
Abstract
Although computational linguistic methods have been applied to spoken and written text, they have only recently been used to study poetry. Here, we examine the linguistic components of contest-winning haiku and compare them to a control sample of poems published in an industry-standard journal. We look also at differences between haiku and senryu and what stylistic trends may have affected these poems over time. The results show that winning haiku are shorter than those in a representative journal. Journal poems also have fewer pronouns and more adjectives and nouns. All of the poems show a decrease in words over a decade-long time span. This trend may reflect changes in stylistic writing conventions. The length of such poems probably also relates to innate working memory span limitations. Haiku that limit the number of images and ideas within this limit likely facilitate cognitive processing and increase aesthetic appeal.
What Is Haiku?
There is continual debate about what exactly a haiku poem is. Like all art forms, the rules for haiku are in constant flux. Nevertheless, we will mention here some guidelines that have been proposed by contemporary experts. A haiku is considered a short poem that focuses on the present moment, containing a fragment and phrase structure. One line is considered the fragment, and the remaining two lines form the phrase. The fragment can occur either at the beginning or the end (Reichold, 2013). Haiku usually exhibit juxtaposition, which is the presentation of two images that then invite the reader to make some sort of inferences or comparisons (Ross, 2002).
Haiku often uses sensory images, sometimes coupled with thoughts or introspections. Brevity of expression is of course important, as is ambiguity of reference or association (Root-Bernstein & Banwarth, 2017). They are meant to make us see the wonder of the world in something small and often enable us to feel surprise and to see the connection between things (Mason, 2020). Most haiku employ disjunction, a disruption in expectation generated by their two-part structure (Gilbert, 2013). A haiku focuses on the natural world or the relation between people and the natural world, while a senryu is psychological and is more about human nature with the use of internal, subjective elements and humor.
This poem can be considered a pure haiku because it portrays a simple observation of an event without any overt psychological overtones: summer sidewalk
a skateboarder's shadow
ripples the bricks
Mark Dailey. Frogpond, Vol. 45:2, Spring/Summer 2022
This poem can be considered a senryu or a hybrid haiku/senryu because it shows a concrete image but pairs it with a psychological observation: mud caked boots
the heaviness
of regret
Gary Hittmeyer. Frogpond, Vol 42:2, Spring/Summer 2019
It is important to note that many traditional Japanese aspects of haiku have been dropped from modern English usage. For example, most haiku are not written in the original 5-7-5 syllable count (Gurga & Trumbull, 2003). They do not necessarily need to refer to a season or use a season word (kigo) although some reference to the cycle of nature is still usually present. Neither do they need to adhere to a three-line format. Many haiku are now monoku, consisting of one line only. Finally, contemporary English-language haiku usually avoids simile, abstraction, overt intellectualization, and rhyme (Digregorio, 2014).
The Computational Linguistics Approach
One quantitative way to study language is known as computational linguistics (CL). It is an interdisciplinary field concerned with the computational modeling of natural language phenomena. Natural languages are those that are spoken, heard, written, and read by humans. This is in contrast to formal languages like logic, mathematics, or computer code, which are primarily used by machines. The applied and less theoretical field of CL is called Natural Language Processing (NLP), but these two terms are sometimes used synonymously.
Historically, CL methods have been used to translate languages, create speech recognition and synthesis programs, and develop search algorithms. However, the focus of these research efforts traditionally has been on prose, which is written or spoken language used in everyday communication that lacks metrical structure. It has only been applied recently to the study of verse, which is poetical language typically characterized by rhythm or meter. Prose is usually expressed in sentences and has a discernible grammatical structure. It follows a set of rules or syntax. Verse is usually organized into lines or groups of lines and is characterized by rhythm and cadence. Poetic verse, including haiku and other Japanese poetic forms, typically adheres loosely to a set of rules, but these rules cannot be called a formal grammar or syntax. For example, the sequential ordering of word types (adjective-noun pairings) and hierarchical organization (verbs grouped into verb phrases) of written verse are often absent in poetry.
Computational Studies of Non-Haiku Poetry
The lack of syntactical structure found in verse however has not discouraged researchers from studying it using CL methods. Several recent studies have applied these techniques to a wide variety of poetic forms. Kao (2011) compared professional and amateur poets to see what might constitute greater beauty in poems composed by experts and found that professionals used fewer sound devices like rhyme and alliteration. They also used fewer emotional words but employed more concrete and specific imagery. Compared to amateurs they also used a greater variety of words implying that they are able to evoke sentiment through imagery rather than abstraction or specific emotion words. These findings using traditional poetry examples are interesting because haiku has always been characterized by its use of concrete imagery and lack of abstraction. This suggests that these features may be universal in what is considered beautiful across all forms of poetry.
Poetic styles change over time, but how? Kao and Jurafsky (2015) studied the stylistic features of 359 nineteenth-century English professional poets. They found that contemporary professional poets use significantly more concrete words than their predecessors in line with the modern Imagist movement, as well as fewer emotional words and more complex sound devices. Amateur contemporary poets in contrast were more similar stylistically to the nineteenth-century professionals, suggesting that the earlier elite standards of beauty had affected the latter group more. Gopidi and Alam (2019) performed a computational analysis of popular prose and poetry for two time periods: 1870–1920 and 1970–2019. The two converged in the later period showing that modern poetry has become more similar to prose.
Other aspects of poetry have been studied using NLP techniques. Agirrezabal, Alegria and Hulden (2016) used machine learning to identify the metrical structure of classical English poetry, marking syllables with stress levels and dividing groups of syllables into feet. Dalvean (2016) also used machine learning to classify canonical English poems from those that would be less likely to be anthologized. Bauman, Hussein and Meyer-Sickendiek (2018) employed deep hierarchical attention networks to categorize six classes of poetic styles in a sample of modern and post-modern free verse poems. McCurdy, Srikumar and Meyer (2015) created an open-source software called RhymeDesign. It can be used to identify sonic devices (those involving sound such as different types of rhyme that convey meaning) in conventional poetry or rap music.
Metaphor is of course used in many forms of poetry, and rule-based and statistical models have enabled the classification of metaphor in a corpus of English language poems (Kesarwani, Inkpen, Szpakowicz and Tanasecu (2017). Other models have enabled the detection of metaphor in expressionistic German poems (Reinig & Rehbein, 2019), identification of features that the predict period of origin, authorship, and goodness ratings (Jacobs & Kinder, 2017), and the differentiation of metaphor created by renowned poets and non-professional authors (Jacobs & Kinder, 2018). Additional examples of CL methods that have been used to study poetry include the detection of emotion in Punjabi poetry using Naive Bayesian and Support Vector Machine techniques (Saini & Kaur, 2020), stanza identification in Hindi poetry (Audichya & Saini, 2021), probabilistic topic modeling to study topic, meter, and authorship in Persian poems (Asgari & Chappelier, 2013), statistical and rule-based methods to determine the metrical and semantic aspects of 16th- and 17th-century Spanish Golden Age sonnets (Navarro-Colorado, 2015), and enjambment detection in a large diachronic corpus of Spanish sonnets (Ruiz, Canton, Poibeau & Gonzalez-Blanco, 2017).
Computational and Experimental Studies of Haiku
The amount of equivalent research devoted to the study of haiku or related Japanese forms is less, perhaps reflecting its lower degree of popularity in the classical and contemporary poetry scene. Kikuchi et al. (2016) used a machine learning approach to estimate the artistic quality of Japanese haikus. Their model is based on word- and sound-based vectors. They employed a convolutional neural network to make a quality estimation function and used it to evaluate 40,000 poems from a community website. Their measure of artistic quality was the number of “likes” on the site, which likely reflects popularity more than the actual quality of poems. Their program at best was only able to predict quality with a value of 0.64.
Most haiku research is of an experimental rather than computational nature. Geyer et al. (2020a, 2020b) presented normative three-line English language haiku with a fragment-phrase structure and recorded eye movements. The reader's eyes focused on the fragment line for a longer duration. This “cut” effect was more pronounced in juxtaposition haiku where meaning is focused on the fragment line and it becomes harder to fuse the two images when they are conceptually distant. In a later study, the researchers used a neural network model to determine the semantic similarity between the fragment and the phrase and assessed whether it would predict eye movements (Geyer et al., 2020a, 2020b). Semantic similarity did influence the cut effect, but their predictions were reversed for context-action haiku in which there is a smaller semantic gap.
Blasko and Merski (1999) had college students interpret 117 haiku written by poets of varying expertise. Imagery, familiarity, and ease of comprehension were found to predict haiku goodness. Goodness in this context was how much the students liked the poems, imagery was the extent to which it evoked a mental image, familiarity was how familiar the ideas and concepts in the poem were, and ease of comprehension was how easy it was to interpret the haiku. All of these factors were measured using a 7-point Likert rating scale. There was no difference in ratings between high- and low-skilled comprehenders. Those with more experience saw haiku as more enjoyable, familiar, and easy to understand. This did not depend only on experience with poetry but also on self-reported activities like singing and studying art, suggesting that more creative individuals are more open to and appreciative of literature. All readers tended to like haiku that were more familiar, comprehensible, and high in imagery.
Belfi, Vessel and Starr (2017) recruited participants through Amazon's Mechanical Turk online platform to read and rate haiku and sonnets based on emotional valence, arousal, vividness, and aesthetic appeal. There was a great deal of variance in the experience of aesthetic pleasure, suggesting underlying individual differences on what poems were considered most appealing. Across all participants and both types of poems though, vividness of imagery contributed most strongly to aesthetic pleasure followed by valence and then arousal. Vividness was measured using a 0–100 rating scale response to how vivid the imagery evoked from the poems was. This and a number of other studies cited previously consistently show that imagery is the most powerful predictor of poem quality.
Hitsuwari and Nomura (2022) had Japanese and German speakers rate haiku online on a variety of characteristics including perceived beauty, ambiguity, awe, and nostalgia. As cognitive ambiguity increased, the aesthetic evaluation of the haiku decreased, and this tendency was greater among German speakers. Ambiguity was measured as how much of the meaning of the haiku they did not understand, using a 0–100 rating scale slider. This finding suggests that haiku that are more difficult to understand are less preferred. There was a positive relationship between the emotions of awe and nostalgia and aesthetic evaluation which was also greater for German speakers. The results were interpreted in terms of cultural differences, suggesting that these emotions may be of greater importance in Western societies.
Purpose
In this study, we seek to apply CL/NLP methods to the study of haiku and senryu. For example, how do haiku writers utilize determiners, nouns, verbs, adjectives, and pronouns? Does the use of language differ between haiku and senryu? We might for example expect senryu to contain more personal pronouns compared to haiku because of its emphasis on personal and subjective experiences. Other questions are whether contest-winning poems differ from typical published poems and if first-place poems differ from those that rank lower in contests. If there are such differences, they can tell us something about what makes a poem judged by an expert to be “better” than another. Finally, we can look at any discernible changes that have occurred over time. All artistic styles evolve, and it will be interesting to examine any such linguistic changes that have occurred in haiku forms.
Method
We collected data from two different sources to include both contest-winning haiku and a control sample of other typical haiku. The first set of poems was the Harold G. Henderson Haiku Contest winners dating from 1976 to 2021, and the Gerald Brady Senryu Contest winners dating from 1988 to 2021. This consisted of a total of 542 poems, 324 haiku and 218 senryu. These were used because they are held annually by the Haiku Society of America, one of the largest and most respected English-language haiku organizations. In addition, the contests have been ongoing for a multi-decade time span that would enable us to examine long-term chronological changes. The variables in the initial dataset consisted of the exact text of the poem, the number of lines, the placing (1st, 2nd, 3rd, or honorable mention), and the year of publication.
The second corpus consisted of a sample of published poems from Frogpond, the official membership publication of the Haiku Society of America. Frogpond is one of the longest continually published journals of English-language Japanese poetic forms. We randomly sampled 40 haiku/senryu from every issue dating from 1978 to 2018, totaling 1,321 poems. The complete poem, year of publication, volume, and issue number were entered into the dataset. Each poem was labeled as haiku or senryu depending on whether it was categorized as such in the journal. We then extracted from the poem text the word length, punctuation length, noun count, verb count, personal pronoun count, adjective count, adverb count, and preposition or conjunction count. This was done using a custom pipeline built with Python's NLTK package; first, we extracted tokens with the tokenizer, then removed punctuation with a regex function, and finally tagged parts of speech, such as nouns, with the parts of speech tagger.
Linear regression models can struggle to estimate coefficients reliably in many common data situations, including sample sizes and sample balance across outcomes within the dataset, collinearity among many predictors, and time dependencies across individuals in the sample (Farrar & Glauber, 1967; Oommen, Baise & Vogel, 2011). To address the issues arising from a smaller sample size in our contest sample and the fact that our contest sample contains more winning poems than first-place winning poems, machine learning extensions of logistic regression are needed. Given that we want to understand the differences between groups of poems explicitly, we need a machine learning model that yields regression coefficients, such as penalized regression models or least angle regression models (Fu, 1998). However, the collinearity we found (seven out of our nine predictors significantly correlate with at least one other predictor in the dataset) coupled with the like time trends across poem years suggests that these models are also unsuitable for modeling our data.
In the field of genomics, it is common for datasets to have small or imbalanced samples, many correlations between predictors, and time effects across the sample. A relatively new method, called differential geometry least angle regression (dgLARS), has shown promise in handling all of these problems while producing regression coefficients for statistically significant predictors. In recent studies, dgLARS has been shown to handle much smaller and more imbalanced samples than ours, as well as strong predictor correlations and time effects, better than existing machine-learning-based regression models (Augugliaro & Mineo, 2015; Augugliaro & Mineo, 2018; Augugliaro, Wit & Mineo, 2018). This suggests that it will suffice for our dataset, as studies have shown that it outperforms other machine learning methods capable of handling high-dimensional data, including a case in risk modeling that involved a sample size of 50 with 100 predictors and another modeling outcomes of 57 cancer patients on 287 gene deletion/amplification measurements (Augugliaro & Mineo, 2015; Augugliaro & Mineo, 2018; Augugliaro et al., 2018).
Because dgLARS is an unfamiliar algorithm to many researchers outside of genomics, we will go through the machinery behind this algorithm and its development. As noted, regression requires many assumptions to be met; this is a function of the least squares algorithm typically used for estimating parameters. Machine learning methods replace the least squares algorithm to relax assumptions about the underlying data matrix and its properties. For instance, adding penalty terms to regression's linear algebra equation can bound beta coefficients (ridge regression), set some beta coefficients to zero if they are close to zero (Lasso regression), or bound the beta coefficients while setting others to zero (elastic net regression) (Fu, 1998). Least angle regression, or LARS, first assumes that all beta coefficients are zero (a null model) and then adds terms in a stepwise fashion. The predictor with the highest correlation to the outcome is then added to the model, and residuals are calculated. The joint least squares space is then explored with the remaining coefficients, adjusting the existing coefficient values and residual calculation until the next most-correlated predictor's correlation is equal to the existing coefficient's correlations. This process continues until all predictors have been added to the regression model (Efron, Hastie, Johnstone & Tibshirani, 2004).
However, the LARS model struggles with multicollinearity like that found in our dataset (Januaviani, Gusriani, Joebaedi, Supian & Subiyanto, 2019). Lasso-LARS models are one option to resolve this issue, but they do not solve the issue of correlations across individual poems in the sample (Januaviani et al., 2019). The dgLARS algorithm takes a different approach to calculating the Lasso-LARS algorithm. Instead of relying on correlation calculations, dgLARS replaces this step with angle computations in the data's predictor tangent space relative to the outcome. Just as functions like a sine wave have tangent lines defined for their points, datasets can be represented geometrically and have higher-dimensional versions of tangent lines, called tangent spaces. When two or more predictors share a full tangent space, only one will be selected as a predictor in the model, as they appear to be the exact same predictor. Correlations across time are simply another geometric feature in the dataset's space. Given that our correlations are partial correlations, we would expect all predictors to be considered, as their tangent spaces do not overlap completely, and we would expect the results to reflect all poems included, regardless of time trends correlating poems.
The result of the dgLARS algorithm is a logistic regression equation with estimated an intercept, beta coefficients for selected predictors (those deemed statistically significant by the algorithm's calculations, which are different from those used in traditional regression), and fit statistics. Because this is not a least squares regression, some statistics commonly reported in regression, such as R-squared values or F-tests, are not computable with this method. However, fit statistics analogous to R-squared do exist, such as model deviance.
Cross-validation of models is a common way to limit bias in machine learning models and derive reliable fit statistics, such as the model deviance (Refaeilzadeh, Tang & Liu, 2009). Bootstrapped sampling is employed to create different training datasets; a model is fit to each sample and evaluated based on fit statistics common to that model. This provides a way to validate the model and ensure it will generalize well. The results are then combined (typically through averaging) to obtain parameters of the model, such as beta coefficients, or fit statistics, such as deviance. In the dgLARS models, cross-validation provides a final summary of beta coefficients (obtained through weighted averaging model results) and a final deviance score (again, through weighted averaging). Individual models are not included in the model output. In our case, we bootstrapped 10 samples to create our cross-validated models.
With respect to fit statistics, in generalized linear modeling (including logistic regression models), the residual sum of squares compared in an ANOVA test has an analogue called deviance, which is computed by taking two times the log-likelihood ratio of the saturated model minus the model that was fit to the dataset (Pierce & Schafer, 1986). dgLARS, like other extensions of generalized linear models, provides a measure of deviance, which can be used to derive other fit statistics, such as AIC or BIC. Here, we report the deviance for our cross-validated models. The F-statistics, R-squared, and other common regression metrics are not calculated by the R package, and in some cases, cannot be computed at all. We report statistics that are possible and calculated by the dglars R package for the models we used.
To mine our data for trends over time, we selected singular spectrum analysis (SSA) to construct nonparametric time series models, with each model tuned to fit the data (Vautard, Yiou & Ghil, 1992). SSA relies on a spectral decomposition approach for time series analysis, rather than purely statistical approach. SSA provided a rough estimation of time trends that exist in the data, as well as a way to compare trends across different poem samples graphically. Many other time series models are not appropriate given the small number of time points and the uncertainty of stationarity.
Results
First, we compared our contest sample by poem type (haiku or senryu) to understand the differences between the two genres within our group of winning poems. From the table summarizing the means and standard deviations of haiku and senryu features, univariate differences do not exist (see Table 1). However, our dgLARS model shows some significant differences exist in the multivariate context, with senryu having more adjectives, verbs, lines, and personal pronouns, and fewer overall words and punctuation marks. The cross-validation deviance of the model was 68.84, suggesting a reasonable fit. Figure 1 shows the mean difference in average adjective count, average personal pronoun usage, and average noun count between haiku and senryu.
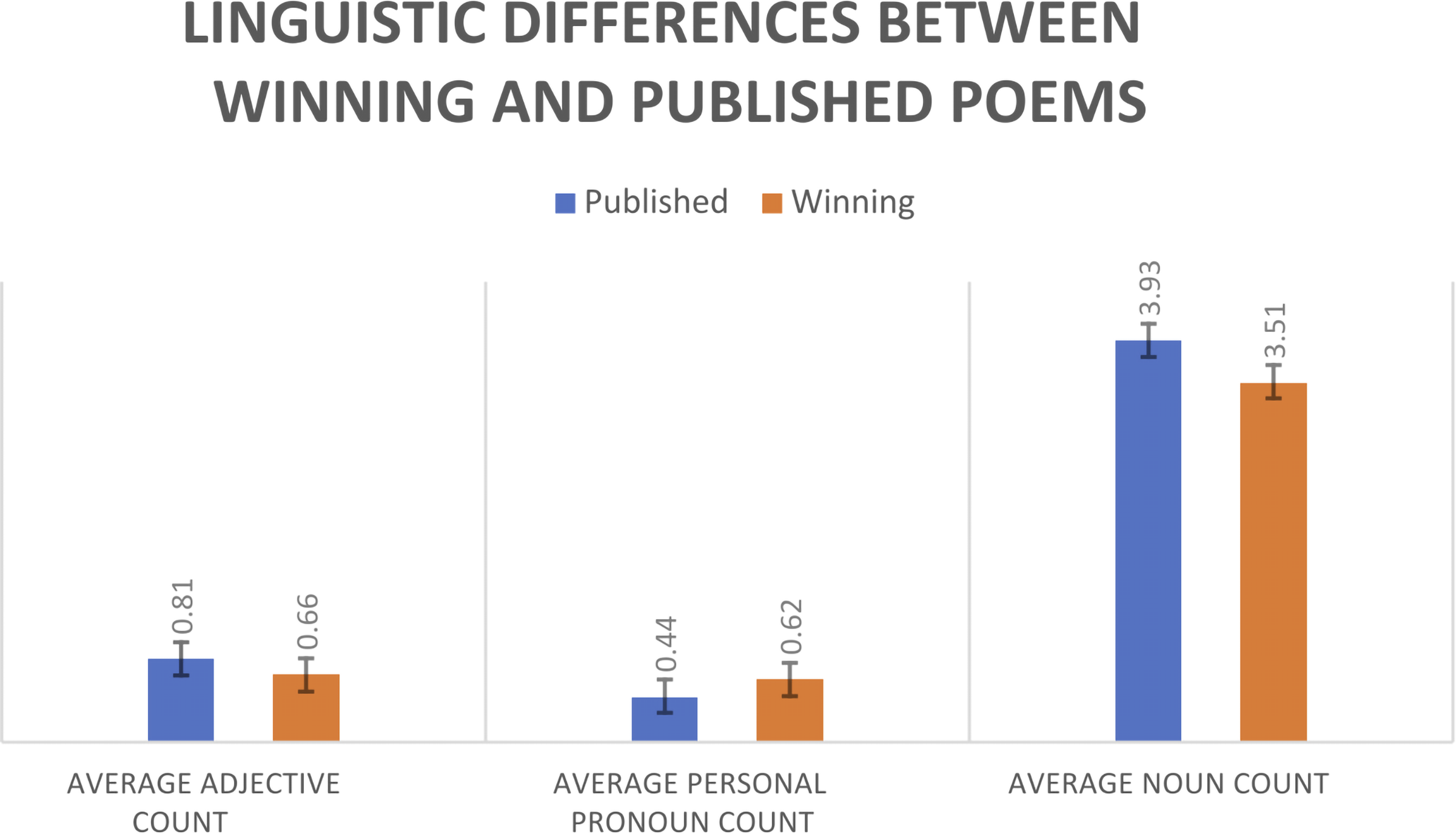
Mean differences in adjective count, personal pronoun count and noun count by published and winning poem categories. The error bars indicate ± 1 standard error of the mean.
Summary Statistics for Language Elements by Poem Type.
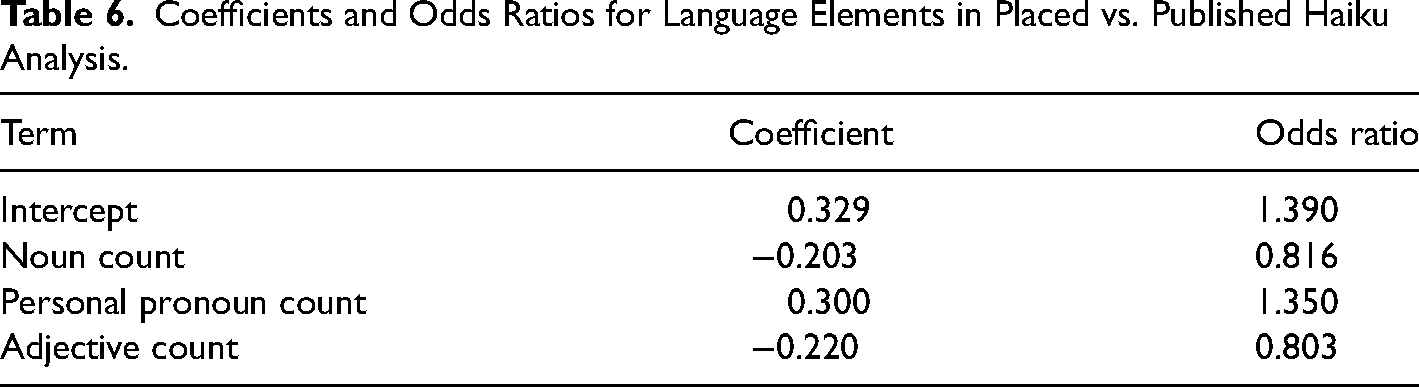
We also analyzed the differences between winning poems and published poems (the contest sample vs. the Frogpond sample). This is shown in Table 2. Running a dgLARS model yielded a few differences between published poems and winning poems, including that published poems have fewer pronouns and more adjectives and nouns compared to winning poems. The cross-validated model deviance was 218.9, which is reasonable given the sample size.
Summary Statistics for Language Elements by Published or Winning Poems.
We dived a bit deeper into these results and compared our first-place winners with other winners to understand what differences are found in the best poems (Table 3). Our dgLARS model suggests that first-place winners have more nouns, verbs, personal pronouns, adjectives, and adverbs compared to other winners, and they have more punctuation. A poem was classified as “other winners” if it was second or third place or an honorable mention. The cross-validated deviance was 46.92, which is a good model fit for this sample size. Figure 2 depicts these differences.
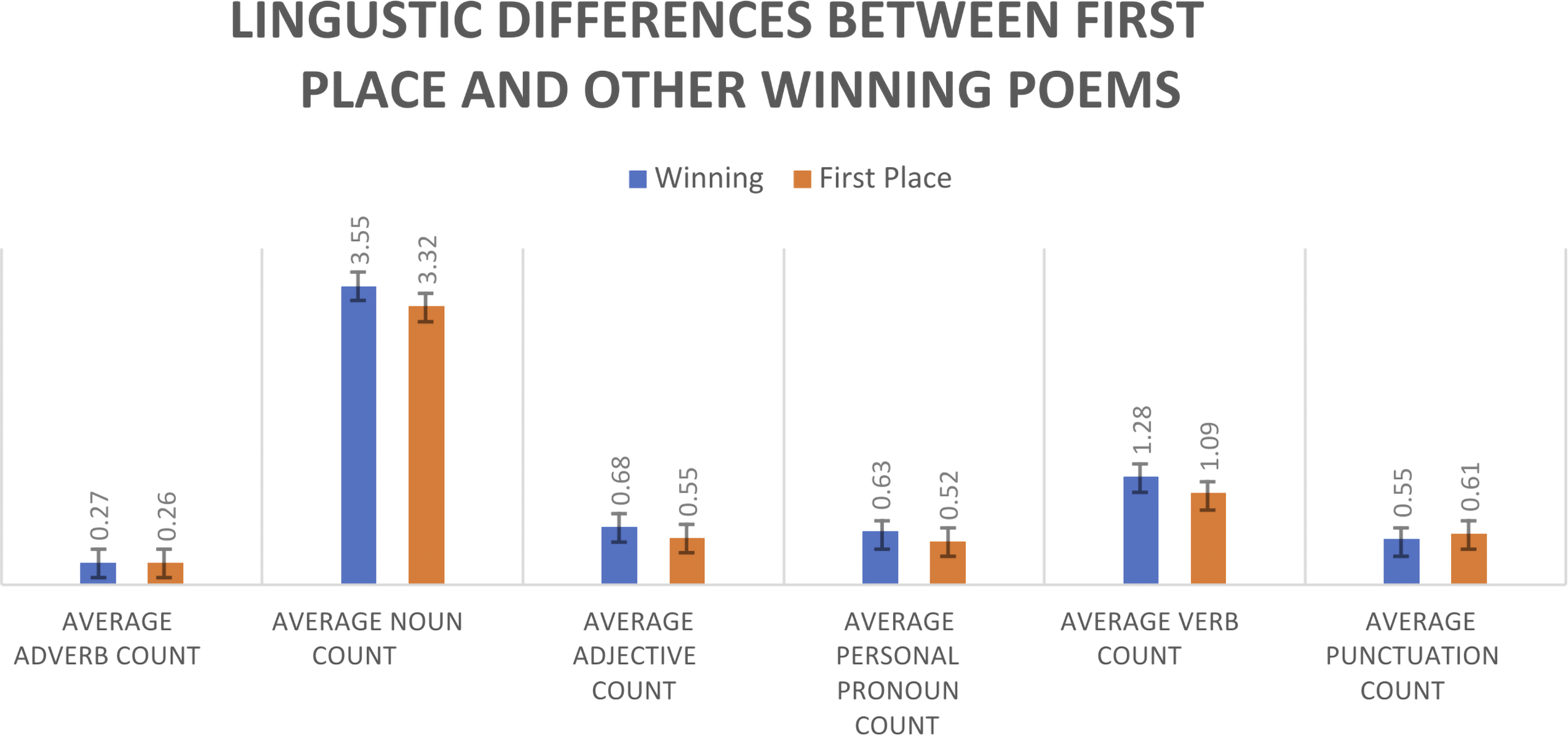
Mean differences in adverb, noun, adjective, personal pronoun, verb and punctuation counts between the first place and other winning poem categories. The error bars indicate ± 1 standard error of the mean.
Summary Statistics for Language Elements by Ranking.
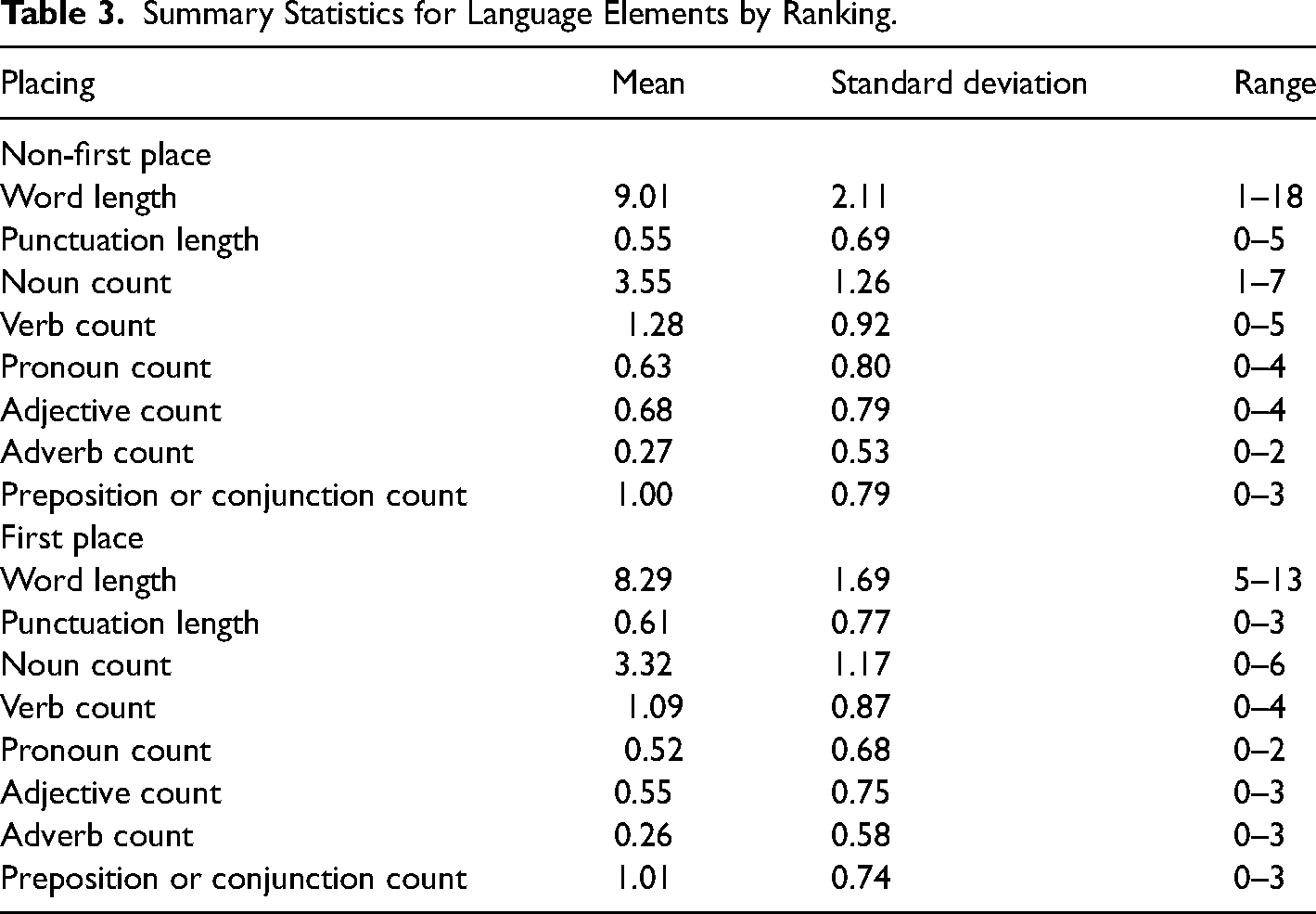
To understand how word length has changed over the past decades, we next tuned and fit singular spectrum analysis models to our word length time series for first place haiku/senryu, winning haiku/senryu, and published haiku/senryu. Optimal time window of the models varies slightly, but all dominant time trends have shown a downward component, particularly in the last two decades. There are no parameters for this model, as it is non-parametric. These changes over time are shown in Figure 3. Tables 4, 5, and 6 show the coefficients and odds ratios for each of our analyses: haiku vs. senryu, first-place vs. other-placed, and contest winners vs. journal publications. We would like to reiterate that the model deviance is the only goodness-of-fit statistic from the dglars models. Also, odds ratios greater than 2.00 or less than 0.50 correspond to a likelihood of more than twice or half as likely to occur.
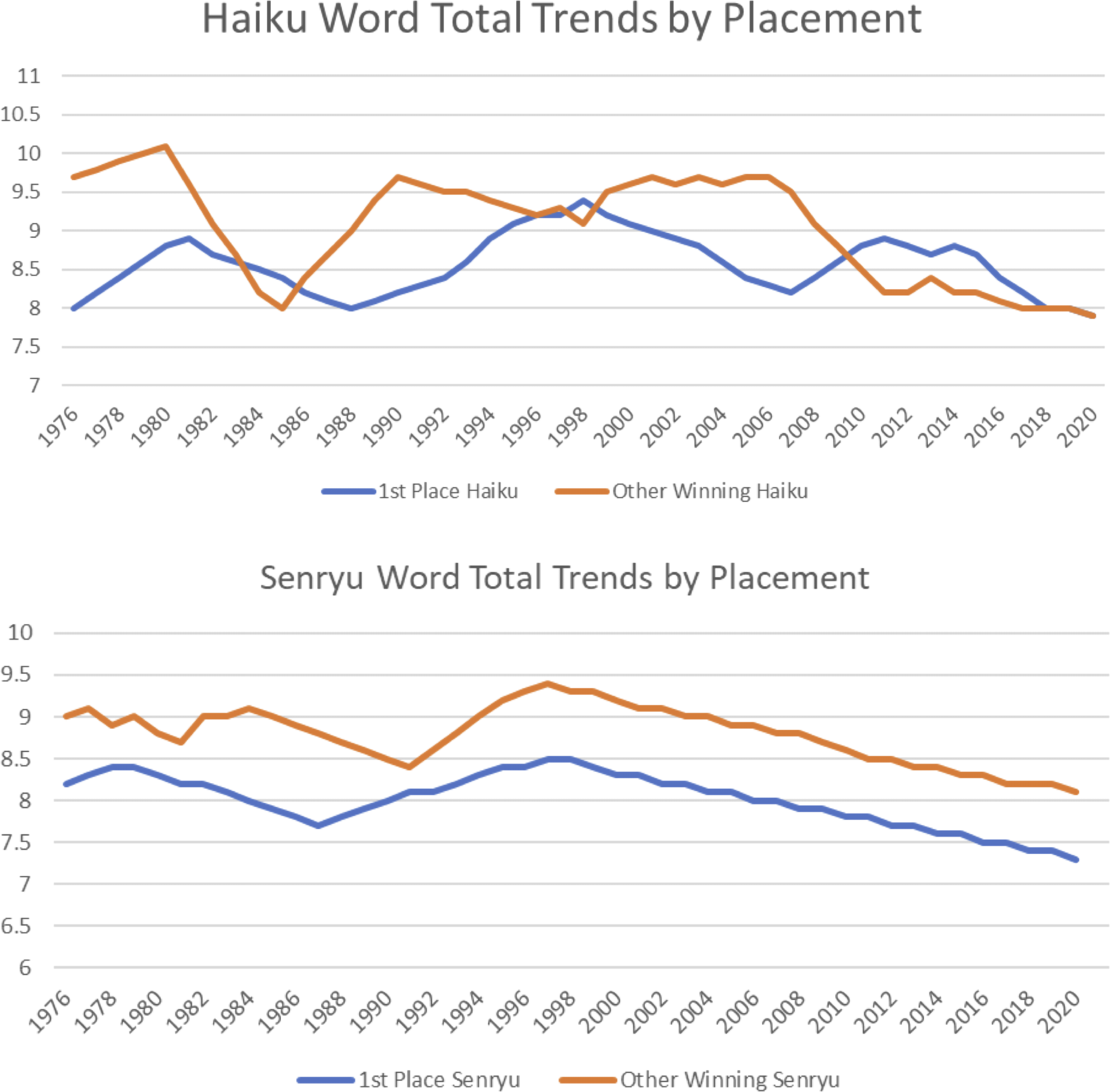
Word totals for first place and other winning categories for haiku and senryu over a multi-decade time span. The error bars indicate ± 1 standard error of the mean.
Coefficients and Odds Ratios for Language Elements in Haiku vs. Senryu Analysis.
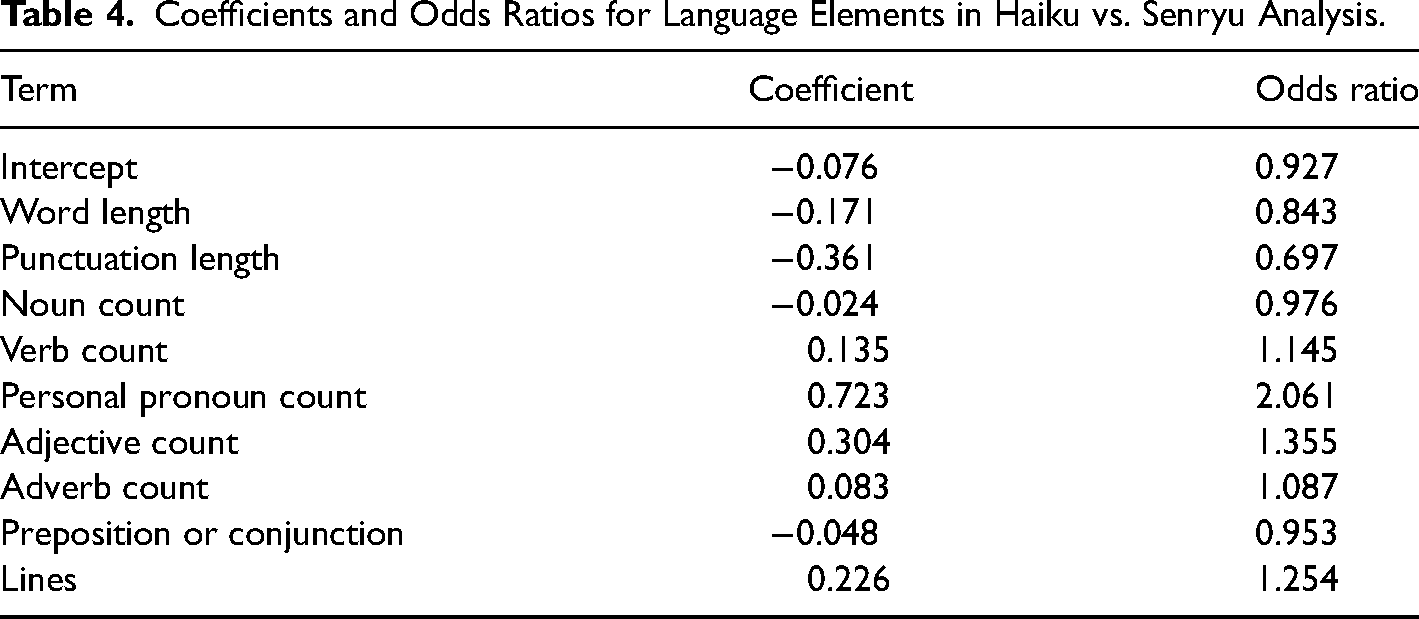
Coefficients and Odds Ratios for Language Elements in First Place vs. Other Analysis.
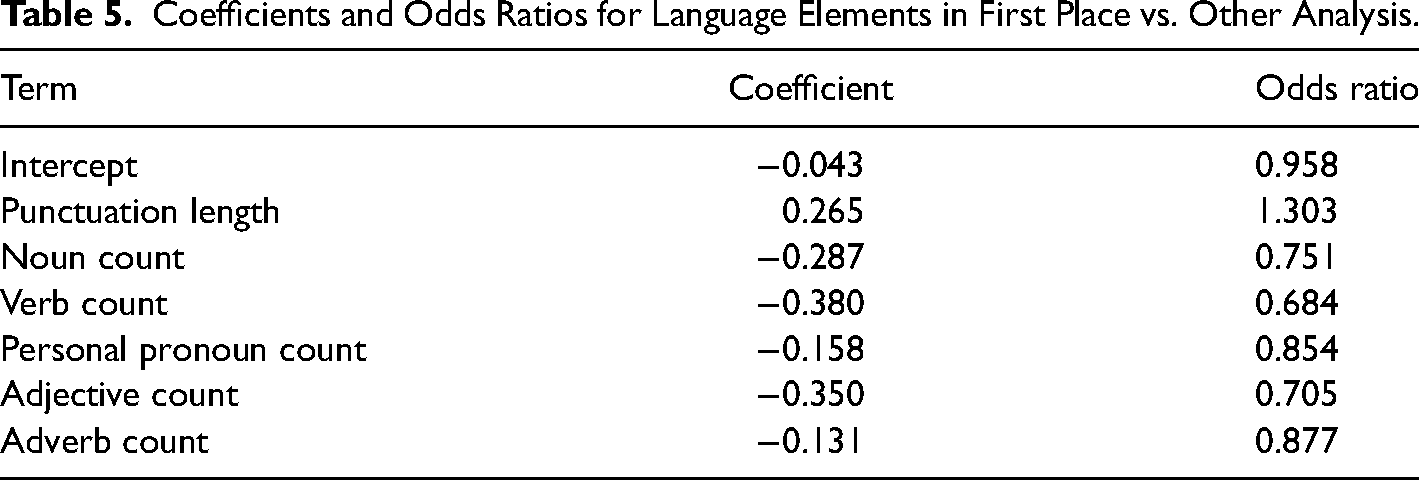
Coefficients and Odds Ratios for Language Elements in Placed vs. Published Haiku Analysis.
Discussion
In this study, we compared basic parts of speech in contest-winning haiku with a control sample to determine whether there were any differences. We examined also any such differences between first-place winners and other levels in the contest as well as haiku and its more psychological counterpart, senryu. Finally, we examined trends over time to see if any stylistic changes had occurred. In summary, we found that winning haiku were shorter in length than those in a representative journal. Frogpond poems had fewer pronouns and more adjectives and nouns. First-place winners were found to have more punctuation and fewer nouns, verbs, personal pronouns, adjectives, and adverbs. Senryu were found to have more adjectives, verbs, lines, and personal pronouns but fewer overall words and punctuation marks compared to haiku. Regarding the time trends, all of the poems showed a significant decrease in the use of number of words over a several-decade-long period.
There are several reasons why we might expect differences between winning and journal poems. Contests are more elitist and could receive submissions from a smaller number of more practiced and experienced poets. These poets may adopt certain conventions like reduced reliance on adjectives. Haiku is written more often than senryu in general, so it could be that fewer senryu get submitted to journals. There are only two specialist journals for senryu, while most other journals accept both forms but don't usually differentiate between them. This could explain the reduced number of pronouns in our Frogpond corpus. These differences might also reflect preferences among journal editors and contest judges, who might have different criteria for selecting and including work.
The use of punctuation requires a greater understanding of what punctuation is and how it is used, which may be found more among experienced poets with a greater knowledge of English language customs. This might explain the greater use of punctuation among first-place winners. For example, different types of punctuation are used to different effects in haiku. An ellipsis (…) is used to generate a very long pause between a fragment and a phrase, with other degrees of pause associated with a dash, en dash, and em dash (-, –, —). Although less frequently used, there are also specific cases where commas, semicolons, and colons (, ; :) are employed to separate words and parts of speech in haiku. The failure to understand the usage of these marks may make less experienced poets hesitant to include them.
The first-place poems in our sample were very brief, in some cases only six or seven words long. Poetry tends to have a more distilled language to convey ideas compared to prose, and haiku/senryu tend to be the most distilled forms of poetry. If brevity is the hallmark of this genre, then elite poets and judges might write and prefer forms that can convey equivalent ideas or images using even fewer words. This could explain why higher ranking poems in contests and the winning poems in general were shorter than those in the journal sample.
Senryu is more about personal experience, so naturally, we might expect a greater use of pronouns like I, he/she, you, they, and we. The increased use of adjectives, verbs, and lines might also reflect the greater action and speaker involvement in these types of poems with the speaker usually being in the poem rather than just observing an external event. The use of less punctuation could reflect a tendency not to use dashes or other cutting designations in senryu, although it is not clear why this trend may have emerged over the years. The brevity of senryu compared to haiku may reflect a recent trend towards monoku, but our sample was too small to confirm the role monoku may have on length. There were approximately 21 monoku in our contest sample and 40 in our control group.
It is possible that if another control sample had been used the results might have differed. However, we deliberately chose our comparison group because it was published by the same organization, making it more closely matched in terms of the authorship population. It was also the only journal that has been publishing over the equivalent time span of several decades, allowing for the subsequent long-term chronological analysis. It would be interesting in a follow-up study to look at different groups to examine further potential linguistic differences. Amateurs for example are much more likely to adhere to the 5-7-5 syllabic structure.
One significant finding in our data was the downward trend in the number of words used over time. This was true over a very extended time span, starting in the 1970s and ending in the 2020s, a span of about half a century. This was true for all categories of poems, whether in contests or journals, whether first or other ranked places, and whether haiku or senryu. The average number of words during the earliest recorded year, 1978, was 10.7. By the last recorded year, it had dropped to 8.9, a drop of about 17%.
First-place poems also tend to exhibit cyclical behavior in the number of words (typically ranging between seven and eleven words). Other winning poems follow these trends by a year or two, suggesting an influence between the two. As can be seen in Figure 3, the pattern set by first-place senryu is followed shortly by poems in other ranked categories. In contrast, haiku and senryu show different patterns over time, suggesting that they do not influence each other. Analyzing the Frogpond sample, we see a fairly consistent downward trend with a noticeable spike in the time series around the year 1988 (Figure 3).
There is some cyclical behavior in the time series with a periodicity that has been longer in recent decades. It is possibile that the recent trend of one-line monoku is driving the forms into shorter and shorter lengths, masking an upward trend that would have arrived in the 2010s. One-line haiku seem to be more popular in recent years, appearing both in contests and journals. There has even been for the first time the establishment of a journal devoted entirely to monostich forms. One-line haiku are generally shorter than three-line haiku and so could be a factor behind the recent decrease, although they would not explain the downward trend in the function in earlier years.
General writing conventions driven by technology may also be at play here. There is historical evidence suggesting that people are adopting shorter forms of communicative writing going from multi-page letters, to paragraphs in e-mails, to abbreviated sentences on platforms like Twitter and even just the use of emoticons in texts. Social media and Internet usage have also been shown to shorten attention spans and increase distractibility with associated neural changes (Firth et al., 2019). Decreased attentional capacity might directly correspond to shorter writing lengths.
An interesting question is why haiku are as short as they are. Why would the length of a haiku be limited to only about three lines? The original conception of an English-language haiku needing to be 17 syllables comes from a mis-translation from the Japanese. This and the 5-7-5 ordering are both constraining in terms of the overall number of words, but there is still considerable room for variability. One could for example imagine haiku and senryu that run up to 15 or 20 words, while capturing a concrete image, using juxtaposition and still remaining reasonably succinct. Instead we see that the average number of words is much lower than this, ranging from only 8.1 to 13.9 words on average from 1978 to 2018.
One explanation for this might be due to limitations in human working memory capacity. In a classic paper, Miller (1958) proposed that the capacity of short-term memory (STM), sometimes also called working memory, might be a “magical number” of seven plus or minus two items. This indicates that most people on average can only recall seven items, with some as low as five and others as high as nine. This is thought to be due to rapid informational decay without rehearsal (Barouillet, Bernardin, Portrat, Vergauwe & Camos, 2007; Jonides et al., 2008) or mutual item interference (Lewandowsky, Duncan & Brown, 2004; Oberauer & Kliegl, 2006).
Items in STM can be any distinct semantically meaningful unit of information such as a letter, number, picture, or word. These units have since come to be known as “chunks” (Anderson, Bothell, Lebiere & Matessa, 1998; Gobet et al., 2001). The total amount of information stored in human STM can be increased by increasing the size of a chunk. For example, the string of letters NFLCBSUSAVCRFBI could either be remembered as 15 single-letter groupings or more easily as five three-letter chunks (NFL, CBS, USA, VCR, FBI). It should be noted that other definitions exist. Mathy and Feldman (2012) define a chunk as a unit in a maximally compressed code and estimate the size of a chunk to be much smaller, at about four.
If we can only hold a limited number of chunks in awareness at one time, then a good haiku may have evolved to include no more than this many words, since any additional words will be forgotten or confused. A haiku with this many chunks will more effectively be able to convey a set of images or ideas because they can sit saliently in conscious awareness. Longer poems might require the recruitment of additional processing resources that would make them harder to comprehend or visualize. Shorter poems might also have the effect of being more aesthetically pleasing. According to the hedonic fluency account, information that is processed with greater cognitive ease is also judged to be more beautiful (Rui & Xiangping, 2011).
The working memory explanation is proposed here as a hypothesis only and was not tested in the current study. However, the implied effect can take place without overt or conscious memorization processes like rehearsal that may be more common for longer poems. Shorter haiku can occupy attentional awareness without requiring such processing. They could form two or three semantic chunks that persist long enough so that other more interpretive processes can be brought to bear. In fact, it is the absence of consolidative processing that may explain their appeal, since in their absence, resources may be freed up for higher-order linguistic analysis like metaphor generation and mapping of analogous content.
The study of haiku as a poetic form both experimentally and from a CL approach has just begun. Future work can examine phonetic properties like accenting, rhythm, and meter as well as syllabic structure and ordering, lineation, emotional valence, and other types of sentiment and keyword analysis. To date there has been little to no scientific study of other Japanese poetic forms. These include haibun (small written pieces followed by a haiku), haiga (the pairing of an image with a haiku), and renku (alternating haiku between different poets). Further comparisons are also needed between haiku and other forms of contemporary poetry as well as with more commonly used written and spoken language.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.