
Abstract
Research findings in cognitive literary studies show that lifetime exposure to literary versus popular fiction has a differential association with social cognition processes such as psychological essentialism, attributional complexity, and, particularly, with Theory of Mind. Experimental findings further show that brief exposure to literary, but not popular fiction, boosts performance on Theory of Mind. These results are interpreted as stemming from the greater complexity of the characters and plots of literary fiction; a claim that is consistent with evidence that readers view literary fiction characters as more complex than popular fiction characters. Here we focus on style, and test whether said differential complexity finds a parallel in the language of these two types of fiction. Results of Natural Language Processing analyses on a corpus of literary and popular fiction texts confirm that literary fiction has greater lexical and syntax complexity than popular fiction.
Keywords
Introduction
“There's no difference between pulp fiction and highbrow fiction, one is as good as the other, the only difference is the aura they have, and that's determined by the people who read the stuff, not by the book itself. There's no such thing as ‘the book itself.” Or so thinks Karl Ove Knausgård, the author that the Wall Street Journal declared to be “one of the twenty-first century's greatest literary sensations” (Schillinger, 2015). The scholarly literature in cognitive science, literary studies, and the emerging field of cognitive literary studies (Zunshine, 2015), however, suggests that popular and literary fiction impact the readers differently. Here we thus propose that these two types of fiction differ not only in the aura they have, but also in the language they use. As it has been discussed elsewhere (see Castano, Martingano, & Perconti, 2020; Castano, Paladino, Cadwell, Cuccio, & Perconti, 2021), this differential impact should not be interpreted as indicating a hierarchy of fiction which is often implied when instead of literary and popular fiction the label highbrow and lowbrow are used.
We first review indirect evidence in support of the idea that distinguishing between literary and popular fiction is a meaningful enterprise, and we then present the results of a linguistic analysis of a corpus to compare the language complexity of these two types of fiction.
Familiarity With Literary and Popular Fiction
One possible approach to investigate the meaningfulness of distinguishing between literary and popular fiction consists in assessing whether people show different patterns of familiarity with the two types of fiction. Scholars have developed instruments to investigate people's familiarity with fiction, the most used of which is the Author Recognition Test (ART). Originally developed by Stanovich and West (1989), the ART consists a list of author and non-author names (“foils”); respondents are asked to identify the names of authors that they do recognize. Different versions of the ART have been proposed, the most used of which to date is the one by Acheson, Wells, and MacDonald's (2008). Kidd and Castano (2017a) factor-analyzed answers to this version of the ART obtained via large samples, and found that two factors emerged, corresponding to the recognition of literary versus popular fiction authors (see also Moore & Gordon, 2015). The literary fiction factor comprises authors such as Michael Ondaatje, Thomas Pynchon, Margaret Atwood, and Alice Walker. The popular fiction factor comprises authors such as Tom Clancy, Nelson DeMille, Danielle Steel, and James Patterson (for a list of authors and their loadings on the literary vs. popular fiction factors, see Kidd & Castano, 2017a). These results can be taken as indirect evidence of the meaningfulness of the distinction between literary and popular fiction.
Correlates of Familiarity With Literary and Popular Fiction
Given the possibility of distinguishing between exposure to literary and popular fiction, researchers have investigated whether such exposure is differentially associated with various social cognition processes. Most research in this area has focused on the relationship between familiarity with fiction and Theory of Mind (ToM), or the capacity to infer and represent other people's mental states, and used primarily the Reading the Mind in the Eyes Test (RMET; Baron-Cohen, Wheelwright, Hill, Raste, & Plumb, 2001) as a measure of ToM. A first set of findings (Kidd & Castano, 2017a) qualified earlier results (Mar, Oatley, Hirsh, dela Paz, & Peterson, 2006; Mar, Oatley, & Peterson, 2009) that familiarity with authors of fiction was positively associated with performance on the RMET. Specifically, while familiarity with authors of popular fiction did not show such a relation with the RMET, familiarity with literary fiction was positively associated with it, after controlling for a series of possible confounding variables (Kidd & Castano, 2017a; see also Castano et al., 2020). Using a simpler measure of familiarity with literary versus popular fiction, the same differential relationship with ToM was found in an Indian sample (Das & Vasudevan, 2022).
Familiarity with literary fiction has also been found to be associated with higher accuracy in social perception and with greater attributional complexity, namely the tendency to appreciate that human behavior is determined by a series of individual differences and contextual factors, which interact in a complex manner. Familiarity with popular fiction, if anything, was negatively associated with attributional complexity (Castano et al., 2020). Finally, while familiarity with popular fiction shows a positive association with psychological essentialism (the idea that certain social categories, such as “male” or “white” have an underlying reality that cannot be observed directly), familiarity with literary fiction is negatively associated with it (Castano, Paladino, Cadwell, Cuccio, & Perconti, 2021; see also Buttrick, Westgate, & Oishi, 2022).
These findings suggest that familiarity with literary versus popular authors is differentially associated with several social cognition processes. Clearly, since these studies are correlational in nature, no strong claim can be made with regard to the direction of causality between reading literary fiction and, say, ToM skills. Probably a circular relation between these two variables exists. The suggestion that reading literary fiction may lead to improvements on ToM skills, however, finds support in experimental research.
Effects of Exposure to Literary versus Popular Fiction Texts
In a set of five experiments, Kidd and Castano (2013) had participants read either literary fiction or popular fiction and later tested their performance on various measures of ToM. Results of their study revealed that subjects who were assigned to read literary fiction performed better on such measures than those who were assigned to read popular fiction. Also, participants in the literary-fiction condition performed better than those who read either non-fiction or read nothing. Some studies did not replicate this finding (e.g., Panero et al., 2016), but their methodology has been questioned (Kidd & Castano, 2017b). Furthermore, many replications have been published using either the exact same methodology (e.g., Kidd & Castano, 2019; Kidd, Ongis, & Castano, 2016; van Kuijk, Verkoeijen, Dijkstra, & Zwaan, 2018) or conceptually similar ones (Black & Barnes, 2015; Castano, 2021; Pino & Mazza, 2016; Schwerin & Lenhart, 2022). Reviews of the experimental work of the effects of brief exposure to fiction on ToM have concluded that the effect of reading fiction on ToM is reliable, if small, but they have not focused on the specific distinction between literary and popular fiction (e.g., Dodell-Feder & Tamir, 2018; Quinlan, Padgett, Khajehnassiri, & Mar, 2022).
It should be noted that the precise nature of this effect has not been fully theorized, partly because the very construct of ToM is multifaceted (Apperly, 2012). We suspect that no author of the above-presented experimental research is suggesting that reading 20 min of literary novels permanently improves the reader's ToM. The temporary enhancement is likely the consequence of an activation of the mentalizing process, which is then utilized in subsequent ToM tasks. Such experiments are simply meant to explore the directionality in the relationship between reading fiction and ToM, broadly conceived (for a discussion see Castano, 2021).
The effect that literary fiction is more likely to enhance ToM is broadly compatible with the argument by Zunshine (2022) that literary fiction makes readers work harder than popular fiction does, at inferring mental states. First, popular fiction tends to only feature the mental states of characters, while literary fiction tends to feature the mental states of not just characters but also of implied readers, writers, and narrators. Second, popular fiction tends to explicitly spell out mental states, while literary fiction makes the reader infer implied mental states in addition to, and sometimes instead of spelling them out. Notably, on rare occasions when works formerly considered popular fiction (e.g., British 18th-century amatory romances) are promoted to the status of literary fiction and begin to be included in college literature courses, instructors encourage their students to look for mental states implied by those texts as opposed to those spelled out by them.
Neuropsychological research also suggests that reading literary fiction is uniquely associated with an increase in the activation of the brain's areas (frontal and central cortex) involved in social-cognitive processes (e.g., Theory of Mind, Cadwell, 2015; Tamir, Bricker, Dodell-Feder, & Mitchell, 2016). Drawing on the argument that mentalizing skills engage the brain's mirroring system (Brown, 2020; Uddin, Iacoboni, Lange, & Keenan, 2007; Schulte-Rüther, Markowitsch, Fink, & Piefke, 2007). Cadwell (2015) examined readers’ neural brain activity (mirror neurons activation) immediately after reading either a literary fiction short story or popular fiction, and while completing some ToM tasks (e.g., Facial Recognition Task, RMET, & Yoni Test). Results of this study indicated that participants who were randomly assigned to read literary fiction displayed stronger mirror neuron activation in brain regions responsible for socio-cognitive processes, and also a significant improvement in performance on a ToM task.
The differential effect of these two types of fiction on social cognition is theorized to be the consequence of differences in complexity. For instance, Kidd and Castano (2013) explain the finding that literary fiction enhances performance on Theory of Mind measures by suggesting that, compared to its popular counterpart, literary fiction has more complex plots and, especially, that it is populated by more complex characters, for the understanding of whom greater mentalizing effort is required. The finding that characters of literary fiction are perceived as more complex than those of popular fiction (Kidd & Castano, 2019) supports this conjecture. A similar result also extends to characters of art films, who are perceived as more complex than those of mainstream Hollywood films (Castano, 2021). Notwithstanding the differences between the two types of media, the art film is considered akin to literary fiction, while the Hollywood movie is akin to popular fiction—and in fact, they are often the film version of popular novels.
From Response to Stimulus
The research reviewed above builds upon work in literary studies to define the differences between literary and popular fiction—for example, the distinction made by Roland Barthes between Writerly versus Readerly fiction (Kidd & Castano, 2013). Barthes, however, also argued for the need to shift the attention away from the characteristics of the text and onto the readers and their subjective experience. Barthes’ view is part of what is known as the reader-response approach to literature. This approach unifies scholars who, starting from theoretical and disciplinary standpoints ranging from psychoanalysis to cognitive science, stress the role of the reader in creating meaning through their reading of the text (Bleich, 1975, 1978; Holland, 1968, 1973, 1975; Iser, 1974, 1978). The reader-response approach developed as a criticism of earlier formalists theories in literary studies, which largely (and purposely) ignore factors such as cultural contexts, the intentions of the author of the text, and even the content of the text, focusing instead on the text itself (Richter, 2007; Tyson, 1999; Habib, 2011).
There is clear evidence that readers play an active role in constructing the meaning out of any kind of text and certainly fiction (Bruner, 1987; Gerrig, 1993; Sharma, 2020; Miall, 2000, 2006; Miall & Kuiken, 1994, p. 1998; Eva-Wood, 2004), and that specific circumstances of reading, in addition to personality and other individual differences (e.g., cognitive style), play an important role in directing readers towards certain types of text as well as in moderating the reader's experience of the text (Annalyn, Bos, Sigal, & Li, 2018; Kuijpers, Douglas, & Kuiken, 2020; Rain & Mar, 2021; Schutte & Malouff, 2004; Mak, Vries, & Willems, 2020). It also seems reasonable that differences in fiction genres, and particularly between literary and popular fiction, are influenced by historical, cultural, and broad socio-political factors (McGregor, 1997; Gans, 1974; Ross, 1989; Walter, 1968). Yet, it is worth exploring whether objective differences in literary versus popular fiction texts exist. In fact, commenting on the experimental studies that used literary and popular fiction texts as stimuli, Kuzmičová, Mangen, Støle, and Begnum (2017, p. 138) noted that “… the literary nature of the stimuli used in these studies has not been defined at a more detailed, stylistic level.”
In the studies reviewed above, the complexity of characters and of plots is hypothesized to be a key difference between these two types of fiction, and some preliminary evidence in support of this hypothesis exists (Castano, 2021; Kidd & Castano, 2019). This evidence is, however, in terms of perceived complexity by the point of view of the readers/viewers. In this article, we focus not on perceived complexity, but on the complexity of the stimulus itself. There are several ways in which the complexity of a stimulus, in this case, a text, can be defined and measured. We focus on two conceptually clear indices of complexity, for which specific empirical indices have been proposed: lexical and syntax complexity. There is a conceptual gap between character and plot complexity on the one hand and these two linguistic indices of complexity. Yet, we believe this to be a meaningful first step.
Similarly to the arguments that have been made about the evolutionary history of intellect (Humphrey, 1976), language complexity, specifically in terms of lexicon and syntax, is thought to have evolved to facilitate social interactions (Burling, 1986); to help us better function in groups, especially as these groups grow larger (Freeberg, Dunbar, & Ord, 2012). We submit that the advantage that increased complexity of language provides is not only in terms of facilitating communication, but also because it scaffolds (and it is in turn affected by) increasingly complex social cognition (we shall return to this point in the discussion). Of specific relevance for the present purposes is evidence that mastering complex syntax and Theory of Mind performance have been found to be associated in both children (De Villiers & Pyers, 2002) and adults (Oesch & Dunbar, 2017). Given the above-described relation between engagement with literary fiction and ToM (a key cognitive process enabling social functioning), we tested the hypothesis that compared to popular fiction, literary fiction uses more complex lexicon and syntax.
Methods
We first assembled two corpora, one for literary and one for popular fiction. Following previous research (e.g., Kidd & Castano, 2013), the first corpus includes novels that were either winners of or shortlisted for the National Book Award, and the second corpus comprises novels that reached the top of the bestselling list as provided by the New York Times, in the two decades spanning from 2000 to 2020. Since the number of books topping the bestselling list is more numerous than finalists and winners of the NBA award, a first selection focused on those books who spent the most weeks on the top of the list. This resulted in too many instances of books with the same author, so we went down the list, also attempting to maximize similarity with the literary fiction texts, with regard to the genre of the author and length of the text.
The sample size was calculated using G*Power. We hypothesized a small effect size of f = .10 at the standard .05 alpha error probability, for a multiple regression with four predictors (type of fiction as the main predictor, plus gender of the author, year of publication, and length of the text). This resulted in a total N of 191. We are slightly over-sampled at N = 203. The complete list is available upon request.
We considered complexity along two dimensions: (a) lexical complexity, defined as the amount of variation in the lexical selection in the vocabulary of a text, and (b) syntactic complexity, defined as the depth and length of syntactic structures of a text.
Research in linguistics offers a variety of indices that are considered measures of lexical complexity. The most basic lexical complexity index is the Type-token ratio (TTR), calculated by dividing the total number of words in a text (tokens) by the number of types of words in a text (types). There are other formulas that can be used to estimate lexical complexity, like the Giraud index or the Herdan index, and the majority of these formulas are variations on the TTR idea, but are usually accompanied by a normalization strategy. One of the notorious biases of these types of indices is their sensitivity to text length. A longer text will tend to have a lower TTR (and associated indices) score. This is due to the very nature of language: the frequency of functional words like the, a/an, of, to, for, who, what, etc. will increase at a disproportionate ratio with respect to content words (typically nouns, verbs, and adjectives), which is a consequence of Zipf's law (Zipf, 1949). A longer text is bound to have an extremely different functional/content words ratio, which affects the validity of any TTR-based index. In order to correct for this bias, we also used a windowed version of a set of lexical indices: every text is split into several portions (windows) of 500 words and for every portion, we calculated the lexical complexity values. The final lexical complexity score for every index is obtained by averaging the value of every portion.
While there are many ways to measure lexical complexity, as attested by a lively literature (Jarvis, 2013), measuring syntax complexity is more challenging, and the extraction of any index in this domain requires a non-trivial language processing. We selected several sentence-based indices and syntactic complexity indices, among which average dependency distance (ADD) and closeness centrality (CC). As explained and discussed by Oya (2013), ADD represents the average distance in a sentence between the “heads” (i.e., the words that govern a syntactic dependence) that it contains and their dependent words; CC represents the estimate of the number of words that occur between a given word and its main verb in a sentence. Both ADD and CC are dependency-based indices, that is to say, that the type of syntactic relationship of every word in a sentence is established using a dependency grammar (see Matthews, 2007 for an overview). Such a grammar would yield the structure shown in Figure 1 for the sentence “Jim watches an old movie”: the subject Jim depends on the verb, the head, watches; the object noun movie, also dependents on the head watches, but the it is also the head of the noun phrase an old movie, and both the article an and the adjective old depend form it. In this example, the distance between the word Jim and its head is 1, while the distance between the object movie and its head is 3.
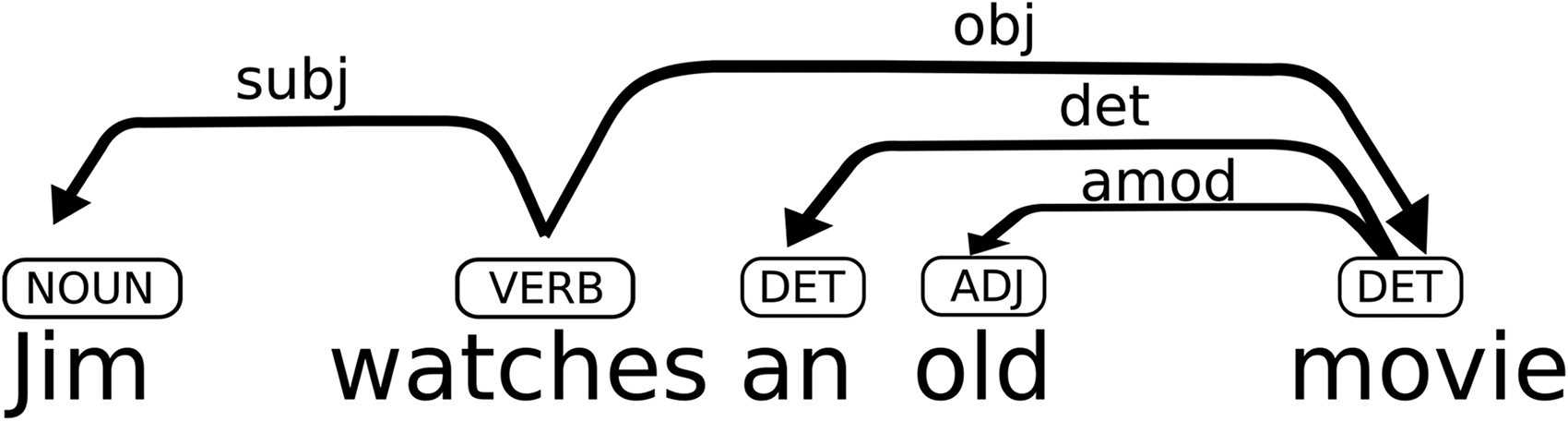
Grammar structure example.
We carried out all text processing operations using a tailor-made Natural Language Processing (NLP) pipeline built on top of two Python modules: Stanza and TextComplexity. Stanza (Qi, Zhang, Zhang, Bolton, & Manning, 2020), for which several robust language models are available, is used for the pre-processing part, which consists of word segmentation (tokenization and multi-word expression resolution), part of speech labeling, and dependency parsing. The processed language data is then processed through the TextComplexity module, which returns a list of lexical and syntactical complexity indices. The complete list of these indices is reported in Appendix A.
Results
We factor-analyzed the lexicon and syntax complexity indices, which as expected loaded on two separate factors explaining 61% and 25% of the variance, respectively. All lexicon indices loaded strongly on the first factor (> .57) and not on the second factor (< .40); all syntax complexity indices loaded strongly (> .86) on the second factor and not on the first (< .12). All indices were standardized, and composite scores were obtained by averaging, separately, the indices of lexical complexity and syntax complexity. These scores were then entered as dependent variables in a GLM using the type of Fiction (Literary vs. Popular) as a fixed factor. This revealed significant mean differences for both Lexical, F(1, 201) = 19.71, p < .001, Cohen's d = .62; and Syntax, F(1, 201) = 22.39, p < .001, Cohen's d = .66. Lexical complexity was higher for Literary (M = .25 than for Popular (M = –.27) fiction, and so was Syntax complexity (Ms = .30 vs. –.29, respectively). See Figure 2. Controlling for the year in which the book won or was a finalist for the NBA for literary texts, or the year in which it topped the New York Times's bestselling list for popular text, as well as for gender of the author and length of the text, did not qualify the results. None of these factors were predictive of either Lexical or Syntax complexity. Lexical and Syntax complexity displayed a low but significant correlation, r = .22, p < .001.
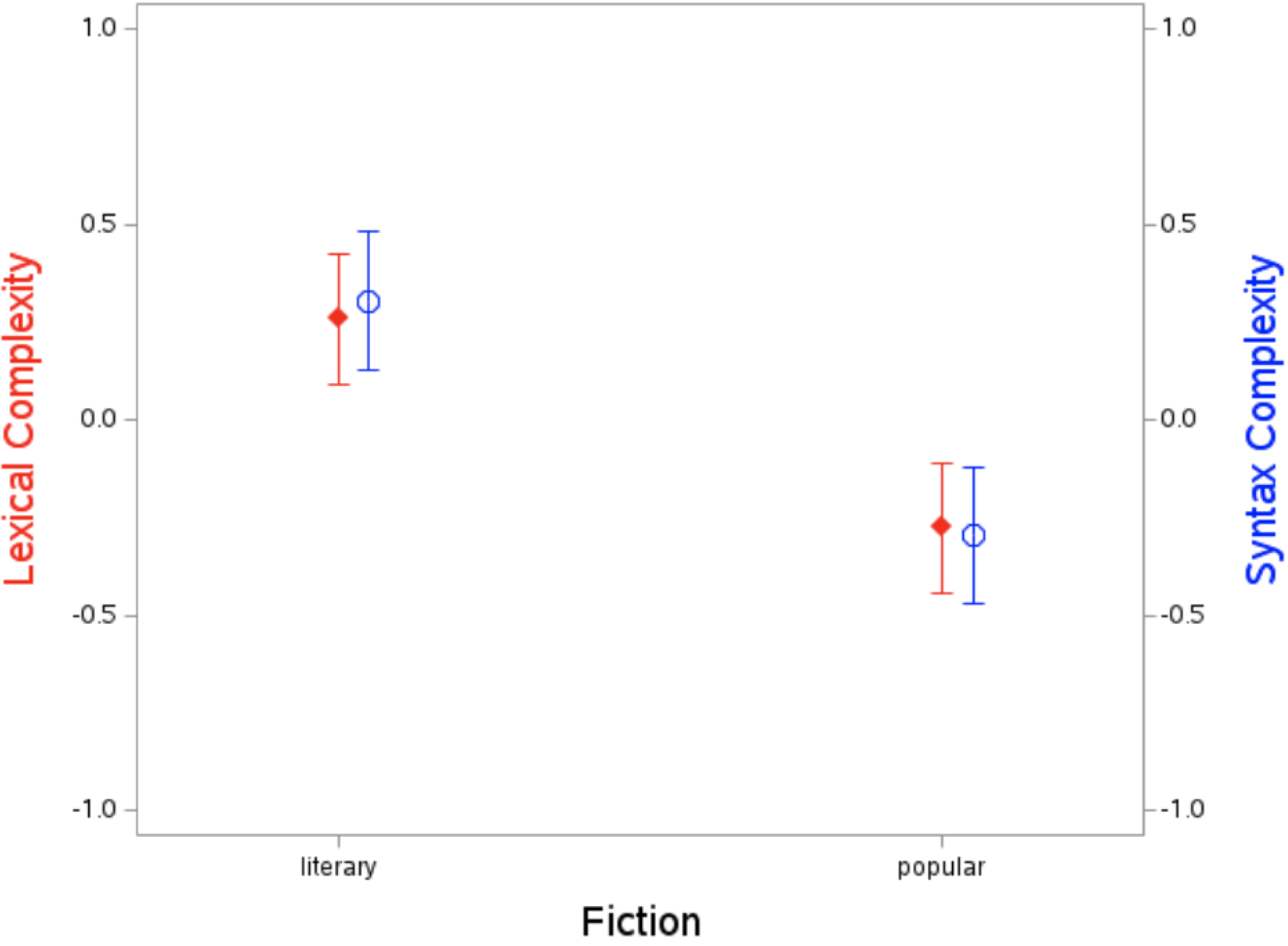
Means and 95% confidence limits (CL) for lexical and syntax complexity as a function of the type of fiction.
Discussion
Research findings suggest that exposure to literary versus popular fiction may foster different social cognition processes and that this might be at least in part due to their different level of complexity (e.g., Kidd & Castano, 2013). Here we asked whether such hypothesized difference in complexity can be found in the language they use. To do so, we built on how the distinction between literary and popular fiction was operationalized by Kidd and Castano (2013), in which the first experimental evidence of the differential effect of these two types of fiction on social cognition was reported, and which is the most cited article in the field. Accordingly, we created two corpora comprising a total of 203 novels, 100 of which were finalists of winners of the NBA award, and 103 of which topped the New York Times' bestselling list, in the two decades spanning from 2000 to 2020. We then relied on existing literature in linguistics to identify and compute a series of indices of lexical and syntax complexity, and compared the two corpora on composite measures of these indices. The results of these analyses revealed a significant difference between the two, with literary texts scoring higher on both lexical and syntax complexity.
This pattern of result is consistent with what was observed in a conceptually similar study carried out by Koolen, van Dalen-Oskam, van Cranenburgh, and Nagelhout (2020), which used a different approach to define literariness. In this work, the authors surveyed a large sample of Dutch citizens asking them to rate a series of approximately 400 novels that the authors had categorized as literary, suspense, or romantic, on a few dimensions, among which, that of literary quality. Dutch citizens showed considerable consensus in what they considered literary novels, differentiating them from the genre ones. The authors also approached the question of literariness on the same corpus using machine learning and again found that the literariness perceived by respondents could also be predicted by a set of basic textual features that included a higher proportion of rare words, a lower proportion of dialogue, and the presence of longer sentences. Sentence length is indeed one of the indices that we included as an indicator of syntax complexity in the analyses reported here, and on which we also found that literary texts scored higher than popular texts. All in all, the convergence of findings between Koolen et al. (2020) bottom-up approach to the question of literariness, with Dutch (or Dutch-translated) books, and what emerges in our own study using a top-down strategy for classification, with English (or English-Translated) texts, is encouraging.
The results we present here are also consistent with an analysis of the literariness of metaphors by Jacobs and Kinder (2018). These authors compared hundreds of literary and non-literary metaphors (Katz, Paivio, Marschark, & Clark, 1988) on a series of linguistic features and concluded that while it remains hard to discriminate between the two types, literary metaphors tend to, among other things, combine concrete words with relatively complex grammar and high lexical diversity, and make it rather difficult to get to the point of the analogy (Jacobs & Kinder, 2018, p. 10). As auspicated by these authors as well, the next step for future research that aims at discerning different types of texts is to go beyond identifying single linguistic characteristics and adopt a multi-level, holistic approach to the texts. This is particularly true, and of course exponentially more complex, when analyzing entire books as we did here, as opposed to single metaphors, or sentences. All in all, the present findings add to the growing literature of computational linguistics that have attempted to explore the textual features of fiction (e.g., poems, short stories, novels), focusing at the lexical, syntactic and semantic level (e.g., Aryani, Conrad, & Jacobs, 2013; Ullrich, Aryani, Kraxenberger, Jacobs, & Conrad, 2017; Jacobs, 2017; Jacobs, 2018a, 2018b; Jacobs & Kinder, 2018, p. 2019; Jacobs, Schuster, Xue, & Lüdtke, 2017).
The study presented here has its own limitations. First, compared to the universe of what could be considered literary and popular fiction, the corpora analyzed here are small. They are also circumscribed to the last two decades. Style changes with time, and transitory critics’ and readers’ preferences are likely to be influenced by socio-cultural trends. Therefore, future research with larger and more time-varied samples may investigate the role of possible moderators of the effect that we show here.
Second, there is a conceptual gap between the type of complexity that previous research (e.g., Kidd & Castano, 2013) has proposed to characterize literary fiction and the indices of language complexity used here. As pointed out by a reviewer to a previous version of this article, the Harry Potter series may not be considered literary fiction according to some criteria, yet it is surely very complex in terms of the worlds depicted therein, and the amount of information that the reader is required to keep in mind to follow the story. Furthermore, depicting complex characters and build complex plots may not require complex lexicon or syntax. We certainly agree that other forms of complexity assessed through other empirical approaches such as qualitative, close-reading techniques, may better capture the complexity that previous research has suggested to contribute to the impact of literary fiction on social cognition. We also agree that other forms of complexity may be training other cognitive skills. For instance, Harry Potter books, because of the characteristics mentioned above, may enhance working memory capacity. What we propose and report here is simply the first evidence that types of novels that have been theorized to differ in several ways, and that research suggests may be eliciting different social cognition processes, also differ in terms of the complexity of the lexicon and syntax that they use.
As discussed earlier, a specific focus on language, and particularly on syntax, is further justified by the evidence that syntax complexity understanding goes hand in hand with the Theory of mind performance (De Villiers & Pyers, 2002; Oesch & Dunbar, 2017). Researchers who have investigated the relationship between syntax, and language more broadly, as the primary form of human social communication on the one hand, and Theory of Mind on the other hand, have debated what comes first (see for instance, Freeberg et al., 2012). Is language necessary for ToM to emerge, especially in its most complex forms, or is language, and particularly complex language and social communication, the result of an evolutionary pressure for greater sociability and social functioning? Probably the relationship is recursive, perhaps with implicit Theory of Mind offering the substrate for the development of complex language and complex language scaffolding the development of more advanced forms of Theory of Mind (Oesch & Dunbar, 2017. This is of course an important question, but for the present purpose, it is enough to agree with the idea that exercising language complexity may boost one's capacity for the type of advanced forms of ToM that are typically investigated in the line of inquiry focusing on fiction and social cognition. This question about causality is similar to the question that has been asked with regard to the relation between exposure to literary fiction and ToM performance. In this latter case, correlational findings are sided by experimental results suggesting that a casual relation going from reading literary fiction to ToM occurs. It is however likely that in this case as well, a recursive relation occurs.
In the debate regarding the relationship between social complexity and communication complexity, it is implied that small increments in either type of complexity may foster an increase in the complexity of the other. Research, however, also suggests that there are limits to the complexity that humans can handle. For instance, when it comes to mentalizing capacity, some authors argue that most of us cannot handle more than fifth-order intentionality (Kinderman, Dunbar, & Bentall, 1998) while others put the limit at seven (O'Grady, Kliesch, Smith, & Scott-Phillips, 2015). Regardless of what the specific number is, it is clear that there are limits to the complexity of our mentalizing and that there are also limits to the language complexity that we can comprehend. With regard to the hypothesized impact that language complexity may have on social cognition, we would argue that it is characterized by a curvilinear relationship: exposing ourselves to complex language in, say, fiction, may help us boos our theory of mind (Oesch & Dunbar, 2017); however, at extremely high levels of language complexity, most of us would simply put the novel down and move on.
The above point brings up another, important question. Complex language, be it in terms of lexicon, syntax, or other features, appears of course not only in fiction, but also in other types of narrative and expository texts. Would exposing individuals to complex language in these other texts, which typically do not focus on human affairs (i.e., interpersonal interaction), also boost ToM? We are aware of no empirical research that provides a direct answer to this question. However, to the extent that ToM relies on a host of cognitive processes that do not exquisitely pertain to social cognition (see Apperly, 2012), and that such processes may be influenced by non-social complex language, we may expect a positive answer to this question. However, albeit reasoning in non-social situations and the ability to employ complex decision rules is a necessary for ToM, research suggests that it is not a sufficient condition (Pruett, Kandala, Petersen, & Povinelli, 2015).
Similarly, we could ask whether exposing individuals to the complex language of literary fiction boost their non-social cognition. Evidence abounds that reading to children boosts their language skills (e.g., Price & Kalil, 2019) and even their intelligence (Batini, Bartolucci, Toti, & Castano, 2022; Weisleder et al., 2018). Since what we read to children is almost exclusively narrative fiction, it is clear that reading fiction to children also impacts their non-social cognition skills.
We found that literary fiction has more complex lexicon and syntax than popular fiction. Is this a trivial finding? It could be argued that those who select novels for literary awards simply look for novels that are complex from a lexicon and syntax standpoint. Our informal discussion with people involved in literary awards juries revealed that, at least explicitly, this type of complexity is not a criterion that they consider. Yet, it could be that it is only novels that possess a certain degree of language complexity that make it to the preliminary phases of nomination. Most importantly, we are not overly concerned as to whether the features of language complexity discussed here are indeed among the criteria that inform the selection of novels for literary awards. The goal of the present article is simply to begin identifying language features of different types of fiction. If such features inform, explicitly or implicitly, the selection for literary awards, these features may still be, as previous theorizing (e.g., Kidd & Castano, 2013) and research findings (e.g., Oesch & Dunbar, 2017) suggest, implicated in bringing about the effects of reading literary fiction on social cognition. Given the downstream effects that these social cognition processes have on important socio-political attitudes and behavior (Castano et al., 2021), we believe it is important to begin to understand how these two types of fiction differ.
Footnotes
Appendix A
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.