
Abstract
Any result from regression analysis may be subject to omitted variable bias of unknown magnitude and direction as, in practice, no dataset contains all the variables of the population model. At the same time, many variables are irrelevant and don’t contribute to the analysis. This paper explores which combination of data sources or structures will produce the best results and should be made available to the research community. We present a unified statistical framework that nests and comparable sets of constraints that characterize the effectiveness of these approaches in reducing omitted variable bias. We demonstrate our framework by estimating a wage and labor market transition model using German administrative data with a large set of linked survey variables. Overall, we find that unobserved effects panel data models with a restricted set of regressors are preferable to cross-sectional analysis with an extended set of variables. Consequently, we recommend that data providers supply administrative panel data for key variables instead of conducting extensive cross-sectional surveys.
1. Introduction
Official data products are increasingly based on combinations of data sources that were previously not used in official data production, such as administrative registers. New data quality frameworks are required to address various issues that are not present in survey data (Berka et al. 2012; Schnetzer et al. 2015; Zhang 2012). A body of literature already exists on the consequences of producing official statistics from linked administrative data, particularly regarding coverage and selectivity (de Wolf et al. 2019; Di Consiglio and Tuoto 2015; Harron et al. 2017; Yildiz and Smith 2015). Other literature focuses on frameworks for evaluating data quality (e.g., Oberski et al. 2017). The advantages and disadvantages of administrative data have been thoroughly elaborated by Hand (2018).
This paper contributes to the literature by considering the consequences of incomplete data structures on estimation results of regression models at the individual level. Administrative data are known to be incomplete, as they do not include all relevant variables. The omission of variables leads to biases and statistical inconsistencies in the estimated coefficients of regression models. From this perspective, we compare different cross-sectional and panel data structures commonly available to the research community. We consider both data that contain only administrative information and data that also include linked survey variables.
We present a general model compatible with a wide range of datasets and applications, though we focus on labor economics as an example. Research in economics, business, and related disciplines increasingly uses linked administrative data to benefit from larger sample sizes and higher precision in key variables, often overlooking the disadvantages of using such data, as elaborated by Hand (2018). One significant limitation is that these data only contain information generated through operational processes. Therefore, there is often a systematic lack of information on factors beyond operational processes, and even if such information is available, one should expect severe misclassification errors, requiring advanced estimation approaches (Dlugosz et al. 2017).
The existence of linked administrative data does not guarantee that all information is made accessible to researchers. In particular, not all variables are available due to data confidentiality restrictions. Tools have been developed to better understand the relevance of omitted variable bias (e.g., Gelbach 2016; Oster 2019). Rather than focusing on a single data structure, this paper builds on three common empirical strategies for reducing omitted variable bias through different combinations of data sources. While these approaches are general and not specific to one subject area, we frame the problem description and methodology illustration in the context of labor market research. The first approach is to include variables constructed from an individual’s work history as recorded in administrative data (e.g., Baptista et al. 2012; Biewen et al. 2014; Fernández-Kranz and Rodríguez-Planas 2011; Kauhanen and Napari 2012). Work history variables may directly correspond to the population model or serve as proxies for otherwise unobserved variables, such as performance. While using proxies is practically appealing, it does not guarantee bias reduction or consistent estimation. A second approach to mitigating the incompleteness of administrative variables is to incorporate survey-based variables, such as information on personality or motivation. Since the production of survey data is typically costly, it is essential to assess how much these variables contribute to the model. The third approach is to use longitudinal data, as panel models operate under weaker assumptions about the relationship between regressors and unobservables, thus facilitating analysis in the presence of omitted variables.
Despite the widespread use of work history and survey-based variables, little systematic research has been conducted to assess how effective they are in controlling for unobserved factors. Analyses aimed at investigating their role have, so far, been limited to sensitivity analyses. For example, Lechner and Wunsch (2013), Arni et al. (2014), and Caliendo et al. (2014) investigate whether the estimated treatment effects of labor market programs on labor market outcomes are sensitive to the inclusion of additional variables. Our analysis goes beyond a sensitivity analysis by suggesting statistical inference approaches to test the validity of model restrictions. We provide a formal framework for understanding estimation bias due to the omission of important variables, as well as estimation bias arising from the use of imperfect proxy variables. Our starting point is a widely used administrative data product that contains only a limited number of variables. We then assess the extent to which additional non-operational, survey-based variables and work history variables contribute to the model and alter the results. Moreover, we compare the results of cross-sectional analysis with those of panel analysis to determine how much the additional cross-sectional variables explain the variation in unobserved, individual, time-invariant effects. We apply our framework to German administrative labor market data that is linked to survey data. Based on our results, we draw conclusions about how different data structures control for unobserved factors and test the validity of the different approaches. Lastly, we derive recommendations for applied researchers and data producers.
In Section 2, the econometric problem is outlined. Section 3 describes the data, and Section 4 presents the empirical findings. The final section summarizes the results and provides recommendations.
2. The Model
Suppose a researcher has access to some standard administrative data product with a restricted set of core variables. We consider the linear multiple regression model with population model

where β (J × 1) and γ (L × 1) are unknown parameters, X (1 ×J) are observable regressors (including the first element being a constant) and W (1 ×L) are unobserved regressors with L being unknown. We will later relax this to some of the components of W being observed. We assume that the components of X and W are not perfectly multicollinear. y is observed and v is unobserved. We assume E(v|X, W) = 0.
2.1. Omitted Variable Bias
Because W is unobserved, the model in Equation (1) cannot be directly estimated. Instead, one could omit the unobserved variables and use Ordinary Least Squares (OLS) to estimate the model

where u = Wγ+v. This is what is typically done in applications. It is well known that if there exists a j such that cov(x
j
, u) ≠ 0, the OLS estimator

with δ is J × L and R is 1 ×L. Let r l be the l’th component of R. By definition E(r l ) = 0 and cov(x j , r l ) = 0 for j = 1, …, J and l = 1, …, L (Wooldridge 2010, 26). When plugging W into Equation (1) we obtain

In this model, all regressors are uncorrelated with the composite error Rγ+v and therefore the probability limit of the OLS estimator

This is the well-known omitted variables bias (e.g., Wooldridge 2010, 66–7) and its size depends on the strength of the partial correlation between W and X and the size of the elements of γ, that is, the relevance of the omitted variables in the population model Equation (1). Since W is not observed, the size and direction of the bias are unknown in an application. This is in contrast to the approach in Gelbach (2016) that focuses on variable selection. Oster (2019) thoroughly examines omitted variable bias, offering estimable expressions under constraints on unobserved variables W. The focus lies on cases where a component of X is correlated with W and requires uncorrelated components within W. We have applied her method to our problem but found the estimated proportional selection relationship to jump strongly across variables. Given this instability and that the restrictions on her model exceed what we assume in our model, we focus on alternative approaches aiming at reducing the omitted variable bias. These are presented in the remainder of this section, along with subsequent validity testing.
2.2. Proxy Variables
One approach to mitigate omitted variable bias is to plug in generated variables from the observable history of cross-section units. In labor market research these are for example variables that characterize the work history of an individual and not simply lagged observable variables. These are denoted as Z (1 ×P). It is required that none of the components of X and Z are highly correlated or perfectly multicollinear, which can be checked in an application. In most applications, P is a small integer and one should expect P ≤ L, that is, there are fewer constructed variables than omitted variables. The role of Z requires some discussion. For the reasons provided in the introduction, a special case is attained if a z j is a proxy variable for one unobserved w l , that is, z j = w l + error with E(error) = 0. However, more generally z j can be related to any W, that is, z j = θ0 + Wθ j + m j with E(mj|W) = 0 for all j. θ0 (1 × 1) and θ j (L × 1) are unknown to the researcher. If z j is a proxy for w l , then only the l’th element of θ j is nonzero. This is the case that is typically considered by the proxy variable literature (Bollinger and Minier 2015; Lubotsky and Wittenberg 2006). Using Z instead of W can be also interpreted as a measurement error problem. Here any deviation from the linear combination Wθ j , which is m j , is the measurement error. Alternatively, one could think of zjεW. In this case, the constructed variable would directly belong to the population model. Then m j = 0, one component of θ j is 1 and the others are 0. Lastly, z j may not be correlated with any component of W. In this case θ j = 0 and z j should not be included at all. A researcher normally faces the problem of not knowing the exact role of the components of Z. In any case, it depends on the statistical relationship between X, W, and the m j s, whether the inclusion of Z mitigates or increases the omitted variable bias. Given that W and L are unknown, it is more convenient to write the linear projection of the linear combination of the w l s onto the z j s, that is, Wγ = α + Zλ+e with E(e|Z) = 0 and parameters α (1 × 1) and λ (P × 1). e can be interpreted as the measurement or approximation error between Wγ and Zλ, which is the variation in the linear combination of unobserved variables that is not explained by the linear combination of constructed and included variables in Z. Therefore

For β in model Equation (4) to be consistently estimated by OLS, it is additionally required that e is uncorrelated with X and v with Z. This is not the case if X plays a role in the linear projection of Wγ on Z and X, so it is required E(Wγ|X, Z) = E(Wγ|Z). v is uncorrelated with Z is ensured by E(y|X, W, Z) = E(y|X, W), that is, the redundancy of Z in the population model. The reason for this is that in this case cov(z
j
, v) = 0 for all j. Whether the bias in
2.3. Survey Data
Another approach to mitigate omitted variable bias is to enhance the regressor set by conducting a survey or by using additional administrative variables that are normally not accessible. Suppose that a subset W1 of W, by assumption the first L1 variables of W, is observable for some random sample of the population. The idea is to do an analysis with a richer variable set. For direct comparability of the results across models, we always restrict the analysis to the cross-section units for which we have information on W1. Thus, we ignore the potential loss in precision and focus on asymptotic bias only. We consider the case, where the researcher is primarily interested in estimating the partial relationship between y and elements of X, rather than between y and elements W1, although the latter will be typically also of interest. W2 is 1 ×L2 and comprises of the last L2 elements of W with L1 + L2 = L. W2, the remaining unobservable variables, may be correlated with X and W1. Therefore, their omission induces a bias for estimated β and γ(1) in the regression of y on X and W1:

where γ(1) contains the first L1 elements of γ and u2 = W2γ(2) + v, where γ(2) consists of the last L2 elements of γ. Unfortunately, there is no guarantee that including more variables indeed will reduce the bias but in practice, one should expect this. The reason is that the number of summands in the bias term in Equation (3) decreases from L to L2 when reducing the number of omitted variables. However, this may not lead to a reduction in the bias as the magnitude and sign of the various components of 6 and γ are not restricted.
2.4. Panel Data
Instead of enhancing the set of observable variables, one can exploit the availability of longitudinal information, that is, panel data, to mitigate the bias from the omission of W. y, X, and Z are observed in periods t = 1, …, T with T ≥ 2 and observations are denoted as y it , X it , and Z it , respectively, for units i = 1, … N. W1 is assumed to be observed in one period only and W2 is never observed. We consider a fixed effects (FE) model:

with a i + q it = u it . a i is assumed to be time-invariant (the so-called fixed effect) and q it is a time-varying error. We choose the FE model because it allows for arbitrary correlations between X and a. A more flexible specification of the individual effect would be a model with individual specific slope parameters (Wooldridge 2010, 11.7.2) but we focus here on the classical model for brevity. The FE estimator only consistently estimates β if E(qit|Xi, ai) = 0 with X i = (Xi1, …, X iT ), but neither γ(1) nor γ(2) are estimated as W1 is not available for more than one period and W2 is unavailable. Whether β is consistently estimated depends on the relationship between W and X because
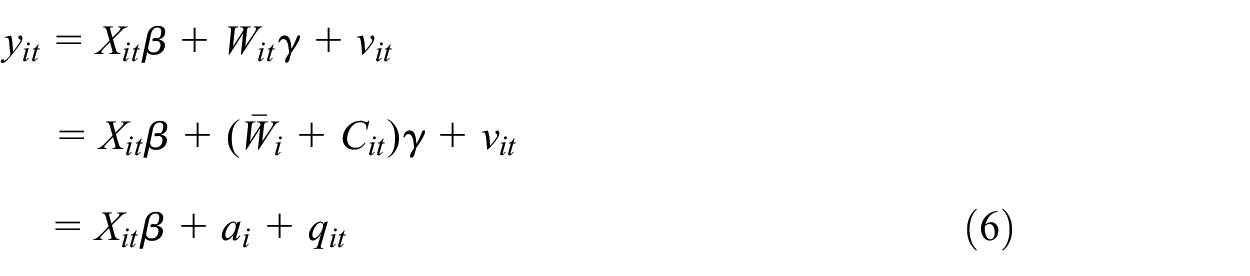
with
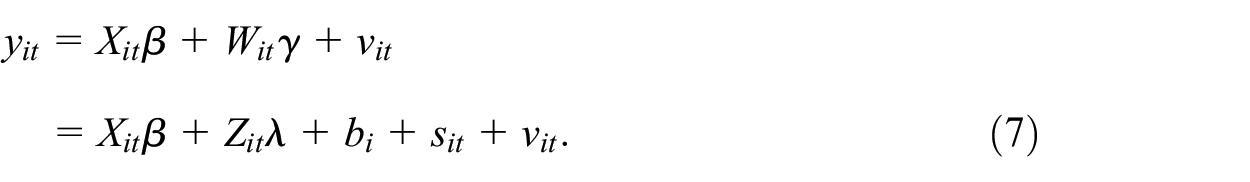
In order to consistently estimate β by means of a FE model, b
i
is allowed to be correlated with X
it
and Z
it
, but we need E(sit|Xi, Zi, bi) = 0 and E(vit|Xi, Zi, bi) = 0 with Z
i
= (Z′i1, …, Z
iT
)′. The latter is again satisfied if Z does not play a role in the population model. The former, however, requires some discussion. b
i
captures all time-constant features of W which are not being absorbed by Z. The more of the time-varying information of W is captured by Z, the smaller is s
it
. If the time-varying information in Z
it
is related to the time-varying part of W
it
, s
it
is smaller in size than Citγ. Then the inconsistency of the estimated β compared to model Equation (6) is smaller. If the measurement error is time-constant, that is, s
it
= 0, the FE estimator for model Equation (7) is consistent (Wooldridge 2010). A roughly time-constant measurement error (i.e., sit
2.5. Validity Testing
The availability of W1 makes it possible to get ideas of how usually omitted variables are related to Z. In particular, one can estimate the strength of the relationship between W1γ(1) and Z. This shows which of the Z variables are related to unobservables and how much the variation in Z can explain the variation in W1γ(1). A high R2 would point to small measurement errors. One can also test restrictions required for Z being a set of valid proxy variables, however, valid inference requires that a model without the omitted W2 can be consistently estimated, that is, W2 is uncorrelated with all included variables. Testable restrictions are E(W1γ(1)|X, Z) = E(W1γ(1)|Z) and E(y|X, W1, Z) = E(y|X, W1), which have been motivated above. However, any correlations between (X, Z) and W2 invalidate the inference.
Once panel models Equations (6) and (7) have been estimated, one can relate the estimated FE to W1 and Z in a cross-sectional model. It is shown that a =


With d and f being unobserved and uncorrelated with W1 (E(d) = E(f) = 0), the dependent variables in these models are estimated components of panel models Equations (6) and (7) designed to control for omitted W. These regressions serve two purposes: first, to assess the linear partial relationship between components of W1 and dependent variables, indicating which components are partially controlled for. Second, the R2 of these models indicates the extent to which variation in W1 explains variation in the components controlling for W. A low R2 suggests that panel models mainly control for information not in W1 and Z (i.e., information in W2), favoring a panel analysis with a reduced regressor set over an expanded cross-sectional analysis. Conversely, a high R2 suggests that the FEs capture little time-constant information from W2, indicating that FE panel analysis may not control for much beyond the contents of W1.
The R2 of models Equations (8) and (9) increase with L1 and can approach one when L1 approaches L, although in applications it is expected to stay below one because L1 < L. Moreover, there are normally time-varying components in W1 in Equation (8), and there is no perfect correlation between the time-varying components in Z and the time-varying components in W1 in Equation (9), which both lead to a R2 < 1 in the respective models.
Simple regression-based tests of endogeneity of X and Z can also be conducted post-FE estimation. Regressing
Another route to tackle estimation biases due to omitted variables is to use instrumental variable estimation approaches, where the instrumental variables need to satisfy some validity conditions. In Supplement S.II, we present validity tests of these restrictions in models Equations (2) and (4) when W1,
3. Linked Administrative and Survey Data
We use the “Integrated Employment Biographies” (IEB) of the Institute for Employment Research (IAB). The IEB are linked administrative labor market data from Germany encompassing socio-demographic characteristics and detailed employment history data of all German workers once employed in a job subject to social insurance contributions since 1975. Although the IEB covers the entire population of contributors to the social insurance system, it does not include the self-employed, lifetime civil servants, and individuals who were never economically active. In total, it contains around 85% of the total working population. Due to confidentiality reasons, the full IEB are not being made accessible for research, but the “Sample of Integrated Labour Market Biographies” (SIAB), a 2% random sample of the IEB with a reduced variable set. We augment the SIAB by linking it with survey data from the household panel study “Labour Market and Social Security” (PASS), aiming to understand the living conditions of unemployment benefit recipients. The resulting linked dataset, known as “PASS survey data linked to administrative data of the IAB” (PASS-ADIAB), is accessible through the Research Data Center (FDZ) of the IAB (Antoni and Bethmann 2014). Table 1 shows key characteristics of the underlying data products and their relationship. To facilitate comparative analysis, we narrow our sample to individuals aged 16 to 64 who participated in the fifth wave of the PASS survey in 2011, resulting in approximately 9,700 individuals. Our sample combines variables from the restricted IEB data available in the SIAB (X), generated work history variables (Z), and additional survey-based variables from PASS (W1).
Structure of Underlying Official Data Products.
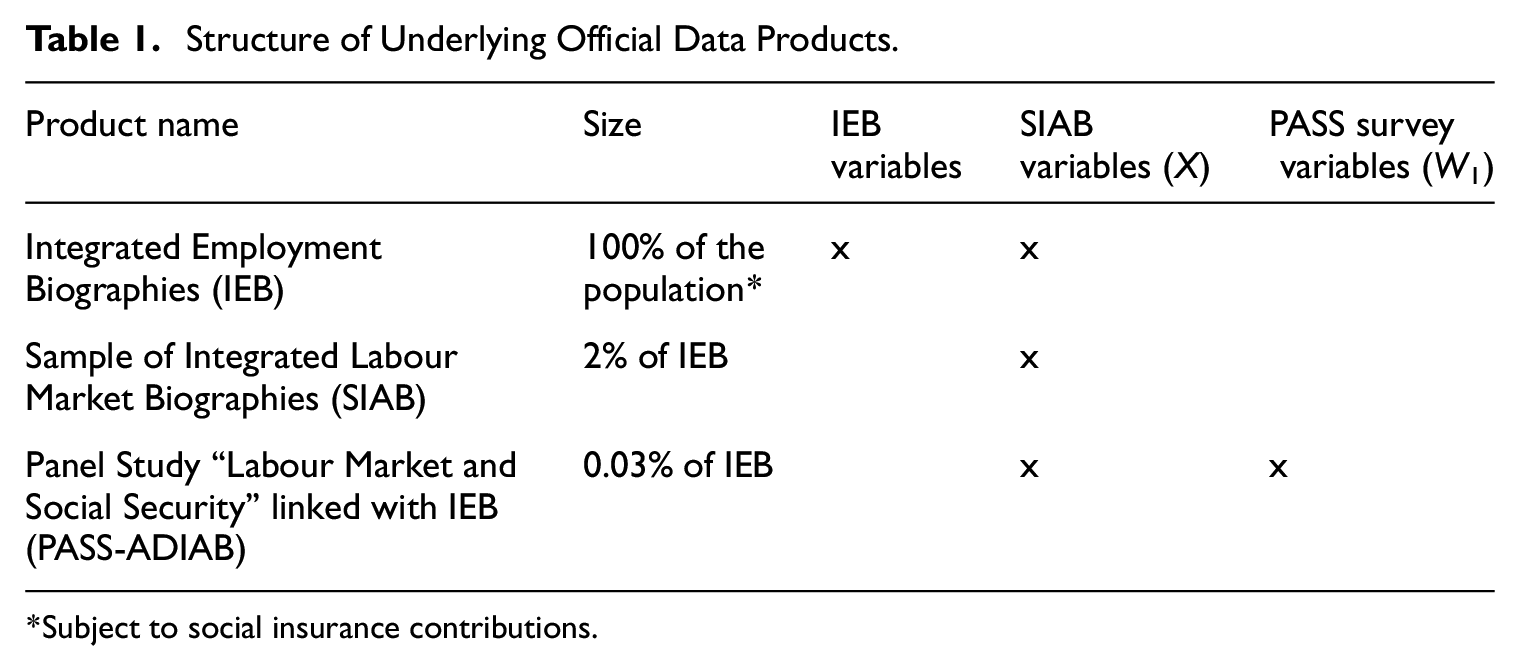
Subject to social insurance contributions.
4. Empirical Analysis
Our empirical analysis exceeds standard sensitivity analysis by applying the theoretical frameworks of Section 2 to the data on X, Z, and W1 of Section 3. Our analysis provides insights into the role of Z, the ability of the different approaches to control for parts of Wγ, and tests for evidence of endogeneity in X and Z. We focus on linear regression models with different dependent variables: a wage regression and a linear probability model for transitions from unemployment to employment. The remainder of this section presents the results for the wage model, while the transition model outcomes are given in Supplement S.III.
Our sample for the wage regression comprises 2,435 individuals observed for at least three years in the administrative data during employment. The dependent variable (y) represents the logarithmized average daily gross wage at the time of the interview, while X includes socio-demographic and employment-related variables such as gender, age, trainee status, education, nationality, and industrial sector. In addition to these variables, we include unemployment-related register dummies, such as the receipt of unemployment insurance benefits (ALG I) and means-tested unemployment benefits (ALG II), as regressors. The W1 variables are extracted from linked PASS data, where we select those reflecting personality traits and attitudes (Big Five), job search behavior, working hours, and social factors. The Big Five variables are used to model personality (for reviews, see John and Srivastava (1999) and McCrae and Costa (1999)). These variables are regularly included in regression analyses to account for the omission of motivation and work attitudes (Heineck and Anger 2010; Mueller and Plug 2006; Nyos and Pons 2005). As a preliminary step, we apply the LASSO and elastic net methods to identify relevant W1 variables in model Equation (5) so that irrelevant variables in W1 can be dropped (see Supplement S.I). Although our set of W1 contains important factors, there are likely still omitted variables in W2. Z consists of variables related to previous work experience, tenure, and prior unemployment experiences, serving as proxy variables. Table S6 in supplement S.IV contains the complete list of variables X, Z, and W1 used in the wage regressions, along with their descriptive statistics.
We start by applying OLS to linear models for E(y|X), E(y|X, Z), E(y|X, W1), and E(y|X, Z, W1), which we denote as W.A-W.D. Table 2 presents the main estimation results for these models, while the coefficients on W1 are reported in Table S7 in Supplement S.IV. The R2 increases progressively from Model W.A to W.D, indicating the contribution of variables in explaining variation in the dependent variable. All Z and most X variables are statistically significant in models W.B and W.D., which points to sufficiently low correlations between Z and X.
Wage Regression: Dependent Variable log(wage).
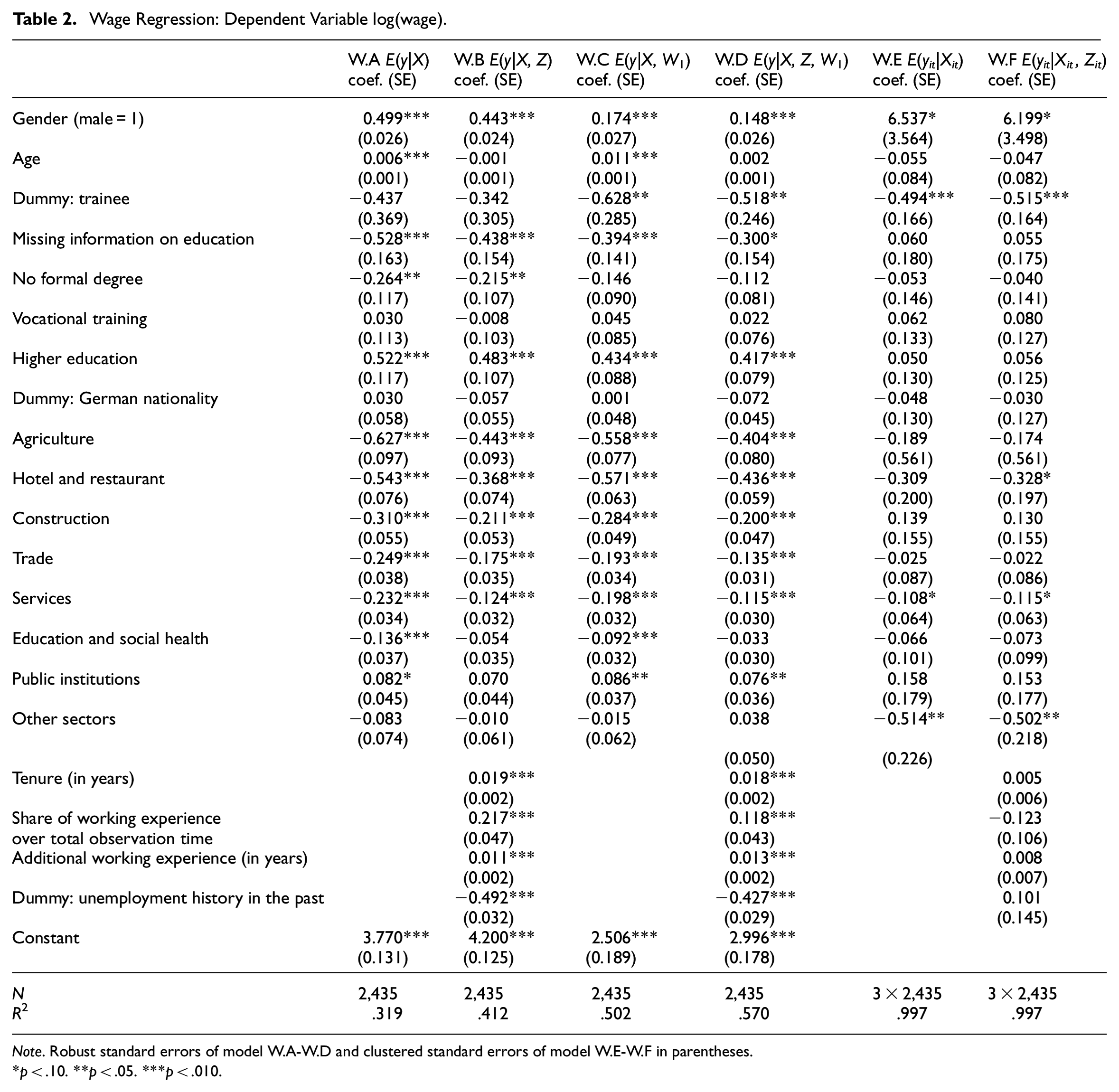
Note. Robust standard errors of model W.A-W.D and clustered standard errors of model W.E-W.F in parentheses.
*p < .10. **p < .05. ***p < .010.
The coefficients on several components of X, such as gender and higher education, change monotonically from Models W.A to W.D. This could be interpreted as an improvement of the estimates and a reduction in the omitted variable bias as the model R2 increases. As outlined in Section 2, however, there is no theoretical foundation that this is always true. For some X, such as vocational training and nationality, the change is small and not statistically significant. For other variables in X, such as trainee, the coefficients do not change significantly but they gain in precision and become statistically significant. As all Z variables are individually significant in Model W.D, the restriction E(y|X, W1, Z) = E(y|X, W1) is violated. It can be seen from Table 3 that all but one component of Z are individually significant in the linear projection on
Wage Regression: Test Restrictions for Z Being Feasible Proxy Variables.
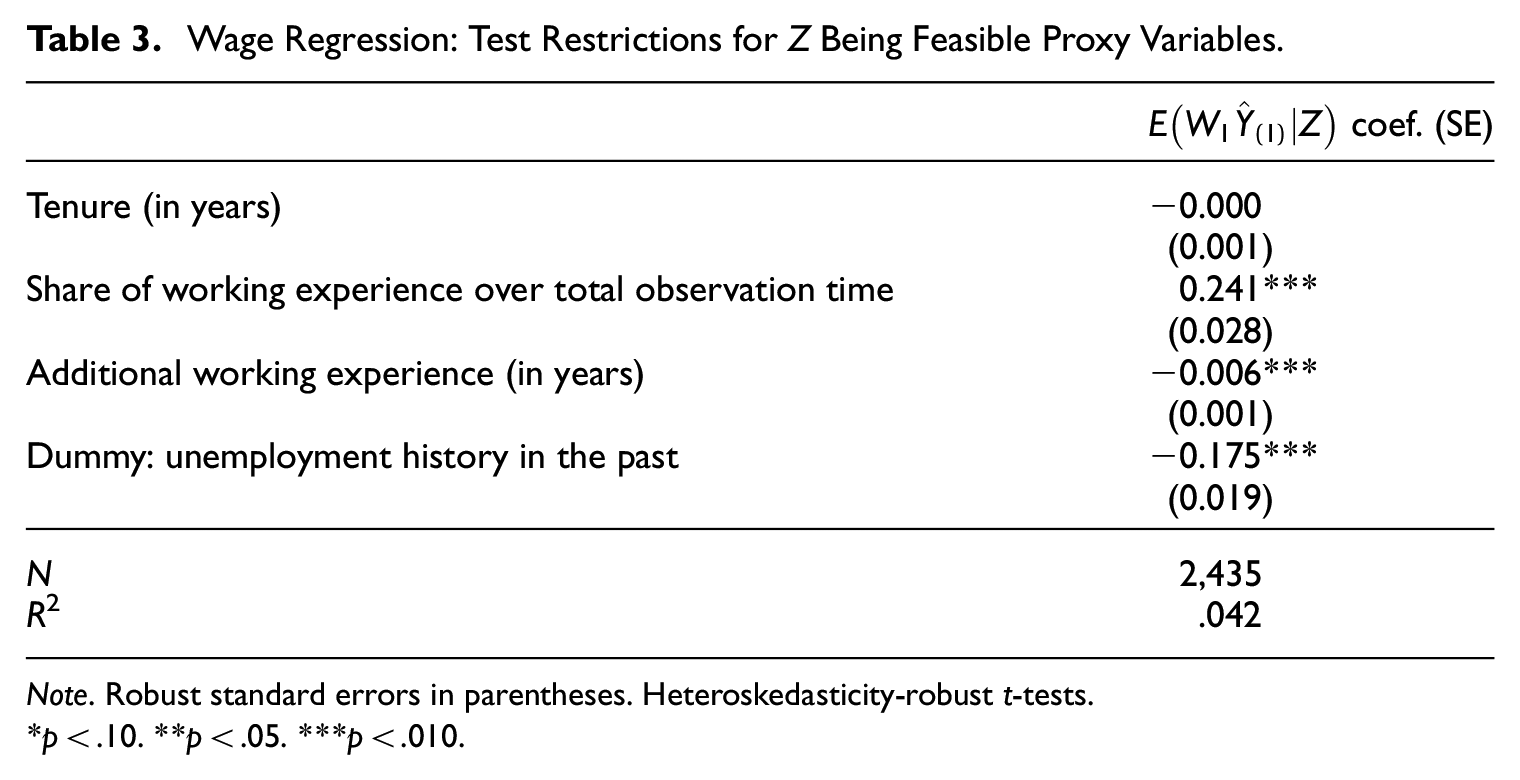
Note. Robust standard errors in parentheses. Heteroskedasticity-robust t-tests.
*p < .10. **p < .05. ***p < .010.
In order to shed more light on the role of W1 and Z in the previous models, we estimate panel data regression Equation (6) and (7) with three periods for the same individuals as for the other models. We include period interactions for all regressors and only report the coefficients for the period that is used in the cross sectional models. In order to obtain coefficients on the time-constant variables, we estimate a dummy variable regression model with 2,435 individual specific dummy variables. The results—without the estimated a—are displayed in Table 2 as Models W.E and W.F, respectively. It is evident that the coefficients on several of the X and Z variables change considerably when using a panel model that allows for correlation between (X, Z) and the time-constant part of the error. This points to violations of the stronger assumptions of cross sectional models. For example, the coefficient on higher education drops sharply from 0.483 in Model W.B to 0.056 in Model W.F. A similar pattern can be observed for several of the business sectors, while other previously strongly significant coefficients become weak or insignificant in the panel analysis (e.g., gender). The multicollinearity pattern driving this result is briefly discussed at the end of this subsection. But there are also variables, such as trainee, for which precision increases. The coefficients on the Z variables decrease in magnitude and these variables become considerably less individually significant. A robust test whether the components of Z are jointly significant in Model W.F has a p-value of .704. This observation and given that the R2 of Model W.F is not higher than that of Model W.E suggest that Z does not additionally contribute to the model. The relevance of Z in Models W.B and W.D is therefore more likely due to correlation with W2 rather than because Z directly belongs to the population model.
In the following we shed light on two more questions: First, to what extent do the variables in W1 explain the variation of the estimated part of the panel model that is supposed to capture the omitted W? Second, to what extent are the estimated FEs statistically related to the included X and Z? Any relationship suggests endogeneity of the latter in a cross sectional regression.
Table 4 displays the results of the linear projections of W1 on the estimated components of the panel models that capture the unobserved W as given by Equations (8) and (9) for the cross sectional data. In the case of model Equation (6) this is simply the estimated FEs
The Statistical Relationship Between the Estimated Component of the Panel Model That Controls for Omitted W and the Observable W1.
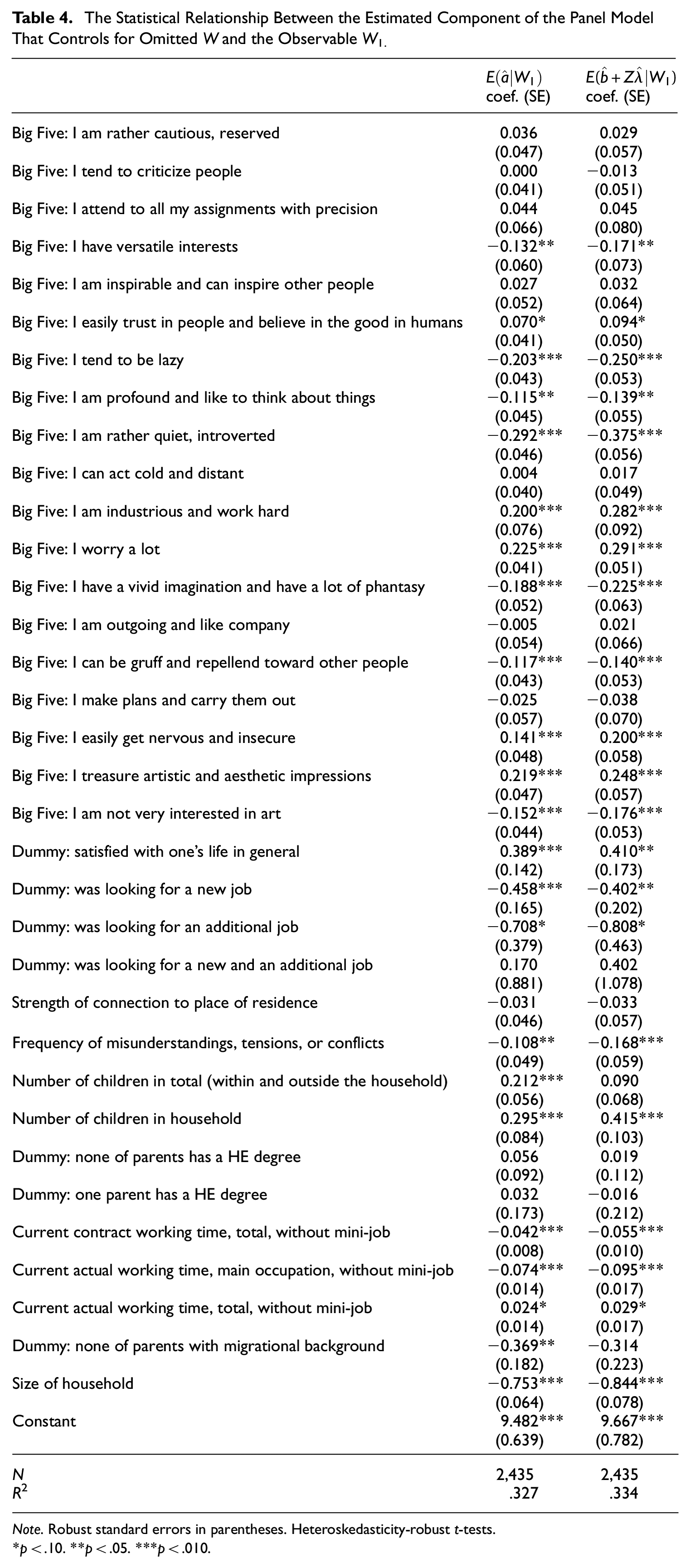
Note. Robust standard errors in parentheses. Heteroskedasticity-robust t-tests.
*p < .10. **p < .05. ***p < .010.
Table 5 reports the results for regressions of the estimated FEs from the panel analysis on the included regressors in the two models using the cross sectional data. It is apparent that a large number of the coefficients differ significantly from 0. This points to partial correlations between FEs and regressors and thus to endogeneity of the latter in the cross sectional models of Table 2. This means there is significant bias in many of the estimated coefficients of the cross sectional models W.A and W.B in Table 2. The large values of the R2 for the two models in Table 5 reveal that the included regressors nearly entirely explain the variation in estimated FEs. This causes a strong multicollinearity pattern between some of the variables in the panel models of Table 2, which is reflected by the partly huge standard errors in Models W.E and W.F., for example, for the coefficient on gender. A solution to mitigate this pattern would be to use information from additional periods but this would be an unbalanced panel as individuals do not always work.
Wage Regression: Regression Based Endogeneity Test for Components of X and Z.
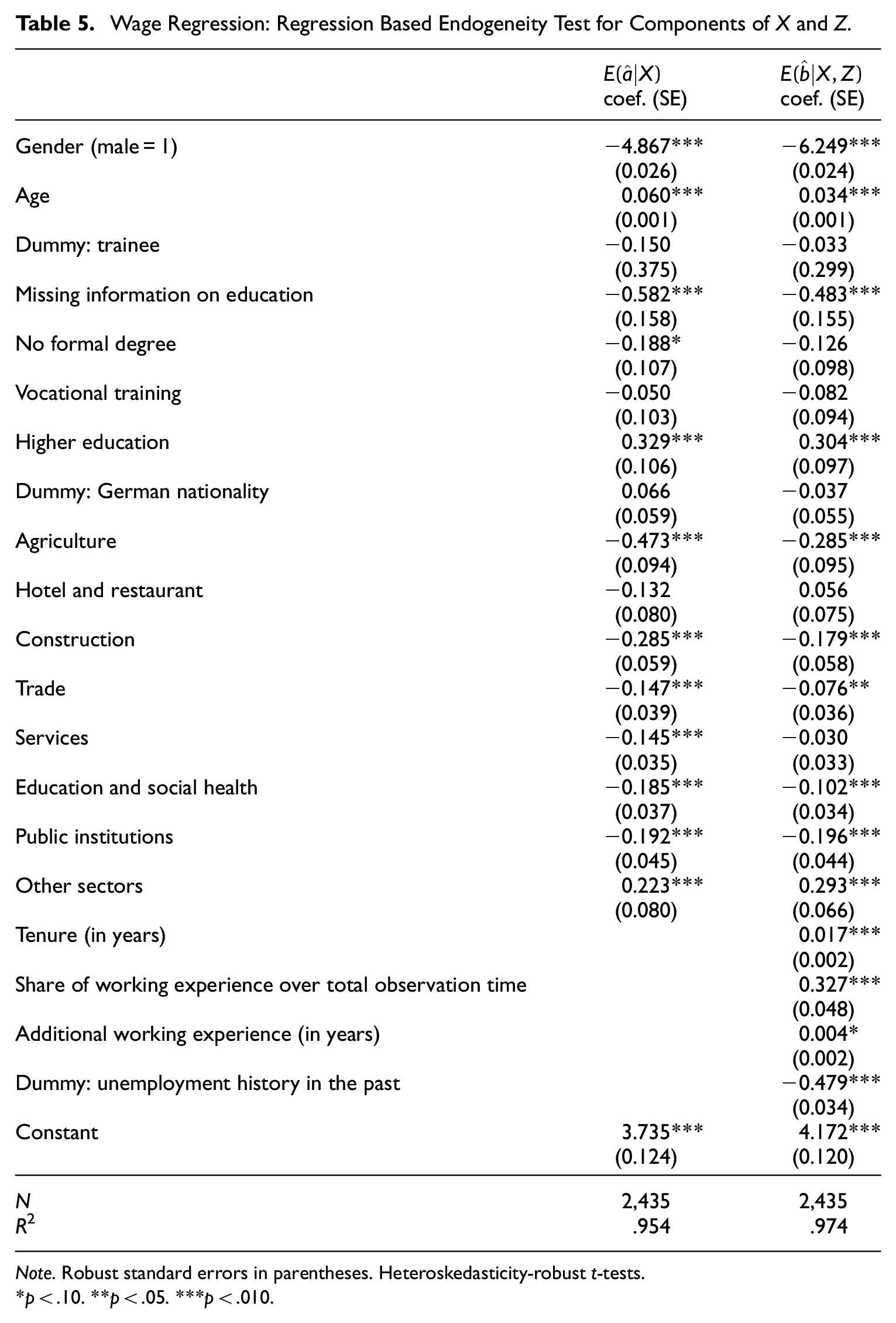
Note. Robust standard errors in parentheses. Heteroskedasticity-robust t-tests.
*p < .10. **p < .05. ***p < .010.
5. Summary and Discussion
This paper presents a unified framework for various approaches to mitigate omitted variable bias in linear regression analysis. We elucidate the mechanisms influencing the magnitude of the bias and explore the relationship between different models with distinct sets of regressors or unobserved effects. Although the theory does not provide a universally applicable model ranking, our empirical analysis sheds some light on how these approaches compare in practice.
In our application, we identify substantial omitted variable bias for several variables in the wage regression. Incorporating work history and survey variables contributes to reducing omitted variable bias. Notably, socio-demographic variables tend to align more closely with results from panel analysis as more variables are included in the model, suggesting convergence toward the values obtained from comprehensive panel data models. Utilizing panel data reveals the presence of omitted variable bias in cross-sectional results, indicating that panel analysis captures relevant unobservable components more effectively than an expanded set of regressors at a single time point. Analysis based solely on administrative data additionally benefits from higher precision due to larger sample size when survey-based variables are only available for a smaller (random) sample. Our findings also suggest that work history variables can serve as proxies for certain unobservable variables in the wage model. We advise researchers to utilize panel data whenever available, as it offers the best prospects for capturing the largest share of unobserved variables.
Our results are not only pertinent to empirical researchers but also to data providers. Given cost and data confidentiality considerations, data providers strive to supply the maximum amount of relevant information while minimizing irrelevant data. Our findings underscore the value of longitudinal information from administrative data, which contributes more substantially to the analysis than the addition of survey variables. Our findings suggest that data producers should consider making panel data based on administrative sources available and restrict surveys to variables that are required for the analysis itself but not available from administrative sources. Since panel models can capture at least partly W, the set of X that is made available to users should be also determined by data confidentiality aspects.
Supplemental Material
sj-docx-1-jof-10.1177_0282423X241312644 – Supplemental material for On Omitted Variables, Proxies, and Unobserved Effects in Empirical Regression Analysis
Supplemental material, sj-docx-1-jof-10.1177_0282423X241312644 for On Omitted Variables, Proxies, and Unobserved Effects in Empirical Regression Analysis by Shihan Du, Ralf Andreas Wilke and Pia Homrighausen in Journal of Official Statistics
Footnotes
Acknowledgements
We are grateful to the DIM unit of the IAB for providing the data, to Arne Bethmann for his support with the PASS data, and to Lisbeth La Cour and Giovanni Mellace for their valuable feedback on an earlier draft. We thank the guest editor and the three reviewers for their detailed comments and insightful feedback.
Funding
The author(s) received no financial support for the research, authorship, and or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Received: April 2023
Accepted: December 2024
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.