
Abstract

Keywords
1. Motivations: Why Do We Care?
The work of statistical offices is in transformation. The datafication of our society induces changes on both ends of the statistical production pipeline. On the output side, more data hungry users expect new, better, and timelier statistics, and such demand cannot be fulfilled by relying solely on traditional survey data and administrative records. On the input side, the profusion of digital traces generated by citizens and companies provide a great variety of new data sources that may be potentially reused for statistical purposes. Together with declining response rate to traditional surveys, these factors drive the interest by statistical authorities for combining (selected types of) nonstatistical data sources with traditional statistical data to produce new, better, and timelier statistical products.
As nonstatistical data sources are often held and managed by different organizations, including public bodies and private companies, the path toward multisource statistics shall unavoidably lead to a proliferation of multiparty data scenarios, that is, settings where multiple sets of confidential data held by different organizations must be processed jointly (combined) to obtain the statistical indicator of interest.
Currently, the standard approach to cope with multiparty data scenarios is … reducing it to a single-party scenario by centralizing the data, that is, moving (a copy of) the data to a single data collector organization—the statistical authority itself or another Trusted Third Party—and then processing the data there in the standard way. The downside of such simple approach is scaling up of risks against data confidentiality. The proliferation of data copies increases the risk surface. Most importantly, centralizing the data implies centralizing the power stemming from the potential use (mis)use of those data in a single hand, thus increasing the attractiveness of the data collector as target for external attackers. Furthermore, on top of the actual risks of data breaches, one should consider also the perceived risk of data misuse: if the statistical authority is poised to become the central collector of vast amounts of highly granular data for the entire population and from multiple sources, what prevents it to be perceived by the general public as a potential backdoor for global surveillance, or at least the golden honeypot for external attackers? In other words, hoarding excessive amounts of nonstatistical data may jeopardize the capital of public trust that statistical offices have built though decades.
As far as combining data held across different organizations remains an occasional activity, limited to sporadic instances, moving the data may still be viable. However, in the perspective of multiparty data processing becoming the new normal of statistical production rather than the exception, statistical authorities may be compelled to look for alternative approaches.
2. Scope: What Are I-PETs?
Privacy-Enhancing Technologies (PETs) is an umbrella term that is used to refer collectively to a wide range of different technologies, conceived for different scenarios and use-cases, but having in common the general quest for reconciling the use of granular data with the protection of their confidentiality in order to safeguard the privacy rights of the individuals to which the data refer. Following Ricciato and Bujnowska (2019) and United Nations (2023) it is customary to divide PETs into two groups, depending on whether they address primarily the so-called Input Privacy problem or, conversely, the Output Privacy problem. In a nutshell, Input Privacy-Enhancing Technologies (I-PET for short) allow multiple parties to execute computation tasks without exposing the input data to each other. Instead, Output Privacy-Enhancing Technologies (O-PET) aim at producing some “sanitized” output result that is sufficiently close to the exact result to be useful for further legitimate analysis, and at the same time sufficiently different from it to prevent disclosure of individual information. In some sense, as exemplified in Figure 1, I-PETs and O-PETs work in opposite directions—I-PETs enable forward computation, O-PETs disable backward inference—and should be seen as complementary rather than competing approaches.
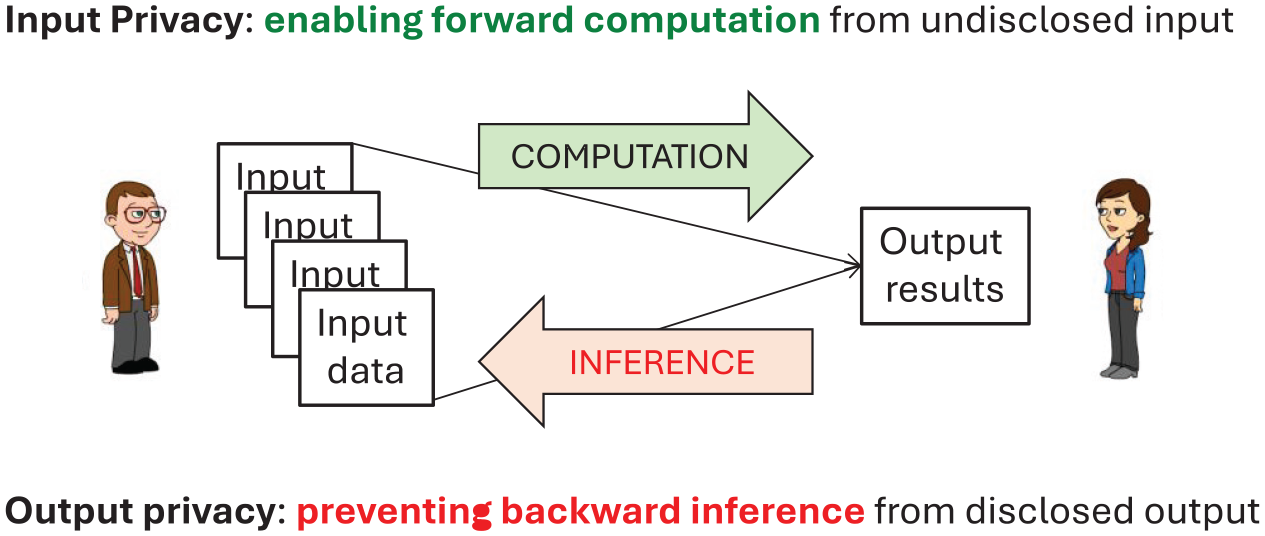
Input Privacy versus Output Privacy goals (adapted from https://doi.org/10.5281/zenodo.14671711).
In the context of official statistics, O-PETs are relevant for statistical dissemination and may be seen as evolutions of classical Statistical Disclosure Control (SDC) approaches (though even the most sophisticated O-PET is no Holy Grail for attaining highly granular data with zero risk and full utility, see e.g., Stadler and Troncoso (2022) and references therein). As the focus of this short contribution is rather on statistical production, we leave O-PETs out of consideration and restrict our attention here exclusively to I-PETs.
The I-PETs family includes cryptographic techniques like Secure Multiparty Computation based on Secret Sharing and Fully Homomorphic Encryption, and hardware-based technologies like Trusted Execution Environment (see Cybernetica (2024) for a comprehensive recent overview). In a multiparty data scenario, the essential element that qualifies all I-PETs is that they enable the computation of the desired statistical result, according to a predefined function (equivalently: method, algorithm, query), without exposing the input data elements to any other party other than their original data holder. No single party can “see” the input data of the others or learn anything about the data other than the final computation result.
Think of the data holders encrypting their input data in a way that allows one or a group of other parties to execute the predefined statistical function without ever decrypting the input data. In other words, the whole computation process is protected, that is, runs in the encrypted domain. Only the final result is revealed (decrypted) and only to the intended recipient(s). With I-PETs, the technology guarantees that, as far as certain scenario assumptions are met—usually represented in the form of an “attacker model,” see Cybernetica (2024)—the input data never gets exposed. In other words, as the computation function and the recipient(s) of the computation result must be agreed beforehand among the involved parties, I-PETs may be seen as tools to enforce technologically data governance policies.
The capabilities of I-PETs present three main trade-off dimensions: degree of security guarantees (equivalently: power of attacker), complexity of the supported operation, and scalability of resource consumption. If the goal is to perform a very complex operation, one may have to accept a somewhat lower degree of security guarantees (e.g., passive security instead of active security). Similarly, for a target level of security guarantees, staying within a reasonable budget of computation resources may impose restrictions on the complexity of the supported computation function or on the size of the processed data. Different I-PET technologies may be combined to build more secure systems. To limit the incidence of development costs, Ricciato (2024) proposed to deploy a single I-PET system to support different computation tasks on-demand, serving different statistical domains and institutions. A concrete example of such system is currently under development by Eurostat in the project JOCONDE—Joint On-demand Computation with No Data Exchange (for more information visit https://cros.ec.europa.eu/joconde).
3. Challenges for Technology Providers
Like with other general-purpose technologies, we can identify two distinct types of actors in the I-PET arena, namely technology providers (including developers) and technology adopters. Statisticians clearly belong to the second group. This distinction helps to delineate the current challenges and the role that statisticians can play to address them.
Pushing the limits of what is practically achievable with I-PETs is an active area of research for cryptographers and security engineers, that is, for technology providers. But potential adopters like statisticians can guide them to identify and prioritize the directions of work that are more relevant and compelling from their perspective. They can do so by detailing application use-cases of present or future interest in their specific domains, going beyond current practices and business processes and anticipating potential future needs. This would help I-PET providers and developers to identify the bottlenecks and critical limitations of current technologies from the perspective of official statistics. In this way, statisticians may orient technology development in the directions that would be most beneficial for them. Toward this aim, it would be important for researchers and practitioners in statistical fields to engage in application-oriented projects together with I-PET developers.
To ease adoption, it is important that I-PETs are wrapped into user-friendly solutions. Statisticians should not be required to become cryptography experts to take advantage of I-PETs, in the same way as they do not have to be experts of CPU design, computer architectures, and software compilers to write an R script. To be usable by statisticians, I-PETs capabilities must be accessed through interfaces and standard programming languages like R, python, or similar variants thereof, that are then “compiled” on platforms supporting I-PET primitives. A commendable initial proposal, targeting specifically statistical applications, was presented by Bogdanov et al. (2018) but more is needed in this area. This is an important direction of development for technology providers, and again statisticians can orient the development by identifying preferred languages, interfaces, and usability requirements.
4. Challenges for Statisticians
As a matter of fact, the I-PETs solutions that available today are already mature to potentially cover a range of statistical use-cases, but they are not being used yet in statistical production settings. This is because technological maturity, that is, readiness on the side of technology providers, is a necessary but not sufficient condition for adoption: it must be matched by readiness on the side of technology adopters for the technology to come into use.
I-PETs introduce a disruptive element of novelty that breaks with the established statistical production paradigm and therefore does not fit well in consolidated practices and processes. In the current paradigm, using the data is coupled with seeing the data: you can use the data set from another entity, that is, analyze or process it for a particular purpose, only if you see it, that is, have direct and unlimited access to the data set. Such coupling has certain implications that are hard coded in the processes, practices, and norms that shape statistical production. On the contrary, I-PETs allow to decouple using the data from seeing the data: with I-PETs one entity (e.g., the statistical office) can carry out a predefined analysis task on the data held by some other organizations without accessing them (the term “eyes-off data” has been recently introduced in the PET community to signify the approach of using-without-seeing the data). This approach implies that the analysis task must be precisely defined beforehand, that is, encoded in a piece of software code that can be “compiled” on the I-PET infrastructure.
On the methodological side, analyzing data through I-PET impacts not only the way the analysis code is executed, but also the way it is developed. To illustrate, consider the case of some analyst team (e.g., statistical office employees) tasked to develop the software script to process some new external data set held by a different organization. In the baseline scenario where the analysts have full direct access to the data set, they would probably perform a preliminary data exploration by interactively querying the data. In this way, they learn the detailed structure of the data (e.g., value ranges and distributions of individual variables, frequency of missing elements), verify and possibly complement the information from the available meta-data with additional knowledge about the data. Along the process, they could even modify the data and prepare them, that is, anticipate some (pre-)processing actions such as, for example, removing or imputing missing values, clipping or censoring extreme values, removing duplicates and alike. If the analysis task at hand requires combination of different data sets, they can test different combination functions (e.g., variations of record matching criteria). Having performed such preliminary exploration and preparation work, the main analysis code (software script) will implicitly incorporate the knowledge acquired through this phase.
Now imagine that the same analyst team is given the same task in a scenario where they do not have access to the external data set, and where launching a “query” on the target data involves a cumbersome procedure—computationally due to I-PET overhead, and organizationally due to the need to secure explicit agreement by the external data holder for each individual query. In the new scenario, the workflow must be organized differently from before. Ideally, the meta-data accompanying the dataset would be so rich and detailed to anticipate as much as possible the information that the analysts would need to consider for developing the analysis code (but without disclosing any individual information). One may think of augmenting the standard meta-data with a snippet of mocked data, similar in structure and value ranges to the original data, to support the analysts in the task of writing the analysis code. The analysis code itself may include a verbose set of consistency checks to verify explicitly, at the code execution stage, that the assumptions taken by the analyst at the code writing stage are consistent with the actual characteristics of the data.
These are just initial examples of actions that could and should be considered to adapt the methodological development practices and processes to a scenario where statistical production relies on I-PETs. As researchers and practitioners in statistical disciplines get engaged in multiparty data projects where data sets cannot be accessed directly and interactively, they will have to develop effective practices and tools to analyze data that they cannot directly see. Once consolidated, such practices and tools should be eventually institutionalized, that is, encoded in the body of soft norms that shape and regulate official statistics production: standardized business processes, codes of practices, quality assurance frameworks, methodological guidelines and alike. Through this path, organizations and individuals improve their readiness to embrace I-PETs components in statistical production.
5. Looking Ahead
Insofar we have considered the multisource scenario where the confidential data in input to the statistical production process are split over a limited number of data sets (two or a few), held by different organizations, with each data set representing a multiplicity of records referred to multiple data units (i.e., a sub-population). In other words, the data holder (e.g., a private company) intermediates between a large set of data units (e.g., the company’s customers) and the statistical office that ultimately pulls the aggregate statistical information from the data sets. This setting, exemplified in Figure 2-left, represents the kind of application scenario that we expect statistical offices will deploy initially. But as statisticians become more acquainted with I-PETs capabilities, and more fluent in working with data that they cannot access directly, it could be then possible to consider more advanced scenarios where I-PETs are leveraged to pull statistical information directly from individual data records held individually by the data units, as sketched in Figure 2-right. In this scenario, the individual data points never leave the private space of individual data units (or “respondents” in case of a survey). This is, in essence, the vision of Trusted Smart Surveys delineated in Ricciato et al. (2020).
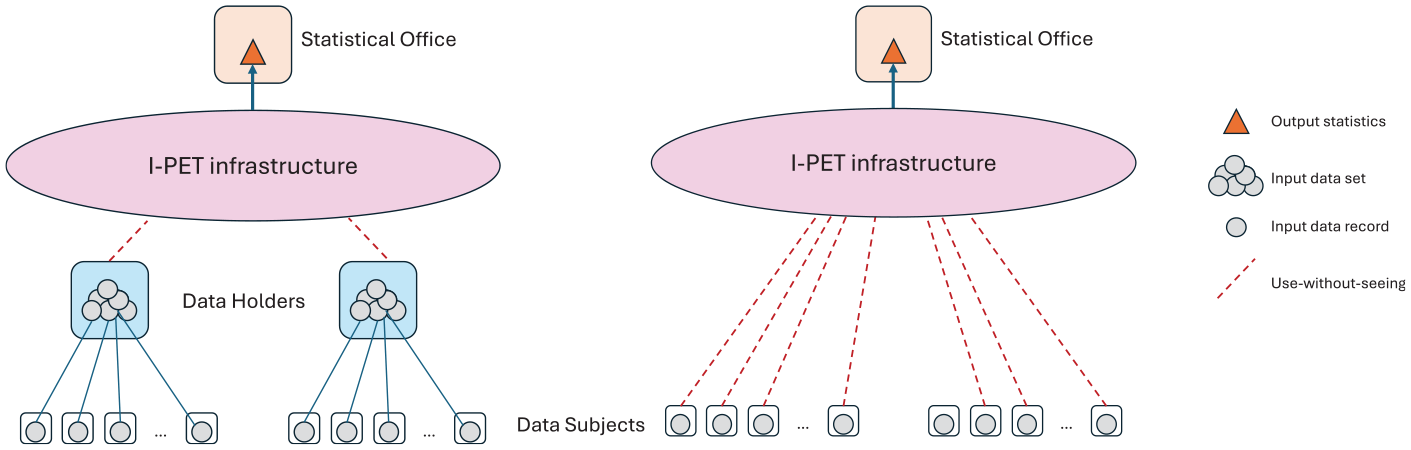
Application scenarios for I-PETs: multisource statistics (left) and Trusted Smart Surveys (right).
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Disclaimer
The views expressed in this paper are those of the author and do not necessarily represent the official position of the European Commission.
Received: January 17, 2025
Accepted: April 17, 2025