
Abstract
The purpose of this editorial is to explore the potential and risks of using AI in the medical field, particularly in oncology. We describe the history of AI from its origins to the present day, highlighting its positive aspects and potential for each type of AI (expert system, machine learning, generative AI). Technologies like ChatGPT are increasingly being used across various domains; however, without proper caution, they can give rise to phenomena such as 'AI hallucinations'—responses that may appear precise, detailed, clear, and logical, but are in fact entirely fabricated and unfounded, potentially confusing those who read them. We want to caution oncologists against the unconditional use of these technologies, where human input remains still essential both in interpreting the responses and in formulating the questions.
Keywords
Generative AI and medical oncologists
Generative Artificial Intelligence (AI) tools, particularly those based on Large Language Models (LLMs), have become increasingly popular among physicians, including oncologists, making it essential to highlight how they are changing medical practice. In recent discussions about the use of Generative AI tools to support diagnostic or therapeutic decision-making, we have observed that physicians tend to be more enthusiastic than biomedical engineers or computer scientists. This is likely because a deeper understanding of how these tools operate allows the latter to better anticipate the potential risks of indiscriminate use. For this reason, we claim that educating and training physicians in the fundamental principles of these technologies, even at a high level, is crucial to prevent misuse. Before focusing on generative AI, since a lot of systems nowadays are labelled as “AI systems”, it is important to point out that AI is a very broad umbrella encompassing various paradigms, as also defined in the AI Act by the European Union. 1 In its history, AI has gone through both periods of great enthusiasm and dark periods, so-called “AI winters”, times of reduced interest and funding. 2 The definition of AI was first formulated by John McCarthy in 1955 in terms of "the science and engineering of making intelligent machines, especially intelligent computer programs". It's also worth noting that many of the techniques used in AI have existed since the 1950s or even earlier. In the following sections, we highlight key milestones in the adoption of AI techniques in medicine. Below, we describe the three main paradigms of AI from the 1970s to the present. Their definitions, along with their main advantages and disadvantages, are summarized in Table 1.
Definition, Pros and Cons of the different AI paradigms.
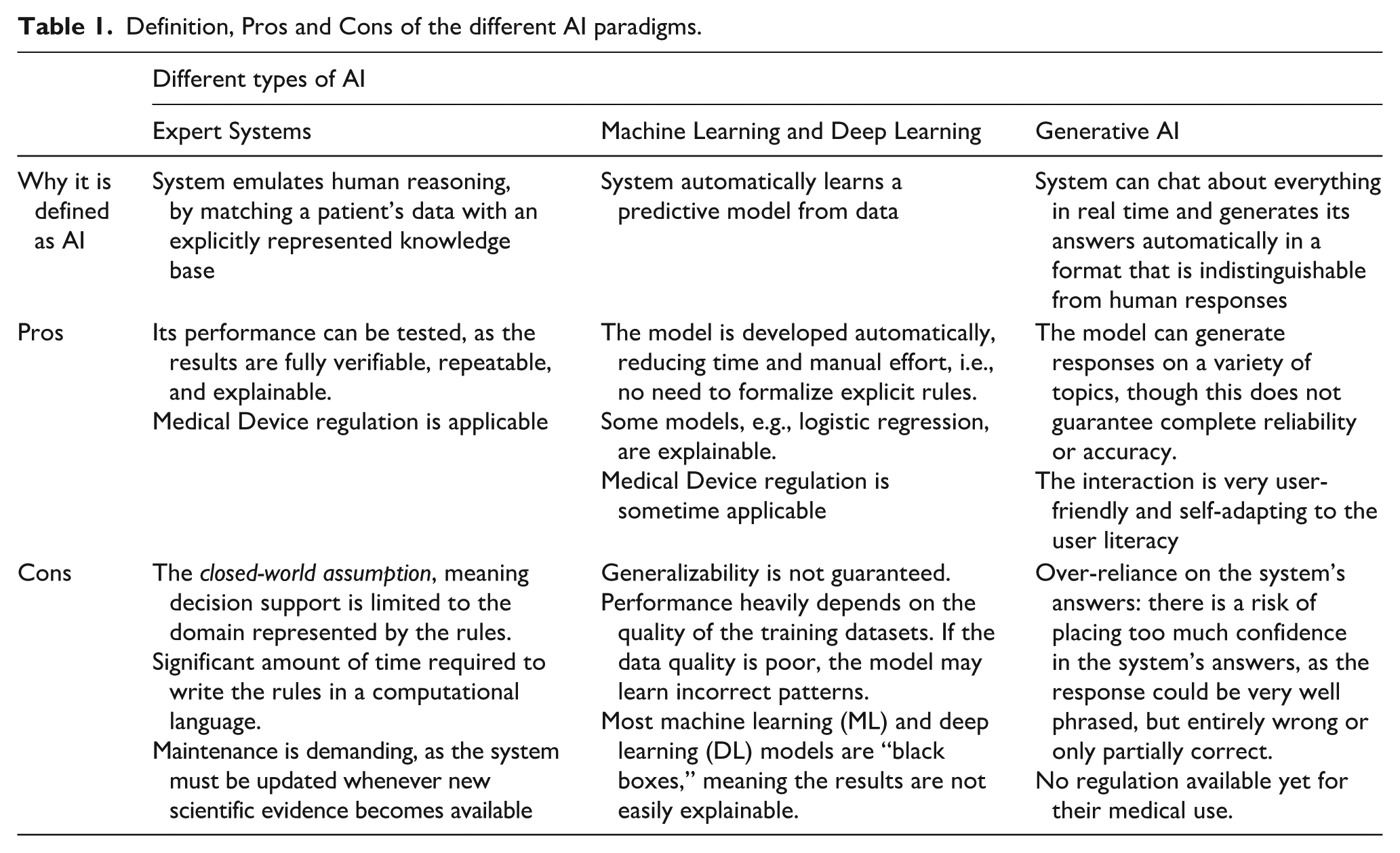
The first significant era of AI in medicine began in the early 1970s with the development of so-called expert systems, notably the seminal work by Shortliffe et al. 3 An expert system is a computerized collection of several explicit rules (e.g., “IF Hemoglobin < 13g/dL AND sex = Female THEN diagnosis = Anemia”) that represent medical knowledge. When matched with a patient’s data, these rules can be used to emulate the reasoning processes of medical experts. Within an expert system, the reasoning process is performed by an inference engine, which may operate using different approaches. For example, the inference engine described by Lanzola et al. 4 implements an epistemological model for anemia diagnosis. This model supports multiple forms of inference: abstraction, to derive higher-level concepts from raw data (e.g., identifying temporal trends in lab values); abduction, for generating diagnostic hypotheses; deduction, for testing those hypotheses; and eliminative induction, for refining them. 5 The results produced by these systems are deterministic, although the combination of rules may involve complex calculations, including uncertainty coefficients associated with the conclusions. This rule-based paradigm remains in use today in decision support systems based on computerized clinical practice guidelines. These systems may be designed for physicians6,7 or for patients,8,9 with the latter often delivered through telemedicine platforms. The validation process 10 developed and refined over the years has also facilitated the certification of such systems as medical devices. Examples are the Deontics Composer (http://deontics.com/technology) and Cureety TechCare, a telemonitoring medical device for oncology (http://www.cureety.com/en/patient-en/).
In the late 1990s, the increasing availability of electronic medical data 11 accelerated the rise of the second paradigm of AI: Machine Learning (ML). Over the years, this has been increasingly strengthened by the introduction of innovative tools for data storage and integration, such as i2b2 (Informatics for Integrating Biology and the Bedside) 12 and REDcap (Research Electronic Data Capture), 13 as well as increased computational power. ML models primarily perform classification tasks, i.e., they can take a patient’s data as input and assist clinicians in selecting a diagnosis or treatment from a predefined set of options. This data-driven AI paradigm relies on models that are able to learn their parameters, in some cases even their structure, from a set of given “examples”. A model is trained on a dataset (a training set of already labelled or classified examples) using supervised classification, where both the input data and the corresponding correct classification are available. For example, a set of biomedical images, each one labelled as “positive” or “negative” according to the presence or absence of a tumor mass as annotated by a clinical expert, can be used as a training set for a ML model. The model’s parameters are usually optimized (or fine-tuned) using a validation set, which may also be used to choose among a set of candidate models the one that performs best. Its performance and generalization power are subsequently evaluated on a third, independent test set. Well-known ML models 14 are decision trees, random forests, support vector machines and neural networks. However, also more “classical” models like Bayesian (causal) networks or even logistic regression can be used for ML, and they are favored by a school of thought that privileges explainable models, claiming that strong AI requires knowledge about causal processes. 15
Starting in the early 2000s, due to technological advancements, ML began to incorporate more complex models, eventually leading to the rise of Deep Learning (DL). This third paradigm represents a significant breakthrough. While traditional ML typically requires preliminary, often human-driven, processing of data for feature extraction, DL models can automatically extract relevant features from raw data during the training process. DL is based on multi-layer neural networks and requires very large amounts of training data and substantial computational power to perform effectively. Highly successful DL-based systems have been developed, particularly in the fields of omics 16 and biomedical image interpretation. 17 However, the black-box nature and low interpretability of most ML and DL systems make their certification as medical devices a challenging task, even though several certified tools already exist. 18 Ongoing efforts in explainability (also referred to as trustworthy AI)19,20 are expected to help overcome these challenges and support the certification process. Beginning in the late 2010s, a specific deep learning architecture known as the Transformer, sparked the revolution we are currently witnessing in the field of AI. 21 This development marks a significant paradigm shift toward what is now referred to as Generative AI. Large Language Models (LLMs), the foundation of widely known tools such as ChatGPT (OpenAI), Gemini (Google), Claude (Anthropic), and others, 22 are essentially deep neural networks that take a sequence of words (the prompt, i.e., the user’s input) and produce another sequence of words as output. LLMs sharing the principle of neural networks as a reasoning model, are not free from the same issues as DL and ML when it comes to certifying the system, as these models are difficult to interpret. Oversimplifying somewhat, since the underlying algorithms are highly complex, LLMs generate responses by selecting the next word in a sequence to maximize the probability of that word occurring in that specific context. In essence, the mechanism is purely statistical. These systems do not rely on explicitly encoded knowledge or structured datasets, nor are they trained on labeled relational datasets, which are typical in supervised learning. Rather, again simplifying, they are trained on massive collections of text documents and web content, that can range from completely unstructured to carefully organized and curated, such as document collections or indexed web pages which are used to build their deep architectures, characterized by an extremely large number (currently billions) of parameters. Generative AI thus operates by capturing statistical correlations between formal symbols, but without knowing their semantics, generating an appearance of meaning similar to what Searle described in the "Chinese Room" argument. 23 Because of this underlying mechanism, the generated answers are always plausible but not necessarily correct. In fact, AI can produce responses that appear precise, detailed, clear, and logical, but these can be completely fabricated and unfounded, a phenomenon known as AI hallucinations.
We observed an example of this phenomenon during an analysis conducted to evaluate ChatGPT-4 performance in selecting the most appropriate treatment for breast cancer patients, based on the guidelines of the Italian Association of Medical Oncology (AIOM) for early-stage breast cancer. A series of clinical questions were prepared and submitted to ChatGPT to obtain treatment suggestions. Four oncologists (three experts and one resident) evaluated the AI-generated responses using the following criteria: (1) compliance with the guidelines; (2) overall quality of the response; (3) appropriateness of the answer; (4) verbosity; and (5) clinical actionability. Each criterion was rated using a Likert scale. 24 In this evaluation, ChatGPT-4 occasionally incorrectly recommended aromatase inhibitors for a subset of patients with ductal carcinoma in situ (DCIS), even though these patients are not eligible for that treatment. This likely occurred because aromatase inhibitors are frequently cited in the guidelines as the recommended treatment for estrogen receptor-positive breast cancer. However, the model failed to recognize that for patients with DCIS, this treatment is explicitly not recommended, as stated in the AIOM guidelines. Additionally, we observed that ChatGPT lacks the ability to prioritize the relevance of clinical problems. In our study, when severe comorbidities, such as neurological impairments, were not explicitly emphasized in the prompt, the system tended to overlook them, focusing its attention on treating the tumor, which was the primary subject of the question. As a result, the model often recommended curative treatments, whereas the guidelines would indicate a palliative approach in such cases. In this context, it is essential to critically evaluate the information provided and assess its reliability; the user of generative AI is responsible for attributing meaning and determining the actionability of the generated content.
The issue of reliability of generative AI models will likely be mitigated by emerging techniques specifically designed to constrain the LLM answers to specific trusted knowledge. This is for example the case of Retrieval-Augmented Generation, a technique that is meant to augment the prompt provided to the LLM by enriching the query with relevant medical knowledge automatically retrieved from the parts of the knowledge (chunks) that are most pertinent with the original question. 25 Additionally, most tools can now indicate the sources from which specific answer chunks are derived. Another promising development in the field of reliability and accuracy of AI models, is the introduction of multimodal LLMs (MLLMs), which are trained on different data modalities, such as text and images. 26 Once trained on full DICOM-format datasets comprising millions of images and corresponding text reports, these models will likely demonstrate improved performance in biomedical image interpretation.
Another observation is that different LLMs can produce variable responses to the same prompt, highlighting the need for comparative analysis among them.25,27 Similarly, due to the way it is built, the model tends to align with the user’s tone, often responding in a manner that reflects the sentiment, if any, expressed in the prompt. A paradigmatic example was recently provided by Nobel Prize in Physics Giorgio Parisi during the National Academy of the Lincei conference "Physical Roots of Modern AI" on February 14, 2025. After initially receiving the correct answer from ChatGPT-4 for the calculation of 5 × 4, he repeatedly prompted the model in an attempt to mislead it, finally convincing it that 5 × 4 equals 25. This episode was reported in the media a few months ago. Given the continuous improvement of LLMs, it is likely that Professor Parisi would not be able to reproduce the same result today. Nevertheless, AI hallucinations still occur. Therefore, to maximize the chances of obtaining accurate and useful answers, medical users must learn how to interact effectively with the chatbot. AI systems rely solely on the data—such as texts and images—used during training, and unlike the human brain, they still lack complex interaction with the external world. This limitation reduces their current usefulness in enhancing multidisciplinary tumor board decisions, particularly in contexts where clinical guidelines are absent. 28
Currently, no LLM-based tool has been recognized as a medical device, especially because of the lack of a standardized validation process, and this represents a significant unresolved issue given their growing use among physicians. 29
Given all the considerations raised so far, it is very difficult to express a definitive opinion on the usefulness of these systems for diagnostic or therapeutic planning, as they are evolving so rapidly.
To conclude, we would like to reiterate that, in this editorial, we have critically discussed the use of generative AI in decision-making processes related to specific cancer patients. In contrast, there is no doubt that AI tools are highly effective in other areas of medical research and application. For example, drug discovery has greatly benefited from AI. 30
AI will play an increasingly important role in scientific discovery in oncology. Assuming the computable nature of biological systems, the unique operational mechanisms of AI offer broad opportunities for generating knowledge from the interpretation of complex and seemingly disordered data—data that often defy traditional analytical tools. AI can integrate seemingly unrelated information, transforming what appears to be noise into a source of insight. What may seem to humans like random perturbation can be recognized and interpreted by AI systems, becoming a vehicle for meaning. Coming to the clinical context and clinical routine, tools now exist that can take notes and summarize discussions during meetings, translate clinical notes into different languages (which is particularly useful when traveling across countries), optimize appointment scheduling, and more. These applications, whose detailed description is beyond the scope of this editorial, do not directly influence decisions regarding a patient’s diagnosis or treatment, making them less critical from the ethical and regulatory standpoint.
As three leading physicists urged last year, scientists, governments, and citizens must come together in a large-scale international collaboration to safeguard humanity and ensure that the potential of AI serves everyone. 31 Similarly, we expect the medical community to do the same, protecting itself from the misuse of AI through knowledge-sharing and by establishing international collaborations aimed at fully harnessing AI’s potential for cancer patients.
Ultimately, there is no domain of human knowledge that AI cannot explore, and there is nothing that humans can do that cannot, at least in principle, be made accessible to AI. The questions concerning the limits of AI usage are neither technological nor mathematical; they are ethical, and they should be addressed through appropriate regulatory and deontological measures. 32 It therefore appears evident that a wise use of AI requires an ever-increasing collaboration, integration, and convergence of different and integrated disciplines.
Footnotes
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: L.D.L. Financial interests: Conference honoraria/Advisory Board: EISAI, MSD, Eli Lilly, Sanofi, Sunpharma, IPSEN, Bayer, New Bridge; Seagen; Novartis; Johnson & Johnson.- Travel grant: Gilead.
The remaining author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.