
Abstract
In this paper, we respond to Grover and Lyytinen (2022). We agree with them that the advent of the digital age is calling for a reconsideration of the role of theory and theorizing. We also think their proposal does not go far enough. The time is ripe to question the role of theory in our field more fundamentally. We propose to instead focus on establishing IS research as a platform through which we can collect, organize, and provide access to digital trace data from various sources to analyze contemporary socio-technical phenomena. We believe that such a move allows us to more fully unleash the unique socio-technical competences of our field in the digital age.
Keywords
Introduction
We thank our colleagues Grover and Lyytinen (2022) for triggering a debate about our research practices in this “digital age” and we are grateful for having the opportunity to respond to their inspirational article. We agree with Grover and Lyytinen (2022) that the advent of the digital age is calling for a reconsideration of the role of theory and theorizing. The degree and extent to which our world is not only digitally enabled or mediated (Baskerville et al., 2020), but also in permanent flux (Mousavi Baygi et al., 2021) are indeed pressuring us as researchers to rethink—and potentially change—the ways we study socio-technical phenomena (Mousavi Baygi et al., 2021, Mendling et al., 2020, Bailey et al., 2022).
We agree with several of the implications that Grover and Lyytinen (2022) sketch out as a consequence of this main argument. First, we agree that a skeptical attitude toward established theories might be a good starting point to ascertain whether explanations from our past get to the core of the phenomena we are confronted with today. We also agree that the granularity and volume of digital trace data, along with the emergence and advancements in computational methods for analyzing them (e.g., Lazer et al., 2009, Zhang et al., 2022, Dimaggio, 2015, Ram and Goes, 2021), are providing us with different and new ways in which we can generate insights into why, how and when socio-technical phenomena take shape (Grover et al., 2020, Miranda et al., 2022). Taken together, these developments indeed demand “openness and originality” on our side (Grover & Lyytinen, 2022, p. 4)—we as a community are well-advised to constantly question our assumptions, approaches and practices.
Where we want to challenge Grover and Lyytinen’s argument, however, is their claim that theory needs to stand as the “basic constituent of the field’s disciplinary knowledge” (Grover & Lyytinen, p. 3). As we will argue, theory—broadly defined as explanation that is generalizable across context and over time—comes with fundamental implications that oppose our ambition to embrace the idiosyncratic and ever-changing dynamics that characterize the digital age. To truly appreciate the “novelty and indigeneity” of contemporary digital phenomena (Grover and Lyytinen, 2022, p. 2), we offer an alternative view: we suggest to focus less on explaining phenomena and instead concentrate on making them explainable, by finding ways to capture and represent the complexity and detail about dynamically evolving socio-technical phenomena in a precise and timely manner (Munger et al., 2021, Mousavi Baygi et al., 2021) such that any researcher, from within our field or from elsewhere, will be better enabled to analyze, reason, or theorize about them.
Our argument rests to a considerable extent on the growing availability of digital trace data that provide increasing opportunities to make sense of the digital world (Leonardi and Treem, 2020). Recent attempts sought to reconcile digital trace data-based research with established practices in our field (Miranda et al., 2022)—but we propose a more fundamental move. We suggest that we need to engage in concentrated efforts to provide these data (Oliver et al., 2020), faithfully represent the complexity of the phenomena captured in these data, and advance researchers’ ability to make sense of phenomena that change rapidly and challenge established theory.
In what follows, we will develop this vision further. We argue that we can embrace the novelty of digital phenomena when we as a discipline do not focus squarely on building better theory but instead jointly focus on building a broader research platform that allows us as well as others to expand our capabilities to collect, organize, and analyze digital trace data.
The problem of blue-ocean theorizing
We currently witness a never-ending stream of new digital technologies that keeps disrupting the ways we live, work, and engage with each other, seemingly at an ever increasing pace and with increasing complexity (Benbya et al., 2020). The phenomena we are observing as IS-scholars are emerging, becoming, and in flux (Tremblay et al., 2021). Against this backdrop, Grover and Lyytinen (2022) encourage us to engage in blue-ocean theorizing. In a nutshell, they ask us to “engage directly with emerging and complex phenomena” (Grover & Lyytinen 2022, p. 1) to build new theories ourselves instead of borrowing established reference theories from other fields. This is meant to help us embrace the unique features and characteristics of contemporary digital phenomena that present themselves “as something different” (Grover and Lyytinen, 2022, p. 2).
To us, blue-ocean theorizing presents two fundamental problems: First, taken to the extreme, Grover and Lyytinen’s suggestions would imply that every single one of us ought to engage in blue-ocean theorizing. As we embrace the uniqueness of each phenomenon, and try to capture this uniqueness by means of new theories, we would essentially stop engaging in collective learning and iterative knowledge accumulation, and, ultimately, risk that IS as a discipline loses its identity and dissolves into an unrelated collection of blue-ocean theories (Sarker et al., 2019). By implication, we would develop more and more new theories, but we would not build on each other’s work anymore.
Second, even if we relax the premise that everyone ought to engage in blue-ocean theorizing, thereby allowing for a collective learning process, it could still be the case that, in the long term, blue-ocean theorizing exacerbates the very problem that Grover and Lyytinen (2022) are trying to address—that our theories become outdated quickly. The logic of collective theorizing and knowledge accumulation implies that we actively try to integrate current and past explanations (e.g., Farhoomand, 1987, Farhoomand and Drury, 2001) in an attempt to respect and accumulate a knowledge tradition. But this process implies that each new theory needs to be carefully assessed, synthesized, and integrated with the extant body of knowledge. Since blue-ocean theorizing would dramatically increase the number of theories that need to be integrated with each other, it would, in the long term, slow down our collective learning process. A direct consequence would also be that our review process becomes even more complex because the number of theories to be considered—along with the time until authors and reviewers find agreement—expands. Hence, as scope and pace of socio-technical change is accelerating in the world around us, our scientific process and progress would inevitably become slower and slower, further delaying the point by which we can publish contributions, and leading to potentially dated and possibly irrelevant contributions at the time of publication.
In conclusion, we argue that blue-ocean theorizing is not a sustainable solution to the increasing misfit between theory and the dynamics of the digital age. While we agree that, historically, theories have been at the core of the development of our field (Grover and Lyytinen, 2022), this does not mean that producing theory needs to remain our only ambition. We should seek other, complementary means to generate knowledge embracing the novelty of contemporary digital phenomena.
Envisioning information systems research as a platform
At the core of our alternative vision is to not only rethink the role of theory in IS, but instead, more fundamentally, engage in a concentrated effort to develop our (emerging) competencies in collecting, organizing, and analyzing digital trace data to make socio-technical phenomena explainable. This requires a fundamental shift in the way we organize as a community. We suggest to engage in no less than a field-level adjustment to move from an integrated, self-sufficient but also siloed field to a platform of research embedded within a broader scientific ecosystem, which is centered around our capabilities to collect, analyze, and organize digital trace data to capture the dynamics of socio-technical phenomena.
Presently, our discipline, like many others, is highly integrated, trying to “do it all”—explain and predict, analyze and prescribe, both empirically and conceptually. Over time, we integrated ever more approaches and paradigms into our field’s architecture so that it now also covers design-oriented research, computational approaches, and whatever else we found important to integrate. What has not changed however is that the main value proposition of our field is theory—the contributions we make to the cumulative body of knowledge on socio-technical phenomena of our times (Hirschheim, 2019).
What if we instead understood and organized ourselves as a platform within a broader scientific ecosystem? Platforms, in simple terms, are based on some sort of infrastructure that facilitates value exchange between suppliers and consumers (Parker et al. 2016). Platforms are loosely organized around a core but are also accessible for complementors in the periphery. Key to the idea of a platform is thus the availability of different value exchange components that are loosely coupled to the core and extend the functionality, value, and reach of the platform in response to demands that arise both from within and outside the platform environment (Baldwin and Clark, 2000, Sandberg et al., 2020). Essentially, because a platform is composed of a stable core that establishes connectivity between variable components, it supports variability, innovation, and evolvability (Baldwin and Woodard, 2009).
The research platform we envision for the information systems research field is shown in Figure 1. In this view, instead of focusing on theoretical contributions, IS research as a platform is built around our competencies to collect, organize, and analyze (digital trace) data to capture the dynamics of socio-technical phenomena. Digital trace data provide granular insights into the activities of social actors at specific points in time and allow us to represent phenomena in ways that foreground their specific features, patterns, and dynamics (Kitchin, 2014, Chen et al., 2012, Lazer et al., 2020). They comprehensively depict how socio-technical phenomena unfold over time and in a given context (Oliver et al., 2020, Pentland et al., 2021, Miranda et al., 2022). And since basically everything we do is mediated by digital technologies, there will be an ever-growing availability of digital trace data. Hence, at the core of the platform is an infrastructure that comprises two layers: A data layer is concerned with the ongoing collection, storage and organization of digital trace data. A method layer contains and advances procedural knowledge for how to analyze digital trace data. IS as a research platform.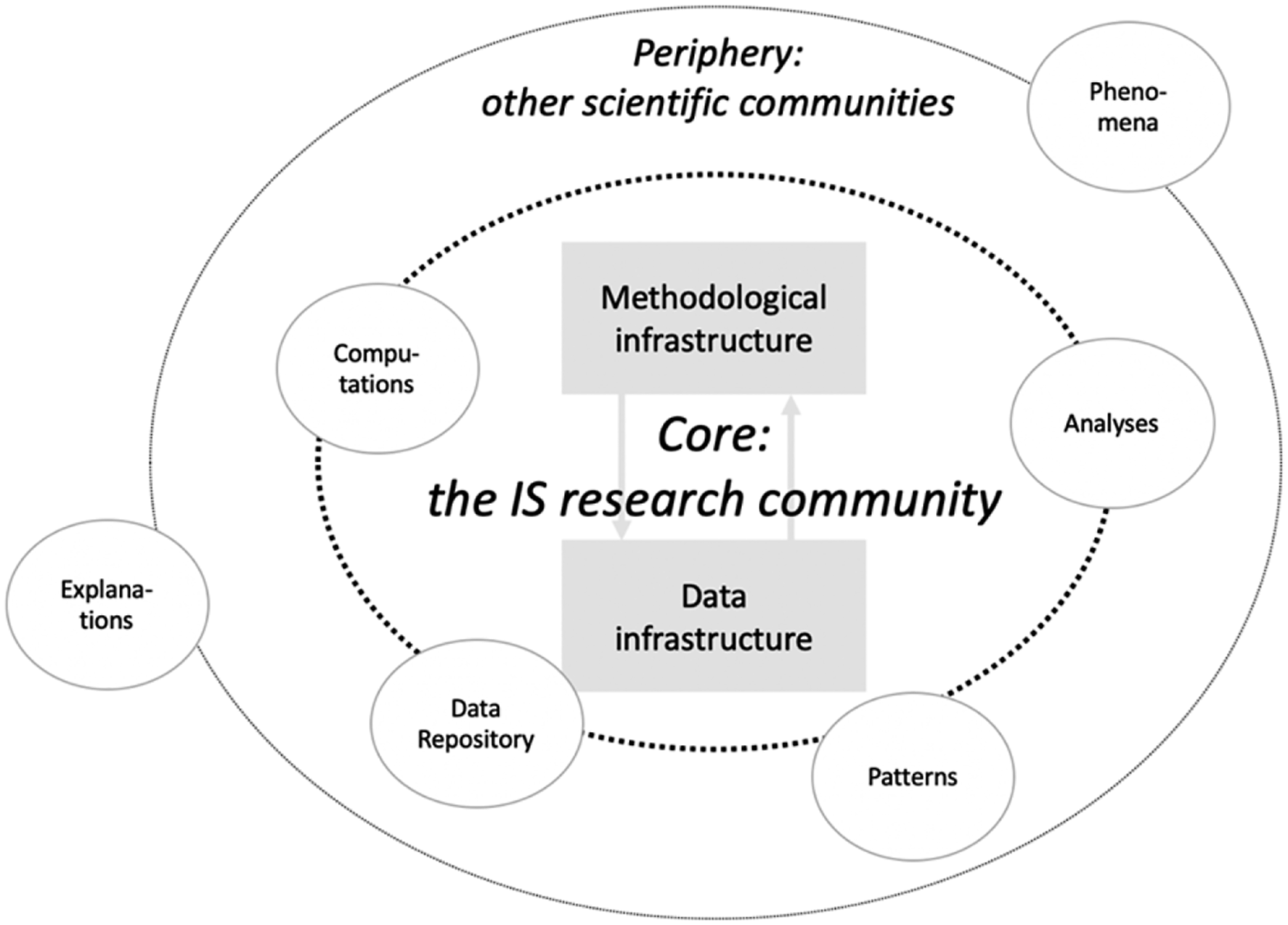
Coupled to this core, we can organize several adjacent and complementary value-add competencies as platform modules. For example, a Data Repository module might include the provision of digital trace data sets of various kinds and from various contexts made available for scientists to analyze a diverse range of socio-technical phenomena; such data can stem from operational processes (Pentland et al., 2021), text (Schmiedel et al., 2019), mobility data from mobile devices (Oliver et al., 2020), among many others. A Computations module could entail computational techniques and methods to analyze digital trace data in different ways. They can include, for example, process mining techniques to perform sequential analyses of time-stamped data (Van der Aalst, 2016) or scripts to analyze social relations in virtual collaboration environments (Hu et al., 2018). Analyses and patterns could be modules that contain insights that were previously obtained from datasets. Patterns—representations that foreground aspects of a phenomenon that are (at least somewhat) repetitive and recognizable—are gaining particular prominence in digital trace data driven research as they allow for exploring how certain phenomena persist or change (Oliver et al., 2020; Miranda et al., 2022). These modules are both the locus for as well as the starting point of our research activities; we contribute to these modules when we develop, for example, new computations, and we draw from the modules when we need, for example, digital trace data sets.
Together, this infrastructure and core modules provide a platform on which value exchanges in science can take place, both within the IS field as well as with, or through, other communities. As complementors, other communities may also add valuable “modules,” such as interesting phenomena, sets of assumptions or explanations, or they could make more direct contributions to analyses, computations, data, or patterns. Importantly, the arrangement of modules in a platform ecosystem is not fixed; they can be extended and adjusted. A platform is a generative organizing model that allows for responding to a dynamic digital world by continuously adjusting how we get at its dynamics and how we can make them explainable. As indicated by the other peripheral service layer, we can still use the insights obtained through these modules to generate explanations in the form of theory (Hirschheim, 2019) and other contributions (Ram and Goes, 2021).
A shift towards IS as a research platform comes with several key implications that considerably change our research practices, which we outline in the following.
Implications
Implication 1: Building the infrastructure for an IS research platform
At the core of the idea to view information systems research as a platform is that we make phenomena explainable on the grounds of digital trace data. Making this move means that we need to bring together, organize, curate, and analyze digital trace data about various phenomena on a continuous basis. Therefore, we need to develop an infrastructure that allows for the continuous collection, storage and analysis of large datasets; this includes integrating different data sources that are continuously updated and readily usable (Hale et al., 2021). In this sense, a core mission of our field would be to establish and develop openly available data infrastructures that connect and integrate different data sources from public and, wherever possible, private contexts. Several examples exist that could guide our efforts. We could turn to open data initiatives (Gewin, 2016, Nosek et al., 2015) to derive guiding principles for design. We could also mimic public data spaces such as X-Road, Gaia-X or GAFAM (Beverungen et al., 2022).
In addition to data, we would also need to provide accessible code, primarily in the form of computational methods and techniques that can be applied, shared, adjusted and improved. While research papers often provide code on various platforms, such as Github (e.g., Zoller et al., 2020), key to the platform we envision here is that all code and procedures will be stored and made available centrally and openly. Methodological contributions can then be evaluated with respect to their ability to capture socio-technical phenomena in better—that is, more reliable, more precise, more contextualized, and faster—ways. Such methods could be supported, for example, in the form of easy to run Jupyter Notebooks (Kluyver et al., 2016).
Taken together, our suggestion implies moving towards alternative, more grounded, and faster available means to create knowledge about socio-technical phenomena as opposed to knowledge aimed at developing generalizable explanations (Hirschheim, 2019). This implies, among other things, that we as a community embrace the idea that the contribution of a study can lie “in the uniqueness of the data set and the rigor of the empirical methods used to analyze the data” (Agarwal and Dhar, 2014), even if it is not (yet) aligned with a theoretical lexicon (Miranda et al., 2022).
Implication 2: Organizing and incentivizing activities to develop IS as a research platform
Our vision also requires us to systematically re-organize and incentivize how we conduct and disseminate our work. While we believe that many of us will draw on and profit from such a platform once it will be available, the key question is: how can we get started and how can we motivate researchers to participate so that the platform will be big enough to generate network effects?
One key area that will require change is the way we handle publications. Because research in our community will have to address all modules depicted in Figure 1, not just “explanations” as a module, we need to incentivize the division of labor through the creation of new publication types that will be treated with equal respect and reputation that our theory-focused top journals receive. One way to achieve this is to introduce paper categories into our established top journals that are concerned, for example, with data collection, computational methods or patterns (e.g., as an alternative category next to research articles or research notes). We could also develop dedicated outlets (such as Methods X or the Journal of Quantitative Description: Digital Media, see Munger et al. 2021) and ensure they receive the same legitimacy and reputation as our established journals. Beyond that, we may find other ways to incentivize impactful contributions to data or methods modules.
Importantly, the relevance of this platform will not only be tied to the scientific discourse. Producers and consumers coming together on the platform can be researchers as well as practitioners. The COVID pandemic has shown that access to digital trace data along with methods to analyze them (Hale et al., 2021) can enable the development of practical solutions to specific problem contexts (Chang et al., 2021). For example, in order to increase the effectiveness of social distancing measures, digital trace data from mobile phone use were leveraged to examine movement patterns along with regulations that had more or less effect on them (Grantz et al., 2020). Therefore, the platform we envision here may draw considerable attention to our community from the side of practitioners, such as policy-makers, data scientists, or systems developers, to name just a few.
Implication 3: Democratizing IS research
A major advantage of positioning IS as a research platform for digital phenomena is that it will further democratize our research practices. Consistent with the pluralistic view that underlies our field (Lyytinen and King, 2004), IS as a research platform encourages contributions from different areas within and outside of our field. To those who argue that the field would be obsessed with theory (Avison and Malaurent, 2014, Hirschheim, 2019), it offers alternative ways to contribute.
Further, IS as a research platform significantly lowers the entrance barriers to study digital phenomena. We deem this particularly important for PhD students and scholars from communities that do not have direct access to digital trace data, or that do not have ready access to literature containing our most reputable theories. Because this type of data allows detailed insights into how organizations work, companies are often reluctant to share these data, even under non-disclosure agreements. If uploaded to the platform in anonymized ways, for example, these data can be analyzed by others. Thus, IS as a research platform would contribute to democratizing access to these valuable and scarce data and would make our community more inclusive and diverse at the same time.
From a broader perspective, we should also make our data, methods, and findings available to other disciplines. Instead of fighting whose explanations about digital phenomena are better—ours or those from our strategy, management, operations, or marketing colleagues—we would instead set a new standard to capture and explore contemporary digital phenomena in all their detail and complexity. We would do so by providing the grounds to represent the world around us in useful, and innovative ways, and advancing our methodological toolkits, which will together ensure that socio-technical phenomena become explainable—by us or by others, through old or new theoretical explanations, borrowed or indigenous, old-fashioned or innovative.
Conclusions
We appreciate Grover and Lyytinen’s (2022) proposal to shed with the old and become more open, more flexible, and more innovative toward the study of digital phenomena. We also think their proposal does not go far enough. The time is ripe to question the role of theory in our field more fundamentally. We propose to instead focus on establishing IS research as a platform through which we can collect, organize and provide access to digital trace data from various sources to analyze contemporary socio-technical phenomena. We believe that such a move allows us to more fully unleash the unique socio-technical competences of our field in the digital age.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by European Commission with grand Erasmus+ program [2019-1-LI01-KA203-000169] "BPM and Organizational Theory: An Integrated Reference Curriculum Design". Research by Jan Mendling is funded by the Einstein Foundation Berlin under Grant No. EPP-2019–524.