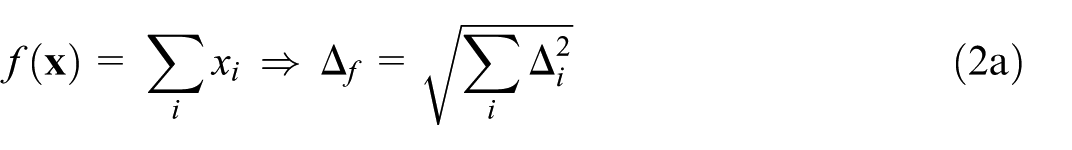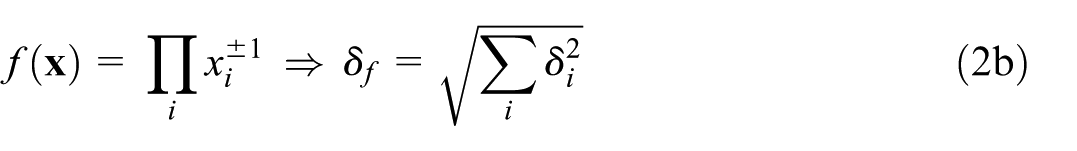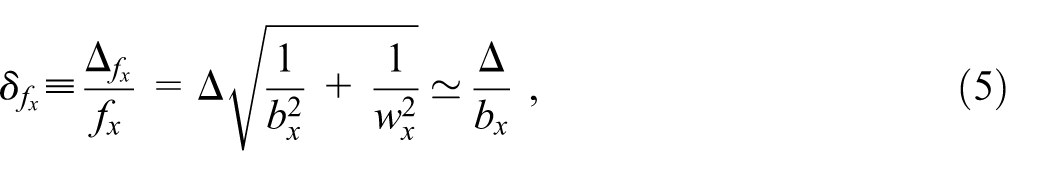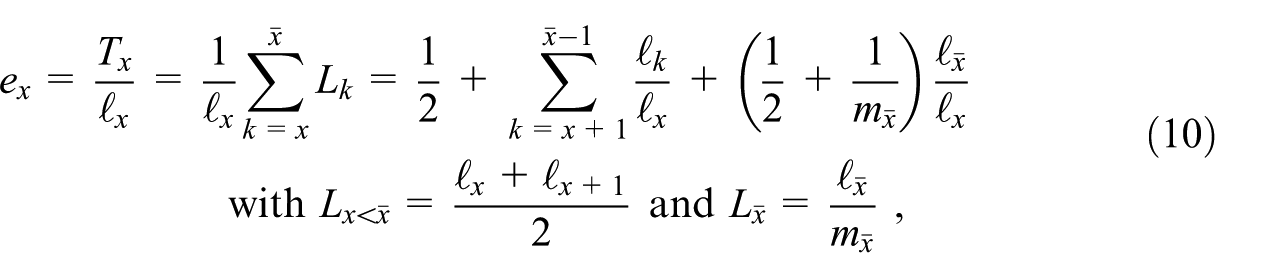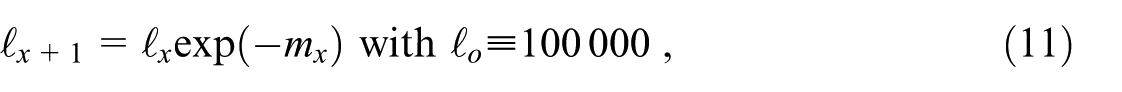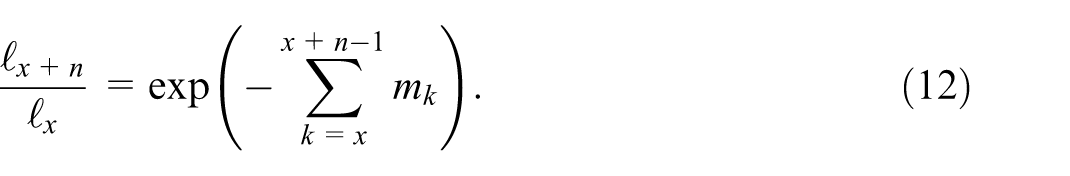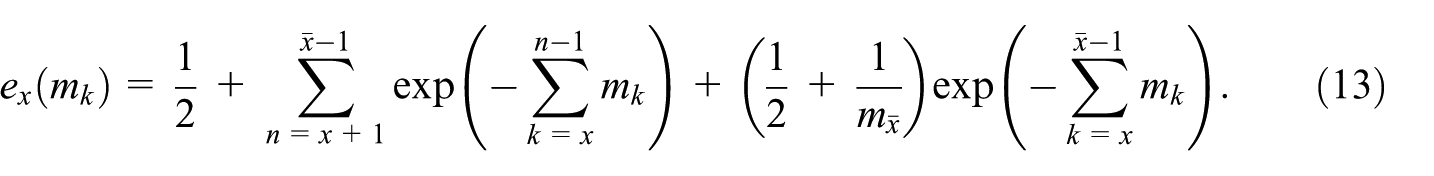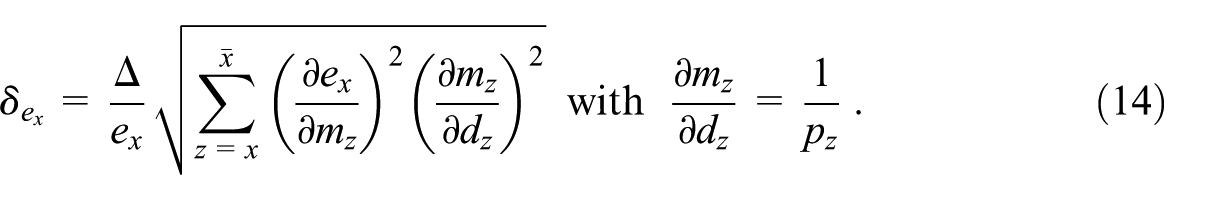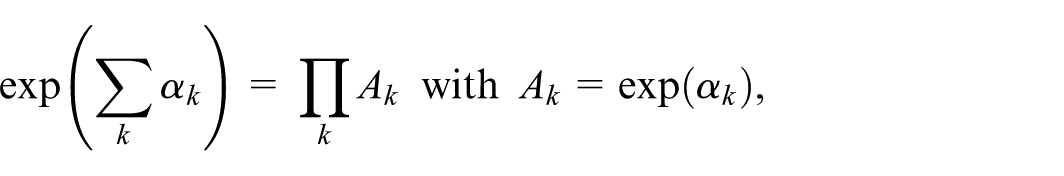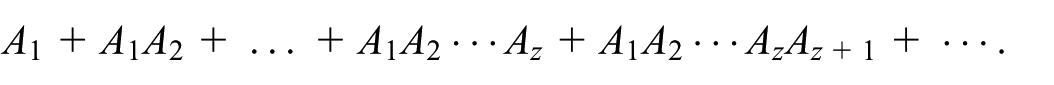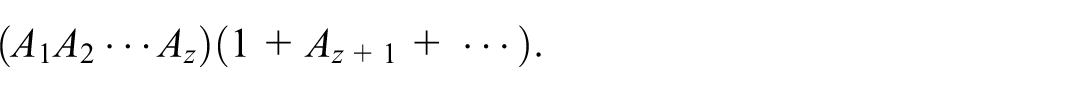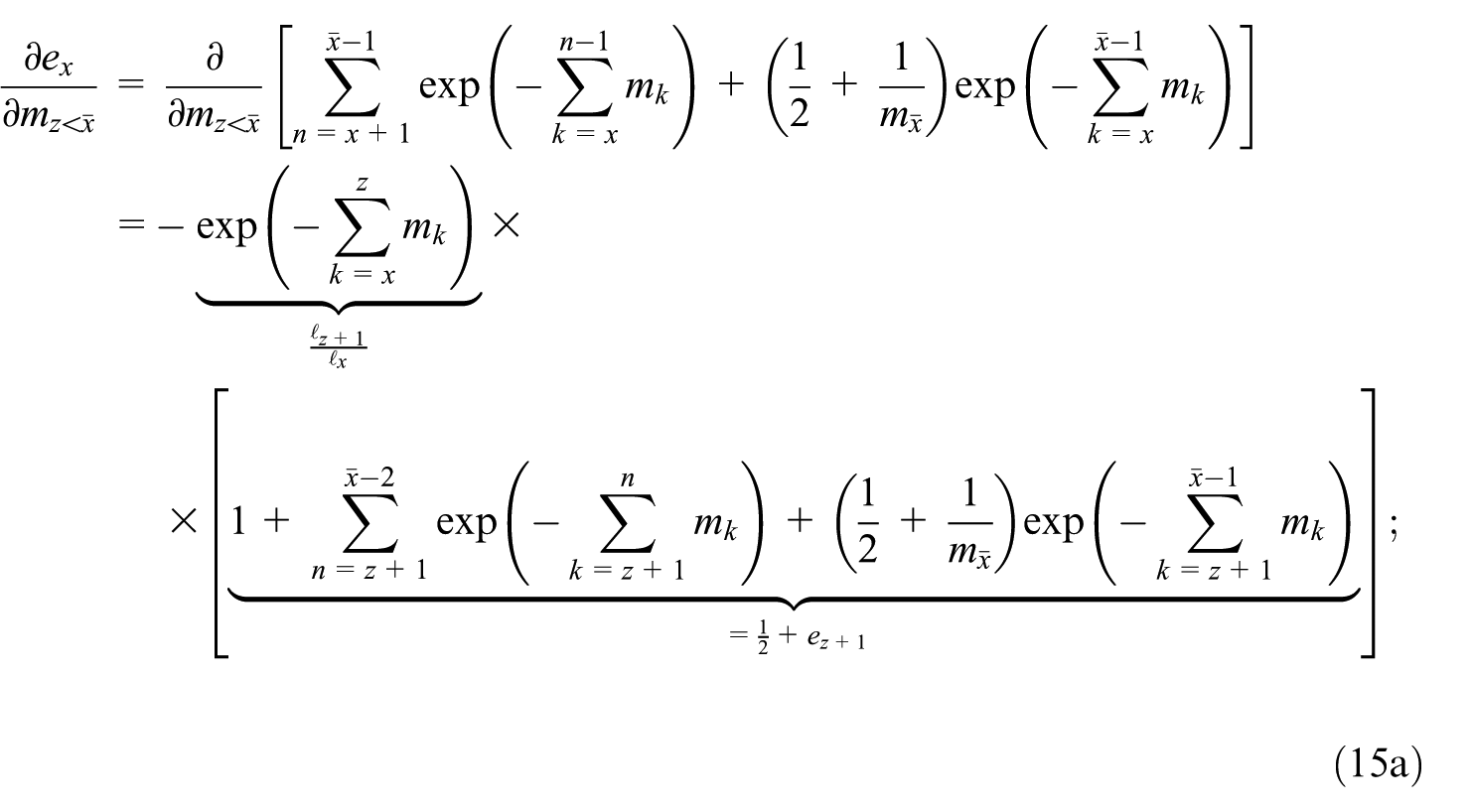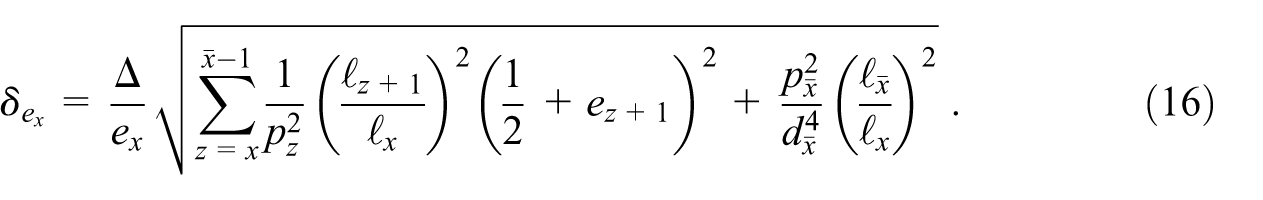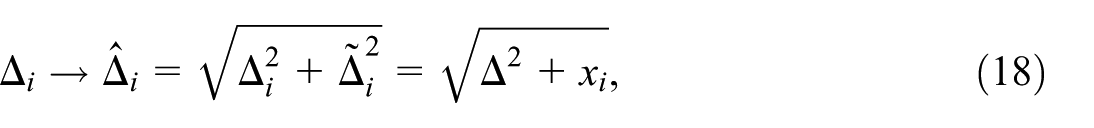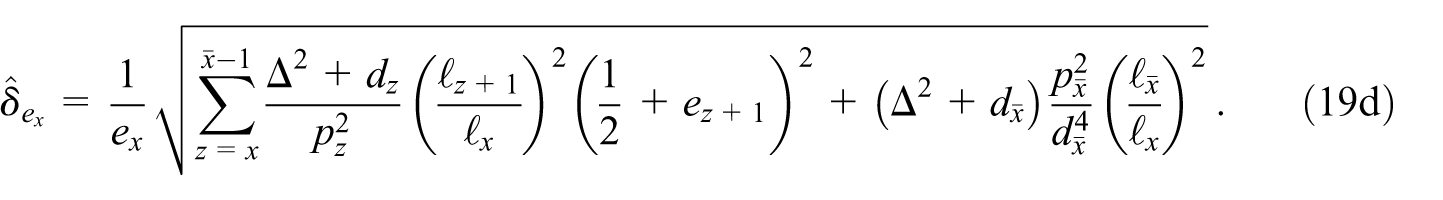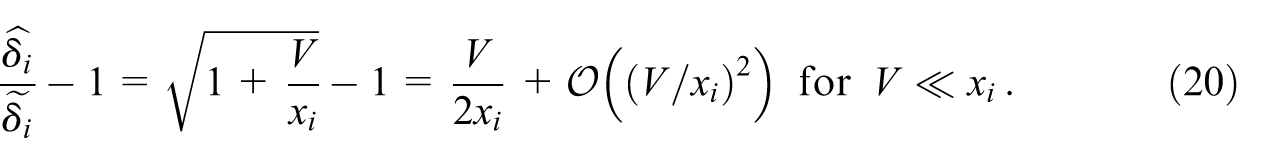New and efficient methods based on noise addition to protect the confidentiality in population statistics have been developed, tested, and applied in census production by various members of the European Statistical System over the past years. Basic demographic statistics—such as population stocks, live births and deaths by age, sex, and region—may be protected in a similar way, but also form the raw input to calculate various demographic indicators. This paper analyzes the impact on the accuracy of some selected indicators, namely fertility and mortality rates and life expectancies, under the assumption that the raw input counts are protected with a generic noise method with fixed variance parameter, by comparing the size of noise uncertainties with intrinsic statistical uncertainties using a Poisson model. As a by-product, we derive and validate numerically a closed analytical expression for the variance of life expectancies in a certain class of calculation models as a function of the variance of input mortality data. This expression also allows to calculate analytically the statistical uncertainty of life expectancies using the mentioned Poisson model for the input death counts.
After the 2011 EU census, European Statistical System (ESS—the joint body of Eurostat and the national statistical institutes of all EU countries and Iceland, Liechtenstein, Norway, and Switzerland) experts realized that traditional statistical disclosure control (SDC) methods like cell suppression become inefficient when applied to very detailed cross-tabulations. Moreover, these methods do not protect outputs effectively when disseminated on non-nested geographical breakdowns like administrative regions and grids (geographic differencing); see Antal et al. (2017). Mainly for these two reasons, ESS efforts began from 2015 onwards to explore new SDC methods that avoid excessive information loss and also protect against geographic differencing. As a result, two methods based on adding some noise to the statistics were tested and recommended for the 2021 EU census (Antal et al. 2017; De Wolf et al. 2019a, 2019b), namely targeted record swapping (TRS; Frend et al. 2012) and the cell key method (CKM; Fraser and Wooton 2005; Marley and Leaver 2011; Thompson et al. 2013). A significant number of ESS members eventually decided to use one or a combination of these methods for their census outputs.
In the wake of the modernization of social statistics in the ESS, it is likely that also the annual demographic statistics would become more detailed and eventually integrated with multi-annual population statistics like censuses. This would entail some new questions, for example, whether some of these annual demographic statistics would require confidentiality protection; how the consistency with census-like (protected) statistics would be ensured; and finally how the key use cases of demographic statistics can be sufficiently ensured; cf. Schulte Nordholt et al. (2024).
For instance, basic demographic statistics including population stocks, live births and deaths by age, sex, and region are needed to calculate various demographic indicators at regional level. If the protection methods originally developed for census outputs were to be applied to these demographic statistics, the question arises how the additional noise-induced uncertainty propagates to the resulting indicator values. This paper analyzes the effects of a generic noise protection method with a fixed variance parameter on some selected demographic indicators. R code implementing the functions introduced in the paper is available on GitHub (https://github.com/bachfab/noisy_demo_indicators).
2. Noise Setup and Uncertainty Propagation
It is one of the features of the CKM introduced in Section 1 that the variance of the noise added to the output counts is a fixed input parameter, here denoted . Moreover, the detailed noise distributions of the CKM typically follow a discretized bell curve (as all noise terms must be integers to retain integer outputs) that is very close to a Gaussian (Bach 2021; Gießing 2016). Through these properties, the CKM is considered a reference example for a generic noise protection method in the sense mentioned above. (Note that TRS—the other method mentioned in Section 1—does not provide the same parametric control over the noise variance and therefore does not allow for such analytical studies of its effects.)
Furthermore, the standard theory of error propagation based on linear response of a measurement function to a set of uncorrelated input measurements can be applied (for a recent reference textbook, see e.g., Morrison 2021):
where runs over the elements of with standard deviation . From Equation (1) it is straightforward to derive two simple but handy special cases: when is a simple sum of independent input measurements, the squares of the absolute uncertainties are added; and when is a simple product (or ratio) of independent input measurements, the squares of relative uncertainties are added—that is,
with relative uncertainties of the input measurements denoted .
As a further simplification, in the specific setup analyzed here where only the CKM effect is to be considered, the standard deviation of all the input measurements is constant:
3. Results for Selected Demographic Indicators
For the quantitative analysis we select three demographic indicators that are generally very important for all kinds of demographic analysis: crude fertility and death rates, and life expectancy. On the rate indicators, that is, simple ratios of input counts, note various earlier studies such as Santos-Lozada et al. (2020), Hauer and Santos-Lozada (2021), and Bach (2021; see Section 4.3 thereof) that the present analysis expands on.
The three indicators depend on three distinct sets of raw input counts for a given region and time period: population stocks by sex and single years of age at the beginning and at the end of a given time period (typically a calendar year), as well as the number of live births (by mother’s single year of age) and the number of deaths (by sex and single year of age) during the same time period. To add some geographical granularity, we analyze all NUTS 2 regions of all ESS members for the latest available reference year 2023, as published in the data sets demo_r_d2jan (Eurostat 2025d), demo_r_fagec (Eurostat 2025c), and demo_r_magec (Eurostat 2025a).
3.1. Fertility Rates
The age-specific crude fertility rate is defined as
with the relevant age in single years, the number of live births by mothers aged and the average female population stock aged during the reference time period. Then the relative error on is given by Equation (2b) as
where in the last step we neglect for simplicity a possible CKM uncertainty on , because in general. In this approximation, the absolute uncertainty on from Equation (5) is .
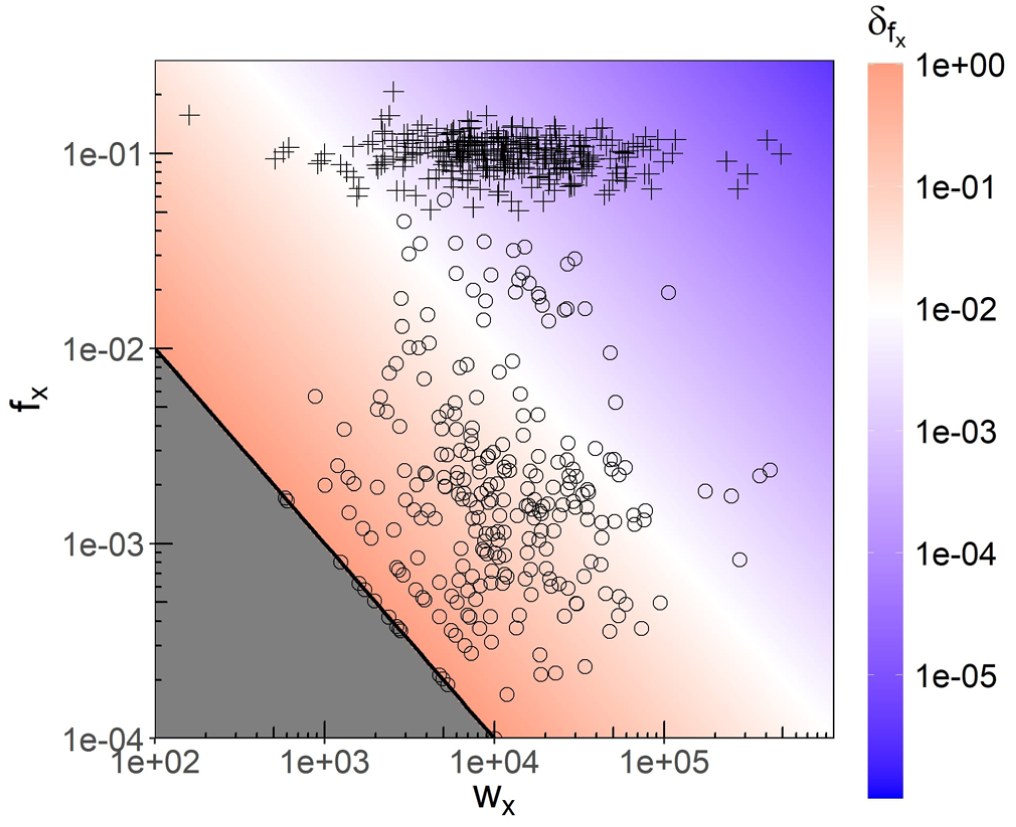
Setting and plugging in the numbers from the data sets, one finds that in the majority of cases the relative CKM uncertainty on the age-specific fertility rates is moderate, with a median relative uncertainty of and more than of all relative uncertainties ( of calculated) . Nevertheless, of the uncertainties found ( of ) are . In line with Equation (5), as expected the largest relative uncertainties, up to for , are found where the numbers of live births are very small, that is, down to . This is illustrated in Figure 1 showing the parametric plot of Equation (5) over the entire relevant – plane.
Relative uncertainty on the age-specific fertility rate from CKM noise with variance as a function of the age-specific number of mothers and fertility rate according to Equation (5). The black line indicates the limiting contour corresponding to the number of live births . Actual fertility rates found in the 2023 NUTS 2 data are shown for ages (circles) and (cross-hairs), showing that most up to while most .
In addition to age-specific rates, one can also analyze the total fertility rate given as
so that by applying Equation (2a) and reusing , the relative uncertainty on amounts to
After plugging in the numbers, there is again little surprise that in this more aggregate indicator the CKM uncertainty is negligible in basically all cases calculated: more than of all calculated ( of ) are , and only for the smallest NUTS 2 region in the entire EU: Åland (FI20). Moreover, where input counts and are available for age bands, for example, , that have been protected with independent noise of the same variance as their single-year components (as the CKM does), the corresponding band-specific rates and total rate calculated from such age bands will be even less noisy. This is clear from Equations (5) and (7), where and only appear in the denominators. Finally, note that this section has not analyzed any bias resulting from noise addition: Enderle et al. (2018) show that such rates, that is, simple ratios, are approximately unbiased for sufficiently large denominators, more specifically that the ratio bias is already for denominators with noise setup and (which reflects well the noise scenario discussed here). This is generally valid for the purposes of this section and the next, where denominators are always , except only average population used in Subsection 3.2 for a few terminal ages years in Åland.
3.2. Mortality Rates
The age-specific crude mortality rate is defined as
with the number of deaths at age and the average population during the reference time period. These rates can be calculated for the total population and for the male and female populations, respectively. Analogously to Equation (5) with , the relative uncertainty is then
Unlike for the fertility rates, the approximation does not hold here in general for very high ages, but still holds up to the cut-off age 85 years applied in this analysis: the largest mortality rate found across the entire data set analyzed is —for males aged 85 years or over in Severozapaden (BG31)—and generally for almost of all rates calculated for all sex categories and regions.
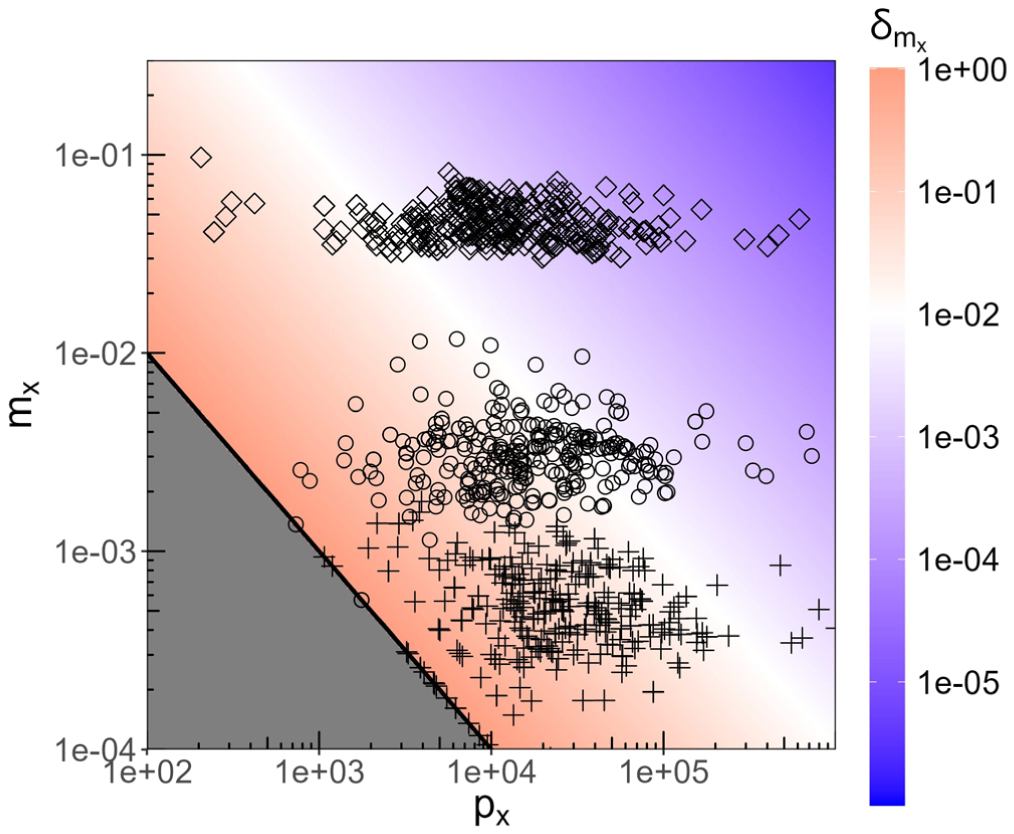
Plugging in the NUTS 2 numbers from 2023 with , one finds qualitatively similar results to Subsection 3.1. However, quantitatively the median relative uncertainty is for the total population across all ages ( for male and for female populations), and in the total population of all uncertainties calculated are ( respectively for males and females). This is because the small-number effect already discussed in Subsection 3.1 is much more pronounced in the age-specific mortality rates: deaths are spread across all ages instead of just a fertile age band (e.g., 16–44 years), and they are (fortunately) very scarce across a majority of ages, increasing only in the terminal ages. Therefore, age-specific death rates stemming from very small death counts are much more numerous than age-specific fertility rates, especially at the NUTS 2 level considered here, leading to the larger typical relative uncertainties found above.
As for the fertility rates, Figure 2 shows the parametric dependence of according to Equation (9) over the entire relevant parameter space and showing some actual data points from the 2023 NUTS 2 data. Moreover, as for the fertility rates, in noise protection methods where count aggregates receive independent noise, the rates for multi-year age bands will be more accurate than for single years; see discussion in Subsection 3.1.
Relative uncertainty on the age-specific mortality rate from CKM noise with variance as a function of age-specific population and crude mortality rate according to Equation (9). The black line indicates the limiting contour corresponding to the number of deaths . Actual crude mortality rates found in the 2023 NUTS 2 data are shown for ages (circles), (cross-hairs), and (diamonds), showing that most up to while most .
3.3. Life Expectancy
The calculation of age-specific life expectancy is considerably more complex than that of the crude rates presented in the previous sections. Therefore, also the uncertainty propagation according to Equation (1) is more complex and it is worthwhile to use the auxiliary indicators published in the so-called life table, see data set demo_r_mlife (Eurostat 2025b) for the ESS (note that the NUTS 2 regions of Germany are not available in the data set and therefore not analyzed here). Most notably, we make use of the total number of person-years lived from age until all have died (), the total number of person-years lived from age to (), the survivorship function () and the age-specific mortality rate (), all included in the life table. The sole raw data input is through depending on the raw number of age-specific deaths and the average population of that age for the given period. All other life table indicators and ultimately are derived from this as follows (cf. e.g., Eurostat’s life expectancy methodology documented at https://ec.europa.eu/eurostat/cache/metadata/Annexes/demo_mor_esms_an_1.pdf):
where the sums run from the age in question until the open-ended terminal age class where the age-specific tabulation stops. The cut-off age depends on national publication practices and other constraints; for example, in the EU life tables (Eurostat 2025b) this terminal age class was “85 years or over” at the time of writing this paper. Note the explicit dependency on the terminal mortality rate entering through the terminal person-years lived . In general, there is some freedom in modeling as a function of , where the relation above is the one used by Eurostat. A further implicit dependency on all other mortality rates enters through the which are here defined recursively as
so that
The attentive reader may have noted the difference between the definitions of the survivorship function in the Eurostat methodology and here in Equation (11): The two definitions have the same Taylor expansion in down to . Since prevalently (cf. Subsection 3.2), the definitions are therefore equivalent for all practical purposes, while the exponential definition of Equation (11), used for example, in the U.S. (see https://www.lifeexpectancy.org/lifetable.shtml), allows for the following analytic manipulations necessary to derive Equation (16).
To derive the uncertainty on , one needs the functional dependency of on and . While again there is some methodological freedom in modeling the mortality rates for life expectancy purposes (e.g., the UK’s Office for National Statistics averages over the three most recent years, see https://www.ons.gov.uk/peoplepopulationandcommunity/healthandsocialcare/healthandlifeexpectancies/methodologies/guidetocalculatingnationallifetables), we assume here for practical purposes the simplest model—also used by Eurostat—that employs the crude age-specific mortality rate of Equation (8), that is, . Ignoring again any potential noise on , as argued in Subsection 3.1, Equation (13) can now be differentiated with respect to the raw input using the chain rule to calculate the resulting uncertainty on as
To evaluate the derivative term , consider rewriting the exponential of a sum as a product of exponentials, that is,
and then consider a sum over such products of exponentials expanded as
The derivative of this expression with respect to index has the form
where Equations (12) and (13) were used in Equation (15a) to identify expressions in terms of and . This can be plugged back into Equation (14) to obtain the final formula for the relative uncertainty
Since the analytical derivation of this result via Equations (13), (14), (15a), and (15b) is not straightforward, its correctness is validated numerically in Appendix A. Equation (16) represents a closed analytical expression for for a class of life expectancy calculation methods characterized by Equations (11) and (8), which includes the EU method. It allows the straightforward calculation of from the CKM setup (recall ), from the life table indicators and , and from the population stocks and the terminal death number .
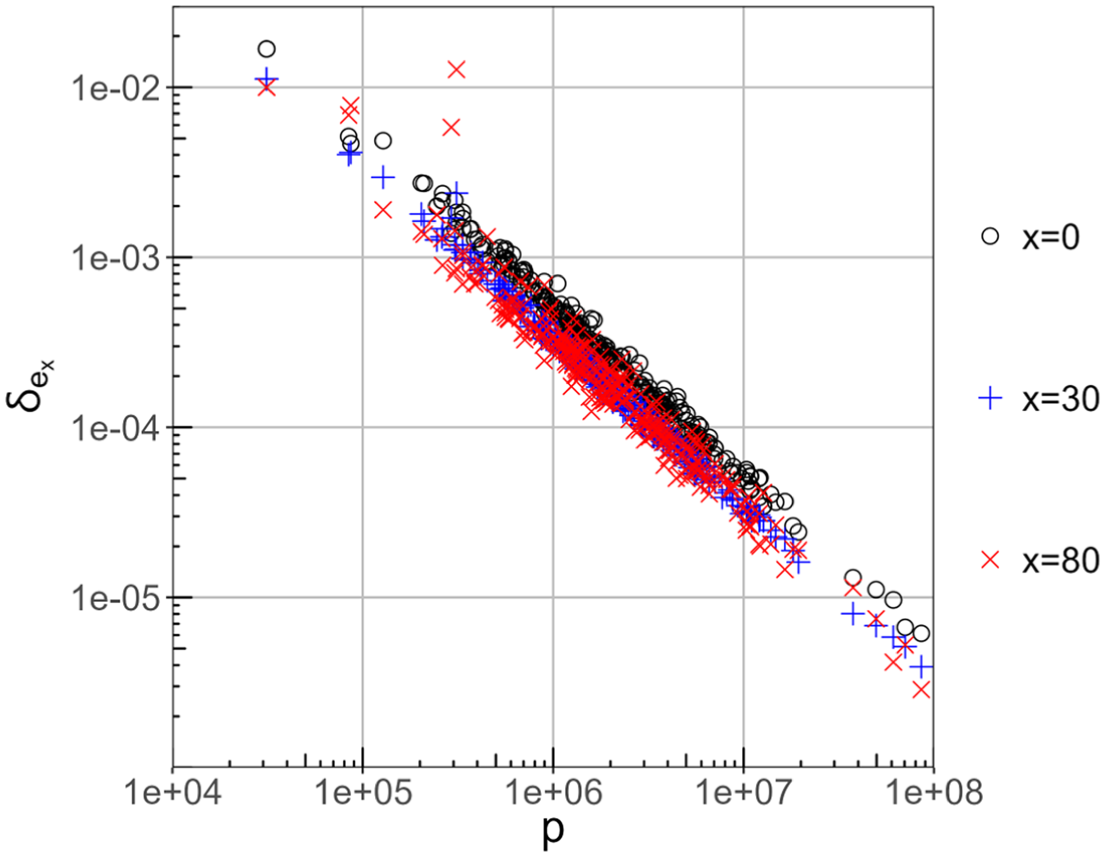
Plugging in the 2023 numbers for NUTS 2 regions published by Eurostat with , one finds very moderate relative uncertainties on the age-specific life expectancies largely prevailing, with a median for the total population ( for the male population and for the female population), and for the total population occurring only in two NUTS 2 regions: Mayotte (FRY5) and again the smallest one, Åland (FI20); see the corresponding data points in Figure 3 above the line at total population values (Mayotte) and (Åland). Furthermore, Equation (16) suggests an inverse correlation with the total (male or female) population aged of a given region (i.e., ). This is also illustrated in Figure 3 for various ages .
Scatter plot of the relative uncertainty from CKM noise on the life expectancy at ages , 30, and 80, according to Equation (16), over the total population , with one dot for each ESS region analyzed.
4. Statistical Fluctuations
Section 3 dealt solely with the effects of artificially adding noise according to a given setup to the raw input counts. A full analysis of the performance of such protection methods, however, should compare these effects to the intrinsic statistical fluctuations that always affect these raw counts—and hence the resulting derived indicators—as well. To obtain a model for these statistical fluctuations, it is a widely used practice in the literature to consider vital events as rare events during the reference period and thus as Poisson distributed; cf. for example, Scott (1981) and Peters et al. (2009). Then the Poisson parameter , and hence the variance stemming from statistical fluctuation, of any given event count can be estimated by the count itself: thus giving
where the tilde is to indicate that this uncertainty comes from intrinsic statistical variation (analog for relative uncertainties).
It can be verified with the data sets used in Section 3 that this provides a robust estimation of the size of the intrinsic statistical variation, namely by calculating the standard deviation across the entire available time series for each NUTS 2 region by age and sex, and dividing it by the estimator of Equation (17). In the death counts, the median of this ratio over all available regions and ages is 1.2 (with lower and upper quartiles ) for males and 1.1 (lower/upper quartiles ) for females. In the live birth counts, the median is 1.8 (lower/upper quartiles ). This shows that the variance estimator of Equation (17) indeed provides a robust estimate of the magnitude of the statistical variation. There is a systematic under-estimation of the actual variation over time (more so in the live births than in the deaths). However, this is not surprising because the validation approach assumes a constant Poisson parameter—that is, constant event rates—over the entire time series, which obviously underestimates the true variation. To reduce this sensitivity of the validation to demographic dynamics, we restrict the validation to infant mortality for the 100 NUTS 2 regions with the smallest total fertility variation. Infant mortality is relatively stable compared to fertility or older-age mortality, so demographic trends have less impact. By choosing regions with low fertility variation, we further minimize demographic changes that hamper the comparison. Here the median ratio of the standard deviation over its estimator for both sexes together is 1.1 (with lower and upper quartiles ).
Using Equation (17), all uncertainties calculated in Section 3 can be modified or extended in a straightforward manner to reflect either statistical uncertainties or the combination of statistical and CKM noise uncertainties. In all cases, the new expressions for combined uncertainties (indicated by a hat) result from replacing
For ease of reference, we write out the modified Equations (5), (7), (9), and (16):
In all cases, setting produces a formula for the purely statistical uncertainty assuming the above-mentioned Poisson model.
5. Combined Analysis and NUTS 3 Picture
A full assessment of the effects of noisy SDC setups based on CKM or similar methods (the key property being a constant noise variance parameter) on the quality of demographic indicators must compare the total uncertainties (, ) to a scenario of only statistical uncertainties (, ), rather than comparing pure noise effects (, ) to a scenario of no uncertainties at all. To this end, we make use of Equations (19a) to (19d) to analyze the relative contribution of CKM noise in the total uncertainty, calculated as (). For the age-specific crude rates and , Equations (19a) and (19c), there is a simple analytic expression as a function of the crude input event count that illustrates the limit in which the CKM contribution becomes negligible:
This makes explicit that relative CKM noise effects for these rates are small and thus negligible except where the CKM variance parameter is of the same order of magnitude as the crude event count, that is, . However, since (e.g., ) by design in all practical scenarios, this implies a regime where the statistical fluctuations are large, too, since .
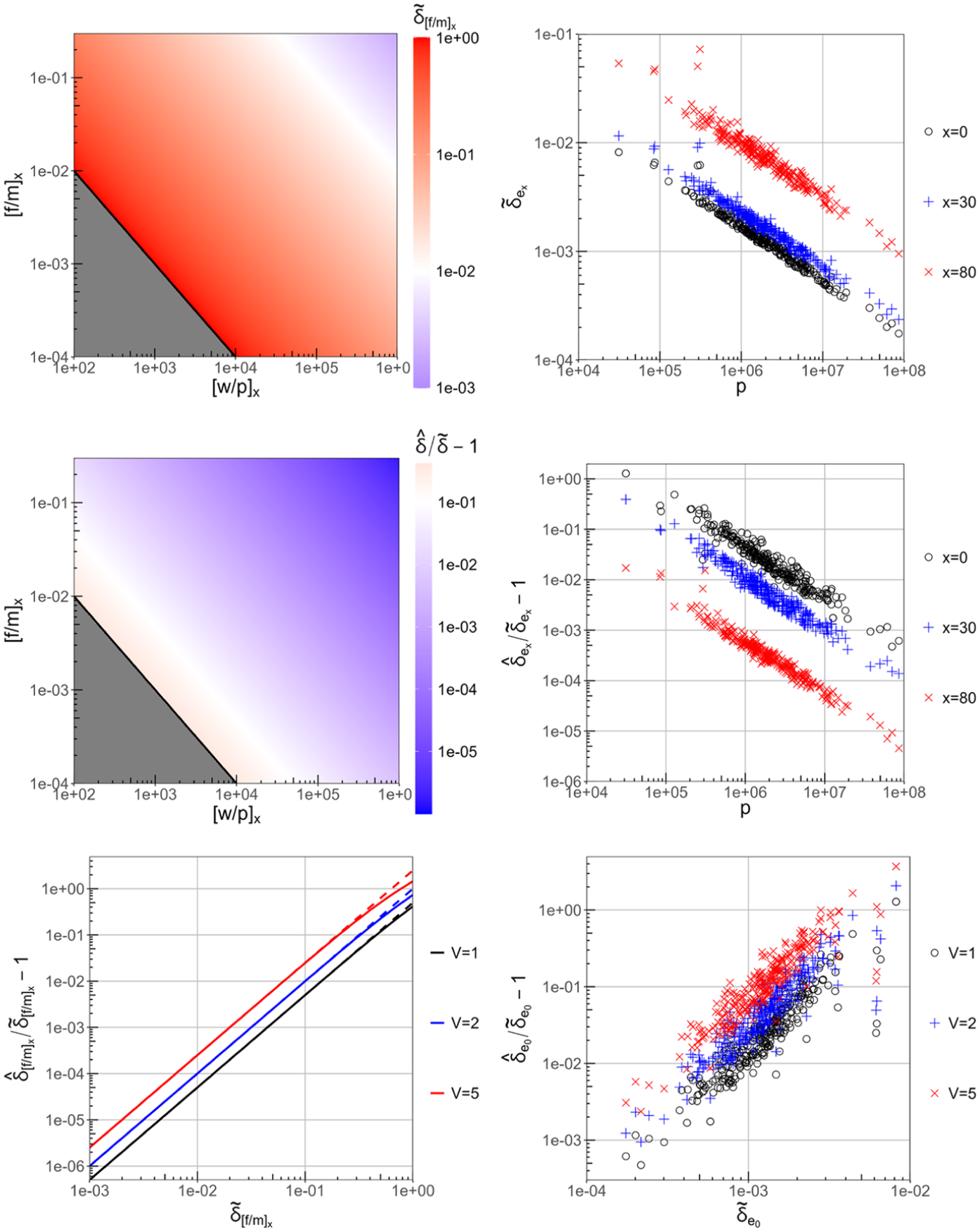
Figure 4 shows the comprehensive results for the age-specific fertility and mortality rates as well as for the life expectancies. These results illustrate several key insights:
in general, statistical fluctuations (assuming the Poisson model of Section 4) are an important source of uncertainty for all indicators considered here, with relative uncertainties and up to for life expectancies in the higher age bands for populations people, and up to for age-specific event rates with underlying crude event counts of ;
for the crude rates and , the relative contribution of CKM noise to the total uncertainty remains negligible—that is, —everywhere except in the extreme corners of the parameter space where the statistical fluctuations themselves become large, , confirming the approximation of Equation (20);
for the life expectancies , the relative contribution of CKM noise to the total uncertainty is generally larger than for the crude rates, with for populations people and corresponding relative statistical fluctuations ;
while increasing the CKM variance parameter within a realistic range has a notable effect on the relative CKM noise contribution to the total uncertainty , even the scenario does not generally lead to a situation where the CKM contribution becomes dominant for any indicator ( only for life expectancy at birth of the smallest NUTS 2 region Åland with a population of people).
Relative uncertainties from statistical fluctuations (top row) as well as relative contribution of CKM noise to the total uncertainty against population size with CKM variance (center row) and against statistical uncertainty for various values (bottom row), as analytic plots for simple age-specific fertility rates resp. crude mortality rates (left column) and as scatter plots showing the 2023 NUTS 2 data for age-specific life expectancies (right column). All results based on Equations (19a)–(19d) and (20) (the linear approximation of Equation (20) is shown dashed in the bottom–left plot).
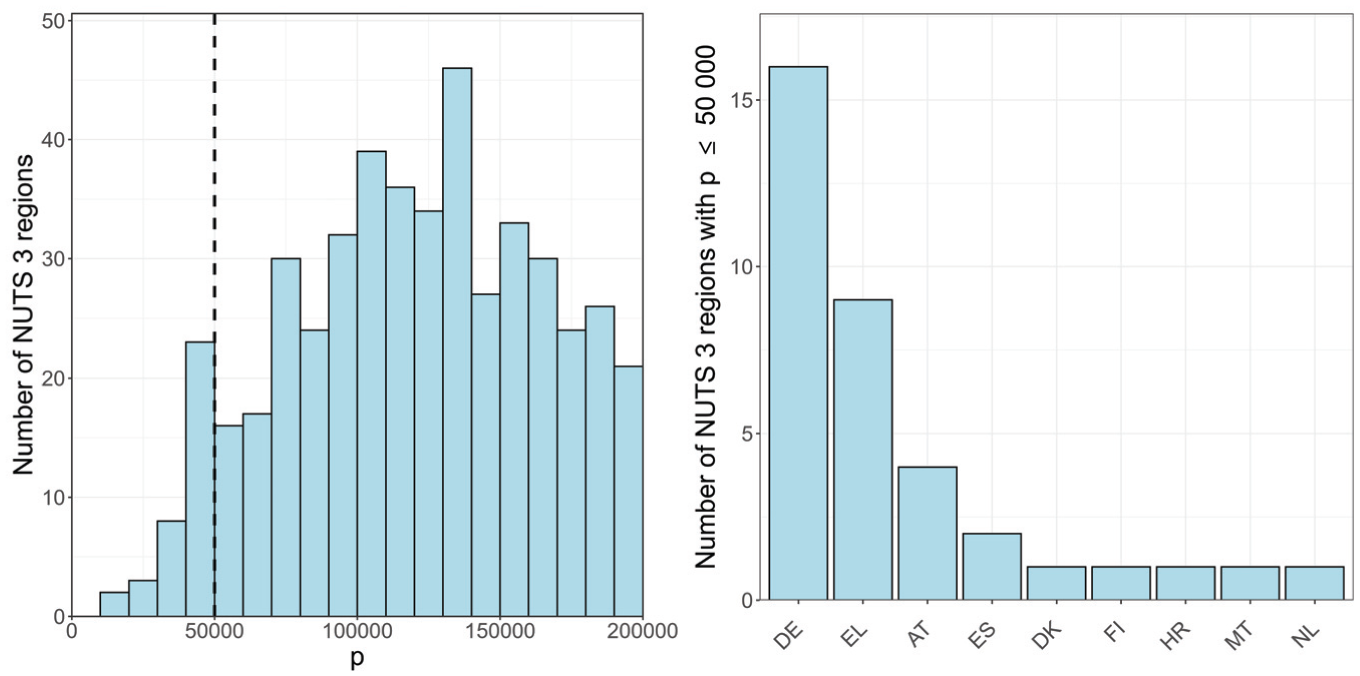
Even though the data sets analyzed here pertain to NUTS 2 level, these findings can be extrapolated to a NUTS 3 picture. This is due to the strong correlation of all uncertainties with population sizes that became explicit in the analysis above. The population sizes of the NUTS 2 regions in the ESS are distributed mainly between and people with a center around people, whereas the NUTS 3 regions mainly lie between and people with a center around people; see Figure 5. There are no NUTS 3 regions with a population people and in fact only five regions people. However, the regime of – people is covered by four NUTS 2 regions, and thus included in principle in the analysis above. This implies that the findings would hold in principle for NUTS 3 level indicators, too, including life expectancies—even though the age-specific indicators and underlying crude event counts considered here are currently not published at NUTS 3 level.
Distribution of the total population of NUTS 3 regions on 1 Jan 2023 in the range up to (left) and number of NUTS 3 regions with by EU country (right).
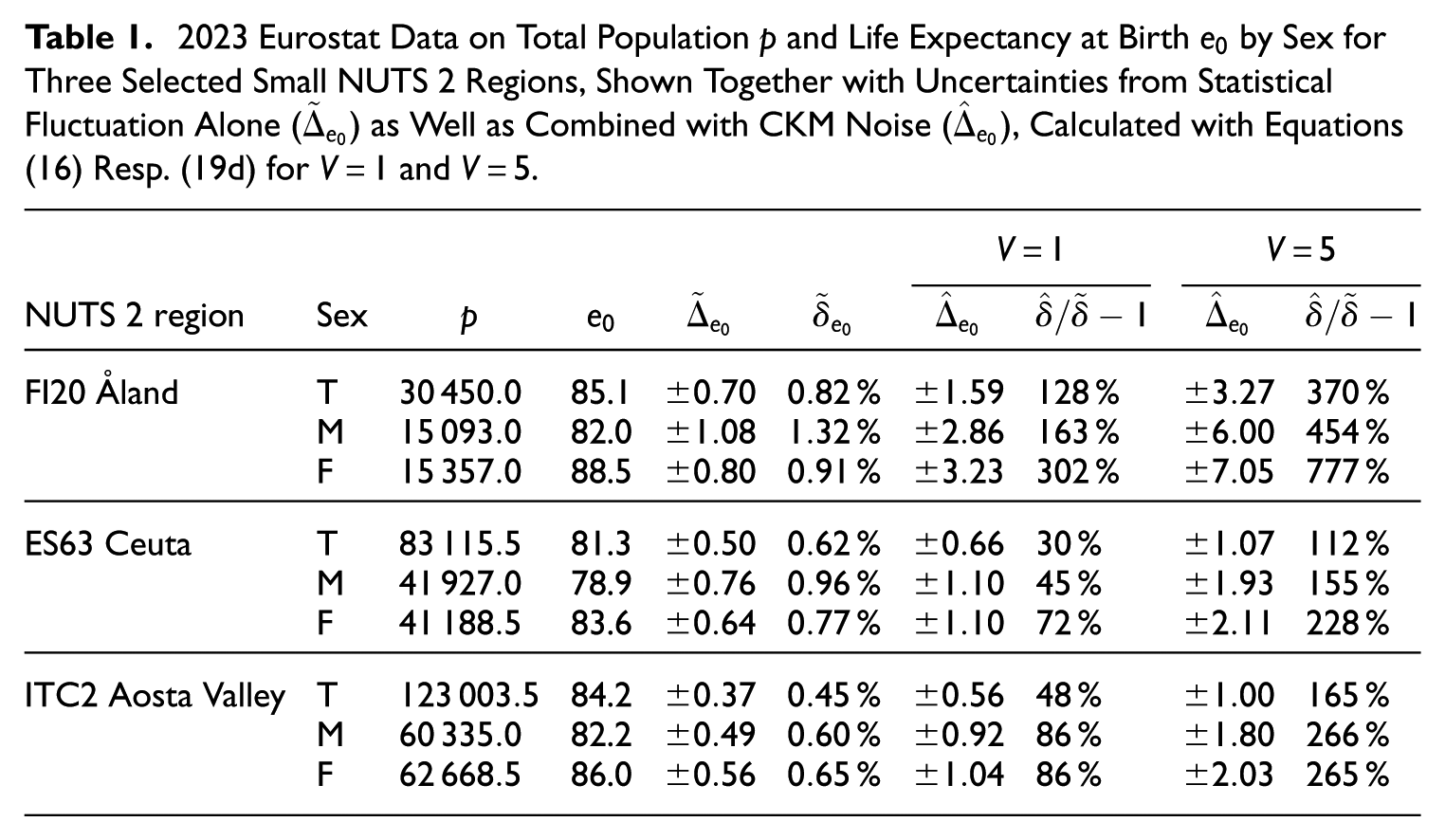
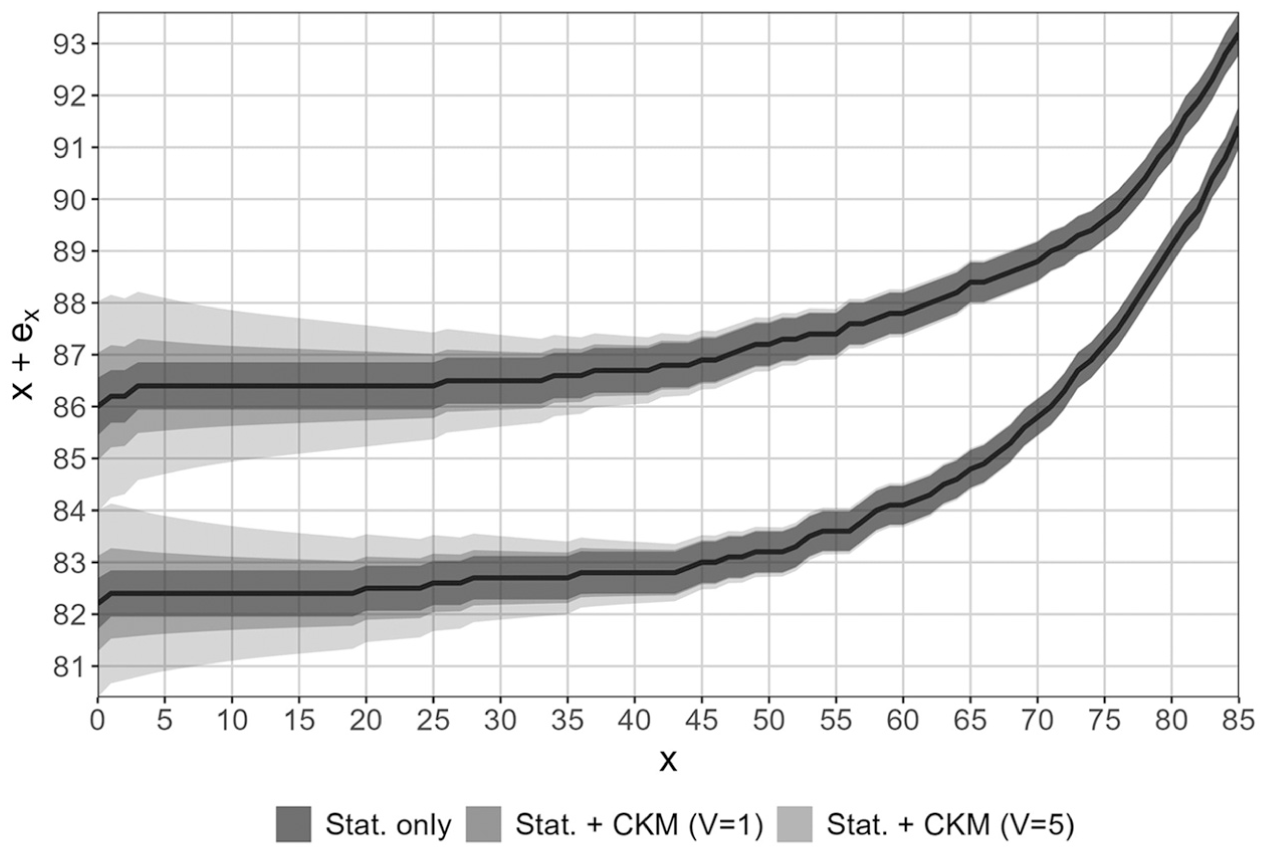
It therefore merits to have a closer look at those few NUTS 2 regions with total population people, as these may be seen as archetypal for NUTS 3 level results, where the previous analysis suggests to focus on life expectancy at birth . As detailed in Table 1, the noise contribution to the total uncertainty becomes relevant in this regime () even though statistical fluctuations remain very moderate (). This means that in this regime, is a statistically very accurate indicator which however receives notable additional uncertainty from noise protection of the underlying raw counts. This is also illustrated in Figure 6 showing the expected total years lived by sex including uncertainty bands for Aosta Valley (). The graph is instructive as it visualizes some insights on uncertainties as a function of the age cohort: effects from protection noise with fixed variance are most relevant at , that is, for life expectancy at birth , and declining gradually to become negligible compared to statistical fluctuations above ; in contrast, statistical fluctuations remain a relevant uncertainty source for all ages.
2023 Eurostat Data on Total Population and Life Expectancy at Birth by Sex for Three Selected Small NUTS 2 Regions, Shown Together with Uncertainties from Statistical Fluctuation Alone () as Well as Combined with CKM Noise (), Calculated with Equations (16) Resp. (19d) for and .
NUTS 2 region
Sex
FI20 Åland
T
85.1
M
82.0
F
88.5
ES63 Ceuta
T
81.3
M
78.9
F
83.6
ITC2 Aosta Valley
T
84.2
M
82.2
F
86.0
Expected total years lived for NUTS 2 region ITC2 (Aosta Valley) shown as a function of age for each sex (upper line females, lower males). The uncertainty bands show intrinsic statistical fluctuations only (dark gray) as well as total uncertainty including a CKM noise contribution with variance (medium gray) and (light gray).
At this point it must be stressed that some notable impact of noise protection on the resulting accuracy should be acceptable in principle. After all, this merely exemplifies the fundamental trade-off between security and quality that is inherent to all disclosure control methods. From this perspective, relative noise contributions up to are not worrisome per se, especially if the noise protection allows in return to publish all raw counts and indicators without suppression.
Nevertheless, Table 1 shows the situation for a rather optimistic noise variance value . In practice, somewhat larger values in the range should be more realistic. However, setting brings relative noise impacts to for all values in Table 1, and even to % to (depending on sex) for the smallest region Åland (cf. lower-right plot in Figure 4), so here the SDC noise arguably starts to dominate the total uncertainty. Again, this should not be a reason to exclude noise protection but rather to apply particular care in analyzing the effects in-depth and selecting an appropriate value as soon as population sizes people come into focus.
In summary, the crude fertility and mortality rate indicators analyzed here do not add relevant accuracy constraints on the choice of the noise variance parameter for protecting the input population stock and event count statistics, as long as the range considered remains reasonable (e.g., ) and noise effects are considered together with intrinsic uncertainties from statistical fluctuations. On the other hand, findings on life expectancies suggest that noise protection effects should be examined closely for any population groups below people, be it small NUTS 2 regions or other geographic units (e.g., NUTS 3, cities or functional urban areas), possibly split further by sex: Here the size of noise effects may exceed that of statistical fluctuations and statistical authorities may thus need to agree on certain accuracy thresholds that will then constrain their fine-tuning of . At this point it merits recalling that these findings are solely based on three basic properties of the protection noise, namely that it is sufficiently centered (bell-shaped underlying distribution), all noise terms are independent from each other and the noise variance is a fixed known value. The results are thus quite generic and hold for a whole class of noise protection methods with the mentioned properties, beyond the CKM used in this analysis.
6. Conclusions
This paper computes and analyzes the absolute and relative uncertainties on selected demographic indicators (age-specific fertility and mortality rates and life expectancies) when the raw input counts of births, deaths and population stocks are confidentiality protected by a generic noise method with fixed variance parameter . We obtain analytical expressions by applying uncertainty propagation based on linear response, as well as numerical results using demographic data published by Eurostat. To quantify the relative effect of noise protection, total uncertainties stemming from statistical fluctuations (according to a Poisson model) combined with additional noise uncertainties are compared to uncertainties only from statistical fluctuations.
The findings for combined relative uncertainties are that these become most pronounced in situations where the demographic indicator is dominated by very small raw input counts . This is the case for crude age-specific fertility rates, where relative uncertainties can thus increase up to for very small birth counts, and in particular for crude age-specific death rates, because small death counts are prevalent in many age bands. Vice versa, the relative uncertainties remain moderate () and are often even negligible () for more aggregated indicators like total fertility rates and age-specific life expectancies.
Regarding the relative impact of noise uncertainty, the analysis has shown that this remains negligible—that is, relative increase of total uncertainty compared to statistical fluctuation —for practically the entire relevant parameter space of all indicators analyzed. In general, noise effects become notable only in regimes where also the statistical fluctuations become large, even though the relative noise impact is bigger for life expectancies than for crude rates. While most results are calculated with , some additional variations with indicate that these conclusions generally hold for the whole range that is relevant in practice. However, for life expectancy at birth of small populations people with still small statistical fluctuations , the noise may start to dominate the combined uncertainty if rather large variances are chosen.
Finally, even though the relative uncertainties on all indicators correlate inversely with the population size, the present NUTS 2 level analysis includes in principle ranges people so that the results are expected to also hold at NUTS 3 level or for other territorial typologies with a larger share of units with to people (e.g., cities or functional urban areas). It was shown that particular care needs to be taken here when fixing the noise parameter appropriately to limit the impact on the total uncertainty of life expectancy at birth.
Footnotes
Appendix A
Acknowledgements
The author would like to thank Frank Espelage for draft reading and checking the analytical calculations. The author also thanks Sarah Gießing and Felix zur Nieden for very useful discussions on the topic.
Author Note
The views expressed are purely those of the author and may not in any circumstances be regarded as stating an official position of the European Commission.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
BachF.2021. “Differential Privacy and Noisy Confidentiality Concepts for European Population Statistics.” Journal of Survey Statistics and Methodology10 (3): 642–87. DOI: https://doi.org/10.1093/jssam/smab044.
De WolfP. P.EnderleT.KowarikA.MeindlB.2019b. “SDC Tools - User Support and Sources of Tools for Statistical Disclosure Control.”https://github.com/sdcTools (accessed September 26, 2025).
5.
EnderleT.GießingS.TentR.2018. “Designing Confidentiality on the Fly Methodology - Three Aspects.” In Privacy in Statistical Databases - UNESCO Chair in Data Privacy, International Conference, PSD 2018, Valencia, Spain, September 26-28, 2018, Proceedings, Lecture Notes in Computer Science, Volume 11126, edited by Domingo-FerrerJ.MontesF.Springer.
FraserB.WootonJ.2005. “A Proposed Method for Confidentialising Tabular Output to Protect Against Differencing.” Monographs of Official Statistics: Work Session on Statistical Data Confidentiality, Geneva, November9–11.
11.
FrendJ.AbrahamsC.ForbesA., et al. 2012. “Statistical Disclosure Control in the 2011 UK Census: Swapping Certainty for Safety.”ESSnet Workshop on Statistical Disclosure Control (SDC) of Census Data, Luxembourg.
12.
GießingS.2016. “Computational Issues in the Design of Transition Probabilities and Disclosure Risk Estimation for Additive Noise.” In Privacy in Statistical Databases - UNESCO Chair in Data Privacy, International Conference, PSD 2016, Dubrovnik, Croatia, September 14-16, 2016, Proceedings, Lecture Notes in Computer Science, Volume 9867, edited by Domingo-FerrerJ.Pejic-BachM.Springer.
13.
HauerM. E.Santos-LozadaA. R.2021. “Differential Privacy in the 2020 Census Will Distort COVID-19 Rates.” Socius7: 2378023121994014. DOI: https://doi.org/10.1177/2378023121994014.
14.
MarleyJ. K.LeaverV. L.2011. “A Method for Confidentialising User-Defined Tables: Statistical Properties and a Risk-Utility Analysis.”International Statistical Institution: Proceedings of the 58th World Statistical Congress (Session IPS060), Dublin.
15.
MorrisonF. A.2021. Uncertainty Analysis for Engineers and Scientists: A Practical Guide. Cambridge University Press.
16.
PetersF.MilewskiN.DoblhammerG.2009. “‘Geburtenmonitor’— Estimating Birth Rates in Germany on the Basis of Monthly Data.” Discussion Paper No. 27 of the Rostock Center for the Study of Demographic Change.
17.
Santos-LozadaA. R.HowardJ. T.VerderyA. M.2020. “How Differential Privacy Will Affect Our Understanding of Health Disparities in the United States.” Proceedings of the National Academy of Sciences of the United States of America117 (24): 13405–12. DOI: https://doi.org/10.1073/pnas.2003714117.
18.
Schulte NordholtE.GolmajerM.de VriesM., et al. 2024. Guidelines for Statistical Disclosure Control Methods for Census and Demographics Data. Publications Office of the European Union.
19.
ScottW. F.1981. “Some Applications of the Poisson Distribution in Mortality Studies.” Transactions of the Faculty of Actuaries38: 255–63. http://www.jstor.org/stable/41218760.
20.
ThompsonG.BroadfootS.ElazarD.2013. “Methodology for the Automatic Confidentialisation of Statistical Outputs from Remote Servers at the Australian Bureau of Statistics.”Joint UNECE/Eurostat Work Session on Statistical Data Confidentiality, Ottawa, ON, Canada, October 28–30.