
Abstract
When a robot has to imitate an observed action sequence, it must first understand the inherent characteristic features of the individual actions. Such features need to reflect the semantics of the action with a high degree of invariance between different demonstrations of the same action. At the same time the machine needs to be able to execute the action sequence in any appropriate situation. In this study, we introduce a new library of actions, which is a generic framework for executing manipulation actions on robotic systems by combining features that capture action semantics with a framework for execution. We focus on manipulation actions and first create a generic representation consisting of symbolic and sub-symbolic components. To link these two domains we introduce a finite state machine allowing for sequential execution with error handling. The framework is developed from observing humans which provides us with a high degree of grounding. To quantitatively evaluate the scalability of the proposed approach, we conducted a large set of experiments involving different actions performed either individually or sequentially with various types of objects in different scene contexts.
1. Introduction
Contemporary research in robotics aims at developing intelligent robotic systems with human-like skills. To perform an action with a robot, very often the action is parameterized and represented by a robotic-compatible encoding that allows execution. Various ways exist for doing this, for example one can employ methods for the imitation of human-demonstrated actions by using low-level continuous sensory-motor data streams (programming by demonstration (PbD); see, e.g., Inamura et al (2005), Aleotti and Caselli (2006), and Dillmann et al (2010)). All these methods have in common that they lead to parametric and, thus, executable action representations. They directly rely on “signals”: for example, PbD needs perception signals from the observed human action and outputs action signals to reproduce it with the machine. The signal level, thus, allows action execution but, owing to its high degree of detail, easily suffers from deficiencies by not being able to generalize action concepts in a meaningful (semantic) way.
This, however, is needed as soon as the robot has to perform a complex task in different situations. For this it requires some conceptual understanding of the required action sequence and it needs to comprehend the general constraints of the individual sub-actions. Several frameworks exist that attempt action generalization and/or action conceptualization. In a nutshell, they range from generalization at the signal (trajectory) level all the way up to generalization of actions by symbolic (planning-compatible) descriptors (for more details see Section 2).
In this paper, we focus on manipulation actions because they allow for a rather rigorous ontological structuring, the germs of which had been discussed in an older paper (Wörgötter et al, 2013). We extend this approach by developing a library of manipulation actions that captures the essence of each action in an abstract way but remains compatible with robotic execution. To this end we use, as previously (Aein et al, 2013; Aksoy et al, 2011, 2015a), the framework of semantic event chains (SECs) to encode the action type. SECs just analyze the sequence of touching and untouching events that happen during an action to do this, but they can, in this way, break the realm of manipulation actions only down into a few semantically similar classes (Pastra and Aloimonos, 2012; Wörgötter et al, 2013). The here-pursued approach enriches this by descriptive movement primitives that allow for two things. On the one hand, many more (possibly all single handed) manipulation actions are now represented by a unique set of symbolic descriptors, which on the other hand remain execution-relevant, because they can at run-time be filled with the required parameters for performing the different movements to execute the action. Therefore, this approach represents one possible way for linking a symbolic action representation in a grounded way with its corresponding signal-level description (derived from observations, hence from sensory experience). All in all, with this framework we hope to achieve a contribution towards closing, or at least reducing, the signal-to-symbol gap (Coradeschi and Saffiotti, 2003; Krüger et al, 2011) in robotics.
Thus, based on prior works from us and others, the main contribution of this paper is the rigorous structuring of a large set of manipulation actions into a three-layer representation starting from a high, symbolic level via a state machine-like encoding and ending at detailed movement primitives. We show that these representations can then act as library functions and that they can be parameterized in a situation-dependent way to execute them either alone or in a sequence.
The rest of the paper is organized as follows. We start with introducing the state of the art in Section 2. We then continue with a detailed description of action definition and execution in Section 3. The results of many experiments using this framework are finally shown in Section 4 followed by a discussion in Section 5.
2. State of the art
There exists a large corpus of work on action representation and execution (Calinon et al, 2007; Ijspeert et al, 2002; Lee and Nakamura, 2006; Simmons and Apfelbaum, 1998; Ude, 1993). Two distinct approaches are commonly preferred in order to represent and execute actions; one at the trajectory level (Ijspeert et al, 2002), the other at the symbolic level (Simmons and Apfelbaum, 1998). The former gives more flexibility for an execution-relevant definition of actions, while the latter defines actions at a higher level and allows for generalization and planning.
For trajectory-level representation there are several well-established techniques: splines (Ude, 1993), hidden Markov models (HMMs) (Lee and Nakamura, 2006), Gaussian mixture models (GMMs) (Calinon et al, 2007), dynamic movement primitives (DMPs) (Ijspeert et al, 2002; Kulvicius et al, 2012; Luksch et al, 2012). With trajectory-level encoding, one can investigate or learn different complicated trajectories, but it is difficult to use them in a more “cognitive sense.” Generalization of the observed trajectories is the main challenge here (and often addressed in different ways in the above-cited papers), because even the same action can be demonstrated by following various trajectories.
High-level symbolic representations many times use graph structures and relational representations (e.g. Ekvall and Kragic, 2006; Pardowitz et al, 2007). Alternative methods, such as that of Lee et al (2013), described a syntactic approach for learning robot imitation by capturing underlying task structures in the form of probabilistic activity grammars. These approaches give compact descriptions of complex tasks, but they do not consider execution-relevant motion parameters (trajectories, poses, forces) in great detail.
In this work, our high-level action descriptor is based on the concept of SECs introduced by Aksoy et al (2011) and used also by others (Luo et al, 2011; Martinez et al, 2014; Vuga et al, 2014; Yang et al, 2013). SECs are generic action descriptors that capture the underlying spatio-temporal structure of continuous actions by sampling only decisive key temporal points derived from the spatial interactions between hands and objects in the scene. The SEC representation is invariant to large variations in trajectory, velocity, object type, and pose used in the action. Therefore, SECs can be employed for the classification task of actions as demonstrated in various experiments in Aksoy et al (2015b) and we have shown in Aein et al (2013) that human-demonstrated actions encoded by SECs can also be executed by robots, once low-level data (object positions, trajectories, etc.) are provided.
Many times trajectory-level descriptions of actions, object properties, and high-level goals of the manipulation were brought together through STRIPS-like planning (Beetz et al, 2015; Dillmann et al, 2010; Kunze et al, 2011), resulting in operational although not very transparent systems. The approaches in Ahmadzadeh and Kormushev (2016); Ahmadzadeh et al (2015) attempted to integrate symbolic action representation and planner with a motor skill learner. The robot learned the goal of the human-demonstrated actions by using a so-called visuo-spatial skill learning (VSL) method, which produced symbolic predicates. Such predicates were directly fed into a standard planner to encode skills in a discrete symbolic form. This framework also considered sensorimotor skills, such as the followed trajectory from the observed action. In contrast to the works in Ahmadzadeh and Kormushev (2016); Ahmadzadeh et al (2015), we do not immediately require any additional symbolic planner because SECs provide a fully observable state sequence. As long as we are only dealing with straightforward linear action sequences, planning is no longer needed. To show this here, we also perform evaluations on long and complex human manipulation actions.
Still the problem of how to bring the signal (trajectory) level together with the symbolic level remains a big challenge in robotics.
There are also many works concentrating on the execution of manipulation actions using cognitive agents. Yamaguchi et al (2014) designed a finite state machine (FSM) to execute a pouring action. Morante et al (2014) used guided motor primitives (GMPs) to perform painting and cleaning tasks on a simulated robot. Another approach to deal with the signal–symbol gap was to combine motion and task planning such as in the work of Srivastava et al (2014). They generated trajectories for tasks such as pick-up and put-down to solve problems in different domains. In Ghalamzan et al (2015), GMM and DMPs were integrated to learn robotic tasks from human demonstrations. He et al (2015) proposed a manipulation planning framework with linear temporal logic specifications. The system was demonstrated on a simulated robot to successfully perform some tasks, but the planning could take a long time as soon as the number of objects and locations in the environment increases. Kappler et al (2015) proposed a decision-making approach to perform robotic tasks. Here, multi-modal sensor data were processed to switch between several movement primitives called associative skill memories.
Morante et al (2014) proposed execution of actions using so-called continuous goal directed actions (CGDAs). They generated a library of GMPs in the joint space of the robot, and later used them in the execution phase. A simulated robot was introduced to perform cleaning and painting tasks. Lioutikov et al (2016) performed a bimanual cutting task by sequencing the learned DMPs. As only position data were used, the quality of execution is highly dependent on the placement of the knife in the robot hand.
In Rozo et al (2013) a pouring task was learned by using parametric HMMs. In addition, in Yamaguchi et al (2015) a pouring task was represented, planned and learned from human demonstration. In this work, pouring of liquids and granular material was modeled by a FM.
Although the existing works show promising results, they are usually limited in the number of actions and manipulated objects. One of the main goals of our study is to develop a generic scheme that allows robots to perform a much wider variety of actions on various object sets.
3. Methods
As illustrated in Figure 1, our proposed perception–action framework involves three main levels: high-, mid-, and low-level action units. To address this we will start with a detailed description of high and low levels together with their components. In the very end, the mid-level action unit that bridges the gap between high and low levels will be introduced. The figure provides in red the section numbers by which the road-map of this section is represented.
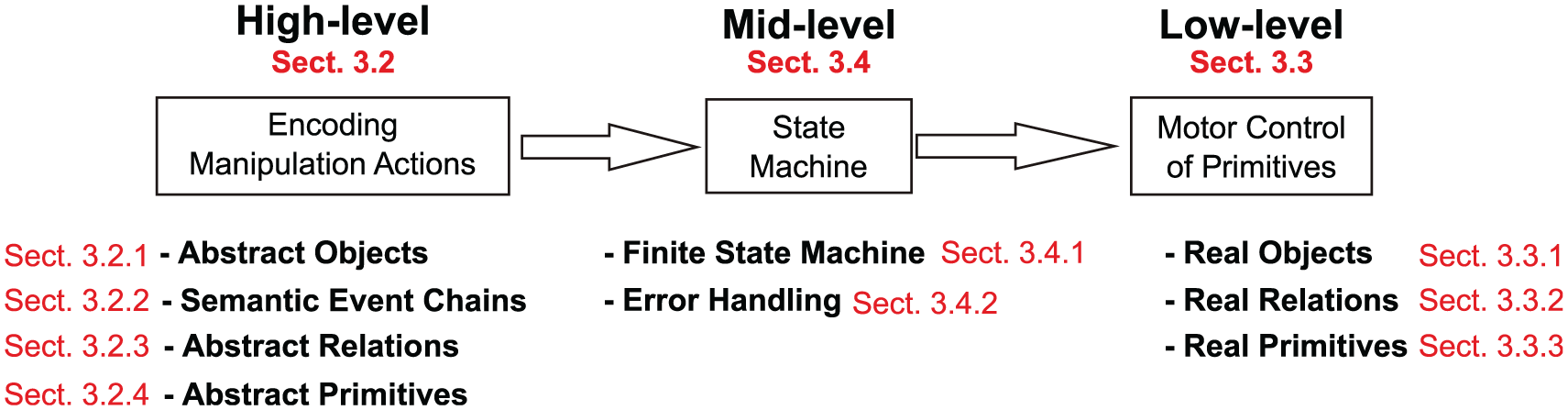
Levels of action definition. The high-level components are symbolic and close to human language. The low-level components are in the signal domain. The mid-level fills the gap and makes execution possible. The red numbers refer to the sections in the text.
First, however, we provide a short overview of the domain in which we operate and also discuss which actions we have implemented. Then we describe the framework using the structure from Figure 1.
3.1. Domain and actions
In our experiments, we are focusing on tabletop manipulations related to cooking tasks, which can be performed with a stationary robot. Note, however, that by design the framework is not restricted to this domain, because the structuring of all actions in high-, mid- and low-level action-units allows transferring the same actions also to (for example) a workshop or other tabletop manipulation action domains.
We have analyzed and structured our library of actions for all 32 manipulation action types described in Wörgötter et al (2013), 10 of those we are investigating in depth performing also robotic experiments with them.
Note that action examples are kept simple to be able to show clearly the belonging trajectories, force, and tactile patterns (see the figures at the end of the Section 4). The same framework, however, had been used to analyze long and complex real-world manipulation actions (Aksoy et al, 2017). Hence, this framework can address much higher levels of scene complexity than shown here.
3.2. High-level action definition
In this section, we give a high-level action definition to extract and encode the semantics of manipulations. Note that, at this level, definitions are mainly symbolic (abstract) and close to human descriptions.
Take the example of a manipulation action “put a bucket on a box.”Figure 2 shows some sample frames from human demonstration. This simple action may be described by a human as follows:
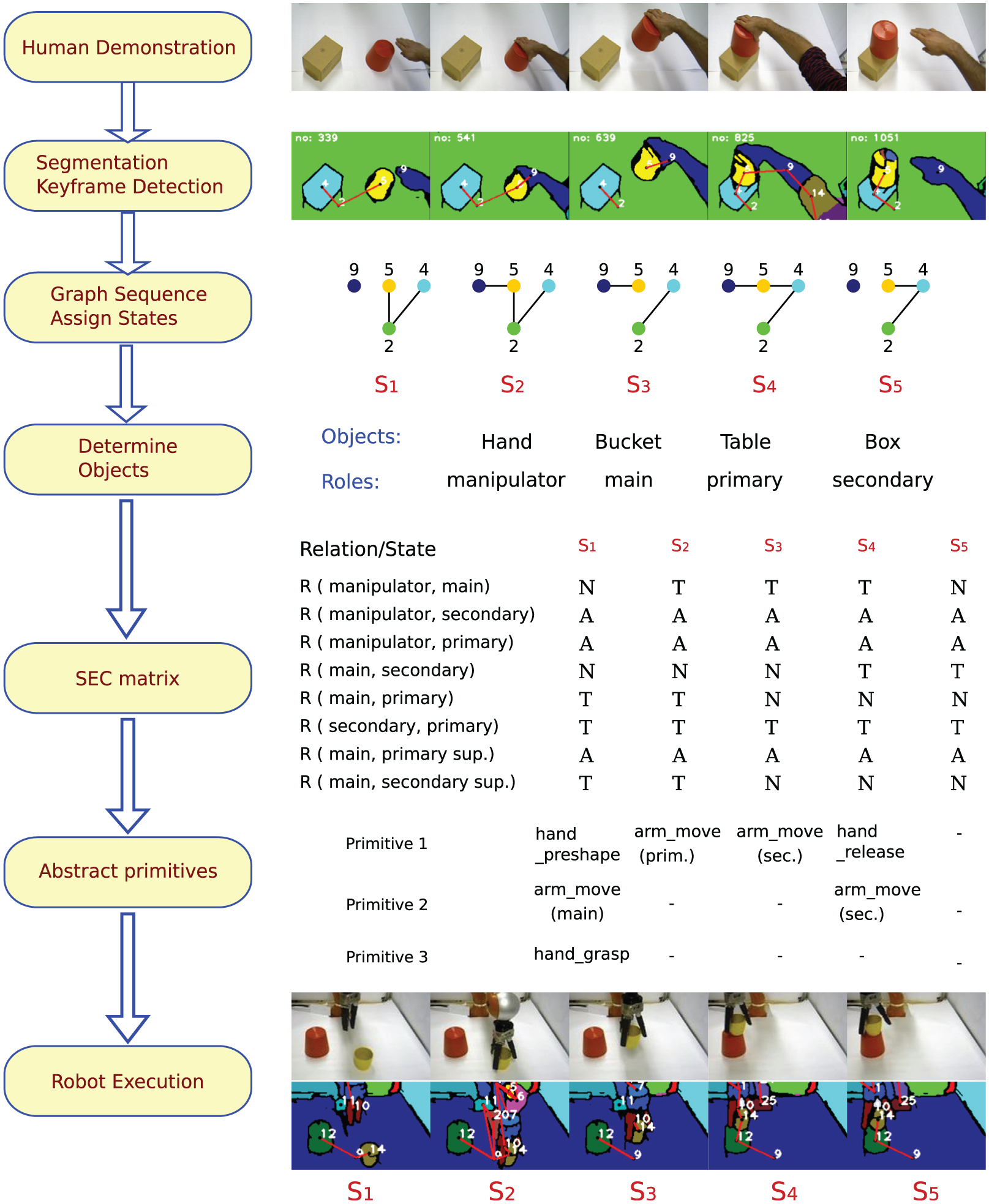
A sample human demonstration and robot execution of a put-on-top action are shown to highlight different action components. At the top, snapshots and segmented images of the human demonstration are shown. Next, a relational graph sequence is computed. Each graph corresponds to one world state (
This description is by no means unique. One could easily describe the same action in different words, with different number of steps and details. However, one could still extract some common and descriptive properties from such a naive description.
The main features that we use here to describe a scene are the touching relations between its objects. During a manipulation action, these touching relations change from some initial state to a final state. A manipulation action is, therefore, represented by a sequence of changes in touching relations of the objects.
Our approach to represent and execute manipulation actions with robots has the following fundamental properties. We introduce a generic high-level definition of actions which is independent of the manipulated objects in the action (Property 1), and consists of a sequence of symbolic primitives (Property 2). The conditions to start and end each primitive are defined by considering the touching relation between objects in the action (Property 3). We also store the default action descriptive parameters (e.g. trajectory) to execute actions at the high-level with symbolic definitions. When novel physical objects are observed at each specific instance of an action, these parameters are adapted according to the situation to generate the required movements (Property 4).
To fully satisfy these four properties in our high-level action definition, we benefit from the ontology of manipulation actions introduced in Wörgötter et al (2013). This ontology structures human-demonstrated manipulation actions, e.g. putting a bucket on a box, as sequences of spatio-temporal interactions between objects (including the manipulator) in the scene by using the concept of SECs presented in Aksoy et al (2011). This ontology suggests about
The ontology also introduces four constraints on the definition of manipulation actions, which are stated as follows.
These constraints had been discussed in great detail in Wörgötter et al (2013) but we would like to add some important notes here, too. (1) Considering one-handed actions is to some degree a simplification, because a supporting hand can also play an active role in a manipulation (for example, in creating counter-forces, etc., see also Section 5). (2) In case multiple objects need to be manipulated at the same time (e.g. pushing clutter away) this framework needs to be extended by a system that can reason about the semantics of single versus multi-objects. Such problems are related to the perceptual binding problem and cannot be solved without additional mechanisms. (3) Constraint 3 is very important to allow for a rigorous cut between each two manipulations. Actions that involve tools can be understood as a broken-up (interrupted) action chain without violating Constraint 3. Constraint 4 is evident without further comment.
From the first two constraints one concludes that in each action there are at least two entities: one hand and one object that is directly touched by the hand. This fact will be used in Section 3.2.1 to define object roles. The second and third constraints together define actions in a way that they cannot be further split into shorter actions. The last constraint assures that there is at least one change in the touching relations. This is essential because the whole framework relies on the touching relations between objects.
In the rest of this section, we describe several components of the high-level action definition that are required to reach these descriptive properties. We refer the interested reader to Wörgötter et al (2013) for details of the manipulation action ontology.
3.2.1. Object roles
There exist many objects in the real world and actions can be performed with different sets of object combinations. It is, however, not practical to define a separate action for each possible object set. Instead, as stated in Property 1, we represent manipulation actions in a generic way to make them applicable to any novel object. For this, we label objects by their roles exhibited in the action. First, recalling Constraint 1, we need an actor to perform the action, which is here called manipulator. As stated in Constraint 2, there exists exactly one object that is directly manipulated by the manipulator. This object is called main. Optionally, there are other objects in the action, which interact with the main object in different ways.
The object roles can be better explained in an example. In the action “putting a bucket on a box” depicted in Figure 2, the human hand is the manipulator, the bucket which is directly touched by the hand is the main object. There are two more objects whose relations with main change in the action: table and box. The relation of main and the table changes from touching
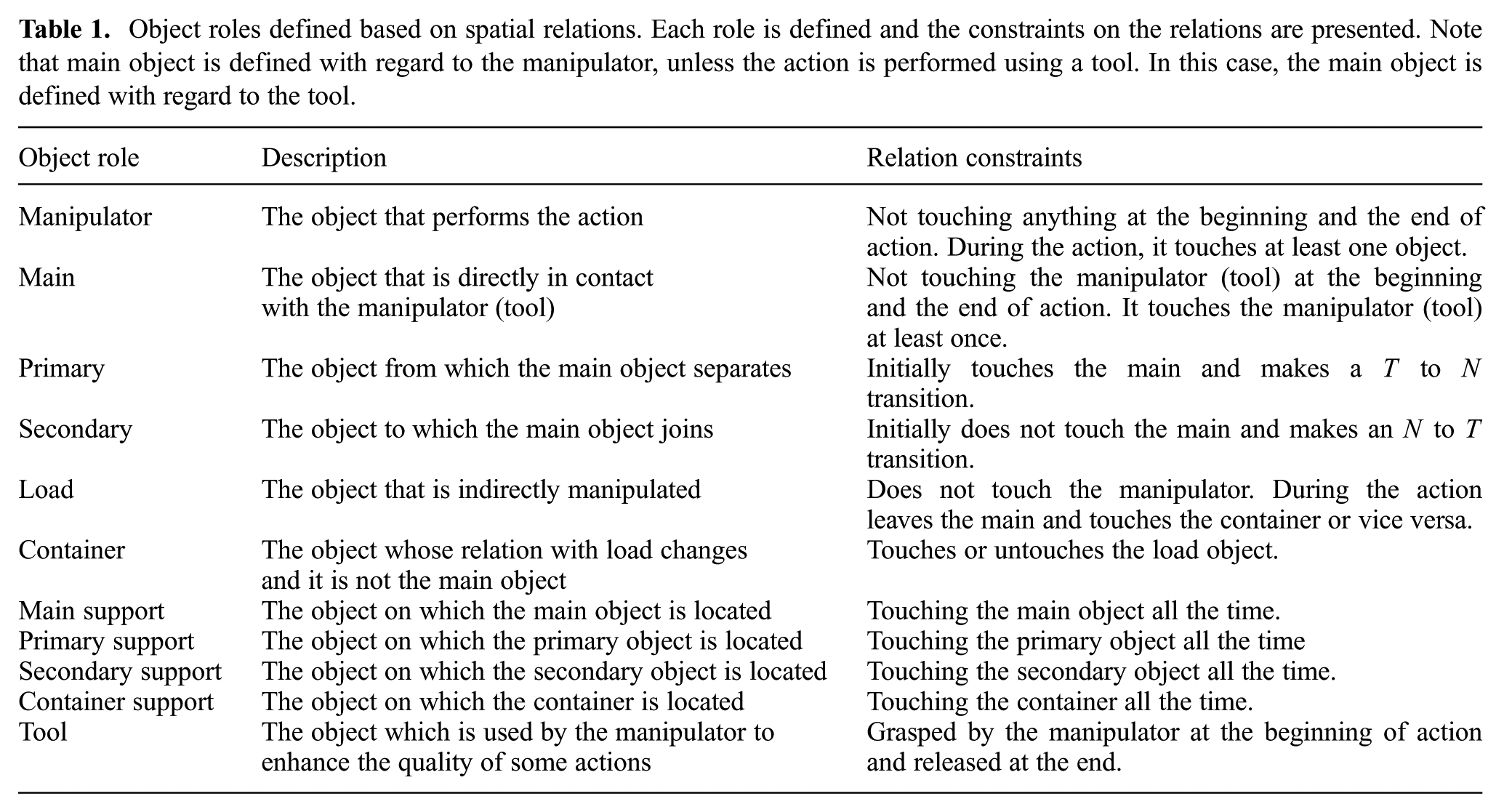
The complete list of object roles with their definitions are shown in Table 1. Some roles are defined by the changes in relations, such as primary and secondary, whereas others (such as support objects) are defined based on constant touching relations. For instance, secondary support is the object on which the secondary object is located. In the above example, the table also plays the role of secondary support. Note that not always all relations are needed to define an action.
Object roles defined based on spatial relations. Each role is defined and the constraints on the relations are presented. Note that main object is defined with regard to the manipulator, unless the action is performed using a tool. In this case, the main object is defined with regard to the tool.
The role of objects are automatically detected with the method described by Aksoy et al (2015b), which explores the temporal evolution of spatial object relations embedded in SECs.
3.2.2. SECs
At the highest symbolic level, actions are represented by the concept of SECs, which captures the essence of an action by employing computer vision techniques as described by Papon et al (2012) and Aksoy et al (2011). A summary of this process is shown in Figure 2 along with the put-on-top example. To calculate the SEC representation, an image sequence of an observed action is first represented by 3D image segments, each of which corresponds to one object in the scene and is consistently tracked during the action. Each frame in the sequence is then converted into a graph: nodes represent tracked segments, i.e. objects, and edges indicate the contact relation between a pair of objects. By employing an exact graph matching method, the continuous graph sequence is discretized into decisive main graphs, i.e. “states,” each of which represents a topological change in the scene. The extracted main graphs form the core skeleton of the SEC, which is a matrix where rows are the spatial relations between object pairs in the scene. Each column of the SEC matrix is interpreted as a state of the scene, which is the combination of object relations when a new main graph occurs.
Possible spatial relations in the SEC matrix are Not touching (
Note that the SEC matrix will not unduly grow when there are many objects in the scene. This is due to the fact that only the (abstract) objects in Table 1 are considered for any possible action. Hence, relations between objects that do not partake in an action do not create additional rows in the SEC.
Thus, in a SEC, the progress of the action from the beginning to the end is stored in a compact way. In addition, the SEC matrix is invariant to large variations in trajectory, velocity, object type, and pose used in the action and, therefore, remains the same for different instances of the same action.
Figure 2 shows a put-on-top action from human demonstration to robot execution. The snapshots of the demonstration are shown together with the tracked segments (colored regions) and main graphs. The objects in the scene and the extracted SEC matrix are shown with the corresponding states and primitives. At the bottom, the snapshots and tracked segments of the robot execution are depicted.
Figure 3 depicts the event chain patterns of different actions in the library as color-coded images. These SEC patterns are stored as high-level action descriptors in the action library. Although SEC patterns are very distinctive, some are semantically identical as in Push by grasp, Poke, and Push by holding actions. This semantic similarity is natural since those actions have the same changes in the touching relation of objects. However, they have different primitives with different object poses, trajectories, and force parameters that are not captured by SECs.
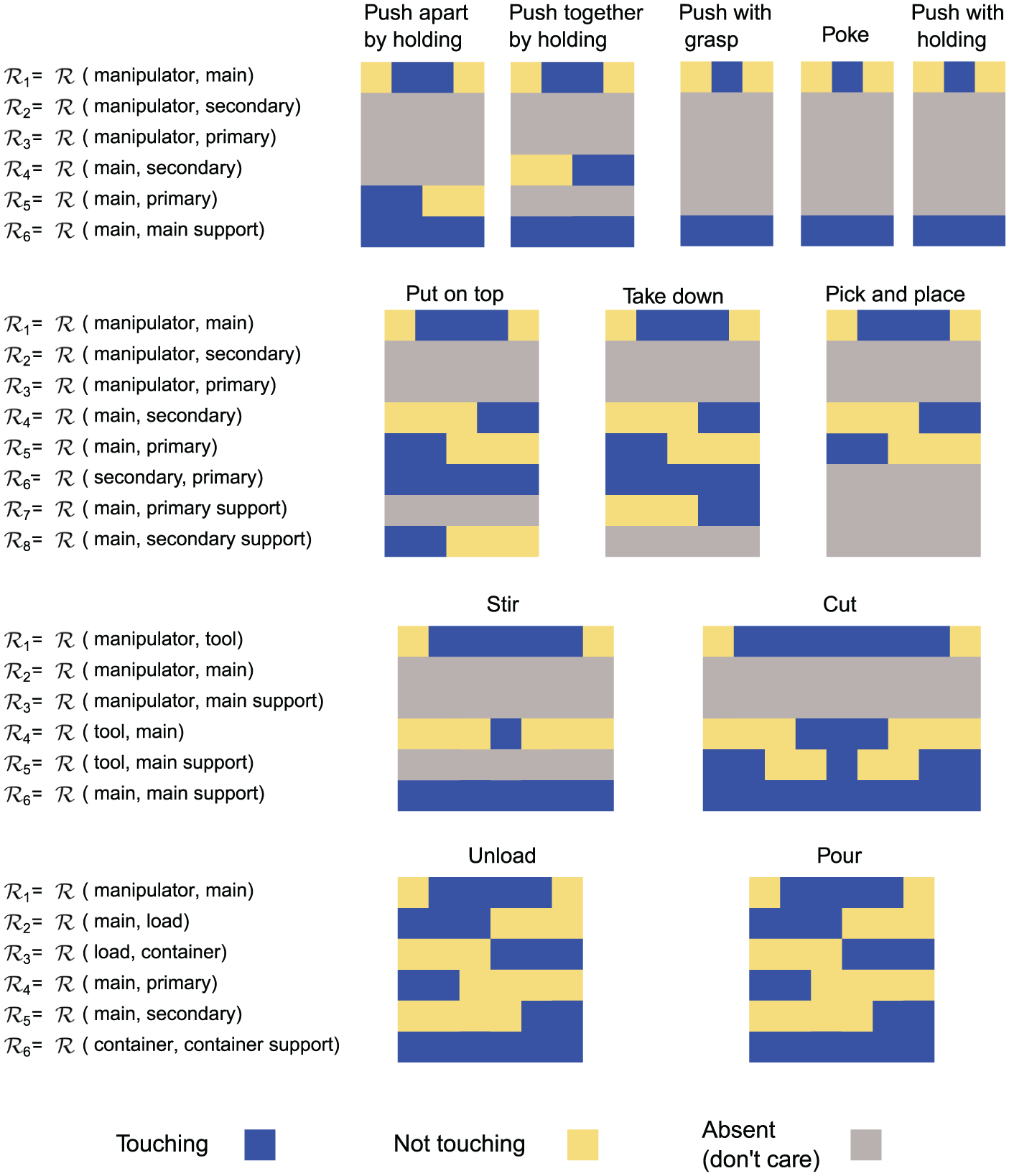
Extracted SEC matrices for
This action descriptive object, trajectory, and force information is separately stored as primitives (see Sections 3.2.4 and 3.3.3).
3.2.3. Abstract relations
We continue with computing the spatial relations between each abstract object pair, e.g. between the manipulator and the main object. Table 2 shows the abstract relations for the action “putting a bucket on a box”, previously shown in Figure 2.
Abstract relations and their attributes for the action “putting a bucket on a box” shown in Figure 2.
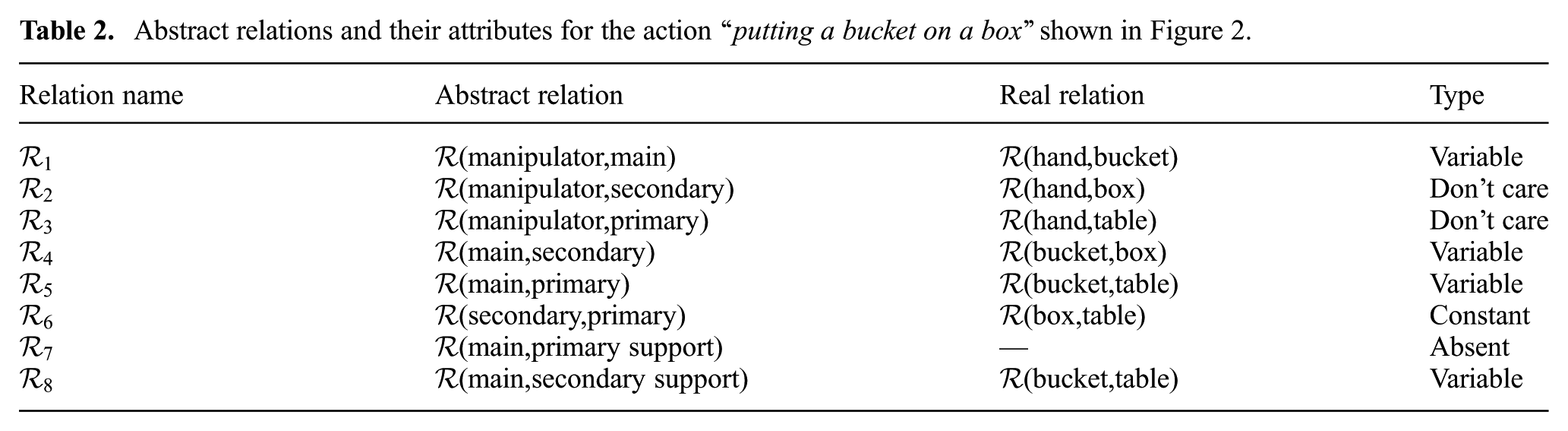
Each relation is defined by two attributes, namely type and value. The type of a relation is determined by the importance and variation of that relation throughout the action. For example, for the action in Figure 2, the relation between the manipulator and the primary is always not touching and does not affect the outcome of the action because they are not directly interacting with each other at all. The type of such relations is don’t care.
Other relations, which are crucial for an action, are categorized as variable and constant relations. For example, the relation between the manipulator (i.e. hand) and the main object (i.e. bucket) in Figure 2 is variable because it naturally alters during the action. The variable relations encode the dynamics of the action. On the other hand, the relation between the secondary object (i.e. box) and the primary (i.e. table) remains constantly touching, and hence is constant. We note that such constant relations highlight the necessary pre-conditions to perform an action and any unexpected change in these constant relations implies a failure of the action.
3.2.4. Abstract primitives
As stated in Property 2 in Section 3.2, an action can be divided into several sub-actions or primitives. In our approach we define the following abstract primitives.
These abstract primitives correspond to the basic functions of the robot manipulator, which can be implemented in many different ways. Our way of implementing such primitives at the lowest motor control level are presented in Section 3.3.3. The focus of our work is, however, not a specific implementation, but rather we would like to propose a way to combine them to seamlessly perform actions. In our approach a state transition in the SEC, i.e. a change from one column to the next, needs at least one of these unique primitives. All manipulations that we have analyzed have a strictly linear sequence of primitives between two subsequent SEC columns. Thus, an action is performed when all of its primitives are sequentially executed while the relations change according to the SEC matrix.
In Figure 2, the necessary primitives associated with each column of the SEC matrix of the put-on-top action are shown. The reason of having multiple primitives is that sometimes more than one primitive is required to induce the desired change in the spatial relation. For example, the combination of
In general, which primitives to choose is determined by the column-to-column transition in a given SEC. Owing to the fact that we had in total analyzed 32 manipulation action types, which on average contain five SEC columns each, we were faced with only about 150 column-to-column transitions in total. It was, thus, possible to analyze all of those “by hand” and manually define the required primitives for every transition.
3.3. Low-level action definition
In this section, the abstract components of the high-level definition are related to their real-world counterparts at the signal level. This includes defining objects in the real world, calculating their spatial relations from the sensor data, and implementing low-level primitives such that proper commands are sent to the robot arm and hand control systems. In the rest of this section, these elements are described in more detail.
3.3.1. Real objects
In real-world experiments, abstract objects (i.e. manipulator, main, primary, etc.) are instantiated by real objects in the scene. For the “putting a bucket on a box” example depicted in Figure 2, these objects are hand (manipulator), bucket (main), table (primary), and box (secondary). We need to identify the real-world objects in the signal space in order to perform the low-level primitives.
For this task, we use our modular computer vision architecture described in Papon et al (2012), which segments each object in the scene by employing the color and depth cues fed from the RGB-D sensor. We further apply the instance-based object recognition method from Schoeler et al (2014) to identify extracted image segments. By incorporating the depth information, we also detect the background segment (supporting surface, i.e. Table), which is in the form of a planar surface.
Once real objects in the scene are detected, we compute each object pose in signal space. In our work, two pieces of information are required to represent an identified object: position and orientation. The position of each object is computed in Cartesian space. To associate a position to an object, we model the object with a single point located at the center of mass. The orientation of objects is defined as the angle that the main axis of the object makes with respect to the
Note that the position of the manipulator, i.e. robot end effector, is directly calculated from position sensors and the kinematics of the arm.
3.3.2. Real relations
The real relations are the values of relations between pairs of objects in the scene. To detect these values, we use a combination of proprioceptive (e.g. position) and exteroceptive (e.g. tactile, force, and vision) sensors.
When it comes to detecting object relations, there are three phases: before, during, and after the action. In the first and last phases, the only source of information is the vision interface, which essentially computes the Euclidean distance between segmented object point clouds to decide whether they touch each other or not. An example of this detection is shown in Figure 4.

Calculating the contact relation with our visual perception interface. The small red lid is touching the jar and the yellow cup is on top of the bucket (left). The red lines indicate the existing touching relations between objects (right).
While the action is being performed, the data acquired by other sensors (position, force, and tactile) are used in addition to the vision system. The data collected from these sensors are fused using several heuristic rules, which are conjunctions of individual conditions on different sensor data. For example, the first rule to detect the relation of manipulator with main object is a combination of conditions on two sensors: position and tactile. This rule declares a touching relation when the Euclidean distance between the two objects is less than a threshold (denoted by
Rules for detecting the spatial relational changes during action execution. Note that

The rules of Table 3 use some intermediate signals that are abstractions of force and tactile sensor data:
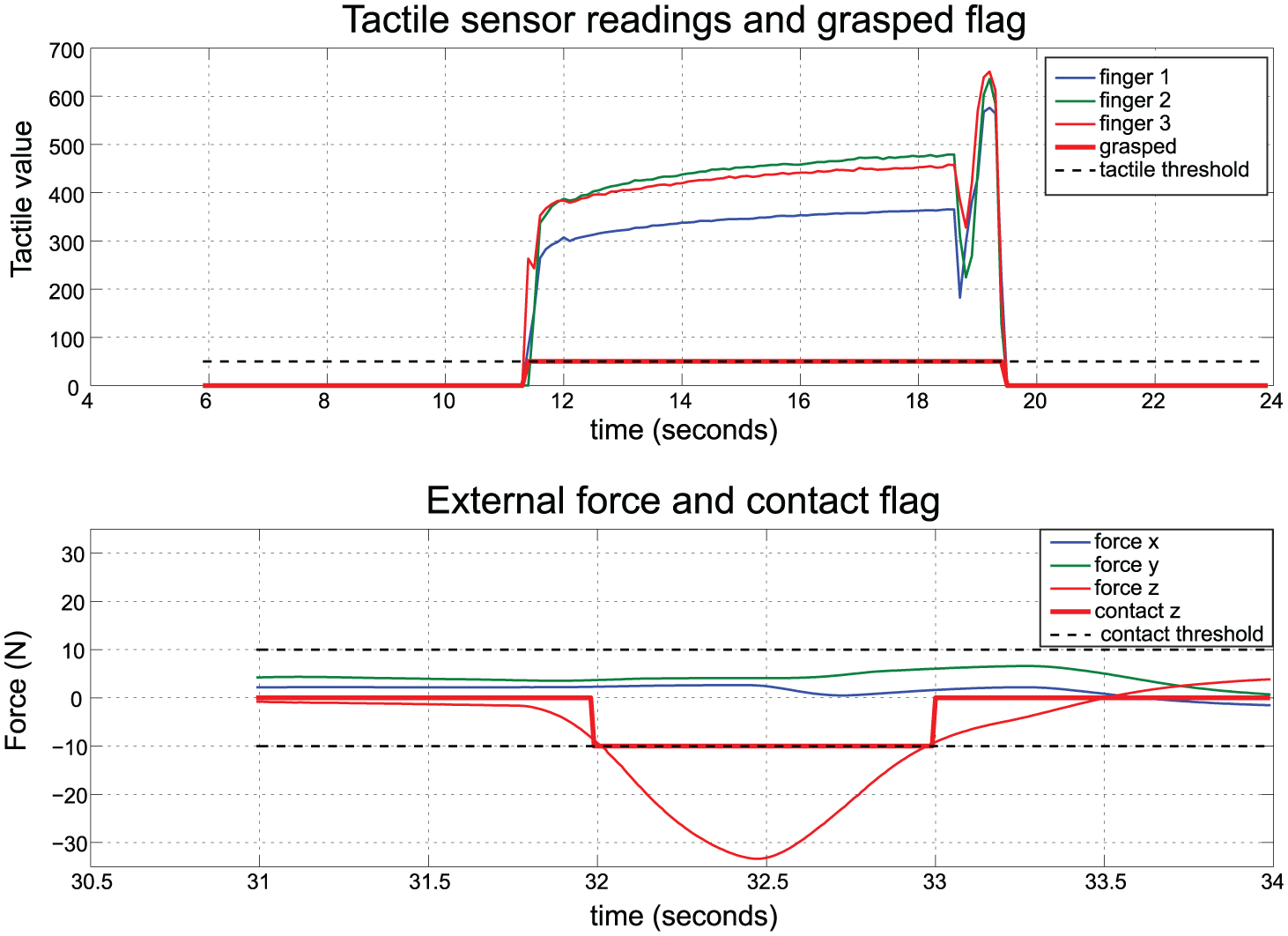
Intermediate exteroceptive sensory input in the process of analyzing the spatial relation rules given in Table 3. The tactile sensor values are used to detect when an object is grasped by the hand (top). The external force signals are processed to detect the touching event (bottom). Here a contact in the
The
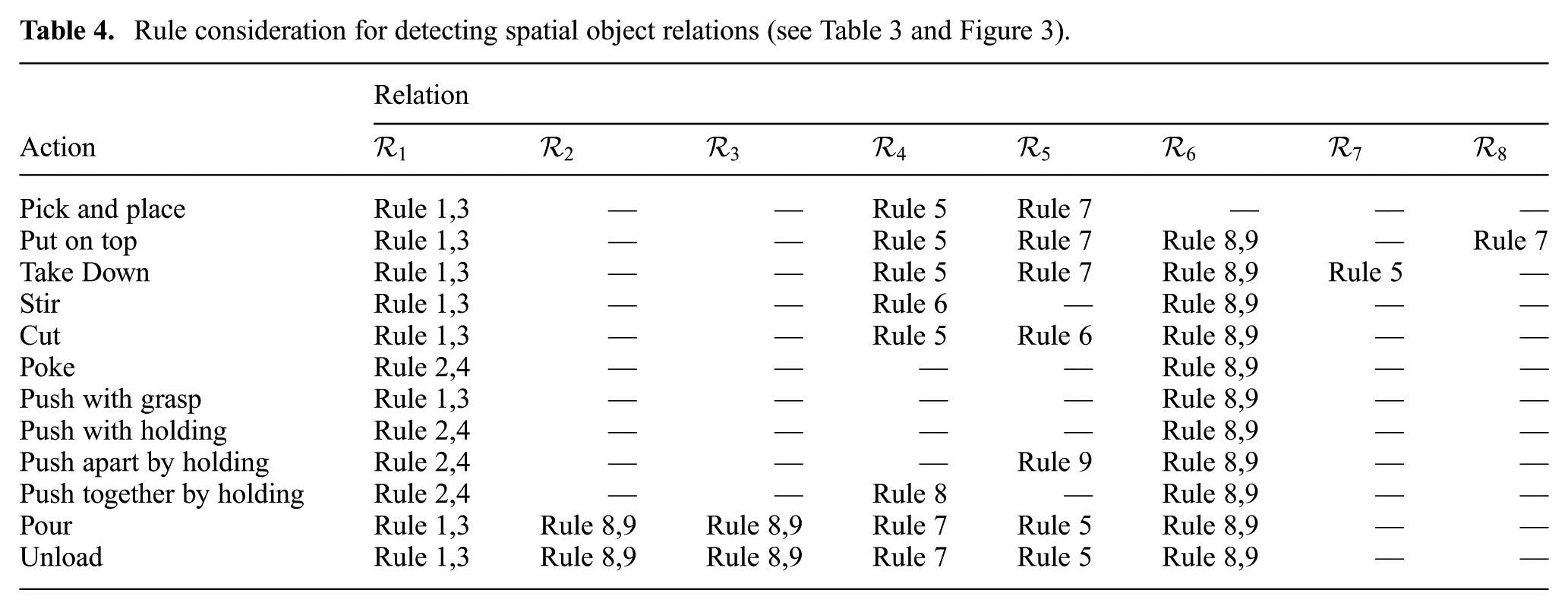
As multiple rules exist to detect the same relation in Table 3, we should assign the rules that need to be considered in each action. This is summarized in Table 4 for the actions in the library.
3.3.3. Real primitives
In Section 3.2.4 we defined the abstract primitives. Here, we re-introduce these primitives by adding their parameters and describe their implementations at the low level.
For the robot arm, we have the following primitives:
For the robot hand we have defined the following primitives:
Here we explain these primitives in more detail and discuss their specific implementation in our system.
This primitive moves the end effector from the current pose to a pose relative to object. The offset of the target is stored in the homogeneous transformation
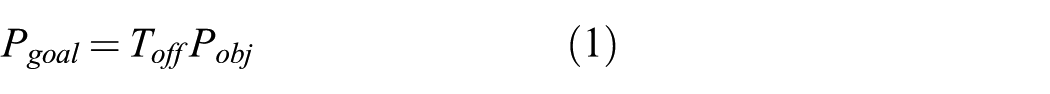
The parameters of the trajectory are stored in
These trajectories are fed as desired values to the low-level control system of the robot arm. In our setup, we have a KUKA LWR robot which has the following control policy to generate commanded joint torques
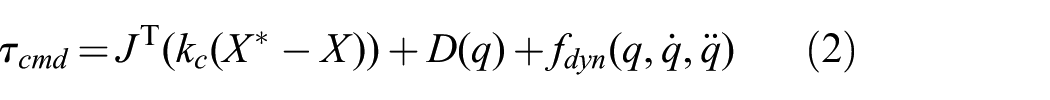
where
For some actions we need to perform some simple periodic motions. There are comprehensive frameworks to create periodic (rhythmic) motions on robots such as rhythmic DMPs. However in our system we only need simple back-and-forth and circular motions, for which a combination of sine and cosine functions suffice. Therefore we implement
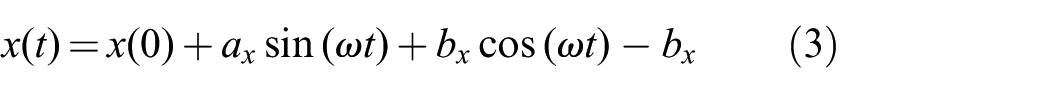
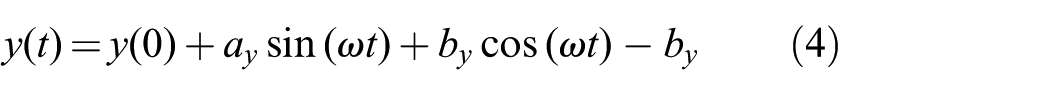
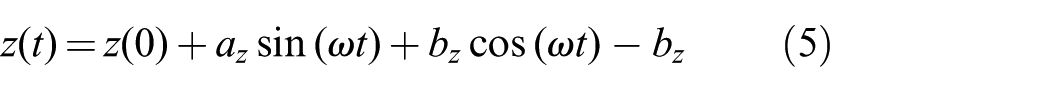
These equations generate smooth trajectories from an initial position (which is
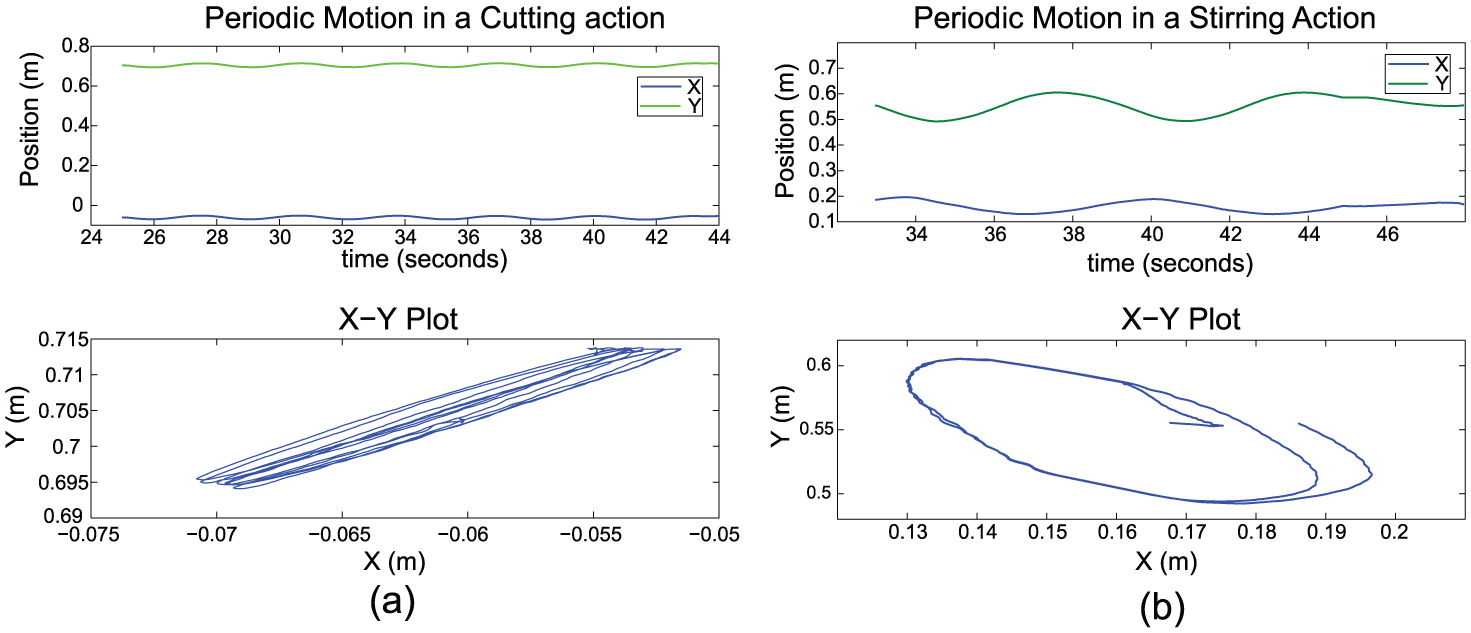
Examples of periodic trajectories in actions. (a) In the cutting action the following parameters are used to generate a back-and-forth motion:
Manipulation actions sometimes need more than just pure position control. In some tasks we need to also regulate the force exerted at the environment. Many times it is important to have both position and force control at the same time. For example, in a cutting action, the robot arm keeps a force between the knife and banana in the
This is possible by using parallel position–force control schemes such as that introduced by Chiaverini and Sciavicco (1993). The following control policy is used in this case:
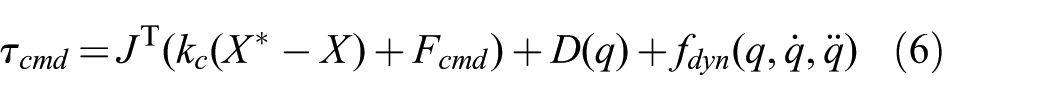
Here the term
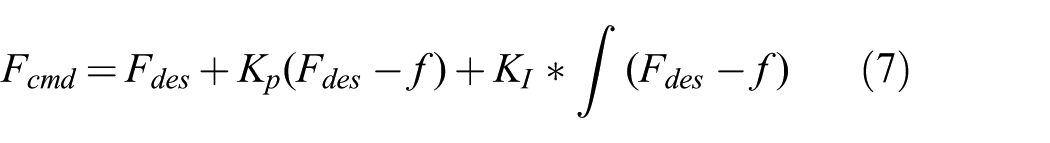
An example of force control is shown in Figure 7 where the desired force is
Example of force control using the
This primitive is used to create a desired shape of the robotic hand. Our robot hand (Schunk SDH-2) has three fingers and in total seven degrees of freedom (DOFs). The control system of the hand has the ability to move to a desired configuration:
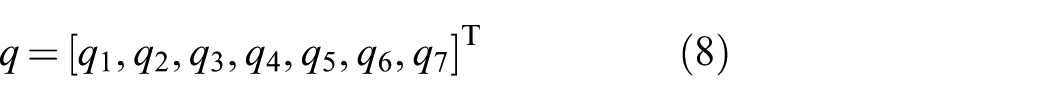
Two sample configurations are shown in Figure 8, which are the power and precision grasps used for round and elongated objects, respectively.

Two pre-shape configurations are used in our system. The power grasp (right) is used for symmetric objects whereas the precision grasp (left) is for elongated objects.
Manipulating objects usually requires grasping them first. For grasping, we use velocity control of finger joints together with feedback from tactile sensors on the fingers. The combination of
This primitive is used to release a previously grasped object, which is simply opening the hand until the tactile sensors show that the object is released.
3.4. Mid-level action definition
So far, we explained high- and low-level action components. In this section, we present a mid-level component that acts as a bridge between those two levels and guides action execution. The core of the mid-level component is a FSM together with an error-handling protocol.
3.4.1. FSM
A FSM has a number of states, inputs, outputs, and transition rules. The states show different stages of the execution algorithm. The inputs are the real relations of the objects. The outputs are the robot primitives that are sent to the control system of robot arm and hand.
In the FSM we have some parameters that define the current action. The main parameters are the number of states, the desired relations and primitives at each state. To execute any action in the library, the proper set of parameters should be loaded into the FSM.
There are also some variables used during the FSM execution. For instance, variables
The FSM is part of a software package to control the robot setup that is implemented using the Open Robot Control Software (OROCOS) framework [Soetens(2013), Soetens(2006)]. The OROCOS framework provides tools to develop real-time robotic software including a useful FSM implementation. The overview of the mid-level FSM and execution process is shown in Figure 9. The details of states and transitions are as follows.
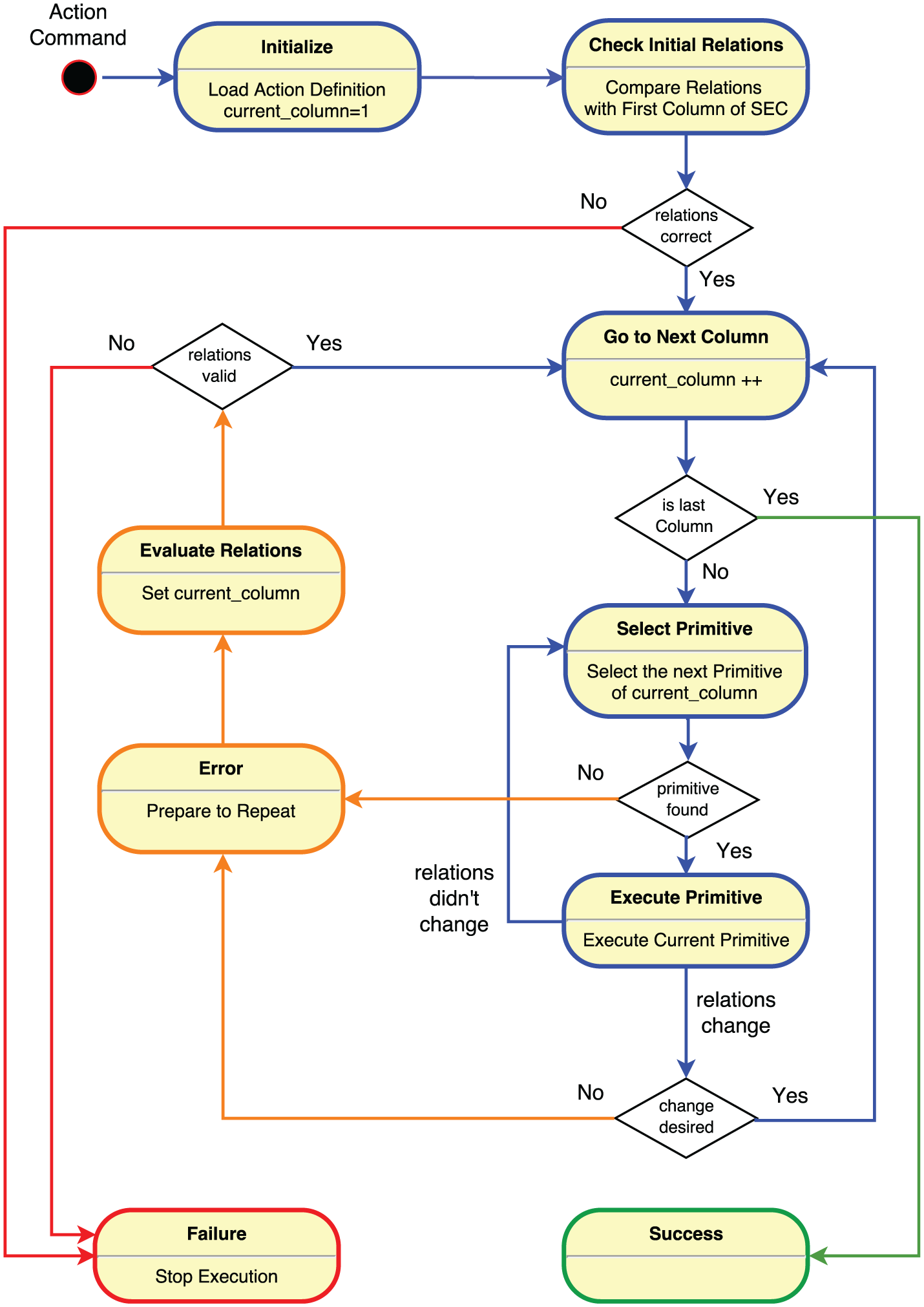
State diagram of the FSM that controls the execution of actions. This state machine is the main component of the mid level. For clarity, different colors are used for normal execution (blue), error handling (orange), failure (red), and success (green) states and transitions.
In this state we try to go back to a previously known state of the action, and continue from that point. Usually this means that the robot arm retracts from the scene and receives new object poses and relations. After receiving the new perception, we transition to
3.4.2. Error handling
The execution of actions could fail due to different problems. Faults may happen in controllers and their interfaces, for which proper detection and recovery systems are necessary. Other errors may happen at more abstract levels like failure to properly grasp or push an object. These errors are detectable by observing the relations of the objects and we can deal with them in our execution engine.
In the previous section we described the
the execution of the primitives does not result at the expected change in relations (from
the execution of the primitives causes unexpected changes in object relations (from
To deal with these errors, first we undo the primitives of the current state (SEC column) to reach the previous known state. Then, we evaluate the object relations again and transition to the
The first example shows an error when expected changes in relations do not happen. In Figure 10, the robot hand approaches the apple to grasp it, but fails, because the apple is not in the expected position. The manipulator retracts and receives the new position of the apple from the vision system and repeats the grasp.

Error handling after failure in grasping an object. 1. The initial scene. 2. Perception of the objects by vision system. 3–5. When the manipulator approaches to grasp the apple, we move it to cause the grasp to fail. 6. The robot hand opens and the robot arm moves up waiting for a new perception. 7. New perception of the objects by vision system. 8, 9. Approaching the apple in its new position and performing a grasp.
An example of the second type of error is shown in Figure 11, in which after a successful grasp, the object is taken away from the robot hand. The robot detects the absence of the grasped object and reacts to it by opening the hand and moving up. After receiving the new position of the object, the grasp is repeated. The videos of error handling cases are shown in Extension 1 submitted with this paper.
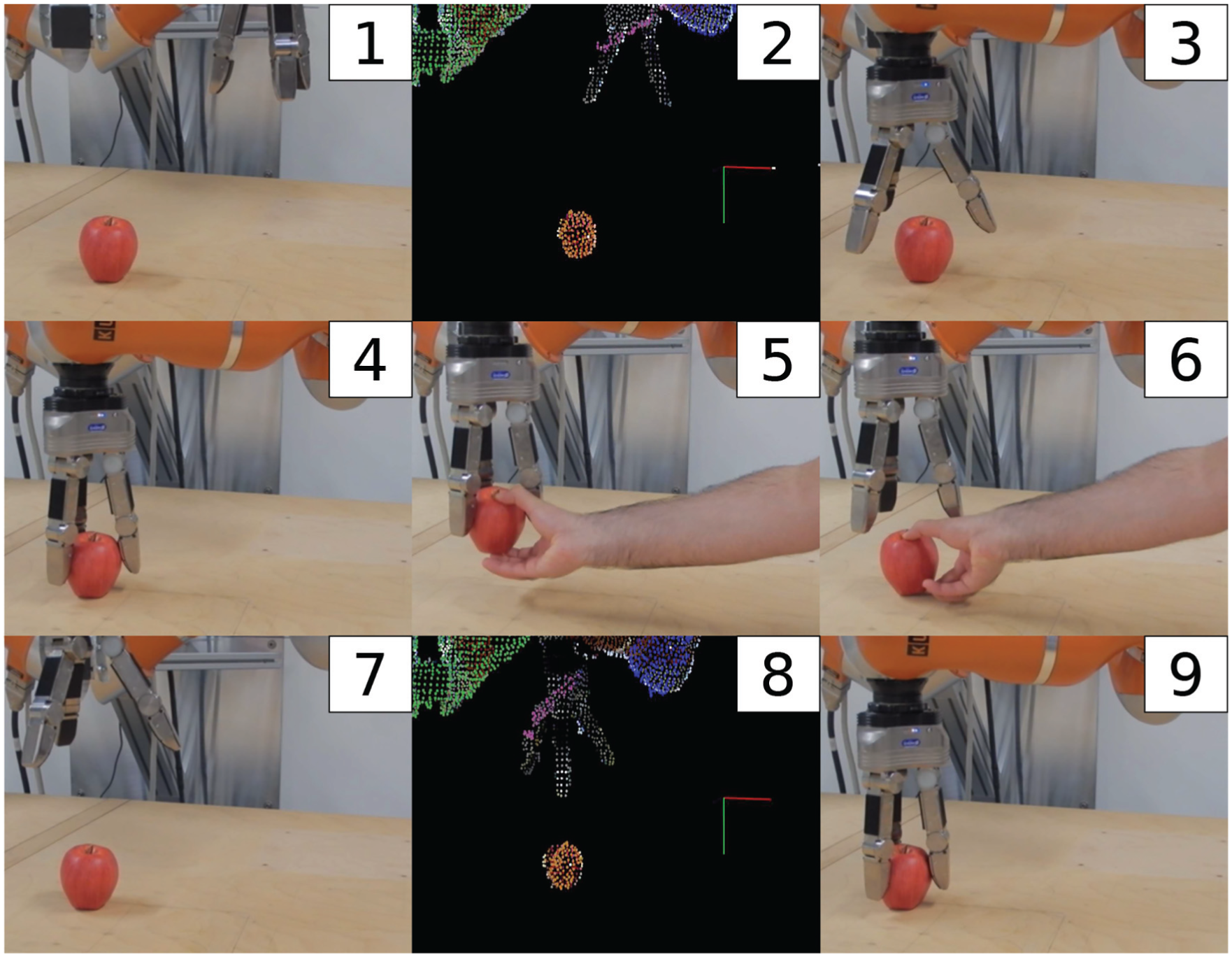
Error handling after the grasped objects slips through the robot hand. 1- The initial scene. 2. Perception of the objects by vision system. 3, 4. The manipulator approaches the apple and grasps it successfully. 5. The grasped object is taken out of the robot hand to cause the error. 6, 7. The robot hand opens and the manipulator retracts. 8. New perception of the objects is received from the vision system. 9. The grasp is repeated successfully.
There are cases where error handling cannot help, for example if we try to cut an uncuttable object (such as a cup). The error handling would try to repeat cutting the cup without success. After a few unsuccessful repetitions, the system transitions to the Failure state.
4. Experimental results
In this section, we present various experimental results of our proposed action execution framework. Results cover execution of both single atomic actions (e.g. cutting, pushing, etc.) and long chained activities such as “making a salad.” Before presenting these results, we briefly introduce our hardware and software tools used in the experiments.
4.1. Hardware
Our setup consists of a robot manipulator, a three-finger robotic hand, and a vision interface.
4.1.1. Robot arm
Our robot arm is a KUKA LWR (Light Weight Robot) IV manipulator. It is a kinematically redundant anthropomorphic manipulator developed jointly by KUKA Robot Group and the German Aerospace Center (DLR). It has 7 DOFs and is equipped with position and torque sensors at each joint. It estimates the external torques applied to each joint, which also gives an estimate of external force and torque at the end-effector. The robot can be controlled both in joint and Cartesian spaces with variable compliance and damping.
4.1.2. Robot hand
Our robot hand is a Schunk Dexterous Hand 2 (SDH-2) produced by the company Schunk. It has three fingers and 7 DOFs, which can be controlled in position or velocity modes. It is equipped with two tactile sensors on each finger, that provide feedback while grasping objects.
4.1.3. Vision system
Our vision system includes a static RGB-D (Asus Xtion) sensor and a DSLR camera (Nikon D7200). The RGB-D sensor provides both color and depth cues that are processed for image segmentation and tracking issues. The DSLR camera is further integrated into the vision system to capture high-resolution images of the scene for the purpose of object recognition. The vision system was developed using the ROS framework (Papon et al, 2012; Schoeler et al, 2014: see).
4.2. Single atomic actions
To quantitatively evaluate the proposed action execution framework, we conducted a large set of experiments with several types of actions and objects. The central goal here is to benchmark the success of the execution of actions provided in the library. Note, to arrive at a useful characterization of this framework all actions are analyzed without error handling. Only by this can decisive percent-success values be measured. We are not concerned with complex computer vision, thus, colored and textureless objects were mostly preferred in the experiments to cope with the intrinsic limitations of the imaging sensors and to have more reliable visual segmentation of perceived scenes. Figure 12 illustrates the set of manipulated objects, which contains in total

The set of objects used in our experiments. There are in total 19 objects in 8 categories: 1. round fruits; 2. long fruits; 3. cubes; 4. cups; 5. containers; 6. plates; 7. spoons; 8. knives.
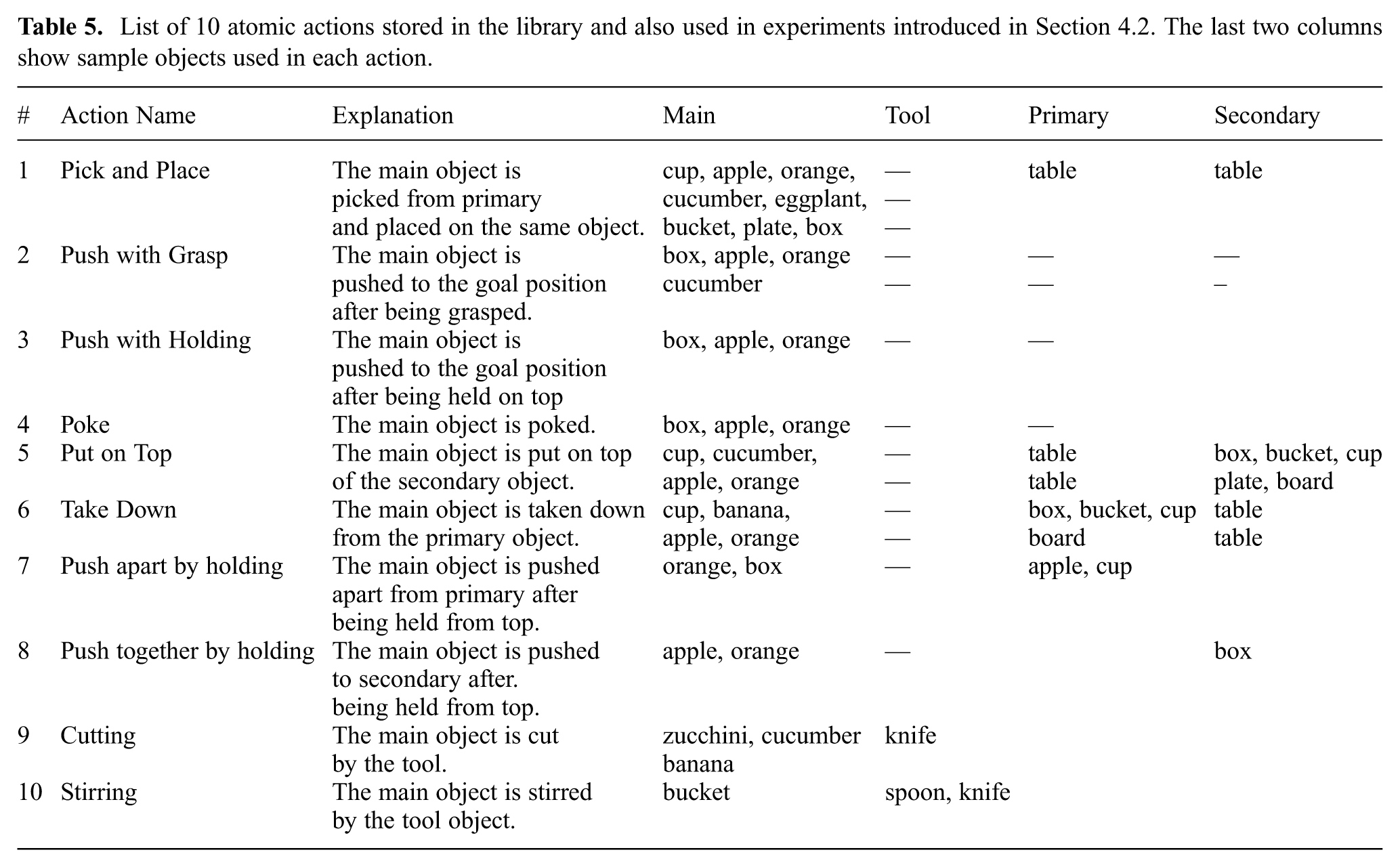
The first part of our experiments covers only single atomic actions, such as pushing, cutting, or stirring. The first 10 actions defined in Table 4 are considered as atomic actions, each of which is performed by the robot using objects of various types, sizes, shapes, and poses (see Figure 12). The executed atomic actions with their brief explanations and involved objects are listed in Table 5.
List of 10 atomic actions stored in the library and also used in experiments introduced in Section 4.2. The last two columns show sample objects used in each action.
To evaluate the atomic actions, we provide two types of results. First, the success rate of execution of each action type is measured. These results give an overview of the execution performance of actions on different object categories presented in various scene contexts. Thus, we can measure the robustness as well as the generalization capacity of the proposed action library. Second, we plot variations in the low-level sensory input, such as tactile, position, and contact signals, while the action is being executed. In these results, we can obtain information on the underlying perception mechanism in the execution framework and the discretization of the low-level continuous sensory data to reach high-level symbolic action representation.
To evaluate success rates, we repeated each atomic action
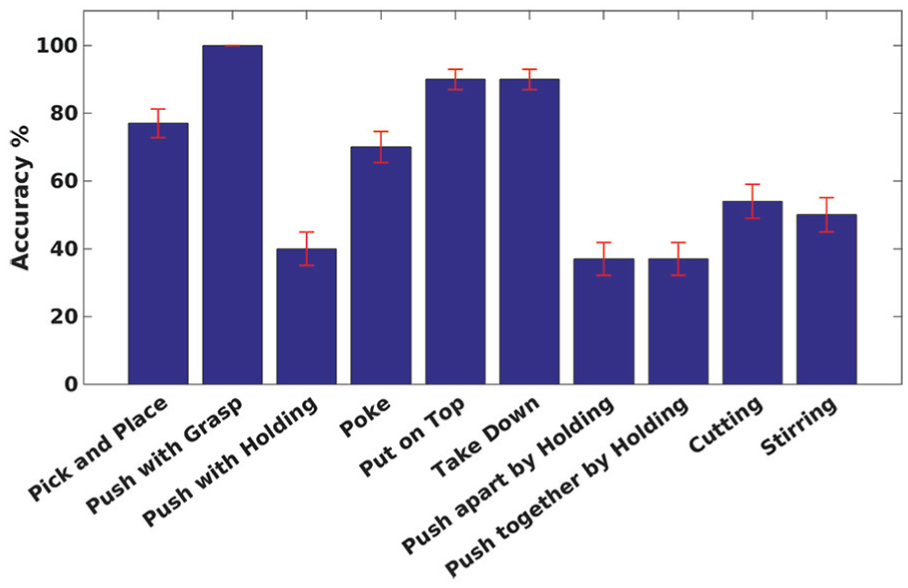
Overall success rate of
The first result is that in
We also observed a low success rate of about
A more detailed analysis on the execution of single actions is given in Figure 14. The results are separately computed for each individual action and object category. For those actions which initially require object grasping, the results are also categorized according to the grasp type. We here note that object grasping is not in the focus of this study and therefore in our experiments we only considered two types of grasps: power and precision. The average success rate for each grasp type and for the entire experiment are shown in the last three columns. For instance, in Pick and place action,
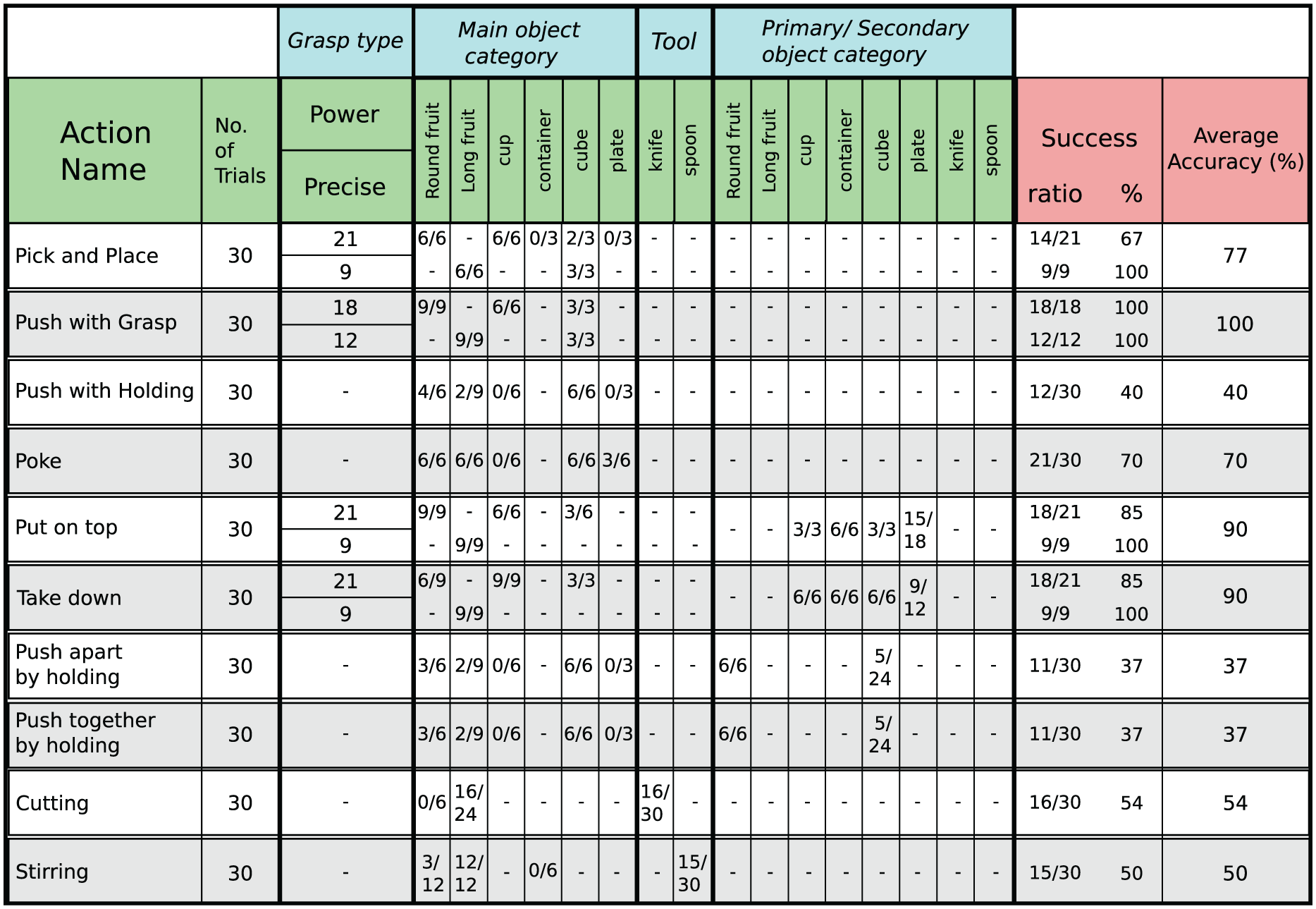
Success rate of executing actions in each object category. Each action is executed 30 times using different object sets. The ratio of successful trials are shown for each object category (middle columns). For actions involving grasp, the results are separately shown for each grasp type. The overall success rates on each grasp type and average success scores are shown in the last two columns. The values in the last column match the final average accuracy rates shown in Figure 13.
A deeper look at the errors encountered for those 300 experiments shows that about one-third of them could have been recovered when switching error-handling on. The rest are non-recoverable. Given that the number of errors is in general relatively small, this estimate could, however, be incorrect, because not enough error data exist for strong statistical evaluation and many more experiments would be needed to achieve this.
Next, we take a closer look at the low-level sensory data including the position, tactile, and force contact signals of the robot arm during the experiments. Here, we aim at topological changes in the perceived scene by fusing data from several sensors, and to calculate object relations.
Figure 15 shows the position, tactile, and force sensor data together with detected relational changes between objects and the robot arm during the execution of a sample Put on top action. The first plot in Figure 15 confirms that due to the use of DMPs with joining, the robot arm seamlessly follows the desired goal positions which are indicated with circles. In the second plot in Figure 15 we also see that the tactile sensor is activated once the primary object is grasped. In a similar manner, the force sensor reports a contact when the object is placed. All these sensory data together with the visual feedback are fused to detect final spatial relational changes in the scene as described in section 3.3.2. Figure 15 at the bottom illustrates the extracted SEC representation over time for the Put on top action as a colored matrix which is identical to the one stored in the action library as shown in Figure 3. This plot confirms that the proposed action execution framework can successfully process continuous sensory data and extract descriptive states in the scene, which yields compact high-level action representation, i.e. SEC.
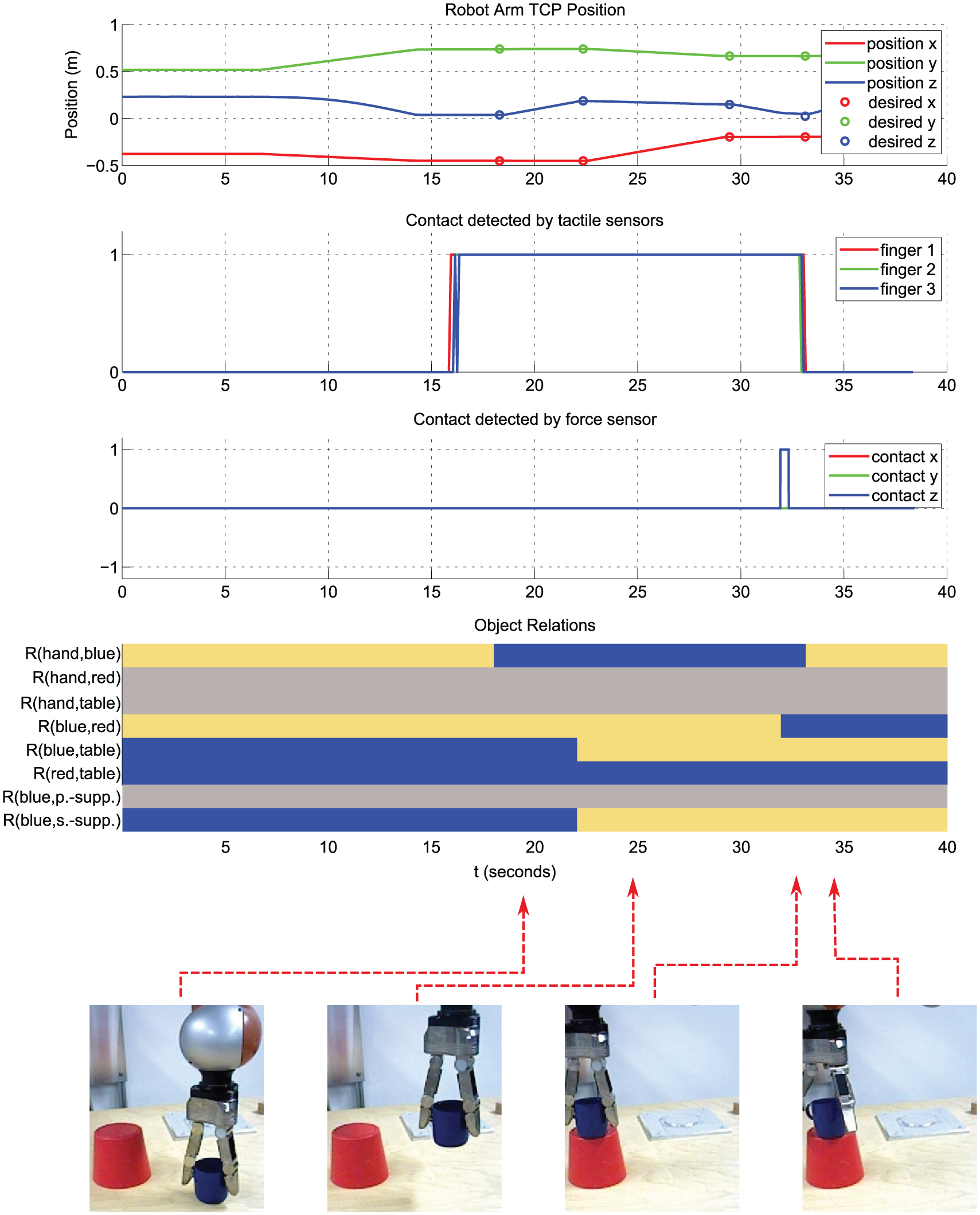
Low-level sensory data in a sample put on top action. The position, tactile, and force contact signals are shown on the top. All changes in object contact relations are shown in the bottom plot as a color-coded SEC matrix. Here, blue and yellow represent Touching (
In Figure 16, we show similar plots for a Cutting action in which the robot first grasps a knife and then cuts a cucumber into pieces. The position plot on the top highlights the oscillatory motion pattern of the robot arm during the actual cutting phase. Note that in some cases the actual robot position does not meet the goal position. This is expected, since whenever the desired relation changes happen, the current primitive is ended and the state machine moves to the next primitive. The second row shows how the tactile sensors detect the contact which happens at the
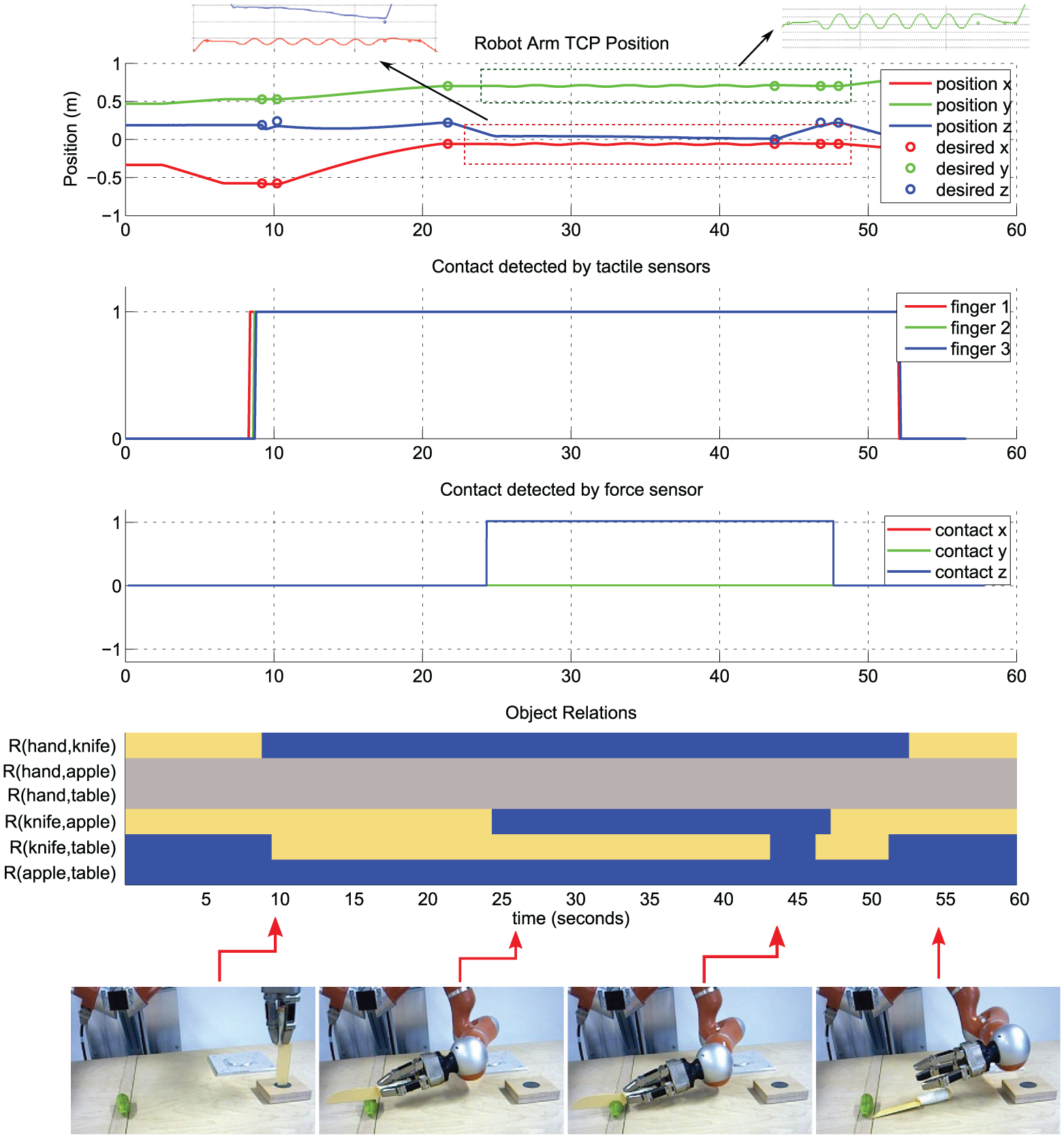
Low-level sensory data in a sample cutting action. The position, tactile, and force contact signals are shown on the top. In the cutting action, a part of the trajectory corresponding to the back and forth motion of knife is zoomed in to show the oscillatory motion pattern. All changes in object contact relations are shown in the bottom plot as a color-coded SEC matrix. Here, blue and yellow represent Touching (
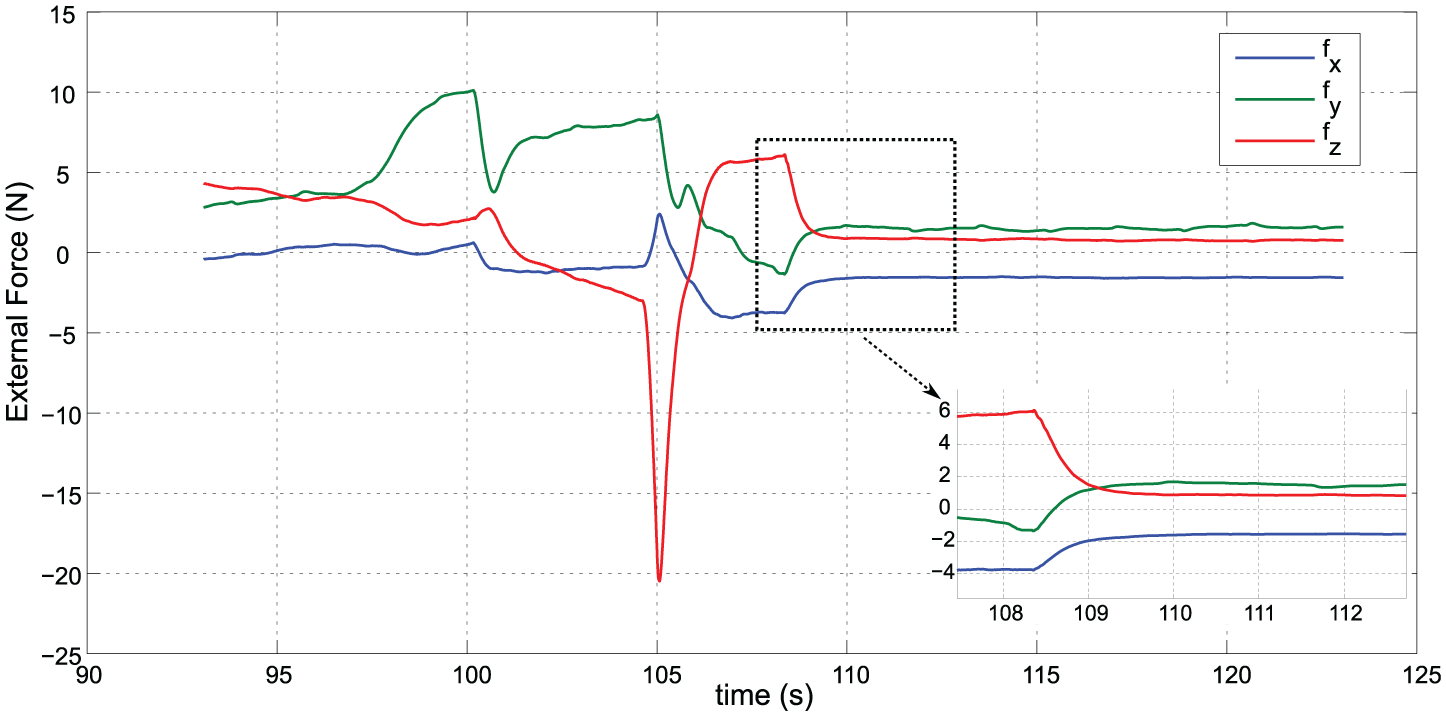
The force signal in
In Figure 17 and Figure 18 we show the
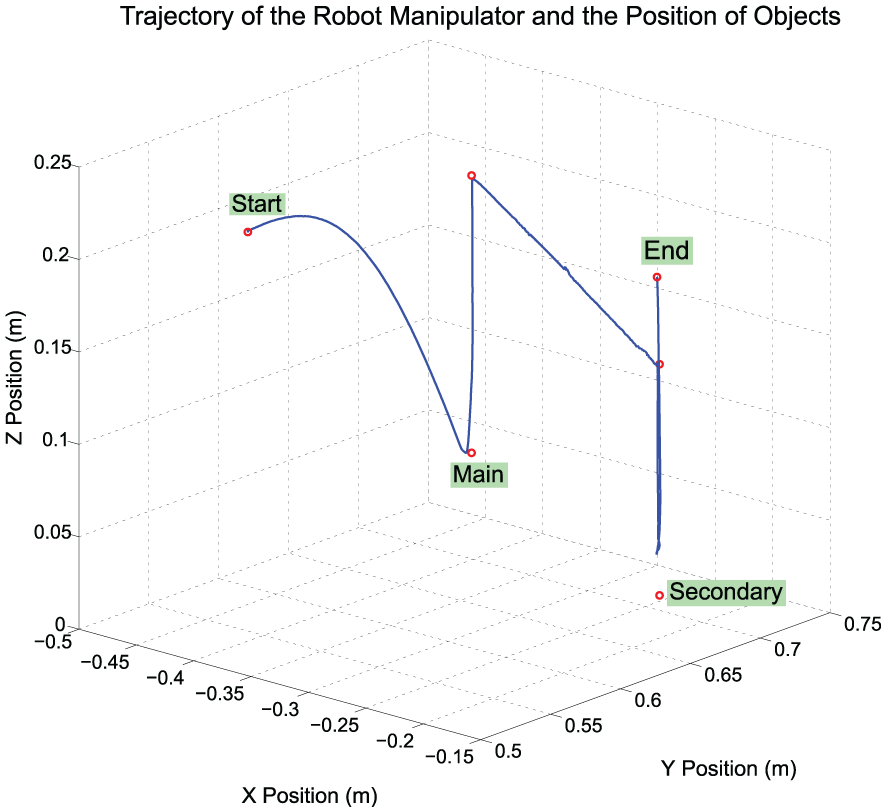
Trajectory of robot arm during the Put on top action shown in Figure 15.
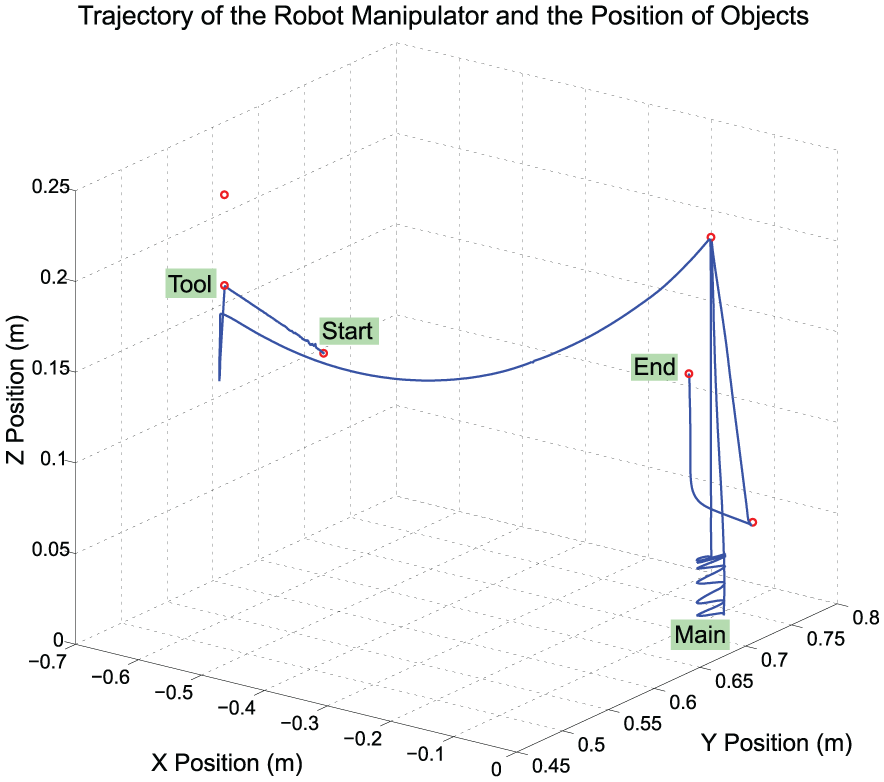
Trajectory of robot arm during the Cutting action shown in Figure 16.
4.3. Chained actions
To demonstrate the scalability and strength of the proposed framework, we further benchmarked our system with execution of chained actions. For this purpose, we defined two scenarios. In the first scenario, the robot arm was given the task of performing three atomic actions: Take down, Push, and Put on top. The second scenario is a more challenging task: making a salad.
Figure 19 shows the robot execution of the first chained action scenario. The first three plots depict the low-level sensory data. Due to having three atomic actions, there exist three peaks in the force sensor, whereas we obtain only two contact changes in the tactile sensor. In each action there is one interval at which the contact in

Robot execution of three chained actions: 1. taking down the red apple from the box; 2. pushing the box by holding; 3. putting the green apple on top of the box. From top to bottom are shown the position, tactile, and force sensor data as well as the changes that are detected in the relation of objects in the scene. Sample snapshots for some SEC states are also depicted with numbers showing their order. Black arrows represent the temporal interval of each action.
In the second scenario, i.e. the salad making task, the robot performed a longer action sequence, in which we additionally introduced the last two actions defined in Table 4: pouring and unloading. Consequently, the salad scenario contains the following steps:
pick up a cucumber and put it on a cutting board;
grasp the knife and cut the cucumber;
grasp the cutting board and unload the cucumber pieces into a bowl;
grasp the bottle and pour its content into the bowl;
grasp a spoon and stir ingredients in the bowl.
The final results of the salad scenario are shown in Figure 20. The low-level signals and high-level symbolic object relations are shown as usual. For the sake of clarity, sample snapshots for all five actions are shown vertically with horizontal arrows on the top showing the corresponding temporal interval of each action.
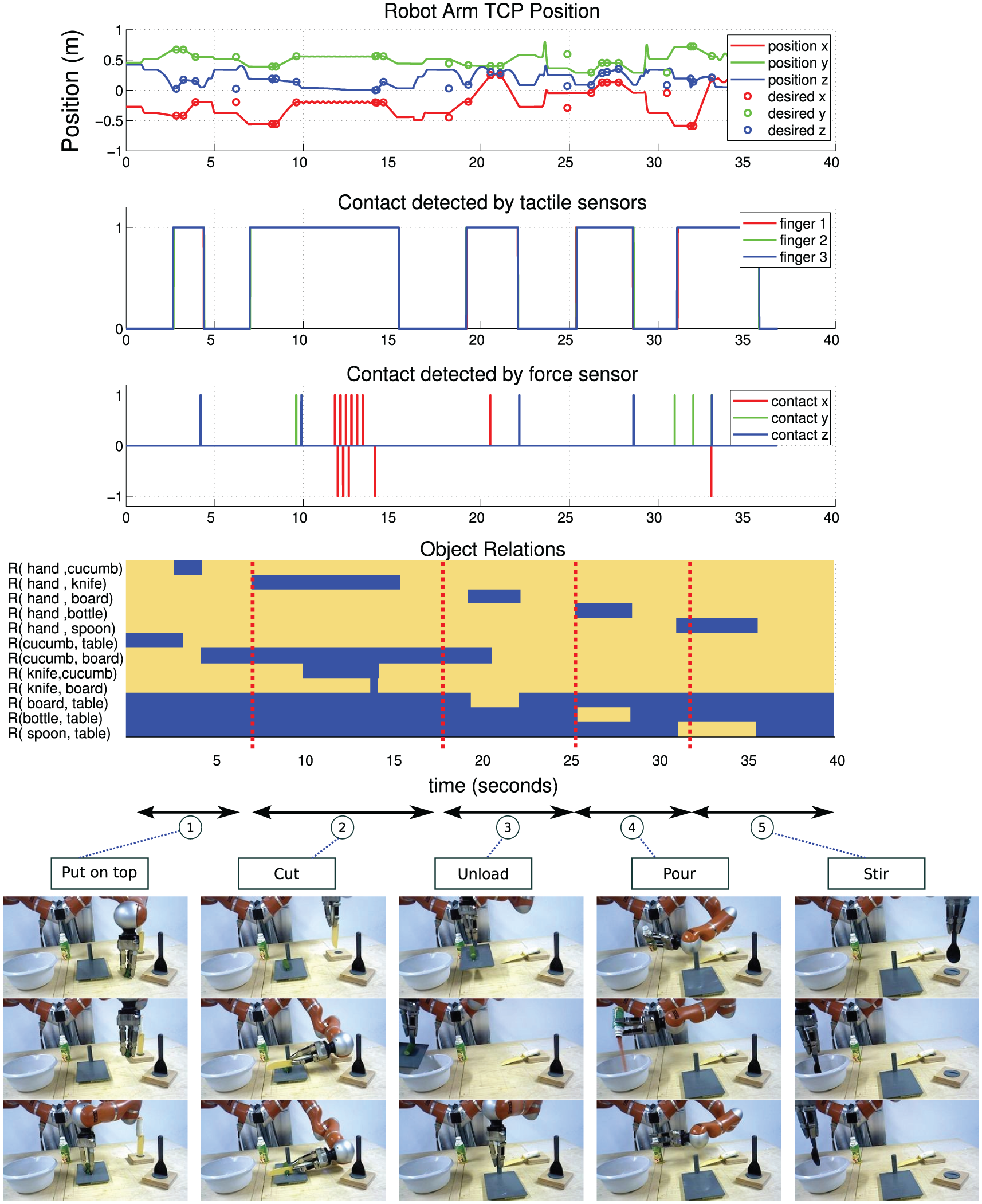
Robot execution of a salad preparation scenario which involves five atomic actions: 1. put on top; 2. cut; 3. unload; 4. pour; 5. stir. From top to bottom are shown the position, tactile, and force sensor data as well as the changes which are detected in the relation of objects in the scene. Sample snapshots for some SEC states are also depicted at the bottom. Black arrows represent temporal intervals for atomic actions.
Note that in both scenarios, we assume that the high-level action plan is given in advance because we are not addressing any planning related issue in this study. Our only aim is to introduce a generic representation for the seamless execution of atomic and sequential actions independent from variations in the scene context.
The videos of chained action executions are shown in Extension 3. 1
5. Discussion
The main contribution of this study was to give a thorough definition of manipulation actions at symbolic (high) and sub-symbolic (low) levels and link them through a mid-level FSM. The proposed state machine provides a mechanism to execute the actions on a robotic arm/hand system. The proposed framework was tested on a wide range of actions and objects and we found satisfactory execution performance on various atomic and chained manipulation actions. Actions that produced problems are those notorious types that also humans find hard. So far our methods are excluding bimanual manipulation actions. True bimanual manipulations are rare, but also in a single-hand manipulation the supporting hand can help to control the force–torque patterns during the action. In Aksoy et al (2017) we performed a machine vision analysis also of manipulations, where both hands are used, which may pave the path for robotic execution.
5.1. Possible extensions
Note that all evaluations had been performed without engaging error correction so as to show the plain (feed-forward) properties of this system in a fair way. Performance increases to near perfect using error correction for all but the systematic errors; those, for example, where the chosen object lacks the required affordance for the action. It is the use of event chains that makes it possible to detect execution failures at all decisive action time points. If an expected object relation has not come into being, then an error must have happened. This event-based error detection is another advantage of our framework. Interestingly, a possible extension of this work would be to use it for active object affordance estimation. Repeated trials of an action will allow distinguishing random from systematic failures because random failures can be corrected, but systematic failures cannot. Hence, an uncorrectable error hints at a systemic lack of the required affordance (e.g. when repeatedly trying to cut a banana with a cup). This touches the field of developmental robotics (Pagliuca and Nolfi, 2015; Tikhano_ et al, 2013) where object affordance estimation remains a difficult issue.
Another way to extend this framework would be to create movement primitives automatically. At the moment we are working on an algorithmic framework that tries to achieve this using humans demonstration combined with DMPs and relying on the temporal chunking that the SECs provide. These preliminary results currently indicated that the here selected and hand-defined set of primitives is quite well reflected also by those that can be created by an automatic procedure.
Along the same lines, it is also conceivable to try to learn (some of) the parameter ranges needed for execution of a movement primitive for example by using reinforcement learning (RL) techniques. So far, parameter ranges have been set manually by us. In general, we observed that the rigorous chunking of the actions, using SECs and primitives, leads to large intrinsic robustness of our framework and it was never a problem to define the required parameter ranges. Still, using RL might lead to even more robustness, but would, very likely, require creating first a detailed simulation of the complete setup/framework to assure convergence of learning by allowing for enough iterations. Thus, implementing automatic primitive generation and/or parameterization via RL would, however, exceed the scope of this study by far.
In the context of a European project ACAT, 2 we had developed a massive XML schema called action data table (ADT) to capture actions generated by the framework proposed here. Essentially, this is the file format used to actually store the library data, 3 which are the high- and low-level data of an action as specified in the current paper. This data format enables us to execute new actions also on different robots and a main advantage of the action library framework is, thus, that it is (within reason) independent of the robot embodiment. Transfer to a different machine requires only the fine-tuning of a set of parameters (e.g. parameters related to the kinematic chain or to the sensor hardware). As a consequence, the framework proposed here has already been used as an action execution routine in different robotic applications (Agostini et al, 2015; Wörgötter et al, 2015). In the work of Agostini et al (2015), we showed that the robot can still generate similar actions by replacing tools in manipulations using the aspect of tool affordance. The work introduced in Wörgötter et al (2015) showed that robots can apply bootstrapping at different cognitive levels to improve their behavior based on the action representation and generation method proposed here. Therefore, we hope that the library of actions as proposed here can, in the long run, turn into a useful (and standardizable) robotics software tool also for other uses.
Footnotes
Appendix. Index to multimedia extensions
Archives of IJRR multimedia extensions published prior to 2014 can be found at http://www.ijrr.org, after 2014 all videos are available on the IJRR YouTube channel at http://www.youtube.com/user/ijrrmultimedia
Error handling cases
Single action executions
Chained action executions
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research leading to these results has received funding from the European Union’s Horizon 2020 Research and Innovation programme (grant agreement number 680431 (ReconCell); ![]() ).
).