
Abstract
Recent work has shown diffusion models are an effective approach to learning the multimodal distributions arising from demonstration data in behavior cloning. However, a drawback of this approach is the need to learn a denoising function, which is significantly more complex than learning an explicit policy. In this work, we propose Equivariant Diffusion Policy, a novel diffusion policy-learning method that leverages domain symmetries to obtain better sample efficiency and generalization in the denoising function. We theoretically characterize when a diffusion policy is equivariant and analyze the SO (2) symmetry of full 6-DoF control. We furthermore evaluate the method empirically on a set of 12 simulation tasks in MimicGen, and show that it obtains a success rate that is, on average, 34.5% higher than the baseline Diffusion Policy. We also evaluate the method on a real-world system to show that effective policies can be learned with relatively few training samples, whereas the baseline Diffusion Policy cannot.
Introduction
The recently proposed Diffusion Policy (Chi et al., 2023) formulates robotic manipulation action prediction as a diffusion model that denoises the action conditioned on the observation, thereby better capturing the multimodal action distribution of the demonstration data in Behavior Cloning (BC). Although Diffusion Policy often outperforms baselines on various benchmarks (Gupta et al., 2020; Mandlekar et al., 2022), a significant limitation is that the denoising function is inherently more complex than a standard policy function. Specifically, for a single state-action pair (s, a), the denoising process utilizes a mapping (s, a + ɛ k , k)↦ɛ k for all possible k and ɛ k , where ɛ k is Gaussian noise conditioned on step k. This formulation creates a considerably more challenging learning problem compared with an explicit BC s↦a.
In this paper, we leverage equivariant neural network models to incorporate task symmetry as an inductive bias in the diffusion process, substantially simplifying the denoising function learning problem. Although equivariant diffusion models have been studied by a number of prior works (Brehmer et al., 2023; Chen et al., 2023; Guan et al., 2023; Hoogeboom et al., 2022; Ryu et al., 2023b), our work is the first to comprehensively study and implement this concept for visuomotor policy learning. As illustrated in Figure 1, when a state and noisy trajectory action are rotated about the gravity axis, the corresponding denoised trajectory undergoes an equivalent transformation. This symmetry-aware approach enables our model to achieve significantly greater data efficiency and generalization capabilities than non-symmetric baselines, effectively addressing the high data requirements typically associated with diffusion-based methods. Equivariance in diffusion policy. Top left: a randomly sampled trajectory. Top right: a valid trajectory after denoising. If the state and the random trajectory are both rotated (bottom left), and we rotate the noise accordingly in the denoising process, we will end up with a successful trajectory in the rotated state (bottom right).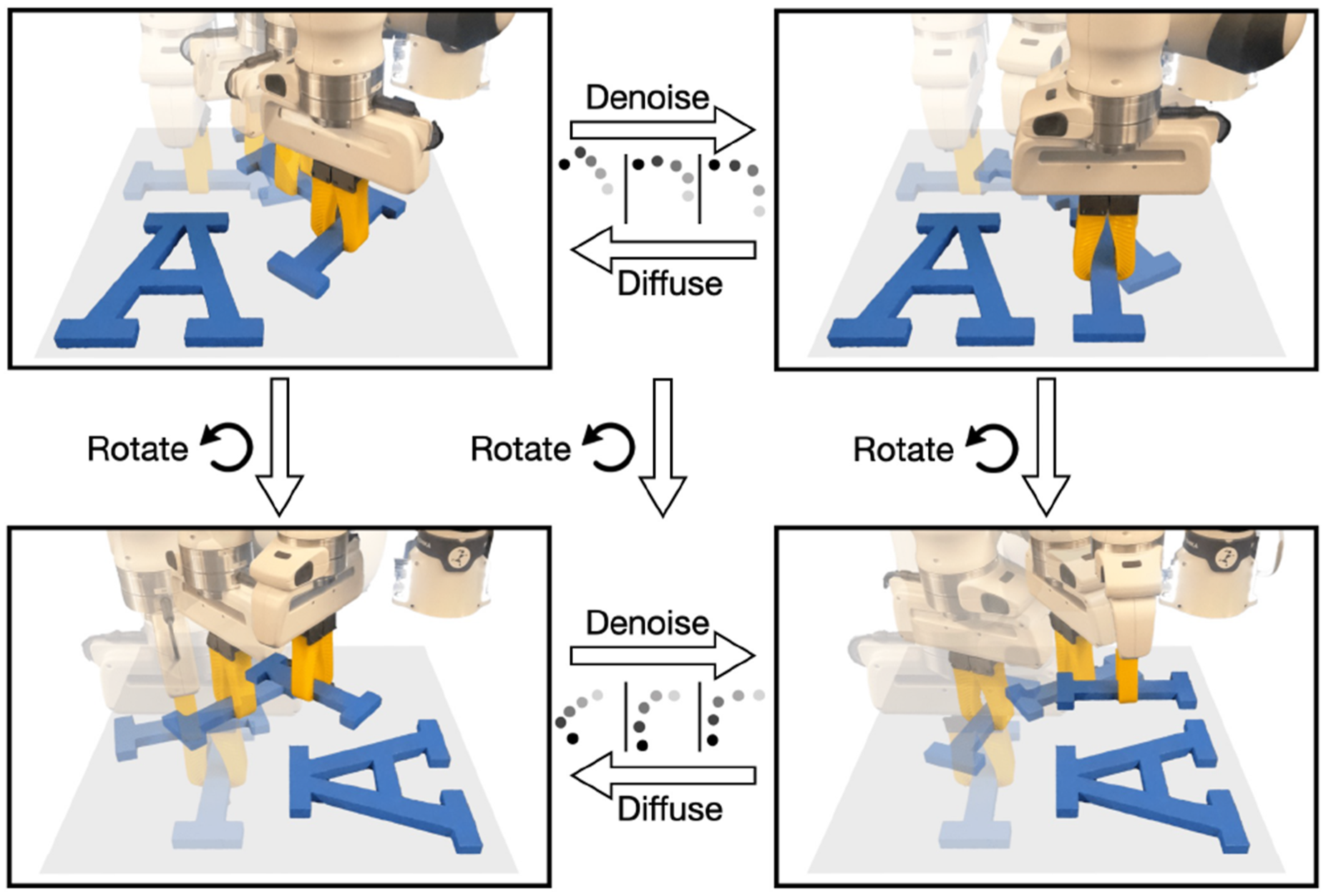
Our contributions are as follows: • We propose Equivariant Diffusion Policy, a novel BC approach based on equivariant diffusion. • We theoretically show that the diffusion policy is equivariant when the denoising function is equivariant, justifying modeling the denoising function using an equivariant network. • We theoretically demonstrate the use of SO (2)-equivariance in the context of 6-DoF control for robotic manipulation, which prior methods (Jia et al., 2023; Wang et al., 2022b) leveraged in a less expressive SE (2) action space. • We provide a thorough demonstration of our method in both simulated and physical systems. In simulation, we evaluate on 12 manipulation tasks in the MimicGen benchmark (Mandlekar et al., 2023) and outperform the baseline Diffusion Policy by an average success rate of 34.5% when trained with 100 demos. On hardware, we show that successful policies can be learned with a small number of demonstrations for 12 different manipulation tasks, including long-horizon tasks like bagel baking, coffee making, etc.
This work is an extended version of our conference paper (Wang et al., 2024b), substantially expanding both the theoretical foundations and practical implementations of Equivariant Diffusion Policy. Particularly, while our conference version focused on SO (2) rotational equivariance, here we include T (3) (the group of 3D translations) translational symmetry alongside rotational symmetry. This extension is enabled by our novel Equivariant Point Transformer architecture, which processes point cloud inputs in a manner that preserves both types of symmetries. Concretely, we extend the content of the prior work in the following ways: • We update the theoretical analysis of Equivariant Diffusion Policy, refining the proposition and proof from a probability density perspective that is more comprehensive. See Section Theory of Equivariant Diffusion Policy. • We propose a new version of Equivariant Diffusion Policy using point cloud input, referred to as EquiDiff (PC), powered by our novel Equivariant Point Transformer architecture. See Section Equivariant Point Transformer and Translation Symmetry. • EquiDiff (PC) achieves additional translational symmetry (and is thus SO (2) × T (3)-equivariant) and reaches a performance that is 12.6% higher than the conference version. See Section Standard Baseline Comparison. • We include an ablation study for EquiDiff (PC) in Section Ablation Study studying the effect of each design choice of our work. • We include a new real-world experiment with six new challenging manipulation tasks, demonstrating the advantage of EquiDiff (PC) compared with the version from the conference paper. See Section EquiDiff with Point Cloud Input.
Related work
Diffusion models
Diffusion models (Sohl-Dickstein et al., 2015) learn distributions by modeling the reverse of a diffusion process, which is a Markov chain that gradually adds Gaussian noise to the data until it transitions to a Gaussian distribution. Denoising diffusion models (Ho et al., 2020; Song and Ermon, 2019) can be interpreted as learning the gradient field of an implicit score during training, where inference applies a sequence of score optimization steps. This new family of generative methods has proven to be effective for capturing multimodal distributions in planning (Janner et al., 2022; Liang et al., 2023) and policy learning (Chi et al., 2023; Pearce et al., 2022; Wang et al., 2022c; Xian et al., 2023; Ze et al., 2024). However, these methods did not leverage the geometric symmetries underlying the task and the diffusion process. Xu et al. (2022); Hoogeboom et al. (2022) show that leveraging SO (3) symmetries from the domain in the diffusion process dramatically improves sample efficiency and generalization ability in molecular generation. EDGI (Brehmer et al., 2023) extends diffuser (Janner et al., 2022) to equivariant diffusion planning with improved performance, but relies on the ground-truth state as the input. Ryu et al. (2023b) propose bi-equivariant diffusion models for visual robotic manipulation, while limited to open-loop settings. Yang et al. (2024a) integrate SIM (3)-equivariant networks with diffusion models to enable scalable, generalizable policy, but is limited to tasks involving a single object. By contrast, we exploit domain symmetries during the diffusion process to attain an effective closed-loop visuomotor policy for complex manipulation tasks.
Equivariance in manipulation policies
Robots operate within a three-dimensional Euclidean space, where manipulation tasks inherently encompass geometric symmetries such as rotations. Recent works (Eisner et al., 2024; Gao et al., 2024; Hu et al., 2024; Huang et al., 2023a, 2023b; Jia et al., 2023; Kim et al., 2023; Kohler et al., 2023; Lim et al., 2024; Liu et al., 2023; Nguyen et al., 2023, 2024; Pan et al., 2023; Simeonov et al., 2023; Wang et al., 2021a, 2022b; Yang et al., 2024b) compellingly show that improvement in sample efficiency and performance can be obtained by leveraging symmetries in policy learning. (Wang et al., 2022a; Zhu et al., 2022, 2023) show the efficiency of equivariant models for on-robot learning. (Huang et al., 2022, 2023; 2024a; 2024b; Ryu et al., 2023a; Simeonov et al., 2022) learn an open-loop pick and place policy with few demonstrations. While this prior work either considers symmetries in SE (3) open-loop or SE (2) closed-loop action spaces, our paper studies symmetries in an SE (3) closed-loop action space, and is the first one to study the symmetries in diffusion policy.
Closed-loop visuomotor control
Closed-loop visuomotor policies are more robust and responsive but struggle with learning from diverse trajectories and predicting long-horizon actions. Previous methods (Florence et al., 2019; Rahmatizadeh et al., 2018; Toyer et al., 2020; Zhang et al., 2018) directly map from observations to actions. However, this type of explicit policy-learning struggles to learn multimodal behavior distributions and may not be expressive enough to capture the full range and fidelity of trajectory data (Orsini et al., 2021; Pearce et al., 2022). Several works propose implicit policies (Florence et al., 2021; Jarrett et al., 2020) with energy-based models (Du and Mordatch, 2019; Grathwohl et al., 2020). However, training is challenging due to the necessity of a substantial volume of negative samples to effectively learn an optimal energy score function for state-action pairs. Recently, (Chi et al., 2023; Pearce et al., 2022) model action generation as a conditional denoising diffusion process and demonstrate strong performance by adapting diffusion models to sequential environments. Our work builds on Chi et al. (2023) but focuses on equivariance in the diffusion process.
Background
Problem statement
We study policy learning using behavior cloning. The agent is required to learn a mapping from the observation
Let
Diffusion policy
Chi et al. (2023) proposed Diffusion Policy to model the multimodal distribution in behavior cloning using Denoising Diffusion Probabilistic Models (DDPMs) (Ho et al., 2020). Diffusion Policy learns a noise prediction function ɛ
θ
(
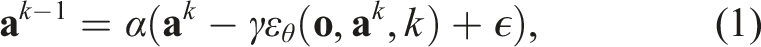
Equivariance
A function f is equivariant if it commutes with the transformations of a symmetry group G. Specifically, ∀g ∈ G,
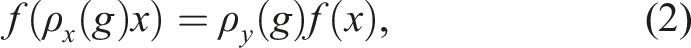
We mainly focus on the group SO (2) × T (3), where SO (2) is a group of planar rotations (i.e., rotation around the z-axis of the world) and T (3) is a group of 3D translations. This group captures the symmetry in many robotic tasks without enforcing unnecessary out-of-plane rotation equivariance (which is often invalid due to gravity and the canonical pose of objects). Notice that SO (2) × T (3) can be decomposed and a function that is both SO (2)-equivariant and T (3)-equivariant would be SO (2) × T (3)-equivariant.
We sometimes approximate SO (2) with the discrete subgroup C
u
⊂ SO (2) containing u discrete rotations, and there are three particular representations of SO (2) or C
u
that are of interest in this paper: 1) the trivial representation ρ0 defines SO (2) or C
u
acting on an invariant scalar 2) the irreducible representation ρ
ω
defines SO (2) or C
u
acting on a vector 3) the regular representation ρreg that defines C
u
acting on a vector
A representation ρ can also be a combination of different representations, that is,
Method
Theory of equivariant diffusion policy
The main contribution of this paper is a method that incorporates equivariance in the diffusion process for policy learning. As a theoretical justification, we analyze the noise prediction function ɛ and show that if ɛ is equivariant, then the policy being modeled is also equivariant. This implies equivariant neural networks have the correct inductive bias to model this function.
If the noise prediction function ɛ:
Notation and Setup.
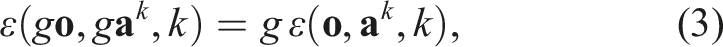
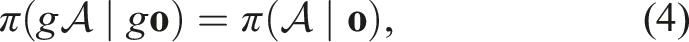
Let q (
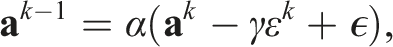
Let p
k
(
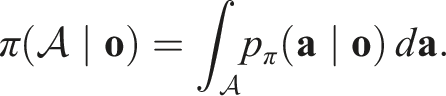
Invariance of q.
Since the group action is linear and acts identically on
Because the Gaussian density is invariant under rotations (i.e., the probability density at gϵ equals that at ϵ) and rotations preserve volume, we have
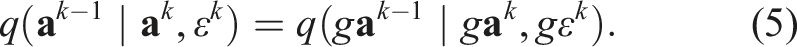
Substituting the equivariance condition (Equation (3)) into Equation (5) yields
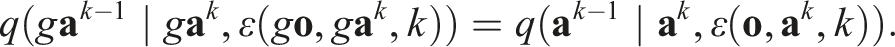
Since
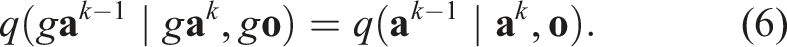
Proof by Induction.
For k = 0, 1, …, K, we prove by backward induction that
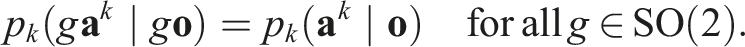
Base Case (k = K):
Since the initial state
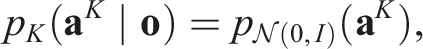
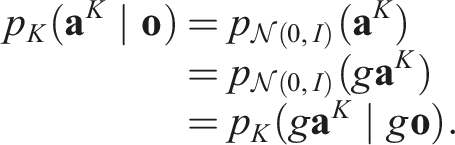
Inductive Step:
Assume that for some k ∈ {1, …, K},
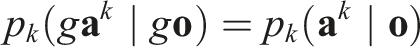
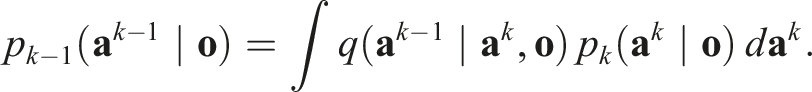
Similarly, for transformed observation and action,
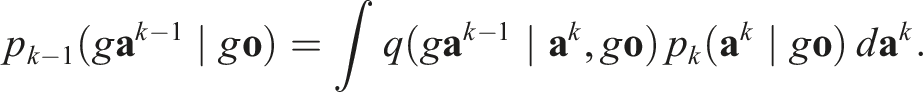
We change variables of integration from
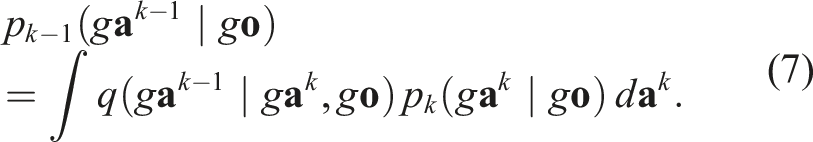
Substituting Equation (6) into Equation (7) and applying the inductive hypothesis,
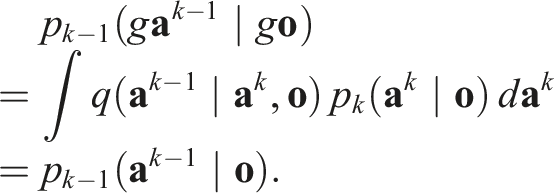
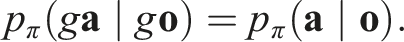
Equivariance of π.
By the invariance of the density p
π
, for any measurable set
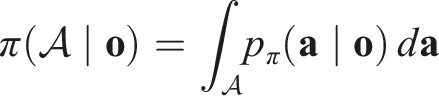
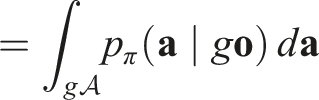
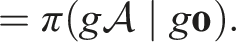
Thus, the policy function is SO (2)-equivariant.
Figure 2 illustrates the equivariance property of ɛ. If we infer ɛ for all actions in the action space, we effectively acquire a gradient field towards the expert trajectory. The figure shows that if the function ɛ is equivariant, such a gradient field would also be equivariant. Thus, the expert policy is equivariant. Notice that the figure shows the average of all action time steps. Equivariance of the denoising function ɛ. Left: In observation 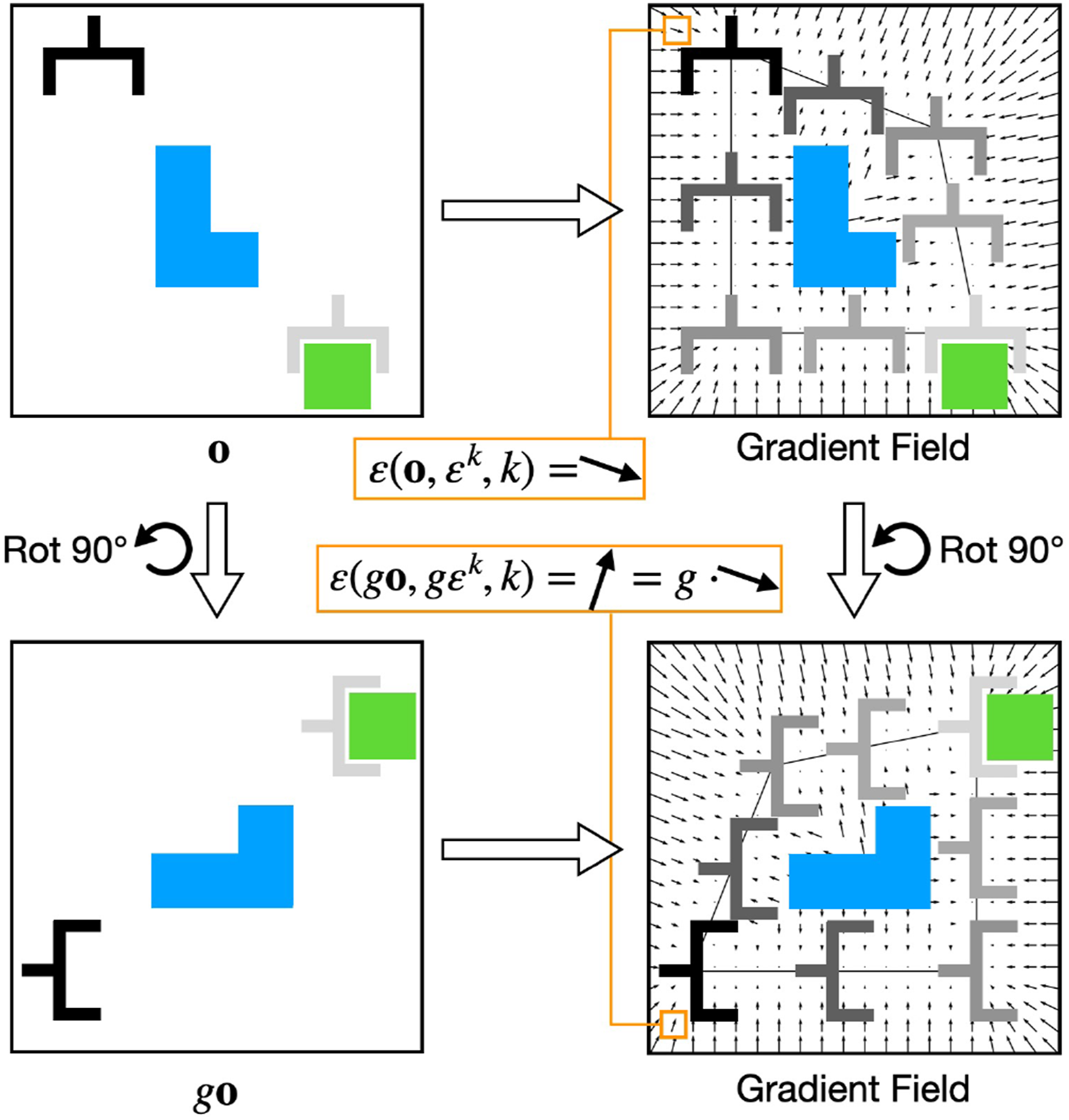
SO (2) representation on 6DoF action
A key step in defining an Equivariant Diffusion Policy is to define how actions
There exist irreducible representations that describe how SO (2) acts on an SE (3) gripper action
Absolute control
We first consider absolute pose control, where the model infers the absolute pose to which the gripper is to move, that is, Tt+1 =
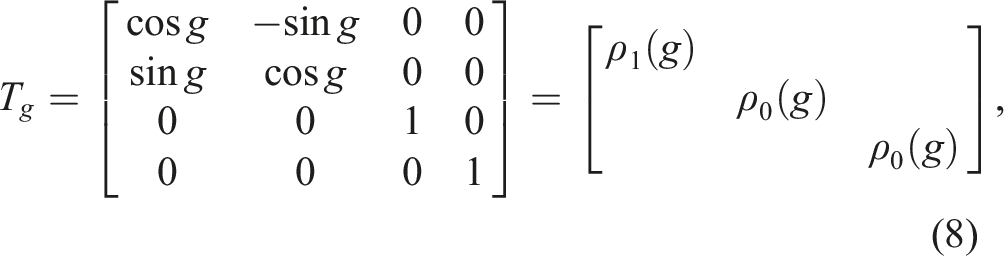
Since the gripper open width is invariant, gw
t
= ρ0 (g)w
t
, we can append w
t
to
Relative control
For relative gripper pose, that is, Tt+1 =

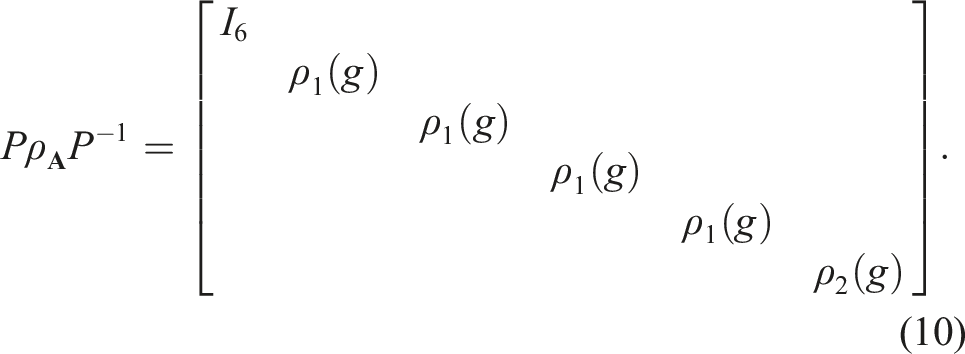
In other words,
Implementation of equivariant diffusion policy
Now that we have the theoretical grounding of the equivariance in the noise prediction function ɛ, this section will introduce the network architecture of our Equivariant Diffusion Policy. We first present an SO (2)-equivariant version in this section, then introduce the SO (2) × T (3)-equivariant version in Section Equivariant Point Transformer and Translation Symmetry.
As is shown in Figure 3, our network consists of three main parts: encoding (white box), denoising (yellow box), and decoding (gray box). We implement our network using the Overview of our Equivariant Diffusion Policy architecture. The first two equivariant encoders take the input observation 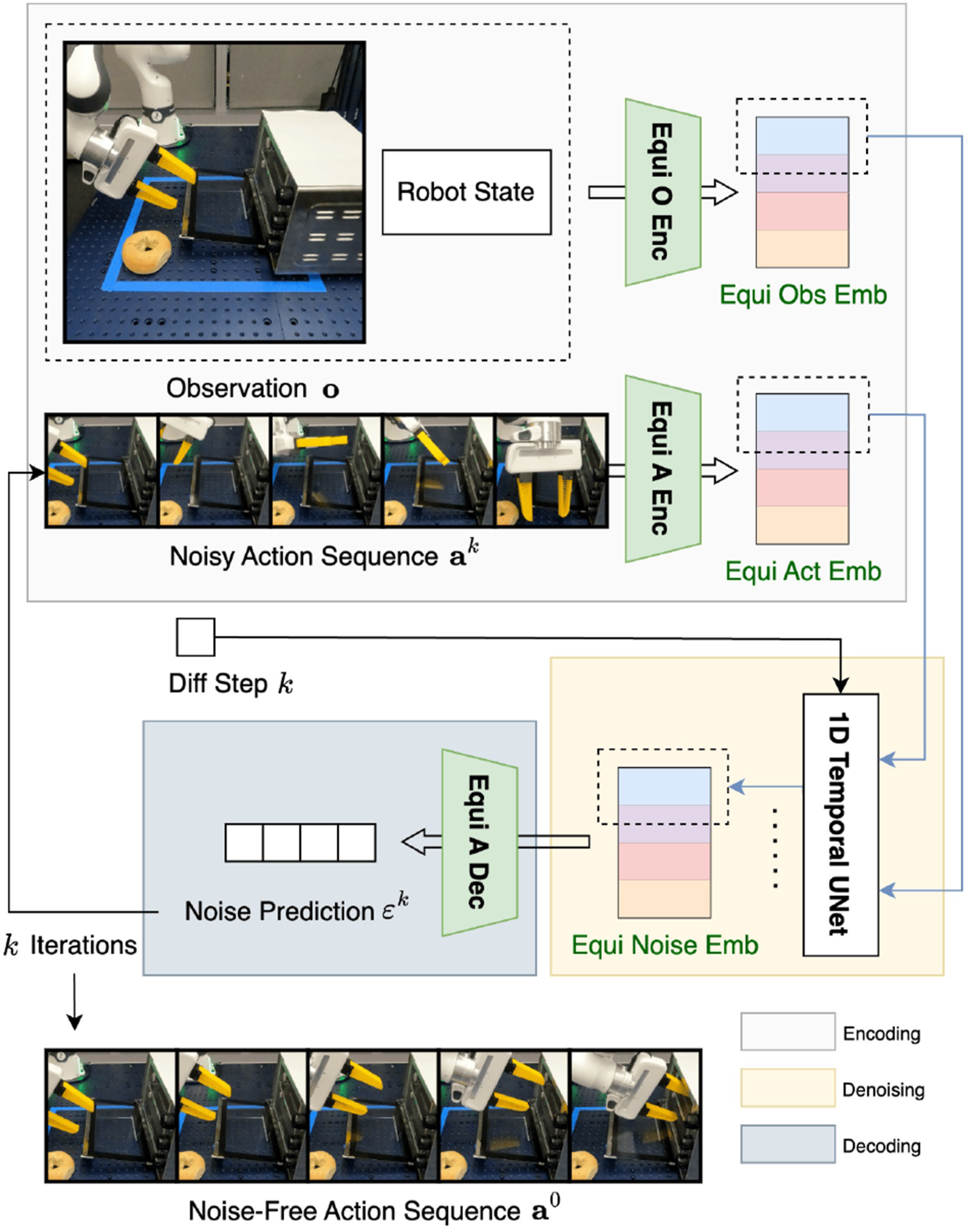
Equivariant point transformer and translation symmetry
We consider different input modalities in our work (i.e., images, voxel grids, and point clouds). Although images and voxel grids can be effective visual observations, point clouds have the advantage of directly capturing the 3D geometry of objects without the limited resolution problem that typically exists with voxel grids. For image and voxel inputs, we can use a simple 2D or 3D equivariant CNN as the equivariant observation encoder (as in Figure 3). However, with point cloud inputs, we found that a simple equivariant version of PointNet (Qi et al., 2017) does not perform well enough in complex manipulation tasks. To address this limitation, we propose an Equivariant Point Transformer that effectively captures geometric relationships while maintaining equivariance properties.
Our architecture is based on point transformer (Zhao et al., 2021). Let Bottom: Our equivariant point transformer architecture. Top (gray): equivariant point transformer layer; middle left (blue): down sample block; middle right (yellow): equivariant point transformer block.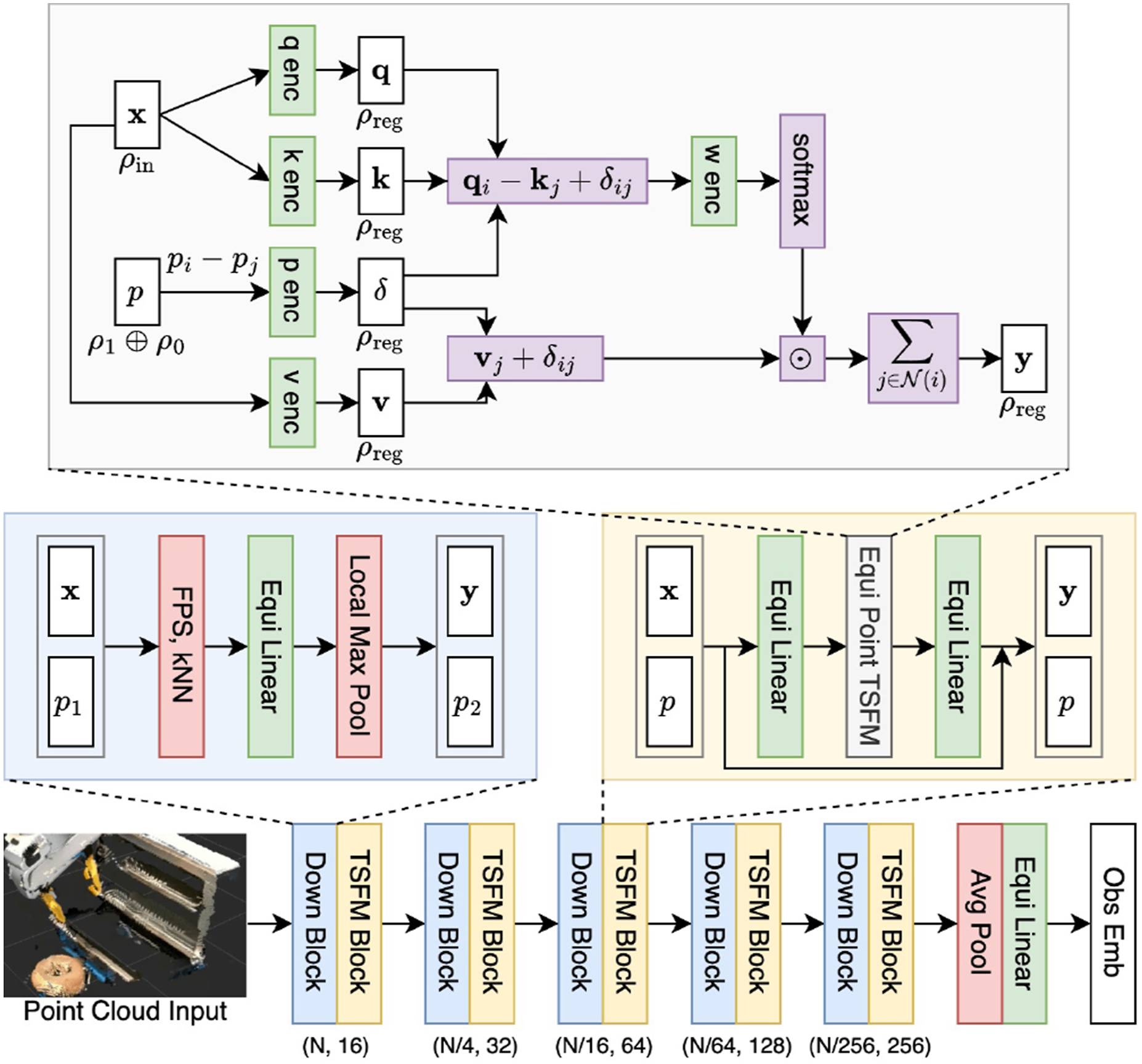
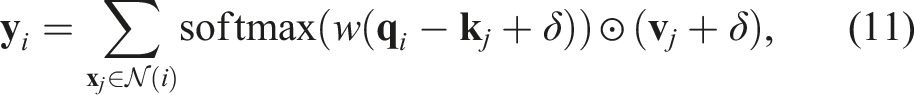
One advantage of our equivariant point transformer is that the relative position embedding δ = θ ( Translation invariance via predicting the action in the gripper translation frame.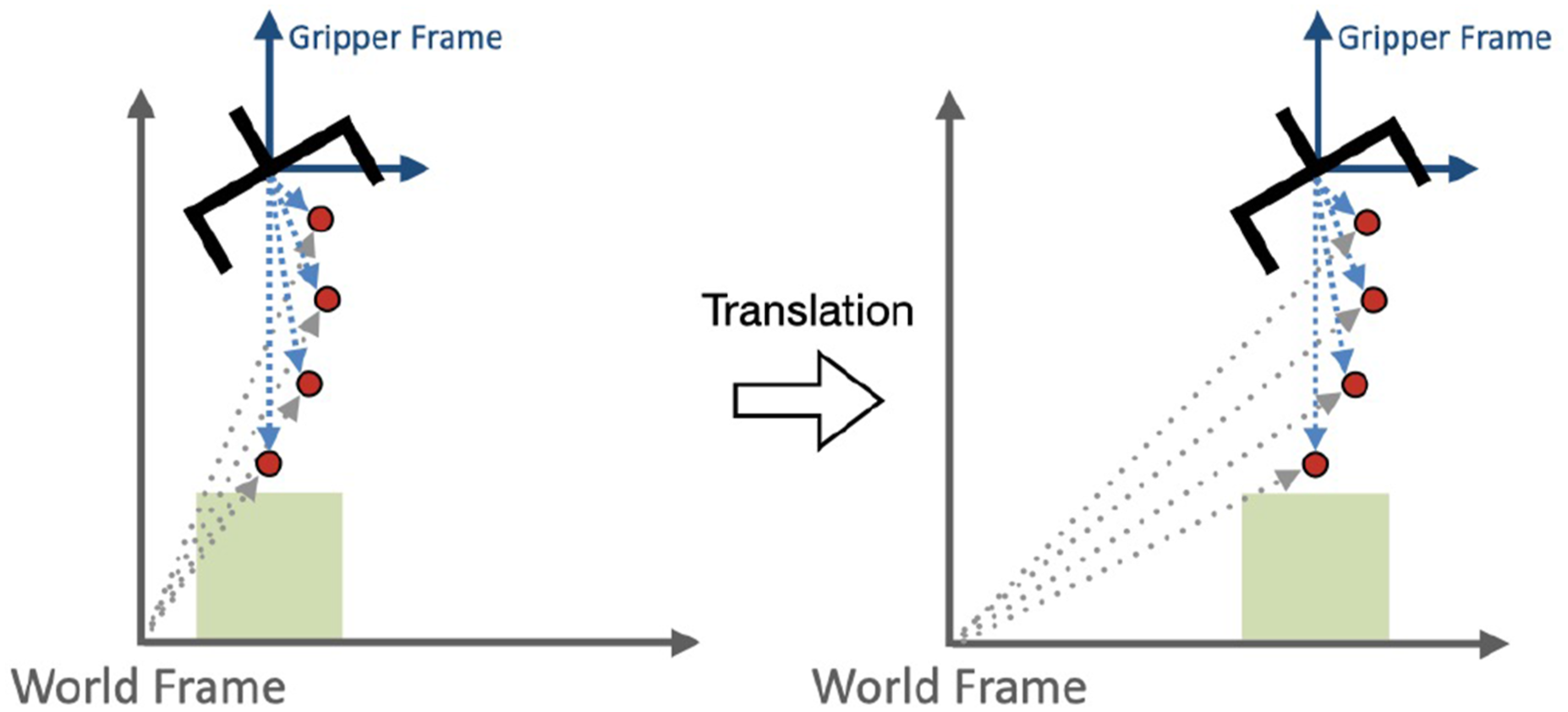
We also replace the pointwise equivariant processing in the U-Net (Section Implementation of Equivariant Diffusion Policy) with a Frame Averaging interface (Puny et al., 2022). Specifically, let U be the U-Net, k be the denoising step, e
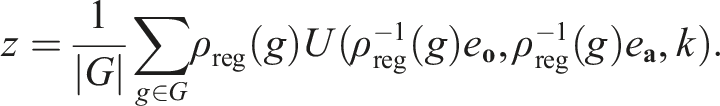
Compared with the pointwise equivariant processing, Frame Averaging enables the U-Net to access the entire regular representation (rather than one element at a time) while also ensuring the equivariance. See Puny et al. (2022) for details.
Simulation experiments
Experimental settings
We first evaluate our Equivariant Diffusion Policy (EquiDiff) with image (Im), voxel (Vo), or point cloud (PC) input on 12 manipulation tasks from MimicGen (Mandlekar et al., 2023) (Figure 6). The RGB observation is an agent-view image and an eye-in-hand image with a size of 3 × 84 × 84. The voxel grid observation has a size of 4 × 64 × 64 × 64 where the first channel is binary occupancy and the remaining three channels are RGB. The point cloud observation has a size of 1024 × 6 (i.e., xyzrgb). The point cloud only contains points above the table, as suggested in Ze et al. (2024). All tasks have a full 6 DoF SE (3) action space. We define the rotation of the observation as a point cloud rotation, a voxel grid rotation, or an image rotation. Notice that in the image version of our method, there is a mismatch between the rotation of the agent-view image and the rotation of the ground-truth state since the agent view is not orthogonally top-down. Although top-down observations could be captured, we use the observation settings in the published dataset from MimicGen (Mandlekar et al., 2023) to demonstrate the generalizability of our method (Notice that the prior work (Wang et al., 2023) has demonstrated that the equivariant CNN is still able to capture symmetry in such a scenario.). On the other hand, the point cloud and the voxel versions eliminate this symmetry mismatch as the rotation of the point cloud or the voxel grid aligns with the rotation of the ground-truth state. To better leverage the equivariance, we also add a rotation augmentation in the point cloud and voxel versions of our method following our analysis in Section Method. The experimental environments from MimicGen (Mandlekar et al., 2023). The left image in each subfigure shows the initial state of the environment; the right image shows the goal state. (a) Stack D1, (b) Stack three D1, (c) Square D2, (d) Threading D2, (e) Coffee D2, (f) Three Pc, Assembly D2, (g) Hammer cleanup D1, (h) Mug cleanup D1, (i) Kitchen D1, (j) Nut assembly D0, (k) Pick place D0, and (l) Coffee preparation D1.
Standard baseline comparison
We evaluate our Equivariant Diffusion Policy for both absolute pose control and relative-pose control. We compare our method with the following baselines: 1. DiffPo-C: the original diffusion policy (Chi et al., 2023) trained with the 1D Temporal U-Net (Janner et al., 2022). Notice that the baseline shares the same U-Net architecture as our method, but it does not have any equivariant structure. 2. DiffPo-T: same as above, but trained with a transformer. 3. DP3: the 3D diffusion policy (Ze et al., 2024) trained with a point net encoder. 4. ACT: the Action Chunking Transformer (Zhao et al., 2023) trained as a conditional VAE. 5. BC RNN: a recurrent architecture from Mandlekar et al. (2022).
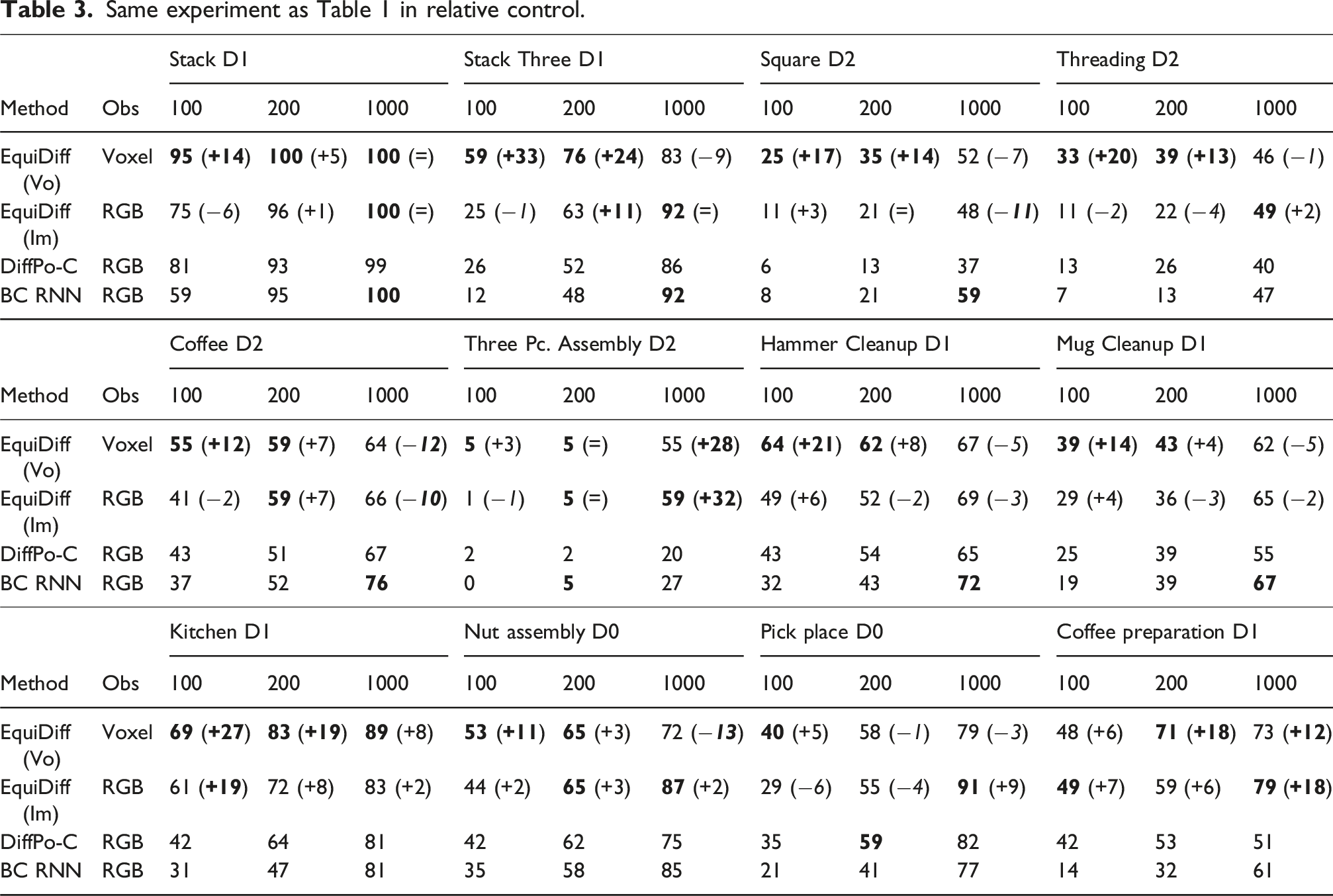
Notice that the voxel version of our method and DP3 utilizes the 3D inputs constructed from four cameras, while the image version of our method and the other baselines directly use the RGB images from two cameras. As our main baseline, we evaluate DiffPo-C in both absolute and relative-pose control. We evaluate the other baselines in the same control mode as in the original work (absolute for DiffPo-T, DP3 and ACT, and relative for BC RNN). See Appendix Simulation Environments and Training Detail for the details.
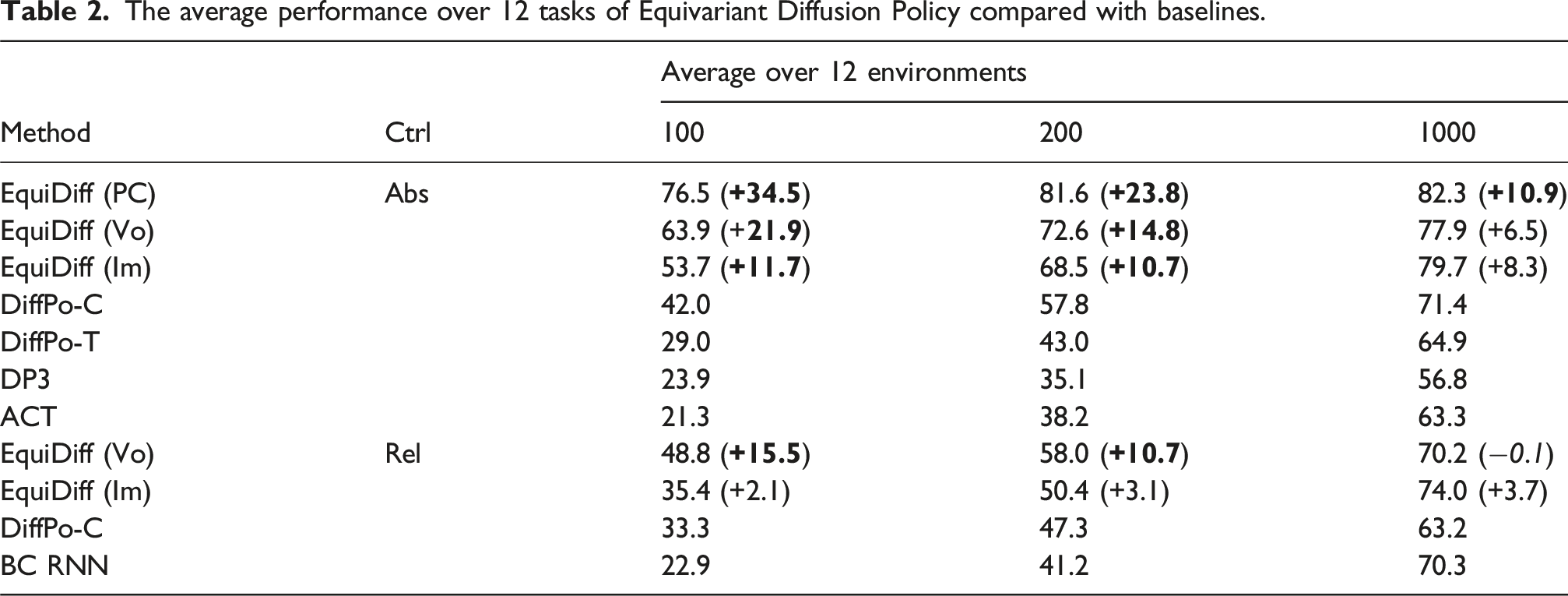
The performance of our method in absolute control compared with the baselines in simulation.
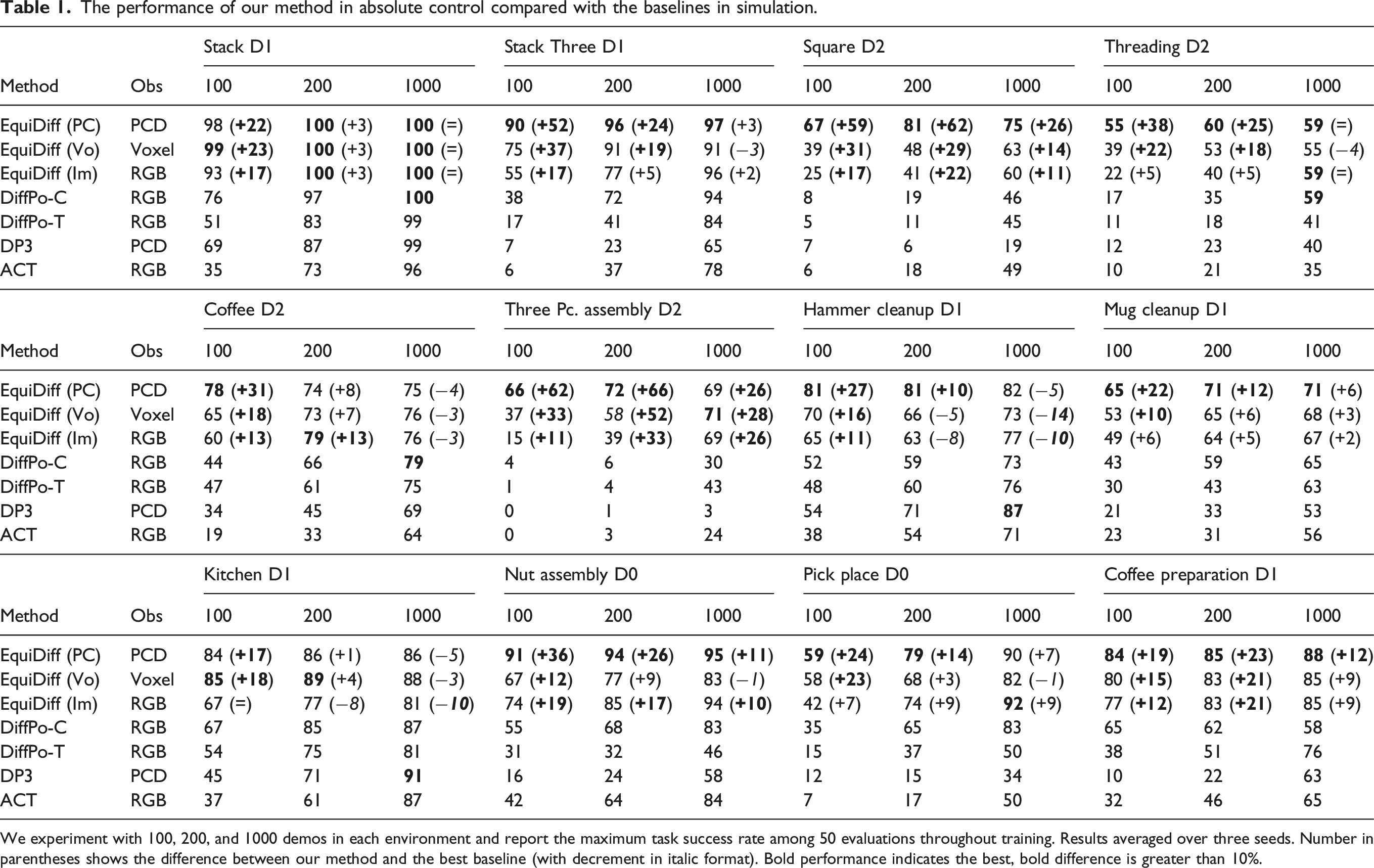
We experiment with 100, 200, and 1000 demos in each environment and report the maximum task success rate among 50 evaluations throughout training. Results averaged over three seeds. Number in parentheses shows the difference between our method and the best baseline (with decrement in italic format). Bold performance indicates the best, bold difference is greater than 10%.
The average performance over 12 tasks of Equivariant Diffusion Policy compared with baselines.
Improvement with different levels of equivariance
We further analyze the performance improvement of our method when the tasks have different levels of equivariance. Since equivariant models generalize automatically across different object poses, equivariance should hypothetically be more useful when there is greater variance in the distribution of initial object poses. We qualitatively group the tasks into three levels: (1) high-equivariance tasks where the poses of the objects are initialized randomly within the workspace; (2) intermediate-equivariance tasks where each object is initialized in a certain range, but with some randomness inside the range; (3) low-equivariance tasks where there is no randomness for the position and/or orientation of certain objects. Figure 7(a) shows the three task groups. We show the performance improvement of our Equivariant Diffusion Policy with point cloud in absolute pose control compared with the standard diffusion policy in Figure 7(b). Generally, the high-equivariance tasks benefit more from injecting symmetry in the network architecture. Moreover, our method’s strong performance in the intermediate and low-equivariance tasks indicates its robustness and generalizability, as the model’s symmetry is helpful even when the task is partially symmetric. (a) The three task groups are based on the level of equivariance and their initial object distribution. Images were generated by taking the average of five random initialization states. (b) The performance improvement of our Equivariant Diffusion Policy (PC) compared with the original diffusion policy in absolute pose control. Blue environments are high-equivariance tasks; green environments are intermediate-equivariance tasks; red environments are low-equivariance tasks.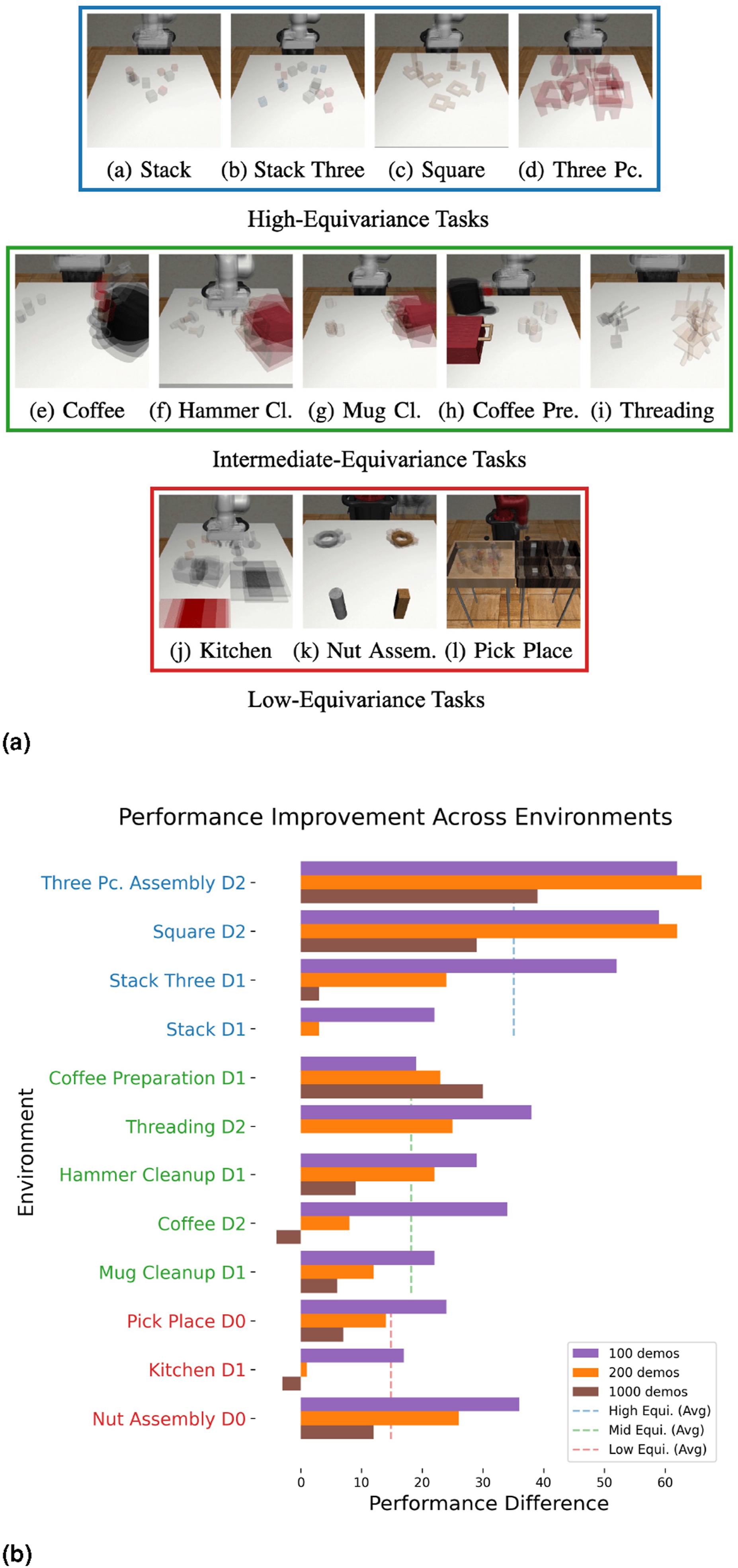
Sample-efficient baseline comparison
In this section, we evaluate our method against two sample-efficient baselines: 1. RISE: a diffusion transformer architecture with a sparse 3D encoder, taking point clouds as inputs (Wang et al., 2024a). 2. ISP: an equivariant policy using spherical projection to project the input eye-in-hand RGB image onto a sphere for equivariant reasoning (Hu et al., 2025).
The performance of our method compared with two sample-efficient baselines in simulation.
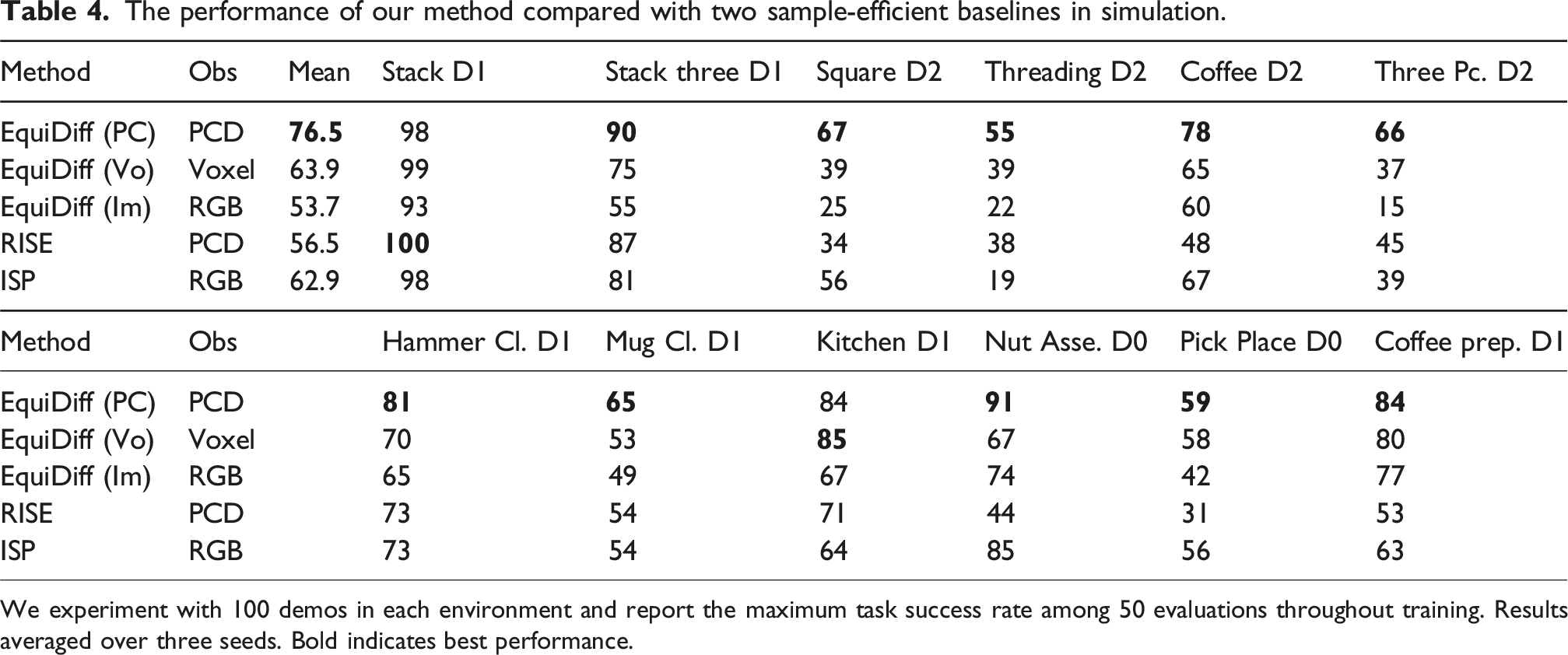
We experiment with 100 demos in each environment and report the maximum task success rate among 50 evaluations throughout training. Results averaged over three seeds. Bold indicates best performance.

The real-world environments. The left image of each subfigure shows the initial state of the environment; the right image shows the goal state. See Appendix Real-Robot Environment Details for a detailed task description. (a) Oven opening, (b) Banana in bowl, (c) Letter alignment, (d) Trash sweeping, (e) Hammer to drawer, and (f) Bagel baking.
Ablation study
We perform an ablation study to understand the importance of different components of EquiDiff (PC). Specifically, we consider the following variations: 1. EquiDiff (PC): the complete model. 2. No FA: replaces the Frame Averaging with the pointwise equivariant processing. 3. No TSFM: replaces the equivariant point transformer with a simple equivariant point net. 4. No Trans Equi: does not translate the action to the gripper frame (thus the policy does not have the translation symmetry described at the end of Section Equivariant Point Transformer and Translation Symmetry). 5. No Rot Equi: removes all the SO (2)-equivariant structure in the model. This is essentially DP3 but with translation symmetry.
The performance of our EquiDiff (PC) compared with different ablated variations.
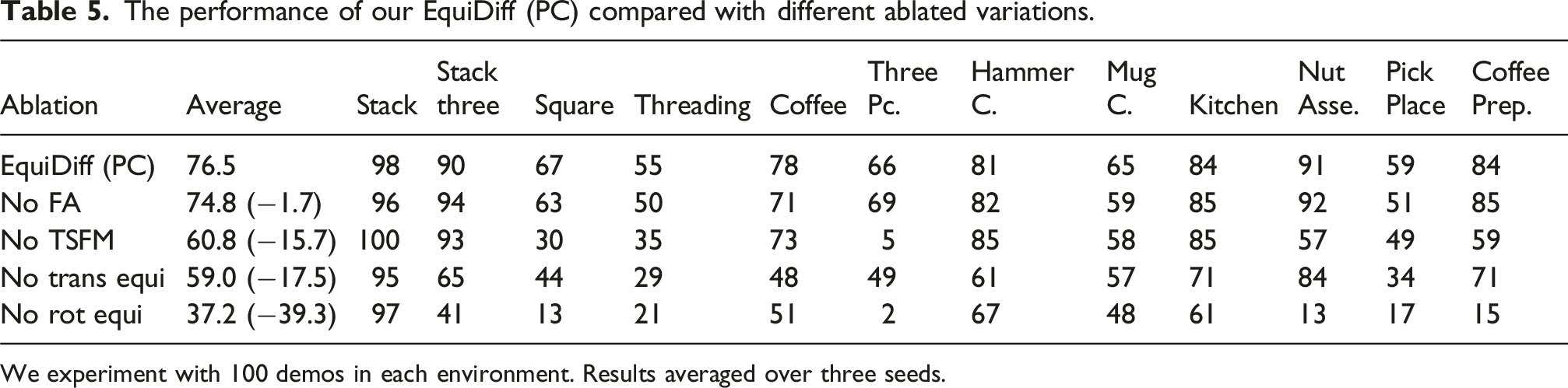
We experiment with 100 demos in each environment. Results averaged over three seeds.
Real-robot experiment
Experimental settings
In this section, we evaluate our method on a real robot system containing a Franka Emika robot arm (Haddadin et al., 2022) equipped with a pair of fin-ray (Crooks et al., 2016) fingers and three Intel Realsense (Keselman et al., 2017) D455 cameras. Demonstrations were gathered by an operator using a 6DoF 3DConnexion mouse. Observations and demonstration actions were recorded at 5 Hz. Similarly to prior work (Chi et al., 2023), we use DDIM (Song et al., 2020) in this experiment to reduce the number of denoising steps to 16.
EquiDiff with voxel input
We first compare our Equivariant Diffusion Policy with voxel input against a baseline Diffusion Policy, which uses the same voxel grid as the vision input and employs a non-equivariant 3D convolutional encoder with approximately the same number of trainable parameters as ours. As we show in the ablation study (Appendix Ablation Study of EquiDiff (Vo)), this baseline works better than the original diffusion policy with image input. Figure 8 shows the six tasks in this experiment. Figure 9 shows the robot system. Our real-robot platform contains a Franka Emika robot arm equipped with a pair of fin-ray fingers, and three Intel Realsense D455 cameras.
Results
Performance of Equivariant Diffusion Policy in real-world robot experiments.

EquiDiff with point cloud input
This experiment evaluates our Equivariant Diffusion Policy with point cloud or voxel input in more advanced tasks. We consider the Bagel Baking and Trash Sweeping tasks in Figure 8, as well as six new tasks in Figure 10. As is shown in Table 7, EquiDiff (PC) can solve those more advanced tasks with significantly higher success rates compared to the voxel version, which aligns with our simulation experiment. The more advanced real-world environments. (a) Coffee making, (b) Twist pipe, (c) Toast making, (d) Seat wiping, (e) Tool box, and (f) Screwdriver to drawer. Performance of Equivariant Diffusion Policy in more advanced real-world environments.

Generalization experiment
In this experiment, we evaluate the generalizability of our Equivariant Diffusion Policy to unseen object poses. We conduct this evaluation in the Bagel Baking experiment in the real world, where the oven is initialized in three different poses during training (Figure 11(a)). At test time, we rotate the oven to eight different, unseen poses (Figure 11(b)). We found that the learned policy can zero-shot generalize to these unseen rotations, with the exception of the scenario where the oven is rotated to the bottom-right corner. In this case, the policy is constrained by the robot’s joint limits. Specifically, the policy was able to open the oven and pull out the tray, but when picking up the bagel, although the policy could generate good gripper poses, the actions were infeasible for the robot due to joint limits. This generalization demonstrates the power of the equivariant structure in our policy. (a) The initial oven poses in the training set. (b) The oven poses in the generalization experiment. Those poses are unseen during training. In both training and testing, the pose of the bagel is random.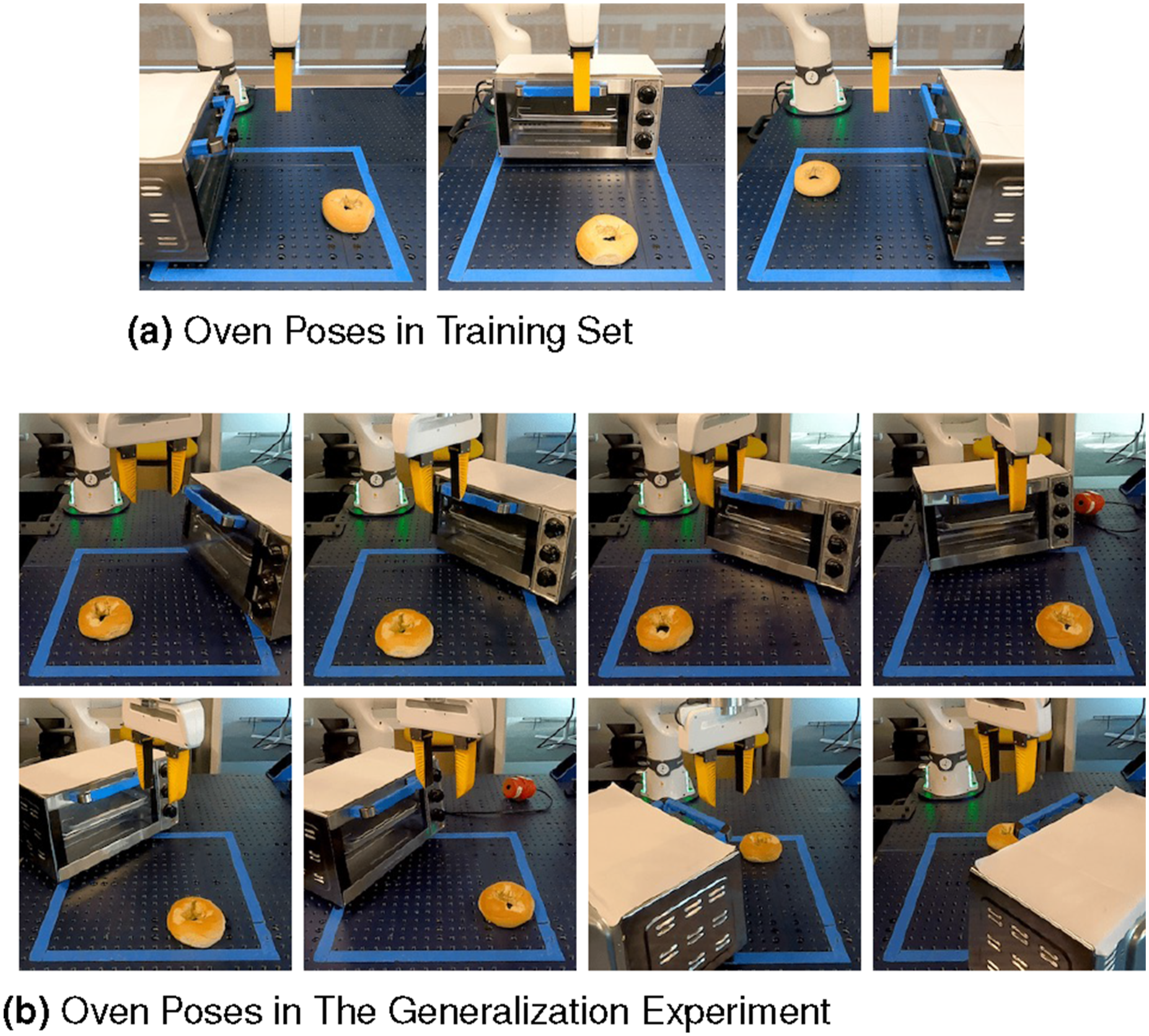
Conclusion
This paper studies leveraging symmetries in visuomotor policy learning. We propose the novel Equivariant Diffusion Policy method and provide a theoretical analysis identifying the conditions under which the diffusion policies are equivariant. We extend our previous work by incorporating both SO (2) rotational and T (3) translational symmetries through our Equivariant Point Transformer architecture, demonstrating a general framework for using these symmetries in 6DoF control for robotic manipulation. Our comprehensive evaluation in both simulation and real-world environments shows that our extended method substantially outperforms both our conference version and the baseline Diffusion Policy, achieving significantly higher success rates with notably fewer demonstrations.
Training stability
We trained our equivariant models with the same optimizer, noise schedule, and U-Net/transformer depth as their non-equivariant counterparts, with no per-task tuning. Across seeds and data regimes, we did not observe gradient vanishing/exploding or mode-collapse behavior. In Appendix Performance under Hyper-Parameter Changes, varying batch size, warm-up, weight decay, and learning rate left Stack D1 at 100% success, indicating our equivariant layers are plug-and-play replacements that preserve Diffusion Policy training dynamics while improving data efficiency and generalization.
Symmetry breakings
One limitation of this work is the partial utilization of equivariance due to symmetry mismatch in the vision system. Even with voxel or point cloud inputs, factors such as occasional arm visibility in the observation and camera noise can introduce imperfect symmetric transformations, leading to an “extrinsic equivariance” (Wang et al., 2023) setting where the symmetry in the architecture transforms the data out of distribution, and the benefit of equivariance degrades. Future work could address this by designing a vision system that avoids such symmetry corruption. Additionally, “incorrect equivariance,” as shown in prior work (Wang et al., 2024c), may harm performance when the model’s symmetry conflicts with the demonstrations. For example, reachability and kinematic constraints of the robot arm are not always symmetric, potentially yielding infeasible symmetric transformations of demonstrated actions. Another example is tasks requiring actions tied to the world frame without visual cues (e.g., “push object to the left”); applying a symmetric transformation could produce the opposite behavior.
It is worth noticing that although both “extrinsic equivariance” and “incorrect equivariance” can be viewed as forms of symmetry breaking, their effects differ fundamentally. Intuitively, extrinsic equivariance can shift inputs slightly out of distribution, but the similarity between the symmetrically transformed data and the in-distribution data can help the network learn the true decision boundary. In such cases, equivariant models often remain beneficial, and the good performance of our method in the intermediate- and low-equivariance tasks in Figure 7(a) confirms this. In contrast, incorrect equivariance places the model in direct conflict with the ground-truth mapping and is therefore harmful and should be avoided. See Wang et al. (2023, 2024c) for further discussion.
Other limitations
While the theory in Section SO(2) Representation on 6DoF Action is not restricted to diffusion policies and in principle applies to other policy-learning pipelines, we have not demonstrated this empirically. Given the strong performance of BC-RNN with relative-pose control in Table 1, an equivariant BC-RNN is a promising direction. Finally, extending our approach to other robotic settings, such as navigation, locomotion, and mobile manipulation, remains important future works.
Footnotes
Acknowledgments
The authors would like to thank Dr Osman Dogan Yirmibesoglu for the design of the fin-ray gripper fingers, Dr Andy Park for building the teleop system for data collection, Emmanuel Panov for collecting demonstration data in the robot experiment, Dr Thomas Weng for the proofreading of the paper, and Dr Cheng Chi for the helpful discussion.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Part of the work was done when Dian Wang was an intern at the Robotics and AI Institute. This work is supported in part by NSF 1750649, NSF 2107256, NSF 2314182, NSF 2134178, NSF 2409351, 2442658, and NASA 80NSSC19K1474. Dian Wang is supported in part by the JPMorgan Chase PhD fellowship.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.