
Abstract
Reward learning enables robots to learn adaptable behaviors from human input. Traditional methods model the reward as a linear function of hand-crafted features, but that requires specifying all the relevant features a priori, which is impossible for real-world tasks. To get around this issue, recent deep Inverse Reinforcement Learning (IRL) methods learn rewards directly from the raw state but this is challenging because the robot has to implicitly learn the features that are important and how to combine them, simultaneously. Instead, we propose a divide-and-conquer approach: focus human input specifically on learning the features separately, and only then learn how to combine them into a reward. We introduce a novel type of human input for teaching features and an algorithm that utilizes it to learn complex features from the raw state space. The robot can then learn how to combine them into a reward using demonstrations, corrections, or other reward learning frameworks. We demonstrate our method in settings where all features have to be learned from scratch, as well as where some of the features are known. By first focusing human input specifically on the feature(s), our method decreases sample complexity and improves generalization of the learned reward over a deep IRL baseline. We show this in experiments with a physical 7-DoF robot manipulator, and in a user study conducted in a simulated environment.
1. Introduction
Whether it is semi-autonomous driving (Sadigh et al., 2016), recommender systems (Ziebart et al., 2008), or household robots working in close proximity with people (Jain et al., 2015), reward learning can greatly benefit autonomous agents to generate behaviors that adapt to new situations or human preferences. Under this framework, the robot uses the person’s input to learn a reward function that describes how they prefer the task to be performed. For instance, in the scenario in Figure 1, the human wants the robot to keep the cup away from the laptop to prevent spilling liquid over it; she may communicate this preference to the robot by providing a demonstration of the task or even by directly intervening during the robot’s task execution to correct it. After learning the reward function, the robot can then optimize it to produce behaviors that better resemble what the person wants. (Left) The person teaches the robot the concept of horizontal distance from the laptop by providing a few feature traces. (Right-Top) In the online reward learning from corrections setting, once the robot detects that its feature set is incomplete, it queries the human for feature traces that teach it the missing feature and adapts the reward to account for it. (Right-Bottom) In the offline reward learning from demonstrations setting, the person has to teach the robot each feature separately one at a time using feature traces, and only then teach their combined reward.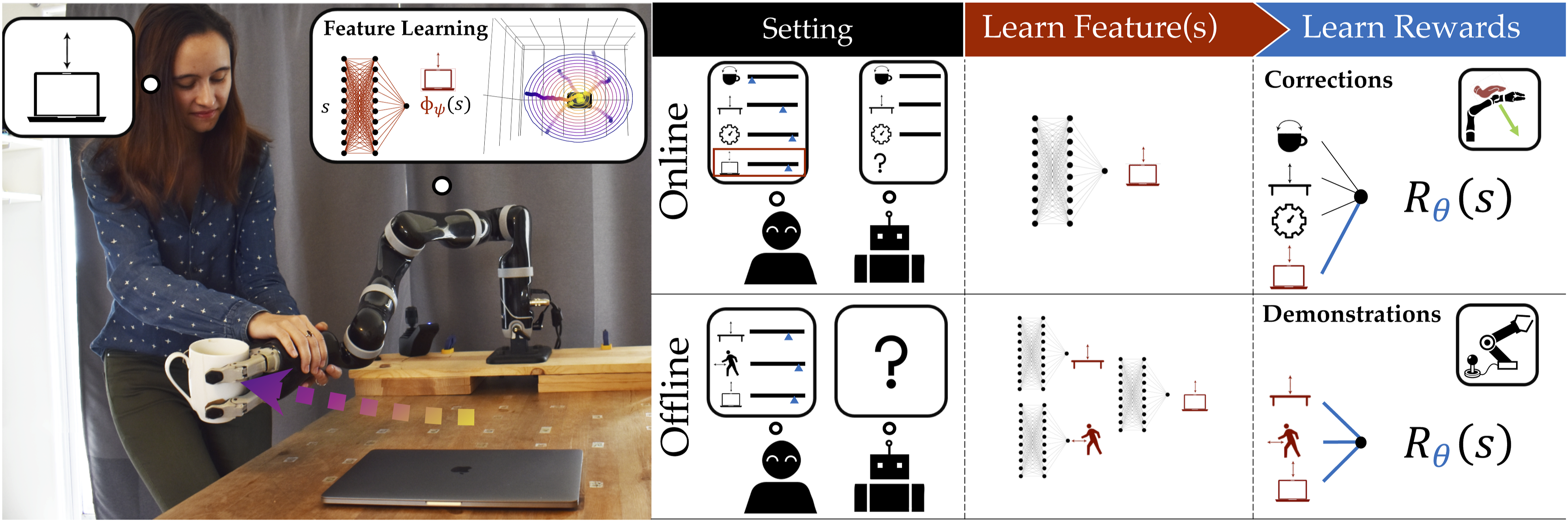
In order to correctly interpret and efficiently learn from human input, traditional methods resorted to structuring the reward as a (linear) function of carefully hand-engineered features—important aspects of the task (Abbeel and Ng, 2004; Bajcsy et al., 2017; Jain et al., 2015; Ziebart et al., 2008). Unfortunately, selecting the right space of features is notoriously challenging, even for expert system designers: knowing and specifying a priori an exhaustive set of all the features that might be relevant for the reward is impossible for most real-world tasks. To bypass this feature specification problem, state-of-the-art deep IRL methods (Brown et al., 2020; Finn et al., 2016; Wulfmeier et al., 2016) learn rewards defined directly on the high-dimensional raw state (or observation) space, thereby implicitly constructing features automatically from task demonstrations.
In doing so, however, these approaches sacrifice the sample efficiency and generalizability that a well-specified feature set offers. While using an expressive function approximator to extract features and learn their reward combination at once seems advantageous, many such functions can induce policies that explain the demonstrations. Hence, to disambiguate between all these candidate functions, the robot requires a very large amount of (laborious to collect) data, and this data needs to be diverse enough to identify the true reward. For example, the human in the household robot setting in Figure 1 might want to demonstrate keeping the cup away from the laptop, but from a single demonstration the robot could find many other explanations for the person’s behavior: perhaps they always happened to keep the cup upright or they really like curved trajectories in general.
The underlying problem here is that demonstrations—or task-specific input more broadly—are meant to teach the robot about the reward and not about the features per se, so these function approximators struggle to capture the right feature structure for the reward. In this work, we argue that the robot does not have to learn everything at once; instead, it can divide-and-conquer the reward learning problem and focus on explicitly learning the features separately from learning how to combine them into the reward. In our earlier example, if the robot were taught about the concept of distances to laptops separately, it would be able to quickly tell what the person wants from a single demonstration.
We make the following contributions:
Learning features from a novel type of human input. We present a method for learning complex non-linear features separately from the reward (Section 4). We introduce a new type of human input specifically designed to teach features, which we call feature traces—partial trajectories that describe the monotonic evolution of the value of the feature to be learned. To provide a feature trace, the person guides the robot from states where the feature is highly expressed to states where it is not, in a monotonic fashion. Looking at Figure 1 (Left), the person teaches the robot to avoid the laptop by giving a few feature traces: she starts with the arm above the laptop and moves it away until comfortable with the distance from the object. We present an algorithm that harvests the structure inherent to feature traces and uses it to efficiently learn a feature relevant for the reward: in our example, the horizontal distance from the laptop. In experiments on a 7-DoF robot arm, we find that our method can learn high quality features closely resembling the ground truth (Section 6.1).
Demonstrating our feature learning method in a user study on a simulated 7-DoF robot arm. In a user study with the JACO2 (Kinova) robotic arm, we show that non-expert users can use our approach for learning features (Section 6.2). The participants were able to provide feature traces to teach good features, and found our teaching protocol intuitive. Unfortunately, due to the current pandemic, we conducted the study online in a simulated environment; despite the inevitable degradation in input quality that this entails, the users were still able to teach features that induced informative bias.
Analyzing generalization and sample complexity benefits of learning features for rewards. We show how our method, which we call Feature Expansive Reward Learning (FERL) because it expands the feature set one by one, can improve reward learning sample complexity and generalization. First, we look at an easier online reward learning setting like the one in Figure 1 (Right-Top) where the robot knows part of the feature set from the get-go, but the person’s preference also depends on other features not in the set (Section 5.2). We show that, by learning the missing feature, the robot obtains a more generalizable reward than if it had trained a deep IRL network directly from the raw state and the known set (Section 7). We then consider the more challenging offline reward learning case in Figure 1 (Right-Bottom) where the person teaches the reward from scratch, one feature at a time (Section 5.1). We find that the robot outperforms the baseline most of the time, with less clear results when the learned features are noisily taught by novice users in simulation (Section 8).
We note that this work is an extension of Bobu et al. (2021), which was published at the International Conference on Human Robot Interaction. We build on this work by formalizing a general framework for feature-based reward learning, and instantiating it in a new offline learning setting where the person can teach each feature one by one before combining them into a reward. Not only is this offline setting more commonly encountered in reward learning, but it also showcases that our approach can be applied more generally to preference learning from different kinds of human input.
Overall, this work provides evidence that taking a divide-and-conquer approach focusing on learning important features separately before learning the reward improves sample complexity in reward learning. Although showcased in manipulation, our method can be used in any robot learning scenarios where feature learning is beneficial: in collaborative manufacturing users might care about the rotation of the object handed over, or in autonomous driving passengers may care about how fast to drive through curves.
2. Related Work
Programming robot behavior through human input is a well-established paradigm. In this paradigm, the robot receives human input and aims to infer a policy or reward function that captures the behavior the human wants the robot to express. In imitation learning, the robot directly learns a policy that imitates demonstrations given by the human (Osa et al., 2018). The policy learns a correlation between situations and actions but not why a specific behavior is desirable. Because of that, imitation learning only works in the training regime, whereas optimizing a learned reward, which captures why a behavior is desirable, can generalize to unseen situations (Abbeel and Ng, 2004).
In the IRL framework, the robot receives demonstrations through teleoperation (Abbeel and Ng, 2004; Javdani et al., 2018) or kinesthetic teaching (Argall et al., 2009) and learns a reward under which these demonstrations are optimal (Abbeel and Ng, 2004; Russell and Norvig, 2002). Recent research goes beyond demonstrations, utilizing other types of human input for reward learning such as corrections (Bajcsy et al., 2017; Jain et al., 2015), comparisons (Christiano et al., 2017) and rankings (Brown et al., 2019), examples of what constitutes a goal (Fu et al., 2018b), or even specified proxy objectives (Hadfield-Menell et al., 2017). Depending on the interaction setting, the human input can be given all-at-once, iteratively, or on specific requests of the robot in an active learning setting (Brown et al., 2018; Lopes et al., 2009; Sadigh et al., 2016).
All these methods require less human input if a parsimonious representation of the world, which summarizes raw state information in the form of relevant features, is available. This is because finite feature sets significantly reduce the space of possible functions which according to statistical learning theory reduces the information complexity of the learning problem (Vapnik, 2013). In the following, we discuss the role of feature representations in reward learning and methods for learning features.
2.1. Feature representations in reward learning
Traditional reward learning methods rely on a set of carefully hand-crafted features that capture aspects of the environment a person may care about. These are selected by the system designer prior to the task (Abbeel and Ng, 2004; Bajcsy et al., 2017; Hadfield-Menell et al., 2017; Jain et al., 2015; Ziebart et al., 2008). If chosen well, this feature set introduces an inductive bias that enables the algorithms to find a good estimate of the human’s preferences with limited input. Unfortunately, selecting such a set in the first place is notoriously challenging, even for experts like system designers. For one, defining a good feature function can be a time-consuming trial-and-error process, especially if the feature is meant to capture a complex aspect of the task (Wulfmeier et al., 2016). Moreover, the chosen feature space may not be expressive enough to represent everything that a person might want (and is giving input about) (Bobu et al., 2020; Haug et al., 2018). When this is the case, the system may misinterpret human guidance, perform unexpected or undesired behavior, and degrade in overall performance (Amodei and Clark, 2016; Haug et al., 2018; Russell and Norvig, 2002).
To tackle these challenges that come with hand-designing a feature set, state-of-the-art deep IRL methods use the raw state space directly and shift the burden of extracting behavior-relevant aspects of the environment onto the function approximator (Finn et al., 2016; Wulfmeier et al., 2016). The objective of IRL methods is to learn a reward which induces behavior that matches the state expectation of the demonstrations. The disadvantage of such approaches is that they require large amounts of highly diverse data to learn a reward function which generalizes across the state space. This is because with expressive function approximators there exists a large set of functions that could explain the human input; that is, many reward functions induce policies that match the demonstrations’ state expectation. The higher dimensional the state, the more human input is needed to disambiguate between those functions sufficiently to find a reward function which accurately captures human preferences and thereby generalizes to states not seen during training and not just replicates the demonstrations’ state expectations. Thus, when venturing sufficiently far away from the demonstrations the learned reward in IRL does not generalize which can lead to unintended behavior (Fu et al., 2018a; Reddy et al., 2020b).
It has been shown that providing linear feature functions as human input can reduce the risk of unintended behavior (Haug et al., 2018). In our work, we argue that generalization with limited input can be achieved without requiring hand-crafted features if the robot explicitly learns features, instead of attempting to learn them implicitly from demonstrations.
2.2. Learning features
In IRL researchers have explored the direction of inferring a set of relevant features directly from task demonstrations. This can take the form of joint Bayesian inference on both reward and feature parameters (Choi and Kim, 2013) or projecting the raw state space to lower dimensions via PCA on demonstrated trajectories (Vernaza and Bagnell, 2012). There are also methods that add features iteratively to learn a non-linear reward, such as Levine et al. (2010), which constructs logical conjunctions of primitive integer features, and Ratliff et al. (2007), which trains regression trees to distinguish expert from non-expert trajectories in a base feature space. Levine et al. (2010) perform well in discrete-state MDPs, but is not suitable for continuous state spaces, does not operate on raw states but rather a hand-engineered set of integer component features, and requires the reward structure to be expressible as logical conjunctions. Meanwhile, Ratliff et al. (2007) allows for larger state spaces and arbitrary continuous rewards, but still relies on engineering a relevant set of base features and severely underperforms in the case of non-expert human input when compared to more recent IRL techniques (Levine et al., 2011; Wulfmeier et al., 2016). Because of these shortcomings, IRL researchers have opted recently for either completely hand-specifying the features or using deep IRL for extracting them automatically from the raw continuous state space with non-expert demonstrations (Finn et al., 2016; Fu et al., 2018a).
Rather than relying on demonstrations for everything, we propose to first learn complex non-linear features leveraging explicit human input about relevant aspects of the task (Section 4). Based on these features, a reward can be inferred with minimal input (Section 5). Our results show that adding structure in such a targeted way can enhance both the generalization of the learned reward and data-efficiency of the method.
3. Problem Formulation
We consider a robot R operating in the presence of a human H from whom it is trying to learn to perform a task, ultimately seeking to enable autonomous execution. In the most general setting, both H and R are able to affect the evolution of the continuous state
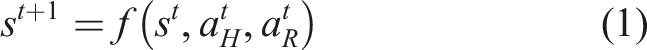
We assume that the human has some consistent internal preference ordering between different trajectories τ, which affects the actions a H that they choose. In principle, these human preferences could be captured by a reward function R*(τ). Unfortunately, the robot does not have access to R*, so to learn how to perform the task it must attempt to infer it. Since R* may encode arbitrary preference orderings deeming the inference problem intractable, we assume that the robot reasons over a parameterized approximation R θ induced by parameters θ ∈ Θ. The robot’s goal is, thus, to estimate the human’s preferred θ from their actions a H .
Even with this parameterization, the space of possible reward functions is infinite-dimensional. One way to represent it using a finite θ is through the means of a finite family of basis functions Φ
i
, also known as features (Ng and Russell, 2000):
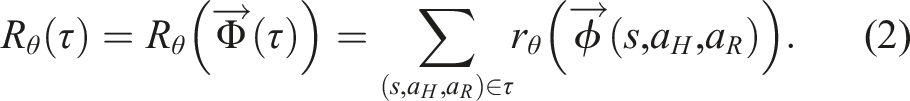
This restriction to a finite set of features
We assume the robot has access to a (possibly empty) initial set of features
4. Algorithmic Approach: Feature Learning
We first look at learning individual feature functions. In this paper, we focus on state features (ignoring actions from the feature representation), which we define as arbitrary complex mappings
One natural idea for learning this mapping is treating it as a regression problem and asking the human for regression labels (s, ϕ(s)) directly. Unfortunately, to learn anything useful, the robot would need a very large set of labels from the person, which would be too effortful for them to provide. Even worse, humans are notoriously unreliable at quantifying their preferences with any degree of precision (Braziunas and Boutilier, 2008), so their labels might result in arbitrarily noisy regressions. Hence, we need a type of human input that balances being informative and not placing too much burden on the human.
4.1 Feature traces
To teach a non-linear representation of ϕ with little data, we introduce feature traces ξ = s0:n, a novel type of human input defined as a sequence of n states that are monotonically decreasing in feature value, that is, ϕ(s i ) ≥ ϕ(s j ), ∀i < j. This approach relaxes the need for accurate state labeling, while simultaneously providing a combinatorial amount of state comparisons (see Section 4.2 for details) from each trace ξ.
When learning a feature, the robot can query the human for a set Ξ of N traces. The person gives a trace ξ by simply moving the system from any start state s0 to an end state s n , noisily ensuring monotonicity. Our method, thus, only requires an interface for communicating ordered feature values over states: kinesthetic teaching is useful for household or small industrial robots, while teleoperation and simulation interfaces may be better for larger robotic systems.
To illustrate how a human might offer feature traces in practice, let’s turn to Figure 1 (Left). Here, the person is teaching the robot to keep the mug away from the laptop (i.e., not above). The person starts a trace at s0 by placing the end-effector directly above the object center, then leads the robot away from the laptop to s n . Our method works best when the person tries to be informative, that is, covers diverse areas of the space: the traces illustrated move radially in all directions and start at different heights. While for some features, like distance from an object, it is easy to be informative, for others, like slowing down near objects, it might be more difficult. We explore how easy it is for users to be informative in our study in Section 6.2, with encouraging findings, and discuss alleviating existing limitations in Section 9.
The power of feature traces lies in their inherent structure. Our algorithm, thus, makes certain assumptions to harvest this structure for learning. First, we assume that the feature values of states along the collected traces ξ ∈ Ξ are monotonically decreasing. Secondly, we assume that by default the human starts all traces in states s0 with the highest feature value across the domain, then leads the system to states s n with the lowest feature value. In some situations, this assumption might unnecessarily limit the kinds of feature traces the human can provide. For example, the person might want to start somewhere where the feature is only “half” expressed relative to the feature range of the domain. Because of this, we optionally allow the human to provide relative values v0, v n ∈ [0, 1] 1 to communicate that the traces start/end at values that are fractions of the feature range of the domain.
4.2 Learning a feature function
To allow for arbitrarily complex non-linear features, we approximate a feature by a neural network
4.2.1 Monotonicity along feature traces
First, due to the monotonicity assumption along any feature trace
We train the discriminative function ϕ
ψ
as a predictor for whether a state s has a higher feature value than another state s′, which we represent as a softmax-normalized distribution
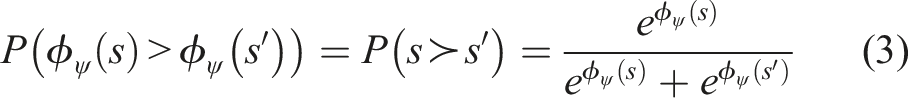
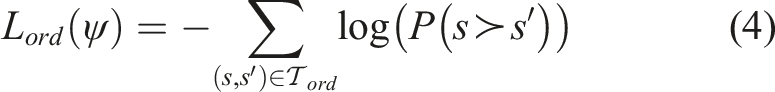
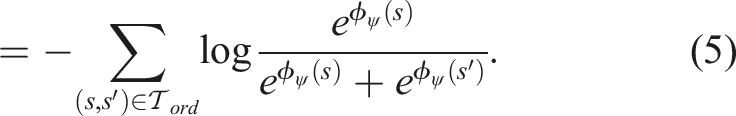
Intuitively, this loss spaces out the feature values ϕ ψ such that they decrease monotonically along every trace; however, this alone does not constrain the traces to have the same start and end values, respectively.
4.2.2 Start/end feature value equivalence
To encourage all traces to start and end in the same high and low feature values, we need an additional loss term encoding
When training ϕ
ψ
, the predictor should not be able to distinguish which state has a higher feature value, hence P (ϕ
ψ
(s) > ϕ
ψ
(s′)) = 0.5. As such, we introduce a second loss function L
equiv
(ψ) that minimizes the negative log-likelihood of both s having a higher feature value than s′ and s′ having a higher feature value than s:
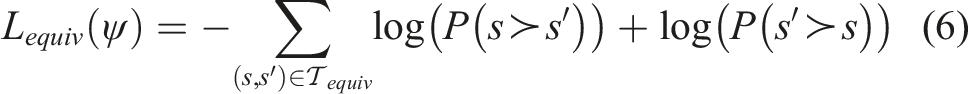
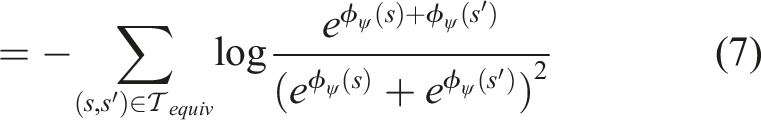
This loss ensures the state space around feature trace starts and ends have similar feature values, respectively. 2
We now have a total dataset
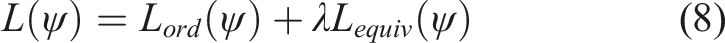
Given the loss function in equation (8), we can use any automatic differentiation package to compute its gradients and update ψ via gradient descent. Note that L equiv is akin to a binary cross-entropy loss with a target of 0.5, whereas L ord is similar to a binary cross-entropy loss with a target of 1. This form of loss function has been shown to be effective for preference learning (Christiano et al., 2017; Ibarz et al., 2018). The key differences here are that our loss is over feature functions not rewards, and that preferences are state orderings provided via feature traces not trajectory comparisons. Additionally, in practice we normalize the feature functions to make their subsequent reward weights reflect importance relative to one another. We present the full feature learning algorithm using feature traces in Alg. 1.
Feature Learning via Feature Traces Query feature trace ξ as in Section 4.1. Ξ ←Ξ ∪ ξ.
Convert Ξ to datasets Initialize ϕ
ψ
randomly. Sample tuples batch Sample tuples batch Estimate L(ψ) using Update parameter ψ via gradient descent on L(ψ).
4.2.3 Incorporating relative values
So far, we have assumed that all feature traces have starts and ends of the same high and low feature value, respectively. The optional relative values v0, v n can relax this assumption to enable the human to provide richer traces and teach more complex feature functions, for example, where no monotonic path from the highest to lowest feature value exists. By default, v0 = 1 communicating that the trace starts at the highest feature value of the domain, and v n = 0 signifying that the trace ends at the lowest feature value. By allowing v0 and v n to be something different from their defaults, the person can provide traces that start at higher feature values or end at lower ones. We describe how to include these relative values in the feature training procedure in Online Appendix A.1.
5. Algorithmic Approach: Reward Learning
Now that we have a method for learning relevant features, we discuss how the robot can include this capability in reward learning frameworks. For exposition, we chose two reward learning frameworks—learning from demonstrations (offline) and from corrections (online)—but we stress that features learned with our method are applicable to any other reward learning method that admits features (e.g., comparisons, scalar feedback, state of the world, etc.).
5.1 Offline FERL
We first consider the scenario where the human is attempting to teach the robot a reward function from scratch; that is, the robot starts off with an empty feature set
In standard learning from demonstrations, deep IRL uses a set of demonstrations to train a reward function directly from the raw state, in an end-to-end fashion. Under our divide-and-conquer framework, we redistribute the human input the robot asks for: first, ask for feature traces ξ focusing explicitly on learning F features one by one via Alg. 1, and only then collect a few demonstrations
Offline FERL K iterations, α learning rate. Initialize empty feature set Learn feature ϕ
f
using Alg. 1. Initialize θ randomly. Generate samples Estimate gradient D*, Update parameter θ using gradient
5.1.1 Creating the feature set
Since the robot starts off with an empty feature set

After being equipped with a new set of features taught by the human, the robot can undergo standard learning from demonstration procedures to recover the person’s preferences. We now review Maximum Entropy IRL (Ziebart et al., 2008) for completion of the offline reward learning exposition.
5.1.2 Offline reward learning
To teach the robot the desired reward function R
θ
, the person collects a set of demonstrations
In order to reason about the human’s preferences, the robot needs to be equipped with a model P(τ∣θ) for how those preferences affect their choice of demonstrations. For example, if the human were assumed to act optimally, the model would place all the probability on the set of trajectories that perfectly optimize the reward R
θ
. However, since humans are not perfect, we relax this assumption and model them as being noisily-optimal, choosing trajectories that are approximately aligned with their preferences. We follow the Boltzmann noisily-rational decision model
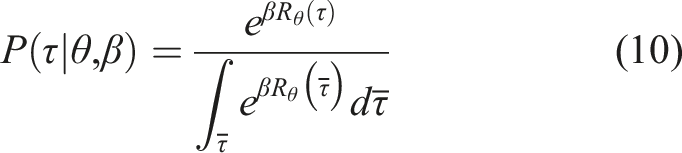
In maximum entropy IRL, to recover the θ parameter we maximize the log-likelihood
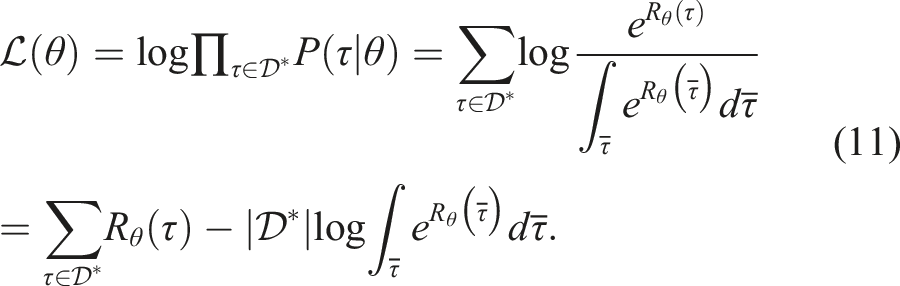
Computing the integral over trajectories is intractable in real-world problems, so sample-based approaches to maximum entropy IRL estimate it with samples
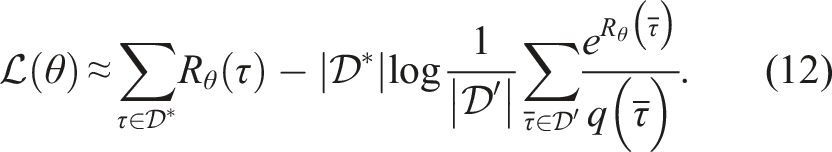
The distribution q(τ) is chosen oftentimes to be uniform; instead, we follow Finn et al. (2016) and generate samples in those regions of the trajectory space that are good according to the current estimate of the reward function, that is,
We may now find θ by maximizing the log-likelihood
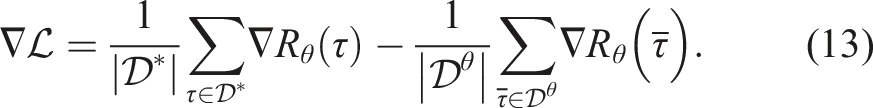
At this point, a standard deep IRL baseline could use any automatic differentiation package to compute the gradient and update the reward parameters directly from the raw trajectory state. Instead, consistent with prior work on reward learning with feature sets, we represent the reward as a linear combination of the learned features
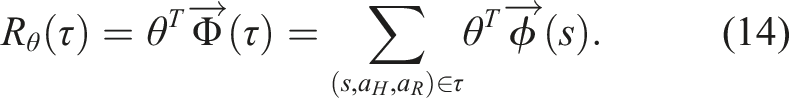
Note that the linear reward assumption is not necessary for our algorithm to work. While in theory the reward could be modeled as non-linear, our divide-and-conquer approach is motivated by keeping the reward parameter space small while still effectively capturing the person’s preferences.
For the linear case, the gradient becomes the difference between the observed demonstration feature values and the expected feature values dictated by the sampled trajectories
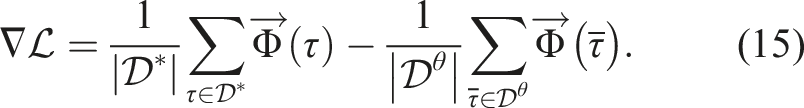
Lastly, we compute an estimate
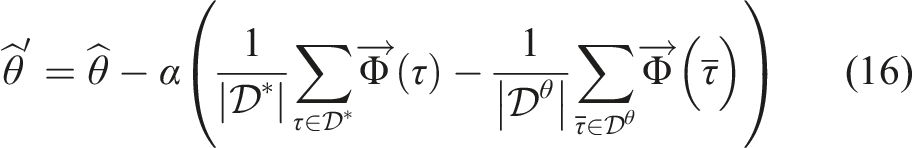
5.2 Online FERL
In Section 5.1, we saw that our method allows the person to specify a reward by sequentially teaching features and adding them to the robot’s feature set before using demonstrations to combine them. However, in many situations the system designer or even the user teaching the features might not consider all aspects relevant for the task a priori. As such, we now consider an online reward learning version of our previous scenario, where the person provides inputs to the robot during the task execution and its feature space may or may not be able to correctly interpret them.
We assume the robot has access to an initial feature set
Online FERL Plan initial trajectory τ by optimizing R
θ
. if a
H
then Estimate confidence if Learn feature ϕ
new
using Alg. 1.
Get induced trajectory τ
H
from equation (17). Update parameter θ using τ
H
in equation (18). Replan trajectory τ by optimizing new R
θ
.
5.2.1 Online reward update
Whether it needs to learn a new feature ϕ ψ or not, the robot has to then use the human input a H to update its estimate of the reward parameters θ. Here, any prior work on online reward learning from user input is applicable, but we highlight one example to complete the exposition.
For instance, take the setting where the human’s input a
H
was an external torque, applied as the robot was tracking a trajectory τ that was optimal under its current reward R
θ
. Prior work Bajcsy et al. (2017) has modeled this as inducing a deformed trajectory τ
H
, by propagating the change in configuration to the rest of the trajectory

If we think of τ
H
as the human observation and of τ as the expected behavior according to the current reward function (Bajcsy et al., 2017), we arrive at a natural alternation of the update rule in equation (16)
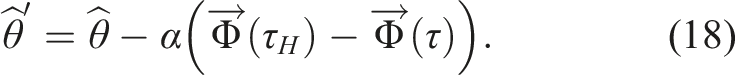
Intuitively, the robot updates its estimate
If instead, the human intervened with a full demonstration, work on online learning from demonstrations (Section 3.2 in Ratliff et al. (2006)) has derived the same update with τ H now being the human demonstration. In our implementation, we use corrections and follow Bajcsy et al. (2018), which shows that people more easily correct one feature at a time, and only update the θ index corresponding to the feature that changes the most (after feature learning this is the newly learned feature). After the update, the robot replans its trajectory using the new reward.
5.2.2 Confidence estimation
The robot can learn a new feature from the person because we assumed it has the capacity to detect that a feature is missing in the first place. We alluded earlier in Section 5.1 how this ability might be enabled by manipulating the β parameter in the observation model in equation (10). We now expand on this remark.
In the presented Boltzmann model, β controls how much the robot expects to observe human input consistent with its reward structure, and, thus, its feature space. A high β suggests that the input is consistent with the robot’s feature space, whereas a low β may signal that no reward function captured by the feature space can explain the input. As such, inspired by work in Fridovich-Keil et al. (2019), Fisac et al. (2018), and Bobu et al. (2020), instead of keeping β fixed like in the maximum entropy IRL observation model, we reinterpret it as a confidence in the robot’s features’ ability to explain human data.
When the human input a
H
is a correction, following Bobu et al. (2020), the robot estimates
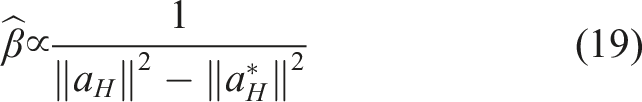
Intuitively, if the person’s input is close to the optimal
Alternatively, if the human input a
H
is a demonstration, like in the classical IRL presented in Section 5.1, also following Bobu et al. (2020), we may estimate
To detect a missing feature, the robot simply needs a confidence threshold ϵ. If
6. Experiments: Learning Features
Before testing FERL in the two reward learning settings of interest, we first analyze our method for learning features in experiments with a robotic manipulator. In Section 6.1, we inspect how well FERL can learn six different features of varying complexity by using real robot data collected from an expert—a person familiar with how the algorithm works. We then conduct an online user study in simulation in Section 6.2 to test whether non-experts—people not familiar with FERL but taught to use it—can teach the robot good features.
6.1 Expert users
We have argued that feature traces are useful in teaching the robot features explicitly. In our first set of experiments, we look at how good the learned features are, and how their quality varies with the amount of feature traces provided.
6.1.1 Experimental design
We conduct our experiments on a 7-DoF JACO robotic arm. We investigate six features in the context of personal robotics: 1. table: distance of the End-Effector (EE) to the table (T), as a z-coordinate difference: EE z − T z (superscript denotes pose coordinate selection); 2. coffee: coffee cup upright orientation, defined by how far the EE is from pointing up: 1 − EE
R
⋅ [0, 0, 1] (superscript denotes pose rotation matrix); 3. laptop: 0.3 m xy-plane distance of the EE to a laptop (L), to avoid passing over the laptop: max{0.3 − ‖EE
xy
− L
xy
‖2, 0}; 4. test laptop location: same as laptop, but the test position differs from the training ones; 5. proxemics: non-symmetric 0.3 m xy-plane distance between the EE and the human (H), to keep the EE away from them, three times as much when moving in front of them than on their side: 6. between objects: 0.2 m xy-plane distance of the EE to two objects, O1 and O2—the feature penalizes being above either object, and, to a lesser extent, passing in between the objects as defined by a distance to the imaginary line O1O2:
Most features can be taught with the default relative values v n = 0 and v0 = 1, but between objects requires some traces with explicit values v0, v n . We approximate all features ϕ ψ by neural networks (2 layers, 64 units each), and train them on a set of traces Ξ using stochastic gradient descent (see Online Appendix C.1 for training details).
For each feature, we collected a set
Our raw state space consists of the 27D xyz positions of all robot joints and objects in the scene, as well as the rotation matrix of the EE. We assume known object positions but they could be obtained from a vision system. It was surprisingly difficult to train on both positions and orientations due to spurious correlations in the raw state space, hence we show results for training only on positions or only on orientations. This speaks to the need for methods that can handle correlated input spaces, which we expand on in Online Appendix B.3.
Manipulated variables
We are interested in seeing trends in how the quality of the learned features changes with more or less data available. Hence, we manipulate the number of traces N the learner gets access to.
Dependent measures
After training a feature ϕ
ψ
, we measure error compared to the ground truth feature ϕTrue that the expert tries to teach, on a test set of states
Hypotheses
6.1.2 Qualitative results
We first inspect the results qualitatively, for N = 10. In Figure 2, we show the learned table and laptop features ϕ
ψ
by visualizing the position of the EE for all 10,000 points in our test set. The color of the points encodes the learned feature values ϕ
ψ
(s) from low (blue) to high (yellow): table is highest when the EE is farthest, while laptop peaks when the EE is above the laptop. In Figure 3, we illustrate the Ground Truth (GT) feature values ϕTrue and the trained features ϕ
ψ
by projecting the test points on 2D sub-spaces and plotting the average feature value per 2D grid point. For Euclidean features, we used the EE’s xy-plane or yz-plane (table), and for coffee, we project the x-axis basis vector of the EE after forward kinematic rotations onto the xz-plane (arrow up represents the cup upright). White pixels are an artifact of sampling. Visualization of the experimental setup, learned feature values ϕ
ψ
(s), and training feature traces ξ for table (up) and laptop (down). We display the feature values ϕ
ψ
(s) for states s sampled from the reachable set of the 7-DoF arm, as well as their projections onto the yz and xy planes. The plots display the ground truth ϕTrue (top rows) and learned feature values ϕ
ψ
(bottom rows) over 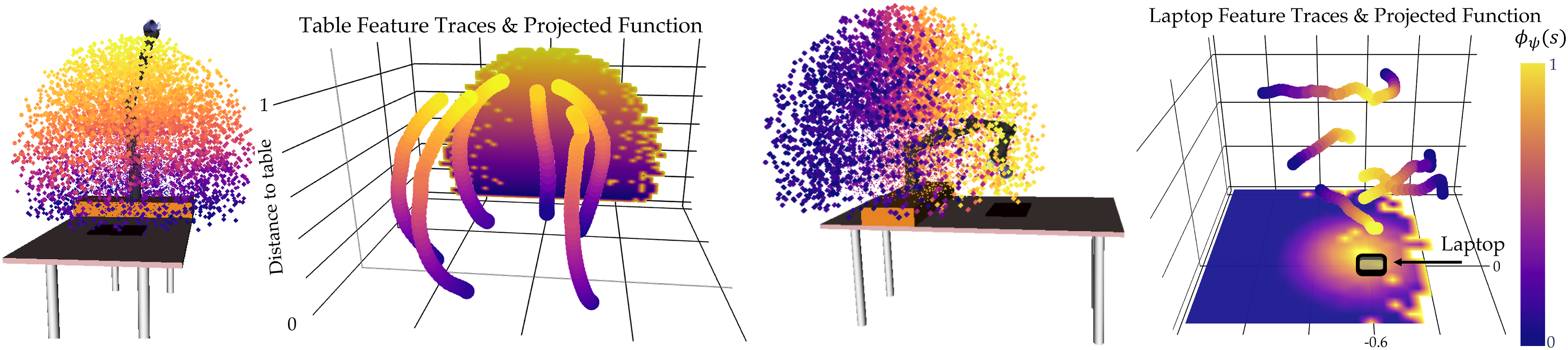
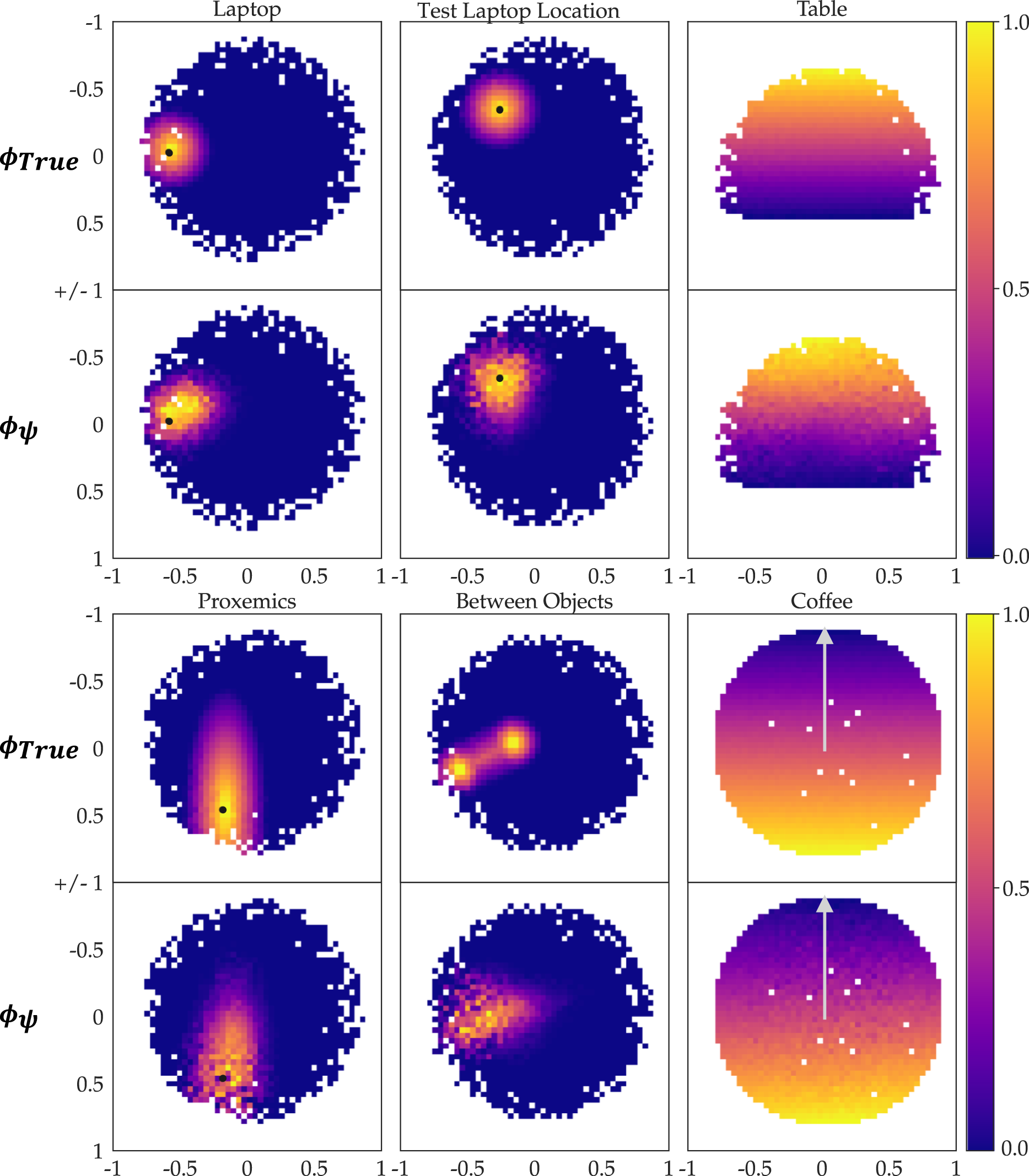
We observe that ϕ ψ resembles ϕTrue very well for most features. Our most complex feature, between objects, does not recreate the GT as well, although it does learn the general shape. However, we note in Online Appendix D.1 that in smaller raw input space it is able to learn the fine-grained GT structure. This implies that spurious correlation in input space is a problem, hence for complex features more data or active learning methods to collect informative traces are required.
6.1.3 Quantitative analysis
Figure 4 displays the means and standard errors across 10 seeds for each feature with increasing amount of data N. To test H1, we look at the errors with the maximum amount of data. Indeed, FERL achieves small errors, put in context by the comparison with the error a random feature incurs (gray line). This is confirmed by an ANOVA with random versus FERL as a factor and the feature ID as a covariate, finding a significant main effect (F(1, 113) = 372.012 3, p < 0.0001). In line with H2, most features have decreasing error with increasing data. Indeed, an ANOVA with N as a factor and feature ID as a covariate found a significant main effect (F(8, 526) = 21.140 7, p < 0.0001). Lastly, supporting H3, we see that the standard error on the mean decreases when FERL gets more data. To test this, we ran an ANOVA with the standard error as the dependent measure and N as a factor, finding a significant main effect (F(8, 45) = 3.098, p = 0.0072). For each feature, we show the MSEnorm mean and standard error across 10 random seeds with an increasing number of traces (orange) compared to random (gray).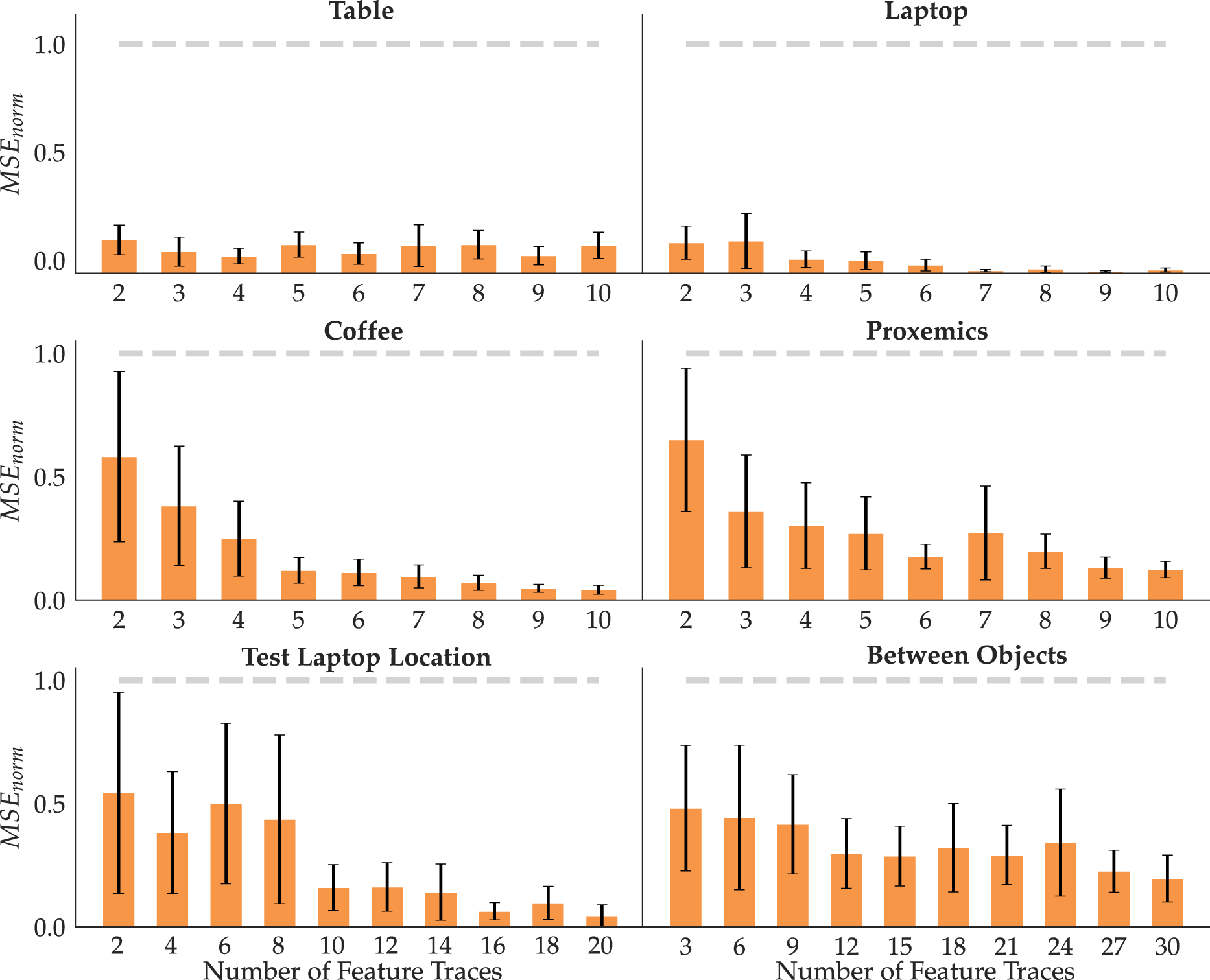
6.1.4 Summary
The qualitative and quantitative results support our hypotheses and suggest that our method requires few traces to reliably learn features ϕ ψ that generalize well to states not seen during training. We also find that the more complex a feature, the more traces are needed for good performance: while table and laptop perform well with just N = 4, some other features, like between objects, require more traces. Active learning approaches that disentangle the learned function by querying traces at parts of the state space that are confusing could further reduce the amount of data required.
6.2 User study
In the previous section, we have demonstrated that experts can teach the robot good feature functions. We now design a user study to test how well non-expert users can teach features with FERL and how easily they can use the FERL protocol.
6.2.1 Experimental design
Due to COVID, we replicated our setup from Figure 1 (Left) in a pybullet simulator (Coumans and Bai, 2016–2019) in which users can move a 7 DoF-JACO robotic arm using their cursor. Through the interface in Figure 5, the users can drag the robot to provide feature traces, and use the buttons for recording, saving, and discarding them. The pybullet simulator interface used in the user study, replicating our lab setup with the JACO robot.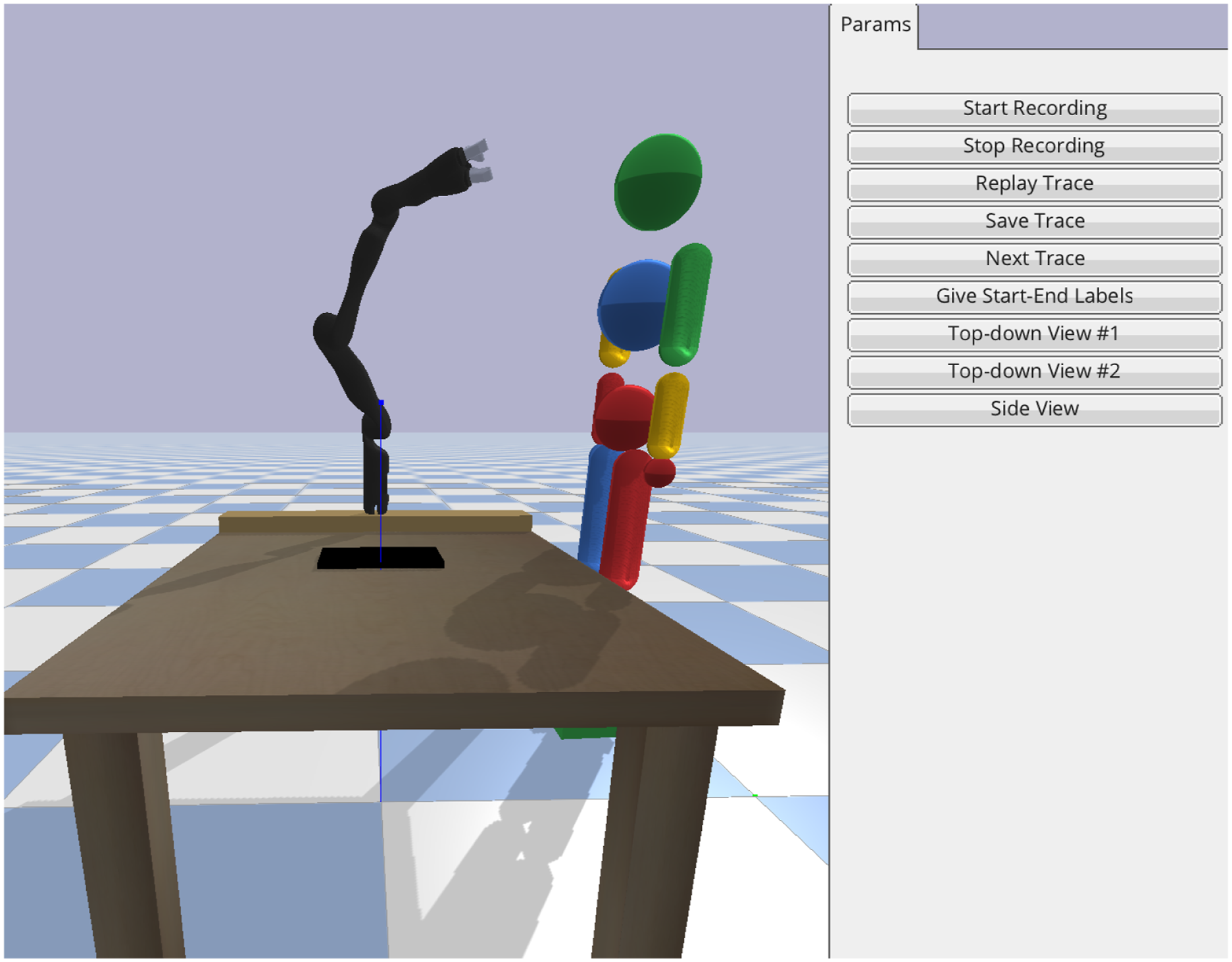
The user study is split into two phases: familiarization and teaching. In the first phase, we introduce the user to the task context, the simulation interface, and how to provide feature traces through an instruction video and a manual. Next, we describe and 3D visualize the familiarization task feature human (0.3 m xy-plane distance of the EE to the human position), after which we ask them to provide 10 feature traces to teach it. Lastly, we give the users a chance to see what they did well and learn from their mistakes by showing them a 3D visualization of their traces and the learned feature. See Online Appendix B.4 for more details on the user training.
In the second phase, we ask users to teach the robot three features from Section 6.1: table, laptop, and proxemics. This time, we don’t show the learned features until after all three tasks are complete.
Manipulated variables
We manipulate the input type with three levels: Random, Expert, and User. For Random, we randomly initialize 12 feature functions per task; for Expert, the authors collected 20 traces per task in the simulator, then randomly subsampled 12 sets of 10 that lead to features of similar MSEs to the ones in the physical setup before; for User, each person provided 10 traces per task.
Dependent measures
Our objective metric is the learned feature’s MSE compared to the GT feature on Questions, answer distributions, and p-values (2-sided t-test against the middle score 4) from the user study. The p-values in orange are significant after adjusted for multiple comparisons using the Bonferroni correction.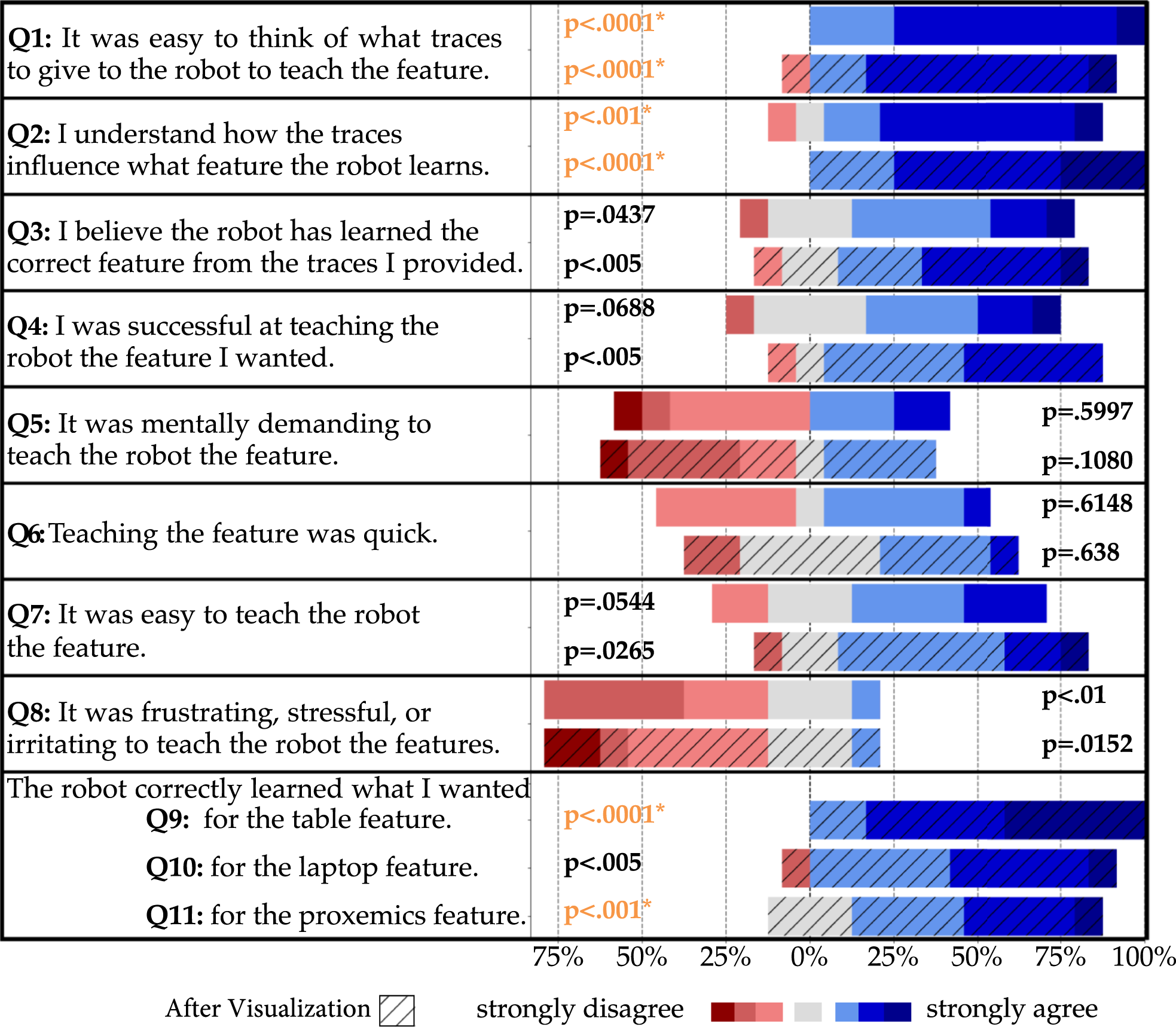
Participants
We recruited 12 users (11 males, aged 18–30) from the campus community to interact with our simulated JACO robot and provide feature traces for the three tasks. All users had technical background, so we caution that our results will speak to FERL’s usability with this population rather than the general population.
Hypotheses
6.2.2 Analysis
Objective
Figure 7 summarizes the results by showing how the MSE varies with each of our input types, for each task feature. Right off the bat, we notice that in line with H4, the MSEs for the user features are much closer to the expert level than to random. We ran an ANOVA with input type as a factor and task as a covariate, finding a significant main effect (F(2, 103) = 132.7505, p < 0.0001). We then ran a Tukey HSD post-hoc, which showed that the MSE for Random input was significantly higher than both Expert (p < 0.0001) and User (p < 0.0001), and found no significant difference between Expert and User (p = 0.0964). While this does not mean that user features are as good as expert features (we expect some degradation in performance when going to non-experts), it shows that they are substantially closer to them than to random; that is, the user features maintain a lot of signal despite this degradation. MSE to GT for the three features learned from expert (orange) and user (yellow) traces provided in simulation, and randomly (gray) initialized feature for comparison.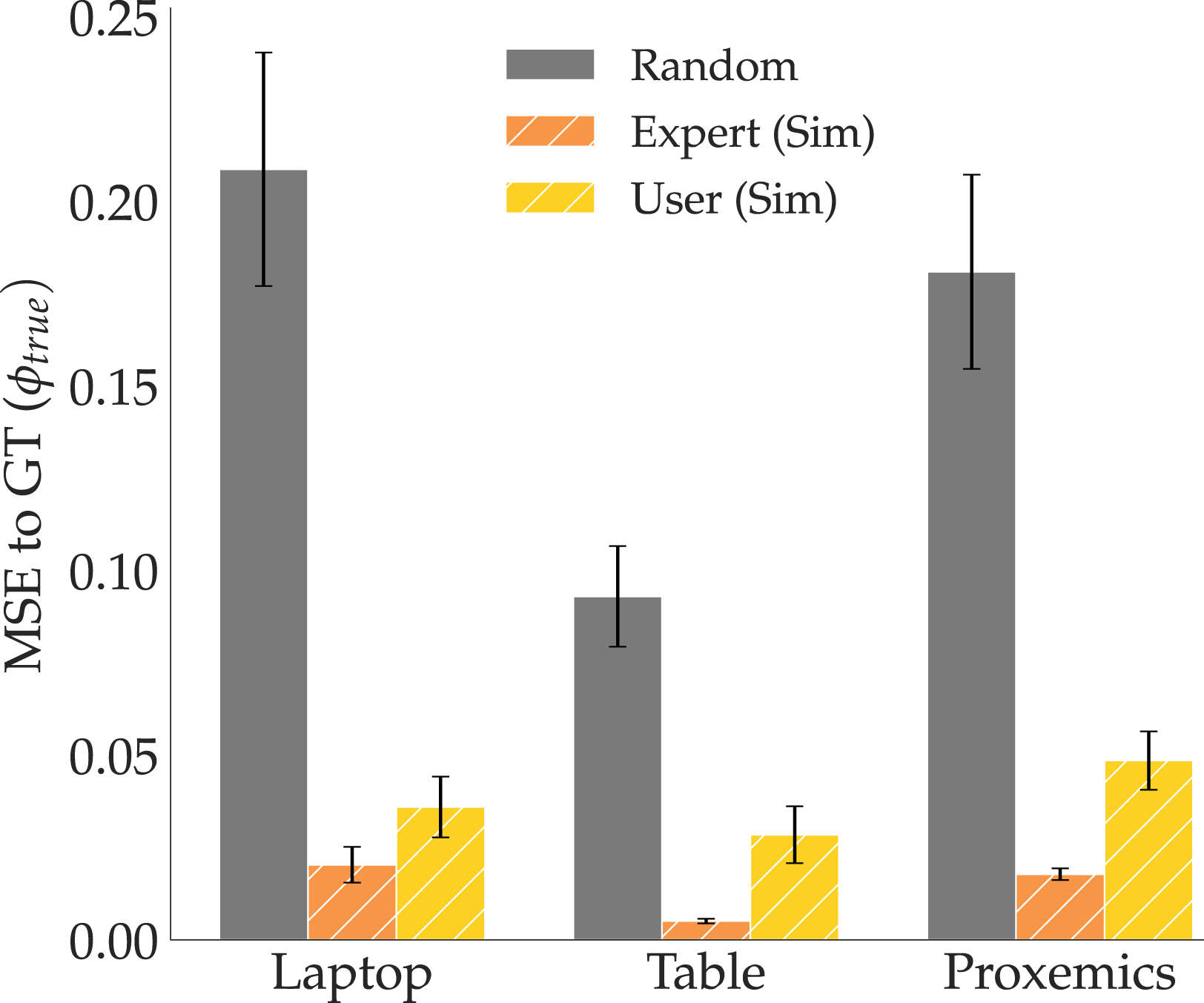
Subjective
In Figure 6, we see the Likert survey scores before and after the users saw the teaching results. For every question, we report 2-sided t-tests against the neutral score 4. These results support H5, although the evidence for finding the teaching protocol intuitive is weaker, and participants might have a bias to be positive given they are in a study. In fact, several participants mentioned in their additional remarks that they had a good idea of what traces to give, and the only frustrating part was the GUI interface, which was necessary because in-person studies are not possible during the COVID pandemic (“I had a pretty good mental model for what I wanted to show, but found it frustrating doing that with a mouse,” “I know what it wants, but the interface makes it difficult to give those exact traces”); performing the experiment as it was originally intended with the real robot arm would have potentially alleviated this issue (“With manual control of the arm it would have been a lot easier.”).
Looking before and after the visualization, we find a trend: seeing the result seems to reinforce people’s belief that they were effective teachers (Q3, Q4), also noticed in their comments (“Surprising how well it learned!”, “Surprised that with limited coverage it generalized pretty well.”). Also, in support of H4, we see significant evidence that users thought the robot learned the correct feature (Q9-Q11).
Lastly, we wanted to know if there was a correlation between subjective scores and objective performance. We isolated the “good teachers”—the participants who scored better than average on all three feature tasks in the objective metric, and compared their subjective scores to the rest of the teachers. By running a factorial likelihood-ratio test for each question, we found a significant main effect for good teachers: they are more certain that the robot has learned a correct feature even before seeing the results (Q3, p = 0.001), are more inclined to think they were successful (Q4, p = 0.0203), and find it significantly easier to teach features (Q7, p = 0.0202).
6.2.3 Summary
Both the objective and subjective results provide evidence that non-expert users can teach the robot reasonable features using our FERL protocol. In addition, participants found our teaching protocol intuitive, suggesting that feature traces can be useful for teaching features outside of the system designer’s setting. In the following sections, we explore whether both expert and non-expert features can be used to improve reward learning generalization.
7. Experiments: Online FERL
Now that we have tested our method for learning features with both experts and non-experts, we analyze how the learned features affect reward learning. In this section, we start with the easier setting where the robot already has a feature set that it is using for online reward learning, but the human might provide input about a missing feature.
7.1 Expert users
When the robot receives human input that cannot be explained by its current set of features, we hypothesize that adding FERL features to it can induce structure in the reward learning procedure that helps better recover the person’s preferences. We first test this hypothesis with expert user data.
7.1.1 Experimental design
We run experiments on the same JACO robot arm in three settings in which two features are known (ϕcoffee, ϕknown) and one is unknown. In all tasks, the true reward is
Manipulated variables
We manipulate the learning method with 2 levels: FERL and an adapted Maximum Entropy Inverse Reinforcement Learning (ME-IRL) baseline 5 (Finn et al., 2016; Wulfmeier et al., 2016) learning a deep reward function from demonstrations. We model the ME-IRL reward function r ω as a neural network with 2 layers, 128 units each. For a fair comparison, we gave r ω access to the known features: once the 27D Euclidean input is mapped to a neuron, a last layer combines it with the known feature vector.
Also for a fair comparison, we took great care to collect a set of demonstrations for ME-IRL designed to be as informative as possible: we chose diverse start and goal configurations for the demonstrations, and focused some of them on the unknown feature and some on learning a combination between features (see Online Appendix B.2). Moreover, FERL and ME-IRL rely on different input types: FERL on feature traces ξ and pushes a
H
and ME-IRL on a set of near-optimal demonstrations
Following equation (13), the gradient of the ME-IRL objective with respect to the reward parameters ω can be estimated by:
Dependent measures
We compare the two reward learning methods across three metrics commonly used in the IRL literature (Choi and Kim, 2011: 1) Reward Accuracy: how close to GT the learned reward is, 2) Behavior Accuracy: how well do the behaviors induced by the learned rewards compare to the GT optimal behavior, measured by evaluating the induced trajectories on GT reward, and 3) Test Probability: how likely trajectories generated by the GT reward are under the learned reward models.
For Reward Accuracy, note that any affine transformation of a reward function would result in the same induced behaviors, so simply measuring the MSE between the learner’s reward and the GT reward may not be informative. As such, we make reward functions given by different methods comparable by computing each learner’s reward values on
Hypotheses
7.1.2 Qualitative comparison
In Figure 8, we show the learned FERL and ME-IRL rewards as well as the GT for all three tasks evaluated at the test points. As we can see, by first learning the missing feature and then the reward on the extended feature vector, FERL is able to learn a fine-grained reward structure closely resembling the GT. Meanwhile, ME-IRL learns some structure capturing where the laptop or the human is, but not enough to result in a good trade-off between the active features. Visual comparison of the ground truth, online FERL, and ME-IRL rewards for Laptop Missing (top), Table Missing (middle), and Proxemics Missing (bottom).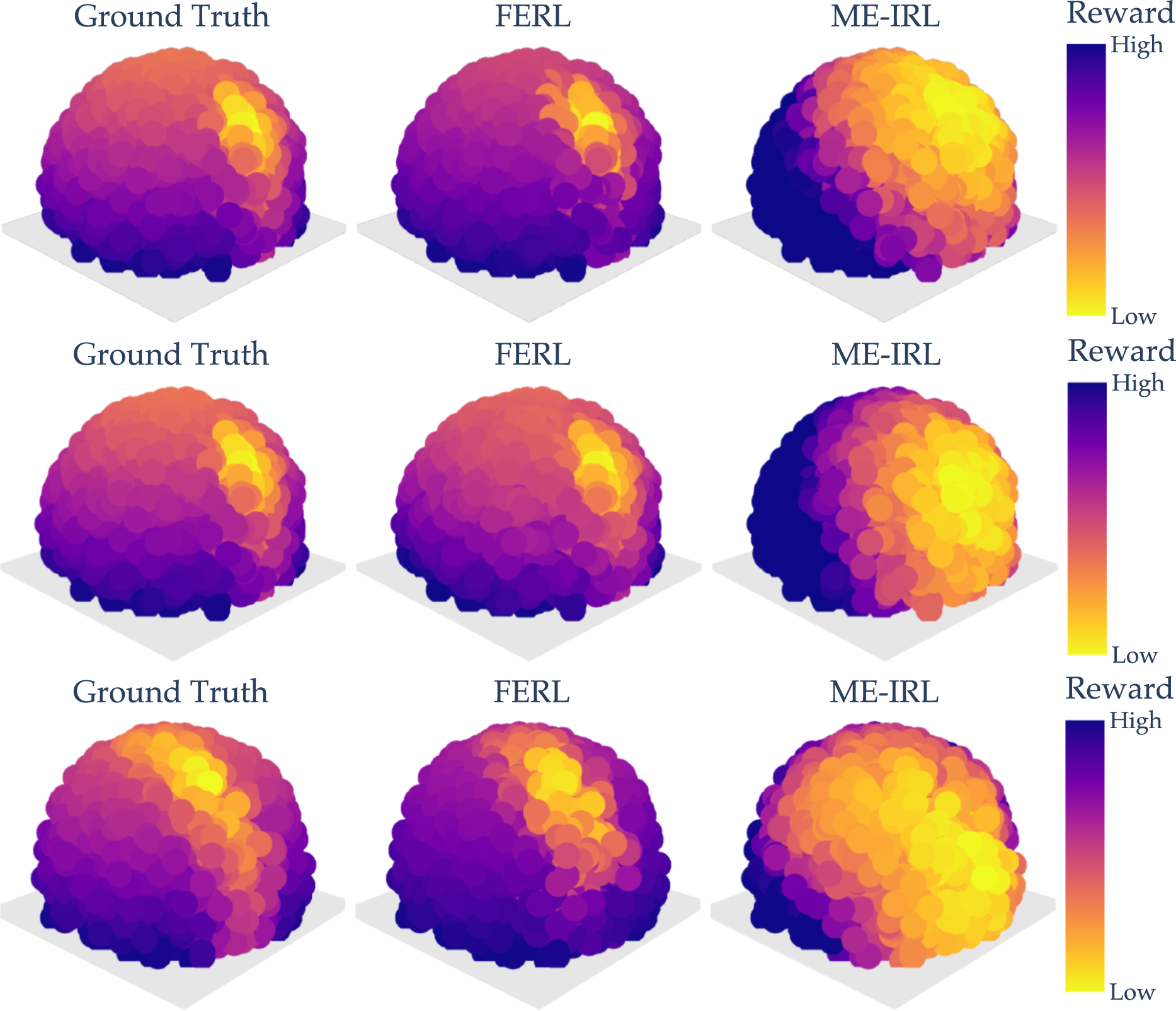
7.1.3 Quantitative analysis
To compare Reward Accuracy, we show in Figure 9 the MSE mean and standard error across 10 seeds, with increasing training data. We visualize results from all three tasks, with FERL in orange and ME-IRL in gray. FERL is closer to GT than ME-IRL no matter the amount of data, supporting H6. To test this, we ran an ANOVA with learning method as the factor, and with the task and data amount as covariates, and found a significant main effect (F(1, 595) = 335.5253, p < 0.0001). MSE of online FERL and ME-IRL to GT reward across all three tasks. FERL learns rewards that better generalize to the state space.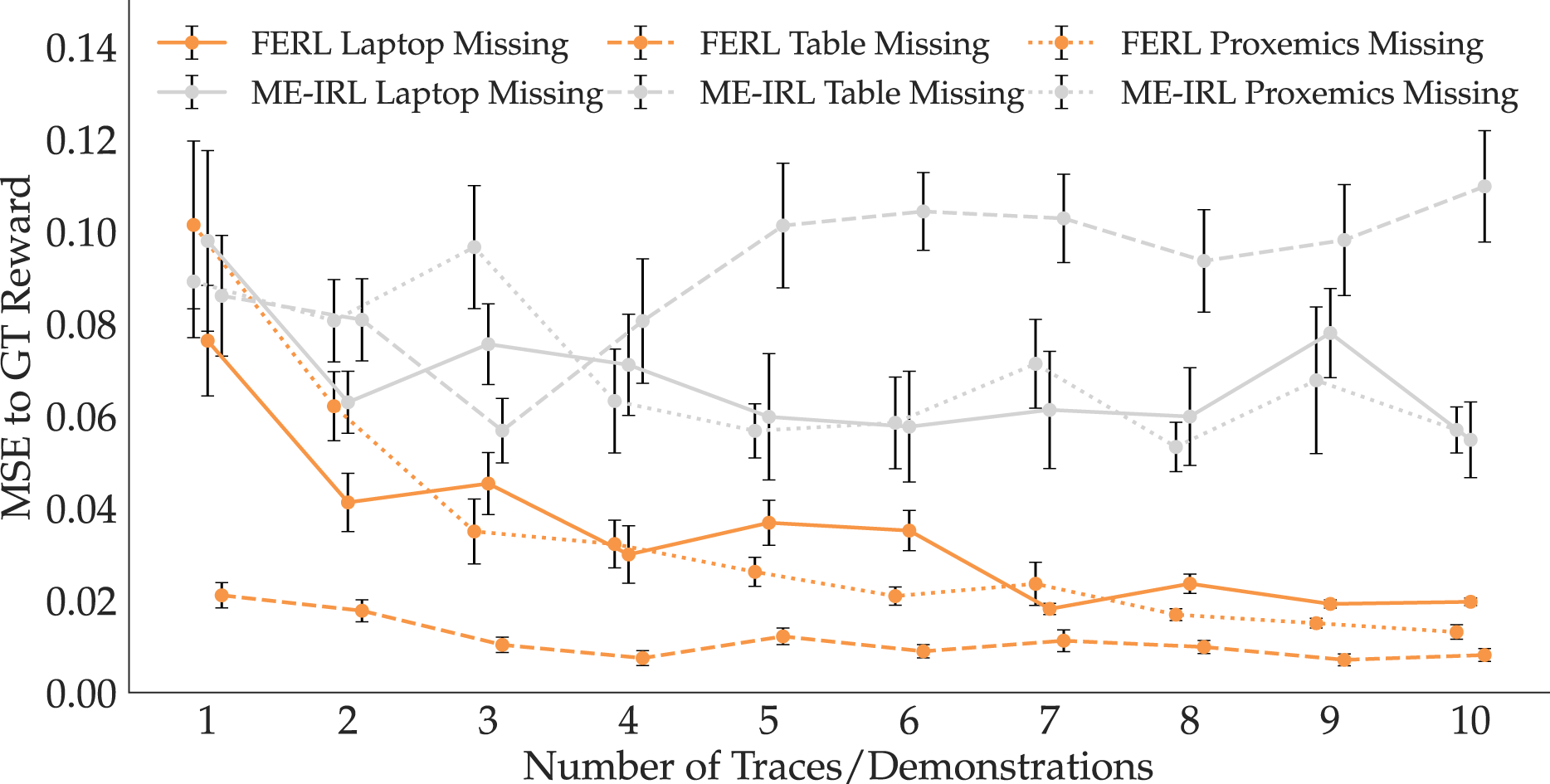
Additionally, the consistently decreasing MSE in Figure 9 for FERL suggests that our method gets better with more data; in contrast, the same trend is inexistent with ME-IRL. Supporting H7, the high standard error that ME-IRL displays implies that it is highly sensitive to the demonstrations provided and the learned reward likely overfits to the expert demonstrations. We ran an ANOVA with standard error as the dependent measure, focusing on the N = 10 trials which provide the maximum data to each method, with the learning method as the factor and the task as a covariate. We found that the learning method has a significant effect on the standard error (F(1, 4) = 12.1027, p = 0.0254). With even more data, this shortcoming of IRL might disappear; however, this would pose an additional burden on the human, which our method successfully alleviates.
We also looked at Behavior Accuracy for the two methods. Figure 10 illustrates the reward ratios to GT for all three tasks. The GT ratio is 1 by default, and the closer to 1 the ratios are, the better the performance because all rewards are negative. The figure further supports H6, showing that FERL rewards produce trajectories that are preferred under the GT reward over ME-IRL reward trajectories. An ANOVA using the task as a covariate reveals a significant main effect for the learning method (F(1, 596) = 14.9816, p = 0.0001). Induced trajectories’ reward ratio for the two methods compared to GT. ME-IRL struggles to generalize across all tasks.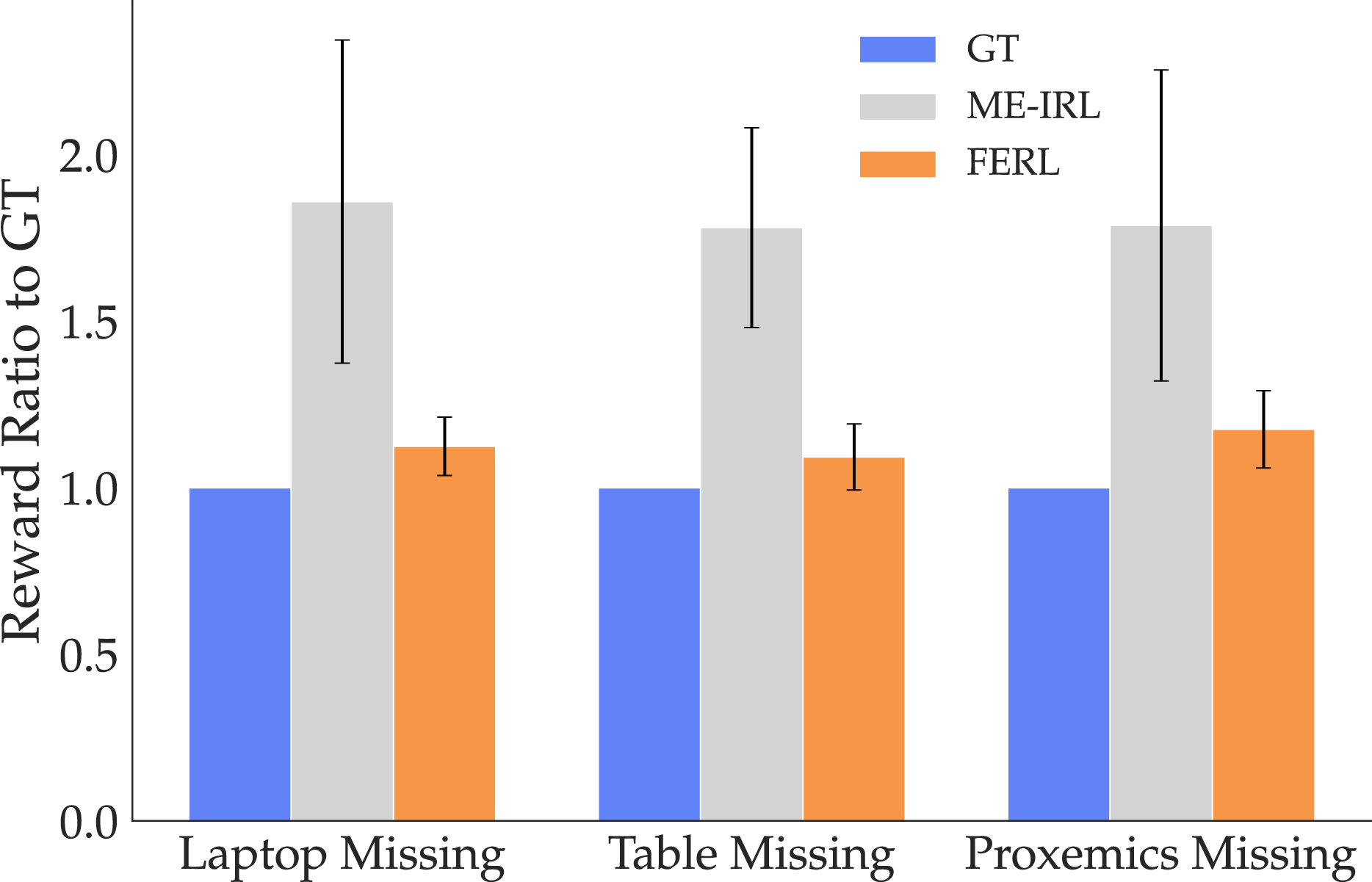
Lastly, we compare how likely a test set of trajectories given by optimizing the GT reward is under the two models. A more accurate reward model should give higher probabilities to the demonstrated trajectories under the Boltzmann noisily-rational assumption in equation (10). Figure 11 illustrates that FERL does indeed assign higher likelihood to the test trajectories than ME-IRL, which is consistent with H6. Probability assigned by the two methods to a set of optimal trajectories under the Boltzmann assumption. The trajectories are more likely under FERL than ME-IRL, suggesting FERL is the more accurate reward model.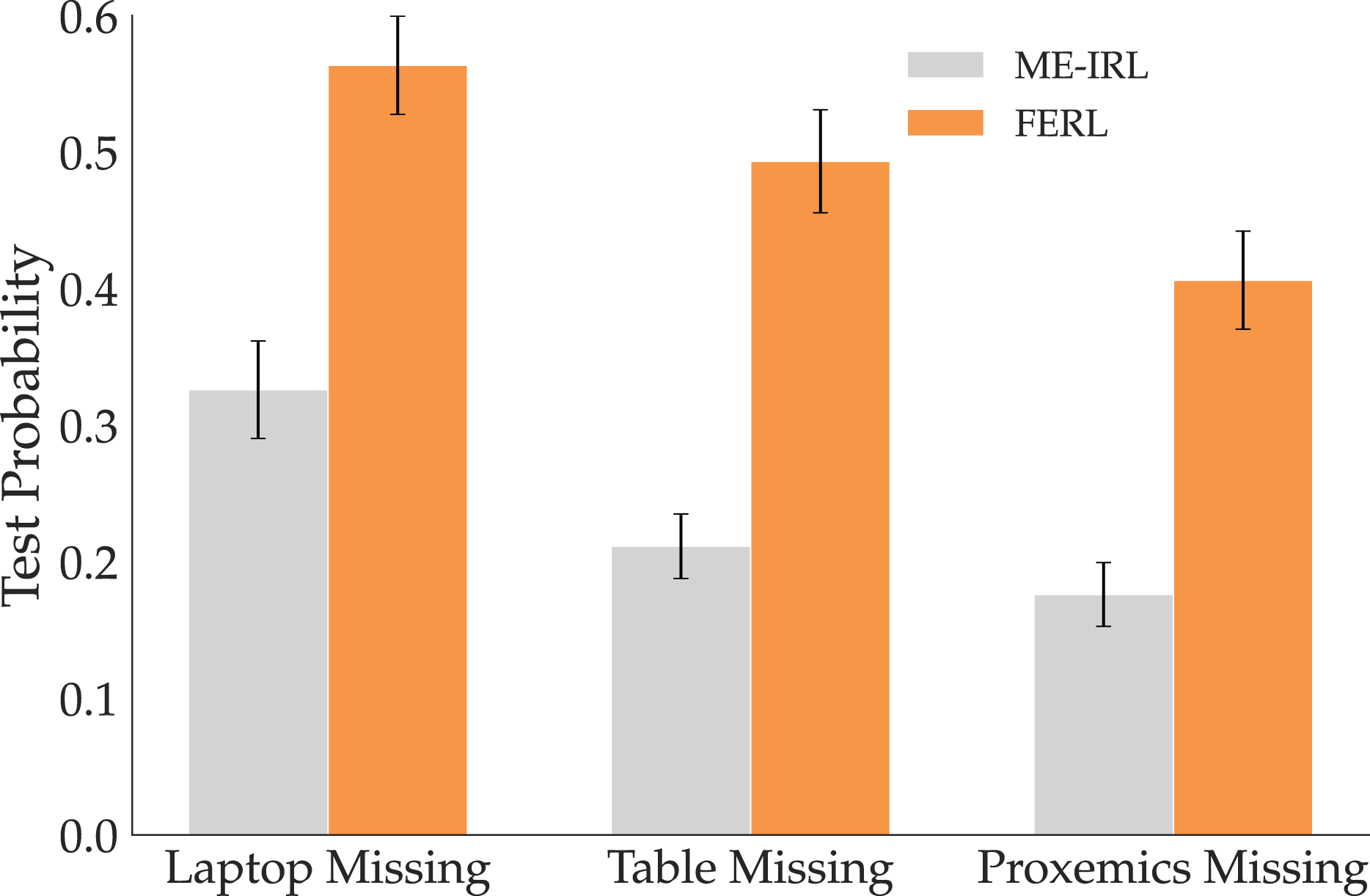
7.1.4 Summary
The rewards learned with FERL qualitatively capture more structure than ME-IRL ones, but they also quantitatively get closer to the GT. Using FERL features—at least when the robot is missing one feature—seems to induce useful structure in the reward learning process that guides the robot to better capture the person’s preferences. These results hold when the person teaching the missing feature is an expert user; we next look at the case where a novice interacts with the robot instead.
7.2 Non-expert users
The objective results in Section 6.2 show that while users’ performance degrades from expert performance, they are still able to teach features with a lot of signal. We now want to test how important the user-expert feature quality gap is when it comes to using these features for online reward learning.
7.2.1 Experimental design
For this experiment, we had a similar setup to the one in Section 7.1, only that we performed reward learning with FERL using the user-taught simulation features from the user study. We wanted to see if the divide-and-conquer approach employed by FERL results in better rewards than ME-IRL even when using noisy simulation data.
Manipulated Variables
We manipulate the learning method, FERL or ME-IRL, just like in Section 7.1. Because corrections and demonstrations would be very difficult in simulation, we use for ME-IRL the expert data from the physical robot. For FERL, we use the user data from the simulation, and the expert corrections that teach the robot how to combine the learned feature with the known ones. Note that this gives ME-IRL an advantage, since its data is both generated by an expert, and on the physical robot. Nonetheless, we hypothesize that the advantage of the divide-and-conquer approach is stronger.
Dependent measures
We use the same objective metric as Reward Accuracy in the expert comparison in Section 7.1: the learned reward MSE to the GT reward on
Hypothesis
7.2.2 Analysis
Figure 12 illustrates our findings for the reward comparison. In the figure, we added FERL with expert-taught simulation features for reference: we randomly subsampled sets of 10 from 20 expert traces collected by the authors, and trained 12 expert features for each of our three task features. We see that, even though ME-IRL was given the advantage of using physical expert demonstrations, it still severely underperforms when compared to FERL with both expert and user features learned in simulation. This finding is crucial because it underlines the power of our divide-and-conquer approach in online reward learning: even when given imperfect features, the learned reward is superior to trying to learn everything implicitly from demonstrations. MSE to GT reward for the three tasks, comparing ME-IRL from expert physical demonstrations (gray) to online FERL from expert (orange) and non-expert (yellow) features learned in simulation and combined via corrections.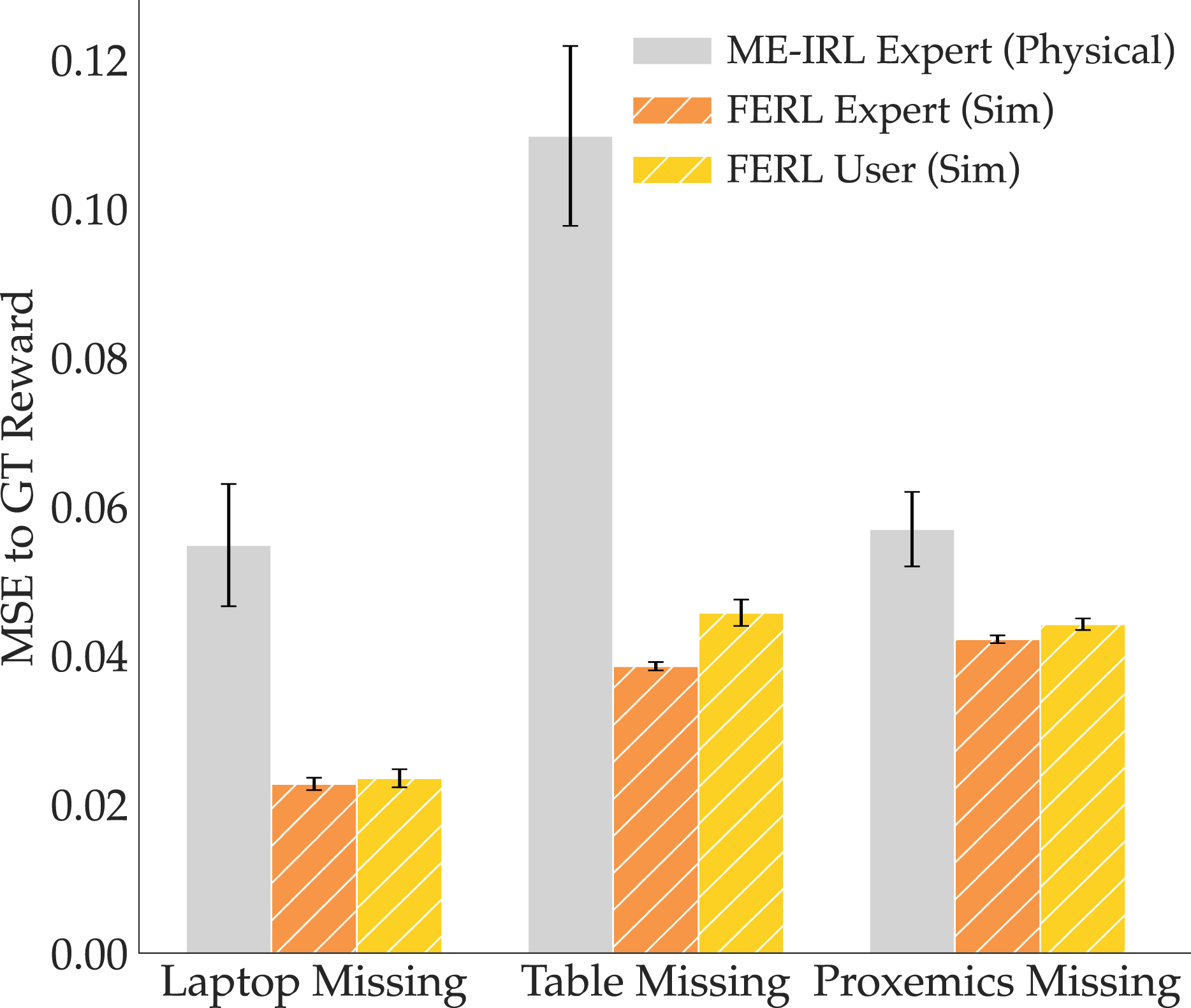
We verified the significance of this result with an ANOVA with the learning method as a factor and the task as a covariate. We found a significant main effect for the learning method (F(1, 62) = 41.2477, p < 0.0001), supporting our H8.
7.2.3 Summary
Despite the degradation in feature quality we see in user features when compared to expert ones, we find that the structure they do maintain is advantageous in online reward learning. This suggests that the online instantiation of FERL can be used even by non-experts to better teach the robot their preferences.
8. Experiments: Offline FERL
In the online reward learning setting, the robot was already equipped with a starting feature set, and we tested how learning missing features affects the reward. We now look at the scenario where the robot’s reward must be programmed entirely from scratch, teaching each feature separately before combining them into a reward via demonstrations.
8.1 Expert users
We have argued that learned features can induce useful structure that speeds up reward learning. We test how the reward is affected when the entire structure is built up from the expert features taught from real robot data in Section 6.1.
8.1.1 Experimental design
We run experiments on the robot arm in three settings of increasing complexity: in the first, the true reward depends on a single feature, and every subsequent task adds another feature to the reward. In task 1, the true reward depends on only ϕtable. In task 2, we add the ϕlaptop feature, and in task 3 the ϕproxemics feature. In both tasks 2 and 3, the reward equally combines the two and three features, respectively. Task 1 should be easy enough for even an end-to-end IRL method to solve, especially since it relies on the simplest feature that we have considered. Meanwhile, tasks 2 and 3 require learning rewards that are more structurally complex. We name the three tasks One Feature, Two Features, and Three Features, respectively.
Manipulated variables
We manipulated the learning method with 2 levels: FERL and ME-IRL. While in Section 7 ME-IRL had access to the known features, this time the reward network is a function mapping directly from the 27D Euclidean input space only. For practical considerations and implementation details of the offline version of FERL we used, see Online Appendix C.3.
For a fair comparison, we once again took great care in how we collected the demonstrations ME-IRL learns from. Just like before, we chose diverse start and goal configurations, and focused some of the demonstrations on each individual feature, and, when it applies, on each combination of features (see Online Appendix B.2). Importantly, while ME-IRL uses a set of near-optimal demonstrations
Dependent measures
We use the same objective metrics as Reward Accuracy, Behavior Accuracy, and Test Probability in Section 7.1. For Reward Accuracy, we vary the number N of traces/demonstrations each learner gets but skip N = 1 because FERL would have an unfair advantage in the amount of data given. We give ME-IRL up to 10, 20, and 30 demonstrations for the three tasks, respectively. Meanwhile, we give FERL up to 10 traces for each feature, and 1, 2, and 3 demonstrations for each task, respectively. Overall, FERL would use up to 10 traces and one demonstration, up to 20 traces and 2 demonstrations, and up to 30 traces and 3 demonstrations, while ME-IRL would be given 10, 20, and 30 demonstrations for each task, respectively. For Behavior Accuracy and Test Probability, we train FERL with 10 traces per feature and 1, 2, or 3 demonstrations, and ME-IRL with 10, 20, and 30 demonstrations, respectively. Just like in Section 7.1, for Behavior Accuracy we produce optimal trajectories for 100 randomly selected start-goal pairs under the learned rewards and evaluate them under the GT reward. Meanwhile, for Test Probability, we generate 100 optimal trajectories using the GT reward, then evaluate their likelihood under the learned models.
Hypothesis
8.1.2 Qualitative comparison
In Figure 13, we show the learned FERL and ME-IRL rewards as well as the GT for all three tasks evaluated at the test points. The figure illustrates that by first learning each feature separately and then the reward that combines them, FERL is able to learn a fine-grained reward structure closely resembling the GT. For the easiest task, One Feature, ME-IRL does recover the GT appearance, but this is unsurprising since the table feature is very simple. For the other more complex two tasks, just like in the online case, ME-IRL learns some structure capturing where the laptop or the human is, but not enough to result in a good trade-off between the features. Visual comparison of the ground truth, offline FERL, and ME-IRL rewards for One Feature (top), Two Features (middle), and Three Features (bottom).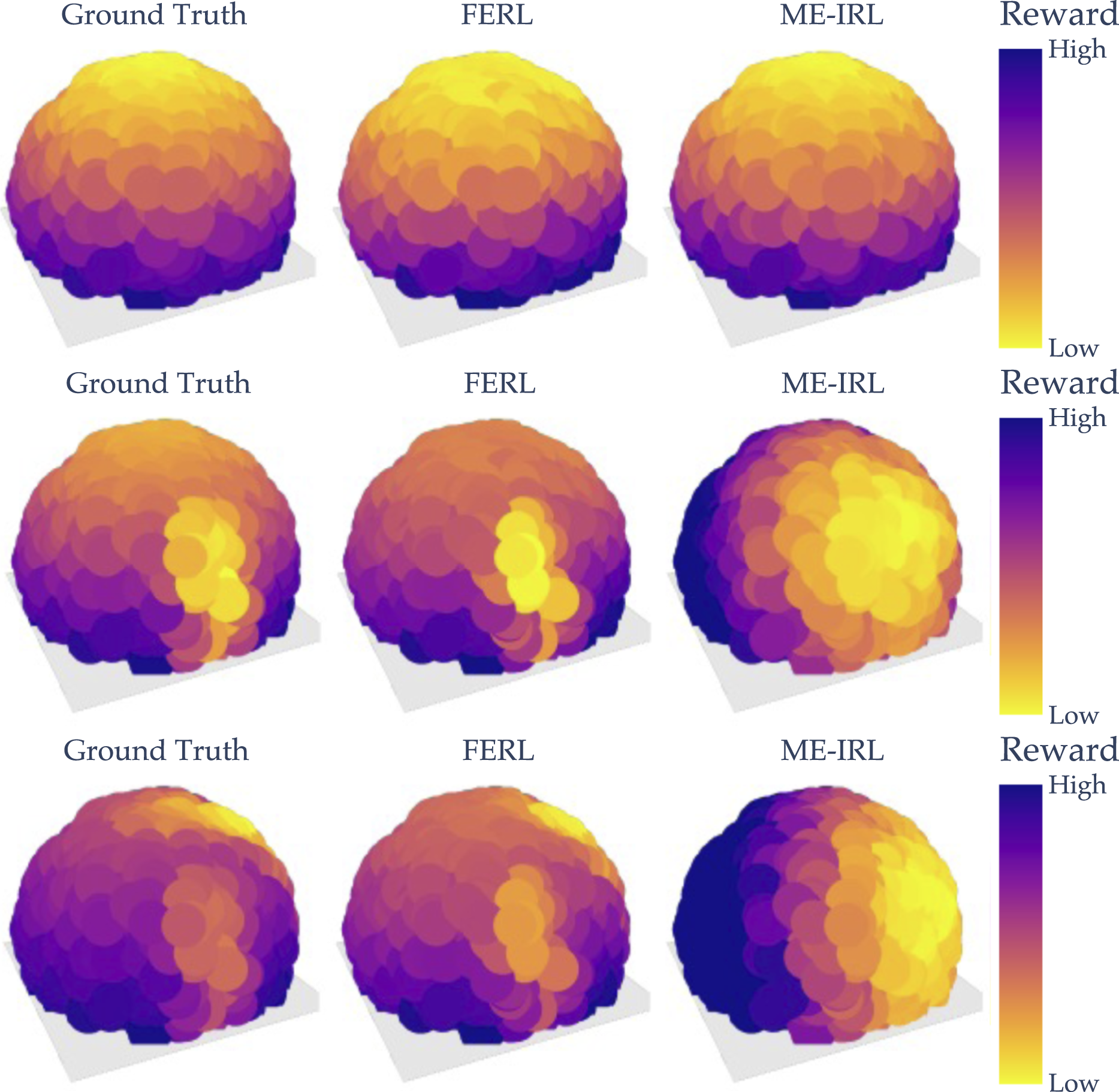
8.1.3 Quantitative analysis
To compare Reward Accuracy, we show in Figure 14 the MSE mean and standard error across 10 seeds, with increasing training data. We visualize results from all three tasks side by side, with FERL in orange and ME-IRL in gray. For One Feature, as expected, ME-IRL does eventually learn a good reward with enough data. However, for the other more complex tasks that combine multiple features, ME-IRL underperforms when compared to our method. Overall, across the tasks, FERL is closer to GT than ME-IRL no matter the amount of data, supporting H9. To test this, we ran an ANOVA with learning method as the factor, and with the task and data amount as covariates, and found a significant main effect (F(1, 535) = 148.8431, p < 0.0001). MSE of offline FERL and ME-IRL to GT reward for One Feature (left), Two Features (middle), and Three Features (right). In most data regimes, FERL learns rewards that better generalize to the state space.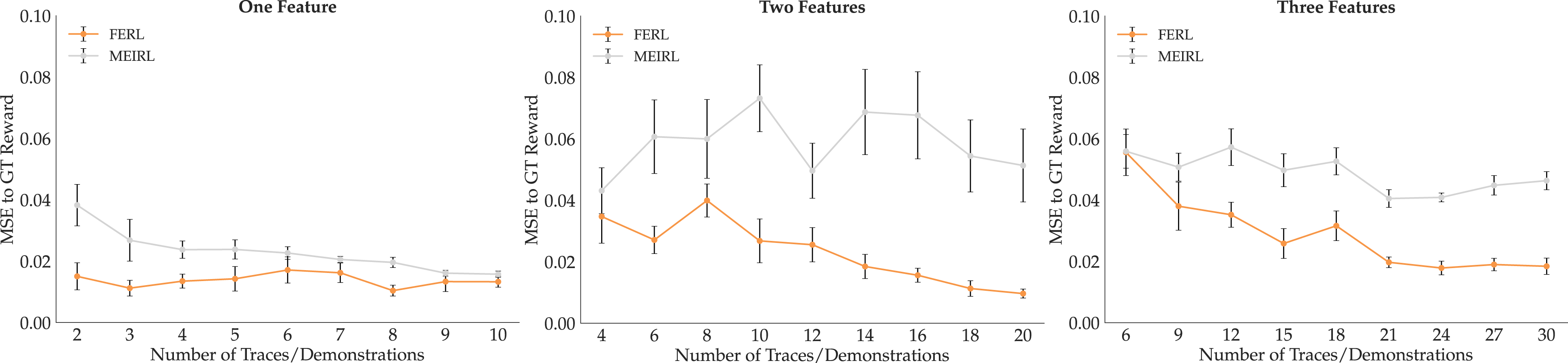
For comparing Behavior Accuracy, Figure 15 illustrates the reward ratios to GT for all three tasks. When the reward consists of a single very simple feature, ME-IRL performs just as well as our method. However, when the reward structure more complexly combines multiple features, ME-IRL does not produce as good trajectories under the GT reward as FERL, supporting H8. We ran an ANOVA using the learning method as a factor and the task as a covariate and did not find a significant main effect, probably due to the One Feature results. To verify this theory, we re-ran the ANOVA using only the data from the more complex Two Features and Three Features tasks, and did, in fact, find a significant main effect (F(1, 397) = 5.7489, p = 0.0097). Results with the Test Probability metric paint a similar picture. Figure 16 shows that for the easy One Feature case, both methods perform comparably, but when the reward is more complex (Two Features and Three Features), FERL outperforms ME-IRL and assigns higher probability to the test trajectories. Induced trajectories’ reward ratio for the two methods compared to GT. While ME-IRL generalizes for the single feature task, it struggles with the more complex multiple feature tasks. Probability assigned by the two methods to a set of optimal trajectories under the Boltzmann assumption. For the more complex multiple feature tasks, the trajectories are more likely under FERL than ME-IRL.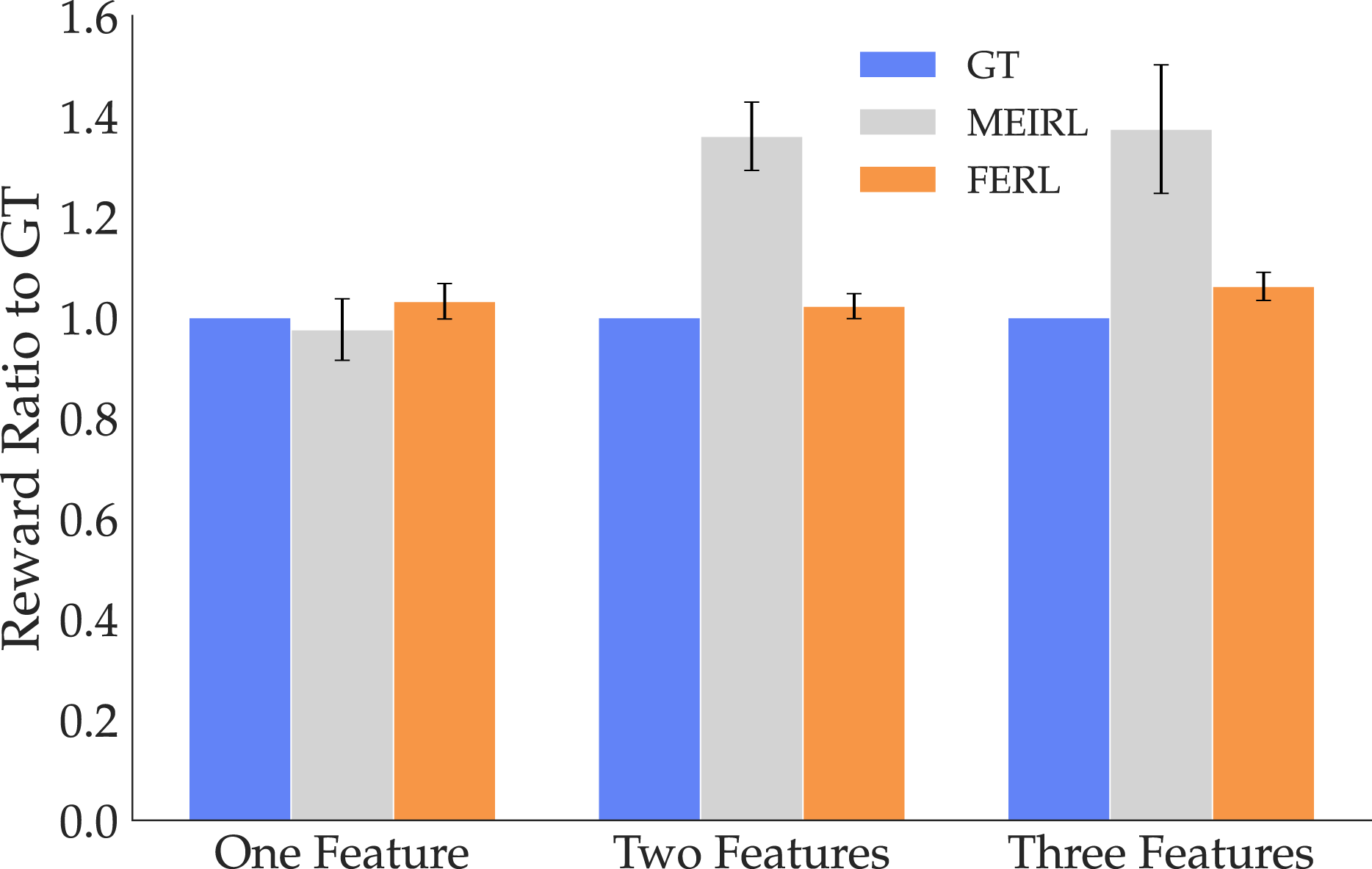
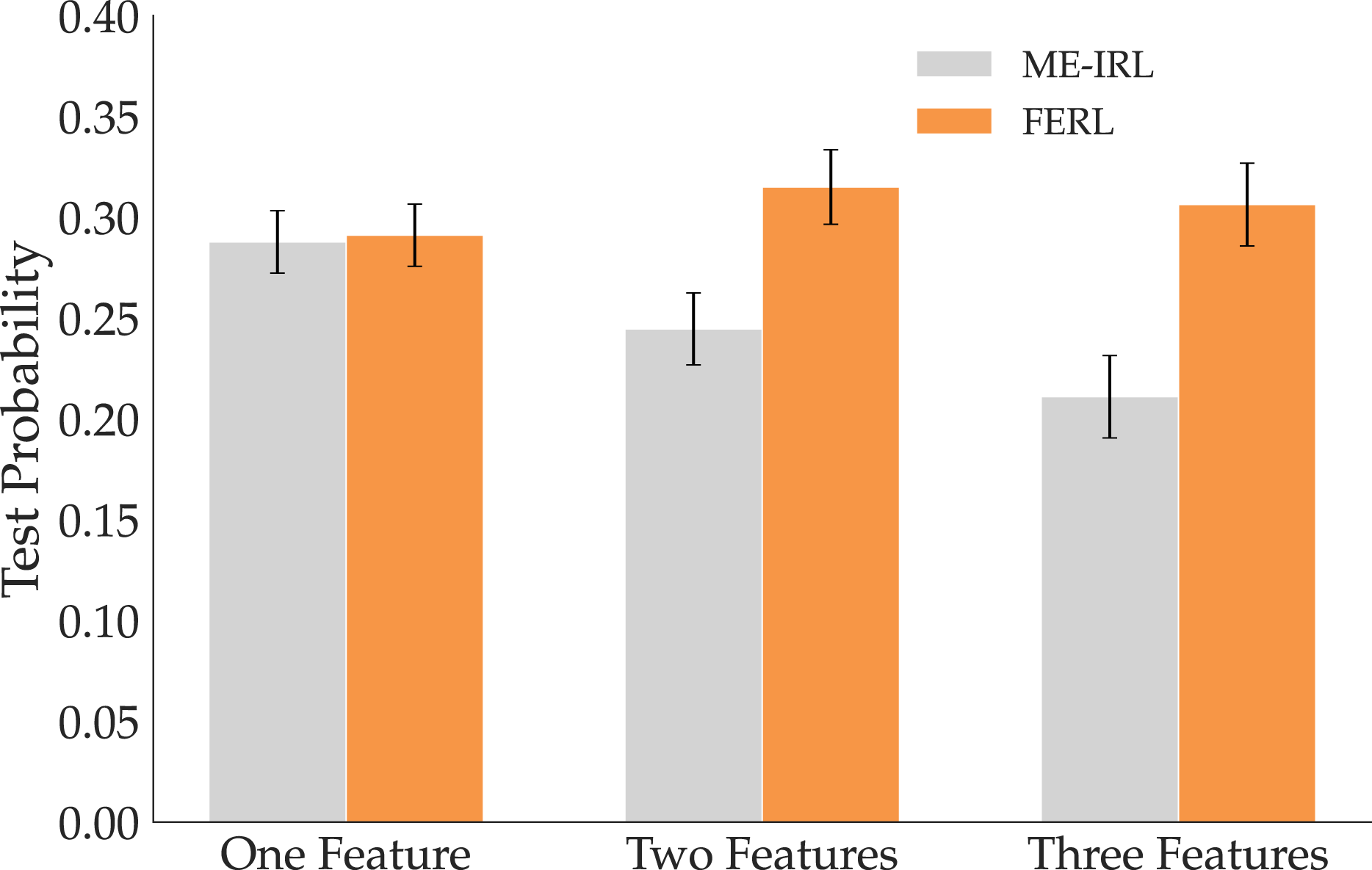
8.1.4 Summary
The results in this section suggest that while ME-IRL is capable of recovering very simple reward structures, it does not perform as well as using FERL features for complex rewards. This observation applies when the features are taught by experts, so we now test what happens if we instead use non-expert user features.
8.2 Non-expert users
In Section 7.2, we saw that user-taught FERL features have enough structure to help the robot recover the human’s preferences in online reward setting where the original feature set is incomplete. However, there we only had one missing feature. In this section, we test the more challenging scenario, where we learn a reward from scratch using the noisy user features learned in simulation.
8.2.1 Experimental design
For this experiment, we had a similar setup as in Section 7.2—using the user-taught simulation features for learning the reward—only this time we tested the offline instantiation of FERL. Given that now we combine multiple noisy features together into a reward, we wanted to see how our divide-and-conquer approach fares against the ME-IRL baseline.
Manipulated variables
We manipulate the learning method, FERL or ME-IRL, just like in Section 8.1. Like in Section 7.2, we use demonstrations collected from the expert on the physical robot for ME-IRL. For FERL, we use the user data from the simulation, and the expert demonstrations that teach the robot how to combine the learned feature into a reward. Note that this gives ME-IRL an advantage, since all its data is both generated by an expert, and on the physical robot.
Dependent measures
We use the same objective metric as Reward Accuracy in the expert comparison in Section 8.1: the learned reward MSE to the GT reward on
Hypotheses
8.2.2 Analysis
Figure 17 illustrates our findings for the reward comparison. We also added the offline FERL reward using expert-taught simulation features for reference, where we randomly subsampled sets of 10 traces and trained 12 expert features for each of the three features. This time, we find that the user features are noisy enough that, when combined into a reward, they do not reliably provide an advantage over ME-IRL. This could be attributed to the difficulty of teaching features in a simulator, especially given that there is no easy way to approximate distances and traces in 3D space with a 2D interface are hard. We verified this result with an ANOVA with the learning method as a factor and the task as a covariate, and, as expected, we found no significant main effect. MSE to GT reward for the three tasks, comparing ME-IRL from expert physical demonstrations (gray) to offline FERL from expert (orange) and non-expert (yellow) features learned in simulation and combined via corrections.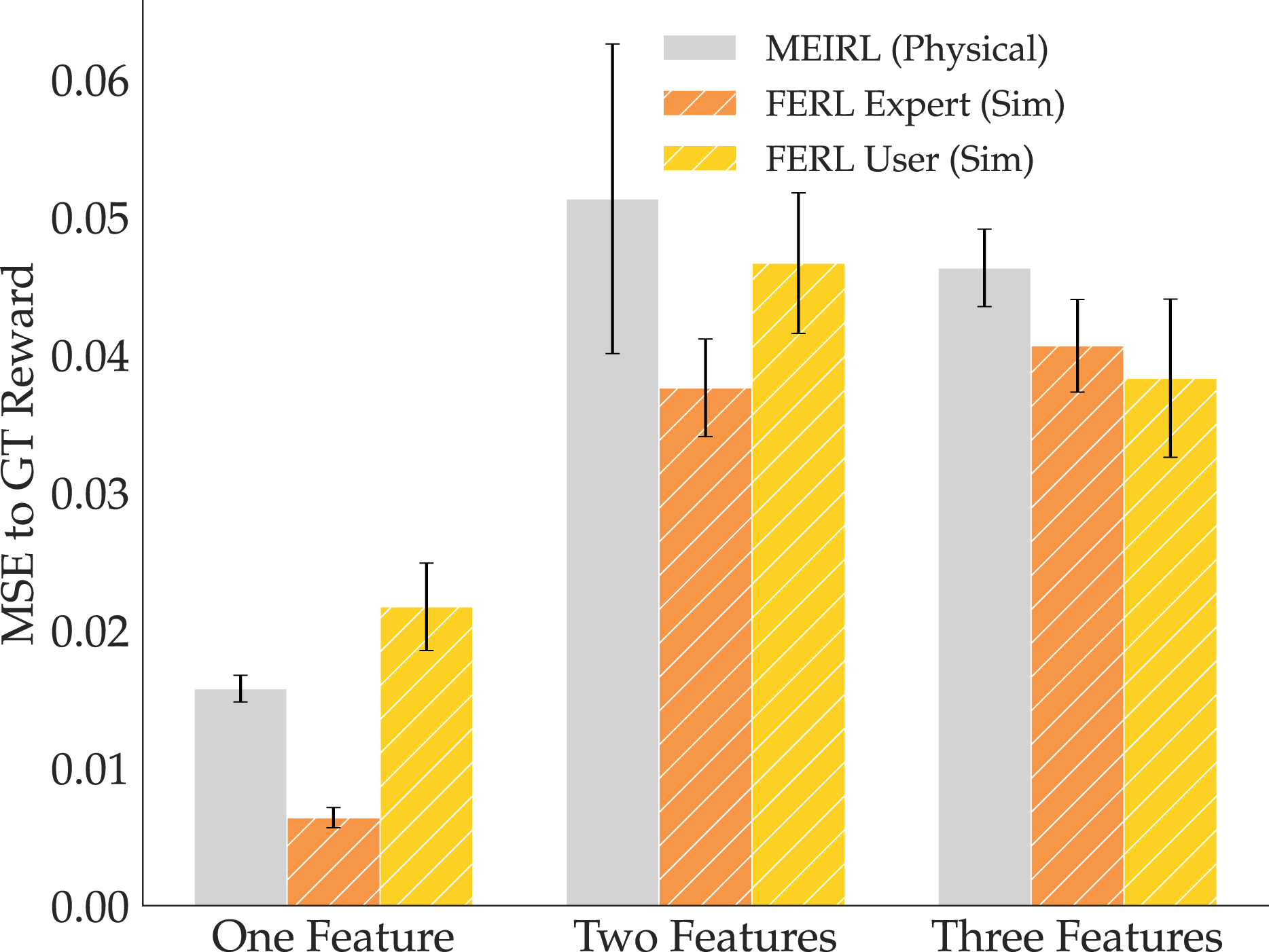
8.2.3 Summary
Previously, we have seen how structure can indeed help reward learning generalizability and sample efficiency; but we now see that the wrong—or very noisy—structure obtained from traces from simulation may diminish the benefits that our divide-and-conquer approach promises. However, we suggest taking this result with a grain of salt, since ME-IRL had the advantage of all-expert, all-physical data, whereas our method was limited to data collected in simulation from novice users. While not possible during the pandemic, we are optimistic that with physical demonstrations the benefits would be more prominent.
9. Discussion
Learning reward functions is a popular way to help robots generate behaviors that adapt to new situations or human preferences. In this work, we propose that robots can learn more generalizable rewards by using a divide-and-conquer approach, focusing on learning features separately from learning how to combine them. We introduced feature traces as a novel type of human input that allows for intuitive teaching of non-linear features from high-dimensional state spaces. We then presented two instantiations of our FERL algorithm: one that enables expanding the robot’s feature set in online reward learning situations, and one that lets the user sequentially teach every feature and then combine them into a reward. In extensive experiments with a real robot arm and a user study in simulation, we showed that online FERL outperforms deep reward learning from demonstrations (ME-IRL) in data-efficiency and generalization. Offline FERL similarly beats ME-IRL when the features used are of high enough quality, but the results are less conclusive when using very noisy features.
Implications for online reward learning
Because they have to perform updates in real time from very little input, online reward learning methods represent the reward as a linear function of a small set of hand-engineered features. As discussed, exhaustively choosing such a set a priori puts too much burden on system designers, and using an incomplete set of features can lead to learning the wrong reward. Prior work enabled robots to at least detect that its feature space is insufficient to explain the human’s input (Bobu et al., 2018), but then the robot’s only option was to either not update the reward or completely stop task execution. Our online FERL approach provides an alternative that allows people to teach features when the robot detects it is missing something, and then update the reward using the new feature set. Although in this paper we presented experiments where the robot learns rewards from corrections, our framework can conceivably be adapted to any online reward learning method, provided there is a way to detect the feature set is insufficient. Recent work on confidence estimation from human demonstrations (Bobu et al., 2020) and teleoperation (Zurek et al., 2021) offers encouraging pathways to adapting FERL to other online human–robot collaborative settings.
Implications for learning complex rewards from demonstrations
Reward learning from raw state space with expressive function approximators is considered difficult because there exists a large set of functions r θ (s) that could explain the human input. For example, in the case of learning from demonstrations, many functions r θ (s) induce policies that match the demonstrations’ state expectation. The higher dimensional the state s, the more human input is needed to disambiguate between those functions sufficiently to find a reward r θ that accurately captures human preferences. Without that, the learned reward is unlikely to generalize to states not seen during training and might simply replicate the demonstrations’ state expectations. In this paper, we presented evidence that offline FERL may provide an alternative to better disambiguate the reward and improve generalization.
The reason our divide-and-conquer approach can help relative to relying on demonstrations for everything is that demonstrations aggregate a lot of information. First, by learning features, we can isolate learning what matters from learning how to trade off what matters into a single value (the features vs. their combination)—in contrast, demonstrations have to teach the robot about both at once. Second, feature traces give information about states that are not on optimal trajectories, be it states with high feature values that are undesirable, or states with low feature values where other, more important features have high values. Third, feature traces are also structured by the monotonicity assumption: they tell us relative feature values of the states along a trace, whereas demonstrations only tell us about the aggregate reward across a trajectory. Thus, by focusing on learning features first before combining them into a reward, the robot can incorporate all three benefits and ultimately improve reward learning from demonstrations.
Limitations and future work
Our work is merely a step towards understanding how explicitly focusing on learning features can impact reward learning generalization and sample complexity. While FERL enables robots to learn features and induce structure in reward learning, there are several limitations that may affect its usability.
Our user study provides evidence that non-expert users can, in fact, use FERL to teach good features. However, due to the current pandemic, we conducted the study in a simulated environment instead of in person with the real robot, and most of our users had technical background. It is unclear how people without technical background would perform, and especially how kinesthetically providing feature traces (instead of clicking and dragging in a simulator) would affect their perception of the protocol’s usability. Further, we only tested whether users could teach features we tell them about, so we still need to test whether users can teach features they implicitly know about (as would happen when intervening to correct the robot or designing a reward from scratch).
Even if people know the feature they want to teach, it might be so abstract (e.g., comfort) that they would not know how to teach it. Moreover, with the current feature learning protocol, they might find it cumbersome to teach discontinuous features like constraints. We could ease the human supervision burden by developing an active learning approach where the robot autonomously picks starting states most likely to result in informative feature traces. For instance, the robot could fit an ensemble of functions from traces online, and query for new traces from states where the ensemble disagrees (Reddy et al., 2020a). But for such complex features, it may be more effective to investigate combining feature traces with other types of structured human input.
The quality of the learned rewards depends directly on the quality of the learned features. When the human provides feature traces that lead to good features, many of our experiments demonstrate that they induce structure in the reward learning procedure that helps generalization and sample complexity. However, if the robot learns features that are too noisy or simply incorrect, that (wrong) structure may impair performance. We saw an example of this when we tried to utilize the user study features for reward learning. In online FERL where a single feature was missing, the structure captured by the (noisy) non-expert features was still helpful in learning a better reward than the baseline. However, when trying to combine multiple noisy features in offline FERL, reward learning did not see a benefit. Future work must investigate ways in which the robot can determine whether to accept or reject the newly learned feature. One idea is to use our current framework’s confidence estimation capability in Section 5.2.2 to determine whether the learned feature set explains the human’s reward input. Another idea is to visualize either the feature function or examples of behaviors induced by it, and let the person decide whether the learned feature is acceptable.
Lastly, while we show that FERL works reliably in 27D, more work is necessary to extend it to higher dimensional state spaces, like images. In our discussion in Online Appendix B.3, we show how spurious correlations in large input spaces may affect the quality of the learned features in low data regimes. To counteract that, we could ask the person for more data, but after a certain point this becomes too burdensome on the user. Alternatively, approaches that encode these spaces to lower dimensional representations or techniques from causal learning, such as Invariant Risk Minimization (Arjovsky et al., 2019), could help tackle these challenges.
Supplemental Material
sj-pdf-1-ijr-10.1177_02783649221078031 – Supplemental Material for Inducing structure in reward learning by learning features
Supplemental Material, sj-pdf-1-ijr-10.1177_02783649221078031 for Inducing structure in reward learning by learning features by Andreea Bobu, Marius Wiggert, Claire Tomlin and Anca D. Dragan, in The International Journal of Robotics Research
Footnotes
Acknowledgements
We also thank Rohin Shah for providing guidance and feedback on our work.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
'The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the Air Force Office of Scientific Research (AFOSR), the Office of Naval Research (ONR-YIP), the DARPA Assured Autonomy Grant, the CONIX Research Center, and the German Academic Exchange Service (DAAD).
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.