
Abstract
The use of hedonic regression models on the sales of detached housing units is widespread in the real estate literature. However, these models do not address the need to decompose the sale price into structure and land components. For many purposes, it is necessary to obtain separate estimates for the price and quantity of housing structures and the land that these structures sit on. The builder’s model accomplishes this decomposition but it takes a producer’s perspective and requires an exogeneous structure price index. In the present paper, a consumer approach to the decomposition problem is taken and this “new” approach to the decomposition problem does not require the use of an exogenous building price index. The paper uses data on sales of detached houses in Richmond, British Columbia in order to implement the new approach. The property price indexes generated by the new approach are compared to the corresponding indexes generated by a traditional time dummy hedonic regression model. The traditional hedonic regression approach does generate reasonable overall property price indexes, but the two approaches do not generate similar land and structure subindexes.
Keywords
1. Introduction
In order to fill out the cells in a nation’s balance sheets, it is necessary to decompose property value into land and structure components. The national balance sheets are used to construct measures of household wealth (which influences consumption decisions) and to construct estimates of the capital stock (by type of asset) that is used by the production sector. Information on the amount of land (and its price) is crucial for determining the productivity performance of the country. Also, there is renewed interest in land taxation; see for example, Kumhof et al. (2021) and Muellbauer (2024). Again, it is necessary to decompose property values into land and structure components in order to tax the land component of property value. The problem is that information on the value of the land component of property value is almost completely lacking. Thus, in this paper, we will attempt to partially fill this statistical gap by indicating how sales of residential property values could be decomposed into land and structure components using the perspective of a purchaser of a residential property.
We used quarterly data for eleven years on the sales of detached houses in a suburb of Vancouver, Canada to illustrate our approach to the decomposition problem. The data will be explained in Section 2.
Constructing price indexes for residential properties is difficult because basically, each property with a structure in each time period is a unique product since each property has a unique location and each structure has a unique age, and the value of a residential property depends on the location of the property and on the age of the structure. This fact means that it is impossible to apply traditional index number theory to the construction of a property price index since traditional theory relies on matching prices over time of exactly the same products over time. Since a property (with a structure) is not the same product over time, the traditional matched model approach to index number theory cannot be used. Instead of the traditional approach to index number theory, the hedonic regression approach to index construction regresses the value of a residential property on the characteristics of the property. The most important price determining characteristics of a property are: (i) the location of the property; (ii) the age of the structure (older structures tend to be of less value to purchasers); (iii) the area of the land plot (bigger is better) and (iv) the floor space area of the structure (bigger is better). Many other property characteristics can be important as well. In Section 3, we will assume that purchasers of residential properties have separate utility functions for the land and structure components of a property, and we will show how these utility functions can be estimated by regressing property value on the characteristics of the property. We will start off by assuming very simple functional forms for these utility functions and make them more complicated by adding more property characteristics to these utility functions in subsequent regressions of property values on property characteristics. The resulting hedonic regressions are nonlinear, but they are nested; that is, we use the estimated coefficients of a previous regression as starting values for the subsequent regression. This nested approach to estimating a final model that is fairly complex worked well for our data set. A biproduct of our approach is the estimation of a geometric depreciation rate for the structure component of property value. Regressions that attempt to provide decompositions of property prices into land and structure components frequently run into a multicollinearity problem due to a positive correlation between land plot size and structure size. We address this problem by smoothing the structure component of the property value.
The regressions that are presented in Section 3 use the data for the entire sample. We estimate four models that show the importance of including the location of the residential property, the age of the structure, the area of the land plot, and the floor space area of the structure. Our final model explains about 87% of the variation in the prices of the residential properties in Richmond over our sample period. Section 4 aggregates the separate land and structure price indexes into overall property price indexes.
In Section 5, we will look at the problems associated with constructing a real time index. Suppose that we have estimated a hedonic regression model for the first twenty quarters and the data for quarter 21 becomes available. Then the data for quarter 1 could be dropped and the data for quarter 21 could be added to the new hedonic regression. The period 21 results for the new regression could be linked to the results of the previous regression and the previous price index series for land and for structures could be updated. This is the rolling window approach to hedonic regressions which was introduced by Shimizu, Nishimura, and Watanabe (2010). However, this approach to updating a price index can lead to a chain drift problem, that is, the price level for the newly added period is not independent of the method used to link the new index level to prior index levels. In Section 4, we will deal with the problems associated with producing real time price indexes that are free from chain drift by using an expanding window approach. For discussions of alternative linking methods that have been used in the multilateral index number context, see Ivancic et al. (2011), de Haan (2015), Krsinich (2016), Chessa (2021), and Diewert and Fox (2022). For empirical examples of how large the chain drift problem can be, see de Haan and van der Grient (2011), Australian Bureau of Statistics (2016), and Fox et al. (2023).
In Section 6, we look at the more traditional property price hedonic regressions which use the logarithm of the property’s selling price as the dependent variable and enter the various characteristics of the property as independent variables along with time dummy variables in a linear regression. We follow the example of McMillen (2003) and Shimizu, Nishimura, and Watanabe (2010) and show how these traditional log price hedonic regressions can be manipulated to give estimates for a geometric depreciation rate for the structure component of property value. We compare this new imputed depreciation rate with the geometric depreciation rates that we obtained in Section 3. We also compare the overall property price index that is generated by the traditional log price hedonic regression approach with the overall property price index generated by our nonlinear regression model, and we find that there is a fairly close comparison. However, we show that the traditional log price hedonic regression approach generates rather different land and structure price subindexes. Section 7 concludes the article.
2. Data
The data for this study were obtained from the Multiple Listing Service for the city of Richmond, British Columbia, Canada. We obtained the data from Raymond Chan, who obtained the data from the MLS@ system (Multiple Listing Service), a branch of the Canadian Real Estate Association, for research purposes at Simon Fraser University. Richmond is a suburb of the city of Vancouver which lies immediately to the south of Vancouver. There were a total of 16,204 observations on the sales of detached houses in the Richmond region for the eleven-year period from January 2008 to December 2018. These sales were aggregated into quarterly data for forty-four quarters. Sales of newly constructed houses are included in our data set. However, not all of these observations were used in our hedonic regressions: before doing the estimation, we deleted the tails of the distributions of the dependent variable (the selling price of the property) and the explanatory characteristics. Including range outliers in the regression can distort the results to a considerable degree. Because the number of observations at the tails of each characteristic distribution is small, a hedonic regression surface cannot be reliably measured at these observations that have extreme values for the underlying property characteristics.
The definitions of the variables used in the regressions and their units of measurement are as follows:
V = selling price of the property in millions of dollars;
L = size of the lot area measured in thousands of square feet;
S = structure area (total floor area) measured in thousands of square feet;
A = age of the structure in years;
N BE = number of bedrooms;
N BA = number of bathrooms.
We now explain the details of our deletion process. Before deleting any observations, we used the Government of British Columbia Property Assessment website to find any missing data on the characteristics of the detached house properties that were sold in each quarter of our sample. We dropped 381 observations that had missing values for the age A and 1 observation that did not have information on the size of land plot area. We also removed fifteen observations that were floating homes. Since selling prices V increased over the years in our sample, we examined the histograms of the selling prices by year. We found that the distribution of selling prices for each year is right-skewed, with the mass of the distribution of the selling prices concentrated on the left part of the histograms. To avoid the problem that a few observations at the top end of the selling price are spread over a large range of prices, we removed properties that were extremely expensive with selling prices higher than 18 million and then we dropped the remaining observations with prices in the top 1% of sales by year and in the bottom 1% of sales by year. Through this process, 332 observations were dropped from the sample.
At the next stage, we deleted outliers for the explanatory variables. Before deleting outliers, we dropped eighty-one observations that had missing values for covered parking spaces and ten observations with zero bedrooms. To determine the range of the main explanatory variables, we examined the histograms of these variables. As mentioned earlier, the purpose of removing the outliers is to avoid having only a few observations at either the bottom end or top end of the distribution. After several rounds of trimming, the final dataset included 13,988 observations with the following characteristics.
The land plot area L is between 3,000 and 12,300 ft2;
Floor space area S (also called living area or structure area) is between 1,000 and 4,800 ft2;
The age A of the structure is less than or equal to sixty years;
The structure has one to six bathrooms (N BA );
The structure has two to seven bedrooms (N BE );
The structure has one to three kitchens;
The structure has less than four covered parking spots;
For the sales prices, we deleted approximately the bottom 1% and the top 1% of selling prices for each year.
We did not use the kitchen or parking characteristics in our regressions; these variables were used to eliminate properties with an unusual number of kitchens or parking spots. At the end of our deletion process, we deleted 13.6% of our original 16,204 observations. This seems to be a high number of deletions, but we feel that accurate hedonic surfaces cannot be estimated when the number of observations is sparse at the edges of the hedonic surface.
In addition to the above variables, we had information on which one of the six postal code regions for Richmond was assigned to each property.
The descriptive statistics of the above variables are listed in Table 1 below.
Descriptive Statistics of the Variables.
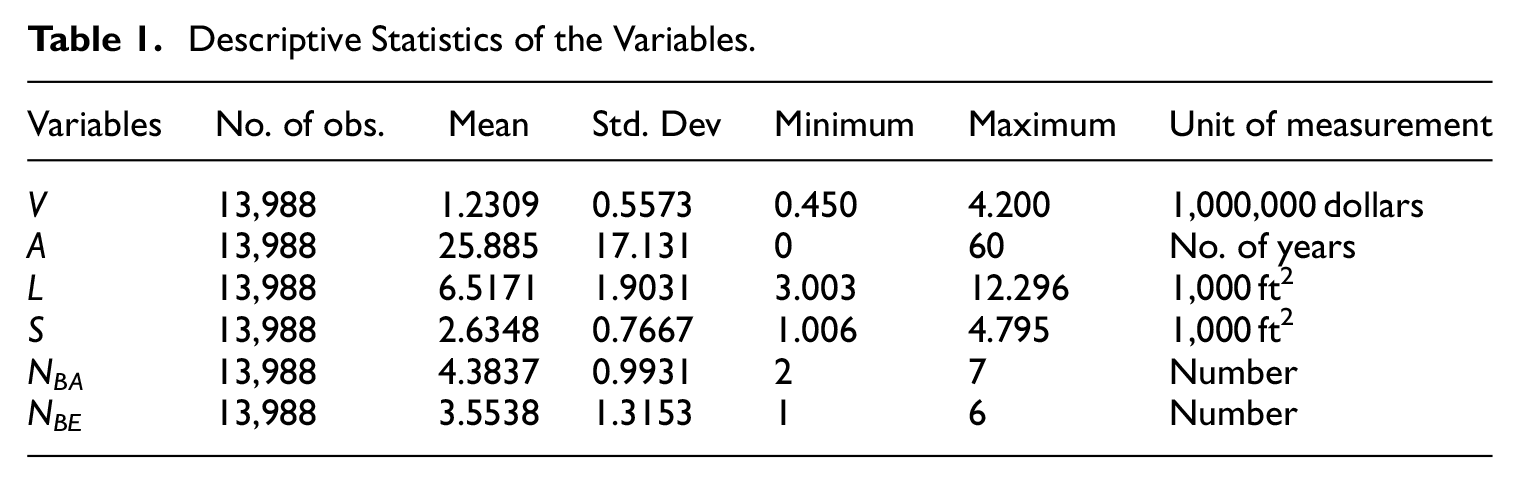
It can be seen that detached houses in Richmond sold for a considerable amount of money over our sample period, that is, they sold for an average of $1,230,900.
3. The Basic Models Using the Purchaser Perspective
Our fundamental problem is to decompose the value of a residential property into additive land and structure components. Our attempt to solve this imputation problem proceeds as follows. We assume initially that the total value of a property is equal to the floor space area of the structure, say S square feet, times the purchaser’s subjective valuation per square foot β t during quarter t, plus the area of the land plot, say L square feet, times the purchaser’s subjective valuation per square foot α t . We let t run from 1 to 44 where quarter 1 is the first quarter in 2008. Now think of a sample of properties of the same general type, which have sale prices or values V tn in quarter t and structure and land areas, S tn and L tn , for n = 1, …, N(t) where N(t) is the number of sales in quarter t. Assume that these property values are equal to the sum of the land and structure values plus error terms ε tn which we assume are independently normally distributed with zero means and constant variances. This leads to the following hedonic regression model for period t where the α t and β t are the parameters to be estimated in the regression:
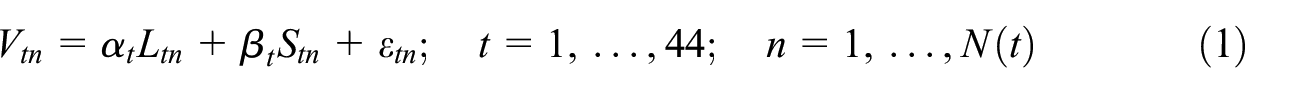
Other papers that have suggested hedonic regression models that lead to additive decompositions of property values into land and structure components include Clapp (1980), Bostic et al. (2007), Francke and Vos (2004), Francke (2008, 167), Koev and Santos Silva (2008), and Rambaldi et al. (2011).
The hedonic regression model defined by Equation (1) applies to properties in the same general location and to structures of the same general quality. The parameter α t can be interpreted as a quarter t average per unit price of land and the parameter β t can be interpreted as a quarter t average per unit price of structures. The model defined by Equation (1) can accommodate residential properties that have no structure on them: S tn is simply set equal to 0 for these properties. This is an advantage of our additive decomposition of property value into the sum of land and structure values.
It is likely that a purchaser’s valuation of the structure on the property declines as the age of the structure increases. Older structures will be worth less than newer structures due to the depreciation of the structure. Assuming that we have information on the age of the structure n at time t, say A(t, n), and assuming a geometric (or declining balance) depreciation model, a more realistic hedonic regression model than that defined by Equation (1) above is the following purchaser’s valuation model:

where the parameter δ reflects the net geometric depreciation rate as the structure ages one additional year.
In general, we would expect an annual net depreciation rate to be around 2% to 3% per year. This estimate of depreciation is regarded as a net depreciation rate because it is equal to a “true” gross structure depreciation rate less an average renovations appreciation rate. Since we do not have information on renovations and major repairs to a structure, our age variable will only pick up average gross depreciation less average real renovation expenditures.
Note that Equation (2) is now a nonlinear regression model whereas Equation (1) was a simple linear regression model. The period t imputed constant quality price of land is the estimated coefficient for the parameter α t and the imputed price or marginal utility value of a unit of a newly built structure for period t is the estimate for βt. The period t quantity of land for property n is L tn and the period t quantity of structure for property n, expressed in equivalent quality adjusted units of a new structure, is (1 −δ)A(t,n)S tn where S tn is the floor space area of the structure for property n in period t. It should be noted that a constant geometric depreciation rate may not provide an adequate description of depreciation in many situations where for example, some structures last for centuries. Thus more complex models of depreciation may have to be used in many situations.
Equation (2) is identical to the simplest version of the Builder’s Model that also attempts to decompose property value into land and structure components; see Diewert (2008, 2010, 2013), Diewert et al. (2011, 2015), Diewert and Shimizu (2015, 2016, 2020, 2022), and Burnett-Issacs et al. (2020) for materials on this model. The Builder’s Model sets the parameters β t equal to a building construction cost index times a constant. This model can be justified for the sales of newly constructed houses but is less well justified for properties with older structures. Moreover, the Builder’s Model requires an appropriate exogenous construction cost index, which is typically difficult to find. The present model does not use a construction cost index; the β t are estimated. Thus, the present model takes a consumer or purchaser perspective and could be called the Purchaser’s Model. See Rosen (1974) for a classification of hedonic models into supply and demand side models.
There is a major practical problem with the hedonic regression model defined by Equation (2): the multicollinearity problem. Experience has shown that it is usually not possible to estimate sensible land and structure prices in a hedonic regression like that defined by Equation (2) due to the multicollinearity between lot size and structure size; see Schwann (1998), Diewert (2010), and Diewert et al. (2011, 2015) on this problem. Thus in order to deal with the multicollinearity problem, we assumed that the forty-four structure valuation quarterly parameters β t in Equation (2) can be described by twelve annual parameters, γ1, γ2, …, γ12, as follows:
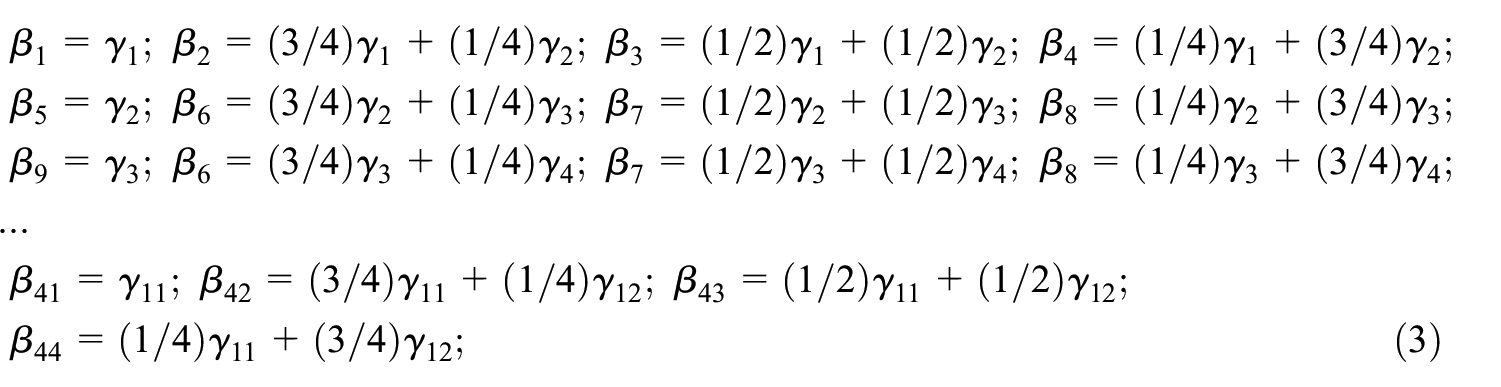
Basically, we replaced the forty-four quarterly parameters β t by a linear spline function with break points or knots at the beginning of each year. Thus, instead of estimating 44 β t , we only estimated twelve annual parameters γ1, …, γ12. This specification of the structure valuation parameters has the effect of smoothing the β t . More complex smoothing procedures could be used such as the Continuously Changing Coefficient smoothing procedure suggested by von Auer (2007), which is a form of polynomial smoothing. Other reasonable smoothing methods include the use of quadratic or cubic splines with endogenous break points. However, the present paper works with the above very simple model that could be the starting point for a better but more complex model (which might be difficult for National Statistical Offices to explain to the public).
An alternative strategy to solve the multicollinearity problem would be to smooth the α t instead of the β t . However, for a property with a new structure, the parameter β t should be approximately equal to the per unit floor space area construction cost. Thus, for newly constructed houses, the movements in β t should be approximately equal to the movements in an appropriate construction cost index. In general, construction cost indexes are not as volatile as land cost indexes, so we chose to smooth the β t instead of the α t .
Model 1 is defined by Equation (2) with the β t defined by Equation (3). This model has forty-four quarterly land valuation or price parameters (the αt), twelve annual structure valuation parameters (γ1, …, γ12) and one (net) geometric structure depreciation rate δ for a total of fifty-seven parameters with 13,988 observations. The lowest number of sales in a quarter was 92 and the highest number was 631. The average number of sales in a quarter was 317.9. The R2 (between the observed values and the predicted values) was .8207, which we regarded as satisfactory for such a simple model. The estimates for the annual structure price parameters γ1*, …, γ12* were 0.233, 0.223, 0.260, 0.285, 0.314, 0.330, 0.321, 0.317, 0.400, 0.425, 0.411, and 0.430. Using these estimates for γ1* to γ12*, definitions Equation (3) were used to form the quarterly structure prices, β t * for t = 1, …, 44. The estimated depreciation rate δ* was 1.98% per year. Land prices grew from α1* = $57.34 per ft2 in the first quarter of 2008 to α44* = $149.08 per ft2 in the last quarter of 2018, a 2.60-fold increase over the sample period.
Structure prices grew from β1* = $233.45 per ft2 in the first quarter of 2008 to β44* = $425.60 per ft2 in the last quarter of 2018, a 1.82-fold increase over the sample period. From the Altus Group (2015) Construction Cost Guide for 2015, we find the following range of house construction costs per square foot for the Vancouver area: Speculative Basic Quality: $100 to $165; Speculative Medium Quality: $165 to $225; Speculative High Quality: $225 to $350; Custom Built: $400 to $1,000. It can be seen that our estimated valuations for units of structure are within the range of construction costs for the Greater Vancouver area. The above ranges also indicate the difficulty in obtaining a representative construction cost index for detached houses.
The estimated land and structure valuation coefficients, α
t
* and β
t
*, were turned into the land and structure price indexes for Model 1,
In order to take into account possible neighborhood effects on the price of land, we introduced (forward sortation area) postal code dummy variables, DPC, tn , j , into the hedonic regression defined by Equations (2) and (3). The number of observations over the sample period in the six postal code neighborhoods are as follows: 468, 1,041, 1,038, 2,930, 4,404, and 4,107. These six dummy variables are defined as follows: for t = 1, …, 44; n = 1, …, N(t); j = 1, …, 6:
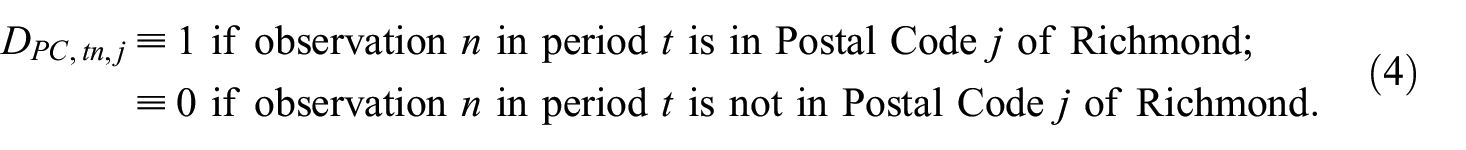
We now modify the model defined by Equations (2) and (3) to allow the level of the quality of land to differ across the six postal-code areas in Richmond. The new nonlinear regression model is defined by Equations (3) and (5):
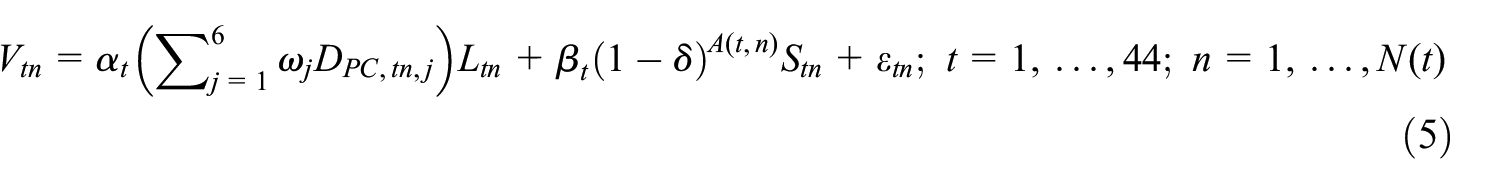
Comparing the models defined by Equations (2) and (5), it can be seen that we have added an additional six neighborhood relative land valuation parameters, ω1, …,ω6, to the model defined by Equation (2). The higher is ω1, the greater is the utility of owning a square foot of land in Postal Code 1 relative to owning a square foot of land in the other Postal Codes. However, looking at Equation (5), it can be seen that the forty-four land aggregate price level parameters (the α t ) and the six location parameters (the ω j ) cannot all be identified. Thus, we need to impose at least one identifying normalization on these parameters. We chose the following normalization:

Model 2 defined by Equations (3), (5), and (6) has five additional parameters compared to Model 1. Note that if we initially set all of the ω j equal to unity, Model 2 collapses down to Model 1. We made use of this fact in running our sequence of nonlinear regressions. Our models are nested so that we can use the final parameter estimates from a previous model as starting parameter values in the next model’s nonlinear regression. In order to obtain sensible parameter estimates in our final (quite complex) nonlinear regression model, we nested our models so that each new model contained by previous model as a special case. This enabled us to use the final estimated coefficients from the previous model as starting values for the same coefficients in the subsequent model. We structured the models and the starting coefficients so that the initial log likelihood for the present model was equal to the final log likelihood for the previous model. This is a useful check on our codes. We used both Shazam and RStudio to perform the nonlinear regressions; see White (2004).
The final log likelihood (LL) for Model 2 was an improvement of 1,257.586 over the final LL for Model 1 (for adding five new neighborhood parameters) which, of course, is a highly significant increase. The R2 increased to .8512 from the previous model R2 of .8207. The new estimated depreciation rate turned out to be 0.0184 or 1.84% per year. The price of land increased 2.90 fold and the price of structures increased 1.87 fold over the sample period. The Model 2 land and structure price indexes,
In our next model, we introduced some nonlinearities into the pricing of the land area for each property. As mentioned in Section 2, the land plot areas in our sample of properties ran from 3,000 to 12,300 ft2. Up to this point, we have assumed that land plots in the same neighborhood are valued by purchasers at a constant marginal utility per square foot of lot area. However, it is likely that there is some nonlinearity in this valuation schedule; for example, it is likely that large lots are valued at a marginal utility that is below the marginal utility of medium sized lots. In order to capture this nonlinearity, we initially divided up our 13,988 observations into five groups of observations based on their lot size. The Group 1 properties had lots less than 4,500 ft2, the Group 2 properties had lots greater than or equal to 4,500 ft2 and less than 6,000 ft2, the Group 3 properties had lots greater than or equal to 6,000 ft2 and less than 7,500 ft2, the Group 4 properties had lots greater than or equal to 7,500 ft2 and less than 9,000 ft2, and the Group 5 properties had lots greater than or equal to 9,000 ft2. The number of properties falling into each group were 2,927, 2,397, 4,236, 3,162, and 1,266. The use of linear splines to model land prices as a function of lot size was first used by Diewert et al. (2011). The four land values L t (in units of thousand ft2) used to define the boundaries of the above five groups are defined as follows:
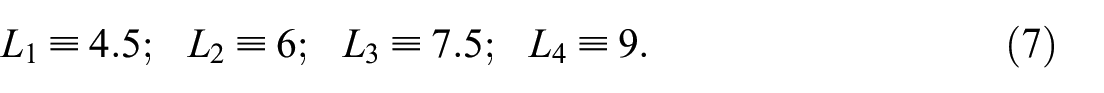
For each observation n in period t, we define the five land dummy variables, DL, tn , k , for k = 1, …, 5 as follows:
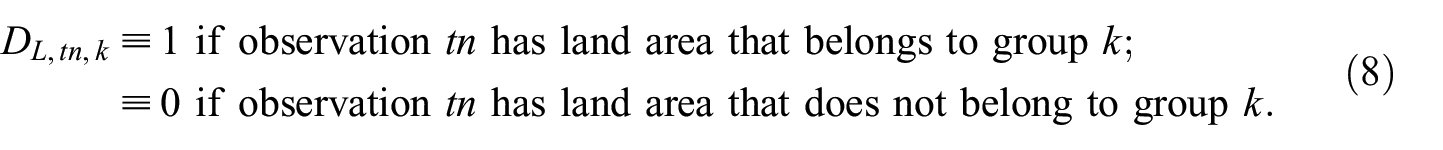
These dummy variables are used in the definition of the following piecewise linear function of L tn , f L (L tn ), defined as follows:
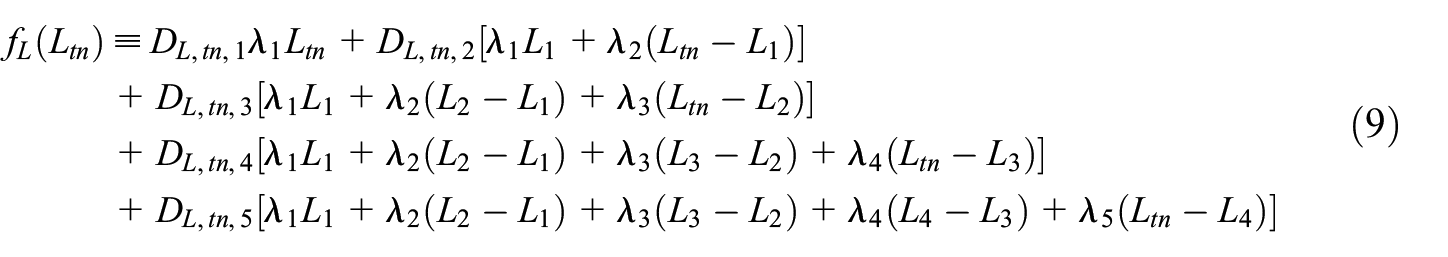
where the λ k are unknown parameters, and the L t are defined by Equation (7). The function f L (L tn ) defines a relative valuation function for the land area of a property as a function of the plot area. Basically, we are assuming that all purchasers of the residential properties in scope have the land utility function u(L tn ) for property n in quarter t equal to (Σ6 j =1ωjDPC, tn , j )f L (L tn ) and the corresponding structure utility function U(S tn ) for property n in quarter t is equal to (1 −δ)A(t,n)S tn . These are very strong assumptions.
The new nonlinear regression model is the following one:
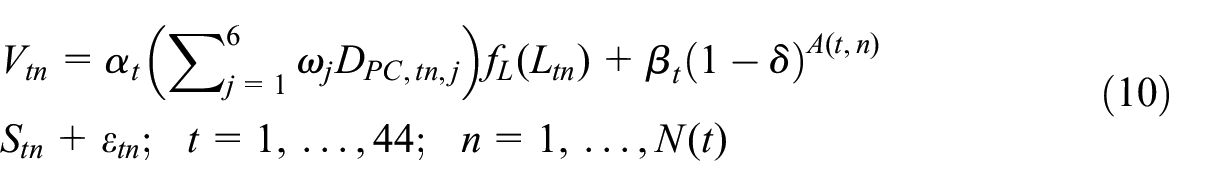
Comparing the models defined by Equations (5) and (10), it can be seen that we have added an additional five land plot size parameters, λ1, …,λ5, to the model defined by Equation (5). However, looking at Equations (9) and (10), it can be seen that the forty-four land price parameters (the α t ), the six postal code parameters (the ω j ), and the five land plot size parameters (the λ k ) cannot all be identified. Thus we impose the following identification normalizations on the parameters for Model 3 defined by Equations (3), (10), and (11):

Note that if we set all of the λ
k
equal to unity, Model 3 collapses down to Model 2. The final log likelihood for Model 3 was an improvement of 1,076.866 over the final log likelihood for Model 2 (for adding four new lot size parameters) which is a highly significant increase. The R2 increased to .8683 from the previous model R2 of .8512. The new estimated geometric depreciation rate for structures turned out to be 0.0328 or 3.28% per year. The price of land increased 2.37 fold over the sample period while the price of structures increased 1.84 fold. Thus the new model has given rise to somewhat different land prices and the new depreciation rate is considerably higher than the depreciation rates in Models 1 and 2. The sequence of marginal utility land quality adjustment factors generated by this model are as follows: λ1 = 1 (imposed), λ2* = 0.26174, λ3* = 0.45155, λ4* = 0.64362, and λ5* = 0.25290. Thus, the marginal utility land valuations as functions of lot size are not monotonic. The Model 3 land and structure price indexes,
For our final model, we introduced bathroom and bedroom variables into the hedonic regression as variables that could affect the quality of the structure on a property. The number of bathrooms in our sample ranged from one to six bathrooms. The number of observations in each of the six bathroom cells was 419, 2,236, 5,664, 2,243, 1,700, 1,726. Thus define the following six dummy variables, D BA , tn,i : for t = 1, …, 44; n = 1, …, N(t); i = 1, …, 6:
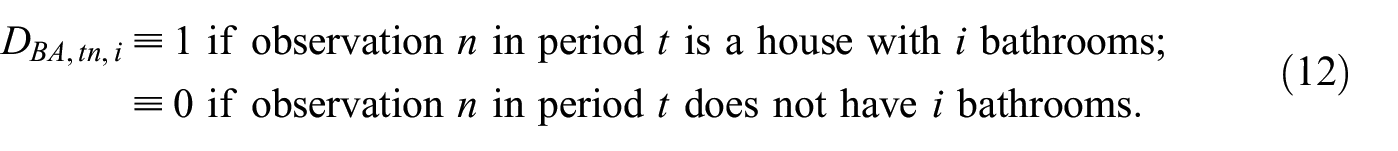
We used the bathroom dummy variables defined above in order to define the following bathroom quality adjustment function, gBA(N BA , tn ), as follows:
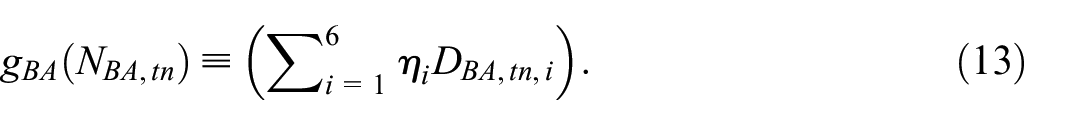
Finally, we introduced the number of bedrooms into the hedonic regression. The number of bedrooms in our sample ranged from two to seven bedrooms. The number of observations in each of the six bedroom cells was 118, 2,832, 4,413, 5,062, 1,316, 247. Define the following six dummy variables, D BE , tn,i , for t = 1, …, 44; n = 1, …, N(t); i = 2, 3, …, 7:
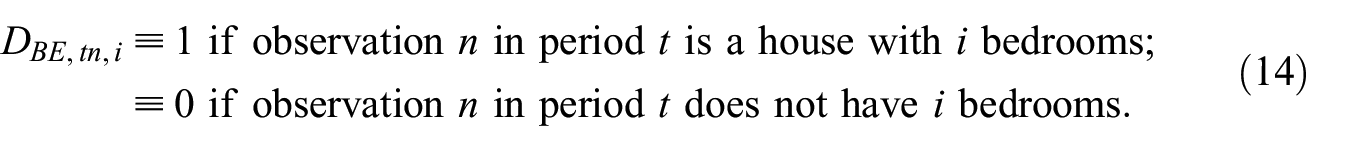
There were not a sufficient number of properties that had only two bedrooms (118) or had seven bedrooms (247), so we combined cell 2 with cell 3 and combined cell 7 with cell 6. Thus we ended up with four cells and four dummy variables of the form D BE , tn,i defined by Equation (14). We use the bedroom dummy variables defined above in order to define the following bedroom quality adjustment function, gBE(N BE , tn ):
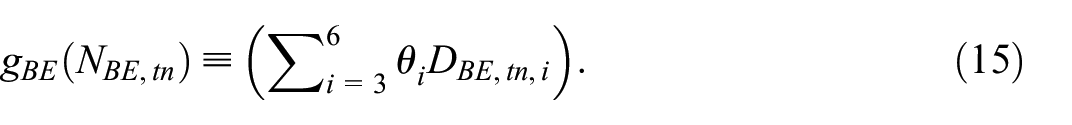
The new nonlinear regression model is the following one:
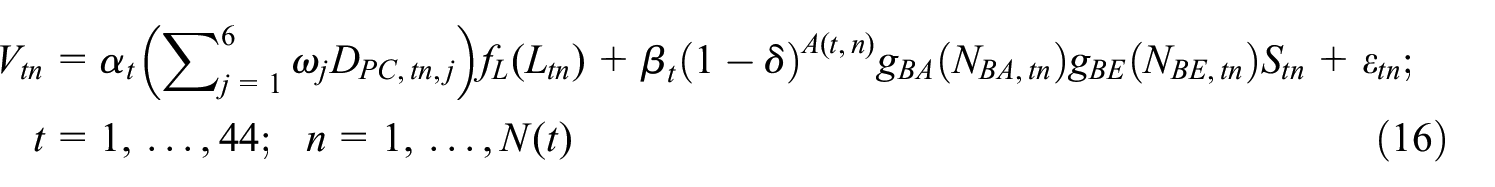
The utility function u(L) that adjusts the quantity of land for observation n in period t, L tn , into quality adjusted land is u(L tn ) ≡ (Σ6j=1ωjDPC, tn,j )f L (L tn ) ≡L tn * and the utility function U(S tn ) that adjusts the quantity of structures for observation n in period t, S tn , into quality adjusted structures is U(S tn ) ≡ (1 −δ)A(t,n)g BA (N BA , tn )g BE (N BE , tn )Stn≡ Stn*. McMillen’s (2003) consumer-oriented approach to property hedonics assumed that all purchasers have Cobb-Douglas preferences over combinations of L tn * and S tn * whereas we assume that purchasers have separate preference functions, u(L) and U(S), for land and structures.
Comparing the models defined by Equations (10) and (16), it can be seen that we have added an additional six bathroom parameters η i and four additional bedroom parameters θ i to the model defined by Equation (5). However, it can be seen that the forty-four land price parameters (the α t ), the six postal code parameters (the ω j ), the five land plot size parameters (the λ k ), the six bathroom parameters (the η k ), and the four bedroom parameters (the θ k ) cannot all be identified. Thus we impose the following identification normalizations on the parameters for Model 4 defined by Equations (3), (10), (13), (15), (16), and (17):
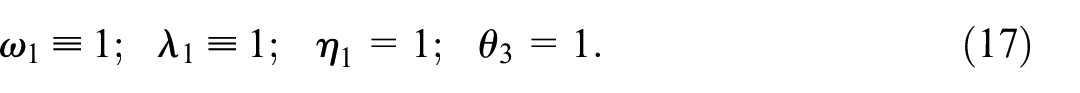
There are a total of seventy-four unknown parameters in Model 4. Note that if we set all of the η k and θ k equal to 1, then Model 4 collapses down to Model 3.
The final log likelihood for Model 4 was an improvement of 264.781 over the final log likelihood for Model 3 (for adding eight new bathroom and bedroom parameters). The R2 increased to .8732 from the previous model R2 of .8633. The estimated geometric depreciation rate was δ* = 0.0281 or 2.81% per year. Using this model, the price of land increased 2.46 fold which is an increase over the 2.37 fold increase that occurred in Model 3. The price of structures increased 1.74 fold. The Model 4 land and structure price indexes,
The estimated coefficients for Model 4 are listed in Table 2.
Estimated Coefficients for Model 4.

The land price indexes generated by Models 1 to 4, P L 1 t , P L 2 t , P L 3 t , P L 4 t , and the corresponding structure prices, P S 1 t , P S 2 t , P S 3 t , P S 4 t , are listed in Table 3.
Land and Structure Price Indexes for Models 1 to 4.

Figure 1 plots the four land price indexes and Figure 2 plots the four structure price indexes.

Land price indexes form Models 1 to 4.

Structure price indexes form Models 1 to 4.
It can be seen that the different models generate substantially different land and structure price indexes at times, although they all pick up the same trends. We prefer the Model 4 indexes since this model fits the data best.
In the following section, we will use the results from Models 1 to 4 to construct overall property price indexes.
4. Property Price Indexes for the Purchasers' Models
The previous section showed how the value of property n in period t, V tn , could be decomposed into the sum of a land component, a structure component, and an error term. In the case of Model 1, the land component was equal to α t *L tn and the structure component was equal to β t *(1 −δ*)A(t,n)S tn . In the present section, we show how the various decompositions of property value can be aggregated to give us overall property price indexes for Richmond.
Using the estimated coefficients from Model 1, quarter t aggregate land QL1 t is defined as the sum of the land that was purchased in quarter t:
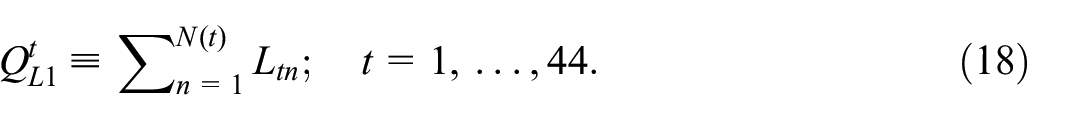
The corresponding aggregate quarter t predicted land price is defined as follows:

The Model 1 quarter t constant quality aggregate structure quantity is defined as the following sum:
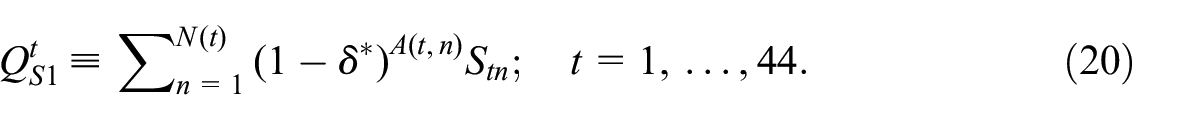
The corresponding constant quality aggregate quarter t structure price is defined as follows:

where the β t * are defined in terms of the estimated annual structure prices γ1*, …, γ12* for Model 1 using Equation (3).
Define the quarter t total property value V t by summing over the individual quarter t transactions, V tn :
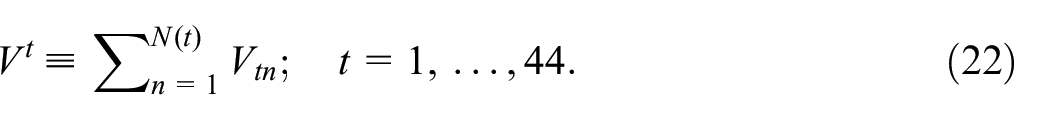
Quarter t predicted aggregate property value V t* is defined as P L 1 t Q L 1 t plus P S 1 t Q S 1 t for t = 1, …, 44. However, due to the error terms in the hedonic regression that defined Model 1, V t* will not equal V t . In order to make the predicted value of property transacted in quarter t equal to the actual quarter t property value, we will not use definitions Equation (18) to define the Q L 1t; instead, we will use the following definitions:
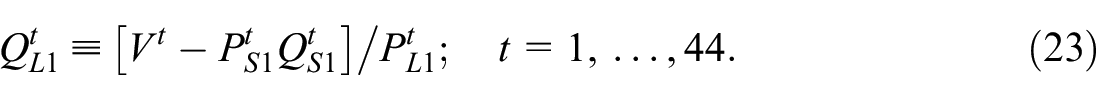
If the fits in the various nonlinear regression models in the previous section are poor, the use of definitions Equation (23) will tend to make the aggregate land quantity levels more volatile than those produced by the original definitions Equation (18).
We use definitions Equations (19), (20), (21), and (23) to define preliminary values for P L 1 t , Q L 1 t , P S 1 t , and Q S 1 t for t = 1, …, 44. Finally, we normalize the price indexes P L 1 t and P S 1 t to equal one for t = 1 and normalize the companion quantity indexes (in the opposite direction) so that aggregate land and structure values remain unchanged for each quarter. In an abuse of notation, we denote the normalized series by P L 1 t , Q L 1 t , P S 1 t , and Q S 1 t for t = 1, …, 44. The Model 1 aggregate normalized price series P L 1 t and P S 1 t are listed in Table 3 and the corresponding normalized quantity series Q L 1 t and Q S 1 t are listed in Table 4.
Land and Structure Quantity Levels for Models 1 to 4.

The same strategy for forming aggregate price and quantity indexes for the aggregate land and structure was followed using the results of Models 2 to 4. The preliminary constant quality land and structure price levels for quarter t were defined using the estimated coefficients from the relevant regression for the α t * and the β t * and using definitions Equations (20) and (23) in order to define the corresponding Model j constant quality quarter t structure and land levels, Q Sj t and Q Lj t . However, Model 4 used a different definition for Q S 4 t instead of using definition Equation (20). The Model 4 counterpart definitions to definitions Equation (20) are the following:
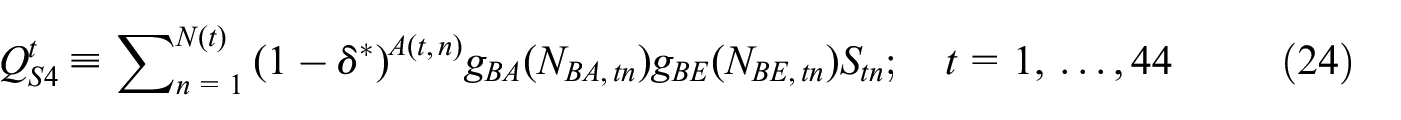
where the functions g BA (N BA , tn ) and g BE (N BE , tn ) are defined by Equations (13) and (15). The resulting normalized aggregate price indexes for land (P L 2 t , P L 3 t , and P L 4 t ) and structures (P S 2 t , P S 3 t , and P S 4 t ) are listed in Table 3 and the corresponding quantity indexes for land (Q L 2 t , Q L 3 t , and Q L 4 t ) and structures (Q S 2 t , Q S 3 t , and Q S 4 t ) are listed in Table 4. These quantity indexes are quality adjusted aggregate amounts of land and structures purchased in quarter t.
It can be seen that allowing land prices to vary with the size of the land plot (Models 3 and 4) substantially changed the relative sizes of constant quality land and structures: the quantity of land increased, and the quantity of structures decreased. This is due to the substantial increase in the structure depreciation rate that occurred using Models 3 and 4.
We conclude this section by forming aggregate residential property price indexes for Richmond. The price and quantity series for land and structures, P Lk t , P Sk t , Q Lk t , Q Sk t for k = 1, 2, 3, 4, are listed in Tables 3 and 4. The fixed base (FB) and chained (CH) Fisher (1922) ideal indexes for the four models, P FFBk t and P FCHk t for k = 1, 2, 3, 4, are listed in Table 5 along with simple mean and median property price indexes, P Mean t and P Med t .
Mean, Median, and Fisher Fixed Base and Chained Property Price Indexes.

The above indexes are plotted in Figure 3.

Mean, median, and Model 1 to 4 fixed base and chained fisher property price indexes.
It can be seen that the Mean and Median price index series, P Mean t and P Med t , are more volatile than the Fisher indexes which are very close to each other. However, P Mean t and P Med t do capture the trends in Richmond property prices over the sample period. The Model 4 fixed base and chained Fisher indexes differ by 1.6% for the final quarter in our sample so chain drift is not a major problem with the Model 4 aggregate property price indexes.
Our conclusion here is that it appears that Model 1, which has only a single geometric depreciation rate and uses information on land plot size, structure size, and the age of the structure, generates an aggregate property price index which approximates our subsequent hedonic regression Models which require additional information on housing characteristics. However, in order to obtain more accurate depreciation rates and to obtain more accurate subindexes for the land and structure components, additional information on property characteristics is required. Information on property location, the floor space area of the structure, the land plot area, and the age of the structure can be sufficient to generate land and structure price indexes that are reasonably accurate, provided that the fit of the hedonic regression is reasonably high.
Of course, additional information on the characteristics of the properties will in general improve the fit of the model. We used the number of bathrooms and bedrooms as indicators of structure quality because these structure characteristics were readily available. But many additional characteristics of the structure could be used as quality adjusting characteristics such as the type of construction, the “greenness” of the structure, the footprint of the structure, and so on. Also, there are characteristics which affect the quality of the land component of property value, such as distance to the nearest bus stop or subway station, distance to schools and hospitals, landscaping and possible views. An alternative to using postal codes as quality adjustment factors for land is the use of spatial coordinates; see for example, Diewert and Shimizu (2022). Moreover aspects of the theoretical model could be improved; the treatment of depreciation could be generalized and alternative smoothing methods could be used to smooth the structure price levels.
It is often difficult to obtain an estimate for the age of a structure and the following question was raised: What happens to Model 4 if we omit the Age variable? Thus, we ran the Model 4 regression without the age variable and the log likelihood fell from 2,771.88 to 1,060.3398. The R2 between the observed and predicted variable fell from .8732 to .8380. The Land, Structure, and overall Property Price indexes that resulted when we dropped the Age variable captured the observed trends in the Model 4 indexes but had a considerable amount of bias. At the end of the sample period, the ratio of the new Land Price index to the Model 4 index was 2.167/2.464 = 0.879, the ratio of the new Structure Price index to the Model 4 index was 1.960/1.744 = 1.124, and the ratio of the new overall Chained Fisher Property Price index to the Model 4 Chained Fisher Property Price index was 2.089/2.201 = 0.949. Thus, it seems to be important to include the Age variable in resale property price hedonic regressions in order to avoid bias.
The above regressions used the data for the entire sample period. In the following section, we address the problems associated with the production of a real time index.
5. The Construction of Real Time Price Indexes
The period t price and quantity levels for land and structures that were constructed in the previous section were constructed for a window of forty-four quarters. How exactly should the quarter 45 indexes be constructed when the data for quarter 45 becomes available? More generally, how should real time land and structure price levels and indexes be constructed? We address these questions in this section.
We introduce some notation so that we can explain alternative price updating methods more precisely. Let P t be a period t price level that is derived from a hedonic regression for t = 1, 2, …, T. Our Models 1 to 4 generate two sets of price levels: one for constant quality land and another for constant quality structures. Think of the P t as representing one of these series for one of our hedonic regression models and let Q t be the companion period t quantity level. The product of P t and Q t is the value V t . We would like our price levels to satisfy the following transitivity relations:
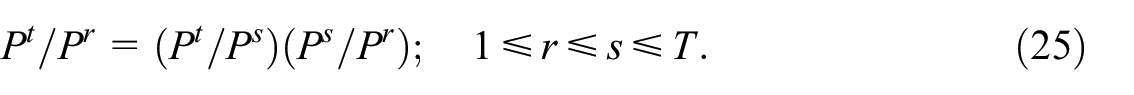
Of course, if the P t satisfy the equalities in (25) and V t = P t Q t for t = 1, …, T, then the Q t will also satisfy the transitivity conditions Q t /Q r = (Q t /Q s )(Q s /Q r ) for 1 ≤ r < s < t ≤ T.
The above relations Equation (25) are equivalent to Fisher’s (1922, 270) Circularity Test for bilateral index number formulae. If the estimated price levels from a hedonic regression satisfy Equation (25), then the resulting price index will not have a chain drift problem which can be a serious problem as was discussed in Section 1.
In order to generate a real time sequence of price levels, run a hedonic regression that uses only the data for periods 1 and 2. Denote the resulting period 1 and 2 price levels for regression 1 as P1(1) and P2(1). Define the real time price levels to be P1*≡P1(1) and P2*≡P2(1). When the data for period 3 becomes available, run a second regression using only the data for periods 2 and 3. This second regression generates period 2 and 3 price levels, P2(2) and P3(2). Define the real time period 3 price level as P3*≡P2*[P3(2)/P2(2)]. Thus we update the period 2 real time price level P2* by the price ratio or movement P3(2)/P2(2) in the price levels generated by our second hedonic regression that used only the data for periods 2 and 3. The third bilateral hedonic regression uses only the data for periods 3 and 4 and the real time price level for period 4 is defined as P4*≡P3*[P4(3)/P3(3)]. This updating process is continued indefinitely. This updating method is known as movement splicing, and it can be traced back to Court (1939, 109–11). The problem with this methodology is that the resulting price levels are not transitive, that is, they do not satisfy the restrictions Equation (25) and hence may be subject to chain drift.
Next, we consider a generalization of the above time dummy, adjacent period approach to the production of real time price levels. Instead of choosing to update the previous real time price levels by using bilateral hedonic regressions which use only the data for two adjacent periods, we use the data for M consecutive periods. First, choose M to be large enough so that the M period hedonic regression model will yield “reasonable” results; this will be the window length for the sequence of regression models that will be estimated. Second, run an initial regression model using the data for the first M periods and calculate the price levels pertaining to the first M periods in the data set. Next, a second regression model is estimated where the data consist of the initial data less the data for period 1 but adding the data for period M + 1. Appropriate price levels are calculated for this new regression model but only the rate of increase of the price level going from period M to M + 1 is used to update the previous sequence of M index values. This procedure is continued with each successive regression dropping the data of the previous earliest period and adding the data for the next period, with one new update factor being added with each regression. If the window length is a year, then this procedure is called a rolling year hedonic regression model and for a general window length, it is called a rolling window hedonic regression model with a movement splice. This is exactly the procedure used by Shimizu, Nishimura, and Watanabe (2010) and Shimizu, Takatsuji, et al. (2010) in their hedonic regression models for Tokyo house prices.
It turns out that there are several ways for linking the results of a new hedonic regression that uses a window length equal to M periods to the results of a previous rolling window regression. Let the price levels generated by the first regression be denoted by P1(1), P2(1), …, P M (1) and set the “real time” sequence of price levels for the first M periods, P t* , to equal the corresponding P t (1), that is, we have P t* ≡P t (1) for t = 1, 2, …, M. The second regression drops the period 1 data and adds the period M + 1 data and generates the price levels P2(2), P3(2), …, PM+1(2). Using the movement splice, the “real time” price level for period M + 1 is defined as PM+1*≡PM*[PM+1(2)/P M (2)]. Using what is called a “window splice,” the “real time” price level for period M + 1 is defined as PM+1*≡P2* [PM+1(2)/P2(2)]. The third regression drops the period 1 and 2 data and adds the period M + 1 and M + 2 data and generates the price levels P3(3), P4(3), …, PM+2(3). Using the movement splice, the “real time” price level for period M + 2 is defined as PM+2*≡PM+1*[PM+2(3)/PM+1(3)]. Using the window splice, the “real time” price level for period M + 2 is defined as PM+2*≡P3*[PM+2(3)/P3(3)].
The term and the concept of a window splice is due to Krsinich (2016). She recommended the use of window splicing over movement splicing because the time dummy variables in a rolling window hedonic regression are determined more accurately for the time dummy coefficients at the beginning of the window relative to the time dummy coefficients at the end of the window.
We calculated Rolling Window real time price levels for our data using Model 4 for window lengths M equal to 9 (which uses two years of data in the window) and 21 quarters (which uses five years of data) and using window splices to update the previous real time price levels. Denote these land price levels for quarter t as P LRW 9 t and P LRW 21 t and the corresponding structure price levels for quarter t as P SRW 9 t and P SRW 21 t for t = 1, …, 44. The various price levels were normalized to equal 1 in quarter 1. These (normalized) series are listed in Table 6. For comparison purposes, the Model 4 (normalized) land price levels P L 4 t and (normalized) structure price levels P S 4 t that are listed in Table 3 are also listed in Table 6 as P L t and P S t .
Rolling Window and Expanding Window Land and Structure Price Indexes.

Rather than using a Rolling Window (RW) approach to the construction of real time indexes, it is possible to use an Expanding Window (EW) approach. It is necessary to choose a window length M to start the EW indexes. The first M observations in our sample of T periods act as “training” periods. Let the price levels generated by the first regression be denoted by P1(1), P2(1), …, P M (1) and set the “real time” sequence of price levels for the first M periods, P t* , to equal the corresponding P t (1), that is, we have P t* ≡P t (1) for t = 1, 2, …, M. Thus, the real time price levels for the first M periods using the EW approach are the same as the corresponding RW price levels. Note that these price levels satisfy the transitivity conditions Equation (25) so there is no chain drift problem with these price levels. However, let us assume that the previous price levels P1*, P2*, …, PM* cannot be revised. We use the window method for price updating the real time price levels. Thus, the EW “real time” price level for period M + 1 is defined as PM+1*≡P1*[PM+1(2)/P1(2)]. The third regression adds the period M + 1 and M + 2 data to the initial data set and generates the price levels P1(3), P2(3), …, PM+2(3). Using the window splice, the “real time” price level for period M + 2 is defined as PM+2*≡P1*[PM+2(3)/P1(3)]. The process continues in the same manner until the period T data has been added to the regression. The final Nonrevisable Expanding Window series does not satisfy the transitivity conditions Equation (25) but the final price level PT* for the EW series cannot be unrealistically too high or too low because PT* is the final price level for a sequence of price levels that does satisfy the transitivity conditions Equation (25).
In our particular context, it can be seen that the Expanding Window approach to linking in the results of a new regression with the results of previous regressions gives the same estimates as the Rolling Window approach for the first M periods. Other methods for linking the results of a new rolling window regression to previous index levels are the half splice due to de Haan (2015) and the mean splice suggested by Ivancic et al. (2011) and Diewert and Fox (2022).
Chessa (2016, 2021) introduced the concept of using an expanding window in a multilateral index number context. The idea of using an infinitely expanding window of observations arose in Diewert (2023) in his discussion of the multilateral index Predicted Share Method that used dissimilarity measures to link the current period price levels to past period price levels. The expanding window approach was used by Diewert and Shimizu (2023) in their analysis of laptop prices in Japan. Diewert (2024) discussed adapting this approach to other multilateral methods based on the use of econometrics. Note that the “real time” nature of the EW and RW approaches starts at period M, that is, at the end of the training periods.
There are at least two potential problems with the Expanding Window price levels:
The EW sequence of real time price levels P t* could differ substantially from the sequence of price levels generated by the final hedonic regression P t (T−M + 1) for some t < T.
The Expanding Window sequence of hedonic regressions does not allow for gradual changes in the underlying utility functions u(L) for land and U(S) for structures whereas the Rolling Window sequence of hedonic regressions does allow for changes in preferences.
Problem 1 can be addressed by comparing the real time EW price levels with the price levels generated by the final hedonic regression that uses the data for all T periods. If the discrepancies between the two series are not too large, then the EW price levels could be accepted as being reasonable.
Problem 2 can be addressed by looking at the fits of the various regressions that are used to calculate the EW price levels. If the fits are low, then other multilateral methods should be considered.
We calculated Expanding Window real time price levels for our data using Model 4 for window lengths M equal to 9 and 21 quarters and using window splices to update the previous real time price levels. Denote the resulting land price levels for quarter t as P LEW 9 t and P LEW 21 t and the corresponding structure price levels for quarter t as P SEW 9 t and P SEW 21 t for t = 1, …, 44. These (normalized) series are listed in Table 6 below.
Here are some points to notice about the above indexes:
The Rolling Window and Expanding Window indexes for both land and structures that used the same number of periods as training periods (9 and 21 quarters) are equal for the training period quarters.
The two Expanding Window indexes for land are equal to each other for quarters 22 to 44 and similarly for the two EW structure indexes.
The two EW indexes for land, P LEW 9 t and P LEW 21 t , are equal to the Model 4 land index P L t for t = 44. Similarly, P SEW 944 and P SEW 2144 are equal to the Model 4 structure index P S 44.
Figure 4 and Figure 5 plot the alternative Expanding Window and Rolling Window (normalized) price levels for Land and for Structures. The Model 4 indexes for Land are plotted as P L t on Figure 4 and the Model 4 indexes for Structures are plotted as P S t on Figure 5.

Alternative rolling window and expanding window land price indexes.

Alternative rolling window and expanding window structure price indexes.
The two Expanding Window series, P LEW 9 t and P LEW 21 t can barely be distinguished from the transitive Model 4 land price series, P L t . Thus, the two real time EW land price series do not suffer from a major chain drift problem. The 21 quarter Rolling Window land price series, P LRW 21 t , is more volatile than the EW series and the 9 quarter Rolling Window land price series, P LRW 9 t , is even more volatile. However, the two RW series do capture the trends in Land prices.
Figure 5 shows that the real time Expanded Window structure price indexes that use the 9 and 21 quarter training periods, P SEW 9 t and P SEW 21 t , cannot be distinguished from each other. However, these Expanding Window structure indexes are much more volatile than the Model 4 structure price index P S t that used the data for all forty-four quarters and is free from chain drift. This is an indication that the training period should be longer than twenty-one quarters in order to obtain less volatile indexes that are closer to being transitive. The Rolling Window structure price index that used 21 quarters of training data, P SRW 21 t , shows a great deal of volatility around P S t and the index that used only 9 quarters of training data, P SRW 9 t , is even more volatile. However, all 4 EW and RW indexes do capture the trends in structure prices that are defined by P S t = P S 4 t .
To know how a Rolling Window approach using a mean splice would work for our data we computed land, structure, and overall Mean Splice indexes using a Rolling Window consisting of twenty-one quarters. The resulting Mean Splice Rolling Window land and structure indexes using a twenty-one-quarter training period were almost identical to the corresponding Expanding Window indexes using a twenty-one-quarter training period. Thus, we have not included these Mean Splice indexes in the above Figures. In a recent comprehensive simulation, von Auer (2025) showed that half splice and mean splice seemed to produce more reliable results than window splice and movement splice so there is room for additional research to determine the “best” way for linking the results of a new set of indexes with an existing set of indexes.
The overall conclusion that emerges from these figures is that the Expanded Window and Rolling Window with Mean Splice indexes based on the Model 4 specification of land and structure utility functions that use five years of training data led to relatively smooth land and structure subindexes that were largely free from chain drift. However, choosing a longer training period would probably improve the smoothness and transitivity of the resulting EW and RW indexes.
Finally, the price levels for land and structures that were generated by the five alternative sets of estimates presented in Table 6 can be combined with the Model 4 utility functions to generate aggregate property price indexes as was done in the previous section. Using chained Fisher indexes to aggregate over the structures and land indexes listed on Table 6 leads to Table 5 alternative aggregate property price indexes. The aggregate Fisher property price index that corresponds to the Model 4 aggregate prices, P L t and P S t listed in Table 6, is equal to the chained Fisher property price index P FCH 4 t that is listed in Table 5. Instead of using P L t and P S t listed in Table 6, we could use P LEW 21 t and P SEW 21 t and construct an alternative chained Fisher property price index. It turns out that this alternative property price index cannot be distinguished from P FCH 4 t that is listed in Table 5. Using the remaining three pairs of price indexes for land and structures that are listed in Table 6 led to alternative aggregate chained Fisher property price indexes that also could not be distinguished from P FCH 4 t . Thus, the various methods that were used to extend the aggregate property price index in real time, in the end, led to more or less the same aggregate property index.
In the following section, we use our data to construct “traditional” log price time dummy hedonic regressions and compare the resulting “traditional” indexes to the indexes generated by our additive approach to the property decomposition problem.
6. Estimating Structure Depreciation Rates from Traditional Log Price Hedonic Regression Models
A way of rationalizing the traditional log price time dummy hedonic regression model for properties with varying amounts of land area L and constant quality structure area S* is that the utility that these properties yield to purchasers is proportional to the Cobb-Douglas utility function LαS*β where α and β are positive parameters (which do not necessarily sum to one). The early analysis in this section follows that of McMillen (2003, 289–90) and Shimizu, Nishimura, and Watanabe (2010, 795). McMillen assumed that α + β = 1. We follow Shimizu, Nishimura, and Watanabe (2010) in allowing α and β to be unrestricted. Our depreciation model is somewhat different from the models of these authors. Initially, we assume that the constant quality structure area S* is equal to the floor space area of the structure, S, times an age adjustment, (1−δ) A , where A is the age of the structure in years and δ is a positive depreciation rate that is less than 1. Thus S* is related to S as follows:

In any given time period t, we assume that the nominal value of a property, V t , with the amount of land L and the amount of quality adjusted structure S* is equal to the following expression:
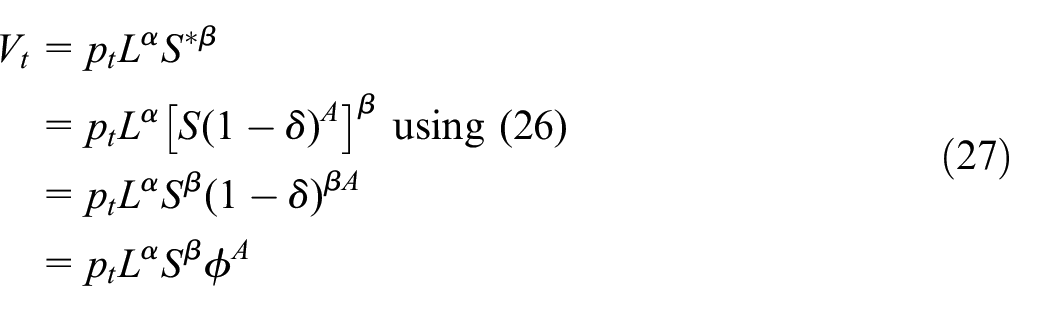
where p t can be interpreted as a period t property price index and the constant ϕ is defined as follows:

If we deflate V t by the period t property price index p t , we obtain the real value or utility u t of the property with characteristics L and S*; that is, we have:

Thus, u t is the aggregate real value of the property with characteristics L and S*.
Define ρ t as the logarithm of p t and γ as the logarithm of ϕ, that is,

After taking logarithms of both sides of the last equation in Equation (27) and using definitions Equation (30), we obtain the following equation:
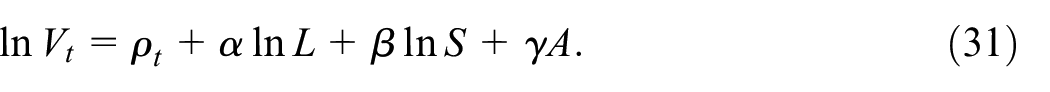
Log price hedonic regressions for property prices that are similar to Equation (31) date back to Bailey et al. (1963).
Suppose that we have N(t) sales of properties in a neighborhood in period t and the purchase price of property n is V tn . Suppose that we have data for T periods. The characteristics associated with property n in period t are L tn , S tn , and A tn . Assuming that the property purchaser valuation model defined by Equation (31) holds approximately, the logarithms of the period t property prices will satisfy the following equations:
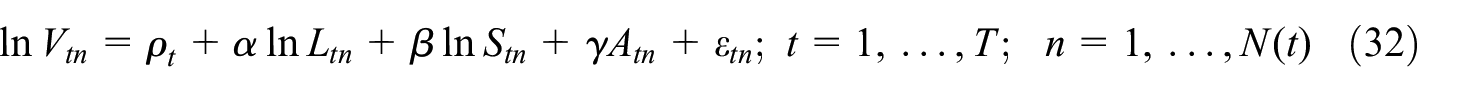
where the ε tn are independently distributed error terms with 0 means and constant variances. It can be seen that (32) is a traditional log price time dummy hedonic regression model with a minimal number of characteristics. The unknown parameters in (32) are the constant quality log property prices, ρ1, …, ρ T , and the taste parameters α, β, and γ. Once these parameters have been determined, the geometric depreciation rate δ which appears in Equation (27) can be recovered from the regression parameter estimates as follows:

We now explain how the hedonic regression model defined by Equation (32) can be manipulated to provide a decomposition of property value in period t into land and quality adjusted structure components.
To justify the hedonic regression Equation (32), we assume that there is a period t constant quality price of property in period t equal to p t (as before) and the period t value of a property with characteristics L and S* is given by the following period t property valuation function, V(pt,L,S*), defined as follows:
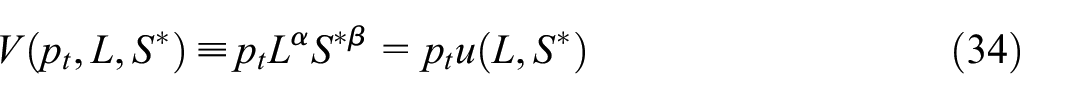
where the purchaser cardinal utility function u is defined as u(L,S*) ≡LαS*β and α and β are positive parameters which parameterize the purchaser’s cardinal utility function. p t is the period t constant quality price of a property with land and quality adjusted structures equal to L and S*≡S(1−δ) A . In our empirical work, our estimates for α and β are such that α + β is always substantially less than 1. This means that a property in a given period that has double the land and quality adjusted structure than another property will sell for less than double the price of the smaller property. This follows from the fact that our Cobb-Douglas utility function, u(L,S*) ≡LαS*β, exhibits diminishing returns to scale when α + β < 1; that is, we have:

for all λ > 0 where α + β < 1. This behavior is roughly consistent with our Models 3 and 4 where there was a tendency for property prices to increase less than proportionally as L and S* increased.
The marginal prices of land and constant quality structure in period t for a property with characteristics L and S*, π tL (pt,L,S*) and π tS* (pt,L,S*), are defined by partially differentiating the property valuation function with respect to L and S* respectively:
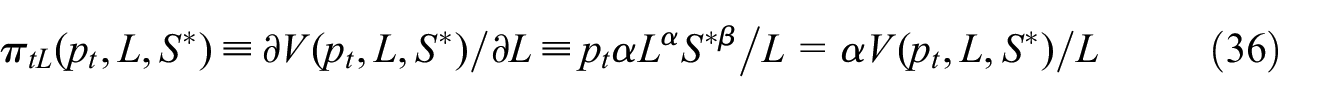
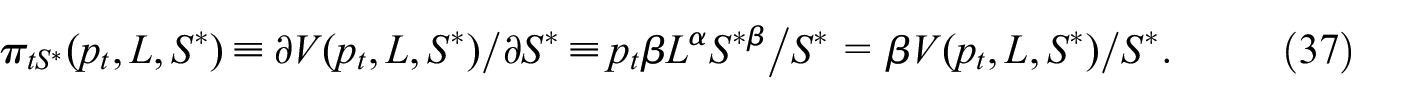
If we multiply the marginal price of land by the amount of land in the property and add to this value of land the product of the marginal price of constant quality structure by the amount of constant quality structure on the property, we obtain the following identity:
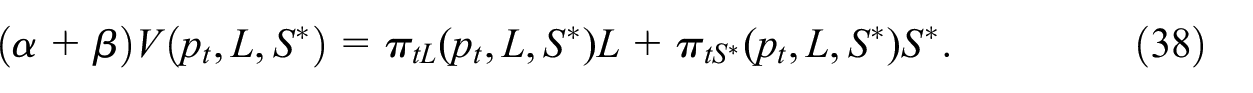
If α + β is less than one, then using marginal prices to value the land and constant quality structure in a property will lead to a property valuation that is less than its selling price. Thus to make the land and structure components of property value add up to property value, we divide the marginal prices defined by Equations (36) and (37) by α + β in order to obtain the following adjusted constant quality prices of land and structures in period t, ptL(pt,L,S*) and p tS* (pt,L,S*):
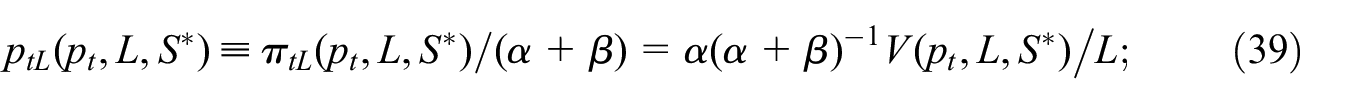
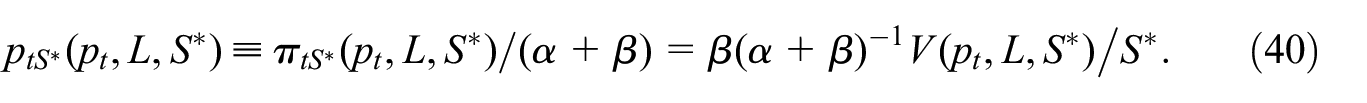
The above material outlines a theoretical framework that could be used to generate a decomposition of property value into land and structure components using the results of a traditional log price time dummy hedonic regression model like Equation (32). Unfortunately, any such decomposition is not likely to be satisfactory. Consider a hypothetical property in periods t and t + 1 where the quantities of constant quality land L and constant quality structure S* remain constant and consider the growth of the price land and structure price levels for this hypothetical property defined by Equations (39) and (40). It can be seen that p t+ 1,L/pt, L = p t +1,S*/pt, S* = V(p t +1,L,S*)/V(pt,L,S*); that is, constant quality price change for structures and for land going from period t to period t + 1 for a constant quality property is equal to the growth in property value going from period t to t + 1. This means that constant quality land and structure prices move in a proportional manner for constant quality properties. But in fact, we observe different rates of change in land and structure prices over time. Moreover, the Cobb-Douglas utility function assumption implies that the land and structure shares of a constant quality property remain constant over time. This is also unlikely to be true. Also, our additive decomposition of property value allows for properties with no structure whereas the Cobb-Douglas model breaks down if S tn = 0. However, these unrealistic aspects of the Cobb-Douglas utility model for residential properties does not mean that this framework cannot generate useful overall property price indexes (for properties with structures) as we will show below.
The hedonic regression model defined by Equation (32) can be generalized to the following model defined by Equation (41), which has added the location, bathroom and bedroom dummy variables, to Equation (32):
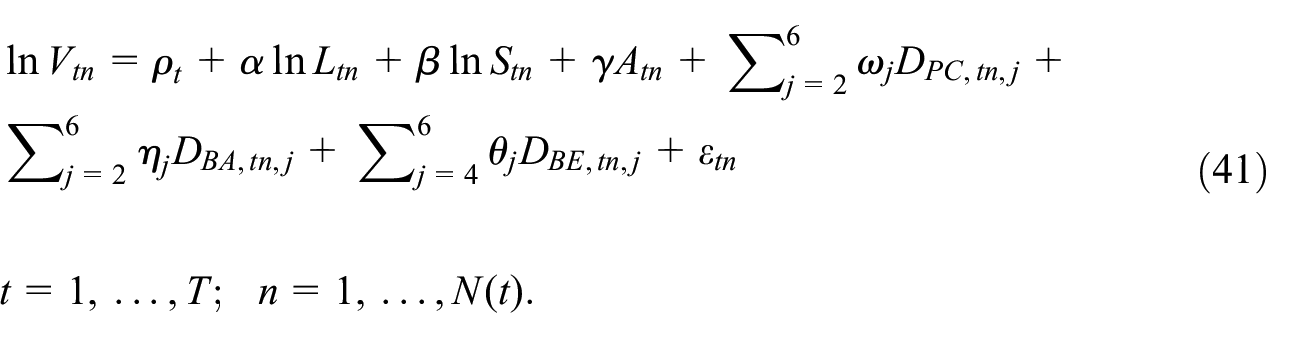
The postal code dummy variables, D PC , tn , j were defined by Equation (4) for j = 1, …, 6; the bathroom dummy variables, D BA , tn,j , were defined for Equation (12) for j = 1, …, 6 and the bedroom dummy variables, D BE , tn,j , were defined for Equation (14) for j = 3, …, 6. To prevent exact multicollinearity in the hedonic regression defined by Equation (41), we set ω1 = 0, η1 = 0, and θ3 = 0.
We used our Richmond data set and ran the hedonic regression defined by Equation (41). The R2 for this regression turned out to be .8734 which is comparable to the R2 we obtained for our Model 4 nonlinear regression. The estimated coefficients for α*, β*, and γ* were 0.39676, 0.25742, and −0.008062 respectively with T statistics equal to 60.64, 28.09, and −50.71. The corresponding annual structure geometric depreciation rate defined by Equation (32) was δ*≡ 1 −eγ*/β* = 0.03084 or 3.084% per year. This is fairly close to the average of the estimated structure depreciation rates that were generated by Models 3 and 4 (3.28% and 2.81% per year).
The time dummy coefficients were used to generate the sequence of quarterly residential property price levels by exponentiating the estimated ρ t *. Define the quarter t property price level, P Prop t ≡exp(ρ t *) for t = 1, …, 44. Construct the Hedonic Property Price Index for quarter t as P HED t ≡P Prop t /PProp1 for t = 1, …, 44. The resulting Hedonic overall property price indexes P HED t were very close to the Fisher Fixed Base and Chained property price indexes, P FFB 4 t and P FCH 4 t that were listed in Table 5. The partial correlations of P HED t with P FFB 4 t and P FCH 4 t were .99943 and .99952 respectively. Thus, for our particular data set, the traditional log price time dummy hedonic regression model generated almost the same aggregate property price index as was generated by our Model 4 nonlinear hedonic regression. Figure 6 plots the two Fisher indexes along with the traditional hedonic property price index.

Traditional hedonic model and purchaser’s model property price indexes.
7. Conclusion
Some of the tentative conclusions we can draw from the paper are as follows:
Our consumer or purchaser approach to developing residential property price indexes that can generate sensible subindexes for the structure and land components of the property worked well for our particular data set. We solved the multicollinearity problem between structure and land size by smoothing (over time) the implied constant quality structure prices.
Our purchaser approach provides an alternative to McMillen’s Cobb-Douglas preferences approach. Our approach is based on separate sub-utility functions for the land and structure components of residential property value. A problem with McMillen’s approach is that it implies that constant quality structure price movements are equal to constant quality land price movements. Another problem with Cobb-Douglas preferences is that this model cannot deal with properties that have no structure whereas our additive decomposition approach can deal with this situation.
The information on property characteristics that we required in order to have a hedonic regression model that fits the data reasonably well was fairly modest. We required information on the purchase prices for the properties in scope, the structure floor space and land plot areas, the age of the structure and some information on the location of the property such as postal code information or spatial coordinate information. Some additional information on housing characteristics that can be used to characterize the quality of the structure is useful. For our Model 4, we used the number of bedrooms and the number of bathrooms as quality indicators. Other indicators will no doubt be useful.
It is important to eliminate extreme outliers on both purchase prices and on the property characteristics. Isolated extreme observations at the tails of the distribution of prices and property characteristics lead to poorly determined hedonic surfaces.
Introducing splines on the land plot area proved to be very important for our example.
Simple mean and median property price indexes generated property price indexes that captured the trend in our constant quality property price indexes. However, these indexes are much more volatile than our hedonic property price indexes.
The traditional log price time dummy variable hedonic regression approach generated overall property price indexes which were virtually identical to our purchaser model overall property price indexes when both types of models used more or less the same characteristics. This result is useful in the context of trying to use existing information on residential property price indexes along with information on the capital stock of residential structures in order to provide a complete decomposition of residential property value into land and structure subcomponents; see Davis and Heathcote (2007) for a useful methodology that accomplishes this task.
The traditional log price time dummy hedonic regression approach generated an implied geometric structure depreciation rate which was close to our Model 3 and 4 depreciation rates. This is a very encouraging result.
Finally, we considered the problems associated with producing real time indexes as opposed to producing retrospective indexes. We applied the Rolling Window and Expanding Window methodologies to this problem and found that for our particular data set, the Expanding Window approach generated smoother price indexes for the land and structure components of residential properties in Richmond. The Rolling Window approach with mean splicing with a window of twenty-one quarters produced results that were virtually the same as the Expanding Window approach.
Footnotes
Acknowledgements
The authors thank Ludwig von Auer for his valuable comments and thank Raymond Chan and the Canadian Real Estate Association for access to the Richmond data. The first author gratefully acknowledges the financial support of the Canadian SSHRC and of CAER at UNSW.
Authors’ Note
The views expressed in this paper are solely those of the authors and do not necessarily reflect those of Statistics Canada.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Received: October 30, 2024
Accepted: April 4, 2025