
Abstract
In this note, we present a plausible structural mechanism by which over-parameterized deep learning models trained on real data may produce pseudo-synthetic data that constitute merely a different representation (or re-encoding) of the training data. We conjecture that, in principle, similar mechanisms may be learned by large-scale AI models even if they are not intentionally designed to do so. From there, we derive some cautionary warnings for potential adopters of pseudo-synthetic data generation tools based on deep learning. We claim that the burden of proof that no data re-encoding mechanism is at play in AI-based generation models rests with their proponents.
1. Context and Motivations
The outstanding success of Artificial Intelligence (AI) based on deep learning in numerous business fields is changing the perception by the society of the value as well as of the risks associated with personal data. Like oil releases energy but also pollution when fueling combustion engines, data creates new value but also new risks when fueling modern AI engines. The availability of more capable and powerful AI technology increases the appetite for granular data, hence the pressure on those who hold the data to make them available to those that own the AI engines. But sharing and releasing granular data referred to natural persons, that is, personal data, comes with privacy risks and must comply with data protection legislation. The combined effect of increasing appetite for granular data by the business and increasing attention to privacy by the general public drives the quest for solutions that, like pollution-free combustion, promise to enable risk-free sharing of granular data with the same general utility as the source data. One approach actively investigated by different research communities, and already offered commercially by several start-up companies, relies on the generation of so-called “synthetic data” by means of large deep learning models trained on real data.
Generally speaking, the term “synthetic data” is used to refer to collections of data records created artificially that should ideally resemble the original data collectively but not individually. In other words, synthetic data should (i) yield the same population-level features of real data, for example, same statistics and joint distributions (population-level similarity) while at the same time (ii) not representing or allowing to derive information about real-world data units (unit-level dissimilarity). The utility of the synthetic data depends on which population-level features (statistics) are retained from the original data: if the analysis task is known in advance, one may engineer the synthesis process to retain exactly the features and statistics of interest—but in this case one may wonder with Domingo-Ferrer et al. (2025) why not just publishing the relevant statistics instead of a synthetic data set. When the analysis task is not known in advance, as is the case with public dissemination, the synthetic data generation process would aim at retaining as much as possible of the population-level features without revealing unit-level information. Underlying this approach is the assumption that population-level features are generally separable from, and not disclosive of, unit-level information—an assumption whose validity ultimately depends on the exact definition of population-level features.
The notion that synthetic data may serve as a means for data dissemination is not new to the official statistics community: over at least four decades researchers and practitioners in the Statistical Disclosure Control (SDC) field have developed a variety of synthetic data generation (or synthesis) methods with different trade-offs between data utility and disclosure risk, see for example, Calvino (2017), Hundepool et al. (2012), Drechsler and Haensch (2024), Domingo-Ferrer et al. (2024), and references therein. These traditional methods consist of sequences of operations designed step by step by human experts based on an explicit understanding of what population-level features to retain and what unit-level information to remove. Some of these approaches make use of “classical” Machine Learning (ML) tools, for example, for ML-based imputation (see Hundepool et al. 2012) but that does not change the essentially human-designed nature of the synthesis mechanism.
Compared to such earlier proposals, the advent of deep learning does not represent an incremental evolution but rather a leap into a new paradigm. Central to our discussion is the distinction between under-parameterized and over-parameterized ML models as separate regimes with different properties, as pointed out for example, by Belkin et al. (2019), Theodoridis (2020), and Rocks and Mehta (2022). Classical ML models are typically under-parameterized: they do not have sufficient capacity (i.e., not enough model parameters) to fit precisely all the training data points. Actually, ML models in the under-parameterized regime are designed purposely to avoid fitting the data too closely, since in this case the prediction performances (generalization power) degrade—a condition called overfitting. Differently from classical ML, modern deep learning networks are often over-parameterized: they do have sufficient capacity to memorize all the training data points and they typically tend to do so, since in the over-parameterized regime achieving good prediction performances on test data is not in contradiction with fitting precisely the training data.
The recent advent of deep learning has impacted research on synthetic data in multiple ways. First, it has extended the appeal of “synthetic data” to applications beyond the field of official statistics dissemination, that is the elective domain of the SDC research community, toward virtually the whole spectrum of data-intensive business sectors, from health to finance, from manufacturing to retail marketing. Second, it has attracted to the problem researchers from other scientific fields, with different backgrounds and mindsets from SDC experts. Third, it has fueled the expectation among potential adopters that synthetic data generation based on large-scale deep learning models is intrinsically superior to traditional schemes based on human design and classic small-scale ML tools.
The SDC community is very well aware that when synthetic data are derived from real data there is an unavoidable trade-off between privacy risk and utility of the resulting data set, and that these two aspects must be balanced against each other. They would therefore audit carefully every step of the data synthesis method and strive to assess, or at least make an educated judgment about the residual level of disclosure risk. They would never consider such assessment to be unnecessary on the basis of the resulting data being labeled as “synthetic.” Instead, the general hype around AI seems to be creating a misguided perception across various business sectors that AI-based synthetic data do not move along the same risk-versus-utility trade-off frontier as the traditional approaches, but rather leap over it and magically resolve the conflict between utility and privacy risk altogether, mystically delivering almost full utility at essentially zero privacy risk. This is, at least, how the narrative goes in certain commercial blogs and business articles, and occasionally also in some research articles, for example, Ammara et al. (2024).
Previous research papers have started to expose the fundamental fallacy of this view, both formally and empirically, see in particular Stadler and Troncoso (2022), Stadler et al. (2022, 2024), and references therein, while others have highlighted the opacity of such approach in the sense of not permitting a clear assessment of the actual level of risk and utility, see for example, Jordon et al. (2022). In line with such previous work, we provide here an additional contribution from a different angle, reinforcing previous efforts to demystify and dispute the claim that synthetic data based on deep learning are intrinsically always risk-free. With this work we contribute to raise awareness among potential adopters and caution statistical offices about the non-zero risks of synthetic data generation based on deep learning. Performing a careful risk assessment is absolutely necessary also with over-parameterized models but much more challenging than for traditional methods, if at all possible, given the lack of interpretability.
1.1. Organization of the Paper
One major source of confusion is the overload of the term synthetic data to refer to a range of fundamentally different paradigms. Therefore, we start by proposing in Section 2 a taxonomy and a differentiated terminology to distinguish the different synthetic data paradigms. We propose to adopt the term “pseudo-synthetic data” to refer to data produced by over-parameterized deep learning models. In Section 3 we introduce the notion of “privacy-deceptive coding” to refer to synthesis mechanisms that conceal rather than remove personal information, and present a simple example based on polynomial interpolation. In Section 4 we show how the pseudo-synthetic data produced in this way are exposed to reveal unit-level information about the source data through membership inference and attribute discovery attacks, that we interpret as partial decoding of the source data. In Section 5 we elaborate on the possibility and plausibility that large-scale over-parameterized models may in principle end up learning some data transformation mechanisms that is akin to a privacy-deceptive coding scheme. From there, we claim in Section 6 that pseudo-synthetic data based on deep learning from personal data cannot and should not be cleared as anonymous or anonymized data unless a formal proof is given that the model has not learned any such structural mechanism, the burden of the proof resting with their proponents. Lacking such a proof, pseudo-synthetic data should be considered as potentially embedding personal data, and therefore fall entirely within the scope of data protection legislation, that is, GDPR in the European Union. That implies that sharing pseudo-synthetic data, like sharing of pseudonymized or encrypted personal data, should be subject to preliminary assessment of risk and lawfulness conditions. Finally, in Section 7 we conclude and identify directions for further work.
2. Data Generation Paradigms: Synthetic, Semi-Synthetic, and Pseudo-Synthetic
In several scientific and technology fields it is customary to generate synthetic data serving the purpose of testing the performance of some system, real or simulated, under configurable conditions. In the most genuinely synthetic scenario, depicted in Figure 1a, both the logic
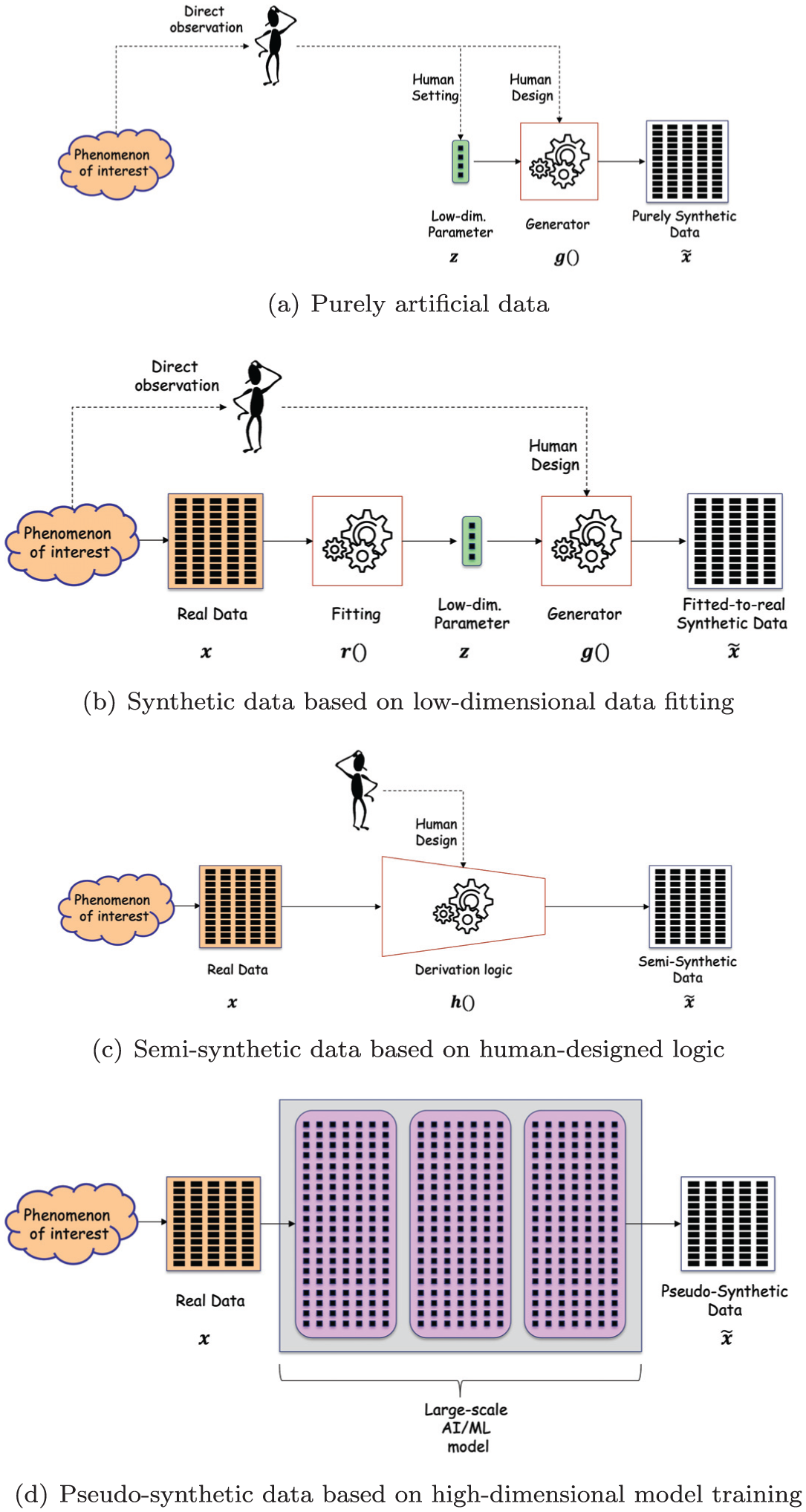
Taxonomy of synthetic data generation paradigms: (a) purely artificial data, (b) synthetic data based on low-dimensional data fitting, (c) semi-synthetic data based on human-designed logic and (d) pseudo-synthetic data based on high-dimensional model training.
In a slightly more sophisticated scenario, depicted in Figure 1b, a set of real data
We claim that the dimensionality of the parameter space
Low-dimensional regime where
High-dimensional regime, for which
Such distinction follows recent developments in deep learning theory (see e.g., Belkin et al. 2018, 2019; Rocks and Mehta 2022; Theodoridis 2020) showing that the under-parameterized and over-parameterized regimes display different characteristics and structural mechanisms, and therefore should be treated separately.
Figure 1b refers to the low-dimensional case where the data generator
For the sake of completeness we mention that, in addition to the risk of conducing personal information from
A third possible scenario is depicted in Figure 1c, where the data
In the scenario depicted in Figure 1c the derivation function
More recently, following the outstanding success of deep learning in other application fields, a new computationally-intensive high-dimensional paradigm has emerged alongside the traditional design-based low-dimensional one. In this new paradigm, graphically sketched in Figure 1d, the generation of
The new paradigm of Figure 1d may be seen as evolved from the low-dimensional data fitting approach of Figure 1b, where (i) the designed-by-human functions
Recalling the distinction between the low-dimensional and high-dimensional regimes, we may consider the case of Figure 1b as the projection of data
In the light of the above, we argue that using the term synthetic to qualify
We do not intend to postulate that pseudo-synthetic data generated by over-parameterized models always and necessarily embeds unit-level information from the training data: we rather dispute that they cannot do so. In other words, we claim that pseudo-synthetic data may bear some non-zero privacy risk, and therefore should be subject to a careful risk assessment that, however, cannot be reduced to merely checking that the constellation of new data points is dissimilar from the original one. In fact, as we show in the following, it is entirely possible to construct a new set of pseudo-synthetic data that appear completely different from the original data points from which they are derived but still contain the whole unit-level information thereof.
3. Privacy-Deceptive Coding
Borrowing terminology from Information Theory, and particularly from Coding Theory, we use the term coding to refer to the way information (or data) is represented. We shall use the term “encoder” to refer to any system that, taking as input the source data set
The problem of exfiltrating personal information may be regarded as a particular type of channel coding problem where the source message
3.1. Definitions
Let us consider a generic process (procedure, algorithm) taking as input a set of records
With reference to the system
In order to certify that the new data set
In other words, we are asking whether it is possible to reduce anonymity to a matter of dissimilarity between the input and the output of the anonymization process. In agreement with Jordon et al. (2022) we argue that the answer to the above question should be negative, and that detailed knowledge of the process
3.2. An Example Based on Functional Interpolation
Let us consider a tabular data set
Let us divide the records into
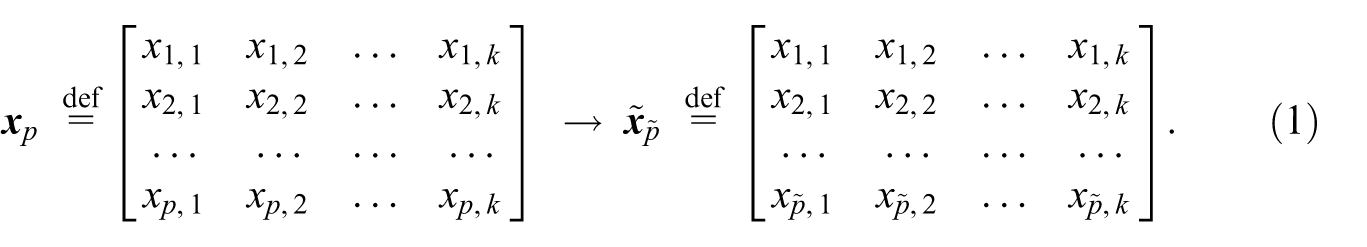
The basic idea, illustrated in Figure 2, is to interpolate the group of
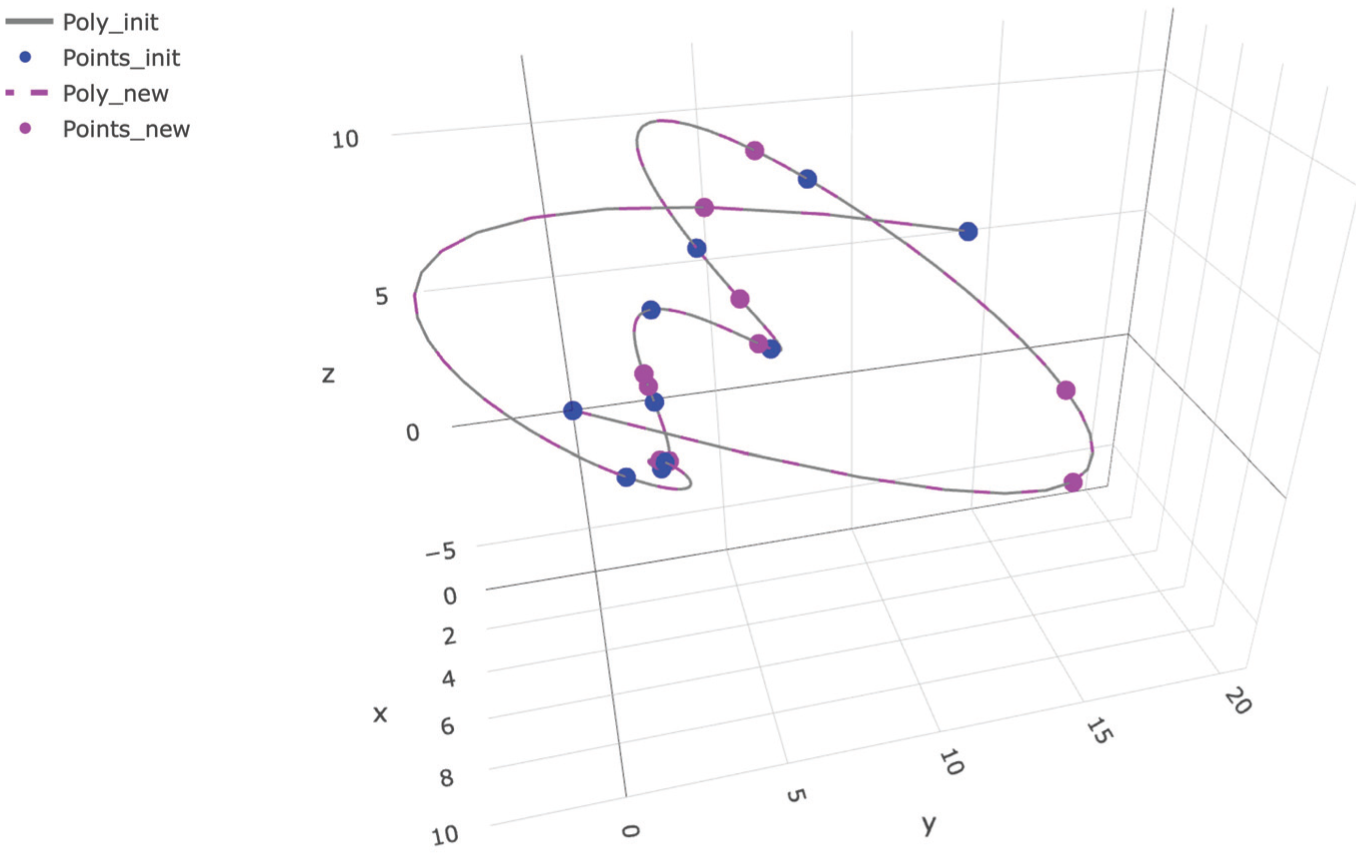
Example of interpolating polynomial curve in three-dimensional space (
A parametric curve in the

wherein the
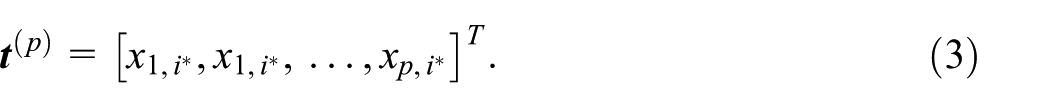
In other words, we are picking the reference dimension
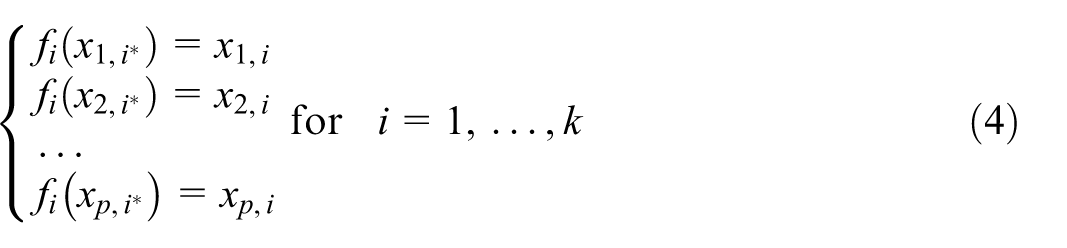
from where the
By stacking the interpolating functions for all variables
We remark that polynomials of degree
In general, given the parametric family

From the interpolating curve, the new points are generated by selecting a new set of

In other words, the generating points
Since the function interpolating the reference variable
The new data set

As the identified curve
In selecting randomly the new points along the curve, the generator may be configured to censor those candidate new points that lie too close to the original points, by whatever distance measure of choice, and to replace the censored points with other randomly selected candidates. In this way, the level of dissimilarity between the new and original data sets can be increased without impairing the possibility for an attacker to recover the interpolating curve.
A graphic example in 3-dimensional space (
3.3. Variants
The basic interpolation scheme presented above may be varied in different ways to build privacy-deceptive coding schemes with additional desirable properties (desirable for the deceiver). In the approach presented above, the original records were divided by the value of their attribute variables into
Another variant of privacy-deceptive encoding goes without grouping and therefore does away with high-degree polynomials. In this variant, each single data point in the original dataset is interpolated separately from the others. Assuming the predictor variables are bounded, and their infimum and supremum values are known (e.g., from metadata) we set two virtual “anchor points”
Taking inspiration from the basic mechanisms presented above, one could conceive dozens of similar schemes and variants thereof, more or less sophisticated. In all cases, the encoding process goes by the following steps:
Identify ordered groups of records in the original data set sharing the same attribute value. As particular cases, we have considered groups consisting of all records sharing the same attribute value in the first variant, and groups consisting of single records (singletons) in the second variant;
For each group of
For each group, find the unique function
For each group, sample the interpolating curve
The criterion by which the new points are selected along the interpolating curve (or equivalently by which the curve is sampled) may be further sophisticated in order to improve the deceptive power of the overall scheme by increasing the dissimilarity between the new and original data. As anticipated above, the generator may apply censorship, that is, discard and resample the points that incidentally fall too close to the original points, by whatever measure of distance in the
As explained above, the possibility for the attacker to recover back the interpolating curve does not depend on the criterion adopted to sample it as long as the number of sampled points equals or exceed the number of original points. This condition is often met in practical applications where pseudo-synthetic data are seen as a tool to “expand” real data sets of limited size (see e.g., Sivakumar et al. 2023).
Once that the interpolating curves are recovered for all the groups in the data set, the attacker can readily infer membership and discover attribute values, as explained later in Section 4. In other words, as long as the new data are sampled from the interpolating curve, censorship or any other stratagem adopted in the data generation phase to ensure target level of data dissimilarity is inconsequential for prospective attackers and does not reduce the actual level of unit-level information carried into (and recoverable from) the pseudo-synthetic data.
For the sake of completeness we now elaborate on how the basic scheme presented above may be further sophisticated to go beyond enabling membership inference and attribute discovery attacks, and allow potential attackers to reconstruct the whole data set, that is, enable full database reconstruction. To achieve this malicious goal it suffices to replace random sampling with deterministic selection in the final generation stage, that is, to generate the new points in the auxiliary variable
4. Recovering Source Information from Pseudo-Synthetic Data
At the receiving end of the new data set
4.1. Privacy Attacks as Decoding
Before proceeding further, we present how the three main types of privacy attacks may be conducted by a potential attacker when the pseudo-synthetic data were encoded with the interpolation mechanism presented in Section 3.
4.1.1. Membership Inference
Given a predictor vector, that is, a test point in the
4.1.2. Attribute Discovery
Given a predictor vector that is known by the attacker to be present in the source data set, that is, a test point in the
4.1.3. Full Database Reconstruction
The two attacks above may be considered as partial recovery of information about the original data from the new data: for a known value of the predictor vector, the attacker discovers the sensitive attribute value and/or infers membership in the source data set. We have already seen that with some additional sophistication of the encoding process, that is, replacing the random selection with a deterministic selection of the new points along the interpolating curves at the time of creating the pseudo-synthetic data, it is possible in principle to enable the complete recovery of the original group of data points, that is, a full database reconstruction attack.
Having clarified these three attacks, and recalling the generative scheme presented in the previous section, we distinguish two general scenarios:
Partial decoding. For each group of data, the new points are generated randomly along the interpolating curve for that group. From the new data
Full decoding. The new points are generated along the interpolating curve based on a deterministic reversible mapping
Full database reconstruction (full decoding) is unlikely to occur in practical settings, unless the pseudo-synthetic data generation is designed purposely to be deceptive, that is, the attacker has control over the data encoding process and uses the pseudo-synthetic data to exfiltrate covertly the original data. We have chosen to present this scenario for the sake of completeness and as a warning against possible scams, but it is not our main focus here. Instead, we argue that the partial decoding scenario may plausibly occur even in benign practical settings, where the attacker is only at the receiving end of the pseudo-synthetic data and has no influence over the encoding process.
4.2. Decoding with and without Auxiliary Information
In presenting the privacy-deceptive coding scheme in the previous section we have assumed that the attacker has some auxiliary knowledge about the encoding process, that in the case of attribute discovery and membership inference attacks (partial decoding) reduces to knowledge of the function family
First, if the pseudo-synthetic data set is disseminated publicly, then the protection of personal information in the source data rests on the secrecy of such auxiliary information. The risk assessment therefore must take into account how well the auxiliary information can be protected, that is, how difficult is for potential attackers to retrieve, discover, or simply guess it. Additional caution should be paid to commercial deployments where the same company offers paired tools for generation (encoding) and analysis (decoding) of pseudo-synthetic data that are developed jointly, as the auxiliary information may be inadvertently passed from the generation to the analysis tool even in absence of malicious intent, due to coupled development. Seen in these terms, privacy attacks against pseudo-synthetic data are analogous to cryptanalysis of ciphertext encrypted with an undisclosed algorithm—the historic failure of security by obscurity should serve as a warning here.
Second, while knowledge of
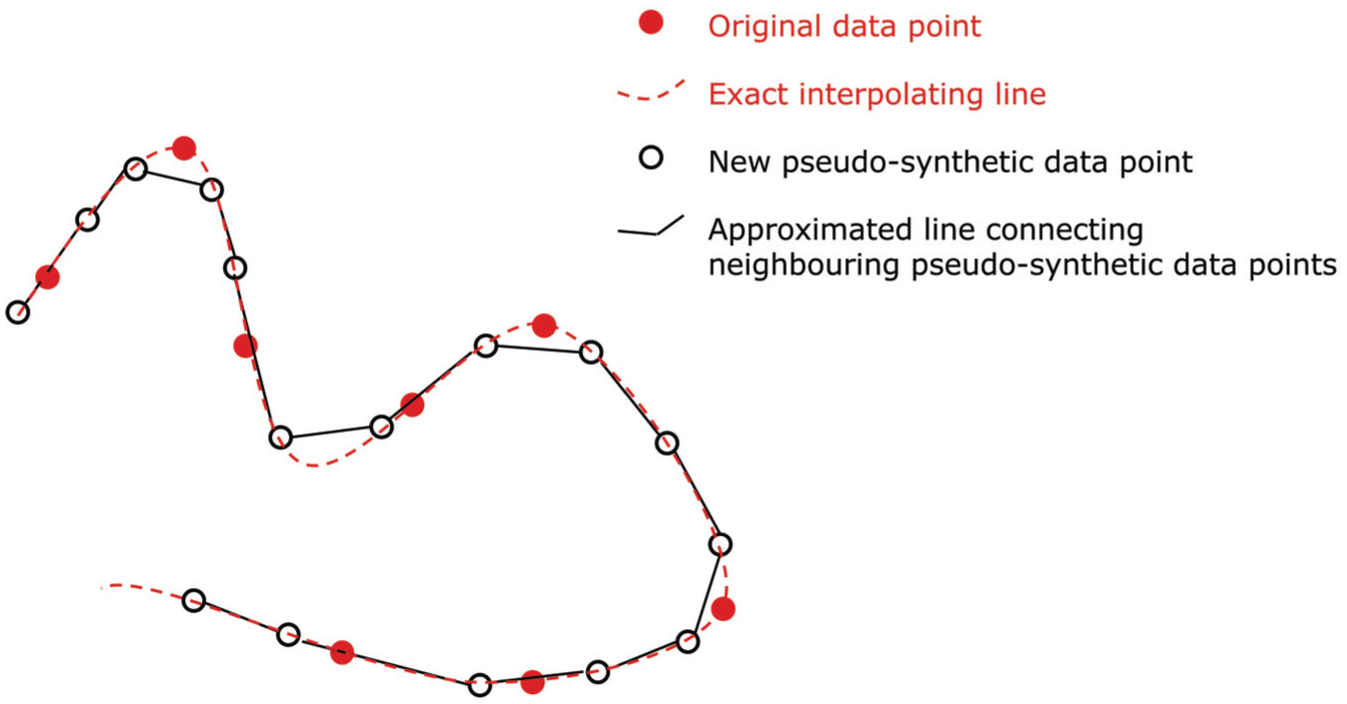
Example of approximate recovery of the interpolation curve. The piece-wise approximation (continuous) is obtained by connecting each pseudo-synthetic point to its closest neighbor through a straight line. In the example it follows closely the smooth interpolating curve (dashed).
The error rates in membership inference and attribute discovery attacks resulting from the approximated curve
5. Learning Privacy-Deceptive Coding Schemes
In the previous section we have hinted at some examples of human-designed privacy-deceptive coding schemes based on a simple and general structural mechanism, namely functional interpolation. We have shown how an attacker with access to the pseudo-synthetic data set built in this way may infer unit-level information about the source data. In this section we elaborate on the possibility for a large-scale AI model to learn some kind of privacy-deceptive coding and (partial) decoding mechanisms that are functionally similar to those that we have presented insofar.
5.1. Interpretation: Interpolating Curve as Latent Space
It is useful at this stage to establish a bridge between the interpolation examples from Section 3 and the terminology in use in AI/ML. The
The subspace learned from the source data in the generation stage (encoding) can be re-learned, at least approximately, from the new data.
The size of the subspace is much smaller than the whole domain space.
These conditions, referred to an arbitrary subspace learned by the AI model, generalize the conditions that enable membership inference and attribute discovery attacks to be conducted based on the knowledge of the interpolating line that, as said above, may be seen as a special case of subspace.
The plausibility of the first condition rests on the fact that both the new and the original data points lie by construction in the same latent subspace or low-dimensional manifold. The second condition is based on the consideration that the decoding success rate, that is, the probability of inferring correctly membership or attribute value for a test data point relative to a random guess, is directly connected to the size of the subspace embedding the data points relative to the total volume of the
5.2. Learning Intentionally Versus Learning Unintentionally
In Figure 4 we show two possible high-level schema of AI settings. We assume the AI models are over-parameterized but do not make any assumption on their specific architecture. A recent survey by Lu et al. (2024) shows that Variational Auto-Encoders (VAE) and Generative Adversarial Networks (GAN) are among the most popular architectures in this field, but our discussion at this early stage is abstract and addresses any over-parameterized network independently from their architecture.
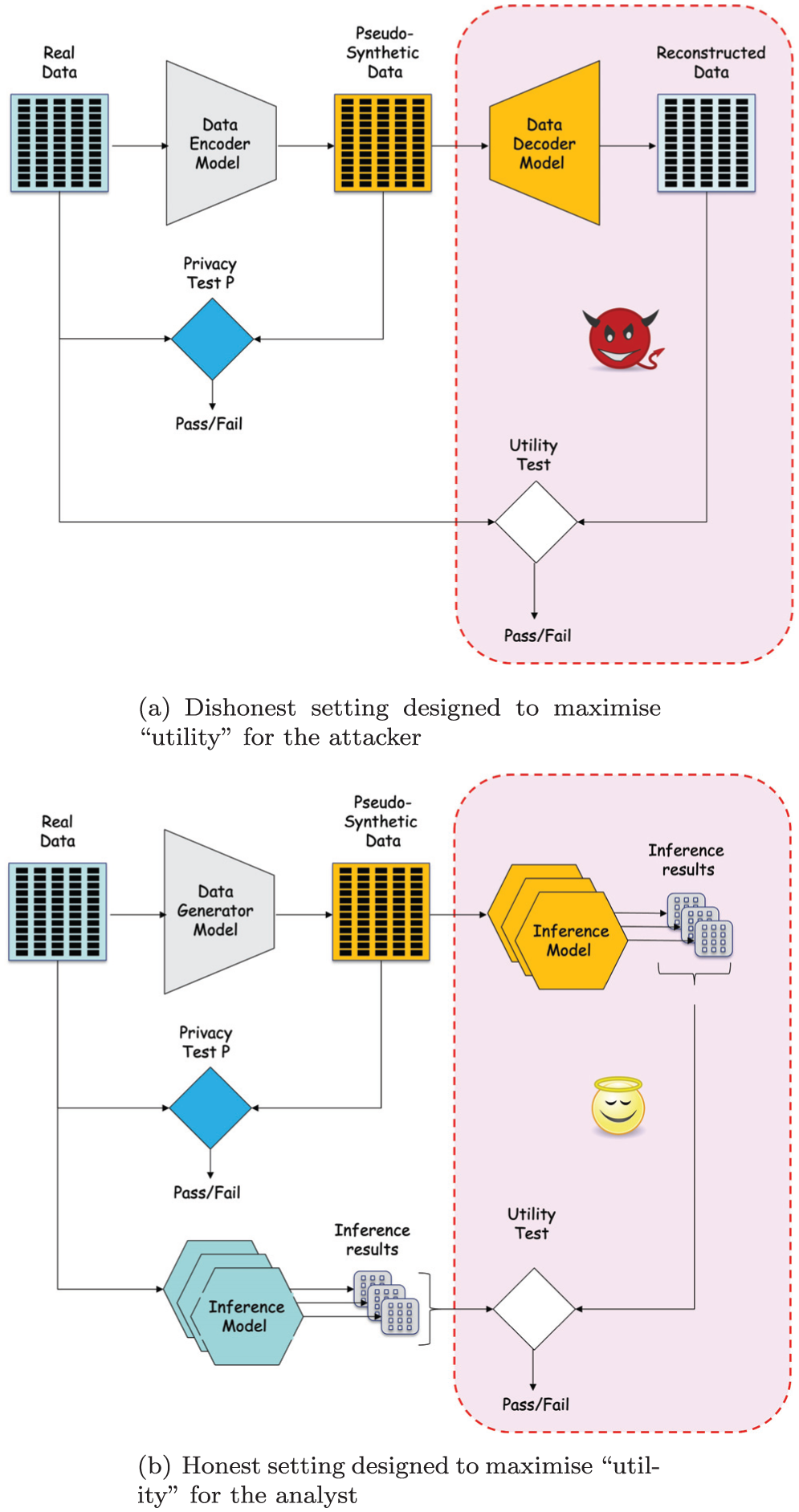
Examples of architectures for data generation aimed at maximizing utility while passing the privacy test. The training signals are derived from the scores in the privacy and utility tests. The utility test for the honest setting may be considered as a relaxation of the utility test in the dishonest setting: (a) dishonest setting designed to maximize utility for the attacker and (b) honest setting designed to maximize utility for the analyst.
Figure 4a shows a dishonest system, designed intentionally to learn some privacy-deceptive coding mechanism. Here the encoder and decoder modules refer to distinct but coupled networks that are trained jointly on the same signals, and may possibly share some layers. Their joint goal is to produce a reversible encoding mechanism that produces encoded pseudo-synthetic data that pass the dissimilarity test
It is clear that only a dishonest actor would be motivated to implement deliberately the architecture of Figure 4a. The only conceivable practical use of such system, beyond legitimate experimental research, would be to setup a personal data exfiltration scam. The encoder module trained in this way would be presented as a genuine synthetic data generator to the data holder. If the only condition to certify the non-personal nature of the data relied on the dissimilarity test
We now move from the dishonest to the honest scenario, where the analyst does not pursue explicitly the reconstruction of the original data from the pseudo-synthetic data, but rather aims to preserve their utility for a rack of legitimate analysis tasks. Toward this aim, the honest analyst may adopt the architecture of Figure 4b. In the new scheme, the utility of the pseudo-synthetic data is expressed in terms of their ability to drive a large-scale AI model trained on such data to deliver correct inference results, ideally the very same results that would be obtained by training the model directly on the real data. This implies that the pseudo-synthetic data retains all the population-level properties from the original data that are relevant across all tested analysis task.
The utility goal expressed in this way, from the perspective of the honest analyst, may be considered as a relaxation of the utility goal for the dishonest analyst in Figure 4a, that is, data reconstruction. In fact, the ability to retain the whole unit-level information from the data, or equivalently learning the data, is sufficient to retain any conceivable population-level pattern that may be learned from the data.
In principle, we cannot completely exclude a priori that the honest architecture ends-up learning into the encoder module some kind of data mapping mechanism similar to the privacy-deceptive coding scheme learned by the dishonest architecture. The risk increases with the number of legitimate tasks considered in the honest setting, as each additional task implies that more information from the source data is retained into the new data set, increasing the probability that the generator end up retaining all information (in some hidden form due to forced compliance with the privacy test). If so happens, an attacker that has access to the pseudo-synthetic data generated with the honest architecture may therefore succeed to elicit personal information about the source data.
5.3. Relation to Recent Experimental Work
We do not intend to postulate here that learning such a privacy-deceptive scheme is necessarily the only possible outcome of honest learning. However, we conjecture that this is a possible and plausible outcome that cannot be excluded a priori. Some recent experimental work by different authors provide empirical support for this claim and serve as early warnings. In an experimental setting similar to the honest analyst scenario described above, Slokom et al. (2022) report that “The ML model trained on the synthetic data […] was found to leak in the same way or slightly less than the original classifier.”Annamalai et al. (2024)find that the value of a sensitive attribute associated with a real record in the original data set can be inferred back from a set of synthetic data that do not appear to contain that specific record (but obviously “encode” such information in some way). More recently, Yao et al. (2025)find that membership inference attacks against synthetic data are successful even if they appear markedly dissimilar from the original data, and conclude that the distance to closest record and other analogous measures of dissimilarity are “uninformative of actual membership inference risk.”
While these empirical studies do not provide a conclusive proof, they represent early warnings that the possibility of pseudo-synthetic data representing the outcome of some kind of privacy-deceptive coding scheme, implicitly learned by the AI model, cannot be dismissed. Our work is complementary to these parallel experimental work in that the privacy-deceptive coding scheme presented above provide hints about the kind of underlying structural mechanism that may possibly explain those empirical findings.
5.4. A Note on Differential Privacy
In some sense, previous proposals of synthetic data generation that combine deep learning with Differential Privacy (DP), for example, McKay Bowen and Liu (2020), represent an implicit admission that deep learning without DP cannot be assumed to produce risk-free data. However, DP has its own limitations, and the formal guarantees that hold on paper under strict conditions are often lost in practical system implementations and application scenarios that do not fully meet those conditions, see for example, the discussion in Domingo-Ferrer et al. (2025), Seeman and Susser (2024), and Stadler et al. (2022). Even when the DP methodology, parameters, and source code are made public, practical DP deployments are often effectively opaque in the sense that assessing (empirically) the actual level of risk and utility remains an extremely hard task. Similarly, large-scale deep learning models are opaque in the sense that interpreting what they have actually learned from the training data, and transferred into the new generated data, remains an extremely hard task even when their architecture, source code, and weights are made public. Overlaying one opaque approach on top of the other should be seen as a way to increase, not reduce the opacity of the overall system. Rather than heuristically piling up one hyped but problematic approach over the other, we believe it would be epistemically cleaner to first investigate the structural mechanisms that make synthetic data based on deep learning problematic, and then leverage such knowledge to identify targeted countermeasures. Our work moves in this direction, therefore mixed approaches that combine deep learning with DP are left out of the scope of the present contribution.
6. Discussion
6.1. Practical Implications of Considering Pseudo-Synthetic Data as Non-Personal Data
To illustrate concretely the potential danger of considering pseudo-synthetic data as non-personal data let us consider a scenario where the source data set
We consider the task of training a diagnostic AI model
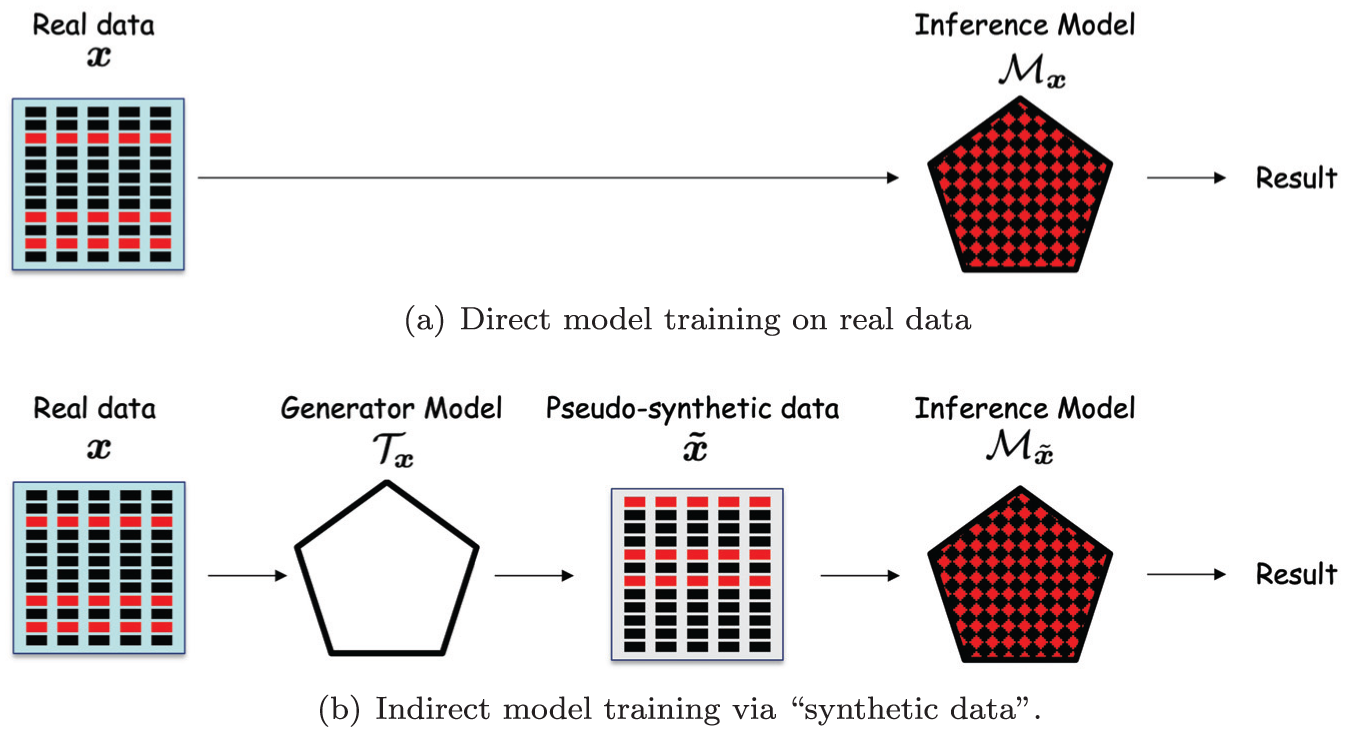
Direct versus indirect model training: (a) direct model training on real data and (b) indirect model training via synthetic data.
Nominally, all such AI models are primarily aimed at learning from the training data some population-level properties linking the predictor variables to the attribute value (e.g., that living in a certain area correlates positively with lung cancer after a certain age). As far as classic under-parameterized ML models are concerned, this is all what they may learn, because such models do not have the capacity to memorize all the data. With over-parameterized models and deep learning the story is different: along the process of learning from the training data the sought-after population-level properties, they may end up the training data, that is, individual data points from the training set (e.g., that one particular person of a specific sex, born on some specific date and resident in one specific place, was diagnosed with lung cancer). We note also that the notions of population-level and unit-level information are not always easily separable: for instance, learning some highly detailed collective characteristics about the data points, like for instance that all the points sharing the same attribute value lie on the same interpolating line
The structural mechanism presented in Section 3 leads to encode the original data
6.2. Analogy with Data Encryption
If the large-scale generative process was to perform some kind of privacy-deceptive coding, the data generator process may be considered similar to an encryption system, for which the decryption key must be kept separate from the encrypted data (or cipher-text)
6.3. Considerations on Legal Implications
We conjecture that any privacy test that reduces to a dissimilarity test and is oblivious to the detailed description of the anonymization process, that is, only considers the apparent dissimilarity at face value of the output data
In our opinion the burden of proof should always be with the proponents of such methods to demonstrate that their model has genuinely removed, and not merely encoded personal information in way that is just not immediately apparent, for example, through some kind of implicitly learned privacy-deceptive coding scheme. In this sense, the lack of interpretability poses a serious problem.
Data Protection Authorities may have to define sound anonymization criteria specific for AI models and the pseudo-synthetic data derived thereby. In the light of the simple yet general privacy-deceptive coding mechanism presented above, and in line with the findings of recent experimental work (see e.g., Annamalai et al. 2024; Yao et al. 2025) such criteria should not be limited to assess the dissimilarity between the transformed and the original data, but should rather consider the detailed characteristics of the pseudo-synthetic data generation mechanism. Such hypothetical future guidelines may possibly distinguish between under-parameterized and over-parameterized models, which in turn implies the ability to quantify the intrinsic size of the data in terms of their amount of information, net of all redundancy. To the best of our knowledge, this aspect remains an open research question (we can only conjecture that the intrinsic size of a data set is linked to the notion of Kolmogorov complexity).
6.4. Directions for Interdisciplinary Research
Taking inspiration from Information Theory, and particularly from Channel Coding, we may interpret the chain
In the same way as research on attack models helps privacy defenders, we believe that devising new privacy-deceptive coding schemes would be instructive and valuable for privacy research in that it would help to identify more robust countermeasures and risk assessment criteria. Moreover, it may also drive privacy researchers to pull concepts and tools from well-established disciplines with a solid theoretical basis, such as Information Theory, Channel Coding theory, and Cryptography, that is, disciplines dealing with different forms of data representations and their properties.
7. Concluding Remarks
There is already wide empirical evidence (see e.g., the survey by Zhou et al. (2024) and the online repository Zhou (2025)) that deep learning models, like a sponge immersed in a liquid, tend to absorb personal information from the training data on which they are trained, and that such information can be then squeezed out from the trained model by means of so-called model inversion attacks when not regurgitated spontaneously. Similarly, we expect in the near future a proliferation of papers on synthetic data inversion attacks, that is, empirical studies showing that also the pseudo-synthetic data generated by deep learning models may carry unit-level information from the original training data, and that such information can be inferred back via membership inference and attribute discovery attacks. In this perspective, recent works like Slokom et al. (2022), Annamalai et al. (2024), and Yao et al. (2025) appear as the first pioneering examples of a line of research that is set to grow.
In parallel to demonstrate empirically the feasibility of privacy attacks against pseudo-synthetic data, it is important to unveil the general structural mechanisms underlying the phenomenon, that is, to explain how and why personal information may flow through the model into the new generated data. Such understanding is necessary for devising robust and theoretically sound mitigation measures. In this work we have attempted to take a step in this direction by formulating an initial hypothesis, inspired by the concept of parametric interpolation as a mechanism for data encoding and non-linear dimensionality reduction. Together with other prominent work in the field, like for example Stadler and Troncoso (2022), Stadler et al. (2022), and Jordon et al. (2022), we hope that our work will contribute to raise awareness among legal experts, data protection officers, and potential adopters, including professional statisticians and managers of statistical offices, that pseudo-synthetic data based on deep learning are not a magic risk-free solution but rather an approach for which risks are yet to be fully understood.
Footnotes
Acknowledgements
I am sincerely grateful to the anonymous reviewers and to the editor for providing an extensive number of accurate and constructive comments and corrections on initial versions of this work.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Disclaimer
The view expressed in this paper are those of the author and do not necessarily reflect the opinion of the European Commission.
Received: April 30, 2024
Accepted: November 11, 2025