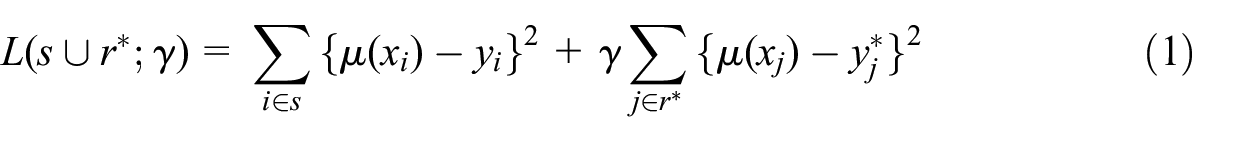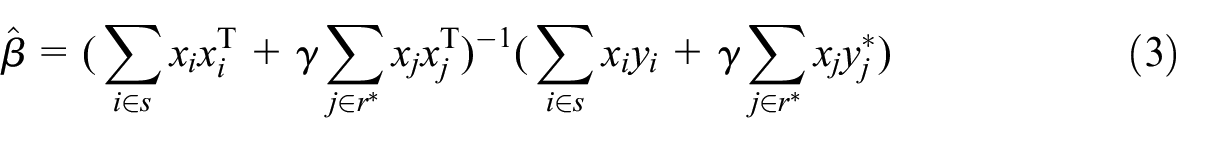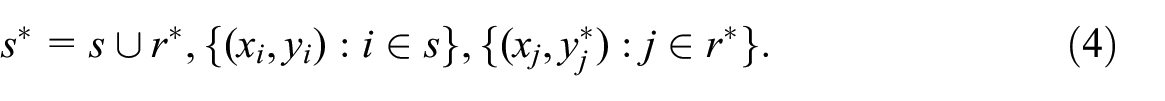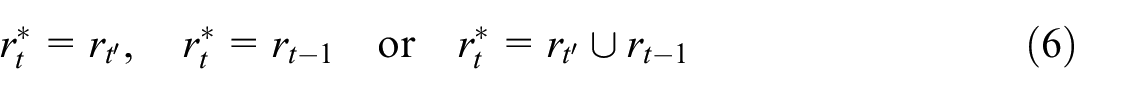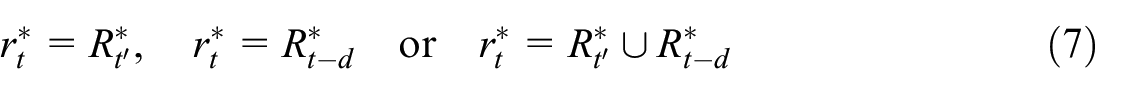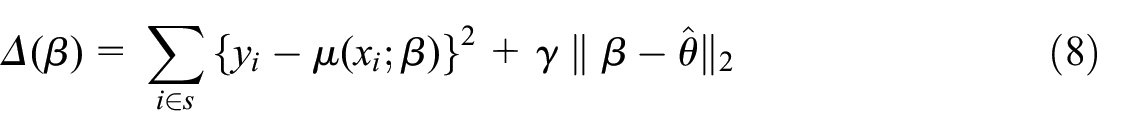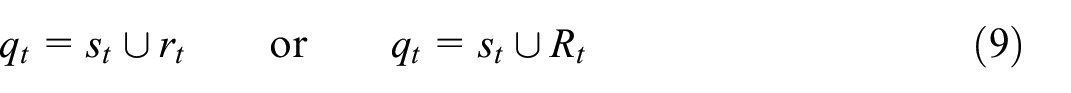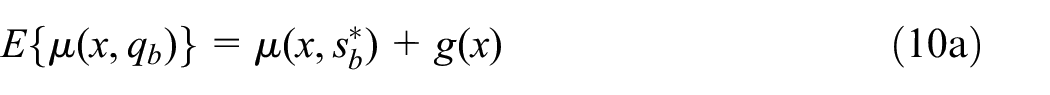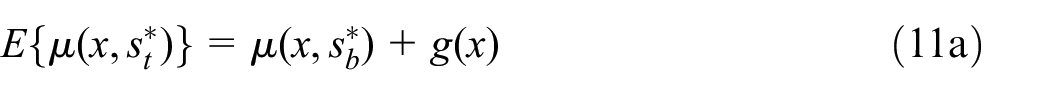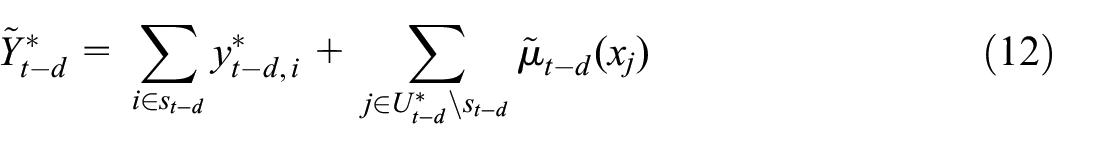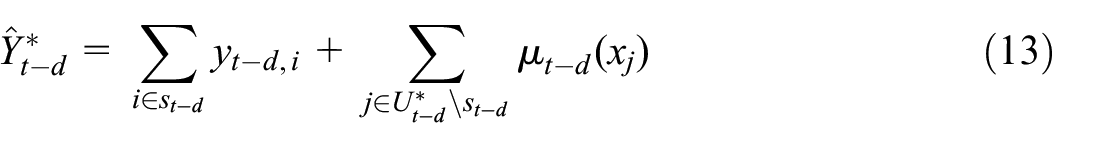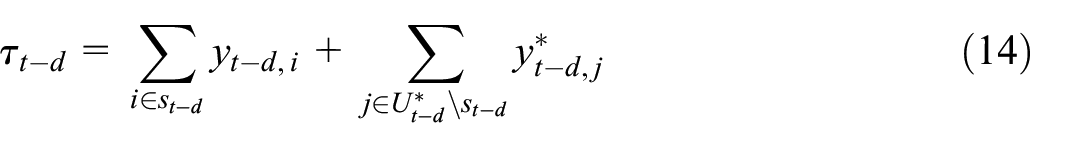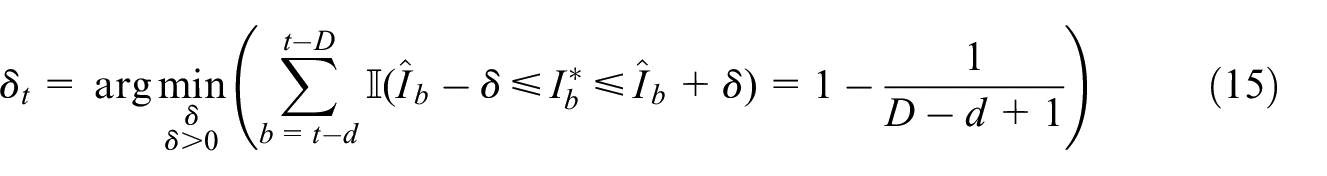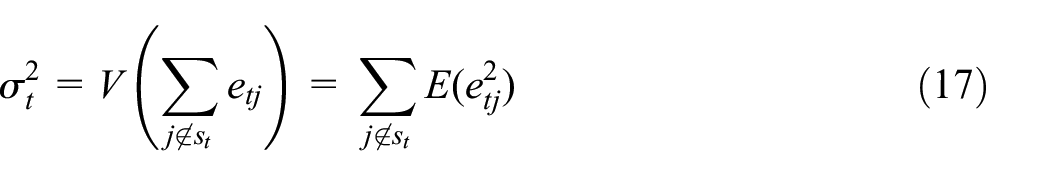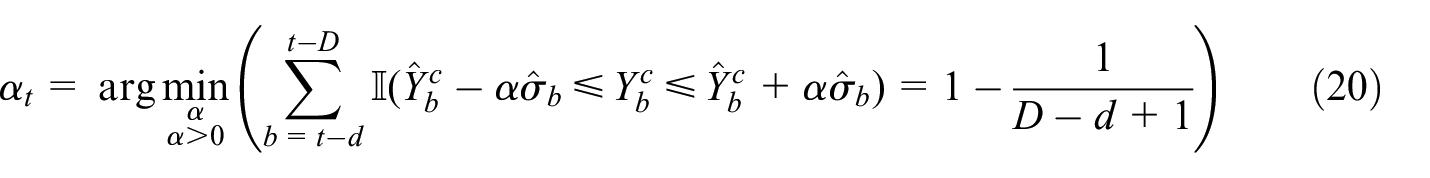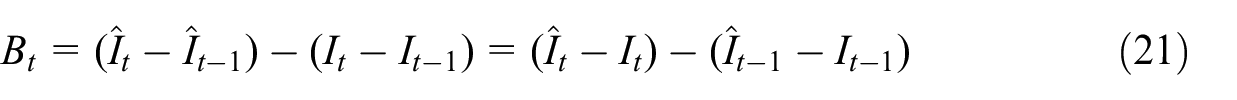Improving timeliness is ever more urgent for official statistics, not least due to the potentials of various non-survey big data that in principle can be made more quickly available than traditional sample surveys. Taking Retail Turnover Index as the case-in-point, we develop new approaches of model learning aimed to achieve flash estimation of acceptable accuracy, as well as the associated methods of uncertainty assessment, when one does not have the target observations that would have been required for unbiased inference by established statistical theories. Applications to the Norwegian data will be used to demonstrate the efficacy of our proposals.
Using non-survey big data to produce rapid estimates of economic indicators has attracted attention in recent years. See Baldacci et al. (2016) and Eurostat (2017) for two early overviews on the relevant background, methods, and challenges, from the perspective of official statistics and under the auspices of Eurostat and United Nations.
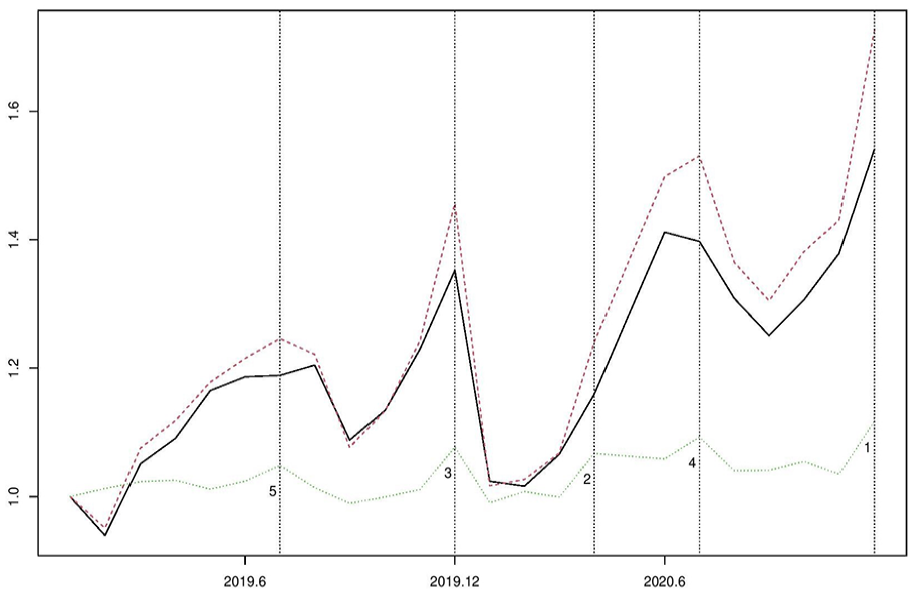
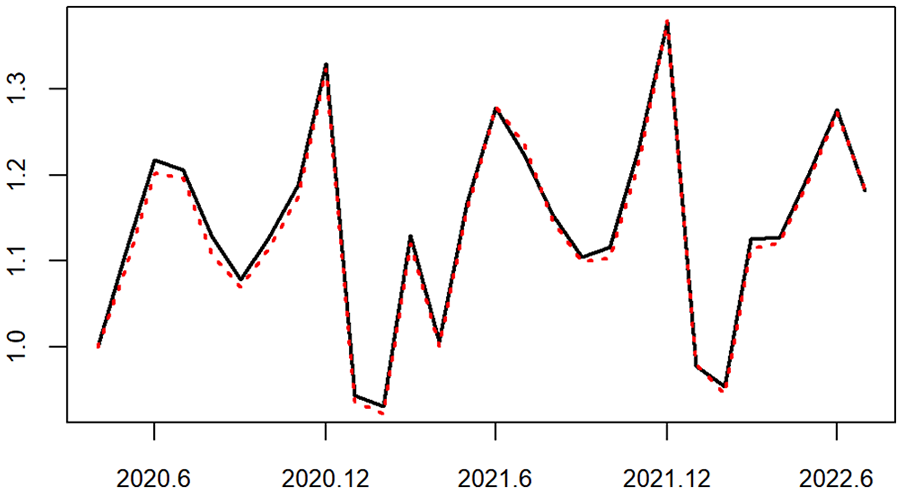
Figure 1 shows the Norwegian Retail Turnover Index (RTI) in the years 2019 and 2020, together with an index calculated from retail transactions directly. This “transaction index” was made available due to the emergency of the covid pandemic in 2020. It is based on the payment total of all domestic debit cards and one major internet payment platform. The ratio between the month-on-month transaction index and RTI , where denotes month, is given in Figure 1 and the five largest fluctuations are marked. Although the two indexes are well correlated, the ratio between them fluctuates too much for the transaction index to be accepted as official statistics, given its obvious error sources pertaining to coverage, measurement, business unit delineation, and population domain classification. For instance, by definition retail trade turnover comprises the total invoiced by the statistical unit during the reference period. It includes all charges such as packaging and transport but excludes VAT and similar deductible taxes; but the deductible taxes cannot be separated from the debit card payment transaction totals.
Retail Turnover Index (solid line) and a transaction index (dashed line) in Norway over twenty-four months in 2019 and 2020. Five largest fluctuations of month-on-month index ratio between them (dotted line) marked by vertical lines (1, …, 5).
This exemplifies a situation where some survey data may still be necessary for producing official statistics, in addition to relevant and timely big data. However, to shorten the lag between dissemination time point and statistical period, one may be prepared to “give up waiting” on the sample units that have not yet responded, if the available non-survey big data can compensate for the loss of information, thereby making flash estimation or nowcasting possible. For instance, Fornaro and Luomaranta (2020) combine traffic volume records with early available firm data for nowcasting Finnish quarterly Gross Domestic Product and Trend Indicator of Output.
For our focus in this paper, the Norwegian RTI for NACE45-47 is currently published by the 30th day after the calendar month , denoted by . NACE is the statistical classification of economic activities in the European Community and is the subject of legislation at the European Union level. By NACE45-47, we refer to G45—Wholesale and retail trade and repair of motor vehicles and motorcycles, G46—Wholesale trade, except of motor vehicles and motorcycles, and G47—Retail trade, except of motor vehicles and motorcycles. For each month , the survey sample has two parts, where denotes the self-representing (or take-all) units with inclusion probability one, and denotes the rest take-some units with inclusion probability less than one. The units in are larger on average; more importantly, they mostly belong to business chains, for which the turnover values can be obtained quickly from the chain headquarters, whereas it takes longer for many units in to respond.
Thus, in order to achieve flash estimation at an earlier time point, as well as to reduce response burden and processing cost, we propose to investigate model-based estimation given only the take-all sample in NACE47 and with the help of all available transactions and administrative data. If feasible, then no sample units will be needed from outside the take-all units, which amounts to adopting a purposive sampling design.
Note that we approach flash estimation as a problem of prediction for the unobserved or out-of-sample units. This allows one to make use of past survey and non-survey data at the business unit level in a flexible manner, and enables novel statistical learning approaches. Since the unit-level prediction errors can be gauged retrospectively, for example, by comparisons to the VAT turnover values, the approach provides also means to detect outliers and other anomalies, which can be helpful for the maintaining and updating the purposive sample that still needs to be surveyed directly.
Note also that the focus on NACE47 at this stage has two reasons. First, the RTI used to be limited to NACE47 before its scope was extended in 2021, and many users actually are still interested in the RTI for NACE47. Second, Statistics Norway currently have only access to debit card transactions data, which have the highest share among all payment transactions in NACE47, while the other forms of payment have a greater share in NACE45-46. Confidentiality of personal data is protected as the transactions are aggregated for each business unit by the debit card payment service operators, and only the totals for each business unit are delivered to Statistics Norway.
In short, we shall consider the strategy of model-based flash RTI using purposive sampling and debit card transactions for NACE47. Provided the turnover values can be obtained from most of the take-all units by , it is envisaged that the Retail Volume Index for NACE47 can be produced by , allowing for the necessary post-RTI processing. This will halve the thirty-day lag of dissemination that is common internationally, while at the same time reducing survey response burden and processing cost.
However, the feasibility of this strategy depends on whether (model) learning can be organized in a fruitful way in the case of purposive sampling, which means that no target observations (of turnover) are at all available for the non-take-all units at the time of flash estimation.
We shall formulate and investigate two new learning approaches. First, by adapting a loss function that bears some semblance to regularization, such as LASSO (Tibshirani 1996), we devise augmented learning that allows one to learn from both the past non-take-all units and current take-all units. Next, taking inspirations from the field of transfer learning (e.g., Ng 2016; Pratt 1993), we formulate quasi transfer learning for situations where observations of the target model can only become available retrospectively.
Although in concept neither form of learning can yield unbiased prediction for the unobserved units, they may be able to reduce the errors of learning only from the purposive sample (which is also biased generally). Moreover, in addition to explaining how the chosen model and learning approach can be validated retrospectively based on relevant VAT data from tax administration, we shall develop a novel approach to real-time error prediction for the flash RTI. In particular, two key points of this error prediction approach applies generally to flash estimation: (a) error prediction is a distinct learning task to outcome prediction because, in the absence of relevant target observations, one cannot pretend that the adopted model would yield unbiased prediction of the target outcome (such as turnover here) and derive the associated uncertainty as a by-product of the outcome model, (b) to improve the efficiency of error prediction one should utilize observed unit-level prediction errors in the past just like one would use observed past outcomes for outcome prediction.
The ideas above will be developed in Section 2 and applied in Section 3 to the Norwegian data in years 2019 to 2022. Some final remarks on implementation and future research topics will be given in Section 4.
2. Methods
We shall consider the following generic setup for flash estimation. Denote by the target outcome and the associated features. Denote by a predictor for any unit with features , which is learned from , where is the training sample of observations. Denote by a target set of units with known , and , for which the predicted -values are of interest. However, it is known that is biased for , because for and for do not have the same distribution conditional on and .
In terms of the Norwegian RTI, is the retail turnover value excluding VAT, whereas one may include in turnover values according to the VAT register and debit card payment totals. The transactions data improve the timeliness of feature since VAT turnover values are only available with a delay of several months, whilst the payment transaction totals are available for the month before t + 7. (More details of these features will be given in Section 2.2.) Notice that for a unit that has both observed VAT turnover and transaction total, its survey turnover value often differs to its VAT turnover value reported to the tax authority, and both these turnovers will surely differ to the payment transaction total that includes VAT or other surcharges.
As a simplistic approach of learning for flash estimation, one may obtain only based on the take-all units that are available by , which yields for any . The approach is called simplistic not only because is known to be biased for the units outside but also because it provides naturally a baseline of comparison. Below we consider two learning approaches that aim to reduce the bias of the simplistic approach.
2.1. Augmented Learning
Given a constant , let the augmented loss function be
where denotes a set of units that are similar to or even overlap with those in , but is a proxy to the target observation including when . The values may either be contemporaneous with or from some earlier time points. For predicting , where , we would like to investigate whether obtained from minimizing may improve simplistic learning that minimizes the loss function
Note that the augmented loss Equation (1) is not a form of regularization (e.g., Hastie et al. 2009), because the second term involving is not a penalty introduced to reduce the variance of unconstrained learning from , such as when the size of is small compared to the number of unknowns in . Rather, augmenting by in (1) primarily aims to reduce the bias of learning only from , by incorporating the additional observations that may resemble the unobserved for the purpose of model learning.
Now, in the case of linear predictor , the estimator minimizing Equation (1) is given by
This is the same as minimizing Equation (2) based on an augmented sample
instead of , where is duplicated times in (if practically possible).
The equivalence between working with the augmented loss and the simple loss based on an augmented sample can be exploited practically. For an arbitrary model or algorithm , one can obtain by training on an augmented sample using standard softwares, instead of working with which may require weighting the observations or other adjustments that are not necessarily implemented by the available software. Instead of choosing a value for , one can directly experiment with how to mix with other units that may be relevant. We refer to this as augmented learning, that is, minimize given by Equation (2) based on
2.2. Turnover Flash Estimation by Augmented Learning
To obtain a turnover flash estimator for each month , consider augmented learning that is targeted at the units in immediately after become available, where denotes the target population for month (whether or not it is actually held fixed over any given period in practice).
Let be the turnover of business unit in month . Let the associated feature vector be selected from the VAT turnovers and debit card payment totals. The VAT register is updated every two months in Norway. At a given month , the six most recent VAT turnover values would cover a twelve-month period, which dates backwards from three or four months before . The debit card payment total is available on a daily basis, including the month of interest.
Next, for each month , let the augmented sample be given as
There are two settings for . In setting-I, where take-some units are sampled but is not ready for month- flash estimation, we may for example, consider
where denotes the -sample (of take-some units) for the same month in the previous year, and denotes the -sample for the previous month. The value for is a past survey turnover value, which is available by month even in case it was unavailable for month- flash estimation.
In setting-II, where non-take-all units are not sampled at all, we may for example, consider
where contains all the non-take-all units with VAT turnover values for the same month in the previous year, and denotes this rest population for month . We can choose in Norway to ensure that the associated VAT turnover values have become available for any .
Notice that in either setting, there will be many units in selected from the past that still belong to the population at time . While we do not observe for such a unit at the time, we may have either its past survey turnovers in setting-I or VAT turnovers in setting-II. The idea of augmented learning is to incorporate these observations to train the model for prediction at time , which can be helpful if relates to in a similar manner as relates to given sensible choice or composition of ,
2.3. Quasi Transfer Learning
Denote by a target model with unknown parameters . Suppose there exists a relevant source model for a different though similar population, which has been estimated separately, denoted by , where the two models belong to the same family with different parameter values and . Transfer learning in such a setting aims to improve the estimation of by leveraging .
For instance, one may estimate based on the target observations that are associated with the units in , subject to a chosen penalty of the discrepancy between and , such as minimizing
given . Although the resulting estimator of is biased generally due to the penalty term, the variance of estimation is reduced compared to estimating only based on . One can thus view the approach as a form of regularization, which has shown to be especially helpful in cases with insufficient number of target observations (e.g., Gu et al. 2023; Li et al. 2020).
However, there is an essential difference to our setting for flash estimation outlined at the beginning of Section 2, in that we have no target observations at all from and the model trained on is biased for predicting the units in . We therefore formulate an approach that will be referred to as quasi transfer learning. Let the learning for RTI flash estimation target the model for
which is partially covered by the available although by stipulation is not “representative” of . Let the choice of or in vary if the take-some sample is only unavailable for flash estimation or abolished altogether. The term “quasi” indicates that we are aiming at something that is not the target model of interest directly but close to it.
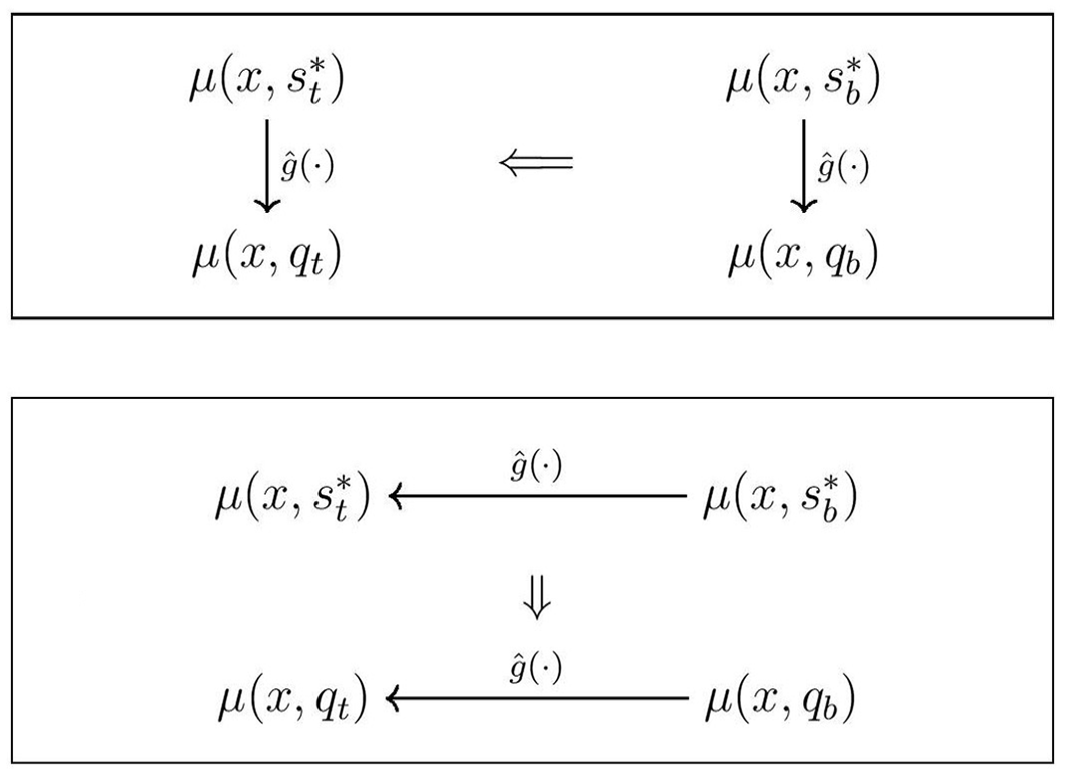
Let a relevant source model be fitted to , as given by Equation (5), denoted by . To leverage it for , choose additionally two source models and in the same setup as and but for some time point in the past, and a transfer scheme such as the two illustrated in Figure 2.
Two schemes of quasi transfer learning.
In scheme A, the estimated relationship between and at the past time point is transferred to the current time point . For instance, one can introduce a model where either figures simply as an offset or is used as a feature generally, that is,
In scheme B, the estimated relationship between and over the time points is transferred to that between and over the same . One can introduce two models similarly to (10a) and (10b), that is,
The scheme A requires the relationship between and to be stable over time. This may be possible for populations that evolve slowly over time, but it is likely to be unrealistic for short-term Turnover Statistics. The scheme B requires the relationship between and over the chosen time lag to be similar to that between and over the same time lag, where and have the same sample composition and likewise for and . Moreover, at any given time point , and overlap each other in terms of , while the units and are comparable and possibly overlapping as well.
2.4. Retrospective Validation
As shown in Figure 3, the survey-based Norwegian RTI tends to agree closely with the “VAT index” calculated from the VAT turnover values, although the two turnover values often disagree with each other at the unit level.
RTI (solid line) and VAT index (dotted line) in Norway over 2020 to 2022.
The VAT register data can therefore provide trustworthy means of validation retrospectively. In particular, one should be able to tell if the chosen model and learning approach for flash estimation have worked satisfactorily, till as recently as months ago, had VAT turnover been the target measure. Such an approach of retrospective validation is described below.
To fix the idea, let be the adopted working model (say, linear regression) with selected features, and let be the predictor applied to the units in , which is obtained by the chosen learning approach (say, augmented learning). For validation purposes, we would like to separate the linear model from the setup of augmented learning (such as the choice of ).
To check the goodness-of-fit of the linear model, we can simply fit it to the population data , where is the VAT turnover value of unit pertaining to month , and contains the relevant features, and is the population of units for which are available at the time point . The time series of any relevant goodness-of-fit measure, such as or mean squared residuals, can provide a basis for assessing how the linear model tracks the population data over time. More directly, let be the fitted linear model, one can simply calculate a model-predicted VAT index, based on the population total estimate
and compare it to the VAT index based on .
To evaluate the adopted learning approach, let be the linear model actually obtained by augmented learning from , based on using survey turnover values for the units in and VAT turnover values in according to the definition of . One can calculate a learned proxy-RTI index, based on the population total estimate
and compare this learned index to the observed proxy-RTI index based on
Notice that the estimate would have been equal to the actual flash turnover estimate, had been equal to defined for RTI in month .
Should the learned index under-perform against the observed index, the additional indexes above based on allows one to potentially detect whether the problem may be attributed to “model drift” or “learning drift.”
2.5. Uncertainty Assessment
Let be the retrospectively observed index for month based on the totals given above, that is, using where and is the VAT turnover value of unit in month . Let be the corresponding flash RTI actually produced for month . For uncertainty assessment we aim to estimate a prediction interval for at a time when we only have but not .
Since we observe retrospectively, it is possible to consider the problem as one of time series forecasting provided a sufficient number of observations of . This is, however, not the case here given the short history of debit card transactions data. Below we consider two feasible approaches.
2.5.1. Empirical Method
One can simply produce a prediction interval with calibrated empirical coverage over the most recent time window, denoted by . Let the prediction interval for month be given as
where
That is, is the minimum positive value of such that the interval achieves the specified coverage over the time window .
For example, if , then the empirical coverage specified by (15) is 91.7%. Though simple, this empirical method is unlikely to be efficient because it does not make use of the VAT turnover values at the unit level.
2.5.2. Error Prediction
To fix the idea, let be obtained by augmented learning and is the predicted turnover value in month for any . Let
be the error (against the VAT turnover value ) that can be observed with a delay. In case is an unbiased predictor and the prediction error is independent over the units outside of , we have
In order to estimate at the population total level, we now devise an error prediction approach that can be viewed as a form of quasi transfer learning.
First, denote the unit-level -predictor by
That is, a chosen model trained on the data associated with the units in , such that an estimate of follows as
Next, for any , we can only train the model Equation (18) based on historical data, since the most recent VAT turnover value refers to month instead of . For a specific description, suppose the setups for outcome prediction of (by augmented learning) and error prediction of are such that
Notice that the predictor Equation (18) trained on the observed errors for past time points is transferred to the current for error prediction, and the squared error is calculated against the VAT turnover value instead of the survey turnover value , where or . Error prediction by (18) is therefore a form of quasi transfer learning.
To illustrate, suppose September 2022 (Table 1). Outcome prediction of by augmented learning uses containing the non-take-all units in September 2021 (i.e., ) and May 2022 (i.e., ) given . Given the same setup of for associated error prediction by (18), the VAT turnover values needed to calculate the relevant -observations are from September 2021 and May 2022. Moreover, to obtain the predictor for , we need augmented learning using data from September 2020 (i.e., ) and May 2021 (i.e., ); whereas, to obtain that for , we need data from May 2021 (i.e., ) and January 2022 (i.e., ). Similarly for month- flash estimation in Table 1.
Illustration of Learning Setup for Error Prediction Given .
Sept ’22
Sept ’21
May ’22
Sept ’20
May ’21
May ’21
Jan ’22
May ’22
May ’21
Jan ’22
May ’20
Jan ’21
Jan ’21
Sept ’21
Note that this setup for Equation (18) requires two years of data backwards from . While the demand on past data is greater compared to uncertainty assessment for the survey sampling estimator, it is much less than what would have been usual for a time series forecasting approach.
To derive a prediction interval using obtained in this way, let and let be its flash estimator. Similarly to Equation (15), an empirically coverage-calibrated prediction interval for is given by
where
The corresponding prediction interval for can be derived straightforwardly given the observed total over in addition.
3. Application
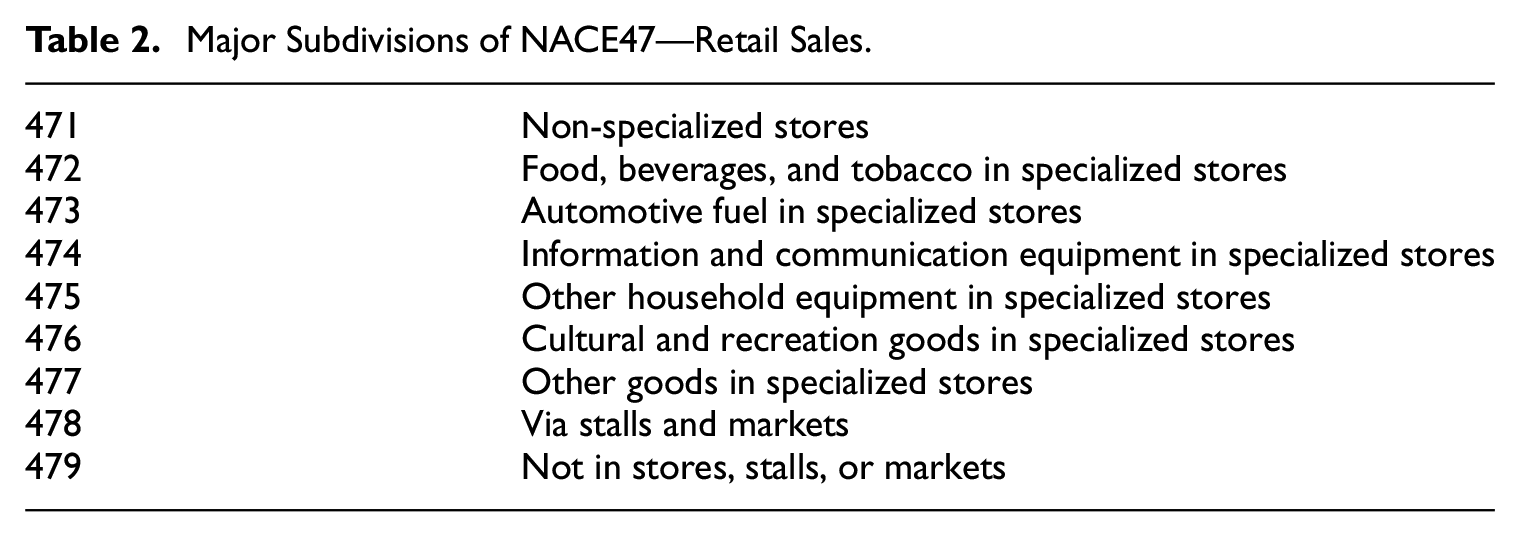
The NACE47 population has nine major domains (or subdivisions) by 3-digit NACE classification (Table 2). The domain NACE478 will be excluded here because it has separate data collection to the main survey.
Major Subdivisions of NACE47—Retail Sales.
471
Non-specialized stores
472
Food, beverages, and tobacco in specialized stores
473
Automotive fuel in specialized stores
474
Information and communication equipment in specialized stores
475
Other household equipment in specialized stores
476
Cultural and recreation goods in specialized stores
477
Other goods in specialized stores
478
Via stalls and markets
479
Not in stores, stalls, or markets
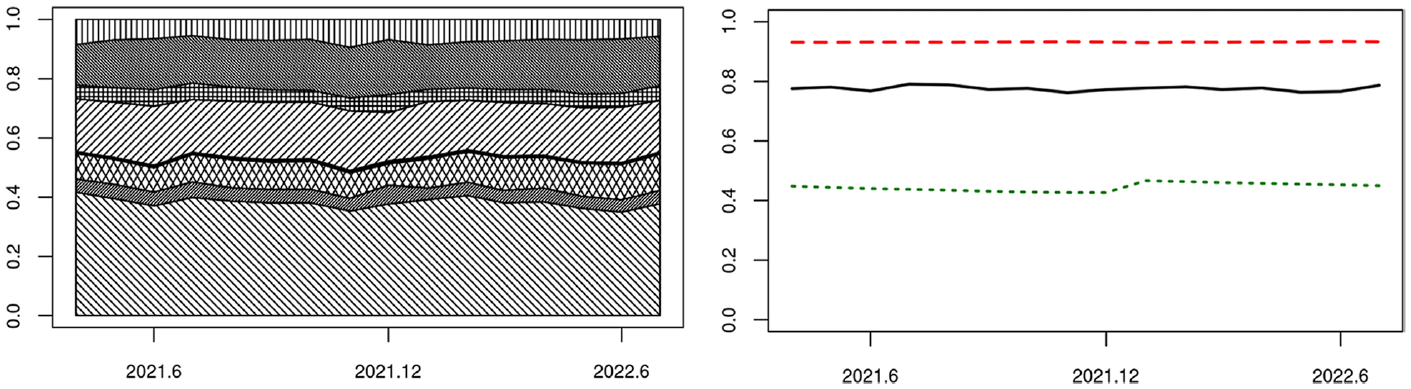
The left part of Figure 4 shows the estimated share of total turnover in the given period over 2021 and 2022, where each layer corresponds to one of the eight domains. The domain NACE471 including all the supermarkets has clearly the largest share of total turnover. The next two largest domains are NACE475 and NACE477. The smallest domain is NACE474.
Left, estimated turnover share of eight domains of NACE47, each layer for a domain. Right, turnover share (solid line), sample proportion (dashed line), population proportion (dotted line) of take-all units. Period: April 2021 to July 2022.
The right part of Figure 4 shows the sample and population proportion of the take-all units over the same period, that is, and respectively, as well as their population share of the estimated total turnover, that is, . The take-all units clearly command a dominant share of the total turnover in NACE47. This is an important premise for the traditional sample survey approach to RTI, as well as the potential success of flash estimation. In other words, the challenge would have been completely different, had one stopped surveying these units altogether.
Below we first show some detailed results comparing alternative models and learning approaches. Next, we report the flash estimates of the Norwegian RTI for NACE47, which are obtained by the chosen random forest model and augmented learning approach. Random forest is obtained by bootstrap aggregating (Breiman 1996a, 1996b) of tree models, where each tree model is generated by data-driven recursive partitioning of the feature space. See for example, Hastie et al. (2009) for more explanations of random forest models, as well as some other machine learning models that are potentially applicable. Our focus here is how to organize the available data for model learning, rather than how such models may be modified or improved themselves. Finally, retrospective validation and real-time uncertainty estimation are demonstrated.
3.1. Model and Learning Approach
For this part of the analysis we extracted the relevant data over 2021 and 2022. After various trials, we choose to let the feature vector of each unit contain its debit card payment total in month as well as its VAT turnover values in the most recent twelve months that are available at . The results to be reported below are not noticeably improved by including past transaction totals as features, but the results would have deteriorated to various extent over time had the concurrent transactions total been removed as a feature.
In particular, we notice that including a binary indicator for whether a unit belongs to or not would actually lead to worse prediction results.
Linear regression and random forest have been compared for all the choices of feature vector we have explored. Only the results obtained with the final choice of feature vector are given here to save space.
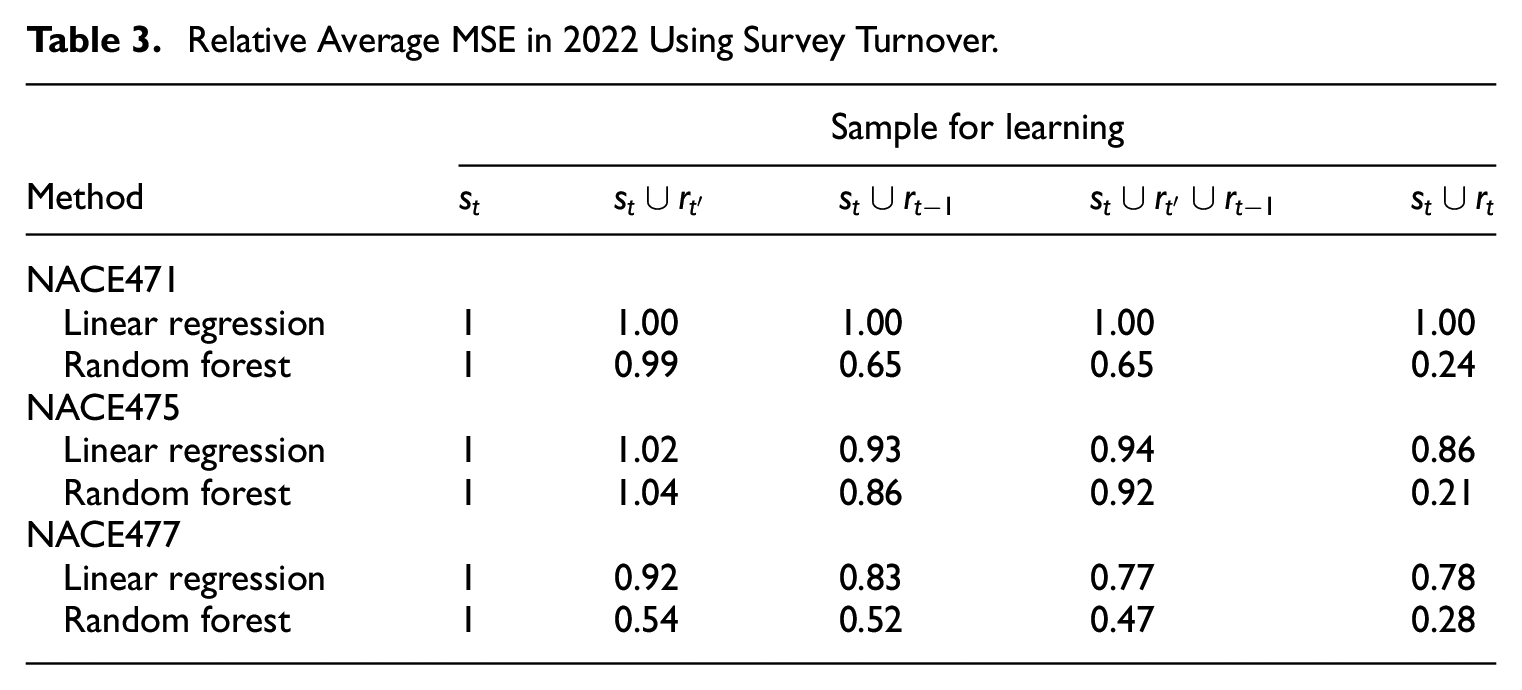
Setting-I. For each month , let the mean squared error (MSE) of a model be calculated from the take-some units in , that is, . Table 3 shows the average MSE over the twelve months of 2022 in the three largest domains, relative to that of the simplistic learning approach of only using . The three choices of in (6) are considered for augmented learning, as well as the hypothetical setting of training the models on as if they were all available for flash estimation. Although “mean squared residual” would have been a more appropriate term when a model trained on is applied to , we shall only use the term MSE for simplicity of description.
Relative Average MSE in 2022 Using Survey Turnover.
Sample for learning
Method
NACE471
Linear regression
1
1.00
1.00
1.00
1.00
Random forest
1
0.99
0.65
0.65
0.24
NACE475
Linear regression
1
1.02
0.93
0.94
0.86
Random forest
1
1.04
0.86
0.92
0.21
NACE477
Linear regression
1
0.92
0.83
0.77
0.78
Random forest
1
0.54
0.52
0.47
0.28
Clearly, with suitable choice of , augmented learning by random forest can yield much greater reductions of MSE compared to linear regression in any of the NACE domains. Although the average MSE by augmented learning is larger than learning based on the true sample , augmented learning is able to improve the simplistic approach of only using .
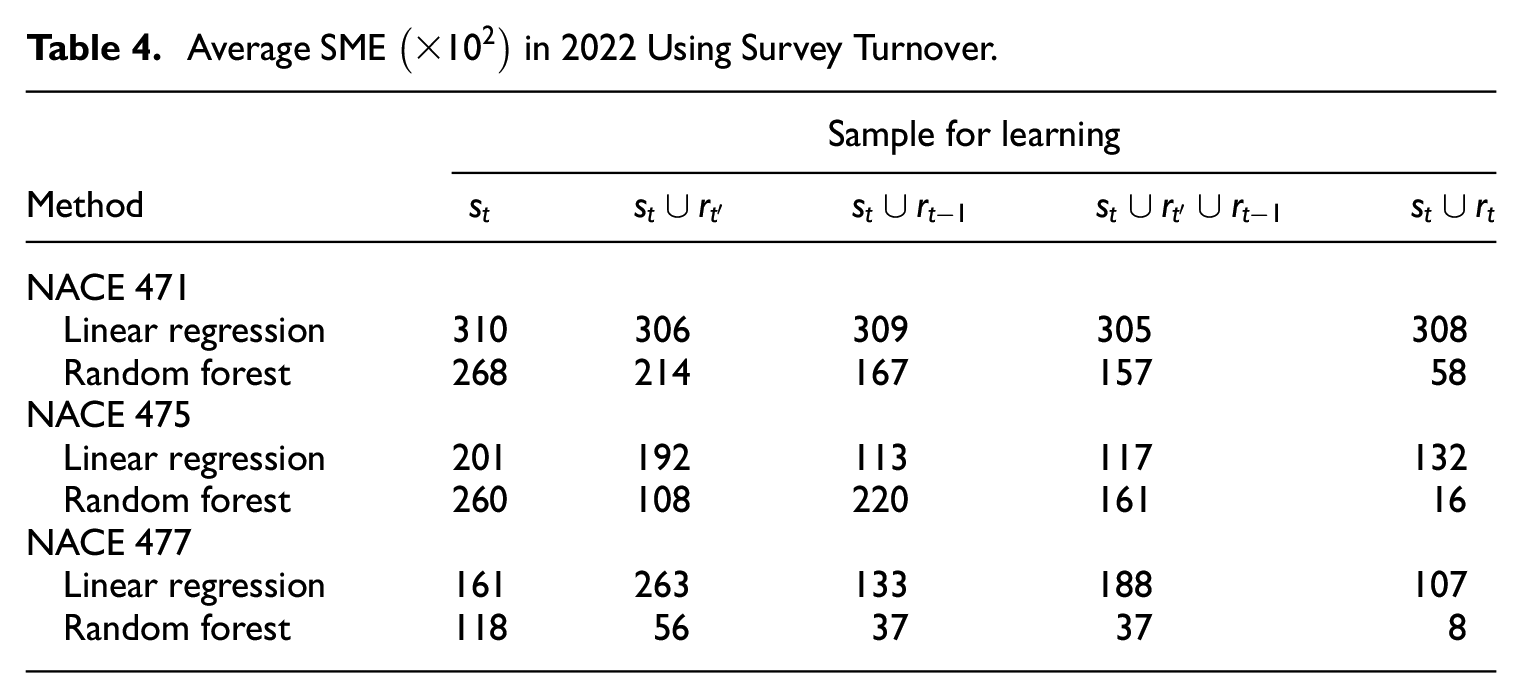
The squared mean error (SME), that is, , is more relevant for RTI than MSE. Table 4 shows the average SME over the twelve months of 2022 in the three NACE domains, by the same models and learning approaches. Random forest yields greatly reduced SME compared to linear regression in all the domains. Notice that the relative improvement of augmented learning to simplistic learning only from is more pronounced than in terms of MSE, for example, for the corresponding cells in the last row of Tables 3 or 4. Finally, the relative performance of training random forest on instead of may have been exaggerated here, due to the use of residuals in the former case, since training the linear model (i.e., less prone to overfitting) does not always lead to as impressive SME reductions.
Average SME in 2022 Using Survey Turnover.
Sample for learning
Method
NACE 471
Linear regression
310
306
309
305
308
Random forest
268
214
167
157
58
NACE 475
Linear regression
201
192
113
117
132
Random forest
260
108
220
161
16
NACE 477
Linear regression
161
263
133
188
107
Random forest
118
56
37
37
8
Setting-II. Augmented learning in setting-I above enables flash estimation without the sample units . Purposive sampling achieves further reduction of burden and resource, whereby the non-take-all units are dropped from the survey altogether. Since this also removes all the survey turnover observations of the cutoff units, augmented learning would depend on proxy values.
All the non-take-all VAT units can be used for augmented learning by Equation (7). However, here we shall present augmented learning based on past -samples associated with VAT turnover values instead of the observed survey turnovers, as well as in for the hypothetical setting of training on . Since the most recent VAT turnovers at refer to , we use instead of in given in Norway. In this way, the differences to the results above would only be due to the use of VAT turnovers that replace the survey turnovers, without the additional effects of including more units in .
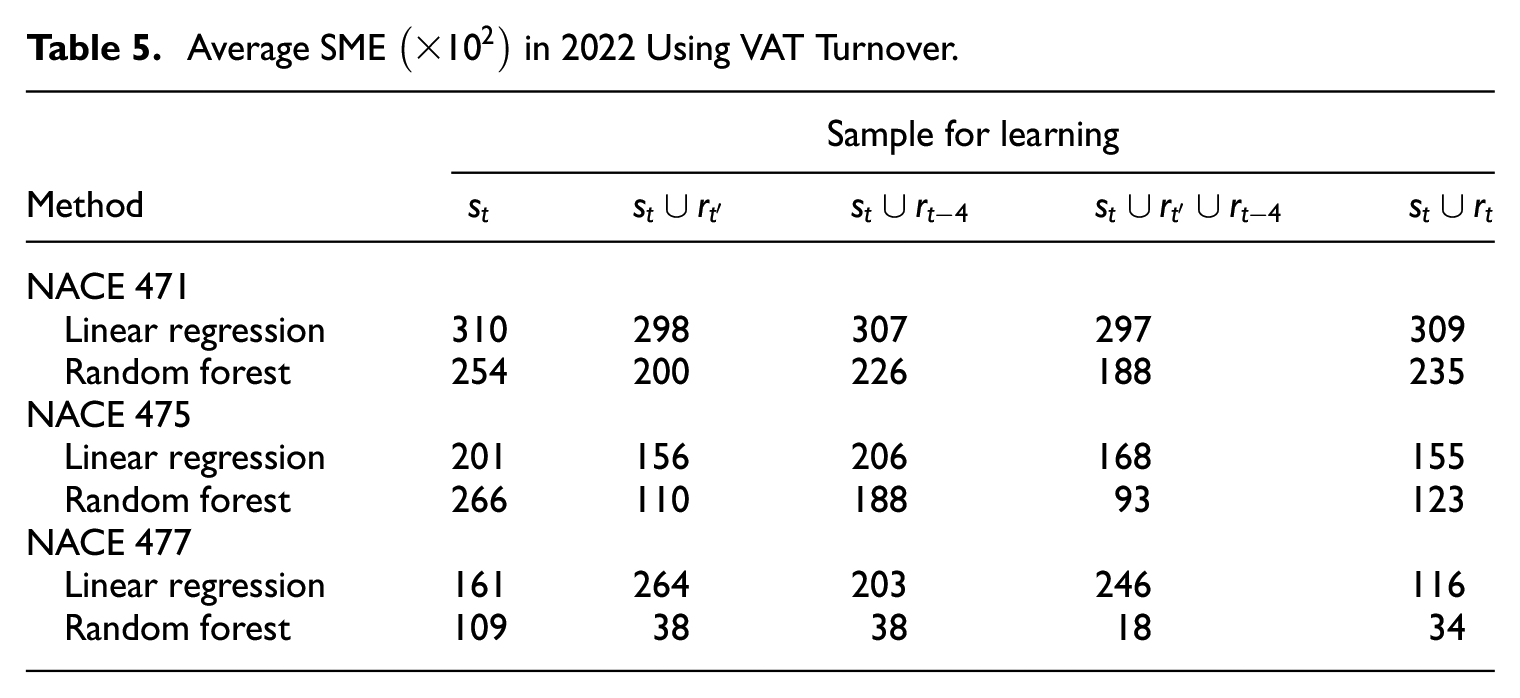
The SME results are given in Table 5 in the same way as Table 4. Random forest remains much better than linear regression. Regarding the learning approach, we conclude the following for augmented learning.
Augmented learning can reduce the SME compared to simplistic learning only from the take-all sample .
Comparing Table 5 to 4, one sees that augmented learning from mixing contemporaneous survey turnover and historic VAT turnover can perform as well as augmented learning fully based on survey turnover observations. This provides a justification for purposive sampling.
Training models on does not reduce SME compared to augmented learning using suitable , if VAT turnover is used as the -values in . Augmenting sample with past units is justified.
In particular, the setup seems to be a robust choice, which uses both the year-on-year and the most recent VAT-turnovers.
Average SME in 2022 Using VAT Turnover.
Sample for learning
Method
NACE 471
Linear regression
310
298
307
297
309
Random forest
254
200
226
188
235
NACE 475
Linear regression
201
156
206
168
155
Random forest
266
110
188
93
123
NACE 477
Linear regression
161
264
203
246
116
Random forest
109
38
38
18
34
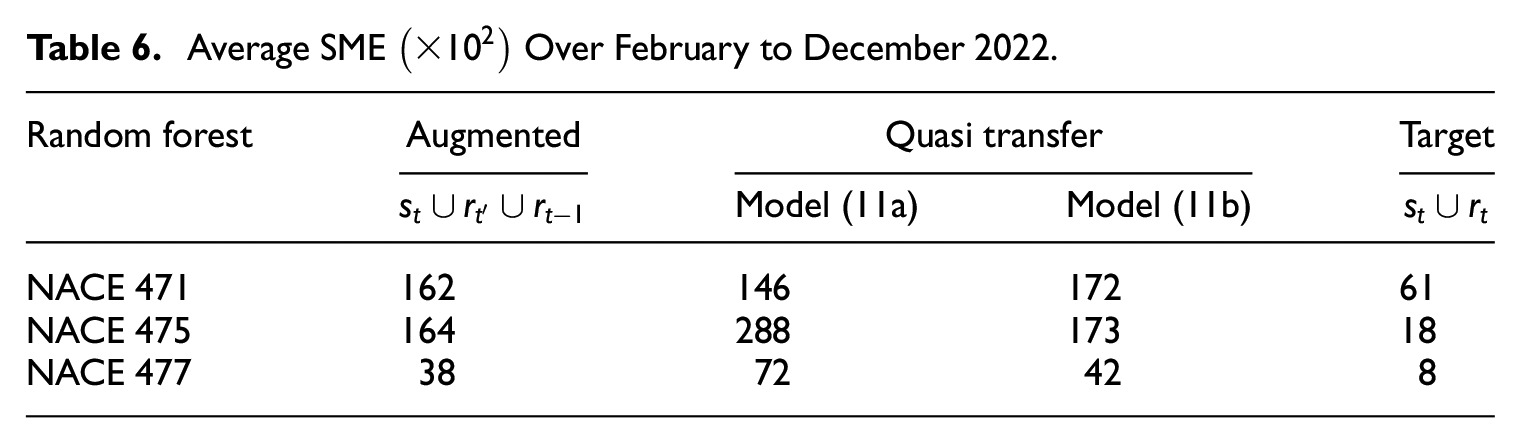
Quasi transfer learning. The scheme A requires transferring a past source model to the current time . It performs poorly for the same data above, which is not surprising given the dynamic nature of RTI. The results below are obtained by the scheme B, given either (11a) or (11b), where the target set is and the source time point is , and survey turnover values are used everywhere. The results are directly comparable to those of Table 4.
Since the sample for quasi transfer learning dates further back in time than for augmented learning, the results is only available for February to December 2022 based on the same data above. Table 6 shows the average SME over these eleven months, together with the results for augmented learning (using ) and target learning (using ), which are comparable to those in Table 4 averaged over twelve months.
Average SME Over February to December 2022.
Random forest
Augmented
Quasi transfer
Target
Model (11a)
Model (11b)
NACE 471
162
146
172
61
NACE 475
164
288
173
18
NACE 477
38
72
42
8
It can be seen that the SME of the model Equation (11a) varies more across the NACE domains than that of the model Equation (11b). Quasi transfer learning using the model Equation (11b) yields slightly larger SME compared to augmented learning. It might be possible to fine-tune the choice of for the past source models (Figure 2), so as to improve the results of quasi transfer learning. However, given the relative simplicity and intuitiveness of augmented learning, we conclude that augmented learning is the preferred learning approach for flash RTI in Norway.
3.2. Flash RTI
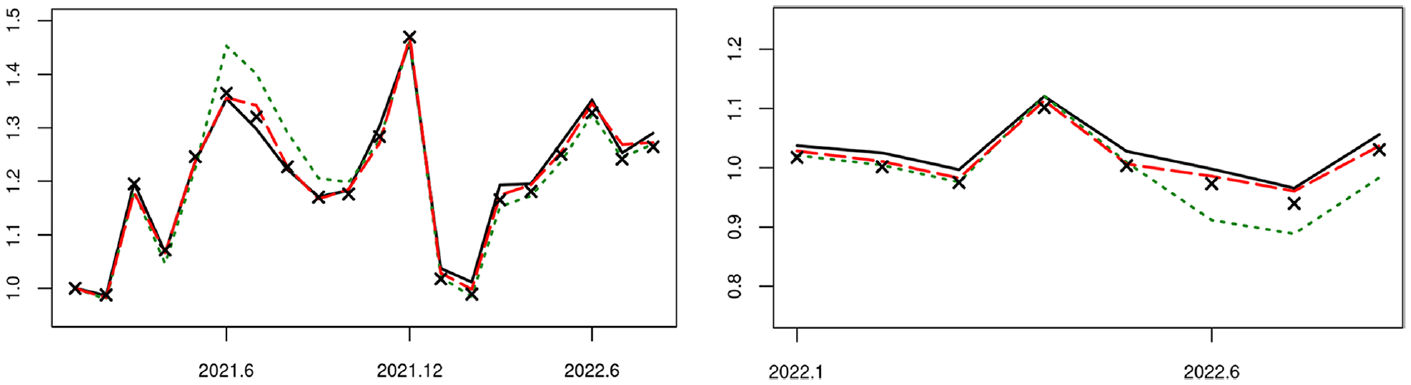
Figure 5 shows flash RTI estimation results for NACE47 (excluding NACE478) over the relevant months in 2021 and 2022, based on purposive sampling and using debit card transactions data, both in terms of the monthly and the year-on-year indices. The chosen random forest model is trained by augmented learning based on , with associated , , and . In addition, the flash RTI by the simplistic learning only from is given, as well as the hypothetical flash RTI that uses the random forest model learned from to predict for .
Existing RTI (solid line) for NACE47 over periods of 2021 to 2022, flash RTI by simplistic learning (dotted line), augmented learning (dashed line), or hypothetical learning from (cross line). Left: monthly index; right: year-on-year index.
The existing survey sampling approach requires both and and serves as the performance benchmark. It is seen that simplistic learning from only can sometimes deviate quite far from the disseminated RTI. The flash RTI obtained by augmented learning without achieves comparable performance to hypothetical learning from the target observations in , although in principle unbiased prediction is only possible with the latter but not the former.
Moreover, let be a given flash RTI for month and let the official RTI which is based on the existing sample survey design. Let the difference between the monthly change by the two be given as
Figure 6 shows for the three learning options in Figure 5. Although auto-correlations exist in all the three times series , , , respectively, one cannot detect any pronounced auto-correlation in the plot of .
Difference of monthly change in flash RTI and official RTI for NACE47 over periods of 2021 to 2022. Simplistic learning (dotted line), augmented learning (dashed line), hypothetical learning from (solid line).
The results suggest that, by adopting an appropriate learning approach, one may be able to drop the take-some sample , reduce the response burden and the processing cost, and greatly improve the timeliness of RTI by halving the current dissemination time lag, without compromising the accuracy of RTI.
3.3. Validation and Uncertainty
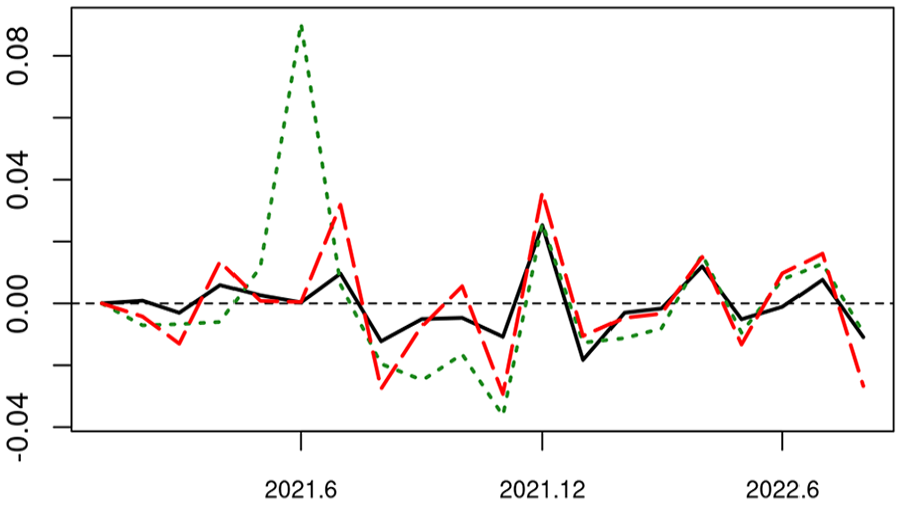
First, Figure 7 shows the results of retrospective validation as described in Subsection 2.4. The adopted random forest model for flash RTI (described above) is fitted to the population of VAT units relevant to each , which yields the model-predicted VAT index derived from (dashed) in the left plot of Figure 7. It can be seen that the model fits the VAT population quite well over the period here, since the discrepancy between the model-predicted VAT index and the VAT index derived from the observed (solid) is barely noticeable in the given period except perhaps for July 2021.
Retrospective validation of flash RTI given in Figure 5. Left, random forest model, VAT index observed (solid line) or model-predicted (dashed line). Right, augmented learning, proxy-RTI index observed (solid line) or learned (dashed line).
In the right plot of Figure 7, the adopted random forest model is trained by augmented learning (as for the flash RTI), which yields the learned index derived from (described in Subsection 2.4). It tracks closely its target proxy-RTI index derived from , although augmented learning does seem to induce some discrepancy in addition to that due to modeling (in the left plot).
It is important to notice that the discrepancy between the learned index (of ) and the proxy-RTI index (of ) in Figure 7 reflects well the discrepancy between the flash RTI (by augmented learning) and the disseminated RTI (by existing survey sampling) in Figure 5. The proposed retrospective validation approach can provide a reliable basis for assessing whether the flash RTI has worked satisfactorily till as recently as months ago.
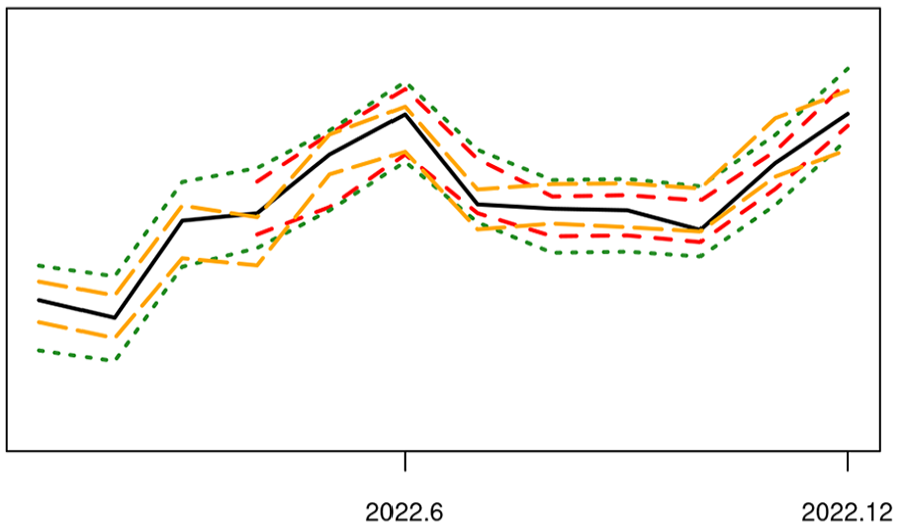
Next, for uncertainty estimation, Figure 8 shows the VAT total that is only available retrospectively (i.e., in Subsection 2.5), together with its prediction intervals by the empirical or error prediction method and its confidence intervals by survey sampling. Whereas the intervals by the empirical method Equation (15) and survey sampling are obtained for all the twelve months of 2022, we could only calculate the intervals for April to December by the error prediction method Equation (20) given the data available, because this method requires more data backwards under the adopted setup of augmented learning.
VAT total (solid line), prediction interval by empirical method (dotted line) or error prediction (dashed line), confidence interval by sampling (long-dashed line).
The prediction intervals are empirically calibrated by either Equation (15) or Equation (20) to the nominal level 91.7% based on a sliding window of twelve months. The nominal level of the confidence intervals by survey sampling is 95%, which are obtained as follows. Let be the ratio estimator based on the existing subsample , which uses the VAT values from the same month in the previous year as the auxiliary. Let be the estimated standard error of this ratio estimator. We obtain an approximate 95% confidence interval by appealing to the Central Limit Theorem.
The actual coverage is 100% by both of the prediction intervals during their respective periods in 2022. The coverage of the 95% confidence intervals based on survey sampling is 91.7%, which are not calibrated empirically as we do for the prediction intervals. Notwithstanding the fairly short time span of these results, the proposed prediction intervals display promising coverage property. As can be expected, error prediction modeling Equation (18) improves considerably the efficiency of estimation compared to the simple empirical method, where the average relative half-length (of prediction interval) is 4.7% by error prediction Equation (18) and 7.8% by the empirical method Equation (15).
Since the average relative half-length of the confidence intervals by ratio estimation is 4.6%, flash estimation without subsample has been about as efficient as the sampling-based ratio estimation that requires . It seems fair to conclude that augmented learning can enable flash estimation with greatly improved timeliness, as well as reduced response burden and processing cost, without compromising the accuracy of RTI.
4. Final Remarks
We have considered a setting for flash estimation, where target observations necessary for unbiased prediction are not available at all outside a purposive sample selected with probability one. Rather than simply applying a model learned from the purposive sample to the rest population units, we propose two general approaches of model learning that make use of data from relevant domains outside the target population, called augmented learning and pseudo transfer learning, respectively. Moreover, retrospective validation of modeling or learning and real-time prediction interval estimation methods are developed in the context of Turnover Statistics.
Application to the Norwegian Retail Turnover Survey data shows that it is possible to obtain flash RTI for NACE47 based on augmented learning, which greatly improves the timeliness by halving the current dissemination time lag, without compromising the accuracy of RTI. The adopted model utilizes relevant auxiliary information in historic VAT reports and contemporaneous debit card transactions, enabling one to remove the non-self-representing sample units, thereby reducing the associated response burden and processing cost.
The flash RTI methodology described above and the related production processes are being implemented at Statistics Norway. Three broad, interrelated aspects are worth noting for other countries with a similar interest.
First, greater uses of historic VAT reports can benefit from improvements of the underlying statistical database. For instance, the bimonthly VAT reports have been apportioned to create a statistical database of monthly VAT turnover values for the local units which can be used for flash RTI estimation, the details of which have been left out to save space. Similar apportioning of available VAT register data may be relevant in other countries, in order to harmonize over the different frequencies and units of VAT reporting that exist. The resulting statistical database is more “complete” and “detailed” than the raw VAT register, which can benefit many relevant statistics.
Second, we have made use of debit card transactions that are available to Statistics Norway, which fundamentally improves the timeliness of auxiliary information compared to the VAT register that is only available months later. Other sources of transaction data are also of interest, such as e-invoices and business-to-business bank transfers. While the different sources have their distinct challenges of access and processing, they complement each other in coverage and content, becoming more useful in combination with each other. This is an area that requires strategic development of knowledge, experience and capacity at National Statistical Offices. A coordinated program across the whole spectrum of business statistics would be more impactful than scattered efforts each focusing on a specific topic.
Third, provided greater access to relevant and timely non-survey big data, improving the timeliness of economic indicators while reducing the response burden and processing cost becomes an ever more urgent matter. The flash RTI exemplifies a situation where some survey data is still necessary to ensure the relevance and accuracy of official statistics. Combining appropriate purposive samples with novel modeling and learning approaches requires attention in practice. Diligent retrospective validation is essential in this respect, in terms of the adopted model, learning approach, as well as the associated uncertainty measures such as prediction intervals. The obtained insights should help to guide the maintenance and updating of the purposive sample, in order to be able to compensate for the data that are either missing structurally (such as when the take-some sample is removed altogether) or randomly (e.g., due to delays of reporting, new or dissolved business units).
Looking ahead we would like to point toward a greater emphasis on novel learning approaches for official statistics. In the context of flash estimation, where the absence of target observations is the fundamental challenge, a key matter of learning is how to organize the data outside the target domain but are nevertheless relevant (for training any given models). Augmented learning and quasi transfer learning have been proposed from this perspective. As official statistics are typically repeated over time and geography, variations of transfer learning (with or without target observations) seems a large topic for future research and application, for example, beyond the common traditional approach of allowing for temporally or spatially correlated observations.
Footnotes
Acknowledgements
This work would not have been possible without Jan Henrik Wang, Jørgen Vinje Berget, and Edvard Garmmanslund at Statistics Norway. We thank also the referees, the Associated Editor, and the Editor-in-Chief for helpful comments and suggestions.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
ORCID iD
Jens Kristoffer Haug
Received: March 1, 2024
Accepted: September 26, 2024
References
1.
BaldacciE.BuonoD.KapetaniosG.KrischeS.MarcellinoM.MazziG. L.PapailiasF.2016. Big Data and Macroeconomic Nowcasting: From Data Access to Modelling. Luxembourg: Eurostat: Statistical Books. DOI: https://doi.org/10.2785/3605875.
2.
BreimanL.1996a. “Heuristics of Instability and Stabilization in Model Selection.”The Annals of Statistics24: 2350–83. DOI: https://doi.org/10.1214/aos/1032181158.
Eurostat. 2017. Handbook on Rapid Estimates. Edited by MazziG. L.Luxembourg: European Union and the United Nations. DOI: https://doi.org/10.2785/4887400.
5.
FornaroP.LuomarantaH.2020. “Nowcasting Finnish Real Economic Activity: A Machine Learning Approach.”Empirical Economics58: 55–71. DOI: https://doi.org/10.1007/s00181-019-01809-y.
6.
GuT.HanY.DuanR.2023. “A Transfer Learning Approach Based on Random Forest with Application to Breast Cancer Prediction in Underrepresented Populations.”Pacific Symposium on Biocomputing28: 186–97. https://pubmed.ncbi.nlm.nih.gov/36540976/.
7.
HastieT.TibshiraniR.FriedmanJ.2009. The Elements of Statistical Learning, 2nd edition. New York: Springer.
8.
LiS.CaiT. T.LiH.2020. “Transfer Learning for High-Dimensional Linear Regression: Prediction, Estimation, and Minimax Optimality.”Journal of the Royal Statistical Society: Series B (Statistical Methodology)84: 149–73. DOI: https://doi.org/10.1111/rssb.12479.
PrattL. Y.1993. “Transferring Previously Learned Back-Propagation Neural Networks to New Learning Tasks.” PhD thesis, Rutgers University, also appeared as Technical Report ML-TR-37. https://dl.acm.org/doi/book/10.5555/193298.
11.
TibshiraniR.1996. “Regression Shrinkage and Selection via the Lasso.”Journal of the Royal Statistical Society: Series B (Statistical Methodology)58: 267–88. DOI: https://doi.org/10.1111/j.2517-6161.1996.tb02080.x.