
Abstract
Given the increasing popularity of person-level cost-effectiveness analysis using “real-world” data, there is a clear need to understand and use methods for observational data. When the cost-effectiveness data are subject to censoring, ignoring censoring is especially error prone for heavily censored data. We summarize best practice and provide a hands-on example of applying the net benefit regression framework for cost-effectiveness analysis, which works for both observational and randomized studies with possibly censored data. Many existing methods are special cases within this framework. We provide step-by-step guidance, user-friendly R programs, and examples to illustrate 1) fitting net benefit regressions for possibly censored cost-effectiveness data; 2) implementing doubly robust methods combining net benefit regressions and propensity scores, which may increase the chances to obtain consistent estimates in observational studies; 3) constructing cost-effectiveness acceptability curves; and 4) interpreting the results. The methods in this tutorial are easy to use and lead to more reliable and robust results using typical administrative data, thus providing an attractive option for real-world cost-effectiveness analysis using possibly censored observational data sets.
Highlights
We illustrate the steps involved in carrying out cost-effectiveness analysis using net benefit regressions with possibly censored demo data by providing step-by-step guidance and code applied to a data set.
We demonstrate the importance of these new methods by illustrating how naïve methods for handling censoring can lead to biased cost-effectiveness results.
Keywords
Background
Clinical studies often encounter challenges associated with right censoring. For instance, at the date of data capture, some patients may have dropped out, been lost to follow-up, or not experienced the event of interest. In such cases, the last date of follow-up is referred to as the censoring time. Patients who are still alive at the time of data capture have costs and survival information available only until their last follow-up times, but their true total costs and full survival time until death are unknown. A recent study of statistical methods used in trial-based economic evaluations found that 15% of methodological studies reviewed described approaches for person-level cost-effectiveness analysis (CEA) with censored data. 1 The study concluded with a recommendation against naïve methods such as, “(1) Simply ignoring the fact that data are censored, and hence assuming that all patients in the study experience the event of interest, and (2) Treating the data as being complete, and hence simply omitting censored cases from the analyses.” All but 1 methodological study in the review was published more than a decade ago. 1 This is surprising given the increasing popularity of person-level CEA using “real-world” data; there is a clear need to understand and use methods for censored data in both randomized and observational studies.
While economic decision analytic models (e.g., Markov models) are commonly used to inform funding decision negotiations in many countries and agencies, the analysis of person-level data (e.g., from a data set with cost and effectiveness information from each patient) is also an important research activity, with many such studies published each year. Cost-effectiveness data sets can be assembled from randomized controlled trials, pragmatic studies, or administrative data sources (e.g., surveillance, epidemiology, and end results linked to Medicare administrative and claims data [SEER-Medicare]). These types of data sets, with person-level information on cost and health outcome, are valuable because they allow researchers to estimate the additional gain from new treatments in actual patients and place the estimate in context with the observed incremental costs. However, these sources often contain observational, censored data requiring special care to adjust for the nonrandomized, incomplete nature of the correlated cost and effect data. Without accounting for the unique characteristics of the data, the CEA can provide a flawed assessment of the incremental costs associated with the incremental health outcomes, yielding biased estimates and inaccurate uncertainty assessments. However, there exist methods from statistical CEA that can address the challenges inherent in real-world data. Next, we summarize best practice and provide a hands-on example.
Main Summary Statistics of Interest in Statistical Cost-effectiveness
The incremental cost-effectiveness ratio (ICER) is a ratio of the incremental cost to the incremental effect, and as a ratio, it has statistical challenges. The incremental net benefit (INB) is not hampered by these shortcomings and provides an important alternative. Both are functions of the cost (
There are various options for characterizing uncertainty (i.e., variability) in statistical CEA, 4 including Fieller’s theorem, bootstrap, and the cost-effectiveness acceptability curve (CEAC). The CEAC shows the probability that the new treatment or intervention is cost-effective as a function of the unknown cost-effectiveness threshold value given the data.5,6
Net Benefit Regression with Complete (Uncensored) Data
A well-established method to analyze a cost-effectiveness data set in statistical CEA involves net benefit regression,7–9 which refers to a regression equation with net benefit (
The above concepts can be formalized with equations by including the treatment indicator
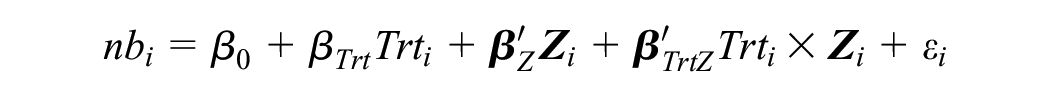
where
Cost-effectiveness with Censored Data
As noted earlier, studies that capture or record the data before complete cost and effectiveness data are available face challenges associated with right censoring, with their true total costs and full survival time until death possibly unknown. It is tempting to simplify the analysis by using simple methods to handle censoring, such as using complete-case data only (i.e., discarding patients without complete data) or using all data ignoring censoring status (i.e., using the observed data at the last follow-up). Although there exist rare special situations in which the ICER and INB could be unbiased with such naïve methods, in general these simple methods are bias prone.
The relevant impact of censoring is related to how it affects estimates of
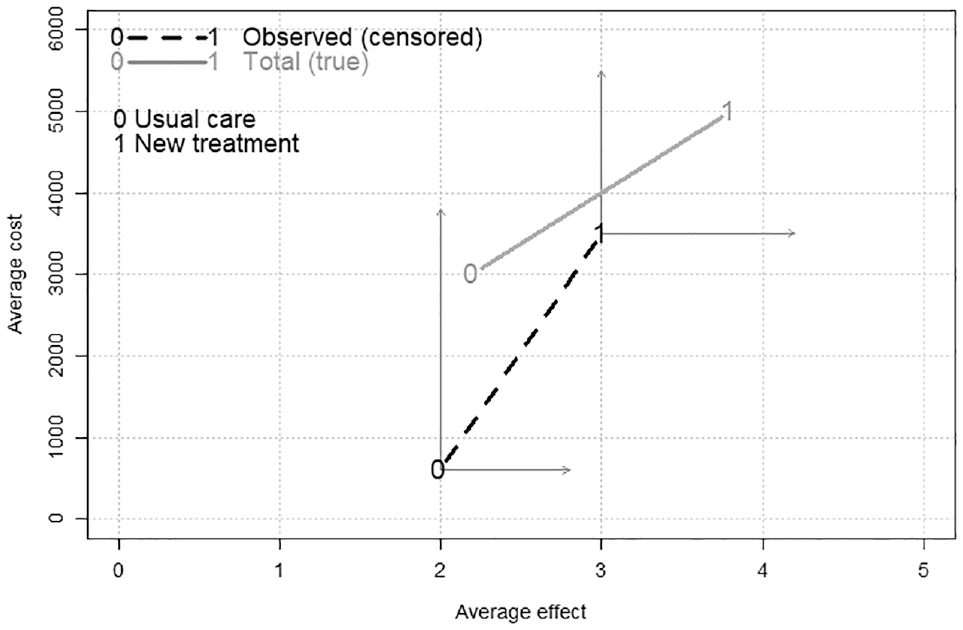
Sample averages for cost and effect for treatment options Trt = 0 (usual care as control) and Trt = 1 (new treatment), indicated with a “0” or “1,” respectively. By using observed data ignoring censoring, the naïve observed incremental cost-effectiveness ratio (ICER) is the slope of the dashed line. In contrast, the true data (with nothing left out) produce an ICER shown as the slope of the solid line. The vertical and horizontal arrows emanating from the observed 0 and 1 connected with the dashed line show that the true average total cost and effect data may be greater or equal (due to further including cost and effect after censoring), indicated by the 0 and 1 points connected by the solid line, whose slope shows the true ICER. For a purpose of illustration, this figure used hypothetical data, assuming that the control and new treatment groups have true average effects of 2.2 and 3.8 and true average costs of 3,000 and 5,000, respectively. Due to censoring, high costs before death are not fully observed. We assume the control and new treatment groups have the average observed effects of 2 and 3 and average observed costs of 600 and 3,500, respectively.
As the different ICERs in Figure 1 suggest, ignoring censoring is often not a good option. For example, if the rate of cost accumulation increases around death, and costs at this time are censored, then costs that are unobserved are both different and important. Because health care costs tend to rise dramatically prior to death, it is incorrect to assume the rate of cost accumulation is similar for the period that is observed (before censoring) and the period that is not observed (censored). 13 Supplementary Figure S1A demonstrates low coverage probabilities for 95% confidence intervals due to bias from using naïve methods (e.g., complete-case data only [CC] and using all data but ignoring censoring status [AL]), based on simulations performed by Chen and Hoch. 8
Potentially Informative Censoring
Statistical methods to address censoring depend on whether the data are subject to informative or noninformative censoring. Most common survival analysis methods (e.g., the Kaplan-Meier method and Cox proportional hazards model) assume censoring is noninformative (i.e., the survival time is independent of censoring time). However, costs and effectiveness such as quality-adjusted life-years (QALYs) are likely to be subject to informative censoring. 14 For example, a healthier patient will accumulate costs more slowly (with higher quality of life), with less costs (and higher QALYs) both at the censoring time and at the potential death time, leading to informative censoring for cost and QALYs. 15 Consequently, standard survival analysis techniques are not valid to analyze costs and QALYs directly on the cost (or QALY) scale.14,16 According to Lagakos, 17 “when the amount of censoring is small, very little bias is likely to result from the use of methods based on noninformative censoring. However, when informative censoring is extensive, substantial biases can occur, and so informative censoring models should be considered.”
Cost-effectiveness Analysis with Censored Observational Data
While using administrative data sets can boost sample size and produce real-world evidence, they are not randomized. For example, Ali et al. 18 assessed the cost-effectiveness of breast-conserving surgery plus hormonal therapy with or without radiotherapy, using SEER-Medicare data, helping to inform the allocation of cancer care resources optimally by generating real-world evidence about the incremental costs of new treatments in relation to their better effectiveness. Their results, based on a real-world data set, suggested that the combination of radiotherapy and hormonal therapy could be cost-effective from a US Centers for Medicare and Medicaid Services perspective.
Although propensity scores and standard survival analysis techniques are often used to evaluate survival using censored observational data, censoring in costs (and QALYs) are more likely to be informative and hence standard methods for noninformative censoring are not recommended. Performing a proper CEA using statistical methods for valid estimation and inference is not very commonplace for such nonrandomized censored data. Various methods for censored CEA14,19–33 have been proposed, providing a good foundation, yet there is room for improvement (e.g., estimates are not adjusted for covariates, not efficient, not doubly robust, and not straightforward to construct a CEAC). This article illustrates net benefit regression for censored cost-effectiveness data from observational studies, 8 which overcomes the aforementioned disadvantages as well as unifying many methods as special cases (e.g., the methods work for uncensored data and unadjusted analysis). 8 In the following sections, we introduce the methods and provide step-by-step instructions with R programs to illustrate 1) running net benefit regressions for censored cost-effectiveness data, 2) performing doubly robust methods that combine net benefit regressions and propensity scores, 3) constructing CEACs, and 4) interpreting the results.
Methods for Censored Net Benefit Regression: The Simple Weighted Estimator
Censored net benefit regression 8 produces consistent estimates when handling censoring using inverse probability of censoring weighting.34,35 The simple weighted (SW) estimator uses total costs (and effectiveness) from patients with complete follow-up only, with the weights to represent potential patients that might have been observed. However, the SW estimator does not use cost/effectiveness “history” and wastes information from censored patients (e.g., the observed costs until censoring are ignored in the analysis).
Methods for Censored Net Benefit Regression: The Partitioned Estimator
When cost/effectiveness history (e.g., the monthly or yearly costs and QALYs) is available, the SW estimator can be improved through partitioning into smaller time “buckets.” For example, if the data are grouped into yearly data “buckets,” for patients censored after the
As such, net benefit regression can be used when carrying out CEA with censored data. If only the total costs and effectiveness are available, the SW estimator is useful. If the cost and effectiveness history for different periods is also available, the PT estimator is generally more efficient than the SW estimator is. Both the SW and PT methods are consistent in the statistical sense, with coverage probabilities that are close to the nominal level of 95% in simulation (Supplementary Figure S1B). 8
Methods for Observational Data: Propensity Scores and Doubly Robust Methods
Define the causal average INB as
Both propensity scores and doubly robust methods are modern causal methods, which are useful for estimating causal average treatment effects (
Censored Net Benefit Regression with Observational Data: A Doubly Robust Estimator
When the net benefit regression (without interaction) is correctly specified, the causal average INB (
Advantages Regarding Statistical Consistency (Asymptotically Unbiasedness) of the Doubly Robust Method Combining Net Benefit Regression and Propensity Scores in Randomized and Observational Studies
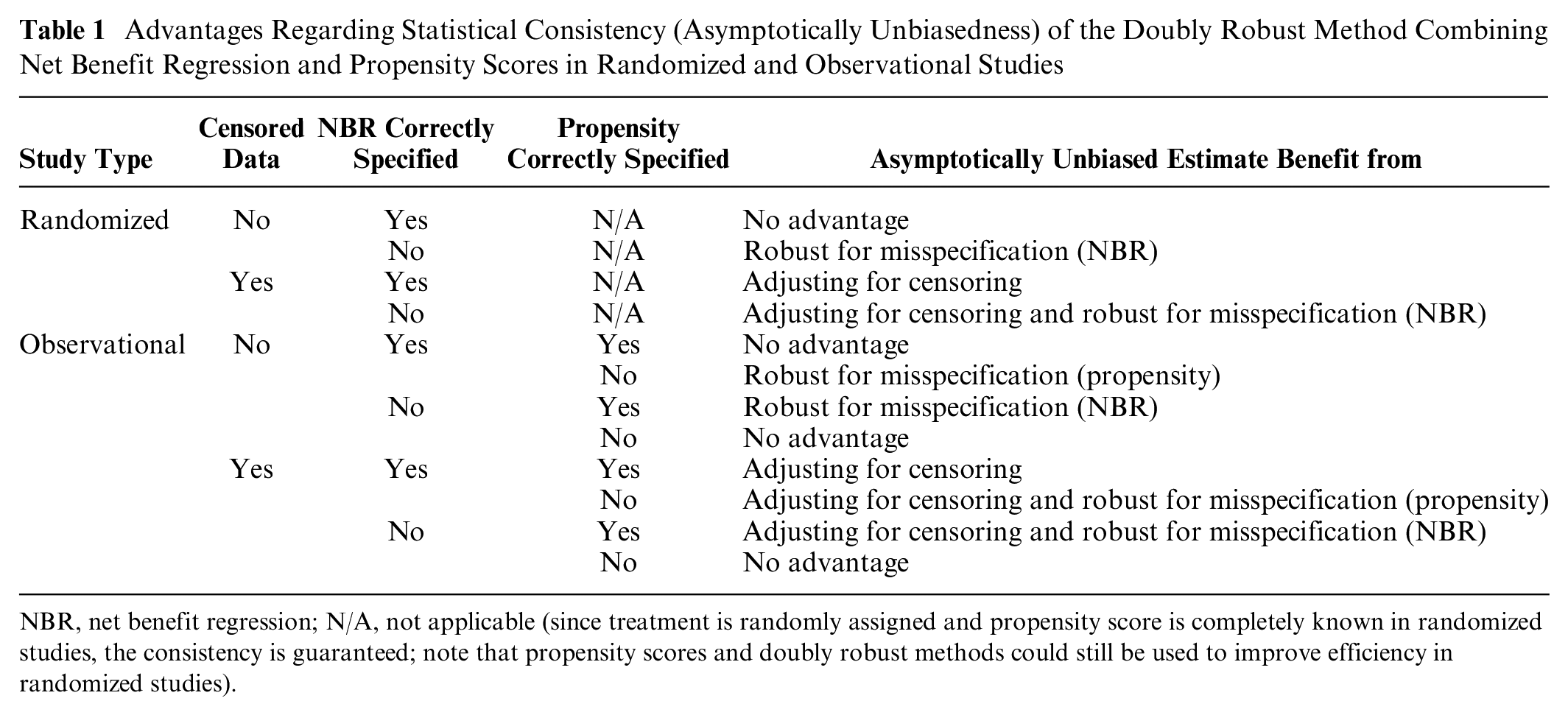
NBR, net benefit regression; N/A, not applicable (since treatment is randomly assigned and propensity score is completely known in randomized studies, the consistency is guaranteed; note that propensity scores and doubly robust methods could still be used to improve efficiency in randomized studies).
Data
To illustrate the methods, we simulated a cost-effectiveness data set mimicking administrative data including 2,000 hypothetical patients with cardiovascular disease, motivated by a real cardiovascular study. The data-generation process is similar to the simulation scenario in Chen and Hoch 8 with these main differences: 1) more covariates are involved (increase from 1 to 3 covariates) and 2) in addition to using life-years as effectiveness, QALYs are also generated based on a heart failure event (i.e., a patient’s quality of life tends to be lower after heart failure). More details of the data generation are provided in the Supplementary Materials. For this simulated data set, we know the true (uncensored and counterfactual potential) means based on statistical theory (Supplementary Table S1) and thus the true INBs, which allows us to evaluate the performance of the different methods.
The first few rows of the data are shown in Table 2. The survival variable is the follow-up time (in years) since the enrollment into the study. The dead variable is mortality indicator with “1” for the occurrence of death (i.e., complete data) and “0” indicating censoring (i.e., time until death is unknown but was known to be alive at the time indicated by survival). The Trt variable indicates the new treatment group (Trt = 1) versus the usual care comparison group (Trt = 0). Patients who are younger, with left bundle branch block (LBBB) conduction disturbance are more likely to receive the new treatment than the comparison. The Age65, LBBB, and Female variables are binary baseline covariates, with “1” for age ≥ 65 y, LBBB, and female, respectively, and “0” otherwise. U-shaped costs (high initial and terminal costs) were generated and grouped into yearly observed cost summary variables called cost.1, cost.2, and all the way up to cost.15 (in $1,000s). In our example, the new treatment has higher initial costs for performing the treatment but lower annual costs subsequently. We used life-years (LYs) and QALYs as outcome measures of effectiveness and grouped QALYs into 15 annual summary variables as well. The patient health-related quality-of-life (QOL) was simulated in each of the yearly intervals, ranging from 1 for good health to 0 at death, and each yearly QALY was calculated as the integration of QOL within that year (see Supplementary Figure S3 for more illustration). When the variables cost.1 to cost.15 (and QALY.1 to QALY.15) are summed, they provide the total observed costs (and QALYs) over 15 y, named tot.cost (and tot.QALY), respectively.
First 3 Rows of the Simulated Data a

Costs are in $1,000s, and survival and quality-adjusted life years (QALYs) are in years.
In this data set, costs and QALY data were collected up to 15 y; however, the longest follow-up time was slightly less than 15 y. Therefore, a smaller time limit should be chosen (e.g., 10 y), and time-restricted mean survival time/QALY/costs42,43 are used (more details in the following section). A consequence of applying such a restriction is that a patient alive at 10 y is considered as having complete data. This leads to a censoring rate of 49% within the 10-y horizon in this data set.
Steps Involved in Performing Net Benefit Regression Methods for Censored Observational Data
The theory behind censored net benefit regression and the doubly robust method have been described elsewhere.8,9 Here, we focus on the steps involved in performing net benefit regression methods for an administrative cost-effectiveness data set. R programs are provided for the main steps, and more examples and technical details are available in the Supplementary Materials.
Step 1: Preparation
Load required package
The first line loads the
Load data
The next line loads the data set
Choose time limit
Due to censoring, the right tail of the distribution of survival time cannot be estimated reliably, leading to unstable estimation of the mean survival/QALY/costs. 44 For instance, if all patients are followed for up to 10 y, the cost after 10 y is not observed, and thus, estimating mean costs after that time is not reliable. Consequently, researchers often turn to the time-restricted mean survival time/QALY/costs.42,43 For example, we can measure survival/QALY/costs saved within a time horizon of L years, where L is chosen such that a “reasonable” number of subjects are still being observed at that time (e.g., choose L as the upper quartile of the follow-up times). This means that we are interested in outcomes accumulated until death or up to L years, whichever occurs first. Although our data set provides the costs observed up to 15 y, the longest follow-up time is 14.99 y, meaning that no patients were observed at the end of 15 y. Therefore, a smaller time limit L (e.g., 10 y with sufficient data using an intuitive cutoff) could be chosen, and patients alive at 10 y have complete data. This time limit is required for both SW and PT methods. Patients censored within L years are still considered as censored within this time horizon, which can be handled by the SW and PT methods appropriately. In the Supplementary Materials, we provide examples showing error or warning messages in R when we choose too large an L.
Choose cost-effectiveness threshold values
To perform net benefit regression, we need to choose a few cost-effectiveness threshold values denoted by λ. A sequence of λ values from 0 to multiple times of the ICER is a good start. We can first fit covariate-adjusted regressions using the SW method to estimate a covariate-adjusted ICER ($2,680/QALY, see step 2). Based on this, we can create a cost-effectiveness threshold sequence of $ 0, $500, $1,000, . . ., $6,000 for 1 additional QALY:
This line generates
Step 2: Fitting Censored Net Benefit Regressions
We can fit a covariate-adjusted net benefit regression using the SW method with QALY as effectiveness:
The first line clarifies that the variable survival in the data set
To explore heterogeneous cost-effectiveness and identify subgroups, we can further include treatment-covariate interactions. The option
Caution
Two naïve methods are also allowed (
Interpretation
Table 3 summarizes the results. To evaluate different methods, we used several methods to obtain “true” ICERs and INBs: 1) the “Theory” method is based on the true mean values analytically derived by statistical theory, leading to the overall ICER of $2,750/QALY (=$2,713/0.99 QALY) in the whole population; 2) the “OLS using uncensored data” method is based on the simulated uncensored outcomes (including cost and effect after censoring time); 3) the “Using true outcomes” method is based on the simulated uncensored potential outcomes (counterfactuals), leading to an overall ICER of $2,501/QALY (=$2,585/1.03 QALY). Although the estimates from the methods (2) and (3) will approach the mean values from the method (1) when the sample size approaches infinity, the 3 methods could be slightly different with smaller sample sizes, as in our example. Methods (2) and (3) might be better “true” values, since our data set is a censored version of the full uncensored data set that was used to calculate (2) and (3).
Coefficient Estimates (Standard Errors) (in $1,000s) and P Values for Treatment and Interaction Terms in Net Benefit Regressions with Different Values of Cost-Effectiveness Threshold λ (in $1,000/QALY) for the Hypothetical Data Using Quality-Adjusted Life-Years (QALYs) as Effectiveness, Limited to a 10-y Time Horizon a
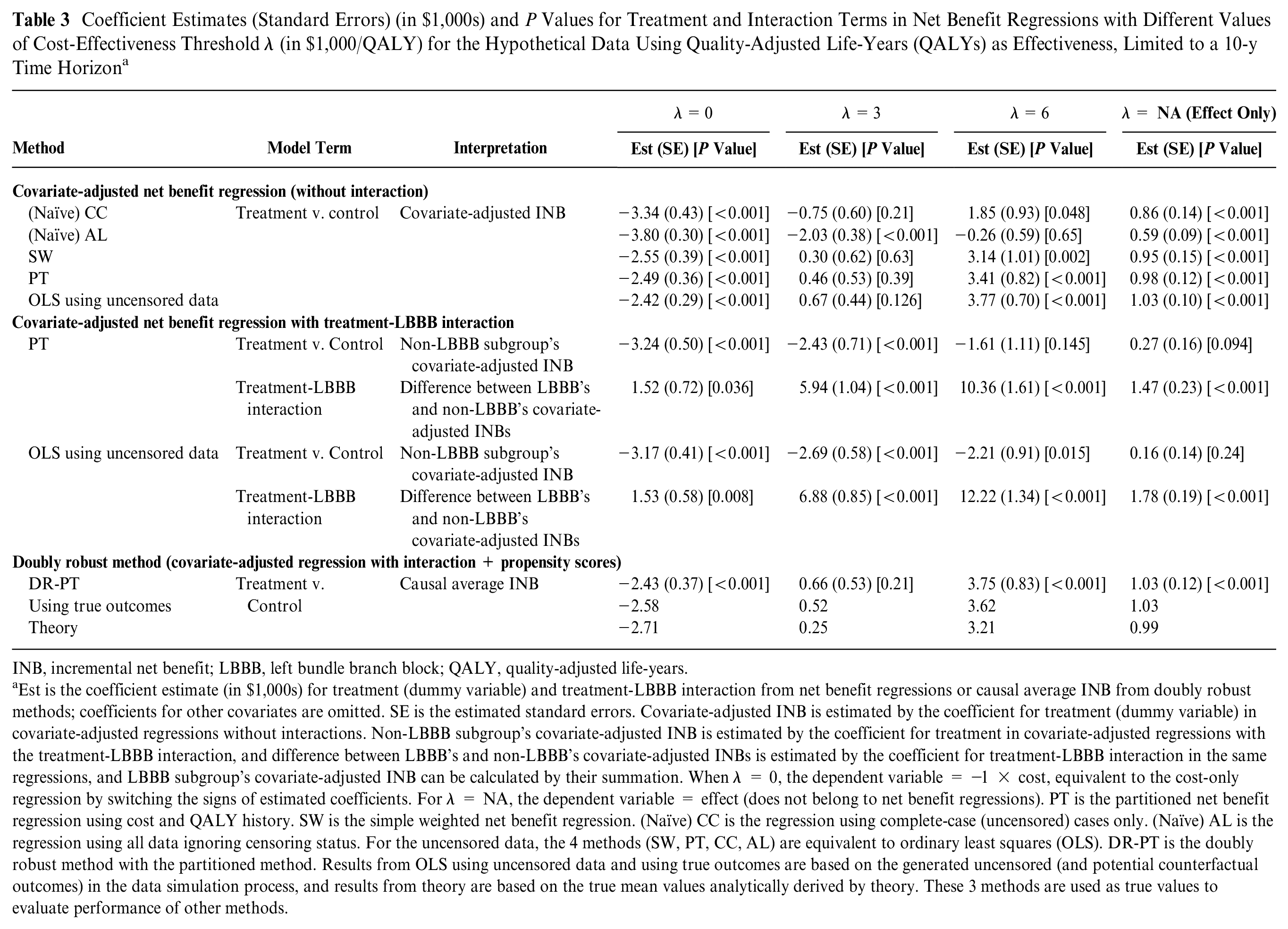
INB, incremental net benefit; LBBB, left bundle branch block; QALY, quality-adjusted life-years.
Est is the coefficient estimate (in $1,000s) for treatment (dummy variable) and treatment-LBBB interaction from net benefit regressions or causal average INB from doubly robust methods; coefficients for other covariates are omitted. SE is the estimated standard errors. Covariate-adjusted INB is estimated by the coefficient for treatment (dummy variable) in covariate-adjusted regressions without interactions. Non-LBBB subgroup’s covariate-adjusted INB is estimated by the coefficient for treatment in covariate-adjusted regressions with the treatment-LBBB interaction, and difference between LBBB’s and non-LBBB’s covariate-adjusted INBs is estimated by the coefficient for treatment-LBBB interaction in the same regressions, and LBBB subgroup’s covariate-adjusted INB can be calculated by their summation. When λ = 0, the dependent variable = −1 × cost, equivalent to the cost-only regression by switching the signs of estimated coefficients. For λ = NA, the dependent variable = effect (does not belong to net benefit regressions). PT is the partitioned net benefit regression using cost and QALY history. SW is the simple weighted net benefit regression. (Naïve) CC is the regression using complete-case (uncensored) cases only. (Naïve) AL is the regression using all data ignoring censoring status. For the uncensored data, the 4 methods (SW, PT, CC, AL) are equivalent to ordinary least squares (OLS). DR-PT is the doubly robust method with the partitioned method. Results from OLS using uncensored data and using true outcomes are based on the generated uncensored (and potential counterfactual outcomes) in the data simulation process, and results from theory are based on the true mean values analytically derived by theory. These 3 methods are used as true values to evaluate performance of other methods.
For covariate-adjusted regression without interaction, the coefficient for the treatment is the adjusted INB. For example, when the cost-effectiveness threshold is $6,000/QALY, the estimated covariate-adjusted INB is $3,410 by the PT method. When λ = 0, the dependent variable is −1 × cost, equivalent to the cost-only regression with switched signs for the estimated coefficients; for the effect-only model, the dependent variable = effect (indicated as λ = NA in Table 3). Then it is easy to obtain a covariate-adjusted ICER: for example, the ICER is $2,680/QALY using the SW method (=$2,550/0.95 QALY as the ratio of the treatment coefficient estimates in cost-only and effect-only regressions). Comparing the estimates from covariate-adjusted regressions using the 4 methods to the true values (“OLS using uncensored data” method) in Table 3, it is apparent that estimates of both naïve methods are far away from the true values, with the CC method less biased than the AL method in this example. Both SW and PT methods produce similar estimates to the true values, but the PT method is generally more efficient, with 8% to 20% reductions in standard errors by using cost and QALY history.
The coefficient for the treatment-LBBB interaction is significantly positive for effect and all cost-effectiveness threshold λ values, indicating that effect as well as cost-effectiveness are heterogeneous across LBBB status. LBBB patients achieve significantly higher INBs from the new treatment as compared with their non-LBBB counterparts, adjusting for other covariates. The coefficients for the treatment (main effect) and treatment-LBBB interaction can be used to calculate adjusted INBs in LBBB and non-LBBB subgroups, respectively. For example, when the cost-effectiveness threshold is $6,000/QALY, the regression adjusted INB is −$1,610 for the non-LBBB subgroup and $8,750 (=$10,360–$1,610) for the LBBB subgroup. This result provides evidence that the cost-effectiveness of the new treatment can vary by LBBB status.
Step 3: Using a Doubly Robust Method to Estimate Causal Average INB with Observational Data
Propensity scores
The propensity score is the probability of receiving the new treatment, which could be estimated by fitting a logistic regression (or other models) with treatment indicator as the dependent variable and the potential confounders as explanatory variables. Generally, if a variable is thought to be related to the outcome but not the treatment, including it in the propensity score (for which it is an irrelevant variable) should reduce bias. 45 More practical guidelines about choice of variables in propensity score models can be found elsewhere.45–48
Implementing the doubly robust method
We can perform the doubly robust method by further specifying the option
Caution
We can examine whether there exists extreme propensity scores close to 0 or 1 (program in the Supplementary Materials), which is important because extreme propensity scores may lead to huge weights and hence unstable results. Crump et al.
49
suggested a rule of thumb of thresholds of 0.1 and 0.9 for extreme propensity scores. By default, the function
Interpretation
The doubly robust method estimates causal average INB, which is causal average treatment effects on net benefit for the entire population (those who did and did not receive the new treatment). Table 3 summarizes the estimates from the doubly robust method, which are close to the true values.
Step 4: Constructing CEAC
For net benefit regression without interaction or the doubly robust method, the CEAC can be constructed based on the P value (
Interpretation
Figure 2 demonstrates 4 CEACs based on the fitted models (made using the program in the Supplementary Materials), showing the probabilities that the new treatment is cost-effective compared with the comparison group at different cost-effectiveness threshold values (a sequence of $ 0, $500, . . ., $6,000 chosen in step 1). Among LBBB patients, the probability that the new treatment is cost-effective is much higher than the probability among non-LBBB patients, indicating heterogeneous cost-effectiveness across LBBB status. This was foreshadowed by the significant treatment-LBBB interaction observed earlier.
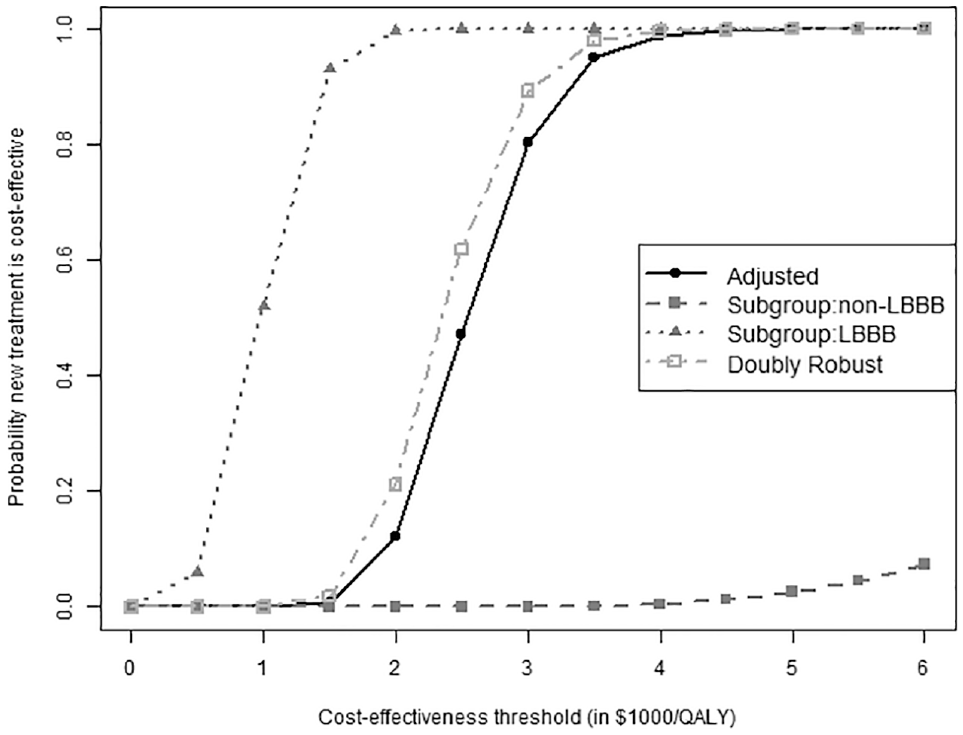
The cost-effectiveness acceptance curves (CEACs) for the hypothetical data limited to a 10-y time horizon, using quality-adjusted life-years (QALYs) as effectiveness with different values of cost-effectiveness threshold. The black solid curve is from covariate-adjusted partitioned regression. The gray dotted and dashed curves are for left bundle branch block (LBBB) and non-LBBB patients, respectively, based on the partitioned regression including treatment by LBBB interaction and adjusting for other covariates (age, gender, in addition to LBBB). The gray dash-dotted curve is from the doubly robust method (combining covariate-adjusted regression with an LBBB-treatment interaction and propensity scores).
Conclusions
Funding negotiations are often informed by research evidence introduced through a health technology assessment (HTA) process. As the field of HTA begins to embrace real-world evidence to address well-known limitations in randomized trials, there will be demand for CEA conducted using person-level administrative data. Even in the United States, increases in available cost and health outcome data combined with Medicare’s new capabilities to consider drug costs as well as their effectiveness suggest that CEA may be a very strategic part of future comparative effectiveness research intent on informing health care funding decisions. In addition, if approvals for new drugs continue to outpace the evidence, 52 the demand for real-world evidence about value (i.e., cost and effectiveness) promises to continue to grow.
Therefore, applying state-of-the-art methods to analyze censored observational data in a net benefit regression framework is essential. When cost-effectiveness data are censored, naïve methods to handle censoring should be avoided, especially for heavily censored data. The doubly robust method combines net benefit regressions and propensity scores in an easy-to-use manner, leading to more reliable results for observational data with censored costs or health outcomes. In addition, the methods can be applied to randomized clinical trials as well. This provides a strong option for CEA using possibly censored data from observational and randomized studies. With the methods illustrated in this article, potential challenges due to nonrandomized and censored data can be addressed in a sound manner.
Supplemental Material
sj-docx-1-mdm-10.1177_0272989X241230071 – Supplemental material for A Tutorial on Net Benefit Regression for Real-World Cost-Effectiveness Analysis Using Censored Data from Randomized or Observational Studies
Supplemental material, sj-docx-1-mdm-10.1177_0272989X241230071 for A Tutorial on Net Benefit Regression for Real-World Cost-Effectiveness Analysis Using Censored Data from Randomized or Observational Studies by Shuai Chen, Heejung Bang and Jeffrey S. Hoch in Medical Decision Making
Footnotes
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Financial support for this study was provided in part by a grant from National Institutes of Health (NIH). The funding agreement ensured the authors’ independence in designing the study, interpreting the data, writing, and publishing the report. This research was partly supported by National Center for Advancing Translational Sciences, National Institutes of Health (UL1 TR001860). The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.