
Abstract
Quality-adjusted life-years (QALYs), calculated by combining life-years gained with a measure of preferences over health states into a single composite measure that captures both mortality and morbidity, are commonly used to quantify benefit in economic evaluations. 1 To obtain societal preferences (or health utilities) from questionnaires, a patient survey instrument measuring general health status is scored using country-specific weights derived from large-scale valuation studies that reflect preferences over health states.2,3 After the patient survey is scored, the resulting metric is often referred to as a “preference index,” from which QALYs can be calculated.
A widely used instrument for measuring preferences is the EQ-5D, which currently has preference-scoring algorithms for many countries, including the US. 4 The EQ-5D is a standardized measure of health status developed to provide a simple, generic measure of health for clinical and economic appraisal, consisting of 5 questions. 5 In the EQ-5D-3L version, each question has 3 levels of severity, while a newer version (EQ-5D-5L) has 5 levels. 6 Together, the 5 questions or domains are meant to capture a holistic view of health. 7 In the UK, the National Institute for Health and Care Excellence (NICE) has indicated that the EQ-5D is the preferred measure of health-related quality of life (HRQL) in adults. 8 In the US, the Institute of Medicine (IOM) recommended the direct elicitation of preferences or the use of generic preference indexes like those derived from the EQ-5D. 9
Unfortunately, the EQ-5D or other preference-based instruments are not routinely collected in clinical trials or existing secondary data sources, thereby limiting their value for economic evaluation. 10 This problem has prompted researchers to propose several methods for predicting (or “mapping”) the EQ-5D based on other instruments that measure health functioning. In the US, these efforts gained steam after the release of the 2000 Medical Expenditure Panel Survey (MEPS), a nationally representative sample of the US noninstitutionalized population. The 2000 MEPS started asking a large and representative sample of respondents to complete both the EQ-5D-3L and the Short-Form Health Survey (SF-12), an instrument that measures general health status. 11 The SF-12 is widely available in clinical trials and in some secondary data sources. The NICE has indicated that when the EQ-5D instrument is not available, prediction methods can be used to obtain a predicted preference index from other instruments that measure HRQL. 12
The unusual distribution of the EQ-5D-3L, however, makes it challenging to predict. The index is bounded on the right at 1, representing preferences for “perfect health,” and it can also take negative values, indicating preference for health states considered “worse than death.” 2 In addition, the EQ-5D-3L distribution tends to have 3 distinct modes, and in samples representing the general population, a large proportion of responses are clustered at 1. To date, most of the methods used to predict the EQ-5D-3L index from the SF-12 instrument in a representative sample of the US population have ignored some or all of these characteristics, with the consequence that prediction may be systematically biased. 13 While statistical methods such as ordinary least squares (OLS), Tobit regression, and two-part models have been previously proposed, none fully captures the idiosyncratic characteristics commonly observed in societal preferences.
The objective of this article is to develop and implement a statistical model that takes into account all the characteristics of the EQ-5D-3L index and to investigate under which circumstances our proposed model leads to improved prediction in a US sample compared with other alternatives proposed in the literature. Our model assumes that the observed EQ-5D-3L index is a mixture of 3 distributions: a degenerate distribution with mass at preference values indicating perfect health and 2 censored normal (Tobit) distributions, which take into account the bounded nature of the EQ-5D-3L index. We use the mental and physical components of the SF-12 health survey as predictors, along with a limited number of covariates. We compare predictions from our finite mixture models to the best-performing alternatives proposed in the literature: linear regression and two-part models. 13
Background
EQ-5D-3L
The EQ-5D-3L questionnaire is made of 2 components: a descriptive classification component and a Visual Analogue Scale (VAS). The EQ-5D-3L descriptive component consists of 5 domains of health: mobility, self-care, usual activities, pain and discomfort, and anxiety/depression. Each question has 3 possible answers that capture a respondent's ability to perform each of the 5 domains: no problems, some or moderate problems, and extreme problems or unable to perform the activity. The EQ-5D-3L describes a total of 35 (i.e., 243) possible response patterns, each defining a “health state.” Perfect health is defined as having no problem in any of the 5 domains, while the worst possible state is being unable to perform any of the 5 activities. To transform the EQ-5D-3L descriptive system into a measure that represents preferences, each of the health states defined by the descriptive system is converted to a preference index using algorithms derived from valuation studies. In the US, the valuation study sample represented the civilian noninstitutionalized population. 2
Figure 1 shows the distribution of the EQ-5D-3L preference index using the MEPS 2000 data (described below) for selected age groups and medical conditions. Several characteristics of the distribution are worth nothing. First, a large proportion of individuals (43.65%) have an EQ-5D-3L index of 1 (Panel A), indicating preferences for perfect health. The proportion of individuals in perfect health decreases with age, as shown in Panels B to E, and for those individuals who have a self-reported medical condition, Panels F to I. Second, the distribution exhibits 3 modes, at approximately 0.17, 0.75, and 1 (Panel A). The location of the modes differs according to the characteristics of the sample, particularly the number and severity of comorbid conditions. Finally, the range of possible EQ-5D scores is limited. The lowest possible score is –0.594 and the highest is 1.
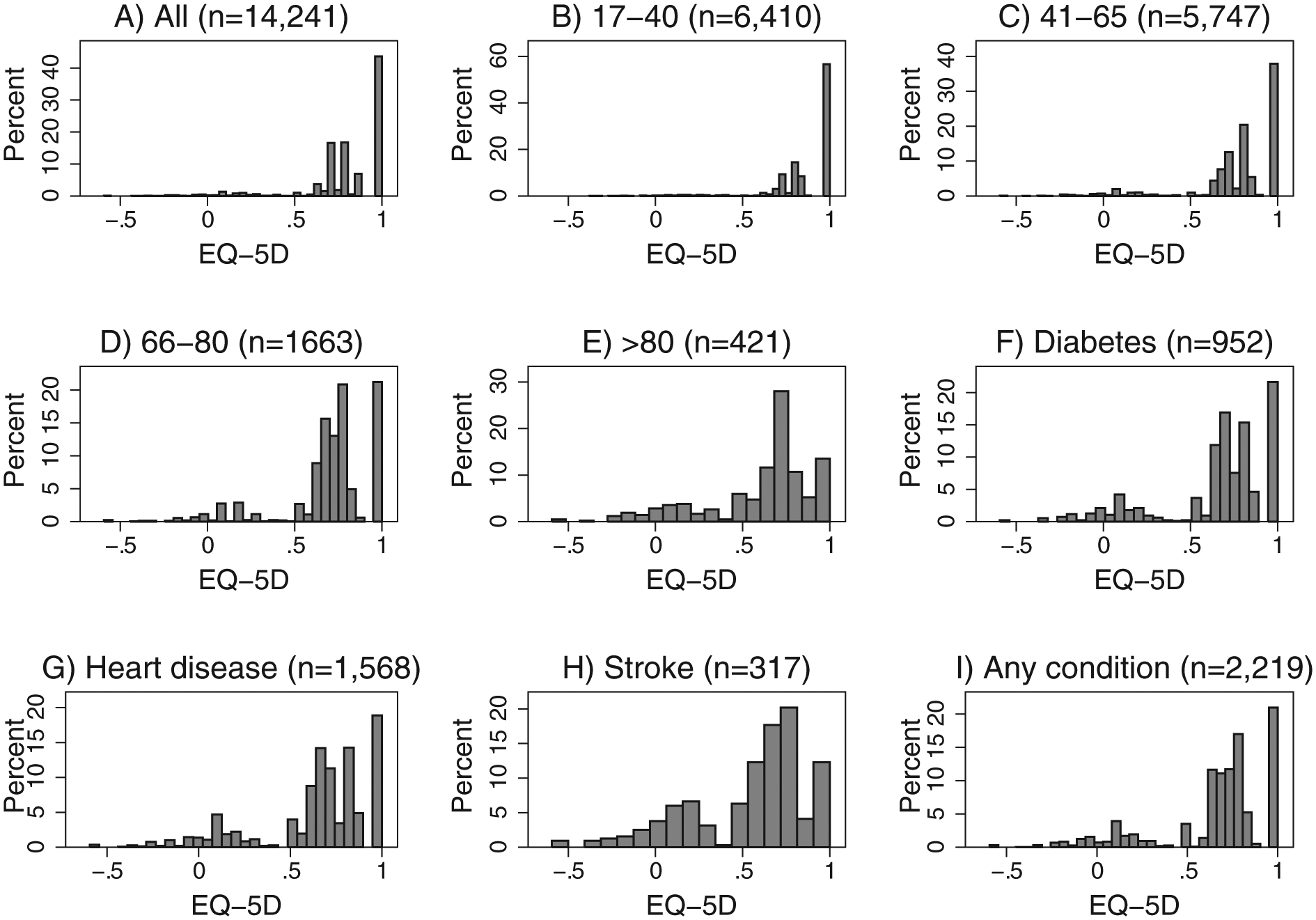
Distribution of EQ-5D-3L by age group and medical condition. Data source: MEPS, 2000. All sample (A); by age group (B–E), and for selected self-reported conditions (F–I). “Any condition” refers to those who have heart disease, stroke, and/or diabetes. Some individuals have more than 1 condition.
SF-12
The 12-item Short-Form Health Survey (SF-12) is an instrument derived from the longer 36-item Short-Form (SF-36), 11 which was designed to measure general health functioning. The SF-12 items measure physical or emotional limitations, physical functioning, pain, general health, vitality, social functioning, and mental health problems. It provides 2 summary scores, the Physical Component Summary (PCS) and the Mental Component Summary (MCS). Scores are standardized; the mean score in the population is 50 with a standard deviation of 10 points. Higher scores indicate better functioning in each domain. The SF-12 instrument is not routinely used in economic evaluations because the resulting functioning scales are not expressed in terms of preferences, although algorithms have been developed for that purpose.14–16
Previous Prediction Approaches
Several methods have been proposed for predicting the EQ-5D-3L from the SF-12 components using MEPS data. These methods can be divided into 2 types, depending on whether the prediction target is the EQ-5D-3L preference index itself or the responses to the EQ-5D-3L descriptive system.
One of the earliest approaches using MEPS data focused on the prediction of the mean EQ-5D-3L preference index using mean values of the PCS and MCS from the SF-12. 17 Franks and others 18 used individual-level data instead and OLS regression with SF-12 components as predictors. They found that OLS models explained approximately 63% of the total variance and performed well for EQ-5D-3L scores close to the observed mean, but they cautioned that their models performed poorly for the worse health states. In addition, OLS models underpredict scores of those in perfect health as these models do not take into account the upper bound of the EQ-5D-3L preference index. Recognizing that the EQ-5D-3L index is bounded at 1, Sullivan and Ghushchyan 19 compared OLS models to Tobit regression and censored least absolute deviations (CLAD) models and concluded that the OLS model outperformed Tobit models, but the investigators recommended CLAD models when the only predictors available are mental and physical scores of the SF-12. Another way to account for the large proportion of EQ-5D-3L scores clustered at 1 is with two-part models, which are commonly used to model cost data. 20 Li and Fu 21 suggested that two-part models are a superior alternative to Tobit and CLAD models for predicting EQ-5D-3L scores, although those authors did not directly compare two-part models with OLS or Tobit/CLAD models using MEPS data.
Gray and others 22 used a different approach. They used multinomial models to first estimate the probability that a respondent would select a particular level of response to each question in the EQ-5D-3L (modeling each of the EQ-5D questions separately). These estimated probabilities were then used to create a simulated pattern of responses, which were then scored and translated into the preference index. The advantage of this method is that if the predicted response pattern is accurate, the predicted EQ-5D-3L index will preserve the characteristics of the observed EQ-5D-3L index. However, Chuang and Kind 13 compared this approach with OLS, CLAD, and two-part models using MEPS data and concluded that OLS was the best method for predicting the EQ-5D-3L, although the accuracy of OLS deteriorated in less healthy groups.
Numerous research articles describe methods for predicting preference-based measures from non-preference-based instruments using datasets from the US and other countries, as well as using instruments other than the SF-12 as predictors. Brazier and others 23 conducted a review of 30 studies and found that most of them used OLS models, with approximately half using either the EQ-5D-3L preference index or the descriptive system as an outcome. The investigators concluded that the performance of models in terms of goodness-of-fit and prediction was variable and difficult to generalize given the myriad of methods and instruments used. Other research has focused on simulation studies comparing different methods that could be potentially used to model preference-based outcomes like the EQ-5D-3L, including mixture models. In simulation studies, Pullenayegum and others 24 compared latent class models (mixture of 2 normals) to OLS, Tobit, CLAD, and two-part models and recommended the use of OLS models with robust standard errors. In contrast, two-part models were recommended by Huang and others 25 over alternatives that included latent class models assuming normal densities. Both studies were concerned about modeling bounded data and did not explore other mixture models. Hernandez and others 26 considered a longitudinal mixed-effects mixture of censored normals, which they called “adjusted limited dependent variable mixture models” (ALDVMMs), using a disability measure, the Health Assessment Questionnaire–Disability Index (HAQ-DI), and a pain measure as predictors of the EQ-5D-3L, in a randomized trial of patients with rheumatoid arthritis. Longworth and others 27 compared several mapping methods, including two-part models, Tobit models, multinomial models, and ALDVMMs using cancer-specific HRQL measures as predictors in a sample of patients with different types of cancer and disease stages.
Our methodological approach is similar to that of Hernandez and others, 26 but we focus on predicting the EQ-5D using a broader measure of health (SF-12) in a nationally representative sample of the US population, incorporating widely available covariates in a cross-sectional context.
Methods
Data
The MEPS is a nationally representative survey of the noninstitutionalized US population. The survey collects detailed information on respondents’ demographics, health care utilization and expenditures, self-reported medical conditions, insurance coverage, and socioeconomic status. In the year 2000, the MEPS added a self-administered module asking a subset of respondents to complete both the EQ-5D and the SF-12 questionnaires.17,28,29
Models
Traditional parametric regression models assume that the observed outcome is a realization from some probability distribution. For example, linear regression assumes that the outcome of interest distributes normally with unknown variance and mean given by a linear combination of covariates. In contrast, finite mixture models assume that the outcome comes from a combination of 2 or more distributions, which are mixed with unknown probabilities. The objective is to simultaneously estimate the parameters of each distribution and the mixture probabilities.
Formally, finite mixture models assume that the probability density generating the observed outcome is a convex combination of k different densities:
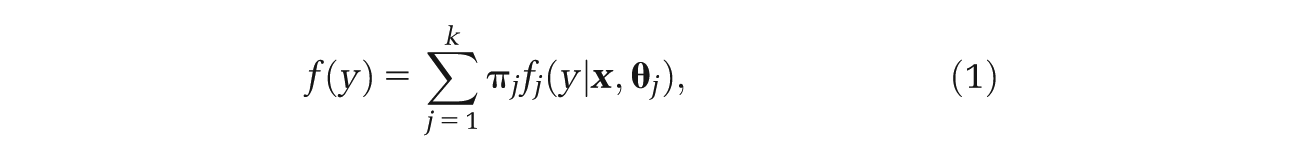
where 0 ≤
Finite mixture models can also be used to classify observations into distinctive classes. The posterior probability that an observation belongs to class c is given by
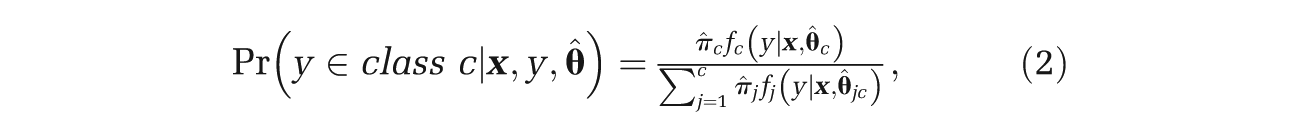
where
Our application of finite mixture models assumes that the EQ-5D-3L preference index is a mixture of 3 classes: a degenerate distribution and 2 censored normal distributions, also known as a Tobit model. With the aim of modeling expenditure data on durable goods, Tobin introduced the concept of censored normals in the econometrics literature.32,33 Expenditure on durable goods can only take positive values, and because households do not purchase durable goods on a regular basis, a sizable portion of expenditures over a period of time are zero. A censored normal model assumes that the observed outcome comes from a latent random variable that follows a normal distribution but realizations of the random variable are censored if they cross a threshold value. In the case of expenditure data, the threshold value is zero, and realizations of the latent variable that are less than zero are observed to be zero.
Formally, the Tobit model assumes that the latent variable
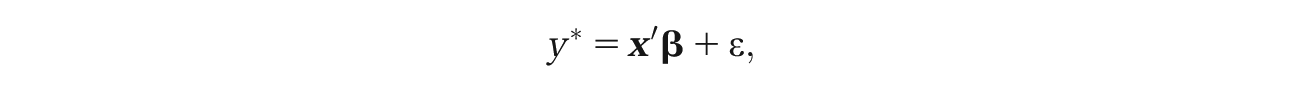
where
The density for the standard Tobit model is given by
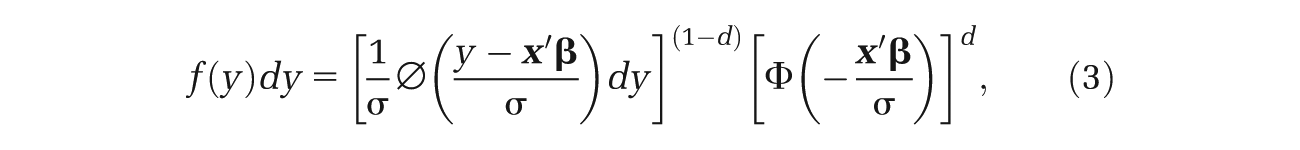
where
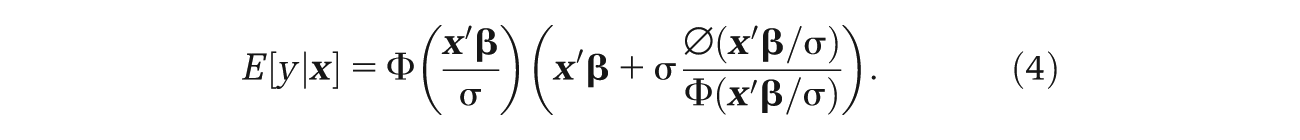
The density of our proposed mixture model consists of 2 Tobit censored normal components and a degenerate distribution with mass at zero. This density is an extension of Equation 3 and is given by the expression
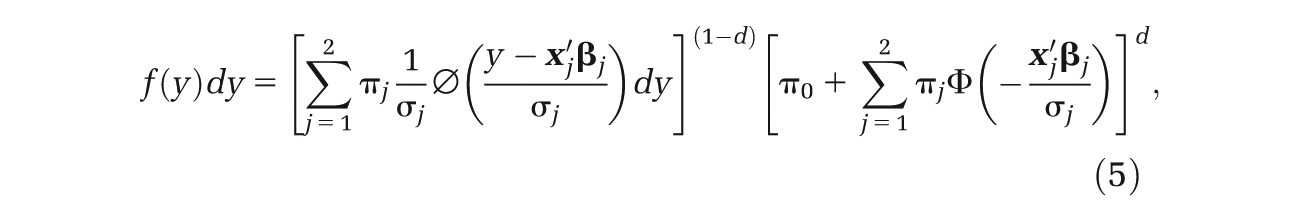
where π
j
are the mixture probabilities. Here,
The model described by Equation 5 can be extended by making the mixture probabilities to be functions of covariates using a multinomial transformation:
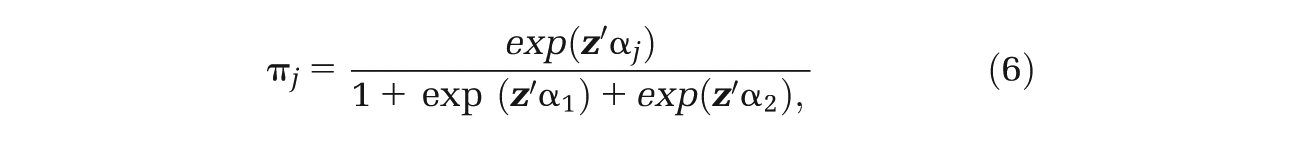
where
Assuming independent observations following the density described by Equations 5 and 6, we estimated the parameters by maximum likelihood. For this purpose, we developed a Stata program that maximizes the log-likelihood. 37 In general, the likelihood function of a mixture model is difficult to maximize because of the possibility of multiple local maxima and nonconcave regions. 31 We developed an algorithm to choose appropriate starting values, which we tested extensively via simulations. We ensured our models converged to a global maximum by trying different sets of feasible starting values. Details of the Stata command and the strategy for choosing starting values are given in Appendix A.
Two types of predictions can be calculated from our models. For models with constant mixture probabilities, the predicted EQ-5D-3L is the sum of the predictions from each component weighted by their estimated mixture probabilities
Analyses
We randomly divided MEPS 2000 data into estimation and validation samples of roughly equal size and estimated 4 types of models using the estimation sample: 1) mixture models without covariates in the mixing probabilities, 2) mixture models with covariates in the mixing probabilities, 3) OLS regression, and 4) two-part models, in which the first part estimates the probability that the EQ-5D index is less than 1 using a logistic model, and the second part uses an OLS model to estimate the expected EQ-5D score based only on those with observed EQ-5D < 1. Assuming that the parts in the two-part model are independent, the predicted EQ-5D index is the product of the predicted probabilities from the first part and the predicted expected value from the second part. 20
Although the MEPS dataset has a rich set of covariates, in practical applications using other datasets, analysts will likely have access to only a limited set of demographic variables. To examine the performance of our method in such circumstances, we only used age, sex, and education in addition to PCS and MCS as predictors. For each method, we selected the best-fitting model specification identified by the Bayesian information criterion (BIC). Functional forms considered included quadratic terms and interactions. In some models, we included the sum of the mental and physical components rather than both components. To facilitate the interpretation of interactions and the intercept, continuous variables were centered. Age was centered at 65, and PCS and MCS were centered at their mean value of 50, with the sum centered at 100. Education was entered as an indicator variable equal to 0 if the respondent did not complete high school and 1 otherwise.
After selecting the best model for each method, we compared their prediction performance using the root mean square error (RMSE) and the mean absolute error (MAE). Both RMSE and MAE quantify the discrepancy between observed and predicted values, but in RMSE larger errors have greater influence than smaller errors.
We conducted a series of sensitivity analyses to evaluate the performance of our model under various circumstances. Because the shape of the distribution varies with age and health status, we compared the prediction performance using a subsample of individuals with diabetes, stroke, or heart disease (Figure 1, Panel I). To determine the performance of our model at the tails of the distribution, we categorized the EQ-5D-3L index into 4 levels (<0, 0–0.699, 0.7–0.899, 0.9–1) and compared the prediction performance by level.
Results
There were a total of 14,241 observations in the MEPS 2000 with complete data in all covariates. Table 1 shows the characteristics of the estimation and validation samples by age, sex, race, education, and selected self-reported comorbidities. In the combined sample, the mean EQ-5D-3L was 0.81 (s = 0.24). The mean MCS was 51.12 (s = 9.49), and the mean PCS was 48.90 (s = 10.34). Mean EQ-5D-3L and PCS scores declined with age and were lower for those subjects with comorbid conditions. The lowest average EQ-5D-3L, PCS, and MCS scores corresponded to medical conditions that are highly debilitating: stroke and emphysema. For the combined sample, the Pearson correlation between the EQ-5D-3L index and the PCS and MCS scores was 0.68 and 0.48, respectively.
Baseline Characteristics by Sample
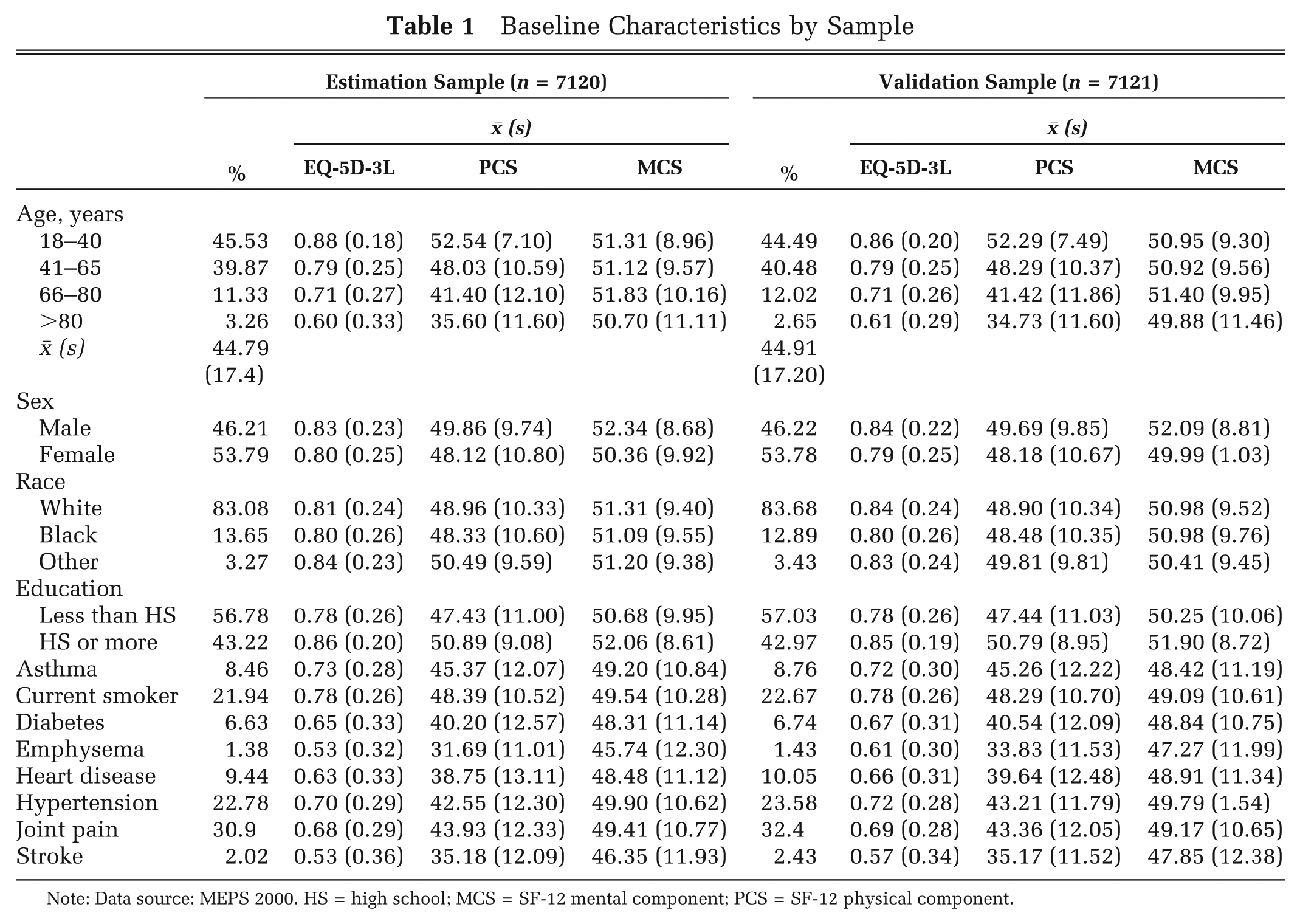
Note: Data source: MEPS 2000. HS = high school; MCS = SF-12 mental component; PCS = SF-12 physical component.
Using the BIC, the best-fitting model within each method had different functional forms. Table 2 shows the estimated coefficients for each model and method. The Mixture 1 model is a model with constant mixture probabilities. The best model of this type corresponds to a mixture of 2 Tobit models, with the degenerate distribution having zero estimated mixture probability. The Mixture 2 model, which allows covariates to alter the mixture probabilities, is considerably simpler. In this model, the mean EQ-5D-3L in each class is a function only of PCS and MCS, and the probability of class membership is a function of PCS, MCS, and age. The estimated average predicted mixture probability corresponding to the degenerate distribution is 0.43, which is similar to the observed proportion of observations with an EQ-5D-3L of 1.
Model Parameters by Method
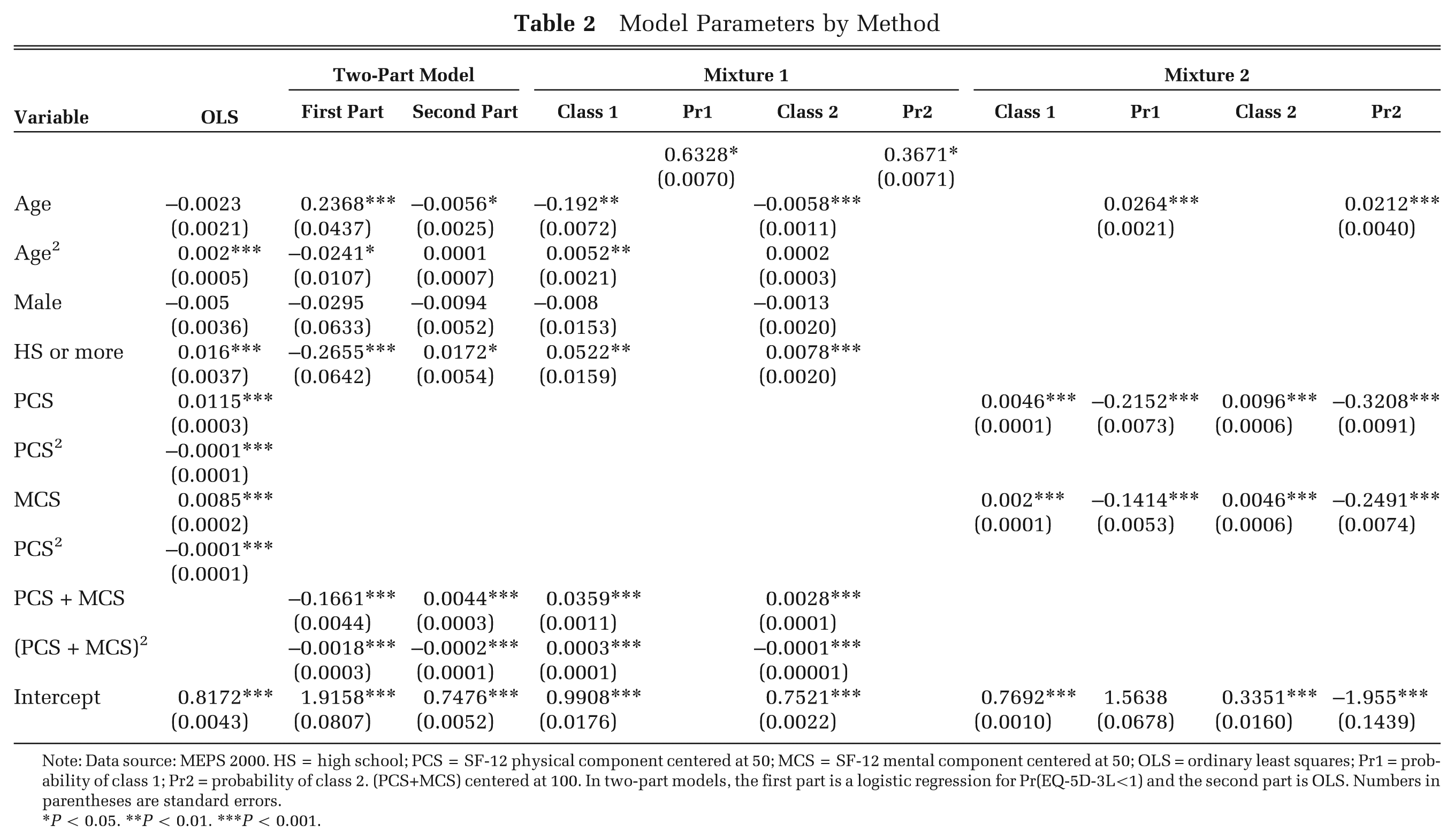
Note: Data source: MEPS 2000. HS = high school; PCS = SF-12 physical component centered at 50; MCS = SF-12 mental component centered at 50; OLS = ordinary least squares; Pr1 = probability of class 1; Pr2 = probability of class 2. (PCS+MCS) centered at 100. In two-part models, the first part is a logistic regression for Pr(EQ-5D-3L<1) and the second part is OLS. Numbers in parentheses are standard errors.
P < 0.05. **P < 0.01. ***P < 0.001.
We attempted to fit a mixture model with 4 classes, but the models failed to converge as there is too little information to distinguish a fourth component. Because the best model with constant mixture probabilities had 2 classes with Tobit components, we also fitted 2-class models with 1 Tobit and 1 degenerate component, with and without covariates in the mixture probabilities. These models, however, were inferior to the models presented in Table 2 in terms of prediction and fit. Models using SF-12 questions as predictors rather than the summary scores did not improve prediction performance considerably, with some models failing to converge due to the larger number of parameters that need to be estimated.
Table 3 shows RMSE, MAE, and summary statistics for different types of predictions in validation and estimation samples. All the statistics are similar in both samples, suggesting that there are no overfitting problems. OLS and two-part models are nearly identical in their prediction ability. A mixture model with constant mixture probabilities (Mixture 1) does not improve prediction. In contrast, based on MAE and CEC predictions, a mixture model with covariates in the probability model is superior to both the linear and two-part models. Mixture 2’s RMSE is larger than that of the linear and two-part models when CEC predictions are used. This is due to the misclassification of some individuals, which produces larger errors that are weighted more in RMSE, even though on average Mixture 2’s prediction ability is superior as shown by MAE. The standard deviation of the predicted EQ-5D obtained from the Mixture 2 (CEC) model is closer to that of the observed EQ-5D-3L in both estimation and validation samples (0.240 and 0.239, respectively), compared with the other models, which underestimate the standard deviation. Table 4 shows prediction performance by levels of the EQ-5D index. Mixture 2 (CEC) model substantially improves predictions at the tails of the distribution while underperforming around the center of the observed distribution when compared with both the two-part and linear models.
Model Comparisons
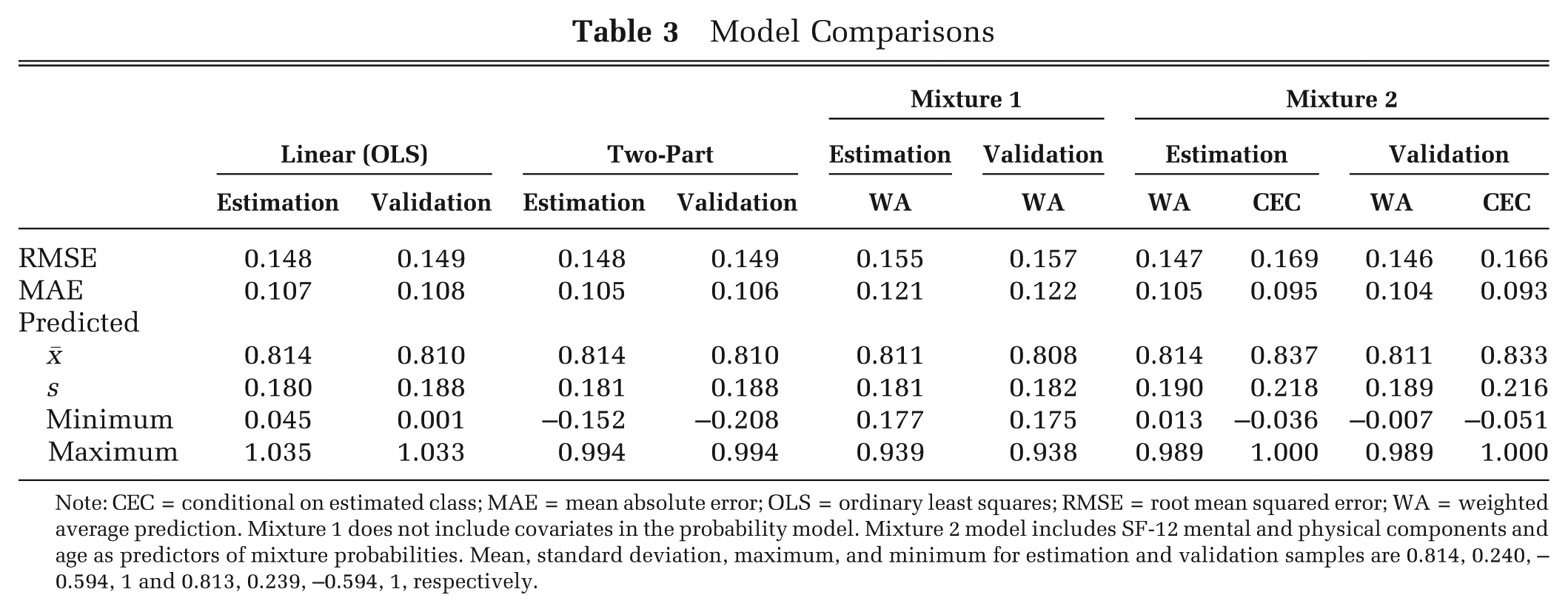
Note: CEC = conditional on estimated class; MAE = mean absolute error; OLS = ordinary least squares; RMSE = root mean squared error; WA = weighted average prediction. Mixture 1 does not include covariates in the probability model. Mixture 2 model includes SF-12 mental and physical components and age as predictors of mixture probabilities. Mean, standard deviation, maximum, and minimum for estimation and validation samples are 0.814, 0.240, –0.594, 1 and 0.813, 0.239, –0.594, 1, respectively.
Prediction Performance in Validation Sample by Level of the EQ-5D-3L Index
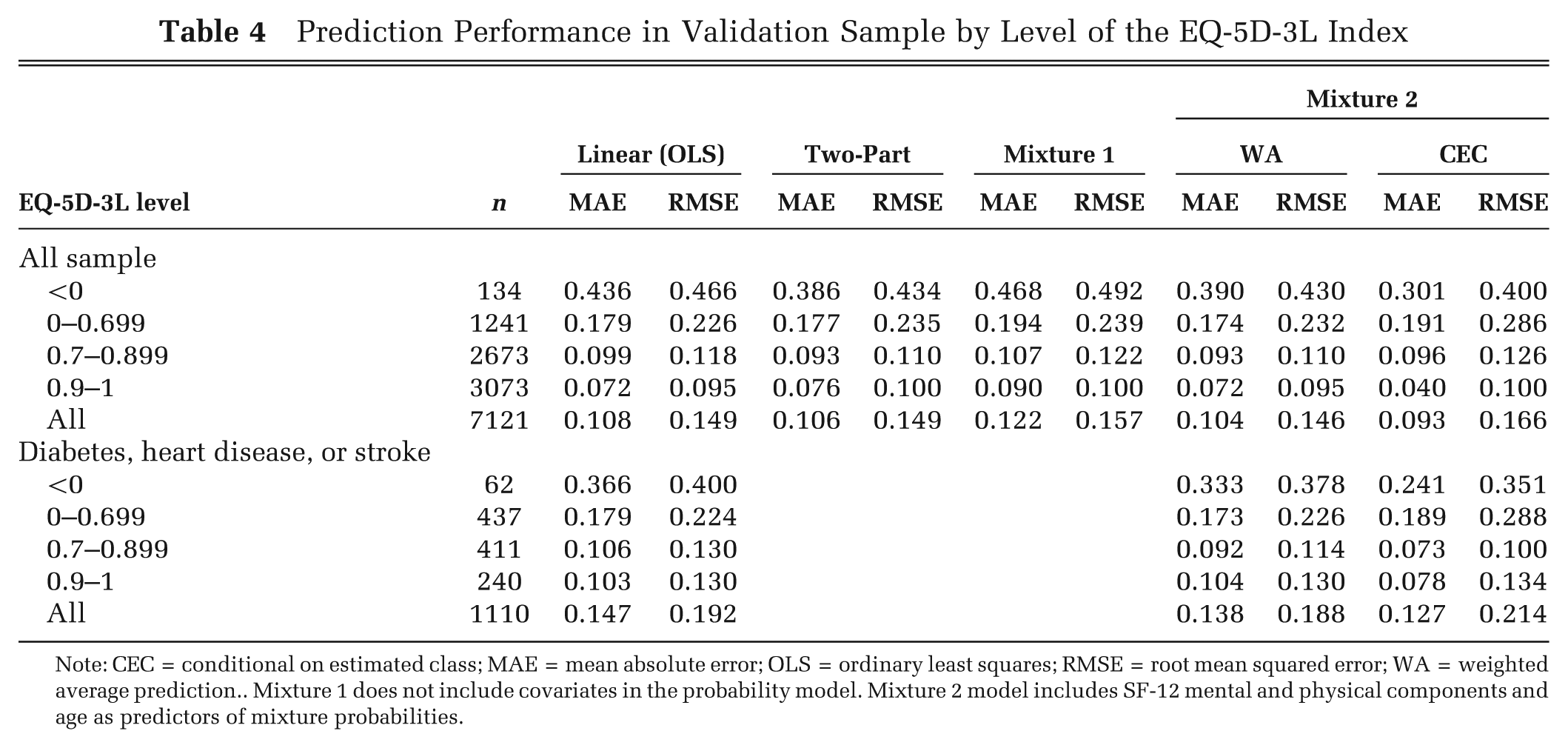
Note: CEC = conditional on estimated class; MAE = mean absolute error; OLS = ordinary least squares; RMSE = root mean squared error; WA = weighted average prediction.. Mixture 1 does not include covariates in the probability model. Mixture 2 model includes SF-12 mental and physical components and age as predictors of mixture probabilities.
Table 5 shows a cross-tabulation of observations classified based on the higher posterior and estimated probabilities using the validation sample and Mixture 2 estimates. The posterior classification (Equation 2) uses the observed EQ-5D-3L to calculate the probability that an observation belongs to 1 of the 3 classes and is thus the most accurate classification. From Table 5, approximately 75% of the observations are correctly classified when using the estimated probabilities for classification, which do not assume the EQ-5D-3L is observed. Observations away from EQ-5D-3L = 1 have a larger misclassification rate because the 2 Tobit components are close to each other and are thus harder to distinguish. These errors in misclassification produce larger RMSE.
Classification Based on Posterior and Predicted Probabilities for Mixture 2 Model
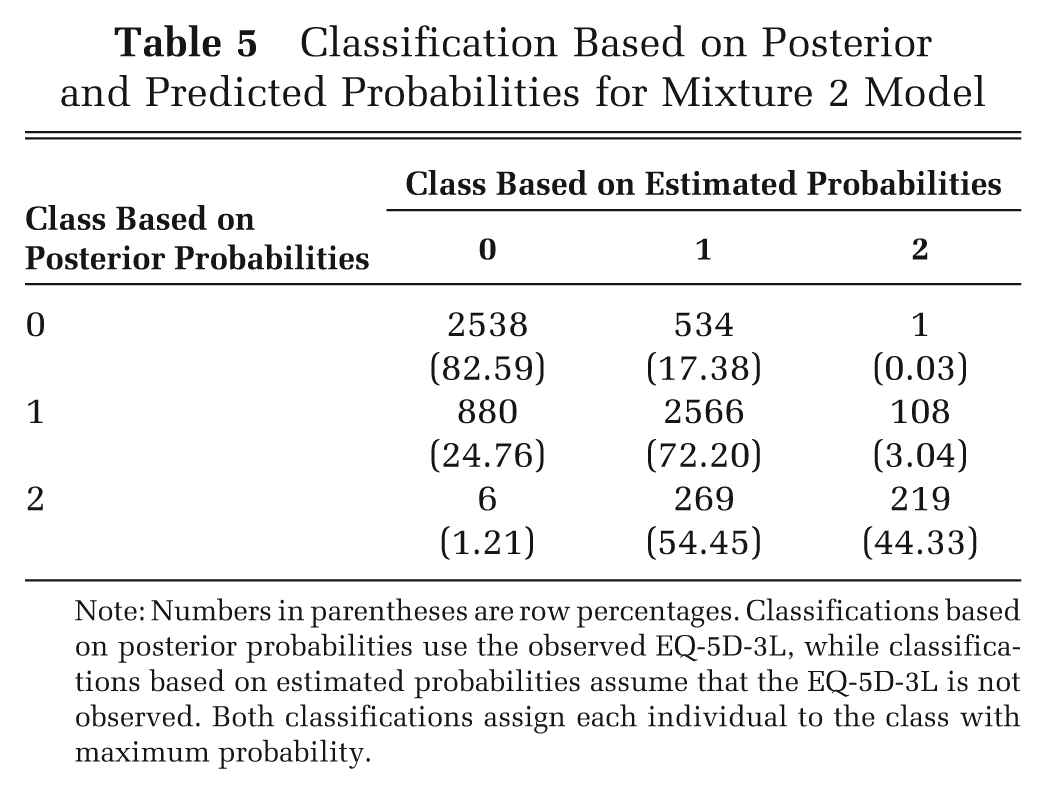
Note: Numbers in parentheses are row percentages. Classifications based on posterior probabilities use the observed EQ-5D-3L, while classifications based on estimated probabilities assume that the EQ-5D-3L is not observed. Both classifications assign each individual to the class with maximum probability.
Table 6 shows prediction comparisons for the linear (OLS) and Mixture 2 models (estimated coefficients not shown) for a subsample (n = 2219) of individuals who reported having diabetes, stroke, or heart disease, randomly divided into estimation (n = 1109) and validation (n = 1110) samples. As with models for the general population, RMSE gave a higher weight to larger errors, but based on MAE, both WA and CEC predictions are superior to those of the linear model. In particular, the MAE for CEC predictions represents a 14% improvement, from 0.147 to 0.127 in the validation sample. A finite mixture for this subpopulation makes better predictions than the linear model at the tails of the distribution, as can be seen from Table 4, although the mixture model underperforms in the interval 0–0.699. Predictions from the linear model regress toward the mean, overestimating the EQ-5D-3L for individuals with lower EQ-5D-3L while underestimating the EQ-5D-3L for those with higher observed values.
Model Comparisons for Those with Diabetes, Heart Disease, or Stroke
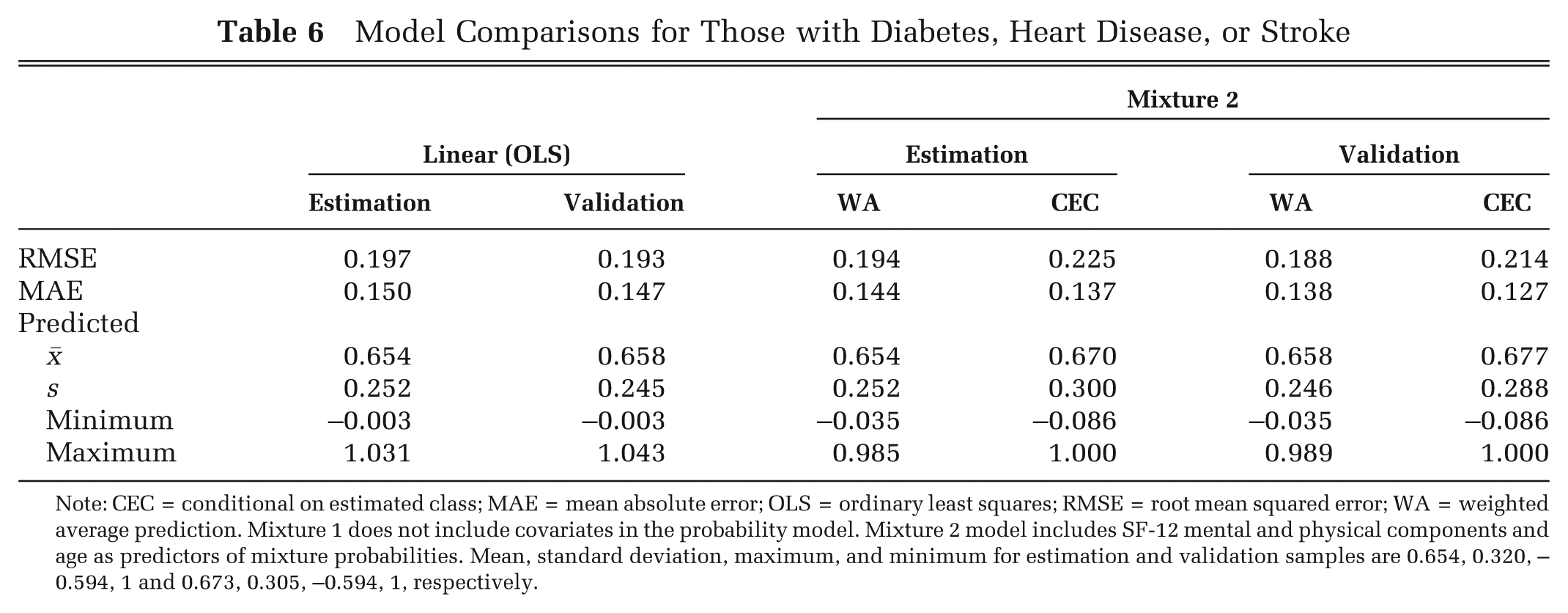
Note: CEC = conditional on estimated class; MAE = mean absolute error; OLS = ordinary least squares; RMSE = root mean squared error; WA = weighted average prediction. Mixture 1 does not include covariates in the probability model. Mixture 2 model includes SF-12 mental and physical components and age as predictors of mixture probabilities. Mean, standard deviation, maximum, and minimum for estimation and validation samples are 0.654, 0.320, –0.594, 1 and 0.673, 0.305, –0.594, 1, respectively.
Figure 2 shows the histograms of predicted values by model type. It can be seen that CEC predictions based on mixture models (Figure 2, bottom row) are able to reproduce the distribution of the observed data (Figure 1, A and I) more closely than are OLS and two-part models.
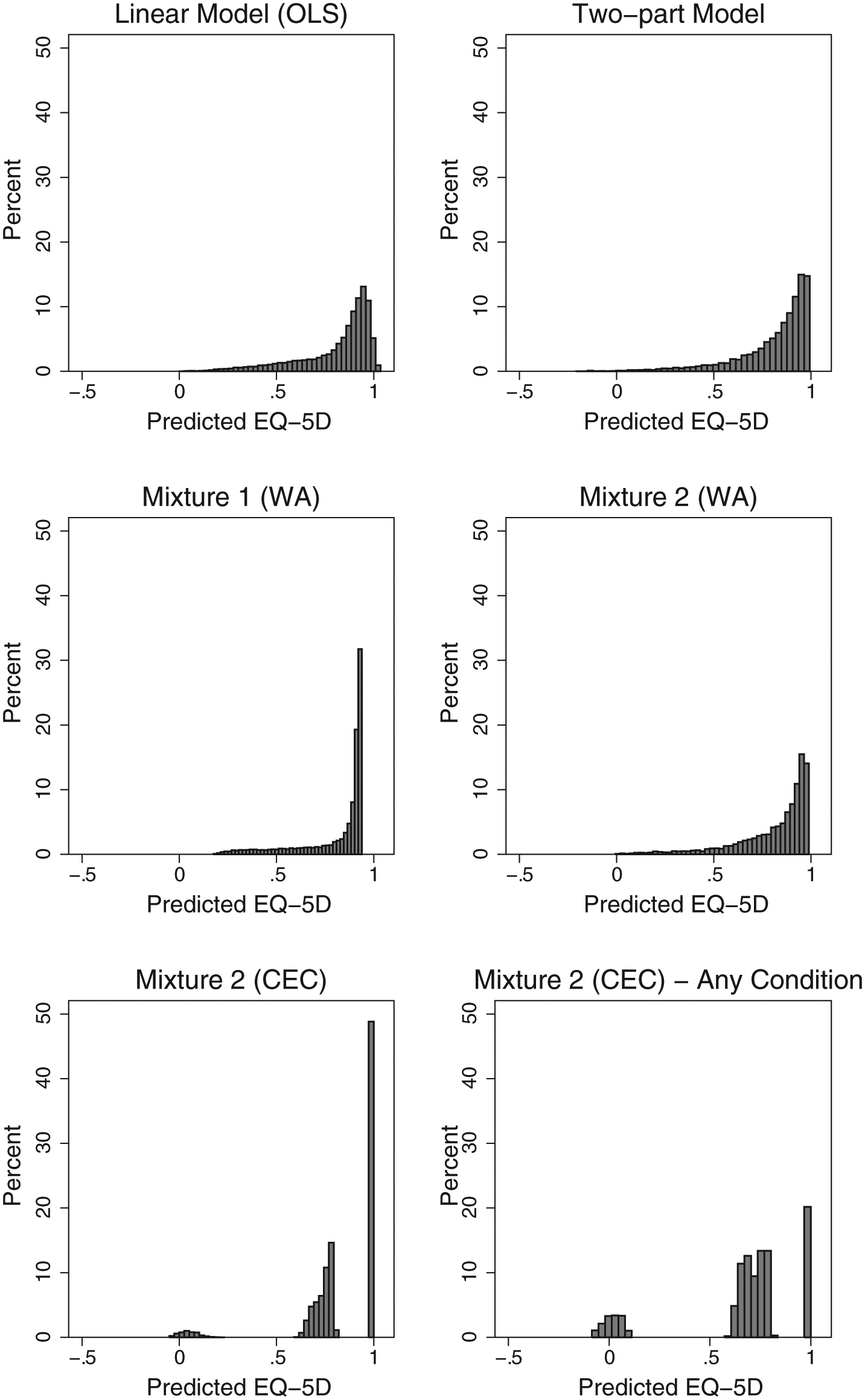
Histogram of predicted EQ-5D-3L scores by model. CEC = conditional on estimated class; WA = weighted average prediction. Mixture 1 does not include covariates in the probability model. Mixture 2 model includes SF-12 mental and physical components and age as predictors of mixture probabilities. Any condition includes respondents who reported having diabetes, heart disease, or stroke.
The best Mixture 2 model included only the SF-12 components as predictors of the mean EQ-5D-3L within each component (Table 2). Alternative models including age and sex fit the data well and could add more variability to the predictions, but the extra parameters that need to be estimated were penalized by the BIC. As a result, the most parsimonious model was preferred.
Discussion
The feasibility of economic evaluations is hindered if the data do not include preference-based measures. When data on preferences are not available, analysts use condition-specific or generic measures of health status to predict preferences. In this report, we showed that finite mixture models with Tobit components capture the idiosyncratic characteristics of the EQ-5D distribution, particularly when the sample does not include a large number of individuals in good health. Predictions from our best mixture model are superior at the tails of the distribution and on average, although some individuals can potentially be misclassified, which is reflected in larger RMSE. Moreover, linear and two-part models tend to perform better around the center of the observed distribution.
We use mixture models to account for a heterogeneous population even though the mixture components do not have a direct physical representation. Finite mixtures offer a flexible modeling approach that takes into account the characteristics of the distribution of societal preferences, which cannot be accurately described by a single probability density. Traditional methods, such as linear regression and two-part models, make poor predictions for extreme values of observed EQ-5D-3L scores and do not take into account the bounded nature of preference-based scores. As a consequence, these methods tend to overestimate preferences for individuals in the poorest health states while underestimating preferences for those individuals in the best health states, potentially biasing economic evaluations, which could then lead to misallocation of resources. In contrast, finite mixture models are able to improve prediction and mitigate biases at both tails of the distribution with only the SF-12 summary scores and age as predictors.
A known limitation of finite mixture models is that they tend to be difficult to estimate. When one is using maximum likelihood estimation, this problem is ameliorated by choosing appropriate starting values for the maximization algorithm regardless of the maximization method. 38 When we applied our strategy for choosing starting values to the MEPS dataset, however, model specifications converged to a global maximum and the estimated parameters were robust to the selection of starting values.
Another potential limitation is that there is no guarantee that mixture models will be appropriate for other datasets or that these datasets will have enough information to correctly separate observations into latent classes. For example, predicting societal preferences using general measures of health like the SF-12 is not as challenging as predicting individual preferences for those currently experiencing a particular health state. Individuals adapt to changes in their health status, and general measures of health may not provide enough information to estimate models as adaption may depend on unmeasured traits. 39 In our models, both SF-12 and age were sufficient to accurately predict class membership.
While Hernandez and others 26 demonstrated that mixture models can be used to predict EQ-5D-3L preferences using a measure of disability in a homogeneous clinic-based population with multiple observations per subject, our analysis shows that mixture models perform well using general health measures in a heterogeneous sample of the US population and cross-sectional data. Furthermore, we also demonstrated that mixture models are more useful when the target sample does not include a large proportion of individuals in good health. Our results using the SF-12 summary scores as predictors were consistent with those of Hernandez and others, which used a disability measure from the HAQ questionnaire and a pain measure as predictors and found improvements in both MAE and RMSE. However, our results show that mixture models do not outperform linear and two-part models over the whole range of observed EQ-5D values and that predictions based on classification may produce larger RMSE.
Finally, concerns have been expressed recently that mapping methods underestimate the observed variance of the EQ-5D-3L. 40 In OLS models, for example, predicted EQ-5D-3L values tend to regress toward the mean while the bulk of the observed values are away from it. However, when the EQ-5D-3L was predicted using mixture models and classification, the variances of observed and predicted EQ-5D-3L were closer in magnitude, although still underestimated but to a much smaller extent than the other methods.
Future research can exploit the richness of information available in the MEPS dataset to estimate mixture models for subpopulations with the same characteristics as those in datasets without preference-based measurements. To facilitate wider use of our proposed mixture models, we have made our Stata program publicly available (see Appendix A) and provide practical guidance on how to use our mixture models in Appendix B. Further research is also needed to evaluate under which conditions a finite mixture model produces better predictions on the whole range of observed EQ-5D-3L scores and whether additional refinement of mixture models can further improve predictions to better capture uncertainty.
Footnotes
Financial support for this study was provided in part by a training grant from the Agency for Healthcare Research & Quality (AHRQ) T32HS000084 (MCP) and a research grant R01HS020263 (YTS), also from AHRQ. The funding agreement ensured the authors’ independence in designing the study, interpreting the data, and writing and publishing the report.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.