
Abstract
Keywords
Evidence of clinical effectiveness can arise from multiple sources. Pairwise meta-analysis (MA) is an established statistical tool for estimating the relative efficacy of 2 interventions evaluated in randomized controlled trials. In the absence of head-to-head studies, network meta-analysis (NMA) can be used to synthesize all available evidence and make simultaneous comparisons between treatments.
A pairwise MA and NMA can be conducted using a fixed effect or a random effects model. These models differ in their assumptions as well as in the interpretation of the treatment effects.1–4 The choice of which model to use depends on the objective of the analysis and knowledge of the included studies. In this paper, we investigate the circumstances when and rationale for using these 2 models in single technology appraisals (STAs) submitted to the National Institute for Health and Care Excellence (NICE), which appraises health technologies and provides guidance to the National Health Service in England. We also propose how to overcome the problem of imprecise estimates of the heterogeneity parameter in the absence of sufficient sample data.
A fixed effect model would be appropriate if the objective is to determine whether the treatment had an effect in the observed studies (i.e., a conditional inference) or it would be appropriate when it is believed that the true treatment effects in each study are the same. Heterogeneity is expected in MAs because they combine studies that have clinical and methodological heterogeneity. 5 A random effects model would be preferred because it allows for heterogeneity in the treatment effects among the studies and allows the results to be generalized beyond the studies included in the analysis. Nevertheless, fixed effect models are still commonly used even when heterogeneity is expected.
Parameters can be estimated from either a frequentist or Bayesian perspective. The Bayesian approach provides more natural and useful inference, can incorporate external information, and is ideal for problems of decision making. There has been an increase in the use of Bayesian evidence synthesis in submissions to NICE, perhaps primarily because the evidence synthesis Technical Support Documents (TSDs) issued by the NICE Decision Support Unit (DSU)6–11 advocate the Bayesian approach.
A random effects model requires an estimate of the between-study SD. When the number of included studies is small, the estimate of the between-study SD will be highly imprecise and biased in a frequentist framework such as using DerSimonian and Laird estimate. 1 Similarly, a Bayesian analysis of only limited data, using a standard, vague or weakly informative prior distribution for the between-study SD will give implausible posterior distributions. 12 A proper Bayesian analysis requires genuine specification of the prior distribution using external evidence, typically including experts’ beliefs. Note that a judgement that a posterior distribution is implausible by an individual suggests that he/she must have some prior beliefs to make elicitation feasible.
NICE DSU TSD 7 suggests comparing goodness-of-fit of both fixed effect and random effects models using the deviance information criteria (DIC). 13 However, when the number of studies is small, it is likely that either model would at least provide an adequate fit to the data, specifically when the data are not sufficiently informative to learn about the between-study SD. Rather than goodness-of-fit, the issue is therefore how best to appropriately represent uncertainty about the treatment effect. When heterogeneity is expected, a fixed effect model is likely to be overconfident, and a random effects model with a vague prior is likely to be underconfident: a compromise between these 2 extremes is needed, which can be achieved with a more informative prior distribution.
Higgins et al. 14 presented an example of a Bayesian MA of MAs to create a predictive distribution for the between-study variance in gastroenterology. Other authors have generated predicative distributions for the heterogeneity expected in future MAs in more general settings using data from the Cochrane Database of Systematic Reviews for a log odds ratio (LOR),15–17 and a standardized mean difference. 18 Smith et al. 19 constructed an informative prior distribution for the between-study variance using a gamma distribution by assuming that odds ratios (ORs) between studies have roughly one order of magnitude spread, and that it is very unlikely that the variability in treatment effects between studies varies by 2 or more orders of magnitude. Spiegelhalter et al. 20 suggested that a half-Normal distribution could be used as a prior distribution for the between-study SD and showed how to interpret the prior distribution. NICE DSU TSD 8 also suggested using an informative half-Normal prior distribution with a mean of 0 and a variance of 0.32 2 , representing the belief that 95% of the study-specific ORs lie within a factor of 2 from the median OR for each comparison. Both half-Normal prior distributions are proposed for treatment effects measured by ORs. To the best of our knowledge, there has been little work on the formal elicitation of experts’ beliefs for the between-study SD in random effects MA models.
To investigate the application of fixed effect and random effects models in submissions to NICE, we conducted a review of all the STAs completed up to 31 October, 2016. (Although this is a selective set, we believe the findings likely to be consistent with the rationale for analyses by international pharmaceutical companies to other HTA decision makers.) The results of the review are presented in Section 2. In Section 3, we propose novel methods to construct an informative prior distribution for the between-study SD using external information for all common types of outcome measures. Examples of re-analyzing 2 STAs using the proposed elicitation framework are given in Section 4.
A Review of NICE STAs
Two hundred and thirty-nine NICE STAs were completed between September 2005 (when the STA process was introduced) and 31 October 2016. After assessment by SR, a final set of 183 STAs was identified for review. Figure 1 presents a flow chart of the identification, inclusion, and exclusion of STAs. We have only reviewed the original companies’ submissions, and not considered additional analyses that may have occurred during the appraisal process.
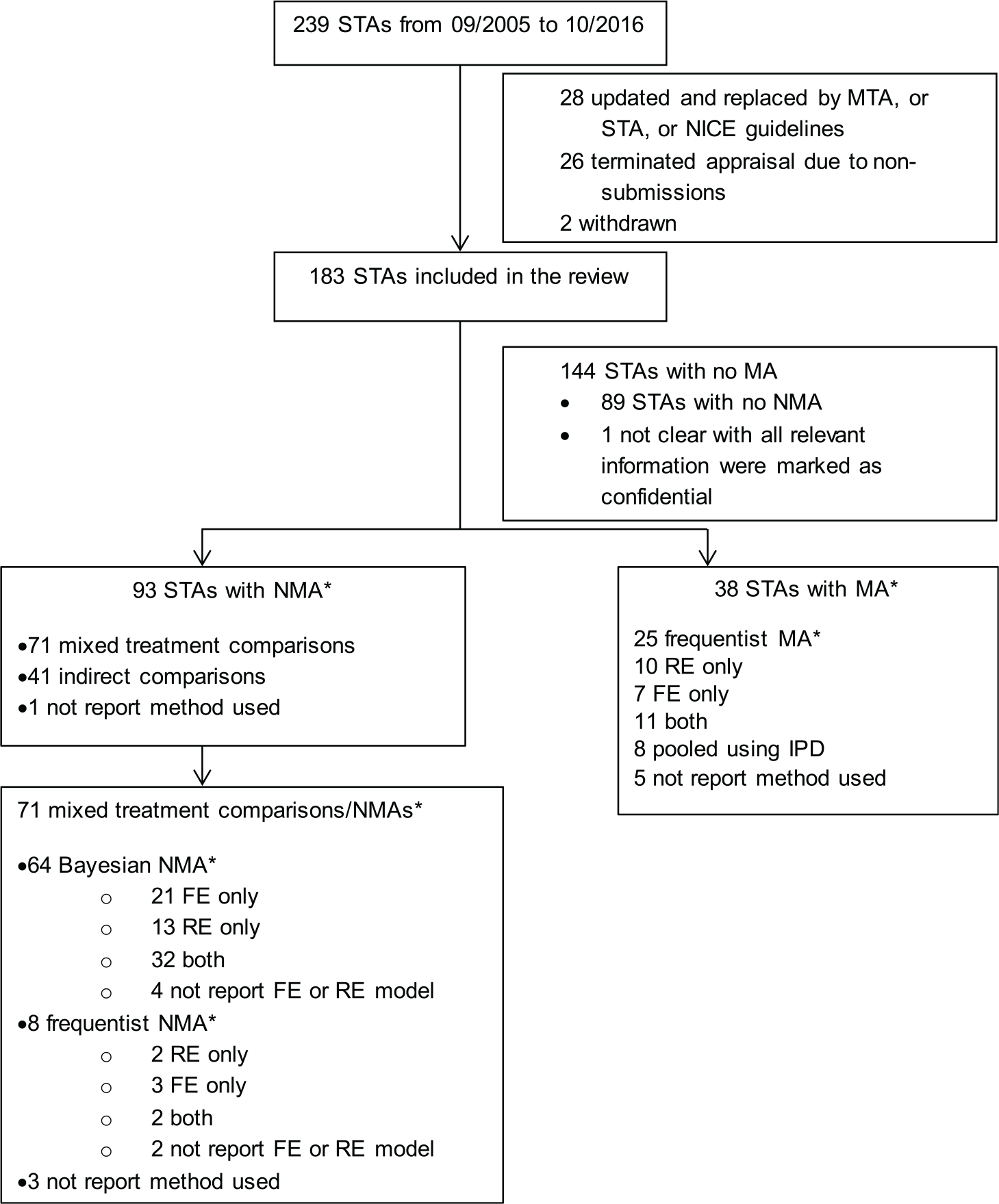
Flow chart showing the identification, inclusion, and exclusion of reviews. STA, single technology appraisal; MTA, multiple technology appraisal; RE, random effects; FE, fixed effect; MA, meta-analysis; NMA, network meta-analysis; IPD, individual patient-level data. *Multiple analyses and analyses for multiple outcomes may have been conducted in one submission.
Thirty-eight STA submissions used pairwise MAs with a single approach being applied within each submission: 25 (66%) used a frequentist approach to estimate parameters and make inferences; 8 (21%) pooled individual patient-level data across studies; and, in 5 cases (13%), it was unclear which method was used. Ninety-three STA submissions included NMAs (multiple approaches may have been used in one submission): 71 (76%) of these used either a Bayesian or a frequentist NMA, 41 (44%) used Bucher indirect comparisons 21 , and 1 (1%) didn’t report the method.
We extracted the rationale for using fixed effect and random effects model for both pairwise MAs and NMAs. The findings of the review are presented in Table 1 and are summarized as follows:
All submissions that performed pairwise MAs used a frequentist approach, and most that performed NMAs used a Bayesian approach (90%).
71% of the submissions that performed fixed effect pairwise MAs did not provide a justification for the model choice. For the submissions that performed random effects MAs, 60% gave no justification for the model choice. Fewer submissions using NMAs provided no justification for the model choice: 25% and 27% for fixed effect and random effects model, respectively.
The most frequently stated reason for the use of a fixed effect model was that there were too few studies to conduct a random effects model.
In some cases, where heterogeneity was noted, there was an acknowledgement that a random effects model would be appropriate but it was not used when there were only few studies.
Among the pairwise MAs that used a frequentist approach, the choice of fixed effect or random effects model was typically assessed using the Q-statistic/I2-statistic.
When Bayesian fixed effect and random effects models were both used in a submission, the most popular method for choosing the final model was comparing the DIC statistic for the 2 models (62%).
Providing either a fixed effect or random effects model within a sensitivity analysis was observed in both pairwise MAs (9%) and NMAs (21%) in the case where both models were used.
Four submissions performed sensitivity analyses using different prior distributions for the between-study SD. TA288 22 considered the possibility of using alternative data sources to inform the prior distribution but concluded that no suitable sources were available. TA341 23 used a prior distribution informed using predictive distributions proposed by Turner et al. 16 TA173 24 used a half-Normal prior based on a re-analysis of the data from a previous systematic review. TA343 25 used a half-Normal prior distribution suggested by NICE DSU TSD. 8
Justifications of Model Choice in Submissions
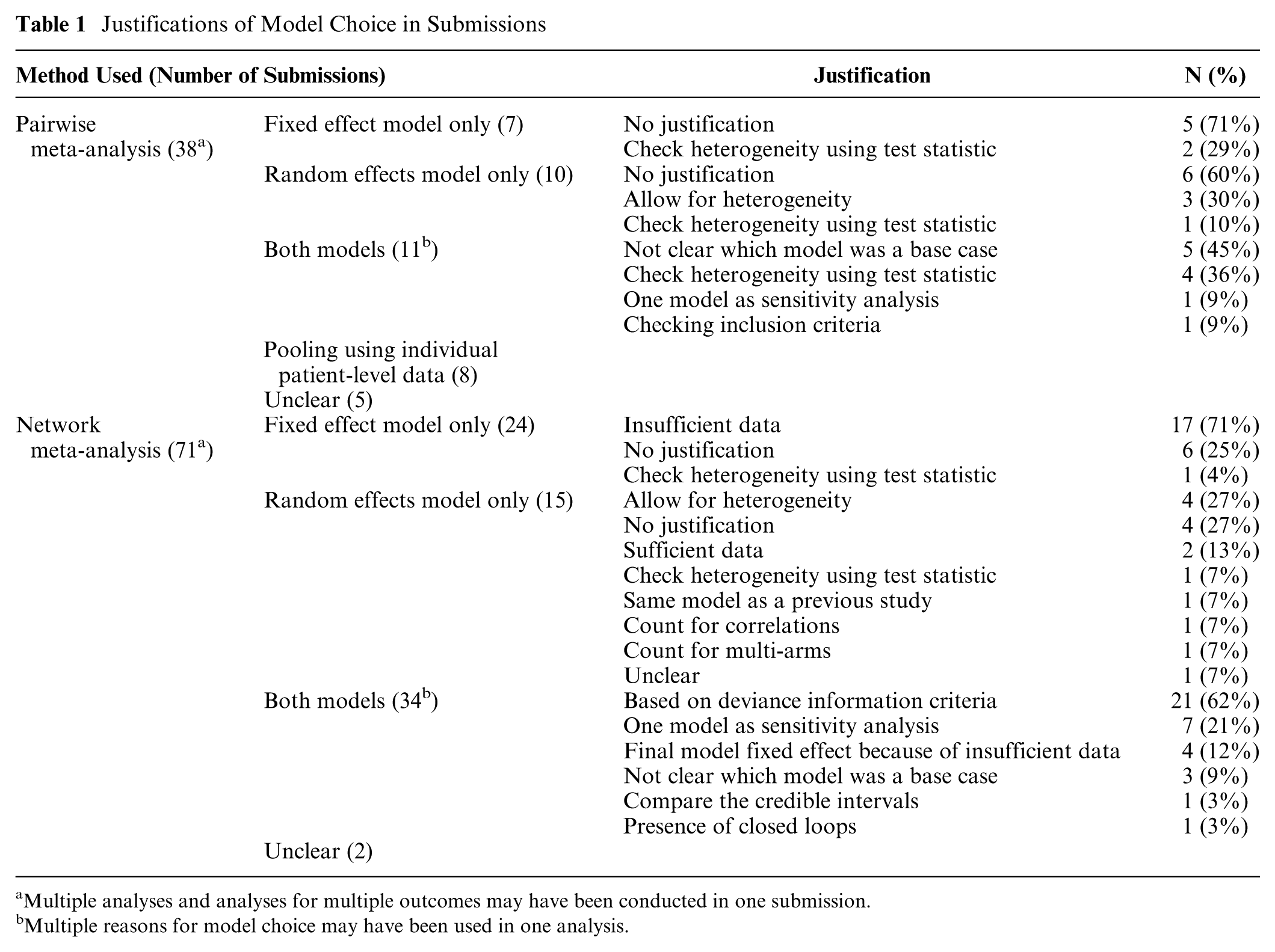
Multiple analyses and analyses for multiple outcomes may have been conducted in one submission.
Multiple reasons for model choice may have been used in one analysis.
Overall, we found that the most frequently stated reason for the use of a fixed effect model was that there were too few studies to conduct a random effects model but not that there was unlikely to be heterogeneity or that a conditional inference was of interest. This showed that there is a need for more guidance on properly accounting for heterogeneity when the number of included studies is small. We now present a framework for constructing prior distributions for the heterogeneity parameter using external information such as empirical evidence and experts’ beliefs.
General Elicitation Framework
For simplicity, we suppose that there is one female expert and the elicitation is conducted by a male facilitator. We do not consider issues such as the selection and training of experts, motivation, and how to elicit a prior distribution from multiple experts, which are covered elsewhere.26–28 The general elicitation framework proposed in this section is for performing a pairwise MA. An extension to the approach for use in NMAs is discussed later.
We envisage that the elicitation will take place after specification of the decision problem and completion of the systematic literature review, with the finding that few studies satisfy the inclusion criteria for the MA. The expert making the judgments could be a clinician or an analyst who conducts the MA. We envisage her to have expertise specific to the disease area and treatments under investigation. She will be given the information on the decision problem, including population, intervention, control, outcome, and the summary of baseline characteristics of the included studies, and is encouraged to think about any potential treatment effect modifiers.
Suppose that there are
We assume that
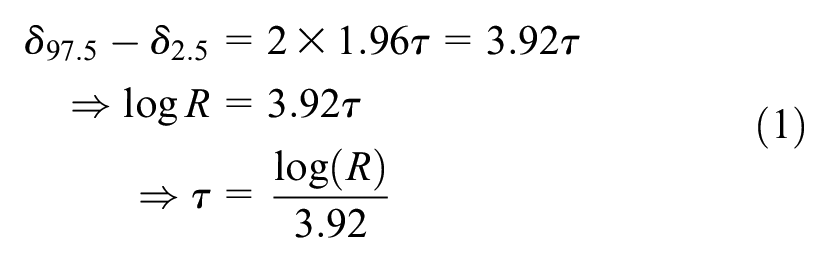
We propose asking the expert to make judgements about
A Three-stage Procedure for Eliciting the Prior Distribution for the Between-study SD
In some cases, even with adequate training, the expert may find it difficult to make the judgements about
Stage 1: Confirmation of the Need for a Random Effects Model
The fixed effect model is a special case of the random effects model, corresponding to the judgement that
“Can you be certain that the treatment effects across the studies will be identical, ignoring within-study sampling variability?”
If she is certain that this will be the case, then a fixed effect model should be used with appropriate justification provided. Otherwise, we proceed to Stage 2.
Stage 2: Consideration of an Upper Bound for R
If a random effects model is deemed to be appropriate, the expert is then asked if she can provide an upper bound for
“Let
If the expert’s answer for
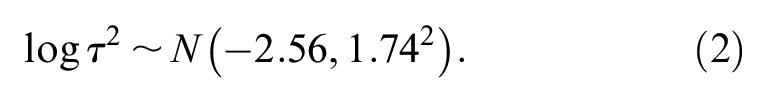
If she can provide
Stage 3: Consideration of a Full Distribution for
We now ask if the expert judges some values in the range
If she can continue with the roulette method, then the range
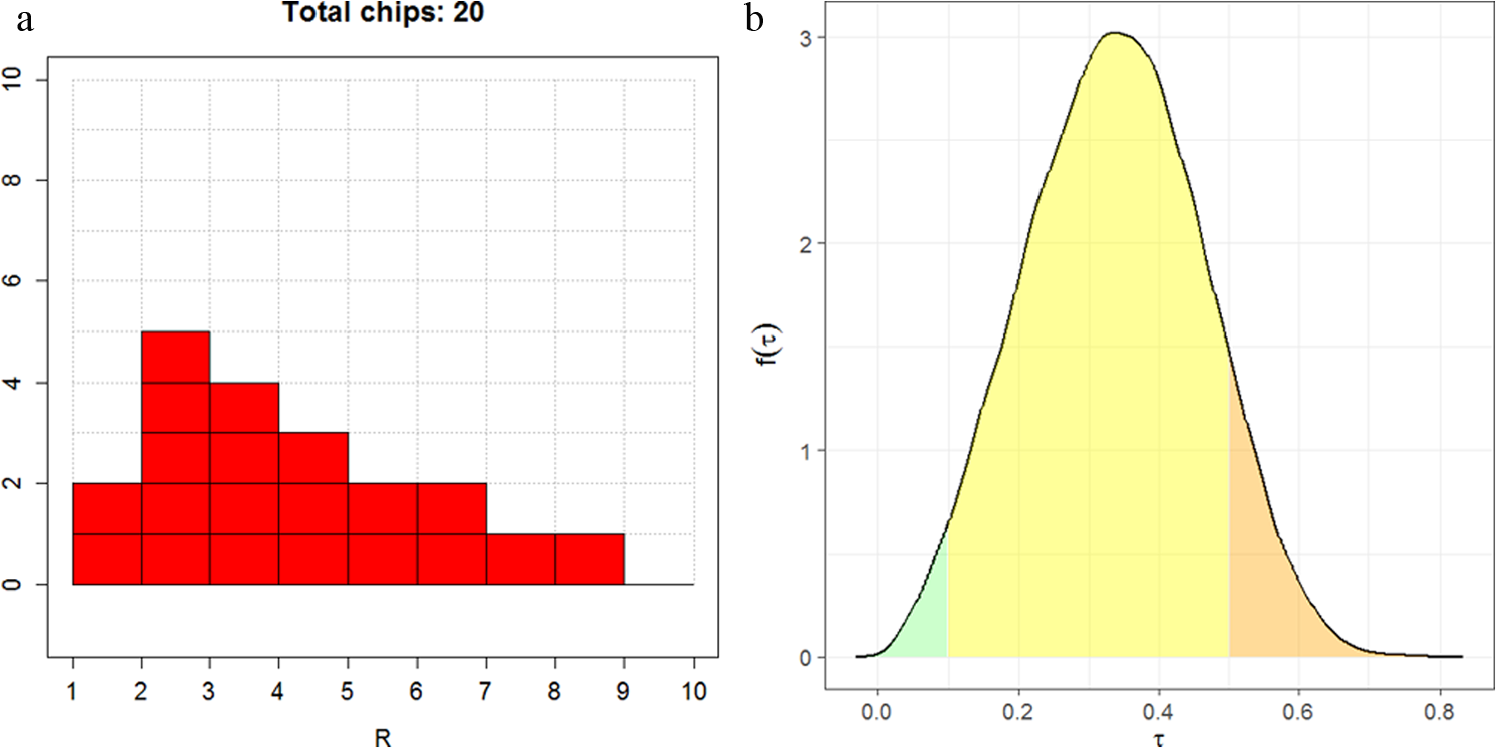
(a) Eliciting beliefs about
We suggest fitting either a gamma or lognormal distribution to the elicited probabilities by choosing the distribution parameters to minimize the sum of squares between the elicited and fitted cumulative probabilities. The R package SHELF
30
will identify the best fitting distribution out of the gamma and lognormal; although, there is unlikely to be much difference in the fitted distributions in most practical situations. Given that
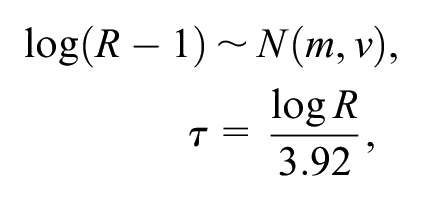
where
Feedback
We propose providing feedback to the expert about the implied distribution of
Other Types of Outcome Measures
Other scale-free outcome measures include hazard ratio, relative risk, and ratio of means for continuous outcomes.32,33 The 3-stage procedure could be used in these cases; although, it is less clear that the prior distributions proposed by previous authors15–17 would be appropriate because the distributions were derived based on empirical evidence of heterogeneity in ORs in MAs. It is likely that an elicitation exercise considering a full distribution for the ratio of treatment effects
When the outcome measure is continuous or ordered categorical with the MA model using the identity or probit link functions, the expert may find it difficult to express beliefs about the “range” of treatment effects because the continuous measurement is not unit-free and the probit scale is difficult to interpret directly. We propose using the method described in Section 3.1 with the following modification:
Dichotomize the response using some appropriate cut-off
Considering ORs for the dichotomized response, use the 3-stage procedure to elicit a prior distribution for
Given a prior distribution for
with
Details of the derivation can be found in Appendix 1.
Network Meta-analysis
NMAs typically assume a homogeneous variance model.7,14,34 A similar elicitation method as described above can be used to elicit the common heterogeneity parameter in an NMA. We suggest asking the expert for the “range” of treatment effects
Examples: Reanalysis of Two STAs
We re-analyzed the data from 2 NICE STAs (TA163 35 and TA336 36 ) to demonstrate the use of our proposed method. BUGS code incorporating the different prior specifications is provided in Appendix 2.
TA163
35
was a technology appraisal of infliximab for treating acute exacerbations in adults with severely active ulcerative colitis. Data were available from 4 studies of 3 treatments (placebo, infliximab and ciclosporin; Figure 3). The outcome measure was the colectomy rate at 3 mo. A fixed effect model was used in the original submission. Table 2 presents results from a Bayesian NMA using a fixed effect model, a random effects model with a vague prior distribution uniform [0, 5], as used in Dias et al.,
7
and 3 alternative informative prior distributions: the prior distribution in equation (2), both untruncated and truncated so that
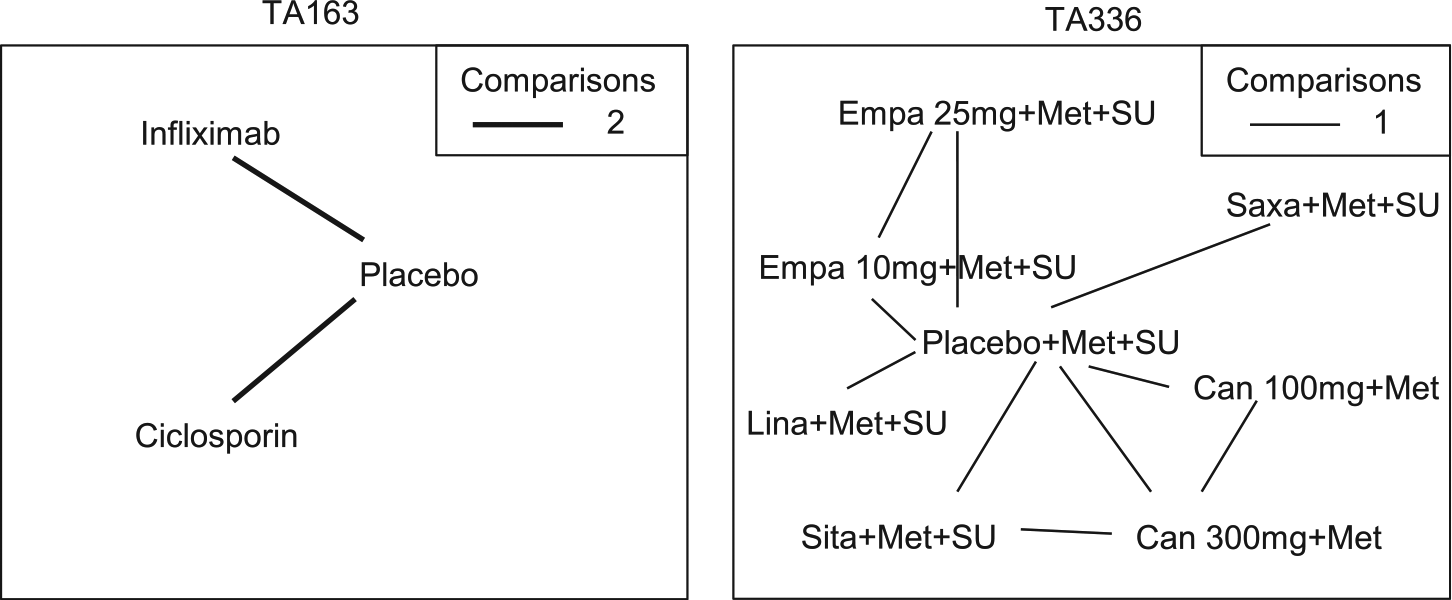
Network diagram for TA163 35 and TA336 36 used in the example. The thickness of the line represents the number of times pairs of treatment have been compared in studies. Empa, empagliflozin; Lina, linagliptin; Sita, sitagliptin; Saxa, saxagliptin; Can, canagliflozin; Met, metformin; SU, sulphonylurea.
Comparison of Results Obtained from Fixed Effect and Random Effects Models a
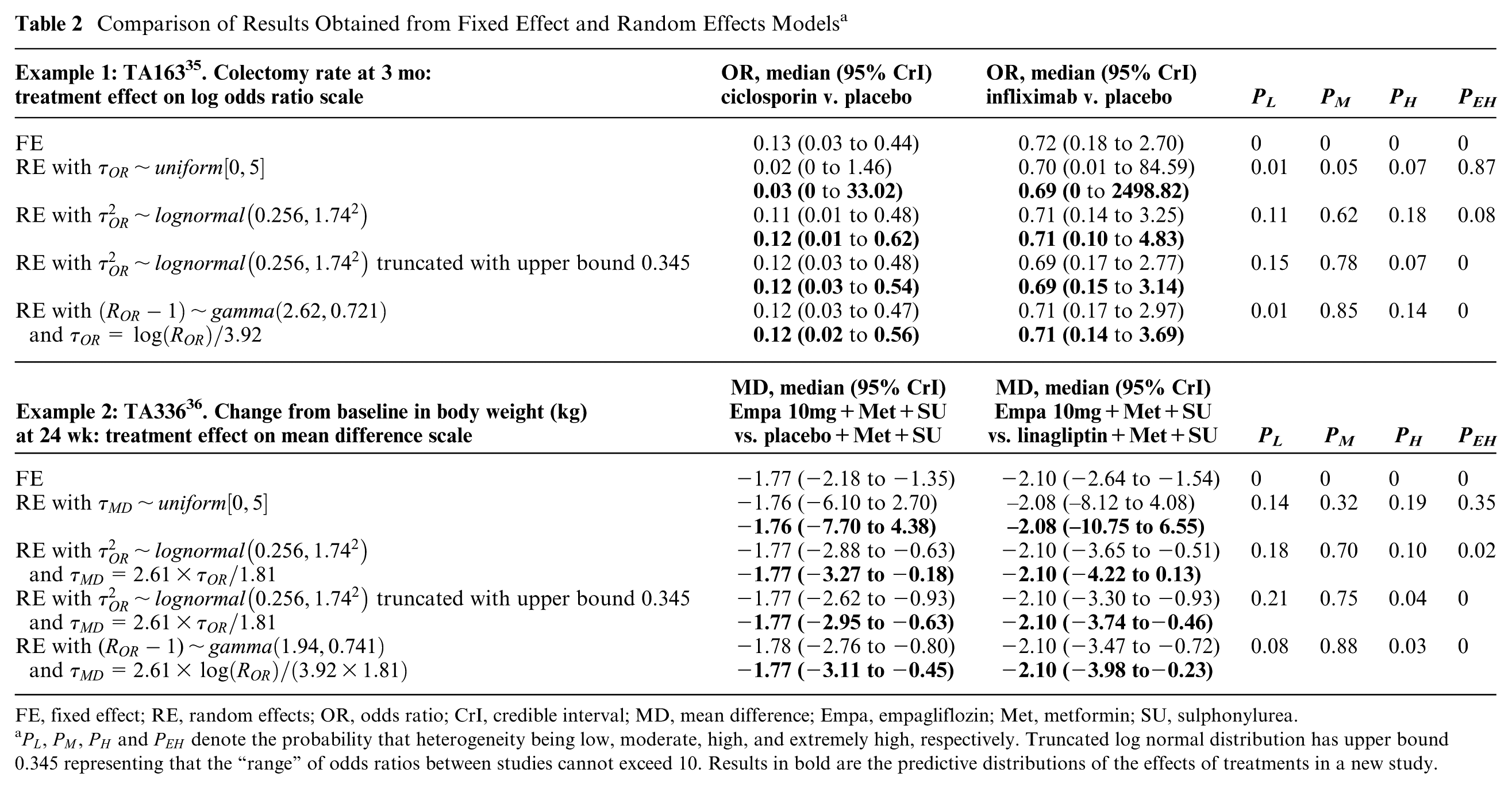
FE, fixed effect; RE, random effects; OR, odds ratio; CrI, credible interval; MD, mean difference; Empa, empagliflozin; Met, metformin; SU, sulphonylurea.
As expected, the DIC statistics for the 5 models were fairly similar: 34.72, 33.44, 34.70, 35.19, and 34.60, and did not provide support for any one model over another. The fixed effect model showed that there was evidence that ciclosporin reduced the colectomy rate at 3 mo relative to placebo in the studies included in the NMA, whereas there was insufficient evidence to conclude that infliximab had an effect relative to placebo in the included studies. As expected, the results of the random effects model demonstrated the sensitivity of the results to the different prior beliefs about the heterogeneity parameter. The uniform [0, 5] prior for the heterogeneity parameter was not “updated” appreciably by the data (Figure 4) and gave very different results compared to the fixed effect model (Table 2). There was a large posterior probability, 0.87, that heterogeneity was extremely high, equivalent to saying that the probability that the OR in a study could be 50 or more times that of the OR in another was 0.87 (The interpretation of the heterogeneity parameter can be found in Appendix 1). This is unlikely to be plausible, and the results using this prior distribution would not lead to reasonable posterior beliefs.
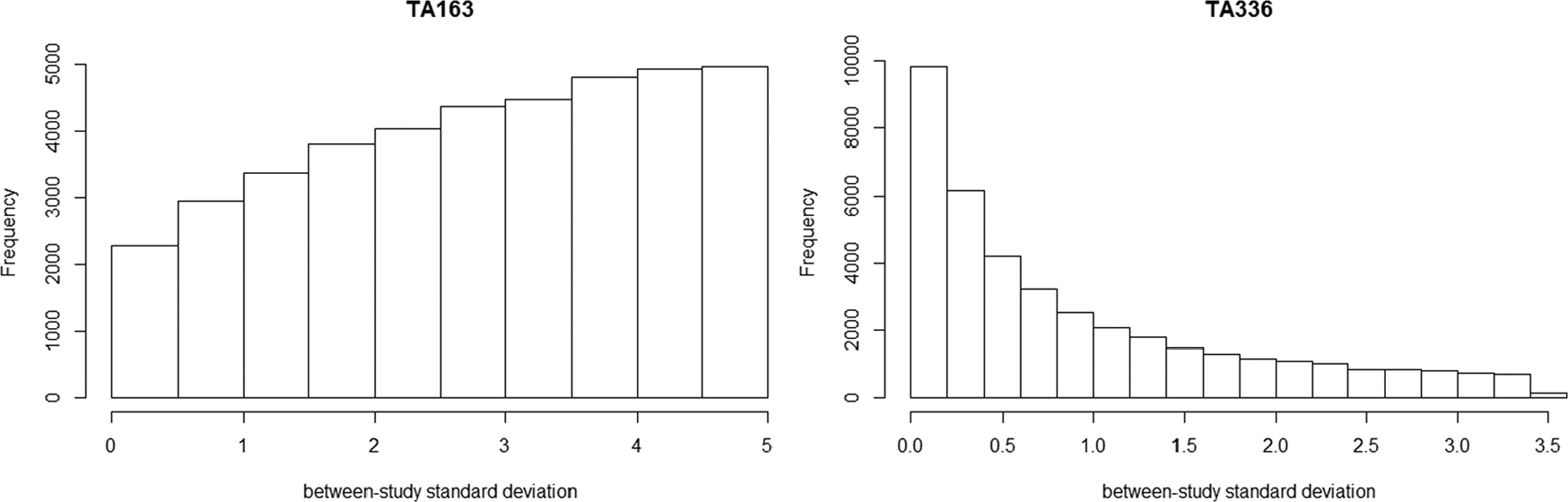
Posterior histogram plot of the between-study SD using prior distribution as uniform [0,5].
Results using empirical evidence as prior distribution and the elicited prior distributions for the heterogeneity were much less uncertain than those produced using the uniform prior distribution but, as expected, differed depending on which prior distribution was used (Table 2). Using the untruncated lognormal prior, there was a small posterior probability that heterogeneity was extremely high, 0.08. The truncated lognormal and elicited prior distributions for the heterogeneity parameter both provided zero posterior probability of extreme values for the between-study SD. The truncating eliminated the possibility of extreme heterogeneity; i.e., the largest OR in one study could be no more than 10 times the OR in another study. The elicited prior distribution can be found in Appendix 3, which resulted in the probability of heterogeneity being low, moderate, and high as 0.01, 0.85, and 0.14, respectively. The analyses using informative prior distributions for the heterogeneity parameter all suggested that ciclosporin reduced the colectomy rate at 3 mo compared with placebo based on both the credible and prediction intervals, but the effect of infliximab v. placebo was inclusive. The credible and predictive intervals in the analyses using empirical evidence and elicited prior distributions were wider than the fixed effect interval because of the extra uncertainty but more plausible than analyses based on the fixed effect model and random effects model with a uniform prior distribution.
TA336 36 was a technology appraisal of empagliflozin for the treatment of type 2 diabetes mellitus. Data were available from 6 studies of 8 treatments in combination with metformin (Met) or metformin and sulphonylurea (Met+SU) (placebo, 10 and 25 mg empagaliflozin, linagliptin, sitagliptin, saxagliptin, and 100 and 300 mg canagliflozin). The outcome measure re-analyzed here is the change from baseline in body weight for the third line treatment of type 2 diabetes mellitus at 24 wk. A fixed effect model was used in the original submission.
Table 2 presents the results of 10 mg empagliflozin + Met + SU v. placebo + Met + SU and linagliptin + Met + SU as an illustration. The DIC statistics for the 5 models were again similar: 3.82, 4.94, 4.61, 5.01, and 4.65. The fixed effect model showed that 10 mg empagliflozin +Met + SU reduced the change from baseline in body weight compared with placebo + Met + SU and linagliptin + Met + SU. When using the uniform [0, 5] prior distribution for the heterogeneity parameter, there was more “updating” in this case (Figure 4) but still a large posterior probability, 0.35, that the heterogeneity was extremely large. There was a small probability, 0.02, that the heterogeneity was extremely large when untruncated lognormal was used as the prior. The truncating eliminated the possibility of extreme heterogeneity in treatment effects between studies. The elicited prior can be found in Appendix 3, which resulted in the probability of heterogeneity being low, moderate and high as 0.06, 0.88, and 0.06, respectively. The analyses using informative prior distributions for the heterogeneity parameter all suggested that empagliflzin 10 mg is associated with a beneficial treatment effect as compared with placebo or linagliptin (all in combination with Met and SU) based on the credible and prediction intervals, except for the prediction interval using untruncated lognormal prior.
Discussion
Our review of NICE STAs showed that 17 (71%) of 24 fixed effect NMAs were chosen on the basis that there were too few studies with which to estimate the heterogeneity parameter, but not that there was unlikely to be heterogeneity or that a conditional inference was of interest. A consequence of this is that decision uncertainty may be underestimated. The choice between using a fixed effect or random effects MA model depends on the inferences required and not on the number of studies. Although a fixed effect model is informative in assessing whether treatments were effective in the observed studies, when we expect heterogeneity between studies and want to make unconditional inferences and predictions about the treatment effect in a new study, a random effects model should be used.
When heterogeneity is expected, the simple framework we have proposed overcomes the inappropriate assumption behind the use of a fixed effect model. We argue that, in the absence of sufficient sample data, a minimum requirement should be to exclude extreme and implausible values from the prior distribution and the common choice of the prior distribution, such as uniform [0, 5] or [0, 2], should not be used. We have shown in the examples that the use of a uniform prior distribution when data are sparse would result in an implausible estimate for the heterogeneity parameter and unreasonable results for the treatment effect.
Our proposed elicitation framework is flexible with the amount of information provided by an expert. The minimum information required from the expert is the maximum possible value of the “range” of treatment effects on the natural scale. For example, if the additive treatment effect is an LOR, then the expert is asked whether the OR in one study could be
In summary, in the absence of sufficient sample data, it is important to incorporate genuine prior information about the heterogeneity parameter in a random effects pairwise MA/NMA. Eliciting probability judgments from experts is not straightforward but is important if the aim is to genuinely represent uncertainty in a justifiable and transparent manner to properly inform decision making. Our proposed elicitation framework uses external information, such as empirical evidence and experts’ beliefs, in which the minimum requirement from the expert is the maximum value of the “range” of treatment effects. The method is also applicable to all types of outcome measures for which a treatment effect can be constructed on an additive scale.
Supplemental Material
DS_10.1177_0272989X18759488 – Supplemental material for Incorporating Genuine Prior Information about Between-Study Heterogeneity in Random Effects Pairwise and Network Meta-Analyses
Supplemental material, DS_10.1177_0272989X18759488 for Incorporating Genuine Prior Information about Between-Study Heterogeneity in Random Effects Pairwise and Network Meta-Analyses by Shijie Ren, Jeremy E. Oakley, and John W. Stevens in Medical Decision Making
Footnotes
The work was done at School of Health and Related Research and School of Mathematics and Statistics in University of Sheffield.
The author(s) received no financial support for the research, authorship, and/or publication of this article.
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.