
Abstract
The European Union’s General Data Protection Regulation (EU-GDPR) has initiated a paradigm shift in data protection toward greater choice and sovereignty for individuals and more accountability for organizations. Its strict rules have inspired data protection regulations in other parts of the world. However, many organizations are facing difficulty complying with the EU-GDPR: these new types of data protection regulations cannot be addressed by an adaptation of contractual frameworks, but require a fundamental reconceptualization of how companies store and process personal data on an enterprise-wide level. In this paper, we introduce the resource-based view as a theoretical lens to explain the lengthy trajectories towards compliance and argue that these regulations require companies to build dedicated, enterprise-wide data management capabilities. Following a design science research approach, we propose a theoretically and empirically grounded capability model for the EU-GDPR that integrates the interpretation of legal texts, findings from EU-GDPR-related publications, and practical insights from focus groups with experts from 22 companies and four EU-GDPR projects. Our study advances interdisciplinary research at the intersection between IS and law: First, the proposed capability model adds to the regulatory compliance management literature by connecting abstract compliance requirements to three groups of capabilities and the resources required for their implementation, and second, it provides an enterprise-wide perspective that integrates and extends the fragmented body of research on EU-GDPR. Practitioners may use the capability model to assess their current status and set up systematic approaches toward compliance with an increasing number of data protection regulations.
Introduction
In 2020, the European Commission (EC) released a plan for a European data strategy. This plan outlines the transformative importance of data in modern economies and strives to position the European Union (EU) at the forefront of data-related innovation (European Commission, 2020). One of the pillars of this strategy is the building of public trust in data processing activities, with the General Data Protection Regulation (EU-GDPR) enabling individuals to have control over their personal data. EC President Ursula von der Leyen even expressed the hope that the EU-GDPR would set data protection “standards for the rest of the world” (von der Leyen, 2020). Since it went into effect in May 2018, the EU-GDPR has initiated a paradigm shift in data protection toward greater choice and sovereignty for individuals and more accountability for organizations (De Hert and Papakonstantinou, 2012). The strict European rules have inspired regulations in other parts of the world, for instance, the California Consumer Privacy Act (CCPA, California State Senate, 2018), India’s new Personal Data Protection Bill (Parliament of the Republic of India, 2018, Govindarajan et al., 2019), and Japan’s update to the Act on the Protection of Personal Information (Japan Personal Information Protection Commission, 2020, Tanaka and Kitayama, 2020).
For organizations, these regulations come with a mandate to clarify whether, how, and how well they protect personal data, along with increased fines for non-compliance. As they apply at a scale larger than any previous data protection regulations, they require a fundamental reconceptualization of how they store and process personal data on an enterprise-wide level. In the case of EU-GDPR, many organizations are still facing significant compliance challenges and struggle with the conflicting interests between legal obligations, business drivers, and innovation (Jakobi et al., 2020). A study conducted in June 2019 among more than 1000 European and US companies reported that organizations had been overoptimistic about their ability to achieve timely compliance. When surveyed in March and April 2018, 78% of responding organizations expected to comply with the EU-GDPR by the time it came into force, but only 28% of them reported being compliant when evaluated a year later (Capgemini Research Institute, 2019). A study released in April 2020 reveals similar difficulties among multinational enterprises: Only 54% of them had achieved operational compliance, while 37% were still conducting “significant readiness actions,” and 9% were still in “project mode” (Dansac Le Clerc and Mannent, 2020). According to this study, a majority of organizations are still implementing mechanisms to manage data protection rights, data storage and retention, and in-depth registries of data processing activities (Dansac Le Clerc and Mannent, 2020).
From a research perspective, the EU-GDPR has been debated in both legal and IS communities (De Hert and Papakonstantinou, 2012, 2016; Jakobi et al., 2020; Mitrou, 2017). Although legal aspects of information privacy had not been among the “topic areas closer to the interests of most IS researchers” (Bélanger and Crossler, 2011), the EU-GDPR has recently attracted more academic interest. Like the idea of regulatory technologies for financial regulations, so-called "RegTech" (Butler and O’Brien, 2019), IS researchers have mostly focused on technical solutions that ease EU-GDPR compliance, such as blockchain (Farshid et al., 2019; Guggenmos et al., 2020; Mejtoft et al., 2019; Rieger et al., 2019) or enterprise architecture (Burmeister et al., 2019, 2020; Huth, Burmeister, et al., 2020). In doing so, the existing body of IS research on EU-GDPR remains fragmented and proposes solutions for isolated aspects of the regulation. It fails to provide an enterprise-wide perspective on the compliance requirements and a broader discussion of the alternative ways to address them.
The difficulties in achieving EU-GDPR compliance highlight the general lack of common ground not only between legal and IS research communities but also between professionals in both disciplines. In most companies, data protection topics have traditionally been addressed by legal and compliance departments, which adapt contracts and general conditions. The new generation of data protection regulations does not allow for such a restricted approach, but requires a fundamental reconceptualization of how companies store and process personal data on an enterprise-wide level (Labadie and Legner, 2020). Since the EU-GDPR does not prescribe concrete implementation options, companies find it challenging to interpret the regulation and develop suitable data management practices that support compliance. Thus, data processing–related issues remain the most challenging topics in the EU-GDPR (De Hert and Malgieri, 2018; Nicolaidou and Georgiades, 2017; Thélisson, 2020).
In this paper, we introduce the resource-based view (RBV) as a theoretical lens that helps explaining the complex and lengthy trajectories towards EU-GDPR compliance. We argue that companies have to mobilize technological, human, and intangible resources and build dedicated, enterprise-wide data management capabilities in order to reach their regulatory compliance objective—or, as conceptualized by Sadiq et al. (2007) their “control objectives.” The latter are directly or indirectly related to firm performance, as non-compliance may have significant direct (e.g., fines) and indirect (e.g., reputation loss) financial consequences. Using the RBV also allows extending the regulatory compliance management (RCM) literature (Abdullah et al., 2009; Cleven and Winter, 2009; El Kharbili, 2012), which provides systematic approaches to analyzing regulations, but has not yet embraced the EU-GDPR. Here, capabilities can serve as a way to translate abstract compliance requirements into routines and practices.
More specifically, this paper addresses the following research question: What data management capabilities need to be built to address the EU-GDPR’s requirements? Following a rigorous design science research process (Peffers et al., 2007), we propose a capability model for the EU-GDPR that synthesizes three groups of capabilities—that is, infrastructure, management, and external linkages—that organizations must build to comply with the regulation. The capability model was iteratively developed based on the interpretation of legal texts, findings from EU-GDPR-related publications, and practical insights from focus groups with experts from 22 companies and four EU-GDPR projects 1 . We find that capabilities can create “common ground” between legal and IS perspectives: they help analyzing compliance requirements and discussing ways to address them before a decision is made on concrete (technical) implementations.
By providing a comprehensive, theoretically and empirically grounded capability model for the EU-GDPR, our study advances interdisciplinary research at the intersection between IS and law with two types of contributions: First, it contributes to the research on regulations, a topic that has seen few contributions in the IS domain in the past but is enjoying a renewed interest in the context of digitalization and Big Data. Specifically, it connects the nascent research on EU-GDPR to the regulatory compliance management literature (Abdullah et al., 2009; Cleven and Winter, 2009; El Kharbili, 2012). It establishes a link between compliance rules and practice in the spirit of the sense-making dimension of IT-based regulation (de Vaujany et al., 2018). Second, our study complements the fragmented research on the EU-GDPR that treats selected aspects of the regulation or proposes specific implementation solutions by providing an integrated, enterprise-wide perspective. The capability model acts as an overarching framework that outlines the links between compliance requirements, capabilities, and their materialization in the form of resources. It allows researchers to theorize about the capabilities required for EU-GDPR-compliant data management, position and compare their suggestions for EU-GDPR-compliant solutions in the larger context and generalize beyond the EU-GDPR. Practitioners may use the capability model to assess their current status and set up systematic approaches toward compliance with an increasing number of data protection regulations.
The remainder of this paper is structured as follows: We start by introducing the EU-GDPR and providing a synthesis of research on the topic, as well as regulatory compliance in general. After outlining the research methodology and process, we motivate the RBV perspective and present the capability model. We conclude by summarizing our contribution and discussing future research.
Background and related research
Paradigm shift in data protection regulations
In January 2012, the European Commission published a proposal for an overhaul of data protection law, which would become the EU-GDPR 2 . The aim was to remedy the fragmented implementations of the previous Data Protection Directive (95/46/EC) and account for the significant changes introduced by the Internet and digital services (Mitrou, 2017; Nicolaidou and Georgiades, 2017). The EU-GDPR is noteworthy for successfully harmonizing the European data protection legal framework and applies directly in all 27 EU member states, a scale much larger than any previous data protection regulation. Moreover, its relevancy extends beyond Europe: On the one hand, any organization that processes the personal data of an EU citizen must comply with it regardless of the geographical location of their operations. If it fails to do so, significant fines will be imposed (i.e., up to 20 million euros or 4% of an organization’s global revenues, whereas previous regulations averaged at around 500,000 euros). On the other hand, the EU-GDPR has been conceived as a worldwide reference for data protection (von der Leyen, 2020), and the strict European rules have inspired data protection regulations in areas of the world that did not have any, such as the California Privacy Act (CCPA) and India’s Personal Data Protection Bill (Parliament of the Republic of India, 2018). In the United States, there have been official calls to complement domain-specific provisions, such as the Health Insurance Portability and Accountability Act (HIPAA) for health information, with a full-fledged data protection regulation at the federal level, similar to the EU-GDPR (Rubio, 2019). Other countries, such as Japan (Japan Personal Information Protection Commission, 2020) and Switzerland (Swiss Confederation, 2020), have been compelled to update their existing data protection frameworks to match the EU-GDPR’s strengthened requirements (Métille and Raedler, 2017, Tanaka and Kitayama, 2020). These developments are a testimony to the EU-GDPR’s global influence and show that it has become the de facto standard for data protection (De Hert and Malgieri, 2018, Thélisson, 2020).
While these new regulations reinforce established data protection concepts (Debet, 2018, Wiese Schartum, 2018), they also introduce a paradigm shift toward greater choice and sovereignty for individuals and more accountability for organizations (De Hert and Papakonstantinou, 2012, 2016; Mitrou, 2017). Most notably, they strengthen existing transparency mandates—in the case of the EU-GDPR, organizations must inform individuals about data processing in clear language and separately from general conditions. They are also required to present more granular consent options (Nicolaidou and Georgiades, 2017). One of the major additions is the concept of accountability, which implies that organizations must be able to demonstrate compliance with the regulation. They must also appoint data protection officers (DPOs) and announce data breaches to both authorities and individuals. Privacy-by-design principles (i.e., implementing privacy from the ground up in systems and offerings) also appear in the regulation, along with new individual rights, such as data portability and a right to oppose automated decision making (Nicolaidou and Georgiades, 2017).
EU-GDPR and data protection in IS literature
Although the EU-GDPR was finalized in 2016 and entered into force in May 2018, it was slow to attract the attention of IS researchers. This mirrors a general reluctance among IS researchers to probe information privacy (Bélanger and Crossler, 2011). In 2018, a query with the keyword “GDPR” on the AIS Electronic Library only returned 27 matches. This number has increased tenfold in the past two years, resulting in 262 matches at the end of 2020. A more detailed review of these studies reveals four categories of contributions, but only the first two categories treat the EU-GDPR as their central topic of interest (see Table 1): 1. Overall regulation (19 studies; for details, see Table 1): These studies analyze the regulation as a whole. Most popular contributions relate to the EU-GDPR’s impact and mapping of the regulation to existing domain-specific frameworks. This is where we position the study at hand. 2. Selected aspects of the regulation (23 studies; for details, see Table 1): These studies treat the EU-GDPR as the central topic of interest, and their outcomes relate to a specific aspect of the regulation. They address five key themes: data protection rights, consent, transparency, accountability, and technical and organizational measures. 3. Data privacy and security (110 studies): These studies contribute to domains that are related to the EU-GDPR and data protection, such as other regulations, general privacy research, cybersecurity, information ethics, information disclosure, and data sharing. While they position the EU-GDPR as a motivating factor for their outcomes, they do not analyze the regulation. 4. General IS research (94 studies): These studies relate to a variety of other IS research areas and only mention the EU-GDPR to back up a specific, isolated argument. Overview of EU-GDPR related studies in IS literature. *C = conceptual, E = empirical. †Based on Bélanger and Crossler (2011).
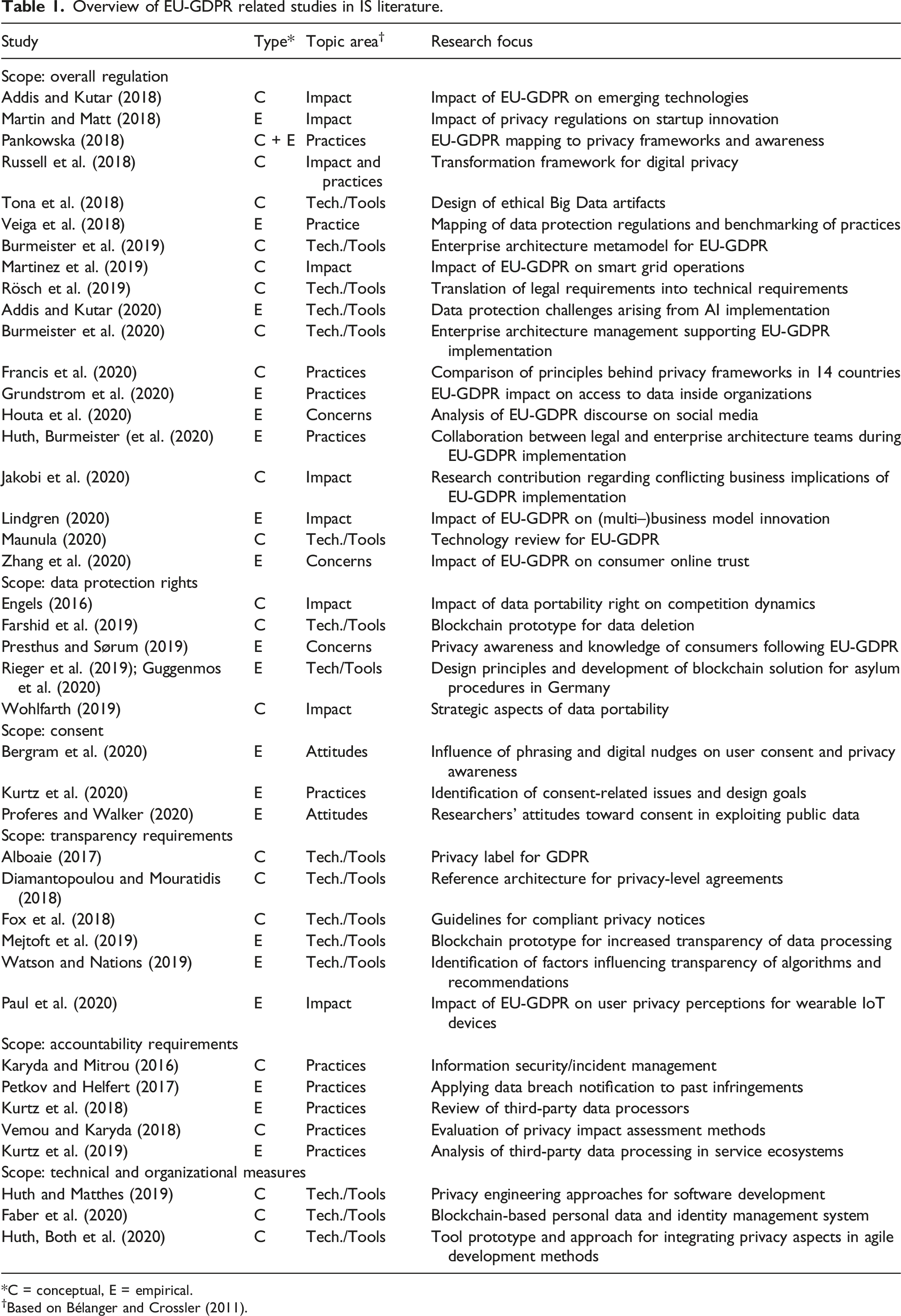
Hence, despite the increasing interest for EU-GDPR, research is still at an early stage and only the contributions in the first and second categories (i.e., 16% of all the studies) can be considered to fully embrace the EU-GDPR topic. Interestingly, these studies address typical topic areas in Bélanger and Crossler's (2011) taxonomy for information privacy research and are classified accordingly in Table 1. The early EU-GDPR studies (published until 2018) fell within the domains of information privacy practices and information privacy technologies and tools. After the EU-GDPR entered into force, researchers broadened their scope and started to investigate the information privacy concerns and attitudes of individuals and specific stakeholder groups (e.g., software developers, researchers, and business executives). Comparing the state of research in 2018 with 2020, we observe the most significant uptake in studies focused on technologies and tools for EU-GDPR compliance, which now constitute the majority of EU-GDPR-related studies (i.e., 41% in 2020, up from 28% in 2018). Four of these studies (out of 16) investigate blockchain as a technological basis for compliance solutions. By contrast, studies on information privacy practices were predominant in 2018 (i.e., 57%) but now rank second after technology and tools-related research (i.e., down to 31% in 2020). They predominantly comprise empirical studies of EU-GDPR-related practices. Finally, the share of studies classified in the information privacy impact category has dropped slightly from 28% in 2018 to 20% in 2020. These studies investigate the impact of the EU-GDPR on emerging technologies (e.g., advanced analytics and smart products) and business model innovation, as well as the economic/market impact of data portability.
Table 1 also illustrates that research on the EU-GDPR is fragmented and many studies narrowly focus on one of the EU-GDPR’s requirements and the technologies, tools, or practices used to address them. With respect to consent, these studies investigate, for example, the means to influence it on digital channels (Bergram et al., 2020) or whether existing implementations comply with the regulation (Kurtz et al., 2020). Several studies suggest blockchain-based solutions (Faber et al., 2020; Guggenmos et al., 2020; Mejtoft et al., 2019; Rieger et al., 2019) or enterprise architecture (Burmeister et al., 2019, 2020). These approaches have two shortcomings: First, most papers take the compliance requirements for granted and directly look into specific practices or solutions. They thereby do not take into account that the regulation remains abstract and does not prescribe nor endorses concrete implementation options, and that enterprises need to translate it and develop suitable data management practices supporting compliance. Second, these studies address isolated aspects of the regulation, that is, a single regulatory requirement or a limited set thereof, and suggest targeted solutions to address them. Hence, we still lack a broader and implementation-agnostic understanding of the compliance requirements and the ways to address them.
The 19 studies on the overall regulation mostly evaluate existing practices and concerns or analyze the EU-GDPR’s impact on a specific domain (e.g., social media discourse, innovation, and Big Data). Yet, they fail to provide insights into the entire regulation’s implications from an enterprise-wide perspective. Russell et al. (2018) address this topic by proposing a digital-privacy transformation “gap-map” that would measure the organization’s propensity for change. However, it exclusively takes a change management perspective without investigating the compliance requirements and their implications for enterprise data management.
Regulatory compliance management
So far, the academic discussion on the EU-GDPR has not connected with the regulatory compliance management (RCM) research domain, although the latter provides systematic approaches to analyzing regulations and their influence on business practice. Regulatory compliance management aims to “ensur[e] that enterprises are structured and behave in accordance with the regulations that apply, i.e., with the guidelines specified in the regulations” (El Kharbili, 2012). Regulatory compliance management introduces useful definitions to delineate relevant legal concepts: It distinguishes between regulations (i.e., binding document), regulatory guidelines, and compliance requirements, as provided in the legal text. After interpretation, this ultimately results in compliance requirements being implemented (El Kharbili, 2012). The so-called concretized compliance requirement describes the implementation of a CR in an enterprise context, fulfilling its legal specification.
Two papers from 2009 analyze the coverage of RCM in IS research. Cleven and Winter (2009) isolated 26 relevant papers and analyze them through the lens of enterprise architecture. They found that while some RCM aspects have been prominently studied (e.g., organizational and behavioral impacts of regulations, compliance-supporting IT solutions), others have been neglected. Specifically, they found no contributions on the operationalization of compliance objectives. The review by Abdullah et al. (2009) on RCM revolves around the approaches (i.e., explanatory or solution) and context (i.e., region, type, and domain) of the considered contributions. Most of the 45 papers concern North America, and only three of them focus on Europe. Regarding data protection, they identify two papers on Fair Information Practices and only one on the European Data Protection Directive (95/46 EC), even though it had been enforced for more than a decade. Furthermore, all identified contributions offer either preventive or detective solutions, but no corrective solutions. The authors hypothesize that corrective solutions are an outcome of legal analysis, which is why they were not addressed by the IS community.
Hence, there is a lack of RCM-related contributions that address data protection regulations, focus on regions other than North America (Abdullah et al., 2009), or provide guidance to achieve strategic compliance objectives (Cleven and Winter, 2009). This last call is echoed by our literature review on the EU-GDPR—although there have been contributions on the topic, they all focus on specific aspects of the regulation. Thus, we lack a single integrated framework for the EU-GDPR that takes an enterprise-wide perspective on the compliance requirements and analyzes ways to address them without prescribing specific implementation choices.
Research design
Context and research objectives
Our research activities were carried out in a multi-year research program on data management, which followed the consortium research method (Österle and Otto, 2010). This setup provides close collaboration between academics and experts from multinational organizations active in various industries 3 and detailed insights into EU-GDPR implementation initiatives. It follows the collaborative practice research tradition and aims to add to the knowledge of involved professional and scientific communities alike, in order to advance practices in the area of interest (Mathiassen, 2002).
Our research objective was to jointly develop prescriptive knowledge in terms of Gregor’s (2006) type V theory that supports companies in achieving EU-GDPR compliance. Accordingly, we adopted design science research (DSR) as our central research paradigm to develop a capability model as an artifact “to solve identified organizational problems” (Hevner et al., 2004) relating to data protection—a highly interdisciplinary topic that is located at the intersection of legal practice and enterprise data management. Capability models are a type of reference models, which build on the RBV as underlying theory and outline the relevant set of capabilities that make up an organization’s ability to “perform a set of coordinated tasks, utilizing organizational resources, for the purposes of achieving a particular end result” (Helfat and Peteraf, 2003). Reference models support the accumulation of knowledge, as they allow to explicate, integrate, and consolidate the fragmented knowledge that is available in the form of situational designs and emerging practices (vom Brocke and Buddendick, 2006). In enterprise data management, capability models have been suggested by academics and professionals to structure and assess data management practices, emphasizing the required capability-building from the deployment of different types of resources (Legner et al., 2020).
Research process
In order to develop the capability model with the due scientific rigor, we followed the research process outlined by Peffers et al. (2007). We initiated our research activities with a problem-based entry point, where objectives and solutions are not yet defined. Following the problem analysis, we developed the capability model in two main phases, each comprising iterative design cycles, as well as demonstration and evaluation steps. We will elaborate on the different steps of our research process in the next sections (see Figure 1 for the overview) and provide evidence on how the capability model developed along the two main phases. The iterative nature of the chosen design science research process allows for the integration of theoretical elements and practitioner feedback. Thus, throughout the research process, we used RBV concepts to theoretically ground and structure our insights from different types of research activities: an analysis of legal texts, official guidelines, and interpretations on the EU-GDPR, a review of EU-GDPR-related tools, and close interactions between academics and practitioners, comprising five focus group meetings with 33 data management experts from 22 companies, as well as insights from four EU-GDPR projects. Research process with problem-centered initiation based on Peffers et al. (2007).
Problem identification and definition of objectives
Preparation for the research activities started in early 2017 and reflects the problem-centered initiation of our research process. These activities were meant to understand the problems that EU-GDPR implementation entails and specify the research objectives. In an initial review of the regulation, we extracted the EU-GDPR’s compliance requirements and analyzed them according to foundational data protection principles in legal literature (i.e., personal data, informational self-determination, accountability, and transparency). Early results of this analysis were discussed with practitioners (focus groups 1 and 2) and revealed two main challenges regarding EU-GDPR compliance. First, while anticipating significant changes to the current way of storing and processing personal data on an enterprise-wide level, participants recognized that they lacked a comprehensive understanding of the regulation itself. Second, they cited a lack of common ground with legal departments. In their organizations, discussions around data protection and privacy regulations are often cut short due to a lack of common approaches and vocabulary, which blocks the identification of feasible and compliant solutions and hinders progress. This led to the research objective of defining a capability model for the EU-GDPR that assists data management professionals in understanding and implementing the regulation and collaborating with their colleagues in the legal departments.
Development of the capability model’s first version
From 2017 to 2018, the first version of the capability model (V1) was developed in three iterations involving insights from field projects and parallel research activities to design the capability model, as well as focus groups to collect feedback and additional instantiations to demonstrate the model. At first, we analyzed regulatory requirements in terms of general capabilities that come into play for achieving compliance. Then, we collected field evidence and expert feedback to further refine the sub-capabilities and analyze implementation options with the required technological, human, or intangible resources.
The first design iteration comprised a project at Engger 4 , a global engineering company, and resulted in the initial draft of the capability model, comprising four capabilities and 15 sub-capabilities. Engger had just started a large-scale project around EU-GDPR-compliant personal data aimed at harmonizing business partner data management in a highly distributed landscape with around 500 systems in different countries and subsidiaries. This project helped to get a better understanding of the issues and define capabilities related to the collection and distribution of personal data and consent. The draft version of the capability model was discussed with experts from other companies in focus group 3.
In the second iteration, two focus group meetings (i.e., 4.1 and 4.2) helped clarify the scope of the capability model. It was decided to set aside all security-related considerations and focus exclusively on data management capabilities. In focus group 4.1, the practitioners indicated that security is usually a distinct function and consulted, while the data management aspects were rarely addressed. From an academic perspective, information security is a well-research field, and the existing concepts may be translated to EU-GDPR, whereas there is little coverage of data management practices in regulatory compliance with data protection regulations. We also performed a re-mapping of the capabilities and grouped five capabilities and 17 sub-capabilities into two capability groups based on the demarcation between organizational and system capabilities found in RBV literature (Bharadwaj, 2000, Baiyere and Salmela, 2014).
The third iteration comprised a project around consent management at Allmed, a global pharmaceutical company. Its technical team had designed a minimum viable product solution, which we analyzed based on the capability model. Insights from the project together with a resulted in a stable set of six capabilities, with a new capability addressing data protection rights specifically, and 18 sub-capabilities, organized around two capability groups.
This capability model was subsequently demonstrated and evaluated: It was demonstrated with the EU-GDPR activities at Leares, a small consulting firm, where it proved to be a useful and efficient tool for assessing the current capabilities, identifying the required capabilities, and prioritizing compliance activities. In parallel, we used the capability model to analyze and classify 23 software tools from major vendors claiming to support EU-GDPR compliance (cf. Appendix 1, with tools falling into the common categories of data management, compliance and identity & access management (CIAM), security, and enhancement). This analysis allowed us to further validate that the identified capabilities and sub-capabilities were complete and exhaustive.
We then conducted additional expert interviews to evaluate the artifact’s simplicity, understandability, fidelity, and completeness (evaluation criteria as suggested by Prat et al., 2015). We selected the data protection officer, as well as a data management specialist from two major insurance companies in Switzerland, Versuisse and Svizzance, which are among the country’s Top 10 providers of life and non-life insurance and also operate in EU countries. Interviews consisted of a walkthrough of each capability to discuss and evaluate the company’s standing and practices. At the end of each interview, we asked participants to rate the capability model’s simplicity, understandability, and completeness using a five-point Likert scale (where 1 = fully disagree, 3 = neutral, and 5 = fully agree). Our respondents rated the capability model’s simplicity, understandability, and completeness with a minimum of 4 out of 5. The fidelity dimension was the only one without a rating of 5, as respondents rated it with 3 and 4. Respondents with a legal education indicated that although the capabilities seemed to adequately reflect the EU-GDPR requirements, they were missing assignments of each capability to the regulation’s principles. Similarly, data management expressed that although capabilities matched the requirements that they discussed with members of their organizations’ legal teams, there was a lack of explicit reference to the regulation. Participants in focus group 5 confirmed those results.
Development of the capability model’s second version
While the first version focused strongly on the practical relevance and utility, it had certain shortcomings in terms of documentation and was mainly built from experiences gained in early-stage initiatives. After the EU-GDPR went into effect, we observed an increase in academic studies and more open debates and testimonials from companies related to their implementation approaches and challenges. In 2019, we decided to launch a second phase that would allow us to validate and enhance the capability model based on the insights from the increasing number of EU-GDPR publications, while improving its theoretical grounding. From 2019 to 2021, we conducted two additional design iterations, with subsequent demonstration and summative evaluation, resulting in the second and final version of the capability model (V2).
In parallel, we continued to analyze EU-GDPR-specific legal literature to inform the development of the capability model, ensuring a proper fit with legal requirements. For this purpose, we gathered and analyzed material from authoritative data protection sources, such as textbooks from multiple legal traditions, for example, pan-European (European Union Agency for Fundamental Rights et al., 2018; Synodinou et al., 2017, 2021, 2020; Voigt and Von Dem Bussche, 2017), French (Bensoussan et al., 2018), Belgian (Docquir, 2018), and Swiss (Meier, 2011), as well as two recent doctoral dissertations (Staiger, 2017; Thélisson, 2020). We complemented this understanding with insights from official guidelines and interpretations from supervisory authorities (e.g., Chatellier et al., 2019; Commission Nationale de l’Informatique et des Libertés, n.d.; European Data Protection Board, 2017, 2018a, 2018b; European Data Protection Supervisor, 2018, 2019; Information Commissioner’s Office, 2017), as well as academic papers and doctrinal opinions (e.g., Armingaud and Ligot, 2019; Castets-Renard, 2019; Cheffert, 2018; De Hert and Malgieri, 2018; De Hert and Papakonstantinou, 2012, 2016; Debet, 2018; Fellous-Sigrist, 2018; Groos and Veen, 2020; Hoeren and Kolany-Raiser, 2018; Karjoth and Langheinrich, 2019; Lazaro and Le Métayer, 2015; Naftalski, 2018; Puyraimond, 2019; Rallet et al., 2015; Solove, 2013; Wiese Schartum, 2018; Zanfir, 2014).
In the fourth iteration, we revised the capability model in light of expert feedback and the latest academic and practitioner literature. We monitored EU-GDPR-related studies until Q4 2020, updated the literature review, and integrated insights from selected publications as support for relevant capabilities and the resources deployed in different implementation options. To improve the documentation’s consistency and completeness, we mapped each capability, sub-capability, and software features with relevant EU-GDPR recitals and articles. The combination of practitioner and research insights also enabled us to specify relationships and dependencies between capabilities and isolate enabling ones. This iteration entailed a project at Shippy, a European shipping company, where the model was applied by a consultant that had not been involved in its development.
In the fifth iteration, we integrated academic feedback and reassessed the capability model’s structure based on the existing theoretical framework on IT capabilities. Specifically, we mapped capabilities and sub-capabilities to prominent RBV-based categorizations (following Bharadwaj et al., 1999, and Wade and Hulland, 2004) in order to accurately reflect their characteristics and theoretical underpinnings. Based on this analysis, we combined the capabilities and sub-capabilities dealing with the relationships with external entities and added a dedicated capability group, resulting in three capability groups (with seven capabilities and 18 sub-capabilities).
Finally, we conducted a summative, two-pronged evaluation consisting of an evaluation questionnaire presented to practitioners after a capstone presentation on the research project, as well as a debriefing session to analyze lessons learned from the Shippy project. Through the questionnaire, we evaluated the capability model’s understandability, completeness, consistency, simplicity, usefulness, and applicability by using the same five-point Likert scale as in the first evaluation. All dimensions received ratings of 4 and above, except for simplicity and applicability, which one of the respondents rated as “neutral” (3 points). The debriefing of the Shippy project confirmed that the capability model creates common ground between legal and data management practice and helps data experts understand the regulation (quotations from the interview can be found in Appendix 3). Regarding the model’s ability to support (i) assessments and roadmap planning, (ii) progress monitoring, and (iii) communication and change management, all dimensions received a minimum rating of 4 (on four counts), and the majority received a rating of 5 (on six counts).
Data management capabilities for the EU-GDPR
Capability model: Theoretical foundations
According to EU-GDPR art. 24 § 1, an organization is responsible for implementing “appropriate technical and organizational measures to ensure and be able to demonstrate that processing is performed in accordance with this Regulation.” Using the RBV as theoretical lens, we argue that achieving compliance with EU-GDPR at an enterprise level requires building dedicated capabilities for processing and storing personal data. Capabilities are “complex patterns of coordination between people and between people and other resources” (Grant, 1991) that are embedded in organizational practices and individual skills (Bharadwaj et al., 1999). In the data protection domain, building these capabilities requires an organization to deploy three types of resources in predictable patterns of activity (Barney, 2001, Bharadwaj et al., 1999): - Human resources taking over relevant roles for data protection, for example, a data protection officer, a contact person for data rights requests, or an enterprise data architect. - Technological resources comprising physical IT assets (hardware, software, and databases) that enable data protection compliance, for example, a data processing system, a dedicated consent-management tool, and a self-service portal for data rights requests. - Intangible resources representing the data protection-related know how, for example, frameworks, standards, process models, as well as data and enterprise architecture documentation.
While the RBV considers firm performance through sustainable competitive advantage (Barney, 1991) as the goal of capabilities (the why), we argue that capabilities for data protection are built with a regulatory compliance objective or, as conceptualized by Sadiq et al. (2007), to reach an organization’s “control objectives ” (see Figure 2). As the business impact of compliance activities is hard to quantify in financial terms, they are seldom cited as a source of competitive advantage. However, non-compliance may have significant direct (e.g., fines) and indirect (e.g., reputation loss) impact on a company’s ability to generate profit, thus impacting its performance. This is also supported by IS studies that have investigated the links between governance and compliance on the one hand, and business value and organizational success on the other hand (Buchwald et al., 2014; Heier et al., 2007; Ritschel et al., 2005). Hence, we argue that such “control objectives” can be viewed alongside competitive advantages as components of firm performance. Therefore, based on Zhang et al.’s (2013) definition of an IT capability, we define data management capabilities for regulatory compliance as a firm’s ability to acquire, deploy, and leverage its technological, human, and intangible resources in combination with other resources and capabilities to achieve an organization’s control objectives related to the relevant data protection regulations. Data management capabilities for regulatory compliance from the lens of RBV and RCM.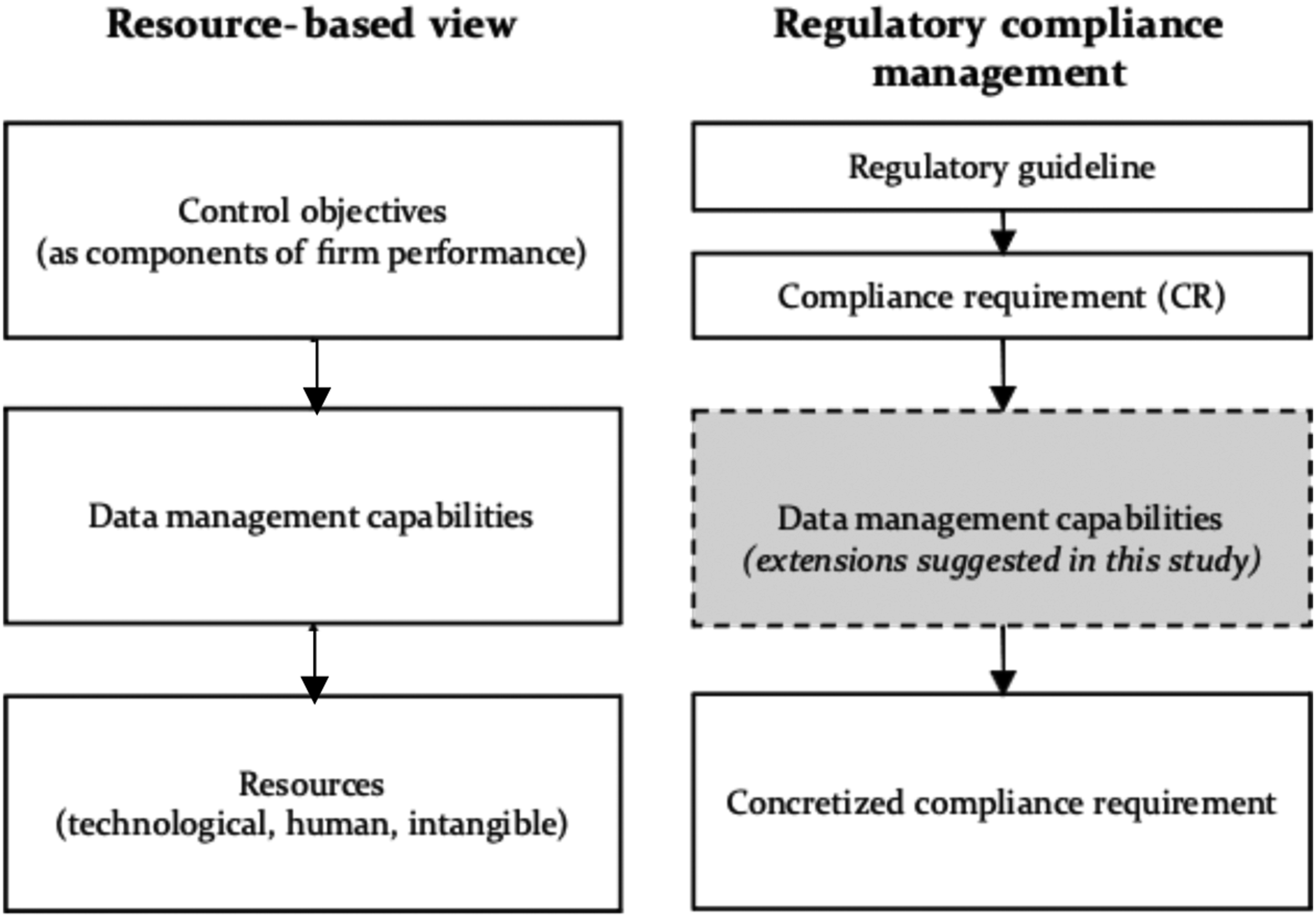
Capabilities as link between compliance requirements and their concretization.

*extension suggested in this study.
Capability model: Structure and overview
Capability model for EU-GDPR.
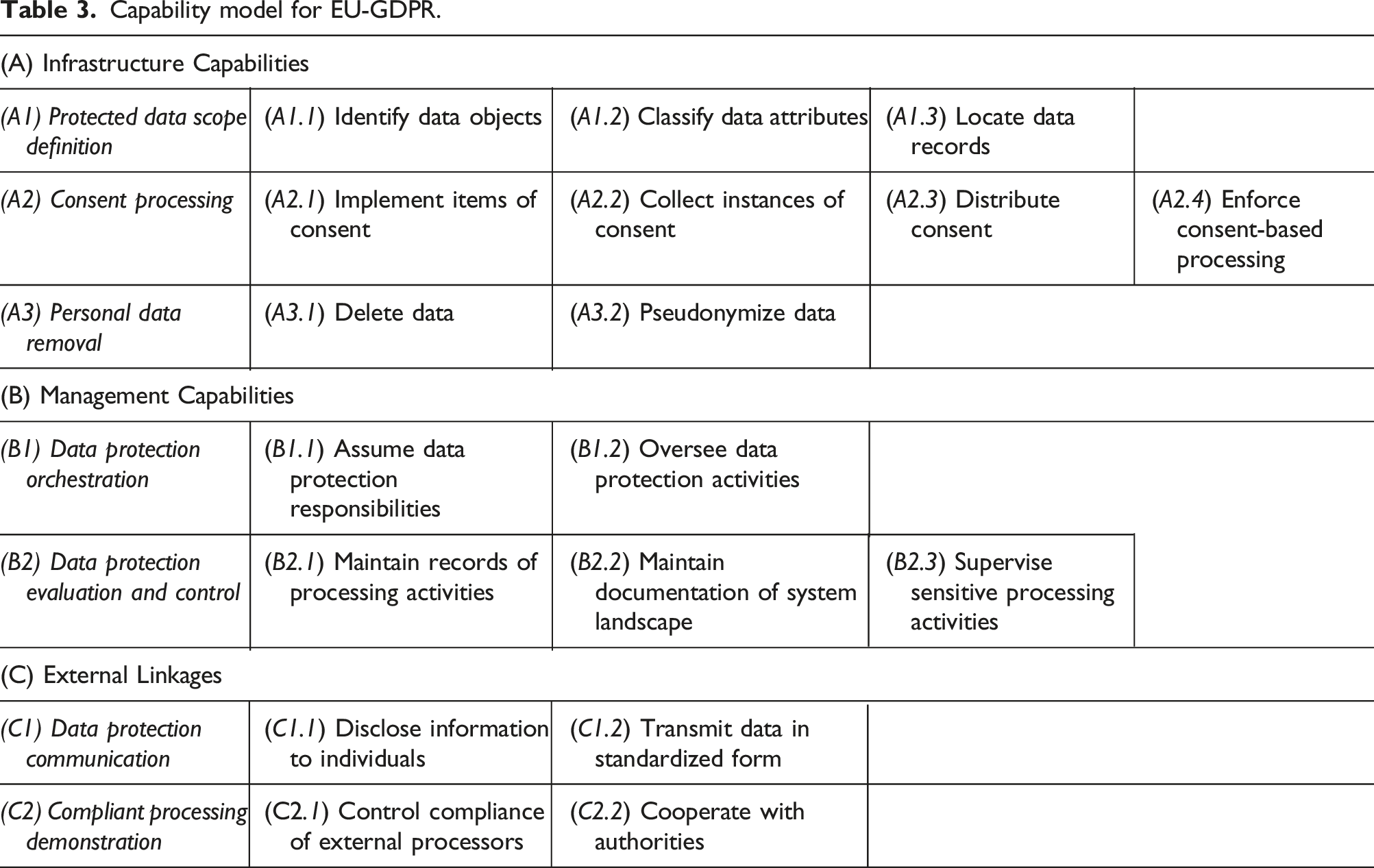
In the following sections, we present each of the identified capabilities, along with the compliance requirements, the empirical insights from focus groups and projects, and the sub-capabilities. We also graphically depict the dependencies with other sub-capabilities (see Figures 3–10) and discuss the required resources for their implementation. For each capability, we also provide a synthesis (in Tables 4–10) with details about the sub-capabilities, their specification, implementation options (with exemplary resources) and the relevant compliance requirements (CR, extracted from the regulation). Capability relationships: Protected data scope definition (A1).
5
Capability relationships: Consent processing (A2). Capability relationships: Personal data removal (A3). Capability relationships: Data protection orchestration (B1). Capability relationships: Data protection evaluation and control (B2). Capability relationships: External data communication (C1). Capability relationships: Compliant processing demonstration (C2). Capability network (see Appendix 4). Capability overview: Protected data scope definition (A1). *Technological – T / Human – H / Intangible – I. Capability overview: Consent processing (A2). *Technological – T / Human – H / Intangible – I. Capability overview: Personal data removal (A3). *Technological – T / Human – H / Intangible – I. Capability overview: Data protection orchestration (B1). *Technological – T / Human – H / Intangible – I. Capability overview: Data protection evaluation and control (B2). *Technological – T / Human – H / Intangible – I. Capability overview: External data communication (C1). *Technological – T / Human – H / Intangible – I. Capability overview: Compliant processing demonstration (C2). *Technological – T / Human – H / Intangible – I.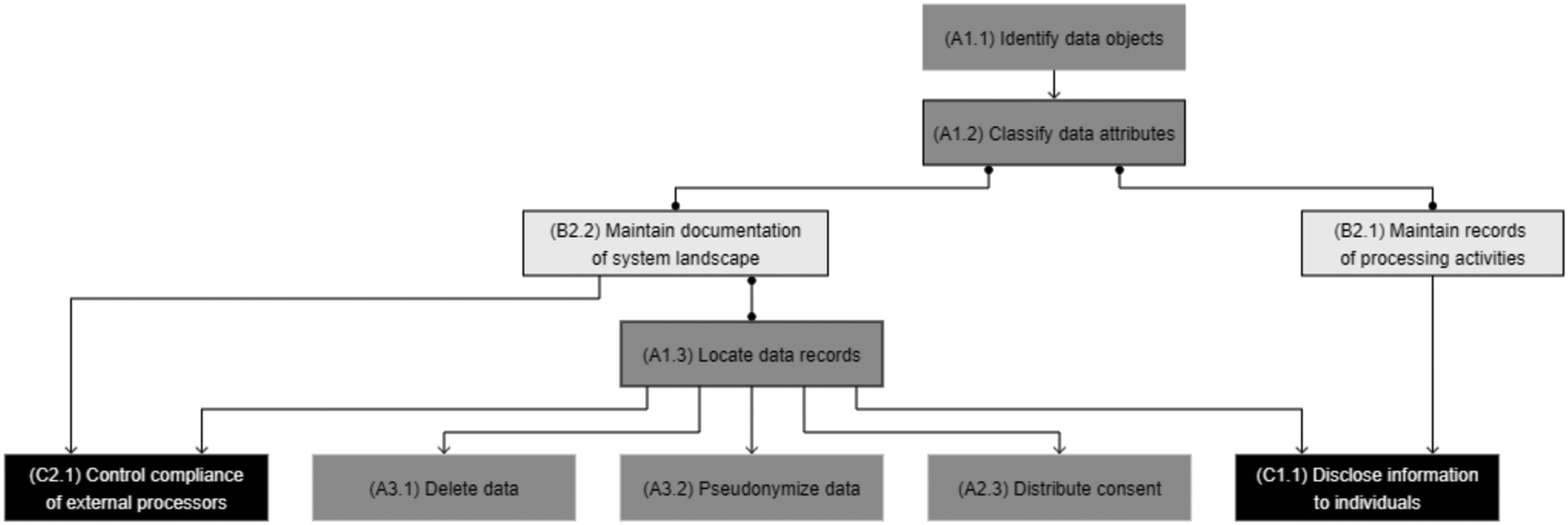


Infrastructure capabilities
This capability group comprises three capabilities that ensure that data processing systems and architecture comply, in particular, with new data-related rights and the increased focus on consent-based processing in EU-GDPR.
Protected data scope definition (A1)
This capability is based on art. 1 § 1 and 4 § 1 and denotes the ability to clearly identify, classify, and locate personal data. Personal data is defined as “data enabling direct or indirect identification of a single physical person, data that is specific to a single physical person without enabling identification, data that can be linked to a physical person, data regarding which anonymization techniques cannot completely mitigate the risk of re-identification”.
Generally, companies faced two main challenges: determining what kind of personal data they were processing and where such data was stored. Focus groups 1 and 2 indicated that before the implementation of EU-GDPR, companies had had little to no real overview of the personal data they collected and used, especially in terms of storage location. A participant in focus group 4.2 asked: “How do you identify personal data in a heterogeneous IT system landscape?”, which led to a follow-up discussion around the means to identify personal data. In the project at Engger, one of the main objectives was to make sure that personal data was consistently kept up-to-date within all customer-facing websites and portals, which proved difficult due to multiple overlapping systems managed in independent subsidiaries.
The resulting capability may be best summarized by Bensoussan et al. (2018): “organizations must have perfect knowledge of personal data.” Iannopollo et al. (2017) recommend two actions that mirror these issues (i.e., data inventory and system mapping) and suggest that personal data should be not only identified but also classified. This is required as the EU-GDPR prescribes higher levels of protection for data that is considered sensitive (R. 51). The resulting sub-capabilities are: - Identify data objects (A1.1): ability to make a list of data objects that fall under the scope of the EU-GDPR in enterprise systems (e.g., customer, employee, or job applicant). - Classify data attributes (A1.2): ability to assign levels of data sensitivity to identify data attributes within personal data objects. - Locate data records (A1.3): ability to retrieve personal data objects from all relevant processing systems.
In terms of implementation, this capability is well aligned with the functional scopes of solutions in the data management and security/protection tool categories, as most of them provide functionalities supporting data discovery (i.e., retrieving data across the organization’s entire system landscape) and classification (e.g., by using data crawlers). Practitioner insights indicate that building this capability is intertwined with intangible resources and creates significant effort for enterprise-wide documentation and classification activities. Svizzance and Versuisse, for example, were in the process of re-aligning existing data and system landscape documentation with their existing databases and systems by specifying additional details and updating them when necessary. For this purpose, both organizations turned to enterprise architecture tools to define and document the protected data scope—an approach that has also been proposed by academic research (Burmeister et al., 2019, 2020; Huth, Burmeister, et al., 2020). In the case of Leares, the company did not have any similar existing documentation, and it became clear that this capability should be the focus of initial efforts, as other capabilities could not be realized without understanding the protected data scope.
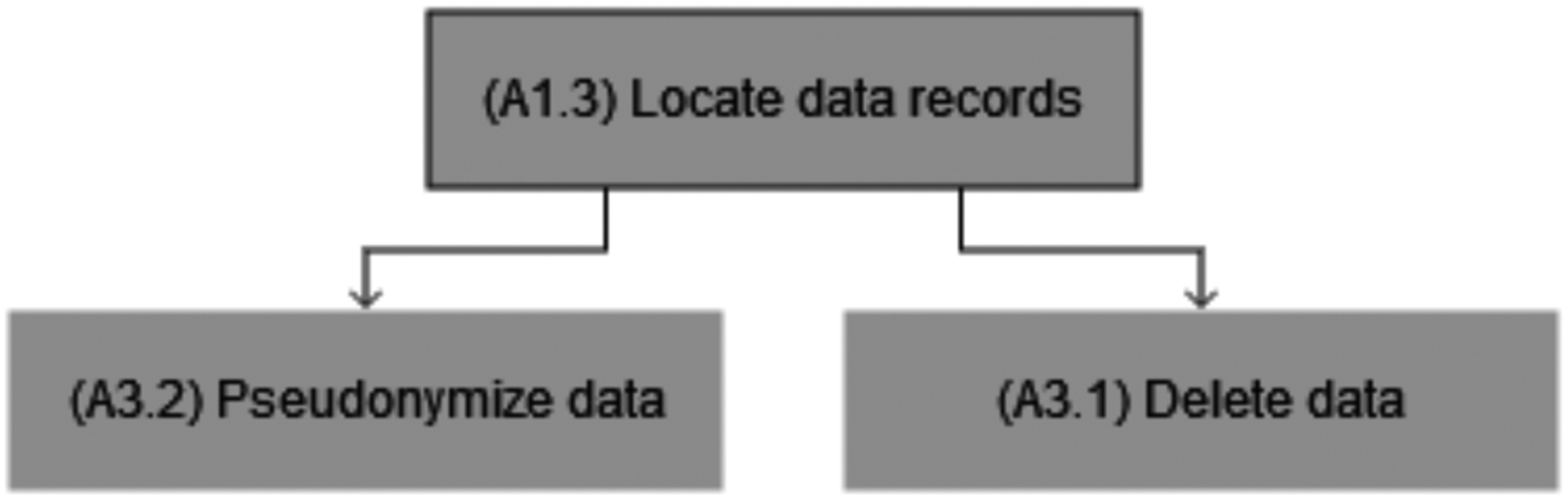
This capability can be viewed as a prerequisite to the two other infrastructure capabilities—that is, consent processing (A2) and personal data removal (A3), which require performing operations on previously identified data records. For instance, it is not possible to delete a data object if it has not been discovered and indexed.
Consent processing (A2)
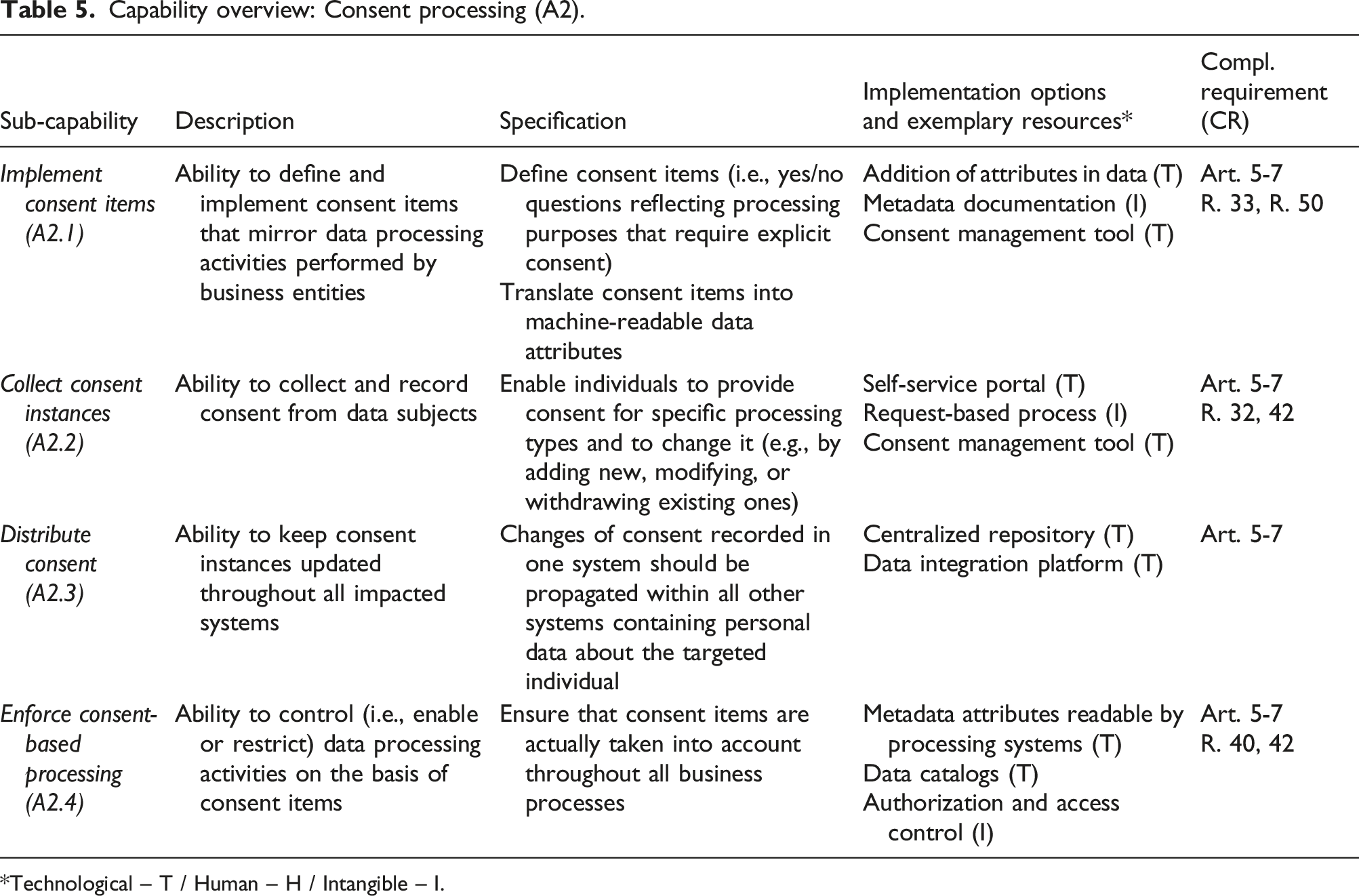
This capability comprises the prerequisites for collecting consent and ensuring the consent-based processing of information. The principle of consent (art. 7, Bensoussan et al., 2018; Nicolaidou and Georgiades, 2017; Voigt and Von Dem Bussche, 2017) is arguably one of the pivotal concepts of the EU-GDPR and an expression of the right to informational self-determination. It can be defined as each individual having the ability to determine whether and to what end information about themselves can be processed (Mitrou, 2017). The related concepts of conditionality, granularity, and specificity are the most challenging for data management (European Data Protection Board, 2018b) if compared with practices before the EU-GDPR, when consent was mostly obtained through the bulk acceptance of general conditions. Conditionality (art. 7 § 4) means consent for processing activities cannot be bundled into general conditions, and a difference should be made between necessary and optional processing activities for a given purpose. Granularity (R. 43) implies that each processing activity and related consent item must be presented separately. Specificity prescribes a 1:1 relationship between processing types and consent items (i.e., yes/no question that relates to a personal data processing activity).
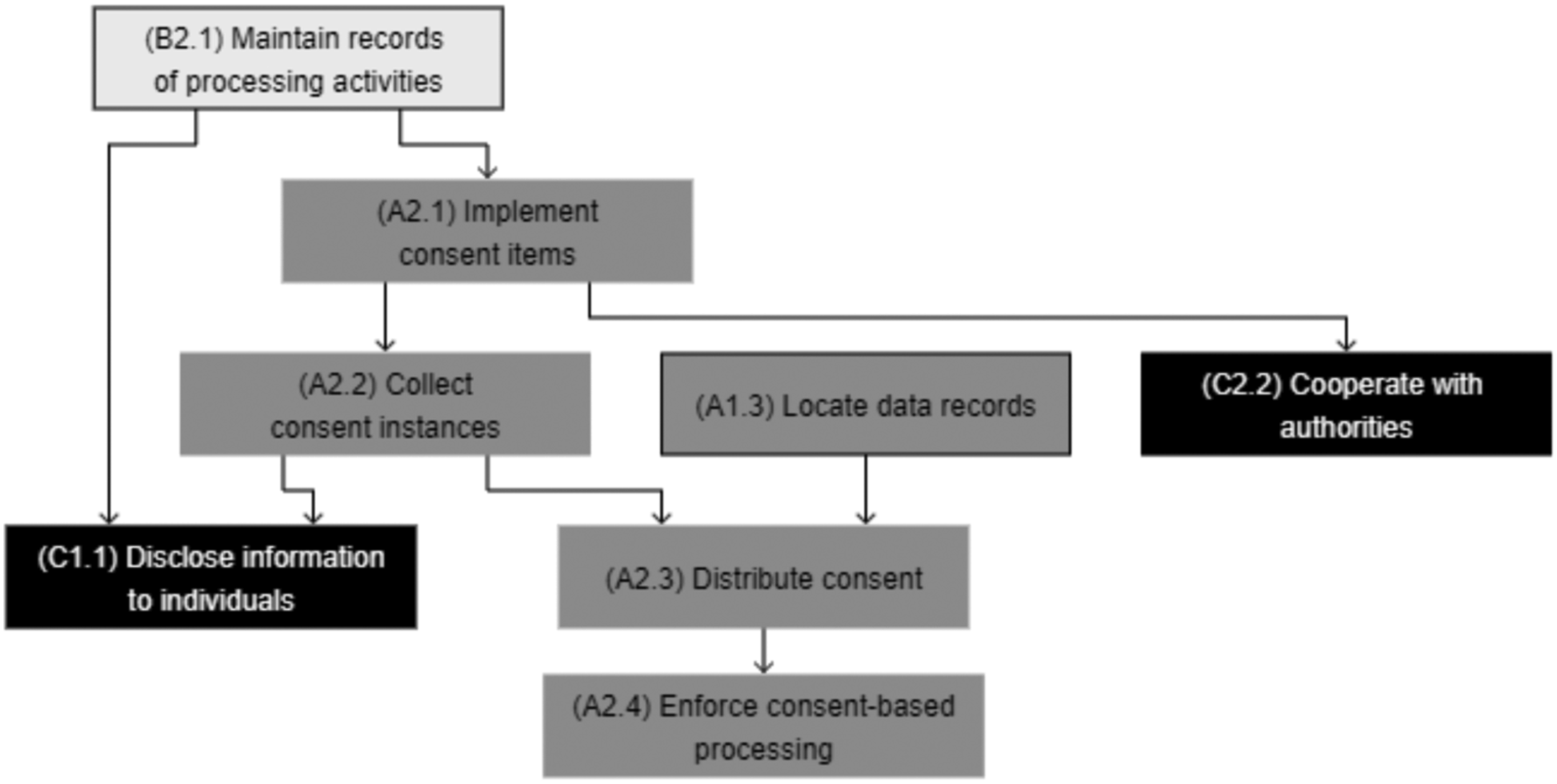
Consent management greatly resonated among the experts in our focus groups and was a key concern in the Allmed project. During focus group 4.1, none of the participants reported solutions either in the final or the operational stages. During focus group 4.2, more questions were asked regarding consent management than all the other capabilities combined. The goal of the Allmed project was to make consent-related information accessible and readable by all the systems and, thus, mirror the “distribute consent” and “enforce consent-based processing” sub-capabilities. However, difficulties arose in two areas. First, the system would need to be connected to every system storing and processing personal data. However, identifying such systems proved difficult, and the existing system landscape documentation was deemed insufficient (see the capability “define protected data scope”). Second, the team struggled to identify consent items, as they were usually contained in an unstructured format (e.g., within general conditions, contracts, and webpages). A specific sub-capability was added to reflect this issue as a prerequisite to all other consent-related capabilities. The resulting sub-capabilities are: - Implement consent items (A2.1): ability to define and implement consent items that mirror data processing activities performed by business entities. - Collect consent instances (A2.2): ability to collect and record consent from data subjects. - Distribute consent (A2.3): ability to keep consent instances updated throughout all impacted systems. - Enforce consent-based processing (A2.4): ability to control (i.e., enable or restrict) data processing activities on the basis of consent items.
This capability relies mainly on new or augmented technological resources. While the concept of consent itself was not new, the granularity requirements introduced by the EU-GDPR posed a significant technical challenge in the existing system landscapes. They imply that additional data reflecting consent must be collected and taken into account when processing the related data objects in both manual and automated processing scenarios. From a tool perspective, data management, compliance management, and access management solutions offer specific modules to record user consent, especially in scenarios involving a web-based frontend. However, even though such tools provide the technical means to communicate and acquire consent, organizations still face the issues of defining and implementing consent items (A2.1). In that regard, the difficulties encountered by Allmed’s team in defining what items should be recorded once again highlight that technical implementations are dependent on the transparency regarding processing activities. This difficulty is also found in the study by Kurtz, Wittner, et al. (2020), which identifies 18 problems related to gathering consent on the eBay platform and highlights gaps between stated and effective processing purposes in digital service offerings. Huth, Both, et al. (2020) also explore the necessity for technical and development teams to recognize consent items and subsequently investigate implementation modalities. They suggest a prototype to support related discussions between development and business teams in the context of agile software engineering. Both studies suggest that consent requirements, due to their impact on final designs, should be integrated during early stages of IT development, which can explain the difficulties in bringing pre-existing solutions to compliance.
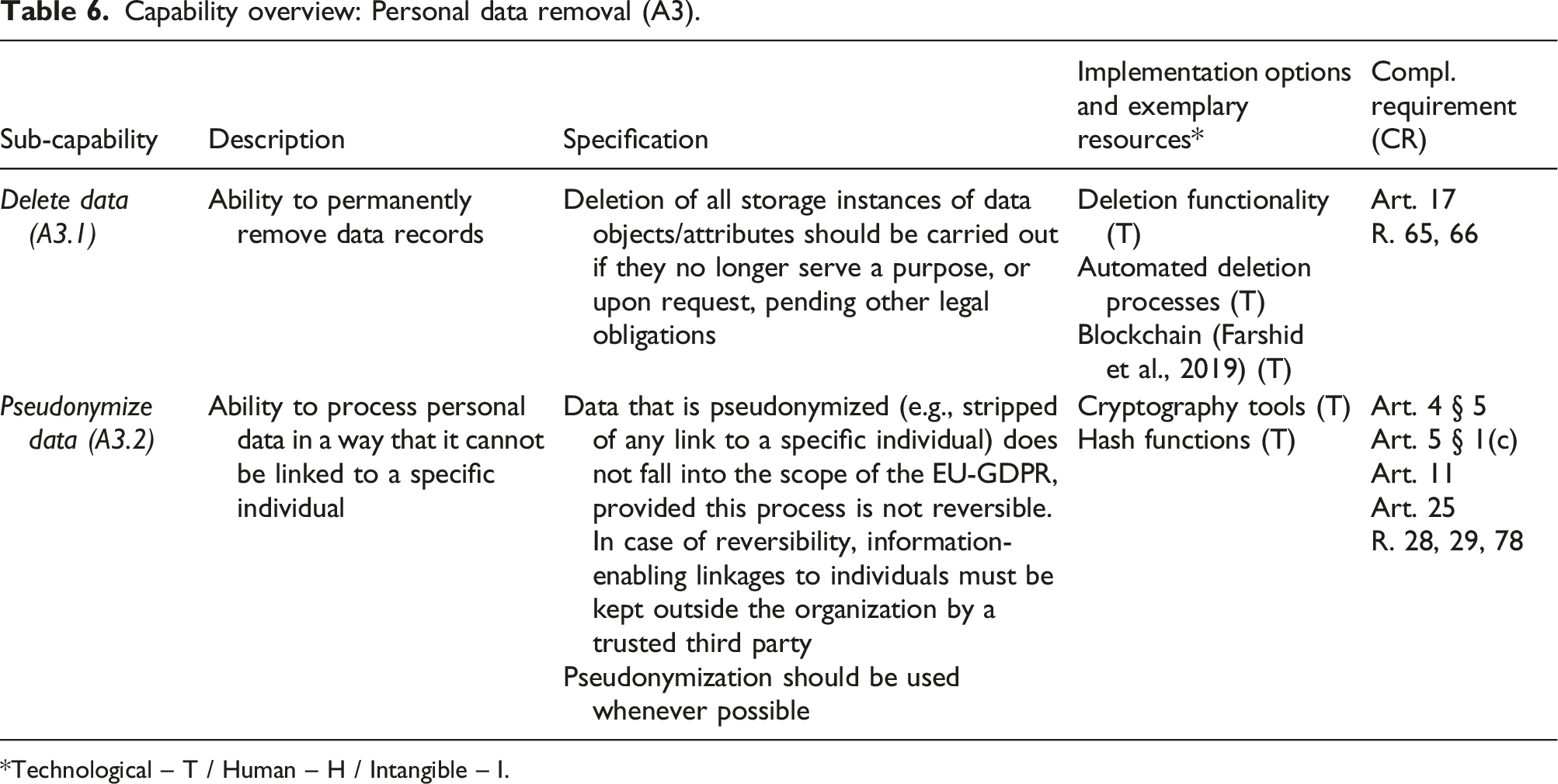
Personal data removal (A3)
This capability denotes the ability to process data according to the EU-GDPR’s data rights and principles. It was derived from the principle of accountability (art. 24 § 1) but covers only the technical aspects to reach compliance, document them, and provide proof of compliance (Bensoussan et al., 2018; Nicolaidou and Georgiades, 2017; Voigt and Von Dem Bussche, 2017).
Art. 17 provides for a right of erasure (“right to be forgotten”), according to which individuals can request that organizations delete their personal data (provided that they have no other obligation to keep said data). Prior to the EU-GDPR, enterprise systems usually prevented users from deleting data, and practitioners expressed frustration in this regard. When asked about it, none of the participants of focus group 4.1 reported that they had operational deletion processes or mechanisms in place, and participants expressed a lack of well-established solutions at this level. Art. 25 mandates privacy by design or by default approaches, including the principle of minimization (Voigt and Von Dem Bussche, 2017), that is, processing as little personal data as possible. One way of operationalizing it is through pseudonymization, which is a rare occurrence of EU-GDPR mentioning a specific technological approach (R. 28-29). Pseudonymization or anonymization is a form of data processing—in that sense, while they may, for instance, enable organizations to lighten the privacy assessment requirements or to use a legal basis other than consent, processing of anonymized/pseudonymized data should still have a legal basis and does not relieve organizations of all data protection responsibilities (Groos and Veen, 2020). For this reason, pseudonymization was added, which resulted in two sub-capabilities: - Delete data (A3.1): ability to permanently remove data records. - Pseudonymize data (A3.2): ability to process personal data in a way that they cannot be linked to a specific individual.
Building this capability relies heavily on technological resources, but features related to data deletion seem to be the least frequent—they were only enabled by two solutions in our tool study, and only one of them supported the enforcement of a data retention policy. Data anonymization and data pseudonymization are also rather uncommon because encryption mechanisms, which are generally already in use for security purposes, seem to be favored. Furthermore, unless the keys are kept by a trusted third party, symmetrical encryption is not a valid means for data pseudonymization as it can be reversed. These shortcomings are confirmed by research, and several studies have investigated blockchain as a technological foundation for the design of systems that enable true pseudonymization (Faber et al., 2020; Farshid et al., 2019; Guggenmos et al., 2020; Mejtoft et al., 2019; Rieger et al., 2019).
Management capabilities
This capability group comprises two capabilities that enable the organization to comply, in particular, with EU-GDPR’s accountability requirements.
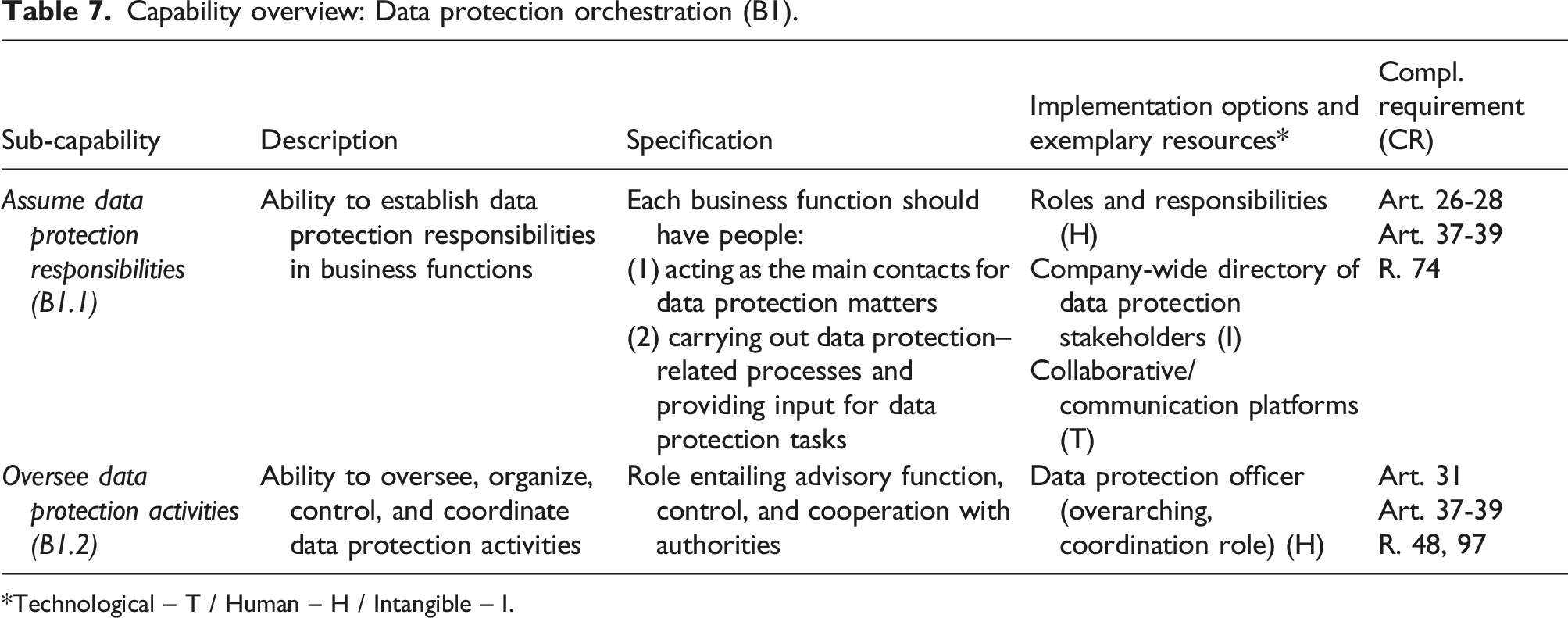
Data protection orchestration (B1)
This capability denotes the organizational ability to coordinate and execute data protection activities involving different roles and responsibilities. It was derived from the organizational component of the principle of accountability (Bensoussan et al., 2018; Nicolaidou and Georgiades, 2017; Voigt and Von Dem Bussche, 2017). As stated, focus group feedback indicated that data managers are often at a loss as to whom they can consult when faced with data protection inquiries. This became particularly clear during the Allmed project, when the team needed to obtain information regarding data protection matters but struggled on several occasions because responsibilities (e.g., defining consent items) were not clearly defined. Art. 37-39 requires that organizations of a certain size appoint a “data protection officer” (DPO). The DPOs should monitor compliance by getting an overview of processing activities, serve as advisory contact person (European Data Protection Board, 2017), oversee record keeping, and cooperate with authorities.
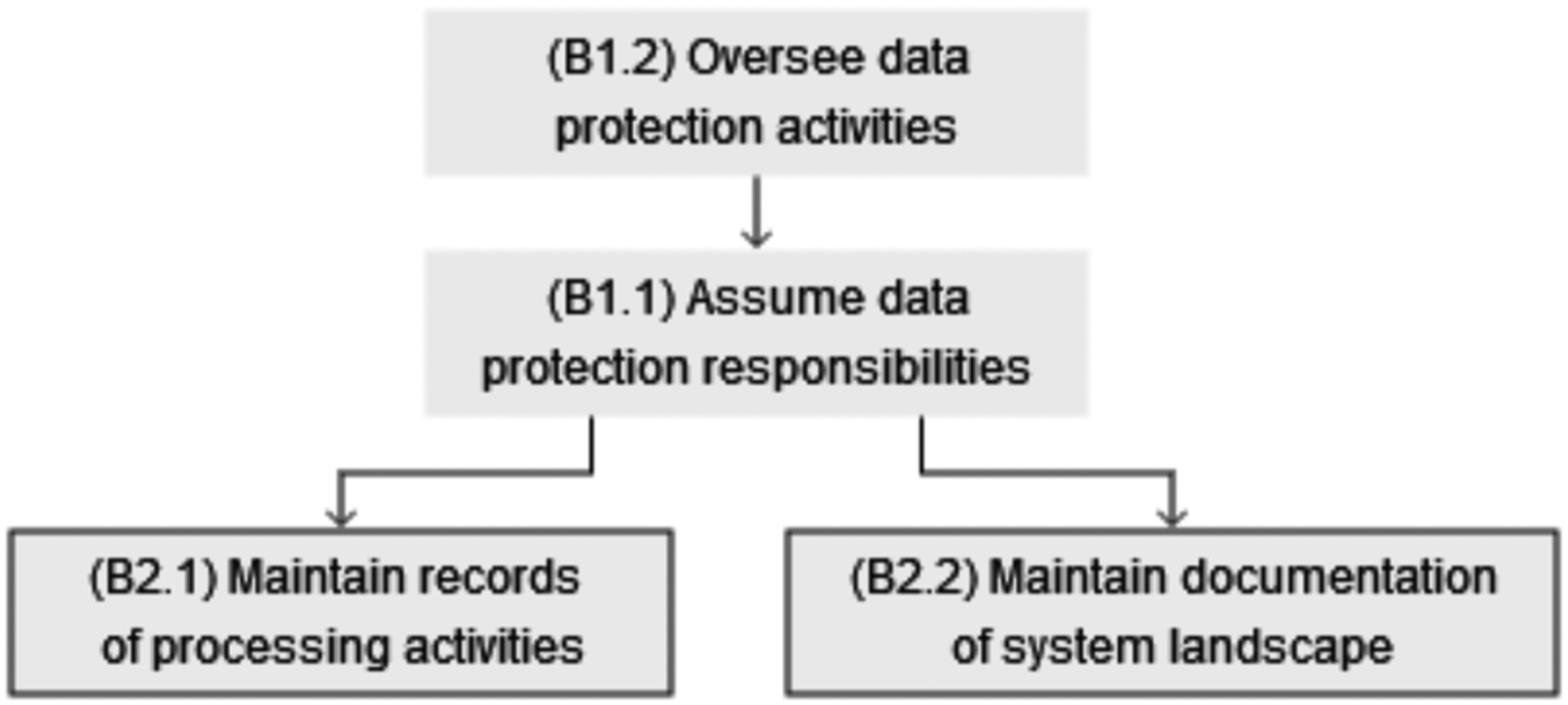
The resulting sub-capabilities are: - Assume data protection responsibilities (B1.1): ability to establish data protection responsibilities in business functions that process personal data. - Oversee data protection activities (B1.2): ability to oversee, organize, control, and coordinate data protection activities.
Building this capability requires companies to focus on the human resources taking over relevant roles for data protection on legal, IT, data management, and business sides. The DPO is a role that already existed in some organizations (e.g., “privacy officer”) before the EU-GDPR and has been made mandatory by the regulation. However, even though the responsibilities are generally described in the regulation, the specificities remain unclear. In their recent EU-GDPR readiness study, Dansac Le Clerc and Mannent (2020) find that most DPOs have a legal background (62%), and only 21% of them are experts in IT/digital domains. They also report that DPOs “have less experience in IT and security than they judge necessary.” This corroborates statements from representatives of Versuisse and Svizzance, where DPOs were both coming from legal teams. Dansac Le Clerc and Mannent (2020) also highlight that EU-GDPR-oriented efforts should involve a “chain of compliance and responsibilities,” extending beyond legal teams toward IT, security, HR, and business units. At Svizzance, the DPO reached out to the data management team and formed a partnership with one team member, who acts as a technical advisor to the DPO and coordinates decisions with the data management team. One of the outcomes of this partnership was a decision to refine existing enterprise architecture documentations of systems and processes in light of data protection requirements. Huth, Burmeister, et al. (2020) analyzed the collaboration between enterprise architecture and data protection teams and found evidence that using enterprise architecture as a basis for joint documentation was a successful course of action. In addition, tools from the data management, compliance management, and security/protection categories can also assist organizations in defining governance and centralizing workflows and policies. Implementing key performance indicators related to data protection activities from content (e.g., proportion of data protection–related fields actually maintained in databases) or process (e.g., frequency of updates of documentation) perspectives may also be considered to keep track of compliance activities.
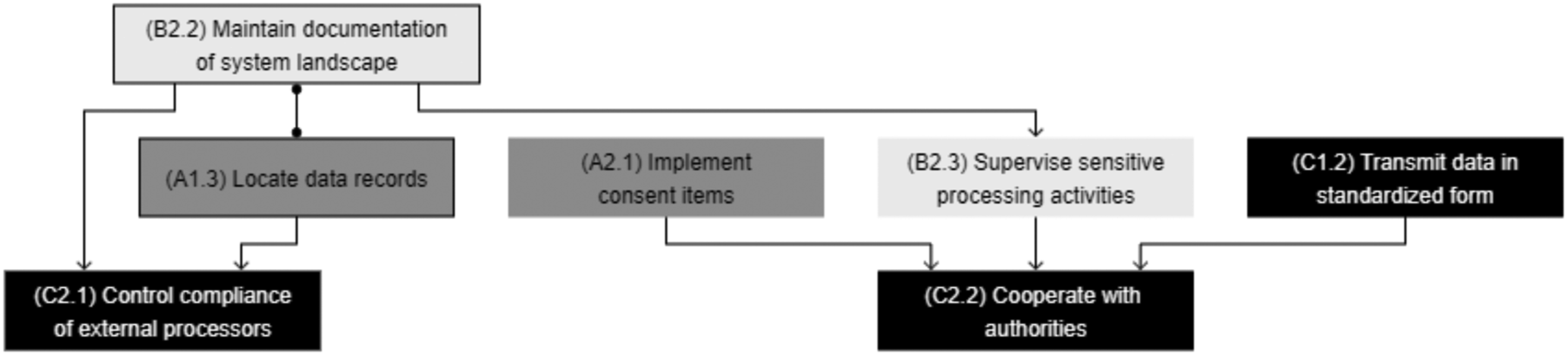
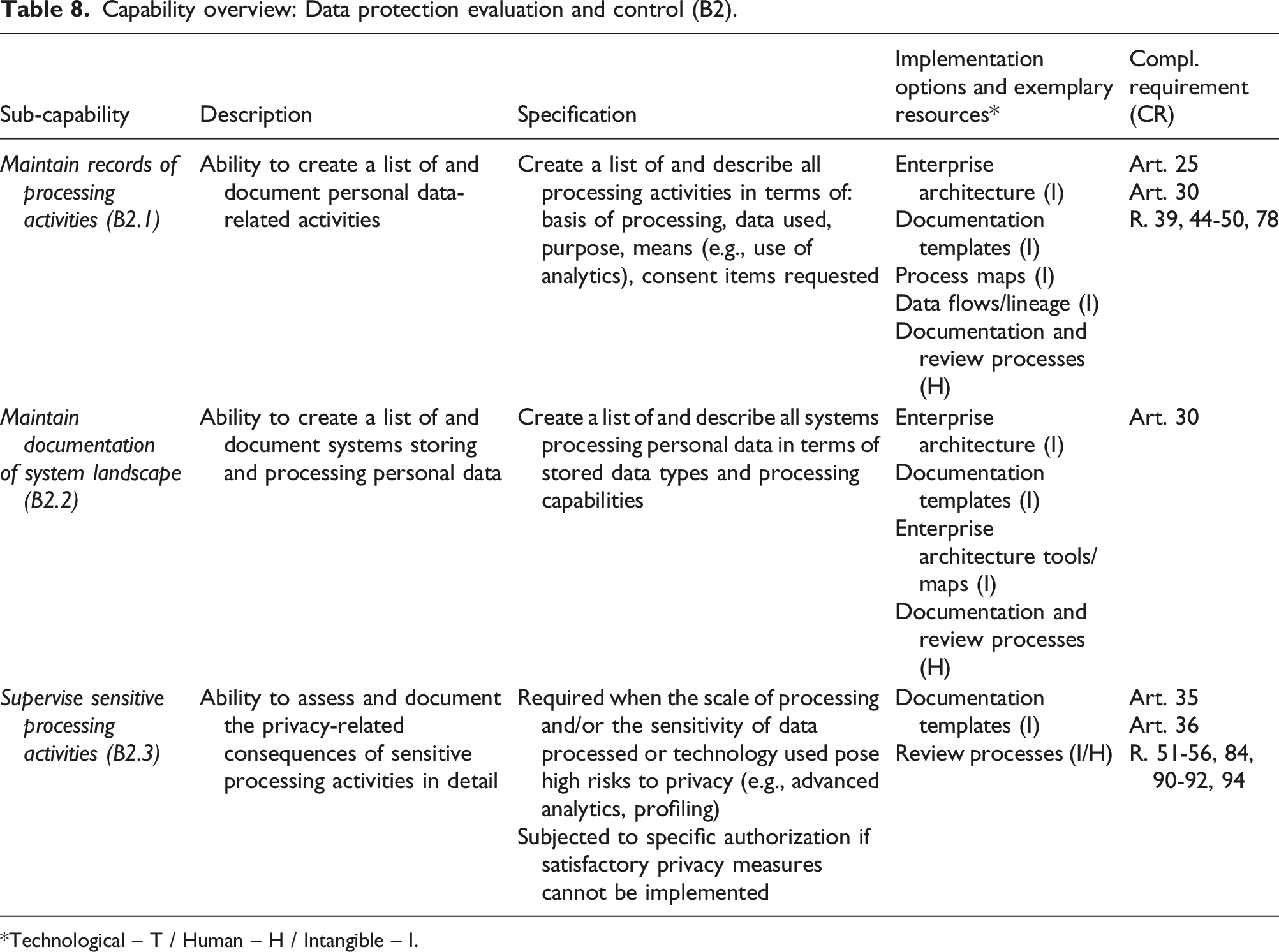
Data protection evaluation and control (B2)
This capability comprises the ability to record and evaluate sensitive processing activities, as well as document system landscapes. It was derived from the documentation component of the principle of accountability (Nicolaidou and Georgiades, 2017; Voigt and Von Dem Bussche, 2017). Art. 30 orders organizations to “maintain a record of processing activities under its responsibility” and details the contents of such documentation. It was identified as a significant difficulty by Iannopollo et al. (2018), and all the participants of focus group 4.2 acknowledged that documentation represented a significant effort. Besides recording processing activities, maintaining system landscape documentation was identified as another sub-capability, as the experts indicate that most organizations have difficulties locating data given the large number of systems—this was the very motivation for the Engger project and a significant roadblock for Allmed’s solution implementation. Art. 35 and 36 further require organizations to conduct and document in-depth data protection impact assessments (DPIAs) when performing sensitive processing activities. The resulting sub-capabilities are: - Maintain records of processing activities (B2.1): ability to create a list of and document personal data-related activities. - Maintain documentation of system landscape (B2.2): ability to create a list of and document systems storing and processing personal data. - Supervise sensitive processing activities (B2.3): ability to assess and document the privacy-related consequences of sensitive processing activities in detail.
Building this capability relies on intangible resources that are the basis for the ongoing recording of data processing activities. Documenting the systems that store and process personal data, as well as for processing purposes, is a pillar of EU-GDPR compliance and highly interdependent with the sub-capabilities for defining the protected data scope (A1). In terms of technological resources, solutions offer functionalities that can support and streamline the documentation process. Tools from most categories offer functionalities to detect irregularities in data use and detect data breaches, with tools in the protection/security category taking the lead. While the majority of surveyed solutions offer logging capabilities, which can prove useful to investigating suspected or known incidents, only three of them assist organizations in running DPIAs. This is partly because DPIAs are about interpreting the purpose of specific processing activities and evaluating potentially nefarious real-world consequences for individuals. Researchers have highlighted the need to refine currently available methods and further investigate tool implementation (Vemou and Karyda, 2018). Another aspect involves the sensitivity of certain processing activities due to their novel technological underpinnings. There is an ongoing debate over the data protection–related risks of technologies such as Big Data Analytics and Artificial Intelligence (Addis and Kutar, 2020, 2018), and EU-GDPR specifically considers decisions that are the result of automated decision-making processes (art. 22). Conversely, researchers are investigating ways to incorporate ethics and transparency considerations into the design of Big Data artifacts and algorithms (Tona et al., 2018; Watson and Nations, 2019).
External linkages
This capability group comprises two “outside-in” capabilities according to Wade and Hulland’s (2004) typology, that enable the organization to manage the relevant external relationships with data subjects and authorities and comply, in particular, with EU-GDPR’s information, notification and cooperation requirements.
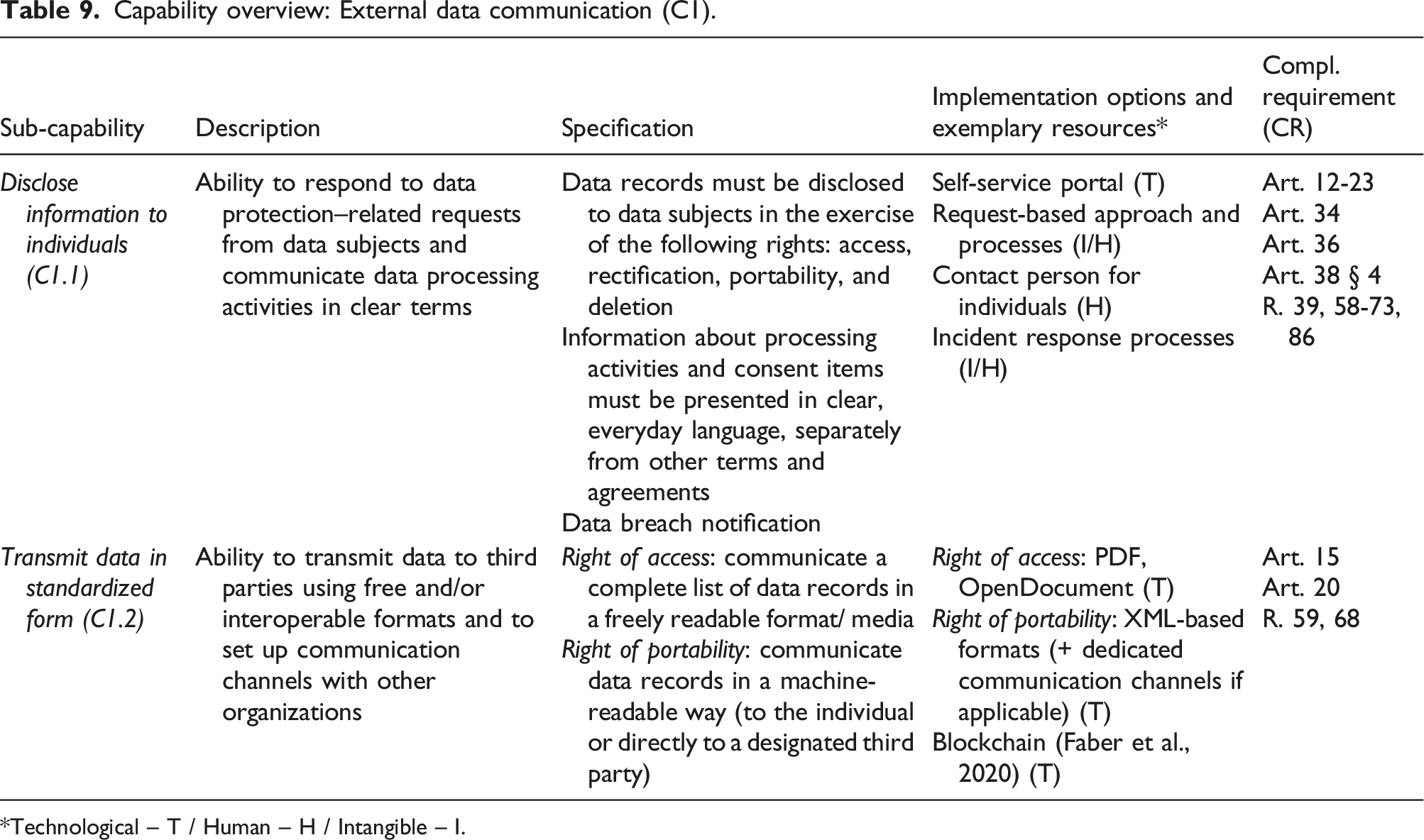
External data communication (C1)
This capability involves the ability to disclose information to individuals (R. 58) and denotes the ability to process data according to EU-GDPR’s requirements when processing activities entail data transmission to other third-party actors. It was derived from the principles of transparency, which requests that data protection measures be clearly presented, as well as the principles of accountability (art. 24 §1) (Bensoussan et al., 2018; Nicolaidou and Georgiades, 2017).
Transparency requirements apply in two cases (European Data Protection Board, 2018a). First, at the point of data collection, organizations must present related information separately in an easily comprehensible manner (e.g., language and illustrations). Transparency also refers to communications with individuals after data is collected, when organizations are faced with right-related requests (e.g., access, rectification, and deletion). The resulting sub-capability is: - Disclose information to individuals (C1.1): ability to respond to data protection–related requests from data subjects and communicate data processing activities in clear terms.
This sub-capability is about presenting all relevant information regarding an organization’s data protection practices at the time of data collection and at any point during data processing. It may be viewed as the operationalization of the principle of accountability, which is materialized through documentation and streamlined request processing.
Extending individual rights, art. 20 introduces a “right to data portability.” Organizations are required to transmit personal data records “in a structured, commonly used and machine-readable format” to individuals and, in some cases, directly to other organizations. Researchers have highlighted that facilitating customer movement between (competing) organizations is a prime example of conflicting interests between compliance and business mandates (Engels, 2016; Wohlfarth, 2019). From a technical standpoint, during focus group 4.1, only a quarter of respondents declared that the provision of data in standardized formats was mature, and none of them reported working communication channels. The resulting sub-capability is: - Transmit data in standardized form (C1.2): ability to transmit data to third parties via free and/or interoperable formats and to set up communication channels with other organizations.
Clear documentation of processing bases, including consent, is mandatory to demonstrate compliance and ensure that consent is reflected in terms of data. However, transparency requirements also relate to the way in which these bases and consent items are presented to users, and there is evidence of discrepancies between how processing purposes are communicated and how the actual data processing occurs (Kurtz et al., 2020). Bergram et al. (2020) also analyze common methods for acquiring consent in digital settings, and both studies derive design recommendations for enlightened user consent. Although this sub-capability emphasizes technological aspects, our tool analysis reveals that features related to data transfer are the least frequent.
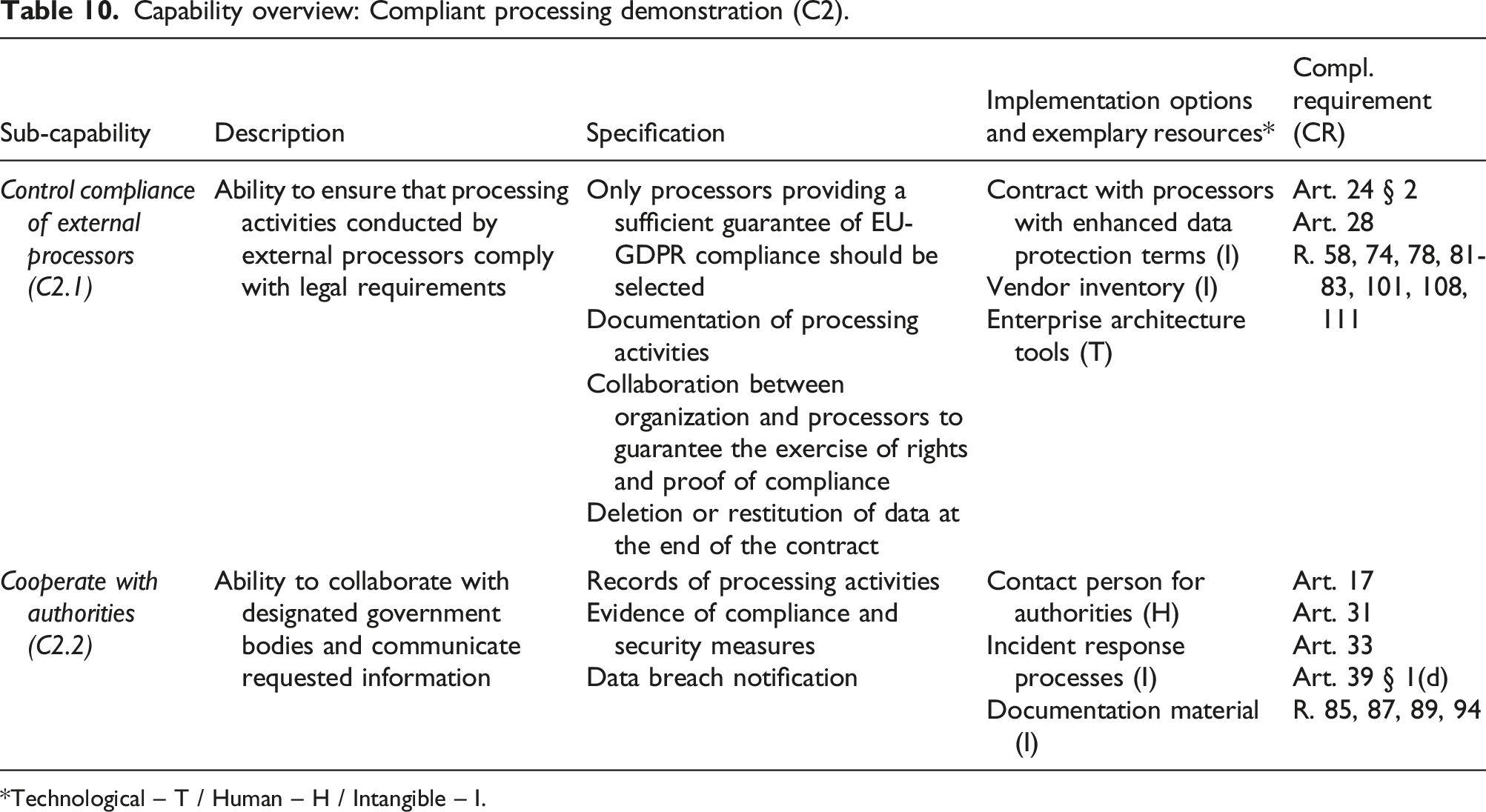
Compliant processing demonstration (C2)
This capability involves the ability to respond to inquiries from public authorities (art. 31) and denotes the ability to coordinate data protection activities with external data processors. It was derived from the principle of accountability (art. 24 § 1) (Bensoussan et al., 2018; Nicolaidou and Georgiades, 2017; Voigt and Von Dem Bussche, 2017).
EU-GDPR makes a distinction between data controllers and processors, and art. 28 orders the former to control compliance of the latter. This distinction is relevant to organizations when they outsource data processing to third-party companies—including the use of cloud services, as merely storing data is considered processing. This became apparent during the Allmed project (cloud CRM) and especially in the case of Leares, which exclusively relies on cloud services (e.g., CRM, content management, and websites) for the storage and processing of data.
Art. 31 specifies that organizations “shall cooperate, on request, with the supervisory authority in the performance of its tasks.” This implies that organizations set up a contact person for authorities (usually the DPO) and are able to present relevant information/documentation as proof of compliance. Since such documentation should contain all relevant information regarding an organization’s data protection practices, this capability is also about ensuring that said documentation considers the processing of data by third parties on behalf of the organization and is readily available for governmental review. The resulting sub-capabilities are: - Control compliance of external processors (C2.1): ability to ensure that processing activities conducted by external processors comply with legal requirements. - Cooperate with authorities (C2.2): ability to collaborate with designated government bodies and communicate requested information.
Similar to 4.5.1, these sub-capabilities may be seen as further operationalization of the principle of accountability, which is materialized through documentation and processes. When it comes to making sense of third-party data processing, enterprise architecture may also be used to document “external” processing systems (e.g., cloud storage). We have identified two software solutions that assist organizations in maintaining an inventory of all the vendors they use. In research, two studies have been published on the matter and focus on the issues of third-party data processing (Kurtz et al., 2018), as well as an investigation of third-party data dissemination in digital service ecosystems (Kurtz et al., 2019). The latter illustrates the challenges from both legal and technical perspectives in the seemingly straightforward use case of a weather app on a smartphone, which transmits data to the operating system provider, the app developer, and an underlying API provider.
Clear documentation of processing bases, including consent, is mandatory to demonstrate compliance. A variety of tools among all considered categories exhibit audit trail functionalities, which record and gather information about data processing and related events.
Building the capabilities
While the capability model comprises the relevant capabilities for achieving EU-GDPR compliance, the focus groups, case study, and expert interviews also highlighted different ways of using the capability model to support EU-GDPR initiatives in their different stages.
In the initial stage, the capability model aids exchanges and communication between legal and data management functions and establishes a common understanding of regulatory requirements. It extends data management professionals’ knowledge of EU-GDPR compliance, which typically focuses narrowly on data objects and attributes—as confirmed by the consultant in the Shippy project: “The capability model is very useful and goes beyond the ‘obvious’ aspects of the regulation. Many of [the capabilities] do not come to data managers’ minds in the first place because the GDPR might be simplified to a perspective of whether I know which records represent a natural person and which don’t.”
Beyond creating a basic understanding about the regulation, the capability model proved to be useful for evaluating an organization’s current state of practice and distinguish areas of attention. Leares, like many other small and medium-sized companies, had compiled a lengthy to-do list compiled with the most visible and pressing compliance issues (e.g., adapting web forms, newsletters, and contracts) in order achieve what was considered a “minimum” level of compliance. These action items were presented as isolated items and focused mostly on technical issues, with no indication of why certain actions were necessary, or what compliance issue they were meant to fix. Using the capability model helped Leares in identifying compliance gaps as well as defining and prioritizing actions. Going through the model, they assigned each check-list activity to the related sub-capabilities and assessed to what extent they contributed to achieving compliance. When capabilities were partially covered by those activities, the model provided guidance to refine them. The capability model also helped identifying capabilities that Leares had not considered at all, such as defining the protected data scope.
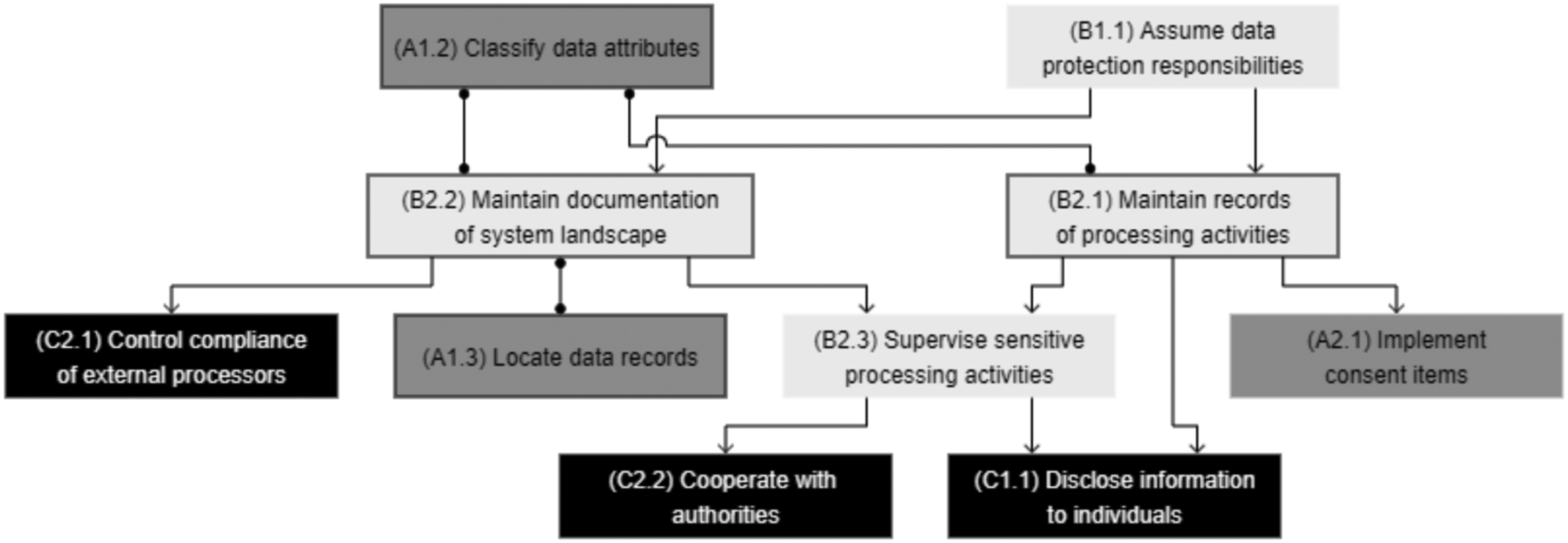
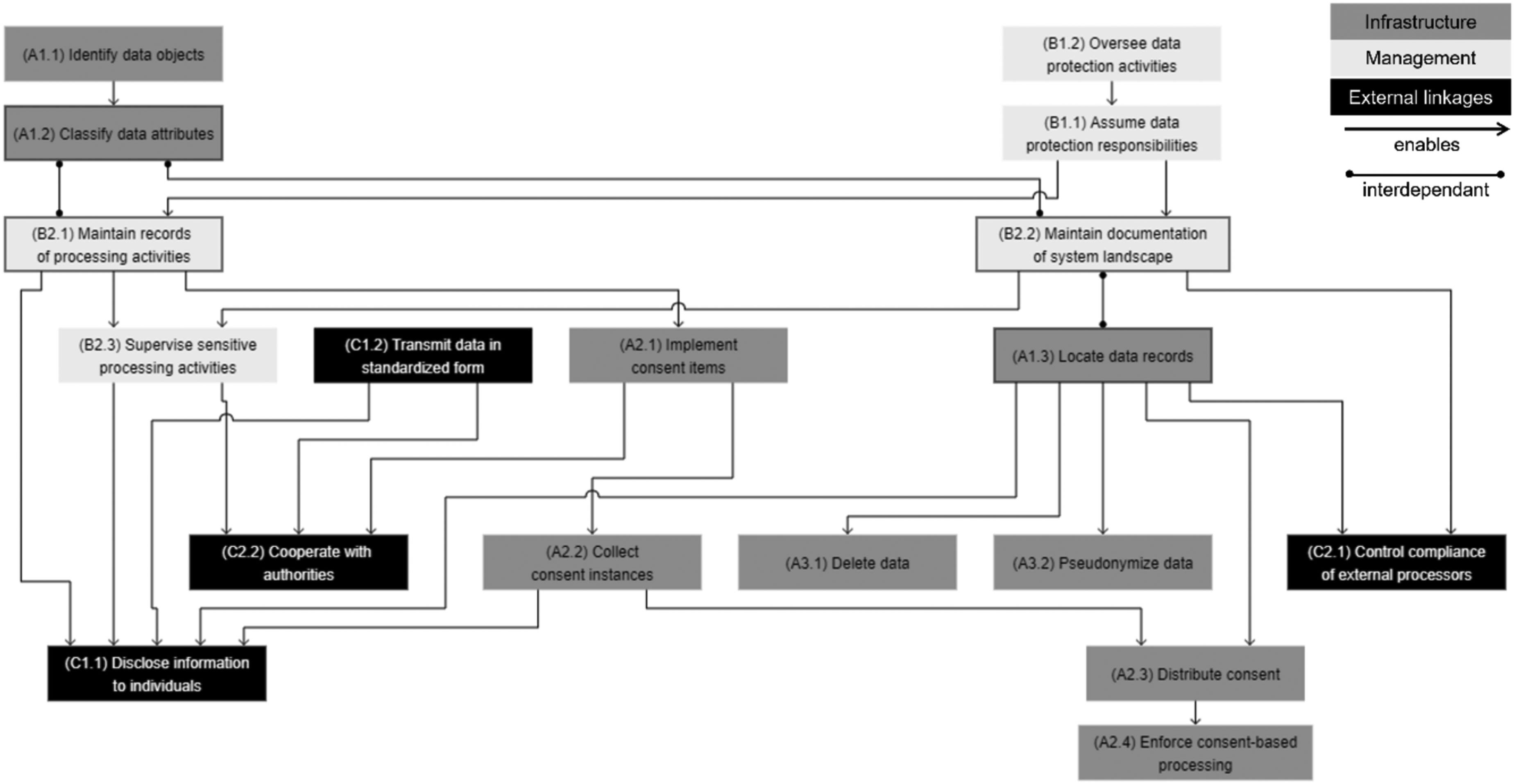
In the focus groups and projects, most companies were overwhelmed when they saw the capabilities and realized that the gaps cannot easily be filled. In line with the RBV, they entail building capabilities as “complex patterns of coordination” between different types of resources (Grant, 1991), which also explains the difficulties with achieving timely compliance. In building the capabilities, understanding the dependencies is crucial for deciding on implementation priorities and defining a roadmap. The consultant at Shippy emphasized this point: “What I really like about the model is [its] attempt to address the dependencies between capabilities. From a data management perspective, a typical challenge is: ‘Now that I’ve identified a plethora of gaps and I’ve thought about what to do with which one, still, what is the sequence? With what do I need to start first? What are the “must-haves”’?’” Figure 10 depicts the relationships between the sub-capabilities as a network. It should be read from top to bottom, as arrows describe dependencies, where the source is a prerequisite to the target. The network shows the multipronged aspect of data protection for enterprises, meaning that achieving compliance requires a combination of three groups of capabilities—infrastructure, management, and external linkages capabilities—and cannot only be tackled from a data object–centric perspective or with a simple tool implementation.
In building the capabilities, organizations may employ a “bottom-up” approach (i.e., starting by tackling infrastructure capabilities) or a “top-down approach” (i.e., starting by addressing management capabilities). In the bottom-up approach, organizations would first perform an exploration of their technological resources at the physical level, for instance by scanning databases and data records (either manually or using automated tools) to identify and classify data objects that may contain personal data (A1.1 and A1.2). In the top-down approach, organizations would start by setting up responsibilities for data protection (B1.1 and B1.2) and building an understanding of the way personal data is processed at the conceptual level. Versuisse and Svizzance were two examples of top-down approaches, as they both emphasized establishing clear reporting lines, thus orchestrating data protection activities (B1). In the case of Svizzance, the company had achieved major progress on the documentation of processing activities and system landscape (B2) and was in the process of linking this documentation to data records (i.e., identifying data objects, classifying data attributes, and locating data records). However, it had not yet started activities related to consent processing (A2) and data removal (A3), as our respondents regarded having a clearly defined protected data scope as a prerequisite. A similar pattern was identified at Versuisse, which was more mature in defining the protected data scope and had just started venturing into consent processing and data removal capabilities at an enterprise-wide level. As insurance companies, Versuisse and Svizzance both operate in a highly regulated market. Such organizations traditionally emphasize control activities and maintain thorough documentation of their operations, which can explain the top-down approach that we have observed (i.e., starting from high-level documentation and investigating links and relationships with data objects). However, we argue that organizations that operate in markets with lower regulatory pressure or are, by their nature, data-driven could also adopt a bottom-up approach (i.e., starting by creating a list of data objects and classifying them to build or enhance their documentation of processing activities and system landscape). Leares is an example of the bottom-up approach, as such documentation did not exist and was built alongside the inventory of systems processing data in the protected data scope.
As depicted by Figure 10, whatever the approach, maintaining documentation of activities performed in either approach starts early in the capability-building process. Our analysis of capability relationships confirms that putting together documentation that reconciles physical and conceptual data layers (B2.1 and B2.2) is a prerequisite to making compliance activities efficient and plays a pivotal role in enterprises’ ability to comply with data protection regulations. This is especially true for large organizations, where an informal understanding of data location (A1.3) or processing activities (B2.1) would inevitably result in compliance silos, which would directly contradict data protection rights and accountability requirements. These findings call back the essence of capabilities as “complex patterns of coordination” (Grant 1991) between technological, human, and intangible resources in the context of data protection. They also underline that achieving EU-GDPR compliance is an ongoing capability-building process.
Conclusion and outlook
Contributions
The EU-GDPR introduces a paradigm shift in data protection regulations, but the academic discourse on this topic is still nascent and lacks consolidation and theoretical integration. Building on the RBV, this paper argues that compliance with the EU-GDPR require companies to mobilize technological, human, and intangible resources and build a dedicated set of enterprise-wide data management capabilities. Our main contribution is a comprehensive, theoretically and empirically grounded capability model for EU-GDPR, which comprises 7 capabilities and 18 sub-capabilities, grouped in infrastructure and management capabilities, as well as external linkages. By translating compliance requirements into capabilities, we advance research at the intersection between legal and IS domains with two main contributions: First, we analyze EU-GDPR, which represents the latest generation of data protection regulations, by using concepts from the RBV, as well as regulatory compliance management literature (El Kharbili, 2012). We introduce capabilities as means to systematically interpret and translate data protection compliance requirements and connect them to implementation options and the required resources. In that sense, we link compliance rules and practice in the spirit of the sense-making dimension of IT-based regulation (de Vaujany et al., 2018). Furthermore, we address a gap in regulatory compliance literature, as our findings derive corrective solutions, that is, providing guidance to reach strategic compliance objectives (Cleven and Winter, 2009) from legal analysis, as opposed to preventive or detective solutions (Abdullah et al., 2009). Second, by linking the regulation to the resource-based view, we propose an enterprise-wide perspective of the what of EU-GDPR implementation rather than the how. Thus, the capability model complements the fragmented body of research on EU-GDPR and extends the scope beyond the isolated investigation of specific implementation options by classifying and integrating these focused research efforts into an enterprise-wide perspective. It also informs the materialization relationship between rules and IT artifacts (de Vaujany et al., 2018) by elaborating on different ways in which rules can be expressed as part of IT design (via dedicated infrastructure capabilities, among others, and by providing a framework to classify IT-based implementation options). Finally, our study enriches the privacy research domain in information systems by analyzing the oft-neglected legal component of information privacy, thereby heeding the call for privacy research to be conducted at the organizational rather than the individual level (Bélanger and Crossler, 2011; Smith et al., 2011).
Implications
As a mature research stream, the RBV helps to explain the difficulties faced by companies with achieving compliance, even several years after EU-GDPR entered into force. The capability model, taken together with practical insights and the analysis of available implementation options, illustrates that no single tool or approach can fulfill all of the regulation’s requirements. It highlights that data protection compliance calls for enterprise-wide approaches, and that achieving EU-GDPR compliance is not a one-time effort but an ongoing capability-building process that relies on a combination of technological, human, and intangible resources. The three groups of capabilities—infrastructure, management, and external linkages capabilities—show that EU-GDPR compliance requires a wide range of capability types, including capabilities that are deployed inside the enterprise (“inside-out” capabilities according to Wade and Hulland’s (2004) typology) as well are externally oriented capabilities (“outside-in” capabilities, ibid.) that create relationships with authorities and data subjects. While prior research has suggested specific solutions to tackle selected aspects of the regulation, the capability model acts as a framework to determine the scope of these solutions, assess gaps and priorities, and illustrate their interplay. For future research, the capability model provides a framework that allows to theorize about the capabilities required for EU-GDPR-compliant data management, position and compare suggestions for EU-GDPR-compliant solutions in the larger context, and generalize beyond the EU-GDPR.
In practice, the capability model supports companies to develop a systematic approach that would enable them to comply with the EU-GDPR and monitor progress instead of “fire-fighting.” According to the experts, it offers a comprehensive perspective of the prerequisites for achieving compliance and draws attention to aspects “beyond the obvious requirements, such as consent,” which are often overlooked by IT and data professionals. The projects carried out as part of our research process demonstrate that companies can use the capability model in different ways: first, as a basis for assessing their current data management capabilities in light of the regulation by identifying the required capabilities and prioritizing them; second, by analyzing software features that help fulfill their capabilities and map them to existing market offerings, thus further informing EU-GDPR implementation initiatives; third, by monitoring progress toward compliance and, thus, supporting the development of capabilities.
Limitations and avenues for future research
While this study does have limitations, it also offers interesting opportunities for future research. First, we acknowledge that the capability model is specific to the EU-GDPR. However, we argue that the identified capabilities are relevant beyond this regulation and its regional scope. As already mentioned, many countries have revised their data protection regulations in recent years or are in the process of doing so. While every country defines specific rules, EU-GDPR has set a global standard, and other regulations are building on similar concepts, as evident in the examples of California, India, and Japan. Furthermore, companies with global operations have to comply with an increasing number of country- and industry-specific data protection regulations. The approach suggested in this paper may serve as a basis for analyzing commonalities and differences between regulations, as well as identifying a "common core." As EU-GDPR has set global standards as a very strict regulation, we can also assume that the identified capabilities are likely to foster compliance with other regulations.
Second, our findings may be biased by the companies that contributed to the design of the capability model. Interestingly, we did not observe industry-specific differences in their approach to achieve compliance. Even B2B companies (machinery, automotive) were highly impacted by the regulation—for instance, because they interact with their (end) customers and partners through of a growing number of websites and digital channels. Nevertheless, we acknowledge that industry-specific compliance requirements and approaches deserve more research.
Another limitation is that we concentrate our research efforts on the capability model as a means to achieve compliance goals but do not substantiate the capabilities’ impact on firm performance. Future research should study the links between capabilities and control objectives derived from regulatory requirements, as well as measure their impact on the firm performance. In fact, non-compliance bears risk of high fines and reputation loss, which negatively impacts firm performance. At the same time, the strict rules imposed by the EU-GDPR can harm value-adding, data-driven activities in the enterprise. Interestingly, we also found evidence that certain capabilities (e.g., transparency on data flows, storage, and usage) are not specific to EU-GDPR and may also serve other purposes in organizations as a way to outweigh potential conflicting interest that some researchers have identified (Engels, 2016; Grundstrom et al., 2020; Jakobi et al., 2020; Lindgren, 2020; Martin and Matt, 2018; Wohlfarth, 2019). Therefore, we see the dichotomy between compliance and business value, and the questioning thereof, as a promising avenue for future research.
Supplemental Material
Supplemental Material - Building data management capabilities to address data protection regulations: Learnings from EU-GDPR
Supplemental Material for Building data management capabilities to address data protection regulations: Learnings from EU-GDPR by Clément Labadie and Christine Legner in Journal of Information Technology
Footnotes
Acknowledgments
The authors would like to thank the CC CDQ partner companies for their financial support and their active contributions to this research.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Competence Center Corporate Data Quality (CC CDQ).
Supplemental Material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.