
Abstract
The expected value of partial perfect information (EVPPI) provides an upper bound on the value of collecting further evidence on a set of inputs to a cost-effectiveness decision model. Standard Monte Carlo estimation of EVPPI is computationally expensive as it requires nested simulation. Alternatives based on regression approximations to the model have been developed but are not practicable when the number of uncertain parameters of interest is large and when parameter estimates are highly correlated. The error associated with the regression approximation is difficult to determine, while MC allows the bias and precision to be controlled. In this article, we explore the potential of quasi Monte Carlo (QMC) and multilevel Monte Carlo (MLMC) estimation to reduce the computational cost of estimating EVPPI by reducing the variance compared with MC while preserving accuracy. We also develop methods to apply QMC and MLMC to EVPPI, addressing particular challenges that arise where Markov chain Monte Carlo (MCMC) has been used to estimate input parameter distributions. We illustrate the methods using 2 examples: a simplified decision tree model for treatments for depression and a complex Markov model for treatments to prevent stroke in atrial fibrillation, both of which use MCMC inputs. We compare the performance of QMC and MLMC with MC and the approximation techniques of generalized additive model (GAM) regression, Gaussian process (GP) regression, and integrated nested Laplace approximations (INLA-GP). We found QMC and MLMC to offer substantial computational savings when parameter sets are large and correlated and when the EVPPI is large. We also found that GP and INLA-GP were biased in those situations, whereas GAM cannot estimate EVPPI for large parameter sets.
Keywords
Cost-effectiveness analysis is used to compare the costs and benefits of medical interventions, which are often combined as a net monetary benefit. 1 Such analyses are internationally adopted by decision makers and health technology assessment agencies, including the National Institute for Health and Care Excellence (NICE) in the United Kingdom, the Institute for Clinical Effectiveness Review in the United States, the Canadian Agency for Drugs and Technology in Health in Canada, and the Pharmaceutical Benefits Advisory Committee in Australia. Costs and effects of interventions can be estimated using trial-based analysis or extrapolated over patient lifetimes using model-based decision analysis. 2 Examples of decision models include decision trees, cohort Markov models, and individual patient microsimulations. 3 These models estimate the net benefit of interventions as a function of input parameters such as treatment effectiveness, drug costs, or quality of life following an intervention. This function will be referred to as the net benefit (NB) function. Because the model parameters are estimated from data, we are uncertain about the true parameter values (due to imperfect information on them). This uncertainty in model parameters is propagated through the model to give our uncertainty in the true costs and effects. This in turn leads to a quantification of our uncertainty around the optimal treatment recommendation, which is known as decision uncertainty arising from imperfect information on input parameters. The expected value of perfect information (EVPI) is the expected improvement in decision making, often valued on the monetary scale, from gaining perfect information on all parameters.4,5 The expected value of partial perfect information (EVPPI) is the value of gaining perfect information on a subset of the parameters. 6 These quantities have the potential to guide research funding, as studies costing more than the EVPI and EVPPI will not be cost-effective, but those costing less may be cost-effective, and this can be explored using the expected value of sample information (EVSI). The EVPPI is also a useful sensitivity analysis, as it can highlight parameters to which the decision is most sensitive.
Estimating PPI requires nesting one Monte Carlo simulation over the subset of parameters on which further research is being considered within a second Monte Carlo simulation of the remaining parameters. This procedure is termed nested Monte Carlo and requires evaluation of the NB function for all samples. EVPPI calculations can be computationally intensive, especially for economic models that involve individual-level simulation or Markov models with large numbers of states, and incur significant computational cost to evaluate the NB functions. As a result, standard nested Monte Carlo simulation often fails because it requires an impractical number of samples to obtain a reasonably precise estimate. In addition, estimation based on the standard nested Monte Carlo method is biased.6,7 Estimation of this bias is computationally expensive, as it requires comparison of EVPPI estimates based on different numbers of samples.6,8 Much recent effort has aimed to reduce the computational burden of EVPPI 7 through approximating the conditional expected NB functions and thus replacing one of the Monte Carlo samples from nested Monte Carlo, by some functions that are less computationally intensive to evaluate. Success has been found through linear approximations to the conditional expected NB functions or exact algebraic solutions of the EVPPI, but these methods are specific to each model design and are not always appropriate, particularly for highly complex and nonlinear model structures. 9 Meta-modeling through generalized additive models (GAMs), Gaussian processes, and integrated nested Laplace approximations (INLA-GP) is an elegant and general approach to reducing the computational burden of EVPPI.10–12 Gaussian process (GP) and GAM methods fit a regression model of NB on the input parameters to then estimate the conditional expected NB, thus removing the need for nested simulation. The INLA-GP method fits a 2-dimensional Gaussian process to a dimension-reduced sample of the model parameters and model outputs. These have been implemented in user-friendly online tools and software packages.13,14 However, all of these methods are based on approximating the conditional expected NB function, incurring a bias that is difficult to quantify. A prohibitively large number of samples may also be required to determine a sufficiently well-fitting regression function.
To fully capture decision uncertainty, cost-effectiveness decision models should reflect all the available relevant evidence. For model parameters in which there are multiple evidence sources available, evidence synthesis methods are used to pool the results, often using Bayesian inference evaluated using Monte Carlo Markov chain simulation. 1 Relative treatment effects, for example, are commonly estimated using Bayesian network meta-analysis (NMA), which delivers a joint distribution for multiple treatment effects that are not available in closed form but instead represented by samples from an Markov chain Monte Carlo (MCMC) simulation. This poses 2 challenges for EVPPI calculation. First, it may require a very large number of samples to characterize the posterior distribution, for example, if correlations between parameters impede mixing of the sampler. In addition to needing a large number of samples, it can also be computationally expensive to generate each sample from the posterior, as for the NMA used in the directly acting oral anticoagulants (DOACs) for prevention of stroke in an atrial fibrillation Markov model.15–18 This can make nested Monte Carlo, or the generation of a sufficient number of samples to determine the regression function for GAM or GP methods, impractical. A further challenge with MCMC is that it is difficult, particularly using off-the-shelf general purpose Gibbs samplers, such as OpenBUGS, 19 to generate the conditional distributions needed for EVPPI estimation by standard nested Monte Carlo. This motivates us to explore new computational methods for EVPPI.
In this article, instead of approximating the conditional expected NB function, we introduce 2 different Monte Carlo methods to reduce the number of samples and NB function evaluations needed for the same accuracy as the standard nested Monte Carlo method: multilevel Monte Carlo (MLMC) and quasi Monte Carlo (QMC). These Monte Carlo methods are unrelated to each other, but we explore them in parallel.
The MLMC method, introduced by Giles,20,21 has been successfully applied to many research fields, such as financial mathematics, mathematical biology, and uncertainty quantification. The first key idea of MLMC is to create a series of estimators for the quantity of interest, such as EVPPI, which are increasing in accuracy and increasing in computational cost. The first term, which is the lowest level, is the least accurate and computationally least intensive, whereas the last term, or highest level, is the most accurate and most expensive. All these terms have similar variance. By careful construction, consecutive estimators in the sequence are designed to be highly correlated. This gives the second key idea, which is that the differences between consecutive terms have much lower variance than the individual terms and thus require fewer total samples to estimate. A combined estimator for the quantity of interest can then be formed by adding the lowest-level estimator to a sum of the differences of consecutive terms, which is a sum over the levels of MLMC and has the highest accuracy. As this is formed of terms that have much lower variance, the total number of samples needed for estimation can be much reduced from that needed for standard (i.e., non-multilevel) nested Monte Carlo. 21 Goda and others have used MLMC to construct an estimator of the EVPPI that has lower cost than standard nested Monte Carlo.22,23 Technical details of MLMC for EVPPI are provided in the “MLMC Estimation of EVPPI” section of this article. MLMC for EVPPI offers the greatest computational savings over Monte Carlo when there are correlations between model parameters. This is because greater correlation requires more inner samples and thus deeper levels of MLMC, which leads to proportionately greater computational savings over Monte Carlo. An additional benefit of MLMC for EVPPI is that it can be used to estimate the bias of EVPPI, and indeed EVPI, and this estimate can be used to form an unbiased estimator of EVPPI.22,24 Inference on EVPPI often focusses on the point estimate and disregards uncertainty in the estimate, which could have an impact on trial-funding decisions. An estimate of both the accuracy and precision of the estimator would therefore be useful, beyond the need to form an unbiased estimator. Previous work has applied MLMC for EVPPI to only simple models and has not considered the case in which the model input parameters have been estimated using Bayesian methods, and uncertainty in the parameters is represented by MCMC simulations rather than a closed-form distribution.
Standard Monte Carlo simulation uses pseudo–random-number generators that attempt to mimic truly random sequences. 25 However, with truly random sequences, the generated sequences tend to include clusters of points separated by large gaps. An example is shown in Figure 1c, which is a standard Monte Carlo sample from a bivariate uniform distribution. These clusters and gaps tend to reduce the efficiency of estimators based on the sample. QMC 26 is an alternative to standard Monte Carlo simulation that instead of using pseudo–random-number generators uses quasi-random sequences that have been specially designed to avoid bunching and gaps in the sampling space (known as “low-discrepancy” sequences). This results in an estimator with a lower variance, which in turn reduces the number of necessary samples and computational cost. However, QMC has not yet been applied to EVPPI.
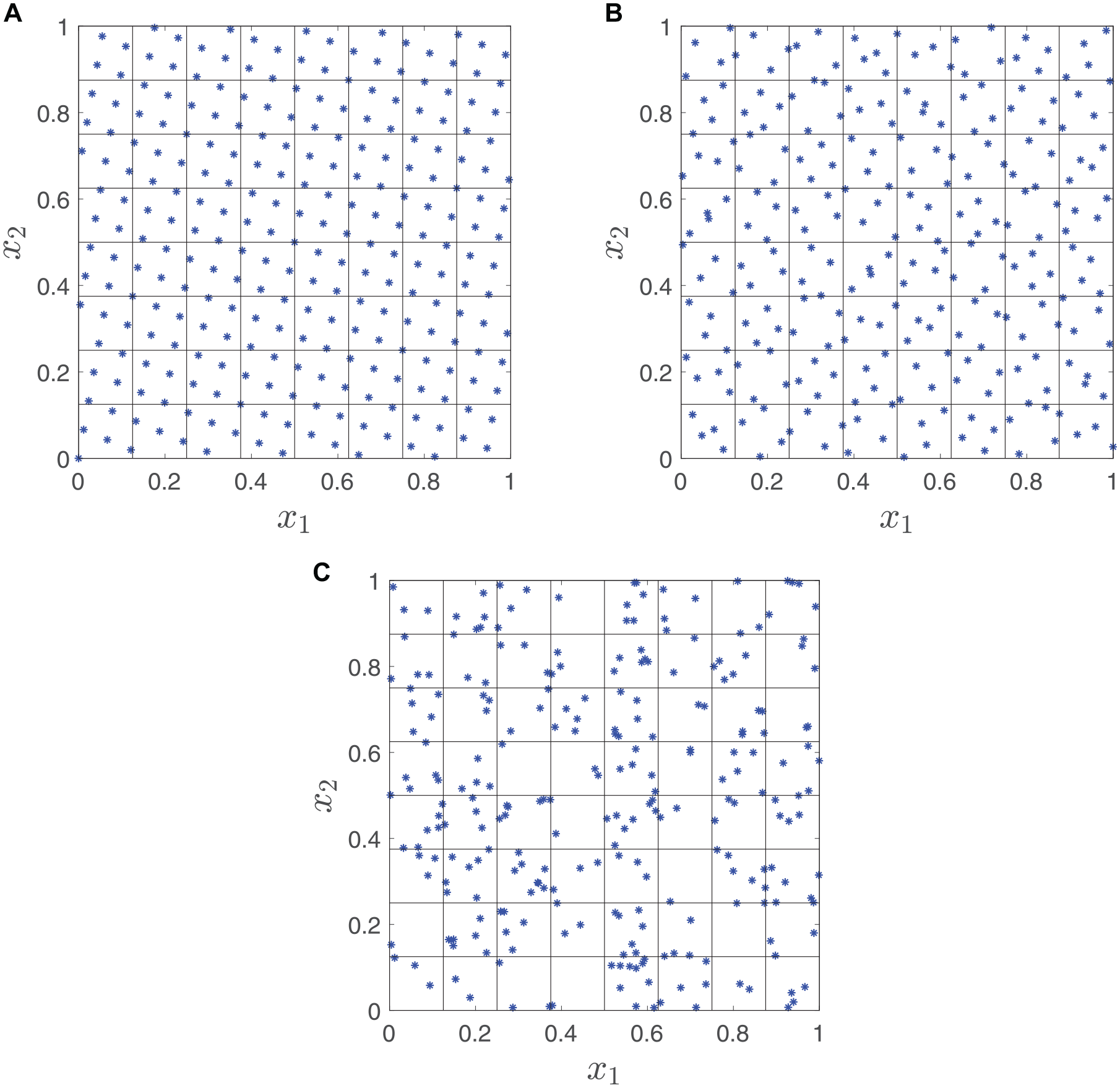
Generating points: quasis Monte Carlo versus Monte Carlo: (a) rank-1 lattice rule, (b) Sobol points, (c) pseudo-random points.
Both MLMC and QMC are variance-reduction methods that allow accurate estimation of the expectations with fewer samples than nested Monte Carlo does. Many other variance-reduction methods are available but out of the scope of this article (e.g., control variables, importance sampling, stratified sampling, and Latin hypercube; see Glasserman 27 for more comprehensive description of these methods).
This article develops a QMC approach and extends an existing MLMC approach to efficient EVPPI estimation. In the “Methods” section, we begin with a discussion of the properties of Monte Carlo nested simulation for EVPI and EVPPI. How MLMC and QMC can reduce the number of samples needed and the extension of MLMC and QMC to MCMC samples are discussed in the “Applications” section. The “Results” section presnts an application to an artificial, but realistic, decision tree depression model with MCMC input parameters. The “Discussion” section presents an application to the published and highly complex DOACs for prevention of stroke in an atrial fibrillation Markov model.16–18 Further discussions and conclusions are provided in the “Conclusion” section. In the appendix, in addition to detailed experiment results, we also show how MLMC and QMC can be applied to value-of-information analysis, through a step-by-step explanation of the method and the provision of code examples.
Methods
Standard Nested Monte Carlo Estimation of EVPI and EVPPI
Suppose our model is a function of input parameters
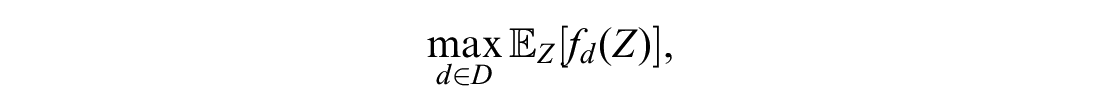
where
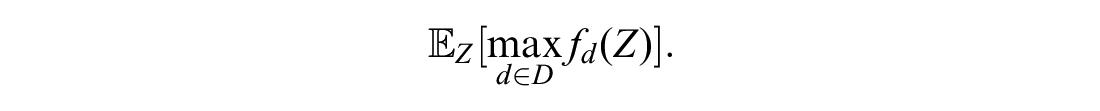
Then, we define EVPI as the extra monetary value expected from learning the true value of
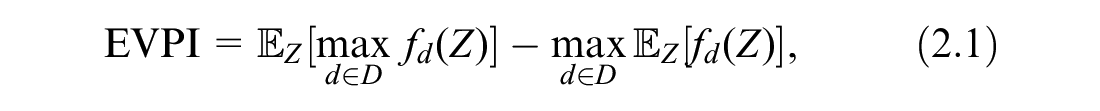
which indicates to the decision maker whether the optimal decision option is sensitive to the uncertainty in the model inputs and whether it is potentially cost-effective to fund new research on
It may be that we are interested only in eliminating uncertainty on a subset
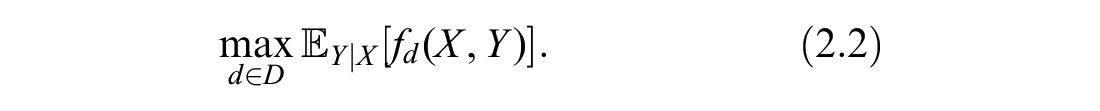
Taking an expectation over the possible realizations of
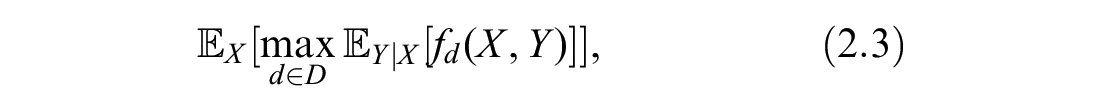
Similarly, we define the EVPPI as the increased value expected from gaining perfect information about
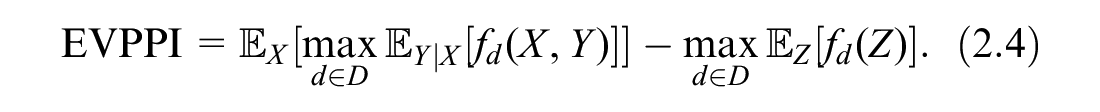
In most practical cases, there is no closed-form solution to the EVPI and EVPPI, and we must turn to numerical methods. One straightforward way is the nested Monte Carlo method, which approximates the expectation as an average of samples. Assuming we can sample from the distribution of
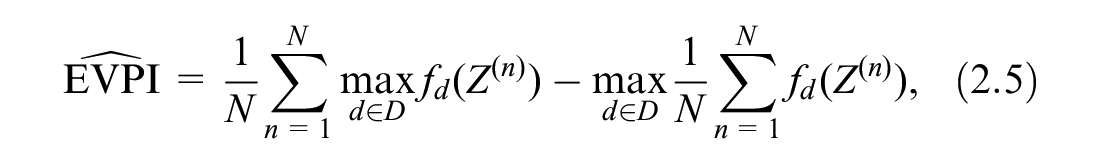
which is biased downward because of the positive bias of the second term. 8
We can form a similar approximation for EVPPI if we can sample from
The
Both the bias and variance of the estimator are important. Bias relates to the accuracy of the estimate, whereas the variance relates to how precise the estimate is. A precise biased estimate can be very misleading, because it gives confidence but in the wrong thing. It is therefore good practice to report both, and as noted, the bias estimate can help obtain an unbiased estimate. In general, we want to find minimum variance unbiased estimators if possible. Therefore, we consider the mean square error (MSE) of the EVPPI, which is defined as

and can be decomposed into two parts,
that is, this is the square of the bias plus the variance of the estimator. For all numerical methods, a prescribed MSE
However, in practice, nested Monte Carlo is computationally expensive. In the following 2 sections, we introduce 2 advanced Monte Carlo methods to improve the computational efficiency and determine an appropriate number of samples to achieve a prescribed bias and obtain corresponding credible intervals systematically.
MLMC Estimation of EVPPI
We follow the recently published approach of Giles and Goda 23 to apply MLMC to the estimation of EVPPI. As explained in the introduction, the first key idea of MLMC is to create a series of estimators of the quantity of interest, in our case EVPPI, which are increasing in accuracy and increasing in computational cost. These estimators are carefully constructed to ensure that consecutive terms are correlated; this gives the second key idea that differences between consecutive terms have low variance and therefore require fewer total samples to estimate as compared with standard Monte Carlo. To illustrate how the MLMC method works, we first consider a simple example; full details on how to construct the necessary estimators for EVPPI will follow below.
First, consider 2 crude estimators for EVPPI, labeled
where
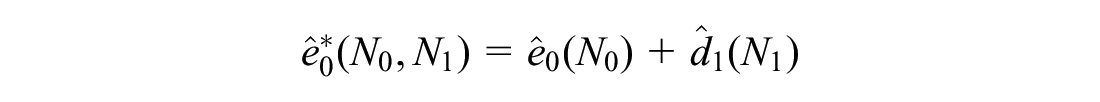
with the same degree of bias as
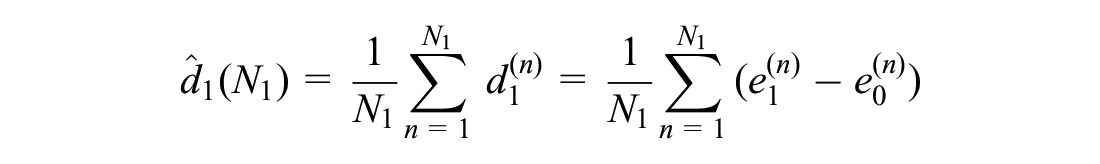
Then, if each term
MLMC is a natural extension of this principle. A sequence of estimators
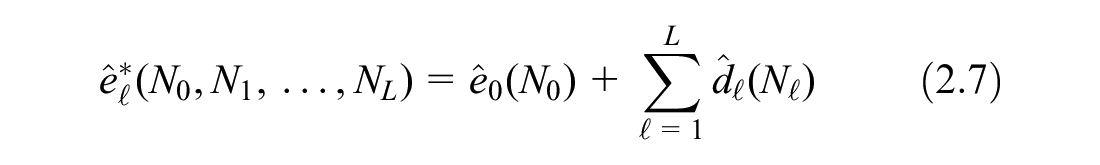
where the

Illustration of multilevel Monte Carlo (MLMC) estimation of expected value of partial perfect information (EVPPI). The horizontal lines represent estimates of the expected net benefit under partial perfect information, using
As shown in Giles and Goda,
23
given a required RMSE of
The number of levels
QMC Estimation of EVPPI
As explained in the introduction, standard Monte Carlo samples are pseudo-random (i.e., random samples from a distribution of interest) that are generated deterministically by a computer but statistically indistinguishable from truly random samples. Quasi-random samples, on the other hand, although not statistically random, can be used to approximate the distribution of interest, with fewer samples required for the same level of precision. Some examples of quasi-random samples are shown in Figure 1a and b, for a bivariate uniform distribution. These can be seen to cover the sampling space more evenly than a standard Monte Carlo sample (Figure 1c).
For example, given a scalar random variable
Two common approaches for generating low-discrepancy sequences are rank-1 lattice rules (illustrated in Figure 1a) and Sobol sequences (Figure 1b).
Rank-1 lattice rules generate samples as (
Sobol sequences
In the bivariate uniform example, using a rank-1 lattice method (Figure 1a), there are exactly 4 points in each small square, and using a Sobol sequence (Figure 1b), there are roughly 3 to 5 points in each small square. Thus, the sample space is covered more evenly than in the Monte Carlo method (Figure 1c).
A QMC estimator of EVPPI is defined by substituting the QMC sample
To do this for Sobol sequences, we perform digital scrambling using a bitwise exclusive-or operation. It maintains the low discrepancy by implementing a uniform random permutation of 0 and 1 for the binary expression of each sample
Then, the randomized QMC estimator of EVPPI is defined by substituting
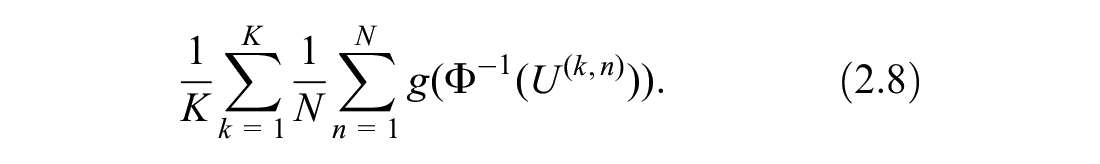
For the estimation of EVPPI, in most practical cases, the random variables
When using QMC for EVPPI, we apply it only to the outer samples
For QMC to achieve an MSE
However, similar to the standard MC method, QMC also fails to provide an estimate of bias. In the numerical tests of this article, we use MLMC only to estimate the bias and determine the number of inner samples required to bound the bias.
Applications
We tested our methods on 2 applications. One is a simplified depression model, while the other is a real atrial fibrillation model comparing DOACs for the prevention of stroke. The latter model, along with its results, is described in the appendix (section 7.4).
Simplified Cost-Effectiveness Model in Depression
We applied our MLMC and QMC EVPPI estimators to an artificial model comparing options for the treatment of depression. We adopted the decision tree structure illustrated in Figure 3. This is based on a previously published model but is populated with artificial quality of life and costs of outcomes as well as a Bayesian NMA, implemented using MCMC, of response and relapse outcomes from constructed randomized controlled trial data.
32
There are 3 options compared: no treatment, cognitive behavioral therapy (CBT), and antidepressants. We label these options
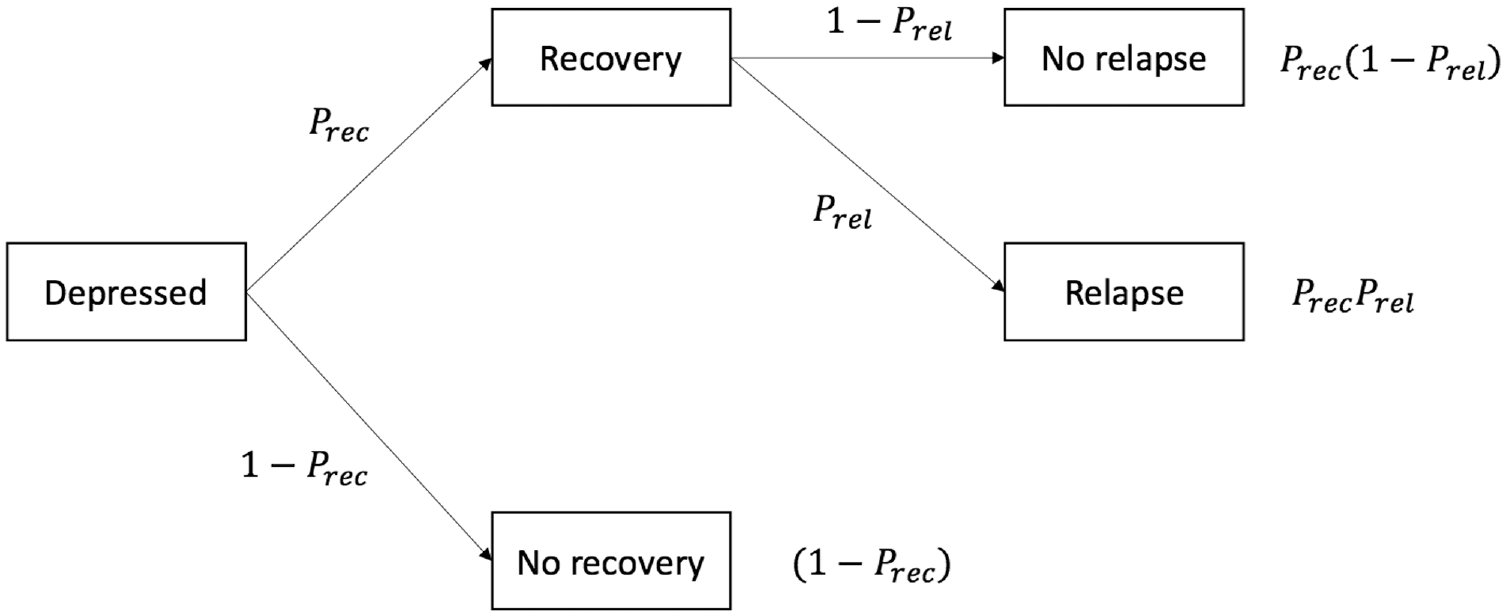
Decision tree for depression toy model (probabilities are defined in Table 2).
Costs and quality-adjusted life-years (QALYs) associated with 30 y (approximately lifetime) in the final states are assumed to follow normal distributions (Table 1).
30-y Costs and Quality-Adjusted Life-Years for the Depression Toy Model

As given in Table 2, we assumed Beta distributions for the probabilities of relapse and recovery on no treatment. Log odds ratios of recovery and relapse on CBT and antidepressants come from 2 NMAs, each of which consist of 5 trials based on constructed data. These data were analyzed using a Bayesian binomial outcomes logistic link NMA implemented in the OpenBUGS software version 3.2.3 rev 1012,19,33 which generated MCMC samples of the posterior distributions for the log odds of relapse and recovery. Because conditional distributions are necessary for EVPPI, we used the multivariate normal distributions to produce the following approximate posterior distributions.
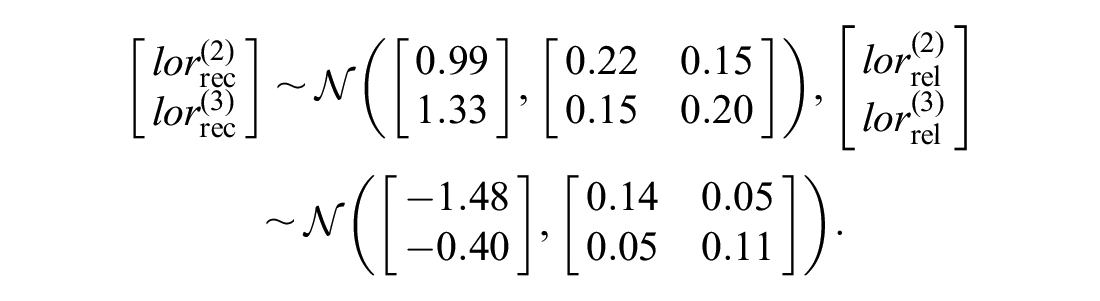
The NB for treatment option
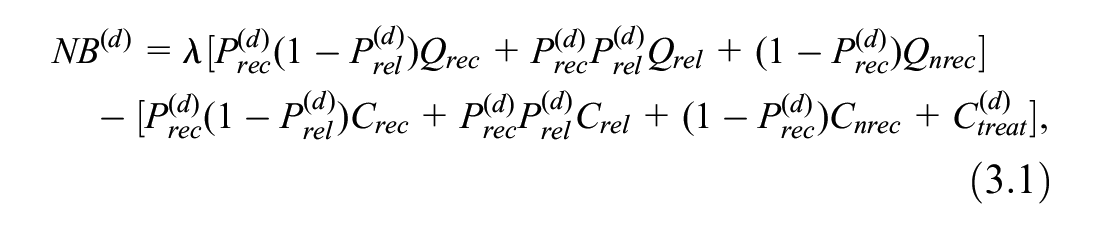
where
In our case,
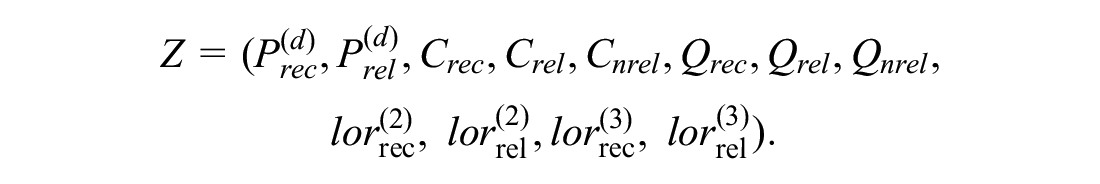
We estimate the EVPPI for 4 subsets
Probabilities of Events for the Depression Toy Model a

The expit is the inverse of the logistic link function with definition
Results
MLMC and QMC Results for Simplified Cost-Effectiveness Model in Depression
For comparison, we set the MSE to be 0.25 (
Comparison of Computational Cost Measured in Units of

From Table 3, we can see that QMC achieves the same degree of accuracy with lower computational cost than standard nested MC and MLMC when the optimal number of inner samples is determined, because QMC has the smallest numbers in the “Computational Cost” column in the table. MLMC starts to show computational savings only relative to standard nested MC for the calculation of EVPPI for
To reproduce the complexity that may be encountered in a real cost-effectiveness model, we extended our example from 3 to 20 treatment options. The model structure, outcome costs, and outcome QALYs remained the same, but treatment effects and costs were randomly generated. Both MLMC and QMC continue to work well, and QMC still has the lowest computational costs given the number of inner samples. Full details of the model and EVPPI results are provided in appendix sections 7.2.2 and 7.2.3.
Comparison with Regression Approximation Methods on a Simplified Cost-Effectiveness Model in Depression
We also calculated the EVPPI using the regression approaches of the GAM and GP, as implemented in the R code of Sheffield Accelerated Value of Information (SAVI) and stochastic partial differential equations INLA-GP, as implemented in the R package BCEA.12,14,34 Since the GP method requires large matrices to be inverted, SAVI is restricted to the first 7500 samples from an economic model for this method, while BCEA struggles with larger samples due to memory restrictions; also, the primary advantage of these methods is their ability to estimate EVPPI with fewer samples and thus lower computational cost. For these reasons, we used only 7500 samples for the comparison. To provide an approximately fair comparison, we restricted MC, QMC and MLMC to 50,000 samples, which has a similar computation time to running 7500 samples followed by GAM, GP, and INLA-GP regression. Note that SAVI automatically uses GP for parameter sets larger than 5, and in this example, with 6 parameters, GAM methods are computationally infeasible, 13 although the BCEA implementation of GAM also suffers with memory restrictions when applied to larger parameter sets. As a consequence, only the GP-based methods are possible for estimating the EVPPI for the 2 sets of 6 parameters. The R code of SAVI provides the estimates of both standard error (i.e., the standard deviation of the estimator) and the upward bias. 13 Similar to MLMC and QMC, the MSE of SAVI would be the sum of the variance of the estimator and the square of the upward bias. Furthermore, BCEA INLA-GP cannot estimate standard errors.
Table 4 suggests that both GP and GAM perform better for 2-dimensional sets of log odds ratios, giving estimates close to the reference and small standard errors. On the more complex 6-dimensional set of probabilities and the 6-dimensional cost and QALYs, QMC and MLMC are close to the reference MC estimate, but only QMC offers computational savings (lower RMSE) over standard MC. On these 6-dimensional sets, the point estimate for probabilities of GP is in agreement with those of MC methods, although the RMSE is larger and estimates appear to be biased. The point estimate for cost and QALYs of GP has a much smaller bias and standard error but is not consistent with the reference MC estimate. INLA-GP agrees on the 6-dimensional probabilities but gives a poor estimate of the EVPPI of the costs and QALYs. This was indicated by the BCEA diagnostic quantile-quantile plots (qq-plots), which suggested poor fit of the underlying regression model for INLA-GP (details in appendix section 7.3).
Comparison of Estimates and Uncertainties for EVPPIs in the Depression Toy Model a
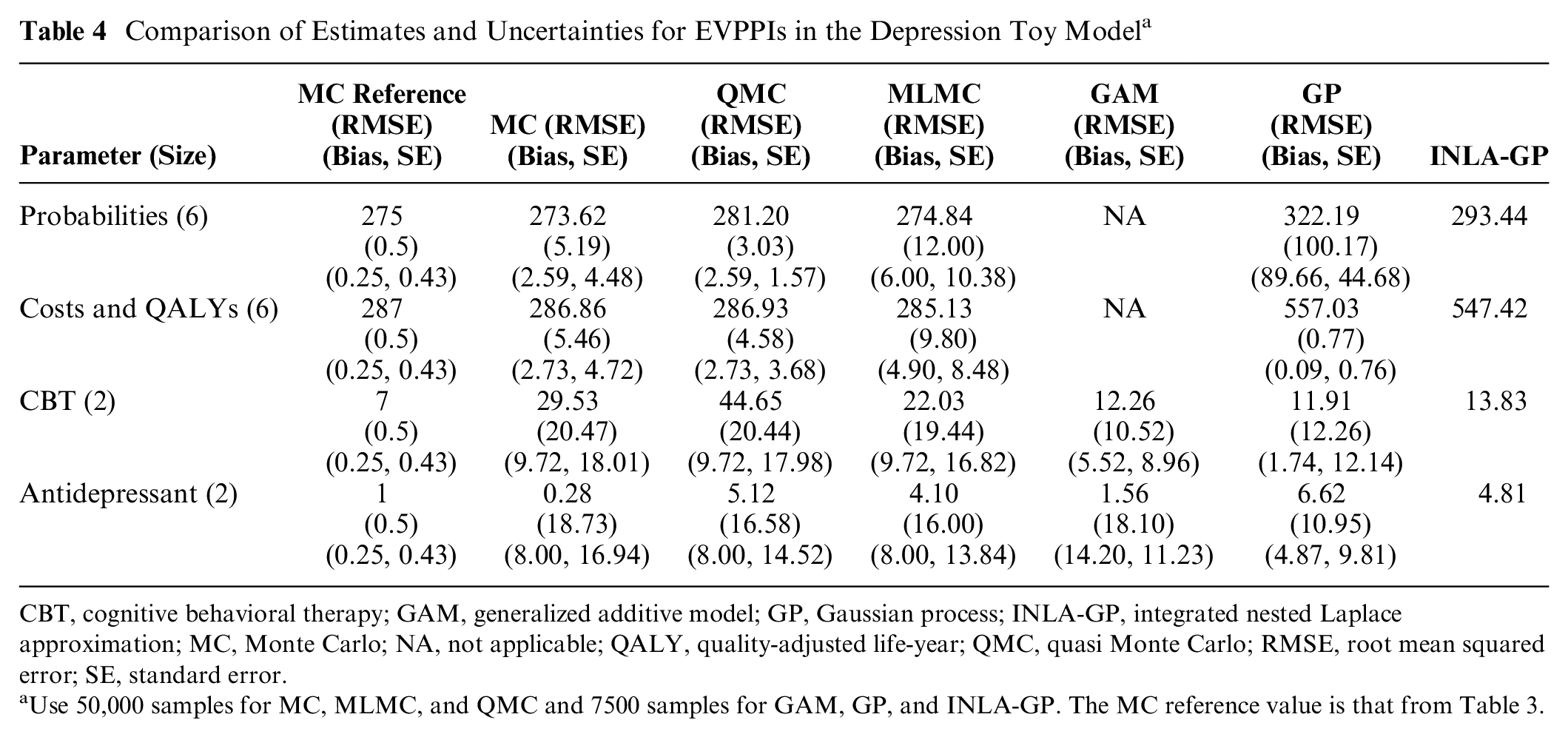
CBT, cognitive behavioral therapy; GAM, generalized additive model; GP, Gaussian process; INLA-GP, integrated nested Laplace approximation; MC, Monte Carlo; NA, not applicable; QALY, quality-adjusted life-year; QMC, quasi Monte Carlo; RMSE, root mean squared error; SE, standard error.
Use 50,000 samples for MC, MLMC, and QMC and 7500 samples for GAM, GP, and INLA-GP. The MC reference value is that from Table 3.
The EVPI and its RMSE for the depression model were 574.91 and 3.12 using standard MC, respectively, and 575.47 and 2.37 using QMC. The lower RMSE suggests computational savings from using QMC.
Discussion
This article has developed more efficient Monte Carlo sampling methods to estimate EVPPI in complex and realistic cost-effectiveness models. We have generalized the previously published MLMC estimator for EVPPI to models in which the distributions of input parameters are known only through MCMC samples and demonstrated that it can be much more efficient than standard MC for computing many-parameter EVPPI in a realistically complex economic model. We have also provided the first implementation of QMC to EVPPI estimation. Unlike previous work on efficient EVPPI estimation via model regression and INLA-GP,12,13,34 we have separately quantified both bias and variance of our estimators and included them in our credible intervals. We have compared the accuracy of the QMC and MLMC methods relative to the GAM, GP, and INLA-GP regression approaches for the same approximate computational cost. The MLMC estimator can easily give an estimate of the bias, and this can be used to obtain credible intervals for MLMC but also for both QMC and standard nested MC estimators, so long as MLMC is conducted in addition to either QMC or MC.
The main contributions of this article have been to extend MLMC for EVPPI and develop QMC for EVPPI. Although our results suggest that QMC and MLMC can provide substantial computational savings over MC, and greater accuracy than regression techniques, we have explored only 2 example models. A more formal investigation would be needed to fully compare MC, MLMC, QMC, and regression. This could involve building a range of models with increasing numbers of health states, input parameters, and decision options and exploring higher correlation and greater MCMC on the input parameters. Further theoretical research is also required to understand why each of the methods performs well under different circumstances. Without such a program, it would be inappropriate to generalize and make firm recommendations. However, we make some observations based on our empirical findings and the theoretical understanding of QMC and MLMC.
Our depression example in the “Results” section and atrial fibrillation DOACs example in appendix section 7.4 may indicate a general trend that QMC outperforms MLMC when the underlying model is simple (e.g., decision tree or Markov model with few states, few parameters, low correlation) and MLMC outperforms QMC when the model is complex (e.g., Markov model with many states, large numbers of correlated or MCMC parameters). Our depression toy example also indicated that MC can outperform MLMC when the models are simple. If an estimate of the bias is required, MLMC must be employed as Monte Carlo and QMC, and regression cannot estimate the bias. Furthermore, if very high accuracy, or low bias, is required, MLMC is likely best, as higher levels of MLMC will eventually achieve any accuracy; however, this may not be computationally feasible. Conversely, if the EVPPI is very small, which could be found by an initial run of Monte Carlowith few samples, then MLMC may offer limited computational savings over Monte Carlo. Indeed, we found in the depression toy example that MLMC could not provide an estimate for small EVPPI in a reasonable time. Theoretically, QMC should be no worse than Monte Carlo in all cases. However, the computational savings depends on the specific case. In practice, furthermore, QMC can perform worse than Monte Carlo, as was seen for the simple trial example in the DOACs model, where our implementation failed to produce an estimate in a reasonable time as too many inverse distribution function evaluations were needed.
We have also found that MLMC and QMC provide more reliable and computationally efficient estimates of the EVPPI than regression techniques when parameter sets are large and when the EVPPI value is large and a precise EVPPI estimate is required. Conversely, and in line with MLMC theory, we did not find a huge advantage over standard Monte Carlo or approximation methods when the EVPPI or parameter sets are small. We also do not expect an advantage of MLMC or QMC when applied to single-parameter EVPPI. However, we found using QMC conferred computational savings over standard Monte Carlo when estimating the total EVPI.
From our experiment, to incorporate inputs whose distribution is estimated by MCMC, our MLMC and QMC methods do not rely on many approximations or distributional assumptions. Note that in QMC, we use Principle Component Analysis (PCA) to identify which of the first 2 dimensions of
A primary disadvantage of the MLMC method from an applied perspective is the requirement for more than a single random sample from a standard probabilistic sensitivity analysis. The model regression approaches of GP, GAM, or INLA-GP require only samples from the input parameters and the estimated costs and QALYs to provide estimates of EVPPI. MLMC requires implementation of a more complicated form of nested simulation than in standard Monte Carlo, plus sampling from conditional distributions to provide the necessary estimates. This challenge may limit its applicability. We have provided R code in the appendix for both the depression and DOACs model, which users can adapt to their own models. QMC also requires conditional sampling but can use the same code as standard nested Monte Carlo; it requires only a switch to quasi-random numbers for the random-number generators (example code also provided in the appendix). However, we found that QMC did not work as well in the case of highly complex cost-effectiveness models such as Markov models.
Although we have used very large numbers of simulations (
Our work so far has been limited to EVPPI, but to truly determine whether a future study will be cost-effective, we would need an estimate of the EVSI. 5 Although the EVPPI for a set of parameters may be large, the EVSI for all but impractical study designs could be small. Despite its importance, EVSI is rarely estimated because of the unfamiliarity with the skills required and, for trials potentially informing many parameters, high computational requirements. 36 Efficient sampling schemes, such as importance sampling, Gaussian approximation, and moment matching approaches have been explored, but a general solution applicable to all model and trial complexities remains elusive.11,37,38 Implementing QMC for EVSI would be straightforward, although the computational savings are unknown. Conversely, constructing an MLMC estimator, necessary for bias estimation, would require considerable research effort. However, MLMC and QMC may provide an accurate and efficient estimator of EVSI and improve its adoption by the heath economic community.
Conclusion
In this article, we developed MLMC and QMC for the computation of EVPPIs and applied them a decision tree and Markov model example. In some cases, both methods improved the computational efficiency of the standard nested MC method, although they are more difficult to implement than standard MC. We found that for small numbers of parameters and small EVPPI values, GAM and GP were sufficient for EVPPI estimation. However, for large numbers of parameters and EVPPI values, where GAM is not feasible, MLMC and QMC can provide substantially more accurate and precise estimates than GP and INLA-GP. Further theoretical and empirical research is required to make formal recommendations between standard nested MC, QMC, MLMC, and the regression techniques.
Supplemental Material
sj-bib-2-mdm-10.1177_0272989X211026305 – Supplemental material for Multilevel and Quasi Monte Carlo Methods for the Calculation of the Expected Value of Partial Perfect Information
Supplemental material, sj-bib-2-mdm-10.1177_0272989X211026305 for Multilevel and Quasi Monte Carlo Methods for the Calculation of the Expected Value of Partial Perfect Information by Wei Fang, Zhenru Wang, Michael B. Giles, Chris H. Jackson, Nicky J. Welton, Christophe Andrieu and Howard Thom in Medical Decision Making
Supplemental Material
sj-pdf-1-mdm-10.1177_0272989X211026305 – Supplemental material for Multilevel and Quasi Monte Carlo Methods for the Calculation of the Expected Value of Partial Perfect Information
Supplemental material, sj-pdf-1-mdm-10.1177_0272989X211026305 for Multilevel and Quasi Monte Carlo Methods for the Calculation of the Expected Value of Partial Perfect Information by Wei Fang, Zhenru Wang, Michael B. Giles, Chris H. Jackson, Nicky J. Welton, Christophe Andrieu and Howard Thom in Medical Decision Making
Footnotes
Acknowledgements
We are grateful to Mark Strong at the University of Sheffield for providing his R code to estimate EVPPI, plus its standard error and upward bias, using GAM and GP. The mlmc.R and mlmc.test.R files used to run multilevel Monte Carlo were developed by Louis Aslett, Mike Giles, and Tigran Nagapetyan. 39 This code has been used previously for published MLMC applications. 40
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: WF, ZW, and HT were supported by the Hubs for Trials Methodology Research (HTMR) network grant N79 for this work. HT and NJW were supported by the HTMR Collaboration and innovation in Difficult and Complex randomised controlled Trials In Invasive procedures (ConDuCT-II). HT and NJW were also supported by the National Institute for Health Research (NIHR) Bristol Biomedical Research Centre (BRC) for part of this work. HT was furthermore supported by MRC grant MR/S036709/1. CA would like to thank the support of EPSRC EP/R018561/1 Bayes4Health. CJ was funded by the UK Medical Research Council programme MC_UU_00002/11. The directly acting oral anticoagulants for prevention of stroke in atrial fibrillation model was funded by NIHR Health Technology Assessment programme project number 11/92/17 and NIHR Senior Investigator award NF-SI-0611-10168.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.