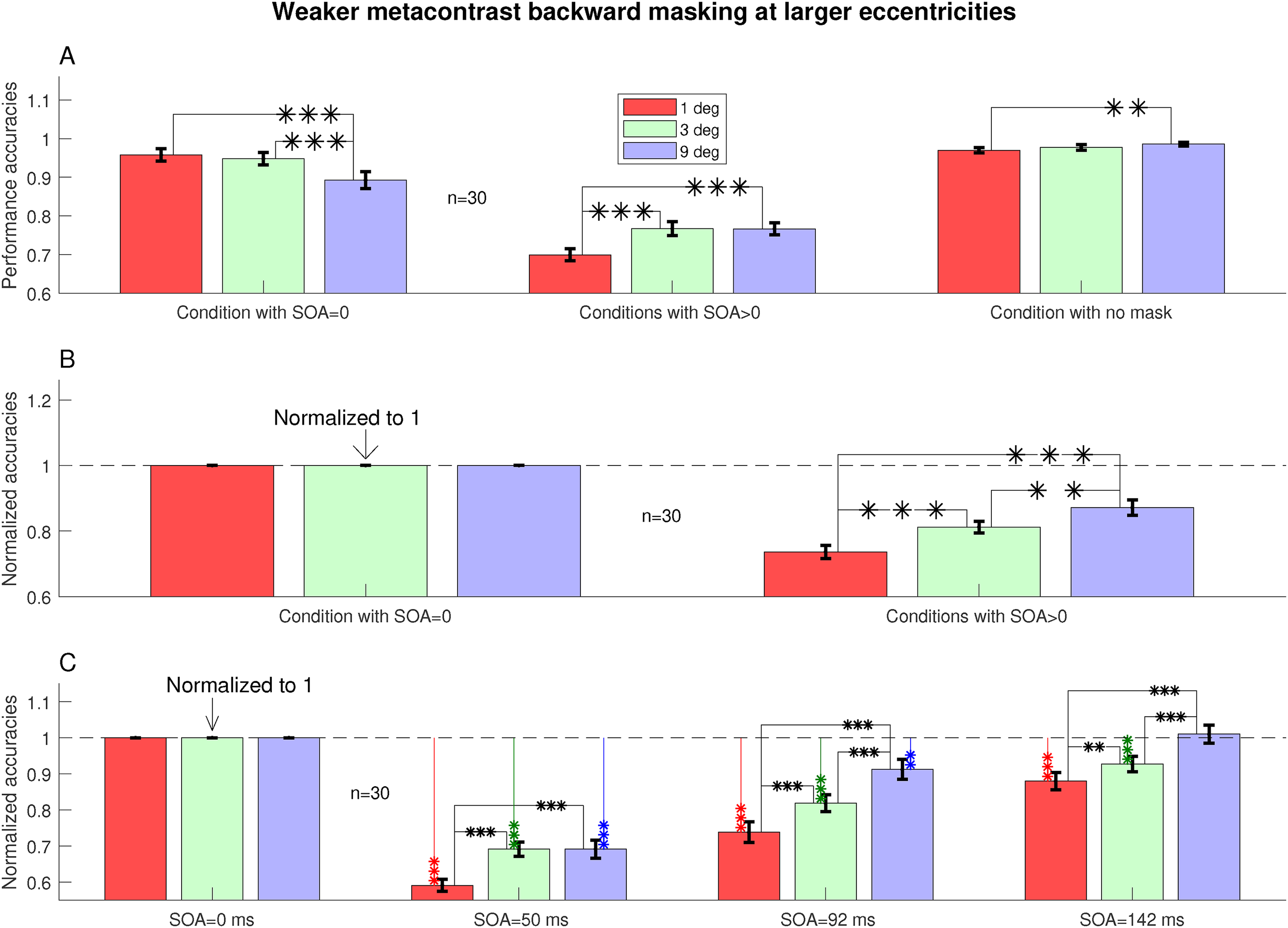
Backward masking (SOA
Backward Masking was Weaker at Larger Eccentricities
Figure 4 examines more closely the differences between different eccentricities for backward masking with SOA
To examine the backward masking (at SOA
Examining the three SOAs (50, 92, and 142 ms) individually, Figure 4C shows that the masking was strongest at
Forward masking is also weaker at larger eccentricities
Forward masking is much weaker than backward masking at all eccentricities (see Figure 3). Meanwhile, a closer examination by Figure 5 shows that there was a dependence on eccentricity when we compare forward masking (SOA
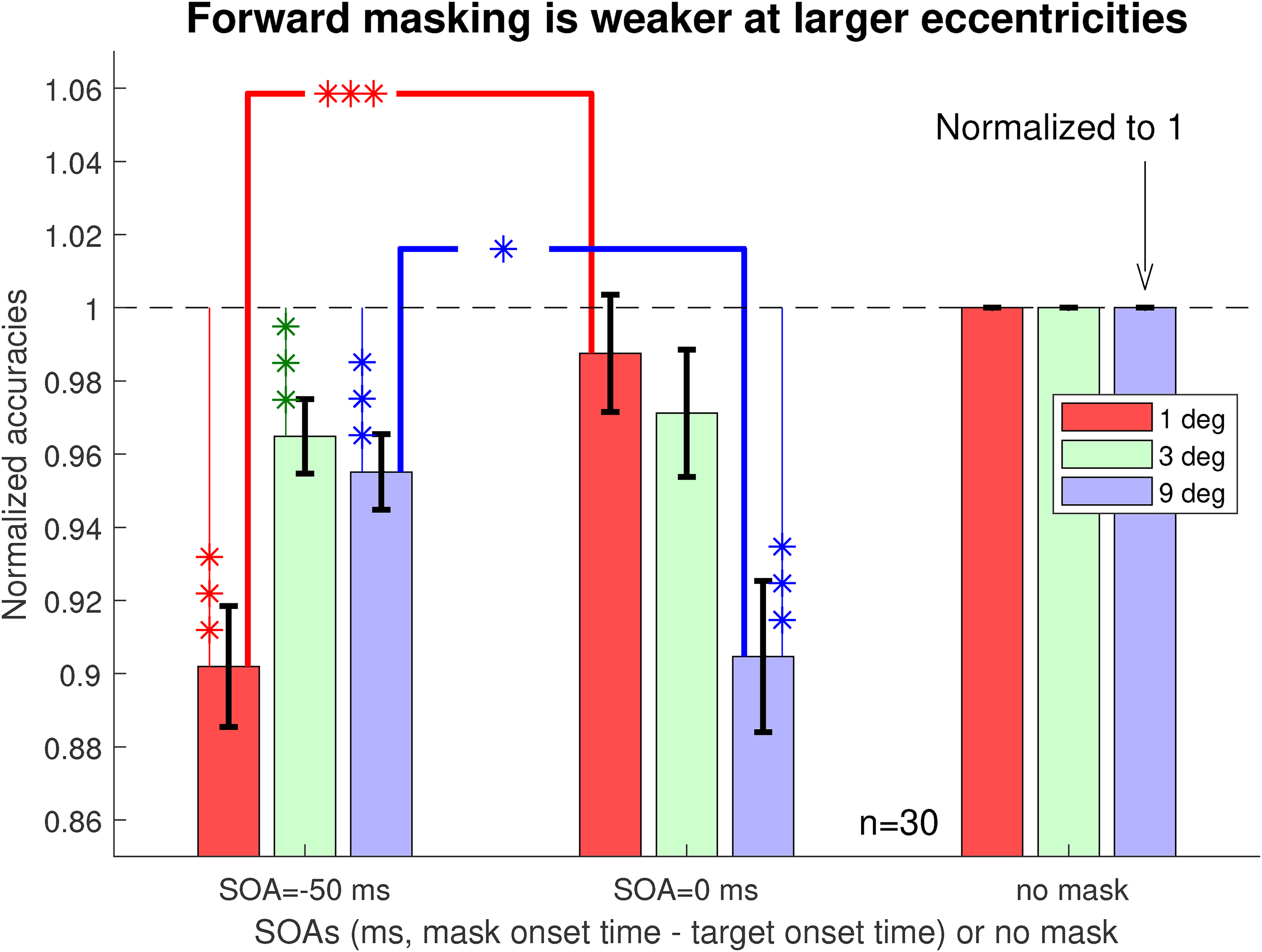
Forward masking is weaker at larger eccentricities. Shown are task accuracies at zero and negative SOAs relative to those in the no-mask conditions, using normalization so that each original accuracy
Summary and discussion
Metacontrast masking is manifested by a U-shaped curve of target recognition performance as a function of SOA, this curve dips substantially around
Our conclusion that metacontrast is weaker at larger eccentricities was reached after we took care of the effects of visual crowding and visual attention. We compensated for crowding by enlarging the visual inputs for larger eccentricities so that target discrimination accuracy was comparably near 100% at SOA
It is a long-standing idea that the brain uses both feedforward and feedback processes for object recognition (MacKay, 1956; Carpenter and Grossberg, 1987; Li, 1990; Kawato et al., 1993; Dayan et al., 1995; Yuille and Kersten, 2006). The feedback component is expected to feature more heavily, and multiple iterations of feedforward and feedback processes are often needed, in more challenging situations such as brief, noisy, partially occluded, and/or ambiguous sensory inputs. OSM (Enns and Di Lollo, 1997; Di Lollo et al., 2000) is a very illustrative manifestation of such interactions between feedforward and feedback signals. The CPD additionally proposes that the feedback component is weaker or absent in the peripheral visual field (Zhaoping, 2017, 2019), since computational resources in the brain are limited. Although this study uses the CPD to investigate whether metacontrast masking interferes with the feedback processes, since the CPD is still a recent hypothesis that is yet to be further tested, this study can also be seen as using metacontrast masking to test the CPD if this masking is assumed to involve interference of the feedback component. Our findings indicate that the CPD and the idea of feedback interference by metacontrast masking are consistent with each other.
Since its recent proposal (Zhaoping, 2017), support for the CPD has come from experimental confirmations of its predicted visual illusions in the peripheral visual field (Zhaoping and Ackermann, 2018; Zhaoping, 2020). These predictions arise because a lack of sufficient feedback process to aid visual recognition in ambiguous situations makes peripheral vision vulnerable to misleading visual inputs, in light of the information bottleneck starting from V1’s output so that perceptual decisions in higher brain areas are made from scanty information sent from V1. Stronger feedback in central vision to aid recognition is supported by a stronger bias to perceive, among multiple plausible perceptual outcomes (in situations of ambiguous perception), the outcome that is more consistent with expectations by brain’s internal models of the visual world (Zhaoping, 2017). The interaction between the feedforward and feedback process can be paraphrased as Feedforward-Feedback-Verify-reWeight (FFVW) (Zhaoping, 2017, 2019) as follows: initial sensory inputs feedforward to initiate candidate hypotheses about the visual scene; higher brain areas synthesize from the brain’s internal models would-be visual inputs consistent with each hypothesis; these would-be visual inputs are fed back to V1 (which has been hypothesized (Zhaoping, 2019) as before the start of the information bottleneck along the visual pathway) to compare with the actual visual inputs; and the weight of each hypothesis for becoming the perceptual outcome is increased or decreased if the match between the would-be and actual inputs is relatively better or worse, respectively. This FFVW process should veto perceptual hypotheses that are suggested by V1’s responses to retinal inputs but are inconsistent with the brain’s internal models. Accordingly, reversed depth from contrast-reversed random-dot stereograms or flip tilt illusions are typically not perceived in central vision (but visible in peripheral vision) (Zhaoping and Ackermann, 2018; Zhaoping, 2020). The target made invisible by metacontrast masking by SOA
Sensitivity to the physical distance between target contours and mask contours (Breitmeyer and Öğmen, 2006; Enns and Di Lollo, 1997) and inhibition of V1 responses to the target by a spatiotemporally nearby mask (Macknik and Livingstone, 1998; Macknik and Martinez-Conde, 2007) have provided perhaps the strongest support to the idea that metacontrast masking interfered mainly with feedforward mechanisms for target recognition. However, for backward masking, although V1 neural responses to the target are most inhibited by masks when the interstimulus interval (ISI) between the target’s offset and the mask’s onset is zero (Macknik and Livingstone, 1998; Macknik and Martinez-Conde, 2007), strongest perceptual masking typically occurs for an ISI
Our forward masking, when SOA is
In summary, according to our data, the CPD, which hypothesizes that top-down feedback for object recognition is weaker in the peripheral visual field, and the idea that metacontrast (backward) masking mainly interferes with feedback mechanisms for object recognition are mutually supportive of each other. This could be tested further in future studies using other stimulus and task examples of metacontrast masking.
This study is also another demonstration showing that peripheral vision cannot be equated with central vision once the visual input size is scaled up to compensate for a reduction in the cortical magnification factor (the extent of the retinotopic V1 receiving inputs from one unit of solid visual angle) (Rovamo and Virsu, 1979; Koenderink et al., 1978). One can apply the CPD to other visual phenomena to infer the underlying neural mechanisms (Zhaoping, 2019). For example, visual hyperacuity (Westheimer, 1981) is the human visual ability to resolve spatial details finer than the image sampling resolution on the retina. This hyperacuity (for a 500 millisecond viewing duration) deteriorates from fovea to periphery faster than suggested by V1’s cortical magnification factor (Westheimer, 1982; Fendick and Westheimer, 1983). This faster deterioration suggests, according to the CPD, that top-down feedback is likely involved to achieve this hyperacuity feat. Indeed, at fovea, this acuity worsens with shorter viewing durations (Westheimer and McKee, 1977), presumably because a shorter viewing hinders or prevents the feedback process to function (as suggested by an example of depth perception at fovea (Zhaoping, 2021)), and, if so, the CPD predicts that, at a more peripheral location, hyperacuity should suffer less from a shorter viewing duration. Many other visual discrimination tasks, on which human performance deteriorates with visual field eccentricity faster than suggested by a reduced V1 cortical magnification factor (Strasburger et al., 2011), could be examined analogously in this light.
Footnotes
Acknowledgements
Zhaoping would like to thank James Enns, Stephen Macknik, and Gerald Westheimer for their help and discussions on the literature, and Ulf Lüder and two anonymous reviewers for very helpful comments.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support with respect to the research, authorship and/or publication of this article: This study was supported by the University of Tübingen and the Max Planck Society.
Supplementary Materials
Supplemental material for this article is available online.