
Abstract
The existence of a central fovea, the small retinal region with high analytical performance, is arguably the most prominent design feature of the primate visual system. This centralization comes along with the corresponding capability to move the eyes to reposition the fovea continuously. Past research on visual perception was mainly concerned with foveal vision while the observers kept their eyes stationary. Research on the role of eye movements in visual perception emphasized their negative aspects, for example, the active suppression of vision before and during the execution of saccades. But is the only benefit of our precise eye movement system to provide high acuity of the small foveal region, at the cost of retinal blur during their execution? In this review, I will compare human visual perception with and without saccadic and smooth pursuit eye movements to emphasize different aspects and functions of eye movements. I will show that the interaction between eye movements and visual perception is optimized for the active sampling of information across the visual field and for the calibration of different parts of the visual field. The movements of our eyes and visual information uptake are intricately intertwined. The two processes interact to enable an optimal perception of the world, one that we cannot fully grasp by doing experiments where observers are fixating a small spot on a display.
Introduction
The one item that 100 years and more of research on visual perception have in common is—the fixation spot! It is at the same time the most frequently used visual stimulus, and the one that was least studied (for a recent exception, see Thaler, Schütz, Goodale, & Gegenfurtner, 2013). The importance of the fixation spot comes from the fact that the human sensory area for visual stimulation is anything but homogenous (for an overview, see Rodieck, 1998). The distribution of cone photoreceptors for daylight vision has a sharp peak close to the center of the retina—the fovea. Cone density in the fovea is extremely high, up to 200,000 cones/mm2, and as low as 2,000 at larger eccentricities (e.g., Curcio, Sloan, Kalina, & Hendrickson, 1990). However, since the area of the fovea is very small, only about 50,000 of the six million cones in each eye are placed there. The fovea centralis covers about 2° of visual angle, which roughly corresponds to the size of a thumb’s nail at arm’s length. Only in this tiny part of the visual field can we achieve high-acuity tasks such as reading the newspaper or threading a needle. Cone density is one of the limiting factors on visual acuity, and visual acuity decreases quickly toward the periphery proportionally to cone density (e.g., Campbell & Green, 1965). For a thorough investigation of the visual system, it seems therefore necessary to specify exactly on what part of the retina the projection of the stimulus falls. The fixation spot is a convenient way to control the eccentricity of stimulus presentation.
The reason why we can cope with such a tiny area of high acuity is that we are able to move our foveal areas to the things we want to see by making very precise eye movements. Three pairs of extraocular muscles are attached to our eyeballs allowing not only horizontal, vertical, and diagonal but also torsional movements. Many animal species have eye movements, and their main function (in a retina without a foveal region) seems to be the stabilization of retinal images (e.g., Walls, 1962). Two very low level reflexive circuits achieve the stabilization, the vestibular-ocular reflex (VOR), and the opto-kinetic nystagmus (OKN). When we move our heads while fixating an object, the VOR counter rotates the eyes with extremely short latency to keep the retinal image stable along any visual axis. When the projection of our surround moves rapidly over the retina, for example due to self-motion, the OKN alternates between periods of smoothly following the retinal pattern and quick jumps in the opposite direction to reposition the eye. Most important for human conscious visual perception are voluntary eye movements, saccades, and smooth pursuit. Saccades direct the fovea sequentially to peripheral objects of interest by single rapid step-like movements. Pursuit movements keep moving objects within or close to the foveal region by smoothly rotating the eye at a speed closely matching that of the object. Interestingly, the movements of the eyes themselves—slow rotations and quick jumps—are similar to what is observed in the VOR and OKN, but now the control circuits and functions have evolved considerably (e.g., Harrison, Freeman, & Sumner, 2014).
Both types of voluntary eye movements have obvious advantages and disadvantages. The biggest advantage is to be able to inspect stationary and moving objects with high-resolution foveal vision. The major disadvantage of both types of eye movements is that the correspondence between retinal and world coordinates is dissociated. For saccades, retinal positions get assigned to new positions in the world, and receptive fields in visual cortex get new input from different parts of the visual world. Vision before and during saccades is extremely poor (Holt, 1903; Latour, 1962; Volkmann, 1962) due to a combination of factors. The retinal image gets blurred due to the high speed of the eye rotation (Burr & Ross, 1982), the retinal image from the landing position masks whatever was on the retina before and during the saccade (Breitmeyer & Ganz, 1976; Campbell & Wurtz, 1978; Diamond, Ross, & Morrone, 2000), and there is an additional mechanism of active suppression that inhibits most information that would be visible otherwise even before the eye has moved (Burr, Morrone, & Ross, 1994). For pursuit, retinal motion no longer corresponds to motion in the world. After the initiation phase, the projection of the tracked object becomes almost stationary on the retina—close to the fovea—and the projection of stationary objects moves across the retina in the direction opposite to pursuit.
We also make tiny fixational eye movements that we will not consider in this review (for recent reviews, see Martinez-Conde, Otero-Millan, & Macknick, 2013; Rolfs, 2009; Rucci & Victor, 2015). They seem to have several functions related to prevent image fading and for precisely moving the retinal image within the small foveal region. There is some evidence that these miniature eye movements improve visibility for some kind of visual stimuli (Rucci, Iovin, Poletti, & Santini, 2007).
Obviously, the advantages of making eye movements outweigh the disadvantages, and we do move our eyes around in the world. So what actually happens when we do look around?
Anatomy of a Saccade
When we look at a static image within a frame, we typically start out with a fixation at the center of the frame, followed by exploratory saccades to various places and objects of interest within the image. We will not go into the question here why certain regions are selected and not others (e.g., Einhäuser, Spain, & Perona, 2008; Itti, Koch, & Niebur, 1998; Kienzle, Franz, Schölkopf, & Wichmann, 2009; Kollmorgen, Nortmann, Schröder, & König, 2010; Tatler, Baddeley, & Gilchrist, 2005). Rather, we will look into the problem how these eye movements affect our perception. Figure 1 shows a scene overlayed with 1 s worth of eye velocity trace, while the observer is making a long saccade from the center to the left of the image, followed by two smaller saccades. The velocity trace in Figure 1 shows that short periods of fixation alternate with rapid jerks during which the eye moves at great speed. It has been shown again and again that our vision is reduced during this movement (for review, see Ross, Morrone, Goldberg, & Burr, 2001). The important question is how much information we can take up in the 150 to 300 ms between saccades. During fixation periods, our visual system uses the limited information present to recognize what it is looking at. For complex objects or scenes, the problem of recognition may appear like some kind of visual jigsaw with vanishing pieces. Therefore information about the object or scene needs to be transferred into some kind of durable storage—visual memory.
Picture of a castle. At the bottom a recording of the eye velocity is shown, containing three saccades. A large saccade from the center to the tower at the left is followed by two smaller ones within the tower object. Regions in red frames and with high-contrast mark fixation positions. Figure created by Alexander Schütz.
There have been a vast number of studies showing the tremendous speed of object recognition. Following work by Potter and Faulconer (1975), Simon Thorpe et al. (Thorpe, Fize, & Marlot, 1996) showed most impressively that observers could discriminate pictures of animals from distractor pictures showing no animal very fast—ultrarapid. On the basis of electroencephalogram (EEG) data, they argued that only 70 to 80 ms of cortical processing are required by the visual system to indicate the difference, and saccades could be made to a peripherally presented animal image in the presence of a distractor image in as little as 160 ms (Kirchner & Thorpe, 2006). While there has been some controversy about the mechanisms by which the visual system achieves this feat, it is quite clear now that the high speed is not compromised by proxy solutions or other shortcuts. This was suggested by Torralba and Oliva (2003), who were able to classify animal versus no-animal images solely based on the power spectrum of the input images. However, Wichmann, Drewes, Rosas, and Gegenfurtner (2010) have shown that there was basically no performance detriment in animal detection when the power spectra of animal and distractor images were equated. In a related study, Drewes, Trommershäuser, and Gegenfurtner (2011) used truly natural images where animals embedded in their natural backgrounds could appear in many different locations. Observers were able to make saccades to the animal at short latencies of 200 ms with less than 5% errors. Performance could not be explained by visual salience (e.g., Itti et al., 1998). These results indicate that the planning of saccades is performed very rapidly. A large proportion of the saccades were aimed at the heads of the animals, indicating a high level of accuracy despite the short latencies.
But recognizing an object is not enough. The information has to be saved to some kind of durable storage. This is a problem that was first addressed by George Sperling (1960). He found that there is a brief visual representation with high capacity that can last for several 100 ms. It seems that this visual representation occurs in V1 and that it roughly corresponds to the “scratch-pad” that David Marr (1982) had postulated. Since the representation in V1 is retinotopic and because eye movements destroy the mapping between the retinal image and world, an eye movement would destroy iconic memory, very much in the same way that a visual mask interferes with it. Rieger et al. (2008) used a noise masking paradigm and presented target images followed by masks at various delays. When the mask comes shortly after the target image, the activity for both, as determined by magnetoencephalography (MEG), overlaps in time. The authors found a negative correlation between recognition of the target image and the degree of overlap between the MEG activity caused by the target and that caused by the mask. Basically, as long as the visual target image can be processed in an undisturbed manner for at least 70 ms, we can recognize the image and transfer the corresponding visual information into durable visual memory storage. The timing in these masking experiments agrees with the timing observed earlier by Thorpe et al. (1996). The timing is also sufficient to completely fill the memory buffer, given its small capacity of 4 to 5 items (Gegenfurtner & Sperling, 1993).
Eye Movements in Action
The above results were obtained in laboratory settings during fixation or when viewing static images. In the real world, we typically interact with people or objects for much longer periods of time in a specific, informative surround. In recent years, it has been shown convincingly that eye movements go far beyond pure perception. It seems that as soon as we act in our environment, the oculomotor system is engaged to provide information to guide our actions, whether it is moving an object around an obstacle (Johansson, Westling, Backstrom, & Flanagan, 2001), making tea (Land, Mennie, & Rusted, 1999), or a peanut butter sandwich (Hayhoe, Shrivastava, Mruczek, & Pelz, 2003). Even when grasping an object, we first explore the potential target positions for our fingers—mainly the index finger—before actually touching (Brouwer, Franz, & Gegenfurtner, 2009). A stunning example of the importance of eye movements was recently given by ‘t Hart and Einhäuser (2012), who had two observers walk up a street. One person walked on a cobbled road and the other on irregularly spaced stairs. While the person walking on the road looked mainly ahead, exploring the area, the person taking the stairs looked mostly down on the ground to co-ordinate his steps. Thus, eye movements play a crucial role whenever we do something. In the following, I will show that they are also essential for very basic perceptual tasks, such as lightness and size judgments.
Interactions Between Vision and Eye Movements
To summarize so far, the visual system is quite well adapted to see things within a single fixation, even though that time is really very brief. Why then do we need more than just a glimpse? For one, we need more fixations on scenes or objects if we want to transfer information into a longer lasting form of memory. The world around us might be useful as an external memory, but this works only as long as we are within a scene. If we go to the room next door, we can still remember some things about the first room. This representation is gradually built up from many fixations (Castelhano & Henderson, 2005; Hollingworth & Henderson, 2002; Huebner & Gegenfurtner, 2010; Melcher, 2006). And while most visual judgments in the lab are based on brief exposures that prevent saccades from taking place, in the real world we look around and make many fixations before arriving at judgments such as whether a fruit is ripe or rotten. And while the preferred object in the lab is a flat, matte, uniform surface on a display, most natural objects vary in surface reflectance, geometry, and illumination. The picture shown in Figure 2 (reproduced from Brenner, Granzier, & Smeets, 2007) illustrates two key issues for making perceptual judgments. When assigning a single color name to each of the two objects, we need to sample from the different regions of the objects that are made up of different colors. The sampling problem relates to how we take these samples, and how we combine them into a single statistic. We have shown that eye movements can play a crucial role for accurate lightness judgments and for achieving lightness constancy, based on a distribution of luminance values as the input. A different issue, which we will term the calibration problem, relates to the proper combination of foveal and peripheral information within the visual system. The peripheral representation and peripheral processing is quite different from its foveal counterpart. For example, color sensitivity decays differentially for the two color opponent channels and for the luminance channel (Hansen, Pracejus, & Gegenfurtner, 2009; Mullen, 1991), leading to different cone excitation ratios when an object is processed peripherally and when it is processed in the fovea. Later, we will show that eye movements play an important role for calibrating peripheral and foveal information with respect to each other, as has been suggested earlier (O’Regan & Noë, 2001).
Picture of a yellow grapefruit and a green apple. To arrive at a single estimate for the hue, lightness, and saturation of each object, we have to sample different regions (pixels) of the object and combine them. Visual information from the periphery and fovea has to be calibrated with respect to each other and combined. Reproduced with permission from Brenner et al. (2007).
We will then turn to pursuit eye movements and investigate how following an object can change our perception of the world and our actions in the world.
Sampling and Lightness Perception
The particular selection of fixation locations during visual tasks has been explored by several investigators, mainly with respect to the efficiency or optimality of such sampling. Some studies have found evidence that the selection of fixation locations maximizes overall information gain during visual search (Najemnik & Geisler, 2005), minimize local uncertainty during shape recognition (Renninger, Verghese, & Coughlan, 2007), or optimize task-relevant information in face perception (Peterson & Eckstein, 2014). However, in several experiments with more direct tests of optimality, there were strong deviations from an optimal choice of fixation locations (Morvan & Maloney, 2012; Verghese, 2012), which could indicate that several more factors—other than a top-down choice of optimal locations by itself—influence saccadic target selection. This, in fact, agrees well with the evidence that several factors (salience, value, object recognition, task, intention, and action), with partially separate neuronal circuitry, contribute to the control of saccadic eye movements (for reviews, see Pierrot-Deseilligny, Milea, & Mueri, 2004; Schütz, Braun, & Gegenfurtner, 2011; Tatler, Hayhoe, Ballard, & Land, 2011; Wurtz, 2015).
We investigated the effect of saccadic sampling on lightness perception (Toscani, Valsecchi, & Gegenfurtner, 2013a, 2013b). We asked our observers to match the hue, saturation, and lightness of a uniformly colored object placed on a pedestal in front of a CRT screen by adjusting the color of a small uniform patch of light displayed on the monitor. The spectral distribution of light reflected into the eye from the objects was measured at a coarse resolution to obtain the ground truth, and eye movements were recorded while the observers performed the matching task. The most important result is that observers could do the task at all. They intuitively matched the reflecting properties of the surface, even though the luminance varied across the surface due to shading caused by the illumination. They did not ask whether to match the brighter or darker parts of the object but perceived the object as uniform and adjusted the patch on the screen the way they would expect the object to look in that context.
In agreement with an earlier study investigating many more objects (Giesel & Gegenfurtner, 2010), we found that observers were extremely accurate and precise at matching the correct hue. They were variable with respect to saturation, a concept that by itself is still poorly understood (see Schiller & Gegenfurtner, 2016). Also in agreement with the earlier result, we found that their lightness matches were close to the very top of the luminance range within the object. Figure 3(a) illustrates for one of the objects, the orange paper cone, that the average match is very close to the maximum luminance within the object, which in turn is very close to the maximum luminance that would be possible, in case the surface of the cone was oriented perpendicular to the light source. The matches are clearly above the mean luminance of the object.
Results of lightness matching experiments. (a) When observers matched the lightness of the orange paper cone, they chose values close to the maximum of the luminance range of pixels within the object. The four patches to the right indicate the maximally possible luminance, the average match, the maximum within the object and the mean, from top to bottom. (b) Regions with a luminance close to that of the match tended to be fixated more frequently than others. The luminance of the data points approximates the corresponding x-axis values. (c) When observers were forced to fixate a light region (LF), their match was also lighter than when forced to fixate a dark region of the object (DF). The luminance of the bars represents the luminance of the fixated regions. After Toscani et al. (2013a).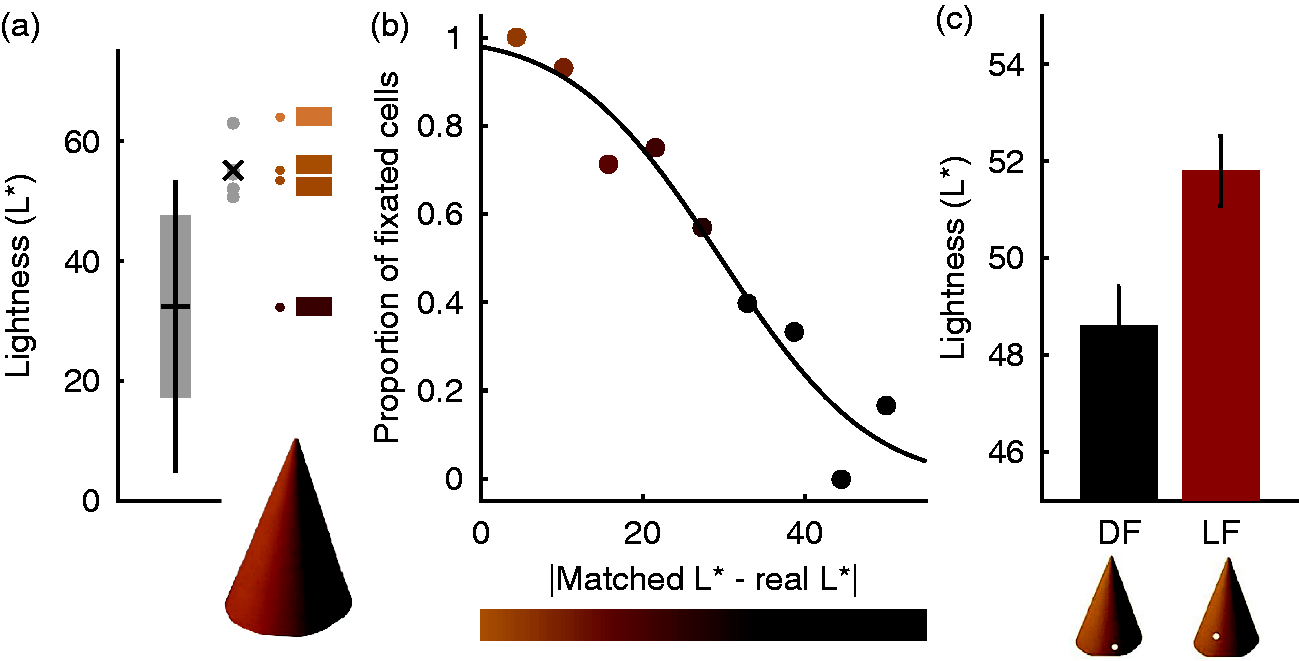
An analysis of the fixation locations showed that observers did not randomly choose regions within the object, but that they preferably chose the brighter regions within the object (Figure 3(b)). Observers fixate regions that have a luminance similar to the matched one. Those regions are almost always fixated, while regions with a different luminance—the darkest regions on the object—are basically never fixated. We went beyond this purely correlative result by using a gaze-contingent paradigm to force the observers to fixate a certain object region, which could either be dark or light. For this experiment, the objects were presented on the computer screen, but only if the observers looked at the desired fixation position. When the gaze moved away from it, the object was extinguished from the screen, and a red spot indicated the desired fixation location. Figure 3(c) shows that this manipulation did indeed have a visible effect. When fixating a brighter region of the paper cone, the match was adjusted to be brighter than when fixating a darker region.
Of course, one could suspect that the observers simply adjusted the local luminance at the forced fixation location in this task. However, in this case, the effect would have been much bigger. The luminance of the fixated dark and light regions differed by as much as 20 cd/m2, while the difference in the match we obtained was rather small (about 4 cd/m2). In addition, we ran further experiments where we used grayscale objects, and observers had to pick a physical piece of paper that they thought would be cut out from the same material as the paper cone displayed on the screen. There was an illumination gradient present in the scene with the papers, leading to a dissociation between luminance and reflectance for the individual paper chips. We found a significant effect of the fixation position only for the reflectance matches, and the chosen paper chips for fixation of light regions were much closer to the reflectance values rendered on the screen (Toscani et al., 2013a).
This leaves us with the puzzling question of why observers would choose regions with the maximum luminance to dominate their lightness match. In statistics, the mean is typically the preferred estimate to characterize a sample, while the maximum has many undesirable properties. We chose to explore this issue by investigating the suitability of a large number of candidate lightness estimates—the mean and all percentiles of the luminance distribution. In particular, we tested how reliable an estimate would be when the object is rotated or under changes of viewpoint. This was implemented by calculating the standard deviation of each estimate under 400 different views. To get the luminance distributions of the different views, we used virtual 3D models of a variety of objects that we rendered under a natural lightfield to obtain the radiance image falling onto the observers’ eyes. In terms of reliability, the minimum and the maximum of the luminance distribution within the object were both adequate and better than the mean (Toscani et al., 2013a).
Reliability, however, is just one aspect of optimality, even though it is very much emphasized by current Bayesian models of visual perception (e.g., Ernst & Banks, 2002). Getting a correct or close to correct answer might be even more important for our visual system than getting a reliable answer (e.g., van Beers, van Mierlo, Smeets, & Brenner, 2011). For example, estimating every surface to be pitch black with zero reflectance is perfectly reliable, but utterly useless. Therefore we also rendered objects with slightly different surface reflectances and tested how well each lightness estimate could separate the 400 different views of the two distributions. Here, the minimum failed completely, while the maximum achieved the highest level of performance, better than the mean. The maximum luminance seems to be, at least for the conditions we simulated, the ideal estimate of lightness. Intuitively, the maximum presents the “ideal” view on the object, when the local surface is oriented perpendicular to the light source. All other luminance values are affected by shading, being dependent on the local surface orientation.
In summary, these results show that the maximum of the luminance distribution is not only what the observers’ use for their match. It is also the optimal solution for the task, and it is supported by the way observers sample the object with their gaze. One could think of this as a heuristic to achieve a stable estimate of lightness, without requiring any knowledge of the high-level visual aspects of the scene, such as geometry, shape, or illumination. While this would work for the task and objects we used in this experiment, real-world situations can be much more complex. For example, for glossy objects the maximum luminance is not at all diagnostic for the lightness. Rather, the intensity of the highlights mainly depends on the illumination. Under such conditions, we observed that observers fixate the regions directly adjacent to the highlights, that is, they use other cues and mechanisms to discount the highlights (Toscani, Valsecchi, & Gegenfurtner, 2013c).
Viewing isolated objects under a neutral illumination bears some resemblance to everyday situations and is therefore of great importance. However, the most stunning cases where lightness perception is of an increased complexity occur when objects are seen in different contexts, rather than in isolation. We used a particularly vivid example of such a lightness “illusion” that was introduced by Anderson and Winawer (2005) in which the identical luminance distribution appears white in one context and black in another context. In this case, this is caused by generating a layered scene using transparent clouds. In the end, the only sensible interpretation of the scene is to segment it into different layers. Our percept is then determined by what we determine as the object, ignoring what is interpreted as occluder (see Figure 4).
Results of lightness matching experiments. Circular luminance distributions are seen as bright uniform discs when the scene suggests that they are occluded by a dark transparent surface (Anderson & Winawer, 2005). Matches in the “dark background” condition are brighter. When we forced fixations to be on the region interpreted as a uniform disc (“consistent”), the context effect gets bigger. In the inconsistent condition, the effect gets abolished for the viewing conditions we used. After Toscani et al. (2013b).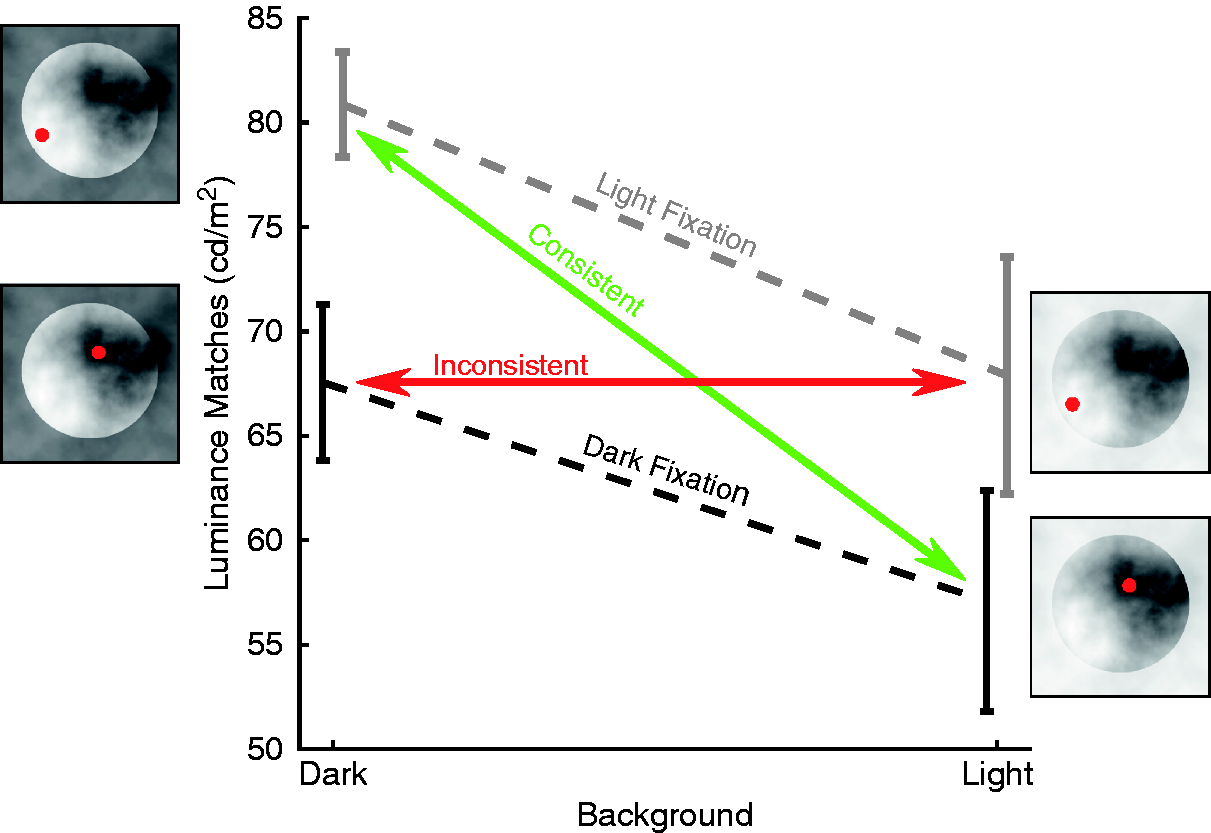
This difference in scene interpretation leads to quite different percepts for the disc areas, even though they are physically identical. This is why it is often referred to as an “illusion.” We replicated this effect by using simplified stimuli, for which we could also measure gaze positions while observers performed the task (Toscani et al., 2013b). Observers did not only perceive the discs as brighter when presented in the dark context but they also tended to fixate on the brighter parts in the dark context. The average fixated luminance correlated strongly with the lightness match across observers, indicating a link between the choice of fixations and lightness perception. As in the previous gaze-contingent experiment with isolated objects, forcing fixations into the dark versus light regions had an effect on the judgments, as illustrated in Figure 4. An inconsistent fixation pattern—fixating on the clouds rather than the object—essentially abolished the illusion, while the consistent fixation pattern led to matches quite similar to the ones obtained in free viewing. As before, fixating a darker region leads to darker matches and fixating a brighter region leads to brighter matches.
In the extreme case, one could argue that the specific visual stimulus leads to the particular pattern of fixations, which in turn forms the percept. This is unlikely, because we do perceive the illusion even when it is briefly presented in the periphery. Furthermore, one can greatly diminish the illusion by rotating the surround with respect to the discs, leaving the luminance distribution within the discs intact. In this case, the pattern of fixations follows the percept. It is no longer discriminable for the two configurations, even though the stimulus pattern itself is unchanged.
The conclusion we can draw from these studies is twofold. First, the choice of our fixation locations on objects has a fundamental effect on our perception of these objects. Now, this could be good or this could be bad. We don’t want an object to change its brightness when we turn it around in our hand or look at it from a different viewpoint. This is not the case. Our eye movements are quite in sync with our perception of the world. We choose those fixation locations that are ideally suited to achieve an optimal and stable percept of our surroundings. In a way, sampling the world with eye movements serves as an amplifier. Eye movements stabilize and strengthen the “correct” interpretation of the world or at least the one that is chosen by our visual system.
Size Perception and Recalibration
The above experiments, and many earlier studies, show that the way we sample the world with our eyes is very important for perception. A second major concern, which is closely related to sampling, is calibration. Before we process an object in foveal vision, it is first processed in the visual periphery and selected as the target for the next saccade. The machinery for processing fovea and periphery is quite distinct. In the fovea, we have not only the highest density of cones, but here cones are wired 1:1 with retinal ganglion cells, and a tremendous part of retinotopic visual areas in the cortex is concerned with central vision. In the periphery, cone density is much lower as cones are interspersed with rod receptors. There is a convergence of cones onto ganglion cells, and much less cortical area is used to process the vast extent of our visual field. Moreover, the properties of neurons representing the fovea and periphery are different. Color sensitivity declines differentially for different colors for peripheral stimuli and also differently from luminance sensitivity (Hansen et al., 2009; Mullen, 1991). High-spatial frequencies are not part of the peripheral representation, because neither the optics of the eye nor the ganglion cell sampling allow for it. For these reasons, one might expect that objects change their appearance dramatically when their projections are moved from periphery into the fovea, as illustrated in Figure 5.
Cortical representation of size and color. The picture of the grapefruit and the apple from Figure 2 gets distorted in its visual cortical representation. Size is changed according to a complex log transform (Schwartz, 1977) that magnifies the foveal representation relative to the periphery. Color sensitivity declines in the periphery differentially for the three color-opponent channels. In the periphery, the colors of the grapefruit become quite similar to those of the apple where the observer is fixating.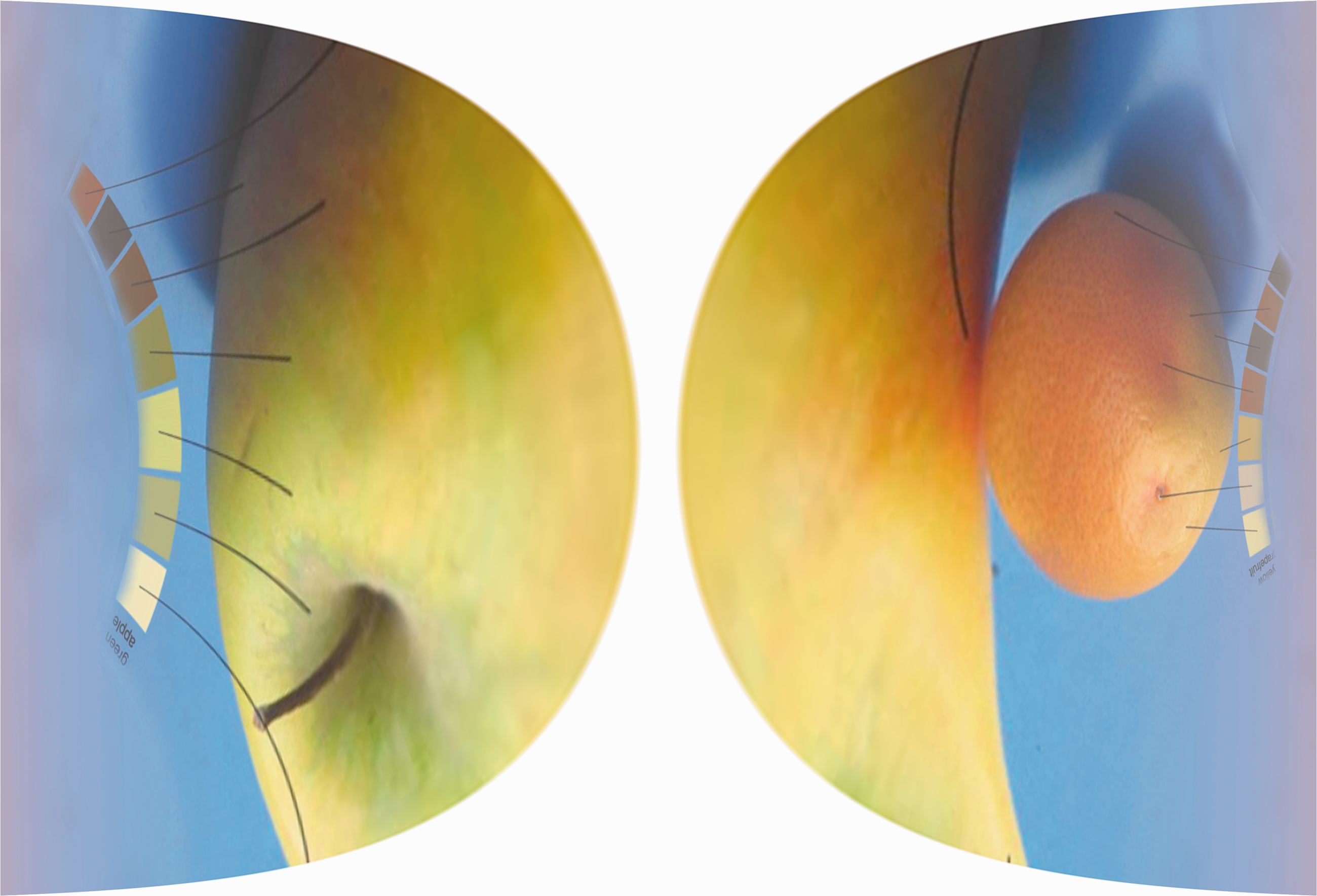
This, of course, is not our experience. We perceive the world as stable and complete everywhere in our visual field at all times. Several mechanisms have been suggested to achieve this. In principle, it is possible that we only “care” about what is in the fovea and throw away peripheral information when the object image is brought into the fovea. This would be in line with studies on change blindness indicating that visual memory is rather poor and that the world seems to act as a memory, which then can be accessed by moving our eyes (O’Regan, Rensink, & Clark, 1999; Rensink, O’Regan, & Clark, 1997). Evidence for using eye movements rather than memory also comes from experiments from manual tasks with a memory demand (Ballard, Hayhoe, & Pelz, 1995). However, numerous studies have shown that our visual system does integrate peripheral and foveal information across saccades (Ganmor, Simoncelli, & Landy, 2015; Oostwoud Wijdenes, Marshall, & Bays, 2015; Wolf & Schütz, 2015). An elegant way to use eye movements to achieve visual stability was proposed by O’Regan and Noë (2001). They proposed that we learn the association between the poor peripheral representation of an object and the rich foveal representation by repeatedly associating the two through motor actions, mainly eye movements. Through this sensorimotor account of vision, we could learn and predict the foveal appearance of objects from their peripheral representation. Evidence for this theory has been sparse in the past and limited to color (Bompas & O’Regan, 2006a, 2006b; Richters & Eskew, 2009).
Figure 5 shows that the cortical representation of size changes dramatically between fovea and periphery. Still, objects do not change their apparent size when viewed peripherally or only very little (Bedell & Johnson, 1984; Brown, Halpert, & Goodale, 2005; Newsome, 1972). It is quite clear that the association between fovea and periphery has to be learned quite early on during development to allow a successful interactions with the world, as is the case for size constancy in general (Mckenzie, Tootell, & Day, 1980; Slater, Mattock, & Brown, 1990). We tested whether this kind of calibration is still possible in the adult visual system, like many other adaptive processes (e.g., saccadic adaptation). Previous studies had shown that an association between foveal and peripheral representations is possible in visual memory (Cox, Meier, Oertelt, & DiCarlo, 2005; Herwig & Schneider, 2014; Herwig, Weiß, & Schneider, 2015; Weiß, Schneider, & Herwig, 2014). We performed experiments testing the idea that their relative appearance can also be changed (Valsecchi & Gegenfurtner, 2016).
Our paradigm is based on the fact that visual sensitivity is very poor during saccades (for review, see Ross et al., 2001), and that changes occurring during saccades cannot be detected well (McConkie & Currie, 1996; O’Regan et al., 1999; Rensink et al., 1997). On each trial, observers viewed two blurry discs, one presented centrally and the other in the periphery, and judged which one of the two discs was larger. These judgments were binned over 50 trials to estimate psychometric functions, which in turn allowed us to estimate the peripheral stimulus appearing as large as the foveal stimulus. In such tasks, peripheral stimuli are known to appear slightly smaller under most viewing conditions (Bedell & Johnson, 1984; Brown et al., 2005; Newsome, 1972), a finding we were able to replicate for our baseline trials.
After the size judgments, we asked our observers to make a saccade to the peripheral stimulus and then to indicate in which direction a tiny protrusion on the peripheral stimulus was pointing. The protrusion was just at threshold in foveal view and could not be seen in the periphery. This second task was used to focus the observers’ attention on the postsaccadic stimulus. The crucial part of the task was that we changed the size of the peripheral stimulus during the saccade. There was an increase or a decrease by 10% that was gradually introduced during the second set of 100 trials. The perisaccadic size change was not noticed by observers. It was clearly below the threshold for detecting such changes, as determined by separate measurements.
Figure 6 shows that our manipulation did have an effect on the relative perceived size of the peripheral stimulus, before making the saccade (Valsecchi & Gegenfurtner, 2016). After 500 trials, the relative size of the peripheral discs changed by about 5% on average or half of the 10% physical size change. Presumably, more trials would lead to further adaptation. To our surprise, this recalibration was stable until we measured the baseline on the next day. Either the adaptation is highly specific to the experimental situation or observers simply do not make enough saccades of the specific size and direction to relearn over night. In further experiments, we were able to show that recalibration does extend to the opposite hemi-field, even though no learning had taken place for saccades into that direction. Adaptation also took place, even though much less, when the association between fovea and periphery was established through visual motion, without making eye movements. There was no reverse recalibration when changing the size of the stimulus that was in the fovea initially (Valsecchi & Gegenfurtner, 2016).
Effects of trans-saccadic size change. (a) Perceived size of the peripheral stimulus is plotted on the y-axis as a function of trial number. During the first 100 trials, no manipulation takes place, then a 10% change in size during the saccade is introduced during the next 100 trials and remains effective until the end of the first session. The perceptual effects agree with the experimental manipulations. The blue dashed curve indicates an increase, the red curve a decrease. (b) On the next day, the two groups were reversed, and with it the perceptual effects reverse. After Valsecchi and Gegenfurtner (2016).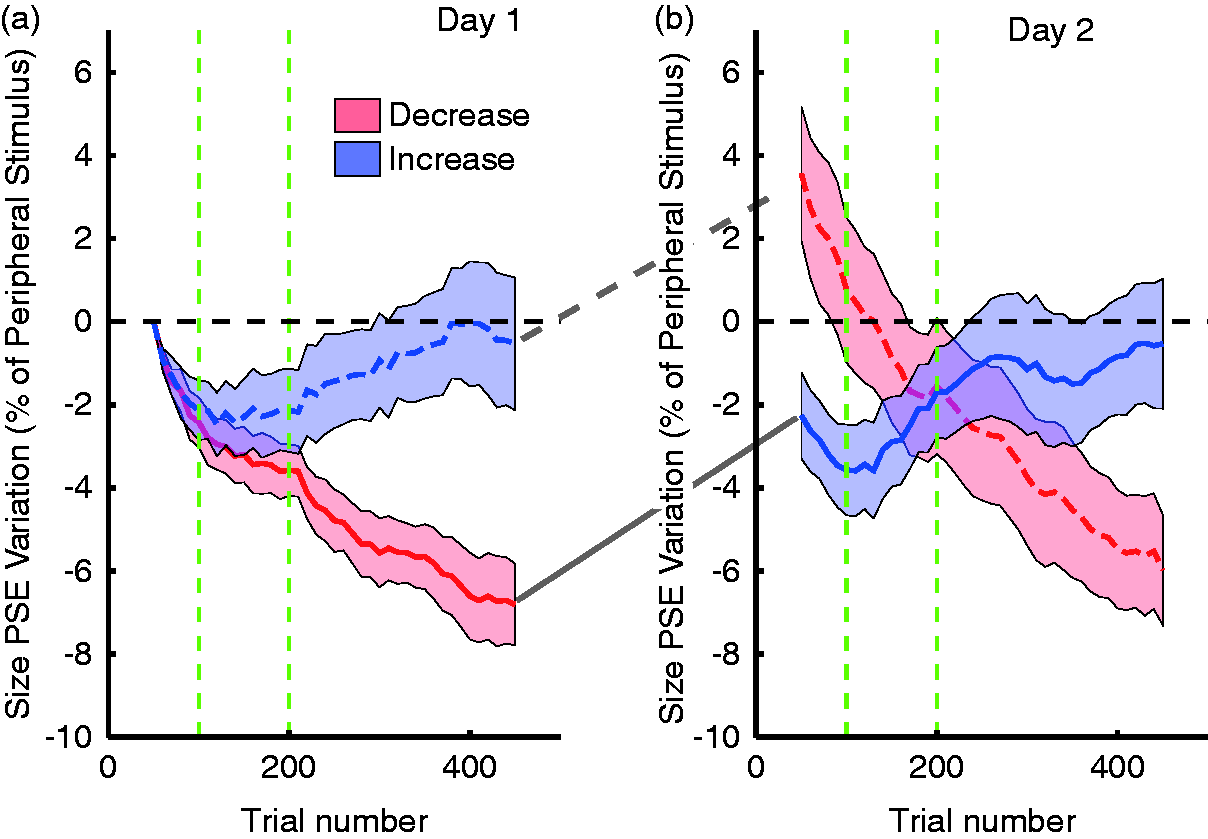
These results show the importance of basic prediction mechanisms for visual perception. What we perceive is not only determined by the sensory signals but also—and maybe even to a larger degree—by the prediction of our visual system. In peripheral viewing, this prediction becomes essential, because the sensory signals by themselves are often highly impoverished. In this case, saccades are the main mechanisms through which to achieve the prediction by repeated association between foveal and peripheral signals. Our perception as well as our behavior is continuously adjusted in order to stabilize both the appearance of the visual world and our interactions with our environments. A single error signal might even be able to induce recalibration in both domains (Bosco, Lappe, & Fattori, 2015).
Pursuit Eye Movements and Motion Prediction
The other major type of voluntary eye movements is smooth pursuit movements. They allow us to follow a moving stimulus, thereby stabilizing it on the fovea. Without pursuit, objects in motion would be very hard to identify, because the image motion on the retina would smear out high-spatial frequency information (Burr, 1980). Of course, smooth pursuit and saccades are intricately related. When a fixated object suddenly starts to move, we have to make an initial saccade to catch up with its movement, because by the time our eyes start to move, the target might have moved several degrees away already. If an object starts to move in the peripheral visual field, we will have to make a saccade toward it first. This made it very difficult to investigate the initiation of smooth pursuit at all, because eye movements always included saccades. Only after Rashbass (1961) invented the “step-ramp” paradigm, smooth pursuit could be studied independently of saccades in the laboratory. In this paradigm, an object moves from the periphery toward fixation so that it reaches the fixation location after about 200 ms since its motion onset. The eyes accelerate with a latency of 120 to 150 ms and smoothly pick up the target as it passes along. In many ways, the Rashbass-paradigm did for pursuit what the Random-Dot-Stereograms introduced by Julesz (1964) did for binocular vision. It was so successful that it was used almost exclusively in work on smooth pursuit (for review, see Lisberger, Morris, & Tychsen, 1987), and pursuit was treated as being distinct and separate from saccades functionally, physiologically, and anatomically.
Only recently has it been shown that there is actually large overlap in the neural circuits controlling saccades and pursuit (for review, see Krauzlis, 2005), and that they interact to bring objects into the fovea and keep them there (for review, see Orban de Xivry & Lefèvre, 2007). This close interaction is not only present in laboratory tasks but can also be observed in reading of drifting text (Valsecchi, Gegenfurtner, & Schütz, 2013). A convincing argument for the close link between saccades and pursuit in the real world is demonstrated in the results of Dorr, Martinetz, Gegenfurtner, and Barth (2010). They measured eye movements of 50 naïve observers looking at videos of natural environments. Most of the time, observers’ eye positions are incoherent, but whenever something in the visual periphery starts to move, all observers converge at that position and start tracking the moving object with smooth pursuit. Motion onsets are the most salient event in the real world, and saccades and pursuit act together in response to these events.
Visual Sensitivity During Pursuit
Most studies on visual perception during pursuit have investigated the major problem of integrating retinal motion and eye motion into a percept that is coherent with the physical motion of objects in the world. Ever since the historical experiments by Aubert (1886), Fleischl (1882), and Filehne (1922), it is known that the discounting of eye motion is at best incomplete, leading to biases in the judgments of object motion (see Freeman, Champion, & Warren, 2010; Souman, Hooge, & Wertheim, 2005). In a number of recent studies, it was shown that the visual motion signals driving pursuit and the ones for speed perception can be uncorrelated or even be dissociated (for reviews, see Schütz et al., 2011; Spering & Carrasco, 2015; Spering & Montagnini, 2011). There has been much less effort investigating potential effects of smooth pursuit eye movements on other aspects of perception, such as visual sensitivity (but see Flipse, van der Wildt, Rodenburg, Keemink, & Knol, 1988; Murphy, 1978).
We performed a series of studies investigating visual sensitivity during pursuit eye movements. It is known from a series of classical studies under fixation conditions that visual sensitivity is at the limits imposed by physics for rod vision (Hecht, Schlaer, & Pirenne, 1942). For daylight vision mediated by the cone photoreceptors, the ideal stimulus was shown to be a moving Gabor patch with a spatial frequency of 8 cycles/degree, a drift rate of 4 Hz, and a duration of 160 ms (Watson, Barlow, & Robson, 1983). Later, Chaparro, Stromeyer, Huang, Kronauer, & Eskew (1993) showed that efficiency is even greater for detecting a red spot on a yellow background. Threshold contrast in this case was 0.63%, about 5 to 10 times better than for luminance stimuli. What these experiments showed was that our visual system is extremely sensitive to the environment. Our goal was to see whether this tuning extends to a situation where the eyes are in motion. Would the visual system make some adjustments in this case, to deal with this challenge?
Our task was very simple. We had observers fixate or pursue a small spot, while a horizontal line stimulus was presented parallel to the pursuit direction. This made sure that the retinal stimulus was the same in both cases and was not affected by the retinal motion. This is similar to setups that were used to study visual sensitivity during saccades, which turned out to be extremely poor (for review, see Ross et al., 2001). We did indeed observe a phenomenon similar to saccadic suppression before and at pursuit onset, but it was much weaker, in line with the reduced speed of pursuit as compared with saccades (Schütz, Braun, & Gegenfurtner, 2007).
However, when investigating steady-state pursuit with isoluminant colored stimuli, the results became quite exciting. When the line stimulus was isoluminantly colored, sensitivity increased by about 16% during pursuit, compared with a 5% decrease of sensitivity to luminance-defined stimuli (Schütz, Braun, Kerzel, & Gegenfurtner, 2008). The same advantage held for color discrimination when the stimuli were displayed in the fovea, ensuring that this result was not based on potential luminance artifacts. This result is surprising because pursuit initiation relies on visual motion processing, and color and motion were treated as being independent for a long time (e.g., Cavanagh, Tyler, & Favreau, 1984; Ramachandran & Gregory, 1978). Newer work shows that chromatic motion can be seen, even though it is processed differently (Gegenfurtner & Hawken, 1996), presumably by a mechanism tuned to slow speeds, and mediated by attention (Cavanagh, 1992; Lu & Sperling, 1995). There was no indication that sensitivity to colored stimuli could be higher while the eye is in motion. We showed that the sensitivity improvement starts before the eyes begin to move (Figure 7), indicating that this is not caused by the eye movement but might instead be initiated by a top-down signal that accompanies the motor signal to the eyes. When exploring the visual characteristics of this effect, we observed that a sensitivity improvement was also present for high-spatial frequency luminance stimuli.
Pursuit improves chromatic contrast sensitivity. The red curve shows a pursuit eye movement velocity trace in a step-ramp paradigm. The eye accelerates with a latency of about 140 ms until it reaches the target speed of 10 deg/s about 300 ms after the onset of target motion. The blue curve shows the proportion of trials in which a briefly flashed isoluminant target was properly localized above or below the pursuit target. Performance is relatively stable at 60% and then rapidly improves to about 90% in the time window between 70 and 140 ms after target motion onset. After Schütz et al. (2008).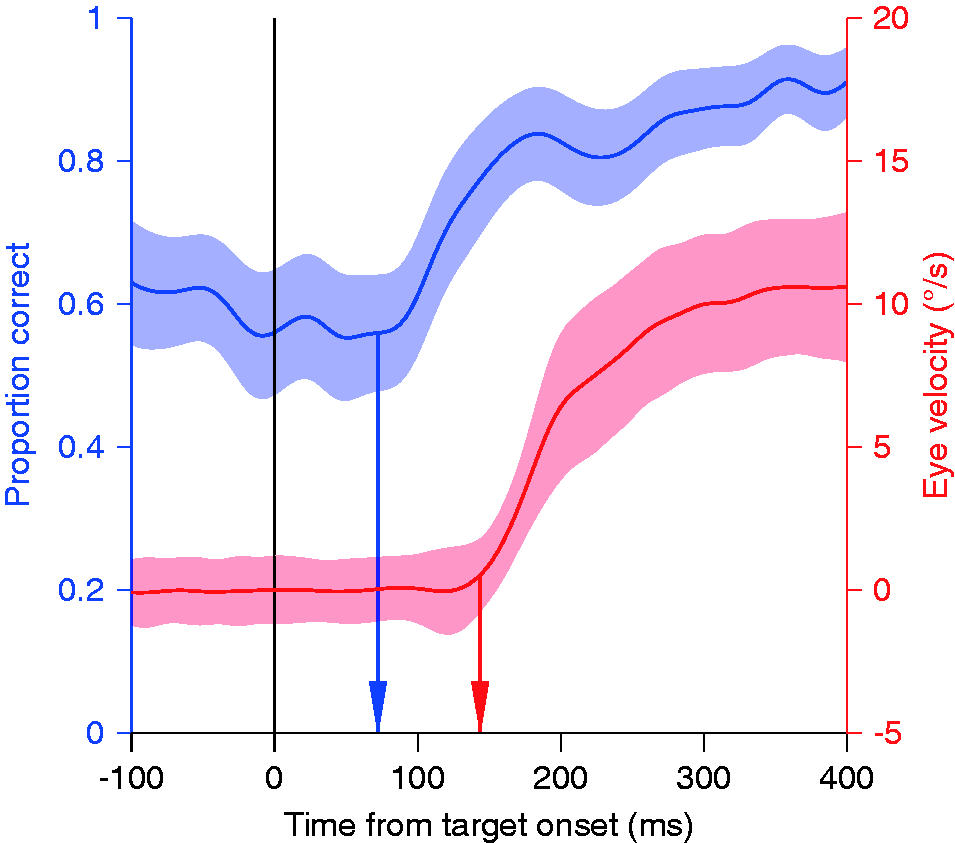
We explored this effect in great detail. The sensitivity improvement is present during the slow phase of the OKN, in which the eyes perform a similar movement as during smooth pursuit (Schütz, Braun, & Gegenfurtner, 2009a). However, it is absent during the VOR, during which the eyes counterrotate to keep stable fixation during head movements (Schütz et al., 2009a). This means that the improved sensitivity must be related to following the image rather than to moving the eyes. We further characterized the effect by measuring the temporal impulse response during fixation and pursuit (Schütz et al., 2009b). There was no change in the temporal characteristics but only an increase in the gain of the impulse response during pursuit, indicating a higher sensitivity.
All of these results point to an active switch in the regulation of visual sensitivity at the point when pursuit is initiated. A similar switch was shown for the motor system, making the response of the eyes’ response to small speed perturbations during pursuit stronger (Tanaka & Lisberger, 2001) and faster (Tavassoli & Ringach, 2009). What is the purpose of the sensitivity change? One hypothesis is that it simply underlies the oculomotor response. During pursuit, the eyes have to react mainly to small changes in stimulus speed. It is well established that there are two temporal channels for motion perception (Gegenfurtner & Hawken, 1996; Kulikowski & Tolhurst, 1973; Thompson, 1983; van der Smagt, Verstraten, & van de Grind, 1999). During fixation, the ratio of the excitation in both channels can indicate the speed of the moving stimulus (Hammett, Champion, Morland, & Thompson, 2005; Watson & Ahaumada, 1985). During pursuit, the retinal speed is typically very low, reducing the importance of the fast channel. Boosting the slow channel would increase sensitivity and could strengthen the eyes’ responses to small speed changes. If one assumes that the slow channel is mediated mainly by activity in the parvocellular regions of the lateral geniculate nucleus (LGN), which are also more sensitive to color and high spatial frequencies, the improvement in sensitivity to color and high-spatial frequency stimuli would be a mere by-product. The main focus of boosting the slow motion channel would be to increase sensitivity to speed changes of the pursued object.
Alternatively, the increase in sensitivity also reduces the effects of blur, which mainly have an impact on colored and high-spatial frequency stimuli (Kelly, 1983). Therefore, it could improve spatial vision for the background by reducing motion blur (Bedell & Lott, 1996; Tong, Aydin, & Bedell, 2007). In line with this hypothesis, we found that luminance sensitivity was higher for stimuli moving in the pursuit direction than to those in the opposite direction (Schütz, Delipetkos, Braun, Kerzel, & Gegenfurtner, 2007). Interestingly, this asymmetry between motion in and against pursuit direction reverses at supra-threshold contrasts (Terao, Muakami, & Nishida, 2015). Both, boosting the slow-motion channel and reducing motion blur may have played a role when evolving the circuitry responsible for this improvement.
Our results also relate to previous findings that attentional shifts enhance spatial resolution (Yeshurun & Carrasco, 1998) and more generally improve the parvocellular system over the magnocellular system (Yeshurun & Sabo, 2012). Since the detection targets in our experiments (Schütz et al., 2008) were near the fovea, it could be hypothesized that at the time of initiating a foveating eye movement, the parvocellular activity is boosted for optimal high-spatial frequency processing of the target.
Whatever the functional role, these results show convincingly that the visual system dynamically adjusts internal weights to ideally support the computations that need to be performed at each instance in time.
Directional Selectivity During Pursuit
The obvious advantage of smooth pursuit is to keep the pursuit target in foveal view. However, recognizing objects is a very fast process (Thorpe et al., 1996), and even during pursuit this amazing capability of our visual system is hardly diminished. Recognition is slowed down by only a few milliseconds during pursuit as compared with fixation (Schütz, Braun, & Gegenfurtner, 2009c). This leaves the question why we would keep pursuing objects for extended periods of time. In sports, coaches have been instructing ball players to “keep the eye on the ball” (e.g., Seiderman & Schneider, 1985), presumably to help players predict the future direction of ball movement. The basis for this recommendation has received little attention, even though it was shown that humans in a manual interception task naturally use smooth pursuit eye movements (Brenner & Smeets, 2009, 2011; Mrotek & Soechting, 2007). It also has been shown convincingly that the visual system is extremely fast at figuring out in which direction a stimulus moves (de Bruyn & Orban, 1988), and that this information is readily available to guide smooth pursuit eye movements (Osborne, Lisberger, & Bialek, 2005; Stone & Krauzlis, 2003).
We asked the question whether pursuit affects the ability to predict visual motion in space, and if so, whether pursuit enhanced or impaired this ability. We developed a paradigm that we call “eye soccer” (Spering, Schütz, Braun, & Gegenfurtner, 2011). Observers have to track a moving “ball” across the screen and estimate whether the ball will hit or miss a “goal,” a vertical line segment shown on the screen. Ball and goal always disappeared shortly before the target would have reached the goal. Therefore, the observer had to extrapolate the motion trajectory of the ball in order to give a judgment. In a control condition, observers fixated on the ball, while the goal was moving toward the target. We chose this fixation condition to keep retinal images comparable under both conditions. The results, indicated in Figure 8, show better perceptual performance when the stimuli were shown for longer periods of time. Most importantly, observers were better during pursuit than during fixation regardless of presentation duration. These results provide the experimental foundation for what sports coaches have been telling their players all along: If you have to make a judgment about a ball’s trajectory, keep your eyes on it. In line with these findings, it has been shown that perceptual performance correlates with the quality of smooth pursuit eye movements, both in a dynamic visual acuity task (Uchida, Kudoh, Murakami, Honda, & Kitazawa, 2012) and in the eye soccer paradigm (Spering, Dias, Sanchez, Schütz, & Javitt, 2013).
Pursuit improves direction judgments. The proportion of correct answers is higher for pursuit trials (filled symbols) than for fixation trials (open symbols). After Spering et al. (2011).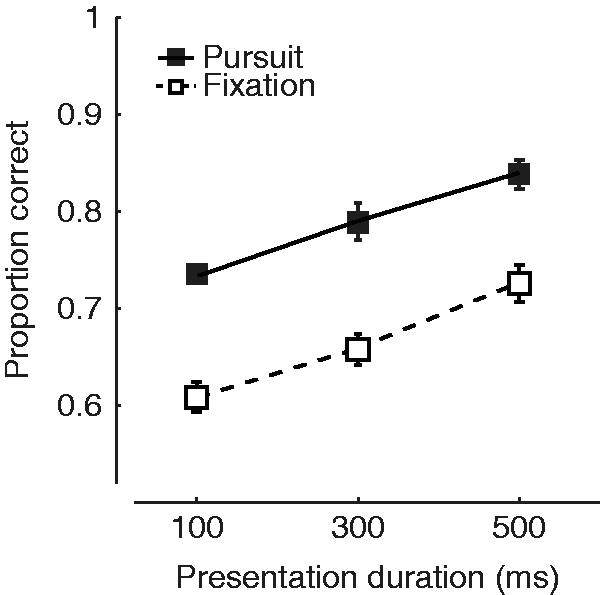
The interesting question then is how this advantage arises. One possibility is that the corollary discharge signal, which is generated mainly to disentangle eye speed from object speed, is used as additional information about the relative direction of the ball with respect to the goal during pursuit. There is some evidence for this proposal, showing that patients with assumed deficits in the corollary discharge do not exhibit the prediction advantage in the eye soccer task (Spering et al., 2013). An alternative explanation would be in line with our previous results on sensitivity changes, suggesting that there might be an active adjustment in directional sensitivity.
Directional Tuning During Pursuit
We tested the hypothesis of changes in directional sensitivity during pursuit by determining how the addition of different moving stimuli would affect eye direction before and during pursuit. In these experiments (Debono, Schütz, Spering, & Gegenfurtner, 2010) akin to determining the “oculoceptive fields” for the smooth pursuit system, observers fixated initially and then smoothly followed a random dot kinematogram with their eyes. At a certain point in time, a small perturbation stimulus was injected into the motion, changing the direction of motion of 20% of all the dots within a sector. Since the stimulus consisted of 20% signals dots and 80% randomly moving noise dots, this perturbation was not noticeable to our observers. The perturbation angle varied from 5°—just slightly different from the target motion—to 90°, orthogonal to the target motion. Since the speed of the perturbation was always the same, one would expect from averaging the motion vectors of all individual dots that the orthogonal perturbation would have the largest effect on eye direction.
In contrast to this expectation, orthogonal perturbations did not affect the pursuit direction, while perturbations 15 to 30° away from the target direction had the largest effect (Figure 9(a)). The effect also changed over time. When the perturbation occurred 300 ms after pursuit onset, we found medium sized effects at 45°. Another 300 ms later, that effect disappeared. When taking the amplitude of the perturbation into account, the effect was largest for perturbation directions closely aligned with target motion direction (Figure 9(b)). The bandwidth of direction tuning becomes narrower as pursuit is ongoing, reducing its half-height from 30 to 45° initially, down to 15° during pursuit. Because pursuit eye movements are closely associated with the activity of neurons in the motion-sensitive middle temporal area (MT), this finding may reflect the effects of feature-based attention on MT neurons (e.g., Treue & Martínez Trujillo, 1999; but see Busse, Katzner, Tillmann, & Treue, 2008). Such a narrowing of directional sensitivity during pursuit could underly the performance improvements with pursuit that we observed in our “eye soccer” paradigm.
Direction tuning during pursuit. Effect of small direction perturbations to random dot stimuli at various times during ongoing pursuit. (a) Absolute effect of the perturbations on eye direction. (b) Effect relative to the vertical component of the perturbation. Directional bandwidth is gradually narrowed during pursuit. After Debono et al. (2010).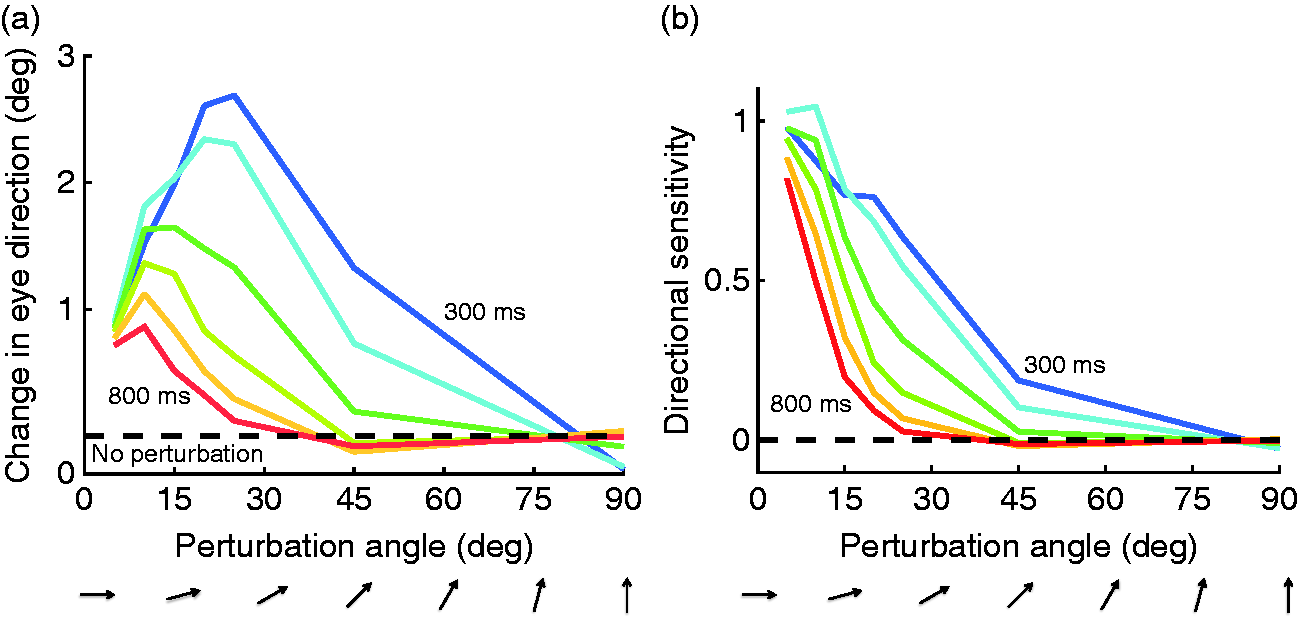
Conclusion
In this review, we presented evidence showing that eye movements and perception are much more closely interwoven than previously thought. There are many obvious benefits of eye movements for visual perception. We can use them to bring objects into high-acuity foveal vision and keep them there. Without them, some tasks like reading would be slow and inefficient. Eye movements also play a crucial role whenever we perform a motor task. Fixations at critical places such as movement obstacles and movement goals make essential perceptual information available for motor planning and execution. There are also some obvious costs of eye movements. Vision is at least partly suppressed during eye movements, and the retinotopic rearrangement that comes with each eye movement requires some form of remapping.
However, on top of all the advantages, our eyes also support very elementary and important perceptual tasks, such as lightness perception, size perception, or direction judgments. When making lightness judgments, fixations on the objects are sampled in a manner that is matched to the proper interpretation of the scene, and the foveal information is weighted so as to support that interpretation. The association between foveal and peripheral information across a saccade is used to calibrate aspects of the visual world such as size and color. During pursuit, visual sensitivity and directional tuning are adjusted to improve perceptual judgments.
We think that these interactions between vision and eye movements are the general rule, rather than merely a few isolated examples. The same way we adapt the exploration of the world with our fingers to optimally explore the properties of objects and surfaces (Lederman & Klatzky, 1987), we choose our eye movements to optimize the visual uptake of information. When doing so, the visual system dynamically adjusts its internal parameters to achieve its goals, namely the generation of a conscious internal representation of our external world and the support for the guidance of our motor actions and mobility.
Footnotes
Acknowledgements
I am very grateful to Doris Braun, Eli Brenner, David Burr, Alexander Schütz, Miriam Spering, and Matteo Valsecchi for intensive discussion and numerous corrections to this manuscript. Alexander Schütz and Matteo Valsecchi had endless patience with me while creating and modifying various figures.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work reported here was supported by several grants from the Deutsche Forschungsgemeinschaft (DFG GE 879), in particular by the DFG research group FOR 560, Koselleck grant DFG GE 879/9, and by DFG Collaborative Research Center SFB/TRR 135.