
Abstract
Multi-step manipulation tasks where robots interact with their environment and must apply process forces based on the perceived situation remain challenging to learn and prone to execution errors. Accurately simulating these tasks is also difficult. Hence, it is crucial for robust task performance to learn how to coordinate end-effector pose and applied force, monitor execution, and react to deviations. To address these challenges, we propose a learning approach that directly infers both low- and high-level task representations from user demonstrations on the real system. We developed an unsupervised task segmentation algorithm that combines intention recognition and feature clustering to infer the skills of a task. We leverage the inferred characteristic features of each skill in a novel unsupervised anomaly detection approach to identify deviations from the intended task execution. Together, these components form a comprehensive framework capable of incrementally learning task decisions and new behaviors as new situations arise. Compared to state-of-the-art learning techniques, our approach significantly reduces the required amount of training data and computational complexity while efficiently learning complex in-contact behaviors and recovery strategies. Our proposed task segmentation and anomaly detection approaches outperform state-of-the-art methods on force-based tasks evaluated on two different robotic systems.
Keywords
1. Introduction
Recent advancements in robot learning leverage large-scale general-purpose models trained on diverse datasets to learn policies capable of handling a broad range of different tasks (O’Neill et al., 2024; Reed et al., 2022). Other works learn end-to-end policies for motion planning (Fishman et al., 2023), or employ pre-trained vision-language models to detect anomalies during task execution (Driess et al., 2023; Du et al., 2023; Zhang et al., 2023). While these deep-learning models perform well for common tasks with many available training examples, such as pick-and-place or free-space motions, they struggle with specialized contact tasks where precise coordination of end-effector pose and applied force is important (see Figure 1). Generating training data for such tasks is expensive as it involves sensing contact forces and torques in the real world, which requires a significantly higher effort compared to obtaining natural language and image datasets and thus leads to less availability of such data. Reinforcement Learning in simulation with sim-to-real transfer attempts to address this challenge and has shown impressive results for learning, for example, legged locomotion policies (Gangapurwala et al., 2022) or dexterous in-hand manipulation (Pitz et al., 2023). However, to focus policy learning on physically accurate environment configurations, it is still necessary to precisely identify and simulate the system. Especially for complex multi-point contact simulations, physics engines are still limited when calculating friction and contact forces (Liao et al., 2023; Yoon et al., 2023). To avoid the required modeling effort for every new setup and to enable learning of specialized skills, we propose a framework capable of learning contact tasks from only a few demonstrations on the real system. The different phases and challenges of the box grasping and locking task. The upper row shows EEF configurations in the subgoal region of the respective skills during the execution which trigger a transition to the successor skills. The bottom row highlights the difficulties during each skill. In the first skill, the lower part of the gripper must not collide with the box, while the movable slides are positioned above the box. In the next phases, the robot must apply force via the front part of the slides, without pushing the locking pin inside the slides, and maintain contact with the side wall of the box until the third subgoal configuration is reached. After that, the locking pin must be pushed to compress the springs in the slides while rotating the gripper into the vertical configuration. If there is not enough force exerted to push the gripper down, the tight clearance between the box and the box locks on the lower part of the gripper causes a collision. A video of the task learning and execution can be seen in Extension 3.
Learning from Demonstration (LfD) is a popular method for transferring task knowledge from humans to robots. A user provides task examples, for example, via remote control of the robot or by kinesthetic teaching, from which the robot learns how to perform a given task, even if the environment conditions change. Modern lightweight robots, like the DLR SARA (Iskandar et al., 2021), can sense the contact forces during demonstrations and reproduce them during execution. To accommodate different environment conditions and to make task decisions online, it is insufficient to simply replay a demonstration. Movement Primitives (Calinon, 2016; Huang et al., 2019; Ijspeert et al., 2002; Pervez and Lee, 2018) or Dynamical Systems (Calinon, 2016; Hersch et al., 2008; Khansari-Zadeh and Billard, 2011) are established approaches to react to low-level perturbations and allow to generalize trajectories to varying start and end points while preserving the nature of the movement. However, they cannot capture the high-level structure of a task, which prohibits adaptive behavior required for making task decisions or recovering from anomalies. Therefore, we propose to learn a hierarchical task representation from demonstrations. Our approach decomposes the task into more manageable sub-problems by first inferring the individual skills that comprise the task before structuring them in a task graph that can be incrementally extended if required.
Our framework is designed to learn complex multi-step contact tasks requiring specialized skills, such as the box grasping task illustrated in Figure 1. In such tasks, precise coordination of end-effector pose and commanded force is essential for successful execution. Since the observed motion and applied force during the grasping sequence are unique for this task, we cannot use prior knowledge about commonly used skills to identify the sub-problems of the task. To address this, we developed an unsupervised task segmentation algorithm, combining inverse reinforcement learning with probabilistic clustering to identify a sequence of unique skills based on their individual subgoals and feature constraints. We assume that each skill intends to reach a specific subgoal, represented by a region of end-effector (EEF) configurations relative to important objects. Reaching the subgoal is considered the intention of a skill and is a postcondition for its successful termination. Further, a skill is governed by constraints that must be satisfied during its execution. The constraints can be described by multimodal features, such as applied force or the relative distances of the end-effector to objects. After segmentation, our framework uses the inferred feature constraints for unsupervised anomaly detection during autonomous skill execution. The anomaly detection approach determines the confidence for its predictions based on the availability of the training data and reacts accordingly. If a deviation from the intended skill execution is detected, a higher-level decision-making mechanism takes over. This mechanism, guided by the task graph and the nature of the anomaly, determines the appropriate recovery action. We make the following contributions: (1) Unsupervised task segmentation approach integrating inverse reinforcement learning-based intention recognition and probabilistic feature clustering. (2) Unsupervised anomaly detection method leveraging each skill’s probabilistic representation of expected features to make decisions based on epistemic and aleatoric uncertainty. (3) Framework for incremental learning of hierarchical task representations.
Throughout this article, we repeatedly mention incremental hierarchical task learning. With hierarchical learning, we refer to the simultaneous process of learning both the low-level data-driven models for motion generation and anomaly detection for each skill, and a more abstract model of the entire task. The abstract model is represented as a Task Graph, which organizes skills at a higher level. Incremental learning, also referred to as continual learning (Lesort et al., 2020), describes the strategy of learning an initial model that can later be refined (Simonič et al., 2021) or extended for novel conditions or situations that were not anticipated in the beginning. The incremental approach applies both to high- and low-level learning.
2. Related work
2.1. Task segmentation
Task segmentation is often a necessary step in robotic task learning approaches to break down the complexity into more manageable sub-problems.
2.1.1. Supervised approaches
Probabilistic models are employed in Eiband et al. (2023a), Wang et al. (2018), Kulić et al. (2012), and Meier et al. (2011) to detect known skills in a task demonstration. Kulić et al. (2012) incrementally learn probabilistic models of motion primitives, whereas Meier et al. (2011) assume a known DMP library for online movement recognition and segmentation. Support Vector Machines (SVM) with a sliding time window are used to predict the most likely skill at each time step from video data in Wang et al. (2018) or using the robot’s proprioceptive sensor measurements in Eiband et al. (2023a).
Semantic skill recognition is used in Eiband et al. (2023a), Wächter and Asfour (2015), Ramirez-Amaro et al. (2017), and Steinmetz et al. (2019). In Eiband et al. (2023a) and Steinmetz et al. (2019), a world model is queried to compare the current semantic object relations to pre- and post-conditions of skills formulated with the PDDL convention (Ghallab et al., 1998). Eiband et al. (2023a) and Wächter and Asfour (2015) use multi-step segmentation processes to refine the first rough result in a downstream step. In Wächter and Asfour (2015), semantic segmentation is followed by a sub-segmentation based on the acceleration of the demonstrated trajectory, while Eiband et al. (2023a) utilize an SVM-based segmentation to further refine identified contact skills.
2.1.2. Unsupervised approaches
Unsupervised methods aim to find characteristic points, similarities between demonstrations, or apply generative models to data to perform segmentation, all without requiring explicit knowledge of the observed skills. A Gaussian Mixture Model (GMM) expresses the joint probability distribution of high-dimensional training data as a weighted sum of independent Gaussian components. Krishnan et al. (2017) utilize hierarchical clustering based on several GMMs to identify similar skill transition states across repeated task demonstrations. Lee et al. (2015) apply Principal Component Analysis to one single task demonstration prior to fitting a GMM on the training data. Segmentation points are determined at the intersection of adjacent Gaussian components. Karlsson et al. (2019) extend this approach by incorporating force measurements, where sudden changes in the interaction force are leveraged to verify or extend existing segmentations. In Krüger et al. (2012) and Figueroa and Billard (2018), a Bayesian nonparametric approach is used to fit a GMM onto demonstrations. In Krüger et al. (2012), every mixture ensures global asymptotic stability for point-to-point motions. In Figueroa and Billard (2018), only physically consistent clusters are generated by considering a similarity metric based on the distance of samples and direction of the velocity. In our approach, we employ a Bayesian nonparametric GMM (BN-GMM) to cluster demonstrated states but quantify action similarity in terms of reaching a common state subgoal using Q-values. In contrast to Figueroa and Billard (2018), this allows us to infer the underlying intentions of actions by comparing the demonstrated actions with the optimal actions to reach a subgoal and thus can identify more complex behavior.
A Hidden Markov Model (HMM) can describe a process that evolves over time and has underlying unobservable modes. The modes can be interpreted as skills in the context of task segmentation. Bayesian nonparametric extensions of the HMM are used in Niekum et al. (2012), Grigore and Scassellati (2017), and Chi et al. (2017) where a beta process (BP) prior is leveraged to infer the number of active modes per demonstration. Grigore and Scassellati (2017) combine a BP-HMM with a clustering approach to determine the appropriate level of granularity for identified motion primitives based on clustering performance. The Beta Process Autoregressive HMM relaxes the conditional independence of observations by describing time dependencies between observations as a Vector Autoregressive process (Chi et al., 2017; Niekum et al., 2012). Kroemer et al. (2015) incorporate state dependency in the HMM’s phase transition probability, which allows the model to learn regions, where phase transitions are more likely. In Hagos et al. (2018), the phase transition probability depends on the measured interaction force, to account for contact changes between the robot and the environment that indicate a phase transition.
In Sugawara et al. (2023), segmentation points of contact-rich tasks are detected based on the time derivatives of force and torque measurements. To reduce over-segmentation due to sensor noise, Bayesian online change point detection (Adams and MacKay, 2007) is used to identify true positive segmentation lines. If a robot’s end-effector enters or leaves the proximity area of an object (Caccavale et al., 2019), or the distance relations between objects change (Wächter et al., 2013), new segmentation lines are detected. Using pre-and post-conditions, the segments are then associated with semantic skills. Shi et al. (2023) propose an algorithm to automatically extract a demonstration’s minimal set of waypoints for which the trajectory reconstruction error lies below a specified threshold when linearly interpolating between the waypoints. In contrast to the approaches mentioned in this paragraph, our proposed approach does not segment each task demonstration individually but finds a combined segmentation result over all demonstrations. It leverages the similarities across different demonstrations, leading to a more consistent result compared to segmenting each demonstration individually. In Ureche et al. (2015), the variance of task variables within one, and across several demonstrations is analyzed to determine task constraints. Segmentation lines are drawn when the relevant task constraints change. Manschitz et al. (2020) focus on segmentation for point-to-point motions, where the demonstrations are first intentionally over-segmented using Zero Velocity Crossing (Fod et al., 2002) before again combining segments converging to the same attractor. Similarly, Lioutikov et al. (2017) iteratively eliminate false positive segmentation lines using a probabilistic segmentation approach with motion primitives as the generative skill models.
In our approach, the observed skill sequence can be inferred from a single or several task demonstrations, where each skill’s intention and feature constraints are used as grouping mechanisms in the data for segmentation. Our method combines a GMM in feature space with Inverse Reinforcement Learning to capture the intention and feature similarities of every state-action observation in a joint mixture model, where every mixture component represents a skill.
2.2. Hierarchical inverse reinforcement learning
Another approach to breaking down the complexity of a task into smaller sub-problems is Hierarchical Inverse Reinforcement Learning (HIRL). IRL as proposed by Ng and Russell (2000) avoids the cumbersome process of manually designing a reward function for a given task by representing the problem as a Markov Decision Process (MDP) with unknown reward function and learning the reward function from expert demonstrations. It may be difficult, however, or even impossible to represent a complex task with a single reward function. That is why HIRL finds segments of corresponding data points in the demonstration and solves the IRL problem per segment. To that end, Michini and How (2012) and Michini et al. (2015) propose Bayesian nonparametric IRL (BN-IRL). Using a Dirichlet Process mixture model as the prior over segments, BN-IRL divides an observed task demonstration into a set of smaller subtasks, so that each subtask can be described by a simple subgoal-based reward function. This approach was extended to constraint-based BN-IRL (CBN-IRL) (Park et al., 2020) to also infer parts of the demonstration where local feature constraints are active. This allows the model to represent complex behavior with a fewer number of segments as in BN-IRL, but requires predefined constraint boundaries for every feature and significantly increases the computational complexity. Since active feature constraints are indirectly determined by changing the restriction of the state transition function in CBN-IRL, only constraints with respect to the end-effector position and orientation can be considered. This approach does not allow to constrain contact forces or torques. Furthermore, changing the constraint boundary of one feature requires expensive recomputation of Q-values. The number of Q-value recomputations grows exponentially with the number of features when altering the boundaries independently. That is why CBN-IRL only distinguishes between constrained segments, where all features lie within the boundaries, and unconstrained segments. Our approach solves the problem of computational complexity by separating the constraint inference from the Q-value-based intention recognition. As a result, the number of required Q-value calculations is independent of the number of considered features. We infer individual feature constraint regions for each segment by modeling them as multivariate Gaussian distributions. This not only reduces the computational complexity but also allows our model to detect correlations between multimodal features across several task demonstrations.
Leveraging the option framework for describing temporally extended actions, the HIRL approaches in Surana and Srivastava (2014), Ranchod et al. (2015), and Fox et al. (2017) can recover complex reward functions or policies from the demonstrations. On the higher level, Surana and Srivastava (2014) model the task as a switched and Ranchod et al. (2015) as a BP-HMM with emissions from different MDPs. Fox et al. (2017) infer high-level meta policies and low-level options based on Deep Q-networks, which requires many training examples of the task. Krishnan et al. (2016, 2019) suggest a multi-step learning process consisting of sequence-, reward- and policy learning. The task segmentation is performed using transition state clustering similar to Krishnan et al. (2017). The transition states are then used to infer simpler rewards per segment via Maximum Entropy IRL (Ziebart et al., 2008) to finally learn a policy via forward RL. In contrast to Krishnan et al. (2016, 2019), our approach solves the segmentation problem with IRL. We identify subgoals by analyzing the actions observed within segments, which are directed toward reaching these subgoals.
2.3. High-level task structuring and decision making
As discussed in the previous sections, robotic tasks often consist of modular skills designed to address specific sub-problems of the task. Task-level decision-making determines how to apply those skills, taking into account the current context or the outcomes of prior skills. In current robotic approaches, the organization of low-level skills and the handling of high-level decisions are often achieved through the use of Behavior Trees (BT), or Task Graphs (TG), which are variants of Finite State Machines. Originally developed for decision-making in computer games, Behavior Trees have gained attention in robotics and have proven their effectiveness in various applications including machine tending (Guerin et al., 2015), polishing and assembly (Mayr et al., 2021; Paxton et al., 2017; Rovida et al., 2018), and autonomous navigation (De Luca et al., 2023). BTs and TGs share close relationships, and the high-level structure of a task can often be effectively represented using either. However, due to their design, BTs can transition more flexibly between skills, which in turn make it more difficult to infer their structure from demonstrations.
The Learning from Demonstration (LfD) approaches in Manschitz et al. (2020), Caccavale et al. (2019), Willibald and Lee (2022), Willibald et al. (2020), Kappler et al. (2015), Niekum et al. (2015), Konidaris et al. (2012), and Su et al. (2018) propose the use of Task Graphs to organize skills at a higher level of abstraction. This structure can be defined manually by an operator (Kappler et al., 2015) or learned from demonstration. For the latter case, multiple task demonstrations are segmented individually and transformed into a TG with Konidaris et al. (2012), Niekum et al. (2015), and Su et al. (2018). Konidaris et al. (2012) employ an iterative merging approach starting from the final segment, while Su et al. (2018) cluster segments based on their final configuration and connect them based on transition frequencies. Niekum et al. (2015) additionally split up nodes in the TG based on groupings of the node’s parents. Willibald et al. (2020) follow a different approach and add decision states with recovery behaviors at fixed time steps when anomalies are detected. The approach presented in this paper involves learning a common skill sequence from multiple task demonstrations, which can be incrementally extended with new skills to flexibly address task decisions or recovery behaviors.
Unlike approaches that do not incorporate higher-level organization (Eiband et al., 2019; Pastor et al., 2012), TG-based methods restrict the number of candidate skills for transitions based on the currently executed skill. This restriction addresses the perceptual aliasing problem, where a task decision cannot be determined solely based on current sensor readings but might require that the robot has already reached certain high-level goals. While Caccavale et al. (2019), Willibald et al. (2020), Niekum et al. (2015), Konidaris et al. (2012), and Su et al. (2018) allow transitions only at the end of a skill, Kappler et al. (2015) introduce an online decision-making system employing supervised classification to determine when and to which successive skill to switch, however, their approach does not autonomously detect and resolve new anomalies but requires human supervision for that. Deniša and Ude (2015) cluster segments of task demonstrations and store them in a hierarchical skill database that can be queried at runtime to generate new movements by recombining partial paths that were not demonstrated together. While this approach reduces the number of required task demonstrations it does not explicitly encode the temporal sequence of partial paths. In Manschitz et al. (2020), a sequence graph synchronizes independent motion primitives for the end-effector pose, force, and finger configuration, where each node has at most one successor and a classifier determines when to transition to the next node. We employ an unsupervised approach to identify deviations in the current execution. When such deviations are detected, we transition to a suitable recovery behavior within the TG, based on the identified failure mode, after which the robot can continue with the intended task execution. Additionally, when the skill’s subgoal is reached, we seamlessly transition to the next task-flow node in the TG. This approach offers the combined advantages of skill transitioning flexibility found in BTs and the candidate skill restriction of TGs.
2.4. Multimodal anomaly detection
Robust anomaly detection and recovery are vital for autonomous robotic systems. To detect anomalies, we employed time-based Gaussian Mixture Regression (GMR) in previous works (Eiband et al., 2019, 2023b; Willibald et al., 2020) to compute the Mahalanobis distance between the robot’s measured and expected proprioceptive sensor values. The probabilistic modeling allows the approach to scale the anomaly detection sensitivity depending on the current timestep. Romeres et al. (2019) use Gaussian Process Regression to learn the expected force profile and epistemic uncertainty during insertion tasks in combination with a predefined anomaly threshold for anomaly detection. A Hidden Markov Model is used to detect multimodal anomalies, either with predefined anomaly thresholds and a sliding time window (Azzalini et al., 2020) or with probabilistic threshold estimation based on execution progress (Park et al., 2019). Chernova and Veloso (2007) encode a simple policy using basic symbolic actions via a GMM, where the observation likelihood of unseen states is used to detect outliers. Stereotypical sensor traces along with movement primitives are used in Kappler et al. (2015) and Pastor et al. (2011) for supervised anomaly detection.
We employ GMR where expected feature values and allowed deviations are predicted by conditioning on the measured end-effector pose relative to the relevant coordinate system for the current skill. Conditioning anomaly detection on time or task progress would require consistent feature profiles across demonstrations, that is, an exact replication of the situation in all runs. We argue that important features, such as contact forces, are influenced by interaction dynamics between the robot and the environment rather than time. Additionally, conditioning on the relative end-effector pose allows our anomaly detection approach to distinguish between epistemic and aleatoric uncertainty and to handle both cases individually. Notably, this makes our approach unique with respect to the state of the art. Epistemic uncertainty arises from incomplete model information and can be reduced by collecting additional data, while aleatoric uncertainty represents the variability in the underlying distribution. While the approach in Silvério et al. (2019) acknowledges the two interpretations of variance, it equally modulates the robot’s control gains to obtain a compliant robot in cases of high uncertainty and variability. Maeda et al. (2017) utilize the epistemic uncertainty of a Gaussian Process in the context of trajectory generation to quantify the generalization capability of the model to unseen goal positions. Our approach, however, leverages the epistemic uncertainty to determine the confidence in the anomaly detection, while the aleatoric uncertainty is used to scale the anomaly detection sensitivity.
Park et al. (2018), Pol et al. (2019), and Azzalini et al. (2021) employ Variational Autoencoders (VAEs) for anomaly detection. VAEs use a decoder network to reconstruct the original input from a compressed latent space representation, learned from normal data instances. Anomalous data leads to a higher reconstruction error, which can be used to identify anomalies. Other works based on deep neural networks use sensor streams including RGB-D images to detect anomalies during robotic manipulation (Altan and Sariel, 2022; Inceoglu et al., 2024; Yoo et al., 2021). Recent works apply pre-trained vision-language models (VLMs) or large vision-language models (LVLMs) to robotics by treating anomaly detection as a visual question-answering problem (Agia et al., 2024; Driess et al., 2023; Du et al., 2023; Zhang et al., 2023). ConditionNET (Sliwowski and Lee, 2024) is a VLM designed to predict preconditions and effects of skills. It frames anomaly detection as a state prediction problem, where an anomaly is detected if the predicted and expected state do not match. While deep-learning-based approaches have shown improved performance over comparable state-of-the-art techniques, they need large annotated training datasets. Our anomaly detection approach is focused on challenging in-contact manipulation tasks where the force between the robot and the environment plays a crucial role for the task’s success (see Figure 1). The vast amount of required training data for deep-learning-based approaches is not available and even hard to obtain in simulation for such scenarios. That is why we propose a Learning from Demonstration setup, using data-efficient methods, that are capable of identifying anomalies with just a few task demonstrations. We demonstrate robust anomaly detection capabilities with only up to three user demonstrations.
3. Incremental task learning framework
In this section, we introduce the overall framework of our incremental task learning approach before describing the individual components in more detail in Sec. 5 and Sec. 6. The framework, as depicted in Figure 2, consists of three sequential phases: Demonstration, Learning, and Execution. These phases form a teaching sequence, which can be triggered multiple times throughout the incremental task-learning process. However, the teaching sequences differ depending on the event that triggered them. Our proposed incremental high- and low-level task learning framework. The process of learning a new task starts with an initial teaching sequence ① (Sec. 3.1), where the user provides several demonstrations of the intended task that are segmented using BNG-IRL to learn an initial task model. The low-level skills of this initial model can then be further refined during the skill refinement teaching sequence ②(Sec. 3.2), depicted at the bottom. During this phase, the robot performs the initial task, while the user supervises and assists in phases, where the skills need refinement. The recorded training data is used to update the skills. The last teaching sequence ③ (Sec. 3.3) is triggered if the execution module identifies a new anomaly (see Sec. 6.1 and 6.3). Similar to the initial teaching sequence, the user provides a demonstration that shows how to recover from the anomaly, which is segmented and appended to the skill during which the anomaly occurred.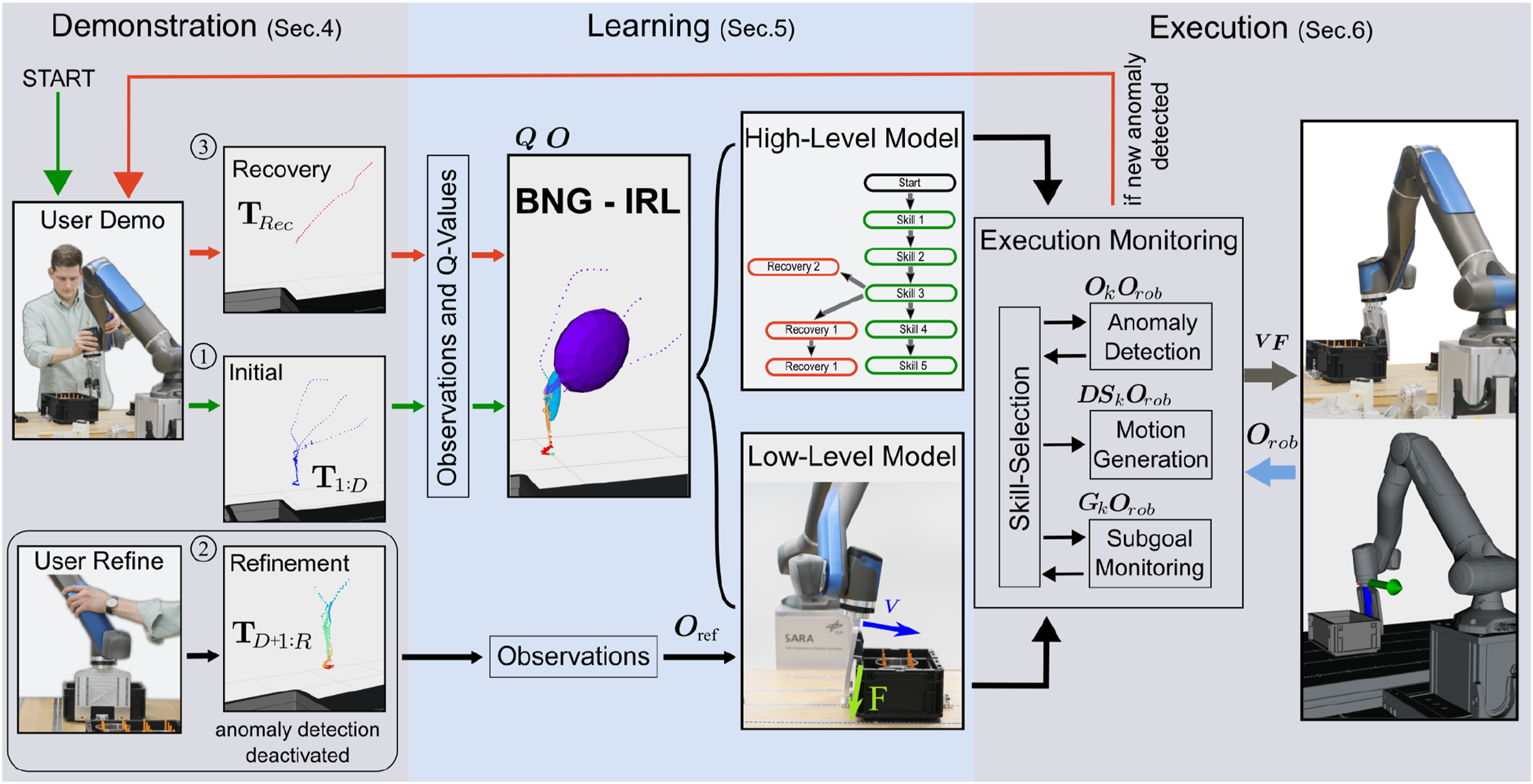
3.1. Initial teaching sequence
The task learning process begins with the first teaching sequence, aimed at learning the intended task flow model. The task model comprises both low-level skill representations and a high-level Task Graph that organizes the skills on a higher level of abstraction. To start the process, a user demonstrates the strategy to solve the task with the robot multiple times. Our experiments demonstrate a good learning performance for a contact-rich task with as few as three initial user demonstrations. The recorded data from these user demonstrations is passed to the learning component, which segments the demonstrations into a skill sequence using our proposed Bayesian Nonparametric Gaussian Inverse RL (BNG-IRL) segmentation approach detailed in Sec. 5.1. The Task Graph is initially based on the inferred skill sequence from the first user demonstrations. The learned task model can already be executed; however, the anomaly detection component is not activated during the first few executions on the robot to allow the user to refine the learned low-level skill representations.
3.2. Skill refinement teaching sequence
In this teaching sequence, the user monitors the robot collecting additional training data while performing the task autonomously. Since the robot is impedance controlled, the user can help the robot during parts where the learned task model is not yet optimal, providing additional training input. The corrective support data, combined with the data collected by the robot during autonomous execution is used to refine each skill’s low-level motion generation and anomaly detection model. Depending on the application and learning setup, our approach can be combined with various motion generation methods capable of learning policies from sparse training data, based on Movement Primitives, or Dynamical Systems. Once the initial task model achieves sufficient robustness, anomaly detection is activated, and high-level task learning can be initiated.
3.3. Task decision teaching sequence
In the final teaching sequence, high-level decisions are learned that cannot be resolved by the low-level motion generation approach but require to change the strategy. These decisions include normal task decisions and recovery behaviors, which may arise due to diverse environment conditions or unintended task interferences. As illustrated in Figure 2, the execution monitoring module of our framework has access to the task model and consists of submodules for skill selection, anomaly detection, motion generation, and subgoal monitoring. Detailed descriptions of these modules are provided in Sec. 6. The skill selection module handles high-level task decisions and communicates the selected skill to the other execution modules. Task decisions can be triggered by either the anomaly detection or subgoal monitoring module. When a skill’s subgoal is reached, the selection module transitions to the intended subsequent skill in the Task Graph, learned from the initial teaching sequence. In contrast, if an anomaly or a different environment condition is detected, the skill selection module must determine the appropriate skill for that situation. As the initial task model only comprises the skill sequence for the intended task flow, recovery skills must be acquired from user demonstrations. To facilitate this, our framework employs an incremental learning approach. When an anomaly is detected and the skill selection module cannot find a suitable skill for recovery in the Task Graph, a new teaching sequence is initiated. During this sequence, the user demonstrates how to resolve the situation with the robot. The recorded data is segmented into a skill sequence, as described for the first teaching sequence. However, this skill sequence is appended to the skill in the Task Graph where the anomaly was detected. In subsequent executions, the robot can autonomously apply the newly learned recovery behavior to address similar anomalies. Thanks to our subgoal and feature-based skill inference, the robot can flexibly reuse the newly acquired recovery behavior throughout a skill, without being limited to the specific time step where the anomaly occurred or needing an exact replication of the anomaly.
4. Demonstration
Each teaching sequence begins with a demonstration phase to gather new training data. As shown in Figure 2, the mode of demonstration depends on whether the goal is to learn a new skill sequence (Sec. 3.1 and 3.3) or to refine existing low-level skills (Sec. 3.2). We distinguish between two modes: User Demonstration and User Refinement.
4.1. User demonstration
In the User Demonstration mode, we adopt a conventional kinesthetic teaching setup for high- and low-level skill learning as described for the initial task model- and the task decision teaching sequence. During this mode, the robot compensates for its own weight, while the user hand-guides the robot to perform the task. The task can be demonstrated either once or repeatedly to increase the variation of the training data across varying environmental conditions. Throughout the demonstration, the robot captures proprioceptive sensor measurements, and we also track the poses of objects within the robot’s workspace using an external camera setup. The recorded data includes the 6D object and end-effector (EEF) poses, the 6D vector of contact forces and torques at the EEF, and, if applicable, data related to an active tool, such as gripper finger distance and grasp status.
We record the robot’s EEF trajectories from D task demonstrations and construct a state-action sequence
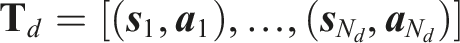
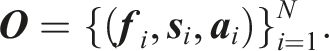
4.2. User refinement
The second demonstration mode is designed to refine low-level models of previously learned skills by gathering additional training data with the robot. In this phase, the robot employs the initial motion generation policy of each skill from the previous teaching sequence and generalizes it to varying environment configurations. While the robot performs the task, the user supervises and provides manual support if the initial model fails to achieve specific task subgoals.
To prevent false positive anomaly detections, caused by external forces applied by the user during corrective support, the anomaly detection mechanism is deactivated during this phase. However, contact forces between the robot’s EEF and the environment, as well as the sensor measurements described in Sec. 4.1, are recorded and used to update the low-level skill models.
For this purpose, we compile an observation set
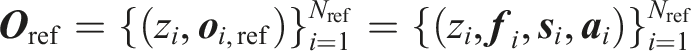
Each observation set
5. Hierarchical task learning
Each demonstration phase is followed by a learning phase to incorporate the newly collected training data into the task model. As different demonstration modes serve to learn different aspects of the model, the learning phases vary accordingly: (1) After new User Demonstrations, the observation sets need to be segmented into skills before they can be added to the task graph (see upper rows in Figure 2). (2) In the case of User Refinements, observations are already assigned to skills and can be directly used as new training data for low-level skill refinement (bottom row in Figure 2).
In our task learning approach, we represent demonstrations as sequences of skills, where each skill comprises a motion primitive, a subgoal, and a feature constraint region. To infer these properties along with the skills themselves, we introduce a novel task segmentation algorithm called Bayesian Nonparametric Gaussian Inverse Reinforcement Learning (BNG-IRL) (see Figure 3). This algorithm combines probabilistic clustering of observed demonstration states in feature space with intention recognition based on inverse reinforcement learning. Model and parameter inference of our proposed unsupervised task segmentation approach BNG-IRL. (a) Three demonstrations of a task consisting of two different skills. Every demonstration 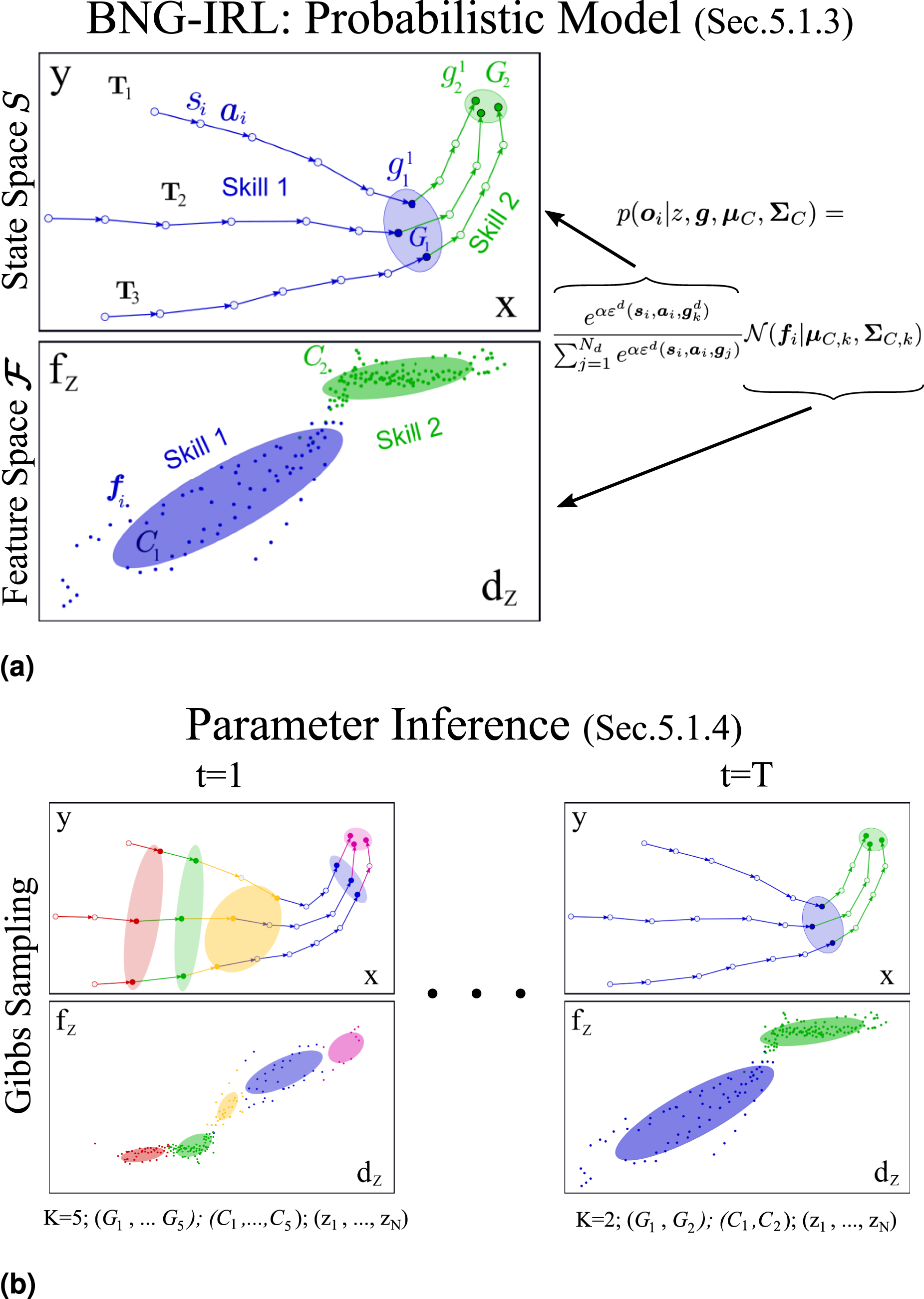
5.1. Unsupervised task segmentation BNG-IRL
In this section, we first introduce the components of the task segmentation approach that are integrated in the probabilistic model. After that, the model parameter inference is explained.
5.1.1. Subgoal-driven intention recognition
The subgoal of a skill serves as a post-condition that must be met at the end of a skill for successful completion. Across all task demonstrations
To determine how good an action is in terms of reaching a demonstration’s state subgoal, we utilize the Q-function. The Q-function is also referred to as the state-action value function and is the expected accumulated reward for taking action
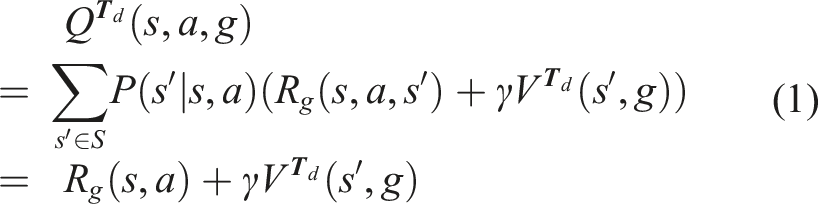
In both equations (1) and (2), we assume the same discount factor γ and a deterministic transition from state
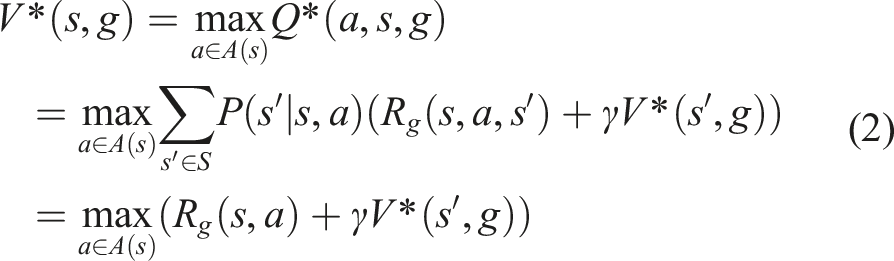
Similar to Michini et al. (2015) and Park et al. (2020), we use a sparse reward function
We illustrate the advantages of our optimality score Simplified 2D example of subgoal-driven intention recognition based on IRL for a single demonstration. (a) Demonstrated trajectory (blue) and random subgoals g1, g2, g3 with respective trajectories following the optimal policy to reach them from state 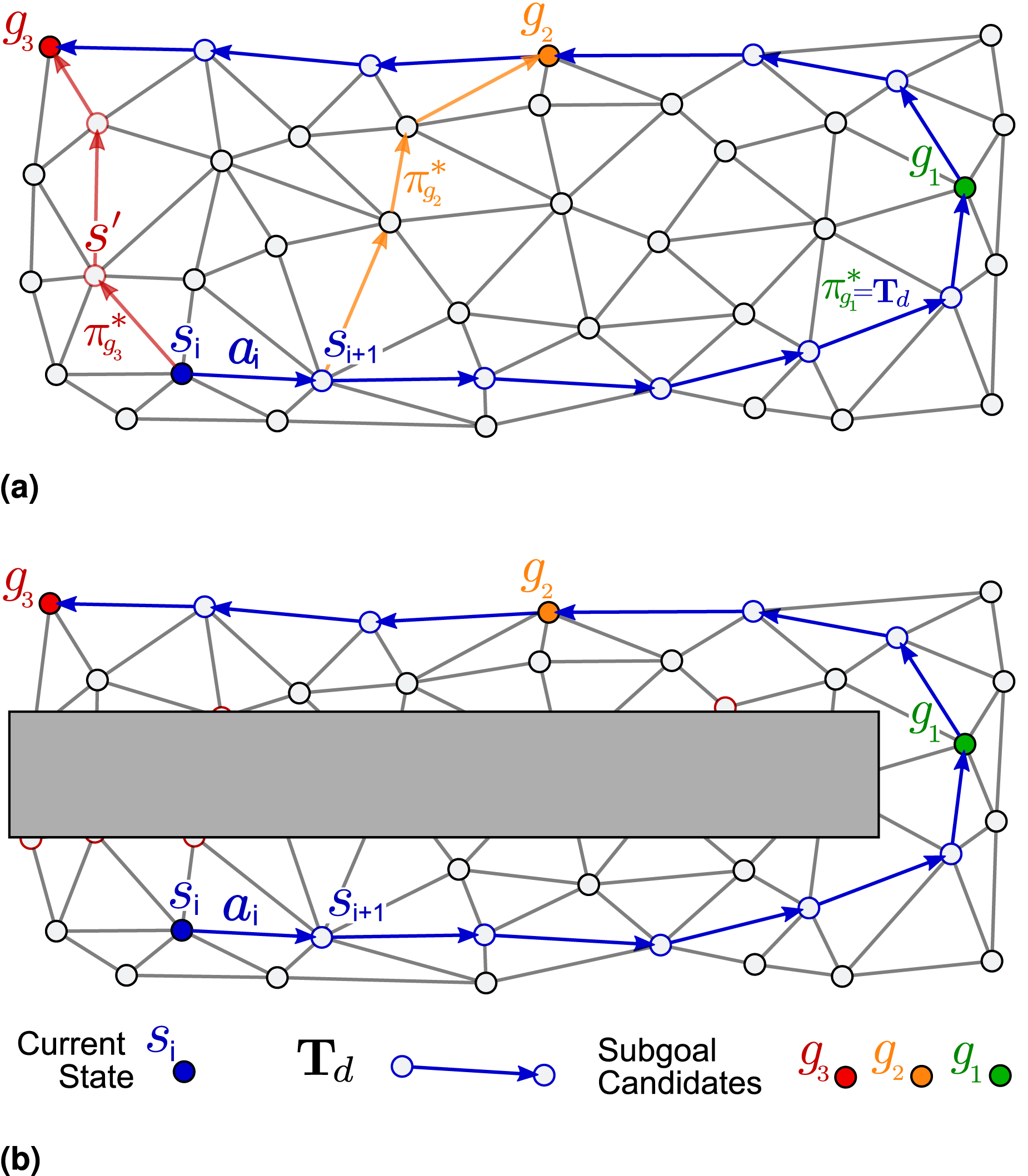
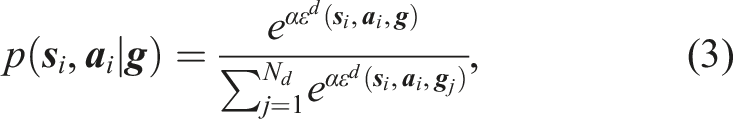
5.1.2. Probabilistic feature clustering
Another source of information that we consider to cluster the different skills that comprise a task are the recorded feature values
5.1.3. Probabilistic model
Combining the aspects of feature clustering and subgoal-driven action generation, we define the following observation likelihood for every
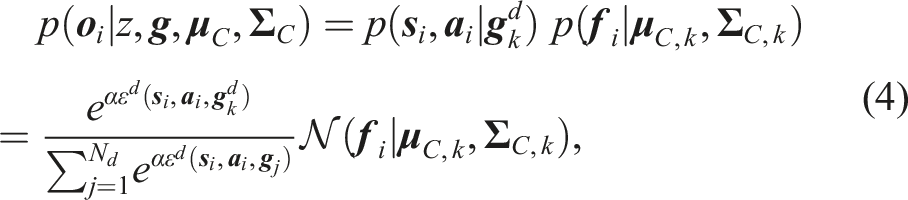
Due to the described underlying grouping mechanism of the task demonstrations into skills with an a priori unknown number of skills, a Bayesian nonparametric Mixture Model with observation likelihood (4) is used as the generative model to explain the observation set (1) The optimal (2) An optimal (3) An optimal (4) The
The joint probability distribution over
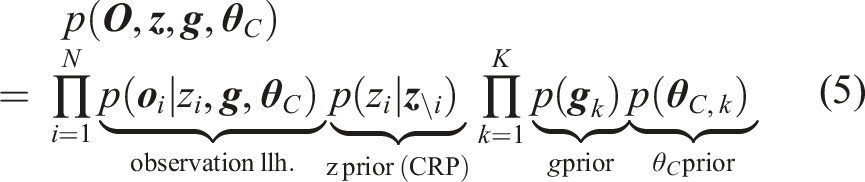
A Chinese Restaurant Process (CRP) with concentration parameter η is used as a prior for the component assignment z
i
, which allows to scale the number of mixture components with a growing number of observations up to a potentially infinite number.
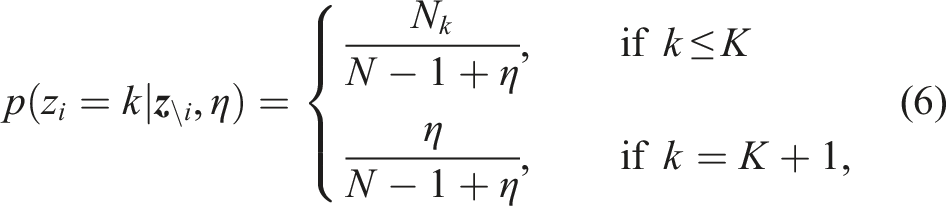
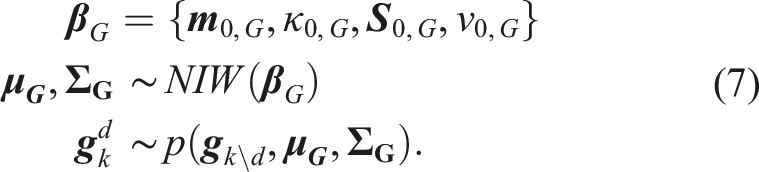
The posterior predictive distribution
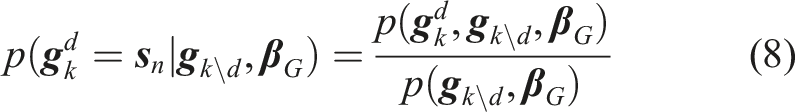
5.1.4. Parameter inference
The optimal model parameters, conditioned on the observation, are obtained by MAP estimation
Due to the conjugacy of its prior, we can marginalize the parameter
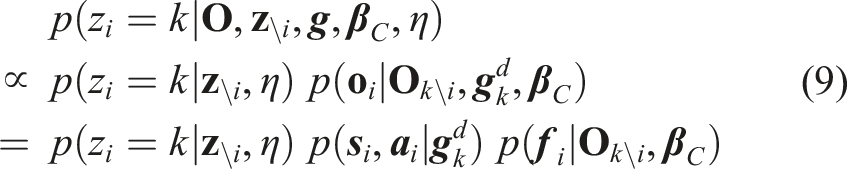
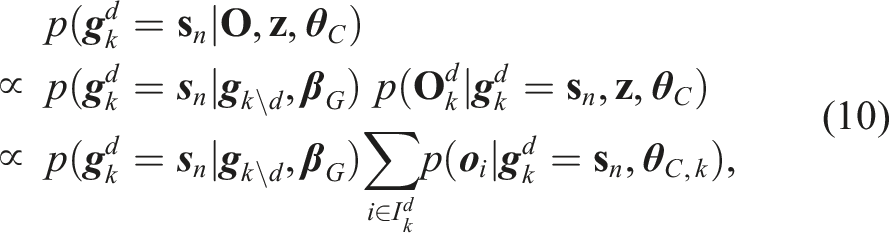

Algorithm 1 starts with initializing
5.2. Task model learning
As described in the previous sections, we propose to learn both the low- and high-level models of a task. Decomposing the task into its individual skills and structuring them in a task graph has several advantages.
Especially when learning low-level policies from demonstration, segmenting the task into skills reduces the problem of accumulating errors caused by training data that are irrelevant for the current part of a task (Shi et al., 2023). For dynamical system-based motion generation and reinforcement learning policies, the decomposition additionally has the advantage that the same state input can be mapped to different actions if different skills are active. Without the decomposition, more complicated policies would be required to achieve that behavior. The BNG-IRL segmentation algorithm provides us with a subgoal region
At the higher level, combining the task graph structure with a subgoal for every skill enables the system to monitor task progress. The next skill in the task graph is only scheduled once the subgoal of the current skill is reached. If an anomaly is detected, the system can trace it back to the specific skill where the error occurred, enhancing the explainability of the issue and allowing the robot to respond automatically. The task graph also narrows the margin for error in high-level decision-making by limiting choices to those relevant for the current skill. After new user demonstrations were segmented with BNG-IRL, the skill sequence is used to update the task graph. The skills inferred from the initial teaching sequence are used to create an initial task graph. This skill sequence can be incrementally extended with task decisions and recovery behaviors as described in Sec. 3.3. If the unsupervised anomaly detection approach recognizes deviations from the skill’s intended execution, the skill selection module needs to determine if an appropriate recovery behavior has already been demonstrated to automatically resolve the situation, or if a new task decision teaching sequence needs to be triggered. The different components of the execution module for this functionality are explained in the following section.
6. Autonomous task execution
As depicted on the right in Figure 2, the execution monitoring module combines several submodules for motion generation, unsupervised anomaly detection, subgoal monitoring, and skill selection. The skill selection module acts as an interface between the task model and the execution modules. We present the individual modules and their interplay in this section.
6.1. Motion generation and unsupervised anomaly detection
In principle, all classical approaches for learning motion primitives, learning policies via Reinforcement Learning, motion planners or even a combination of them are suited to be used in the motion generation module. We present a data-efficient dynamical systems-based approach using Gaussian Mixture Models (GMM) and Gaussian Mixture Regression (GMR) to learn motion primitives and feature constraints for every contact skill from a few demonstrations. We argue that the behavior of a skill depends on the configuration of the robot relative to important objects to interact with and not on time. The aspect of time or sequentiality plays rather a role in the higher-level representation of the task, where subgoals have to be reached one after another in order to continue with the next skill. That is why we propose to generate a velocity and force command based on the robot’s measured end-effector pose.
For every skill, we thus construct a training data set
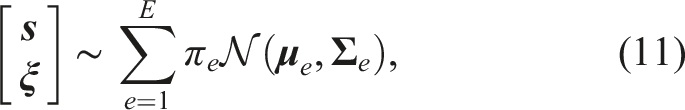
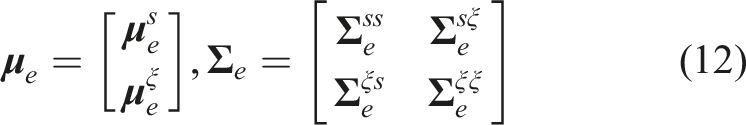
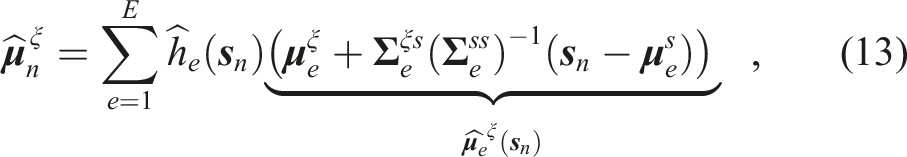
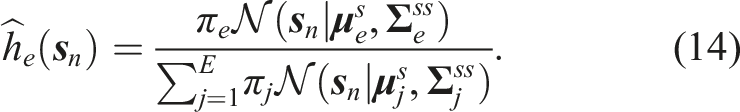
Starting with an initial end-effector pose
We leverage the conditional covariance matrix
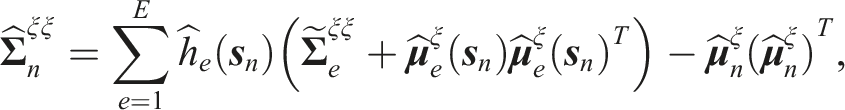
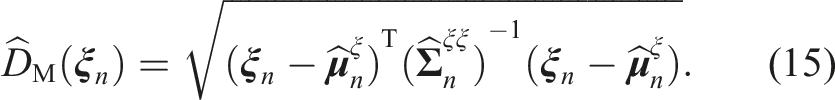
To determine if the deviation is within the expected constraint region for the skill or if it constitutes an anomaly, we set
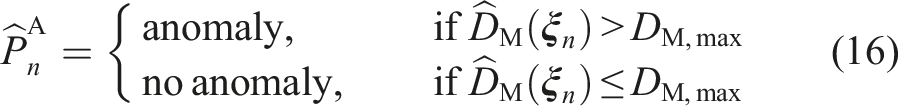
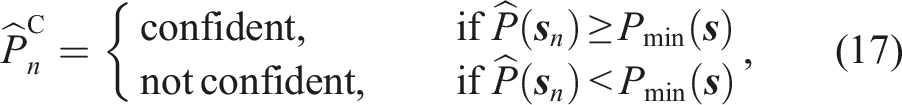
This results in a two-step process for detecting anomalies. Only if the algorithm determines with
6.2. Subgoal monitoring
The last low-level execution module takes care of the subgoal monitoring. It runs in parallel to the other modules and constantly checks if the skill has reached its subgoal region

6.3. Skill selection
The skill selection module is triggered by events from either the anomaly detection or subgoal monitoring module and determines how to react to the incoming events based on the task model. If the subgoal of a skill k is reached, the skill selection module forwards the corresponding low-level skill parameters of the next skill k + 1 of the intended task flow from the task graph to the execution components or terminates the execution successfully if skill k is a termination state in the task graph.

In case an anomaly is detected during skill k, the skill selection module stops the current execution and needs to determine if an appropriate recovery behavior has already been learned for that skill and anomaly case or if a new recovery behavior for a new type of anomaly needs to be learned from demonstration (see Algorithm 2). To check if the detected anomaly is not within the region of known anomalies for skill k, we train a GMM:
7. Experiments
We conducted experiments in simulation and on two different robots to evaluate the individual aspects of our proposed approach. First, we implemented a simple box-pushing task in simulation to compare our segmentation approach to other state-of-the-art methods. The other experiments are contact-based manipulation tasks conducted on real robots, where we increase the complexity of the task to show the applicability of the entire framework, including autonomous detection and recovery from anomalies in a real-world scenario. Supplementary videos for the experiments are provided in Extensions 1–3.
7.1. Box pushing in simulation
In this experiment, we conduct an ablation study to examine in detail the influences of the IRL-based intention recognition and GMM-based feature clustering on our BNG-IRL segmentation approach.
7.1.1. Setup and task description
The setup is shown in Figure 5, where we simulate a user demonstration of a pushing task. Steps of the box pushing task demonstration.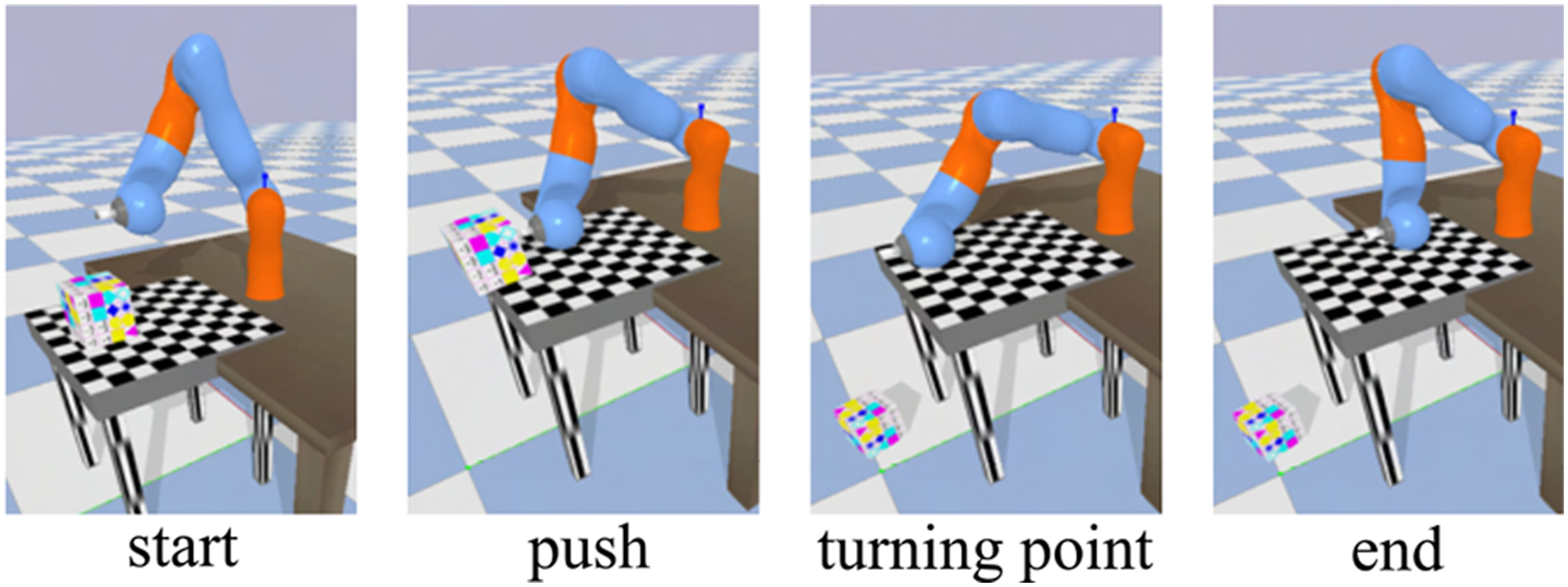
The robot starts from an arbitrary start configuration and moves toward the box on the table. The box is then pushed toward the edge of the table with the robot until it falls on the floor. After the box has fallen from the table, the robot moves until a turning point and retracts back toward the table. The demonstrated end-effector (EEF) trajectory can be seen in the upper row of Figure 6. The state space The top row shows the segmentation result of the three compared methods BNG-IRL, BNGMM (Rasmussen, 1999), and BN-IRL (Michini et al., 2015), mapped onto the end-effector (EEF) trajectory of the task demonstration. The skill assignment z is represented by the color of each sample. The subgoals, which are only inferred in our approach and BN-IRL, are represented by an X in the skill’s color. The next two rows show the segmentation results in feature space, where the normalized distance of the EEF to the edge of the table and the normalized force on the EEF are plotted over time. The three distinct events during the task demonstration: The start and end of the box pushing as well as the turning point after pushing are highlighted in the figures. It can be seen, that by combining the influence of subgoals and feature constraints, only our approach reliably detects the distinct phases of the task and groups them in individual skills. The sampling-based parameter inference leading to the results is shown in Extension 1.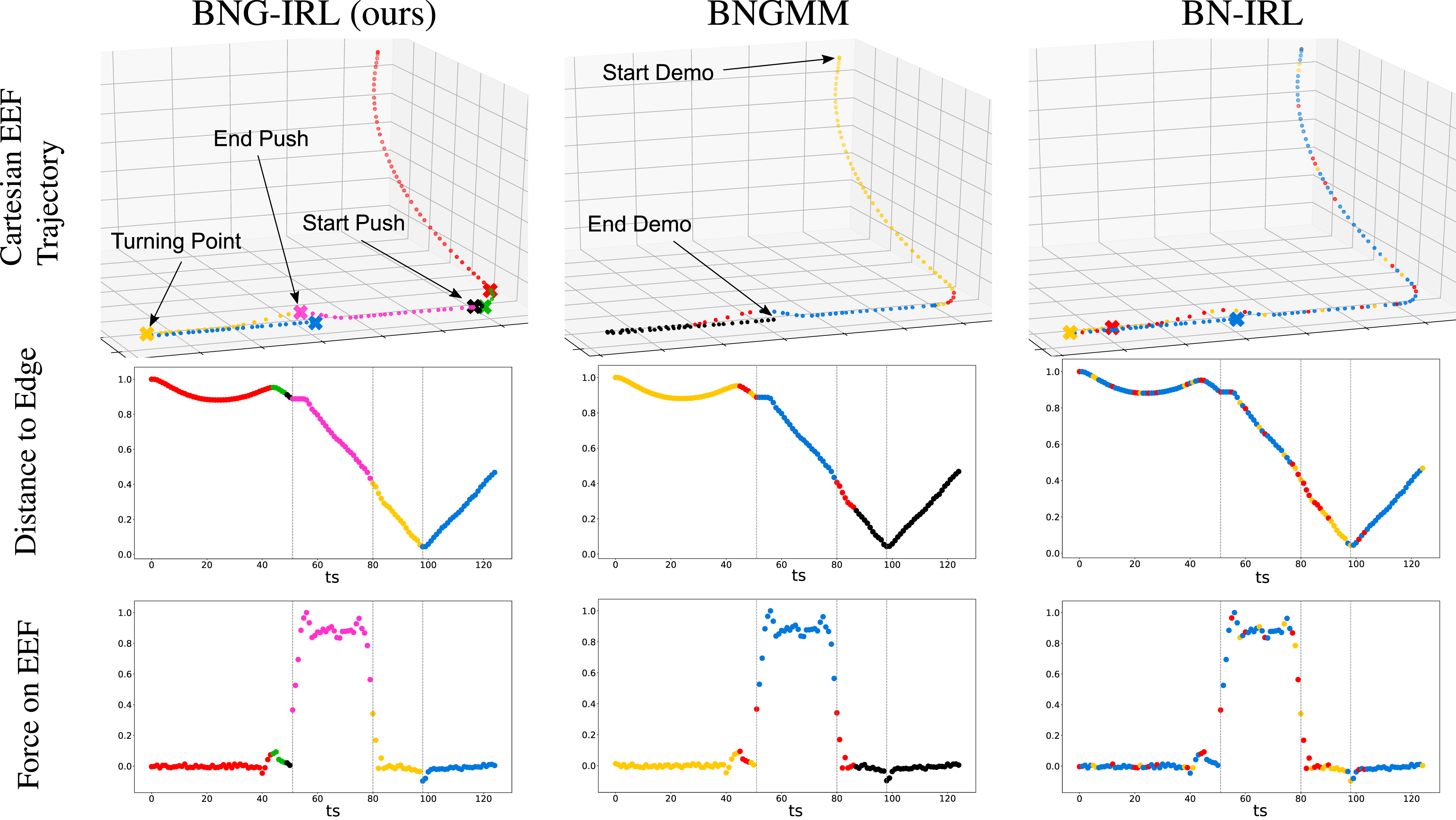
7.1.2. Unsupervised task segmentation baselines
7.1.3. Metrics
To evaluate the segmentation performance of the different methods, we compute the frame-wise accuracy (Acc), the edit score (Edit), and F1 scores at overlap thresholds of 10%, 25%, and 50% (F1@10, 25, 50). The accuracy evaluates performance at the frame level, while the edit score and F1 scores assess segmentation quality at the segment level (Liu et al., 2023). We calculate the overlap between each detected segment and the ground truth segments and assign ground truth labels to maximize the overall intersection rate across the entire task.
7.1.4. Results and discussion
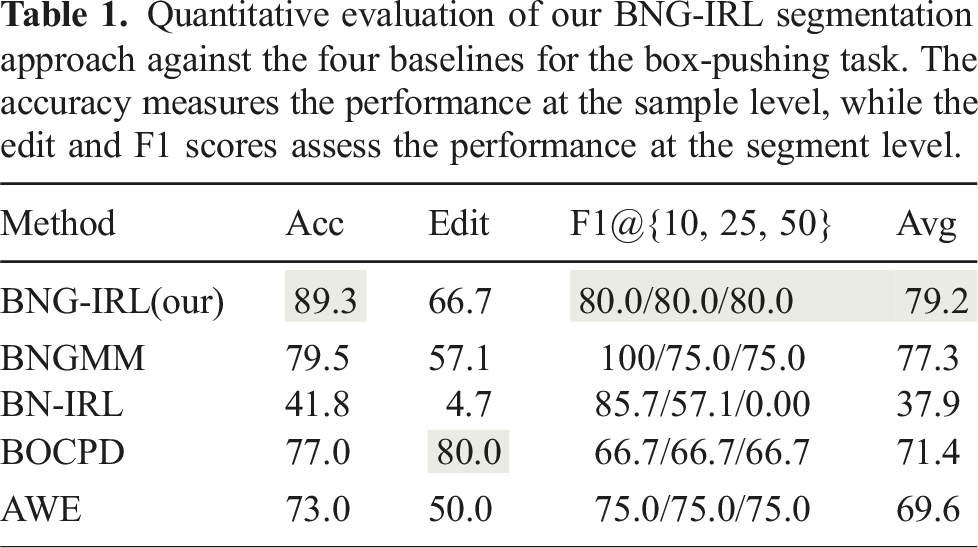
Quantitative evaluation of our BNG-IRL segmentation approach against the four baselines for the box-pushing task. The accuracy measures the performance at the sample level, while the edit and F1 scores assess the performance at the segment level.
Due to the similarity in the force domain, BNGMM groups the samples before and after pushing the box in one cluster, see red samples in the center column of Figure 6. The turning point is also not identified with this approach, since without considering the intent of the actions, the black samples appear close in feature space. However, this method reliably detects the approach and the push phase, which leads to the second-highest quantitative evaluation results after BNG-IRL reported in Table 1.
BN-IRL, on the other hand, which solely considers the subgoal’s influence on the actions when subdividing the demonstration has difficulties inferring coherent skills in this setup, leading to both the lowest frame-wise and segment-wise performance scores. The majority of observations (blue samples in the right column of Figure 6) are assigned to the same skill, whose subgoal is the last state of the demonstration. With the proposed observation likelihood in Michini et al. (2015)
7.2. Manipulation task with DLR LWR IV
7.2.1. Experimental setup
As seen in Figure 7, a DLR LWR IV robot (Albu-Schäffer et al., 2007), equipped with a 2-finger gripper and a force-torque (FT) sensor, is mounted on a linear axis. The FT sensor measures the forces and torques acting on the end-effector. An Intel Realsense camera tracks the 6D poses of objects. Two pedals near the workspace allow the user to start and stop the demonstration and operate the gripper. When the demonstration mode is activated, the robot compensates for its own weight, enabling kinesthetic teaching. The task for the robot is to pick up object 1 and to place it on top of object 2 such that their edges are aligned. Both objects can have arbitrary initial 6D poses. Additionally, the robot should detect and recover from a task anomaly, where the robot loses the object during transport. A video of the experiment setup, as well as the task learning procedure and autonomous error recovery, are provided in Extension 2. The feature space The task graph structures the low-level skills on a higher level of abstraction. The green sequence of skills represents the intended task flow from the initial demonstration. The recovery behavior in red restores a situation from which the robot can continue with the intended task flow. The monitored execution of the “Approach Object 1” skill is shown on the right.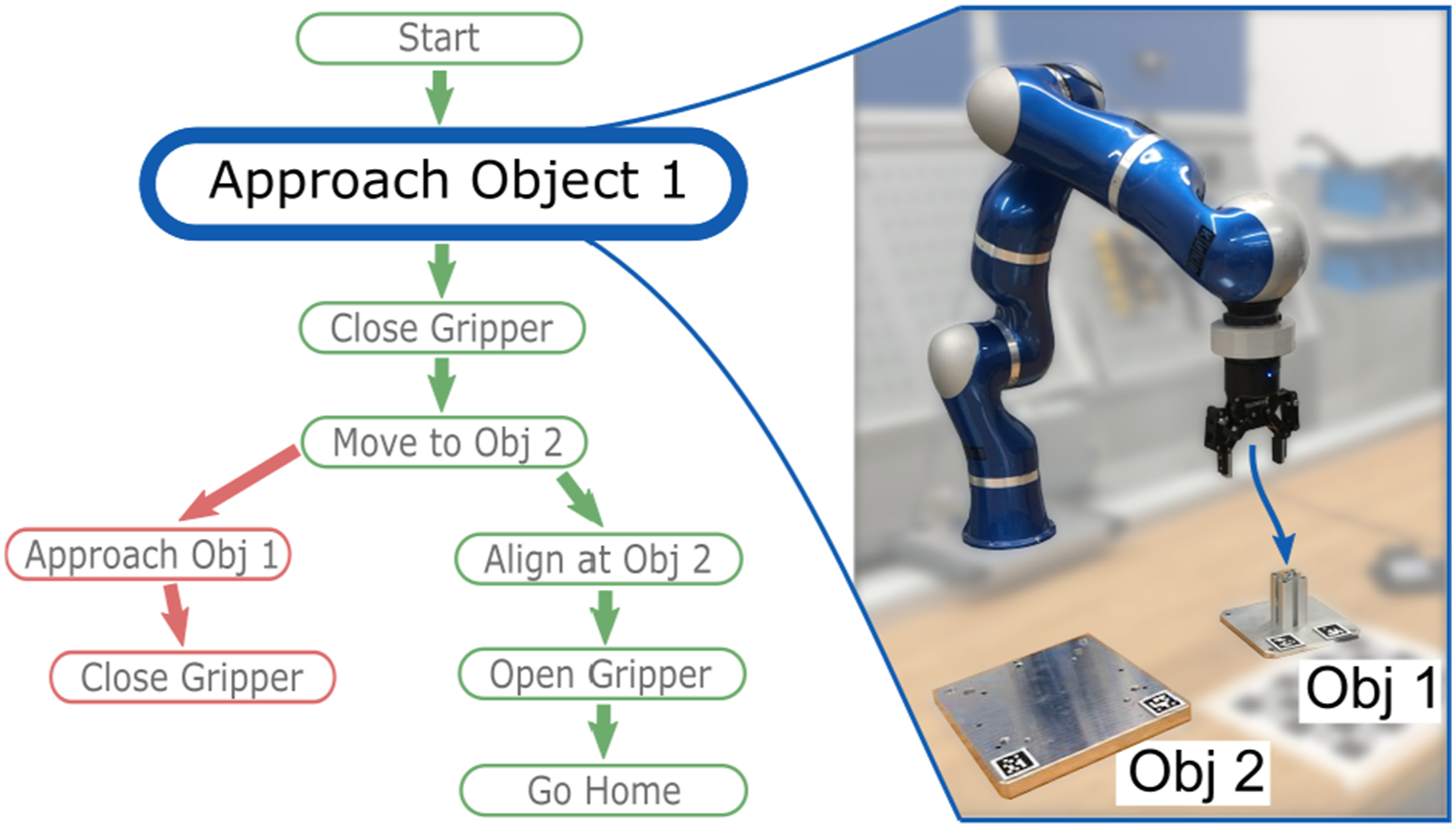
7.2.2. Incremental task learning procedure
The teaching procedure starts with an initial demonstration of the task, where the user picks up object 1 with the robot and places it on top of object 2 in the desired goal configuration. The segmentation result can be seen in Figure 8, where the important subgoals of the task are correctly identified. The inferred sequence of skills is then used to construct an initial task graph (see the green sequence in Figure 7 and Extension 2), where the skills are encoded as DMPs. The Cartesian end-effector trajectory during the user demonstration of the manipulation task. Samples with the same color are assigned to the same skill. The state subgoals of all six skills are depicted with an X. Several subgoals are inferred in the vicinity of the objects, as objects are grasped or released here. The features between the skills therefore only differ in the gripper finger distance and grasp status.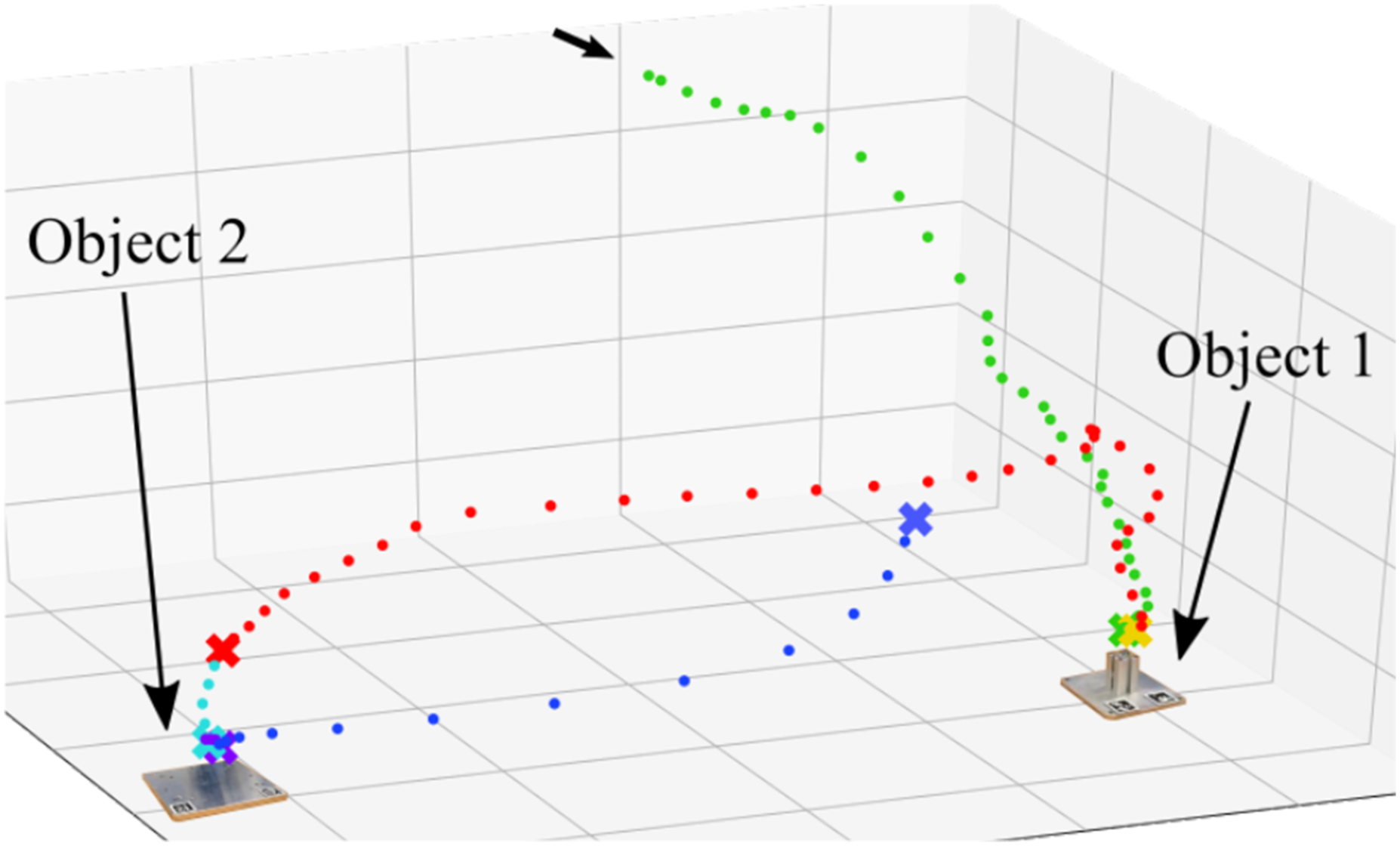
The system then switches to the autonomous execution phase, in which the robot performs the skills from the initial task graph. Using the skills’ DMPs, the robot’s EEF trajectories can be generalized to varying subgoal configurations. In case a task anomaly occurs, like losing the object during manipulation, the anomaly detection component automatically registers a deviation of the features from their expected region. The anomaly detection mechanism is visualized for the measured end-effector force in Figure 9. It can be seen that the measured samples before the task anomaly (green) were confidently classified with the two-step anomaly detection approach as belonging to the executed skill. As soon as the measured force leaves the expected constraint region, the Mahalanobis distance exceeds the anomaly threshold (16). After 300 ms, an anomaly is confidently detected and the robot stops. Since no recovery behavior is available in the task graph, the robot requests a user demonstration to resolve the anomaly. Anomaly detection mechanism illustrated with the expected force during the transportation skill. In blue are the samples collected during the user demonstration ①–② which were used to infer the skill’s expected feature region, represented by a 2D Gaussian (light blue area). The green and red samples are recorded during the robot execution ③, ④. First, the features lie within the expected region (green samples) but as soon as the object falls out of the gripper and the force on the end-effector suddenly decreases, the samples are classified as anomalous (red samples) which eventually triggers an anomaly.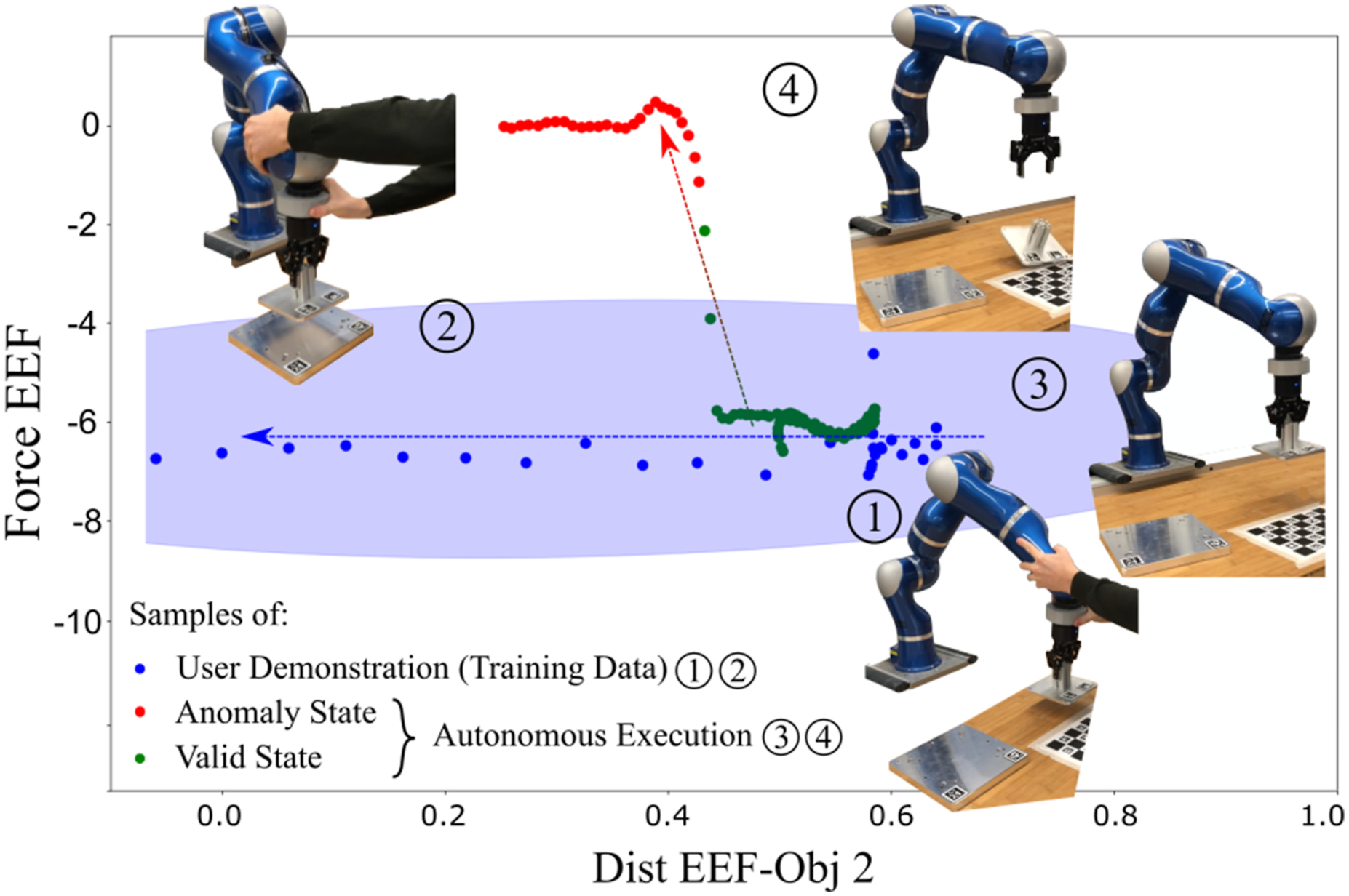
The demonstrated recovery behavior is segmented, encoded analog to the initial demonstration, and appended to the skill in the task graph during which the anomaly was detected (see sequence connected with red arrows in Figure 7). The robot can now leverage this recovery behavior to automatically resolve similar situations occurring at any phase of the transportation skill.
7.3. Box grasping and locking with DLR SARA
This task stands for a variety of specialized contact tasks that require precise coordination of end-effector pose and applied force in the different phases. The phases that make up this task cannot be described by common robot skills, but require precise coordination of end-effector pose and applied force and therefore must be learned through demonstration on the real system. We utilize this task to demonstrate the different capabilities of our proposed framework, which include (A) the three variants of teaching sequences, (B) the hierarchical task decomposition based on a few user demonstrations, and (C) the autonomous task execution, where new anomalies can be detected and autonomously resolved after a recovery behavior has been learned. A video showcasing these capabilities is provided in Extension 3.
7.3.1. Experimental setup
The DLR SARA robot (Iskandar et al., 2020), is equipped with a 6-DOF FT sensor in the wrist that can measure task forces and torques during kinesthetic demonstration which need to be reproduced during the execution (Iskandar et al., 2021). On the last robot link are buttons and a display that the user can interact with during the demonstrations. The display provides the user with information about the robot’s status and informs which buttons to press to navigate the desired teaching sequence. As shown in Figures 1 and 10, a passive gripper is mounted on the robot which is designed to pick and lock the standardized euro boxes using a sequence of specific motions with the robot. A euro box with a known pose relative to the robot’s base coordinate frame is located in the robot’s workspace. Passive box gripper design with movable linear slides to grasp and lock a euro box.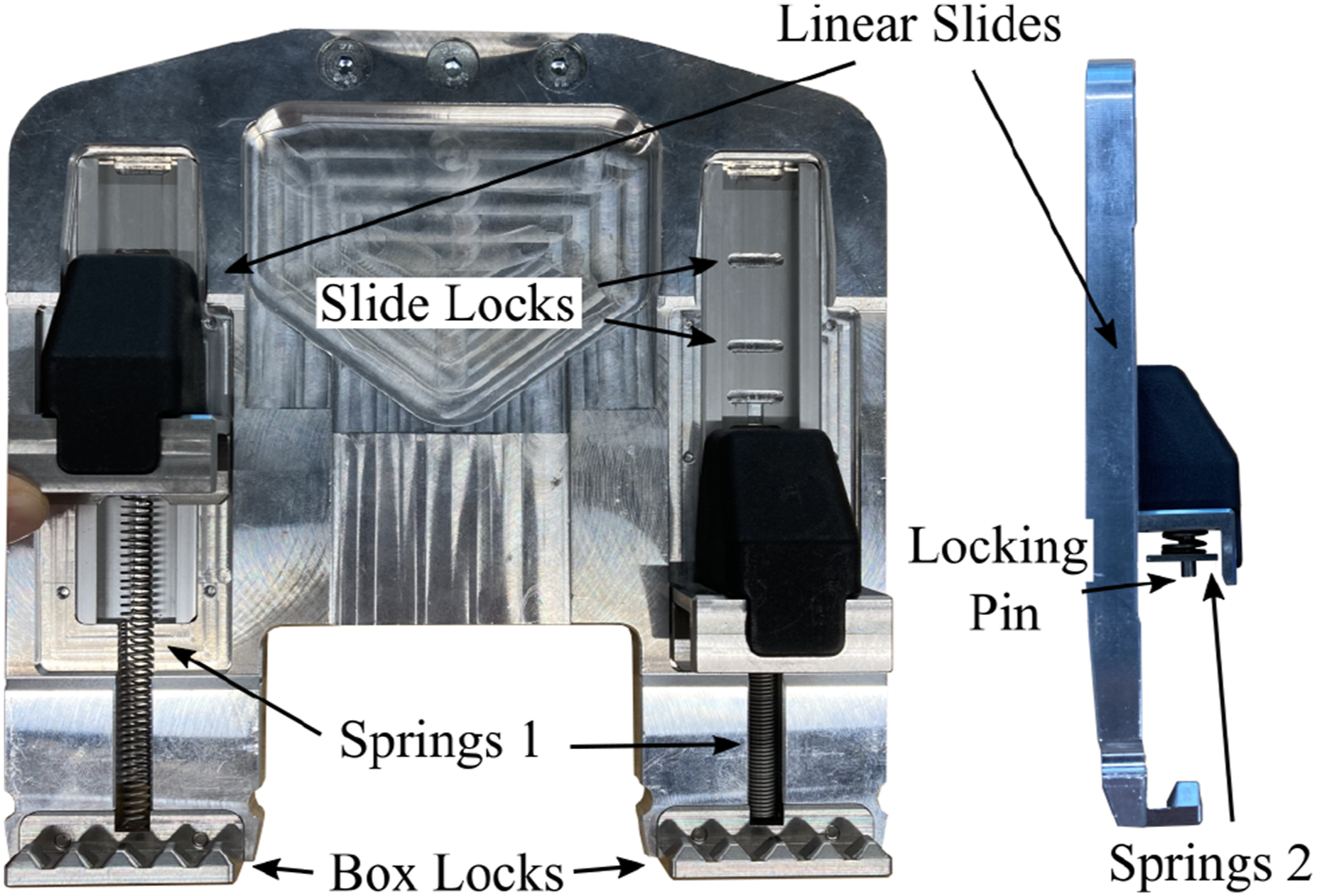
7.3.2. Recorded data
The state vector
7.3.3. Task description
To better understand how the grasping and locking mechanism of the box gripper works, which has to be learned from demonstration, we first describe the gripper hardware and functionality before explaining the sequence of motions and difficulties during the task.
7.3.3.1. Gripper design
The gripper (Eiberger, 2022), as depicted in Figure 10, has two movable linear slides. When moving the linear slides up, springs 1 are tensioned and pull the slides back into the neutral configuration if the slides are released. When the locking pin in the linear slides is pushed, a latch at the back of the slides retracts and engages in one of the slide locks. This blocks the linear movement of the slides, which enables the grasping of boxes of different heights. To fixate a box inside the gripper, springs 2 are compressed to maintain a constant force between the linear slides and the box locks. The box locks engage at its counterpart at the bottom of the box and prevent movement perpendicular to the linear motion of the slides.
7.3.3.2. Kinematic sequence to grasp and lock the box
The task, as depicted in Figures 1 and 11, consists of five different phases. In the first phase, the robot moves from a start configuration closer to the box, while slightly tilting the end-effector to avoid contact between the box locks of the gripper and the box. In the second phase, the gripper moves closer to the box until both linear slides evenly contact the side wall of the box (see column 2 of Figure 1). After that, while maintaining contact between the slides and the box, the gripper is pushed down along the side wall of the box, tensioning springs 1 until the third configuration in the upper row of Figure 1 is reached. In the next phase, the box gripper is moved closer to the box, such that the locking pins in the slides are pushed and the linear movement of the slides is blocked. In the final phase, springs 2 are compressed, while rotating the box gripper into a vertical configuration, such that the box locks can engage at the bottom of the box. The mean EEF poses 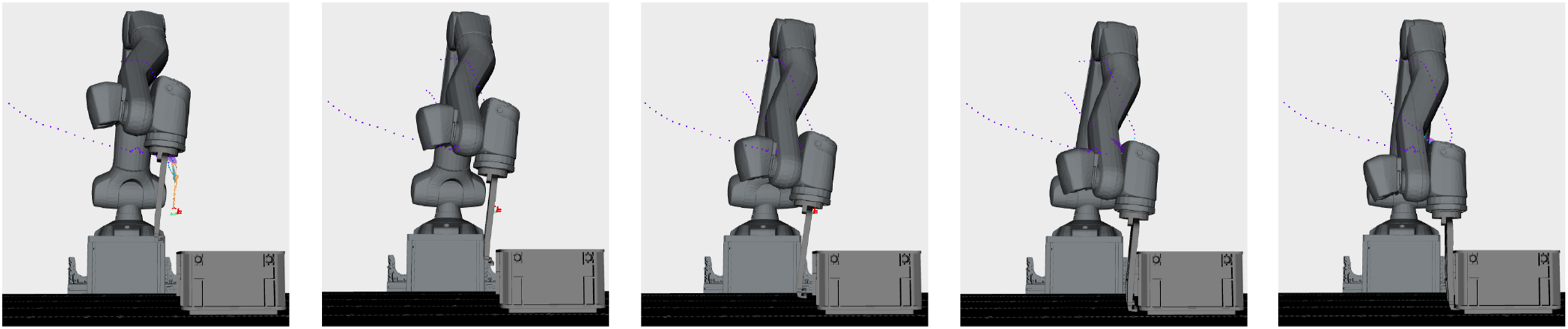
7.3.3.3. Difficulties
The task poses several difficulties that can prevent successful grasping and locking of the box. The challenges of every phase are depicted in the bottom row of Figure 1. In the first phase, the box locks of the gripper must not collide with the box, while the slides are already located over the wall of the box so that in phase 2, only the front part of the slides contact the wall of the box. If the gripper moves too close to the box in phases 2 or 3, the locking pin is pushed too early and the sliding mechanism is blocked. If the gripper moves too far away from the box and the slides lose contact with the wall, the springs 1 pull the slides into the neutral configuration. In both cases, configuration 3 cannot be reached. If configuration 3 has been reached, the gripper can move closer to the box, such that the locking pins are pushed and the springs 2 can be compressed. Before rotating into the vertical configuration, the robot must push the gripper further down to avoid a collision between the box locks and the lower part of the box. Precise coordination of applied force in the direction of spring 2 and rotation of the gripper is required during this phase since there is only a very small clearing between the gripper and the box. If the robot does not exert enough force or rotates too early, the box locks collide with the box and the final configuration cannot be reached.
7.3.4. Initial teaching sequence
To learn an initial model of the task of grasping and locking the box with the gripper, a user provides three demonstrations using kinesthetic teaching. These demonstrations are then segmented with our BNG-IRL approach. The results of the sampling procedure with the highest MAP likelihood are shown in Figures 12 and 13. The results indicate a segmentation of the task into the five skills, which were described above. As shown in Figure 12, the further the task progresses, the more restricted the subgoal (right) and constraint regions (left) become, because the process requires more precision once contact between the robot and the box is established. As expected, the subgoal regions are located at the end of each skill. The skills’ actions are targeted toward reaching its subgoal configuration. In the upper two rows of Figure 12, only the 3D position component of the subgoal region is depicted, however, the subgoal regions are defined in state space, which also includes a 3D orientation component. To illustrate this, Figure 11 depicts the mean 6D EEF pose Position part of the subgoal and constraint regions inferred with BNG-IRL. The constraint regions Characteristic features during the initial task demonstrations, which are utilized to segment the task into skills based on consistent correlations among the demonstrations. The features define the constraint regions 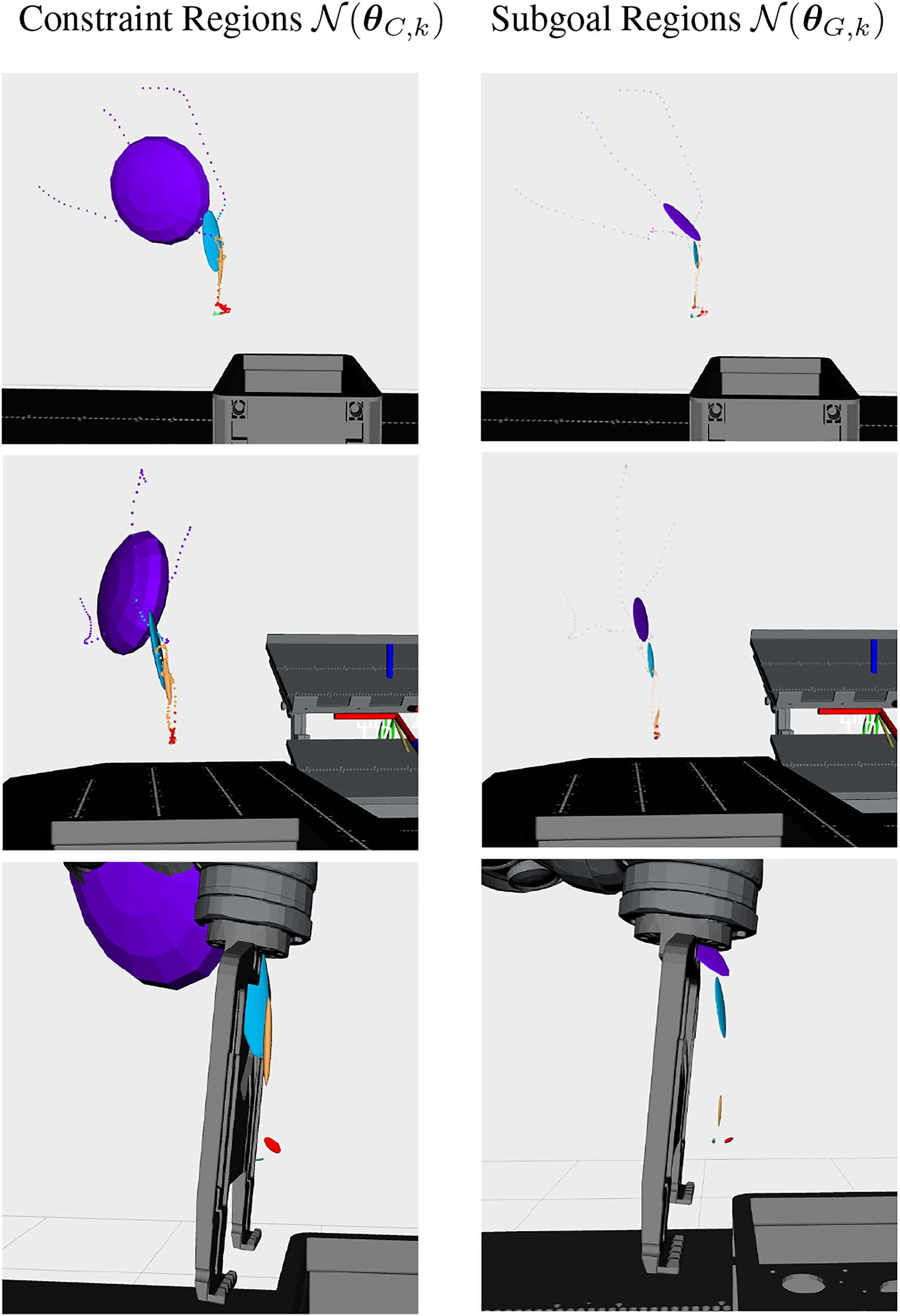
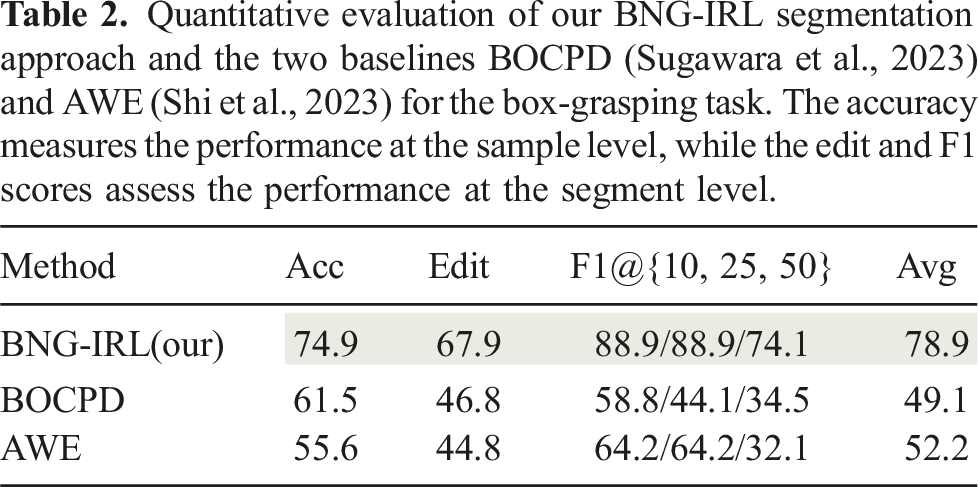
7.3.4.1. Quantitative evaluation of unsupervised segmentation
We evaluate the task segmentation performance of BNG-IRL against the two baseline approaches AWE (Shi et al., 2023) and BOCPD Sugawara et al. (2023) described in Sec. 7.1.2. We compute accuracy, edit and F1@10, 25, 50 scores, as explained in Sec. 7.1.3.
7.3.4.2. Results
Quantitative evaluation of our BNG-IRL segmentation approach and the two baselines BOCPD (Sugawara et al., 2023) and AWE (Shi et al., 2023) for the box-grasping task. The accuracy measures the performance at the sample level, while the edit and F1 scores assess the performance at the segment level.
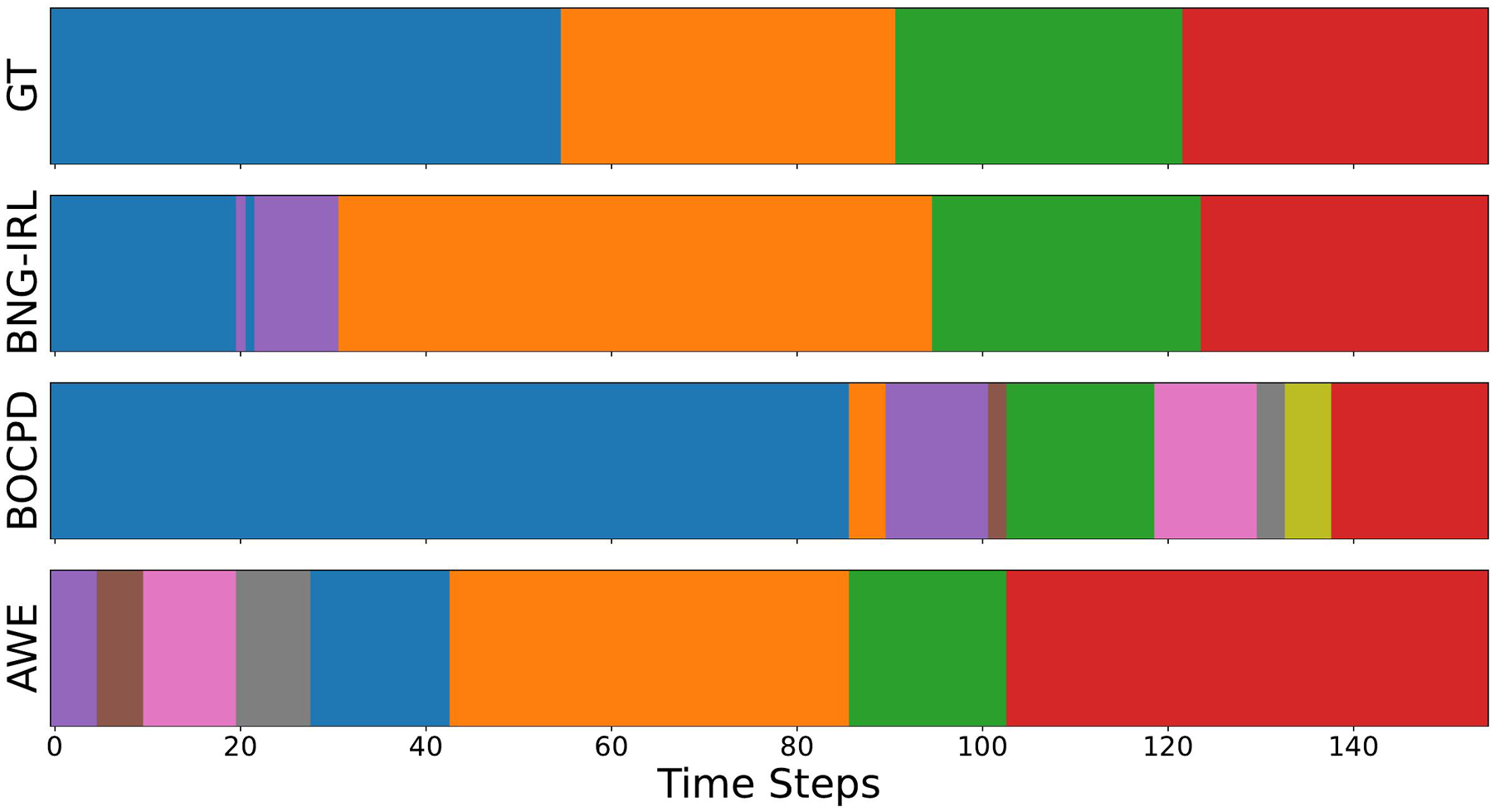
Comparison of the ground truth segmentation of demonstration 1 with the task segmentation results of BNG-IRL, BOCPD, and AWE. BOCPD suffers from over segmentation in the final phase of the task, while AWE detects too many segments in the beginning.
7.3.5. Skill refinement teaching sequence
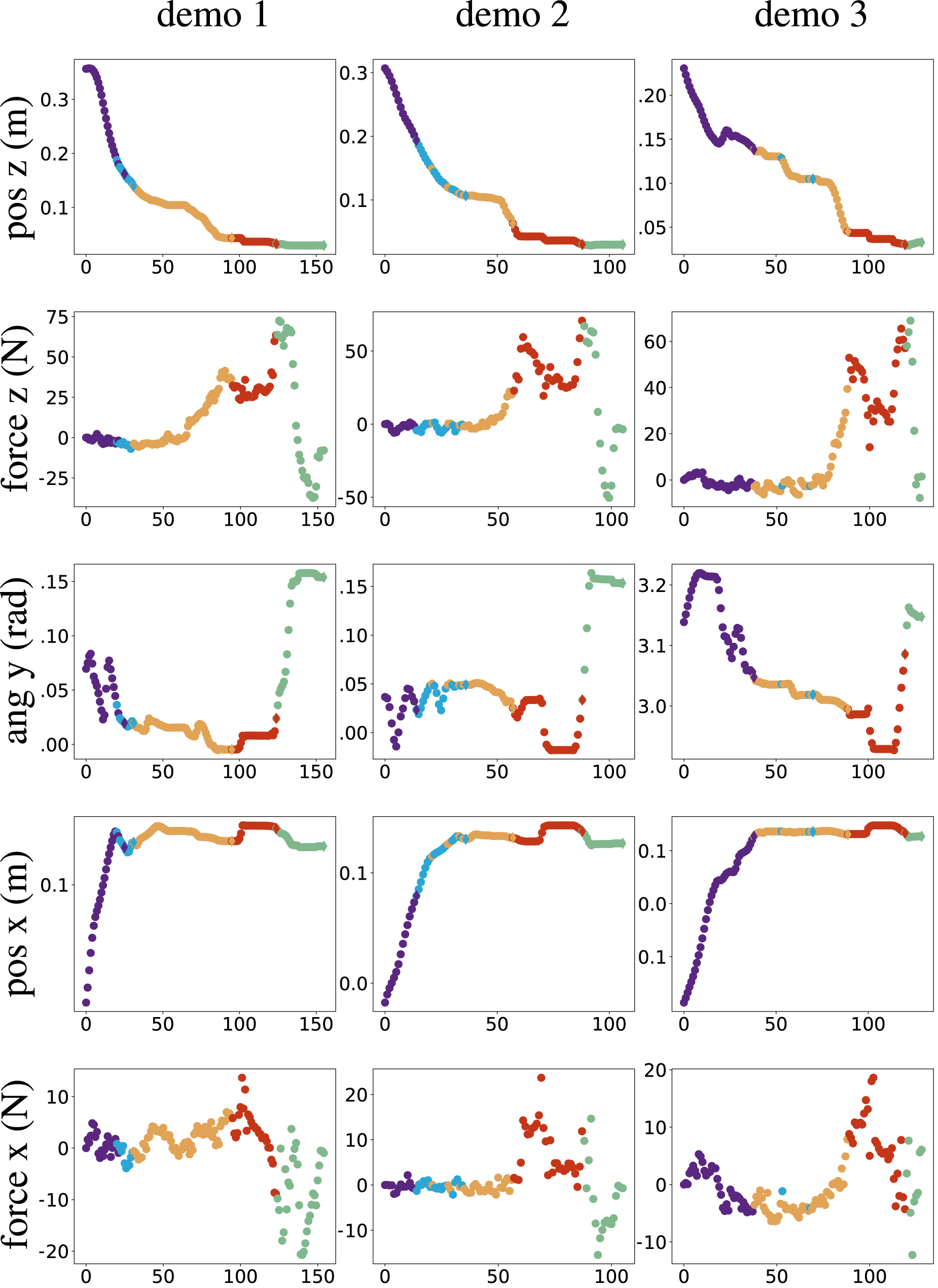
The inferred skills from the previous teaching sequence are encoded as dynamical systems for motion generation and anomaly detection as described in Sec. 6.1, where we set the number of mixture components per skill equal to two. The robot is already capable of autonomously executing the learned skills, however, incremental refinements in the force domain might still be required to complete the task successfully. We additionally utilize the refinement sequence to increase the variation in the training data for each skill’s low-level model in a combined robot execution and user support phase. Since the autonomous execution does not simply replicate the demonstration, the contact forces during autonomous execution typically differ slightly from the ones recorded during the user demonstrations. As seen in the upper right graph of Figure 15, the commanded force in the last part of the skill 4 is not enough to fully compress springs 2 in the commanded EEF configuration. That is why a user supports during this phase by applying additional force in z-direction so that the task can be successfully completed. As seen in the lower row of Figure 15, the recorded force is used to update the low-level model, which results in a higher commanded force for that EEF configuration in the next autonomous execution. Force refinement of skill 4. The relation between z-position and commanded force in z-direction for skill 4 is illustrated by the 2D excerpt of the GMM for motion- and force generation (left). The measured and commanded forces in z-direction during the entire task are depicted on the right. As shown in the upper row, the low-level skill model from the initial user demonstrations generates a force command in z-direction, which is not enough to fully compress springs 2. After collecting new user support training data, the low-level skill model is updated, which results in a higher commanded force during skill 4 for the same EEF configuration.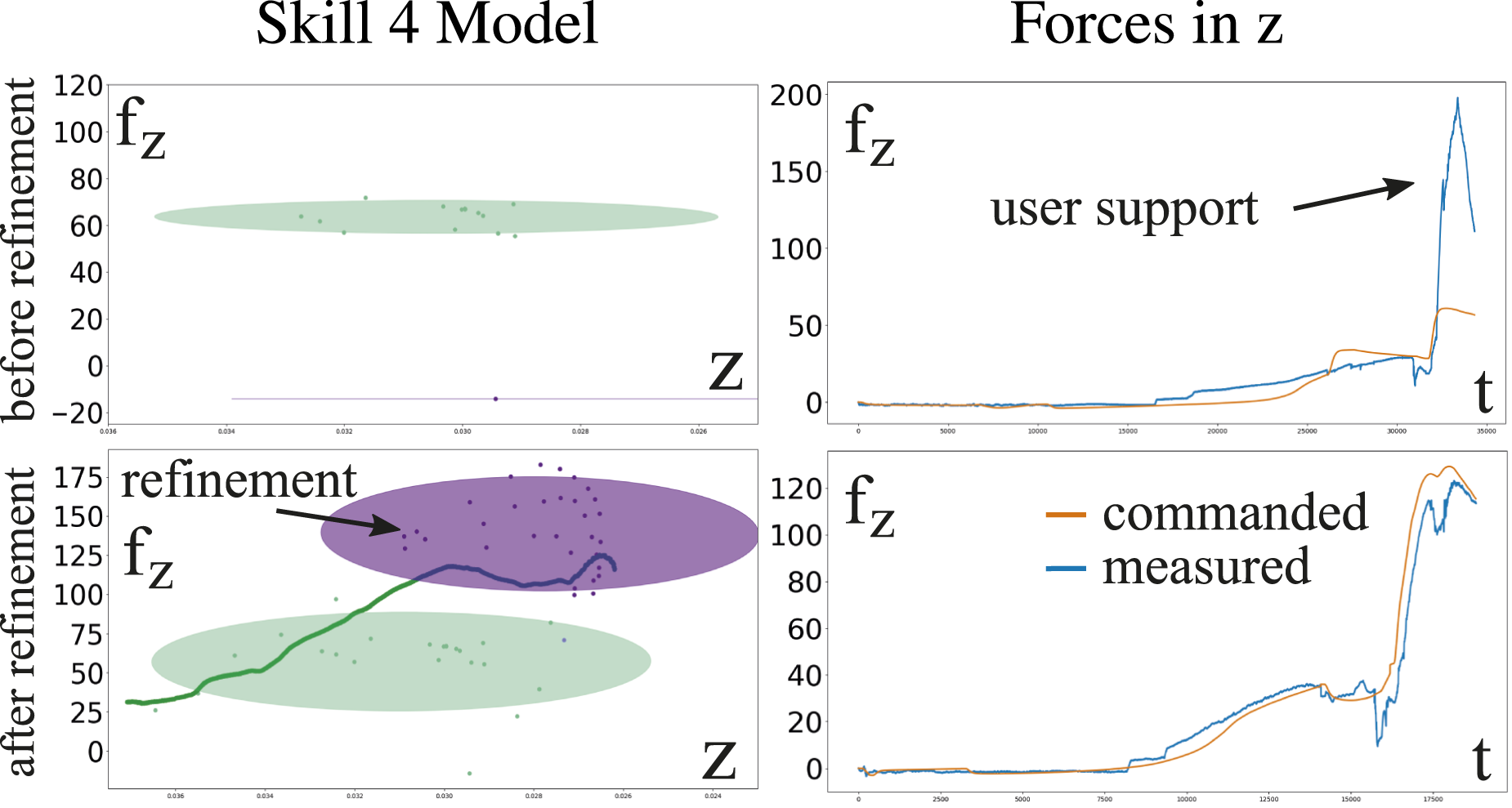
7.3.6. Unsupervised anomaly detection
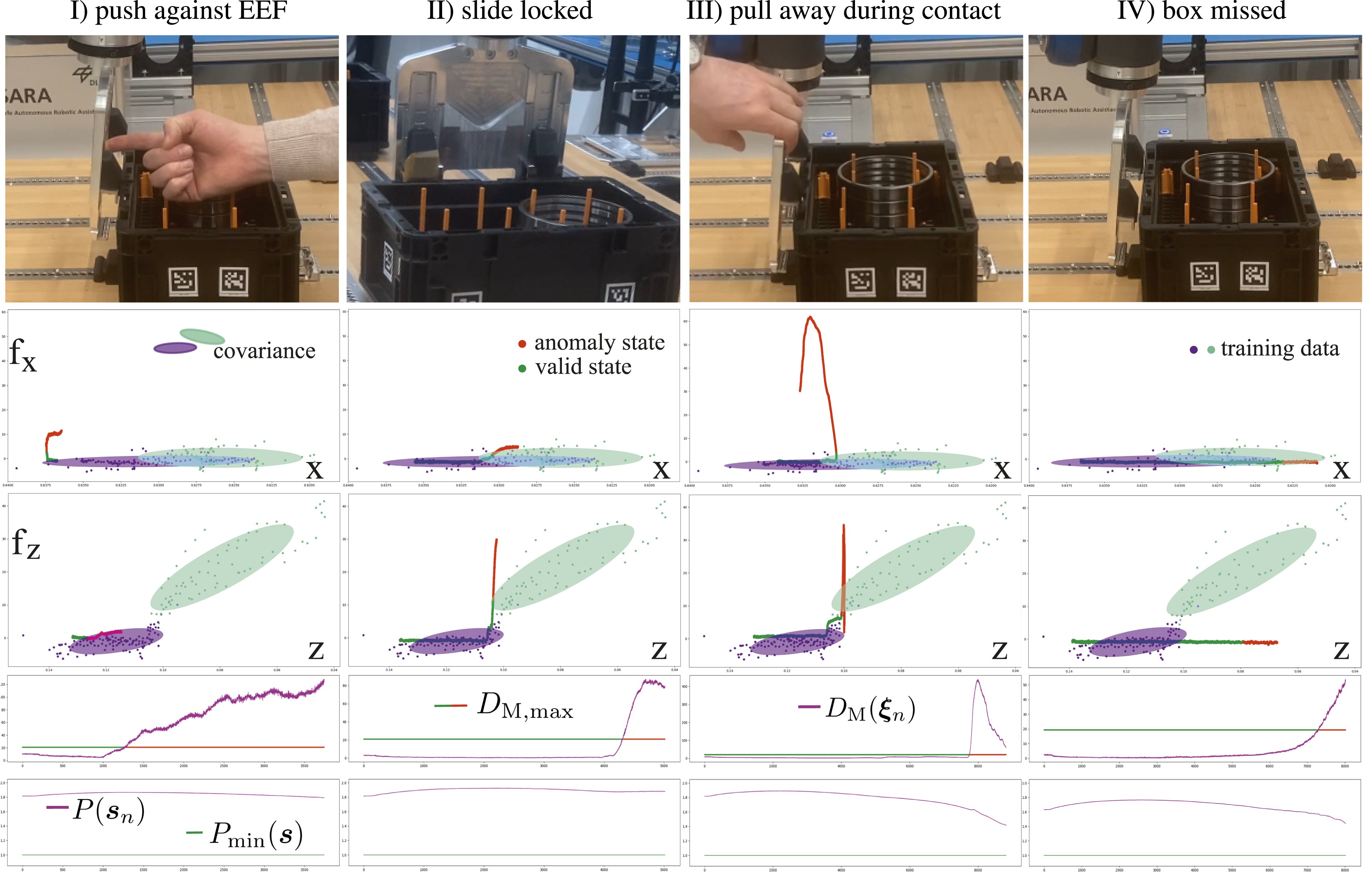
The refined skill sequence can now be executed on the robot with active anomaly detection. To test the anomaly detection and recovery capability of our approach, we simulate four different anomalies during the third skill of the task, depicted in Figure 17. The anomalies are (I) pushing against the end-effector before tensioning springs 1, (II) prematurely locked linear slides, (III) pulling the gripper away from the box during tensioning springs 1, and (IV) missed contact between the slides and the box. Anomalies (I) and (III) simulate user interference with the task, (II) simulates a hardware defect, and (IV) a perception error, that causes a wrongly predicted box configuration resulting in a gripper offset relative to the box.
As shown in Figure 17, our approach successfully detects all anomalies before a potentially dangerous situation can occur. The second and third row of Figure 17 show the measured force in x and z-direction over the EEF position in the same direction as well as the corresponding training data for the skill. The expected force region with respect to the EEF pose is depicted by the ellipsoids representing the covariance of the training data. As shown on the left in Figure 16, the measured forces during the execution are expected to lie within the region of the training data. If the measured and commanded forces do not deviate more than expected, the Mahalanobis distance computed with (15) stays below the skill’s anomaly threshold (see right side of Figure 16). However, if the measured forces deviate from their expected region, and the Mahalanobis distance successively exceeds the threshold for more than 300 ms, an anomaly is triggered (see second last row in Figure 17). Since the variation in the training data is smaller in the first part of the skill, represented by the purple ellipsoids, the anomaly detection is more sensitive to deviations in that phase. As shown in the bottom row of Figure 17, the model can confidently predict anomalies for the measured EEF poses, since condition (17) is continuously met. Nominal execution of skill 3. The relation between f
x
and x, as well as f
z
and z for skill 3, is illustrated by the 2D excerpts of the GMM for motion- and force generation (left). As seen on the left, the measured forces during the execution f
x
and f
z
are within the expected constraint region for the measured EEF pose. The deviation between the commanded- and measured forces (upper right) is in a tolerable region, which is why the computed Mahalanobis distance DM( When interfering with the task, our method consistently detects anomalies before potentially dangerous situations can occur. As shown in rows 2 and 3, when the measured forces f
x
and f
z
are outside the expected range with respect to the measured EEF pose, our unsupervised anomaly detection approach classifies the measurements as anomalous (red samples). As more variance in the force f
z
is present in the training data for the phase where the robot tensions springs 1 (turquoise region), the anomaly detection is less sensitive toward deviations in f
z
in that phase during the execution. If the computed Mahalanobis distance DM(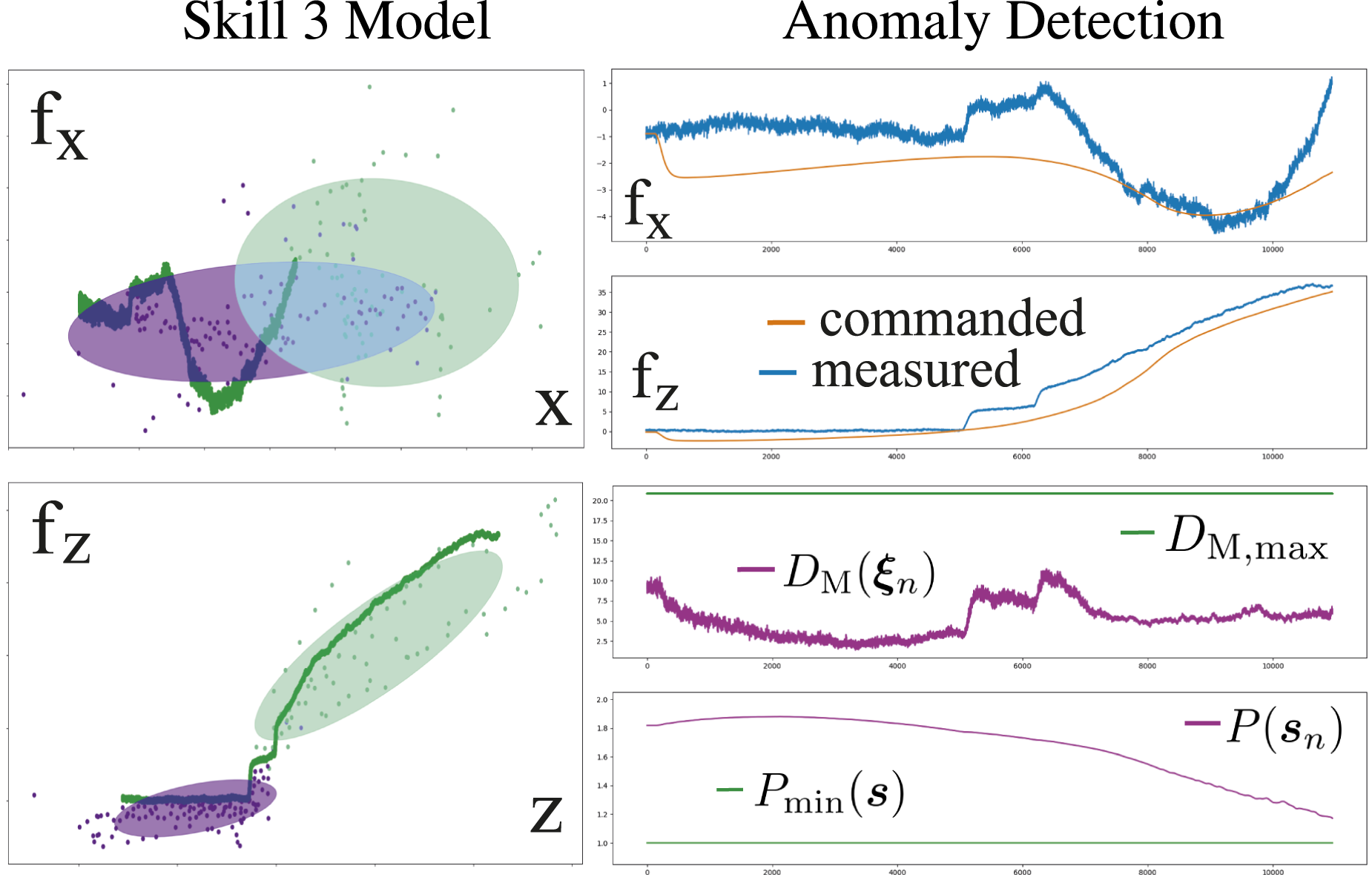
7.3.6.1. Quantitative evaluation
Characteristics of the compared anomaly detection approaches during the training and prediction phase.

7.3.6.2. Dataset and metrics
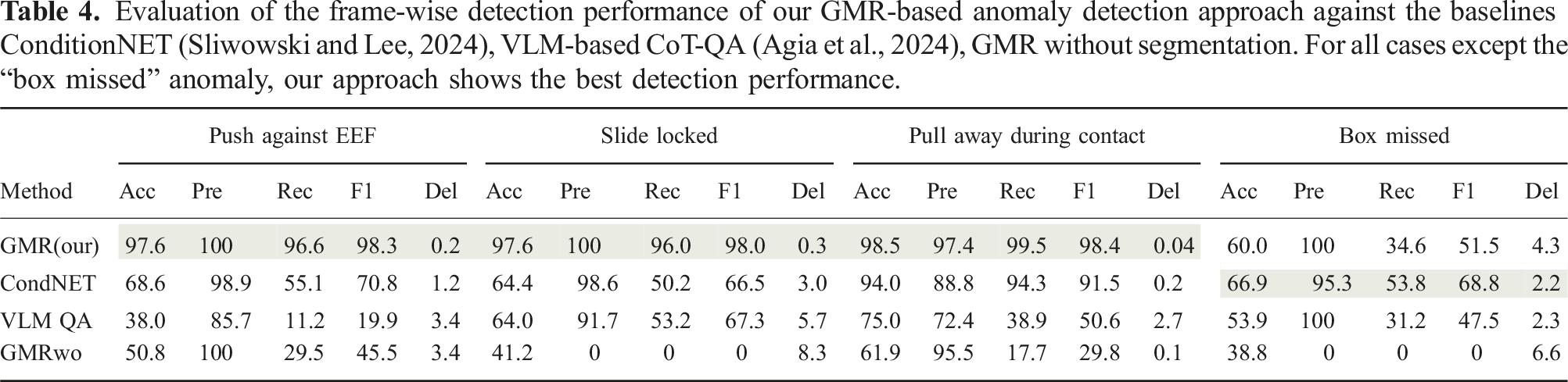
Evaluation of the frame-wise detection performance of our GMR-based anomaly detection approach against the baselines ConditionNET (Sliwowski and Lee, 2024), VLM-based CoT-QA (Agia et al., 2024), GMR without segmentation. For all cases except the “box missed” anomaly, our approach shows the best detection performance.
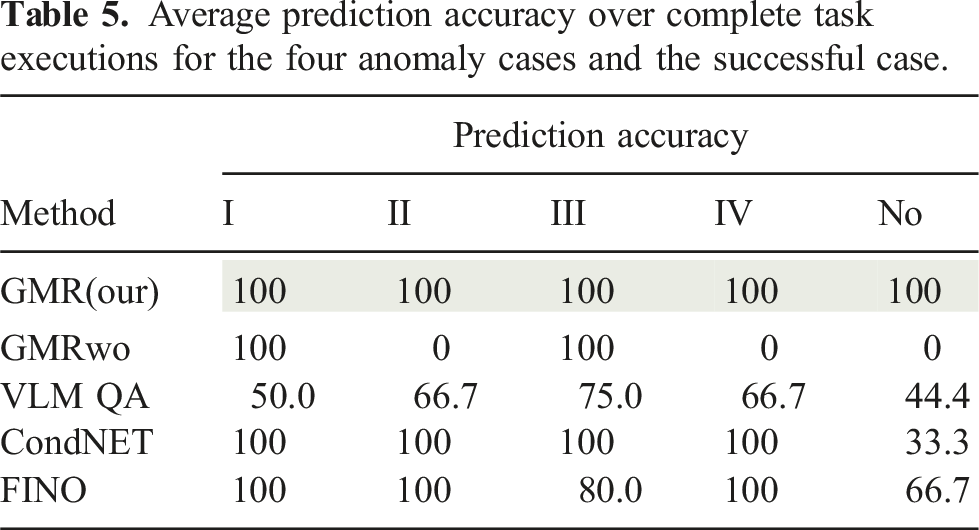
Average prediction accuracy over complete task executions for the four anomaly cases and the successful case.
7.3.6.3. Results
As shown in Table 4, our approach outperforms all other online detection baselines in frame-wise prediction performance and detection delay for anomaly cases I–III. Unlike other methods, our detector identifies subtle force deviations before anomalies become visually observable. For the “box missed” case, ConditionNET achieves better detection performance, as this anomaly is visually observable before anomalous force readings occur. Table 5 further demonstrates that our approach is the only one that confidently detects all anomalies without triggering false positives during successful executions. Methods relying on vision are sensitive to camera viewpoints and degrade in performance under occlusions. GMR without segmentation performs the worst in this setting, as its mixture components are unevenly distributed across skills, and the anomaly detection threshold in (16) remains fixed throughout the task, reducing the overall sensitivity to deviations. The VLM CoT-QA baseline correctly describes observed video frames and focuses on relevant questions for anomaly detection. However, it often struggles to determine whether a described situation constitutes an anomaly. Most detected anomalies with this method result from exceeding the skill’s time limit. Even in such cases, the VLM fails to maintain consistent predictions across multiple time steps.
7.3.7. Task decision teaching sequence
Finally, to autonomously recover from the detected anomalies, the anomaly cases need to be classified to select the appropriate recovery behaviors. For this, we utilize the anomalous observations
If a new anomaly is detected with Algorithm 2, the task graph in Figure 18 is extended with a new recovery behavior. Just like the initial task flow skills, recovery behaviors are learned from demonstration, however, they are appended to the skill in the task graph during which the anomaly was detected. If, during the execution, the recovery behavior’s final subgoal is reached, we assume that the robot can continue with the nominal execution of the task (green skills in Figure 18). To choose the next skill after a recovery behavior, we select the nominal skill whose low-level motion model according to Sec. 6.1 maximizes The task graph for the box grasping and locking task, including recovery behaviors for the different anomalies (I–IV) of skill 3. After the initial demos, the TG consists of the intended task flow skills in green. As new anomalies are identified, the TG can be incrementally extended with recovery behaviors. They recover from anomalies, such that the robot can continue with the intended task flow.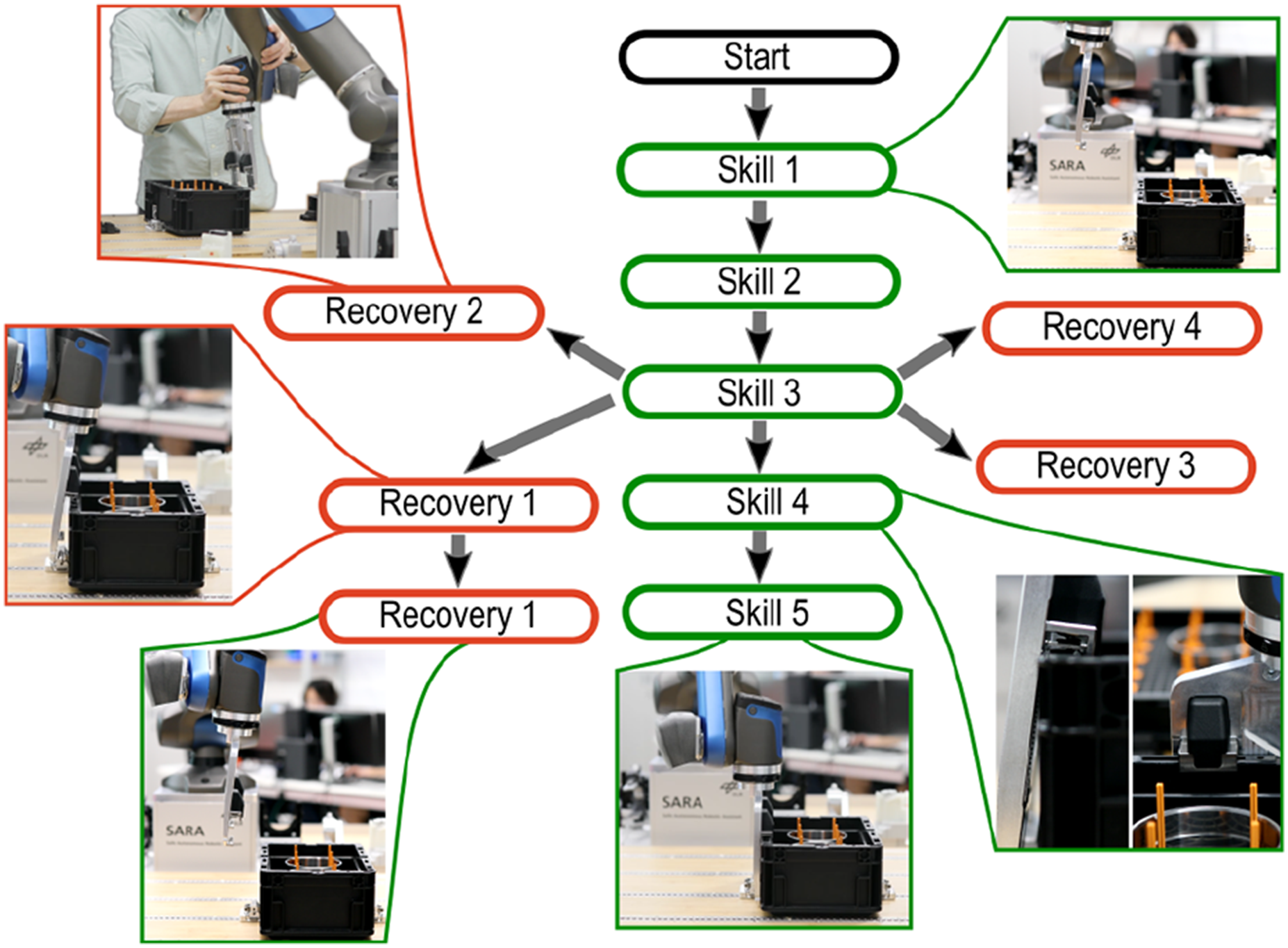
7.4. Discussion and limitations
For input far away from the training data, the GMM/GMR-based motion generation approach struggles to produce meaningful output commands, which may instead converge to spurious attractors. To increase the generalization capabilities of our framework in areas beyond the observed EEF poses during the demonstration, we propose to distinguish the skills in contact and free-space motion skills using, for example, the classification proposed in Eiband et al. (2023a). For free-space motion skills, the only aim is to reach their subgoal configurations, which are by design within the training region of the next skill. A motion planner can thus be used to generate a collision-free trajectory to the subgoal region, from which a contact skill can continue with the execution. Dynamical Systems learned from user demonstrations can furthermore suffer from local minima in absolute velocity in the training data, which can cause the robot to get stuck in these regions during the execution. States during the demonstration, where low EEF velocities close or equal to zero are recorded, are more likely to be important states where high precision in the EEF configuration is required. Our approach can identify these states as subgoals. If such a subgoal is reached during the execution, our system transitions to the next skill in the task graph, using a new low-level skill model that can escape from the local minimum of the previous skill.
Another advantage when distinguishing between contact and free-space motions concerns safety during the execution. Since unintended contacts with the environment usually trigger a collision stop of the robot, this safety feature needs to be deactivated during contact tasks to avoid false positive collision detection. However, our anomaly detection approach still registers unintended forces that exceed the expected process forces and thus increases user safety in contact situations. When commanding a robot using impedance control, the presence of unmodelled contact forces and torques causes a stiffness-dependent offset between the commanded and measured EEF pose of the robot. However, the box-grasping mechanism requires precise EEF configurations to complete the task. To compensate for this offset, we actively command the configuration-dependent force in every cycle needed to counteract the force resulting from the springs of the gripper.
Since we assume, that the features of every skill follow a multivariate Gaussian distribution, we are limited to inferring linear correlations between the features when segmenting skills with our BNG-IRL approach. We demonstrated that we can solve challenging tasks with this approach, however, there may exist tasks, where nonlinear relations between the features play an important role. Additionally, when computing the epistemic uncertainty for step 1 of the anomaly detection, the likelihood for states in the beginning and end of the skills that lie closer to the boundary of the training data are closer to the confidence threshold (17). This means that the anomaly detection is by design less confident for states in the beginning and the end of the skill. Lastly, the selection of a nominal skill after a recovery behavior does not consider high-level or semantic task information. Instead, the skill best suited to generate a motion based on the current EEF configuration is chosen. However, incorporating semantic information could be beneficial in narrowing down candidate skills for transitions. Similarly, augmenting recovery behaviors with semantic information could enable their reuse across different skills, allowing for automatic recovery from similar anomalies without explicitly demonstrating the recovery behavior. An automatic evaluation of whether the current situation meets the precondition of another skill is proposed by Sliwowski and Lee (2024) to select an appropriate recovery behavior from known skills. Instead of demonstrating a new recovery behavior, users could assess whether an existing skill in the task graph is suitable for recovery and select it via a user interface, similar to the proposed approach in our previous works (Eiband et al., 2023b; Willibald et al., 2020). This would allow the system to gradually add new connections between existing skills, without the need for semantic annotation. Future research could explore those ideas to reuse existing skills to improve automatic recovery from anomalies.
8. Conclusion
We introduced a novel incremental learning framework designed for complex contact-based tasks composed of multiple sequential sub-steps, which are challenging to learn with existing LfD methods. The initial task demonstrations are segmented using our unsupervised BNG-IRL segmentation approach to learn a nominal task model. Our framework facilitates incremental learning at both high and low levels, simplifying the teaching process for users by eliminating the need to anticipate anomalies or new scenarios. Our unsupervised anomaly detection technique identifies deviations from the intended task execution without prior knowledge of potential anomaly cases. Only if the approach detects a new anomaly, the user is queried to provide a recovery behavior, which can then be used to automatically recover from that anomaly in the future. Additionally, the low-level model is updated with new training data collected during execution to continuously refine the existing skills.
Our segmentation approach shows improved performance over four baseline methods by combining the advantages of subgoal-based inverse reinforcement learning with probabilistic feature clustering in one model. Furthermore, we demonstrated the applicability of the framework with delicate tasks performed on two robotic systems. Notably, only three demonstrations were needed to learn a robust initial model of the box grasping task, capable of identifying several different anomaly cases based on the expected contact force depending on the robot-environment interaction. Our unsupervised anomaly detection approach outperforms all other supervised visual anomaly detection baselines in three out of four anomaly detection cases and is the only one to confidently detect all anomalies, while not triggering any false positive detection during successful executions.
Supplemental Material
Supplemental Material
Supplemental Material
Footnotes
Acknowledgments
The authors would like to thank Daniel Sliwowski and DLR’s ISL and FCI groups for their support, especially with the experimental evaluation.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been supported by the Helmholtz Association and by the DLR internal projects “Factory of the Future Extended” and ASPIRO.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.