
Abstract
Ultrasound (US) imaging is widely used for biometric measurement and diagnosis of internal organs due to the advantages of being real-time and radiation-free. However, due to inter-operator variations, resulting images highly depend on the experience of sonographers. This work proposes an intelligent robotic sonographer to autonomously “explore” target anatomies and navigate a US probe to standard planes by learning from the expert. The underlying high-level physiological knowledge from experts is inferred by a neural reward function, using a ranked pairwise image comparison approach in a self-supervised fashion. This process can be referred to as understanding the “language of sonography.” Considering the generalization capability to overcome inter-patient variations, mutual information is estimated by a network to explicitly disentangle the task-related and domain features in latent space. The robotic localization is carried out in coarse-to-fine mode based on the predicted reward associated with B-mode images. To validate the effectiveness of the proposed reward inference network, representative experiments were performed on vascular phantoms (“line” target), two types of ex vivo animal organ phantoms (chicken heart and lamb kidney representing “point” target), and in vivo human carotids. To further validate the performance of the autonomous acquisition framework, physical robotic acquisitions were performed on three phantoms (vascular, chicken heart, and lamb kidney). The results demonstrated that the proposed advanced framework can robustly work on a variety of seen and unseen phantoms as well as in vivo human carotid data.
1. Introduction
Ultrasound (US) is one of the most widely used imaging techniques to visualize internal anatomies. Unlike computed tomography (CT) and magnetic resonance imaging (MRI), US imaging is real-time, low-cost, and radiation-free (Hoskins et al., 2019). In conventional US examinations, sonographers often need to search for some standard US planes for diagnosis. The standard US planes are important for performing quantitative biometric measurements (Rizi et al., 2020; Baumgartner et al., 2017), image-guided interventions (Stone et al., 2010; Chen et al., 2020), and identifying abnormalities, for example, the longitudinal view of vascular structures (see Figure 1), which is often required to estimate the flow velocity in clinical practice (Bi et al., 2022). However, substantial experience and visuo-tactile skills are needed to locate such planes correctly and accurately from speckled US images. The potential inter- and intra-operator variations will challenge the achievement of consistent and repeatable diagnoses, particularly for novice sonographers. Therefore, the development of the robotic US system (RUSS), which can learn the underlying physiological knowledge from experienced sonographers to identify the standard US planes, is meaningful for obtaining standardized and operator-independent US images. This can also release sonographers from repetitive and cumbersome operations and reduce work-related musculoskeletal disorders (Jiang et al., 2023a). Illustrations of standard planes for different organs. (a) The longitudinal view of a mimicked vascular phantom, (b) the longitudinal view of a chicken heart, and (c) the longitudinal view of a lamb kidney. For each object, three representative frames are depicted to demonstrate the early, middle, and end phases in the corresponding demonstration. All the displayed US images share the same scale bar. US imaging depth is 5 cm.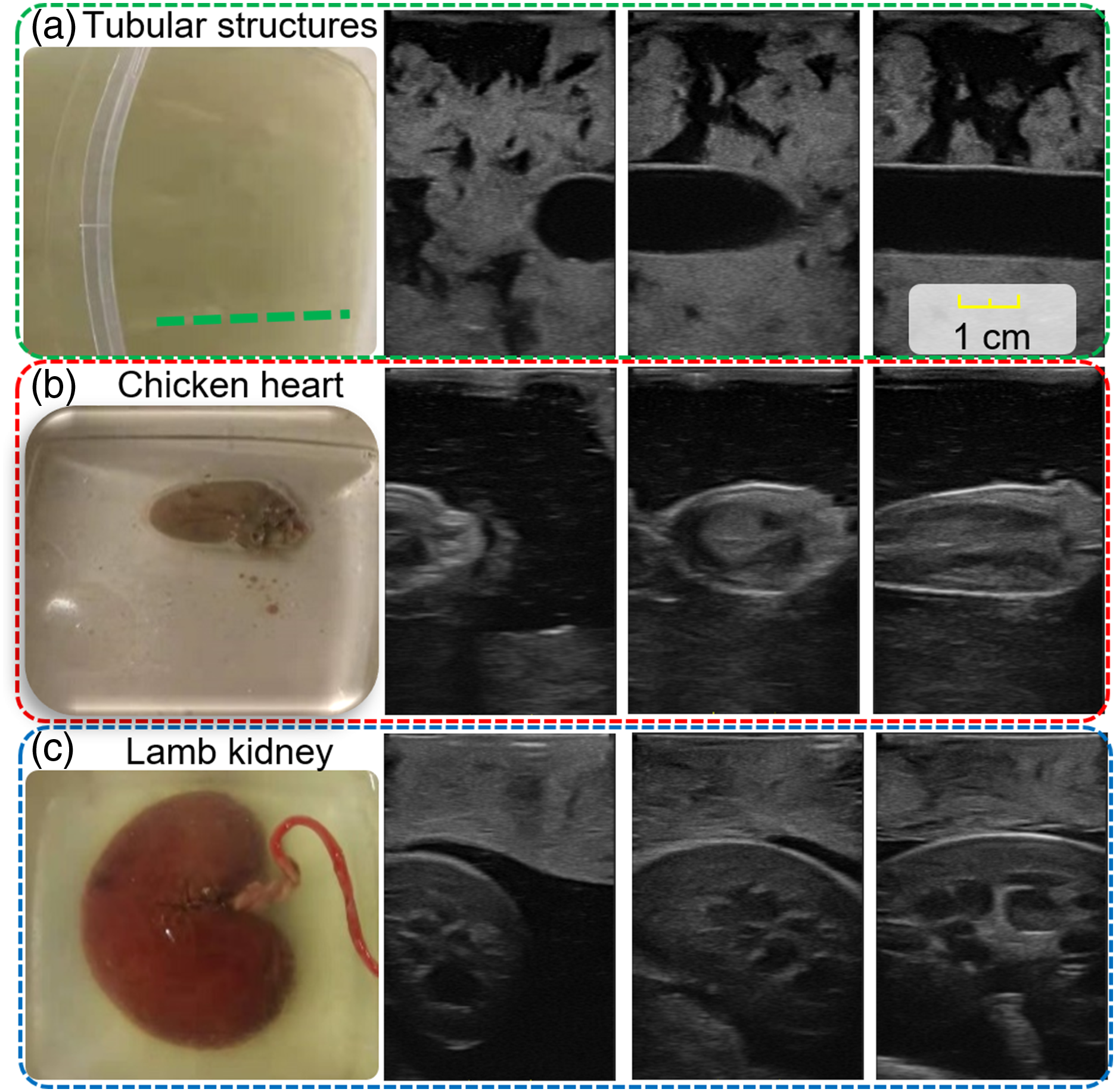
Due to the advantages of accuracy, stability, and repeatability, robot-assisted US imaging has been investigated for decades. Pierrot et al. developed an RUSS that can maintain a constant force between the probe and patients for cardiovascular disease prevention (Pierrot et al., 1999). Gilbertson et al. designed a one-degree-of-freedom (DoF) hand-held device to reduce force-induced image quality variation during free-hand scans (Gilbertson and Anthony, 2015). Conti et al. proposed a collaborative RUSS, which allows operators to instinctively operate a US probe remotely, while contact force is automatically maintained using compliant force control (Conti et al., 2014). To accurately control the US acquisition parameters (e.g., contact force and probe orientation) for stable and repeatable US images, Jiang et al. proposed a method to automatically position a linear probe to the normal direction of the contact surface using a confidence map and the computed Cartesian force at the tool center point (TCP) (Jiang et al., 2020a). Then, a mechanical model-based method was proposed to adjust the orientation of both convex and linear probes (Jiang et al., 2020b). In addition, Huang et al. and Chatelain et al. computed the desired probe orientation based on an RGB-D camera (Huang et al., 2018a) and a visual servoing framework (Chatelain et al., 2017), respectively. To estimate the region of interest, which refers to high-quality regions for examinations, Goel et al. (Goel et al., 2022) and Raina et al. (Raina et al. 2023a, 2023b) delved into the application of Bayesian Optimization methods in the context of RUSS. The aforementioned RUSSs are promising to overcome the limitations of free-hand US, while the ability to learn from human experts to search for the standard US planes has not been fully researched yet.
To develop an intelligent RUSS that can automatically identify and navigate the probe to the standard scan planes, various advanced learning-based approaches have been developed to improve the understanding of both images and the dynamic environment. Regarding carotid examination, Huang et al. divided the robot-assisted scanning procedure into three sub-stages to mimic the behavior of clinicians (Huang et al., 2021). Baumgartner et al. proposed the SonoNet to automatically detect fetal standard views during free-hand scans in real-time using convolutional neural networks (Baumgartner et al., 2017). To further develop an automatic navigation system toward target US planes, Droste et al. trained the US-GuideNet to predict the final goal pose and the next movement action (rotation) based on the recorded US sweeps from experts (Droste et al., 2020). Although the US-GuideNet was only validated in a virtual environment (recorded images from experts), its results proved the feasibility of learning such challenging tasks and understanding the human operator’s intention from their demonstrations. To automatically locate the sacrum in US view, Hase et al. trained a deep Q-network (DQN) to move the US probe in 2-DoF translational motion (Hase et al., 2020). To fully control the 6-DoF motion of the probe, Li et al. presented a deep Reinforcement Learning (RL) framework to control the 6D pose of a virtual probe to a standard plane in simulation (Li et al., 2021a). The results suggested that the proposed method can work effectively on intra-patient data (92%), while the performance on unseen data (46%) still has space for improvement. The significant difference in the performance between trained and unseen data is caused by the variations in patients’ data. In addition, the inherited characteristics of RL methods, like requiring rich dynamic interaction with the environment and performance decay in diverse settings, will limit the deployment of RL-based approaches in real scenarios. This is particularly important for clinical applications where patient safety is of paramount importance.
In this work, we propose a novel machine learning framework to learn the underlying physiological knowledge from a few expert demonstrations and automatically navigate a probe to the desired US planes. To guarantee the generalization capability of the proposed approach on unseen patients, mutual information is employed to explicitly disentangle the task-related and domain features for the input images in the latent space. To eliminate the need for cumbersome annotation, spatial ranking approaches are used to enable self-supervised training. After training, an estimated reward is computed for each individual image in real-time, which reflects the preference of the sonographers during the US examination. The main contributions are summarized as follows: • To understand expert sonographers’ semantic reasoning and intention from a few demonstrations, a novel learning-based framework is proposed to predict the reward associated with the US images. The use of the probability ranking approach enables the training process to be done in a self-supervised fashion without any requirement for cumbersome annotation. • To deal with the two most common US scanning objectives (“point” and “line” task) in one framework, we propose a global probabilistic spatial ranking (GPSR) network to generate unbiased image comparisons from all expert demonstrations. The GPSR can improve data efficiency, and it is especially valuable for sub-optimal expert demonstrations, where the target US planes are often observed multiple times during a single acquisition. • To ensure the generalization capability, we integrate the Mutual Information (Belghazi et al., 2018) (MI) into GPSR (MI-GPSR) to explicitly disentangle the task-related features from the domain features. The MI-GPSR is validated to be able to properly estimate the rewards for US images on unseen phantoms and volunteers with significantly different geometrical sizes and image artifacts from the training data. • To enable the possibility of applying robotic navigation in a real scenario, we propose a coarse-to-fine navigation framework instead of using RL or informative path planning approaches. Considering the time efficiency, a 3D reconstruction volume is generated based on a US scan of the target anatomy. Therefore, a large number of US images are simulated from this 3D US volume and the coarse acquisition pose for the standard plane is obtained by finding the simulated image with maximum reward. Then, a fine-tuning process is carried out around the coarse location to bridge the potential gap between simulated and real US images.
Finally, to validate the performance of the proposed approach, experiments have been carried out in a simulated grid world and two representative cases on gel vascular phantoms, alongside more challenging ex vivo animal organ phantoms (lamb kidney and chicken heart). To ensure transferability for real human tissues, the reward inference network was further validated on real data of volunteers’ carotids. The results demonstrate that the proposed MI-GPSR can properly predict the reward of US images from unseen demonstrations of unseen phantoms and volunteers.
The remainder of this paper is organized as follows. Section 2 presents related work. The proposed MI-GPSR is presented in Section 3. Section 4 describes the details of the autonomous US-guided navigation procedures. The experimental results in grid-world, three representative types of phantoms (vascular, chicken heart, and lamb kidney phantoms), and real carotid data from volunteers are described in Section 5. The discussion about the current challenges and potential directions are presented in Section 6. Finally, in Section 7, the paper concludes with a summary of the presented approach.
2. Related work
2.1. Robotic US system
Due to high inter-operator variability and the lack of reproducibility of free-hand US examination, RUSS has been considered as a promising solution to achieve standardized acquisition and diagnosis. Virga et al. presented an approach to automatically acquire 3D US images for abdominal aortic aneurysms screening (Virga et al., 2016). The scan path was determined based on the registration between the patient’s surface and a generic MRI-based atlas. To consider the non-rigid motion between human bodies, Jiang et al. proposed an atlas-based framework allowing autonomous robotic US screening for limb arteries by using a non-rigid registration approach (Jiang et al., 2022b). To eliminate the requirement for the pre-operative images, Jiang et al. developed an end-to-end workflow for autonomous robotic screening of tubular structures based only on real-time B-mode images (Jiang et al., 2021a). Huang et al. proposed a camera-based method to automatically determine the scan path (Huang et al., 2018a). To utilize human experience, Abolmaesumi et al. developed a shared control method to visualize carotid arteries in 3D (Abolmaesumi et al., 2002). In addition, RUSS has been widely used in different applications, such as visualizing underlying bone surfaces (Jiang et al., 2020b) and imaging human spines (Zhang et al., 2021).
Considering pandemics such as COVID-19, Akbari et al. developed an RUSS that allows the physical separation of sonographers and patients (Akbari et al., 2021). Antico et al. employed the Bayesian CNN to segment the femoral cartilage and use the volumetric US as the guidance in minimally invasive robotic surgery for the knee (Antico et al., 2020). Kim et al. considered the real-time contact force feedback to perform a heart scan autonomously (Kim et al., 2020). Naidu et al. incorporated tactile sensing to augment US images to enhance the location accuracy of tumor tissues (Naidu et al., 2017). Besides, Monfaredi et al. discussed the development of a parallel telerobotic system (Monfaredi et al., 2015). Due to the focus of this article, we cannot provide a comprehensive overview of RUSS. For readers who are interested in a deep overview of the field, there are several survey articles that have investigated the developments of RUSS from distinct perspectives. Von Haxthausen et al. systematically summarized the related publications between 2016 and 2020 (Von Haxthausen et al., 2021). Li et al. categorized the existing RUSS in terms of the level of automation (Li et al., 2021b). In addition, Jiang et al. provided a comprehensive survey including both teleoperated and autonomous RUSS, which also systematically summarized the related technologies, such as enabling techniques, advanced application-oriented techniques, and emerging learning-based approaches (Jiang et al., 2023a).
2.2. Detection and navigation of standard planes
Due to the potential deformation of soft tissue and the often hard-to-interpret US images, guiding a probe to proper planes is a highly sophisticated task, which requires years of training (Maraci et al., 2014). In addition, limited by human hand–eye coordination ability, these tasks suffer from low reproducibility and large intra-operator variations (Chan et al., 2009). These drawbacks severely limit the clinical acceptance of US modality for tasks requiring repeatable, quantitative, and accurate measurements, e.g., monitoring tumor growth. To address this challenge, Chen et al. proposed a learning-based approach to locate the fetal abdominal standard plane in US videos using a deep convolutional neural network (CNN) (Chen et al., 2015). Each input video frame was processed by a classifier to detect the standard plane using a sliding window. To further eliminate the requirement for the cumbersome annotation, Baumgartner et al. proposed the SonoNet using weak supervision to detect standard views during US scans in real-time (Baumgartner et al., 2017). The experiments validated that the SonoNet can effectively extract multiple standard planes on free-hand US images.
To automatically navigate a probe to standard planes, Droste et al. trained a policy network to estimate the next probe movement aiming to mimic the expert behavior (Droste et al., 2020). The network included the gated recurrent unit (GRU) and was trained based on the recorded consecutive US images and probe orientations extracted from expert demonstrations. Due to the limitation of the inertial measurement unit (IMU), this work was only validated in terms of rotational movement, while there is no technical gap in applying the proposed method to the translational motion. Hase et al. trained a DQN to navigate a probe to sacrum in a virtual 2D grid word, and a binary classifier was used to terminate the RL-based searching process (Hase et al., 2020). To navigate to the paramedian sagittal oblique plane (a standard plane used in spine US examination), Li et al. considered both rotational and translational movements in a simulated environment using a deep RL framework (Li et al., 2021a). This approach can effectively work on the images recorded from patients included in the training dataset (92%), while further development is needed to improve the generalizability on unseen patients (46%). To autonomously navigate a probe to the longitudinal view of tubular structures, Bi et al. proposed a method with high generalization capability by using segmented binary masks as the inputted state to an RL agent (Bi et al., 2022). The use of binary masks bridges the gap between the simulation and B-mode images obtained in real scenarios. Without any fine-tuning steps, the trained VesNet-RL model can reliably navigate the probe to the standard plane on a vascular phantom (92.3%) and on in vivo carotid volumes from a volunteer (91.5%).
2.3. Learning from demonstration
Since RL algorithms often require rich interaction with the environment to learn the policies for a given task (Kurenkov et al., 2020), most of the aforementioned studies were trained in simulation or using recorded US examination videos rather than on real patients. Besides RL methods, some existing approaches tried to directly teach RUSS to perform US scans based on expert demonstrations, which have the potential to effectively alleviate the complexity of robotic programming. In addition, such a system can learn the underlying physiological knowledge from experienced experts and used the knowledge to help train young sonographers. Learning from demonstration (LfD) can be broadly categorized into two approaches: imitation learning (IL) (Ross et al., 2011) and inverse reinforcement learning (IRL) (Abbeel and Ng, 2004). Imitation learning directly generates a predictive model to estimate the next action based on the current state, which requires optimal demonstrations because the fundamental logic of such approaches is to imitate the behavior rather than to understand the latent objective. On the contrary, IRL aims to represent a given task by a reward function with respect to state features, which often assumes that the reward value can be linearly or exponentially linked to the number of times of the features witnessed (Abbeel and Ng, 2004) or the likelihood of features observed in a demonstration (Ziebart et al., 2008). In other words, a higher reward should be assigned to the states more frequently observed. Due to the acoustic shadows, poor contrast, speckle noise, and potential deformation in resulting images (Mishra et al., 2018), guiding a probe to the standard US planes is sophisticated, even for senior sonographers. This means the experts’ demonstrations of searching for standard US planes will be sub-optimal and even contradictory (Burke et al., 2023). Therefore, the popular maximum-entropy IRL method (Aghasadeghi and Bretl, 2011) cannot be directly applied in our applications.
Specific to the field of robotic US, Mylonas et al. employed Gaussian Mixture Modeling (GMM) to model the demonstration in a probabilistic manner (Mylonas et al., 2013). This pioneering study only considered the trajectory rather than US images. In order to achieve good performance, it has strict requirements for the initial position and phantom position. Besides, Burke et al. introduced a probabilistic temporal ranking model which assumes that the images shown in the later stage are more important than the earlier images (Burke et al., 2023), allowing for reward inference from sub-optimal scanning demonstrations. They use this model to coarsely navigate a US probe to a mimicked tumor inside of a gel phantom, followed by an exploratory Bayesian optimization policy to search for scanning positions that capture images with high rewards.
2.4. Mutual information-based feature disentanglement
Recent developments of deep neural networks (DNNs) demonstrated expert-level accuracy in a broad range of computer vision tasks like image segmentation (Minaee et al., 2021), object detection (Liu et al., 2020), and classification (Russakovsky et al., 2015). However, the performance is often reduced when a trained model is applied to unseen domains, for example, different scanner vendors and US acquisition settings. Considering the task of learning from clinical experts’ demonstrations, the limited training datasets will result in poor generalization. Inspired by the way of feature representation in DNNs that progressively leads to more abstract features at deeper layers of DNNs, a feature disentanglement process is carried out to explicitly separate the task-related and domain features to improve the generalization capability on unseen data. Theoretically, explicit feature representations will have the potential to deal with previously unseen domains, which is particularly valuable for US applications.
Mutual information (MI) is a fundamental quantification for computing the correlation between variables, which captures non-linear statistical dependencies. MI will be maximized when the two inputs share the same information. Therefore, to explicitly disentangle task-related and domain features, we can minimize the MI between these two feature representations of the same input in a deep layer (Liu et al., 2021). Nevertheless, the fast computation of MI is restricted to discrete variables (Paninski, 2003). Due to the use of both marginal probability and joint probability of two variables, the computation complexity is related to the sample number. To achieve the computation of MI between high-dimensional continuous random variables, Belghazi et al. proposed an MI Neural Estimator (MINE) by gradient descent over neural networks (Belghazi et al., 2018). The MINE is scalable in dimension and sample size, and it provides unbiased MI estimations as well. Based on the MINE, Meng et al. developed MI-based Disentangled Neural Networks to extract generalizable categorical features from US images to transfer knowledge to unseen categories (Meng et al., 2020). Based on the experiments, they claimed that the proposed method outperformed the state-of-the-art on the task of classification of unseen categories. Similarly, Liu et al. employed MI to extract discriminative representations to improve the generalization of recognition tasks against the disturbances of environment (Liu et al., 2021). Bi et al. applied MI to explicitly disentangle the domain and anatomy features to enhance the generalization capability for US segmentation tasks (Bi et al., 2023).
2.5. Proposed approach
To assist the sonographer in achieving consistent and repeatable diagnosis during US examinations, we developed an intelligent RUSS to navigate the probe to standard scan planes by learning from few demonstrations. To the best of our knowledge, this is the first work that aims to learn the underlying skill and anatomical knowledge directly from human experts to align a probe to standard scan planes automatically. The ability to learn from demonstrations allows sonographers to intuitively transfer their physiological knowledge to an RUSS without the requirement of any robotic programming. This is still a challenging task in the area of robot learning, particularly when the demonstrations are not optimal (Eteke et al., 2020). Inspired by Burke et al. (2023), a global probabilistic spatial ranking (GPSR) method was developed to learn the latent skills and overcome the potentially biased results caused by inconsistent demonstrations. To increase the generalization capability and adapt the variation between patients, the MINE is employed (MI-GPSR) to explicitly disentangle the task-related features from the domain features. The MI-GPSR mainly consists of two feature encoders to extract the task-related and domain features of the input images, a decoder to reconstruct the input images based on the extracted features in latent space, and a fully connected network (FCN) to predict the reward for individual images. Considering the time efficiency, and the safety concerns about the rich interactions with patients, it is impractical to train an agent using RL (Bi et al., 2022; Li et al., 2021a) or apply Gaussian process path planning (Burke et al., 2023) in a real scenario. Therefore, we divided the navigation process into coarse and fine-tuning procedures. Regarding the first step, a US sweep over the target anatomies was performed, and then a virtual probe was generated on the upper surface of the compounded 3D volume. By assigning various probe poses, a larger number of simulated 2D images were created. Based on the predicted reward for individual synthetic images, a greedy algorithm is employed to detect the desired plane. Finally, to further bridge the gap between simulated images and real images, the probe was finely adjusted around the coarse location to achieve a more precise result, like human operators. An overview of the proposed approach is shown in Figure 2. Schematic overview of the proposed framework.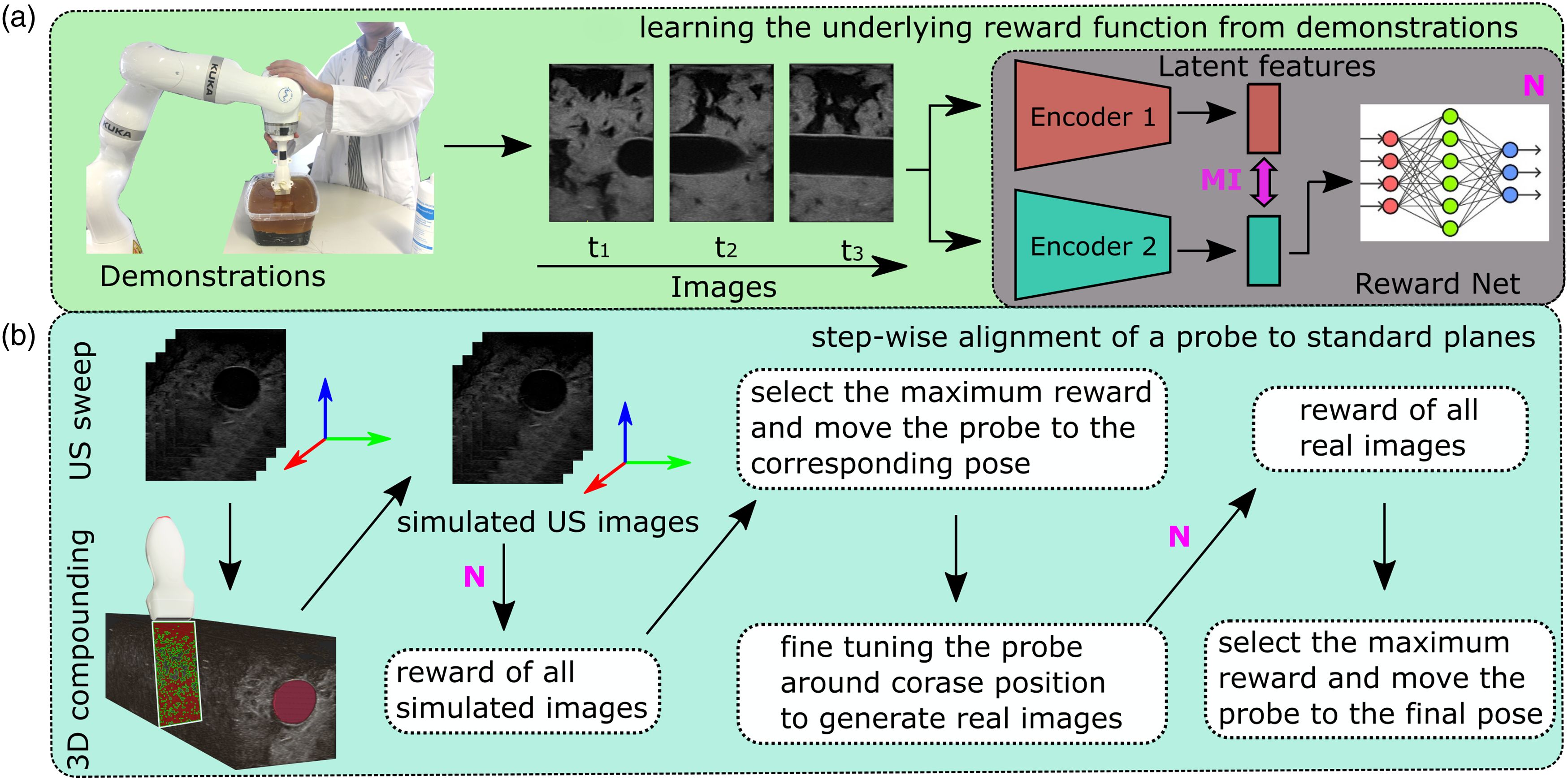
In addition, to demonstrate the effectiveness of the proposed approach, beyond grid world analysis, the proposed method was validated on gel vascular phantoms and more challenging ex vivo animal organ phantoms (chicken heart and lamb kidney). In contrast to simulation, such tasks are more realistic and more challenging in a physical environment because the resulting images are sensitive to practical factors, e.g., probe pose and contact force. To further validate the generalization capability of the proposed MI-GPSR, the trained models were tested on demonstrations acquired from unseen phantoms with different anatomical structures and image styles compared to the trained phantoms. Additionally, the models were assessed on unseen in vivo demonstrations from volunteers not included in the training dataset.
3. Learning from few demonstrations
This section describes the probabilistic temporal ranking approach (PTR) and the proposed GPSR and MI-GPSR methods to learn the latent reward function for individual B-mode images from expert demonstrations. In addition, a confidence-based approach is developed to filter out the abnormal demonstrations to avoid inconsistent target standard US planes. It is noteworthy that the presented three approaches (PTR, GPSR, and MI-GPSR) are independent and can be used individually.
3.1. Probabilistic temporal ranking (PTR)
Probabilistic temporal ranking (PTR) allows for uncertainty quantification and reward inference from demonstrations (Burke et al., 2023). Considering the characteristic of US examinations, experts often need to move a probe around to search for the target anatomy and finally stop at some specific US planes to do biometric measurements. This characteristic will result in sub-optimal US demonstrations, even for experienced sonographers. Therefore, the existing IRL approaches (Abbeel and Ng, 2004; Ziebart et al., 2008) cannot be directly applied because the states or images observed most frequently in the sub-optimal demonstrations may not necessarily be the states that should be assigned the highest reward. To tackle this problem, PTR incorporates an additional assumption that the images observed in the later stage of the demonstrated US sweeps should have a larger reward than the ones seen at an earlier stage. Based on this assumption, PTR is trained to infer the reward of individual images based on the pairwise comparisons sampled from expert demonstrations.
For PTR, a convolutional variational autoencoder (CVAE) was used to extract the latent features (z
t
) of each observation (x
t
). The reward is predicted using an FCN r
t
= R
ψ
(z
t
) because an FCN is often used to approximate the Gaussian processes (Neal, 1996). To train the PTR, a differentiable neural approximation is employed with two observation inputs, that is, pairwise image comparisons generated from demonstrations. To optimize the reward network parameters, the comparison outcome g
t
∈ {0, 1} is used, which is automatically generated with respect to the temporal information of each frame in the demonstrations. Based on the assumption, ground truth of comparison outcome is g
t
= 0 if t1 > t2, and g
t
= 1 if t1 < t2. To use this self-supervised signal to train the PTR, the generative process for a pairwise comparison outcome is modeled as a Bernoulli trial as equation (1).
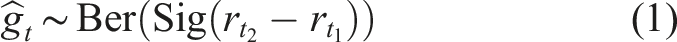
According to equation (1), the sigmoid of the reward difference will be greater than 0.5 when
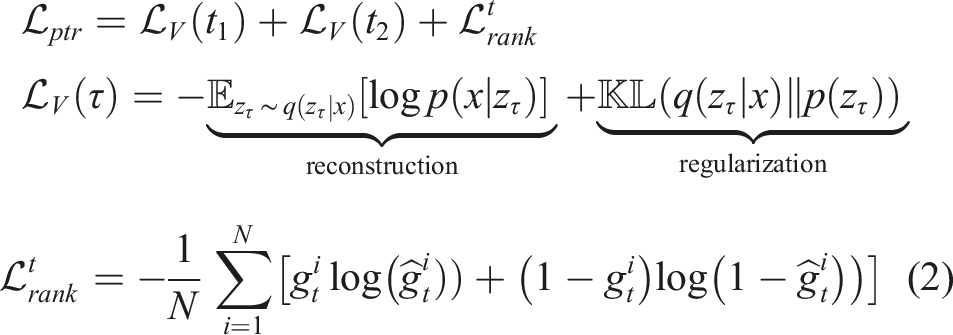
Since the image comparisons can only be generated internally among each demonstration, PTR will assign the highest reward to the end frames of each demonstration. Therefore, PTR is theoretically only able to search for the “point” object, where the target US plane can only be visualized at a unique pose. Compared with the concept of a “point” object, a “line” object means the standard planes can be achieved in multiple points. The standard US plane for a “line” object is also often needed in clinical practice, such as the longitudinal view of vascular structures for estimating blood flow for peripheral arterial disease (PAD) diagnosis. In addition, without considering the global information, the generated temporal image comparisons are biased, which will hinder the accurate understanding of the expert’s intention.
3.2. Expert demonstration evaluation and cleaning
Since biased data would mislead the correct understanding of the expert’s intention, we propose a probabilistic approach to evaluate the quality of recorded demonstrations and filter out the undesired ones from training data. A confidence value between [0,1] will be assigned to each demonstration based on the positional information of the final frames in all demonstrations.
Considering the task of visualizing standard US planes, a demonstration ending at a good viewpoint, where the standard planes could be displayed, is considered as a good demonstration. Since the resulting B-mode imaging depends on the end-effector pose, the end-effector poses of the last frames in all demonstrations were employed as the surrogate of the corresponding US images. Then, the last end-effector poses

Regarding the multivariate normal distribution, the confidence interval for a certain significance level p
ci
results in a region, in which
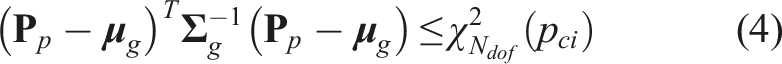
3.3. Data augmentation
Data augmentation is one of the most commonly used regularization methods. It prevents the model from overfitting and increases generalizability. During the training phase, the input data will be randomly augmented by a set of transformation functions

3.3.1. Image style transformations
Domain shift in US images is often observed in daily US practice. US images acquired from the same patient using different US machines or acquisition settings will lead to different imaging styles. Due to inter-patient variations, US images of the same anatomy also appear visually different. One data-efficient solution for this is to do style augmentations to the training data. The transformations of blurriness, sharpness, Gaussian noise, brightness, and contrast are involved in this work. For blurriness, Gaussian filtering is used, where the magnitude α is defined as the standard deviation of the Gaussian filter, ranging between [0.25,1.5]. The augmentation in sharpness is done by implementing the unsharp masking technique, where the magnitude α ranges between [10,30]. Gaussian noise with zero mean and a standard deviation between [1,10] is used to generate noised images. The brightness of the image is transferred in the range of [−25, 25], while the contrast of the image is manipulated using gamma correction with a gamma value ranging between [0.5,3]. All transformation functions have the same probability p of 10%.
3.3.2. Image spatial transformations
Apart from the style transformations, the spatial augmentations of US images should also be considered, in particular for US images. Two types of spatial transformation are involved: crop and flip. In some scenarios, like vessels, the horizontal position of the target anatomy is linked to the ranking results. Therefore, the crop is only carried out in the vertical direction. The magnitude, in this case, is the scaling factor ranging between [0.8,0.9], while the probability p is 50%. Flipping the images horizontally can also increase the variations of limited training images. The probability of flipping is set to p = 10%.
3.4. Global probabilistic spatial ranking (GPSR)
Regarding PTR, a few limitations have been discussed in Section 3.1, for example, biased training comparisons and the inability to be used for “line” targets. To further overcome these challenges, we consider using spatial ranking instead of temporal ranking. Since the US images, timestamp, and probe pose are paired, the temporal assumption used in Section 3.1 can be adapted as assuming that the US images observed at the position closer to the end pose should have a larger reward without further claims. Since the temporal information is unique and non-repeatable, the time-based image comparisons can only be generated from individual demonstrations, which could result in biased training data. Without global pairwise comparisons, the difference between the last observations of all involved demonstrations will limit the achievement of a precise and unbiased result. In the worst case, inappropriate comparisons will decay the reward inference capability of the PTR approach. In contrast, physical location is repeatable. The use of spatial information enables the generation of unbiased comparisons from all experts’ demonstrations. Since all demonstrations are used, the number of training data (pairwise comparisons) generated from a few demonstrations will be soaring. Compared to the temporal differences, the differences between the probe poses of the two images are more intuitive and suitable to represent the difference between the current US image and the target images. Ranking based on spatial information is especially valuable for sub-optimal demonstrations, where the target US planes could be witnessed multiple times during a single acquisition.
To display the US plane of the target anatomy, a US probe needs to be controlled in four DoFs for most applications (“point object”), for example, the task of visualizing and horizontally centering the lamb kidney and chicken heart (Figure 1). Two translational movements in the plane orthogonal to the probe centerline and two rotational movements along the probe long axis and the probe centerline, respectively. The remaining two DoFs: the translation along the probe centerline and the rotation around the probe short axis, only change the visualized part of the same plane. To obtain high-quality US images, the probe is required to make firm contact with patients’ skin. To ensure patient safety and avoid significant variation of image deformation during scans, a compliant controller (Jiang et al., 2021a; Hennersperger et al., 2016) is employed to maintain a constant contact force in the probe centerline direction. Besides, for some anatomies, e.g., tubular structures, the translational position along the centerline of tubular structures is flexible to display a longitudinal vascular view (“line object”).
For the proposed GPSR, the spatial cue of each frame is used as the supervisory signal to generate image comparisons among all demonstrations. Considering the “line” object, target US planes could be achieved at different locations, and the relative positional and rotational differences are computed internally for each demonstration. The use of relative spatial difference
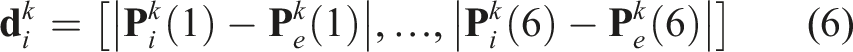
To generate global comparisons between frames from different demonstrations, the computed
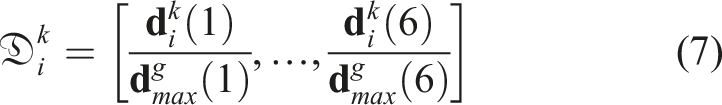
The generalized global distance
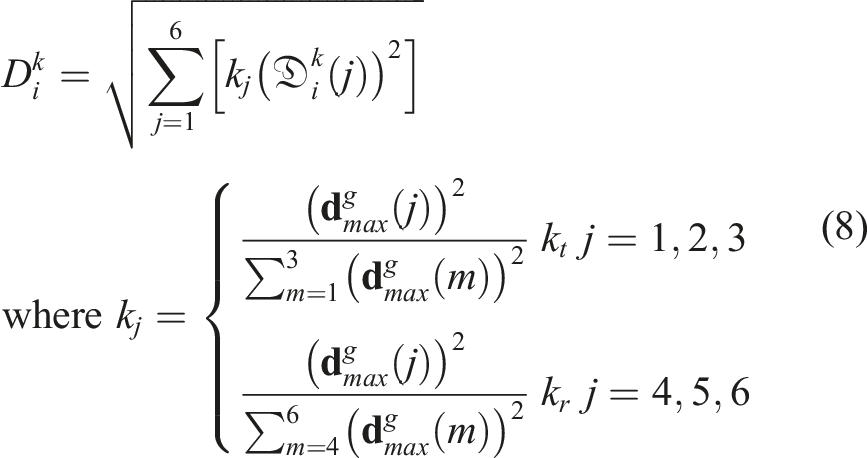
Based on the computed generalized distance
The structure of the GPSR is detailed in Figure 3. The VAE encoder q (z|x) is pre-trained on a large dataset to make GPSR adaptable to different image styles. Then, the extracted features in latent space are directly fed to an FCN reward prediction network R
ψ
(Z). To optimize the parameters of the FCN, the binary cross entropy loss over the comparison outcome is used as reward loss function Architecture of the GPSR reward network. The paired images are encoded by a pre-trained VAE. Then, the image features Z
p
in latent space are fed to an FCN R
ψ
(Z) to predict the reward for individual images. Based on the predicted rewards for paired images, the comparison outcome can be estimated using h(*).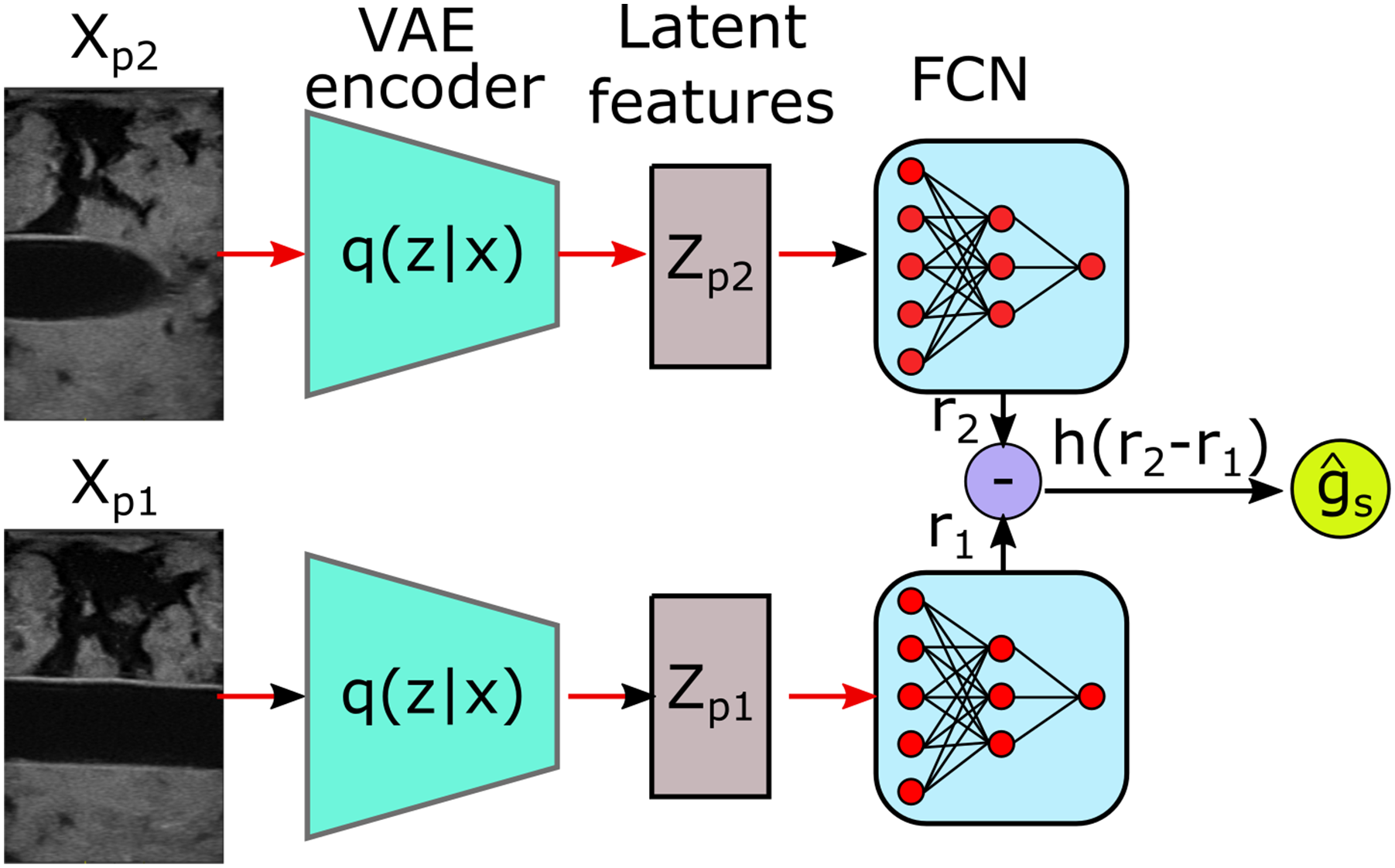
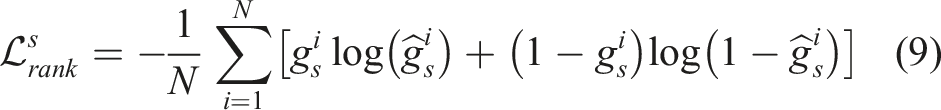
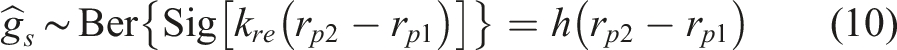
3.5. Mutual information-based feature disentanglement
In this work, feature disentanglement requires task-related features Z
r
and domain features Z
d
to have their specific information, while they do not incorporate the information of others. Such explicit feature disentanglement will improve the generalization capability on unseen images by removing the potential disturbs caused by unseen domain information from the task-related features. To this end, we need to quantitatively estimate the dependence between Zr and Zd. MI which measures the amount of information obtained from one random variable by observing the other random variable is the metric we need. The definition of MI is defined as follows:
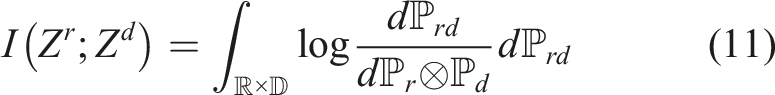
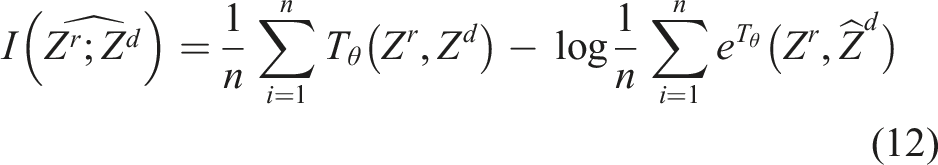
3.6. Training of the proposed MI-GPSR framework
Based on the MINE, the architecture of the novel MI-based disentangled reward network (MI-GPSR) is depicted in Figure 4. To train the MI-GPSR, three different loss functions are employed: (1) image reconstruction loss . Architecture of the proposed mutual information-based disentangled reward network (MI-GPSR). The inputs are image pairs randomly sampled from demonstrations. For each image, two independent encoders (Ed and Er) are used to extract latent features. To explicitly enforce the disentanglement between task-related features Zr and domain features Zd, their MI is minimized during the training process. To ensure the latent features can preserve all information of inputs, Zr and Zd are concatenated to reconstruct the original images. To train the reward network FCN, the pairwise 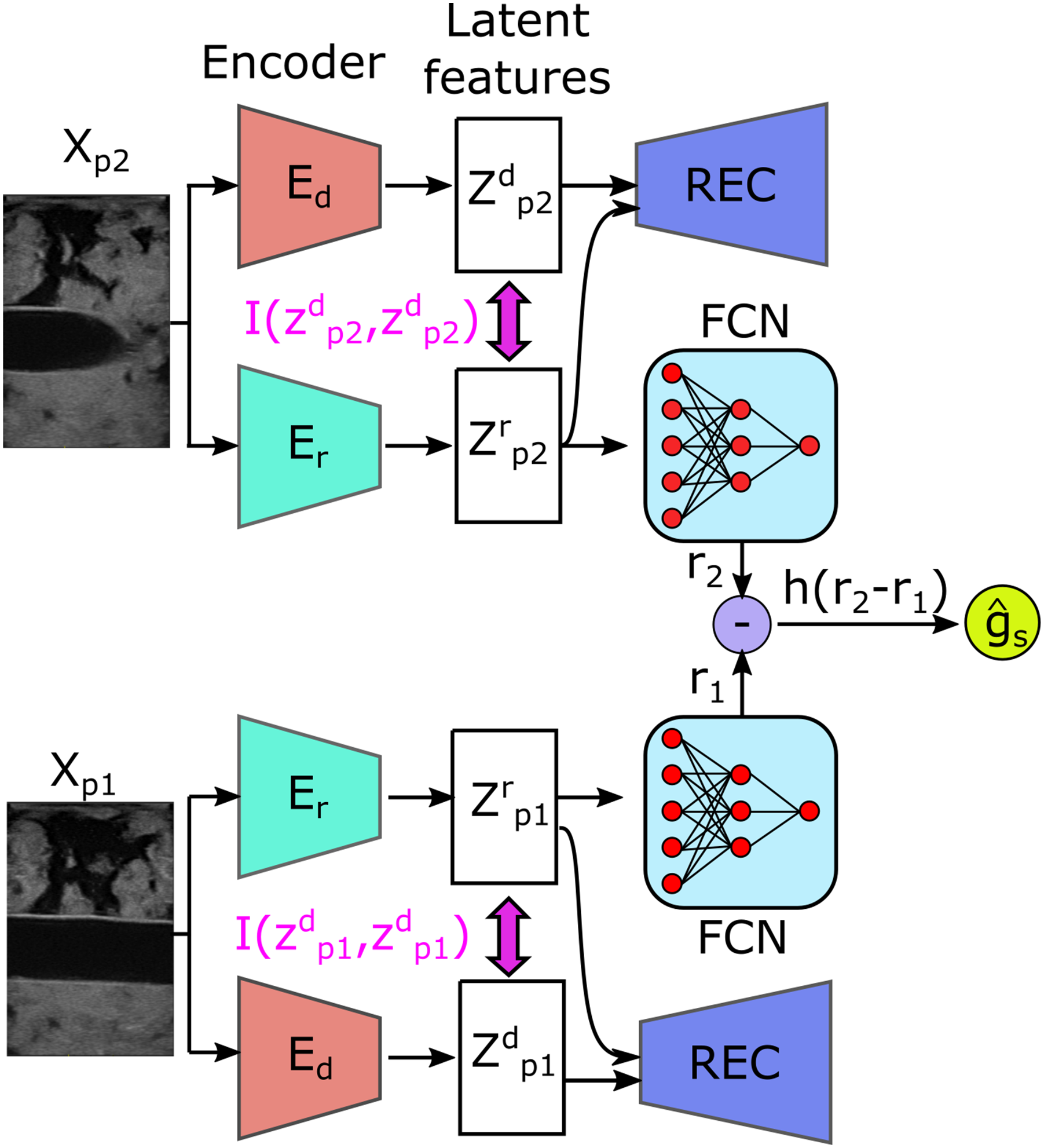
3.6.1. Image reconstruction loss
The MI-GPSR is implemented in the structure of Encoder-Decoder where two encoders independently extract latent representations from the original input Xp. Two encoders Er and Ed are used to, respectively, extract task-related features Z
r
and domain features Zd, where Zr = Er (Xp, θEr) and Zd = Ed (Xp, θEd). The decoder REC is employed to guarantee the combination of features Zr and Zd can recover the original input images, where
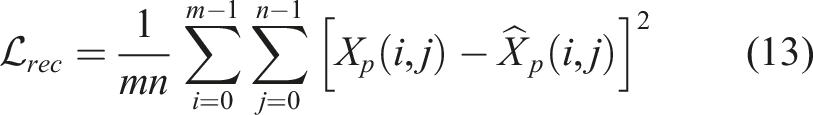
3.6.2. MI neural estimator loss
To enforce the explicit feature disentanglement in latent space, MI neural estimator Tθ (see Section 3.5) is employed. To optimize the network parameter θMI of Tθ, we need to maximize the lower bound of MI

3.6.3. Spatial information-based pairwise image ranking loss
In order to make the network understand the underlying expert “intention,” this work proposes a spatial ranking approach (see Section 3.4) to train the MI-GPSR in a self-supervised mode. The proposed MI-GPSR also eliminates the requirement of burdensome manual annotation. The expert’s “intention” is inferred as reward r ∈ [0, 1], where a high value will be assigned when the image is close to the target standard US planes. To estimate the reward value for individual images, an FCN FCNθ is used to compute the reward of random input Xp as r = FCNθ(Er(Xp)). To train the MI-GPSR in a self-supervised mode, pairwise image comparisons are used. The spatial information-based pairwise image ranking loss
The MI-GPSR is trained in an alternating fashion, and the estimated MI I(Zr, Zd) is used as the supervision to update both Er and Ed.

4. Autonomous navigation to standard planes
To autonomously locate the standard plane, a coarse-to-fine navigation framework is implemented. The coarse location is determined using simulated images generated from a recorded volume, utilizing the inferred reward for each image. Subsequently, a fine adjustment in the neighboring region is applied on the actual target to determine the target US plane. The details can be found in the subsequent sections.
4.1. Generation of simulated US images
The proposed reward inference network MI-GPSR enables reward estimation of individual images based on the disentangled task-related features FCN θ (Z r ). Theoretically, it is possible to evolve a policy to navigate a US probe towards target standard planes using RL methods or Gaussian processes. Nevertheless, to find an optimal policy in real scenarios, rich interaction between RUSS and patients is needed to balance both exploration and exploitation. Due to safety concerns and time efficiency, these approaches are not suitable for medical US examination tasks.
4.1.1. Robotic scanning and US volume reconstruction
To tackle the practical limitations, a new framework is proposed in this work. Instead of real-time interaction with patients, a single sweep over the anatomy of interest is carried out first. The region of interest is manually defined by operators by selecting three points Representative scanning trajectory generated for fully covering the anatomy of interest.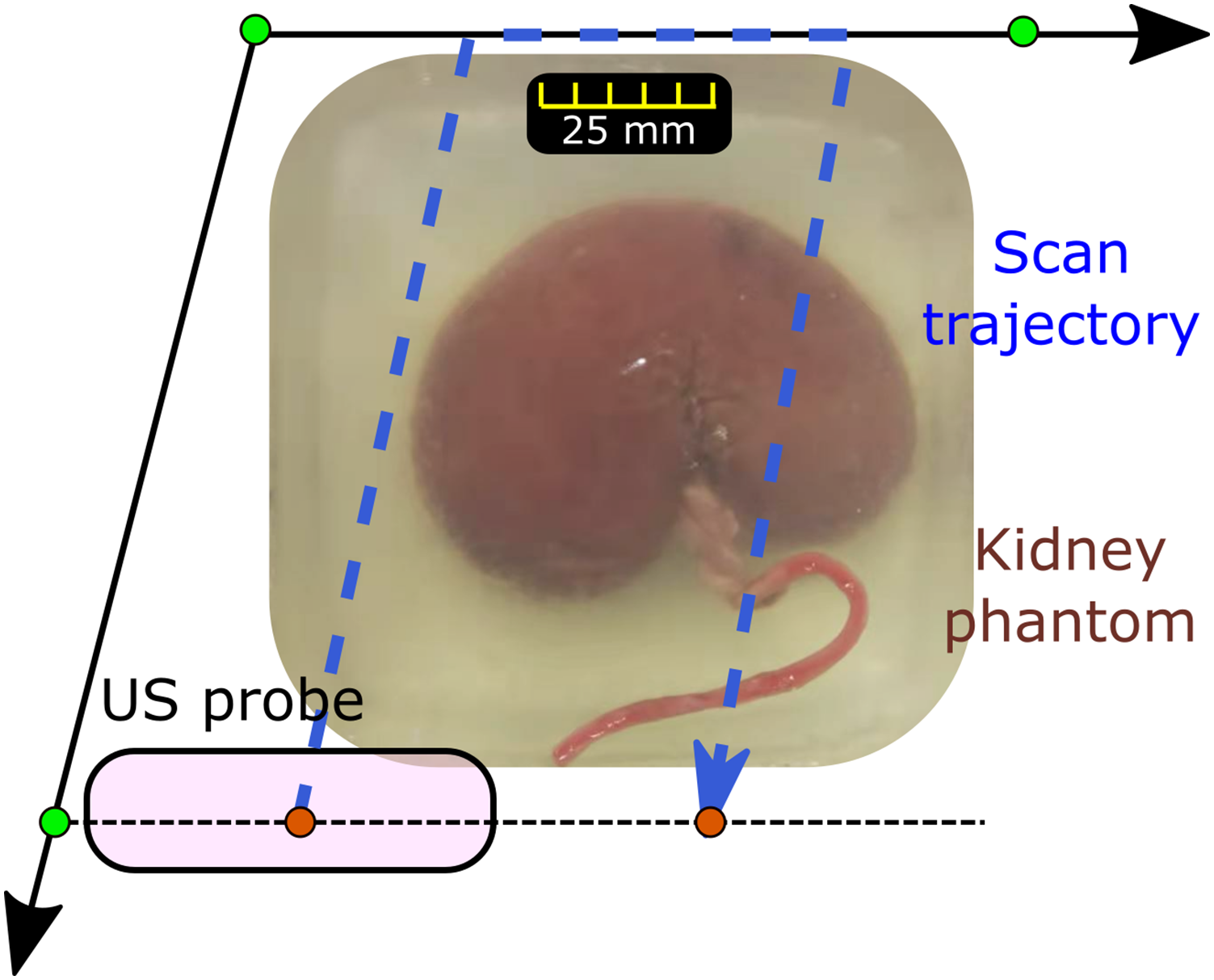
Based on the planned trajectory, the tracked B-mode images can be stacked spatially in 3D space based on the known robotic kinematic model. To generate 3D volume, a linear interpolation was employed using PLUS (Lasso et al., 2014).
4.1.2. Simulated US images from real volume
To ensure patient safety, only one US sweep over the target is carried out. Since the US standard plane can only be achieved by correctly positioning and orienting the probe, the standard US plane may not be contained in the recorded 2D US images. Compared to taking multiple sweeps on patients, simulating 2D US images with varying acquisition parameters from the compounding volume can reduce the dynamic contact with patients and time to get images with different acquisition parameters. Thereby, it can minimize the risk for patients and improve the efficiency of the US examination procedure. To obtain 2D images from the compounding result, a virtual rectangle (w
p
× d
p
) is employed to mimic US imaging plane, where w
p
and d
p
represent probe footprint width and the acquisition depth, respectively. Afterward, the US volume is projected into the X-Y plane of the robotic base coordinate system {b} (Figure 6(a)). The detailed coordinate systems of the setup can be found in our previous publications (Jiang et al., 2021a). The probe pose in the projected 2D view can be defined as (
b
x,
b
y, and
b
R
z
). In case the desired plane is only able to be seen when the probe is tilted, additional rotation around probe long axis Illustration of generating simulated images from a recorded volume. (a) The projected view (X-Y plane of robotic base frame) of a representative US volume. (b) The masked version of the projected view.
By tuning the probe pose (
b
x,
b
y,
b
R
z
, and
p
R
x
) in a virtual environment, a large number of simulated images could be generated in a shorter time (around 10 ms per image) compared to physical acquisitions. The detailed parameters involved here are (1)
b
x = [xmin, x
s
, xmax], (2)
b
y = [ymin, y
s
, ymax], (3)
To filter out the simulated images without meaningful context (part/full of the simulated image is out of the recorded real volume), the recorded volume mask M
v
(2D) was generated by projecting the 3D compounding volume onto the X-Y plane of coordinate system {b} (Figure 6(b)). The white area (I = 1) represents the projected volume with context inside, while the black area (I = 0) is the area padded during 3D compounding. Besides, another mask representing a probe M
p
with various acquisition parameters (
b
x,
b
y, and
b
R
z
) can be seen as a binary mask with a line on it (see green line in Figure 6). The line mask length is defined as the probe width w
p
. Then, an element-wise multiplication is carried out (
4.2. Alignment of US probe
4.2.1. Coarse positioning of US probe
Due to the explicit feature disentangle process, the well-trained reward inference network MI-GPSR FCN
θ
(Z
r
) can be directly applied to the unseen simulated images (potential with unrealistic artifacts). Thereby, a corresponding reward volume map can be achieved by exhaustively creating simulated images using varying probe poses in the virtual environment. To intuitively visualize the reward distribution, two representative reward volumes of tubular phantom and ex vivo kidney phantom are depicted in Figure 7. The tubular phantom and kidney phantom are used to mimic two common navigation tasks for a “point” object and a “line” object, respectively. In the 3D reward volumes, blue means low reward while yellow represents high reward. A higher reward means being closer to the desired US plane. It can be seen from Figure 7 that the high reward Illustration of two inferred reward volumes of (a) ex vivo kidney phantom and (b) tubular phantom.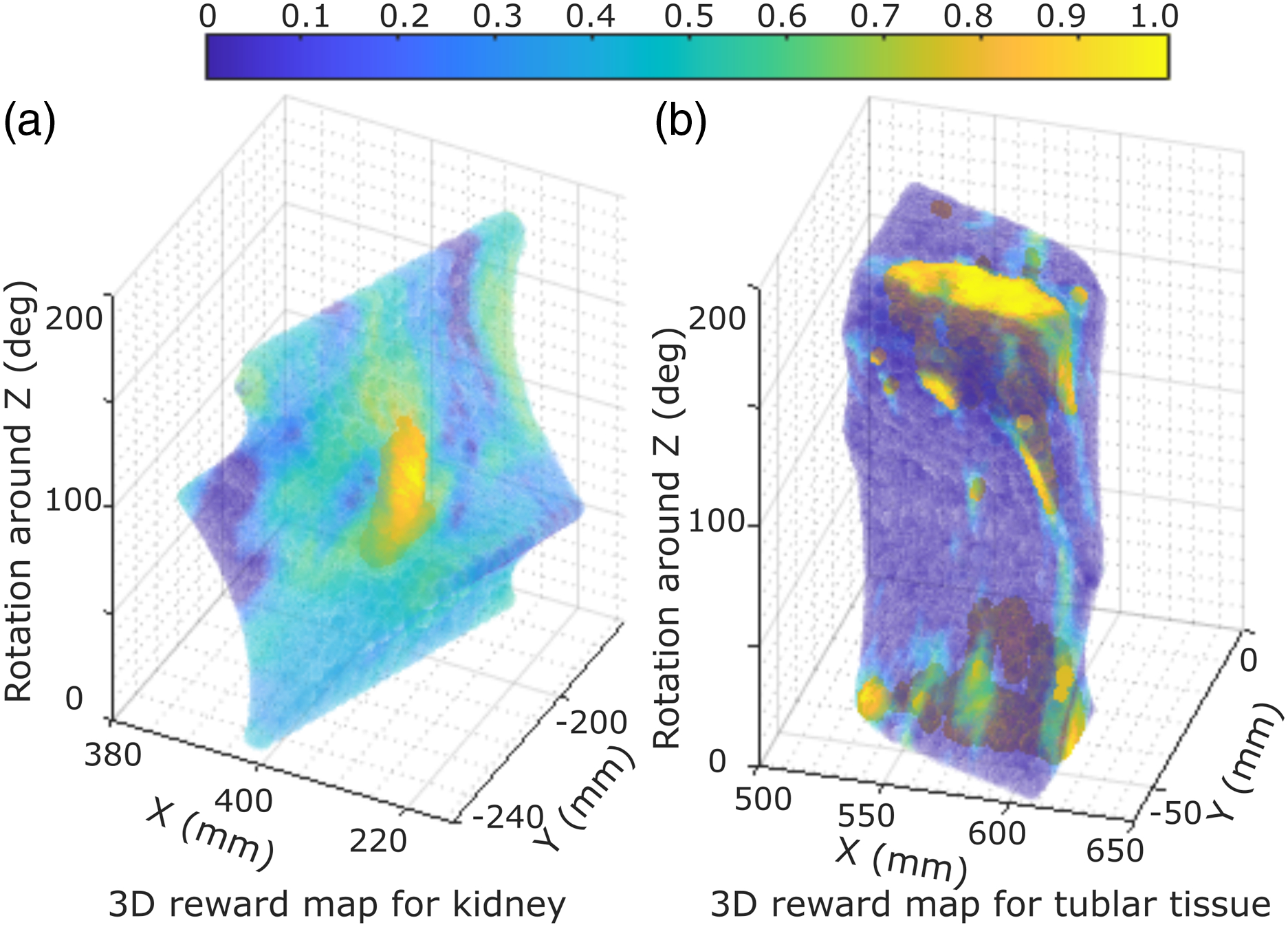
To avoid the effect of the potential inaccurate reward prediction, a 3D moving window is employed to smooth the 3D volumetric rewards. Afterward, the simulated image with the highest average reward value is picked, and its acquisition parameters are considered as the coarse location of the target pose displaying the target US plane. During the approaching process of the identified coarse location, the robotic manipulation is controlled in the impedance control mode to maintain the contact force in the direction of the probe centerline, which is achieved by setting a stiffness and desired force. For more detailed implementation of this controller, refer to Hennersperger et al. (2016) and Jiang et al. (2021a). In order to accurately position the probe to the recapped location from the recorded US volume in the current setup, a relatively larger stiffness is used for other DoFs of the robot (1000 N/m and 20 Nm/rad for the translational and rotational movement, respectively). Finally, a safety limitation is set to 25 N to restrict the maximum force exerted by the robot. If the contact force is larger than 25 N, the robot will automatically stop to avoid excessive force.
4.2.2. Fine adjustment of US probe
To mimic human experts’ behavior and bridge the potential gap between simulated US images and real images, a fine-tuning process is performed after coarse positioning of US probe. Considering the size of objects, a searching area ( b x: ±10 mm, b y: ±10 mm, b R z : ±10°, and p R x : ±10°) is defined around the coarse pose determined by simulated images. The step size for the involved translational movement was 5 mm and the one for the rotational movement was 5°. The searching procedure is automatically performed inside the predefined area. During the fine-tuning procedure, the reward for each image was computed in real-time. The US image with the maximum reward was finally considered as the best pose to visualize the target standard plane. In addition, the searching parameters used in the fine-tuning procedure can be changed according to the requirements (e.g., accuracy and/or time) of targets with varying sizes.
5 Results
5.1. Hardware setup
The proposed RUSS mainly consists of a robotic arm (KUKA LBR iiwa 7 R800, KUKA Roboter GmbH, Augsburg, Germany) and a US machine (Cephasonics, California, USA). A linear probe (CPLA12875, Cephasonics, California, USA) is rigidly attached to the robotic flange using a 3D-printed holder. B-mode images are accessed using a USB interface provided by the manufacturer in 50 fps. The robot is controlled using a Robot Operating System interface (Hennersperger et al., 2016). The real-time US images and robotic poses were synchronized and further used for 3D compounding in a software platform (ImFusion GmbH, Munich, Germany). The US setting was mainly determined by the default setting file for vascular tissues provided by the manufacturer: brightness: 66 dB and dynamic range: 88 dB. The depth, focus, and frequency were 5.0 cm, 3.1 cm, and 7.6 MHz for vascular phantom, respectively, while these parameters were changed to 5.5 cm, 5.0 cm, and 5.7 MHz for the ex vivo phantoms.
To validate the performance of the proposed approach for various organs, three types of phantoms (lamb kidney, chicken heart, and vessel) were used in this work. The blood vessel phantom was primarily made using gelatin powder, while the ex vivo organ phantoms were made using candle wax. Candle wax has a good sealing ability, which allows for longer preservation of fresh animal organs. To construct the vascular phantom, gelatin powder (175 g/L) was dissolved into water, and the mixed solution was heated to 80°. To mimic human tissue artifacts, paper pulp (3–5 g/L) was randomly mixed into the solution. After solidification, a round tube was used to create two holes at different depths of the phantom for mimicking vascular structures. For the ex vivo organ phantom, hot candle wax liquid was used to cover the organs in a small box. After the liquid was fully solidified, it was taken out and placed in another box. Then, candle wax liquid was poured into the box to submerge the upper surface of the phantom. Like paper pulp used for vascular phantom, ginger powder (10 g/L) was mixed with the candle wax for ex vivo organ phantoms.
5.2. GPSR performance on 2D grid world
To intuitively demonstrate that the proposed method works for both “point” and “line” objects, which are the two most representative tasks in clinical practices, a grid world environment (20 × 20) is built for qualitative and quantitative analyses. In the grid world, the aim is to move an agent initialized at a random position toward the target position (marked in yellow in Figure 8). Since there is no need to disentangle image features in latent space in grid-world environments, the advanced version of GPSR (MI-GPSR) is not tested here. Reward maps obtained from sub-optimal demonstrations in grid worlds. Red lines represent the given demonstrations in the grid world, and the color in each grid shows the inferred reward of the corresponding position. In ideal cases, the predicted reward value ([0,1] in yellow) reflects the distance between each position and the target grid position/positions.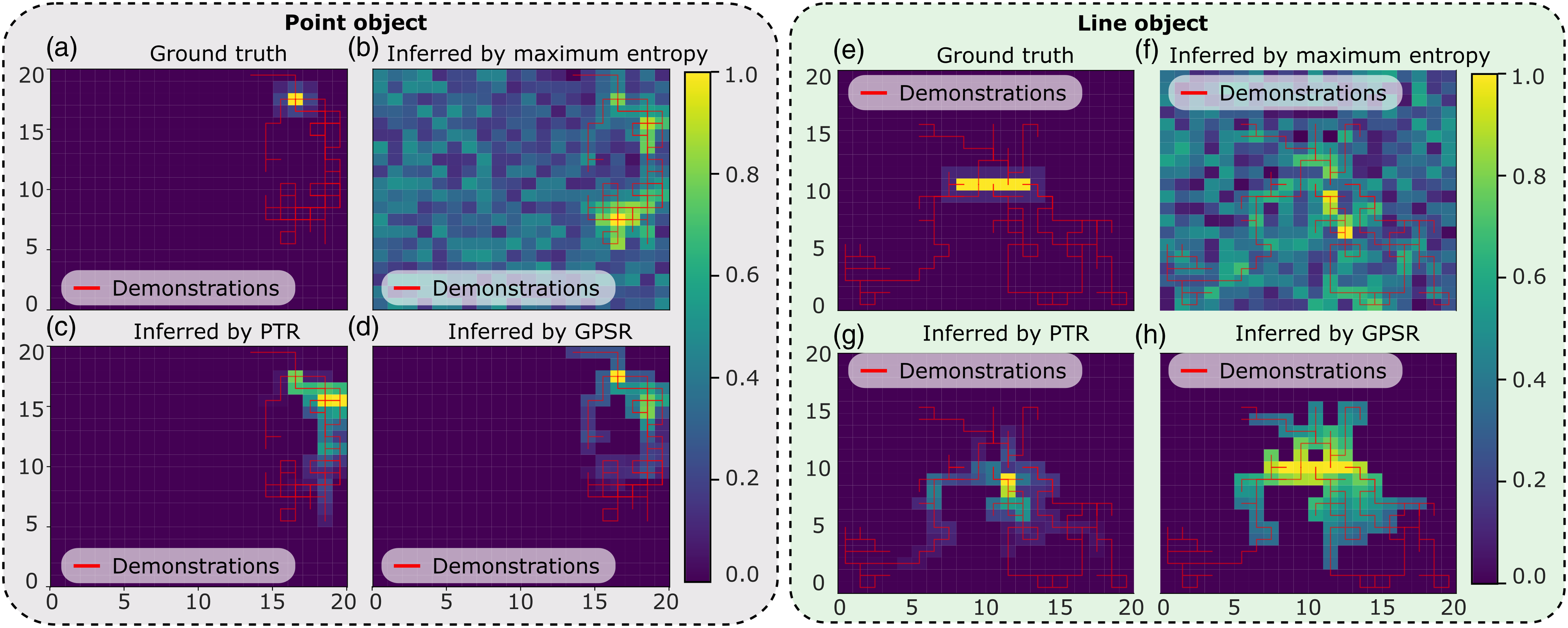
In order to generate sub-optimal trajectory demonstrations, two q-learning policies were trained separately for the “point” and “line” objects in the grid world, in which the reward of the target position was set to one, while the rewards of other positions were zero. The maximum number of episodes and steps for each episode were set to 50 and 100, respectively. Based on the sub-optimal trained model, an agent will move toward the target position from a random position. For point object, five demonstrations ending at the target position were generated to mimic standard planes in US applications. In addition, for the line object (1 × 5), 10 demonstrations ending at the target line were generated. Since the model was only trained with limited epochs, the generated demonstration was sub-optimal; namely, the trajectory cannot directly move toward the target position in the minimum number of steps.
Based on the given sub-optimal demonstrations, three reward models were trained using maximum entropy IRL (ME-IRL) (Aghasadeghi and Bretl, 2011), PTR (Burke et al., 2023), and the proposed GPSR, separately. The ground truth and the reward maps inferred by the three models are shown in Figure 8. It can be seen from the figure that the reward map inferred by the proposed GPSR is the closest to the ground truth, in which the highest reward clearly shows at the correct position in the grid world. The result achieved using the maximum entropy (Aghasadeghi and Bretl, 2011) approach failed to correctly recover the reward value from the sub-optimal demonstrations, particularly for the line object. This is mainly because of the inherited limitation of the maximum entropy approach, which tends to assign larger reward values to states observed more often in the demonstrations. However, demonstrations of US examinations are often sub-optimal. The positions observed more often in the demonstrations may not be the desired positions. Regarding PTR approach (Burke et al., 2023), the inferred reward map is better than the one obtained from maximum entropy while still worse than the one achieved from the proposed GPSR approach. It can be seen from Figure 8(c) that the position with the maximal reward is close to the desired position. However, since the pairwise training data was generated from individual demonstrations, a biased result occurs, especially when the lengths of demonstration are significantly different from each other. For the line object, PTR fails to realize that the object is a line. Only one grid point of the line is successfully assigned with a large reward (see Figure 8(g)).
Considering the intrinsic properties of US examination, the target standard planes correspond to a unique or a set of probe poses with a unified character. Thus, the proposed GPSR approach directly generates the paired training data from all demonstrations based on the probe spatial cues rather than temporal cues. Due to the global consideration of all demonstrations, more training data could be generated from the same demonstration using the GPSR approach. The performance of inferred reward in grid world using different approaches also demonstrates the superiority of GPSR over the PTR and ME-IRL approaches, particularly for unstructured objects like a line object (Figure 8).
Performance of Learning From Demonstrations Methods.
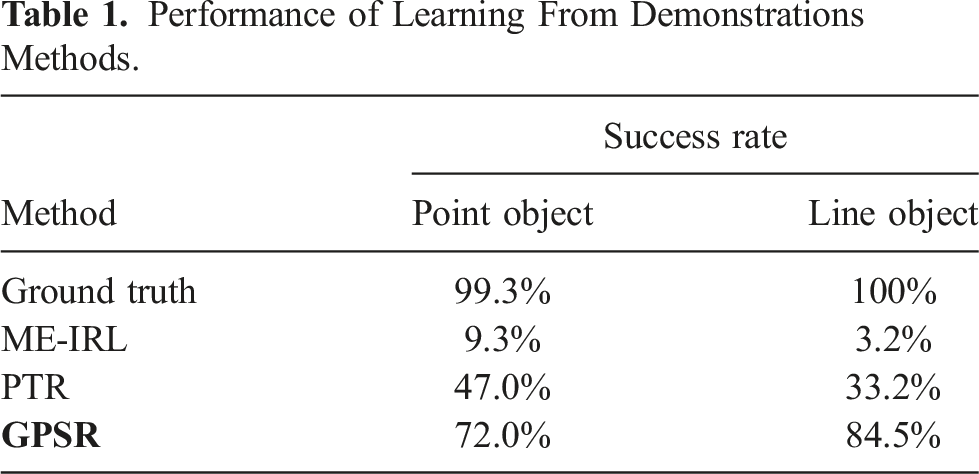
It can be seen from Table 1 that the ME-IRL results in the worst case in our setup, where the success rate is only 9.3% and 3.2% for the point and line objects, respectively. In contrast, the result obtained using the ground truth is the best (99.3% and 100%). The success rates achieved using the PTR and the proposed GPSR are 47.0% and 72.0% for the point object, respectively. Although GPSR results are still worse than the ground truth, the performance has already significantly improved from the state-of-the-art approaches (62.7% and 25%, respectively). In addition, regarding the line object, the success rate for PTR further decreases to 33.2% while the GPSR increases the number to 84.5%. This is because PTR can only consider the individual demonstrations based on temporal information, while the proposed GPSR globally generates pair-wise comparisons between all available demonstrations using spatial information. But it needs to be noted that the presented comparison results are achieved when only a few demonstrations are available, and they are sub-optimal. If a large amount of demonstrations becomes available, the performance of PTR and ME-IRL could be improved. But, theoretically, they still lack the capability to successfully reconstruct the reward map of a “line” object. In addition, it is noteworthy that the MI-GPSR was not compared in the grid word experiments. This is because the state inputs (grid position) in the grid world are ideal without any noise. So there is no need to further disentangle the features in latent space.
5.3. MI-GPSR performance on unseen demonstrations from phantoms
5.3.1. Training details
Regarding the training process of the proposed MI-GPSR approach, only six demonstrations were randomly selected out of ten expert demonstrations. Five of them were used as training dataset, while the remaining one was used for validation. To balance the weights of different demonstrations, all demonstrations were down-sampled to 100 frames. Therefore, the size of the pair-wise training dataset is C (500, 2) = 124,750, while the size of the validation dataset was C (100, 2) = 4,950. The network parameters of the proposed MI-GPSR are updated based on the three loss functions,
5.3.2. Inferred reward from unseen demonstrations and unseen phantoms
To validate the performance of the proposed models, we tested the well-trained GPSR model on unseen demonstrations acquired from the same phantoms as training data. Considering inevitable variations for different patients, we further tested the GPSR and MI-GPSR on the demonstrations acquired from unseen phantoms. As defined in Section 3.4, the desired reward is negatively correlated to the global generalized distance Illustration of inferred rewards from three unseen US clips acquired from the trained phantoms, as well as three unseen demonstrations on three unseen phantoms (vascular phantom, ex vivo chicken heart, and lamb kidney phantom).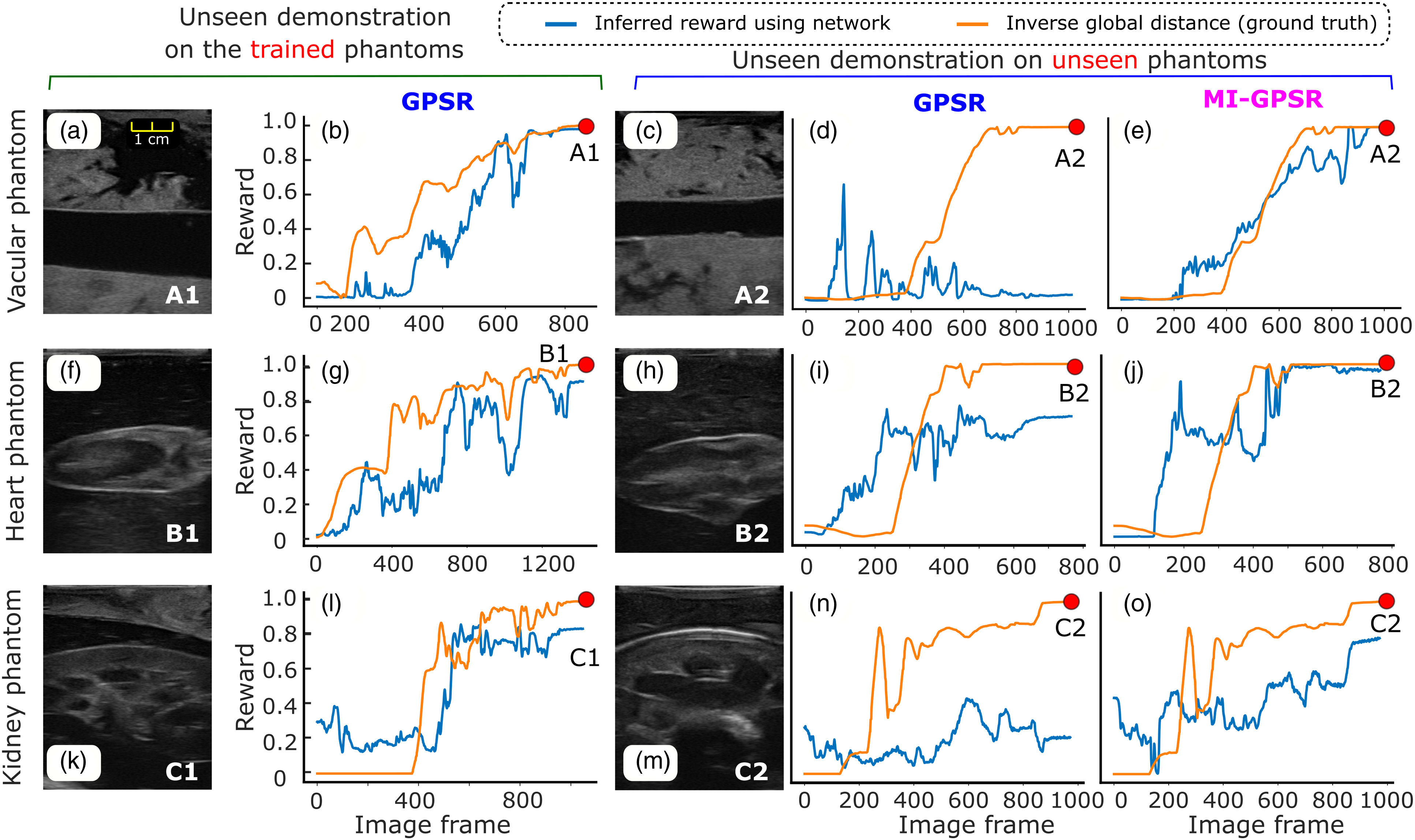
Figure 9 (a), (f), and (k) are the last frames of the unseen demonstrations obtained on the vascular phantom, heart phantom, and lamb kidney phantom, respectively. The inferred rewards of the unseen demonstrations by GPSR are depicted in Figure 9 (b), (g), and (l). It can be seen from the figure that the change tendency of the predicted rewards is consistent with the reference index. For the vascular phantom, the predicted reward of the final frame of the demonstration achieved the highest reward value (0.98). For the more changeling task of ex vivo phantoms (chicken heart and lamb heart), the inferred rewards of the last frames also achieve 0.90 and 0.84, respectively.
The aforementioned results are achieved on the same phantoms as the training data. To mimic the variations between patients, three new phantoms with the same anatomies are built. Comparing the images presented in Figure 9 (c), (h), and (m) with the ones listed in the first column, the sizes, shapes of the involved tissues, and artifacts of the image are different. The same expert is asked to perform three demonstrations on each unseen phantom, respectively. Due to the significant difference, the GPSR fails to predict the reward for the vascular and kidney phantoms (0.01 and 0.21 for the last frame). The GPSR inference result of the heart phantom of the last frame achieved 0.70, while it is still significantly less than the one achieved on the trained phantom (0.92). We consider the relatively high reward inference of the heart phantom mainly because the new phantom is still similar to the one used for training (see Figure 9 (f) and (h)).
To improve the generalization capability of the reward prediction network to tackle inter-patient variations, we further proposed MI-GPSR to explicitly separate the task-related and domain features of input images. Then, only the task-related features are used to compute the reward. The MI-GPSR results on the same demonstrations acquired from the unseen phantoms are depicted in Figure 9 (e), (j), and (o), respectively. In all cases, MI-GPSR achieved much better results than the ones obtained by GPSR. For the unseen phantom, the predicted rewards of the last frame in the demonstrations by the MI-GPSR are 1.0 and 0.98 for the vascular and heart phantom, respectively. Similar to the second column, the predicted reward of the kidney phantom is slightly lower than others (0.78). We consider that this phenomenon is mainly caused by the more complex structures of the kidney in the B-mode images. To further improve its performance on complex anatomy as well, more data can be recorded from the expert.
5.4. MI-GPSR performance on unseen demonstrations from volunteers
In order to ensure the transferability of the proposed MI-GPSR in real scenarios, we further compared its performance with GPSR on in vivo carotid data recorded from six healthy volunteers. To validate the generalization capability on different patients, six demonstrations (two for each volunteer) recorded from three volunteers’ carotids were used as the training dataset, while three distinct demonstrations (one for each volunteer) recorded from three unseen volunteers were used for testing. The expert demonstrations were given by manually maneuvering the linear probe (Siemens AG, Germany) fixed at the robotic end-effector. The acquisitions were performed within the Institutional Review Board Approval by the Ethical Commission of the Technical University of Munich (reference number 244/19 S). A certified Siemens Juniper US Machine (ACUSON Juniper, Siemens AG, Germany) was used with the default US parameters for carotid imaging to acquire in vivo data. The US images from the Juniper US machine were accessed in real-time using a frame grabber (Magewell, Nanjing, China). It is worth noting that both GPSR and MI-GPSR models were retrained for human carotid scans. The training details were the same as the ones used for phantoms (see Section 5.3.1).
The interpreted rewards for individual images from unseen demonstrations on unseen volunteers have been depicted in Figure 10. The reward was computed purely based on US images without additional information during inference. Each row represents the results of one volunteer. To provide an intuitive understanding of in vivo data, two intermediate images and the last frames in each demonstration have also been shown in Figure 10. It can be seen from Figure 10 that GPSR can roughly track the changes in the inverse global distance (orange curves). However, the interpreted reward (∈ [0, 1]) curves using GPSR are not as accurate as the ones computed using MI-GPSR. More fluctuations are witnessed in the end phase for all three unseen demonstrations, which will hinder the achievement of an accurate understanding of the sonographer’s intention. The predicted reward values of the three last frames (A3, B3, and C3) of the three unseen volunteers are 0.82, 0.65, and 0.67, respectively. In contrast, the reward values of the same three frames, namely, the target standard plane, are accurately predicted by the evolved MI-GPSR as 0.99, 0.99, and 0.99, respectively. Regarding the intermediate frames B2, the computed rewards using GPSR and MI-GPSR are 0.53 and 0.95, respectively. By comparing the images in B2 frame, it is quite similar to the standard plane shown in the last frame (B3) for Volunteer 2. Thereby, we consider the MI-GPSR can better predict the reward of individual B-mode images. Illustration of inferred rewards computed using GPSR and MI-GPSR from three unseen US carotid clips acquired from three unseen volunteers. The three volunteers’ data was not involved in the training data at all. Three rows represent the results of the unseen clips recorded on three unseen volunteers.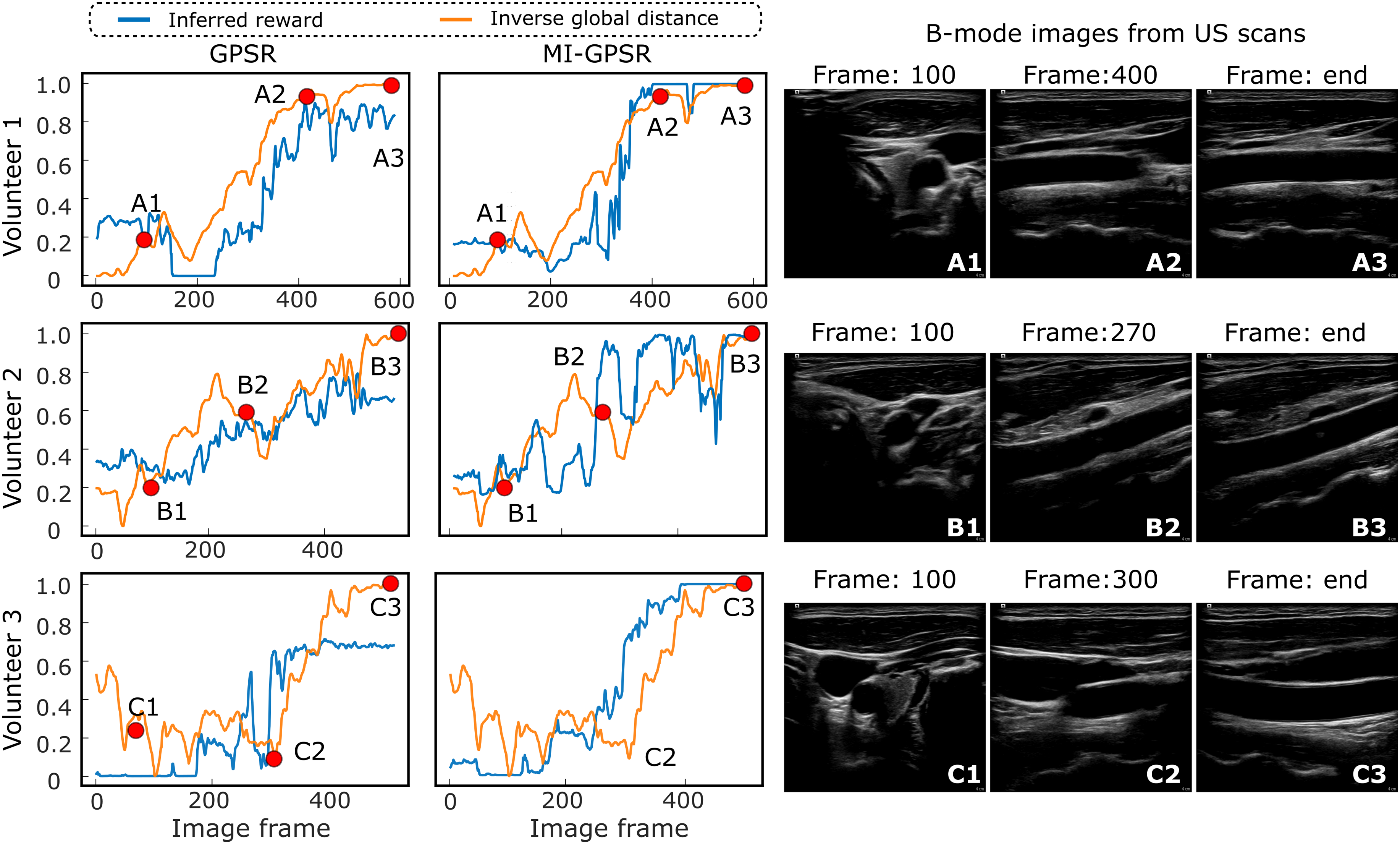
The proposed MI-GPSR can significantly improve the generalization capability to adapt patient-specific data with a limited training dataset. This is consistent with the results on three types of vascular and ex vivo phantoms. By comparing the results on unseen volunteers (Figure 10) to the ones obtained on unseen phantoms (Figure 9), we can find GPSR performs much better on human carotids than on phantoms. This is different from what we thought before the experiments. We consider the reason for this phenomenon to be that human tissues (same organs) usually share much more structural similarities than phantoms, particularly when a generally optimal US acquisition setting is used. It can be observed from Figure 10 that although the carotid images (each row) are obtained from three different volunteers, the structural information, including background intensity and surrounding tissues, is similar. In contrast, the custom-made phantom was made by randomly mixing paper pulp into the gelatin powder. It is evident from Figure 9 that the background information in the training and testing phantoms differs significantly from each other. Consequently, better performance is observed using GPSR on human carotid data than the phantom data.
5.5. Performance of standard scan planes alignment
In order to validate the proposed approach in realistic cases, the mimicked vascular phantoms with a “line” objective and ex vivo animal organ phantoms with a “point” objective were built. To guarantee the generalization capability, the MINE is employed to explicitly disentangle the task-related and domain features in the latent space. To validate whether the proposed method can robustly deal with an unseen case, two mimicked tubular structures located at different depths (vessel 1: 36 mm vs vessel 2: 27 mm) of the custom-designed phantoms were used. All the training data was recorded from the vessel 1. To further increase the differences (in both geometry and style) between the B-mode images obtained from the two phantoms, a different brightness 48 dB was used for the unseen vessel 2 from the default one (66 dB) used in other acquisitions. Two significantly different images obtained from vessel 1 and vessel 2* (a different acquisition setting) are depicted in Figure 11. The autonomous navigation results obtained using GPSR and MI-GPSR on the unseen vessel 2* are described as well. Besides, to compare the performance between the proposed approach and a human expert, the variations on final position and orientation for different experiments were recorded. Finally, considering that objects could be moved after training, the phantoms were rotated into different angles (30, 60, and 90°) to validate whether the method is still able to place the probe in the target planes correctly. Performance of an experienced human expert, GPSR, and MI-GPSR on two different vessels. All the training data are only obtained from vessel 1. To validate the generalization capability of the proposed MI-GPSR, an unseen vessel 2 with a smaller diameter is employed. The sign “*” means the US brightness value is 48 dB in acquisitions, which is different from the default one (66 dB) used in other acquisitions.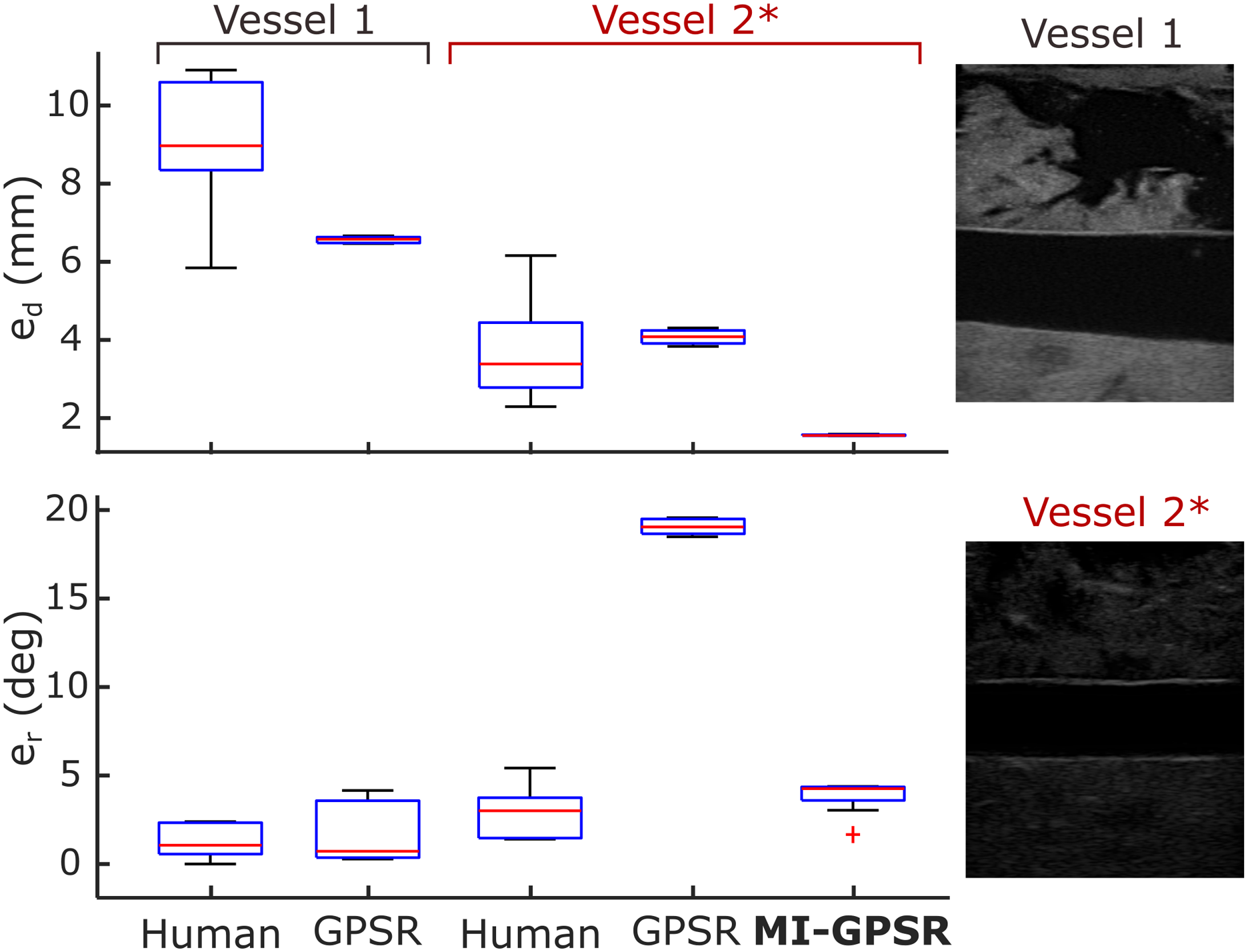
5.5.1. Comparison with a human expert and the validation of the generalization capability
To quantitatively compare the performance between an experienced human expert, GPSR, and MI-GPSR approaches, 10 navigation experiments were performed by the expert and the proposed GPSR approach, respectively, to position the probe along the longitudinal plane of the vessel 1. The mimicked blood vessels are straight holes inside the phantom, allowing positional slack in the direction of the vessel centerline. Thus, the distance error (e d ) is defined as the distance between the vessel centerline and the US imaging plane in 3D space instead of the absolute positional difference. The centroid of the vessel in US images was calculated using the same steps as Jiang et al. (2021a): (1) using a U-net to segment the vessel from US images, (2) computing the centroid based on the binary map using OpenCV, and (3) applying the spatial calibration result to calculate the 3D position of pixel-wise centroid in 2D images. The ground truth of the vessel centerline was computed by moving the probe along the vessel centerline. Besides metric e d , the absolute rotation error (e r ) between the probe long axis ( p X) and the vessel centerline was further defined to assess the probe orientation accuracy.
The results of e d and e r over the 20 trials (10 for each phantom) performed by the same expert and the GPSR approach on vessel 1 are summarized in Figure 11. Regarding e d , GPSR results are more concentrated and the average e d (Mean±STD: 6.6 ± 0.1 mm) is less than the one obtained from the expert (9.1 ± 1.7 mm). Regarding e r , the GPSR achieves comparable results (1.5 ± 1.6°) to the expert (1.3 ± 1.0°). Based on a significant test (t-test), the probability between e r obtained from the expert and the GPSR is 0.72 > 0.05, which means there is no significant statistical difference between these data.
To further compare the generalization capability of the GPSR and the evolved MI-GPSR, an unseen blood vessel, namely, vessel 2, was employed to represent a patient-specified anatomical structure. To perform such validations in a challenging case, a different brightness of 48 dB was used for unseen vessel 2 rather than the default one (66 dB) used in other acquisitions. The resulting images obtained from vessel 2* become significantly different from the ones used in training from vessel 1. To compare the human performance for different vessels, 10 independent trials were carried out by the same human expert. Without further updating the parameters in the trained reward network using the demonstrations for vessel 1, the GPSR and the evolved MI-GPSR were also run 10 times, separately, on unseen vessel 2*. The navigating results are depicted in Figure 11.
In terms of e r , the expert achieved close results on two different phantoms (1.3 ± 1.0° and 2.9 ± 1.3°) while e d obtained for vessel 2* is significantly smaller than the one obtained on vessel 1 (3.7 ± 1.1 mm and 9.1 ± 1.7 mm). We consider the observed intra-operator variations of a positional error on different phantoms are caused by the geometry characteristic of tubular structures. Due to the limited human spatial perception, experts determine the standard US plane (longitudinal view) only based on B-mode images rather than probe position. Considering the tubular structures, the target geometry in the resulting 2D images will be changed significantly from an ellipse to a rectangle when the probe rotates around the probe centerline; in contrast, the translational deviation orthogonal to the vessel centerline will only change the height of the resulting rectangle shape (longitudinal view). The significant changes in terms of shape are beneficial for human experts to capture the rotational variations, while the translational motion-induced rectangle height change is not easily visible for humans. Therefore, we think biased e d results for the same expert on two different phantoms could happen, particularly for the tubular phantoms.
It can be seen from Figure 11 that e r results of the GPSR and MI-GPSR on vessel 2* are 19.1 ± 0.4° and 3.8 ± 0.9°, respectively. Based on this, we can conclude that the GPSR failed on significantly different vessel 2*, while the proposed MI-GPSR can still accurately navigate the probe to the standard planes in terms of angular error. The er results obtained by MI-GPSR are comparable to the ones obtained by the human operator (3.8 ± 0.9° vs 2.9 ± 1.3°). However, it is noteworthy that although the e r of GPSR is very large, the positional errors of GPSR are still comparable to the human operators, even more concentrate (4.1 ± 0.2 mm vs 3.7 ± 1.1 mm). We believe this is because human experts usually can swiftly move the probe toward the target vessel and then slowly rotate the probe to find the objective plane. During the rotational adjustment, the probe tip position does not change. Such behavior is implicitly represented in the expert demonstrations and can be learned by the GPSR (also for the evolved MI-GPSR) by generating pairwise image comparisons. The e d of the proposed MI-GPSR is only 1.5 ± 0.1 mm, which is more stable than human experts. These results demonstrate that the MI-GPSR has the potential to deal with inter-patient variations occurring in real scenarios. In addition, it is also noteworthy that the MI-GPSR can generate better results than human demonstrations, that is, e d in Figure 11. This is because the examples with low confidence values have been filtered out and also the demonstrations are considered globally to balance the variation between individual demonstrations.
5.5.2. Quantitative assessment of standard planes alignment on various anatomical targets
This section demonstrates the quantitative results of the proposed MI-GPSR approach on different objects (tubular tissues, chicken heart, and lamb kidney phantoms). It is notable that the phantom used for testing here is different from the phantom for training. To validate whether the MI-GPSR has the potential to be used in real scenarios, the phantoms are placed in different positions and orientations during the experiments. This is because patients’ positions in different examinations are different. For each phantom, four groups of experiments with different angles (0, 30, 60, and 90°) rotated around a given point on the flat table were carried out. Each group consisted of 10 independent experiments. In each experiment, the 3D scan is needed to compute the coarse localization in the current setup; then followed by a fine-tuning process to overcome the potential variations between simulated images and real images.
The performance of the final alignment was assessed using positional (e
d
) and rotational (e
r
) errors as defined in the last subsection. However, differing from the e
d
defined for vascular phantom, the absolute positional error, computed between the final position achieved using the MI-GPSR approach and the ground truth, was used for kidney and chicken heart phantom. This is because that the standard planes are only able to be obtained by a unique pose for the “point” objective. The ground truth of each case was manually determined by the mean of the final frames’ poses in 10 expert demonstrations. The final performance is summarized in Figure 12. Spatial alignment errors between the target probe pose and the automatically identified pose using the proposed MI-GPSR approach.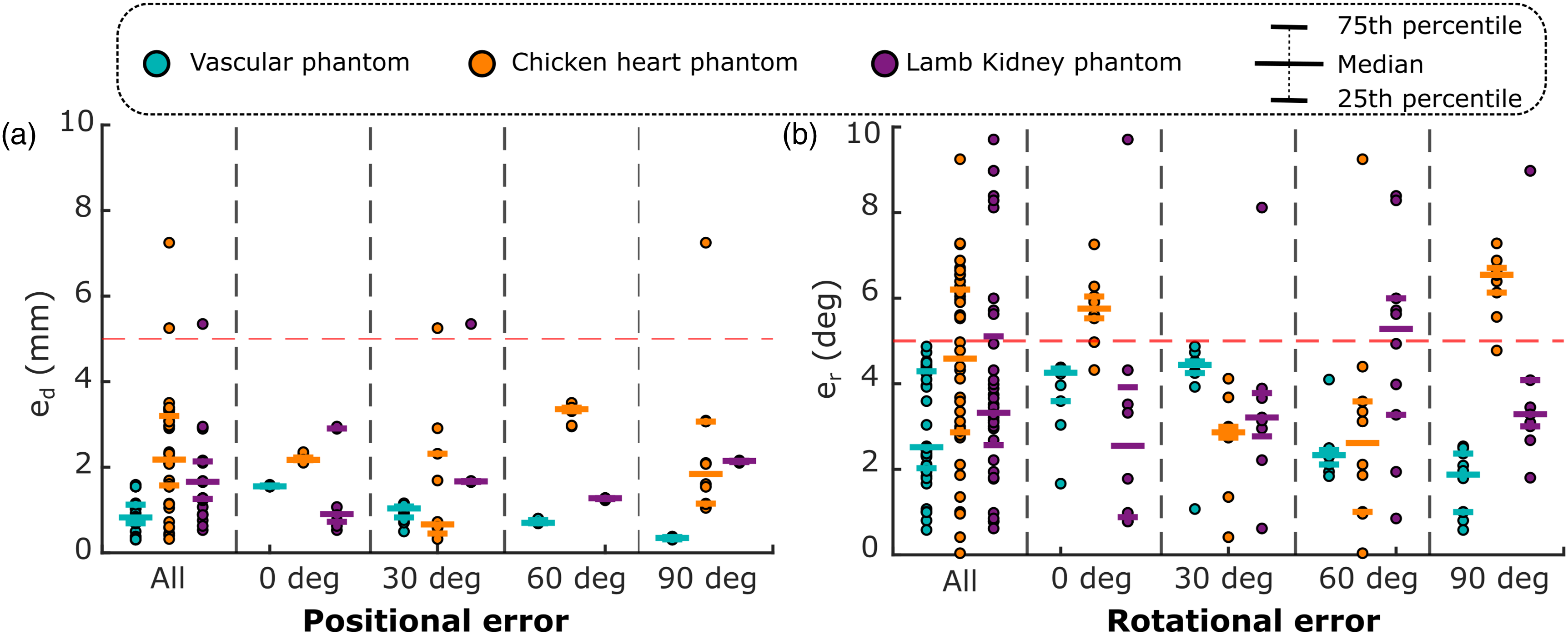
In general, e d for tubular structure, chicken heart, and lamb kidney are 0.9 ± 0.4 mm, 2.4 ± 1.3 mm, and 1.7 ± 0.9 mm, respectively. Besides, e r for the three different phantoms are 3.0 ± 1.3°, 4.4 ± 2.2°, and 4.0 ± 2.5°, respectively. Compared to the results obtained on ex vivo phantoms, the average e d and e r obtained from the vascular phantom are slightly smaller and more concentrated. This is because the B-mode images obtained from the custom-built vascular phantom are more stable and closer to the training data than the ones obtained from the animal organs.
It can be seen from Figure 12 that the trained MI-GPSR model can also robustly work when the phantoms are rotated in different angular deviations without the requirement for further training. In the worst case, the maximum e d and e r for all phantoms are 7.2 mm and 9.7°, while the best results can achieve 0.3 mm and 0.04°, respectively. Overall, both positional and rotational errors are mainly distributed below 5 mm and 5°, respectively, among all experiments carried out on different phantoms. This means that the proposed approach can automatically identify the standard planes for challenging ex vivo animal organs even when the object’s position and orientation change. This capability enables the possibility of addressing the practical factors, that is, patients’ position variations, for different trials in real scenarios.
Besides the navigation accuracy, the execution time of the main components of the proposed MI-GPSR approach is also summarized as follows: the simulation process costs 244 s for generating 4643 images (52 ms for each image), and the reward network costs 11 ± 4 ms for computing the reward for each image. In terms of time efficiency, the proposed approach is more practical than the RL-based methods (Li et al., 2021a; Hase et al., 2020) in real scenarios because it can significantly reduce the dynamic interaction with patients.
6. Discussion
Considering the potential inter-operator variation in free-hand US examinations, only one experienced expert was engaged to both provide the training demonstrations and acquire experimental results in this study. This approach was adopted to facilitate a fair comparison between the human expert and the proposed MI-GPSR approach. Technically, the proposed MI-GPSR can learn operation skills from multiple experts as well if there is no significant inter-operator variation witnessed in the given demonstrations. While we emphasize in the article that MI-GPSR is introduced to tackle the issue of sub-optimal demonstrations, it’s worth noting that the framework can also be applied to optimal US demonstrations. If the demonstrations can terminate at the desired US standard planes, both GPSR and MI-GPSR can be trained to learn the implicit reward function using the self-supervised probabilistic ranking approach.
The MI metric is employed to explicitly disentangle the task-related features and domain features. By extracting disentangled anatomy-related features from varying US images, the generalization capability of MI-GPSR can be enhanced. However, it is noteworthy that the whole framework (learning from demonstration and autonomous navigation) was only validated on different phantoms in the current study. Considering the significant variations among human tissue properties, the reproducibility of final probe navigation results could be reduced in real scenarios. To tackle this issue, either a post-processing approach can be used to correct the image deformation after scans (Sun et al., 2010; Jiang et al., 2021c, 2023b) or an online tuning process of the contact force could be implemented based on real-time feedback (Virga et al., 2016). Both types of approaches require a deep understanding of US images, while there is no unified quality assessment metric yet, and the definition of quality could be different for various applications. Thereby, future work should further clearly define the definition of imaging quality for given downstream applications, which will further enable the automatic contact force optimization procedure. In addition, to bridge the gap between the phantom trials and real patients, some practical factors should also be properly considered, for example, patient physiological movements during the scans. The research community has already noted these problems, and there are some emerging articles focusing on monitoring and compensating for rigid motion (Jiang et al., 2021b, 2022a), articulated motion (Jiang et al., 2022b), and breathing motion (Dai et al., 2021).
In addition to the primary objective of developing an autonomous RUSS, we believe understanding the “language of sonography” from expert demonstrations could be as valuable as the advancements made in the robotic US examination itself. To ensure the proposed MI-GPSR can also effectively recover the “language of sonography” for real human examination, we recorded examination demonstrations for carotid on six volunteers. The results obtained on unseen demonstrations from unseen volunteers demonstrate the proposed MI-GPSR can precisely predict the reward for individual images. To avoid misleading information, we want to emphasize that specific anatomical images recorded from unseen volunteers still share the same shape priors and statistical distributions as the training data. In order to extend to unseen anatomies, new images should be obtained to retrain or refine the network models. To inspire further study, it is also worth noting that the baseline GPSR achieved better results on unseen demonstrations of human carotid (Figure 10) than of unseen phantoms (Figure 9). We consider this is because that human tissues (same organs) usually share much more similarities than homemade phantoms with randomly mimicked noise backgrounds. This finding suggests that the collection of massive examination demonstrations from real patients holds good potential to contribute to the understanding of the common knowledge underlying US examinations. The research in the direction of recovering the “language of sonography” will benefit in transferring senior sonographers’ physiological knowledge and experience to novices.
7. Conclusion
In this work, we present an advanced machine learning framework to automatically discover standard planes based on a limited number of expert demonstrations. To understand the “language of sonography,” a neural reward network is optimized to compute reward value for individual images based on the given expert’s demonstrations. Besides, to guarantee the generalization capability to overcome the inter-patient variations, the proposed MI-GPSR explicitly disentangles the task-related and domain features in the latent space. To validate the proposed approach, experiments were performed on typical “line” targets (vascular phantoms) and “point” objects (ex vivo chicken heart and lamb kidney phantoms), respectively. The experimental results of the MI-GPSR on tubular structure, chicken heart, and lamb kidney phantoms are 0.9 ± 0.4 mm, 2.4 ± 1.3 mm, and 1.7 ± 0.9 mm in terms of e d and are 3.0 ± 1.3°, 4.4 ± 2.2°, and 4.0 ± 2.5° in terms of e r , respectively. To show the potential to be used on real images from humans, the performance of reward inference was also validated on the carotid images recorded from six volunteers. Several conclusions can be drawn from this study: (1) Learning high-level physiological knowledge from human experts from demonstrations is feasible using a reward network. (2) The explicit disentanglement process of latent space features can significantly contribute to improving the generalization capability of the proposed MI-GPSR to overcome variations between the trained data and unseen phantoms.
Beyond the contributions to autonomous robotic US navigation, we also want to emphasize the importance of the side results of this study about the understanding and modeling of expert sonographers’ semantic reasoning and intention. We believe that the understanding of the “language of sonography” could be considered as valuable and essential as the progress made in robotic sonography itself. This can not only allow for autonomous intelligent RUSS development but also for designing US education and training systems and advanced methodologies for grading and evaluating the performance of human and robotic sonography. In the future, the proposed intelligent robotic sonographer can be extended by further considering the practical factors in real scenarios and testing the method on real patients. Such an intelligent system will have the potential to enable the development of a fully automatic intervention system (i.e., vessels [Chen et al., 2020]) and extensive US examination programs for the early diagnosis and monitoring of internal lesions or tumors.
Supplemental Material
Footnotes
Acknowledgments
The authors would like to thank Dr Med. Reza Ghotbi from the vascular surgery department of Helios Klinikum München West and Dr Med. Angelos Karlas from the vascular surgery department of Klinikum Rechts der Isar for their valuable feedback and insightful discussions. In addition, the authors would like to acknowledge the editors and volunteering reviewers for their time and implicit contributions to the improvement of the article’s thoroughness, readability, and clarity.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.