
Abstract
The World Health Organization has not only signaled the health risks of COVID-19, but also labeled the situation as infodemic, due to the amount of information, true and false, circulating around this topic. Research shows that, in social media, falsehood is shared far more than evidence-based information. However, there is less research analyzing the circulation of false and evidence-based information during health emergencies. Thus, the present study aims at shedding new light on the type of tweets that circulated on Twitter around the COVID-19 outbreak for two days, in order to analyze how false and true information was shared. To that end, 1000 tweets have been analyzed. Results show that false information is tweeted more but retweeted less than science-based evidence or fact-checking tweets, while science-based evidence and fact-checking tweets capture more engagement than mere facts. These findings bring relevant insights to inform public health policies.
Introduction
The overabundance of data and knowledge is one of the characteristics of the information society. Power no longer resides in having access to information but in managing it. Indeed, the arrival of the internet and social media has undeniably facilitated the circulation and outreach of information, opening up the possibilities that users have to access, interact and produce content (Del Vicario et al., 2016). This situation has led to a democratization of the existent relationship between knowledge and citizens. However, social media and online sites have also become the primary platforms from which to disseminate false and misleading information (Lazer et al., 2018) since they allow rapid and large-scale sharing (Vosoughi et al., 2018) and lack the traditional mechanisms of quality control and ‘gate-keeping’ (Lewandowsky et al., 2012). Indeed, the presence of fake-news found and distributed in online settings is increasing over the years (Vosoughi et al., 2018).
The term fake-news (i.e. fabricated information mimicking real news; Lazer et al., 2018) has been widely used in recent years (Guess et al., 2019), especially linked to the US presidential election of 2016 (Allcott and Gentzkow, 2017; Bovet and Makse, 2019). However, following Wang et al. (2019), we will refer to false information to describe any form of falsehood, including rumors, hoaxes, myths, conspiracy theories and other misleading or inaccurate (purposely or not) shared or published content. In 2013, the World Economic Forum (Howel, 2013) released a report entitled Digital Wildfires in a Hyperconnected World in which the organization pointed to false news as being one of the main threats of our current society. Research (Del Vicario et al., 2016; Lazer et al., 2018; Lewandowsky et al., 2012) has already demonstrated that people tend to prefer, are more persuaded by, and are more prone to accept information that confirms and is consistent with their pre-existing attitudes and beliefs. Thus, partisan ideology makes an individual more prone to ignore or reject dissonant information, as well as less likely to accept any fact-checking that questions his own system of beliefs. In addition, the more individuals are exposed to false news, the likelier they are to accept this kind of information (Del Vicario et al., 2016).
In this vein, a study that investigated how true, false and mixed news were differentially diffused on Twitter found that rumors circulated significantly ‘farther, faster, deeper, and more broadly than the truth in all categories of information’ (Vosoughi et al., 2018: 2). In this vein, the authors found that since its inception in 2006 to 2017, the truth on Twitter reached an average of 1000 users, whereas the top 1% of false news tended to reach between 1000 and 100,000 users, and false news, on average, was 70% more retweeted than veracious information. In addition, a study that focused on how communities of users consuming conspiracy-news and scientific news interacted with their preferred type of content found that polarized consumers of false information usually concentrate greater on the posts shared within their community and are more committed and active in the diffusion of such content (Bessi et al., 2015). Conversely, these same authors found that consumers of news based on scientific facts are less active or engaged in the dissemination of science-based information but do tend to comment more on posts containing fake or misleading information to debunk it with their knowledge.
Indeed, the increase of false information is fostering the denial of scientific evidence and could potentially be a threat to democracy and to citizens (Allcott et al., 2019), as the dissemination of such content has been demonstrated to foster cynicism, apathy and extremism (Lazer et al., 2018), possibly misleading decisions affecting public policy and people’s lives. In this vein, false-news can lead individuals and institutions to make choices which end up being against their own best interests or against society’s needs (Merino, 2014).
One of the most relevant examples of this negative effect of false news can be found in the field of health. Scientific research focused on the study of false information (Wang et al., 2019) is mainly centered on issues around vaccination (Betsch, 2017; Hotez, 2016) and infectious diseases (Fung et al., 2016). Research has found that the spread of false information in this context can have severe consequences for public health (Scheufele and Krause, 2019), such as those caused by the anti-vaccination movement (Jamison et al., 2019). For instance, Lewandowsky et al. (2012) point out how the prevalence of myths surrounding vaccinations (i.e. its link to autism) has led an increasing number of parents to hold out on such measures, and how this is directly related to an increase in a number of preventable diseases. Furthermore, such prevalence is still found among health practitioners (Le Marechal et al., 2018).
Another case which is currently raising public concern is that of the COVID-19, also popularly known as coronavirus disease. On 31 December 2019, the first case of the outbreak was reported in China. By 7 February, when the data collection finished, there were 31,481 confirmed cases worldwide. Of these, 31,211 had been confirmed in China, were the virus had already caused 637 deaths. Outside of China, there had been 270 confirmed cases by 7 February in 24 different countries and one casualty had been reported (World Health Organization, 2020c). By 29 February, when this manuscript was submitted, the number of cases globally had risen to 83,652 cases, which are present in 52 countries, including China. Worldwide, 2858 people have died from this disease (World Health Organization, 2020d).
In this context, the circulation of false information on the COVID-19 outbreak is growing fast (Chakravorti, 2020; Taylor, 2020) and includes, among others, references to pretended cures, such as rinsing one’s mouth with salty water, eating oregano, or even drinking bleach. Other types of misleading information are contributing to the dissemination of myths, such as pointing at the consumption of ‘bat soup’ as the cause of the infection, or conspiracies, such as the virus being engineered by the US. This type of news not only favors the increase of racist attitudes and behaviors (Aguilera, 2020) but also puts at great risk populations’ health and the ability of governments to effectively implement prevention measures. Before this situation, the WHO declared that besides the pandemic threat, originated by the SARS-CoV-2 virus, an infodemic has been generated by a large amount of information available on the matter, as well as by the difficulty to sort the veracious information from the false (World Health Organization, 2020a). To fight this, WHO has created a section on its website devoted to myth-busting and the debunking of false information (World Health Organization, 2020b) and is publishing daily reports to provide the population with reliable data.
As well, search engines such as Google and social media platforms like Facebook, YouTube and Twitter are putting in place measures to both limit the spread of false information and direct users to reliable sources (Rubio Hancock, 2020). Under other circumstances, measures taken to the limit the circulation of fake-news have yielded mixed results. For instance, Allcott et al. (2019) analyzed the circulation of false information on Facebook and Twitter between 2015 and 2016 after the algorithmic and policy changes that both social networks had introduced in order to limit the spread of such content on their platforms since the 2016 presidential election in the US. Results from their study show that before the 2016 election, interactions with fake-news were steadily increasing. However, one month afterwards, interactions with fake-news were being cut to more than half on Facebook, while on Twitter such interactions continued to increase.
In order to respond to this infodemic, the present article aims at shedding new light on the circulation of misinformation on Twitter in relation to the 2020 COVID-19 health emergency, with the aim to unveil new insights on how false information and evidence-based information are circulating in this network. Our goal is to research how many of the tweets shared in a specific time-period contained false information, how many were aimed at debunking such information and how many were based on scientific information. We also wanted to explore the corresponding user engagement measured though the number of retweets (RT). To this end, we have developed the following research questions:
RQ1: How many tweets contain false information? How many RT do these get?
RQ2: How many tweets debunk false information? How many RT do these get?
RQ3: How many tweets are based on scientific information? How many RT do these get?
RQ4: What are the implications of the results?
Method
There is much interest in the study of global processes through the analysis of social media (Pauwels, 2019: 2). Social media research has used different methods to analyze the datasets obtained from social media data: quantitative and qualitative approaches are used as well as a combination of the two (Snelson, 2016). In this vein, the systematic review done by Snelson found that results often take the form of counts of themes or topics identified, and both approaches require the development of a codebook to develop the coding analysis of the dataset; this being the typical pattern. However, according to this author, researchers conduct content analysis inductively sometimes instead of using a codebook. Other researchers try to combine social media analysis results with other qualitative research techniques (Galarza Molina, 2019).
We have developed Communicative Content Analysis, a novel contribution to the field of content analysis methods. Communicative Content Analysis applies the postulates of communicative methodology (Gómez et al., 2019). This communicative methodology is based on a dialogic co-creation of knowledge between researchers and citizens; with researchers providing the already existing scientific evidence and citizens contributing with their plurality of voices. This methodology has acquired scientific and social recognition, to the extent that co-creation principles are acknowledged as important in EU Research Programs. In fact, the impact assessment of communicative methodology is crucial (Redondo-Sama et al., 2020).
The current article will follow the following postulates of communicative methodology (Gómez et al., 2019: 3–4):
Universality of language and action: following a communicative approach that draws from contributions made by Habermas, Austin and Vygotsky, communicative methodology acknowledges the inherent capacity of all individuals, regardless of their culture or background, for communication and interaction.
Individuals as transformative social agents: based on Freire and Garfinkel, it assumes that all individuals are able to comprehend the world around them, build knowledge and transform the existing structures in society. The theory of dialogical action provides communicative methodology with the foundations of its transformative dimension.
Common sense: building on Schütz, this postulate is based on the understanding that the context in which the interactions take place is a key element of communicative acts. Thus, communicative methodology respects and values this factor and allows for the collection of data in the different cultural spaces. In this case common sense is established by taking the plurality of voices into account.
Equal epistemological level: consequently, with the other postulates, communicative methodology fosters the co-creation of new knowledge on an egalitarian basis. Thus the participation of individuals is no longer instrumental (i.e. as a source of data), but they participate with their knowledge and experience and researchers have the responsibility to combine such knowledge with scientific evidence to ensure that an egalitarian dialogue can take place.
Dialogic knowledge: building on Vygotsky, Freire, Beck, Flecha and Habermas, communicative methodology fosters the creation of knowledge through the principles of dialogic learning, which include, among others, solidarity, dialogue and consensus, and incorporate the objectivist and subjectivist approach to the interpretation of reality.
Communicative Content Analysis is based on communicative methodology’s contributions and one of the first points is that the communicative analysis of data has as its main goal to contribute to the social impact of the research (Pulido et al., 2018), and for this purpose, the analysis is focused on exclusionary and transformative dimensions, which are explained below. The next sections will explain in detail the different steps followed in this research.
Data collection
To develop this study, the first step was to select the sample of social media data to analyze. The selection was made according to the following criteria (see Figure 1):
Criterion 1. The first criterion was to select a social media source. For this study, we have selected Twitter due to the global concern of false information being spread on this specific social media platform.
Criterion 2. Selection of the keyword instead of a hashtag. In this case, we have selected the keyword ‘coronavirus’ for searching tweets that contain this keyword. This option is more inclusive because it also includes tweets that have the hashtag #coronavirus.
Criterion 3. The period in which tweets were published. We have selected tweets published on 6 and 7 February 2020 in all available languages.
Criterion 4. Software used. The extraction of the sample was done with NVivo.
Criterion 5. Selection of the 1000 tweets with more RT. After obtaining the full sample on Twitter on the defined days, the 1000 tweets with more RT have been selected, in order to analyze those that have received more attention from citizens.
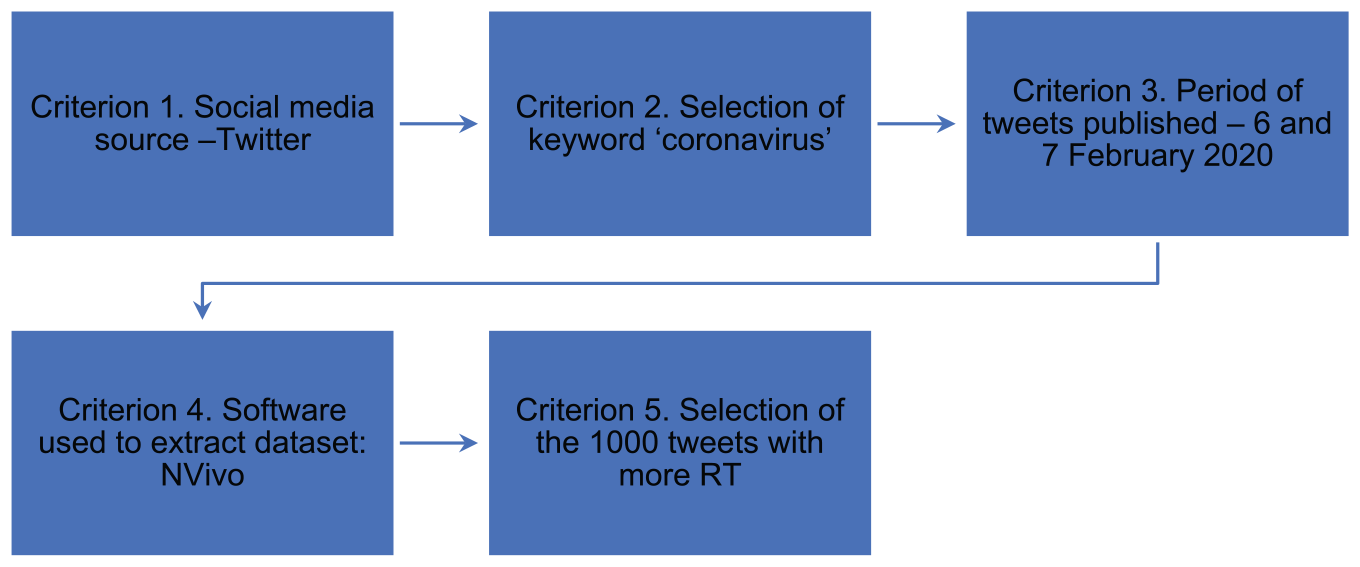
Criteria for data collection.
The Excel list exported contained 17,988 tweets. We ordered this list by highest numbers of RT and selected the first 1000 tweets for the analysis.
Dialogic codebook
The researchers who carried out the analysis of the collected social media data are specialists in social media research and the detection of false information and evidence-based tweets. The authors of this article guaranteed the accurate analysis of data collected in dialogue with a Chinese researcher, since the COVID-19 outbreaks were mostly concentrated in China at the time of the analysis.
The unit of analysis is the complete tweet. This means that not only the text written in the tweet was considered, but also two more pieces of information: if the tweet has a link the information provided in this link is part of the unit of analysis too, and the number of RT obtained. The profile user of the tweet analyzed is checked in order to establish if the profile is true or false or is a bot.
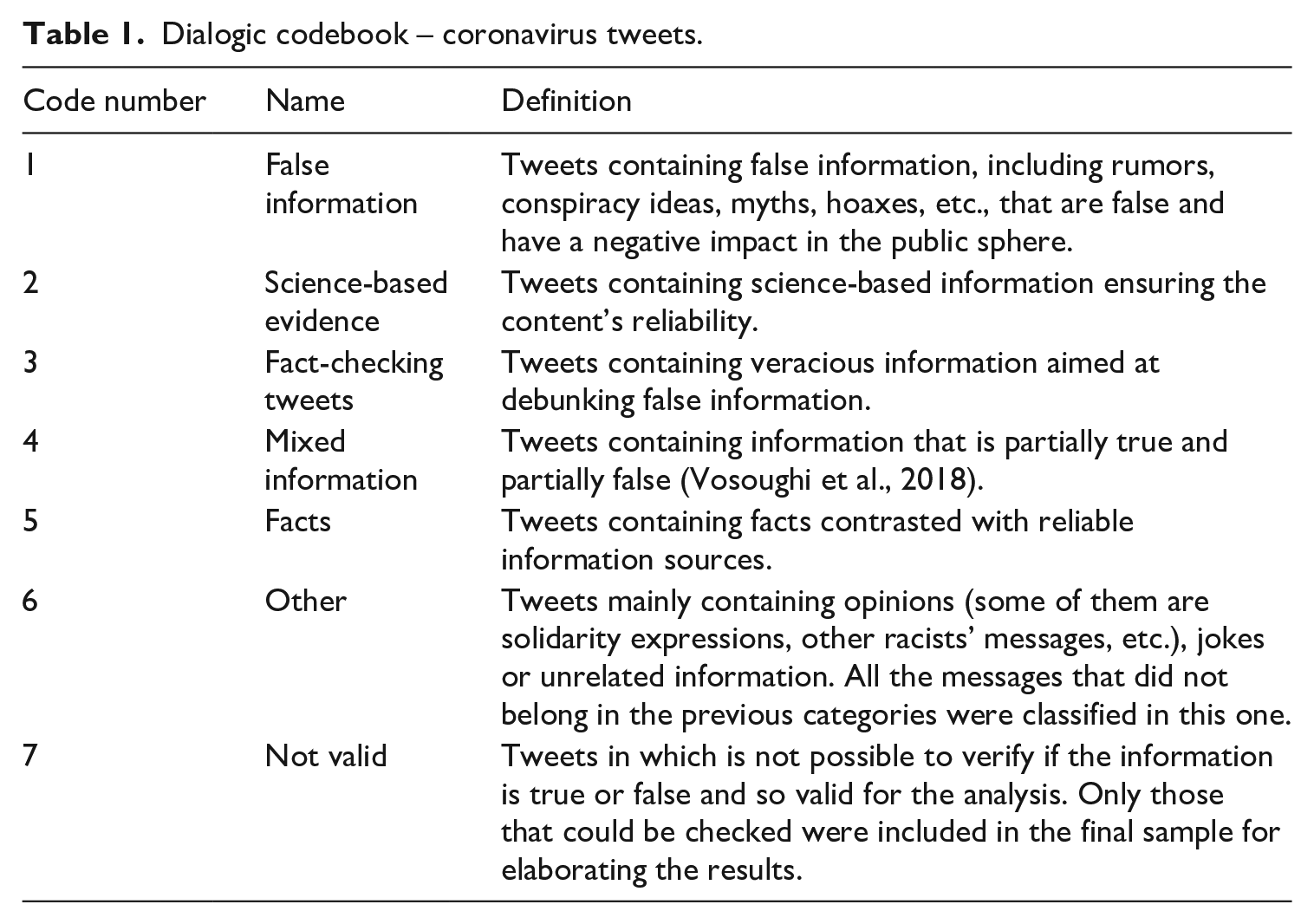
The elaboration of the codebook was dialogic, combining predefined categories with those categories that emerged during the analysis. Different researchers tested the categories and decided which were the most suitable through consensus. The first version of the codebook contained four main categories: (1) False information, (2) Science-based evidence, (3) Fact-checking tweets and (4) Mixed information. Once the research team tested these categories in a first analysis of the sample, three new categories emerged; these were the following: (5) Facts, (6) Other, (7) Not valid. Table 1 shows the codebook used to carry out the final analysis of the sample.
Dialogic codebook – coronavirus tweets.
In-depth dialogic data analysis
One of the characteristics of Communicative Content Analysis is the type of data analysis conducted. In this case, in-depth dialogic data analysis implies a profound human analysis of each tweet. In this vein, the global sense of the same tweet was analyzed, not only the text, in order to classify each tweet into the correct category. Most of the papers that conduct research with social media obtain results from quantitative methodologies, which are very useful to identify a trend, but in our case, we are interested in deepening the analysis far more. The researchers conducting the analysis do not work separately, coding tweets and then comparing them if they have obtained the same classification, and calculating the posterior kappa coefficient, which is the traditional way to conduct a content analysis. This is a correct way to do it, but not the only one.
In our case, researchers work collaboratively and dialogically: once all researchers have the codebook, the analysis begins, and researchers together comment on each case. Indeed, this in-depth dialogic analysis is an ongoing process from the first step of the analysis until the very end of the research. The coding process includes the application of the codes to detect if a tweet belongs to one category or another. When researchers have any doubts about how to classify a tweet, they immediately discuss it and reach an agreement based on validity claims. As an example, with regard to the tweets that provided numbers of persons infected by the coronavirus, we reached the agreement to code as ‘fact’ those tweets providing numbers consistent with those published by WHO, while those that were inconsistent were coded as ‘false information’.
Thus, the dialogue that we establish is one between scientific evidence and facts and the information that we have in our sample. The postulate of dialogic knowledge (Gómez et al., 2019) is applied in this analysis as well as other postulates. Those tweets that contained opinions were directly coded as ‘others’, and those tweets that appeared to contain facts or evidence were checked with scientific evidence, reliable sources and fact-checker software in order to establish if they were true or false. The in-depth dialogic analysis also includes the cultural dimension in the verification process of the retrieved information.
Once all tweets from the dataset had been analyzed, we proceeded to elaborate on the quantitative and qualitative evidence, respectively calculating the number of tweets in each category, and analyzing each message’s content. The communicative analysis of quantitative and qualitative results allows us to detect the transformative and exclusionary dimensions. In this study, the transformative dimension includes all the tweets that contain true information (science-based evidence, fact-checking tweets and facts) and the exclusionary dimension tweets that contain false information, as well as mixed information.
Dialogic reliability
There are different assessments of the reliability of data coding. Quantitative content analysis includes the calculation of the kappa coefficient or other types of coefficient; qualitative content analysis requires time for the analysis, substantial human resources and time to get together and discuss common coding policies, as well as their application (Oleinik, 2011). In the case of dialogic reliability this too requires time, plurality and egalitarian dialogue, but this time use is efficient in order to guarantee the reliability of the analysis obtained. Dialogue is present throughout the process to guarantee the consistency of the analysis, and characterized by being (a) evidence-based and (b) intercultural, because the Western and Chinese researchers worked in an egalitarian way that ensures the accuracy of the results shown.
Results
The 1000 extracted tweets were classified in the seven aforementioned categories (see Table 1). Of these, 58 were not valid and were thus excluded from the analysis (Table 2).
Frequency and percentage of retrieved tweets and retweets.
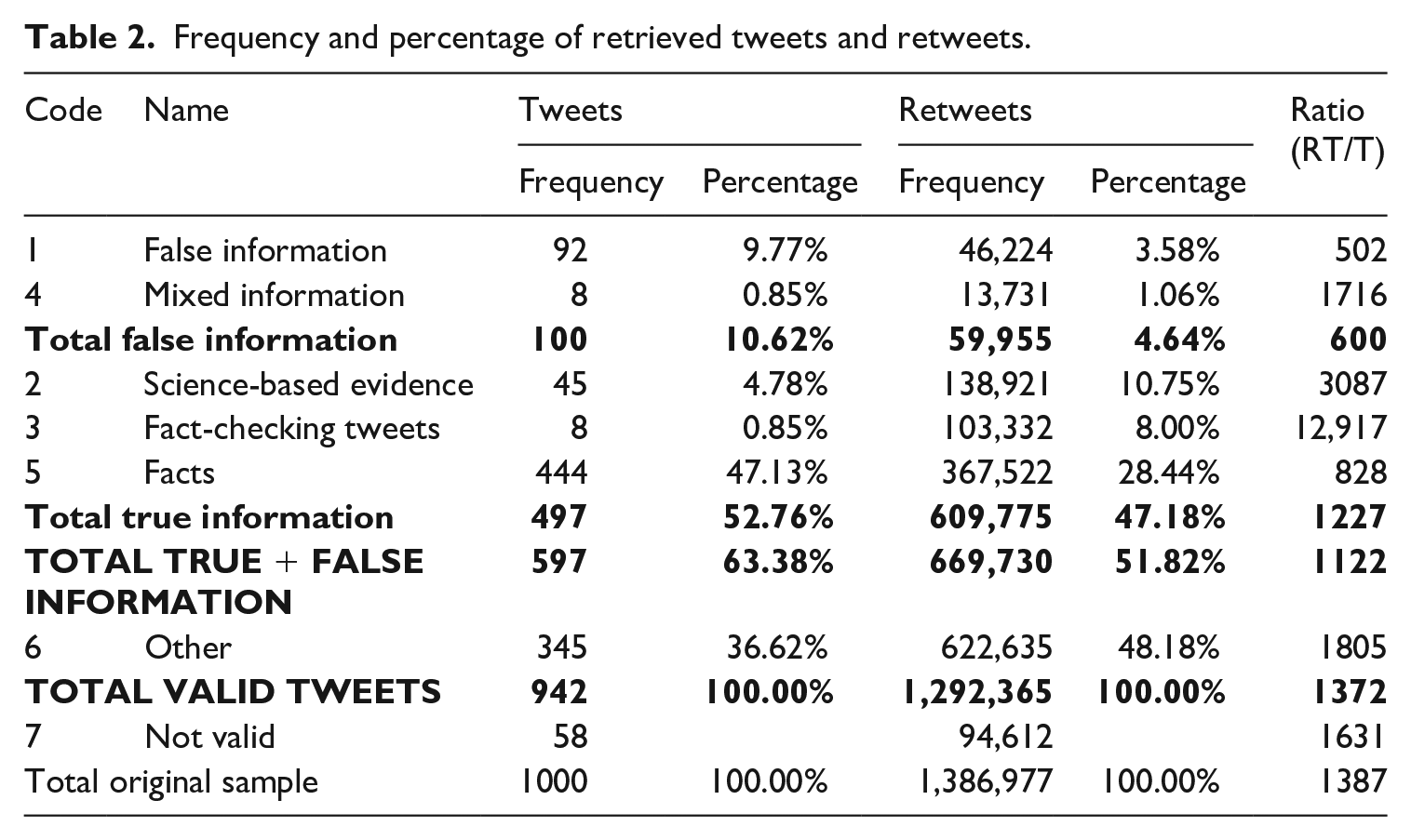
False information is more tweeted but less retweeted than science-based evidence or fact-checking tweets
In the final sample (N = 942), a total of 597 tweets contained either true or false information, representing 63.38% of the sample (Table 2). The category of message that emerged the most was Facts, followed by False news, Science-based evidence, Debunking information and Mixed information. Thus, the extracted sample contained more true information (i.e. science-based information, debunking information and facts) than false information (including mixed information), with the former being almost five times more likely to be posted than the latter (Table 2).
Regarding false information (RQ1), 92% of the messages were unambiguously false (Table 3). These included fake-news, rumors, myths and conspiracy theories. Examples of these are the tweets pointing at the virus being a biological weapon or the messages containing videos and images of people suddenly collapsing or have a seizure due to being infected by the virus. The number of tweets containing false information as a proportion of the whole sample is low (10.62%) (Table 2). These results are consistent with the findings of Guess et al. (2019), who pointed out, with regard to their data, that most users on Facebook did not share fake-news during 2016. However, it must be taken into account that neither the network (Facebook) nor the scope of their research (US presidential election of 2016) is the same as in the current research. Nevertheless, false information was twice as likely to be posted as scientific evidence-based information. These findings are consistent with research that reports that consumers of false information are more active in the publication of such content than evidence-based consumers (Del Vicario et al., 2016).
Frequency and percentage of retrieved tweets and retweets containing false information.
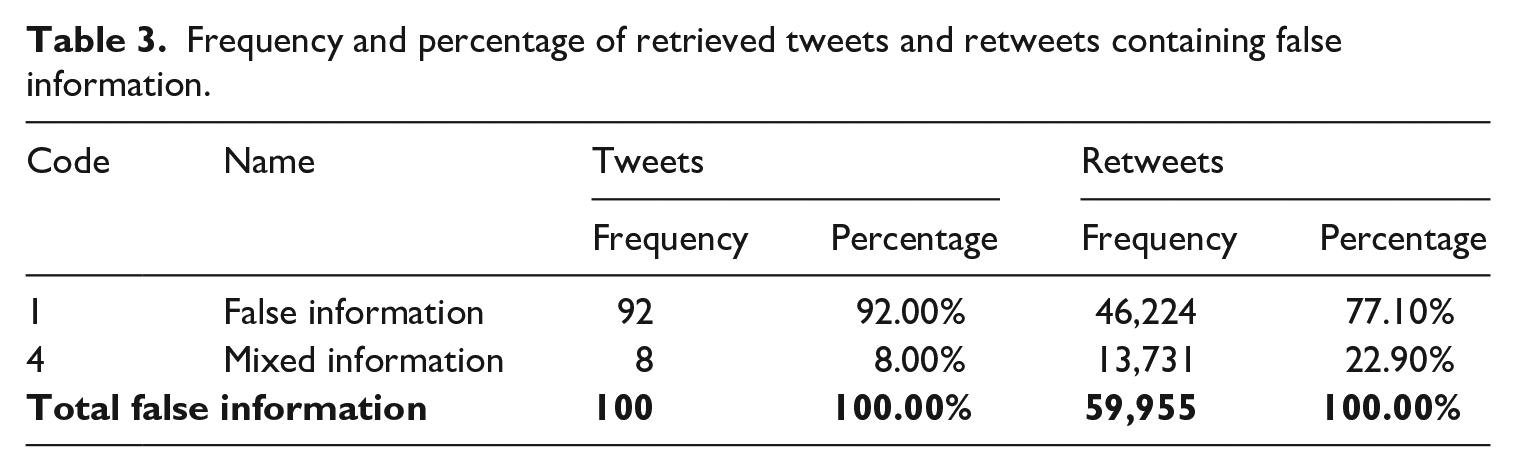
When looking at the trends in retweeting, a different kind of behavior was observed. In this category, most RT included a meme of a celebrity allegedly diagnosed with coronavirus; rumors about Chinese authorities’ measures to tackle the virus; how the virus spreads; conspiracy theories; fake viral videos (e.g. one of a guy supposedly infected spitting on bottles of drink in a supermarket); the origins of coronavirus; and number of deaths. The remaining 8% (Table 3) referred to messages in which true facts were mixed with false ones, such as using some facts regarding the situation in China to spread partisan information. Most retweeted Mixed information included viral videos (e.g. a citizen from Wuhan reporting on the gravity of the situation but giving out some fake information). Other tweets in which true facts have been mixed with false ones refer to the origins of the virus, actions taken by the Chinese authorities to fight it, and to how the disease spreads. We identified that some of the misleading information was released through the press, mostly through misleading headlines.
Regarding Fact-checking tweets (RQ2), 2% corresponded to messages aimed at debunking false information (Table 4), by providing either facts or science-based information to refute the falsity in the message. Tweets in this category were almost 13,000 times more likely to be retweeted than tweeted (Table 2). The retweeted fact-checking messages included tweets challenging misleading facts about common flu vs. coronavirus; checking on false cases; debunking dodgy cures; rumors about the Hong Kong cruise and about the origins of the virus; and identification of misleading images. Other studies confirm the relevance of online social networks for the fast dissemination of evidence-based health information (Fung et al., 2016). Indeed, after WHO’s declaration of the Ebola outbreak as a Public Health Emergency of International Concern in August 2014, it was revealed that most information on social media (Twitter and Sina Weibo – the Chinese platform) were outbreak-related news and scientific health information, mostly coming from news agencies reporting information disseminated by public health agencies (Fung et al., 2016). These two social networks helped spread the key messages from WHO (i.e. current scientific understanding of Ebola and its prevention and control) immediately after the announcement of the global health emergency, suggesting that these social media played an important role in the efforts to control the propagation of the Ebola virus (Fung et al., 2016).
Frequency and percentage of retrieved tweets and retweets containing true information.
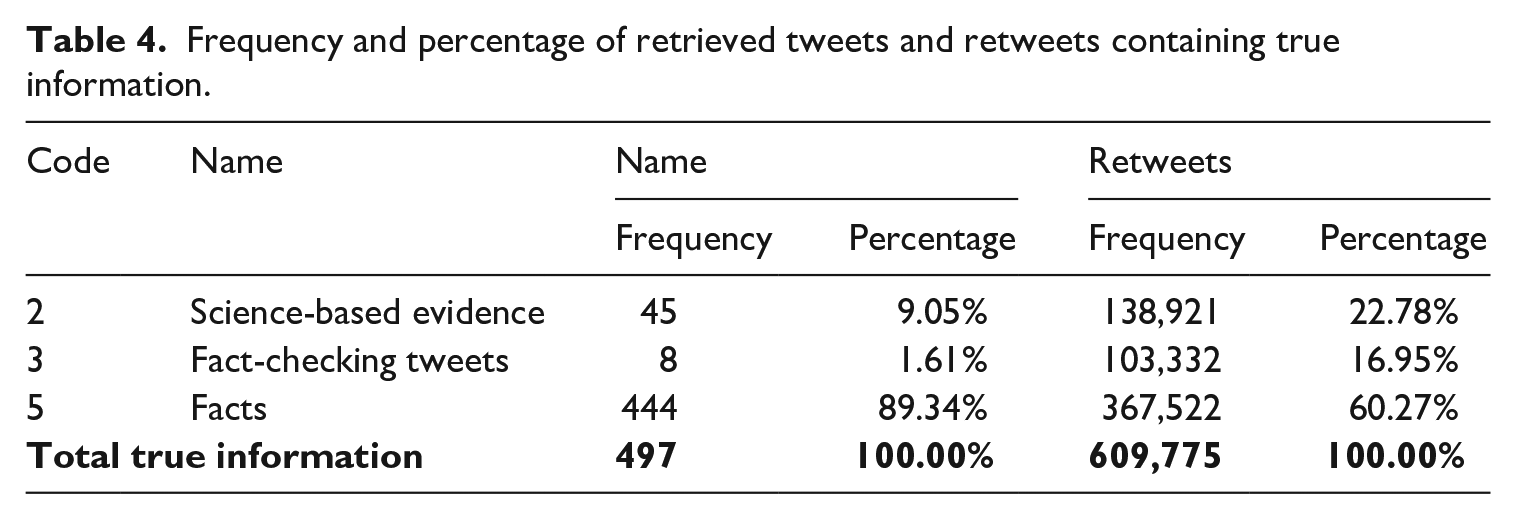
In reference to science-based evidence (RQ3), roughly 9% of the veracious tweets contained science-based evidence (Table 4). These tweets were around 3000 times more likely to be retweeted than to be tweeted (Table 2). The retweeted messages in this category included information on how to wear a mask properly; information to spread awareness on prevention and control measures; information on what coronavirus is, the symptoms, transmission and complications of the disease; the complete genome of the virus; reference to antiviral drugs under experimentation; percentage of detected cases vs. possible non-detected cases in China; the US medical system’s unhealthy reliance on China for drugs and supplies; information on the test kit for this novel virus; confirmed cases; and virus mutation. As well, these results are similar to those identified in a study which analyzed the initial reaction to information and misinformation on the Ebola outbreak (Fung et al., 2016). In this research, only 2% of the retrieved tweets contained misinformation, while a higher percentage of tweets containing news and health information were posted.
Science-based evidence and fact-checking tweets capture more engagement than merely facts
Thus, looking at the retweeting trends in this sample, containing veracious information increased the probabilities of a tweet being retweeted. Indeed, tweets containing true information were almost 10 times more likely to be retweeted than those sharing fake content (Table 2). Even within the category of true information, tweets disseminating fact-checking information and evidence-based information were proportionately receiving more RT than simply factual information, which implies a higher potential of true information in our sample to engage users. These findings are not in line with previous research focusing on the circulation of false news in general that points out that false information is retweeted more than true information (Vosoughi et al., 2018). This could be due to the fact that, in this case, the scope of false information was narrowed down to a health emergency. The data obtained are not in accordance either with research that shows that people prefer information confirming their pre-existing attitudes and beliefs, precluding acceptance of fact-checking (Lazer et al., 2018; Lewandowsky et al., 2012). Neither it is in line with research pointing at consumers of conspiracy news being more active in the diffusion of their preferred contents, while consumers of scientific-news are allegedly less engaged in the diffusion of evidence-based information and more inclined to comment on posts sharing misinformation (Bessi et al., 2015). However, the current case is in accordance with other research which has proved that science-based news in online social media reaches a higher level of diffusion, is spread more quickly, and has a longer life than false information (Del Vicario et al., 2016).
Conclusions
The COVID-19 outbreak in 2019–2020 has led to a situation of public health emergency, but also to an infodemic (World Health Organization, 2020a). The findings in the current study provide new insights into how false information and evidence-based information around the COVID-19 emergency circulated on Twitter, over two days in early February 2020. The 942 tweets that comprised the final sample show some differing trends regarding tweeting and retweeting.
The sample contained more veracious information than misinformation, which challenges the results of studies suggesting that for all content categories, false information is more likely to shared (Vosoughi et al., 2018). More precisely, false information was more likely to be tweeted but less likely to be retweeted than science-based evidence or fact-checking tweets. The findings of the current study are more aligned with research on the Ebola outbreak in 2014 (Fung et al., 2016), which shows that after the declaration of the emergency, true information circulated more than false information, which points at health information, or where it is the case of an emergency, disseminating in a different way. Further research is needed in this regard.
In addition, the fact that in our sample twice as much false information as evidence-based information was posted points to the need of finding strategies to bring scientific knowledge closer to the broader population. The internet and the Web 2.0. have democratized how citizens access, produce and interact with contents. However, advancing in such democratization requires users to be able not only to have access to scientific knowledge, but also to have the skills to critically assess information and to sort out valid content from falsehood. In this vein, further research should focus on preventive educational interventions that provide users with the necessary skills to access evidence-based information and reject falsehood.
Furthermore, considering all shared true information, both fact-checking tweets and tweets sharing evidence-based information were retweeted proportionately more than any other category. In this respect, other research has provided evidence that science-based news in online social media reaches a higher level of diffusion, spreads more quickly and has a longer lifetime (Del Vicario et al., 2016). However, our results are not consistent with studies finding that false news consumers tend to share this kind of news more, while science-based evidence consumers seem to be less engaged in sharing their preferred posts and more likely to respond with evidence-based information to false tweets. This could point out, again, that users’ trends on information consumption and sharing on social media are different when this involves a health emergency. Following the principles of democracy, an active citizenship against the production, circulation and spread of false information could indeed provide an answer to the measures needed to control any infodemic. In this vein, this type of analysis can help the health authorities to be up-to-date on how social media users are sharing information. For instance, knowing that users prefer to RT evidence-based tweets can help health authorities publish more tweets from their official accounts. In addition, users could also be trained to debunk false information through scientific literacy training promoted, for instance, in family training, life-long learning, schools, universities and civil grassroots movements, among others. Further studies on how to promote such engagement and its effects in limiting the circulation of false information are needed.
Future research should also study the measures implemented in this outbreak by public organizations such as WHO, as well as the role of social media in the efforts to control the outbreak (Jamison et al., 2019; Wang et al., 2019). Indeed, it should also be explored what the best strategy is for the promotion of true information in an attempt to use this against the proliferation of false information.
Finally, our Communicative Content Analysis approach offers a novel methodology in social media analysis that provides a deeper understanding of the reality under study. In this vein, this methodology has allowed the identification of one of the main findings of the study: the fact that evidence-based information is retweeted more than false information. In addition, this methodology could be transferred to other fields of knowledge: for instance, to the analysis of fake news and evidence-based information in gender issues, such as gender violence prevention, education, minority groups, as well as other social realities where there is a need to address and overcome the circulation of false information.
Supplemental Material
Dataset_analyzed – Supplemental material for COVID-19 infodemic: More retweets for science-based information on coronavirus than for false information
Supplemental material, Dataset_analyzed for COVID-19 infodemic: More retweets for science-based information on coronavirus than for false information by Cristina M Pulido, Beatriz Villarejo-Carballido, Gisela Redondo-Sama and Aitor Gómez in International Sociology
Footnotes
Author contributions
Responsible: AG
Conceptualization: CP, BVC
Investigation: GRS
Methodology: AG, CP
Analysis: CP, BVC, GRS
Writing: AG, CP
Review: AG
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This work was supported by the Catalan Agency for Management of University and Research Grants, Ref. 2017 SGR 01674, for open access publication of the article.
Data availability
Supplemental material
We have added the analyzed dataset as well as the calculations done in an Excel file, taking into consideration the criteria explained in the above section ‘Data availability’.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.