
Abstract
National Statistical Offices (NSOs) collect extensive data on the international activities of firms within their borders. However, they typically lack information about the foreign partners with whom these firms trade. Linking import data from one NSO to corresponding export data from a partner NSO could significantly enhance statistics on firms’ international operations. While technically feasible, such linkage is legally constrained by strict privacy laws. Private set intersection (PSI) protocols may help address privacy concerns but require unique identifiers to avoid linkage errors. To overcome this limitation, we propose a PSI protocol with three innovations. First, we estimate the rates of linkage error by modeling the number of links from a given record. Second, we adjust an estimated population mean according to the estimated linkage accuracy. Lastly, our adjustment explicitly accounts for this accuracy without assuming a particular relationship among the target variables.
1. Introduction
National Statistical Offices (NSOs) collect a wide range of detailed information about the international activities of the firms located within their national borders. From their customs agencies, they typically receive information on which products are traded with which countries, by which firms, and at what time. NSOs can then link this information to business registries to get a sense of the difference in trading activity by firms of different characteristics such as age or size. So, while NSOs have an extensive picture of the trade activities of the firms active within their borders, they do not know anything about the partner firm involved in each transaction. That information is only available to the NSO of the partner country. Linking both data sets on a transaction level could vastly improve our understanding of firms’ international trade and investment activities.
To illustrate this point, we focus on the issue of firms using preferential trade agreements when they trade internationally. While such agreements can significantly lower the trading costs by reducing import tariffs, preference utilization rates, that is, the proportion of eligible trade that actually uses the trade agreement, typically stagnates at around 60% to 70% (e.g., Nilsson 2022). Better understanding the obstacles that firms face in using trade agreements can significantly increase their utility. And while NSOs have information that can provide an understanding of the barriers that the importer faces, it has no information about the exporter. This is a significant shortcoming, as it’s the exporter who is responsible to provide the relevant documentation that can allow the importer to apply for preferential access.
Due to the lack of a unique firm identifier, linking these data sets would require the exchange of firm names. Privacy regulations complicate this process, especially between EU and non-EU NSOs. In this situation, private set intersection can offer a solution as it can link the data sets and compute the desired summary statistics without any exchange of microdata in the clear.
Indeed, private set intersection techniques have already demonstrated their usefulness in many applications in the public and private sectors, whether to track the spread of COVID 19 (Andreea 2021; United Nations 2023, 9), enable the sharing of administrative data across different government organizations (Straus 2021), or enable users to use mobile messaging applications without disclosing all their contacts to the service provider (Andreea 2021). Meanwhile, NSOs are also experimenting with these techniques to gain access to more data sources (Bruno et al. 2018; Dugdale et al. 2022).
Private set intersection techniques are input privacy techniques because they aim to allow “two or more parties to submit data into a calculation without the other respective parties seeing data in clear” (United Nations 2023, 20). Quite a few methods have been described to implement a private set intersection, which are reviewed by Andreea (2021). In general, these methods assume the presence of a unique identifier and make no provision for linkage errors, that is, false negatives (not linking records from the same unit) and false positives (linking records from different units), where the linkage is based on quasi-identifiers, that is, nonunique variables that may be susceptible to recording errors, such as names. Two such solutions are the protocol from De Cristofaro and Tsudik (2010, Section 5.6) and its more recent extension by Bruno et al. (2018).
To deal with the linkage errors, the authors have enhanced this latter protocol with the following three innovations. First, the rates of false negatives and false positives are estimated by modeling the number of links from a given record (Dasylva and Goussanou 2020). Second, an estimated population mean (hereafter also called mean for brevity) is adjusted according to the estimated linkage accuracy. Finally, the applied adjustment explicitly accounts for the false negatives and false positives, without assuming a particular relationship (such as a generalized linear model) among the target variables. Thus, this procedure represents a natural extension of the approach described by Judson et al. (2013) where the linked records are weighted to represent all the records under the assumption that there are no false positives. To the authors’ best knowledge, the resulting protocol is the first private set intersection protocol that addresses the issue of linkage error. It may serve to estimate a mean over a finite population of export transactions from a first country into a second country, where the import and export data sets are perfect censuses of this population, and each data set includes the linkage variables as well as one or many private variables unknown to the other party. This paper is an extension of work done by the authors as a part of the United Nations Economic Commission for Europe Input Privacy Preservation (UNECE IPP) project (UNECE 2023a).
The rest of our paper is structured as follows. The next section describes the use case. It is followed by Section 3, which provides the notation, and Section 4 that gives some background on private set intersection including the protocol by Bruno et al. (2018). Section 5 covers the statistical methodology to deal with the linkage errors, while Section 6 presents the modified protocol. In Section 7, the performance of the proposed statistical methodology is examined through simulations. Finally, Section 8 discusses the limitations and potential next steps, while Section 9 concludes the paper.
2. International Trade Use Case
As stated in the introduction, our goal is to link import data from Statistics Canada to export data from Statistics Netherlands, which would allow for a better understanding of the obstacles faced by small Dutch exporters in using the Comprehensive Economic Trade Agreement (CETA); a free trade agreement between Canada and the European Union which entered into force provisionally in 2017. While both agencies record exporter names, product codes, dates, and transaction values, only Canada records the tariff regime, and only Statistics Netherlands stores exporter details like firm size. Common variables (e.g., names, product codes, dates, and values) can serve as linkage variables, while private variables, such as Canada’s tariff data or the Netherlands’ exporter size, must remain confidential. This situation is represented in Table 1.
Variables Included in the Different Data Sets.
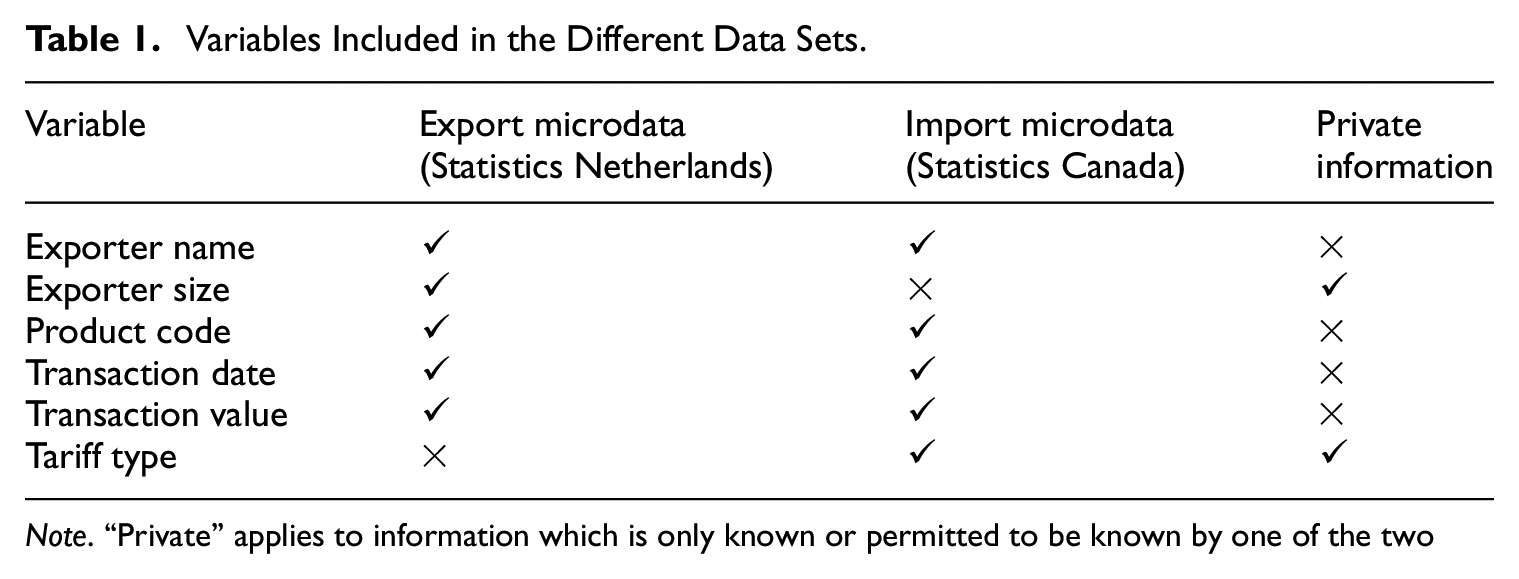
Note. “Private” applies to information which is only known or permitted to be known by one of the two parties and never shared openly.
Statistics Netherlands could assess the use of the preferential tariff by exporter characteristics based on the related proportion of transactions with this tariff, if it were authorized to link the two data sets in the clear. Instead, the two data sets must be linked in a manner that is privacy preserving and accounts for the potential linkage errors, since there is no unique identifier.
In practice, the import microdata and the export microdata are expected to be near censuses of the target population, which comprises Dutch export transactions into Canada, over a given reference period. For simplicity, the two data sets are assumed to be perfect censuses, and the values of the common variables are not considered confidential, with respect to the two data holding parties. However, this information is considered confidential with respect to any other third party. In general, each data set may comprise many private variables. Then the challenge is that of estimating a population mean that involves at least one private variable from each data set, while minimizing the information that is disclosed about the private variables for any specific transaction.
3. Notation and Assumptions
In what follows, two records are called matched if they refer to the same transaction in accordance with Fellegi and Sunter (1969), Newcombe (1988), and Herzog et al. (2007). Note that this use of the word “matched” departs from that in Christen (2012), where it means that two records are declared (based on the available information) to be from the same unit (a transaction here) regardless of whether this is true.
This work considers a target population of N mutually independent transactions indexed over
Each transaction is recorded separately in the import and export tables, with possible typos on the quasi-identifiers. However, the recorded covariates and response are assumed to be error-free. Since there is no unique identifier, the records are labeled independently in the two tables, such that their records correspond through an unknown permutation. Without losing any generality, this permutation is assumed to be uniformly distributed and independent of the attributes (quasi-identifiers or responses) of all the transactions. Also, no generality is lost by assuming that record i corresponds to transaction i in each table. This is equivalent to conditioning on the event that the permutation matrix is the identity. It is further assumed that the tuples
The population mean may be estimated by the naïve estimator that is based on the links, that is,
Confusion Matrix.
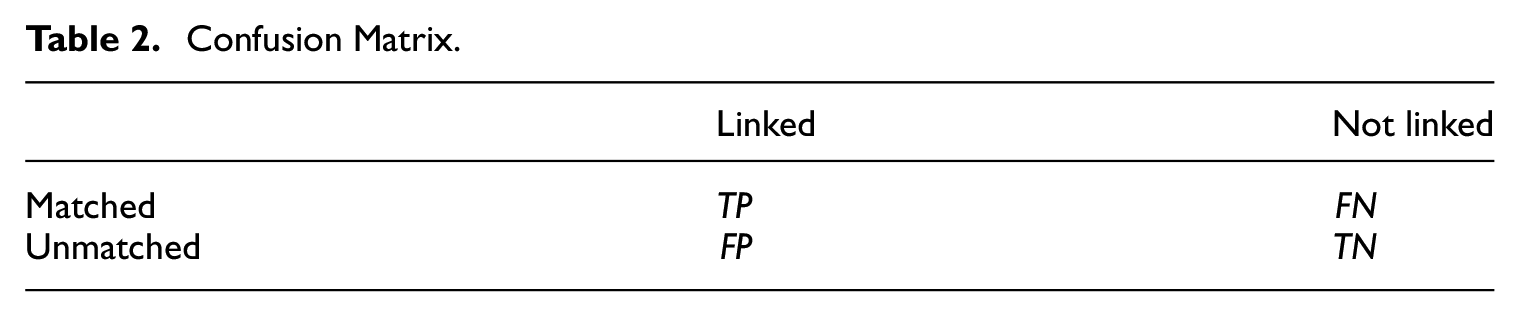
There are many measures of the linkage accuracy, which include the recall, the precision, and the false positive rate (FPR). The recall is the proportion of matched pairs that are linked (i.e.,
Finally, the standard assumption is made that the linkage errors are noninformative, that is, the linkage decisions (i.e.,
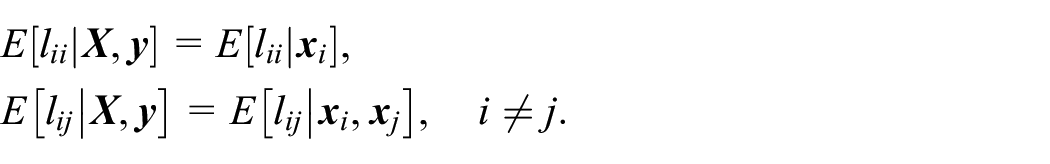
4. A Private Set Intersection Protocol
A private set intersection is an example of secure multi-Party computation (United Nations 2023, 28), where two parties determine the units represented in both their data sets without revealing any information about the other units. Additionally, some statistics (e.g., a total or a mean) may be computed over the intersection.
Bruno et al. (2018) describe such a protocol, which comprises a setup phase, a loading phase, and a query phase in this order. In the setup phase, the two parties determine the intersection of their data sets by exchanging their lists of unique identifiers that are encoded through hashing and encryption (see Appendix A for details). In the loading phase, each party encrypts the records (including the unique identifier and target variables) from the intersection with a symmetric encryption key, and it uploads them to a neutral third party called linker, who ignores the symmetric key. Also, the two data sets are linked by the third party with the encoded unique identifier. Finally, in the query phase, one of the two data-holding parties may send a request for a total over the intersection to the linker, who responds with the requested total.
The protocol is secure if the parties are non-colluding and honest but curious, that is, no two parties collaborate to defeat the protocol, and each party scrupulously follows the protocol but learns anything it can about the other parties. However, it must be adapted to deal with the linkage errors, which may occur when there is no unique identifier, such as when linking international trade data. While many other private set intersection protocols may be considered, such as the one by Pinkas et al. (2019), none of them address linkage errors. The protocol by Bruno et al. (2018) is chosen because it is easier to adapt to handle this issue than the other options.
5. Statistical Methodology
In the protocol by Bruno et al. (2018), two records are linked if they perfectly agree on a linkage key that is ideally based on a unique identifier. However, such an identifier may be unavailable, for example, when linking international trade data from different countries. Instead, the linkage key may be a concatenation of many quasi-identifiers, such as the exporter name, product code, and transaction date, at the risk of introducing linkage errors and potential bias. In this section, the authors propose to estimate the linkage accuracy with a model, and to adjust the estimated mean accordingly with a generalization of the method described by Judson et al. (2013). While the original method only adjusts for the false negatives, the proposed extension also accounts for the false positives. It requires the reliable estimation of the linkage accuracy, which is discussed next.
5.1. Estimating the Linkage Accuracy
Estimating the recall and false positive rate is what is required for adjusting the statistics derived from the linked data. In practice, these measures are typically estimated with clerical-reviews on a probability sample of record pairs, if the records are linked in the clear (Dasylva et al. 2016). These reviews consist in the visual inspection of the sampled pairs to determine if they are matched. Unfortunately, such visual inspections are usually impossible in a privacy-preserving setting. Instead, one may consider one of the many statistical models that are reviewed by Dasylva and Goussanou (2024). These solutions include models of the number of links from a record (Blakely and Salmond 2002; Dasylva and Goussanou 2020), which are preferred to other options because they have modest computation requirements, implicitly account for all the interactions among the linkage variables and are not limited to the probabilistic method of record linkage. Thus, they are easier to use in the current setup than the other options, provided that the decision to link two records involves no other record, for example, if the linkage is based on the perfect agreement of a linkage key. In this class of models, the model by Dasylva and Goussanou (2020) has the additional advantage of accounting for the records heterogeneity. It operates by modeling the number of links from a given record with a finite mixture, where each component is the convolution of a Bernoulli distribution with an independent Poisson distribution. In this model, a component represents the latent class of a record. To be specific, denote by n i the number of links from record i, in the export table. Then the model is
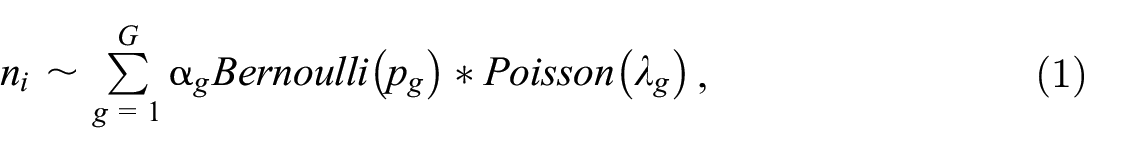
where * denotes the convolution operator, G is the number of latent classes,

as
The model may be fitted to
The same methodology applies when hashing the records into Bloom filters, which are long strings of zeros and ones (Schnell 2016). Then, two records are linked according to the number of bit positions that are set to one in the corresponding filters. Bloom filters have been used to privately link health records (Schnell 2016). The proposed model may also serve to evaluate the linkage accuracy when it varies across known strata (e.g., based on the covariates
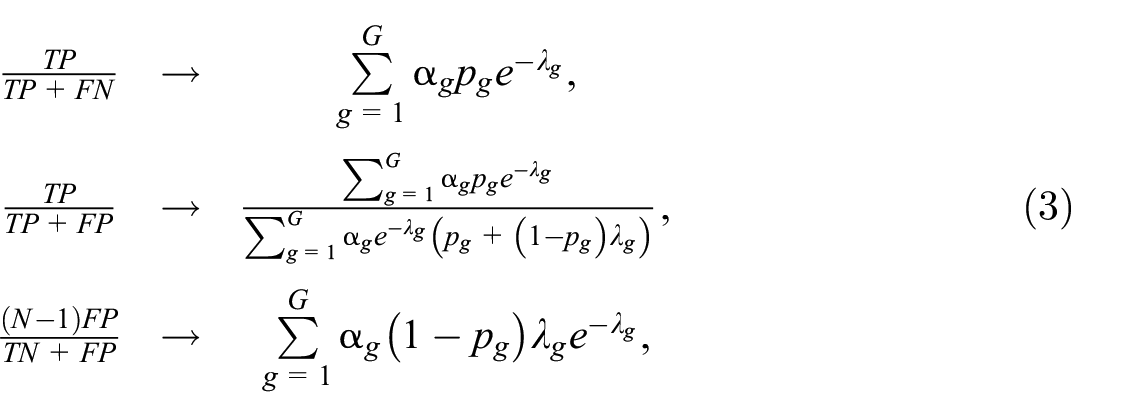
where the → symbol indicates a convergence in probability. It is important to note that the parameters are based on the n
i
’s before deleting some links. Since
Proposition 1: Suppose that all the p
g
’s are equal or
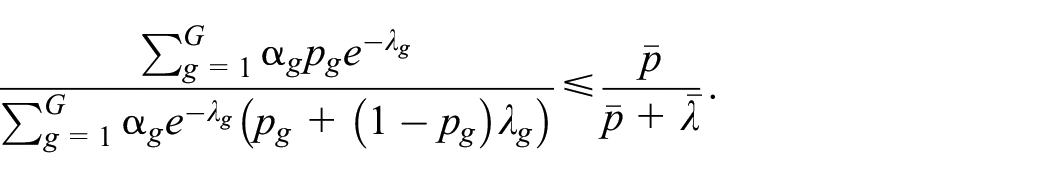
The proof is given in Appendix B.
The estimated linkage accuracy provides a basis for deciding whether to ignore the errors or to adjust for them. In general, the first option may be chosen if the estimated accuracy is sufficiently high, that is, the recall and precision are both sufficiently high, according to the population mean. The second option is adjusting the naïve estimator. When the function
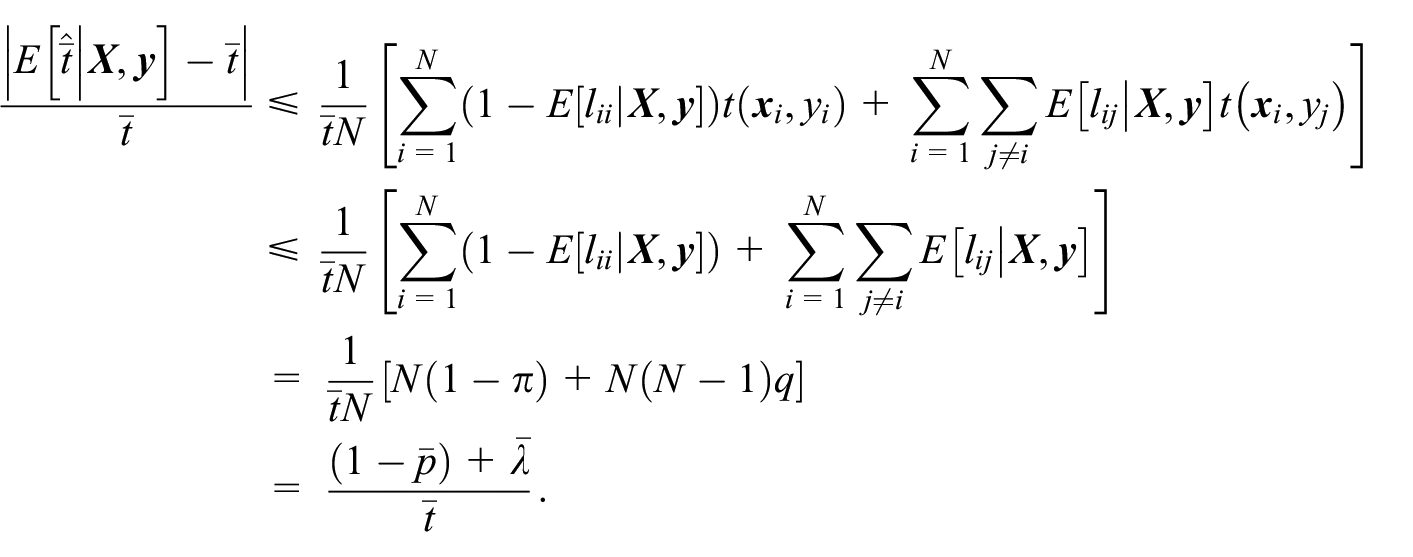
Since
5.2. Accounting for the Linkage Errors
Thanks to the pioneering work of Neter et al. (1965), it has been long known that ignoring linkage errors can seriously bias the population estimates that are derived from linked data. Since then, many methods have been proposed to account for these errors, of which most fit within the super-population inference paradigm, where the inferences are not conditional on the realized values of the response in the finite population, and the focus is on a particular parametric or semi-parametric model of the response. See Han (2018) for a review of these solutions.
Weighting the linked records: Judson et al. (2013), and Christidis et al. (2018) describe an alternative approach that is common in health and social studies. It is also better suited to the finite population inference paradigm and does not assume a particular response model, in contrast to the situation under the super-population paradigm. This approach consists of linking the records with a high precision, and in reweighting the linked records to account for the false negatives, under the assumption that there are no false positives. Then, the linkage process is essentially equivalent to a sampling process (the sample comprising the true positives), so that one may draw from classical sampling theory to derive consistent estimators and study their properties, for example, the Horwitz-Thompson and Hajek estimators. Indeed, denote by

while Hajek’s estimator is

It is also possible to use a calibrated estimator of the form

where the weight w
i
is obtained by calibrating the sampling weight
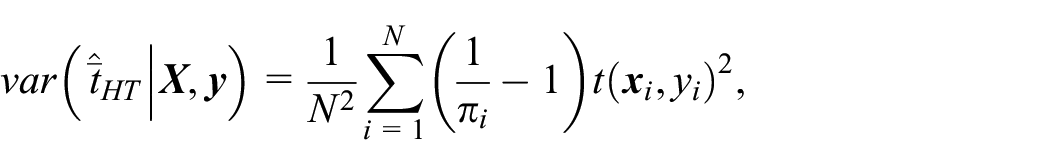
which is estimated without bias by
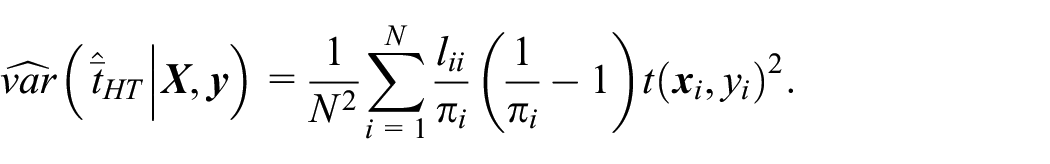
The variance of the Hajek and calibrated estimators have no closed-form expressions, but they may be estimated by linearization or resampling. The same is true for the Horwitz-Thompson, where the recall is estimated.
New point estimators: A potential limitation of the above methodology is the assumption that the false positives are negligible. The authors have addressed this limitation with two distinct linkages, where the first linkage may be stricter than the second one. For example, the first linkage key may concatenate the exporter name, product code, transaction date, and transaction value, while the second linkage may only concatenate the exporter name, product code, and transaction date. For the pair
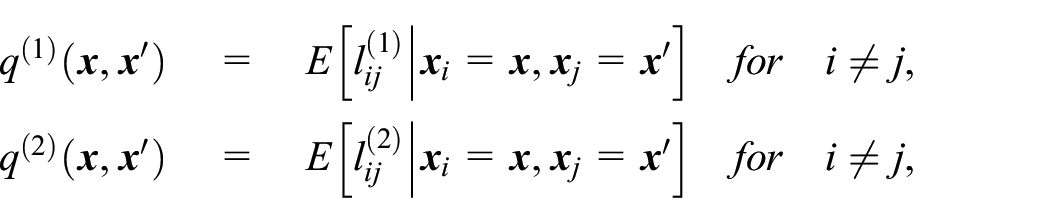
which give the false positive probabilities for an unmatched pair given
Proposition 2: Suppose that
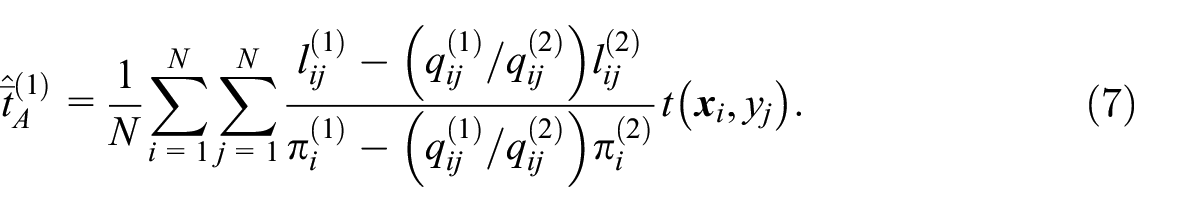
The proof is given in Appendix C.
The estimator
In what follows, it is assumed that the false positive probabilities are such that
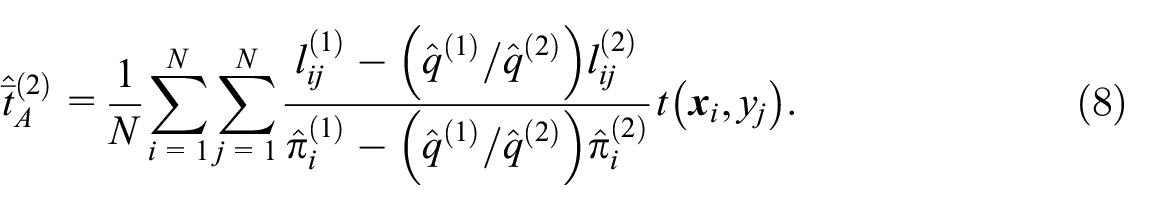
Another simplification occurs when the probabilities
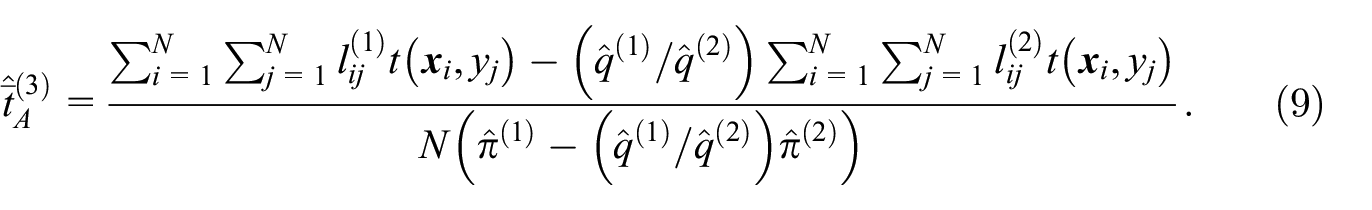
Further simplifications occur, if the function
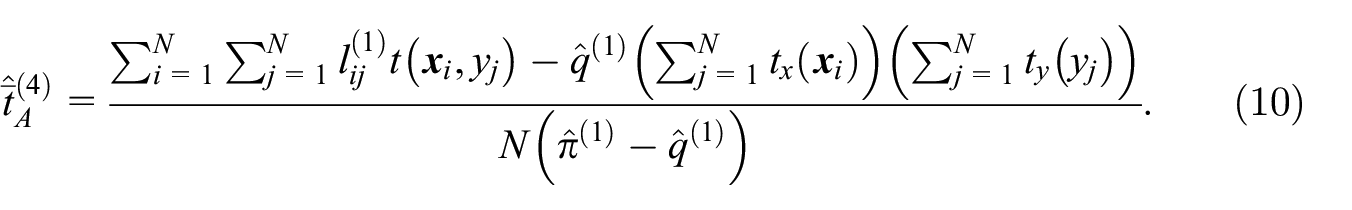
Variance estimation: The authors have developed a bootstrap procedure to estimate the variance of
6. Modified Protocol
To handle the linkage errors, the authors have modified the protocol by Bruno et al. (2018) under the assumption that
Setup: In this step, there are three changes. First, the setup now comprises four rounds for two distinct linkage keys (including two rounds per key), instead of two rounds for a single key previously. Second, each round incorporates the computation of the n i ’s and the subsequent estimation of the linkage accuracy. For a given client record (i.e., a record from the data-holding party that is the client in the round), n i is set to the number of server records (i.e., records from the data-holding party that is the server in the round) with the same value of the encoded linkage key. Then, this information is used to estimate the linkage accuracy according to Equations (1) and (2). Third, the intersection of the two data sets is based on the two linkage keys instead of a single key previously. To be specific a client record i is placed in the intersection if n i is positive for at least one linkage key. When the second linkage key is laxer than the first one (i.e., perfect agreement on the first key implies perfect agreement on the second key), this means that the record is placed in the intersection if n i is positive for the second linkage key. Figure A2 shows the modified setup phase in Appendix A.
Loading phase: In this step, the change is that the two encoded linkage keys are included in the intersection data set, instead of a single encoded key based previously. The remaining details are as before, that is, the intersection data set also includes the target variables, it is encrypted with a symmetric key, and it is sent to the linker by each data-holding party.
Query phase: In this step there are two changes. The first change is implemented at the linker, who responds to a count request (e.g., the number of transactions for a given exporter type and tariff type) from a data-holding party, by computing two totals, including one total for each linkage key. These totals are
The above protocol has been implemented in Python, in the special case where the second key is error-free (i.e.,
7. Simulations
Simulations are performed to evaluate the error estimation and error adjustment procedures, when the goal is to estimate the proportion of transactions with a preferential tariff, that is, the unweighted Preferential Utilization Rate, for small and large Dutch exporters. They are based on mock transactions and are implemented in R without running the implemented private set intersection protocol.
7.1. Simulation Setup
The simulations comprise the following two steps.
First step: A finite population of transactions is generated, including the product code, date, value, and tariff preference for each transaction. This population comprises two strata of equal sizes for small and large Dutch exporters. The product code is selected with replacement from a list of ten six-digit codes in keeping with the standard format of these codes (World Customs Organization 2022). The date is sampled with replacement from the days in the year 2021. The tariff preference follows a Bernoulli distribution with probability .25 or .40 according to whether the exporter is small or large, respectively. Finally, the value is selected by drawing a number uniformly between 0 and 1,000,000.
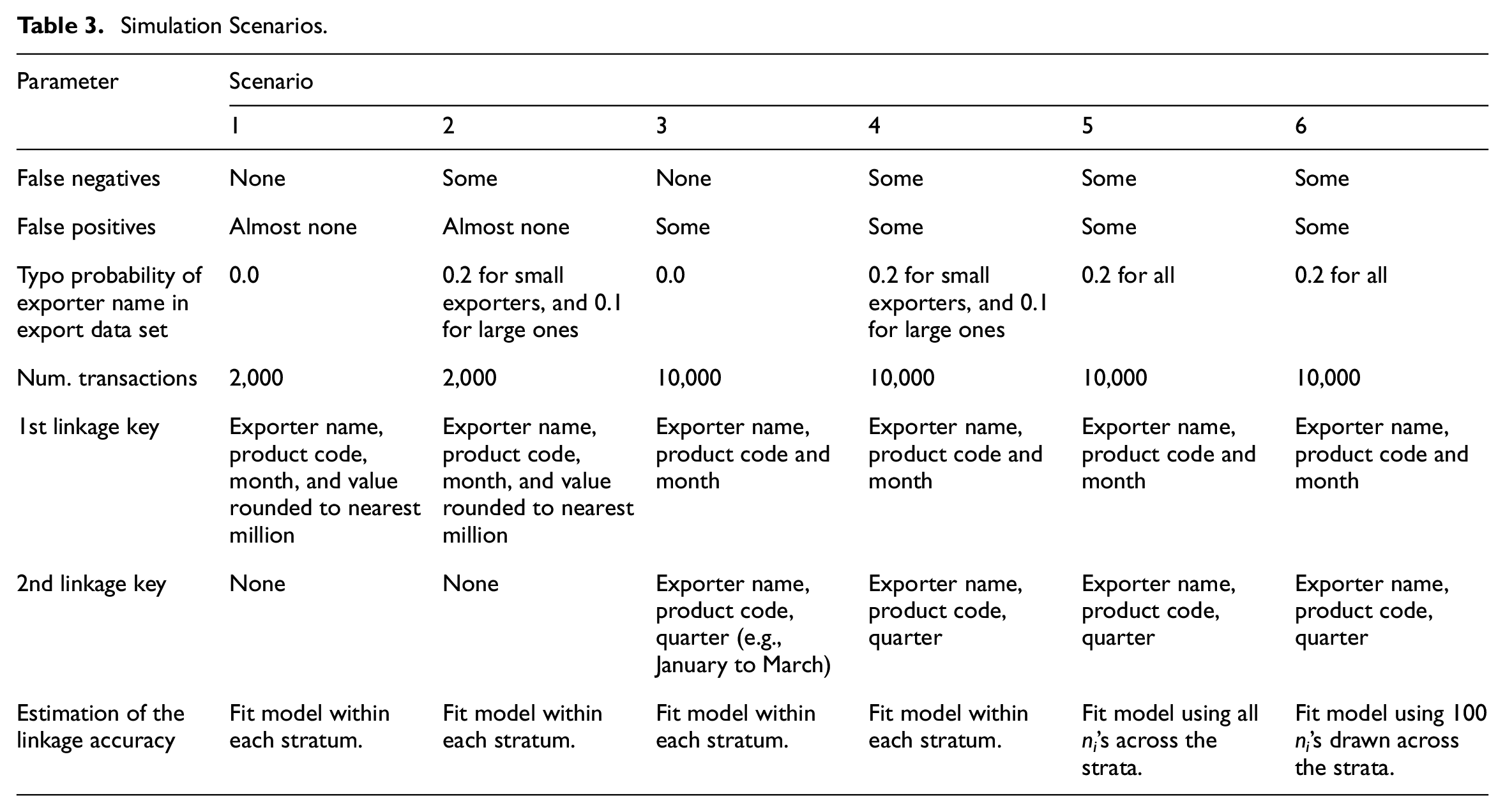
Second step: It comprises 100 repetitions, where the product code, date, value, and tariff preference are held fixed for each transaction. In a repetition, each transaction is assigned an exporter name that is sampled with replacement from 947 publicly listed firms (Securities and Exchange Commission). Next, the import and export data sets are created by recording the attributes of each transaction, that is, the product code, date, value, and tariff preference, in addition to the exporter name. The latter is recorded without errors on the import side set but possibly with typos on the export side. Finally, the data sets are linked using the available variables, and the proportion of transactions with a preferential tariff is estimated for each exporter size. There are six scenarios that are described in Table 3. In scenarios 1 and 2, there are 2,000 transactions. In scenarios 3 to 6, there are instead 10,000 transactions, which results in a significant increase in the number of false positives compared to scenarios 1 and 2, where there are almost none. In scenarios 5 and 6, the variance is estimated with the bootstrap procedure described in Appendix C.
Simulation Scenarios.
7.2. Results
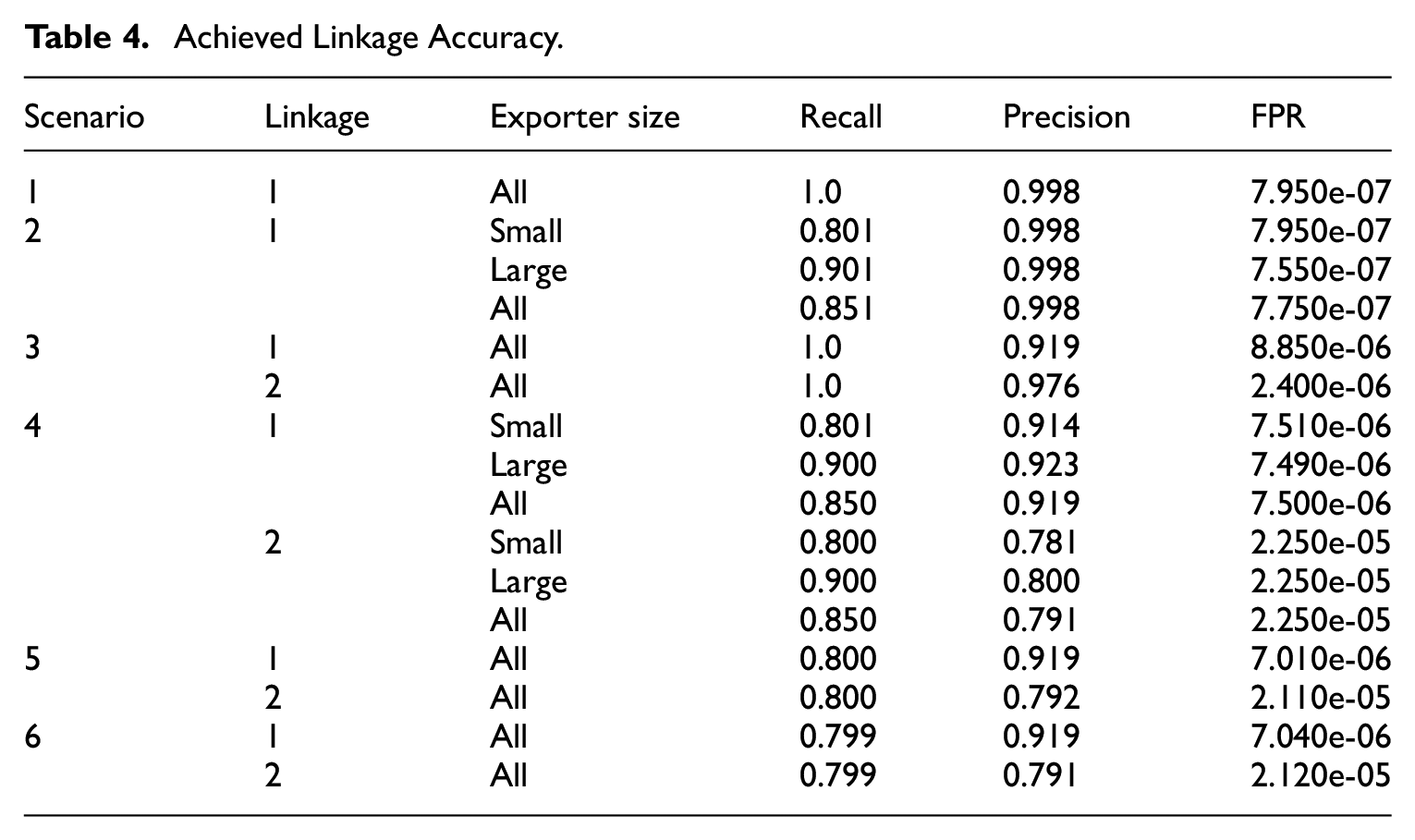
The results are shown in Tables 4 to 9, where RRMSE means relative root mean squared error, and FPR means False Positive Rate. Tables 4 and 5 show the achieved and estimated linkage accuracy, where the recall and precision are always estimated with a small relative bias and RRMSE. The FPR is estimated with a moderate relative bias, which does not exceed 10% in absolute value. However, the variance may be quite large as evidenced by the RRMSE where the precision is very high or few n i ’s are used to estimate the linkage accuracy, as in scenarios 1, 2, and 6. Tables 6 and 7 show the performance of the estimated proportion based on the proposed adjustments. In scenario 1, where there are no false negatives and the precision is very high, the linkage errors can be ignored. In scenario 2, where there are false negatives and almost no false positives, only adjusting for the false negatives is sufficient and preferred to applying a full adjustment, because of the large variance of the estimated FPR. In scenario 3, where there are no false negatives but nonnegligible false positives, it is beneficial and sufficient to only adjust for the false positives. In scenario 4, where the false negatives and false positives are nonnegligible, a full adjustment is required and beneficial. This is also true in scenarios 5 and 6, where the adjustment based on Equation (10) is more effective than that based on Equation (8), when it comes to the RRMSE. Tables 8 and 9 show the bootstrap variance in scenarios 5 and 6, where the relative bias may be large if using all the n i ’s to estimate the linkage accuracy as in scenario 5. However, in scenario 6 (using only 100 n i ’s instead of all of them), the bootstrap variance has a small bias. All these results demonstrate that the proposed methodology performs as expected.
Achieved Linkage Accuracy.
Estimated Linkage Accuracy.
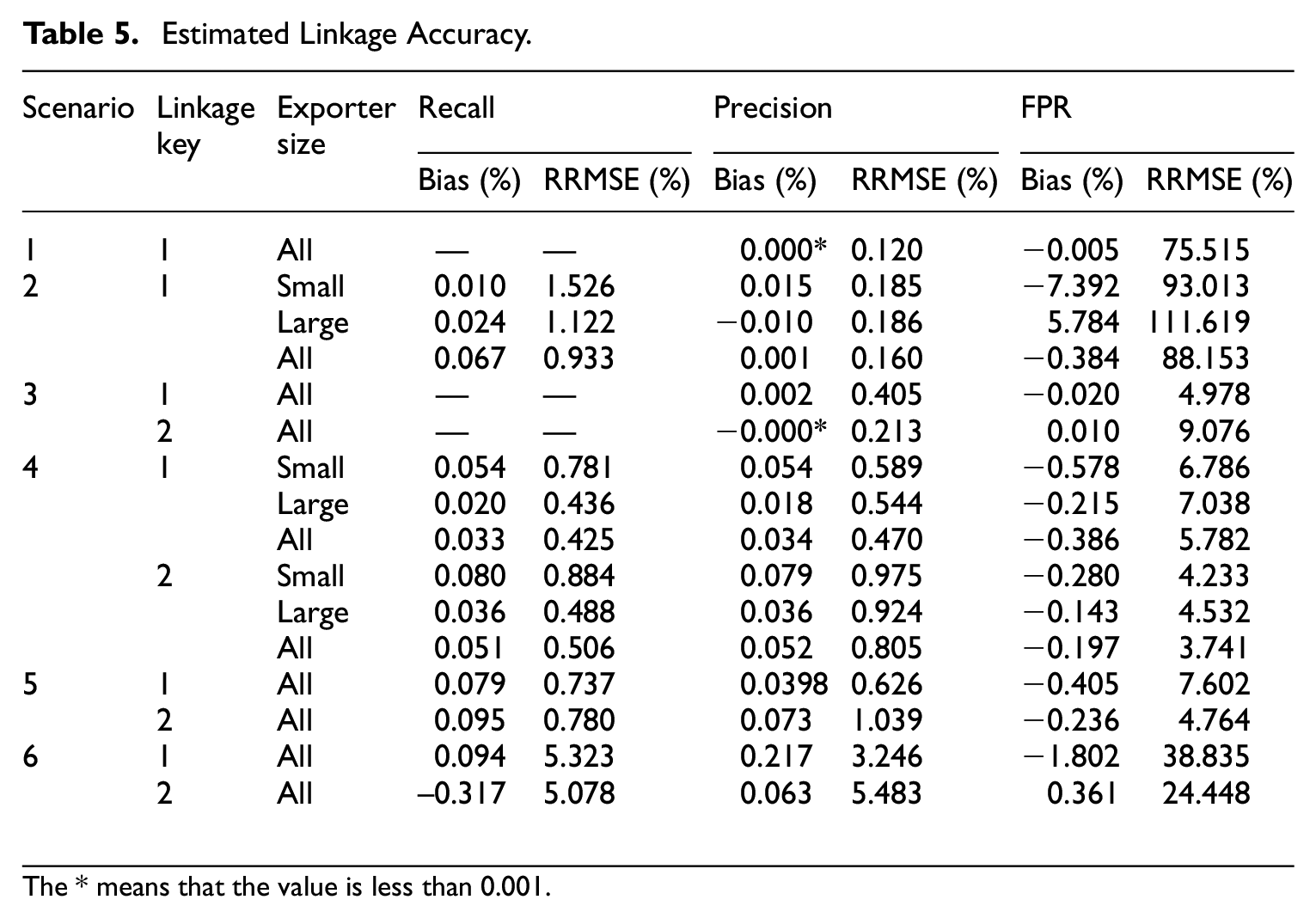
The * means that the value is less than 0.001.
Estimated Proportion with the Preferential Tariff in Scenarios 1 to 4.
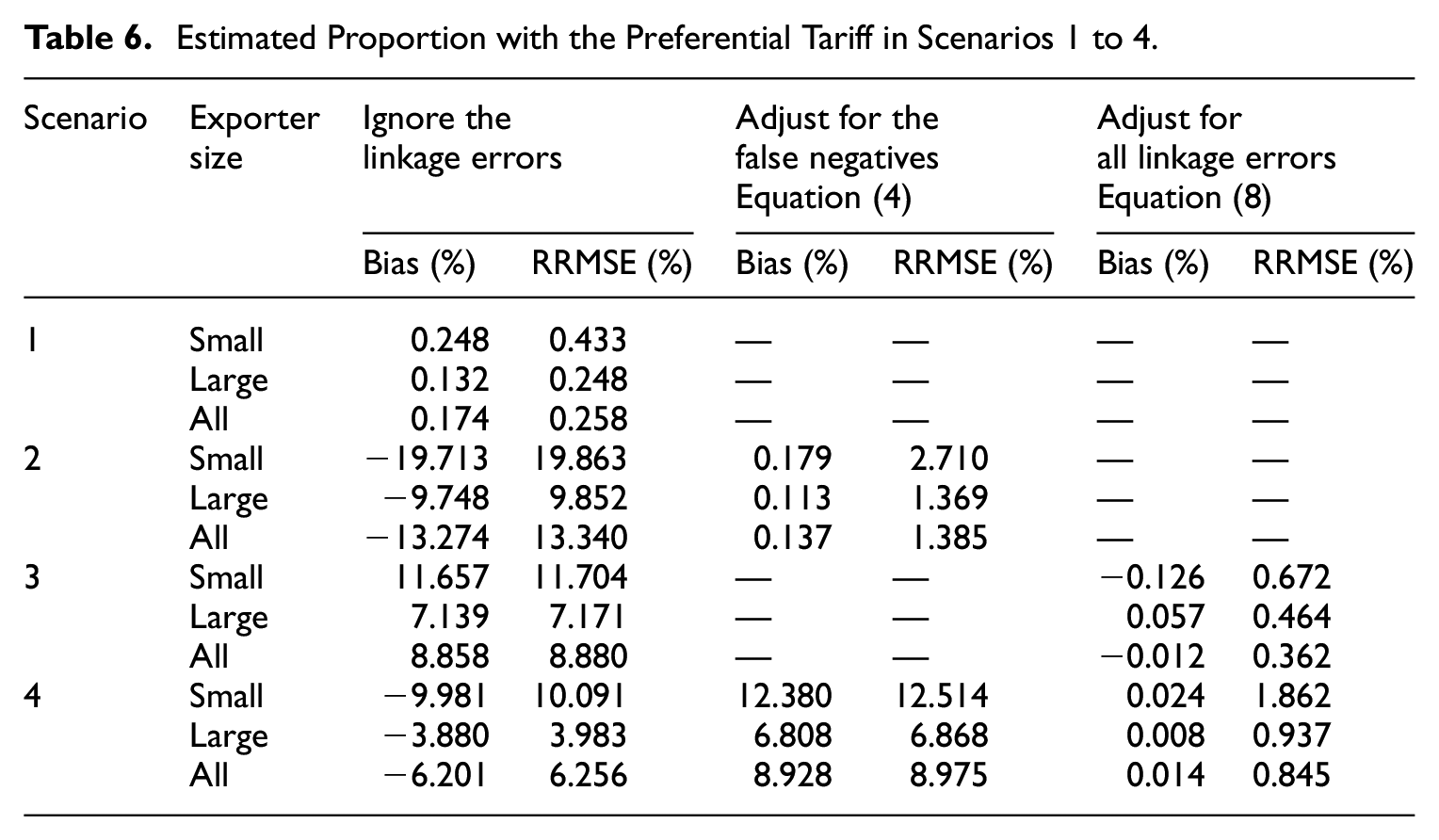
Estimated Proportion with the Preferential Tariff in Scenarios 5 and 6.
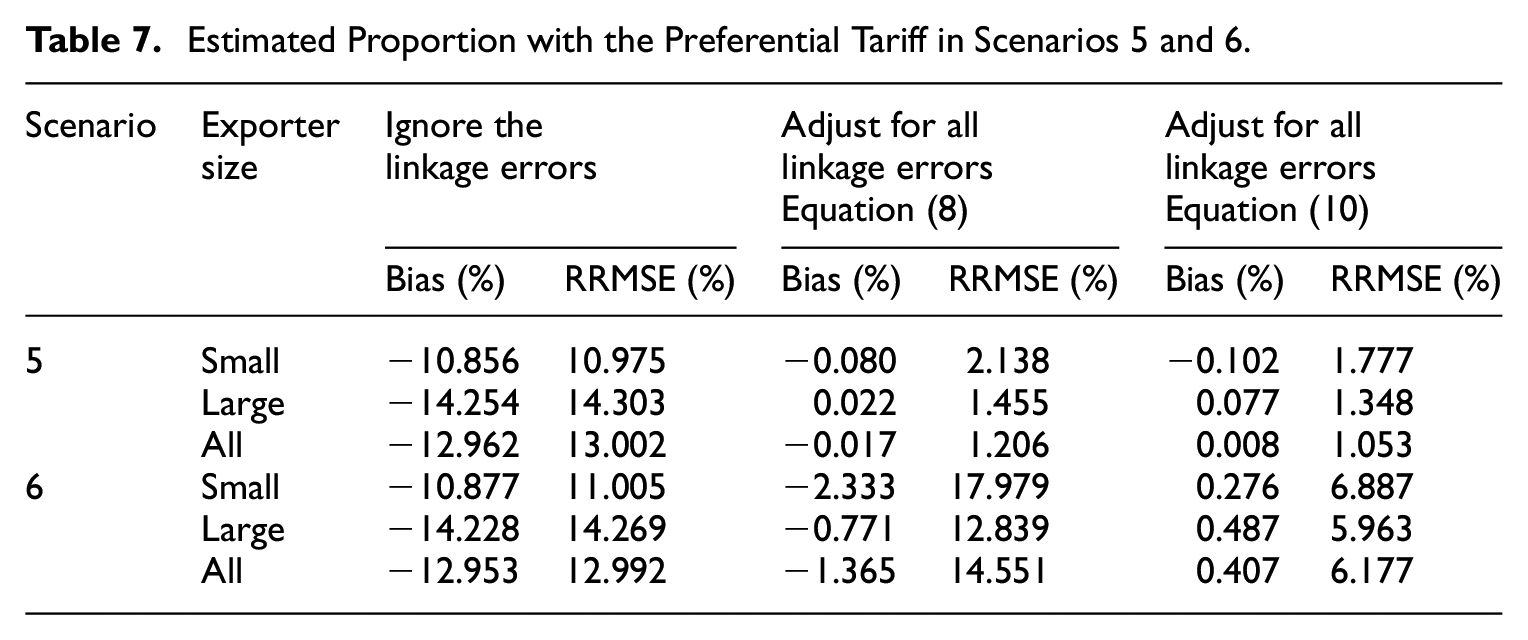
Bias (%) of the Bootstrap Variance for the Estimated Linkage Accuracy in Scenarios 5 and 6.
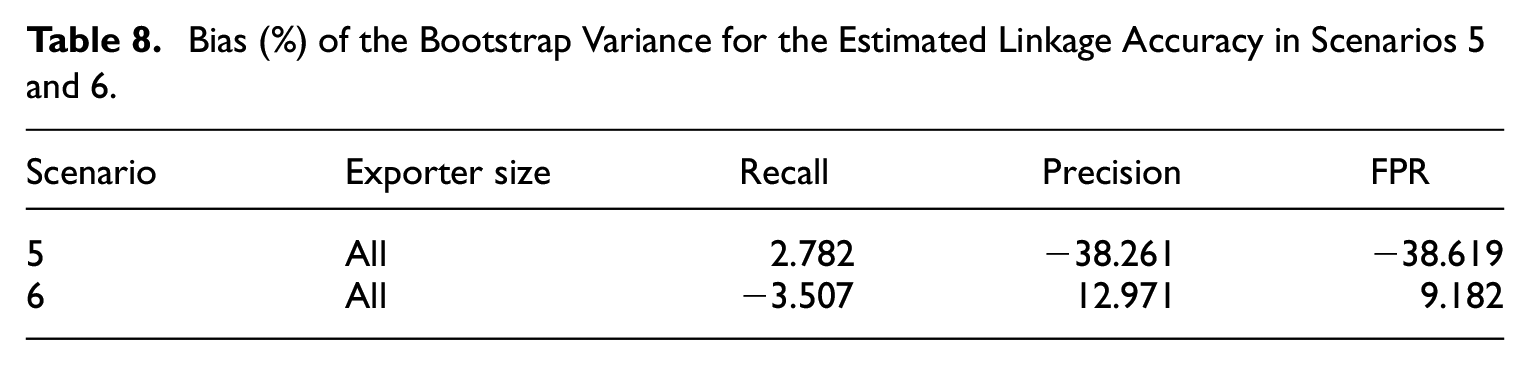
Bias (%) of the Bootstrap Variance for Estimated Proportion with a Preferential Tariff in Scenarios 5 and 6.

8. Limitations and Next Steps
The proposed solution performs well in simulations, but it has many limitations. For example, it does not apply when the data sets are samples, in which case the estimated population mean may be biased. A second issue is the lack of support for continuous target variables. A third limitation is the absence of mechanisms to audit the queries from the data-holding parties or to control the statistical disclosure. One way to address these limitations is to perturb the linked data according to differential privacy techniques, and to implement the resulting methodology within a trusted execution environment as suggested by Zhang and Haraldsen (2022). A trusted execution environment is a technology that endeavors to “mimic the behavior of a trusted third party by attesting the functionality performed by hardware or by a cloud provider” (United Nations 2023, 20). It allows more flexible computations than cryptographic solutions, which means that the target variables may be continuous, and the linkage strategy may be more flexible and based on available packages in Python or R. It is also easy to accommodate situations where the membership in the intersection is sensitive, and to produce some synthetic data from the linked data using state-of-the-art solutions for this purpose (UNECE 2023c). For applications, the most immediate way to exploit the described solution is to link the records with a high precision and weight the linked records under the assumption that there are no false positives. Indeed, this leads to correct statistical inferences according to classical sampling theory.
There are also many open problems, which represent so many opportunities for advancing the state of the art. One of them is developing statistically sound resampling techniques for linked data. Indeed, progress in this area would enable correct statistical inferences, when relaxing the assumption that there are no false positives. A second research avenue concerns the development of the linkage strategy when using a trusted execution environment. Indeed, when linking with quasi-identifiers, the final linkage strategy is usually an iterative process that involves some trial and error, for example, to choose the record comparison functions and other critical parameters such as the weight threshold in the probabilistic method of record linkage (Fellegi and Sunter 1969). In the clear, each iteration typically involves many human interventions to evaluate the linkage accuracy and tune the linkage parameters. With a trusted execution environment, these interventions may be based on the reported linkage accuracy. However, the release of this information is likely to have an impact on the privacy budget, which must be studied, especially if the membership in the intersection is sensitive information. Another way to address this problem is to minimize and possibly eliminate human interventions by fully automating the design of the linkage strategy with machine learning techniques, within the trusted execution environment. This requires the development of machine learning solutions that can automatically choose from a large catalog of record comparison options without any training data. Additionally, this must be done while retaining the ability to evaluate the impact of each choice on the linkage accuracy. Dasylva and Chen (2022) describe an adaptation of recursive partitioning that is a step in this direction.
9. Conclusion
Linking international trade microdata from different countries could lead to a step change in providing better statistics and research into international dependencies. In this regard, private set intersection techniques could be a useful tool as they allow linkage while safeguarding privacy in accordance with the law. However, they must be adapted to link with quasi-identifiers and handle linkage errors. To do so, the authors have modified the protocol by Bruno et al. (2018) to estimate the linkage accuracy and adjust an estimated population mean according to the linkage error. This procedure allows us to calculate a novel statistic, in this case the preference utilization rate of Dutch exporters categorized by their size, which would provide further insights into the (lack of) use of preferential benefits by different types of firms. Through better statistics, governments can better understand the obstacles faced by firms, when trying to use preferential trade agreements, since current utilization rates typically fall between 60% and 70%. In turn, the resulting knowledge can guide policies aimed at further lowering firms’ trading costs. Furthermore, the low utilization of preferential tariffs clearly demonstrates that international trade statistics must keep up with globalization, which increases interdependence among countries.
Footnotes
Appendix A
Appendix B
Appendix C
Acknowledgements
This study was carried out in the context of the United Nations Economic Commission for Europe Input Privacy Preservation (UNECE IPP) project.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Disclaimer
The views expressed represent the authors’ opinions and not those of their respective statistical organizations.
Received: July 31, 2023
Accepted: March 5, 2025