
Abstract

Secure Private Computation (SPC) technologies may play an important role in the production of future official statistics, particularly in multi-party (MP) settings where the desired statistics or indicators of interest involve computation over multiple stocks of confidential data held by different organizations. SPC technologies enable the implementation of collaborative computation processes that allow the final statistics or indicator to be computed exactly with no need for the data holders to share their input data in intelligible form with other entities. The design, building, deployment, and operation of Multi-Party Secure Private Computation (MPSPC) solutions involves non-negligible efforts and specialized skills on the technological side, but also a careful analysis of organizational and legal aspects. Eurostat is considering the possibility of building a shared MPSPC system for the European Statistical Systems (ESS) to be used on-demand by ESS members and their partners, a model called MPSPC-as-a-Service (MPSPCaaS for short). In this way, the technological and non-technological aspects involved in the design and deployment of the MPSPCaaS system can be addressed directly at the European level. In this letter we present the key elements of the MPSPCaaS concept and outline the activities conducted by Eurostat in this field.
1. Context and Motivations
The world of official statistics is under transformation and several innovation trends concur to increase the demand for producing output statistics based on the integration of multiple data sets held by different organizations. First, there is a rising interest by statistical agencies to produce new, richer, and timelier statistics based on external data sources, that is, data collected primarily for non-statistical purposes by other public or private entities. Privately held data are seen as increasingly central for the prospective production of future new statistics (see e.g., Baldacci et al. 2021) notwithstanding several challenges and issues to be solved, as elaborated for instance by the Expert Group on facilitating the use of new data sources for official statistics (2022) in their final report. In 2023 the European Commission has taken the initiative to propose a review of the Regulation 223/2009 on European statistics that, among other goals, aims at providing legal enablers for the (re)use of privately held data for official statistics (European Commission 2023a). Second, there is increasing demand of cross-border and trans-national statistics based on the combination of national data from different countries or regions. Third, the cooperation between statistical authorities and other national or international bodies holding complementary data (e.g., financial authorities, central banks) creates further opportunities for multi-source statistics based on the combination of their data.
All these trends concur to increase the demand for statistical agencies to establish agreements with other statistical or non-statistical entities in order to make the most of their combined data. In several cases, it will suffice to resort to traditional data sharing arrangements based on plain data transmission (possibly with some mild form of protection, e.g., standard pseudonymization) whereby the involved data holders exchange the input data either directly with each other or with a trusted third party. However, in other cases such “traditional” data exchange arrangements will not suffice or will not be accepted. These are the cases where advanced solutions based on Privacy Enhancing Technologies may come to the rescue.
2. Input Privacy and Output Privacy
Privacy Enhancing Technologies (PETs) is a general umbrella term used to refer collectively to a broad range of diverse technologies aimed at reconciling protection of data confidentiality with data utility. Following Ricciato et al. (2019) and UN Big Data Global Working Group (2019) we divide the family of PETs into two groups, namely Input Privacy and Output Privacy techniques. To explain the distinction, consider a generic computing instance where the desired output result
Given the above setting, Input Privacy techniques allow computing the exact desired output
Output Privacy techniques have a different goal. They aim at producing a quasi-result
Input Privacy and Output Privacy techniques may be seen as complementary ingredients and, depending on the use-case at hand, one may need one, the other or some combination of both.
The present contribution is scoped exclusively on Input Privacy techniques. Previous studies have exposed fundamental flaws of some recently proposed Output Privacy approaches aimed at sharing highly granular data (individual records, micro-data) and/or high-dimensional AI/ML models trained on personal data, see for instance Stadler and Troncoso (2022), Stadler et al. (2022), Blanco-Justicia et al. (2022), and Domingo-Ferrer et al. (2021) and references therein. In the author’s opinion, the hurried adoption of these techniques, in certain business application contexts and without careful further scrutiny, may be more akin to privacywashing than to privacy enhancing. The statistical community should exercise careful discernment in selecting the “PET” approaches that can genuinely improve the protection of personal data along the statistical production process, without indulging in the “futile search for a silver bullet solution to all-purpose-utility high-privacy sharing of fine-grained data” (quote from Stadler and Troncoso 2022). Elaborating on the limitations and risks of Output Privacy techniques falls outside the scope of this letter. Therefore, unless explicitly specified differently, any statement made hereafter about “PETs” and any reference to PET-based solutions should be interpreted as being referred exclusively to Input Privacy techniques.
3. Differentiating Confidentiality Protection Measures
The General Data Protection Regulation (GDPR) embraces a risk-based approach, based on the notion that different kinds of data and processing operations carry different levels of sensitivity and risk, and therefore require different degrees of protection. We are using the term “risk” in a broad and qualitative sense here, encompassing both the probability and the impact of identification, disclosure and any other privacy attacks. The level of risk must be assessed case-by-case, and the strength of the protection measures must be defined correspondingly, taking into account all relevant contextual elements.
Making reference to a generic set of individual records, among the various dimensions that concur to determine the level of risk, the following three are particularly prominent:
The share of the population represented in the data set: a sample data set covering 0.1 percent of the population carries lower risk than an exhaustive data set covering the entire population.
The granularity and level of detail of the information encoded at the individual level: for example, a data set encoding the place of living or the annual expenditure of individuals (as typical in micro-data records) carries lower risk than a data set tracking their exact geographical position at every minute 24/7 or the detailed description of each and every purchase or transaction (as is typical with the “nano-data” now available from digital traces (Ricciato et al. 2020)).
The semantic of the information encoded in the data base: in fact, certain categories of data are explicitly singled out in GDPR as “special” and deserving stronger protection (e.g., data related to racial or ethnic origin, political opinions, religious or philosophical beliefs, trade union membership, sex life, sexual orientation, and health).
In addition to the above dimensions, related to the type of data, other contextual aspects must be taken into account, including who will have access to such data, what other auxiliary data may be available to them, etc. Clearly, different scenarios entail different levels of risk, and therefore call for different levels of protection measures and safeguards.
Indeed, the general principle of proportionality is at work here. Quoting from European Data Protection Supervisor (2007): “Proportionality is a general principle of EU law. It restricts authorities in the exercise of their powers by requiring them to strike a balance between the means used and the intended aim. In the context of fundamental rights, such as the right to the protection of personal data, proportionality is key for any limitation on these rights. More specifically, proportionality requires that advantages due to limiting the right are not outweighed by the disadvantages to exercise the right. In other words, the limitation on the right must be justified. Safeguards accompanying a measure can support the justification of a measure.”
The implications of the principle of proportionality branch out to multiple dimensions in our context. Firstly, as sketched graphically in Figure 1, since different kinds of data and processing operations carry different degrees of initial risk, they require proportionally stronger protection measures and safeguards to bring the residual risk down to a negligible or acceptable level.
Secondly, as stronger protection involves higher costs, at both the organizational and technological level, dealing with riskier data requires proportionally higher investments.
Thirdly, when the residual risk cannot be neglected, it must be proportionate to the expected benefit deriving from the data processing operation. In fact, at some point the strength of protection measures and safeguards that can be realistically deployed reaches an upper limit due to some combination of technological state-of-the-art limitations and/or budget availability constraints. For the rightmost point in Figure 1, associated with a very high level of initial risk, it is assumed that it would not be possible to step up to a proportionally higher level of protection, leaving a non-negligible level of residual risk (corresponding to the length of the vertical dashed line in the figure). In this situation the data processing operation may be justified only if the level of residual risk can be considered acceptable vis-à -vis the expected benefit deriving from the data processing operation (according to GDPR Recital 94 in this case the data protection supervisory authority should be consulted).
We highlight that proportionality works in both directions. On the one hand, it implies that, when dealing with data sets carrying only a moderate level or risks, standard approaches based on plain data sharing arrangements and purely organizational safeguards may be perfectly sufficient: in other words, resorting to more sophisticated PET-based solutions may be unnecessarily and disproportionately expensive in such cases. On the other hand, it implies that standard protection measures cannot suffice for the riskier data sets, for which more sophisticated protection solutions that include safeguards at the technological level must be put in place: this is where PET-based solutions come into play.
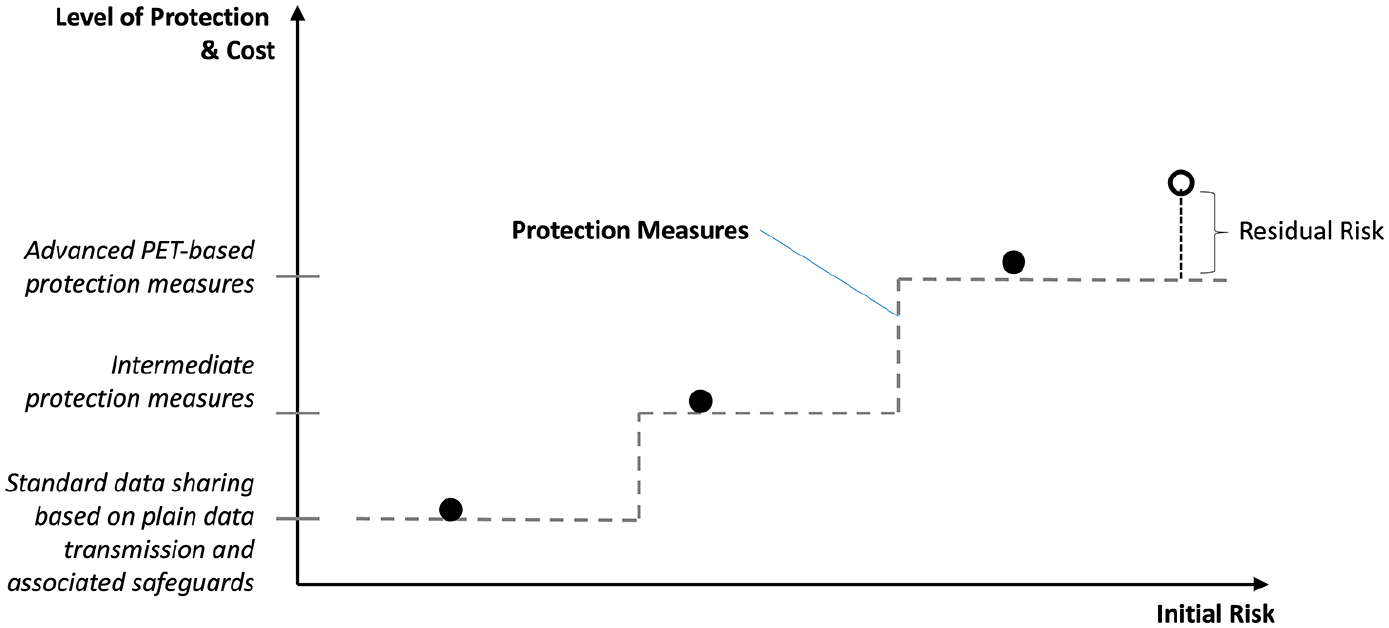
The strength (and cost) of protection measures must be proportionate to the level of (initial) risk.
In the framework outlined above, advanced PET-based solutions are instrumental to achieve the strongest protection level feasible today (given the current state-of-the-art of technology) as required to deal with new kinds of data at the upper end of the risk spectrum. As such, PET-based solutions should not be seen as competing with but rather complementing more traditional approaches based on plain data sharing. The more sophisticated and costly PET-based solutions are additional instruments in the toolbox of statistical agencies, to be used when the simpler and cheaper approaches of direct data sharing do not suffice. Quoting Zhang and Haraldsen (2022): “Instead of merely considering [PET-based solutions] as extra troubles, we prefer to welcome them as the means for providing opportunities to better, quicker and richer data that can both improve and enlarge the outputs of official statistics”.
Finally, it is important to remark that, again as noted earlier by Zhang and Haraldsen (2022), adopting adequate data protection measures is not only a legal obligation but often also a necessary condition to gain trust and acceptance by the involved stakeholders. In other words, PET-based solutions are not only a means to assure legal compliance but also to reassure data providers and the general public, paving the way toward the (re)use of more pervasive data for statistical purposes.
4. Barriers to Adoption of PETs in the Public Sector
Despite increasing awareness and interest by public institutions and the proliferation of research projects, pilots, and case-studies, the actual adoption of SPC in the public sector is still in an early pioneering stage. Several factors and barriers concur to slow down initial adoption, including:
Lack of skills and expert knowledge on the side of potential adopters. SPC technologies are relatively recent and often based on concepts (e.g., from advanced cryptography) that are difficult to grasp by non-experts. In this case, the asymmetry of knowledge between technology providers and potential adopters represents a slowing factor.
Costs. SPC technologies have been maturing quickly in the last decade and moved out of research lab into commercial ready-to-use products. Nonetheless, they are still far from being “commoditized” and, as with any recent technology, the total costs for acquisition, deployment and operation may still be substantial.
Organizational impact. Technologies are never just a matter of technology. In the same way as any technology gadget induces behavioral change at the individual level, the adoption of certain technologies in large organizations, whether private companies or public institutions, involves changes in the way organizations operate internally and impacts business processes, distribution of roles and responsibilities. The mutual coupling between the organizational and technological levels is even stronger for security-oriented technologies, for which issues of trust and liabilities are very central. In many respects, the adoption of PETs entails a significant change in the way organizations deal with data and consequently, as far as multi-party settings are concerned, also in the way they deal with each other.
Legal uncertainty. There are still some open questions as to how PETs should be considered in the context of current data protection legislation, for example, concerning the conditions by which PET components qualify as anonymisation or pseudonymisation procedures, or how the notions of data controller and data processor apply to PET-based solutions. These aspects lie at the border between law and technology, and clarifying them is necessary to reduce legal uncertainty and the associated compliance risks (actual or perceived).
All potential adopters, and most prominently public sector bodies, will be facing the above challenges when approaching or considering adoption of PETs in production settings, beyond pilots and case-studies. Under certain conditions, such “commonality of challenges” may be turned into an opportunity: if multiple potential adopters face the same problem, they can join forces, pool resources, and develop a common shared solution. Such a collaborative scenario may not be viable when potential adopters are in direct mutual competition, as is often the case with private companies in the same business sector, and is anyway difficult to implement when a cooperation framework is not already established among organizations. The European Statistical System (ESS) is an exceptional case in point where a solid cooperation and coordination framework is already in place: indeed the ESS defines itself as a “partnership” between multiple statistical institutes and authorities (Eurostat 2011). This facilitates the exploration, development, and eventually the adoption of shared PET solutions in the ESS context.
5. The Vision of a Shared PET-Based Solution for the ESS
Motivated by the considerations made above, Eurostat started to consider the idea of building a shared ESS infrastructure, based on Input Privacy technologies, to enable collaborative processing of confidential data sets among ESS members and their partners. Such an infrastructure would be developed and owned by the ESS and provide service to the ESS. The concept went under the name of Multi-Party Secure Private Computing-as-a-Service (MPSPCaaS for short). The envisioned MPSPCaaS infrastructure would consist of a combination of technological components (primitives, protocols) and organizational elements (policies, processes) to be defined, implemented, deployed, and maintained by the infrastructure owner(s). Once deployed, different groups of input parties and output parties can use it “on demand” to perform their collaborative computation tasks, taking advantage of the horizontal primitives, protocols, policies, and processes made available by the infrastructure.
The technical and strategic aspects of this concept were first discussed in the context of the UNECE Project on Input Privacy-Preservation (UNECE 2022). Among the activities of this project, an informal public consultation was carried out, targeting external experts and potential stakeholders, in order to ensure that all important aspects and challenges relevant to the concept were properly considered (the outcome of the consultation can be found in the final report of the project (UNECE High-Level Group for the Modernisation of Official statistics 2023)). Furthermore, the concept was presented at various occasions, events, and workshops inside and outside the ESS (presentations can be retrieved from the web page on Privacy Enhancing Technologies for Official Statistics (PET4OS) available at https://cros.ec.europa.eu/PET4OS).
Following such preparatory work, in April 2023 Eurostat launched a public call for tender for “specification, feasibility analysis and prototype demonstration of a multi-party secure private computing system for processing confidential sets of micro-data across organisations in support of statistical innovation” (European Commission, DG Eurostat 2023). At the time of drafting this letter the received applications are under evaluation. The project is expected to start in the first quarter of 2024 and deliver the final results within two years.
Working in tight consultation with Eurostat, the company or consortium that will be awarded the contract is tasked to produce a detailed definition of the MPSPCaaS concept, including all technological, organizational, and legal aspects. At the organizational level, the project will define rules and roles of the involved entities, procedures, policies, and governance mechanisms. These organizational aspects must be encoded, on the one side, into binding contracts and agreements, for which models and templates will be drafted within the project along with any other relevant legal documents (e.g., models of Data Protection Impact Assessment) in a specific work-package dedicated to legal aspects. On the other side, organizational rules and roles defined and encoded in legal documents must be enforced by technological means, making use of PETs among other components. In other words, the project will address coherently and holistically the three levels, legal, organizational, and technological, and will develop a coherent “package” of specifications based on, but not limited to PET-based components.
On top of the technical, organizational and legal aspects, the project shall address also a fourth aspect, namely trust building. Our goal is to build a system that is both trustworthy and trusted by the relevant stakeholders, including data holders, data subjects, and the general public. In doing so, building a system that is robust, secure, and ultimately worthy to be trusted is absolutely necessary, but not sufficient, and additional explicit actions are needed toward building trust into system by the relevant stakeholders. In other words, building a demonstrably secure and robust system is a distinct task from demonstrating the security and robustness of the system itself. Based on the above considerations, the project includes a dedicated work-package focusing on actions for building trust into the system.
Finally, the project shall not be limited to analysis and specification paperwork, and will also include a thorough demonstration phase based on a prototype implementation to verify the technical feasibility and scalability of the proposed specifications. During the demonstration phase, it is planned to offer interested statistical authorities the opportunity to engage, on a voluntary basis, in pilots and test trials aimed at verifying the usability and suitability of the proposed system to meet their needs. The details of such possible engagement will be defined in the course of the project.
If successful, the outcome of this project will enable Eurostat to move toward the procurement of an operational production system in the following phase.
6. System Requirements
In this section we highlight some key high-level requirements and features that the envisioned MPSPCaaS system should fulfill, as extracted from the Technical Specifications of the call for tender (European Commission, DG Eurostat 2023).
The envisioned system will offer the possibility to small groups of organizations, comprising one or more statistical agencies and possibly also other partner entities (public or private), to perform computation tasks “on demand” over their confidential data without the need for any data provider to disclose its input data or any other derived information other than the final result of a pre-defined function or statistical procedure encoded into pre-authorized program code.
The system will be designed to display no “single point of trust” (SPoT), that is, no single entity shall have the technical capability of configuring the processing operations (and possibly launching new computation tasks that reveal the input data or other information derived from there) without the explicit authorization by a pre-defined set of other entities. This is a critical requirement that differentiates our proposal from the traditional “trusted third party” (TTP) approach, where a single entity is in full control of the data (if not legally at least technically) and for this reason must be “trusted” not to misuse such power: a system featuring a SPoT would basically reduce to a technology-heavy version of the TTP model.
For the sake of fulfilling the “no SPoT” requirement, the envisioned system will be designed around technological solutions that split the power of configuring the processing operations (process control) among different and mutually independent entities (institutions, organizations) acting as “processing parties” (the role of “processing parties” corresponds to that of “computing parties” in the terminology of secret sharing and relates purely to a technical capability: it should not be confused with the legal notions of “processor” or “controller” in GDPR). In other words, the system will rely on a distributed multi-party core infrastructure, with multiple processing nodes deployed at the premises of mutually independent entities serving as PPs. Following a security-in-depth approach, the system shall provide protections at both hardware and software levels. Considering the current state of technology, we expect the system to embed some combination of SMPC and TEE components.
Every computation task will involve at least three distinct PPs. We expect that in most practical scenarios three PPs will be sufficient to achieve the target level of robustness while keeping a manageable level of system complexity. Support for two-party protocols is not included in the initial design but may be considered as a possible extension for future versions of the system.
The system will be engineered to be robust to collusion of and intrusions at up to two out of three PPs (or
Data providers will be given the option to assume also the PP role (in addition to the input party role) or alternatively rely on a set of external PPs. In the latter case, we highlight that the three or more PPs must be trusted collectively, not individually. By assuming the PP role, the data provider will be effectively sharing with, rather than delegating to other entities the control power over the processing operation. We believe this feature will be critical in certain application scenarios to reassure data providers and lower the barriers against their participation.
On a more technical level, the system design requirements will be directly derived from GDPR principles. The envisioned system shall avoid the exchange of input data or any other related information in intelligible form. Only non-intelligible information derived from the input data through advanced cryptographic methods (including secret sharing) shall be transmitted from the input parties to the system, and only for the part that is strictly necessary to compute the desired result, in line with the GDPR principle of data minimisation. Built-in protection measures shall ensure that, within the considered set of attack models, no entity internal or external to the system can gain access to such information, ensuring compliance with the GDPR principle of data integrity and confidentiality. The system shall ensure and that only explicitly authorized computation tasks can be executed, thus enforcing the GDPR principle of purpose limitation. Finally, upon completion of each computation task, all exchanged information must be certifiably erased from the system, in agreement with the GDPR principle of storage limitation. In other words, the envisioned system design process will translate point-by-point the GDPR principles and prescriptions into technical specifications for the SPC-based system, and in this sense the role of SPC is to reinforce the implementation of GDPR (see e.g., Ricciato 2023).
7. PETs and Legislation in the Making
Complementary to the technical work outlined above, Eurostat is also contributing to prepare legislative enablers for the prospective adoption of PET-based solutions in official statistics. Upon initiative by Eurostat, the European Commission has recently adopted two proposals for EU regulations making explicit references to PETs. First, the already cited proposed revision of Regulation (EC) No 223/2009 on European statistics (European Commission 2023a) refers to PETs in Article 17f and Recital (15). Second, the proposed EU regulation on European statistics on population and housing (ESOP) (European Commission 2023b) mentions explicitly PETs in Article 13, Article 14 and Recital (30).
The proposed legal text refers to data sharing mechanisms based on privacy enhancing technologies that are specifically designed to implement the GDPR principles of purpose limitation, data minimisation, storage limitation and integrity and confidentiality, stating that such PET-based mechanisms should be preferred over direct data transmission. This particular formulation implies that, from a legal perspective, the role of PET-based solutions is to support compliance to GDPR, by offering a means to implement and enforce technologically its core principles. This view is fully consistent with the statement made in the Technical Specifications of the Eurostat project (European Commission, DG Eurostat 2023) that the operation of the envisioned MPSPCaaS system is assumed to represent “processing of personal data” insofar the input micro-data represent personal data according to GDPR and the MPSPCaaS system may be considered as a coherent system of “safeguards” and supplementary “technical and organisational measures” in the sense of GDPR Article 89.
For both legal proposals cited above, the European Data Protection Supervisor (EDPS, 2023a, 2023b) has issued opinions that are generally supportive of the perspective of using PETs as means to “implement the data protection principles effectively and integrate necessary safeguards into the data processing” and recommends to conduct pilots and feasibility studies aimed at assessing their “maturity, suitability, cost and effectiveness in terms of possible impact on individuals’ fundamental rights.” These recommendations are fully in line with the goals of the forthcoming Eurostat project.
8. Final Thoughts
The essential mission of official statistics is to provide the society with knowledge about itself. From the perspective of official statistics, citizens have collectively a dual role as “data subjects” (those who are measured) and “statistical users” (those who eventually receive the measurement results). This dual role entails a tension between, on the one hand, the benefits that official statistics bring to the citizens in their role of statistical users, and on the other hand, the risks that the use of wider and more granular personal data introduces for the privacy of the citizens in their role of data subjects. The current well-established sets of norms and practices in official statistics represents an equilibrium point, balancing between benefits and risks, that works well as long as traditional data sources and established statistical processes and products are concerned. But, like any other societal construction, also the system of official statistics is a dynamic and ever-evolving system, and when the terms of the equation change, a new solution or equilibrium point has to be found.
On the one side, statistical institutions must respond to the increasing demand for more, better, richer, and timelier statistical information expressed by a society that is more and more eager for and dependent on information. On the other side, they must cope with the higher risks (actual or perceived) associated with the processing of wider and deeper data and digital traces produced by a data-rich society, in a context where privacy concerns by the general public and pressure from data protection authorities is increasing. If new and richer data sources are to be used to produce new and richer statistics, new instruments must be envisioned to protect the data throughout the whole computation process and to protect the computation process itself in the new context, and ultimately achieve a new equilibrium point between protection of individual privacy and promotion of informed citizenship and evidence-based policy-making through the production of more, better and timelier statistics.
Finally, we remark that technology alone cannot be “the” solution or the only ingredient—we should not indulge in techno-solutionism or technological worship, but it may play an important role as part of a greater solution approach in combination with other organizational and legal components. In this perspective, properly designed and carefully implemented PET-based solution may be an important ingredient of the future statistical production. The questions we face is not whether PETs can be useful, but rather how to make good use of them in the particular context of official statistics. The capability, on the side of prospective adopters, of formulating a clear and sound vision of how technological and non-technological components interact with and depend from each other, and of engaging the other relevant stakeholders on the basis of this vision, are important pre-requisites for facing the many challenges ahead along the path from conceptualization toward actual implementation. Eurostat and the ESS are pioneering the way forward, one step at a time, with the due mix of caution and determination that is required in innovative endeavors.
Footnotes
Acknowledgements
Thanks to Giuseppe D’Acquisto for a series of fruitful and intensive discussions that helped to shape and sharpen the author’s view on the legal aspects of PETs.
Author’s Note
The views expressed in this article are those of the author and do not necessarily represent the official position of the European Commission.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Received: December 2023
Accepted: January 2024