
Abstract
Background
Survival extrapolation is essential in cost-effectiveness analysis to quantify the lifetime survival benefit associated with a new intervention, due to the restricted duration of randomized controlled trials (RCTs). Current approaches of extrapolation often assume that the treatment effect observed in the trial can continue indefinitely, which is unrealistic and may have a huge impact on decisions for resource allocation.
Objective
We introduce a novel methodology as a possible solution to alleviate the problem of survival extrapolation with heavily censored data from clinical trials.
Method
The main idea is to mix a flexible model (e.g., Cox semiparametric) to fit as well as possible the observed data and a parametric model encoding assumptions on the expected behavior of underlying long-term survival. The two are “blended” into a single survival curve that is identical with the Cox model over the range of observed times and gradually approaching the parametric model over the extrapolation period based on a weight function. The weight function regulates the way two survival curves are blended, determining how the internal and external sources contribute to the estimated survival over time.
Results
A 4-y follow-up RCT of rituximab in combination with fludarabine and cyclophosphamide versus fludarabine and cyclophosphamide alone for the first-line treatment of chronic lymphocytic leukemia is used to illustrate the method.
Conclusion
Long-term extrapolation from immature trial data may lead to significantly different estimates with various modelling assumptions. The blending approach provides sufficient flexibility, allowing a wide range of plausible scenarios to be considered as well as the inclusion of external information, based, for example, on hard data or expert opinion. Both internal and external validity can be carefully examined.
Highlights
Interim analyses of trials with limited follow-up are often subject to high degrees of administrative censoring, which may result in implausible long-term extrapolations using standard approaches.
In this article, we present an innovative methodology based on “blending” survival curves to relax the traditional proportional hazard assumption and simultaneously incorporate external information to guide the extrapolation.
The blended method provides a simple and powerful framework to allow a careful consideration of a wide range of plausible scenarios, accounting for model fit to the short-term data as well as the plausibility of long-term extrapolations.
Survival or “time-to-event” data from randomized control trials (RCTs) are typically used to assess the cost-effectiveness of new interventions. However, the observed data from RCTs are often censored and immature with limited duration of follow-up, 1 so the clinical benefits regarding life expectancy or quality-adjusted life-years (QALYs) cannot be estimated directly. Consequently, it is necessary to extrapolate the estimates of the resulting survival proportions, often long beyond the data observed in the trial period. 2
Methods of extrapolation most used in submissions to health technology agencies such as the National Institute for Health and Care Excellence (NICE) in the United Kingdom often consider a parametric model for the control arm and assume proportional hazard (PH) to derive the survival curve for the treatment arm.3–5 This implicitly assumes a constant treatment effect beyond the trial period. However, a treatment performing well over the course of the trial is unlikely to remain consistent on account of various factors such as waning treatment effects or competing risks from other causes of mortality. The typical length of follow-up in clinical trials has been shown to account for no more than 40% of the modeled time horizon, 6 failing to reach median time. In the absence of long-term data, care should be taken in whether the extrapolation is realistic, as the long-term modeling assumptions can have a dramatic impact on the decisions.7,8
Historically, conventional approaches involved fitting the most appropriate parametric model to the observed data. 9 In fact, different models with a similar fit to the data may generate highly divergent long-term survival estimates due to the differences in the tails of survival distributions. Recently, there has been an increasing recognition that external long-term validity is essential when the extrapolation period is substantial with heavy censoring in the trial data.4,10–12 Current guidelines recommend the inclusion of both statistical criteria for model fitting as well as clinical plausibility of extrapolation, which may be achieved through the use of external data or expert opinion. 13 In recent times, the proportion of health technology appraisals (HTAs) using external information for validity has increased sharply,2,6 in which clinical experts assess the plausibility of extrapolation or evaluate which models fall in with the elicited plausible range of survival. 14
There are many different ways that external data can be leveraged.10,15 While the most frequent methods are indirect or retrospective, direct utilization of patient-level data for the extrapolation have increasingly been considered.12–14 It is possible that historical data are formally integrated into the extrapolated portion as informative priors via a Bayesian framework. 16 In addition, a piecewise or hybrid approach where observational data are used to facilitate the extrapolation has been undertaken, although the selection of where to implement cut points can be fairly subjective or arbitrary.11,17,18 Commonly, external data from a different source will not match the trial population perfectly19–21 so that hazard rates from a model fitted to external data could be matched to the control arm using a time acceleration adjustment after follow-up of the trial and anchoring/hazard ratio tapering for the investigation arm. 12 Further methods were attempted to combine evidence from a variety of available sources: especially under the Bayesian framework, disease-specific external data from registries might be extrapolated using general population data12,15,22-25 or informed by justifiable clinical opinion where the external data are not fully mature.15,26
This article presents a method based on “blending” survival curves as a possible solution. A similar approach has been presented previously in other applied fields 27 but we adapt it to survival modeling for cost-effectiveness analysis. The basic idea is to mix a flexible model (e.g., Cox semiparametric) to fit as well as possible the observed data and a parametric model encoding assumptions on the expected behavior of underlying long-term survival. The blended curve will improve decision making especially in cases in which decisions are made accounting for survival in long-term timeframes relative to the available trial data but expert knowledge or external information about the long-term is available and can be coherently combined. Extrapolated curves using only the short-term data are likely to be biased or overestimate survival, whereas the blended model helps constrain the tail and retain the information in the early time period. For HTA, cost and QALY calculations can use the estimated survival in the blending interval, which is consistent with information from both the early and later stages.
Motivating Case Study
Our motivating example is the one considered in NICE technology appraisal TA174 28 and in other methodological contributions.29,30 This is based on the CLL-8 trial, 31 which compares rituximab with fludarabine and cyclophosphamide (FCR) to fludarabine and cyclophosphamide (FC) for the first-line treatment of chronic lymphocytic leukemia.
Among 810 patients enrolled in the trial, 403 were randomly assigned to receive the treatment of FCR and the remaining 407 to the control arm of FC. There were 41 and 52 deaths in the FCR and FC arms, respectively. 29 While this study has a relatively large sample size and a relatively long follow-up (about 4 y), it is also characterized by a large amount of censoring such that more than 70% of individuals were not observed to die, as is common in this type of investigation. Following existing guidance,13,32 a set of standard parametric distributions were fitted to the digitized data on overall survival from published Kaplan-Meier (KM) curves, as shown in Figure 1.
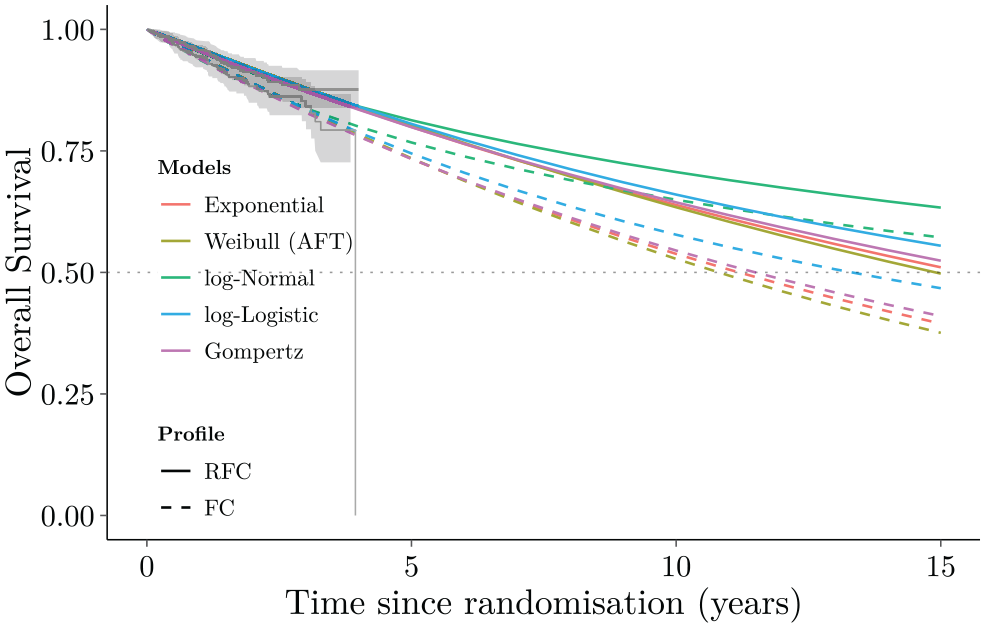
Overall survival curves for the parametric models (Exponential, Weibull, log-Normal, log-Logistic, Gompertz) fitted to the 4-y CLL-8 trial data (Kaplan-Meier curves) and long-term extrapolation to 15 y.
These models achieved a reasonable fit to the observed data (as evident in the left portion of Figure 1), but none of them generated credible extrapolations. All models suggested greater than 30% survival at 15 y, which was in stark contrast with expert estimates, suggesting instead that only 1.3% of the cohort would be likely to survive beyond that time. 33
Blended Survival Curve Methodology
Denote the available data as
Blending considers 2 separate processes to describe the long-term horizon survival. The first one is driven exclusively by the observed data. Similar to a “standard” HTA analysis, we use this to determine an estimate over the entire time horizon, which we term
For the second component of the blending process, we consider a separate external survival curve,
The blended survival curve is simply obtained as
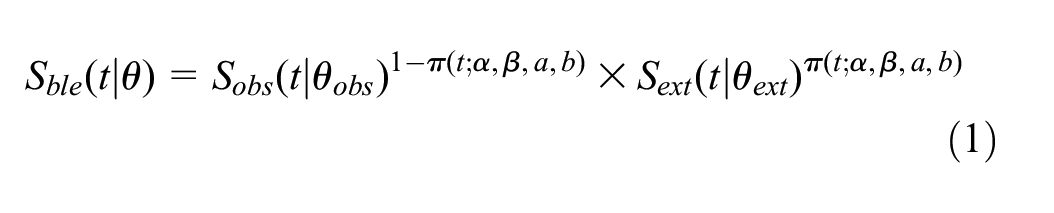
where
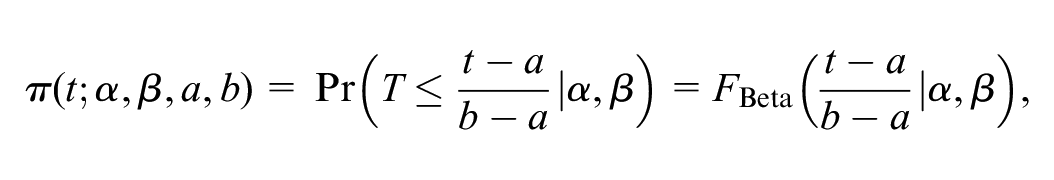
for
Figure 2 depicts this process graphically. In this case, we assume that the trial data span over the interval
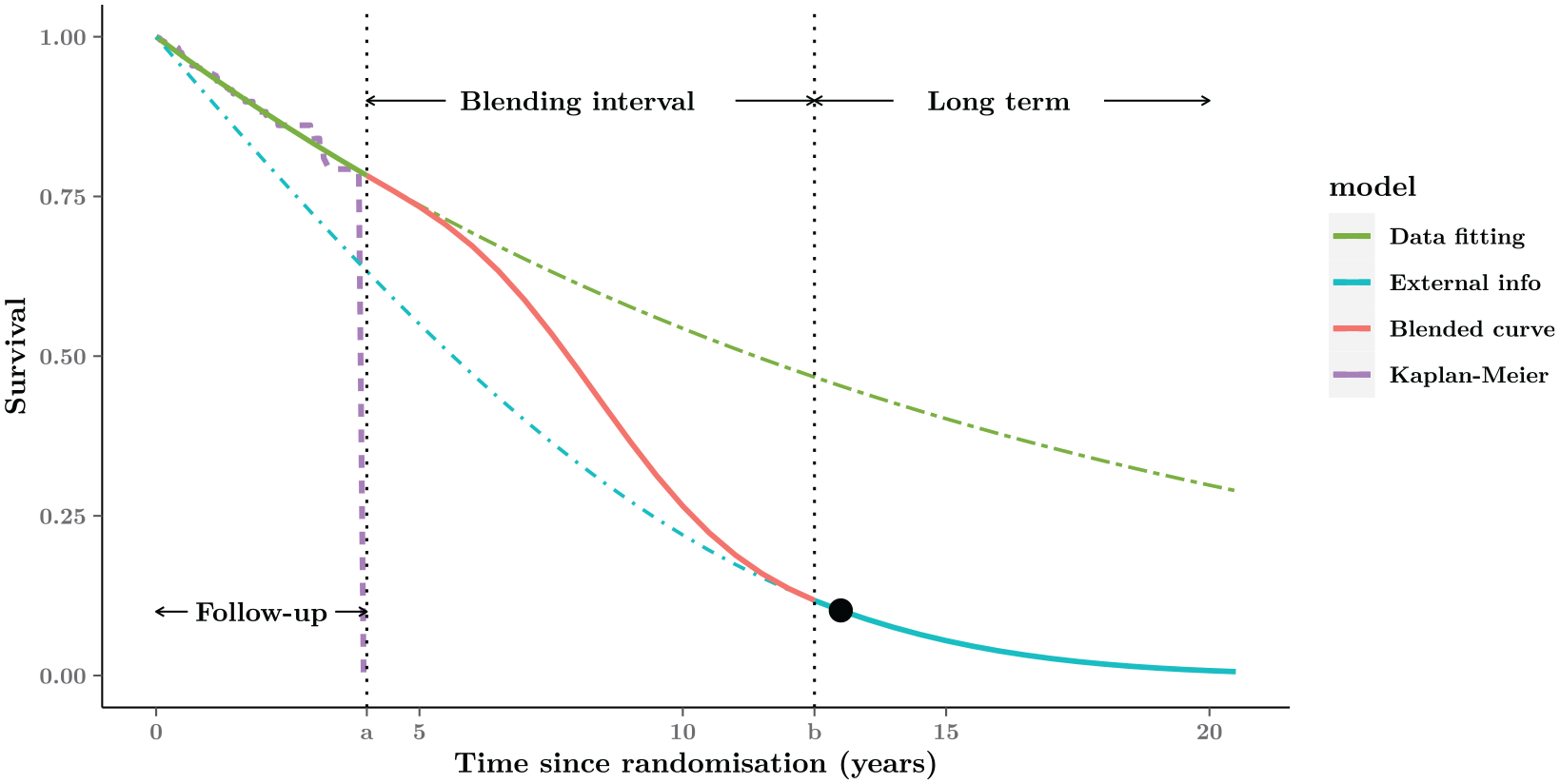
Graphical representation of the blended curve method. The whole time-horizon is partitioned into 3 parts: Follow-up, Blending interval, and Long-term. The blended survival is equivalent to the model fitted to the short-term data (purple Kaplan-Meier curve) within the Follow-up period (green curve), then gradually approaching the external estimate in the Blending interval (red curve), and eventually consistent with the expected behavior (blue curve) in the Long-term. The black point in the Long-term is an example of external information about 10% expected survival at the 13 y from experts.
The blue curve, indicated as
In summary,
Between times 0 and
Between times
Between times
We can control the rate at which the blending process occurs by using specific values for the parameters (
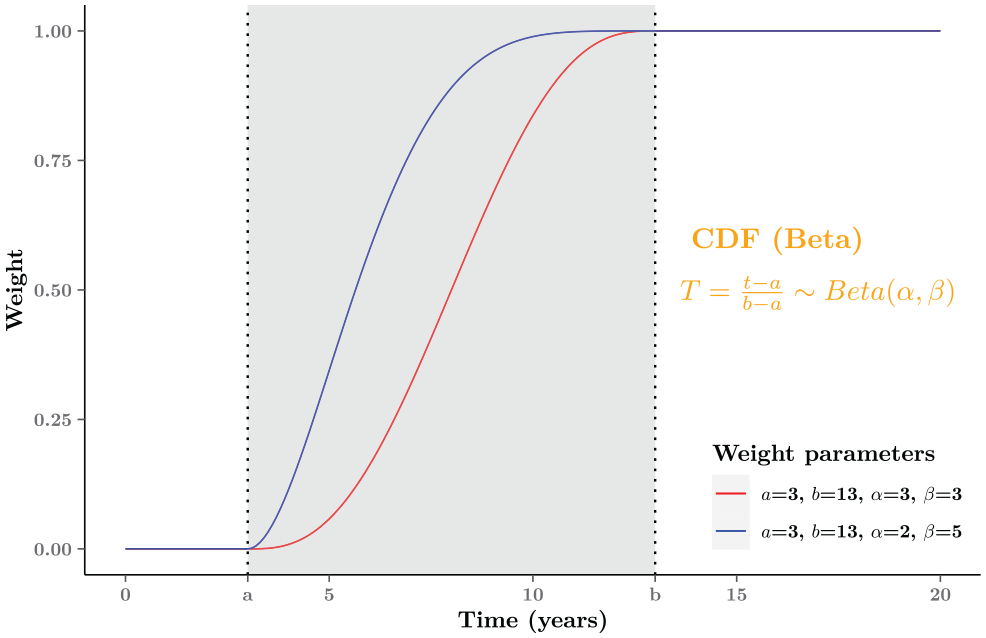
Graphical examples of the weight function
Different assumptions about how quickly the treatment effect might wane can be easily examined by adjusting the choice of parameters regarding the weight function
Note also that our method is fundamentally different from well established mixture cure models (MCMs
35
). In the MCM case, it is assumed that the observed trial data correspond to a mixed survival curve resulting from the experience of 2 subgroups (“cured” v. “noncured” patients). Conversely, we model 2 components,
Blending Hazard Functions
By simply rescaling Equation 1, our method can also be expressed in terms of hazard functions. This is helpful because hazard plots often aid understanding of long-term survival mechanism and provide useful insights into suitable model selection.
2
Specifically, the blended hazard rate
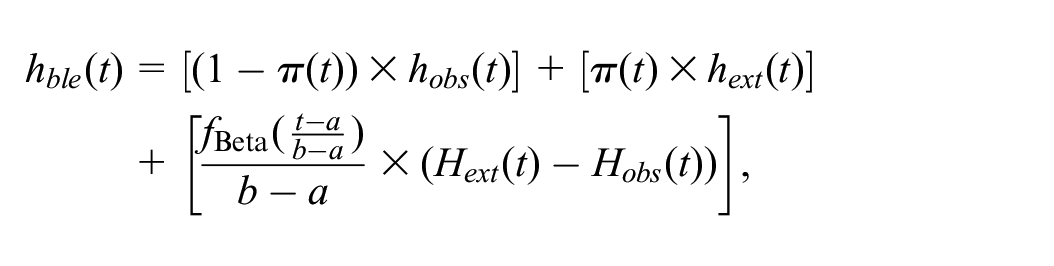
where
The hazard function depends on the same subset of parameters as the corresponding survival functions. Given the properties of the Beta distribution,
The slope of the blended hazards as well as the location of the turning point can be determined by the value imposed for the parameters
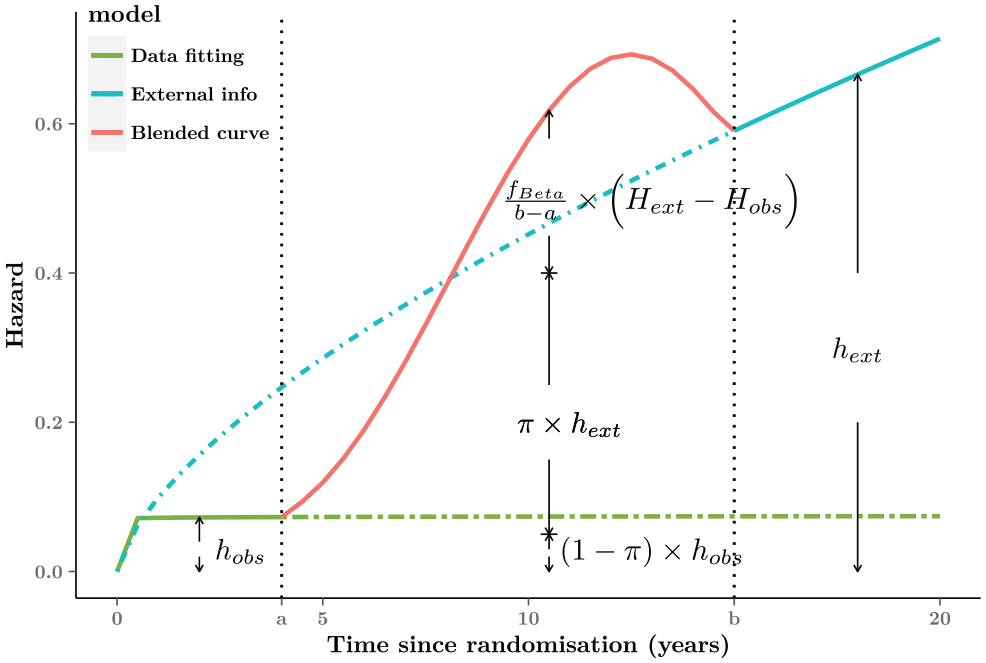
Graphical representation of the blended hazard. For interval
Technical Implementation
Observed Time Period: Best Fit to the Internal Data
Generally speaking, there is no restriction to the distributional assumptions used to model the observed data. With a view to providing the best fit possible and a good level of flexibility, here we recommend a Cox semiparametric model with piecewise constant hazards. We choose a Bayesian approach, which naturally allows the incorporation of external evidence and lends itself to the conduct of “uncertainty analysis.”36,37 The R code is provided for the motivating case study, which is available at the GitHub repository (https://github.com/StatisticsHealthEconomics/blendR-paper).
To construct the model, we partition the time period into
Note that, using this model, we can still extrapolate beyond the observed times using the RW structure. Obviously, in the presence of large censoring, the extrapolation is likely to be not credible, with substantial uncertainty around the average. This, however, is a minor concern in our modeling structure, because as time progresses outside of the blending interval, the extrapolation from the semiparametric component has increasingly low weight.
Of course, other choices are possible: we could select a parametric model (e.g., Weibull, Gompertz, or any other from the set suggested in various guidelines 2 ); in reality, a flexible semiparametric model may not increase the computational complexity by a substantial amount, compared with alternatives such as Royston-Parmar splines 39 or fractional polynomials. 40 In addition, because of the blending process, we need to worry only about the performance of any model chosen in the follow-up period.
Unobserved Time Period: Extrapolation Using External Data
In the best-case scenario, long-term data can be accessed from a relevant study, possibly of an observational nature, such as a registry or a cohort study; this is naturally unlikely to contain direct information on the intervention under investigation from the trial data. But, perhaps, we may have information on drugs with similar mechanisms of action or tackling the same condition. In these circumstances, we could simply use the survival result from an appropriate model fitted to the relatively complete data externally or include additional assumptions such as a time acceleration adjustment to match the reconstructed external data to the trial data. 12 Whatever the distributional assumptions, we would be able to determine an estimate of the survival curve for the extrapolation period and then plug that into the blended model. Note that it is not simple to adjust the external population to accurately represent the trial population, 15 so the blending procedure would allow further assumptions for the extrapolated curve, in which different weights could be given to the external component over time.
Unobserved Time Period: Extrapolation Using Expert Judgment
A more general situation, encountered in real-life applications, is when only tentative knowledge is available, typically in the form of expert elicitation. It is rather common for modelers to ask “key opinion leaders” for their assessment of the validity of a given extrapolation, perhaps in the form of plausible ranges or point estimates for the survival probabilities at given times. For example, experts may suggest that, given their clinical knowledge, the plausible interval of 10-y survival probability is between 10% and 30% or that no more than 5% of participants would survive beyond 15 y. We thus need to map those numerical estimates onto a suitable model and construct a representative curve of the external information.
Elicitation of survival estimates could be expressed as the expected number of individuals who, in a population of a given size, will survive at the specific point; for instance, 20% survival at 10 y could be interpreted as “20 in 100 patients would survive beyond 10 years.” We could translate the clinical constraint into an artificial data set and then use the standard method to analyze the pseudo data. Given that 80% of time-to-event data should be shorter than 10 y, we could use a uniform distribution with boundaries 0 and 10 to generate the individual survival times, because there is no knowledge or assumption about the time-to-event outcome in this synthetic data set. To build up survival outcomes for the remaining 20% of the population who would survive at least 10 y, it is essential to determine a maximum lifetime
Figure 5 (top plot) illustrates the above example, and the synthetic data set consists of the 2 groups of time-to-event data
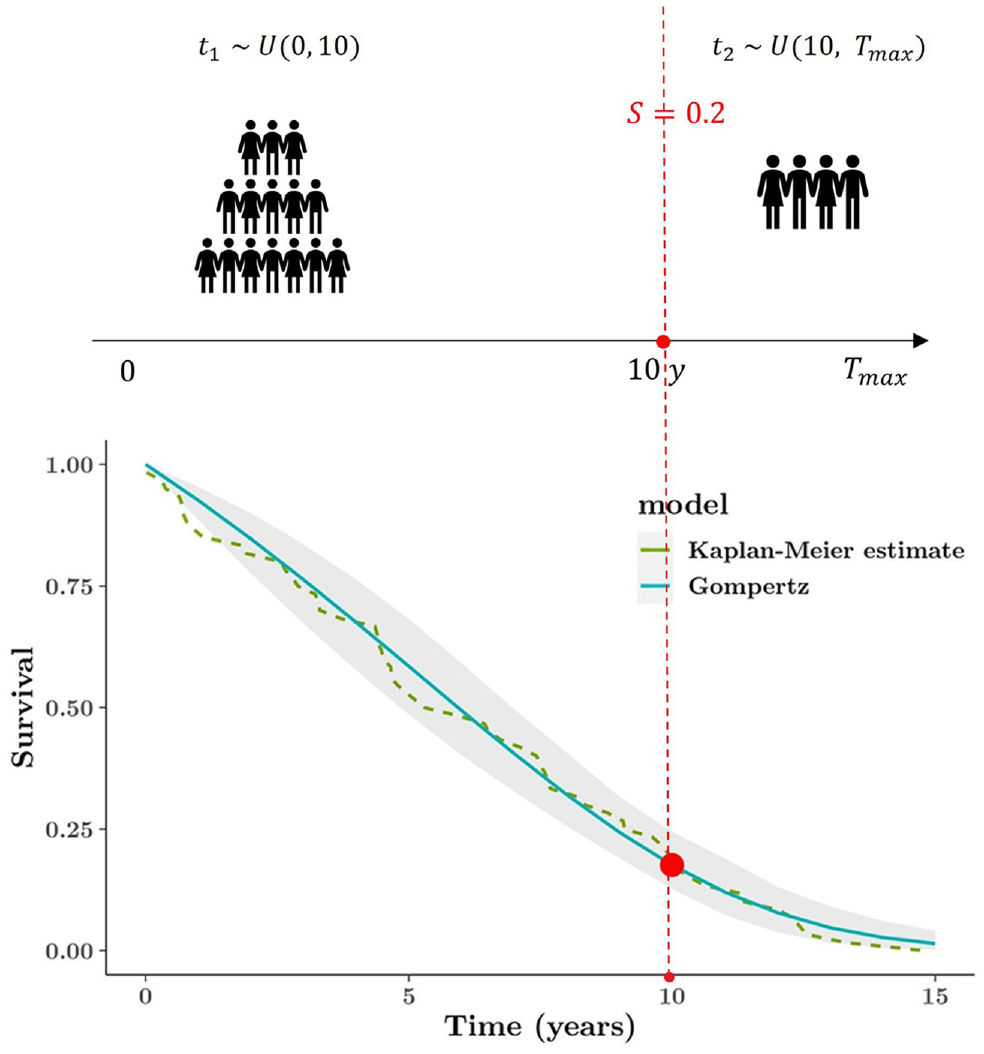
Graphical representation of constructing external survival curve (based on the subjective opinion). The top plot illustrates mechanism of generating the artificial data set, and the bottom plot is the Gompertz model fitted to the synthetic data set. The elicitation is only at 1 time point: 20% expected survival at 10 y.
This simple case only considers 1 time constraint, but more importantly, the process would be essentially identical and easy even if there are multiple elicited time points. Given more information about several time points, it is required only to partition a whole time horizon into 3 or more portions while constructing the external data set; other than that, all procedures should be consistent. The method of using an artificial data set enables a range of possible constraints to be flexibly considered. Moreover, based on more externally specific details, the resulting curves can align more closely with substantive expert beliefs.
Results
Interim Analysis for Observed Time Period
The piecewise constant hazard model in the Bayesian framework provided a good fit to the observed data (with 8 intervals over the 4-y follow-up; green curve in Figure 6). As is known, a greater number of intervals might lead to lower deviance (better fit); however, in this particular case, no meaningful improvement was seen by increasing the number of intervals. Notice that, unsurprisingly, the extrapolation from the model is not reasonable, as it implies artificially and unrealistically large survival probabilities at the end of the follow-up period.
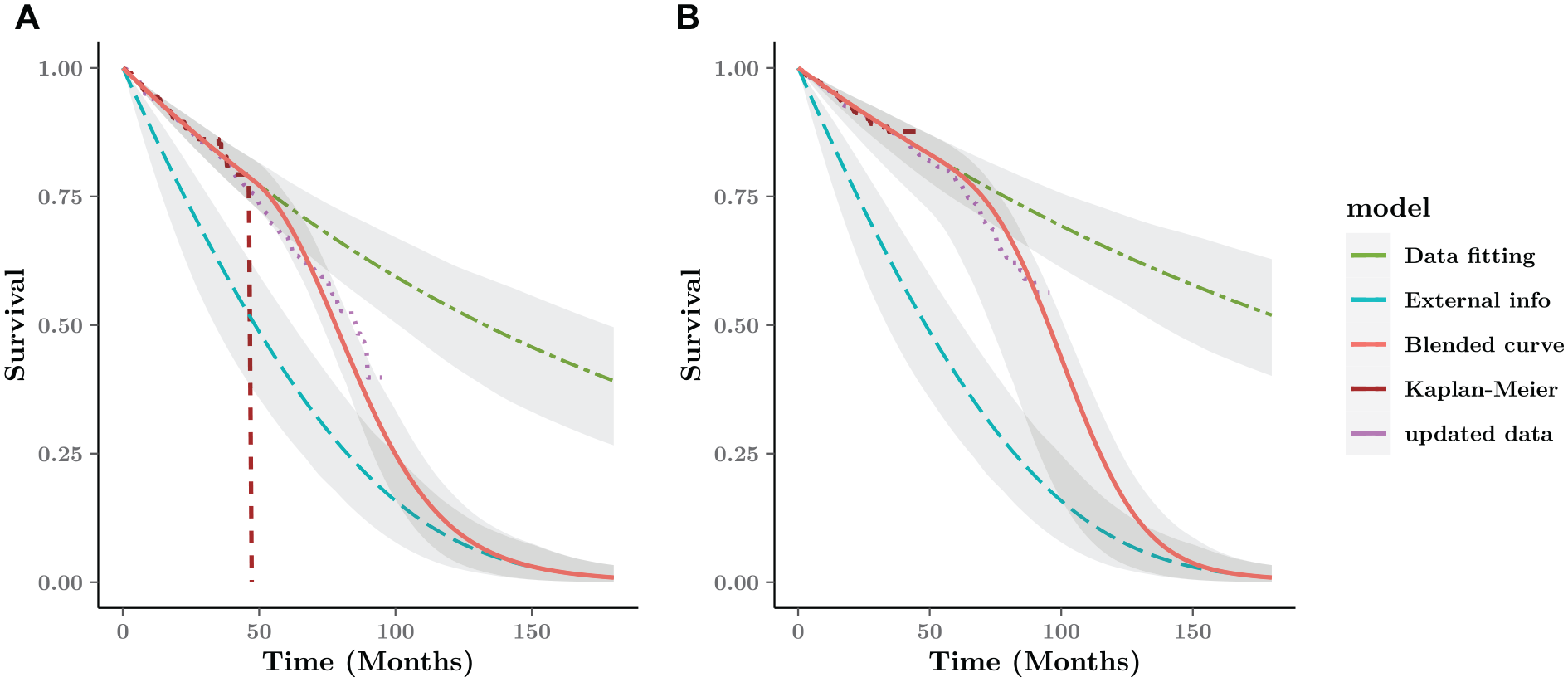
Blended survival curve based on short-term data and external information for the FCR arm. The digitized data from CLL-8 are updated with longer follow-up until 96 mo (purple dotted line). (a) FC arm. (b) FCR arm.
External Curve with Expert Information
Given the relatively strong opinion that approximately 1.3% of the cohort would be alive beyond 15 y, we construct a synthetic data set with 300 participants, in which no more than 4 individual times are longer than 15 y (180 mo). We can experiment with different sample sizes (in our case, we used a number of scenarios, with the sample size ranging from 10 to 500) to get a better sense of the implied uncertainty around the resulting survival curves.
Among the candidate parametric models, the Gompertz distribution fits the external data very well, describing the belief specified above accurately. In a real-life case, the experts and modelers should be able to defend this assumption, in the absence of hard evidence to justify it. We note, however, that this process happens irrespective of the modeling strategy chosen; in our case, we make it in a way that does not affect directly the fit to the observed data.
Blended Estimate Compared with Updated Data from the CLL-8 Trial
Figure 6 shows the blended survival curve driven by the internal and external curve and 95% interval estimates around the average curves over the whole time horizon. Under the Bayesian framework, the interval estimates are simulations generated from the posterior distribution as the probabilistic sensitivity analysis. Without any further information about the blending process, we assume a constant rate over the blending interval, based on a linear weight function with
When compared with a later data cut for the CLL-8 trial until 96 mo, 41 the blended survival curve after 48 mo is generally very close to the updated data. Unsurprisingly, the observed survival without external information overestimate the longer value, 40% higher than the updated result.
Discussion
There is a growing need to improve extrapolation of immature survival data when interim analysis is frequently carried out in the context of accelerated regulatory approvals. A short duration of follow-up is often subject to a substantial amount of censoring, which can lead to implausible extrapolations with conventional approaches based only on observed data. In addition, innovative cancer drugs are evaluated on the back of limited information, because no alternative treatment is available as a viable option for patients affected by a specific disease. To obtain credible estimation of overall survival gains, it is essential to relax the traditional PH assumption and supplement the external information to guide the extrapolated curve. In this article, we have introduced an innovative approach based on blended survival curves as a possible solution to these issues in the extrapolation.
In the cases in which the hazard early on is unlikely to reflect the long-term behavior, our blended approach enables the extrapolated survival to be less and less affected by the short-term data as time progresses. Long-term outcomes would be dominated by the external information. Providing a best fit to the observed data, the blended curve would gradually approach the prediction derived from the external sources over the extrapolated period. In the blending interval, time-specific weights are allocated to the observed and external survival to allow for varying proportions of the 2 components contributing to the overall estimate in the course of time, which largely differs from the other mixture models with time-independent mixtures over time. As mentioned in the “Blended Survival Curve Methodology” section 2, a mixture cure model also consists of 2 components (survival profiles of cured and uncured patients) but is distinct because it assumes a constant weight, namely, the proportion of cured patients, through the entire time range. 42 The mixtures are time independent, and cure fractions—as well as the survival of uncured patients—often rely solely on short-term data. 43 Conversely, weight functions, together with external projections in the blended curves, would be governed by information outside an RCT. Finally, MCMs are based on the assumption that the underlying data-generating process gives rise to a single survival mechanism that is a combination of 2 subgroups; in our case, we explicitly consider 2 separate processes (the short-term and long-term survivals) and ensure that extrapolation from the former is anchored in a principled and flexible way to the latter.
With the use of external sources, our novel method allows turning points in the extrapolated hazard, which may provide a more flexible and realistic shape beyond the trial period. By adjusting relevant parameters of the weight function, the blended procedure permits nonmonotonic hazards (as shown in Figure 4) that might be more practical in the extrapolation. For example, if a trial period ends with a low but increasing hazard, there could be several turning points over time, such as a temporary decrease due to the long-term survivors then a following increase due to aging effects. 43 Although the flexible parametric models, such as splines or fractional polynomials, can also capture a complex hazard function, a turning point cannot be generated in the posttrial period, and the monotonic hazard based on the final observed segment is likely to be undesirable without external data.
It is important to identify appropriate external information to facilitate the extrapolation. A key assumption in the blended method is that from a specific time point, the extrapolated survival is consistent with the estimate from external evidence. Before using potential data from other sources, researchers should examine if the external population matches some characteristics for the patients of interest and have equivalent mortality in the long-term. Conveniently, there is one advantage to the blending process that no adjustment would be required, even if 1:1 matching between 2 sources were unavailable. The matching procedure is replaced by the blending process.
Expert opinion as a kind of subjective information is frequently used for model validation rather than formal incorporation in the modeling. However, some research indicated the potential benefits of formally integrating expert opinion to aid the long-term extrapolation, 15 especially in situations in which no access is given to the patient-level external data. Therefore, we focus on more general cases such that only expert/clinical subjective beliefs are available in the long-term. Experts may have some knowledge about the likely values or plausible ranges of survival in the future according to the trial data and their experience. Different from expressing the evidence via informative priors of relevant parameters, our approach translates the beliefs about long-term survival to a representative curve by interpreting the elicitation as an artificial data set and then using standard methods to analyze it. Meaningfully, the number of elicited time points is not limited and depends completely on the clinicians. Obviously, the curve would be closer to what the expert believes if more elicited information are collected. The procedure is simple and straightforward, yet the expert-based survival estimates are inherently subjective and might be limited in scope, which means attention should be given to the selection of more appropriate knowledge if possible.
In the absence of long-term data within a trial itself, scenario-based sensitivity analyses should be performed for uncertain assumptions of the extrapolations. Uncertainty of the underlying evidence may have a large impact on the prediction. It may be worthwhile to test a range of plausible scenarios about the future trend, especially when integrating limited or conflicting elicitation into the extrapolations. 32 This implementation is not hugely complicated, in which the modeler simply changes the values of the parameters associated with the blended model for defensible circumstances. In the extrapolated period, they can select suitable values (e.g., plausible ranges) of survival at multiple time points and flexibly determine the number of the elicited points and their locations. Besides, the blending operation, including the interval and the rate, can be characterized by the weight function if there is any available knowledge about biologically plausible shapes for the extrapolated hazard. A web-based application is being developed to aid the elicitation process, in which immediate outcomes (i.e., survival and hazard plots) would help the experts to obtain reliable estimate.
Due to the lack of long-term data, extrapolation is always going to be a problem, which largely involves the subjective modeling assumptions. Crucially, we believe that the blending method allows to shift elements of subjective assumptions away from the extrapolation derived from the observed data, although the blending operation cannot necessarily avoid the issue of subjectivity. It is our view that untestable assumptions are all but unavoidable in the range of survival models that are relevant in HTA. The blending procedure attempts at recognizing and embracing this feature by providing a simple and powerful framework for its incorporation and evaluation on the model fit as well as on the long-term economic outputs.
There is no restrictive technical implementation for modeling the observed data. The piecewise Cox model is recommended due to the potential advantage of extremely good fits to the data without substantial computation required. Under a Bayesian framework, it allows a high level of flexibility and does not bring extra complexity, compared with spline or fractional polynomial models. Furthermore, the PH assumption is not necessary, as a stratified version of the Cox model exists in which we can control for covariates that do violate the assumption by stratifying, effectively creating many versions of the baseline hazard. 44
Current implications focus on the absolute effectiveness of treatments in a trial; however, decision making requires a combination of different trials that compare multiple treatments with the relative effectiveness of interest. In fact, it is not difficult to implement the blended approach into network meta-analysis with a hierarchical structure that synthesizes all direct and indirect evidence across trials. 45 The mechanism of separately estimating observed and external hazards achieves flexibility in a simple way, and obtaining the blending result is not complex given a weight function identified by the experts. It is possible to apply a common weight function with consistent values for the relevant parameters to all treatment arms or alternatively to consider different choices for each specific treatment if justified information is available externally. For the trial data, the Cox model would be beneficial, providing the same structure as other studies based on the PH assumption in the network. Moreover, the interpretation of the parameters in the Cox model is explicit. As the piecewise exponential model does not add much computation under the Bayesian framework, the implementation of the blending approach is less computationally intensive, and therefore, time consumption is probably less than that of alternative flexible models.
Conclusion
Long-term extrapolation entirely driven by the immature trial data is highly unreliable, and varying assumptions of the treatment effect can have a great impact on the survival estimate. To improve the credibility of the prediction, the blended survival curve method allows the extrapolation to take advantage of external knowledge that manufacturers might have in form of hard data or just elicited belief from clinical experts. The formal inclusion of external evidence considers a variety of available sources, especially the subjective opinion that is more common in reality. Therefore, not only internal but also external validity can be fully taken into account for the survival model. Considering a range of easily plausible scenarios, the blended approach provides a simple and robust framework to ensure sufficient flexibility for the long-term survival estimate.
Footnotes
Acknowledgements
Dr Nathan Green is partially funded by a research grant sponsored by ICON. Additionally, the authors would like to thank Prof Håvard Rue and Victoria Federico Paly for helpful discussion on the methodology and two anonymous reviewers for their helpful comments.
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Financial support was provided by a joint doctoral training grant from the University College London and China Scholarship Council (No. 201908060054). Zhaojing Che was funded by the University College London and China Scholarship Council (UCL-CSC) joint research grant. No other conflicts of interest were disclosed.