
Abstract
Motion planning under uncertainty is essential for reliable robot operation. Despite substantial advances over the past decade, the problem remains difficult for systems with complex dynamics. Most state-of-the-art methods perform search that relies on a large number of forward simulations. For systems with complex dynamics, this generally requires costly numerical integrations, which significantly slows down the planning process. Linearization-based methods have been proposed that can alleviate the above problem. However, it is not clear how linearization affects the quality of the generated motion strategy, and when such simplifications are admissible. To answer these questions, we propose a non-linearity measure, called Statistical-distance-based Non-linearity Measure (SNM), that can identify where linearization is beneficial and where it should be avoided. We show that when the problem is framed as the Partially Observable Markov Decision Process, the value difference between the optimal strategy for the original model and the linearized model can be upper-bounded by a function linear in SNM. Comparisons with an existing measure on various scenarios indicate that SNM is more suitable in estimating the effectiveness of linearization-based solvers. To test the applicability of SNM in motion planning, we propose a simple online planner that uses SNM as a heuristic to switch between a general and a linearization-based solver. Results on a car-like robot with second order dynamics and 4-DOFs and 7-DOFs torque-controlled manipulators indicate that SNM can appropriately decide if and when a linearization-based solver should be used.
1. Introduction
An autonomous robot must be able to compute reliable motion strategies, despite various errors in actuation and prediction of its effect on the robot and its environment, and despite various errors in sensors and sensing. Computing such robust strategies is computationally hard even for a 3-DOFs point robot (Canny and Reif, 1987; Natarajan, 1988). Conceptually, this problem can be solved in a systematic and principled manner when framed as the Partially Observable Markov Decision Process (POMDP) (Kaelbling et al., 1998). A POMDP represents the aforementioned errors as probability distribution functions and estimates the state of the system as probability distribution functions called beliefs. It then computes the best motion strategy with respect to beliefs rather than single states, thereby accounting for the fact that the actual state is never known due to the above errors. Although the concept of POMDPs was proposed in the ‘60s (Sondik, 1971), only recently that POMDPs started to become practical for robotics problems (e.g., (Hoerger et al., 2019; Horowitz and Burdick, 2013; Temizer et al., 2009)). This advancement is achieved by trading optimality with approximate optimality for speed and memory. But even then, in general, computing close to optimal POMDP solutions for systems with complex dynamics remains difficult.
Several general POMDP solvers—solvers that do not restrict the type of dynamics and sensing model of the system, nor the type of distributions used to represent uncertainty—can now compute good motion strategies online with a 1-10 Hz update rate for a number of robotic problems (Kurniawati and Yadav, 2016; Seiler et al., 2015; Silver and Veness, 2010; Ye et al., 2017). However, their speed degrades when the robot has complex non-linear dynamics. To compute a good strategy, today’s POMDP solvers forward simulate the effect of many sequences of actions from different beliefs are simulated. For problems whose dynamics have no closed-form solutions, a simulation run generally invokes many numerical integrations, and complex dynamics tend to increase the cost of each numerical integration, which in turn significantly increases the total planning cost of these methods. Of course, this cost will increase even more for problems that require more or longer simulation runs, such as in problems with long planning horizons.
Many linearized-based POMDP solvers have been proposed (Sun et al., 2015; Agha-mohammadi et al., 2013; van Den Berg et al., 2011,0; Prentice and Roy, 2010). They rely on many forward simulations from different beliefs too, but use a linearized model of the dynamics and sensing for simulation. Together with linearization, many of these methods assume that beliefs are Gaussian distributions. This assumption improves the speed of simulation further, because the subsequent belief after an action is performed, and an observation is perceived can be computed in closed-form. In contrast, the aforementioned general solvers typically represent beliefs as sets of particles and estimate subsequent beliefs using particle filters. Particle filters are particularly expensive when particle trajectories have to be simulated and each simulation run is costly, as is the case for motion planning of systems with complex dynamics. As a result, the linearization-based planners require less time to estimate the effect of performing a sequence of actions from a belief, and therefore can potentially find a good strategy faster than the general method. However, it is known that linearization in control and estimation performs well only when the system’s non-linearity is “weak” (Li, 2012). The question is, what constitute “weak” non-linearity in motion planning under uncertainty? Where will it be useful, and where will it be damaging to use linearization (and Gaussian) simplifications?
This paper extends our previous work in Hoerger et al. (2020) towards answering the aforementioned questions. Our main contribution is a measure of non-linearity for stochastic systems, called Statistical-distance-based Non-linearity Measure (SNM), to identify the suitability of linearization in a given motion planning under uncertainty problem. SNM is based on the total variation distance between the original dynamics and sensing models, and their corresponding linearized models. It is general enough to be applied to any type of motion and sensing errors, and any linearization technique, regardless of the type of approximation of the true beliefs (e.g., with and without Gaussian simplification). We show that the difference between the value of the optimal strategy generated if we plan using the original model and if we plan using the linearized model, can be upper-bounded by a function linear in SNM. Furthermore, our experimental results indicate that compared to recent state-of-the-art methods of non-linearity measures for stochastic systems, SNM is more sensitive to the effect that obstacles have on the effectiveness of linearization, which is critical for motion planning.
To further test the applicability of SNM in motion planning, we develop a simple online planner that uses a local estimate of SNM to automatically switch between a general planner (Kurniawati and Yadav, 2016) that uses the original POMDP model and a linearization-based planner, adapted from Sun et al. (2015), that uses the linearized model. Experimental results on simulated motion planning under uncertainty problems, including a car-like robot with acceleration control, 4-DOFs and 6-DOFs manipulators with torque control, and a 7-DOFs manipulator in a human-collaboration task indicate that this simple planner can appropriately decide if and when linearization should be used, and therefore computes better strategies faster than each of the component planner.
2. Background and related work
We provide a brief overview of the class of motion planning under uncertainty problems considered in this paper and their POMDP formulation in Section 2.1, followed by a discussion on related measures of non-linearity in Section 2.2.
2.1. Motion planning problems under uncertainty
In this paper, we consider motion planning problems, in which a robot must move from a given initial state to a state in the goal region while avoiding obstacles. The robot operates inside deterministic, bounded, and perfectly known 2D or 3D environments populated by static obstacles.
The robot’s transition and observation models are uncertain and defined as follows. Let
This class of motion planning problems under uncertainty can naturally be formulated as a Partially Observable Markov Decision Process (POMDP). Formally, a POMDP is a tuple ⟨S, A, O, T, Z, R, b0, γ⟩, where S, A, and O are the state, action, and observation spaces of the robot. T is a conditional probability function T(s, a, s′) = p(s′ | s, a) (where s, s′ ∈ S and a ∈ A) that models the uncertainty in the effect of performing actions, while Z(s′, a, o) = p(o | s′, a) (where o ∈ O) is a conditional probability function that models the uncertainty in perceiving observations. R(s, a) is a reward function, which encodes the planning objective. b0 is the initial belief, capturing the uncertainty in the robot’s initial state and γ ∈ (0, 1) is a discount factor.
At each time step, a POMDP agent is at a state s ∈ S, takes an action a ∈ A, perceives an observation o ∈ O, receives a reward based on the reward function R(s, a), and moves to the next state. Now, due to uncertainty in the results of action and sensing, the agent never knows its exact state and therefore, estimates its state as a probability distribution, called belief. The solution to the POMDP problem is an optimal policy (denoted as π*), which is a mapping
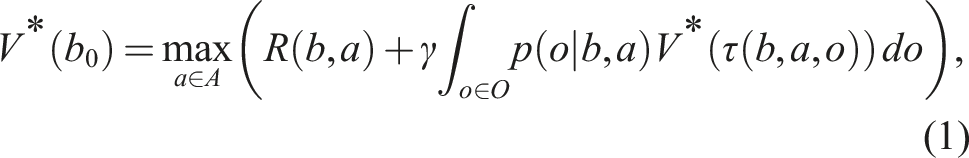
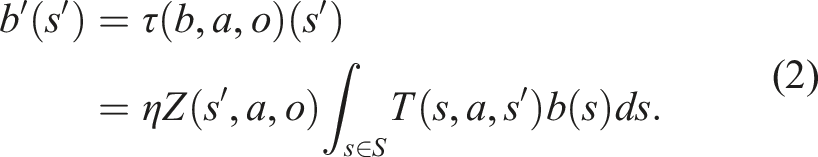
2.2. Related work on non-linearity measures
Linearization is a common practice in solving non-linear control and estimation problems. It is known that linearization performs well only when the system’s non-linearity is “weak” (Li, 2012). To identify the effectiveness of linearization in solving non-linear problems, a number of non-linearity measure have been proposed in the control and information fusion community.
Many of these measures (Bates and Watts, 1980; Beale, 1960; Emancipator and Kroll, 1993) have been designed for deterministic systems. For instance, Bates and Watts (1980) proposed a measure derived from the curvature of the non-linear function. The work in Beale (1960) and Emancipator and Kroll (1993) computes a measure based on the distance between the non-linear function and its nearest linearization. A brief survey of non-linearity measures for deterministic systems is available in Li (2012).
Non-linearity measures for stochastic systems have been proposed. For instance, Li (2012) extends the measures in Beale (1960) and Emancipator and Kroll (1993) to be based on the average distance between the non-linear function that models the motion and sensing of the system, and the set of all possible linearizations of the function.
Another example is the work in Duník et al. (2013) which proposes a measure based on the distance between distribution over states and its Gaussian approximation, called Measure of Non-Gaussianity (MoNG), rather than based on the non-linear function itself. Assuming a passive stochastic system, this measures computes the negentropy between a transformed belief and its Gaussian approximation. The results indicate that this measure is more suitable to measure the non-linearity of stochastic systems, as it takes into account the effect that non-linear transformations have on the shape of the transformed beliefs. This advancement is encouraging, and we will use MoNG as a comparator of SNM. However, for this purpose, MoNG must be modified since we consider non-passive problems in work. The exact modifications we made can be found in Section 5.2.
Despite the various non-linearity measures that have been proposed, most are not designed to take the effect of obstacles to the non-linearity of the system into account. Except for MoNG, all aforementioned non-linearity measures will have difficulties in reflecting these effects, even when they are embedded in the motion and sensing models. For instance, curvature-based measures requires the non-linear function to be twice continuously differentiable, but the presence of obstacles is very likely to break the differentiability of the motion model. Furthermore, the effect of obstacles is likely to violate the additive Gaussian error, required for instance by Li (2012). Although MoNG can potentially take the effect of obstacles into account, it is not designed to. In the presence of obstacles, beliefs have support only in the valid region of the state space, and therefore computing the difference between beliefs and their Gaussian approximations is likely to underestimate the effect of obstacles.
SNM is designed to address these issues. Instead of building upon existing non-linearity measures, SNM adopts approaches commonly used for sensitivity analysis (Mastin and Jaillet, 2012; Müller, 1997) of Markov Decision Processes (MDP)—a special class of POMDP where the observation model is perfect, and therefore the system is fully observable. These approaches use statistical distance measures between the original transition dynamics and their perturbed versions. Linearized dynamics can be viewed as a special case of perturbed dynamics, and hence this statistical distance measure can be applied as a non-linearity measure, too. We do need to extend these analyses, as they are generally defined for discrete state space and are defined with respect to only the transition models (MDP assumes the state of the system is fully observable). Nevertheless, such extensions are feasible and the generality of this measure could help to identify the effectiveness of linearization in motion planning under uncertainty problems.
3. Statistical-distance-based non-linearity measure (SNM)
Intuitively, our proposed measure SNM is based on the total variation distance between the effect of performing an action and perceiving an observation under the true dynamics and sensing model, and the effect under the linearized dynamic and sensing model. The total variation distance D
TV
between two probability measures μ and ν over a measurable space Ω is defined as D
TV
(μ,ν) = supE∈Ω|μ(E) − ν(E)|. An equivalent definition of D
TV
which we use in our analysis is D
TV
(μ,ν) =
Let P = ⟨S, A, O, T, Z, R, b0, γ⟩ be the POMDP model of the system and Note that SNM can be applied as both a global and a local measure. In the latter case, the supremum over the state s can be restricted to a subset of S, rather than the entire state space. Furthermore, SNM is general enough for any approximation to the true dynamics and sensing model, which means that it can be applied to any type of linearization and belief approximation techniques, including those that assume and those that do not assume Gaussian belief simplifications. We want to use the measure
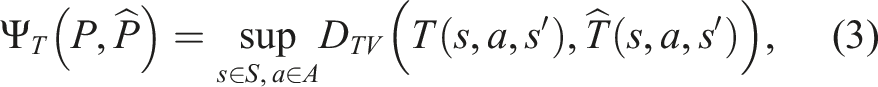
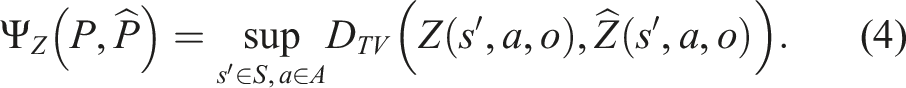
If π* denotes the optimal policy for P and To prove Theorem 2, we first assume, without loss of generality, that a policy π for a belief b is represented by a conditional plan σ ∈ Γ, where Γ is the set of all conditional plans. The plan σ can be specified by a pair 〈a,ν〉, where a ∈ A is the action of σ and ν: O → Γ is an observation strategy, which maps an observation to a conditional plan σ′ ∈ Γ. Every σ corresponds to an α-function For a given belief b, the value of the policy π represented by the conditional plan σ is then V
π
(b) = ∫s∈Sb(s)α
σ
(s)ds. Note that equation (5) is defined with respect to POMDP P. Analogously, we define the linearized α-function Now, suppose that for a given belief b, σ* = arg supσ∈Γ ∫s∈Sb(s)α
σ
(s)ds and
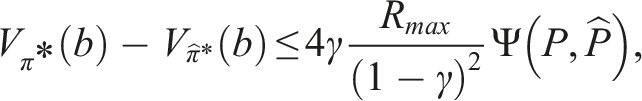
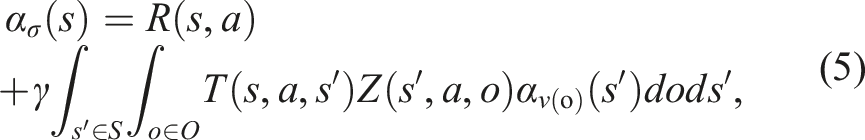
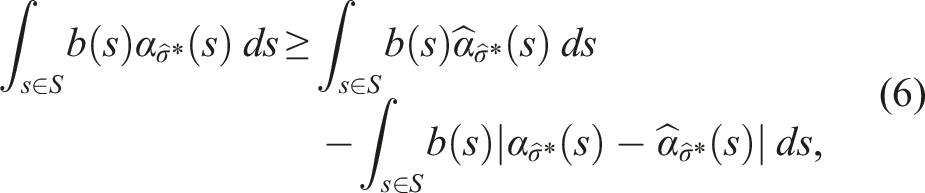
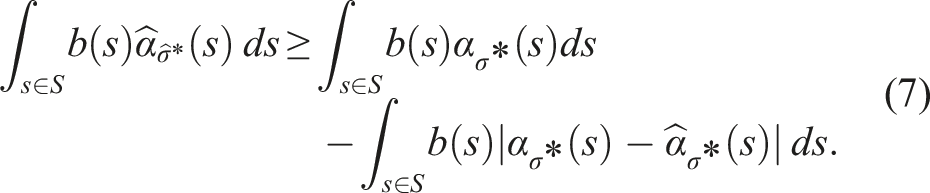
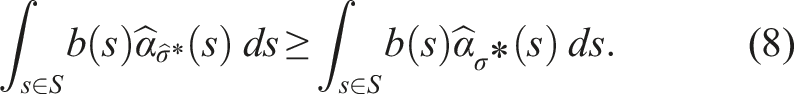
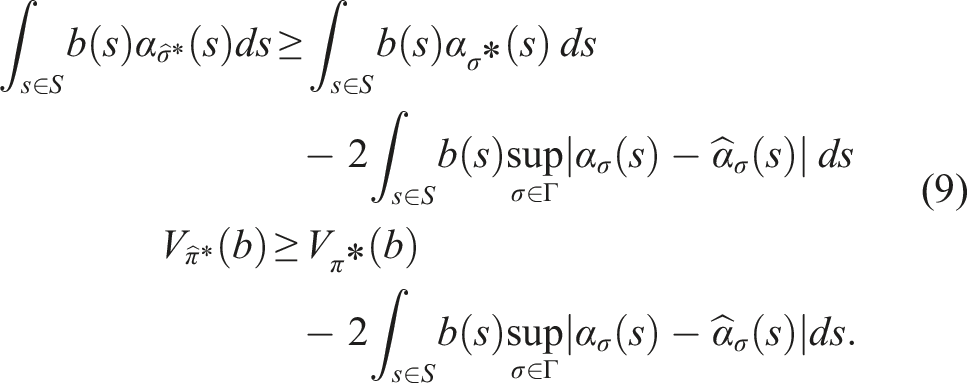
Let R
m
= max{|R
min
|,R
max
}, where R
min
= mins,aR(s, a) and R
max
= maxs,aR(s, a). For any conditional plan σ ∈ Γ and any s ∈ S, the absolute difference between the original and linearized α-functions is upper-bounded by The proof of Lemma 3 is presented in Appendix A.1. Using the result of Lemma 3, we can now conclude the proof for Theorem 2. Substituting the upper bound derived in Lemma 3 into the right-hand side of equation (9) and re-arranging the terms gives us
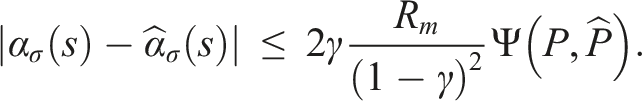
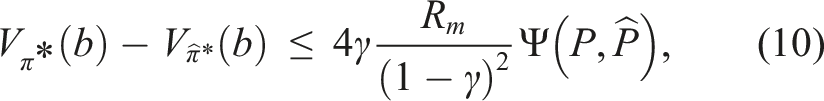
4. Approximating SNM
Ultimately, we want to use SNM as a heuristic during online planning to decide when a linearization-based solver will likely yield a good policy and when a general solver should be used. However, computing SNM exactly is challenging, due to having to find the suprema over the state and action spaces in equation. (3) and equation. (4). Here, we provide an efficient approximation algorithm to estimate SNM. We focus on approximating the transition component Ψ T of SNM. The observation component Ψ Z is approximated similarly.
Let us first rewrite the transition component of Ψ
T
as
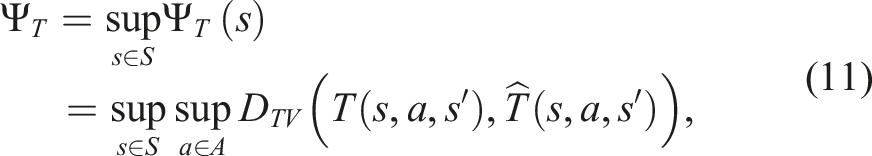
To construct
To approximate the supremum over the action space in equation (11), we discretize the action space, leaving us with a maximization problem over discrete actions, denoted as
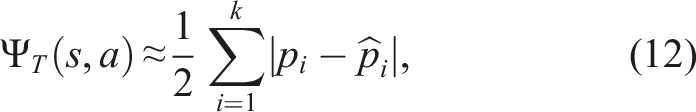
During planning, we can use the lookup-table and a sampled representation of a belief b to approximate SNM at b. Suppose
The above approximation method assumes that states that are close together should yield similar values for SNM. At a first glance, this is a very strong assumption. In the vicinity of obstacles or constraints, states that are close together could potentially yield very different SNM-values. However, we will now show that under mild assumptions, pairs of states that are elements within certain subsets of the state space indeed yield similar SNM-values.
Consider a partitioning of the state space into a finite number of local-Lipschitz subsets S i that are defined as follows:
Let S be a metric space with distance metric D
S
. S
i
is called a local-Lipschitz subset of S if for any s1, s2 ∈ S
i
, any s′ ∈ S and any In other words, S
i
are subsets of S in which the original and linearized transition functions are Lipschitz continuous with Lipschitz constants
Let S be a n − dimensional metric space with distance metric D
S
and assume S is normalized to [0,1]
n
. Furthermore, let S
i
be a local-Lipschitz subset of S, then The proof for this Lemma is presented in Appendix A.2. This Lemma indicates that the difference between the SNM-values for two states from the same local-Lipschitz subset S
i
depends only on the distance D
S
between them, since
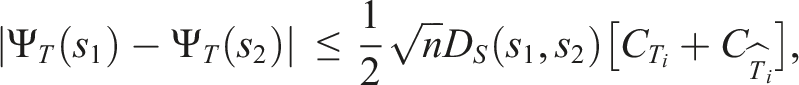
5. SNM-planner: An application of SNM for planning
SNM-Planner is an online planner that uses SNM as a heuristic to decide whether a general, or a linearization-based POMDP solver should be used to compute the policy from the current belief. The general solver used is Adaptive Belief Tree (ABT) (Kurniawati and Yadav, 2016), while the linearization-based method called Modified High-Frequency Replanning (MHFR), which is an adaptation of HFR (Sun et al., 2015). HFR is designed for chance-constraint POMDPs, that is, it explicitly minimizes the collision probability, while MHFR is a POMDP solver where the objective is to maximize the expected total reward. An overview of SNM-Planner is shown in Algorithm 1. During run-time, at each planning step, SNM-Planner computes a local approximation of SNM around the current belief b (line 5). If this value is smaller than a given threshold, SNM-Planner uses MHFR to compute a policy from the current belief, whereas ABT is used when the value exceeds the threshold (lines 7 to 11). The robot then executes an action according to the computed policy (line 12) and receives an observation (line 13). Based on the executed action and perceived observation, we update the belief (line 14). SNM-Planner represents beliefs as sets of particles and updates the belief using a SIR particle filter (Arulampalam et al., 2002). Note that MHFR assumes that beliefs are multivariate Gaussian distributions. Therefore, in case MHFR is used for the policy computation, we compute the first two moments (mean and covariance) of the particle set to obtain a multivariate Gaussian approximation of the current belief. The process then repeats from the updated belief until the robot has entered a terminal state (we assume that we know when the robot enters a terminal state).
In the following two subsections we provide a brief an overview of the two component planners ABT and MHFR.

5.1. Adaptive belief tree (ABT)
ABT is a general and anytime online POMDP solver based on Monte-Carlo-Tree-Search (MCTS). ABT updates (rather than recomputes) its policy at each planning step. To update the policy for the current belief, ABT iteratively constructs and maintains a belief tree, a tree whose nodes are beliefs and whose edges are pairs of actions and observations. ABT evaluates sequences of actions by sampling episodes, that is, sequences of state—action—observation—reward tuples, starting from the current belief. Details of ABT can be found in Kurniawati and Yadav (2016).
5.2. Modified high-frequency replanning (MHFR)
The main difference between HFR and MHFR is that HFR is designed for chance-constraint POMDP, that is, it explicitly minimizes the collision probability, while MHFR is a POMDP solver, whose objective is to maximize the expected total reward. Similar to HFR, MHFR approximates the current belief by a multivariate Gaussian distribution. To compute the policy from the current belief, MHFR samples a set of trajectories from the mean of the current belief to a goal state using multiple instances of RRTs (Kuffner and LaValle, 2011) in parallel. It then computes the expected total discounted reward of each trajectory by tracking the beliefs around the trajectory using a Kalman Filter, assuming maximum-likelihood observations. The policy then becomes the first action of the trajectory with the highest expected total discounted reward. After executing the action and perceiving an observation, MHFR updates the belief using an Extended Kalman Filter. The process then repeats from the updated belief. To increase efficiency, MHFR additionally adjusts the previous trajectory with the highest expected total discounted reward to start from the mean of the updated belief and adds this trajectory to the set of sampled trajectories. More details on HFR and precise derivations of the method are available in Sun et al. (2015).
6. Experiments and results
The purpose of our experiments is two-fold: To test the applicability of SNM to motion planning under uncertainty problems and to test SNM-Planner. For our first objective, we compare SNM with a modified version of the Measure of Non-Gaussianity (MoNG) (Duník et al., 2013). Details regarding MoNG are provided in Section 6.1. We evaluate both measures using two simulated robotic systems, a car-like robot with 2 nd -order dynamics and a torque-controlled 4DOFs manipulator, where both robots are subject to increasing uncertainties and increasing numbers of obstacles in the operating environment. The selected robotic systems are commonly used to evaluate linearization-based solvers (van Den Berg et al., 2011; Sun et al., 2015; Prentice and Roy, 2009). Furthermore, we test both measures when the robots are subject to highly non-linear collision dynamics and different observation models. Details on the robot models are presented in Section 6.2, whereas the evaluation experiments are presented in Section 6.3.
To test SNM-Planner, we compare it with ABT and MHFR on four problem scenarios, including a torque-controlled 7DOFs manipulator operating inside a 3D office environment, and a 7DOFs velocity controlled manipulator working collaboratively with a human worker on a factory control terminal. Additionally, we test how sensitive SNM-Planner is to the choice of the SNM-threshold. The results for these experiments are presented in Section 6.4.
All problem environments are modeled within the OPPT framework (Hoerger et al., 2018). The solvers are implemented in C++. All simulations were run on an AMD EPYC 7003 CPU with 8 GB of memory. For the parallel construction of the RRTs in MHFR, we utilize 8 CPU cores throughout the experiments. All parameters are set based on preliminary runs over the possible parameter space, the parameters that generate the best results are then chosen to generate the experimental results.
6.1. Measure of non-gaussianity
The Measure of Non-Gaussianity (MoNG) proposed in Duník et al. (2013) is based on the negentropy between the PDF of a random variable and its Gaussian approximation. Consider a n-dimensional random variable X distributed according to PDF p(x). Furthermore, let 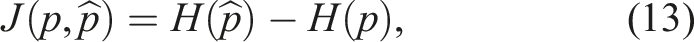
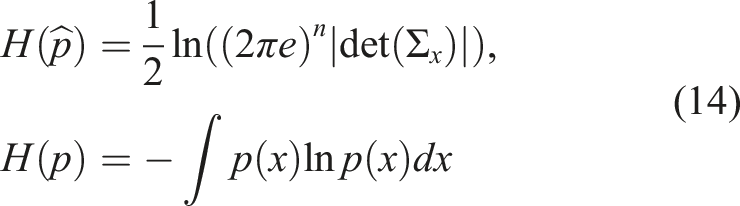
In Duník et al. (2013) this measure has originally been used to assess the non-linearity of passive systems. Therefore, in order to achieve comparability with SNM, we need to extend the Non-Gaussian measure to general active stochastic systems of the form st+1 = f (s t , a t , v t ). We do this by evaluating the non-Gaussianity of distribution that follow from the transition function T(s, a, s′) given state s and action a. In particular, for a given s and a, we can find a Gaussian approximation of T(s, a, s′) (denoted by T G (s, a, s′)) by calculating the first two moments of the distribution that follows from T(s, a, s′).
Using this Gaussian approximation, we define the Measure of Non-Gaussianity as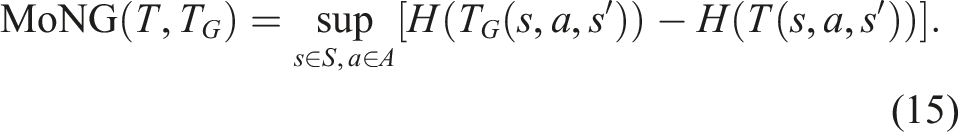
Similarly, we can compute the Measure of Non-Gaussianity for the observation function: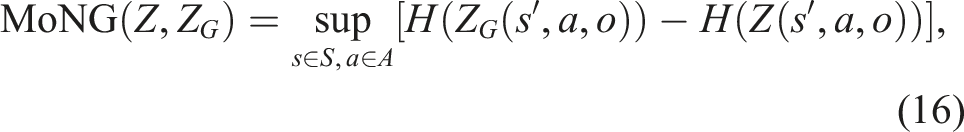
In order to approximate the entropies H(T(s, a, s′))) and H(Z(s′, a, o)), we are using a similar histogram-based approach as discussed in Section 4. The entropy terms for the Gaussian approximations can be computed in closed form, according to the first equation in equation (14) (Ahmed and Gokhale, 1989).
6.2. Robot models
6.2.1. 4DOFs manipulator
The 4DOFs manipulator consists of 4 links connected by 4 torque-controlled revolute joints. The first joint is connected to a static base. In all problem scenarios, the manipulator must move from a known initial state to a state where the end-effector lies inside a goal region located in the workspace of the robot, while avoiding collisions with obstacles the environment is populated with.
The state of the manipulator is defined as
The control inputs of the manipulator are the joint torques, where the maximum joint torques are (20, 20, 10, 5)Nm/s in each direction. Since ABT assumes a discrete action space, we discretize the joint torques for each joint using the maximum torque in each direction, which leads to 16 actions.
The dynamics of the manipulator is defined using the well-known Newton-Euler formalism (Spong et al., 2006). For both manipulators, we assume that the input torque for each joint is affected by zero-mean additive Gaussian noise. Note however, even though the error is Gaussian, due to the non-linearities of the motion dynamics the beliefs will not be Gaussian in general. Since the transition dynamics for this robot are quite complex, we assume that the joint torques are applied for 0.1s, and we use the ODE physics engine (Drumwright et al., 2010) for the numerical integration of the dynamics, where the discretization (i.e., δt) of the integrator is set to δt = 0.004s.
The robot is equipped with two sensors: The first sensor measures the position of the end-effector inside the robot’s workspace, whereas the second sensor measures the joint velocities. Consider a function 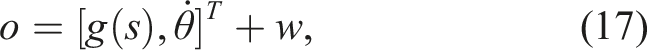
The initial state of the robot is a state where the joint angles and velocities are zero.
When the robot performs an action where it collides with an obstacle, it enters a terminal state and receives a penalty of −500. When it reaches the goal area, it also enters a terminal state, but receives a reward of 1000. To encourage the robot to reach the goal area quickly, it receives a small penalty of −1 for every other action.
6.2.2. 7DOFs Kuka iiwa manipulator
The 7DOFs Kuka iiwa manipulator is very similar to the 4DOFs manipulator. However, the robot consists of 7 links connected via 7 revolute joints. We set the POMDP model to be similar to that of the 4DOFs manipulator, but expand it to handle 7DOFs. For this robot, the joint velocities are constrained by (3.92, 2.91, 2.53, 2.23, 2.23, 2.23, 1.0)rad/s in each direction and the link masses are (4, 4, 3, 2.7, 1.7, 1.8, 0.3)kg. Additionally, the torque limits of the joints are (25, 20, 10, 10, 5, 5, 0.5)Nm/s in each direction. For ABT, we use the same discretization of the joint torques as in the 4DOFs manipulator case, that is, we use the maximum torque per joint in each direction, resulting in 128 actions. Similarly to the 4DOFs manipulator, we assume that the input torques are applied for 0.1s, and we use the ODE physics engine with an integration step size of 0.004s to simulate the transition dynamics. The observation and reward models are the same as for the 4DOFs manipulator. The initial joint velocities are all zero and almost all joint angles are zero too, except for the second joint, for which the initial joint angle is −1.5rad. Figure 1(c) shows the Kuka manipulator operating inside an office scenario. Test scenarios for the different robots. The objects colored black and gray are obstacles, while the green sphere is the goal region. (a) The Maze scenario for the car-like robot. The blue squares represent the beacons, while the orange square at the bottom left represents the initial state. (b) The 4DOFs manipulator scenario. (c) The KukaOffice scenario. (d) The JacoCollab scenario.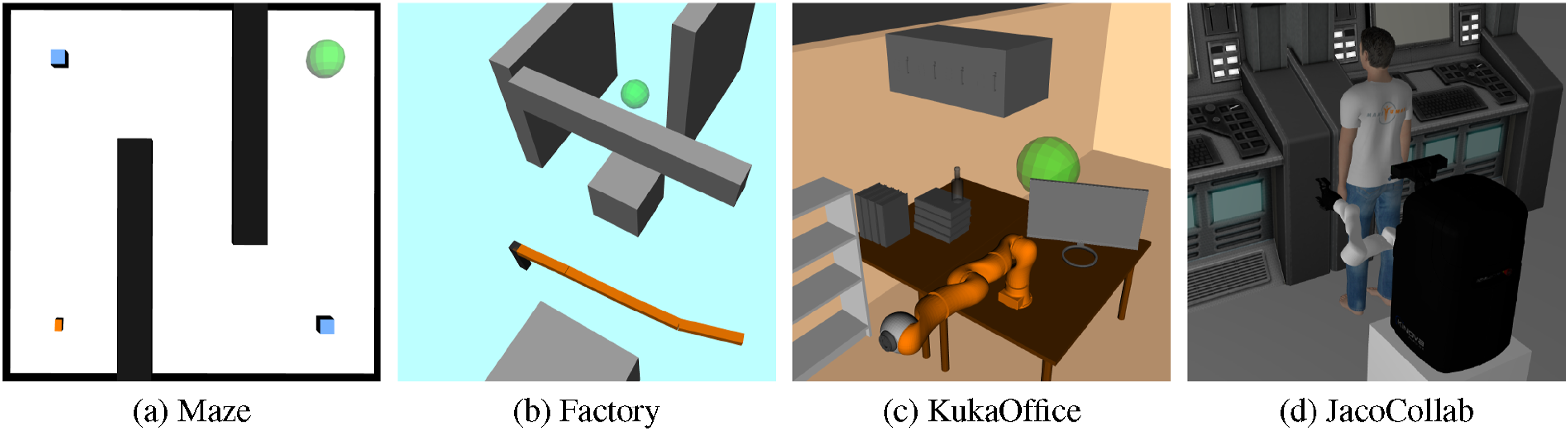
6.2.3. JacoCollab
The third robot we consider is a 7DOFs Jaco arm mounted on a fixed base, as shown in Figure 1(d). The robot consists of 7 links connected via revolute joints. In addition to the arm, the robot is equipped with a RGB-camera that is mounted on the base. The robot operates inside a control room in a factory, which consists of a control terminal located in front of the robot. In addition, a human worker moves around in front of the terminal, operating it collaboratively with the robot. In particular, we assume that the worker is located at x = 1m in front of the robot and moves along the y-axis of the robot’s base frame. However, the worker is not used to collaborate with a robot, and their motion becomes more erratic as their distance to the robot decreases. The goal of the robot is to reach the terminal with its end-effector, without colliding with the worker.
Here, the state space is defined as S = Θ × Y, where Θ is the set of all joint angles, and
While the exact position of the worker is only partially observed, the robot can estimate it using its onboard camera. We use a simplified observation model and assume that the robot receives observations regarding the worker’s y-position according to o t = y t + e Z , where e Z ∼ U[−0.038, 0.038].
The robot receives a reward of 100 for reaching the control terminal with its end-effector. Upon collision with the worker, the robot receives a penalty of −100. Both events lead to a terminal state. Additionally, the robot receives a penalty of −1 for every step to encourage it to reach the control terminal quickly. The initial configuration and y-position of the worker are fully known and set to θ = (−0.37, 2.11, 0.29, 2.59, 0.54, 0.51, 1.62)rad and y = 0.2 m, respectively. The discount factor is γ = 0.99.
To reach the control terminal, the robot must act strategically by considering the behavior of the worker. Getting too close to the worker might lead to collisions, due to the increased uncertainty in the worker’s motion, while waiting too long for the worker to move out of the way leads to an increased time to reach the control terminal.
6.2.4. Car-like robot
A non-holonomic car-like robot of size (0.12 × 0.07 × 0.01) drives on a flat xy-plane inside a 3D environment populated by obstacles. The robot must drive from a known start state to a position inside a goal region without colliding with any of the obstacles. The state of the robot at time t is defined as a 4D vector 
This robot is equipped with two types of sensors, a localization sensor that receives a signal from two beacons that are located at 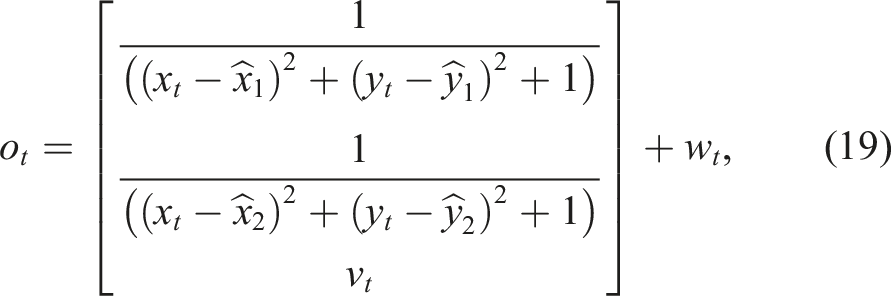
Similar to the manipulators described above, the robot receives a penalty of −500 when it collides with an obstacle, a reward of 1000 when reaching the goal area and a small penalty of −1 for any other action.
6.3. Testing SNM
In this set of experiments, we want to understand the performance of SNM compared to MoNG in various scenarios. In particular, we are interested in the effect of increasing uncertainties and the effect that obstacles have on the effectiveness of SNM, and if these results are consistent with the performance of a general solver relative to a linearization-based solver. Additionally, we want to see how highly non-linear collision dynamics and different observation models—one with additive Gaussian noise and non-additive Gaussian noise—affect our measure. For the experiments with increasing motion and sensing errors, recall from Section 6.2 that the control errors are drawn from zero-mean multivariate Gaussian distributions with covariance matrices Σ
v
. We define the control errors (denoted as e
T
) to be the standard deviation of these Gaussian distributions, such that
6.3.1. Effects of increasing uncertainties in cluttered environments
To investigate the effect of increasing control and observation errors on SNM, MoNG and the two solvers ABT and MHFR in cluttered environments, we ran a set of experiments where the 4DOFs manipulator and the car-like robot operate in empty environments, environments with obstacles, and environments where the robots interact with the environment via collision dynamics with increasing values of e
T
and e
Z
, ranging between 0.001 and 0.075. For the last set of environments, the robots are allowed to collide with the obstacles, that is, a collision does not result in a terminal state. The dynamics effects of collisions are reflected in the transition model. In particular, for the 4DOFs manipulator, collisions are modeled as additional constraints (contact points) that are resolved by applying “correcting velocities” to the colliding bodies in the opposite direction of the contact normals. For the car-like robot, we modify the transition model equation (18) to consider collision dynamics such that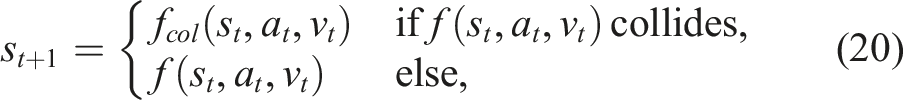
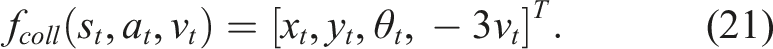
This transition function causes the robot to slightly “bounce” off obstacles upon collision.
The environments with obstacles (both with and without collision dynamics) are the Factory and Maze environments shown in Figure 1(a) and (b). For each scenario and each control-sensing error value (we set e T = e Z ), we ran 100 simulation runs using ABT and MHFR, respectively, with a planning time of 2s per step.
Figures 2 and 3 show the average values of SNM and MoNG and the relative value differences between ABT and MHFR for the 4DOFs manipulator and the car-like robot, respectively. The results show that in empty environments, both SNM and MoNG are sensitive to increasing transition and observation errors. This resonates well with the relative value difference between ABT and MHFR. However, for environments with obstacles and environments with collision dynamics, SNM increases significantly compared to the empty environments, whereas MoNG remains almost unaffected in the Factory and Maze environments and only increases marginally as collision dynamics are introduced. Overall, the added non-linearities introduced by obstacles and collision dynamics increase the value difference between ABT and MHFR, except for large uncertainties in the Maze environment. This indicates that MHFR suffers more from the added non-linearities compared to ABT. SNMis able to capture these effects much better compared to MoNG. Evaluations of the tested measures and the relative value difference between ABT and MHFR for the 4DOFs manipulator operating in an empty environment (red lines), the Factory environment (green lines) and the Factory environment with collision dynamics (blue lines). (a) The average values of SNM as the transition (e
T
) and observation (e
Z
) errors increase. (b) The average values of MoNG as the transition and observation errors increase. (c) The relative value difference between ABT and MHFR as the transition and observation errors increase. Evaluations of the tested measures and the relative value difference between ABT and MHFR for the Car-like robot operating in an empty environment (red lines), the Maze environment (green lines) and the Maze environment with collision dynamics (blue lines). (a) The average values of SNM as the transition (e
T
) and observation (e
Z
) errors increase. (b) The average values of MoNG as the transition and observation errors increase. (c) The relative value difference between ABT and MHFR as the transition and observation errors increase.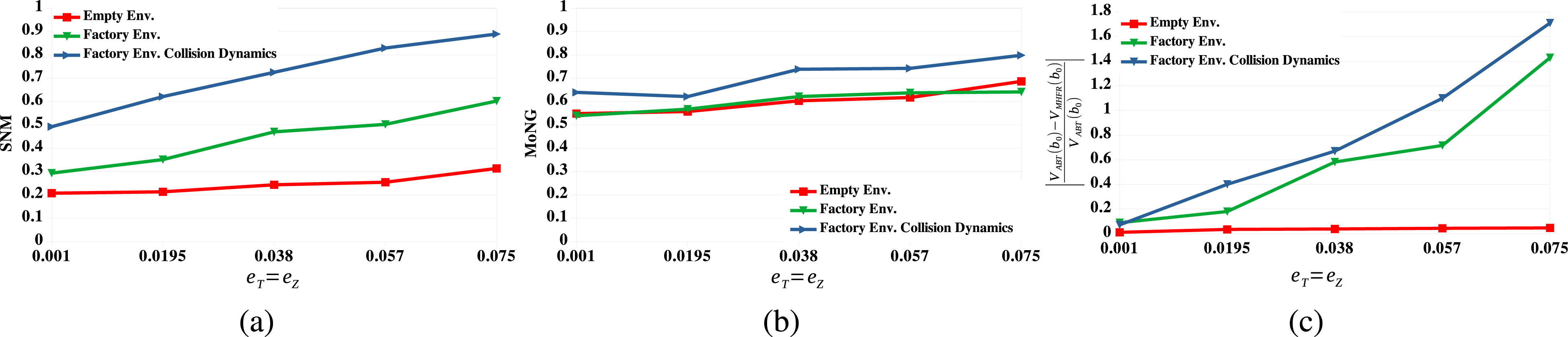
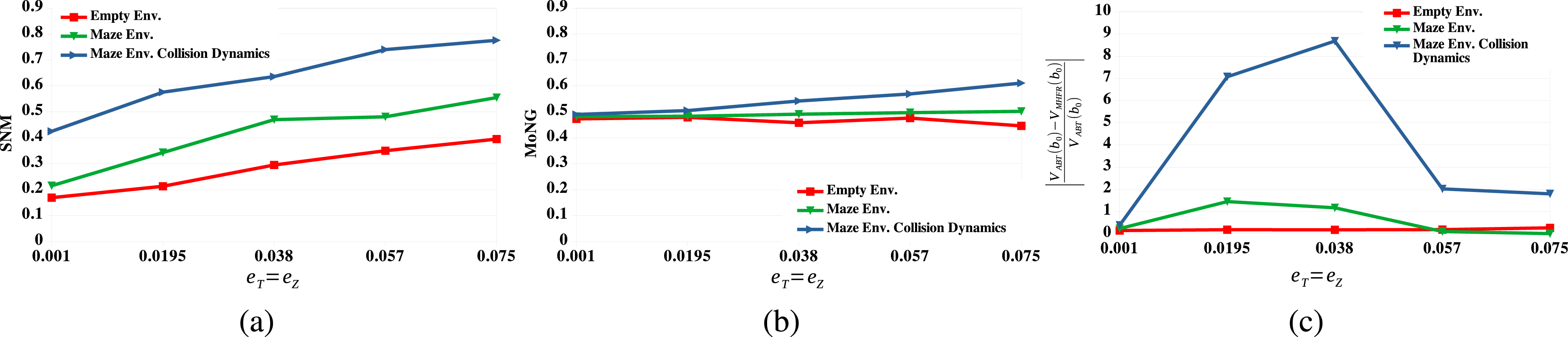
An interesting remark regarding the results for the Maze scenario in Figure 3(c) is that the relative value difference actually decreases for large uncertainties. The reason for this can be seen in Figure 4. As the uncertainties increase, the problem becomes so difficult, such that both solvers fail to compute a reasonable policy within the given planning time. However, clearly, MHFR suffers earlier from these large uncertainties compared to ABT. The average total discounted rewards achieved by ABT and MHFR in the Maze scenario, as the uncertainties increase. Vertical bars are the 95% confidence intervals.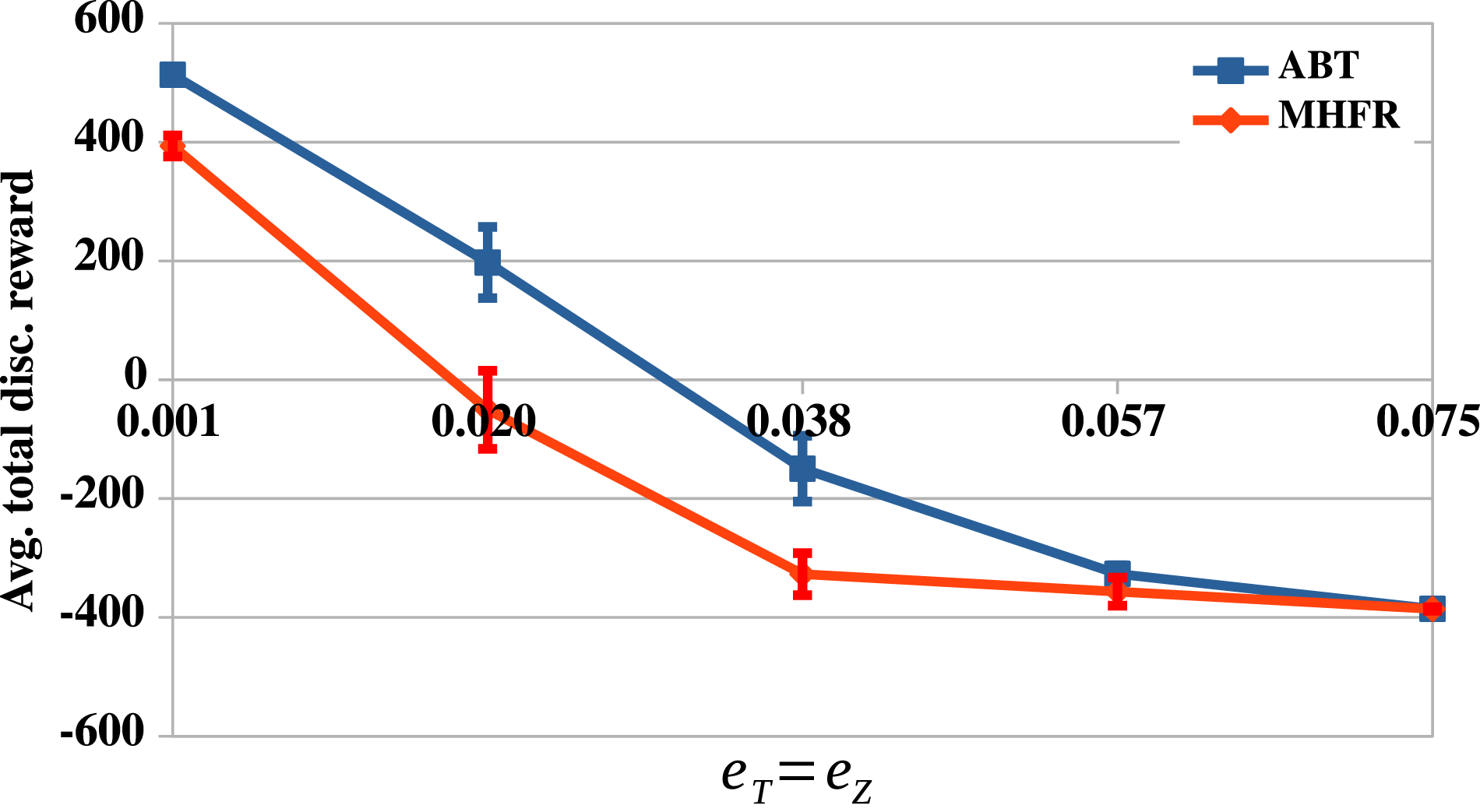
6.3.2. Effects of increasingly cluttered environments
To investigate the effects of increasingly cluttered environments on SNM and MoNG, we ran a set of experiments in which the car-like robot and the 4DOFs manipulator operate inside environments with an increasing number of randomly distributed obstacles. For this we generated test scenarios with 5, 10, 15, 20, 25 and 30 obstacles that are uniformly distributed across the environment. For each of these test scenarios, we randomly generated 100 environments. Figure 5 shows two example environments with 30 obstacles for the Car-like robot and the 4DOFs manipulator. For this set of experiments, we do not take collision dynamics into account. The control and observation errors are fixed to e
t
= e
z
= 0.038 which corresponds to the median of the uncertainty values. Two example scenarios for the Car-like robot (a) and the 4DOFs manipulator (b) with 30 randomly distributed obstacles.
Figure 6 presents the results for SNM, MoNG and the relative value difference between ABT and MHFR for the 4DOFs manipulator (top row) and the car-like robot (bottom row). From these results it is clear that, as the environments become increasingly cluttered, the advantage of ABT over MHFR increases, indicating that the obstacles have a significant effect on the Gaussian belief assumption of MHFR. Additionally, SNM is clearly more sensitive to those effects compared to MoNG, whose values remain virtually unaffected by the amount of clutter in the environments. Evaluations of the tested measures and the relative value difference between ABT and MHFR on the 4DOFs manipulator (top row) and the Car-like robot (bottom row) operating in environments with increasing numbers of obstacles. (a) The average values of SNM (red line) and MoNG (blue line) for the 4DOFs manipulator operating inside environments with increasing numbers of obstacles. (b) The relative value difference between ABT and MHFR for the 4DOFs manipulator operating in environments with increasing numbers of obstacles. (c) The average values of SNM(red line) and MoNG (blue line) for the Car-like robot operating inside environments with increasing numbers of obstacles. (d) The relative value difference between ABT and MHFR for the Car-like robot operating inside environments with increasing numbers of obstacles.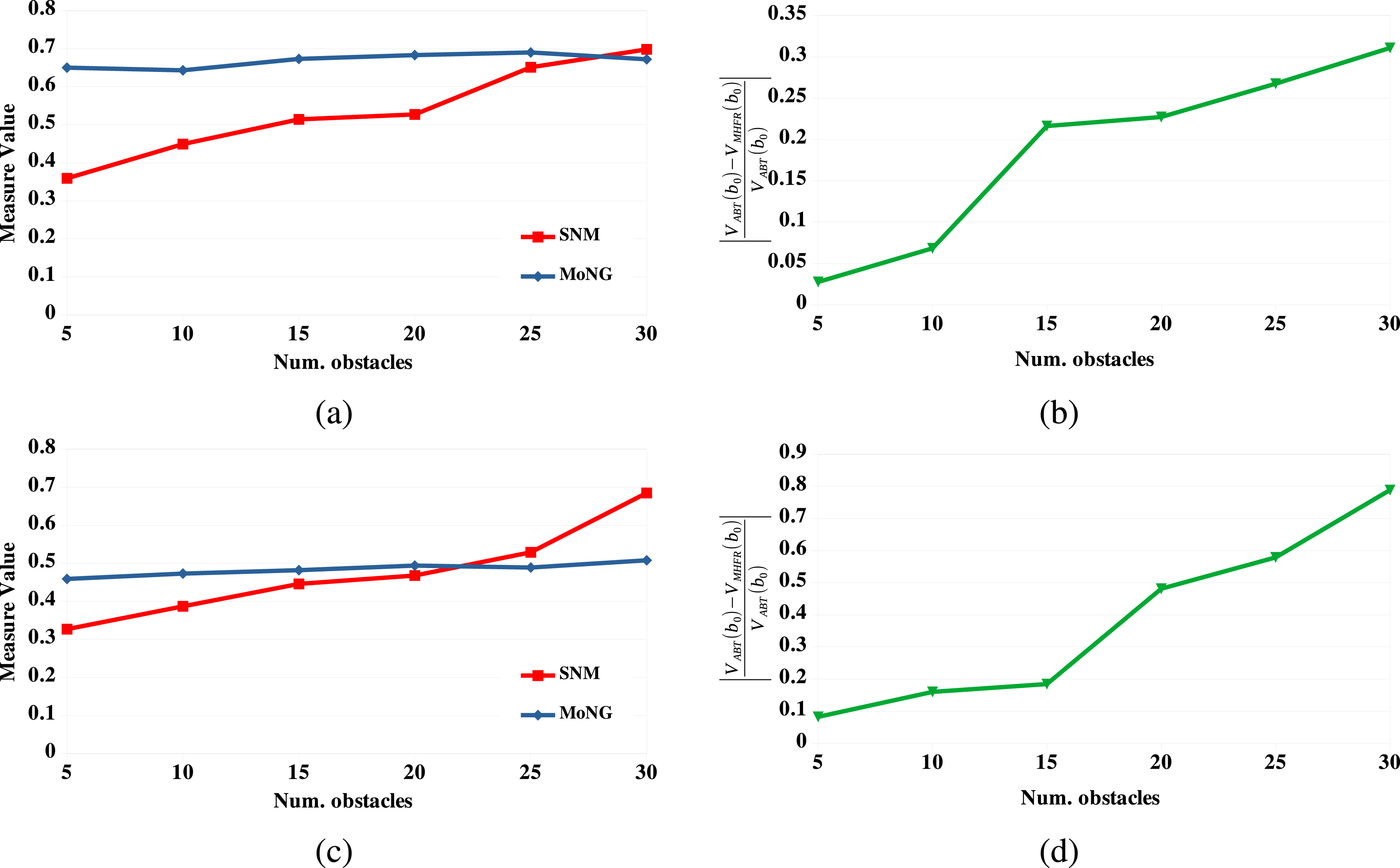
6.3.3. Effects of non-linear observation functions with non-additive errors
In the previous experiments, we assumed that the observation functions are non-linear functions with additive Gaussian noise, a special class of non-linear observation functions. This class of observation functions has some interesting implications: First, the resulting observation distribution remains Gaussian. This in turn means that MoNG for the observation function evaluates to zero. Second, linearizing the observation function results in a Gaussian distribution with the same mean but different covariance. We therefore expect that the observation component SNM remains small, even for large uncertainties. To investigate how SNM reacts to non-linear observation functions with non-additive noise, we ran a set of experiments for the 4DOFs manipulator operating inside the Factory environment and the car-like robot operating inside the Maze environment where we replaced both observation functions with non-linear functions with non-additive noise. For the 4DOFs manipulator, we replaced the observation function defined in equation (17) with
For the car-like robot, we use the following observation function: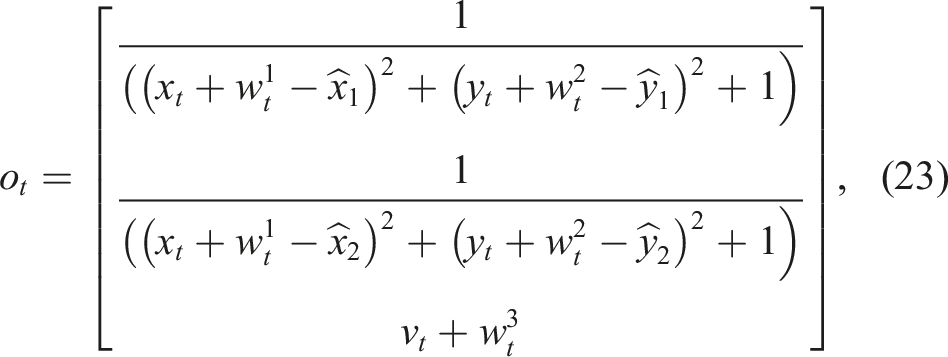
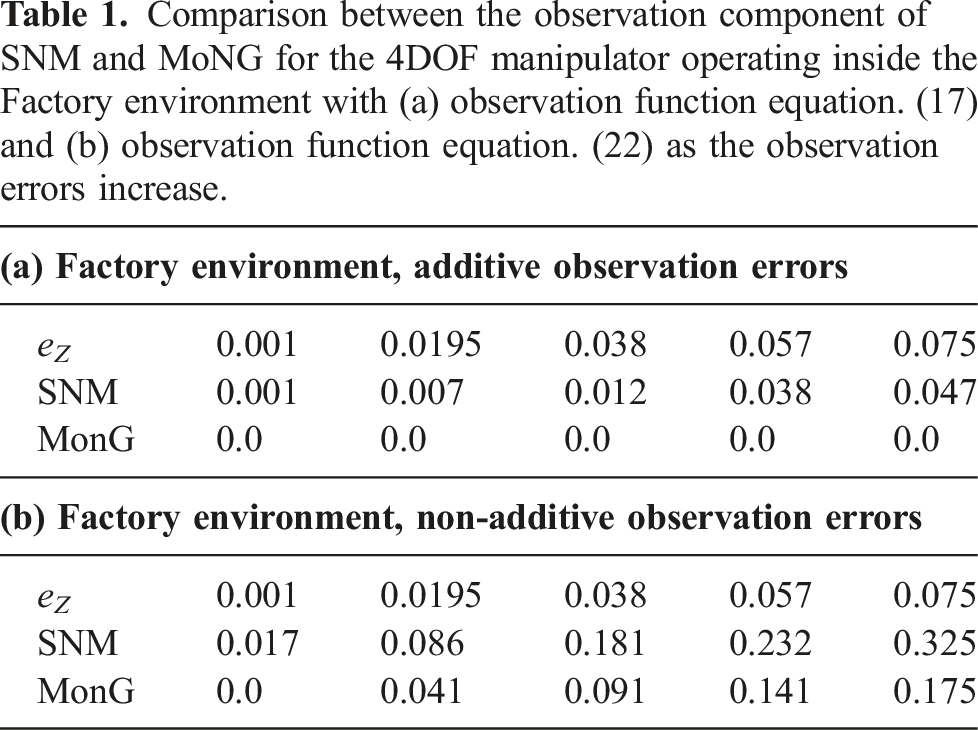
Comparison between the observation component of SNM and MoNG for the car-like robot operating inside the Maze environment with (a) observation function equation. (19) and (b) observation function equation (23) as the observation errors increase.
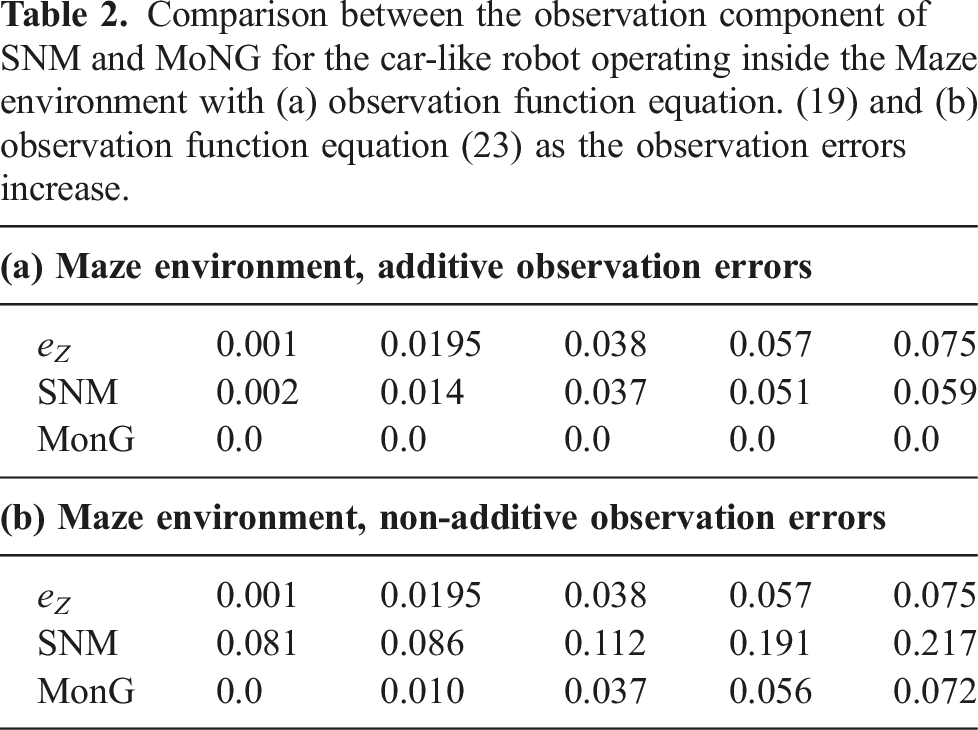
The question is now, how do ABT and MHFR perform in both scenarios when observation functions with non-additive Gaussian errors are used? Figure 7 shows this relative value difference for the 4DOFs manipulator operating inside the Factory environment and the car-like robot operating in the Maze environment, both robots subject to non-additive observation errors. It can be seen that as the observation errors increase, the relative value difference between ABT and MHFR increase significantly. This is in line with our intuition that non-Gaussian observation functions are more challenging for linearization-based solvers. Relative value difference between ABT and MHFR for the 4DOFs manipulator and the car-like robot operating in environments with non-additive observation errors, as the observation errors (e
Z
) increase. (a) The 4DOFs manipulator operating in the Factory environment. (b) The car-like robot operating in the Maze environment.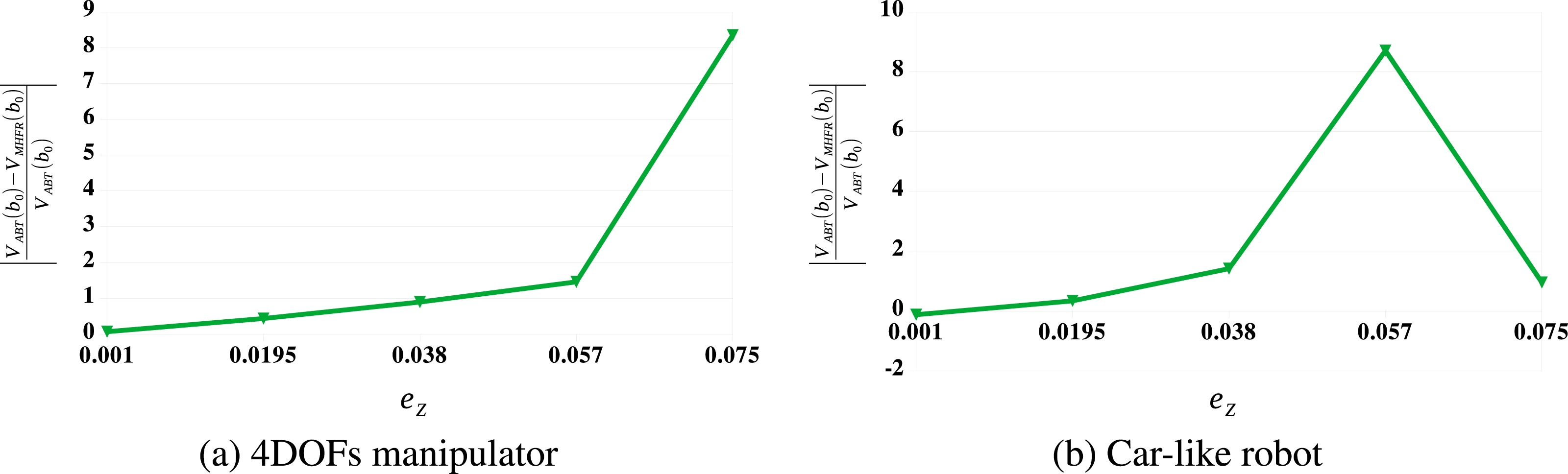
6.4. Testing SNM-planner
In this set of experiments, we want to test the performance of SNM-Planner in comparison with the two component planners ABT and MHFR. To this end, we tested SNM-Planner on four problem scenarios: The Maze scenario for the car-like robot shown in Figure 1(a) and the Factory scenario for the 4DOFs manipulator. The third scenario is the Kuka iiwa robot operating inside an office environment, as shown in Figure 1(b). Similarly to the Factory scenario, the robot has to reach a goal area while avoiding collisions with the obstacles. Finally, we tested SNM-Planner on the JacoCollab scenario described in Section 6.2.3 and shown in Figure 1(d). To further test the advantage of SNM in online POMDP planning compared to MoNG, we implemented a variant of SNM-Planner that uses MoNG as the heuristic instead of SNM. In particular, we replace line 5 in Algorithm 1 with a function
To determine the best SNM and MonG thresholds, we first ran a set of preliminary tests using 10 values between 0.1 and 0.9. We found that for both measures, a value of 0.5 performed best across the scenarios. Thus, in all scenarios, we set the SNM and MonG threshold to 0.5. In Section 6.4.1 we provide a more in-depth analysis on how varying threshold values affect the performance of SNM-Planner. Additionally, for all scenarios, we use e T = e Z = 0.038. The planning time per step for the Maze and Factory scenario is 2s, while we use a planning time of 8s and 1s for the KukaOffice and JacoCollab scenarios, respectively.
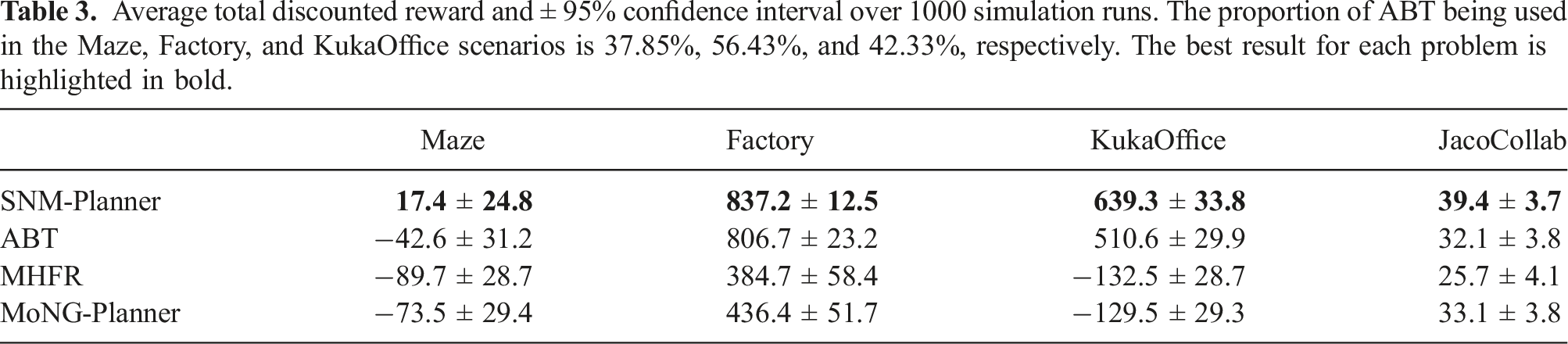
Average total discounted reward and ± 95% confidence interval over 1000 simulation runs. The proportion of ABT being used in the Maze, Factory, and KukaOffice scenarios is 37.85%, 56.43%, and 42.33%, respectively. The best result for each problem is highlighted in bold.
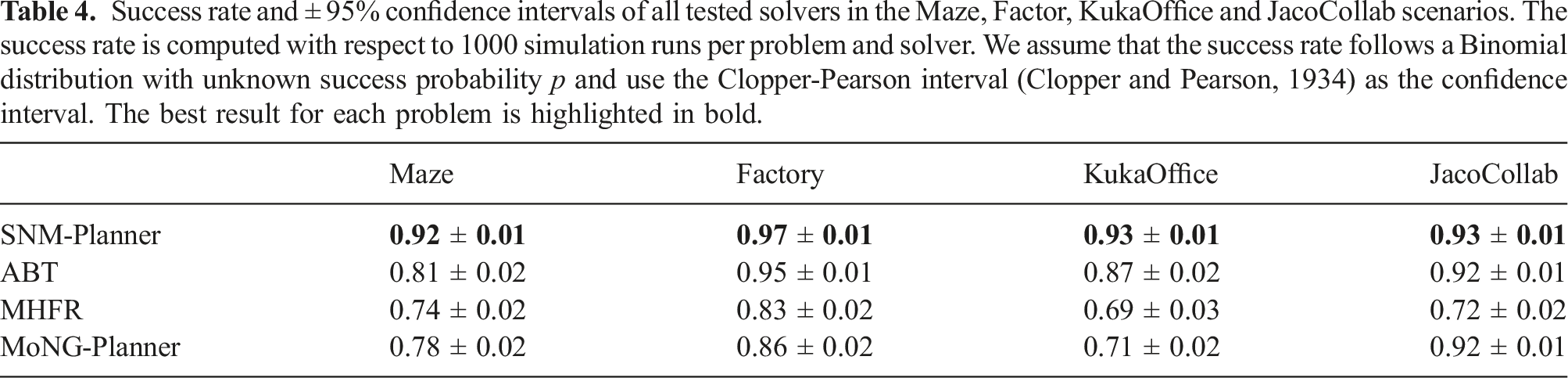
Success rate and ± 95% confidence intervals of all tested solvers in the Maze, Factor, KukaOffice and JacoCollab scenarios. The success rate is computed with respect to 1000 simulation runs per problem and solver. We assume that the success rate follows a Binomial distribution with unknown success probability p and use the Clopper-Pearson interval (Clopper and Pearson, 1934) as the confidence interval. The best result for each problem is highlighted in bold.

State samples in the Maze scenario for which the approximated SNM value exceeds the chosen threshold of 0.5.
A similar behavior was observed in the KukaOffice environment. During the early planning steps, when the robot operates in the open area, MHFR is well suited to drive the end-effector towards the goal area, but near the narrow passage at the back of the table, ABT in general computes better motion strategies. Again, SNM-Planner combines both strategies to compute better motion strategies than each of the component planners alone, while MoNG-Planner is unable to correctly identify situations in which MHFR or ABT should be used.
In the JacoCollab scenario, MHFR tends to compute strategies that move the robot to the goal as quickly as possible. However, those strategies are often too aggressive, resulting in collisions with the worker. On the other hand, for ABT, the robot tends to spend too much time in a safe region behind the worker, and only making slow progress towards the goal. SNM-Planner uses MHFR to compute a strategy that quickly leads to the goal, while it uses ABT when the robot is in the vicinity of the worker. This results in strategies that reach the goal quickly, while maintaining safety when the robot is near the worker, as reflected by the results in Table 3 and Table 4.
6.4.1. Sensitivity of SNM-planner and MonG-planner
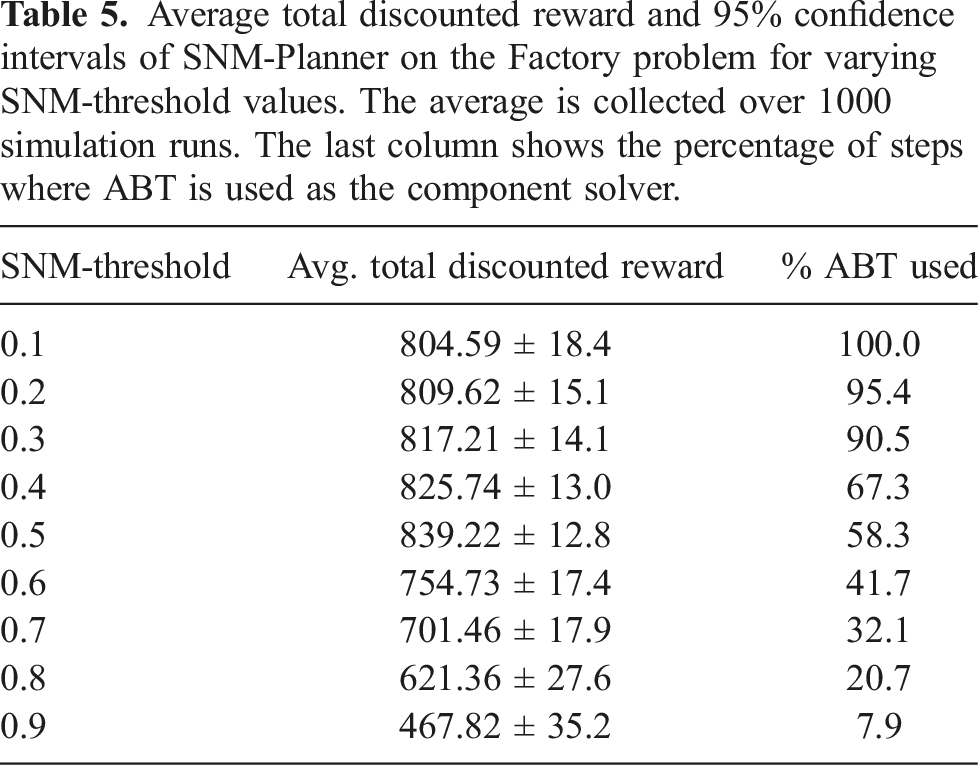
In this experiment, we test how sensitive the performances of SNM-Planner and MonG-Planner are to the choice of the SNM and MonG thresholds, respectively. Recall that both planners use these thresholds to decide at each planning step which solver to use for the policy computation, based on a local approximation of the measures. For small thresholds the planners favor ABT, whereas for large thresholds MHFR is favored.
For this experiment, we test both SNM-Planner and MonG-Planner on the Factory problem (Figure 1(b)) with multiple values for the SNM and MonG thresholds, ranging from 0.1 to 0.9. For each threshold value, we estimate the average total expected discounted reward achieved by both planners using 1000 simulation runs. Here we set e T = e Z = 0.038.
Average total discounted reward and 95% confidence intervals of SNM-Planner on the Factory problem for varying SNM-threshold values. The average is collected over 1000 simulation runs. The last column shows the percentage of steps where ABT is used as the component solver.
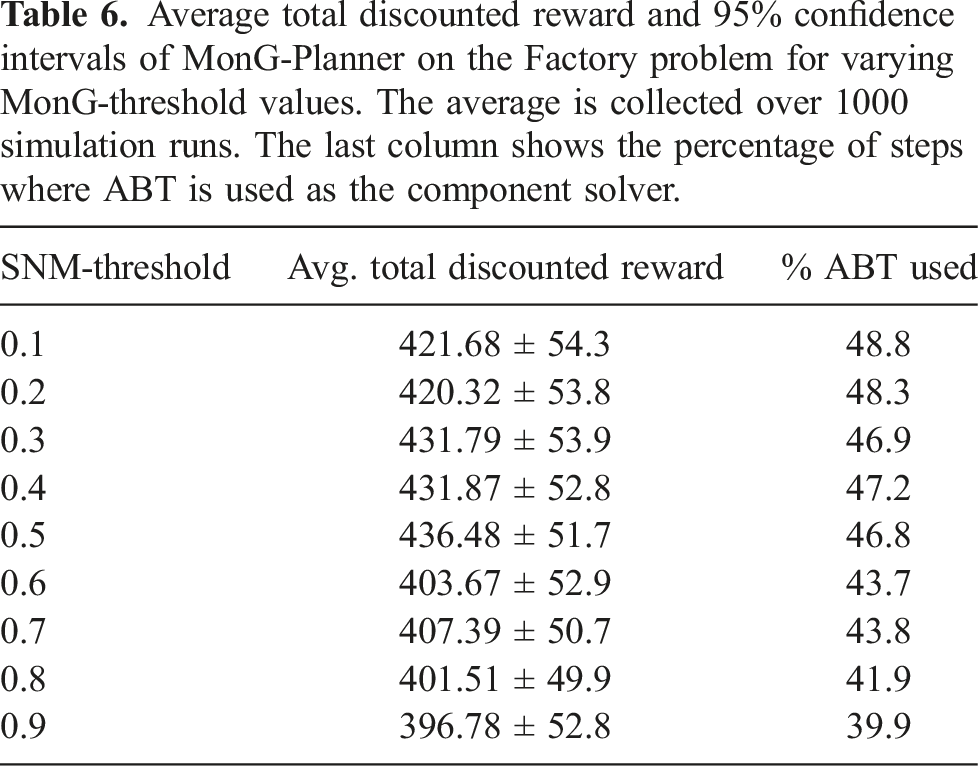
Average total discounted reward and 95% confidence intervals of MonG-Planner on the Factory problem for varying MonG-threshold values. The average is collected over 1000 simulation runs. The last column shows the percentage of steps where ABT is used as the component solver.
7. Summary and future work
This paper presents our preliminary work in identifying the suitability of linearization for motion planning under uncertainty. To this end, we present a general measure of non-linearity, called Statistical-distance-based Non-linearity Measure (SNM), which is based on the distance between the distributions that represent the system’s motion–sensing model and its linearized version. Comparison studies with one of state-of-the-art methods for non-linearity measure indicate that SNM is more suitable in taking into account obstacles in measuring the effectiveness of linearization.
We also propose a simple online planner that uses a local estimate of SNM to select whether to use a general POMDP solver or a linearization-based solver for robot motion planning under uncertainty. Experimental results indicate that our simple planner can appropriately decide where linearization should be used and generates motion strategies that are comparable or better than each of the component planner.
Future work abounds. For instance, the question for a better measure remains. The total variation distance relies on computing a maximization, which is often difficult to estimate. Statistical distance functions that rely on expectations exists and can be computed faster. How suitable are these functions as a non-linearity measure? Furthermore, our upper bound result is relatively loose and can only be applied as a sufficient condition to identify if linearization will perform well. It would be useful to find a tighter bound that remains general enough for the various linearization and distribution approximation methods in robotics.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is partially funded by ANU Futures Scheme QCE20102. The early part of this work is funded by UQ and CSIRO scholarship for Marcus Hoerger.