
Abstract
Cognitive automation (CA) moves beyond rule-based business process automation to target cognitive knowledge and service work. This allows the automation of tasks and processes, for which automation seemed unimaginable a decade ago. To organizations, these CA use cases offer vast opportunities to gain a significant competitive advantage. However, CA imposes novel challenges on organizations’ decisions regarding the automation potential of use cases, resulting in low adoption and high project failure rates. To counteract this, we draw on an action research study with a leading European manufacturing company to develop and test a model for assessing use cases’ amenability to CA. The proposed model comprises four dimensions: cognition, data, relationship, and transparency requirements. The model proposes that a use case is less (more) amenable to CA if these requirements are high (low). To account for the model’s industry-agnostic generalizability, we draw on an internal evaluation within the action research company and three additional external evaluations undertaken by independent project teams in three distinct industries. From a practice perspective, the model will help organizations make more informed decisions in selecting use cases for CA and planning their respective initiatives. From a research perspective, the identified determinants affecting use cases’ amenability to CA will enhance our understanding of CA in particular and artificial intelligence as the driving force behind CA in general.
Introduction
Organizations’ front and back offices annually face a steadily increasing amount of work (between 8% and 12% per year) (Willcocks, 2020). Simultaneously, studies have indicated that 45% of work activities can be automated, and machine learning (ML) can enable 80% of these operations (Chui et al., 2012). Moreover, ML is increasingly becoming the dominant technical application of the artificial intelligence (AI) phenomenon (Janiesch et al., 2021), particularly in the realm of non-rule-based, probabilistic AI, which is currently on a steep upward incline as a result of the technological advancements in algorithms, computing power, and data storage that have occurred in recent decades (von Krogh, 2018). In light of this, ML-facilitated business process automation, better known as cognitive automation (CA), is redefining the frontiers of front- and back-office automation.
Cognitive automation aims to automate or augment tasks and processes using ML algorithms that facilitate the processing of structured and unstructured data, leading to probabilistic outcomes (Butner and Ho, 2019; Lacity and Willcocks, 2018a, 2018b). Cognitive automation thus moves beyond deterministic automation by assuming certain degrees of cognition that lie beyond IT-facilitated business process automation approaches, such as robotic process automation (RPA), workflow management, and straight-through processing. Arguably, the rise of RPA and CA is to front and back offices what pervasive automation through physical machinery and robots was to production plants. That is, CA now has the potential to facilitate the automation of core business activities, overhead tasks, and processes (Coombs et al., 2020), something that was previously unimaginable.
Companies can actively give time back to the business by utilizing these unique automation opportunities, improving process efficiency and effectiveness, and thereby obtain a significant competitive edge (Lacity and Willcocks, 2021; Zarkadakis et al., 2016). In this context, CA is a strategic enabler of business transformation and productivity improvements, increasing enterprise, customer, and employee value (Lacity and Willcocks, 2021).
However, only 26% of potential adopter organizations are believed to have these systems in place (Lacity and Willcocks, 2018b). This is hardly surprising: organizations perceive CA endeavors as risky, as they impose multiple novel challenges and perils that must be managed (Lacity and Willcocks, 2021). For instance, organizations are confronted with various risks that this new class of front- and back-office automation systems exhibits: strategic risks (e.g., misunderstood value), sourcing risks (e.g., cloud data or compliance risks), tool selection risks (e.g., tool lock-in), stakeholder buy-in risks (e.g., employee resentments), execution risks (e.g., costly maintenance), change management risks (e.g., lack of communication), maturity risks (e.g., skills shortages), and finally, project management risks (e.g., selecting unsuitable use cases) (Lacity and Willcocks, 2021).
As a consequence, the world has already witnessed several high-profile CA failures, including Amazon’s sexist resume screener that discriminated against women (Dastin, 2018) and Google’s racist computer vision software that tagged an electronic device in a light-skinned hand as an electronic device but as a gun when held in a dark-skinned hand (Kayser-Bril, 2020). These examples demonstrate that CA initiatives can fail even when companies exhibit considerable maturity in using cognitive technologies. The novel obstacles and risks associated with implementing this new class of front- and back-office automation technology may be magnified for firms with comparably little expertise in cognitive technologies. To mitigate the aforementioned risks, a rigorous, upfront assessment of CA use cases’ preparation for their organizational embedding is necessary to successfully implement CA initiatives and reduce the risk of large-scale legal and reputational harm. This requires procedural models to guide the assessment of use cases in a structured manner.
This paper focuses on mitigating the risk of selecting unsuitable use cases for CA. Hereby, we aim to support organizational decision-making—particularly targeting managers accountable for the potential implementation of CA use cases—regarding the selection of CA use cases, termed “CA use case assessment.” This is in line with scientific discussions on what to (cognitively) automate and why, which call for theoretical research that has a practical impact on solving this problem (Huysman, 2020; Riemer and Peter, 2020; Willcocks, 2020, 2021). To this end, we address the following research question:
What task- and process-related determinants explain why use cases are more or less amenable to CA?
We argue that, against steep technological advancements in AI technology, particularly ML, we face changing assumptions regarding the determinants (i.e., model constructs) affecting the amenability of business process automation use cases. In particular, the models and sets of criteria developed for rule-based automation need to be carefully reviewed, potentially adapted, or extended to grasp the novel ML-facilitated CA phenomenon. Furthermore, the extant research in AI use cases has mainly focused on crafting novel use cases rather than assessing their organizational appropriateness.
Thus, we draw on an action research (AR) project with a leading European manufacturing company to develop a model for assessing CA use cases. The resulting model comprises four dimensions that must be assessed to determine use cases’ amenability to CA and estimate the respective monetary and time-related project efforts: data requirements, cognition requirements, relationship requirements, and transparency requirements. To verify the model’s applicability and usefulness for supporting CA use case assessments, we evaluated the model in an internal evaluation at the AR company. In addition, we externally enriched the evaluation by having three independent teams (consisting of team members who were not involved in the model development process) apply the model in three distinct industries: banking, online retail, and manufacturing. This extended evaluation approach will give the model a broad conceptual basis and demonstrate its generalizability to different industrial contexts.
Finally, we position this work’s contribution within the ongoing scholarly debate surrounding research efforts to manage AI (Ågerfalk et al., 2021; Aleksander, 2017; Benbya et al., 2021; Berente et al., 2021). From a research perspective, the identified determinants affecting use cases’ amenability to CA will deepen our conceptual understanding of CA in particular, and of AI as the driving force behind CA in general. From a practice perspective, the model will help practitioners in making more informed decisions and in planning respective CA endeavors.
Conceptual foundations and related work
First, we lay out the conceptual foundations of CA and present and discuss our unit of analysis (i.e., use cases), before positioning our intended contribution in relation to the extant related research.
Cognitive automation
Lacity and Willcocks (2018a) and (2018b) define CA as automating or augmenting tasks and processes using inference-based algorithms to process structured and unstructured data, leading to probabilistic outcomes. Today, ML represents an increasingly used technology for designing, creating, and running CA systems (i.e., probabilistic, non-rule-based systems) as a concrete example of AI-specific technological advancements (Janiesch et al., 2021). Machine learning involves building computer programs that improve automatically when executing tasks, based on improved performance measures through training experience (Jordan and Mitchell, 2015). Conversely, AI encompasses all techniques that allow machines to mimic human behavior, reproducing or surpassing human decision-making in solving complex tasks with minimal or no human intervention (Russell and Norvig, 2021). Building on these terminologies, we adopt the following integrated definition of CA: “Cognitive automation refers to the use of ML for automating cognitive knowledge and service work to realize the value that AI offers, which is based on implementing artificial cognition that mimics and approximates human cognition in machines” (Engel et al., 2022).
Cognitive automation impacts front and back offices similarly to the ways in which physical machinery and robots have impacted production plants. However, in CA and RPA, we are faced with software robots rather than physical robots (Hofmann et al., 2020). While RPA relies on so-called rule-based software robots that operate according to predefined rules, CA relies on so-called learning-based software robots that use ML to develop data-based experiences (Kroll et al., 2016). In contrast to rule-based front- and back-office automation with RPA, CA is characterized by its experimental character (Amigoni and Schiaffonati, 2018), learning requirements (Jordan and Mitchell, 2015), context sensitivity (Lieberman and Selker, 2000), and black box characteristics (Castelvecchi, 2016). These properties of CA should help us account for a representative share of CA’s distinguishable characteristics (Engel et al., 2021).
Experimental character denotes CA systems that do not follow “if-then” structures but produce probability-based outcomes (Amigoni and Schiaffonati, 2018). Learning requirements refer to the need for CA solutions in learning and developing experiences to improve their performance over time, comparable to training new employees (Jordan and Mitchell, 2015). This means that CA systems often do not run as intended from day one and require more patience from particular stakeholders than traditional IT systems. This is related to the context sensitivity of CA solutions, which makes them only as good as the data their context provides to reflect on and predict the latter (Lieberman and Selker, 2000). Finally, the black box character refers to CA systems, particularly in the deep learning field, which face challenges in explaining what happens between data input and output (Castelvecchi, 2016). This is particularly crucial when processes are required to be highly auditable—for example, in the financial services industry.
Use cases as the unit of analysis
In general, use cases represent a widespread instrument for capturing the requirements of IT artifacts. They describe operational interactions involving systems and their environment by specifying a sequence of actions a system needs to perform (Somé and Nair, 2007). Well-defined use cases are actionable by a certain stakeholder or class of systems and reflect the intended user goals (Constantine and Lockwood, 2001). However, research and practice often struggle to determine the appropriate level of use case granularity. Given that determining this level of granularity is highly subjective (Van Der Aalst et al., 2004), it usually requires an iterative process of (re-)defining use cases (Constantine and Lockwood, 2001). From an organizational perspective, the proper level of use case granularity then facilitates communication with and between IT and business representatives (Dutoit and Paech, 2002).
Use cases always involve a process that must be performed (Van Der Aalst et al., 2004). Each process comprises several tasks and conditions that determine the task sequencing. A task is a piece of work with a predetermined scope and varying levels of responsibility and autonomy for the agent carrying out the task, ultimately turning the respective task inputs into respective task outputs (Goodhue and Thompson, 1995). A task can also be defined as an atomic process, that is, a process that cannot be specified further (Van Der Aalst et al., 2004).
The scope of our research is purposefully set at the use-case level to elucidate the creation of business value in the bigger picture and to link it to the organizational business requirements and context, which are use-case specific.
Research need for developing a model for assessing cognitive automation use cases
Based on the conceptual foundations and after having defined use cases as our unit of analysis, we provide an overview of the extant research assessing (cognitive) automation use cases and position the intended contribution of this paper. The debate surrounding what should be automated and what should be performed by humans is not new (van der Aalst et al., 2018). If organizations select a use case that is not amenable to automation, the endeavor will inevitably fail. To maximize the likelihood of success, structured approaches to assessing and selecting use cases are required (Bachrach, 1997; Leshob et al., 2018). Research has identified various use-case characteristics, including task complexity (Campbell, 1988) and routine/non-routine or manual/cognitive tasks (Autor et al., 2003), and deduced use cases’ automation potential based on their required skills, such as perception, manipulation, creative intelligence, or social intelligence (Frey and Osborne, 2017).
The emergence of RPA has fueled recent research on assessing automation candidates in business process automation. For instance, new models have been developed to select suitable automation candidates for RPA (e.g., Leshob et al., 2018). These models build upon the assessment criteria developed for these purposes. Robotic process automation is recommended when levels of standardization, maturity, transaction volume, and the existence of business rules are high (Lacity and Willcocks, 2018a). Other criteria indicate that rule-based routine tasks with few exceptions and little or no cognitive reasoning are best suited to RPA (Asatiani and Penttinen, 2016). Thus, we can summarize that selecting the optimal automation use cases—single tasks or entire processes—constitutes an essential step in determining automation endeavors and has attracted attention from both researchers and practitioners. However, we argue that the aforementioned models and criteria developed for rule-based automation exclude CA due to its experimental and black box character, which is rooted in the probabilistic outcomes “produced” by CA solutions, the need for such context-sensitive systems to learn from data, and specific organizational challenges, such as fear of job losses.
Recent work in AI and ML use case assessment has developed methodical and model support, which largely emphasizes the explorative phases of use-case generation at the general AI and ML levels. For instance, guided by Osborn’s (1953) divergence–convergence dualism, Sturm et al. (2021) drew on a qualitative study with 24 experts to design a framework for problem detection for AI solutions. This represents an initial step in problem-solving activities with AI and particularly emphasizes the explorative identification of AI use cases through the ideation and evaluation of problems. Their procedural framework consists of data- or purpose-driven ideation phases, the evaluation of the problem substance for general ML suitability (hard factors), and the evaluation of the problem particularities (soft factors specific to a problem’s particular context) (Sturm et al., 2021).
Hofmann et al. (2020) similarly used design science research and situational method engineering to develop a five-step method for developing purposeful AI use cases. Companies must first consider the technology, organization, and environment as context factors before collecting existing domain problems and AI solutions abstracted in a third step (Hofmann, Jöhnk et al., 2020). Fourth, Hofmann et al. (2020) introduced a problem–solution matrix to help companies match AI functions with problems. Finally, in the fifth step, companies derive implications using case implementation.
In this paper, we build on this existing research that explores AI and ML use cases (Hofmann et al., 2020; Sturm et al., 2021) by purposefully focusing on the phases that follow the exploration of general AI use cases. In CA, divergent phases, such as the exploration and ideation of potential use cases, are emphasized less than in cases with a broad general AI scope, because CA bases future initiatives on existing activities and procedures, resulting in a limited solution space. However, this does not mean that re-engineering processes or tasks can be neglected in CA use-case assessment; rather, we seek a level of abstraction that will allow organizations to conduct in-depth assessments of particular tasks or processes to be performed by CA systems and will then also serve as an input for their redesign (Durward et al., 2020).
In this study, we provide a novel CA use-case assessment model that considers CA specificities. The model will be particularly valuable to organizations intending to leverage CA to create a competitive advantage for their core businesses. In particular, organizations should be supported in making more informed decisions on selecting use cases and strategically planning use-case portfolios. In addition, we empirically demonstrate in this paper that using the model can serve further managerial purposes of strategically using CA.
Related theories on the amenability of use cases
In this chapter, we review theories from information systems (IS) research in relation to the amenability of use cases to CA and discuss how these theories help us structure the concepts described in the previous section. In particular, we use this review of theories to sharpen our conceptual understanding of use-case amenability to CA in terms of its level of abstraction and the scope we aim to model.
First, we review the theory of task–technology fit (TTF), which explains the extent to which a certain technology with particular characteristics matches a task (Goodhue and Thompson, 1995). This theory considers individual users operating at the task level and is particularly concerned with how TTF affects individual performance, indicating the amenability of technology to supporting task performance. Here, TTF focuses on users being supported by technology in carrying out tasks without the tasks themselves being (partially) transferred to machines, as would be the case when modeling the amenability of a use case to CA. In addition, we note a level of abstraction in generic task and technology characteristics with no specific consideration of, or explanatory value for, AI technology such as ML, which is required for CA. It has to be noted that TTF has also been extended to technology at a group level—so-called group support systems (Zigurs and Buckland, 1998). Task–technology fit, as well as its extensions and adaptations, are concerned with the “idea of fit as an ideal profile” (Zigurs and Buckland, 1998), which is an unequivocally valuable concept that we gladly adapt but it still follows a static perspective that does not explain the proliferation of tasks and processes that CA performs.
The second theory we discuss is process virtualization theory, which explains the transition from a physical to a virtual process in the light of generic IT (Overby, 2008). The theory operates with a scope on the process level and investigates generic IT rather than CA. Thus, it appears to be a valuable preceding explanation of what is possible today. Although the investigated phenomenon of interest differs from ours, we find the explanatory structure of process virtualization theory to be a valuable orientation point for our research endeavor and one upon which we can build. Process virtualization theory seeks to explain the degree to which processes are suitable for migration to virtual environments, such as those facilitated by IT (Overby and Konsynski, 2010). Thus, it is posited that certain process characteristics (sensory requirements, relationship requirements, synchronism requirements, and identification and control requirements), which represent the main constructs of the theory, and IT characteristics (representation, reach, and monitoring capability), which represent the moderating constructs of the theory, affect the dependent variable “process virtualizability,” that is, the amenability of a process to being conducted virtually (Overby, 2008). The theory views it as a key premise that IT can be used to raise the amenability of a process to be virtualized by contributing to the satisfaction of sensory, relationship, synchronism, and identification and control requirements. Overby (2008) explicitly emphasized the theoretical importance of IT in process virtualization by presenting representation, reach, and monitoring capability as moderating constructs. This elucidates the reason for the proliferation of virtual processes that did not exist two decades ago by incorporating the role of IT as a moderator of these changes.
The theories presented above inform our conceptual understanding and provide highly valuable structural and logical guidance and frames to position our phenomenon of interest and the unit of analysis in terms of the level of abstraction and theoretical scope. After reviewing the theories, we specifically saw the opportunity to apply the logical and theoretical reasoning developed in valuable previous work, such as process virtualization theory, and using it to position the study to model the specific phenomenological and technological developments that are on the rise today, such as CA being facilitated by AI technology, in other words, ML. Elucidating the phenomenon of CA for research and practice (i.e., making it more explainable and predictable) will help us investigate why we are seeing a proliferation of CA-affected tasks and processes which were not evident a decade ago. Thus, we specifically consider the role of AI technology and position the distinct concepts of CA explained in the previous section against the backdrop of the theoretical foundations presented above to demonstrate how the theories help our research study and how we aim to contribute to IS theory by extending the theoretical landscape with CA-specific dimensions and constructs. Against this backdrop, this paper refers to CA use cases as task- or process-related opportunities for deploying CA.
The dependent variable we aim to explain and predict in this work is a use case’s amenability to CA, that is, the likelihood of the successful (i.e., value-adding) deployment of CA, typically performed in the context of projects in organizations. As such, we aim to equip decision-makers with the means to evaluate and prioritize CA use cases and decide on the respective initiatives. We define the characteristics of AI technology (i.e., ML for CA) along with the properties explained in the previous section: the experimental character, the learning requirements, the context sensitivity, and the black box characteristics. In addition, we aim to identify and operationalize the characteristic and CA-specific factors that impose the requirements of the particular use case’s amenability to CA (i.e., the likelihood of its successful deployment). Ultimately, this will allow us to develop theoretical propositions that relate the use-case characteristics to the viability and thus the performance, of CA use cases in organizations.
Regarding the scope and level of abstraction that we intend to achieve in examining the phenomenon of CA in this paper, the following reasoning is provided to critically reflect on selecting process virtualization theory as a structural and conceptual foundation for our research study. First, process virtualization theory operates on the process level rather than the task level. Second, it investigates generic IT rather than AI technology. These raise two points that need to be addressed here: regarding the difference between a process and a task, Overby and Konsynski (2010) have argued that this is a terminological debate about granularity, but in reality, processes are often thought of as tasks, and so-called “tasks” often consist of multiple sub-tasks (Overby and Konsynski, 2010). When discussing this point, which at first may appear to be a mismatch, Overby and Konsynski (2010, p. 13) argued that “the focus on tasks vs processes is arguably more of a similarity than a difference.” Thus, this paper refers to CA use cases as task- or process-related opportunities for deploying CA.
Regarding the second point that Overby (2008) investigates, IT rather than AI technology, we specifically see this as a chance for seizing the logical and theoretical reasoning that has been developed in process virtualization theory, and to transfer it to CA being facilitated by AI technology. The explanatory structure of process virtualization theory (Overby, 2008) is a valuable orientation point that we can build on.
To summarize, we employ our theoretical pre-understanding to position our model-building approach and empirically validate and challenge our results within the novel context of CA, which will ultimately allow us to extend the IS knowledge base with CA-specific model dimensions and constructs that characterize use-case requirements and their relationships to a particular use case’s amenability (Reason, 2006).
Research method
We draw on action research (AR) to develop and test the model (Baskerville, 1999). Action research aims to tackle real-world problems at individual and organizational levels by creating solutions for these problems, that is, finding and establishing links between the problem and solution space (Reason 2006). Thus, AR follows two underlying assumptions: “(1) social settings cannot be reduced for study, and (2) action brings understanding” (Baskerville, 1999). Action research has proven suitable for investigating phenomena of interest in realistic environments, combining research and practice to produce highly relevant findings (Baskerville and Wood-Harper, 1996). In particular, it has proven to be a suitable method for developing models relevant to managerial challenges in organizational contexts (Brown et al., 2018; Peak et al., 2011; Pino et al., 2010). As such, AR constitutes a post-positivist research method from the social sciences that is highly suited to studying technology in socio-technical contexts, such as organizations, as it places IS researchers in a supporting role (Baskerville and Wood-Harper, 1996). We present the AR mode in terms of the five phases of the AR cycle (Baskerville, 1999): (1) diagnosing, (2) action planning, (3) action taking, (4) evaluation, and (5) specifying learnings.
Table 1 provides an overview of the concrete steps we took in this AR study. 1. Diagnosing: This phase focuses on identifying and describing the organization’s underlying problem (i.e., mapping the organization’s problem space while developing the first working hypothesis). In particular, after assembling an AR team, the latter conducted several workshops with the AR company to define the business needs (i.e., problem definition) and substantiate the need for a use-case assessment. 2. Action Planning: The AR team, which includes representatives from both research and practice, then engaged in planning the resolution of the problem, guided by theoretical and conceptual frameworks from research to help determine the desired end states and the requisite steps to achieve them. Here, we drew on an interview study (semi-structured), following Longhurst (2003), to retrieve a discrete set of cases (besides the AR company) to create generalizable insights beyond the scope of the AR project. Furthermore, we engaged in open, axial, selective coding, in accordance with Saldaña (2021), to derive the use-case requirements dimension from the data that allowed us to characterize and thus model the amenability of a particular CA use case. Furthermore, to operationalize the model and make it qualitatively testable, we identified constructs from the literature and created a set of standardized questions to measure them. Finally, we used two focus groups (Longhurst, 2003) and additional interviews with experts from various industries to conduct a first evaluation of the retrieved model dimensions and the main proposition in the manner of a proof of concept (POC), according to Nunamaker et al. (2015), in terms of exhaustiveness, understandability, and potential utility for practice. 3. Action Taking: In this phase, the planned actions are carried out in an interventionist manner within the organization by causing change through the collaboration of the AR team (i.e., researchers and practitioners). In this step, the AR team applied and evaluated the baseline assessment model in the AR organization using interviews, document analysis, observation studies, and mystery shopping. 4. Evaluating: Next, the outcomes of the AR interventions are assessed in terms of the initial assumptions and the adopted theoretical and conceptual frameworks, as well as whether the problem can be solved and exactly what role the intervention will play. In this step, we drew on iterative discussions among the core project team and conducted a review workshop with the interviewees and the core project team to clarify whether the documented assessment interview insights were complete and correct. In addition, we enriched this evaluation by having three more teams, consisting of team members who were not involved in the model development process, apply the model in three distinct industries: banking, online retail, and manufacturing. This evaluation strategy will help to indicate that the model is based on a broad conceptual basis and is generalizable to different industrial contexts. 5. Specifying Learnings: Finally, the knowledge created in relation to the intervention, its success or failure, and possible causes are documented and communicated to the stakeholder group of interest—which may be scientific or practice oriented. This final step resulted in the paper at hand and project documentation being provided to the AR company. Applied AR steps.

Both the methodology details and the outcomes of the individual AR steps are explained in the next section.
Model development and testing using action research
To approach the AR project, an AR team consisting of two researchers and two project managers from our case company—a large European market-leading manufacturing firm in the sanitary industry, abbreviated as ManuFact Corp—was assembled. ManuFact Corp’s project managers came from the IT and business departments, as ManuFact Corp hosts a business-to-business (B2B) customer service line that they intend to support using CA.
Diagnosing
The case of ManuFact corp.

To account for ManuFact Corp’s limited understanding of CA, it was deemed necessary to conduct an initial use-case assessment to determine whether the use case was suitable for CA and which requirements needed to be addressed to ensure the success of a future CA project.
Action planning
The following steps were carried out to prepare the CA use-case assessment. First, we researched the theoretical frameworks presented in this paper (see Related Theories on the Amenability of Use Cases) that serve as a guiding theoretical lens and structural basis to conduct the use-case assessment. Second, we collected empirical data through interviews with practitioners from multiple industries to derive overarching and potentially industry-agnostic assessment dimensions. In the third step, we operationalized the assessment dimensions using constructs from the extant literature that allow for carrying out the assessment at ManuFact Corp, based on which we developed the propositions of the assessment model presented herein.
Interview study and preliminary evaluations of model dimensions
Drawing on the theory-informed notion of CA use-case amenability described earlier, we identified a first set of dimensions for a CA use case in terms of the requirements its characteristics. As theoretical research in this field is still nascent, we then inductively identified the additional dimensions from the organizational context and used semi-structured interviews (Longhurst, 2003) with practitioners in the field. We purposefully selected the interviewees to achieve a high level of variation, to ensure that our analysis had a broad conceptual basis. To maintain comparability, the interviewees were representatives of large corporations involved in implementing CA projects (see Appendix 1). This purposeful sampling strategy, in line with Patton (2002), should account for a sufficiently large sample size (10 different organizations) to achieve a high level of diversity in the 10 projects from different organizational contexts and at different maturity levels (see Appendix 1). This will allow for the investigation of potential variations in the different use-case dimensions and underlying constructs we aim to model.
Over the course of a year, we interviewed 19 company representatives from various industries involved in 10 CA projects and from different organizational hierarchy levels. This allowed us to comprehensively understand the dimensions affecting CA endeavors. The semi-structured interviews followed predefined guidelines but allowed for naturally evolving conversations by allowing for topic variations and emerging themes (Longhurst, 2003). We asked the interviewees about the assessment criteria for CA use-case selection and about the tasks and processes subject to CA, their reasons for selecting the latter, and the efforts and risks they encountered during the projects.
Two researchers extracted data from the interview transcripts and engaged in open, axial, and selective coding (Saldaña, 2021). First, we openly coded the documents and assigning relationships among the open codes (axial coding). Next, we identified the core variable for selective coding as “requirements dimensions of use-case characteristics” to identify the determinants that need to be assessed to determine the degree to which a use case is suitable for CA. This led to the dependent case variable “amenability of a use-case for CA.” Then, we iteratively evaluated the coding in discussions between the two researchers to reach validity and reproducibility (Saldaña, 2021).
The interviews revealed four use-case dimensions that need to be considered when characterizing the use-case requirements for assessing the amenability of CA use cases (see Table 3). Based on the interview insights, we developed the following main proposition that the model should be based on:
Model dimensions derived from interview coding.
To conduct a first evaluation of the retrieved model dimensions and the main proposition in the manner of a POC, according to Nunamaker et al. (2015), in terms of exhaustiveness, understandability, and potential utility for practice, we drew on two focus groups (Longhurst, 2003) and further interviews with experts from various industries. One focus group (lasting 30 min) purposefully sampled four IT decision-makers, particularly CIOs, two of whom had participated in the original interview study, to obtain a top management perspective on the model’s relevance and utility. Another focus group (lasting two hours) sampled six participants from various industries and project (portfolio) management levels, including banking, insurance, manufacturing, and the telecommunications industry, to evaluate whether the model is industry-agnostic yet applicable in and adaptable to different contexts. Finally, we interviewed two ML experts from a global business process automation solution provider seeking to move beyond RPA toward CA in their consulting and implementation practices.
Operationalization through literature
To operationalize the use-case assessment dimensions, we followed the logic suggested by Becker et al. (2009), which includes problem formulation (see Introduction), model comparison (see Conceptual Foundations and Related Work), development strategy determination, and iterative development of the model. Thus, we used existing constructs from theory as a result. For this, we derived a list of initial construct candidates for each dimension by reviewing the literature on our dimensions (data, transparency, cognition, and relationship). The longlist of constructs is presented in Appendix 2.
Next, the model dimensions were consolidated. In this step, two researchers independently coded the previously identified constructs. We followed this procedure for each of the four dimensions and discussed the discrepancies. After comparing the independent coding and discussing the cases we did not agree upon, we cleaned the initial list of constructs. We then discussed our constructs with the research team, which led to further consolidations of the set of constructs, leading to nine data constructs, ten recognition constructs, five transparency constructs, and seven relationship constructs. The final list of constructs and their respective definitions can be found in Appendix 3.
Further to this end, and to render the identified constructs manageable and usable for assessing use cases in organizational contexts, we developed a closed set of standardized questions. The AR team agreed to extend the set of questions with an introductory section explaining the assessment, to better contextualize the assessment and to consider the organizational specificities, needs, and professional backgrounds of potential assessment interviewees.
Action taking
To test the model’s main proposition, we operationalized constructs to apply to the case of ManuFact Corp. We chose this approach to specify the main proposition of our assessment model, which was challenged in the preceding evaluation iteration in terms of the four identified dimensions to assess their validity and reproducibility.
Thus, two researchers conducted two-hour structured interviews with four B2B customer helpline experts, including the hotline head, who was also involved in operational activities. The interviews were conducted separately with each helpline expert to prevent bias caused by psychological peer pressure or more dominant participants. The individual responses were documented along the model dimensions and subsequently aggregated by removing duplicates. Document analyses of exemplary customer queries, helpline experts’ job profiles, and recent performance reports were also performed. Furthermore, the researchers contacted the helpline themselves with a scripted professional query provided by ManuFact Corp to experience the process firsthand and contextualize the interview insights. This was supplemented with an on-site visit, during which the researchers could observe the helpline experts at work.
Finally, the assessment results were retrieved by analyzing the gathered data structured along the model’s four assessment dimensions. The researchers iteratively paired the insights from the interviews, the document analysis, and the on-site observations with the respective constructs and items of the requirement dimensions. Furthermore, they indicated whether a particular construct leads to increased use-case requirements for the planned CA endeavor. To operationalize this and facilitate appropriate visualization, we used a five-point Likert scale (1 = “Disagree that construct increases CA project effort”; 5 = “Agree that construct increases CA project effort”). This resulted in both qualitative insights and quantified assessment scores for each dimension. The overall assessment of the use case revealed that it varied widely among the distinct assessment dimensions. Essentially, the use case is data intensive and transparency averse, with medium requirement levels in the dimensions of relationship and cognition requirements. Here, in line with the four specifications of the model’s main proposition, we present the most pivotal insights
The higher (lower) the data requirements of a use case, the lower (higher) the use cases’ amenability to being conducted with CA will be.
Overall, the data requirements for this use case were high (see Figure 1), owing to the prevalence of undocumented knowledge and processes and the high degree of distributed and implicit experience knowledge. Furthermore, the employees needed to process images, videos, and even audio data as essential sources to handle a large portion of the queries. This means that this requirement dimension imbues potential projects with considerable effort. Thus, preparatory work is required prior to embarking on CA projects. Assessment results of data requirements at ManuFact Corp.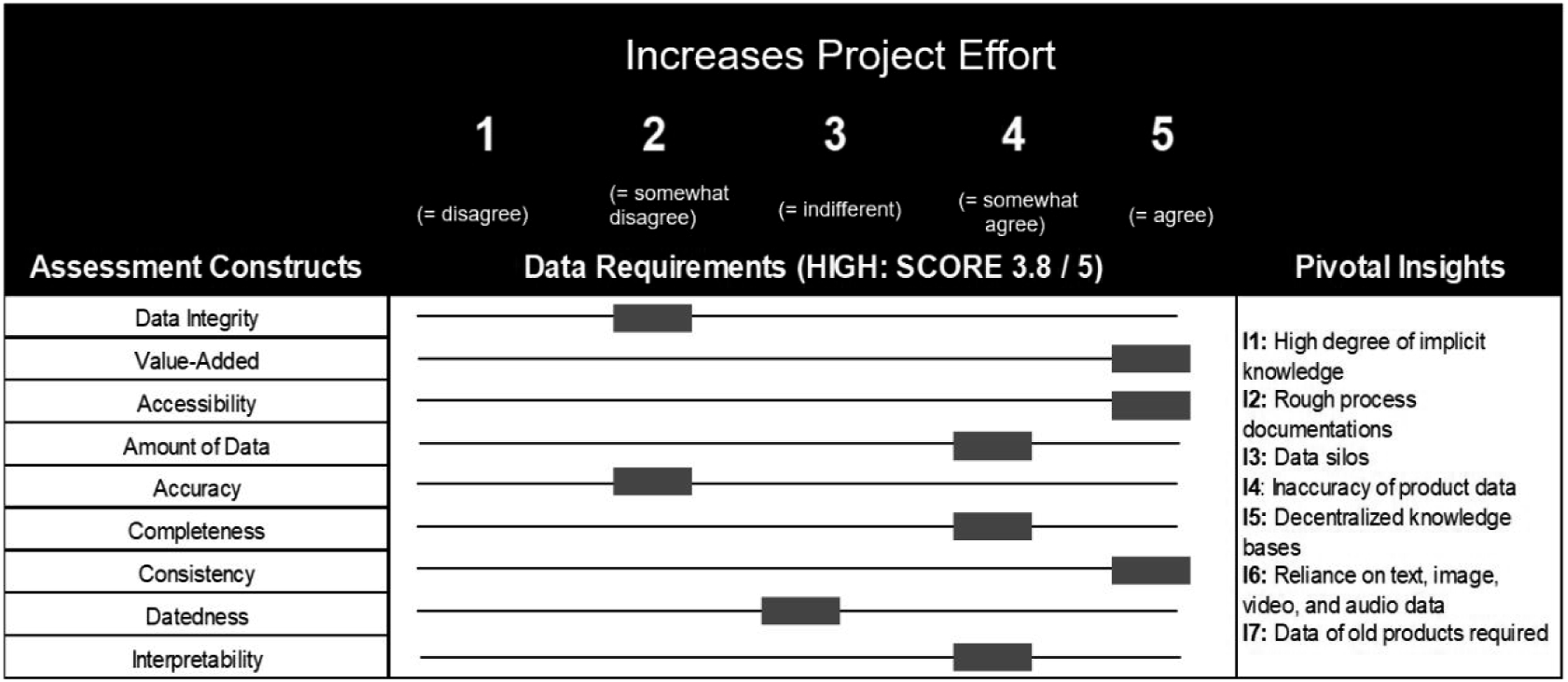
Work in the customer service department is based on the employees’ experience-based knowledge. Much of this knowledge is not written down but exists only in their minds (
This basic knowledge is demanded and required. The employee answers the simple questions directly from the hip because the employee has the information stored on their “disk.” – Head of B2B Customer Service Department
Process documentation, which determines how customer inquiries are handled, exists only in a vague form (
How we work and how we formulate our response isn’t documented, and we do it out of habit. – Customer Service Expert 3
In light of this, data silos exist in relation to other departments, even though knowledge transfer and data exchange occur within the department (
The Excel is read-only, so it’s not for anyone to work on it. There are numbers in the Excel files that you can’t find anywhere else. – Head of B2B Customer Service Department
The department’s databases are thus protected, leading to numerous queries from other departments.
These silo effects also concerned product data, which were outdated and posed a challenge. One possible reason is that communication between branches has a time delay (
Some of the technical drawings’ measurements are incorrect. These will eventually be corrected at some point in time. – Customer Service Expert 2
Knowledge is stored in individual databases distributed throughout the department (
You will then find your way better on your drive and don’t have to search so long on the centralized department drive. You can’t know everything; you just have to know where it is. – Customer Service Expert 2
The B2B customer service department relies on unstructured and heterogeneous data (
Pictures are worth a thousand words. […] We strongly encourage customers to send us photos and video clips. […] even with sound, such as flow sounds. – Head of B2B Customer Service Department
Furthermore, owing to the product’s high quality, their age, and long service lives affect daily work (
There are also products that were produced 15 years ago. – Customer Service Expert 1
Having assessed the use case’s data requirements, the assessment team derived the following recommendations for action that were communicated to ManuFact Corp’s CIO and CMO. To begin, the large amount of implicit experience knowledge must be systematically recorded in advance to render the data machine readable. To prepare a CA initiative, processes of frequently occurring queries should be jointly documented, and standard answers or text modules should be developed for frequent queries. Furthermore, a mutual exchange with other departments (e.g., product managers) should be initiated to store and maintain the required knowledge in an institutionalized manner, accessible to all relevant stakeholders. Before launching a CA project, an interdepartmental agreement regarding how data should be shared and kept up to date is required. In addition, a mutual collection of the best components of individual knowledge documentation should be established in preparation.
Finally, CA serves to process both structured and unstructured data and can thus be highly effective in this case. However, a training dataset consisting of text, images, videos, and audio files has been established and interlinked between the distinct data types. This will be effort intensive, considering the broad spectrum of products. To keep the data current, a database should automatically archive the website’s product information over time.
The higher (lower) the cognition requirements of a use case, the lower (higher) the use case’s amenability to being conducted with CA will be.
Overall, the cognition requirements are at a medium level (see Figure 2); however, the complexity varies depending on the customer’s requirements and query types, resulting in high volatility. Consequently, problem identification and resolution may occasionally be more challenging for B2B customer service experts. Thus, a CA solution should be able to recognize and classify these cases. Assessment results of cognition requirements at ManuFact Corp.
Due to the “human factor,” customer inquiries are highly individual, differing significantly in complexity levels (
If an inquiry is particularly complex, I may be off the line for half an hour to research it.
In addition, as Customer Service Expert 1 emphasized, identifying the product and gaining an initial understanding of the problem can be difficult (
The hardest part is when you have a query and must identify what product it is and what the problem is. – Customer Service Expert 1
Inaccurate customer information and a wide range of products increase the task’s complexity, particularly for older products. Most of the time is typically spent identifying the problem, while the solution can be worked out relatively quickly.
As noted, one challenge within the B2B customer service department is that two different channels must be processed simultaneously, which is a cognitive stress factor for employees (
The client controls the timing of calls and chats. I can clock the emails myself. It can happen that I’m on the phone, and there comes a chat, and then I have to do both. – Customer Service Expert 2
Finally, a high level of expert knowledge based on employees’ experience is required. Practical experience (both prior to and during their time at ManuFact Corp) is essential to task mastery, leading to swift cognitive processing of queries.
I’d say I can already answer 60% from my knowledge. – Customer Service Expert 2
All employees are individual knowledge carriers. However, in the case of complex or special topics (e.g., fire protection), the solution of tasks often requires an exchange of information between employees (
Having assessed the use case’s cognition requirements, the assessment team derived the following recommendations for action, which were communicated to ManuFact Corp’s CIO and CMO.
An automated subdivision of customer queries into simple and complex through CA should be planned to increase the tasks’ plannability in terms of time leveling. A cognitive system must be trained accordingly to exhibit the required cognitive capabilities. Moreover, separating the problem-identification-intensive from the solution-creation-intensive sub-use cases is required to properly assign the respective ML capabilities. This will increase the effort in a prospective CA project. Furthermore, a reduction in time pressure is conceivable by assisting employees with a “live chat buffer,” automating the initial reception of live chat queries, and creating structured querying of the query and customer data. The live chat buffer may serve as a further sub-use case for a future project. Finally, queries requiring cognitive exchange among multiple customer service experts should be identified by a CA solution to meet customers’ expectations. Workshops with customer service experts (potentially also from other service departments) should be held to define these query classes.
The higher (lower) the relationship requirements of a use case, the lower (higher) the use case’s amenability to being conducted with CA will be.
Overall, the relationship requirements are at the intermediate level (see Figure 3); however, exhibiting a high level of volatility, as in this use case, the requirements for relationship building (trust building, etc.) vary depending on the inquiry type and the customer’s characteristics. Furthermore, regional idiosyncrasies in culture and communication, such as dialects, influence relationship-intense inquiries. Assessment results of relationship requirements at ManuFact Corp.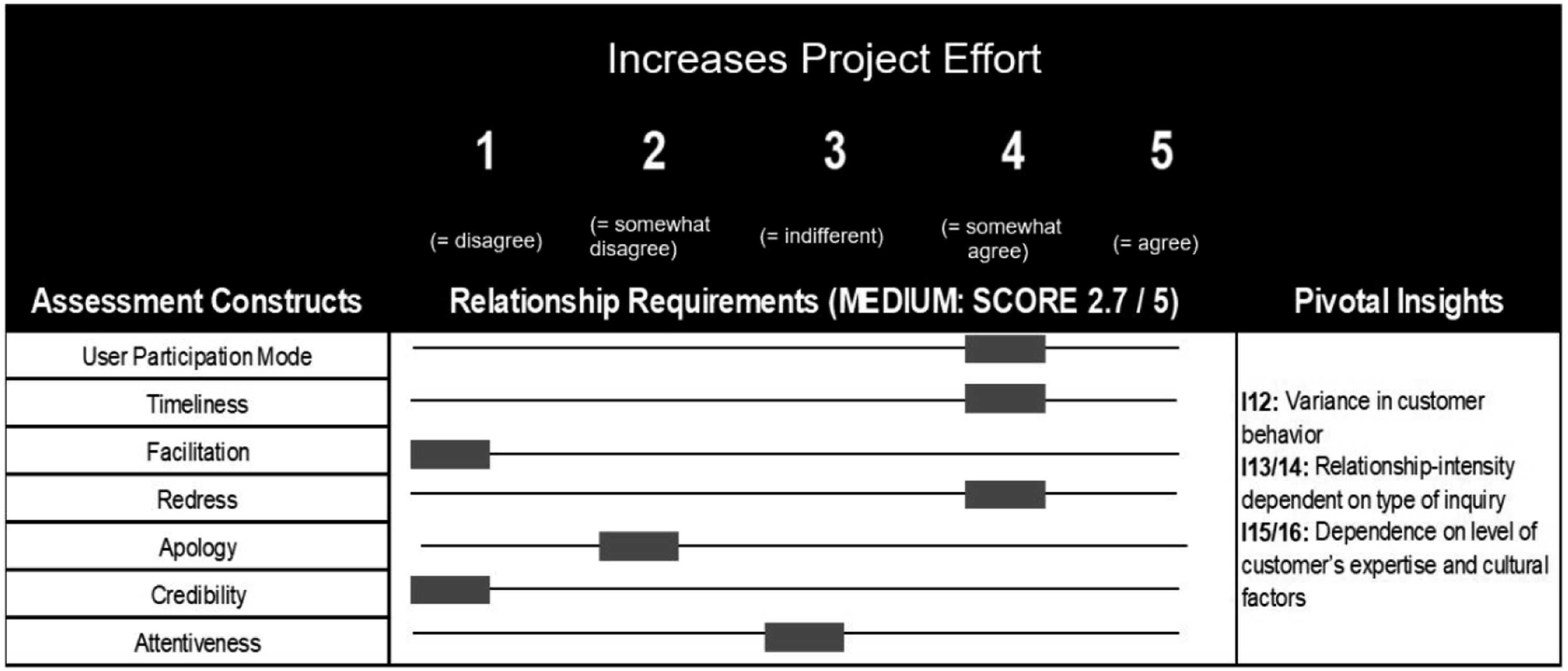
Customer behavior can vary depending on the customer’s issue (
About two or three times a year, I also have to say, “Alright, well, let us calm down, or we have to end the conversation.” – Customer Service Expert 1
In such cases, the B2B customer service department requires time, tact, and sensitivity, which require personal human interaction. However, communication can often be less complex because many inquiries concern numbers, data, and facts (
For queries for data sheets, the answers are very short and crisp. The customer will not get a love letter from us. – Head of B2B Customer Service Department
Complex inquiries demand greater communication skills from employees. In complex matters, ManuFact Corp’s expertise is valued, and building trust is more important (
The emotional component comes into play when desperate customers call as a last resort. – Customer Service Expert 1
As different customer groups have different needs and differ in communication and problem complexity, ManuFact Corp has more than one customer type (
The question often depends on the customer. Questions from planners and architects are more difficult and complex to answer. – Head of B2B Customer Service Department
Finally, cultural factors and the customer’s level of knowledge also affect how the conversation is conducted (
Having assessed the use case’s relationship requirements, the assessment team derived the following recommendations for action, which were communicated to ManuFact Corp’s CIO and CMO.
The highest added value for the customer relationship can arise in complex conversations with high efforts to build trust and interpersonal relationships. Nonetheless, significant mistakes may also occur, which increases the requirements that must be met for a successful project. Therefore, ManuFact Corp must facilitate a CA tool capable of recognizing the customer’s problem and categorizing the customer type. This is essential for an individualized conversation using a CA tool, thus intensifying the use case’s relationship requirements. Once ManuFact Corp conducts additional research into the various conversation types, it will be possible to support less complex communication via CA. In addition, a CA solution would need to distinguish between relationship-intense and relationship-weak queries. Finally, ManuFact Corp will need to enable the CA solution to detect and specify the point of handover between human and machine and vice versa. Simultaneously, the most relationship-intense customer queries should be outside the scope of CA endeavors’ early project phases to minimize the risk of disappointing customers.
The higher (lower) the transparency requirements of a task, the lower (higher) the use case’s amenability to being conducted with CA will be.
Overall, the transparency requirements were relatively low (see Figure 4), with no need for costly reporting or special audits. Except for topics such as fire protection, customer service experts can work directly with customers to find appropriate solutions without involving third parties. Assessment results of transparency requirements at ManuFact Corp.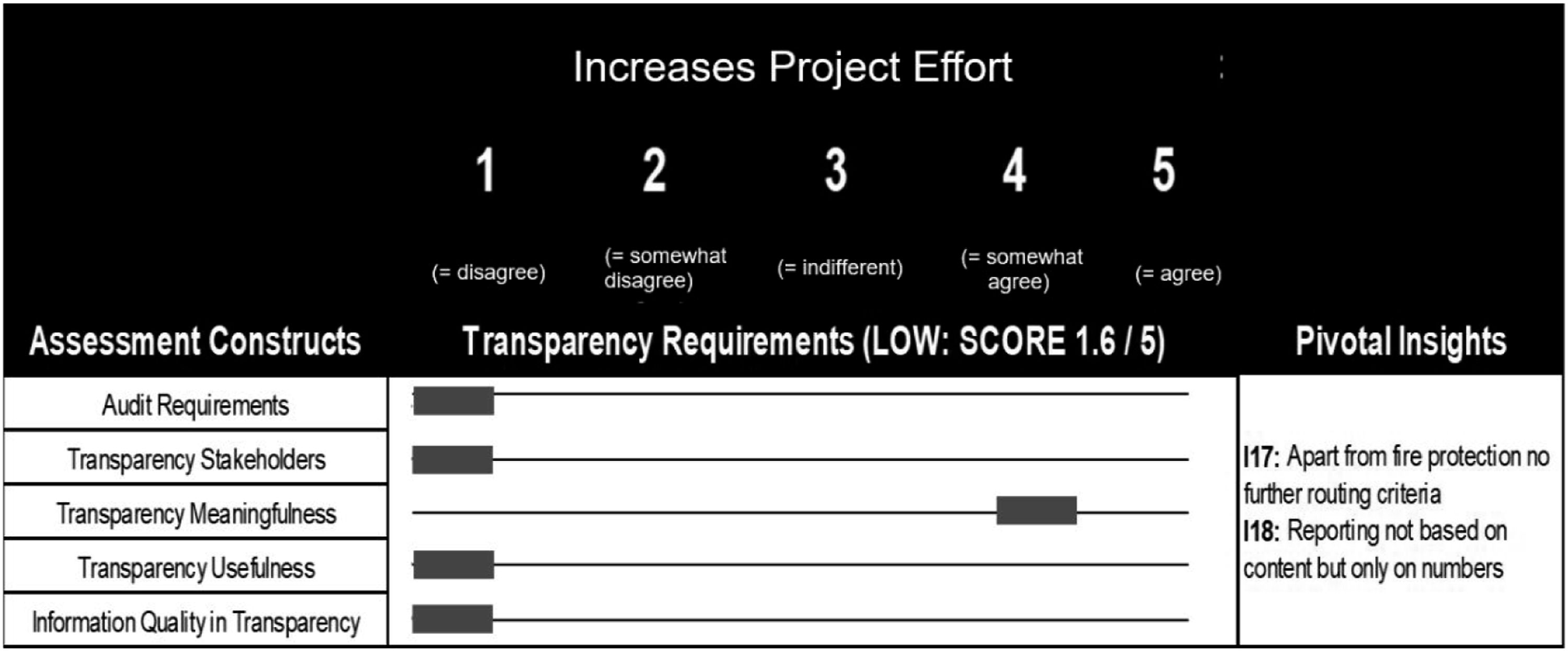
Email queries are distributed evenly among employees for processing according to the first in, first out principle. Apart from fire protection topics, no other criteria exist for routing or reporting queries (
The emails are not distributed according to any specific criteria. [...] Or rather, there is one criterion: fire protection. Everything must be legally protected, and we have specially trained experts who do that. – Head of B2B Customer Service Department
Second, the department only reports on the number of in- and out-bound communication flows. Reporting is not based on content-related criteria (
We have to count the emails manually. The phone calls are counted automatically. But we don’t see what was received every day. – Customer Service Expert 3
Consequently, this dimension does not lead to many additional requirements for a CA solution, as the need to disclose information to third parties outside the department is kept lean. The assessment team’s only recommendation to the CIO and CMO is that “critical” cases, such as queries subject to fire safety regulations, should be identified by a CA solution to achieve the required level of process transparency and reduce failure costs (e.g., legal risks).
Evaluation
To verify the model’s applicability and usefulness for supporting CA use-case assessments, we first evaluated the model in the AR company as an internal evaluation. In addition, we externally enriched the evaluation by having three independent teams, consisting of team members who were not involved in the model development process, apply the model in three distinct industries: banking, online retail, and manufacturing. This extended evaluation approach gave the model a broad conceptual basis and demonstrated its generalizability to different industrial contexts.
Internal evaluation at action research company and managerial implications
Following iterative discussions among the core project team, a review workshop was conducted with the interviewed helpline experts and the core project team to clarify whether the documented interview insights were complete and correct.
Overall, the assessment provided a solid basis for the CIO to prepare the decision-making process with the CMO as to whether and how to deploy the CA use case in ManuFact Corp’s customer support department. The assigned IT and business project managers could use the assessment model to identify stumbling blocks early on, such as the use case’s high data requirements. The project managers could enrich their line of argumentation with senior management by deriving and structuring these insights within the use-case assessment model to prepare managerial decision-making and realistically manage expectations within the organization. The assessment results were presented in a workshop with the CIO and the CMO, and managerial consensus on how to proceed was reached.
Now, we are one round smarter again, but we also have a lot of luggage in our backpacks. [...] These are important points that came out of the analysis. – CMO of ManuFact Corp
Based on the use-case assessment, the CIO and CMO were convinced that the use case could not be implemented in its entirety and had to be deconstructed into sub-use cases. Furthermore, preliminary work and investments are required before a CA project can be considered.
Originally, the total use case would have targeted the CA of phone, email, and live chat channels in ManuFact Corp’s customer support department. However, the assessment revealed that, owing to the variability in the use case’s cognition and relationship requirements, a prime focus on the email channel (i.e., implementing an email bot) is the most feasible option in terms of expected impact and effort.
As the email bot use case was too large to handle at once, it was divided into sub-use cases: (1) automated email classification and routing, (2) automated solution recommendations, and (3) a fully automated email bot that combines the first two sub-use cases. These were prioritized in an impact-effort matrix (see Figure 5) based on the expected monetary effort and the time saved (time back to the business) by deploying the particular sub-use cases. Use-case specification and project planning.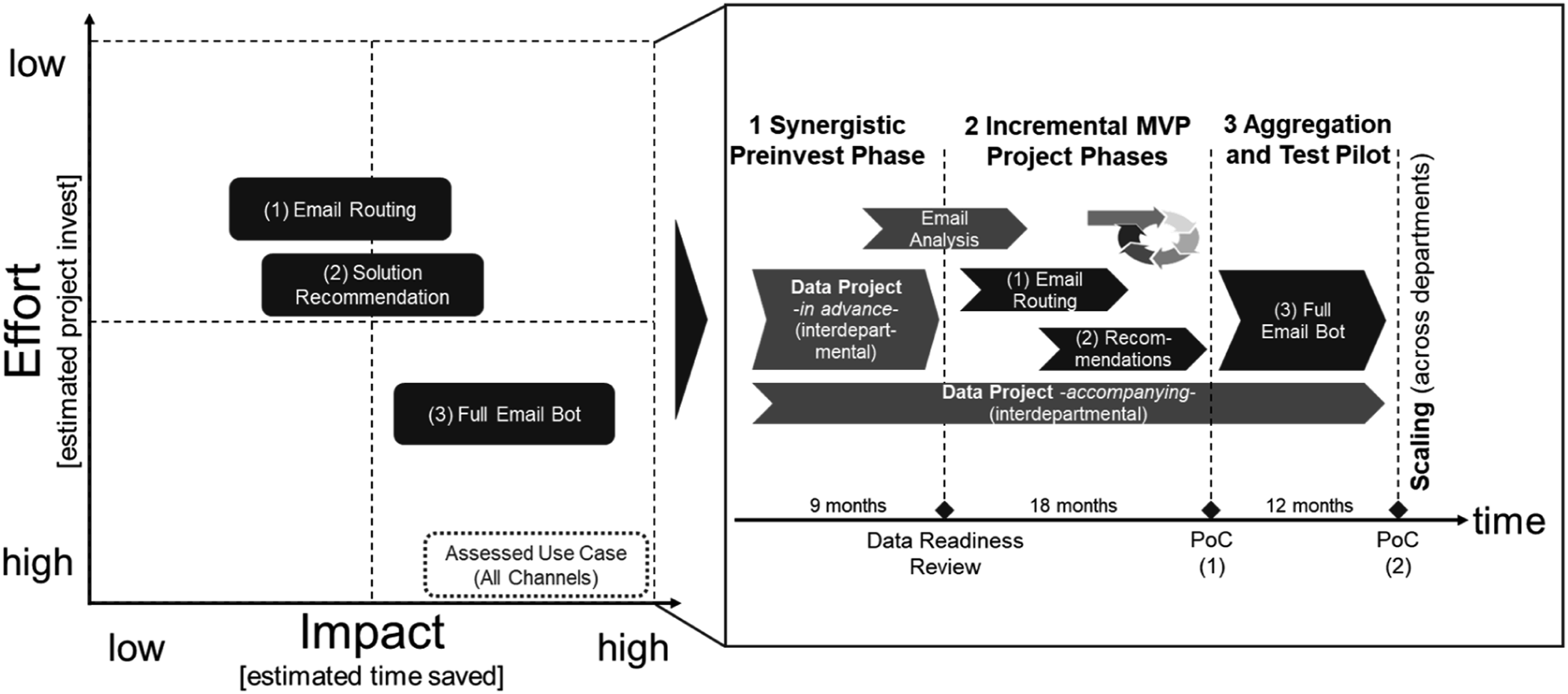
Overall, the B2B customer support department at ManuFact Corp handles over 160,000 emails per year, demonstrating the potential impact of a CA project. For example, if ManuFact Corp can save 30 s per email in processing time through CA, that would translate back to the company as approximately 1333 h (167 workdays). Rolling the use case out to the other customer service department, which handles 900,000 emails and is expected to reach over 1 million by 2021, can bring 1040 workdays back to the business.
Figure 5 visualizes the project plan that resulted from assessing the CA use case in the B2B customer support department. The plan informed business and project portfolio planning and was used to secure buy-in from ManuFact Corp’s Chief Executive Officer.
I will bring the results to the next steering meeting for next year’s business planning. – Chief Information Officer (CIO) of ManuFact Corp
Finally, due to the human-centered approach of basing the assessment on interviews with the people who perform the actual tasks and processes, the assessment was well perceived by them. This was surprising, as CA initiatives often lead to negative organizational feedback due to the fear of job loss associated with such systems.
If we didn’t have the simple emails, we would have more time for other things, [the simple emails make up for] about 30–40%. You would help us there if there were any solutions. – Customer Service Expert 2
The assessment model can help integrate internal stakeholders early on and prepare them to accept CA. This reduces both the hype and fear surrounding this novel technology.
External evaluation of the model in three further projects by independent teams
As an external evaluation, the CA use-case assessment model was used to examine three use cases to show the model’s applicability in various domains, as well as its usability when applied by assessors who had not been involved in the model development. In the following, we will focus on the most salient results from our perspective.
To evaluate the applicability and usefulness of our model, we asked practitioners to assess a use case with the help of the model within their work contexts and companies. Three different companies each identified one potential use case for this purpose, which was to be evaluated using the provided model and support. The evaluation was carried out by a project team consisting of two to three members. To ensure the proper model application, each project team was initially briefed on how to use the CA use-case assessment model. This four-hour briefing comprised an introduction to the model’s dimensions and constructs, as well as an introduction to the set of standardized questions being used for assessing the individual constructs. In addition, the project teams received guidelines to illustrate the application of the model.
Following the initial briefing, the project teams independently assessed their use cases. At this stage, the research team was not involved in the use-case assessments but rather assumed the role of silent observers. Finally, a reflection meeting with all three project teams took place to evaluate the applicability and usefulness of the CA use-case assessment model and to document key learnings from the projects. The findings of the individual assessments, as well as the main learnings for each use case, are illustrated structured along the three use cases that were assessed. Table 4 presents an overview of the external evaluation. 1. External evaluation of the model in three distinct industries.
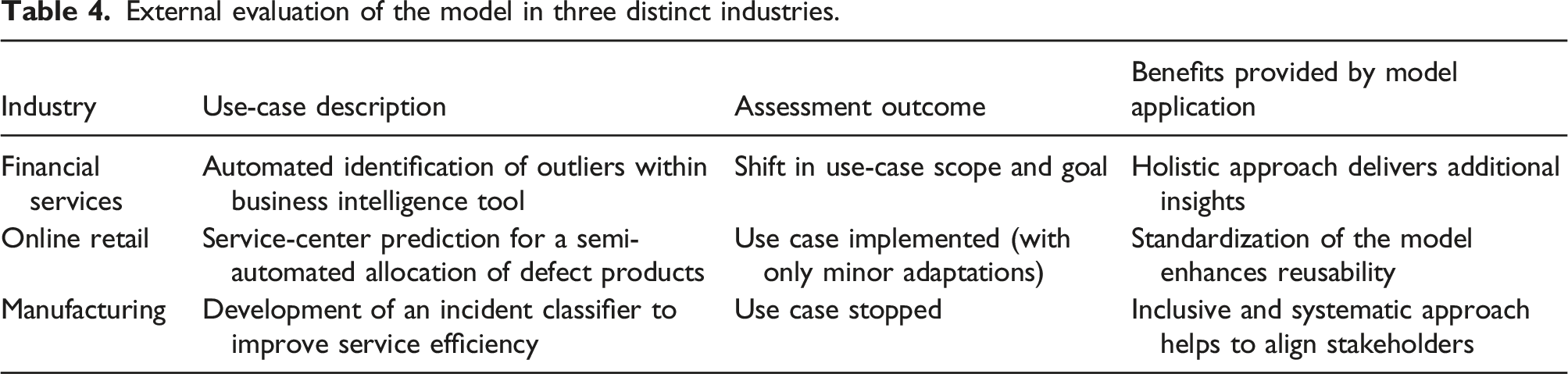
By applying the CA use-case assessment model, the project team identified previously undiscovered requirements, particularly in the data and cognition dimensions, resulting in not moving forward with the automated detection of outliers but pursuing a different use case that was relevant in order to pursue the originally proposed use case. Furthermore, the project team identified unanticipated opportunities while interviewing stakeholders during the use-case assessment, as stakeholders suggested that the project might consider the potential for improved work experience owing to less repetitive data cleaning. 2.
During the assessment, the project team discovered data relevant to the product, that is, defects that are not documented and not digitized, thus posing a challenge for a CA solution. In particular, the assessment revealed deficits within the company’s data collection and consolidation processes that had to be addressed before the project could be implemented. Consequently, a large database was generated to meet the data requirements of the use case. 3.
I think it was extremely helpful that we were guided because we were unfamiliar with how to approach this before. Case 3 – Manufacturing
In addition, the project team was confident that they would be able to reproduce comparable results when assessing a further use case within the company.
I feel that if I were to do another project, I would be even more efficient with the use case assessment. Case 2 – Retail
The project team in use case 2 emphasized the value of the requirements analysis (cognition, data, relationship, and transparency requirements), which provided them with additional insights that had not been considered before. For instance, one team member concluded as follows:
Logically, the model made sense and provided us with a very good guideline for the use case assessment. Case 1 – Financial Services
Although the project was terminated relatively early, the project team in use case 3 valued the use of the CA use-case assessment, as it helped to make and communicate the decision to terminate the project in a structured manner. They especially positively underlined the inclusive and systematic approach, which enabled them to win relevant stakeholders’ trust and support early in the project. This is illustrated by the following quote:
Spending time to talk to people with knowledge of the underlying processes is critical. It is beneficial to use the listening muscle and show enthusiasm for what they are doing. It allows to collect and understand business requirements, which are essential in order to develop solutions that are aligned with business needs. Case 3 – Manufacturing
To conclude, based on the internal and external evaluations of the model, its applicability and usefulness could be positively evaluated in a qualitative manner. We note here that further quantitative evaluations can be a fruitful avenue for further research, which we outline in more detail in the discussion section of this paper.
Specifying learnings: A model for assessing cognitive automation use cases
Here, we present the final assessment model for CA use cases that we developed in the course of our AR project, described in the previous subsections.
Figure 6 provides an overview of the use-case assessment model and its operationalizing constructs (for a list of detailed definitions of the constructs, see Appendix 3). The latter makes the assessment dimensions quantitatively measurable and offers in-depth qualitative insights into the use cases that are potential automation candidates. We defined the “amenability of a use case for CA” as the proposed model’s dependent variable. It refers to a use case’s suitability for transfer from humans to machines producing cognitive tasks or process outputs, such as decisions or solutions. The dependent variable can be measured either in terms of adoption or quality of outcomes (Overby, 2008). For instance, translation, which continues to be conducted predominantly automatically by machines, and translation outcomes of machines being as good as if they had been translated by humans, would call for the use case of translation to be amenable to CA. Therefore, we stress that the dependent variable is neither discrete nor binary but should be interpreted as a continuous measure of degree. Cognitive automation use-case assessment model.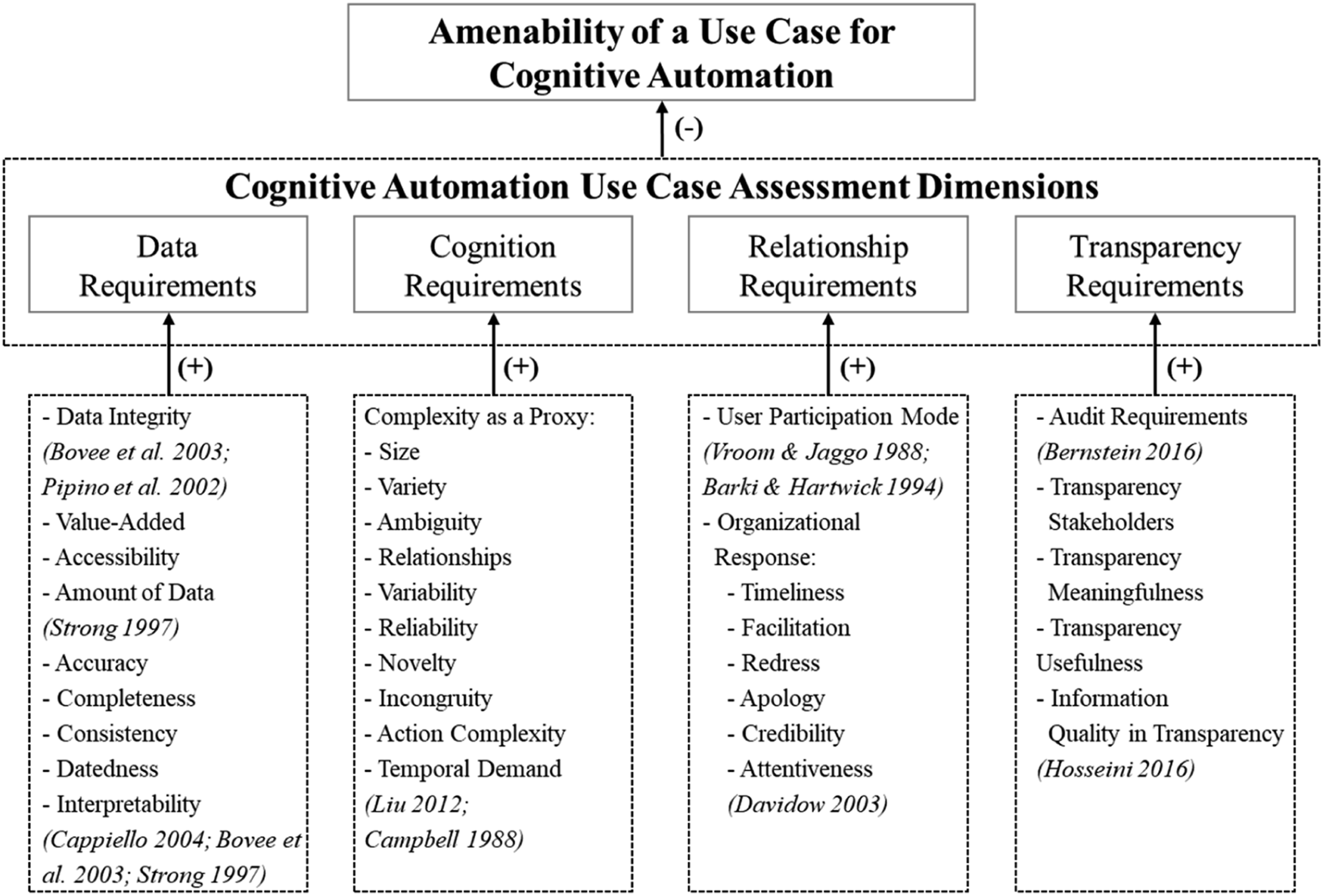
The model components are purposefully positioned as requirement dimensions to facilitate the translation between use-case characteristics and the implications for CA projects in terms of feasibility, time, and monetary effort. This will serve as a mediator between business and IT departments. The model’s main proposition, which was developed and positively evaluated, is that if the requirements of the model components are high (low), a use case’s amenability to CA will be high (low).
Below, we describe the single assessment dimensions of the model that will help organizations decide on single-use cases and facilitate the prioritization of multiple-use cases in portfolios to plan these initiatives strategically.
The data requirements of a use case include the need for a CA solution to acquire, store, and access data concerning the task or process inputs, the task or process outputs, and the use-case context. The required use-case data must be gathered and processed into information that results in knowledge about how a task or process should be performed (Ackoff, 1989). This creates use-case-specific challenges that vary with the degree of data quality, widely defined as fitness for use (Cappiello et al., 2004).
To estimate how data-intense the use case is, organizations must clarify several points. They must assess whether the data sets needed to perform the use case are error-free (data integrity) (Bovee et al., 2003; Pipino et al., 2002), complete, and consistent and ensure that the existing data support accurate decision-making (Bovee et al., 2003; Cappiello et al., 2004; Strong et al., 1997). This aligns with organizations’ capability to derive meaning from the data sets and connect them to the business context (i.e., subject matter experts must be able to interpret the data to create value) (Strong et al., 1997).
Obstacles to CA use cases may arise when data are not digitized or readily accessible (Strong et al., 1997). Only machine-readable data sets can be combined and analyzed to add value to a use case. If, for instance, the data constitute tacit knowledge or are documented in an analog manner, extracting or making them interpretable by machines will require effort (Strong et al., 1997). However, even if the data are digitized, they can still be spread across the entire organization (e.g., in data silos) (Strong et al., 1997), leading to high search costs associated with accessing the data required to train a cognitive machine. Data can also be located outside an organization, leading to costly retrieval processes.
Data requirements are also determined by the amount of data (e.g., big data) required to execute a task or process (Strong et al., 1997). Finally, the datedness (e.g., periodic vs. real-time data) that the data must exhibit is a major factor that determines the effort that will be required by CA use cases (Bovee et al., 2003; Cappiello et al., 2004; Strong et al., 1997).
Cognition requirements are the needs that a task or process imposes on the capabilities of a CA tool with respect to entity perception, learning, reasoning, and interacting. This assessment dimension is linked to task complexity: a complex task is one that imposes high cognitive requirements on a task agent (Campbell, 1988; Liu and Li, 2012).
To estimate whether a task or process exhibits high or low cognition requirements, organizations must grasp how many steps (size) the task or process consists of and how these steps vary, how well they are specified (level of ambiguity when moving from problem to solution), how interdependent they are (relationships), and finally, how stable they are over time (Campbell, 1988; Liu and Li, 2012). Furthermore, conflicting tasks and processes (incongruity), which can go hand in hand with high levels of physical and mental distress (action complexity), combined with a high level of time pressure as perceived by employees, raise cognition requirements (Campbell, 1988; Liu and Li, 2012). The latter are excellent candidates for CA but also serve as indicators for potentially high cognition requirements that must be considered when planning use cases.
Finally, cognition requirements increase if employees must detect inaccurate information owing to unreliable data sources and novel non-routine events (“exceptions”) (Campbell, 1988; Liu and Li, 2012). Therefore, it is necessary to assess which elements in a use case can feasibly be implemented with CA and what (currently) remains an activity that can only be performed by humans (Haefner et al., 2021).
Relationship requirements pertain to the degree to which a CA tool must perceive or form social and professional bonds while performing a task or process. If a use case’s relationship requirements are high, a machine must establish social presence (Short et al., 1976) and human-like behavior (Rahwan et al., 2019; Seeger et al., 2021). However, machines face several challenges in conveying social cues in the same manner as humans do (Louwerse et al., 2005): To assess relationship requirements, organizations can use the assessment model to determine the intensity of relationship requirements, such as trust building, interhuman warmth, and emotional factors (Fernandes and Oliveira, 2021). First, the mode of user involvement in value creation is critical, as it determines whether value is predominantly created indirectly between customers and employees or through intensive contact between them (Barki and Hartwick, 1994). This often pertains to the employee–customer relationship’s formality. Furthermore, the specificities of human-to-human interactions, which characterize the organizational response to the environment, such as impatience, apologizing, granting benefits to one another, and justifying actions, determine relationship requirements (Davidow, 2003). Companies often enforce codes of conduct or policies for customer relationship management on employees in environments with high relationship requirements to control the determinants of relationship requirements (i.e., timeliness, facilitation, redress, apology, credibility, attentiveness) (Davidow, 2003). A cognitive machine would thus be required to meet these policies and should be trained accordingly.
Transparency requirements refer to the degree to which a CA tool must be capable of understanding and explaining what happens between task/process inputs and outputs. This relates to “explainable AI,” which investigates the tradeoff between cognitive machines’ accuracy and explainability (Bologna and Hayashi, 2017). Thus, developers face the challenge of designing their cognitive systems to be performant while allowing for the necessary level of transparency (Theodorou et al., 2016). Organizations must also thoroughly investigate whether any audit-related risks (audit requirements) pose an obstacle to the use case (Bernstein, 2017). Furthermore, stakeholders related to the use case must be identified, and the intensity of reporting about the use case in terms of meaningfulness, usefulness, and information quality must be determined (Hosseini et al., 2016). This ultimately comes down to the relevance of the information being reported to the decisions about the use case.
Discussion
Overall, we position this work in the greater ongoing scholarly debate and research on managing AI (Berente et al., 2021). For organizations, the introduction of CA results in a variety of socio-technical challenges, such as finding effective solutions for human interaction, allocating the workforce appropriately, and avoiding de-skilling (Ågerfalk et al., 2021; Aleksander, 2017; Stone et al., 2016). Managers within these organizations are responsible for coordinating these efforts in order to navigate these challenges and, at the same time, realize their goals. Thus, it is necessary for managers to constantly reflect on their actions and to orchestrate activities related to CA with great caution (Berente et al., 2021; Elshan et al., 2023).
Information systems research is well positioned to help managers with the respective decision-making due to the interdisciplinary nature of our domain (Sarker et al. 2019; Winter et al., 2014). In this paper, we developed a model to guide more informed decisions and planning CA endeavors. In this way, we are contributing to both research and practice.
From a research perspective, our research delivers new conceptual foundations for CA. Due to the changing interaction between user and system that is the result of employing AI in automation use cases, many of the previously held assumptions regarding the interaction between users and IT artifacts are no longer valid (Schuetz and Venkatesh, 2020, Zierau et al., 2022). Instead, new conceptual foundations are required in order to better understand how cognitive systems can be successfully managed (Lyytinen et al., 2021; Schuetz and Venkatesh, 2020). The identified determinants affecting use cases’ amenability to CA will deepen our understanding of CA in particular, and of AI as the driving force behind CA in general. In addition, the introduction of AI results in new questions regarding the nature of the tasks that are appropriate for CA (Benbya et al., 2021). The model developed in this paper offers researchers a theoretical framework to answer these questions and to explain and predict the amenability of a use case for CA.
From a practice perspective, the model will help managers in making more informed decisions and in planning their respective endeavors (Berente et al., 2021). In a nutshell, this work contributes to the IS research stream of managing AI, within the scope of AI endeavors with the goal of ML-based business process automation on a level of abstraction of CA use cases, that is, existing tasks or processes potentially amenable to CA.
In the following sections, we discuss the intended contributions of the CA use-case assessment model. Particularly, we describe how this work contributes to different notions of managing AI from both a practice and research perspective. We also present the limitations of this study and suggest future research opportunities.
Contributions to practice
Our main contribution is a set of requirement dimensions for CA use cases, along with empirical details on how these requirement dimensions emerge in practice. In this regard, our CA use-case assessment model provides an analytical viewpoint on task and process automation as these transition from human to machine agents. To reduce hype and fear and to foster collaboration between business and IT, the assessment model can assist practitioners in signaling a realistic view of CA. Furthermore, by viewing CA use cases in terms of the dimensions of cognition, data, relationships, and transparency requirements, the model provides a structure for handling potentially complex use cases. This divides the complexity into an intelligible set of realistic requirements, which may subsequently be utilized to make decisions on specific organizational initiatives. Practitioners can utilize the model as a signaling and expectation-management tool to successfully communicate and eventually launch CA programs in their businesses.
Another contribution is that the model aids in determining whether a use case must be broken down into its constituent parts and further described based on its requirements to divide and conquer CA use cases in a realistic, risk-minimizing manner. The divide-and-conquer technique will equip practitioners to use synergies within and beyond individual projects’ scopes, and within and beyond the scope of CA when utilizing the model to examine various use cases in the manner of structuring a project portfolio.
Finally, we provide practitioners with a mechanism that allows them to say “no.” Because CA is not an end in itself, practitioners can use the model early on to limit risks and foster transparency within the business to obtain clarity on the “if question” of respective efforts. Therefore, we assist practitioners in demonstrating to the organization that an assessment will be conducted to critically reflect on the question of whether to even begin a CA project before proceeding to the “how” question of the project’s implementation and managing organizational change.
Regarding the generalizability of our empirical findings from the application of the model at ManuFact Corp, we highlight the challenges and organizational implications that similar companies may face, such as sourcing technical and human resources and talent from the market and encountering resentment in their organizations regarding automation and novel cognitive technologies. Thus, our empirical research results apply to firms facing similar challenges when pursuing the strategic implementation of CA.
Contributions to research
The model for assessing CA use cases that we developed, operationalized, deployed, and tested consists of four main dimensions—cognition, data, relationship, and transparency requirements—that affect whether a use case is amenable or resistant to CA. As such, this research offers an analytical assessment model for use cases transitioning from human execution to being performed by cognitive machines. It suggests that the model’s components provide the foundation for diagnostic tools to assess a task’s amenability to CA (Benbya et al., 2021). By basing the model on interviews regarding various CA use cases and a different of industrial contexts, we aimed to introduce dimensions and constructs that are valid and industry agnostic on a broad conceptual basis and allow for the proposal of relationships that are both empirically and logically adequate (Bacharach, 1989). Regarding the model’s usefulness, we aimed to provide both explanatory and predictive value by establishing the constructs’ substantive meaning, by anchoring these in empirical data from the interviews and enriching these with construct clarity from the literature (Suddaby, 2010). Furthermore, we demonstrated the model’s applicability and value in in-depth, real-world settings through AR. We defined the dependent variable “amenability of a use case for CA” and its relationships to the dimensions and constructs (explanatory usefulness). We tested their substantive meaning by comparing it to empirical case evidence (predictive usefulness) (Bacharach, 1989).
Overall, our proposed model for assessing CA use cases will contribute to the theoretical knowledge base on organizational AI and ML implementation and adoption and add to the CA literature (Lyytinen et al., 2021; Schuetz and Venkatesh, 2020). Based on the identified determinants, the model offers researchers a theoretical framework to explain and predict the amenability of a use case for CA. Furthermore, we consider the model’s scope of impact to include researchers from IS as well as various disciplines beyond IS, as the allocation of tasks between humans and AI is a global, ubiquitous phenomenon that impacts almost all fields of society and business and various research disciplines, such as economics, psychology, sociology, and organizational science (Ågerfalk et al., 2021; Aleksander, 2017; Stone et al., 2016).
The model further provides a basis for developing diagnostic tools and services. The model will serve as a structural and conceptual frame that researchers can adapt or extend to guide their empirical research, or to function as a foundation for developing future decision support for CA. This will enrich the IS knowledge base with respect to determinants affecting the adoption of CA, deepening our understanding of the CA phenomenon in particular and AI in general.
Overall, the model poses a foundation for further theorizing in the realm of CA in particular and the greater phenomenon of managing AI toward the potential generation of novel grand theories.
Limitations and future research
This paper is not without limitations. However, these limitations highlight further research opportunities.
First, regarding model development, although we tried to establish a broad and heterogeneous empirical database by interviewing company representatives from different hierarchical levels and various industries, certain personal, organizational, and industry biases may remain in the assembled data set. We also note that, although we believed we had reached theoretical saturation in the later interviews, other dimensions could be added by interviewing more people, which simultaneously bodes well for our model’s extendibility. The final point regarding limitations in the model development phase concerns the data analysis (i.e., the coding of the interview transcripts): we note here that some coder bias always remains, even though we followed established coding guidelines through open, axial, and selective coding iterations and iteratively discussed the results after each iteration.
Second, the evaluation of the model should be extended to more use cases to strengthen the empirical basis for demonstrating the use-case assessment model’s usability and robustness. Similarly, the model should be benchmarked against comparable models, as described in the related work section of this paper. Moreover, the model is not yet optimized for scalable use in organizations. This means that assessing multiple-use cases against the backdrop of fast and efficient assessments in organizations was beyond the scope of our research. Here, we specifically advocate for the investigation of the model with respect to its actual efficiency, actual effectiveness, perceived ease of use, perceived usefulness, intention to use, and, ultimately, its actual usage in organizations.
The model is further applicable to a multitude of use cases in society and business. Due to this broad scope, we acknowledge that the model might lack precision in certain domains, as other socio-technical determinants may affect the amenability of a use case for CA in a particular domain but not in others. We developed the model to be applicable to a multitude of various use cases. We thus recognize the potential for future model extension and advancement by considering constructs that are specific to particular domains (e.g., banking, where we might expect transparency requirements to play a special role) to mitigate this limitation. Here, a cross-industry study might help to control for industry-specific socio-technical context factors. Researchers can build on the model by applying it in further case settings, thus extending its evaluation. This presents the opportunity for model derivatives for different organizational contexts. Furthermore, to approach the model’s proof of use (POU), according to Nunamaker et al. (2015), the last research mile, developing IT-based tool support (i.e., technical use of the developed model) presents fruitful avenues for future research and practice projects on the model’s transference to practice for continued use. Ultimately, this may help to increase the scalability of CA use-case assessment in organizations, such as by developing employee-triggered self-service automation hubs for creating and handling use-case backlogs.
Finally, considerations such as whether a use case is better or worse when conducted by a CA system than by a human agent are beyond the model’s scope. However, future research may shed light on the organizational perspective on CA’s integration into socio-technical systems. In addition, how these use cases interact with other (non-)automated use cases and which further managerial and technical challenges are induced by CA may also be fruitful areas for further research. Given these limitations, we regard empirical testing in a quantitative manner as a major opportunity from which the model can benefit. Researchers can adapt and extend the developed model, identify additional constructs, and derive propositions, as well as determine the relative impact of the constructs, which is likely to vary between different use cases and different domains.
Concluding remarks
Many organizations intend to adopt a strategic approach to CA and capitalize on its enormous potential. However, the failure rate of such projects remains high. We drew on an AR project with a leading European manufacturing company to develop, operationalize, deploy, and test a model for assessing CA use cases. In particular, the proposed model consists of four dimensions: cognition, data, relationship, and transparency requirements. If these requirement dimensions are high (low), the use case will be less (more) amenable to CA. We applied the model to the organizational context at the B2B customer service department of ManuFact Corp. The model’s applicability and utility were demonstrated by the insights gained from its application and the organizational impact at ManuFact Corp. In addition, we extended this evaluation by having independent project teams apply the model in three other use-case assessment projects, namely in the financial service, manufacturing, and online retail industries. This shall account for the model’s applicability and utility across different industries and further strengthen its evaluative and conceptual basis.
The detailed reporting of the use-case assessment at ManuFact Corp demonstrates how use of the assessment model can aid in establishing a managerial consensus between IT and business leaders when deciding on respective initiatives, how the model helps inform project portfolio planning, and how it creates organizational acceptance by reducing the hype and fear that surround CA. This research will improve organizations’ decision-making processes for CA initiatives.
Moreover, the identified assessment dimensions affecting use cases’ amenability to CA can deepen our understanding of AI’s role as the driving force behind CA and, in particular, CA itself. Against this backdrop, we conclude that CA is not an end in itself, and organizations should thus avoid mistakenly using the model to force CA initiatives. Rather, they should use it to aid a structured decision-making process at an organizational level to decide whether CA is the best option. This can also lead to a simple answer of “no.” Overall, the model will help us understand and predict which tasks and processes will be more resistant to CA than others, or might at least take longer to become automated.
Footnotes
Acknowledgements
We would like to extend our thanks to all experts involved in the studies. This research builds on a paper presented at the 54th Hawaii International Conference on System Sciences 2021 and at the 42nd International Conference on Information Systems 2021. We appreciate the valuable feedback from the Last but not least, we also want to acknowledge the guidance of the involved Senior Editor, as well as the constructive feedback from the two anonymous reviewers during the review process. Your contributions were instrumental in shaping this paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This research received funding by the Swiss National Sciences Foundation (192718). P. Ebel acknowledges funding from the Basic Research Fund (GFF) at the University of St.Gallen.