
Abstract
Data analytics provides versatile decision support to help employees tackle the rising complexity of today’s business decisions. Notwithstanding the benefits of these systems, research has shown their potential for provoking discriminatory decisions. While technical causes have been studied, the human side has been mostly neglected, albeit employees mostly still need to decide to turn analytics recommendations into actions. Drawing upon theories of technology dominance and of moral disengagement, we investigate how task complexity and employees’ expertise affect the approval of discriminatory data analytics recommendations. Through two online experiments, we confirm the important role of advantageous comparison, displacement of responsibility, and dehumanization, as the cognitive moral disengagement mechanisms that facilitate such approvals. While task complexity generally enhances these mechanisms, expertise retains a critical role in analytics-supported decision-making processes. Importantly, we find that task complexity’s effects on users’ dehumanization vary: more data subjects increase dehumanization, whereas richer information on subjects has the opposite effect. By identifying the cognitive mechanisms that facilitate approvals of discriminatory data analytics recommendations, this study contributes toward designing tools, methods, and practices that combat unethical consequences of using these systems.
Introduction
Today’s working life often requires employees to make numerous complex decisions. Among many other factors, this rising complexity is fueled by the phenomenon of big data, leading to higher data variety, volume, and velocity that need to be considered for decision-making processes (Acquisti and Fong, 2020; Markus, 2015). Rising task complexity constitutes an issue for employees and firms alike as it can negatively affect decision-making performance (Lankton et al., 2012; Liu and Li, 2011). Firms therefore invest in training to improve employees’ expertise, as expertise can enable them to better deal with complex tasks (Hoffmann, 1999). In addition to investments in human capital, data analytics is being increasingly adopted to support employees by analyzing data, providing data-driven insights, and even recommending decision options. Across companies, this leads to the digitalization of formerly often analog and unstandardized decision-making processes, for which employees can now profit from the recent advances in data analytics algorithms as a means to reduce cognitive load and task complexity. However, notwithstanding its benefits to reduce complexity, former research has shown that the use of data analytics systems as decision aids can provoke discriminatory business decisions (Chan and Wang, 2018; Ebrahimi and Hassanein, 2021). The literature suggests various reasons for this issue such as the data being biased by including discrimination against a group (due to traditional prejudices in societies), over/under-sampling (d’Alessandro et al., 2017; Pedreschi et al., 2008), analytical models including protected variables (e.g. gender) or their proxies (Dwork et al., 2012; Pedreschi et al., 2008), and mis-labeling of historical data, used for training new models (Barocas and Selbst, 2016; Calders and Žliobaitė, 2013).
Although data and technology-related factors have been confirmed as central sources for the emergence of morally problematic data-driven decision-making, a crucial element in this process has so far received less attention: the decision-makers and their behavioral responses toward algorithmic outcomes (Kordzadeh and Ghasemaghaei, 2022). Research is still lacking a comprehensive understanding of the underlying factors leading to human approval of potentially discriminatory analytics recommendations (Lambrecht and Tucker, 2019). Neglect of the human factor is particularly serious considering that it is the employees who are faced with the increasing complexity, but who most often still need to make final decisions and either adopt or reject data analytics recommendations. The burgeoning field of people analytics has also indicated the potential ethical issues that data-driven decision-making can cause when such decisions concern human subjects (Giermindl et al., 2022; Tursunbayeva et al., 2018). However, the provision of a discriminatory analytics recommendation does not automatically lead to discriminatory actions. Along with the legal responsibility to take the “final call,” it is also employees’ moral responsibility to validate any computerized recommendations for compliance with ethical 1 standards (ACM, 2017). It is in companies’ interest that their employees should be able to discover and potentially reject discriminatory recommendations, not just from a normative point of view (Demuijnck, 2009), but also to avoid legal charges and reputation damage (James and Wooten, 2006).
Instead of assuming this to be a purely technical issue that can be fixed by improving underlying datasets or algorithms for automatized decision-making, we focus on the user side to better understand why employees confirm potentially discriminatory recommendations and identify the triggers behind this process. This is even more relevant, given that today’s application possibilities allow for data analytics usage in scenarios with high task complexity, complicating employees’ possibilities to verify these systems’ recommendations manually. While both research (e.g. Huang, 2018) and practice (e.g. Snowden and Boone, 2007) generally see high expertise as a proper means to better deal with complexity and take better decisions (Huang, 2018; Snowden and Boone, 2007), we do not know whether this also holds for discrimination-free decision-making as an ethical instance of decision-making quality. This also fuels previous discussions of whether increasing algorithmic decision support would lead to lower requirements for employees’ skills and expertise (Kaplan and Haenlein, 2020). We hold that while employees might not require advanced levels of expertise if data analytics support works flawlessly, it is their expertise that enables them to better assess and potentially reject discriminatory analytics recommendations particularly in complex decision situations.
Drawing from technology dominance theory (Arnold and Sutton, 1998), we take a critical view on the roles of task complexity and employees’ expertise, as two previously identified major determinants for assessing reliance on computer-generated advice (e.g. Hampton, 2005; Parkes, 2017). To study how expertise and task complexity influence employees’ decision about approval of a discriminatory data analytics recommendation, we examine the impact of these two variables on employees’ cognitive processes. To adequately cover the pivotal role that cognitions play in driving individuals’ behaviors, we draw upon the literature on moral disengagement (Bandura, 1986), which has been extensively used to study individuals’ cognitive mechanisms when engaging in unethical behavior. Through the theoretical lens of moral disengagement, we study why employees approve unethical discriminatory recommendations of data analytics systems, and pose our main research question: How do task complexity and employees’ expertise affect their approval of discriminatory data analytics recommendations?
We carried out two large online experiments, using an HR bonus assignment task as a typical decision situation across companies. Bonus payments and other HR-decisions are often confronted by moral critique due to fairness being endangered (e.g. where gender-bias is immanent) (Roth et al., 2012). By integrating three primary cognitive mechanisms of moral disengagement—dehumanization, advantageous comparison, and displacement of responsibility—we clarify the link between user and task characteristics as initial drivers, and actual discriminatory decision-making as its finite outcome. Specifically, our findings indicate that while task complexity generally contributes to enhancing the three moral disengagement mechanisms, employees' expertise diminishes them. Our findings provide important insights for practitioners who need to assess both the potential of increasing data analytics decision support and the associated moral risks. Firms as well as regulatory authorities can learn that richer data about human subjects can lower decision-makers’ risk of dehumanizing the individuals they decide about. It is therefore a step toward better decision aid design that can counter the increased hazards of more discriminatory decision-making owing to increasing data analytics support.
Theoretical background
Complexity and expertise as antecedents of reliance on data analytics
With increasing task complexity and decision aids becoming more intelligent, users have also become more dependent, reaching a state of reliance rather than only traditional adoption of an IS (Parkes, 2017). To account for the increasing reliance on decision aids, the theory of technology dominance (TTD) was first proposed to explain accounting professionals’ decision-making behavior when they employed intelligent decision aids (Arnold and Sutton, 1998). Since then, TTD has seen applications in various contexts such as insolvency practice (Arnold et al., 2006), tax compliance decisions (Noga and Arnold, 2002), internal control adequacy assessment (Hampton, 2005), use of knowledge-based systems (Arnold et al., 2006), credibility assessment (Jensen et al., 2010), and users’ interaction with online recommendation agents (Al-Natour et al., 2008). TTD provides conditions under which users are more likely to become reliant on decision aids, centered around the variables employee expertise, task complexity, decision aid familiarity, and cognitive fit (between a decision aid’s supported processes and the users’ normally utilized cognitive processes). Owing to recent advancements in algorithms for data-driven decision-making, task complexity and expertise have particularly come to the center of public debate. Since more advanced algorithms allow for a use in scenarios with an increasingly high task complexity, this has fueled discussions on required levels of expertise that employees still require (Kaplan and Haenlein, 2020). Besides its practical relevance, the literature has also identified task complexity and employees’ expertise as being two major determinants for assessing reliance on computer-generated advice (e.g. Hampton, 2005; Jensen et al., 2010; Parkes, 2017).
Task complexity is “the degree to which task completion or resolution taxes the cognitive abilities of the decision- maker” (Arnold and Sutton, 1998, p. 180). Complex tasks have various characteristics, such as being ill-structured; taking place in uncertain dynamic environments; having shifting, ill-defined, competing goals; having action/feedback loops; involving multiple players, time-stress, and high stakes (Orasanu and Connolly, 1993). The emergence of big data and sophisticated data analysis tools and techniques has brought about data complexity, computational complexity, and system complexity (Jin et al., 2015). The typical characteristics of big data as extremely large amounts of data that are often of diversified types and include complicated inter-relationships make its processing, computation, and perception challenging. Complex decision processes often demand both increasingly high computational and system complexity as well as high cognitive load from users. Systems designed to handle these complexities are often opaque, making it difficult for users, especially those lower in technical literacy, to understand the complex algorithms embedded in them (Vimalkumar et al., 2021). Such opacity often stems from corporate secrecy and/or high dimensional optimization, a by-product of analyzing large data sets with thousands of properties (i.e. features, characteristics) for data subjects (Burrell, 2016). Undertaking a complex task without relying on an intelligent decision aid involves high effort. Since individuals tend to exert the least amount of effort in their information processing (Chen et al., 1999; Fiske and Taylor, 1991), reliance on intelligent decision aids is likely to increase as a task becomes more complex, albeit differently for expert and novice users (Williams, 2020).
Expertise is a combination of tacit and explicit knowledge and skills that enable individuals to effectively perform a task (Draganidis and Mentzas, 2006). It is the “the level of experience a decision-maker has with respect to completion of a given decision task and the degree to which the decision-maker has formed strategies for completing or solving the task” (Arnold and Sutton, 1998, p. 180). According to TTD, when decision-makers have low expertise, they are more likely to rely on a decision aid’s recommendation. This is based on logical and empirical reasons. Observing human behavior shows that when individuals do not have the required capability to perform a task or to make a decision on their own, they are more likely to seek help (Arnold and Sutton, 1998). Inexperienced users also mainly rely on system outputs without engaging in more careful scrutiny of supply data or decision-support models (Mackay and Elam, 1992).
When using data analytics, expertise includes an understanding of the facts and procedures involved in the task in question (Ghasemaghaei et al., 2018), fundamental business principles, and domain knowledge of the firm’s products, services, processes, value chain, and industry (Cosic et al., 2015). Without such expertise, individuals lack the required sophistication to judge the quality of input data and output recommendations (Arnold et al., 2004). Therefore, these recommendations and potential useful insights extracted from data will be of little use when a firm lacks the expertise to make sense of these insights in the context of the business, its business units, customer, and partners (Gupta and George, 2016). Similarly, in cases where recommendations generated by data analytics tools are potentially discriminatory against a protected group (e.g. women), domain expertise is required for recognizing traces of discrimination and a subsequent scrutiny to find out whether the recommendations are discriminatory. For instance, a human resource expert, who has years of experience in hiring employees, is more likely to be aware of discrimination-related laws and regulations and investigate outputs of data analytics tools to make sure they are free of discrimination. Therefore and overall, users who lack domain expertise are more likely to readily approve recommendations generated by algorithms embedded in intelligent decision aids (Hampton, 2005; Jensen et al., 2010).
TTD argues that the combination of low expertise and high task complexity causes users to rely heavily on decision aids. In this case, it is likely that “the decision aid, rather than the user, takes primary control of the decision-making process” (Arnold et al., 2004, p. 7). In other words, technology dominance is not merely about the outcome of a decision-making process but also about the process itself. We suggest that in situations when data analytics as a decision aid dominates the decision-making process, users are less likely to step in, take over, and reject analytics discriminatory recommendations.
Moral disengagement
The concept of moral disengagement arose from Bandura’s research on social cognitive theory (Bandura, 1986). At the heart of social cognitive theory is the notion of “reciprocal determination,” which contends that the functioning of individuals is a result of a dynamic interplay between cognitive, environmental, and behavioral influences (Newman et al., 2020). Indeed, in a “triadic reciprocality,” cognition, behavior, and environment influence and are influenced by each other (Bandura, 1983). As such, in contrast to trait-based approaches, social cognitive theory acknowledges the interaction between personal and situational variables.
Social cognitive theory situates moral agency within a broader socio-cognitive system, governed by a self-regulatory system that includes self-monitoring, judgmental, and self-reactive sub-functions (Bandura et al., 1996). In this system, moral reasoning and agency is exercised through moral standards that individuals have developed over time. These standards guide good behavior and discourage bad behavior through individuals’ use of the standards to anticipate, monitor, and judge their own behaviors (Detert et al., 2008). The reasons for individuals engaging in unethical behavior is explained by their engaging in moral disengagement, which is described as “a set of eight cognitive mechanisms that decouple one’s internal moral standard from one’s actions, facilitating engaging in unethical behavior” (Moore, 2015, p. 199).
The first three moral disengagement mechanisms—namely moral justification, euphemistic labeling, and advantageous comparison—cognitively misconstrue unethical behavior to increase its moral acceptability (Bandura, 1986). The next three mechanisms—displacement of responsibility, diffusion of responsibility, and distortion of consequences—obscure the moral agency of the actors or the harmful impacts of unethical actions (Moore et al., 2012). Finally, dehumanization and attribution of blame prevent users from seeing the cost their actions may bring about for the subjects they decide upon (Detert et al., 2008).
We suggest that in the context of users’ reliance on data analytics as decision aids and the contemporary alternative to traditional intuition-based decision making, three mechanisms of moral disengagement, one from each of the aforementioned groups of moral disengagement mechanisms, play an important role as enablers of discriminatory decision-making: advantageous comparison, displacement of responsibility, and dehumanization. Advantageous comparison compares an unethical harmful action with a more reprehensible behavior to render the action in question less harmful or even benign (Bandura et al., 1996). Displacement of responsibility refers to individuals’ viewing their actions as arising from dictates of others or social pressures as opposed to something for which they are personally responsible (Bandura et al., 1996). Dehumanization involves depriving the subjects of an unethical action from their human qualities and attributes (Bandura et al., 1996). These three mechanisms are particularly relevant given the contextualized conditions facilitated by using data analytics systems for decision-making tasks in firms. Specifically, advantageous comparison thoughts could be sparked due to the high sophistication of data analytics tools and the “implicit assumption that data is objective” (Mingers, 1995, p. 285). Because data analytics tools are capable of conducting advanced analyses on “objective” data, it is likely that users consider the outcome more morally acceptable than cases where decisions are made unaided, especially given the long history of well-known examples of discriminatory decisions made by individuals. Such advanced analyses and computations that are perceived as powerful aids for decision-making in firms can give rise to thoughts related to displacement of responsibility especially because data analytics systems have been associated with superior performance in several studies and reports (e.g. Ghasemaghaei et al., 2018; Mikalef et al., 2019). These thoughts could be further amplified due to a lack of transparency that is often embedded in data analytics systems (Burrell, 2016) as lack of transparency decreases chances of one accepting responsibility for their actions (Eriksson and Svensson, 2016). In addition, dehumanization is relevant to using analytics as decision aids since these systems contribute to mechanization of workspaces and deprive data subjects of their unique identity (Gal et al., 2017). In the next section, we will discuss how these three mechanisms are enhanced by the two factors of task complexity and employees’ expertise. In addition, we will elaborate how they can facilitate users’ intention to approve discriminatory recommendations of data analytics systems.
Research model and hypotheses development
Connecting TTD with the concept of moral disengagement, we suggest that task complexity as well as employees’ expertise affect their cognitions, that is, advantageous comparison, displacement of responsibility, and dehumanization, which in turn facilitate approving discriminatory data analytics recommendations. The following sections present and delineate our hypotheses, as depicted in Figure 1. Research model.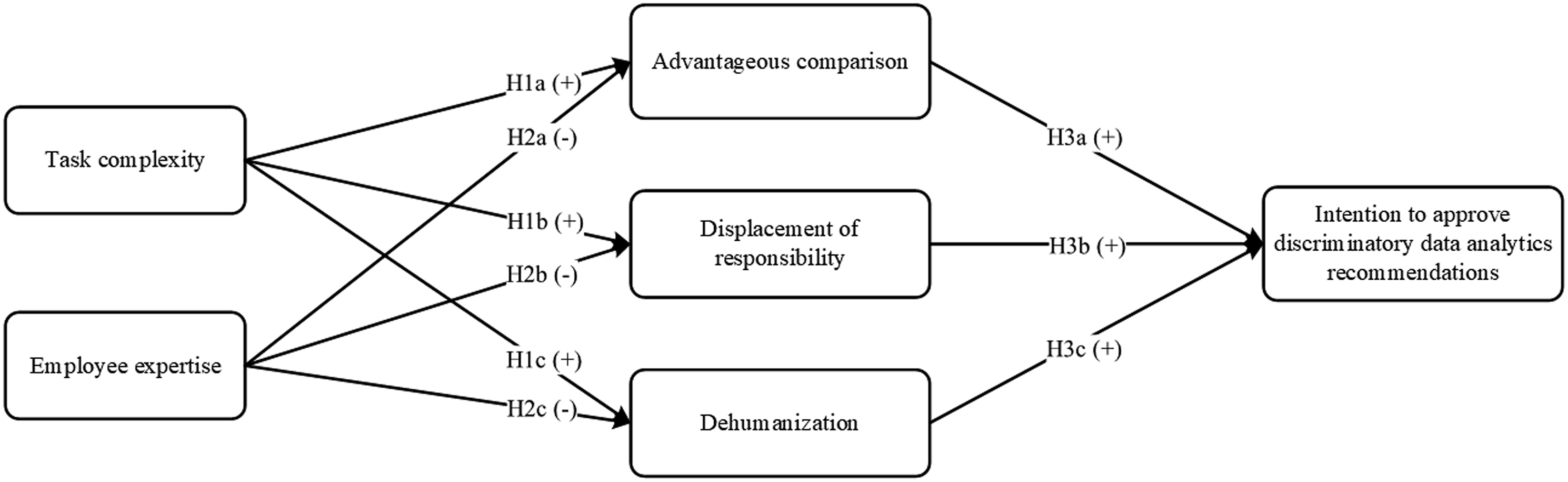
The impact of task complexity on moral disengagement mechanisms
Task complexity is mainly related to the number of information cues to consider, the number of actions to execute, and the amount of interdependence between the information cues to consider (Wood, 1986). Tasks involving a high degree of complexity require decision-makers to consider and process more information cues simultaneously, which thereby increases their cognitive effort (Parkes, 2017). If the amount of information processing exceeds a certain limit, decision-makers are likely to resort to cognitive simplification strategies (Speier and Morris, 2003) such as dismissing a portion of information consciously or subconsciously (George et al., 2008; Lewis, 2004), dismissing some of the alternatives to reduce the size of the solution scheme (Klemz and Gruca, 2003; Olshavsky, 1979), or relying on some simple decisional heuristics such as their trust in decision aids (Petty and Cacioppo, 1986).
In the data analytics era, employees, might face decisions for which they have to select and process items from large data sets involving hundreds or thousands records of data each with numerous attributes (as an example, consider selecting a subset of customers to receive a specific promotion). Therefore, employees are likely to feel overwhelmed by the sheer amount of data and engage in the aforementioned simplification strategies to conserve cognitive effort (Jiang and Benbasat, 2007). In such cases, employees tend to think that handling, analyzing, and making decisions without the use of data analytics tool might be very cognitively taxing. As a result, they are more likely to engage in advantageous comparison by comparing approving analytics-generated recommendations that could be imperfect (e.g. potentially disadvantaging a specific group) with making intuition-based decisions which are prone to a wide variety of biases and prejudices (Arnott, 2006; Hilbert, 2012).
In addition, higher data volumes underlying a decision increase users’ confidence in its accuracy and importance (Arnott, 2006). To accommodate for high complexity of decision tasks, analytics tools are designed to have high system complexity (Jin et al., 2015; Ranjan, 2019), which often makes it challenging or even impossible for users to understand the analysis performed by these tools (Newell and Marabelli, 2015). Since analytics systems are often seen as “powerful aids to decision-making” (Davenport et al., 2010, p. 17), users who find the complexity of decision tasks beyond their cognitive capabilities are more likely to trust these systems, displacing the responsibility of potentially unethical decisions to them.
Furthermore, since data analytics represents data subjects as a collection of data, users who feel overwhelmed with the complexity of the task are more likely to not consider its human aspect. The issue is exacerbated when higher number of data subjects need to be considered for a decision because analytics tools represent data subjects as a set of records, which are incapable of carrying individuals’ full individuality (Ebrahimi et al., 2016). Neglecting and denying a person’s identity is an important element of dehumanization, which occurs in mechanistic or animalistic form (Haslam, 2006). While the former includes denying human nature characteristic (e.g. individuality, emotional responsiveness), the latter involves denying uniquely human characteristics (e.g. civility, rationality, maturity). Our focus is on mechanistic dehumanization and we suggest that when task complexity is high, data analytics users are likely to neglect the individuality of the subjects of their decision and engage in mechanistic dehumanization of them.
Task complexity will positively affect data analytics users’ engagement in (a) advantageous comparison reasoning; (b) displacement of responsibility; and (c) dehumanization of data subjects.
The impact of expertise on moral disengagement mechanisms
Employee expertise involves the possession of domain knowledge required to carry out certain tasks. Individuals who possess expertise have accumulated relevant knowledge about the tasks in question (Schmidt et al., 1986). This accumulated knowledge enhances individuals’ “self-efficacy,” that is, beliefs about their capability to undertake the task successfully (Bandura, 1986; Judge et al., 2007). When comparing data analytics recommendations with their own judgment and performance, individuals with high self-efficacy are less likely to believe that system-generated recommendations are unquestionably better and thus, do not simply rely on them. This is because individuals with high expertise have often already formed strategies for completing certain tasks (Arnold and Sutton, 1998).
Individuals who possess high expertise (and motivation) are more likely to expend their cognitive resources and engage in an effortful process of examining the information available about a given decision (Petty and Cacioppo, 1986). This careful deliberation increases the likelihood of engaging in ethical decision-making, and thus lowers the need to displace the responsibility of a questionable decision to the decision aid (Street et al., 2001). Higher expertise also helps decision-makers retain a higher perception of control over a given action (Hartshorne and Ajjan, 2009; Taylor and Todd, 1995). When individuals feel in control, they rather take the responsibility for their actions and potential consequences (Trevino and Youngblood, 1990). Those individuals are therefore less likely to attribute the responsibility of taking unethical decisions to powerful others (Detert et al., 2008).
Individuals with high expertise have developed domain-specific knowledge and mental models, which are “representations of objects, events, and processes that people construct through interaction with their environment” (Savage-Knepshield, 2001, p. 2). Mental models guide individuals’ behavior in their problem-solving tasks as well as their interactions with IT (Schumacher and Czerwinski, 1992). When using data analytics systems for decision-making, experts draw upon their well-developed mental models for a given task and are less prone to remain at the pure “data level.” Instead, they tend to look deeper into the data and see the human aspects of the decision at hand. Individuals with high expertise are “able to make a meaningful whole out of the disparate pieces” (Posner and Rothbart, 2007, p. 191). Thus, when interacting with analytics systems, they are more likely to think about human beings in their entirety rather than individual data-specific characteristics of the human beings that the pieces of data represent. In addition, experts have well-developed strategies to handle tasks within their domain (Arnold and Sutton, 1998) that they gain through practice, implicit learning, and experiential learning (Dane, 2010). Therefore, we expect individuals with high expertise to be less likely to feel overwhelmed by the data and sophisticated models embedded in analytics tools.
Employee expertise will negatively affect data analytics users’ engagement in (a) advantageous comparison reasoning; (b) displacement of responsibility; and (c) dehumanization of data subjects.
The impact of moral disengagement mechanisms on users’ intention to approve discriminatory data analytics recommendations
High levels of moral disengagement mechanisms predict a wide range of generally undesirable behaviors, such as social loafing in virtual teams (Alnuaimi et al., 2010), unethical work behavior (Detert et al., 2008; Moore et al., 2012), unethical pro-organizational behavior (Chen et al., 2016), accident underreporting (Petitta et al., 2017), and information security policy violations (D’Arcy et al., 2014). According to the social cognitive theory, this is because moral disengagement mechanisms allow individuals to commit unethical actions while disengaging from ethical standards and self-sanctions that normally prohibit such behaviors (Bandura et al., 1996; Chen et al., 2016).
In the context of discriminatory recommendations of data analytics systems, we expect advantageous comparison to increase users’ approval of the recommendations. Users who approve such recommendations may compare their actions with decisions that are made without the use of these systems. Since those decisions are known to often be contaminated by various personal and organizational biases and prejudices, users could justify their approval of a potentially discriminatory analytics-generated recommendation as less (or not) problematic. Displacement of responsibility as another moral disengagement mechanism facilitates the approval of discriminatory data analytics recommendations by obscuring the responsibility of this decision. When users view their approval of potentially discriminatory recommendations as a result of what has been “dictated” by the tool, they may displace the responsibility of their actions to it. This displacement of responsibility eases the unethical action of approving the discriminatory recommendation by negating any personal accountability for the unethical act in question. Finally, the dehumanization of data subjects, which takes place by considering data subjects as collections of data with rows and columns as opposed to human beings with emotions facilitates the approval of analytics discriminatory recommendations by reducing identification with the targets of unethical behavior. This mechanistic dehumanization enables users to emotionally distance themselves from the subjects of their decisions and as such, increases users’ indifference toward them. Therefore, mechanistic dehumanization displaces data subjects (Haslam, 2006) and facilitates approving discriminatory data analytics recommendations.
Users engaging in (a) advantageous comparison reasoning; (b) displacement of responsibility; and (c) dehumanization of data subjects will have a higher intention to approve discriminatory data analytics recommendations.
Methodology
Experimental task
We tested our research model in two online experiments. In both Study 1 and Study 2, we invited participants to interact with an online fictitious data analytics tool (“Smart HR-Data”) designed to provide specific HR recommendations. To create a sense of realism, we informed participants that we were a premium manufacturer of small kitchen appliances and that every year we reward 25% of our best-performing employees with a GBP 1000 bonus. Furthermore, we notified participants that the process of selecting best-performing employees used to be done manually in the past, but this year we were testing Smart HR-Data to support us in the task. We asked participants to use Smart HR-Data and decide whether it “did a good job” in identifying and recommending the best-performing employees.
Manipulations and samples for study 1 and study 2.
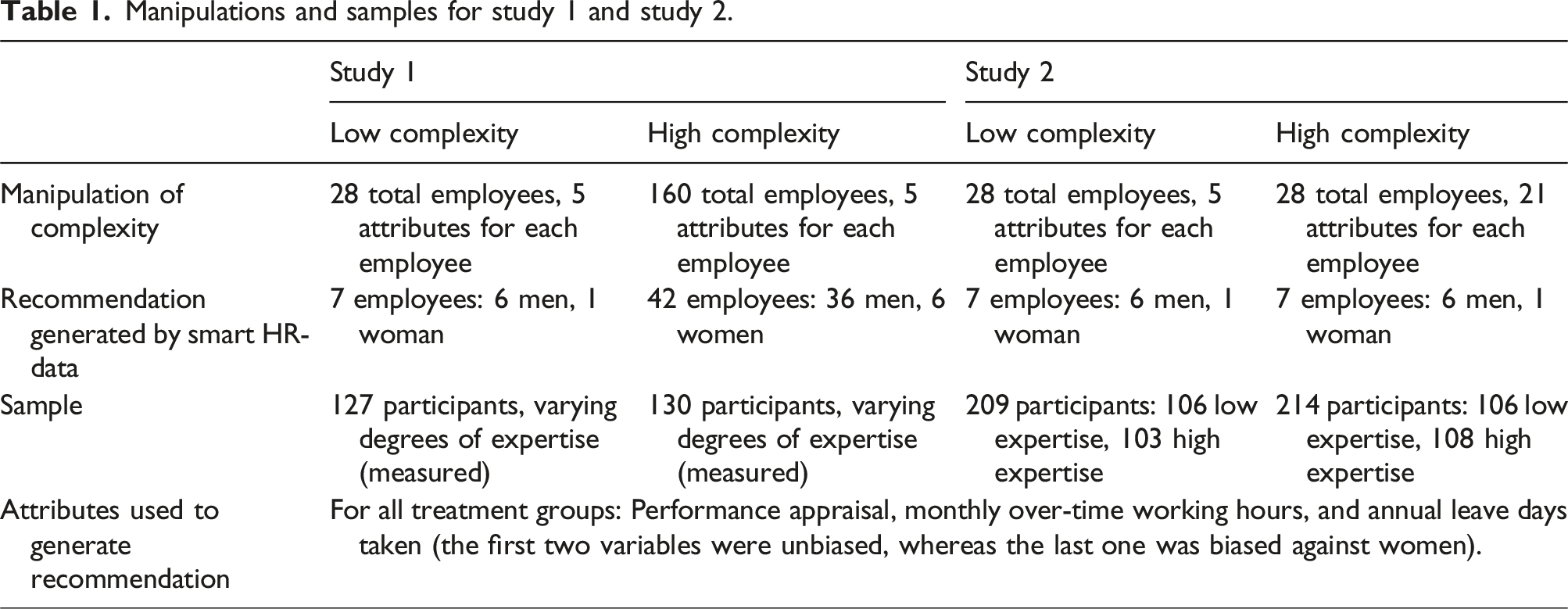
During the experimental task, participants first received an introductory script, where we emphasized the importance of thoroughly examining the data set and the recommendations generated by Smart HR-Data. We informed participants that the 20 best-performing participants will receive an additional GBP 10. Subsequently, participants received a list of variables included in the data set along with their definition, followed by several tables and figures with additional information on the data set (see Appendix A, Table A-1, and Figures A-I and A-II), mainly to increase participants’ familiarity and cognitive fit with the tool, and resemble an experience similar to real data analytics tools. Thereafter, participants obtained Smart HR-Data’s recommendations on employees to receive the bonus. To verify the suitability of the recommended employees, participants could toggle between viewing all employees and the recommended employees only. In addition, Smart HR-Data provided participants with several sorting and filtering functionalities as well as the option to export the data to Microsoft Excel (Appendix A, Figure A-III). After completing the experimental task, participants were directed to an online questionnaire.
Manipulations and sample collection
Both Study 1 and Study 2 included a between-subjects experimental design. To design different levels of task complexity, we employed the comprehensive framework proposed by Wood (1986). Wood suggests that the complexity of a task mainly relates to the characteristics of information cues that are utilized in its relevant judgment and inference processes. He further argues that three dimensions of these information cues make up the complexity of a task: component complexity, coordinative complexity, and dynamic complexity. The focus of this study is on component complexity, which refers to the number of distinct acts that must be executed and the number of distinct information cues that need to be processed in performing the task (Wood, 1986). In the context of multi-attribute multi-alternative problems component complexity refers to the number of attributes for certain alternatives and/or the number of alternatives (e.g. Kamis et al., 2008; Swait and Adamowicz, 2001). To provide a more nuanced picture of the impact of complexity, we implemented task complexity in two forms: In Study 1, by increasing the number of alternatives (i.e. employees to choose from), and in Study 2, the number of attributes (i.e. the number of attributes about an employee).
In Study 1, we manipulated task complexity by varying the number of employees (i.e. alternatives) that were included in the data set. Specifically, we randomly assigned participants to either a low or high task complexity treatment, thus receiving information on 28/160 employees out of which 7/40 were recommended by Smart HR-Data. Expertise was not explicitly manipulated but directly assessed from participants. In both treatments, the proportion of women in the entire data set of all employees was 50 percent and the proportion of women in the subset of employees recommended to receive the bonus was 7.5 percent.
For Study 2, we employed a two (high vs. low task complexity) by two (high vs. low expertise) design. To manipulate task complexity, we varied the number of attributes (i.e. characteristics about employees). Specifically, the data set given to participants in the low complexity treatment group included 5 attributes, whereas those in the high complexity treatment group were presented with 21 attributes for each employee (see Table A-I, Appendix A). It is noteworthy that although treatment high task complexity included more attributes of employees, the same attributes in both treatments were used in generating the recommendation. Therefore, the same employees were included in the recommended list to receive the GBP 1000 cash bonus. Concerning expertise, participants in the high expertise group had different pre-determined characteristics from those in the low expertise group (Table 1).
We recruited 257 (Study 1) and 423 (Study 2) subjects via Prolific, a platform designed to enroll subjects for surveys (Palan and Schitter, 2018). A power analysis determined that these numbers would assure a sufficient statistical power of 0.80 to detect a medium effect size (f = 0.25) (Cohen, 1988). Participants for our studies consisted of full-time employees in the United Kingdom. For Study 2, participants with high expertise needed to be at least in a Junior Management position with 7+ employees as subordinates and an organizational tenure of more than 1 year. Participants with low expertise were full-time employees without managerial roles and managerial experience. The sample for both studies included a balanced number of men and women. Subjects were employed in various departments (e.g. sales, finance) and in various industries (e.g. finance and insurance, arts, entertainment, retail). There were no significant differences in gender, industry, and department across the different treatment groups.
Operationalization of variables
For our survey instrument, we adapted established scales for perceived expertise, advantageous comparison, displacement of responsibility, dehumanization, and intention to approve discriminatory data analytics recommendations. Specifically, advantageous comparison and displacement of responsibility were adapted from Moore et al. (2012), dehumanization was adapted from Alnuaimi et al. (2010), and intention to approve recommendations was adapted from Benlian et al. (2012). Expertise was measured with a self-reported instrument in Study 1 adapted from Montazemi and Gupta (1997).
In both studies, we controlled for the effect of participants’ gender as the context of this study is about discrimination against women. Furthermore, previous studies have shown that, compared to men, women tend to behave more ethically (e.g. Singhapakdi et al., 2001). Gender was coded as a categorical variable where female = 0 and male = 1. Moreover, following the common emphasis in the business ethics literature, we accounted for participants’ tendency to respond in a socially desirable way when answering sensitive items on our survey instrument (Chen et al., 2016; Umphress et al., 2010) by controlling for participants’ impression management, their propensity to “consciously over-report their performance of a wide variety of desirable behaviors and under-report undesirable behavior” (Paulhus, 1984, p. 4). Impression management has been shown to significantly impact self-reported ethical conduct (e.g. Schoderbek and Deshpande, 1996). To prevent participants’ fatigue, we adapted a shortened 6-item version of the impression management scale developed by Paulhus (1984). Using Paulhus’ method, after reversing the negatively worded items, we added one point for each extreme response (i.e. 6 or 7 on the Likert scale). Following this approach, the minimum score in social desirability is 1 (when a participant did not provide an extreme response for any of the questions) and the maximum score is 7 (for a participant who provided extreme responses for all of the questions). This approach ensures that “high scores are attained only by subjects who give exaggeratedly desirable responses” (Paulhus, 1991, p. 37). Furthermore, we controlled for participants’ awareness of the ethicality of the situation at hand by measuring their moral awareness using May et al.’s (2014) 4-item scale. Additionally, in Study 2, we also controlled for the effect of participants’ general trust in technology. The items were adapted from McKnight et al. (2011). Table B-I (Appendix B) includes a complete list of all survey items.
Results
Study 1 results
Measurement model assessment
We conducted a manipulation check of task complexity using an independent sample t test to analyze participants’ average responses to the two questions about perceived levels of task complexity (i.e. “How would you rate the complexity of the task?” and “I found the number of employees in the data set (very low … very high)”). The results show that perceived task complexity was significantly higher for participants in the high complexity treatment than in the low complexity group (M = 4.12 vs 4.57, p < 0.001). Therefore, the manipulation check confirmed that subjects in the group high (low) task complexity did perceive the task as more (less) complex.
We assessed the measurement model by conducting tests for reliability, convergent validity, discriminant validity, as well as common method bias (CMB) using IBM SPSS 27 and partial least squares (PLS) analysis using SmartPLS 3.3.3. We assessed the reliability of all constructs in the model using composite reliability and Cronbach’s alpha and observed that all constructs met the benchmark of acceptable reliability of 0.7 (Appendix C, Table C-I) (Hair et al., 2010). We tested the convergent validity by the average variance extracted (AVE) for each construct. The AVE of all constructs exceeded the threshold value of 0.5, indicating acceptable convergent validity of the constructs (Fornell and Larcker, 1981). To assess discriminant validity, we examined two criteria: First, the square root of the AVE of all constructs was greater than the correlation between the construct in question and other constructs (Appendix C, Table C-I). Second, measurement items posited to reflect each construct differed from those that were not believed to make up the construct (Appendix C, Table C-II). Therefore, we can conclude that our constructs indicate an acceptable level of discriminant validity.
Since we measured all of our constructs using the same method, we tested for CMB with two different approaches. We first conducted a Harman’s single-factor test (Podsakoff et al., 2003). We conducted an unrotated principal component analysis as a result of which (1) more than one factor with eigenvalues greater than one emerged, and (2) the first factor did not explain a majority of the variance (33.27%), suggesting that CMB is not likely to have a significant influence on the results. As a second test, we conducted a marker variable technique following Lindell and Whitney (2001), who suggest that a theoretically unrelated construct should be used to adjust the correlations among the principal constructs. We used participants’ coffee-drinking habit as the marker variable. We observed that the average correlation between the five principal constructs in our study and participants’ coffee-drinking is r = 0.06 (average p-value = 0.45). Subsequently, since participants’ coffee-drinking habits are theoretically unrelated to their intention to approve the data analytics recommendation, the correlation between these two constructs could be considered as CMB. Therefore, following Lindell and Whitney (2001), we parceled out this value (0.015) from the other correlations and repeated our analyses. The results did not show any significant difference between the original correlations and the adjusted ones. The results of the Harman’s single-factor test and the marker variable analysis together suggest that CMB is not a major concern in this study.
Structural model and hypotheses assessment
Figure 2 presents the results of the structural model testing. Our findings demonstrate that task complexity positively influences advantageous comparison (β = 0.30, p < 0.001), displacement of responsibility (β = 0.34, p < 0.001), and dehumanization (β = 0.30, p < 0.001), providing support for H1. Expertise negatively influences advantageous comparison (β = −0.17, p < 0.05), displacement of responsibility (β = −0.22, p < 0.001), and dehumanization (β = −0.26, p < 0.001), supporting H2. The positive relationships between the three moral disengagement mechanisms and approval of the recommendation are also confirmed by the data. Specifically, advantageous comparison (β = 0.37, p < 0.001), displacement of responsibility (β = 0.20, p < 0.005), and dehumanization (β = 0.16, p < 0.005) positively influence intention to approve the discriminatory data analytics recommendation. In addition, among our three control variables, moral awareness is the only construct with statistically significant impact on intention to approve the recommendation (β = −0.19, p < 0.001). The three mechanisms of moral disengagement along with our control variables jointly explain 36 percent of the variance in approval of the discriminatory data analytics recommendation. Results of research model for study 1.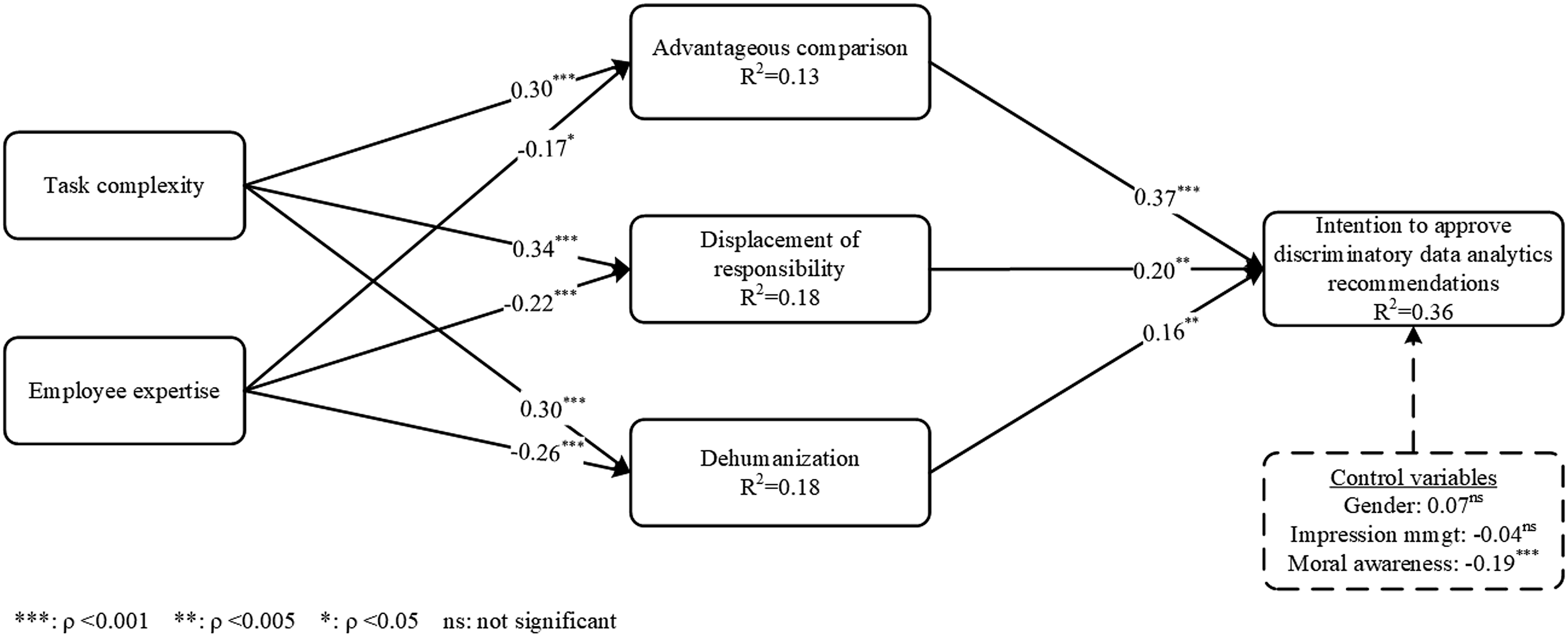
Study 2 results
Measurement model assessment
We asked participants two questions about the level of perceived task complexity (i.e. “How would you rate the complexity of the task?” and “I found the number of variables (columns) in the data set … (very low … very high)”). A respondent’s responses to the two questions were averaged and an independent sample t test indicated that participants in higher task complexity perceived the task to be more complex (M = 3.79 vs 5.17, p < 0.001). Therefore, we can conclude that our manipulation of complexity was successful. Additionally, we conducted an independent sample t test on participants’ responses to the two questions measuring their self-reported expertise (Appendix B) and found that the average of the responses was significantly higher for participants in the high expertise group compared to their counterparts in the low expertise group (M = 1.80 vs 3.90, p < 0.001). We assessed the psychometric properties of the measurement model by examining reliability, convergent validity, and discriminant validity of all latent constructs in our model. We evaluated the reliability of the constructs using composite reliability and Cronbach’s alpha, which all exceed the acceptable reliability of 0.7 (reported in Table C-III, Appendix C) (Hair et al., 2010). To assess the convergent validity of the constructs, we calculated their AVEs, which all exceeded the recommended threshold of 0.5 (Fornell and Larcker, 1981) (Appendix C, Table C-III). We examined two criteria for discriminant validity: (1) the AVE of each construct was greater than the correlation between the construct in question and any other construct in the model, and (2) measurement items posited to reflect each construct differed from those that were not believed to make up the construct. According to the correlations, and square roots of AVEs (Table C-III, Appendix C) and loadings and cross loadings of measures (Table C-IV, Appendix C) both of these criteria were met.
To address the potential concern for CMB, we performed a Herman single-factor test, as a result of which, (1) more than one factor with eigenvalues greater than one emerged, and (2) the first factor did not explain a majority of the variance (30.82%). These results provide no indication of CMB (Podsakoff et al., 2003). Furthermore, we conducted a marker variable analysis. Since the average correlation between the four main constructs in our study and the marker variable (i.e. participants’ coffee-drinking habit) is r = 0.13 (average p-value = 0.79) and the correlations between our principal constructs do not change after parceling out this value (−0.002), we can conclude that CMB is not a major concern for Study 2 (Lindell and Whitney, 2001).
Structural model and hypotheses assessment
Figure 3 depicts the results of the structural model, including path coefficients and the variance explained. The model successfully explains a considerable amount of variance in approval of discriminatory data analytics recommendations (adjusted R2 = 0.36). The results confirmed our expectations about the positive impact of task complexity on advantage comparison (H1a) (β = 0.38, p < 0.001) and displacement of responsibility (H1b) (β = 0.29, p < 0.001). However, the influence of task complexity on dehumanization of data subjects although significant, but in the opposite direction to the hypothesis. While H1c suggests that increasing task complexity increases dehumanization of data subjects, the results of our analysis show that when task complexity is increased by increasing the number of variables available to users, task complexity decreases dehumanization (β = −0.12, p < 0.005), rejecting H1c. Furthermore, in line with our expectations, expertise strongly reduces the three mechanisms of moral disengagement, namely, advantageous comparison (β = −0.29, p < 0.001), displacement of responsibility (β = −0.31, p < 0.001), and dehumanization (β = −0.41, p < 0.001), providing support for H2. Similarly, finally, the impacts of the three mechanisms of moral disengagement on approval of discriminatory data analytics recommendations are found to be significant, providing support for H3. Specifically, advantageous comparison (β = 0.39, p < 0.001), displacement of responsibility (β = 0.11, p < 0.05), and dehumanization (β = 0.23, p < 0.001) increase intention to approve the discriminatory recommendation. Similar to study 1, among our control variables, only moral awareness significantly impacts intention to approve the recommendation (β = −0.21, p < 0.001). Results of research model for study 2.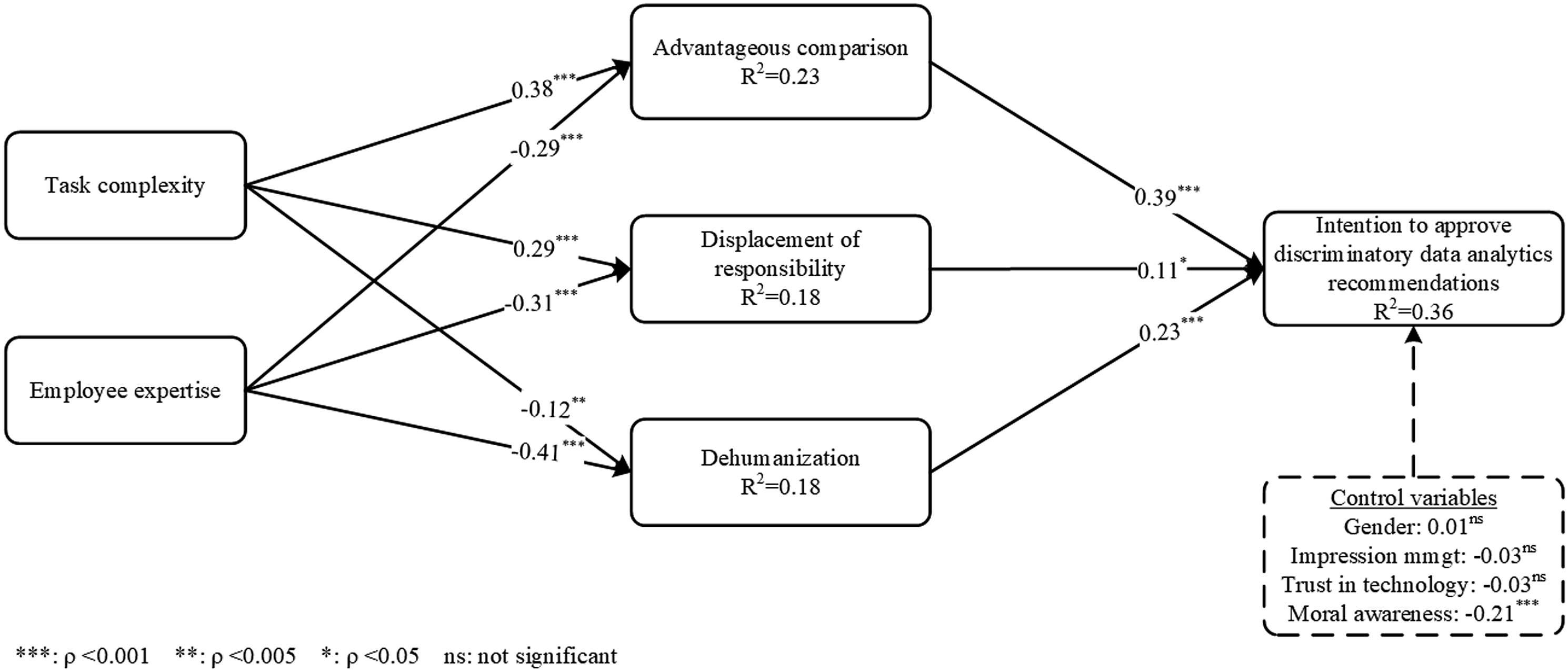
Post hoc analysis using group comparisons
Given the emphasis of the theory of technology dominance on the differences between experts and novices as well as differences between more and less complex tasks, we conducted group comparison tests to investigate the impact of these variables on intention to approve discriminatory data analytics recommendations as well as the three moral disengagement mechanisms in our research model. To that end, two sets of independent sample t-tests were conducted on data collected in each study. The first set of tests compared the intention to approve discriminatory recommendations and the three moral disengagement mechanisms for novices (i.e. subjects with below 4 average for two expertise questions in Study 1 and subjects in the low expertise group in Study 2) with experts (i.e. subjects with above four average for two expertise questions in Study 1 and subjects in the high expertise group in Study 2). The results confirmed the existence of significant differences in terms of our dependent variables between novices and experts in Study 1 and Study 2 (results reported in Tables D-I and D-II in Appendix D). Similarly, differences in terms of our four dependent variables were found between participants in more and less task complexity groups in both studies (results reported in Tables D-III and D-IV in Appendix D).
We also investigated whether participants who intended (did not intend) to approve the recommendations perceived them as fair (unfair). To do so, we asked participants about how they rate the fairness of the recommendations provided by the tool. Subsequently, we coded perceived fairness as 0 (meaning low perceived fairness) for those who answered “very low,” “moderately low,” and “slightly low” and coded it as 1 (meaning high perceived fairness) for those who answer “very high,” “moderately high,” and “slightly high.” Responses of participants who answered “neither high nor low” were excluded from this analysis. The results of an independent samples t-tests between participants with low and high perceived fairness of the recommendations in terms of their intention to approve them show statistically significant differences between the two groups in both Study 1 (M = 3.11 vs 5.31, p < 0.001) and Study 2 (M = 3.08 vs 5.55, p < 0.001).
Discussion and implications
Discussion
Our main research question was to identify how task complexity affects employees’ intention to approve discriminatory data analytics recommendations, and how employees’ expertise could counter this undesired behavior. To better understand the cognitive mechanisms, which connect the initial task and user characteristics with the final approval decision, we built upon the three moral disengagement mechanisms of dehumanization, advantageous comparison, and displacement of responsibility.
Previous studies show a differential picture on the effects of task complexity on data analytics usage patterns. Some have shown that higher complexity can reduce the use of data analytics (e.g. Ghasemaghaei, 2020), while others showed that complexity can lead to a more frequent use of search advisors, also because the motivation and purpose of its use changed from reassessment to exploration (Capra et al., 2015). Our findings illustrate that task complexity impacts individuals’ moral compass, which leads to higher moral disengagement and higher intention to approve discriminatory recommendations. While Speier (2006) showed that task complexity moderates the relationship between information presentation format and decision performance, we hereby demonstrate that task complexity plays an important role in affecting the ethical aspects of decision-making quality. Our results are intriguing as they not only show that task complexity generally increases the probability of approving discriminatory data analytics recommendations, but that the type of complexity affects the level of dehumanization. Across the two studies, we distinguished between complexity by more alternatives (i.e. a higher number of individuals with relatively few characteristics) and complexity by more characteristics about alternatives (i.e. fewer individuals with more characteristics). While complexity by more alternatives leads to higher dehumanization, the opposite is true for complexity by more characteristics, which leads to lower levels of dehumanization. This is because individuals are more likely to personally distance themselves in decision-making situations with a large number of people, in which they see the individuals as just one of many (Haslam, 2006). Also from social psychology, we know that humans have a limited capacity to engage or familiarize with larger numbers of humans (e.g. Dunbar, 1993; Granovetter, 1973). However, when decision-makers are confronted with fewer people described by more characteristics, they can learn more and better empathize with the individuals in question, which makes distancing themselves more difficult. This is in line with previous research from organizational behavior, which has not only shown that dehumanizing employees can deteriorate trust within organizations, but also that there are different forms of how dehumanization can be elicited (Väyrynen and Laari-Salmela, 2018). Nevertheless, it should be noted that higher complexity by more characteristics still leads to an increase of the other two moral disengagement factors, advantageous comparison and displacement of responsibility, which speaks against artificially increasing task complexity by providing more characteristics about human subjects if there is no requirement for it.
Concerning expertise, previous research has shown that it not only influences decision-making capability but also how individuals view tasks and the final decisions they make (Haerem and Rau, 2007). Our results show that more expertise leads to less moral disengagement as a determinant of ethical decision-making. Indeed, individuals with higher expertise could act more confidently because they do not need to rely on the analytics-generated recommendations alone but also draw from a rich body of accumulated experiences, which can enable them to discover pattern in the datasets that inexperienced users are less likely to identify. Nah and Benbasat (2004) already discovered that individuals with lower expertise are more likely to approve conclusions of knowledge-based systems and rate these systems as more useful. On the other hand, higher expertise might also lead employees to unjustifiably turn down computer-based recommendations owing to overconfidence bias (Vetter et al., 2011).
Experts have been found to have relatively constant perceptions of task variability and analyzability across tasks of different complexity (Haerem and Rau, 2007). We confirm that employees with higher expertise can cope better with higher complexity and are more likely to question the moral integrity of the recommendations. While today’s dynamic market environments often make employees face complex decision tasks, which make them more susceptible to falling for discriminatory recommendations, it is their expertise that can counter this effect to some degree. Therefore, as the results of both studies also confirm, experts are less likely to approve discriminatory recommendation of data analytics systems, thereby converting them to discriminatory decision. Taking both factors into account, this situation might become more difficult if employees with lower expertise need to deal with highly complex tasks. Here, using analytics as decision aids may entail even higher risks of moral disengagement as well as approval of unethical recommendations.
Our findings also depict that the three moral disengagement mechanisms of dehumanization, advantageous comparison and displacement of responsibility are associated with employees’ intention to approve discriminatory data analytics recommendations. Therefore, these factors all serve as triggers to turn morally problematic recommendations into discriminatory actions. This is in line with the previous literature on moral disengagement in other contexts (Moore et al., 2012; Moore, 2015), which has shown that moral disengagement mechanisms can explain the motives for employees to conduct unethical organizational behavior. Among the three, advantageous comparison proves to have the strongest influence across our two studies, while dehumanization and displacement of responsibility have similar, but considerably smaller effects. The strong impact of advantageous comparison seems reasonable since data analytics provides new ways of conducting established tasks. Employees are familiar with previous mechanisms to conduct the task and they can therefore also compare the potential downsides of the new procedure with the previous ones. In line with the literature on technology dominance, which emphasizes the important distinctions between novices and experts when they engage in tasks of high or low complexity using intelligent decision aids (e.g. Hampton, 2005; Jensen et al., 2010; Parkes, 2017), our findings across two experiments confirm that low expertise and high task complexity significantly increase the probability of approving discriminatory data analytics recommendations. Recognizing the unfairness of these recommendations, however, significantly reduces the likelihood of approving and potentially converting them to discriminatory decisions. This finding corroborates prior research in business ethics literature which has long argued that once an individual recognizes the ethical aspect of a situation, they are more likely to engage in an ethical behavior (Rest, 1986).
Theoretical implications
Our work paves the way for a better understanding of the underlying mechanisms of employees’ processing and responding to discriminatory data analytics recommendations, and it thereby adds important dimensions to the extensive previous works on how digitalization can foster discriminatory decision-making. This research stream has so far focused mostly on either technological factors that could spur more discriminatory decision-making as well as factors related to characteristics of the underlying data set (Calders and Žliobaitė, 2013; Dwork et al., 2012; Pedreschi et al., 2008). Our work shows that in addition to these arguably important overarching factors, it is both complexity as a characteristic of the particular decision task as well as expertise as an attribute of the decision-maker, that affect the likelihood of discriminatory data analytics recommendations being turned into discriminatory actions. By examining the moral disengagement cognitive mechanisms that facilitate users' approvals of discriminatory analytics recommendations, we respond to the call of Kordzadeh and Ghasemaghaei (2022) to study the mechanisms through which algorithmic bias impacts individuals’ behavioral responses toward algorithmic outcomes. In addition, by extending the scope of interest on ethical decision-making to the human factor, we hereby contribute to the previous literature in several ways:
First, we contribute to research with an improved understanding of the impact of task complexity and employees’ expertise on the likelihood to approve discriminatory data analytics recommendations. While previous research focused more on their impact on overall decision quality, we now better understand the cognitive processes involved in the processing and responding to data-driven recommendations with potential ethical harm, and the overall decision outcome as an ethical component of decision quality. As such, by testing TTD in a new context and adopting a new outcome variable, we contribute to the literature on technology dominance, which to date has mainly focused on general agreement with or divergence from decision aids’ recommendation (e.g. Gomaa et al., 2008; Jones and Brown, 2002), decision confidence (e.g. Hampton, 2005), and performance accuracy (e.g. Jensen et al., 2010). This study, therefore, tests and extends the theory of technology dominance by empirically validating the impacts of the theory’s two main bases, employees’ expertise and task complexity, on increasing users’ reliance on decision aids even when the system outputs are morally charged.
Second, our results shed light on the influences of users’ expertise when using information systems to handle tasks of various complexities. While Sedera and Dey (2013) conceptualized, measured, and applied the notion of user expertise to contemporary information systems, highlighting that individuals with different levels of expertise evaluate systems differently, we extend this view by showing that different levels of expertise not only affect system adoption but also the evaluation of system outputs. Responding to Liu and Li (2011), who found that the relationship between task complexity and task performance can be positive, negative, contingent, or inverted-U-shaped, we showed that expertise is another crucial variable that can explain differences to ethical decision quality, even at the same level of task complexity.
Third, we identify the moral disengagement mechanisms that are facilitated by using data analytics systems and clarify their role in driving employees’ vulnerability to approve their discriminatory recommendations. We contribute to previous research on dehumanization, which has found that the source of the data (AI-generated vs human) can impact whether users perceive the subjects in a dataset as numbers or humans (Huang et al., 2020). We have shown that not just the source of the data but also the richness and the form of presentation can have differential effects on dehumanization. We also contribute to the social psychology literature by extending the theory of moral disengagement to a context of rising interest given the widespread use of intelligent decision aids. While moral disengagement has already been applied in other technology-related contexts, such as virtual team collaboration (Alnuaimi et al., 2010) or cyber security (Herath et al., 2018), we have confirmed its applicability also for the domain of decision support in data-driven applications. Beyond data analytics, this can also spur future research on human-machine and intelligence augmentation, in which employees might be exposed to unethical machine recommendations or actions, to which human users still need to give their blessing. Our findings are also important considering the tendencies of increasing environmental data-driven complexity on the one-hand side, and increasing levels of IT-driven decision support—seeking to counter the increasing external complexity—on the other side. Given the substantial potential of data science to drive ethical issues on a societal level, we suggest future research to build upon a common framework centered around the three corner stones of external complexity, the degree of computerized decision support and employees’ expertise to further guide this development.
Fourth, by connecting moral disengagement with technology dominance theory, we identify this missing link to show that moral disengagement is not a fixed, immutable state, but depends on individuals’ expertise and the task complexity in the respective context. By identifying the three moral disengagement mechanisms that are relevant to the context of approving discriminatory data analytics recommendations, we respond to Newman et al.’s (2020) call to examine the cognitive mechanisms of moral disengagement as unique factors as opposed to treating moral disengagement as a higher-order factor that comprises eight different cognitive mechanisms. We recommend considering these moral disengagement factors not just for other models that seek to focus on the unintended effects of data-driven decision-making but also for research on adoption and use of data analytics tools to capture moral disengagement as an important side effect that can particularly arise if the decision task and the actions carried out by more advanced tools are difficult to comprehend by employees. Based on our results, which identify moral awareness as a significant control variable that decreases the likelihood to approve discriminatory data analytics recommendations, another fruitful alley for future research seems to be a closer analysis of the interactions between moral awareness and moral disengagement subject to various types of users and expertise.
Practical implications
Considering the widespread use of data analytics and the meaningful processes they support nowadays; our results have important implications for practitioners. Besides firms and employees that take decisions with data analytics systems as decision aids, it is also important for their manufacturers to learn more about how users interact with their products, and whether and why potentially problematic decisions could arise from their deployment, to be able to take first steps to mitigate potentially problematic system behavior.
First, we inform companies who increasingly employ data analytics for supporting their employees in decision-making, that in addition to the underlying technological factors it is also their employees who constitute an important determinant in giving their blessing to morally problematic analytics-generated recommendations, particularly when task complexity is high and user experience is low. While companies might neither be able to constrain the increasing environmental complexity, nor to improve their employees’ expertise immediately, we suggest they assess and potentially adopt their system design to reduce the underlying complexity. This could be, for instance, by splitting larger data sets into smaller ones or by dividing larger decision problems into smaller, sequential ones. To reduce potential dehumanization, we further suggest providing more information about human subjects in their datasets even if these are not directly considered for the decision. We further recommend training their employees to not blindly trust analytics recommendations, but to assess rather critically any data-driven decision support for moral integrity. This is particularly relevant for employees with lower expertise to avoid developing a false sense of security.
Second, we demonstrate the relevance of expertise even in times of increasing decision automation by IT, which can help reduce humans’ cognitive efforts. Although its benefit might primarily no longer be in the processes of decision-making itself, expertise can still be highly relevant for employees in the review and approval of (partly) automated decisions. Thus, employees might increasingly function as a control instance for the decision aids that support them. This role shift could reduce employees’ temporal engagement in a decision task, but it does not make their job any less important, since decision-making with data analytics tools still requires compliance with ethical guidelines to avoid unintended consequences for firms (Favaretto et al., 2019).
Third, by understanding the employees’ and tasks’ characteristics that increase the chances of employees’ falling for discriminatory data analytics recommendations, firms can now better determine where they should best implement analytics tools for improving decision-making. This is also a pragmatic insight since the technical deficiencies of algorithms and datasets could not always be immediately fixed. Companies should also look at how expertise and complexity can be considered together during the development and design of analytics tools. One approach might be to develop more participative tools, which elicit lower information overload and more employee engagement compared to predefined ones (Lankton et al., 2012). Another potential solution lies in deploying highly personalized interactions that better adapt to individual employees’ requirements, since perceptions of task complexity may vary between employees, and thus different information that is useful for task completion (Choi et al., 2019). Here, employees with high expertise could still obtain more complex decision tasks with data analytics support. In contrast, employees with lower expertise could receive split-up decision tasks or be equipped with additional information about human subjects to enable them to better empathize with the human beings they are deciding about. For the selection of appropriate information about human subjects, companies could link this to value-sensitive design approaches that seek to identify which value-related characteristics are important for users during system use (Lüthi et al., 2021).
Fourth, while we conducted our analysis in the context of HR bonus payments, thus pertaining a context where the resulting consequences mostly stay within the company, it seems fairly plausible that similar results could apply also in other decision contexts that are highly relevant for firms. For instance, this could also pertain to corporate decisions about customers or other stakeholders, where improper decision-making can easily lead to public outrage and reputational damage (Newell and Marabelli, 2015). We therefore see a strong practical need to reassess and potentially reconfigure data analytics as decision aids in important tasks across industries and potentially even provoke necessary regulatory measures to make sure data analytics tools do neither overburden nor lull users into a false sense of security (Woerner and Wixom, 2015).
Conclusion and limitations
Building upon the literature on moral disengagement and technology dominance theory, our goal was to clarify how data analytics, that originally seeks to mitigate the rising task complexity for employees in decision-making, affects employees’ cognitive processes that turn discriminatory analytics recommendations into discriminatory decisions. The three cognitive mechanisms of advantageous comparison, displacement of responsibility, and dehumanization, constitute the missing link between task complexity, employees’ expertise, and the approval of discriminatory recommendations. While higher task complexity generally increases moral disengagement, we find that the nature of task complexity matters when employees need to decide about other human subjects. While complexity owing to a higher number of alternatives increases dehumanization, the opposite is true for complexity by more characteristics about the alternatives, as the richer information can make the data subjects appeal more human and therefore decrease dehumanization. This study also shows that despite rising technological capabilities of data analytics as decision aids, higher expertise can still be essential to critically assess the moral suitability of their recommendations. By identifying the cognitive mechanisms that facilitate such approvals, our study takes the first step toward designing participatory mechanisms that can better integrate users in guided decision support. Given the increasing use of data analytics tools for various decision tasks across industries, and the daily lives outside work, we hope this first step can stimulate other researchers to contextualize our work to other types of decision situations as well as to other forms of how complexity can emerge in large datasets.
Despite the utmost care, our study is not free from limitations. First, the applied experimental methodology restricted the number of implemented scenarios. With HR bonus appointment, we have chosen a task that was easy to explain and with which most participants were familiar. The manipulation checks confirmed that the manipulations were successfully perceived by participants and our sample selections mechanisms ensured that they included employees with different levels of expertise. Nevertheless, we were only able to implement one particular setting of an HR bonus payment. Although the task is relevant for many firms, different firms might employ different levels of data analytics support and vary in terms of other firm-specific characteristics, such as the number and type of variables considered for the decision. In addition, we cannot rule out that employees’ susceptibility to approve discriminatory recommendations might differ between tasks, also because participants might employ different heuristics to assess morally problematic recommendations or also because they might employ different levels of personal care to a particular decision task. Here, we must acknowledge that while non-transparent bonus payments might severely endanger the work climate, such a decision-making task is potentially not “mission critical” to all decision-makers and some might just accept a discriminatory recommendation because of laziness. When dealing with life-or-death decision-making as a doctor, deciding upon jail sentences as a judge, or securely running a nuclear power plant, it could be expected that decision-makers take every possible effort to obtain the best decision possible. However, data analytics tools are also increasingly used in non-mission critical situations, and we believe that especially for such situations we need to learn more about decision-makers’ propensity to accept discriminatory recommendations.
Furthermore, our implemented decision task was characterized by discrimination based on gender. However, besides gender there are various characteristics that might constitute the basis for discrimination, such as race, age, religion, and others. In our case, the potential disadvantage stemming from the adoption of a discriminatory recommendation was lost financial benefits for unselected employees. In other contexts, potential disadvantages might also relate to missing out on opportunities, non-admission to institutions, social stigma, or other types of social harm (Marjanovic et al., 2021). While the negative effects for discriminated individuals might vary, so too potentially do the perceptions of consequences across decision-makers. We therefore recommend that future research replicates our work with different types of decision tasks and different levels of data provision on subjects (Cybulski and Scheepers, 2021).
As with other experimental settings which are conducted in a lab or over the Internet, the external validity of the experiment needs to be critically discussed as the decisions in our experiment were not directly linked to a real corporate environment, in which they are usually taken, and in which they are subject to many external factors. To name a few, such factors could include whether HR-employees who assign the rewards a) have existing relations with potential grantees, b) have their own personal agendas and therefore intentionally foster certain groups, c) not only have to prepare a list of grantees but also have to justify their choice to a manager or co-workers, or d) have high (low) workloads that lead them to devote less (more) time to the selection task. These are all among the factors which, despite providing a realistic scenario and a data analytics tool for participants, we were not able to directly map in our experiment. It should be noted that our decision to use an experiment as opposed to a field study was to have control over the variables that could contaminate our results. For instance, without a controlled experiment it would not have been possible to ensure that participants (in the same treatment group) received identical recommendations that are uniformly discriminatory against women. Further, using a self-developed experimental data analytics tool in this experiment allowed us to let participants experience the actual setting and let them conduct the actual decision task, instead of just requesting hypothetical information in a survey. Nonetheless, we took various steps to help alleviate the concern related to external validity of this study. First, by introducing incentives for the best-performing participants, we increased the chance that participants paid sufficient attention to how they carried out the decision task, therefore increasing the “experimental realism” (i.e. whether laboratory events are believed, attended to, and taken seriously) of the study (Swieringa and Weick, 1982). In addition, by presenting the task to participants in the context of a (fictional) company, which was going to use a (fictitious) data analytics system, we strived to increase participants’ sense of “mundane realism” (i.e. whether laboratory events are similar to real-world events) (Swieringa and Weick, 1982). Furthermore, controlling for impression management enabled us to gain a clearer picture of the authenticity of participants’ responses.
Adding to this, several previous studies have already highlighted the importance of trust in relations between systems and humans and in particular when receiving computerized decision support (Wang and Benbasat, 2008). While we implemented trust in technology as a control variable, we are aware that trust between systems and humans usually develops over time, and also that specific incidents (such as a particularly problematic recommendation) might impact employees’ future susceptibility to adopt problematic recommendations. We therefore see it as an opportunity for future research to conduct longitudinal studies in which explicit “disappointments” of employees by providing problematic recommendations are integrated to better understand such effects over time.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was financially supported by Social Sciences and Humanities Research Council of Canada (SSHRC).