
Abstract
This article describes methods used to estimate parameters governing long-term survival, or times to other events, for health economic models. Specifically, the focus is on methods that combine shorter-term individual-level survival data from randomized trials with longer-term external data, thus using the longer-term data to aid extrapolation of the short-term data. This requires assumptions about how trends in survival for each treatment arm will continue after the follow-up period of the trial. Furthermore, using external data requires assumptions about how survival differs between the populations represented by the trial and external data. Study reports from a national health technology assessment program in the United Kingdom were searched, and the findings were combined with “pearl-growing” searches of the academic literature. We categorized the methods that have been used according to the assumptions they made about how the hazards of death vary between the external and internal data and through time, and we discuss the appropriateness of the assumptions in different circumstances. Modeling choices, parameter estimation, and characterization of uncertainty are discussed, and some suggestions for future research priorities in this area are given.
Keywords
Models for health economic evaluation typically use observed data from randomized controlled trials (RCTs) comparing survival (or times to other events) between competing alternative interventions. However, the choice of intervention will often affect outcomes over a longer period than the follow-up time of the RCTs. Policy makers responsible for making funding decisions will then require estimates of expected survival for a longer period, and a lifetime horizon is often appropriate. 1 If the observed follow-up time covers a sufficiently large proportion of the overall survival time, then parametric models could be used to extrapolate the observed trends in the hazard of death for each treatment arm. This is the conventional approach to long-term survival estimation in health technology assessments, 2 but it assumes that the observed hazard trends will continue into the long term, which becomes less plausible as the unobserved period increases. The extent of uncertainty surrounding any extrapolation should also be quantified,1,3 and this is difficult to determine from short-term data alone for the same reason.
In general, long-term survival can be reliably estimated only if there are long-term data, since the impact of long-term modeling assumptions on the decision can be substantial. 4 Since maximum follow-up in clinical trials is typically only 1 to 5 y, some external information is required. This could be taken from a disease registry, cohort or the general population, a formally elicited expert belief, or a combination of observed data and informal assumptions. Most simply, the external “information” could consist of a defensible clinical belief that the risks of death will continue in a particular way in the long term. The National Institute for Health and Care Excellence (NICE) for England and Wales 1 recommends that any extrapolation should be assessed by “both clinical and biological plausibility of the inferred outcome as well as its coherence with external data sources,” although it does not suggest specific methods to do this. A number of other national funding agencies have a similar requirement for long-term outcomes predictions. 5 This article discusses methods that have been applied to use external data explicitly to facilitate survival extrapolation, as well as their merits in different circumstances. Below we describe the scope and provide the terminology used throughout the article.
We consider situations where we have both of the following sources of data.
RCTs providing estimates of the relative treatment effect on survival for the patients of interest, with individual-level survival or censoring times available for at least 1 treatment arm (either directly or estimated from published Kaplan-Meier curves 6 ).
Information on longer-term survival from another source, describing a population with some characteristics (to be discussed later) in common with the patients of interest. After some adjustments, these data can be used to estimate the baseline long-term survival of the patients of interest. If any treatments are given, this is unrecorded, so these data give no information about intervention effects.
We assume the trial data are representative of the population for which the decision is required. In practice, however, given the selection criteria of trials, this will not always be strictly true,7–9 which we will briefly discuss at the end of the article.
The data and extrapolation problem are illustrated by the hypothetical survival curves in Figure 1. Each of the 3 “observed” curves are representative samples of survival from the populations labeled A, B, and C. The population of interest receiving a control intervention is labeled A, the population of interest receiving the intervention of interest is labeled B, and the external population is labeled C. The survivor functions assumed to generate each data set are labeled
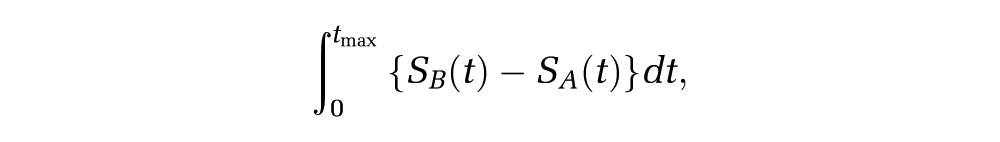
which is illustrated by the shaded area between the 2 curves. The upper limit
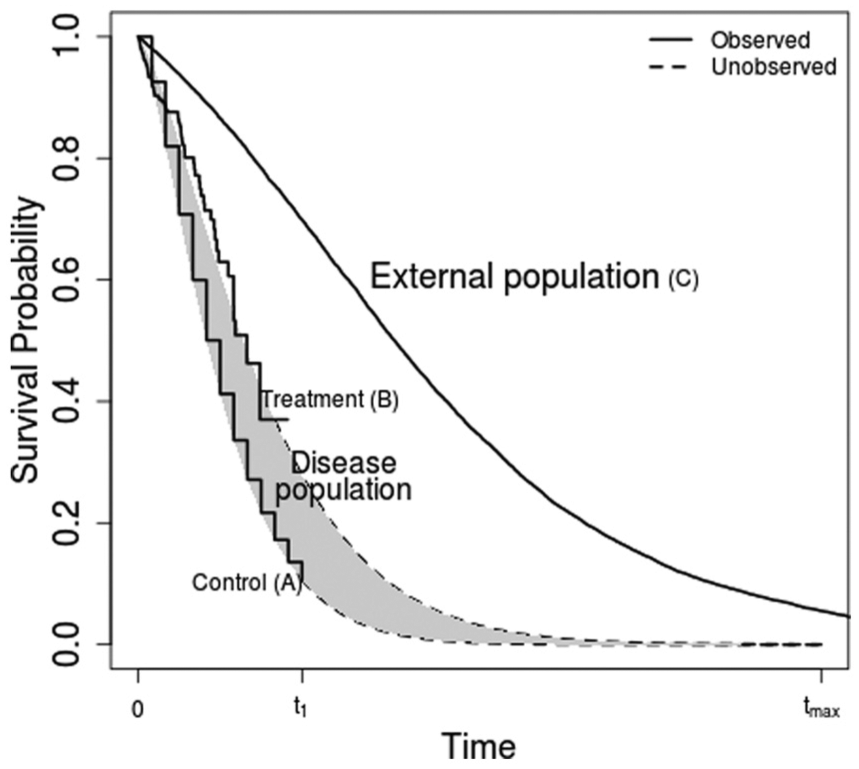
Example survival data. The aim is to extrapolate the incremental expected survival between interventions (B–A) by using long-term data from an external population (C).
In the conventional approach,
2
How survival will differ between the population of interest and the external population. Specifically, how
How observed survival trends under each intervention will continue in the long term, that is, how
Commonly, instead of using this formula directly to calculate the incremental survival,
To find methods that have been used for survival extrapolation in cost-effectiveness analysis using external data, we searched the reports of studies carried out under the National Institute of Health Research Health Technology Assessment Programme in the United Kingdom and searched academic literature, focused on health economics and medical statistics journals, using “pearl-growing” search methods. 10 The exact search strategy, and a broad classification of the 38 relevant papers that we found, are given in the online appendix. In this article, we summarize the methods that have been used, discuss their appropriateness in different circumstances, and suggest where further research might be focused.
Potential External Data Sources
The long-term survivor function for the external data source
Framework for Survival Extrapolation Using External Data
Figure 2 illustrates the choices that need to be made when using external data for survival extrapolation. The structure is based on our categorization of different methods used in the literature and our judgment of when they are appropriate. Each of the next few sections of the article discusses a different portion of the figure in detail. Here, we give a brief overview.
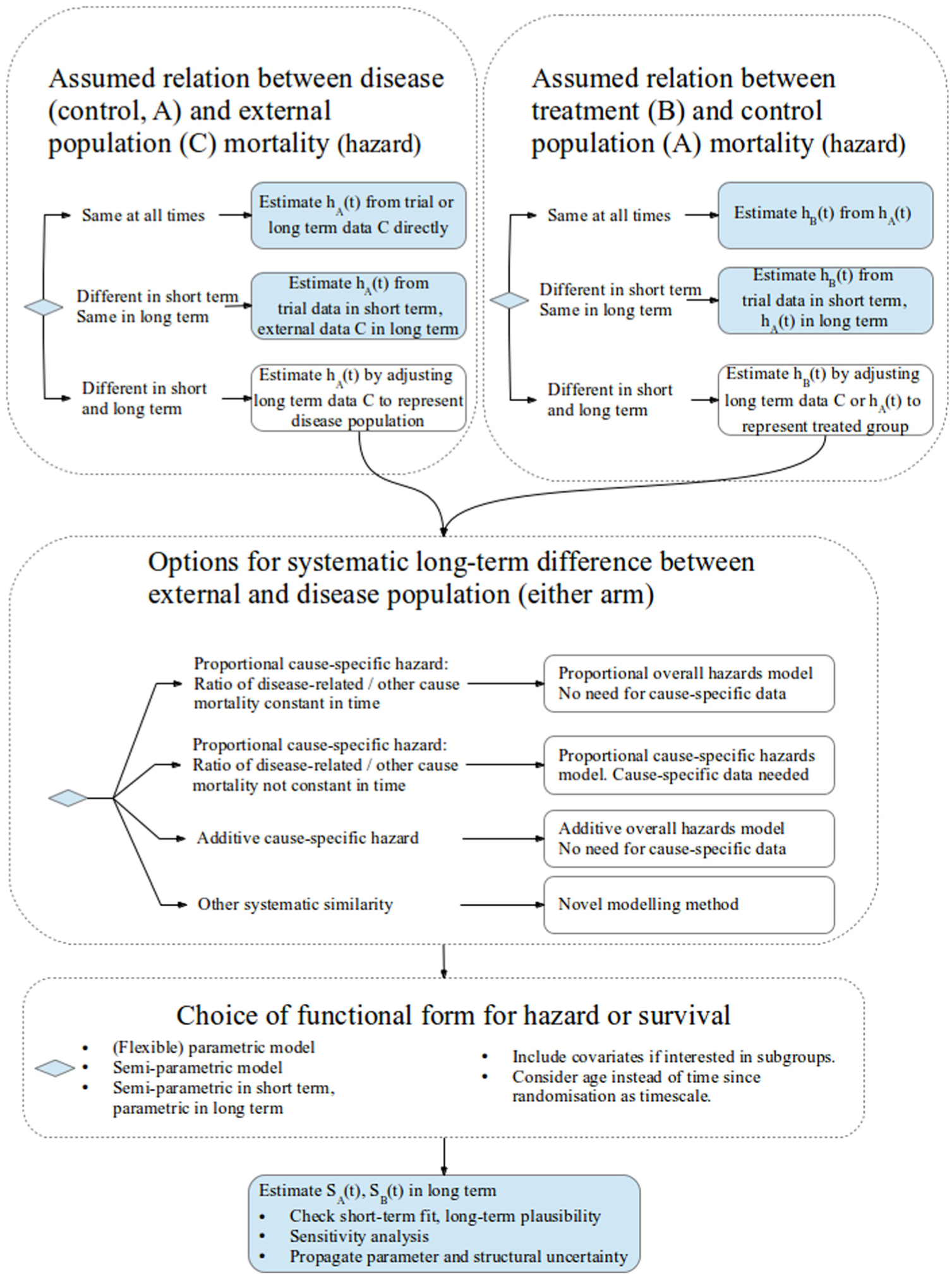
Framework of model choices for survival extrapolation using external data. Long-term survival S for control and treatment groups A and B is estimated via assumptions about equivalence of hazards h between populations A, B, and C.
First, researchers should identify if the external population (C) has the same mortality at all times, or at least in the long term, as that of the disease population receiving a control intervention (A, top-left panel) and the disease population receiving the intervention of interest (B, top-right panel). In this case, the data can then be used directly to estimate each
Otherwise, the long-term mortality of populations A and C (and/or B and C) is assumed to be different but is systematically similar in such a way that the external data (C) can be adjusted to estimate the long-term mortality for the target population with the disease (A or B). The assumptions that have been used to do this are represented by the large middle panel of the figure.
Once any systematic similarity between the internal and external data has been characterized, completing the analysis requires a choice of the functional form for each of the
Difference in Mortality Between the Disease and External Populations
Disease and External Populations Have the Same Mortality at All Times
Sometimes, the disease or baseline intervention of interest is not expected to affect mortality; for example, it may affect only quality of life. Then, long-term survival of the patients of interest can be assumed to be the same as that of the national population of a similar age and sex distribution and taken directly from the relevant life-table.11,12
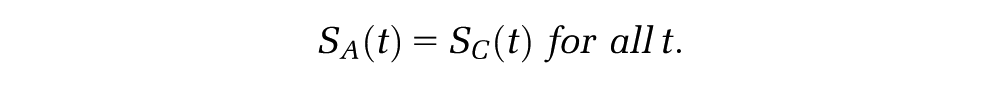
This assumption may also hold if the disease or baseline intervention affects mortality, but the external data come from a disease registry or cohort of patients having the same disease and/or intervention, so that the survival of the control group in the trial data is the same as that of the external population.13–19
Disease and External Populations Have the Same Mortality after Some Time
In other cases, the disease population may have a higher initial mortality than does the general population, but this decreases until at some time (after
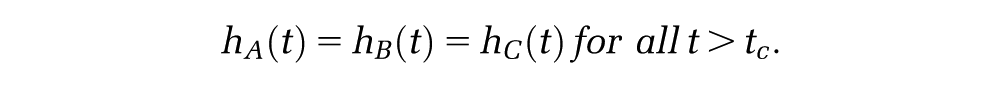
If
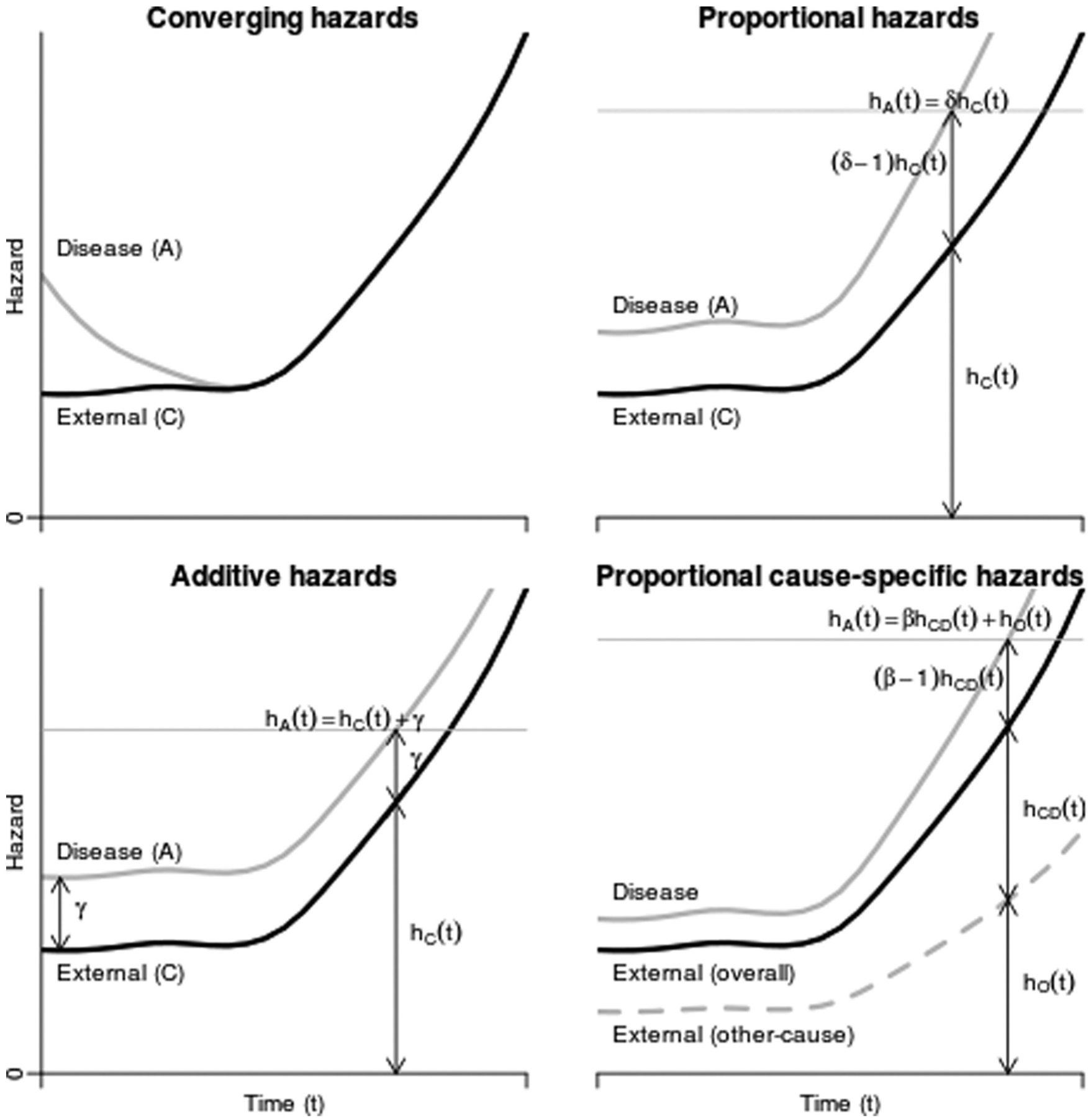
Example hazards for disease and external populations as functions of time, under 4 different assumptions about how the disease population hazards relate to the external population hazards.
Disease and External Populations Have Different Mortality in the Short and Long Term
If the mortality of patients with the disease is different from that of the population represented by the external data at all times
Difference in Mortality Between the Treatment and Control Populations
A similar decision should be made about the difference in mortality between the intervention and control groups (B and A, respectively). If the intervention is not expected to affect mortality (e.g., if it affects only quality of life), then
The assumption about how the relative treatment effect is likely to change as
null, so that
the same as in the short term, thus
diminishing in the long term, thus
Beyond informal sensitivity analysis, we did not find any literature where external information, such as elicited beliefs or the effects of related treatments with longer follow-up, was used formally to quantify future changes in expected treatment effects on survival.
Adjusting External Data to Represent the Population of Interest
If patients with the disease (under either intervention) and the external population have different long-term mortality, then one of the following assumptions might be used to estimate
Proportional Hazards for All-Cause Mortality between the Disease and External Populations
Several authors35–37 obtained cause-specific mortalities
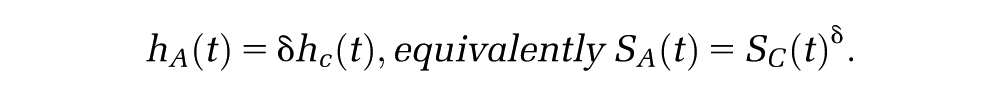
This is sometimes implemented approximately by assuming the probabilities of death over a short period of time (e.g., the cycle length of a state-transition model) are proportional, instead of the hazards (the instantaneous rates of death, which are not probabilities 39 ). Instead of taking the hazard ratio from the literature, Demiris and Sharples 40 estimated it using a joint statistical model for the disease-specific and external data.
Proportional Cause-Specific Mortality
The proportional hazards assumption can be convenient since comparisons of mortality between groups are often published as hazard ratios. However, all-cause mortality may not be proportional. For example, consider the causes of death that contribute to overall mortality. Let
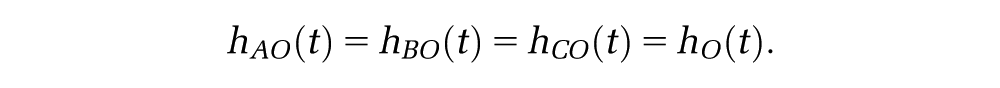
Mortality for disease-related causes is typically higher. Suppose the hazards for disease-related mortality are proportional, so that
To implement a proportional cause-specific hazards model, estimates of
In Benaglia and others,
41
cause-specific death rates were published in the population life-tables; thus,
A related method, originating from Boag,
31
assumes a certain proportion of patients are cured and estimates a parametric survival function for the noncured patients. The cure fraction and the parameters of the noncured survival function are estimated jointly from individual data on survival and disease status. Hisashige and others
26
and Maetani and others
46
used this approach to obtain a disease-related survival curve
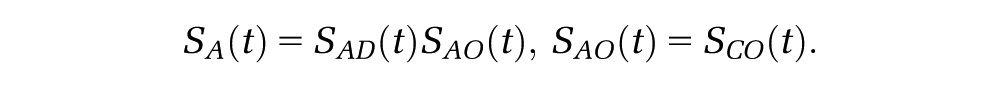
Additive Hazards for All-Cause Mortality between the Disease and External Populations
Instead of a constant risk ratio between internal and external data sources, some authors47–49 have assumed that the disease-specific population had a constant additive excess hazard compared to the general population (Figure 3, bottom left).
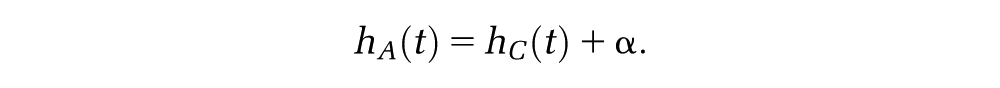
Under this assumption, it can be shown
47
that
The short-term fit of either the proportional or additive hazards assumption can be checked from the data by diagnostic plots2,30 or by embedding in a model that contains both as special cases, as discussed by Breslow and Day. 50 The assumptions required to apply either in the long term, however, are untestable from data.
Other Models for Parameterizing Mortality Differences between Populations
Other ways of parameterizing difference in survival between groups include accelerated failure time models, in which
Survival Model Choice When Combining Internal and External Data
To complete the estimation and to characterize the long-term differences between the disease and external population survival
Without external data, extrapolation of
Alternatively, survival extrapolation can be performed semiparametrically with external data if these are available up to
However, if the parametric form fits well, then fully parametric models can lead to greater precision in estimates. 54 The advantages of parametric and semiparametric models are combined in a class of flexible parametric models based on modeling the log hazard as a spline, or piecewise cubic, function of log time,52,55 which can adapt to represent survival arbitrarily well. Since these models are fully parametric, they enable extrapolation beyond the times observed in the data. 56 The spline function is defined to be smooth, and given a particular number of pieces, results have been shown to be not sensitive to the choice of where to subdivide the log time axis. 55 Therefore, we would expect extrapolations from this model to be more robust than those from the “hybrid” approach mentioned above. Guyot and others 56 used these models, implemented in the BUGS software, 57 for survival extrapolation using a combination of trial and long-term external data. They can also be fitted to single survival data sets using Stata 58 and R. 59 Also, unlike the Cox model, they permit nonproportional hazards to be modeled 52 and extrapolated if necessary. 51
The choice between alternative parametric models for extrapolation is conventionally based on fit to the short-term data A, B. 2 However, as recommended, for example, in the NICE guidelines, 1 long-term plausibility should be considered based on external information such as knowledge of the disease, treatment and trial protocol, 30 or related long-term survival data. External information could simply be used to inform the choice of model for extrapolation or to inform particular parameters of a chosen model. A plausible distribution might be chosen to represent how the hazard of death is expected to change over time. For example, the exponential distribution corresponds to a constant hazard, which is generally unrealistic in the long term as the hazard will increase as people get older. Therefore, even though data might suggest a constant hazard over the duration of the RCT, distributions that allow changes in hazards over time are likely to be more appropriate. Bagust and Beale 30 also discuss how the apparent better fit of some parametric models may be an artifact of between-patient heterogeneity; for example, a Weibull distribution with shape less than 1 could be explained by a mixture of 2 subpopulations with different constant hazards.
Once the most appropriate model family has been chosen, its parameters can be estimated; this might be done using a combination of disease-specific data A and external evidence C. For example, Nelson and others 60 used a 2-parameter Gompertz model, which has an exponentially increasing hazard, to extrapolate survival beyond the follow-up of an RCT. The parameter governing the baseline hazard was estimated using disease-specific data, and the hazard “acceleration” parameter was estimated from national population life-tables including older people.
When long-term data are not available or sparse, expert belief about long-term survival might be elicited to either choose the parametric form or estimate particular parameters, as we discuss later.
Explaining Population Differences Through Observed Covariates
Under models such as the proportional or additive hazards specifications described above, the long-term difference between the populations underlying the trial and external data is characterized by a parameter such as the all-cause or cause-specific hazard ratio
It is common to assume that the increase in the hazard of death as a person gets older is fully explained by his or her increasing age. Thus, survival extrapolations often rely principally on modeling how the hazard increases with age. Population-based data commonly cover a wide range of ages and calendar periods. To exploit this diversity, Nelson and others
60
fitted joint models to a combination of RCT and cohort data in an age metric, where the
Without long-term follow-up data, age effects on mortality could be estimated from shorter-term data on individuals with widely varying ages at baseline. Speight and others 13 estimated long-term cancer survival using registry data in this way. The (within-person) increase in the risk of death as a person gets older was assumed to equal the risk ratio between people with different baseline ages.
Representing Uncertainty and Parameter Estimation
It is important to characterize uncertainty in all model inputs and “structural” model choices
3
in order to determine the uncertainty surrounding the treatment decision and assess the value of further research. In the presence of substantial decision uncertainty, the treatment might be recommended for use only in research or with otherwise limited coverage.
61
If parameters used to extrapolate survival are estimated from data, the uncertainty inherent in estimating them can be handled by probabilistic methods. For example, in Fang and others,
47
uncertainty about the estimation of the hazard increment
Bayesian methods are particularly suited to combining evidence from different sources in a model. 63 The process involves defining a joint model with shared parameters representing the aspects that the different sources of data have in common (e.g., mortality for causes other than the disease of interest) and different parameters for the parts where they are expected to differ (e.g., cause-specific mortality). The posterior distributions of model outputs (such as incremental expected survival) are estimated simultaneously conditional on all data, and the uncertainty about the model inputs is propagated to the outputs. This approach has been used for combining data in the context of survival extrapolation,40,41,56,64 as well as in many other decision modeling contexts.65,66 External aggregate data or expert beliefs and associated uncertainty can be included as prior distributions, for example, published hazard ratios obtained from meta-analysis. 41
A potentially more important uncertainty may arise in how the differences between the external and internal data are modeled—in other words, whether assumptions, such as those set out in this article, are valid in the long term. This is more problematic to identify from data; therefore, elicited beliefs might be used instead.
Using Elicited Beliefs in Survival Extrapolation
Expert elicitation has been used to estimate uncertain quantities in health economic models,67,68 although we are unaware of this approach having been used in survival extrapolation. Here, we discuss the potential and challenges.
For example, beliefs about long-term survival might be elicited directly. Suppose that expert belief suggested that the 5-y survival probability,
If some of the assumptions used to extrapolate are uncertain, then sensitivity analysis should be performed. The most basic form of sensitivity analysis is to present results under alternative scenarios and assumptions; however, scenario analyses can be difficult to interpret. Instead, the model might be extended by adding extra parameters representing these uncertain features, with prior distributions elicited from experts, then observing how the results are affected. 71 For example, to assess the assumption of a constant hazard ratio between treatment groups, the treatment effect in the extrapolated period could be represented by a parametrically decreasing function of time, and plausible values for the parameter(s) could be elicited. This allows the associated decision uncertainty to be formally quantified and “value of information” methods used to determine whether it is worth doing further research to assess the assumption. 72 Even without elicited information, informal beliefs could be used to demonstrate, for example, that the decision about which treatment would be preferred is robust within a plausible range of assumptions about some parameter. This might involve showing that the cumulative incremental net benefit of the intervention of interest is unlikely to cross the decision threshold in the period of time being extrapolated over. 73
More research and experience are needed on the accuracy (and cost) of different methods to elicit uncertain quantities, ways to combine beliefs of different experts, what quantities should be elicited in this context, how best to use elicited information in models, and how the results can be communicated to decision makers.
Summary and Research Priorities
Survival extrapolation given short-term data is a challenging task, involving prediction of data that have not been observed. Data on a related long-term population can often be exploited, but the necessary assumptions about how the populations differ, and how short-term trends might continue into the long term, must be clearly expressed and examined for plausibility and consistency with external data. This article reviews typical assumptions that might be made. However, we may sometimes not be confident in making any of these assumptions—it may be unclear whether the external data are relevant or how to explain differences between the data sets. The information required to adjust the external population to represent the internal population may not be available, for example, a marker of disease severity. In those cases, careful sensitivity analysis and characterization of uncertainty will be important. Since long-term assumptions, such as proportional hazards, are untestable from data, they should be clearly explained and justified to decision makers. More experience is needed in situations where neither proportional nor additive hazards assumptions are appropriate to distinguish the external and disease populations, and similarly when the treatment effect or other key parameters are not constant or otherwise predictable in the long term. Important open questions concern how “soft” information, such as formally elicited beliefs or the analyst’s own assumed distribution for uncertain quantities, can be obtained and used in modeling. Finally, we assumed that the trial data are representative of the target population that will ultimately receive the treatments of interest. This is not always true given the selection criteria of trials, although is more plausible for the phase III, pragmatic trials that typically inform cost-effectiveness models. Various authors7–9 have suggested methods and conditions for using external evidence to adjust the treatment effect from a trial to obtain the effect in an overlapping but nonidentical population. The covariate adjustment methods we discussed may also be used to explain differences in baseline survival between populations, if the relevant covariates are recorded.
Footnotes
Acknowledgements
Thanks to the rest of the project team, including Alan Brennan, Patrick Fitzgerald, Miqdad Asaria, Ronan Mahon, and Steve Palmer.
This work was supported by the Medical Research Council, grant code G0902159 (“Methods of Extrapolating RCT Evidence for Economic Evaluation”). The first author also acknowledges support from Medical Research Council grant code U015232027.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.