
Abstract
This study investigates how auditory, visual, and lyrical features in music videos shape emotional responses, using EEG data from 26 participants. Five widely viewed music videos were selected based on their global popularity and cross-cultural appeal. A CNN–LSTM model classified emotional states with 97.67% accuracy, and complementary regression results showed strong generalization (best model RMSE = 0.15, MAE = 0.10). Feature selection reduced 27 candidates to a sparse set dominated by auditory and visual cues, and SHAP interpretation revealed a clear modality hierarchy: pitch- and dynamics-related auditory features accounted for the largest share of predictive importance, visual color properties (hue, saturation) provided secondary influence, and lyrical sentiment contributed least. These findings support neuroaesthetic accounts in which low-level sensory structure drives rapid affective appraisal, with visual tone refining emotional meaning. Practically, the results suggest that deliberate control of pitch/dynamics can reliably steer emotional engagement in music-video creation for diverse audiences.
Introduction
The relationship between art and emotional well-being has become a central focus in empirical aesthetics, cognitive science, and health psychology. Engagement with diverse art forms—visual, auditory, or multimodal—has consistently been linked to positive emotional states, improved cognitive functioning, and enhanced psychological well-being (Susino et al., 2025). Art offers a unique mode of emotional engagement that supports mood regulation and can alleviate stress and anxiety (Castellotti et al., 2025; Hunter et al., 2010; Mastandrea et al., 2019). Music, in particular, evokes strong emotional responses that correspond with physiological indicators such as heart rate variability and EEG patterns, which serve as biomarkers of emotional health (Schreuder et al., 2016; Thompson & Quinto, 2012).
Recent work in multimodal emotion recognition (MER) shows that the integration of auditory, visual, and lyrical cues—especially in audiovisual formats like music videos—produces richer and more complex emotional experiences than any single modality alone (Baltrusaitis et al., 2019; Han et al., 2022). Because emotional engagement with such multimodal stimuli contributes to both immediate affective responses and longer-term psychological benefits, understanding the mechanisms through which art induces emotion is essential for advancing research on art and well-being.
Despite this progress, significant gaps remain. Empirical studies seldom isolate how specific low-level features of artistic experiences—such as pitch, dynamics, hue, or textual sentiment—shape emotional and cognitive outcomes. Existing models often focus on broad emotional categories or rely on static self-reports, which fail to capture the dynamic nature of emotional responses (Kim & Provost, 2016) and can result in inconsistencies between human judgments and machine predictions (Muszynski et al., 2021; Pandeya et al., 2021b). Recent findings highlight the importance of capturing real-time fluctuations in emotional salience, as continuous emotional engagement appears critical for fostering long-term psychological resilience (Liu et al., 2026; Schreuder et al., 2016).
To address these gaps, the present research investigates the cognitive and emotional impact of art within an empirical aesthetics framework, using music videos as a naturalistic, multimodal stimulus. Although art clearly shapes emotional experience, the pathways linking emotional engagement to cognitive and psychological well-being remain insufficiently understood. This study bridges that gap by integrating neurophysiological data (EEG) with computational analyses of auditory, visual, and textual features to identify which elements most strongly induce emotion and how emotional salience shifts over time across modalities. EEG's high temporal resolution enables fine-grained tracking of dynamic emotional states, providing new insights into how music videos evoke emotion in real-world contexts. This multimodal, temporally sensitive approach advances the development of modality-aware MER models and offers implications for the therapeutic use of art, the design of emotionally supportive media environments, and the creation of affect-sensitive technologies that better adapt to users’ emotional experiences.
Literature Review
Perceived and Induced Emotions
Music videos are a powerful medium for conveying and eliciting emotional experiences, which is a key factor behind their broad appeal (Kallinen & Ravaja, 2006). In affective science, a distinction is made between perceived emotions—those expressed or signaled by the music video—and induced emotions, which refer to the actual emotional states experienced by the audience (Fan et al., 2017). This distinction is crucial for understanding the emotional processing of music videos, as it helps differentiate between the emotional tone of the content and the emotional responses triggered by the viewer's engagement.
Perceived emotions are typically inferred from multimodal cues, such as auditory features (e.g., tempo, intensity, pitch), visual elements (e.g., facial expressions, gestures, scene dynamics), and semantic/textual content like lyrics. In contrast, induced emotions are measured through physiological responses (e.g., EEG, heart rate variability) and behavioral indicators, which reflect the internal emotional states triggered by the stimuli (Tsai et al., 2015). While self-reports are commonly used to measure induced emotions, they can be biased and fail to capture the fluctuating emotional responses during video consumption (Soleymani et al., 2012). EEG-based approaches, however, offer a promising alternative by providing high-resolution measures of emotional states that directly correlate with audiovisual stimuli (Jenkins et al., 2009). With its high temporal resolution, EEG is particularly well-suited for studying the dynamic changes in emotional responses to stimuli (Alarcão & Fonseca, 2019).
Although perceived and induced emotions are often related, their relationship is complex. While perceived emotions generally have a higher magnitude, changes in perceived emotions tend to strongly correlate with changes in induced emotions (Thompson & Quinto, 2012). For instance, music with different emotional valences can influence EEG activity and align with perceived emotional states (Plourde-Kelly et al., 2021). However, other studies indicate that perceived and induced emotions may diverge. For example, Dibben (2004) found that the perceived emotional tone of music remained stable across contexts, even as induced emotions fluctuated. This highlights the dynamic and context-sensitive nature of emotional induction, suggesting that temporal, personal, and situational factors influence induced emotional responses, which may not always align with the perceived emotional content (Kallinen & Ravaja, 2006).
In the broader context of emotional computing and sentiment analysis, this variability underscores the need to improve the precision of sentiment recognition and address the so-called semantic gap between media content and user affective experience. Recent research emphasizes the value of incorporating user features, such as emotional predispositions captured through EEG or eye-tracking, into models of image and video sentiment recognition to enhance interpretive accuracy and real-world applicability (Liang et al., 2024). These approaches help bridge the divide between content-level analysis and the lived emotional experiences of users, offering a more personalized and dynamic understanding of emotion.
To model these complex emotional dynamics more effectively, scholars have increasingly adopted dimensional models of affect, which conceptualize emotions along continuous scales. Two key dimensions—valence (positive to negative) and arousal (high to low activation)—are widely used in the study of music and media-induced emotion (Cespedes-Guevara & Eerola, 2018; Wang et al., 2024a). This study adopts Russell's circumplex model of affect as its analytical framework, scoring emotional responses along these two axes. Guided by this model, we investigate how distinct unimodal features—auditory, visual, and semantic—contribute to induced emotional experiences. In doing so, this research addresses a critical gap in existing literature, which has predominantly focused on perceived emotional cues, by emphasizing the dynamic and individualized nature of induced emotional states during real-world multimedia engagement.
Multimodal Emotion Recognition
Emotions elicited by music videos are inherently multimodal, arising from the complex interplay of auditory, visual, and textual stimuli. Recent advancements in multimodal emotion recognition (MER) have capitalized on this integration, improving the accuracy of emotional predictions by employing architectures such as late fusion, hybrid fusion, residual-fusion models, or more sophisticated approaches like multi-stage fusion networks designed for modality collaboration (Li & Zhao, 2023). These approaches extract distinct features from sound, visuals, and lyrics and subsequently combine them to estimate emotional intensity and valence (Baltrusaitis et al., 2019; Han et al., 2022).
Within this domain, two core challenges emerge: feature extraction and cross-modal fusion. In terms of feature extraction, a wide range of deep learning techniques have been applied, including Recurrent Neural Networks (RNN), Long Short-Term Memory (LSTM) networks, Gated Recurrent Units (GRU), Convolutional Neural Networks (CNN), and attention mechanisms—all of which aim to capture the dynamic and hierarchical structure of multimodal emotional signals (Wang et al., 2024a). For cross-modal fusion, integration strategies are typically classified into three categories: feature-level fusion, decision-level fusion, and hybrid fusion. In most frameworks, unimodal features are first extracted independently and then combined to generate a unified emotional prediction (Han et al., 2022). Empirical findings consistently demonstrate that multimodal models significantly outperform unimodal systems in affective recognition tasks, highlighting the value of integrating complementary cues across modalities (Rouast et al., 2021).
Modality-Specific Contributions
Research across modalities suggests that each sensory channel contributes uniquely to emotional perception. In the auditory modality, emotional cues are conveyed through features such as timbre, rhythm, pitch, and dynamics (Fu et al., 2011; Zhang, 2021). These features can strongly influence perceived arousal and emotional intensity. For instance, Geringer et al. (1996) found that while the addition of visuals slightly enhanced emotional engagement, audio alone exerted a stronger influence on the overall affective experience.
In the visual modality, emotion is communicated through facial expressions, movements (scene-change speed), and visual aesthetics such as lighting and color (Lee et al., 2017). Facial expressions, in particular, provide immediate emotional signals—such as a smile indicating happiness or wide eyes signaling surprise (Bhattacharya et al., 2021). Body movements and gestures have also been shown to modulate the perceived emotional tone of accompanying music (Krahé et al., 2015; Vines et al., 2011; Vuoskoski et al., 2016). These visual cues often serve to amplify or reshape the emotional interpretations initiated by audio or text.
The textual modality, especially lyrics, plays a distinct role by conveying higher-order semantics and emotional meaning. Lyrics can anchor the narrative of a music video, frame emotional context, and influence perceived valence (Wang et al., 2024b). In multimodal sentiment analysis, text is often found to be the most predictive modality, especially for valence estimation (Poria et al., 2023). Supporting this, Lavy (2001) demonstrated that supplementary textual information, such as a short story presented alongside music, could alter the listener's emotional evaluation of the auditory experience. This highlights the complementary role of lyrics in augmenting the emotional content conveyed by sound and visuals.
Modeling Multimodal Emotional Integration
Despite the growing body of research in multimodal emotion recognition, most existing models prioritize predictive accuracy or rely on fusion strategies that often obscure the distinct contributions of individual modalities. Such approaches offer limited insight into the underlying mechanisms of emotional processing, as they tend to treat modalities as interchangeable or additive rather than examining how each uniquely contributes to the emotional experience. Emerging evidence, however, underscores the persistence of modality-specific effects even in integrated contexts. For example, Bhattacharya et al. (2021) demonstrated that auditory features (e.g., in A and A + V conditions) are more effective in predicting arousal, while textual features (e.g., T, A + T, V + T) better predict valence. These findings suggest that emotional information is encoded and conveyed differently across modalities, challenging assumptions of uniform integration.
EEG-based studies have provided valuable insights into how the brain differentially processes emotional cues across sensory channels. Desai et al. (2024) found that neural response patterns during audiovisual presentations closely resembled those elicited under unimodal conditions, indicating that the brain integrates multimodal information while retaining modality-specific representations. However, they also noted a tendency for visual evoked potentials (such as early P1 or N1 components, or specific occipital alpha/beta desynchronization patterns) to dominate in EEG recordings, potentially masking the contributions of auditory or semantic inputs, like narrative understanding beyond direct lyrical content (Desai et al., 2024). This dominance of visual information is consistent with earlier foundational findings. Mehrabian and Ferris (1967) reported that, in emotion communication, visual cues were approximately 1.5 times more influential than auditory ones. Subsequent studies have further confirmed this asymmetry. Schreuder et al. (2016) observed that in audiovisual contexts, emotionally congruent visual stimuli enhanced positive affective appraisals more effectively than audio alone. Similarly, Coutinho and Scherer (2017) reported strong correlations between unimodal and multimodal evaluations, emphasizing the weight of visual information in shaping emotional judgments during performance assessment.
Previous research on emotional processing has primarily focused on modality-level dynamics, often relying on controlled experimental stimuli. This approach overlooks the potential of computational modeling using rich, real-world data. Moreover, much of the existing literature examines emotions at a broader modality level (e.g., auditory, visual, textual), neglecting the finer-grained feature-level interactions within each modality. To address these gaps, this study employs naturalistic EEG data and computational modeling to explore emotional integration in a more detailed and ecologically valid manner. The key objectives of this research are to examine how auditory, visual, and textual features contribute to emotional responses in naturalistic settings (such as music video consumption) and to explore the dynamic interactions of feature-level cues from these modalities and their influence on emotional states, as measured by EEG. By addressing these objectives, the study aims to provide deeper insights into how multimodal cues shape emotional experiences and offer a more ecologically valid framework for multimodal emotion recognition.
Method
Material Preparation
Five high-quality music videos (MVs)– Let It Go, Sugar, See You Again, Stay, and Because of You—were selected from YouTube, Bilibili, and TikTok based on clearly defined empirical and methodological criteria. First, we chose videos with exceptionally high global view counts, as popularity is a reliable proxy for cultural reach, emotional resonance, and familiarity, all of which strongly influence the robustness and consistency of affective responses in empirical studies (Liikkanen & Salovaara, 2015; Schubert, 2004). Second, we selected MVs that demonstrated substantial cross-platform presence and audience diversity, ensuring cross-cultural validity and reducing the likelihood that emotional reactions would be driven by culturally specific cues (Lee et al., 2024; Susino et al., 2025). Such widely recognized stimuli are commonly recommended in affective neuroscience and empirical aesthetics because they enhance comparability across participants and support stable neural and behavioral responses (Koelsch, 2014).
Beyond popularity and cultural reach, these MVs were chosen because they exhibit clear narrative structure, strong audiovisual integration, and emotionally expressive musical features, all of which are known to reliably elicit affective engagement without overwhelming cognitive load (Liao et al., 2020). Their multimodal richness—combining music, lyrics, and visual storytelling—provides the necessary complexity for studying multimodal emotional processing while maintaining ecological validity. Collectively, these characteristics make the selected MVs well aligned with the study's goal of examining how auditory, visual, and lyrical features jointly shape emotional responses.
To provide a clearer understanding of the experimental workflow, a flowchart is included to visually represent the sequence of steps involved in the study. This flowchart outlines the process from the selection of music videos, through the extraction of multimodal features, to the analysis of the emotional responses (see Figure 1).
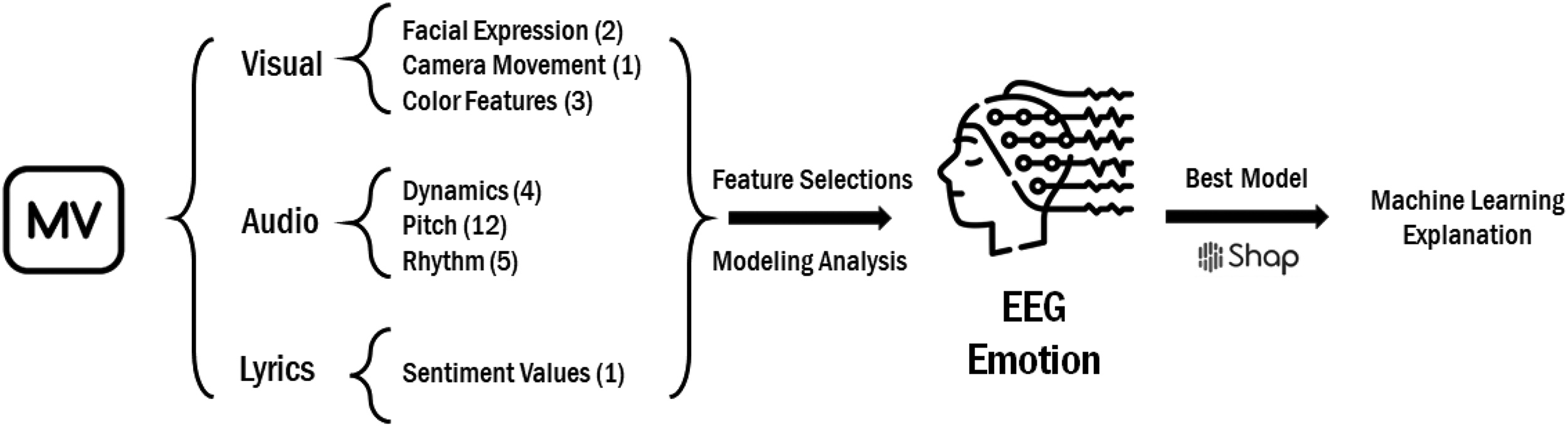
Workflow for feature selections, extraction, analysis, and explanation.
Material Multimodal Analysis
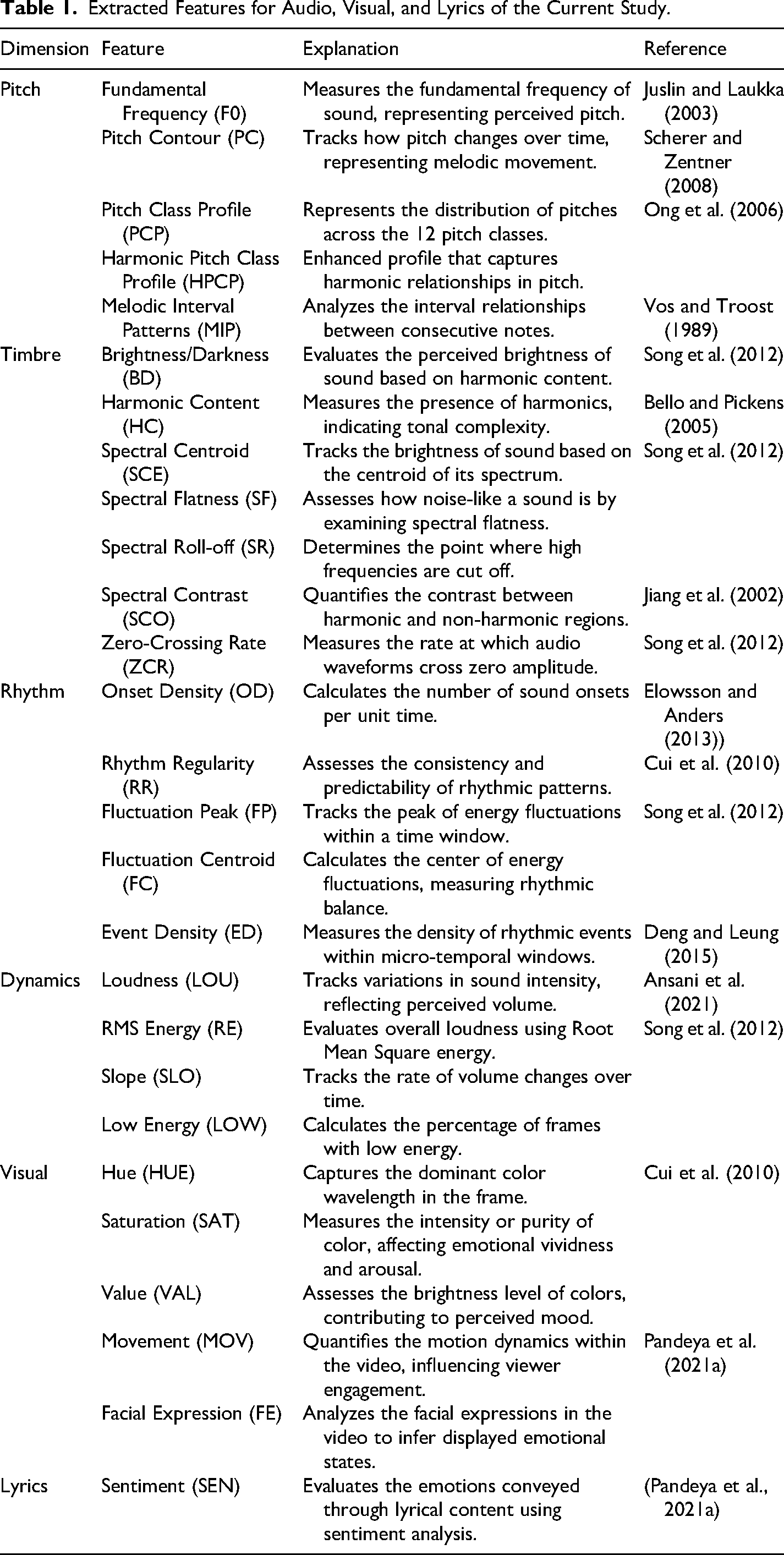
To comprehensively investigate emotional processing in music videos, a multimodal analysis framework was adopted, incorporating auditory, visual, and textual information. Auditory features were extracted to capture emotional cues conveyed through sound characteristics such as pitch, timbre, rhythm, and dynamics, which are known to influence perceived arousal and emotional intensity. Rather than relying on low-level features obtained through signal processing techniques like Fourier transform, spectral or cepstral analysis, and autoregressive modeling—methods that are not directly related to the intrinsic properties of music as perceived by human listeners (Fu et al., 2011; Song et al., 2012)—this study focused on features with semantic content. These high-level features provide meaningful insights that better explain the emotional impact of music due to their closer alignment with human understanding (Fu et al., 2011; Song et al., 2012). Visual features were analyzed to assess emotional signals transmitted through color composition, movement dynamics, and facial expressions, reflecting the visual modality's role in shaping and amplifying emotional engagement. Additionally, the lyrical content of each music video was subjected to sentiment analysis to evaluate the semantic and affective dimensions conveyed through text, recognizing its distinct contribution to emotional meaning and valence perception. This multimodal approach allowed for a comprehensive assessment of how sensory and semantic information interact to shape emotional experiences during music video viewing (Table 1).
Extracted Features for Audio, Visual, and Lyrics of the Current Study.
EEG Emotion Analysis
Grounded in contemporary cognitive neuroscience research, this study explores the relationship between brain activity and emotional processing during music video exposure. Electroencephalography (EEG) offers a reliable and efficient method for capturing emotional responses, providing high temporal resolution and sensitivity to neural dynamics underlying affective states (Papez, 1937).
Data Source and Preprocessing
EEG training data were sourced from the SEED dataset (Zheng et al., 2019), specifically designed to study neural correlates of emotion during multimedia exposure. Standard feature extraction methods were applied to segment the EEG signals into canonical frequency bands—delta, theta, alpha, beta, and gamma—each associated with distinct cognitive and emotional processes (Papez, 1937; Tian et al., 2020; Zheng et al., 2019). Frequency-domain features were obtained via power spectral density (PSD) analysis, while time-domain features were captured using the short-time Fourier transform (STFT) (Chen et al., 2019). Additionally, differential entropy features were extracted to characterize the nonlinear dynamics of the EEG signal (Du et al., 2021).
During preprocessing, standard filtering and Independent Component Analysis (ICA) were applied to remove artifacts, followed by segmentation of the EEG signals into temporal windows (e.g., 0.5 s) to capture dynamic changes. These segments were then used for frequency band energy extraction via Fourier transform. The signals were decomposed into five frequency bands—delta (0.5–4 Hz), theta (4–8 Hz), alpha (8–14 Hz), beta (14–30 Hz), and gamma (30–50 Hz)—each associated with specific emotional or cognitive states, such as alpha for relaxation and beta and gamma for heightened arousal or attention. To improve cross-subject generalization, domain adaptation strategies and data augmentation techniques, such as time-frequency perturbations and pseudo-labeling, were applied. These methods preserved physiological signal characteristics while enhancing model robustness.
Following feature extraction, a feature matrix was constructed, and two additional preprocessing steps were applied: a Kalman filter for temporal smoothing and StandardScaler normalization to standardize feature distributions. These steps ensured appropriate feature scaling and minimized noise prior to model training. This comprehensive pipeline enabled the SEED dataset to provide high-quality EEG data for emotion recognition and serve as a benchmark for deep learning applications in EEG-based affective computing.
Participants and Experimental Design
Twenty-six native Chinese speakers (19 females, 7 males; mean age = 20.65 years, SD = 1.77) participated in the experiment. All participants were undergraduate students recruited from a major university in western China. They reported no history of neurological or psychiatric disorders, were right-handed, and had normal or corrected-to-normal vision. In addition to basic demographic information, participants were asked to report their prior exposure to music videos and general familiarity with popular music. Because the selected stimuli were globally circulated and widely recognized, and the participant group belonged to a relatively homogeneous age cohort, overall familiarity with this type of content was ensured at the group level. However, no formal assessment of artistic training or expertise was collected, as the study focused on naturalistic emotional responses rather than expertise-related differences. Likewise, no psychometric questionnaires (e.g., anxiety, depression, personality scales) were administered. This decision was made to minimize participant burden and to avoid introducing additional variability unrelated to the primary aim of examining multimodal feature contributions to emotion; however, we acknowledge that psychological traits may modulate emotional responses and address this as a limitation in Section 5.2.
Prior to participation, written informed consent was obtained in accordance with ethical guidelines approved by the university's ethics committee. Participants were seated 135 cm from a monitor and wore headphones during the experiment. Music videos were presented in randomized order to counterbalance potential order effects. Participants first completed a demographic questionnaire and consent form before beginning the task. Upon completion of the session, participants were thanked and compensated with approximately 10 USD.
EEG data were recorded using a SynAmps2 amplifier (NeuroScan, Charlotte, NC, USA) with a 64-channel Ag/AgCl electrode cap arranged according to the extended 10–20 international system. The ground electrode was placed at AFz, and recordings were referenced online to the nasal tip, with offline re-referencing to the averaged mastoid electrodes (M1, M2). Vertical electrooculogram (VEOG) signals were collected using bipolar electrodes placed above and below the left eye to monitor ocular artifacts. Data were sampled at 1000 Hz with 24-bit resolution and a bandwidth of 0.03–100 Hz.
To ensure high-quality signal acquisition and facilitate emotion recognition, the recording setup and preprocessing procedures were informed by the protocols established in the SEED dataset. Bandpass filtering was applied within the 0.5–50 Hz range to eliminate low-frequency drift and high-frequency noise, retaining the frequency components most relevant to cognitive and affective processes. ICA was subsequently employed to identify and remove artefacts related to ocular and muscular activity, thus enhancing signal purity.
In alignment with SEED preprocessing methods, the EEG data were segmented into temporal windows and decomposed into five canonical frequency bands—delta (0.5–4 Hz), theta (4–8 Hz), alpha (8–14 Hz), beta (14–30 Hz), and gamma (30–50 Hz)—each of which has well-established associations with emotional and cognitive states. Delta activity reflects motivational and affective intensity, theta is associated with emotional arousal and memory-related processing, alpha suppression indicates increased emotional engagement and attentional demands, beta reflects cognitive evaluation and emotional intensity, and gamma is implicated in the integration of complex emotional information (Aftanas & Golocheikine, 2001; Codispoti et al., 2023; Knyazev, 2012). These theoretical and empirical links justify the selection of these bands for emotion recognition.
Channel-wise z-score normalization was performed to reduce inter-individual variability and support model generalization. Although auxiliary data such as eye-tracking and behavioral responses were recorded, this study focuses exclusively on EEG signals to explore the direct neural correlates of emotion. The rigorous acquisition and preprocessing procedures ensure that the extracted features are both physiologically meaningful and suitable for machine learning-based affective state classification.
Model Construction
To predict emotional responses from EEG, we developed a custom CNN-LSTM model for integrated spatial and temporal feature extraction. This hybrid architecture was selected to leverage the complementary strengths of Convolutional Neural Networks (CNNs) in extracting high-level spatial invariant features from frequency bands and Long Short-Term Memory (LSTM) networks in capturing temporal dependencies inherent in dynamic emotional processing (Alhagry et al., 2017; Chuankun et al., 2017). The architecture processes input EEG through two CNN blocks: the first with a Conv1D layer (filters=64, kernel_size=5, activation = ReLU), MaxPooling1D (pool_size=2), and Dropout (0.5); the second with a Conv1D layer (filters=128, kernel_size=3, activation = ReLU), MaxPooling1D (pool_size=2), and Dropout (0.5). The use of ReLU activation ensures non-linearity while mitigating the vanishing gradient problem, facilitating the learning of complex patterns (Nair & Hinton, 2010). This output feeds an LSTM layer (units=128, dropout=0.3, return_sequences = False). Finally, two Dense layers (units=64, activation='relu’; then units=1, activation='linear’) and a concluding Dropout (0.5) produce the output. During training on an appropriate train/validation split (80%/20%), the Adam optimizer was used. Hyperparameters (as detailed in Appendix A) were optimized via grid search on the validation set, and overfitting was mitigated using early stopping and the specified dropout layers (0.3, 0.5).
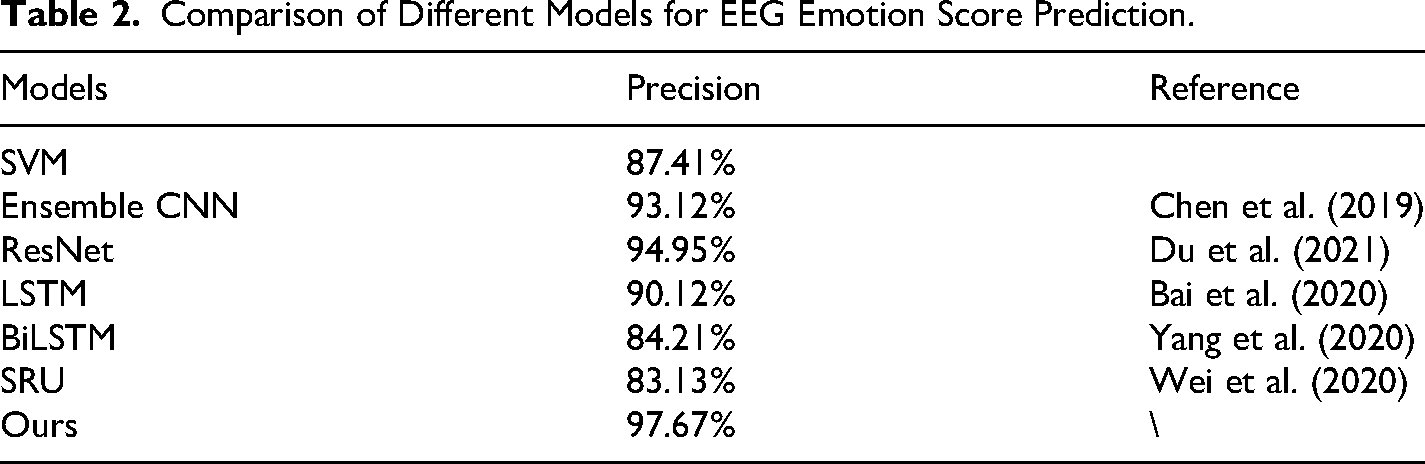
To assess the effectiveness of this hybrid architecture, we conducted ablation experiments comparing the full CNN + LSTM model against several baselines, including CNN-only, LSTM-only, and traditional machine learning models such as Support Vector Machines (SVM). The results, summarized in Table 2, show that our CNN + LSTM model achieved a precision of 97.67%, outperforming both its individual components and previously reported models. This demonstrates the efficacy of combining spatial and temporal modeling techniques for EEG-based emotion recognition.
Comparison of Different Models for EEG Emotion Score Prediction.
Analysis Process
The detailed analysis procedure was as follows:
Results
Descriptive Analysis
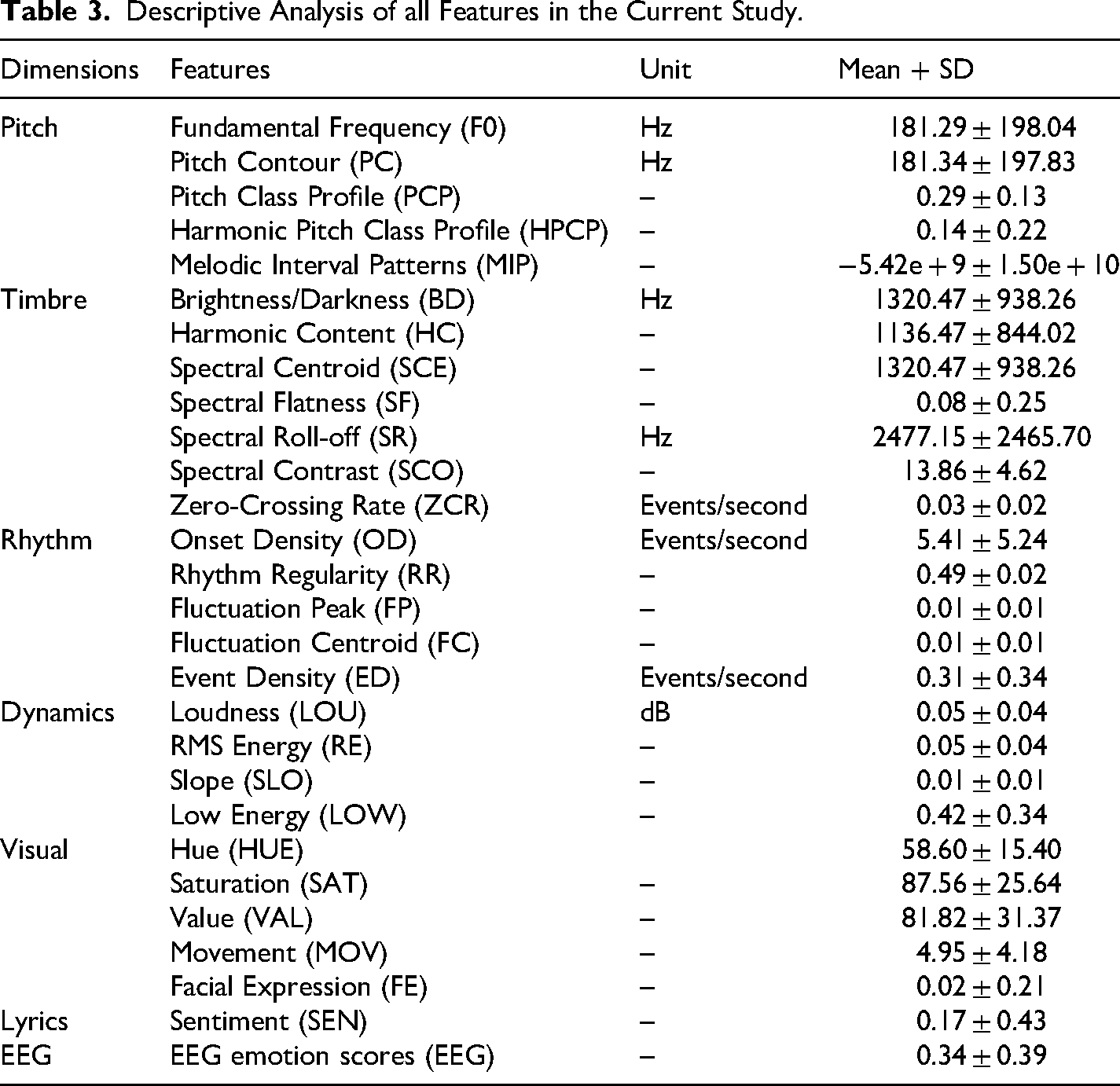
To provide an overview of the dataset characteristics, a descriptive analysis was conducted on all key variables. This analysis included measures of central tendency (mean) and variability (standard deviation) for each multimodal feature and the corresponding emotional response scores (See Table 3).
Descriptive Analysis of all Features in the Current Study.
Feature Selection
LASSO regression analysis was performed on all independent variables, using the presence of the EEG emotion score as the dependent variable (Figure 2). LASSO, which is effective at compressing variable coefficients to prevent overfitting and addressing multicollinearity issues, identified the optimal model with a minimum mean squared error at λ\lambdaλ (log value ≈ −3.3). As a result, 27 independent variables were reduced to 7 key predictors: Harmonic Pitch Class Profile (HPCP), RMS Energy (RE), Low Energy (LOW), Hue (HUE), Spectral Contrast (SCO), Event Density (ED), Pitch Contour (PC), Loudness (LOU), and Saturation (SAT).
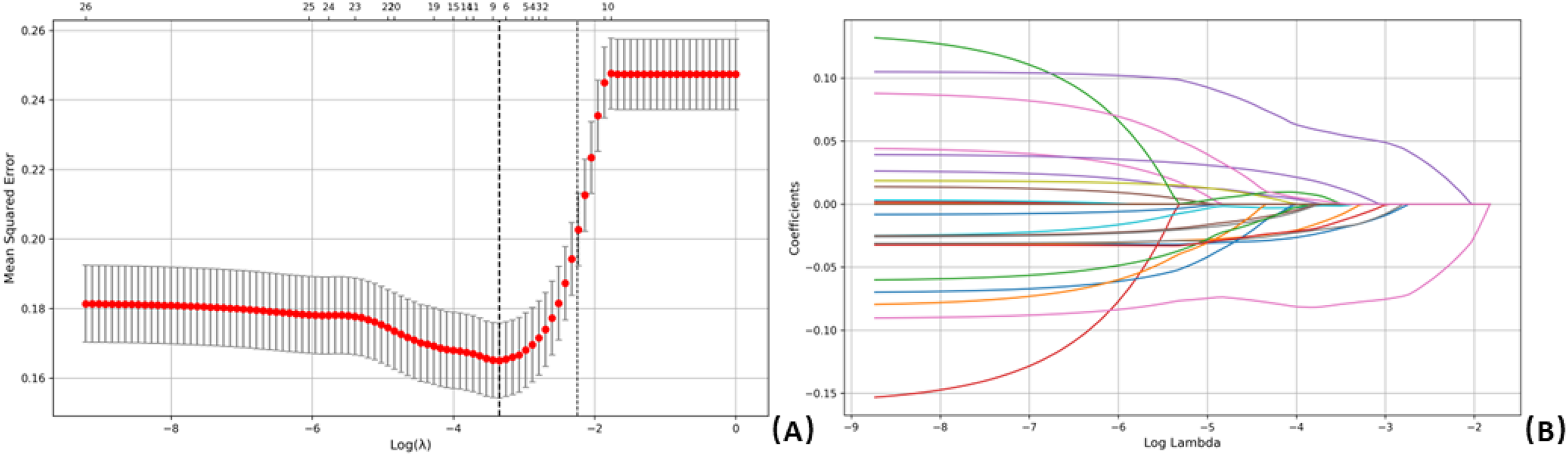
LASSO regression analysis was employed to select characteristic factors. (A) Ten-fold cross-validation was conducted to determine the optimal penalty parameter λ\lambdaλ, with vertical lines indicating selected values. The optimal λ\lambdaλ resulted in 7 nonzero coefficients. (B) Coefficient profiles of the 27 features were plotted against the log(λ\lambdaλ) sequence. Vertical dotted lines indicate the λ\lambdaλ corresponding to the minimum mean squared error (MSE) (λ\lambdaλ ≈ 0.035) and one standard error from the minimum (λ\lambdaλ ≈ 0.106).
Modelling Analysis
Multiple regression models—including LSTM, 1D CNN, XGBoost, MLP, Random Forest (RF), Bayesian Ridge Regression, Gradient Boosting Regressor, Support Vector Regressor (SVR), CatBoost, and Transformer-based architectures—were trained and evaluated. Each model underwent 10 repetitions to ensure result stability. Model performance was assessed using root mean square error (RMSE) and mean absolute error (MAE) metrics. As shown in Table X and Figure 2a,b, XGBoost (RMSE = 0.15, MAE = 0.10), 1D CNN (RMSE = 0.15, MAE = 0.11), LSTM (RMSE = 0.15, MAE = 0.11), and MLP (RMSE = 0.15, MAE = 0.11) demonstrated superior predictive performance relative to the other models across both the training and testing sets (see Figure 3).
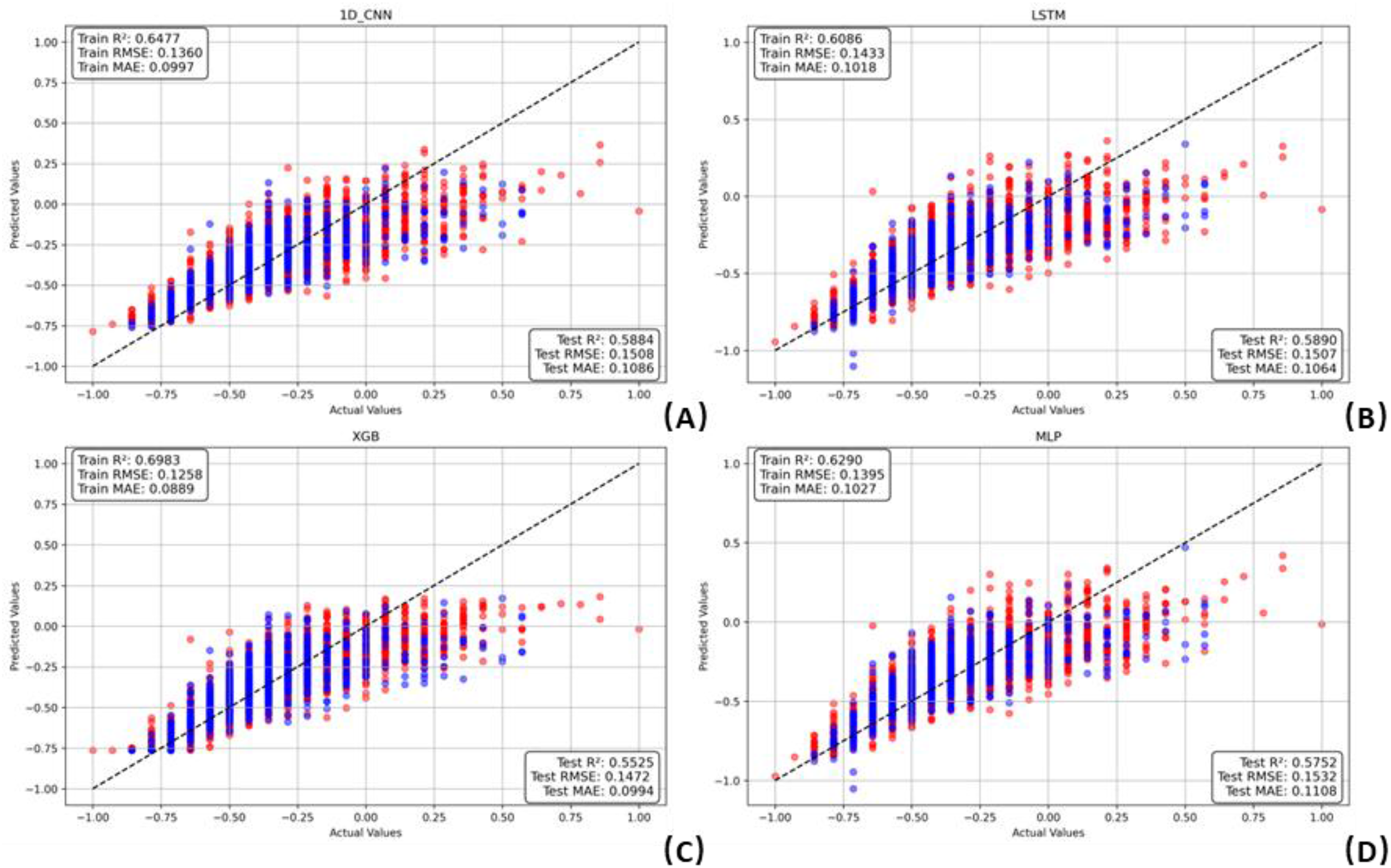
Training and testing performance of the four top-performing machine learning models in predicting EEG emotion scores. Red dots represent the training set, and blue dots represent the testing set: (A) 1D CNN, (B) LSTM, (C) XGBoost, and (D) MLP.
Among these, XGBoost achieved the lowest RMSE and MAE, indicating its strong ability to generalize and accurately capture the nonlinear relationships inherent in the EEG emotion prediction task. This advantage is likely due to XGBoost's robustness to multicollinearity, its regularization mechanisms that prevent overfitting, and its ability to efficiently model complex interactions between features. Consequently, XGBoost was identified as the optimal model for subsequent analysis.
Model Interpretation
To interpret the model's prediction of EEG emotion scores, we applied the SHAP framework. SHAP provided insights into both global feature importance and individual prediction contributions. The global importance ranking (Figure 4B) showed that Harmonic Pitch Class Profile (HPCP), Root Mean Square (RMS) Energy, and Low Energy were the most influential features, followed by Hue, Spectral Contrast, Event Density, and Pitch Contour. The SHAP summary plot (Figure 4A) demonstrated that higher values of HPCP, RMS Energy, and Low Energy generally increased predicted EEG emotion scores, while lower values of Spectral Contrast and Pitch Contour were similarly associated with higher predictions. At the individual level, SHAP force plots (Figure 4C) illustrated how specific features contributed to a single prediction. For example, in one instance, Pitch Contour, Spectral Contrast, Low Energy, and RMS Energy increased the prediction relative to the base value, whereas HPCP, Event Density, and Hue decreased it. These results enhance the model's interpretability and confirm the relevance of multimodal features in predicting EEG-based emotional responses.
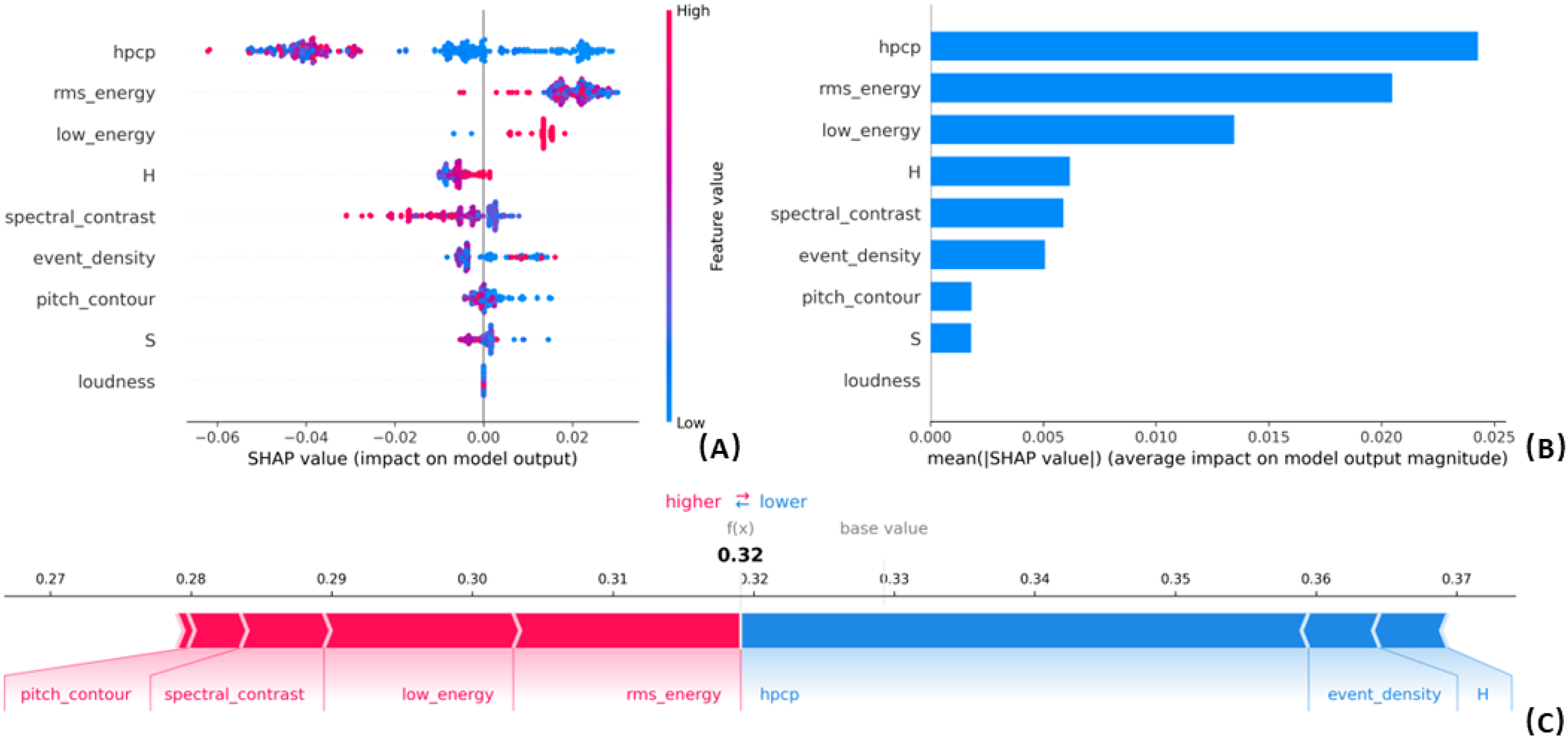
SHAP was employed to interpret the model's predictions. (A) The SHAP summary plot displays the contribution of each feature, where each line represents a feature and the x-axis denotes the SHAP value. Red dots indicate higher feature values, while blue dots represent lower feature values. (B) The SHAP feature importance plot ranks features according to their overall contribution to the model's predictions. (C) The SHAP force plot illustrates how individual features influence a specific prediction.
Discussion
This study reveals the significant roles of auditory, visual, and lyrical modalities in shaping emotional responses during music video consumption. Among these modalities, auditory features emerged as the most influential in shaping emotional states, followed by visual features, with lyrical content exerting the least impact. This hierarchical pattern aligns with aesthetic theories proposing that low-level perceptual features—such as pitch, timbre, hue, and saturation—serve as primary drivers of emotional induction, shaping affect before higher-level cognitive interpretation occurs (Brattico & Pearce, 2013; Leder et al., 2004). Recent work further demonstrates that low-level artistic features—such as color temperature, brightness, and saturation—shape affective judgments through rapid perceptual pathways (Elliot & Maier, 2014). These findings support our EEG-based evidence that early, sensory-driven mechanisms play a central role in the formation of aesthetic emotions.
The prominence of the auditory modality in emotion induction aligns with existing research highlighting the emotional significance of sound in music. In music videos, the auditory channel provides continuous, structured emotional information that primarily influences affective judgments. This supports the channel dominance model (Somsaman, 2004), which suggests that viewers align their emotional perceptions with the dominant modality when modalities convey emotionally coherent cues. Lee et al. (2017) demonstrated that strong arousal signals from the auditory channel outweigh visual input in emotional appraisals, leading to sustained attentional focus and stable emotional responses. These findings underscore that music—through pitch and dynamics—serves as a primary emotional conduit, engaging both low-level sensory and higher-order affective processes (Koelsch, 2014; Schubert, 2004).
Auditory features, particularly pitch and dynamics, were the most significant predictors of emotional states in this study. The negative correlation between Pitch Class Profile (PCP), Harmonic Pitch Class Profile (HPCP), and emotional responses, as measured by EEG, contrasts with Ilie and Thompson's (2011) findings, which linked higher pitch in speech and lower pitch in music to positive emotions. Our findings indicate that higher-pitched musical elements—particularly those associated with dissonance or tension—tend to evoke negative emotional reactions, aligning with recent work on harmonic roughness and emotional disfluency in music (Athanasopoulos et al., 2021; Giannos et al., 2025). This pattern also aligns with contemporary auditory aesthetics research showing that harmonic roughness and spectral dissonance reliably modulate arousal and valence, often eliciting tension or negative affect (Smit et al., 2019). This discrepancy may reflect the complex interaction between dissonant pitch content and other sensory modalities, which together create multifaceted emotional experiences.
Similarly, the relationship between dynamics and emotional responses was nuanced. Low-energy sounds, characterized by softer, subdued musical elements, were positively associated with emotional states linked to calmness, in line with findings that connect low-energy sounds to positive emotions (Juslin & Västfjäll, 2008). In contrast, higher Root Mean Square (RMS) Energy, indicating intense or abrupt musical elements, was negatively correlated with emotional responses, suggesting that high energy can induce overstimulation or anxiety, particularly when the viewer's emotional state does not align with the music's intensity (Brattico et al., 2013; Huron, 2005). These results underscore the complexity of emotional processing in music videos, where the emotional impact of dynamics depends on both energy levels and the viewer's emotional state.
Although rhyme and timbre had a lesser impact on emotional responses compared to pitch and dynamics, their influence should not be overlooked. Rhyme enhances emotional resonance by reinforcing the emotional content in music (Mayer & Rauber, 2010). Similarly, timbre—conveying tonal qualities like warmth or sharpness—plays a key role in evoking distinct emotional states (Juslin & Laukka, 2003). Moreover, emotional information from one modality can influence emotional processing in another, especially when cues from one modality are ambiguous. This cross-modal interaction highlights the complexity of emotional processing, demonstrating that even subtle features like rhyme and timbre contribute to the overall emotional experience (Rigoulot & Pell, 2012).
Surprisingly, in the visual modality, hue (H) and saturation (S) emerged as the most influential features, rather than facial expressions or scene movement. While facial expressions were not the primary focus of this study, prior research suggests that even unconscious recognition of facial cues can influence emotional processing (de Gelder et al., 2002). In this study, lower saturation colors were associated with more positive emotional reactions, consistent with research suggesting that different colors evoke distinct emotional responses. For example, lighter or more saturated colors are often linked to happiness (Wright & Rainwater, 1962), while blue hues evoke calmness and red is associated with excitement (Hevner, 1935). These color-emotion associations are consistent across cultures (D’Andrade & Egan, 1974). This outcome aligns with emerging neuroaesthetic research showing that color properties influence affective processing through early visual pathways, modulating arousal and valence before complex semantic interpretation occurs (Palmer & Schloss, 2010). Our EEG-linked findings extend this work by demonstrating that color features meaningfully shape neural emotion responses during dynamic audiovisual experiences, supporting theories that emphasize visual tone as a foundational component of aesthetic emotion.
Overall, our findings resonate with and extend prominent neuroaesthetic frameworks—such as the Leder et al. (2004) model and the Brattico and Pearce (2013) model—which posit that aesthetic emotions emerge from interactions between early perceptual analysis and later cognitive appraisal. The strong predictive power of low-level auditory and visual features in EEG emotion responses suggests that aesthetic experience in music videos is primarily driven by fast, sensory-perceptual mechanisms, with higher-order meaning (e.g., lyrics) exerting only secondary influence.
In summary, this study provides valuable insights into the hierarchical and complex nature of multimodal emotional processing. Auditory features, particularly pitch and dynamics, dominate emotional induction, while color properties in the visual modality also significantly influence emotional responses. The interaction between modalities, especially when emotional cues are ambiguous, further enriches our understanding of how viewers process and respond emotionally to multimedia content.
Implications and Contributions
Theoretically, this study advances the understanding of multimodal emotional processing by establishing a validated hierarchy of sensory modalities—auditory>visual>lyrical—in shaping emotional responses to music videos. By integrating neurophysiological data (EEG) with audiovisual feature analysis, the research anchors emotional responses in both perceptual input and affective processing systems. Crucially, the findings demonstrate that specific low-level features—such as pitch dissonance, RMS energy, and color attributes like hue and saturation—differentially predict emotional outcomes. These results refine existing frameworks, such as the channel dominance model, and challenge reductive assumptions that associate high pitch or vivid visuals uniformly with positive affect. Notably, the strong influence of hue and saturation on emotional responses highlights the critical role of visual tone, an often-overlooked component in emotion-related studies of music video content, which typically prioritize narrative or facial expressions.
This study also distinguishes itself from prior research that often isolates a single modality for analysis. By adopting a multimodal approach and capturing interactions among auditory, visual, and lyrical cues, it offers a more ecologically valid account of how emotions are experienced in real-world multimedia environments. The inclusion of EEG-based evidence further strengthens the contribution by linking subjective emotional outcomes to measurable neural correlates, thus bridging psychological theory and affective neuroscience.
Practically, the findings hold valuable implications across several applied domains. In music, film, and digital media production, the demonstrated influence of pitch, dynamics, and visual color attributes offers actionable insights for shaping audience emotional engagement. Content creators and editors can deliberately manipulate auditory intensity or adjust visual tones to align with the intended emotional trajectory of a scene, enhancing narrative coherence and affective impact. In the realm of affective computing, where technologies aim to recognize and adapt to users’ emotional states, prioritizing auditory and color-based features may improve system sensitivity and responsiveness—particularly in recommendation engines or personalized user interfaces.
In therapeutic and educational contexts, this research supports the targeted use of low-energy soundscapes and calming visual palettes to promote emotional regulation. For instance, music therapists might employ subdued auditory and visual stimuli to reduce anxiety or enhance mood stability in clinical settings. Similarly, educators could apply these insights in designing emotionally supportive learning environments. The findings also inform user experience (UX) and interface design, suggesting that sensory alignment across modalities can contribute to more immersive, emotionally attuned digital interactions. In marketing and branding, understanding how specific sensory features evoke particular affective responses—such as excitement, calmness, or nostalgia—can enhance emotional resonance with target audiences and increase engagement.
Ultimately, this study offers a nuanced and empirically grounded framework for designing emotionally intelligent multimedia experiences. By revealing how individuals process and respond to the interplay of auditory, visual, and lyrical cues, it contributes both to the refinement of theoretical models and to the development of practical tools for emotion-driven design and communication.
Limitations and Future Directions
Several limitations should be noted. First, different modalities—such as auditory and visual channels—express emotions in distinct ways, with interactions that may lead to redundant or complementary information exchange. This complexity can influence emotional perception across various multimedia formats (Liu et al., 2023). Second, the relatively homogeneous sample of native Chinese-speaking undergraduate students may limit generalizability. Although the selected music videos possess broad cross-cultural appeal, future work should recruit more diverse participants to examine how factors such as cultural background, music preference, and emotional predispositions shape multimodal emotional processing. Third, Large Language Models (LLMs) were not employed in the current analysis due to inherent limitations in their design and application to EEG-based emotion recognition. LLMs are pretrained primarily on large-scale text corpora and lack the native capacity to interpret raw biological time-series data such as EEG (Lee et al., 2024; Wang et al., 2024). Even with structured preprocessing, their performance in cross-modal tasks remains unstable, prone to reasoning biases and output variability (Liu et al., 2026). Furthermore, fine-tuning LLMs on small, individualized EEG datasets is computationally demanding and susceptible to overfitting, rendering them impractical for this study's scale and design (Lee et al., 2024; Wang et al., 2024).
Finally, the study did not include psychometric assessments of participants’ psychological traits, such as mood, personality, emotion regulation tendencies, or baseline anxiety. Although this decision minimized participant burden and maintained focus on neural and multimodal features, individual psychological dispositions are known to modulate subjective and physiological emotional responses (Gross & John, 2003; Larsen & Ketelaar, 1991) and can alter neural dynamics during emotion processing (Moser et al., 2013). The absence of these measures may introduce unexplained variance in EEG responses. Future research should incorporate standardized instruments (e.g., PANAS, BFI, ERQ) to better account for individual differences and clarify how stable psychological traits interact with artistic features to shape emotional responses.
Conclusion
This study underscores the significant contributions of different sensory modalities to emotional responses during music video consumption. Among the auditory, visual, and lyrical modalities, the auditory channel emerged as the most influential in shaping emotional engagement, particularly through pitch and dynamics. The visual modality also played a crucial role, with color features—especially hue and saturation—significantly impacting emotional responses. In contrast, lyrical content had a relatively minor effect. These findings align with the channel dominance model, emphasizing the primacy of auditory input in conveying emotional cues when modalities present coherent emotional information. Moreover, the interaction between auditory and visual features highlights the complex, multimodal nature of emotional processing, where low-level sensory cues, such as pitch and color properties, significantly influence emotional states. The study also reveals that even less prominent features, like rhyme and timbre, contribute to the overall emotional experience.
In the context of Information Systems research, which often examines the comparison between different formats of information presentation, this study addresses the simultaneous perception of auditory and visual information in emotional processing. This research contributes to understanding how the human perceptual and cognitive systems process emotional information from multimodal sources. These insights provide a foundation for future investigations into information systems usage and offer valuable guidelines for the design of multimedia information systems. By ensuring that emotional cues are effectively conveyed and processed across different channels, the findings can aid in creating more engaging and emotionally resonant multimedia experiences.
Footnotes
Ethical Approval and Informed Consent Statements
N/A
Funding
This work was supported by the Sichuan Province Philosophy and Social Sciences Fund Youth Talent Project (SCJJ25QN19), the HKBU Start-Up Grant, and the HKBU FASS Start-Up Research Fund.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.