
Abstract
Objective
To develop an explainable ResNet–long short-term memory model based on multifeature fusion for classifying bowel sound frequency—a key indicator of gastrointestinal motility. Accurate and objective classification of bowel sound activity levels holds significant clinical value in clinical settings.
Methods
As a prospective multicenter study conducted across three medical institutions, the primary outcome involved three-way classification of bowel sounds as normoactive, hyperactive, or hypoactive. Bowel sounds were collected and segmented into 10-s clips. Audio features—Chroma, Filter Bank Energies, and Mel-Frequency Cepstral Coefficients—were extracted to train deep learning models using transfer learning with ResNet50 V2, followed by feature fusion and classification via long short-term memory and automated machine learning methods.
Results
The independent test demonstrated superior performance of the long short-term memory model, achieving an accuracy of 0.927, Matthew’s correlation coefficient of 0.885, and weighted Cohen’s kappa of 0.930—outperforming both automated machine learning models and gastroenterologists. Additionally, the model was evaluated in two clinical scenarios: (a) feeding timing after general anesthesia and (b) bowel preparation for colonoscopy, showing high sensitivity and specificity. Local interpretable model-agnostic explanations were used to enhance model transparency.
Conclusions
This framework offers a novel, accurate, and explainable approach for bowel sound classification, demonstrating strong potential for clinical applications in gastrointestinal function assessment.
Keywords
Introduction
Bowel sounds, or borborygmi, are the noises produced by the movement of food, liquids, and gases through the gastrointestinal tract. 1 Traditionally, these sounds have been assessed by clinicians using a stethoscope, but this method is highly subjective and can be influenced by various factors such as the experience of the examiner and the presence of background noise. 2
Artificial intelligence (AI), specifically machine learning (ML) and deep learning (DL) techniques, offers a more objective and precise approach to bowel sound analysis. 3 By leveraging advanced algorithms, AI systems can process large volumes of audio data captured from the abdomen identifying patterns and features that may be indicative of underlying gastrointestinal conditions.4,5 For instance, ML models can be trained to differentiate between normal bowel sounds and those associated with conditions such as intestinal obstruction,6,7 irritable bowel syndrome, 8 or gastrointestinal motility disorders.9,10 One of the key advantages of AI in this context is its ability to detect subtle changes in bowel sound frequency, intensity, and duration that may be missed by human listeners. Through the use of convolutional neural networks (CNNs) and recurrent neural networks (RNNs), AI systems can analyze the temporal and spectral characteristics of bowel sounds, creating a detailed “acoustic fingerprint” of the gastrointestinal tract.11,12 This fingerprint can then be compared against a database of known sound patterns associated with various conditions, allowing for accurate and timely diagnoses. Moreover, AI–powered bowel sound analysis can be integrated into wearable devices or mobile applications, enabling continuous monitoring of patients' gastrointestinal health in real time. This is particularly beneficial for patients with chronic gastrointestinal issues, as it allows for early detection of flare-ups or complications, facilitating prompt intervention and improved management of their conditions. 7
However, bowel sounds exhibit significant diversity and variability, encompassing a range of types such as splashing and bubbling noises. 8 This diversity poses a significant challenge for accurate labeling of these sounds. 13 Moreover, previous studies have predominantly focused on classifying short audio segments, which may not accurately reflect the dynamic nature of bowel sounds as physiological signals that can change over time. 14 Additionally, most previous research has used Mel-Frequency Cepstral Coefficients (MFCCs) as the sole feature for ML tasks related to bowel sounds, rather than using multifeature fusion. 15
To address these challenges, we propose a novel, explainable DL framework for the classification of bowel sound frequency. Unlike prior studies that focus on short audio segments (e.g. 5–10s) and rely solely on MFCCs, our approach integrates multifeature fusion of Chroma, Filter Bank Energies (FBank), and MFCC to capture complementary spectral and harmonic characteristics of bowel sounds. These features are processed through a ResNet50 V2 backbone for spatial feature extraction, fused, and then analyzed by a long short-term memory (LSTM) network to model temporal dynamics across full 60-s recordings. This design enables the model to learn from both fine-grained acoustic patterns and long-range temporal dependencies, which better reflect the physiological nature of bowel sounds. Furthermore, we incorporated local interpretable model-agnostic explanations (LIME) to enhance model transparency, allowing clinicians to understand the contribution of specific time segments and features to the final prediction. The framework was validated on an independent multicenter test dataset and evaluated in two real-world clinical scenarios: postoperative feeding decisions after general anesthesia and assessment of bowel preparation for colonoscopy. By combining multifeature fusion, long-sequence modeling, and explainability, our study advances the state-of-the-art in AI-driven bowel sound analysis and offers a robust, interpretable tool for noninvasive gastrointestinal function assessment.
Methods
The study included the following steps: bowel sound collection from center 1, segmentation of sound samples, extraction of audio features, fusion of feature models, development of sound classifiers, independent tests in centers 2 and 3 for the primary outcome, and practice in clinical sets.
Study design
As shown in the flowchart (Figure 1), this prospective multicenter study was conducted across three medical institutions: the first and fourth affiliated hospitals of Soochow University (center 1, the training dataset), Jintan Affiliated Hospital of Jiangsu University, and Yongding Hospital (centers 2 and 3, respectively; the test dataset). Patients admitted to these hospitals who underwent colonoscopy or general anesthesia between June 2024 and January 2025 were included in the study. The study was approved by the ethics committee of the Affiliated Hospital of Soochow University (approval number: 2022098).
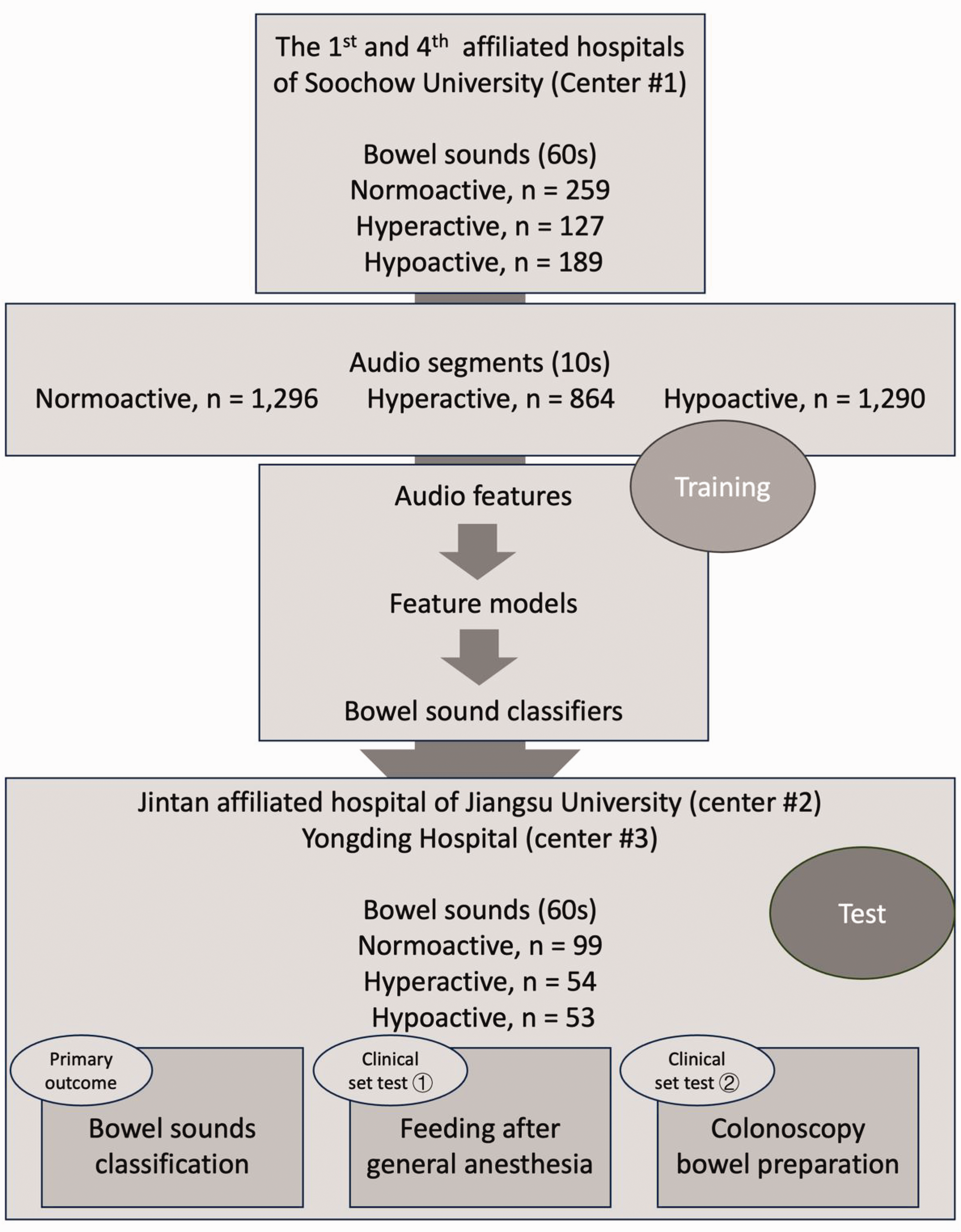
The study flowchart.
Audio collection and labeling
The audio recordings were obtained in a separated room under quiet conditions, with patients were in the supine position quietly in bed. An electrostethoscope (POPULAR-3; Hanhongmed Ltd) was placed on the right lower quadrant of the abdomen to capture bowel sounds from both the small and large intestines. Once the recording conditions were met, the recording commenced and lasted for at least 60s. In the collection of audio files, we filtered out low-quality recordings with excessive noise and weak signals to ensure audio quality. The audio files were saved in 16-bit with a sampling rate of 11 kHz and subsequently transferred to computers. Following the collection of the raw 60-s recordings, continuous 10-s segments were split from the audio files (Figure 1).
At center 1, 575 audio samples (60s) were collected to form the training dataset. The distribution of bowel sound frequency categories was as follows: normoactive (n = 288, 50.1%), hypoactive (n = 152, 26.4%), and hyperactive (n = 135, 23.5%) categories. These samples were further divided into 3450 sound segments (10s) for the development of audio feature models and feature fusion. During training, the 575 samples were divided into training and validation sets in an 8:2 ratio, resulting in 460 and 115 samples, respectively. In training, model performance was evaluated based on their performance in the validation set.
In centers 2 (n = 94) and 3 (n = 112), 206 recordings (60s) were collected to form the test dataset, which showed a distribution of normoactive (n = 98, 47.6%), hypoactive (n = 62, 30.1%), and hyperactive (n = 46, 22.3%) categories. These recordings were used for evaluation of the primary outcome: bowel sound classification, and for practice in two clinical sets: (a) feeding after general anesthesia and (b) bowel preparation for colonoscopy.
Clinical set 1: feeding after general anesthesia
General anesthesia is known to suppress gastrointestinal function, necessitating a delay in postoperative feeding until gastrointestinal function gradually recovers to allow appropriate and timely nutrition. 9 Noninvasive methods for assessing the recovery of gastrointestinal function after general anesthesia primarily include anal exhaust, electrogastrogram, bowel sound auscultation, and dynamic magnetic resonance imaging. 16 Auscultation of bowel sounds represents an important noninvasive method for assessing gastrointestinal function. In clinical practice, the observation of gastrointestinal peristalsis is commonly used to monitor feeding events. For the evaluation of feeding after general anesthesia, we randomly selected 94 inpatients from the Department of Orthopedics at center 2. Recordings from each patient were collected 2 h after extubation.
Clinical set 2: bowel preparation for colonoscopy
Bowel preparation for colonoscopy is primarily assessed through visual inspection of the colon during the procedure, using standardized scales such as the Boston Bowel Preparation Scale (BBPS). 17 This scale evaluates the cleanliness of the colon based on the presence of fecal residue, fluid, and overall visibility. The quality of bowel preparation is crucial for the effectiveness of colonoscopy because inadequate preparation can lead to missed lesions and reduced adenoma detection rates. 18 Several factors have been identified as predictors of inadequate bowel preparation, including comorbidities (e.g. constipation and previous abdominopelvic surgery) and medications that impair bowel motility (e.g. tricyclic antidepressants, opioids, and calcium channel blockers). These factors are related to gastrointestinal motility, which may be reflected in bowel sounds. 19 For the set of bowel preparation for colonoscopy, we randomly selected 112 inpatients from the Department of Gastroenterology at center 3. Recordings from each patient were collected 2 h after the intake of bowel preparation agents. Patients with intestinal obstruction were excluded.
The primary outcome was the performance of three-way classification of bowel sounds (60s). Each audio sample and segment were manually labeled by gastroenterologists experienced in identifying the frequency of bowel sounds frequency as normoactive, hyperactive, or hypoactive, based on the following standards: 1 1. normoactive: 5–30 bowel sounds per minute (about 1–5 sounds every 10s), 2. hypoactive: fewer than 5 bowel sounds per minute (no sound every 10s), and 3. hyperactive: more than 30 bowel sounds per minute (more than 5 sounds every 10s).
Two gastroenterologists (Z.X. and W.Z.), each with over 15 years of experience, independently reviewed each audio sample and segment to assign the three-way classification. In cases of disagreement between the two gastroenterologists, a senior physician (X.D.), with over 20 years of experience, intervened to resolve the discrepancies.
Audio feature extraction
Chroma features (Figure 2(a)) represent the distribution of energy across the 12-pitch classes in an audio signal. 20 They are particularly useful for tasks related to musical harmony and tonality. The extraction process starts with converting the audio into the frequency domain using fast Fourier transform. The spectrum, a multidimensional vector, is then mapped onto the 12-pitch classes, typically by summing the energy of frequencies that correspond to each pitch class across octaves. Chroma features are invariant to octave changes, making them ideal for tasks such as key detection, chord recognition, and music similarity analysis. 21 They capture the harmonic structure of music and are less sensitive to the specific frequencies of individual notes, focusing instead on the overall tonal content. In the study, chroma features (number of chroma bins = 80) were calculated from each audio segments, with a frequency range of 60–1500, frame length of 20 ms, and frame shift of 2 ms. Hence, for each signal piece, the shape of the input tensor was 385 × 308.

Visualization of the example segments based on three audio features. (a) Chroma-based feature images of normoactive, hyperactive, and hypoactive audio segments. (b) FBank-based feature images and (c) Mel-Frequency Cepstral Coefficient (MFCC)-based feature images.
FBank (Figure 2(b)) features are derived from the energy distribution across different frequency bands of an audio signal. 22 Similar to MFCCs, the audio signal is first transformed into the frequency domain using fast Fourier transform. The resulting spectrum is then passed through a set of overlapping filters arranged in a filter bank. These filters are often designed based on the Mel scale or linear spacing, depending on the application. The output is the energy in each filter band, which provides a detailed representation of the spectral shape of the audio signal. Unlike MFCCs, which involve a discrete cosine transform step to decorrelate the filter bank energies, FBank features retain the full energy information across all bands. 23 This makes FBank more suitable for tasks where fine-grained spectral details are important, such as speaker verification or certain types of audio classification. In this study, FBank features (number of Mel bins = 128) were calculated from each audio segments, with a frequency range of 60–1500, frame length of 20 ms, and frame shift of 2 ms. Hence, for each signal piece, the shape of the input tensor was 505 × 308.
The MFCC (Figure 2(c)) is a widely used feature extraction method in speech and audio processing. 24 It is inspired by the human auditory system’s perception of sound. The process begins with converting the audio signal into the frequency domain using the fast Fourier transform. The power spectrum is then filtered through a bank of triangular filters spaced according to the Mel scale, which reflects how humans perceive frequency. 25 The logarithm of the energies in these Mel-frequency bins is taken, followed by the discrete cosine transform to obtain the MFCCs. MFCCs are effective in representing the timbral characteristics of sounds and are robust to variations in pitch and loudness, making them suitable for applications such as speech recognition and music classification. In this study, MFCC features (number of coefficients = 36) were calculated from each audio segments, with a frequency range of 60–1500, frame length of 20 ms, and frame shift of 2 ms. Hence, for each signal piece, the shape of the input tensor was 775 × 279.
The whole framework
As shown in the Figure 3, all audio samples (60s), in both the training and the test sets, were first segmented into audio segments (10s) and then extracted with the abovementioned three features. In other words, each audio segment (10s) was transferred into three images of audio features. Audio features were extracted via librosa (version 0.10.2.post1). The three categories of images were then used to train three computer vision DL models of classification. Furthermore, each audio segment (10s) could be transferred into three feature vectors generated by DL models. Lastly, all feature vectors were used to train bowel sound classifiers, based on a series of algorithms of automated machine learning (AutoML) 26 and LSTM. 27 To sum up, a classification task of bowel sounds was eventually turned into a classification task of images, through audio splitting, feature extraction, and multifeature fusion.

The framework of explainable ResNet–long short-term memory model. MFCC: Mel-Frequency Cepstral Coefficient.
Models for audio feature–based images
Based on three audio features, that is, Chroma, FBank, and MFCC, three models of image classification were all 3-way supervised training by the categories of bowel sounds segments: normoactive, hyperactive, and hypoactive. As shown in Figure 3, ResNet50V2, an ImageNet-pretrained backbone, was trained for the audio feature–based images. Four fully connected layers (1 × 2048, 1 × 256, 1 × 64, and 1 × 16) and a Softmax classifier were added to the backbone without a head. In the transfer learning procedure, the four added fully connected layers and the classifier were trainable, whereas the backbone were nontrainable. Keras (version 3.8.0; TensorFlow, version 2.8.0) was used to train the models on mac mini (Apple M1; RAM 16G with internal eight cores graphics processing unit). The training parameters were listed as followed: batch size = 16; epoch number = 50 with an early stop; initial learning rate = 0.0001; loss = categorical crossentropy; and optimizer = Adam. Each image was resized to 224 × 224 pixels and input into the models in the form of RGB channels. The training code is available at https://osf.io/qf8ux. 28
Fusion of feature vectors for classifier
Each audio sample (60s) was split into six segments (10s). Through the three images models, the outputs of the six segments were a 6 × 3-feature vectors, which then were fused for the development of classifiers. On one hand, the AutoML of H2O platform (‘h2o package’, version: 3.38.0.1) offers six ML algorithms, including general linear model (GLM), gradient boost machine (GBM), extreme gradient boosting (XGBoost), DL, random forest (RF), and ensemble. On the basis of the platform, six ML-based classifiers were developed. On the other hand, in consideration of continuity in time of audio segments, a sequential model of LSTM was setup with two LSTM layers (50 hidden units) and two dropout layers (0.2) for regularization. The final output layer uses the Softmax activation function to produce probabilities for the three classes. The model is designed to process input sequences with 6-time steps and 3-feature per time step.
Independent test
The primary outcome was the performance of three-way classification of bowel sounds (60s). To compare with the models, audio samples from the test datasets were also appraised by two independent gastroenterologists: one junior gastroenterologists (L.L.), with 3 years of clinical experience; and one senior gastroenterologists (X.L.), with 12 years of clinical experience. All of them were unaware of the samples’ collection and labeling process.
Statistical analysis
To assess the performance of models and gastroenterologists on the three-way classification, three key metrics were used: accuracy, the Matthew’s correlation coefficient (MCC), and weighted Cohen’s kappa. 29
Local interpretation
LIME (lime package, 0.2.0.1) was used to elucidate the decision-making process of the classifier. 26 The method was crucial in providing a transparent and understandable rationale behind the AI’s predictions, thereby enhancing the interpretability and trustworthiness of the AI models in a clinical context.
Results
Performance of models in training
During the training, given the 8:2 ratio, the 575 samples were divided into 460 and 115 samples as the training and the validation sets. Evaluation in the training process depends on the performance of models in the validation. As shown in Table 1 and Supplementary Figure 1, LSTM model presented the best performance in training, with an accuracy of 0.957, MCC of 0.932, and Cohen’s kappa of 0.960, higher than the AutoML models, for example, ensemble (0.939, 0.905, and 0.940, respectively).
Performance of models and gastroenterologists in datasets.
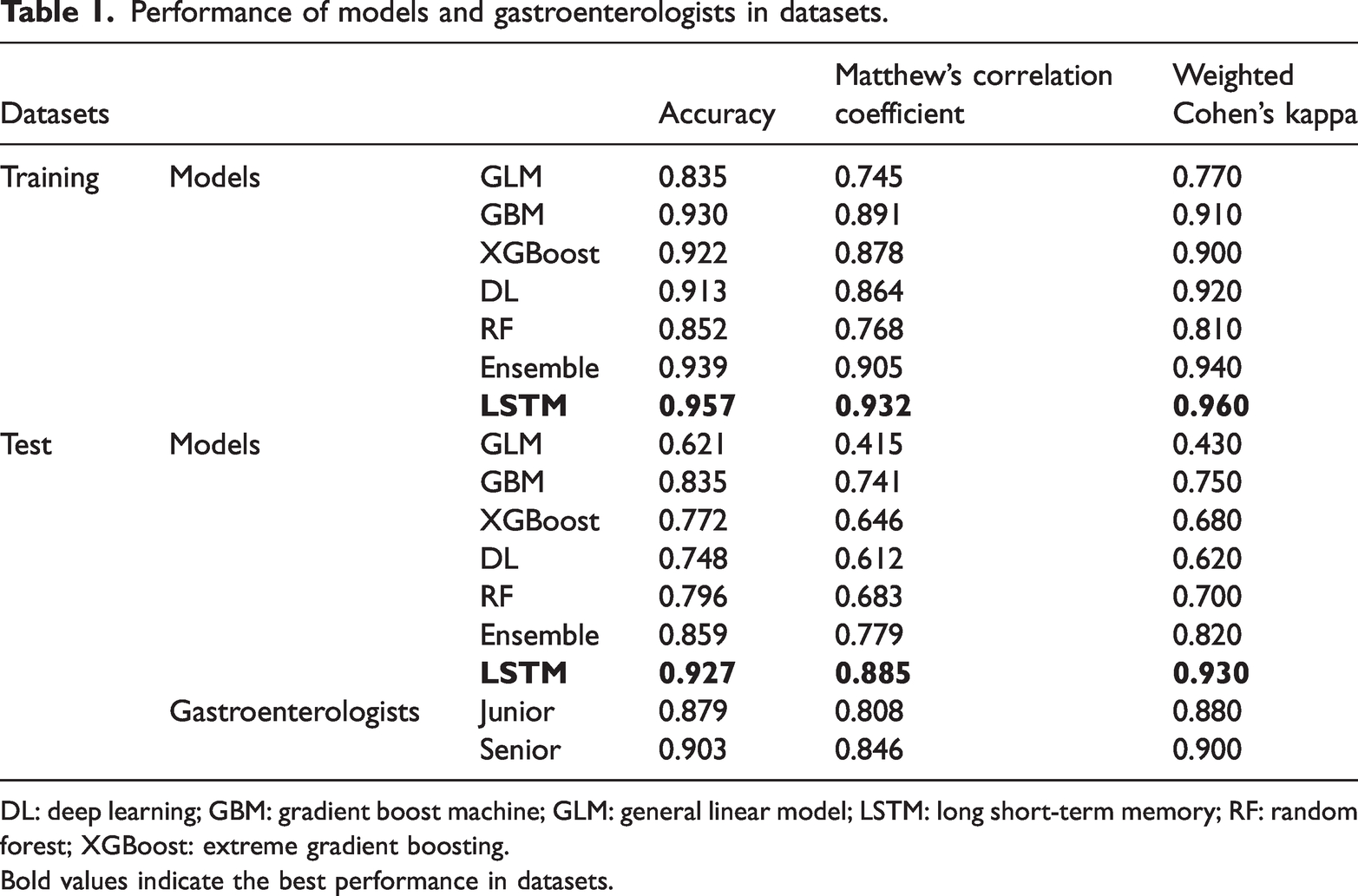
DL: deep learning; GBM: gradient boost machine; GLM: general linear model; LSTM: long short-term memory; RF: random forest; XGBoost: extreme gradient boosting.
Bold values indicate the best performance in datasets.
Performance of models and gastroenterologists in test
In the test dataset, the performances and confusion matrices of models and gastroenterologists are shown in Table 1 and Figure 4. LSTM model still achieved the highest accuracy (0.927), with the highest MCC of 0.885 and Cohen’s kappa of 0.930, which were better than the AutoML models (ensemble: 0.859, 0.779, and 0.820, respectively) and both the gastroenterologists (junior: 0.879, 0.808, and 0.880, respectively; senior: 0.903, 0.846, and 0.900, respectively).
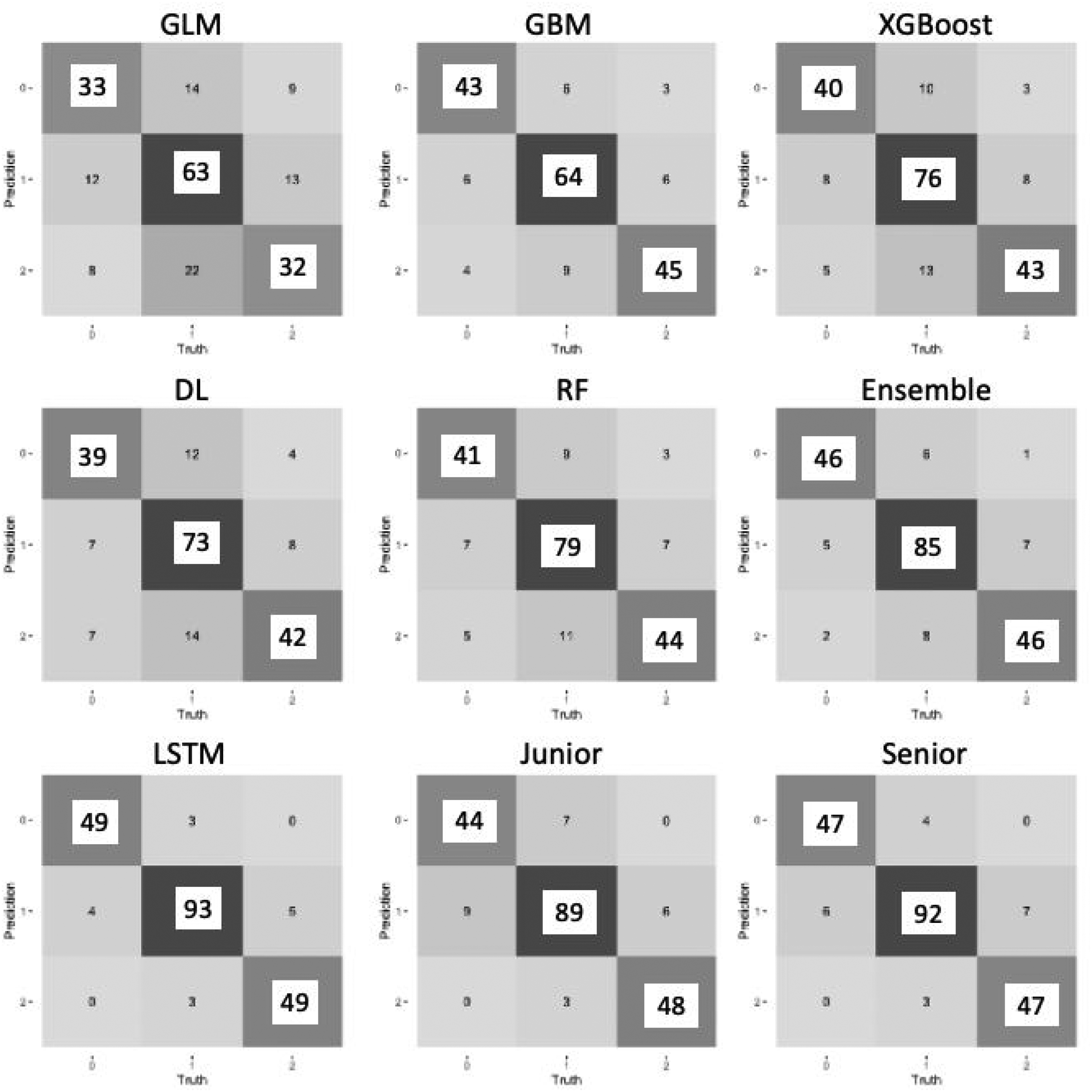
Confusion matrices of models and gastroenterologists in the test. DL: deep learning; GBM: gradient boost machine; GLM: general linear model; LSTM: long short-term memory model; RF: random forest; XGBoost: extreme gradient boosting.
Local interpretation of the LSTM model
The local interpretation plotting (Figure 5) revealed the local association between the time-series audio features and the prediction within three random cases: 1. In sample 1 (Figure 5(a)), the LSTM model’s prediction indicated an 84% probability that the input belongs to hypoactive, which mainly based on the features of Chroma and FBank during the 20th–30th seconds. 2. In sample 2 (Figure 5(b)), the model’s prediction indicated a 77% probability of normoactive, mainly because the features of the first, second, and fourth segments. 3. In sample 3 (Figure 5(c)), the model’s prediction indicated an 91% probability of hyperactive, which was mainly owing to the features of the first and third segments.

Local interpretation of the LSTM model. The local interpretation plots reflected the contribution of the audio features to the prediction within three samples: (a) a hypoactive sample; (b) a normoactive sample; and (c) a hyperactive sample.
The performance of LSTM model in clinical sets
To further evaluate the LSTM model in clinical, we selected two common clinical sets.
The first set was the timing of feeding after general anesthesia. For nonabdominal surgeries under general anesthesia, the timing of feeding mainly depends on the recovery of spontaneous anal exhaust and bowel sounds. We collected bowel sound samples from 103 patients who underwent general anesthesia for otorhinolaryngological surgery, taken 2 hours after extubation. After evaluation by the two gastroenterologists, it was found that bowel sounds were normoactive or hyperactive in 50 patients, who were thus allowed to feeding, whereas bowel sounds were still hypoactive in 44 patients. Figure 6 shows the performance of the LSTM model, 42 of the 44 patients with unrecovered bowel sounds were correctly identified. Among the 50 patients with recovered bowel sounds, 49 were correctly identified. In this set, the model achieved an accuracy of 0.968, sensitivity of 0.980, and specificity of 0.955.

The performance of the LSTM model in two clinical sets: (a) feeding after general anesthesia and (b) bowel preparation and bowel sounds. BBPS: Boston bowel preparation scale; LSTM: long short-term memory model.
The second set was to assess the relationship between bowel preparation and bowel sounds during the preparation period. We collected bowel sound samples from patients preparing for colonoscopy, taken 2 h after the start of laxative administration. During colonoscopy, according to the BBPS criteria, among 112 patients, 2 had a BBPS score of 0, 8 had a score of 1, 61 had a score of 2, and only 41 achieved a score of 3. Among the 10 patients with scores of 0–1, the LSTM model classified their bowel sounds as hypoactive in 7, whereas in bowel sounds of patients with scores of 2–3, 100 of 102 were classified as normoactive or hyperactive. In this set, the model achieved an accuracy of 0.955, sensitivity of 0.980, and specificity of 0.700.
Discussion
The application of AI in bowel sound detection and analysis is a promising and innovative approach in medical diagnostics.30,31 With ongoing advancements in technology and increasing clinical validation, AI has the potential to transform the way gastrointestinal disorders are detected, monitored, and managed, ultimately improving the quality of life for patients and advancing the field of gastroenterology. 32
ML techniques typically involve feature engineering as a preprocessing step to extract relevant features from raw data. These features are then used as inputs for a designed classifier. In 2008, Dimoulas et al. 33 proposed an Autonomous Intestinal Motility Analysis System, which used time-frequency features and wavelet-adapted parameters for feature extraction. A multilayer perceptron with a single hidden layer was used to automatically detect bowel sound events, achieving an overall recognition accuracy of 94.84%. In 2018, Yin et al. 34 used the fast Fourier transform to convert time-domain signals into the frequency domain, followed by a radial-basis function kernel-based support vector machine for bowel sound classification. Moreover, in 2021, Qiao et al. 35 used a RF classifier comprising 20 decision trees for bowel sound detection with a wearable system. This approach further expanded the application of ML in the context of bowel sound detection.
In the past decade, DL methods have revolutionized bowel sound detection due to their powerful function-fitting capabilities. In 2018, Liu et al. 36 proposed a wireless audio recording system for bowel sound acquisition. The MFCC was used for feature extraction, followed by the design of an LSTM network for bowel sound classification. The system indicated an accuracy of 85.7% on identifying bowel sound clips. In 2020, Zhao et al. 37 developed a convolutional neural network to segment bowel sound events from background noise. They used 5-s audio clips as inputs and compared the performance of MFCC and short-time Fourier transform for feature extraction. Its accuracy achieved at 91.8%. In 2022, Sitaula et al. 38 proposed a novel detection algorithm that combined a CNN with a Laplace hidden semi-Markov model to classify peristalsis and nonperistalsis sounds. The proposed algorithm was validated on abdominal sounds from 49 newborn infants, which showed an accuracy of 89.8%. In 2024, Zhang et al. 10 presented a lightweight DL-based algorithm for bowel sound segmentation. They proposed a novel approach combining one-dimensional convolutional layers and bidirectional gate recurrent unit layers to improve feature extraction. The proposed method achieved better performance (precision, 0.66; recall, 0.77) than other traditional algorithms. The integration of ML and DL techniques has significantly enhanced the field of bowel sound detection. These advanced methods offer improved accuracy and robustness, paving the way for more reliable and efficient diagnostic tools in clinical settings.8,36,39 Future research should continue to explore the potential of these technologies to further optimize bowel sound detection and analysis.
Bowel sounds are complex acoustic signals generated by the movement of gas and fluid within the gastrointestinal tract. These sounds can vary significantly, encompassing a range of types such as gurgling, rumbling, bubbling, and even clicking.1,13 The diversity and variability of these sounds present a significant challenge for accurate classification. It has demonstrated that bowel sounds can be categorized into subtypes, including single burst, multiple bursts, continuous random sound, and harmonic sound, each with distinct characteristics. 8 If research focus on counting bowel sounds, it is essential to determine whether the developed detector can identify all bowel sound subtypes. Previous studies have often relied on manual labeling of counting different subtypes of sounds, which is not only time consuming but also highly susceptible to subjective biases.9,37,38 This subjectivity for labeling can lead to inconsistencies and reduced robustness in the classification models. Another critical issue is the lack of a unified international standard for describing bowel sounds, particularly in terms of frequency.1,40 This absence of standardization can lead to significant errors when applying models across different countries and populations. For instance, models trained on bowel sound frequency counts may perform poorly when deployed in diverse clinical settings. Moreover, bowel sounds are dynamic physiological signals that can change over time. 13 Previous studies have predominantly focused on classifying short audio segments, which may not accurately reflect the temporal variations in bowel sounds. This approach is inconsistent with the real-world clinical setting, where continuous monitoring over longer periods is often required. Additionally, most previous research has used MFCCs as the sole feature for ML tasks. 36 This single-feature approach may overlook other important characteristics of bowel sounds and limit the potential of computer audio. In recent years, the interpretability of AI models has garnered significant attention, with numerous methods emerging to explain ML models. Previous studies on bowel sound models have primarily focused on counting the occurrences of bowel sounds, yet there have been no reports on visualizing these models. The interpretability of AI decisions remains a concern, as clinicians need to understand the reasoning behind the model’s output to trust and effectively use the technology.
To address these challenges, this study introduces a novel framework that leverages DL to classify frequency of bowel sounds. Instead of relying on frequency counts, we focus on describing and characterizing audio segments of bowel sounds. This method provides a more comprehensive representation of the sounds, capturing their temporal dynamics and variability. Furthermore, we integrated multiple audio features, including MFCC, FBank, and Chroma, into the classification model. 41 By fusing these features, we enhanced the model’s ability to discern subtle differences in bowel sounds in a multifeature fusion, leading to more accurate and robust classification. In terms of interpretability, we address this gap by incorporating local interpretability into our model analysis. This approach not only enhances the transparency of our DL model but also allows for a better understanding of how the model processes and classifies bowel sound data. By doing so, we aim to provide clinicians with more actionable insights derived from our AI-driven bowel sound frequency classification. Moreover, our study demonstrated that the LSTM algorithm outperformed other ML algorithms during the process of the multifeature fusion, which was consistent with previous findings.27,36,37 LSTM networks, a type of RNN, have significant advantages over traditional ML models when dealing with time-series data. 42 LSTMs can capture complex temporal dependencies through their unique gating mechanisms. The input gate decides how much new information to incorporate, the forget gate determines which parts of the previous memory to discard, and the output gate controls what information to pass on. This allows LSTMs to selectively remember or forget information over long sequences, making them highly effective for tasks such as stock price prediction, weather forecasting, and sound recognition. In terms of classification accuracy, the ResNet–LSTM model surpassed that of gastroenterologists in the independent test dataset. Given that prior studies have primarily focused on sound splitting and counting, differences in design and datasets have rendered model performance incomparable. Lastly, we evaluated the model in two clinical settings: postgeneral anesthesia feeding and bowel preparation. The model’s performance highlighted the potential of AI models in clinical management.
However, this study has some limitations. To begin with, the definition of bowel sounds is often subjective and lacks a standardized definition. This variability can lead to inconsistencies in clinical practice, particularly when applying diagnostic models across different regions or health care settings. Moreover, clinical application is further challenged by patient-related factors such as movement and diet, which can affect the quality and reliability of recordings. Future work should also focus on incorporating additional diagnostic functionalities, such as differentiating normal from pathological sounds (e.g. intestinal obstruction), and integrating multimodal data (e.g. gastrointestinal pressure sensors) to enhance diagnostic accuracy. Standardization and multimodal approaches are essential for advancing the clinical utility of bowel sound analysis models. Lastly, bowel sounds are complex acoustic signals that can vary in morphology, including types such as gurgling, rumbling, bubbling, single burst, multiple bursts, and harmonic sounds. Our current model focuses on frequency-based classification and does not incorporate morphological subtype analysis, which may provide additional diagnostic value. Future work should aim to integrate fine-grained sound characterization and subtype classification to further enhance the clinical utility of AI-driven bowel sound analysis.
Conclusion
This study presents a novel, explainable ResNet–LSTM framework for the classification of bowel sound frequency based on the multifeature fusion. By integrating Chroma, FBank, and MFCC features and leveraging the temporal modeling capabilities of LSTM, our model achieved superior performance compared with both AutoML models and experienced gastroenterologists. The incorporation of LIME enhanced model transparency, supporting clinical trust and adoption. Validated in two real-world clinical scenarios—postoperative feeding decisions and bowel preparation assessment—the framework demonstrates strong potential as a reliable, objective tool for noninvasive gastrointestinal function monitoring. This work advances the field by addressing key limitations in data duration, feature diversity, and model interpretability, paving the way for future AI-driven solutions in gastroenterology.
Supplemental Material
sj-pdf-1-imr-10.1177_03000605251376915 - Supplemental material for Explainable ResNet–long short-term memory model for the classification of bowel sounds frequency based on multifeature fusion
Supplemental material, sj-pdf-1-imr-10.1177_03000605251376915 for Explainable ResNet–long short-term memory model for the classification of bowel sounds frequency based on multifeature fusion by Wenchao Zhang, Yu Wang, Jinzhou Zhu, Qiang Wu, Congying Xu, Lihe Liu, Shiqi Zhu, Xiaolin Liu, Jiaxi Lin, Chenyan Yu, Qi Yin, Xianglin Ding and Zhonghua Xu in Journal of International Medical Research
Footnotes
Acknowledgments
NA.
Author contributions
W. Zhang, L. Liu, and J. Lin wrote the manuscript; Y. Wang, Q. Wu, S. Zhu, Q. Yin, and C. Yu collected clinical data; Y. Wang, X. Liu, C. Xu, and J. Zhu analyzed clinical data; W. Zhang, Z. Xu, and X. Ding contributed to the study design.
Data availability statement
The code used in this study is available upon reasonable request from the corresponding author.
Declaration of conflicting interests
The authors declare no competing interests and financial disclosure.
Funding
This study was supported by Changzhou Municipal Health Commission Science and Technology Project (QN202139), Science and Technology Plan (Apply Basic Research) of Changzhou City (CJ20210006), Medical Education Collaborative Innovation Fund of Jiangsu University (JDY2022018), Frontier Technologies of Science and Technology Projects of Changzhou Municipal Health Commission (QY202309), Youth Program of Suzhou Health Committee (KJXW2019001), and the Open Fund of Key Laboratory of Hepatosplenic Surgery, Ministry of Education (GPKF202304).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.