
Abstract
This study tests young learners’ ability to segment foreign-language words before they receive classroom instruction in English as a foreign language (EFL). We focus on speech segmentation, one of the earliest hurdles in second-language (L2) acquisition, but essential to building a vocabulary in a new language. Specifically, we examine whether segmentation is influenced by individual differences in phonological awareness, the presence of first-language (L1) phonotactic cues to word boundaries, and L1 skills. Primary-school students in Germany (6- to 9-years old), either monolingual with German only or bilingual with German and another language, were tested on their ability to recognize pseudowords in English speech that were presented in contexts that cued word boundaries either consistent or inconsistent with German phonotactics. Results show that participants recognized pseudowords and that this improves with increasing phonological awareness skill. Nonetheless, L1 phonotactic boundary cues neither influenced performance at the group level nor when individual L1 skills were considered. An exploratory analysis of English receptive vocabulary, however, revealed that pre-EFL learners may initially use L1 phonotactic cues to detect word boundaries but rely less on them once their receptive English vocabulary grows. Similar to adults, pre-EFL learners are able to segment and recognize words in English prior to systematic exposure and classroom instruction, which may be supported by developing phonological awareness skills. However, this does not seem to be underpinned by the transfer of phonotactic cues from the L1, suggesting a lack of continuity in the influence of the L1 on the L2 in foreign language learning across development.
I Introduction
One of the first tasks for a language learner is to identify words in the incoming speech signal, a process known as speech segmentation. This is certainly no easy feat for the learner, as normal speech does not contain noticeable pauses between words within utterances which would signal a word boundary (Cole and Jakimik, 2005). At the same time, speech input contains regularities that may signal the boundary between words in different ways. Since these regularities are language-specific, they must be acquired from the input. Starting within the first year of life, language learners exploit different prosodic and phonotactic regularities (Mattys and Jusczyk, 2001; Mattys et al., 1999) as well as distributional regularities in the input (Saffran et al., 1996) to posit word boundaries in the language(s) they acquire.
Although the use of language-specific cues leads to efficient speech segmentation in the first language, these procedures cannot be easily transferred to other languages. Nonetheless, adult foreign language (FL) learners typically continue to use first language (L1) cues in segmenting the foreign language (Cutler et al., 1986; Mehler et al., 1981), even when the language input contains cues that contrast those used in the L1 (Finn and Hudson Kam, 2008) and the learners have reached advanced proficiency in the second language (L2; Hanulíková et al., 2011; Weber and Cutler, 2006). In contrast, little is known about how younger learners approach segmentation in a FL. The current study focuses on 6- to 9-year-old German children’s ability to segment words from a FL, English, before they receive classroom instruction in English as a foreign language (EFL). Our study examines different factors that may contribute to L2 segmentation, including individual differences in metalinguistic abilities, the similarity of the input structure with the L1, and learners’ general L1 knowledge, and it explores the influence of any foreign-language knowledge they may have acquired through overhearing.
Young pre-EFL learners may or may not approach segmentation in a new language in a similar manner as that of adult language learners. When young learners begin to learn a FL in school, they, like adults, are already active users of their L1. Adult ab initio learners have been found to segment and recognize words after only several minutes of exposure to a new language (Gullberg et al., 2012), although their brain signatures appear to be delayed in comparison to L1 speakers of this language (Snijders et al., 2007). Evidence of fast-acquired segmentation and subsequent recognition has also been found after foreign-language exposure as brief as a single sentence. In their study, Shoemaker and Rast (2013) presented adult ab initio learners of Polish with one full sentence produced in Polish, followed by a single probe word that either was or was not present in the sentence. Learners accurately differentiated between probe words present and absent in the sentence, suggesting that adult learners rapidly segment and recognize words in a FL even if they have not previously been familiarized with input in that language. Using the word recognition paradigm employed by Shoemaker and Rast (2013), the current study investigates whether primary school students are similarly able to segment words from English before they have received systematic exposure to it via classroom instruction.
In comparison to adults, however, young pre-EFL learners are still developing their cognitive and metalinguistic abilities as well as their linguistic abilities in their first language(s), which have all been found to affect both FL segmentation more specifically and learning more generally in adults. As a result, we may find that young pre-EFL learners may approach the task of segmenting and recognizing words at the onset of FL learning differently compared to adult FL learners.
With respect to cognitive skills, the use of statistical regularities to segment speech can be disrupted when working memory load is too high, suggesting that these cognitive processes are actively engaged during and support initial speech segmentation (Palmer and Mattys, 2016). Working memory (WM) describes the capacity constraint for holding temporary information, while performing manipulations on it (Baddeley, 1992), whereas phonological short-term memory (STM) supports the initial storing and processing of phonological information (Norris, 2017). The consequences can be seen for FL learning in general, as individual differences in both WM and phonological STM predict both initial FL vocabulary and grammar acquisition (Martin and Ellis, 2012) as well as later L2 outcomes (Linck et al., 2014). Considering the trajectory of cognitive development from childhood to adulthood and evidence that cognitive abilities underpin learners’ approach to FL segmentation and learning, we may find that, unlike adults, younger learners as a group show poor detection and recognition of words from continuous English speech before receiving systematic exposure and instruction in the classroom.
Young learners also differ from adults in their metalinguistic skills. As a component of metalinguistic awareness, phonological awareness, referring to listeners’ abilities to explicitly manipulate phonemes in spoken language (Anthony and Francis, 2005), has been found to support early L2 word learning (Hu, 2014). Emerging literacy boosts the development of phonological awareness (Anthony and Francis, 2005), which means that as students are learning to read and write, they are also developing their phonological awareness skills. This makes young school age a particularly dynamic time to study whether and how individual differences in phonological awareness skills already impact FL segmentation abilities at the very initial stages of FL exposure. In the present study, we therefore specifically study the role of phonological awareness skills on FL segmentation abilities in primary school students, while controlling for variation in cognitive skills (WM and phonological STM), predicting that initial segmentation and recognition abilities will be positively related with phonological awareness skills.
In the present study, we study both monolingual German-speaking students as well as students using both German and one or more additional languages at home. Not only does the inclusion of bilingual students reflect the general population of students receiving English instruction in primary school in Germany (Pöhlmann et al., 2013), but it also takes into account results from studies showing that bilingual students may differ in their FL development from monolingual students (Hopp et al., 2019). Furthermore, monolingual and bilingual FL learners have been argued by some to differ from one another in their cognitive (Morales et al., 2013; Thorn and Gathercole, 1999) and metalinguistic skills (Hopp et al., 2019), although this may depend on the particular population studied (e.g. Bialystok et al., 2003). Against this backdrop, we study pre-EFL learners both with and without previous knowledge of more than one language in addition to the majority language, while testing for the effect of phonological awareness skills and controlling for the effect of WM and phonological STM, which have an impact on FL learning and in which these two groups of learners may differ.
Finally, although young pre-EFL learners are capable users of their L1(s), they are still developing their linguistic skills in comparison to adults (Foster-Cohen, 2014). This may have consequences for how they approach FL segmentation. When learners first encounter the FL, they bring knowledge of their L1(s) with them, including the L1-specific cues that signal word boundaries. In turn, these could shape their segmentation of speech in other languages they encounter. Considering that these cues are gradually learned from the L1 input, young learners and adults may differ in how strongly they apply L1-specific cues to a new language. We investigate the application of L1 cues in phonotactics. Phonotactics describes the permissible combinations of sound sequences in a language and defines its restrictions. Languages vary in which phonotactic sequences are legal. While the sequence /ʃm/ is not a permissible onset in English, it is common in German (e.g. /ʃmaːl/ ‘narrow’, /ʃmɛɐt͡s/ ‘pain’). In contrast, /sm/ is phonotactically well-formed in English (compare small, smoke), but ill-formed in German, and it only occurs in English loanwords such as smart. Other phonotactic restrictions are shared between languages, such as the ill-formedness of /tl/ in both onset and coda position in English and German. Knowledge of these restrictions can serve as a general cue to word boundaries. For example, the phonotactically illegal consonant sequence /tl/ in English signals a syllable boundary and hence a potential word boundary between /t/ and /l/ to the listener (e.g. smart look), since the two consonants cannot occur within the same syllable.
Phonotactic cues are amongst the cues that learners transfer from their L1 to other languages. Weber and Cutler (2006) found that highly proficient L1-German users of English continue to apply phonotactic cues from German when segmenting speech in their L2. In contrast to adults, younger learners seem to be more flexible in their application of phonotactic constraints from their L1. For instance, Smalle et al. (2017) found that 9-year-olds were faster to produce words that contain novel (illegal) phonotactic structures than adults, indicating that children more readily adapt to non-L1 phonotactic structures. Although these children have certainly acquired the phonotactic constraints in their L1, the ability to generalize these constraints across lexical items is still developing (Edwards et al., 2004). For young FL learners, then, L1 phonotactic cues may not have the same privileged role in segmenting speech in a new language as for adults, in part perhaps because their L1 language skills are still developing. Indeed, the development of L1 skills appears to have a direct relationship with phonotactic processing, at least in the initial stages of L1 acquisition. As an infant’s vocabulary grows in their first language, their ability to acquire novel (illegal) phonotactic structures decreases (Graf Estes et al., 2011, 2016). Likewise, at a later age, young EFL-learners with more advanced L1 skills may be more likely to apply phonotactic cues from their L1 than those with less advanced L1 skills.
II Current study: Research questions and hypotheses
By testing the cognitive and (meta-)linguistic factors that modulate young learners’ segmentation abilities in a FL, this study investigates whether there is continuity in the mechanisms and factors that shape the early stages of FL learning in children and adults. The current study therefore has several research questions. First, we ask whether German-speaking students in primary schools can segment words from speech produced in a novel language, English (research question 1). English instruction starts in grade 3 in the German state where we collected data; we therefore tested first- and second-graders to gain insight into their segmentation strategies before the onset of formal EFL instruction. In a word recognition task, following the procedure used in Shoemaker and Rast (2013), participants first listened to a sentence in English (e.g. ‘I really need soos midluff so I can sleep’) that was followed by a probe pseudoword presented in isolation that was either present in the sentence (e.g. ‘midluff’) or not (e.g. ‘ternack’). Participants then decided whether the probe pseudoword had been present in the sentence, producing a word acceptance score. We predict that if participants are able to segment words when confronted with continuous English speech, then their word acceptance scores will be higher for probe pseudowords that occurred in the sentence, labelled target words, than those that did not, lure words (hypothesis 1).
We further investigate whether initial speech segmentation skills are influenced by different participant- and item-level factors. We ask whether phonological awareness specifically supports the explicit manipulation of phonemes present in continuous speech and the segmentation of words (research question 2). If this is the case, then the difference in word acceptance scores between target and lure probe items should increase with increasing phonological awareness skills (hypothesis 2). To study whether the presence of L1 phonotactic cues to word boundaries influences initial speech segmentation (research question 3), sentences in our study were constructed such that the word boundaries preceding and following the embedded target pseudowords were either clearly cued by L1 German phonotactics (e.g. /sm/ and /fs/ in /suːs_mɪdlʌf_soʊ/; clear boundary) or not (e.g. /ʃm/ and /fɪ/ in /suːʃ_mɪdlʌf_ɪf/; ambiguous boundary). We predict that, before acquiring English phonotactics, participants will make use of these L1-based cues when trying to extract individual words from English sentences, showing higher word acceptance scores for target words presented in clear compared with ambiguous boundaries (hypothesis 3). However, the extent to which children use these L1 phonotactic cues may depend on how well-developed their L1 German already is. We ask whether the use of L1 phonotactic cues is influenced by participants’ L1 skills (research question 4). If this is the case, then the difference in word acceptance between target words in the clear and ambiguous boundary contexts will increase as children’s L1 skills increase (hypothesis 4). In exploratory analyses, we also consider the role of students’ emergent English skills, acquired through extramural exposure before EFL instruction (e.g. Lindgren and Muñoz, 2013), by assessing whether their receptive lexical knowledge of English words affects initial English segmentation (research question 5).
Planned research questions and hypotheses (1–4), as well as measurements and analyses, were pre-registered on OSF (https://doi.org/10.17605/OSF.IO/58BHV). The present article was written with embedded analysis scripts in R (R Core Team, 2018) using the papaja package (Aust and Barth, 2018) in R Markdown (Allaire et al., 2018). The stimuli and programs to run the study, the de-identified data and the R files to produce this manuscript are available on Open Science Framework (https://osf.io/aucn8/).
III Methods
1 Participants
The final sample comprised a total of 113 students (M age = 7.50; SD = 0.74, range = 6–8.75), recruited from 1st (n = 50; 30 females, 20 males) and 2nd (n = 63; 36 females, 27 males) grade classrooms from four local schools in a mid-sized city in Northern Germany. This sample size met the pre-registered sample size of 96 to meet the required power of 80% and test for the hypothesized role of individual differences. 1 All caregivers provided informed consent and filled out a questionnaire reporting the general health of the child (vision, hearing, diagnoses), their language background (adapted from the LEAP-Q; Marian et al., 2007), and their socio-economic status (SES; KiGGS Welle 2; Lampert et al., 2018). The German and English versions of the questionnaire can be found in supplementary material A. All participants included in the final sample had normal or corrected-to-normal hearing and vision as well as no diagnoses that impacted cognitive function or language development. No participant in the final sample had been systematically exposed to English, either at school or at home. A total of 29 participants indicated that they spoke a language in addition to German and were able to complete additional tasks in this minority language (semantic fluency, Delis et al., 2001; LITMUS-CLT production task, Rinker and Gagarina, 2017; see below); we consider them bilingual and the remaining 84 participants monolingual. Bilingual participants reported speaking Arabic (n = 7), Russian (n = 5), Turkish (n = 4), Bulgarian (n = 2), Mandarin Chinese (n = 2), Polish (n = 2), Italian (n = 1), Catalan (n = 1), French (n = 1), Portuguese (n = 1), Serbian (n = 1), Spanish (n = 1), or Urdu (n = 1) in addition to German. The final sample of participants was skewed towards having a high socio-economic status according to the KiGGS Welle 2 (Lampert et al., 2018): 50 high SES, 57 middle SES, 4 low SES, and 2 that did not complete that section of the questionnaire. The local state school authorities approved the recruitment and testing of children in schools, and the ethics committee of the Linguistic Society of Germany approved the study (#2020-07-200812). Participants were given a certificate of participation and small toys (e.g. pencil, eraser, and books) as a reward for participating.
Table 1 gives information about participants’ age, language background, and scores in the additional tasks separated by school grade (first or second graders) and language status (monolingual or bilingual). As expected, bilingual participants had significantly lower scores than monolingual participants in measures pertaining to their use and knowledge of German (e.g. percent of German passive exposure, German semantic fluency score, German production LITMUS-CLT) and additionally had higher scores in the English comprehension LITMUS-CLT task. No other comparisons were significant (a summary of t-tests comparing bilingual and monolingual participants’ scores in the additional tasks can be found in supplementary material B). 2
A summary of the participants’ age, language background, and scores in the additional tasks.
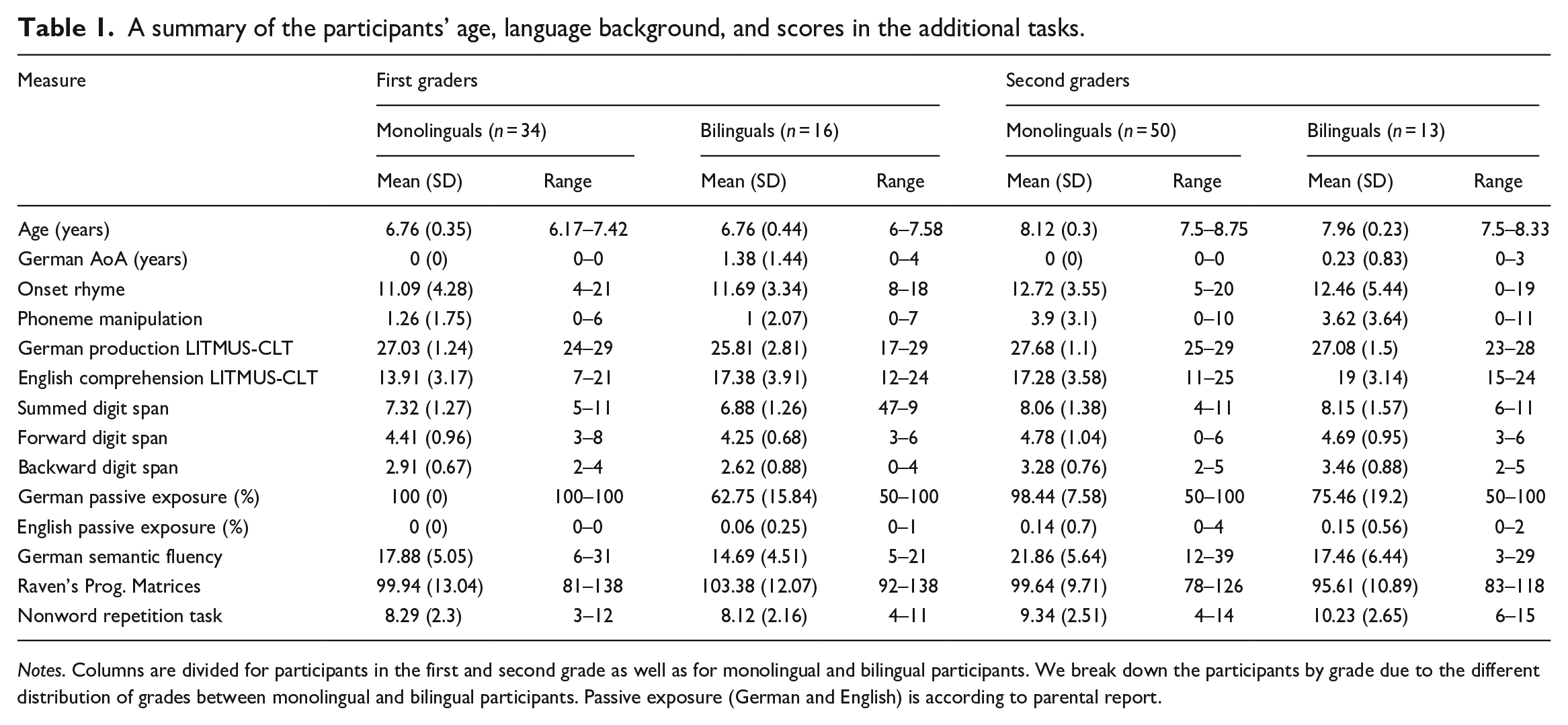
Notes. Columns are divided for participants in the first and second grade as well as for monolingual and bilingual participants. We break down the participants by grade due to the different distribution of grades between monolingual and bilingual participants. Passive exposure (German and English) is according to parental report.
An additional 23 participants were tested but not included in the final analysis because they did not complete the testing sessions (n = 3), their parents did not return the questionnaire (n = 7), their hearing was not corrected to normal (n = 3), they were diagnosed with ADHD (n = 2) or a developmental language disorder (n = 1), their parents reported suspicion but no official diagnosis of autism (n = 1), they had only started learning German recently (n = 1), they were reported to be exposed to English more than 10% of the time (n = 4), or they reported speaking English and successfully completed the LITMUS-CLT production task in English (n = 1).
2 Materials and design
a Segmentation task
In order to create clear and ambiguous boundary conditions, a set of 20 consonant clusters were identified, half of which constituted legal onset clusters in German (ambiguous boundary; /ʃl-/, /ʃt-/, /ʃp-/, /ʃm-/, /ʃn-/, /pl-/, /pf-/, /kv-/, /kn-/, /kr-/). The other half were illegal as onsets in German and would be separated by a syllable boundary when encountered in continuous speech (clear boundary; /sl-/, /st-/, /sp-/, /sm-/, /sn-/, /tl-/, /kf-/, /lv-/, /pn-/, and /nr-/). Overall, half of the cluster pairs had a sibilant in the initial consonant position, while the other half had a stop, liquid, or nasal. Some of the sibilant-initial clusters in the clear boundary condition (e.g. /st-/) are licit in some closely related languages, such as English and the Scandinavian languages, while the clear boundary clusters starting with a stop, liquid, or nasal are universally dispreferred (e.g. /lv-/). Some of the clusters in the clear boundary condition are attested in loan words used in German (e.g. /sl-/ in ‘Slang’, /pn-/ in ‘Pneumonie’), but none of them occurs in a native German word.
A total of 120 pseudowords were created to serve as targets. Pseudowords, rather than real words, were used to increase flexibility in terms of which phones could occur at the boundaries and make for a more balanced design than real words would have allowed for. Each of the consonant clusters in the clear boundary condition was paired with a consonant cluster in the ambiguous boundary condition that matched on the second consonant in the cluster (e.g. /sl-/ and /ʃl-/; /pn-/ and /kn-/). The second consonant in the cluster served as the onset for the target words. Half of the target words were monosyllabic (e.g. /lɔɪk/) and the other half were bisyllabic (e.g. /neɪ.sɛt/). Two pseudowords – one for the clear boundary condition and one for the ambiguous boundary condition – were created to pair with each target pseudoword and create two combinations. These pseudowords always preceded the target word in the combination and differed from one another only in their coda consonant, leading to an illicit (clear boundary: /hiːs_lɔɪk/) or licit (ambiguous boundary: /hiːʃ_lɔɪk/) boundary context (Online Wortschatz-Informationssystem Deutsch [OWID], 2003). A detailed description of stimuli creation and a list of all the target words and information about the context in which they were presented (clear, ambiguous boundary) can be found in supplementary material C.
For each pair of combinations, a sentence frame was created. In the sentences with the clear boundary combination inserted, the boundaries at each side of the target word were clearly cued (e.g. /sl/ and /kp/ in ‘I’m glad to see the /hiːs_lɔɪk/ peek up’), while in the sentences with the ambiguous boundary pseudowords, they were not (e.g. /ʃl/ and /kr/ in ‘I’m glad to see the /hiːʃ_lɔɪk/ rise up’). This way, a total of 120 sentences with clear boundary combinations and 120 sentences with ambiguous boundary combinations were created. The onset of the following word was distributed roughly evenly between liquids (54 sentences) and vowels (60 sentences), and some stop consonants (2 sentences) and fricatives (4 sentences) were also used. Sentence length was on average 10 syllables (SD = 0.77; range = 9–11), and the position of the target pseudoword varied between sentences (nth syllable: M: 5.91; SD = 1.75; range = 2–10). As the sentence frames were identical in their syllable count for each clear and ambiguous boundary sentence pair, total length and position of the target pseudoword did not differ between these conditions. A list of the sentences can be found in supplementary material D.
A female, first-language speaker of American English, with a Midwestern accent, recorded all sentences and target words several times and the best tokens were chosen by the second author for further processing. Criteria for choosing the best tokens were clear pronunciation and stress placement, uniform speech rate across stimuli and a natural intonation. Recordings were post-processed in Praat (Boersma and Weenink, 2016), including noise reduction and segmentation into individual wave files.
Each participant listened to 120 trials, each consisting of one sentence followed by a probe pseudoword. Six lists were created which counterbalanced for the type of sentence (clear boundary, ambiguous boundary) and probe pseudoword status (short target, long target, lure). Both types of target words were present in the sentence, but short target words were presented without their onset boundary context (/lɔɪk/), while long target words were presented including their onset boundary context (/slɔɪk/, /ʃlɔɪk/). Lure words were not heard in the sentence, but matched in syllable length to the target word heard in the sentence and were dissimilar to the target word and all other words in the sentence. Each participant heard 20 trials for each combination of boundary type (clear, ambiguous) and probe pseudoword status (short target, long target, lure), half of which were monosyllabic probe pseudowords while the other half were bisyllabic. Participants never heard the same probe pseudoword or sentence more than once. The assignment of targets and lures to sentences is given in supplementary material D.
b Participant-based predictor variables
Phonological awareness was measured in a modified version of the phoneme manipulation and onset-rhyme task used by Bialystok et al. (2003). In the onset-rhyme task, participants heard recordings of three German-sounding pseudowords and were instructed to indicate the word that did not fit. One of the pseudowords either did not share the onset (e.g. /ʃlɪk/ in the set of /ʃlɪk/– /kɛlp/ – /kɔlx/) or the rhyme with the other two pseudowords (e.g. /mɛl/ in the set of /mɛl/– /zɛt/ – /vɛt/). In the phoneme manipulation task, participants were told that they would play a game with words and sounds. They completed a series of practice trials to scaffold the game, completing each sub-component first with real German words and then with German-sounding pseudowords. First, they identified the first sound of a word/pseudoword (e.g. /t/ in Tisch) and then what would remain if the first sound of a different word/pseudoword was left out (e.g. /ʏːl/ in Müll). Finally, they were shown how the game works by hearing pairs of words/pseudowords and then an example of how they would be combined in the game (e.g. /baʊx/ and /tɪʃ/ become /bɪʃ/) and asked to complete a few examples. The test items were all German-sounding pseudowords (e.g. /viːl/ – /buːn/ become /vuːn/ or /biːl/).
In our preregistration, we did not specify which of the two tasks to use as our measure of phonological awareness, but instead specified a procedure for determining which one to choose. There was more variation in scores in the phoneme manipulation task (Coefficient of Variance (CV) = 1.12) compared with the onset-rhyme task (CV = 0.33), but a Shapiro–Wilk test for normality revealed that scores in the phoneme manipulation task were significantly different from a normal distribution (W = 0.83, p < .001), while the scores were not significantly different from a normal distribution in the onset-rhyme task (W = 0.98, p = 0.23). As per our preregistration, we took the score from the onset-rhyme task as our phonological awareness predictor variable, as it best captures variation within our population. Descriptive statistics for scores in both tasks are provided in Table 1.
The variable of L1 German skill, which we predict should influence children’s use of L1 phonotactic cues while segmenting English speech, was measured using a modified version of the semantic fluency task used in the ‘Delis–Kaplan Executive Function System’ (D-KEF; Delis et al., 2001). Participants were given one minute each to produce as many items as possible that they could think of on the topic of ‘plants’, and then the topic of ‘clothing’. For each participant, the total number of correct category members, excluding repetitions of the same item, was summed across the two categories to create our predictor variable of L1 German skill. Descriptive statistics for the German semantic fluency score are provided in Table 1.
c Participant-based control variables
Participants also completed additional tasks examining non-verbal intelligence, phonological short-term memory, and working memory to control for potential variation in cognitive skills that may impact their segmentation abilities (Table 1 provides the descriptive statistics). Non-verbal intelligence was measured using Raven’s Progressive Matrices 2 Clinical Edition (NCS Pearson, Inc., 2019). Phonological short-term memory was measured using a modified version of the crosslinguistic nonword repetition task (Chiat, 2015; Polišenská and Kapalková, 2014) and the score calculated using the total number of correctly repeated nonwords. 3 We used a modified version of the forward and backward digit span tasks from the ‘Hamburg-Wechsler-Intelligenztest für Kinder’ (HAWIK IV; Petermann and Petermann, 2008) as our measure of working memory, taking the length of the longest correctly repeated sequence of digits (span) for each sub-task. In our preregistration, we did not specify which of the two sub-tasks to use as our measure of working memory, as there is disagreement as to whether the two sub-tasks measure different abilities (e.g. Bowden et al., 2012; Reynolds, 1997). Instead, we specified a procedure for determining which one to choose. Variation in both sub-tasks was similar (Forward CV = 0.21; Backward CV = 0.26) and scores for both were significantly different from a normal distribution (Forward: W = 0.82, p < .001; Backward: W = 0.85, p < .001). Scores in the forward digit span task did not correlate significantly with the scores in the crosslinguistic nonword repetition task (r = 0.16, p = .1), but did with scores in the backward digit span task (r = 0.27, p < .01). We therefore added up participants’ scores in the forward and backward digit span tasks to produce a summed digit span score.
In addition, we also measured participants’ productive vocabulary in German and receptive vocabulary in English. Neither of these measures were intended to be included as predictor or control variables in our models, but instead serve to give a better picture of participants’ linguistic skills in German and English, although the latter was pre-registered to use among our exclusion criteria. L1 German productive vocabulary was measured by summing the total number of correct responses to a computerized version of the LITMUS Crosslinguistic Lexical Task (CLT; Rinker and Gagarina, 2017) for the production of German nouns (maximum score of 32). English receptive vocabulary was measured by summing together the total number of correct responses to a computerized version of the LITMUS-CLT (Haman et al., 2017) for the comprehension of English nouns (maximum score of 32). Of the 32 items on the English comprehension LITMUS-CLT, 13 are similar in phonological form to their German translation equivalents (ball, stool, nest, penguin, glass, motorcycle, watermelon, carrot, cow, star, balloon, tiger, apple) and may be recognizable to German children even without English knowledge (Von Holzen et al., 2019). The remaining 19 items, however, should not be recognizable based on knowledge of the German form. In our pre-registered approach to data exclusion, we had specified that we would exclude data from children who performed better than chance (25%) on these words, to ensure that they had little knowledge of English. However, considerably more than half of the children in our sample would have been excluded using this criterion (n = 74). We therefore opted to not use this exclusion criterion but rather include exploratory analyses on the segmentation task using English comprehension LITMUS-CLT.
3 Procedure
Participants were tested either in a quiet classroom during their school’s after-school program (n = 104) or accompanied by a caregiver and tested in a quiet room at the university (n = 9). For participants tested at school, the tasks were distributed over two testing sessions; participants tested at the university completed all tasks within a single session. The participant was seated alone in front of a laptop with an experimenter seated either next to them or opposite them, depending on the task. All tasks were administered using OpenSesame (Mathôt et al., 2012), with the exception of Raven’s Progressive Matrices 2, which used a test booklet. Experimental stimuli were presented visually on a laptop (HP 250 G6 or Lenovo E51-80) and auditorily via child-appropriate headphones (JBL JR310). Non-oral responses were collected via an Xbox controller (segmentation task) or noted down by the experimenter (Raven’s Progressive Matrices 2 and English comprehension LITMUS-CLT), while oral responses were recorded with a digital recorder (Olympus WS-853) and either scored in real time by the experimenter via keyboard (digit span tasks) or later transcribed for scoring (German semantic fluency task, German production LITMUS-CLT, crosslinguistic nonword repetition, and onset-rhyme tasks). Every task consisted of practice trials where participants received feedback on their responses, but during the actual test no feedback was given. The only exception was the onset-rhyme task, for which no feedback was given, even during the practice trials. Experimenters communicated with participants using German throughout the testing session.
The participants were told that the experimenters were from the local university and had discovered an alien. The tasks were introduced as helping the researchers to decipher what the alien was saying or as playing a game with the alien. At the beginning of the first session, participants were asked about their experience with English and whether they spoke any other language in addition to German. Their first task was an unrelated segmentation task, not examined in this study, which investigated the role of lexical overlap with the L1 in initial foreign speech segmentation using a similar task as the current segmentation task. This was then followed by Raven’s Progressive Matrices 2, the forward and backward digit span tasks, and the German production LITMUS-CLT. The segmentation task of the current study began the second session, which took place between 0 and 28 days after the first session (M = 7.45 days; participants tested at the university completed both sessions on the same day). The segmentation task followed a procedure similar to that of Shoemaker and Rast (2013). Participants first listened to a sentence, followed by a probe pseudoword and were instructed to indicate by button press on an Xbox controller whether they heard the probe pseudoword in the sentence. This was followed by the crosslinguistic nonword repetition task, the phoneme manipulation and onset-rhyme tasks, the German semantic fluency task, and the English comprehension LITMUS-CLT. If participants indicated that they spoke an additional language, they were asked to complete the production LITMUS-CLT and semantic fluency tasks in that language immediately after completing it in German.
4 Analysis
In tasks where participants had to indicate their answer orally (i.e. German production LITMUS-CLT, crosslinguistic nonword repetition task, the phoneme manipulation and onset-rhyme tasks, and German semantic fluency task), responses were first transcribed and then scored by two independent coders. The coders discussed cases of disagreement first during transcription and then later during scoring and if resolution could not be found, the item was juried by a third coder. The audio file was not available for one child in the German production LITMUS-CLT to be transcribed and coded afterwards, so for this child the live coding done during testing was used for analysis.
Data pre-processing and statistical analyses were conducted using R version 4.2.2 (R Core Team, 2018). Participants’ responses in the segmentation task were used to calculate participants’ word acceptance scores, our dependent variable, by assigning a value of 1 to participants’ responses indicating that they had previously heard the probe pseudoword in the sentence and a value of 0 when they indicated they had not heard it. Word acceptance thus reflects the likelihood that participants accepted a particular probe pseudoword as occurring in the previously heard sentence. Generalized linear mixed effects models were used to model the binary variable word acceptance using the lme4 and lmerTest packages (Bates et al., 2015; Kuznetsova et al., 2017). The maximum random effects structure was determined using the ‘order’ function from the buildmer package (Voeten, 2023; see also Barr et al., 2014) and in cases where the full model did not converge, the ‘backward’ function was additionally used to produce the best-fitting model. The emmeans package (Lenth, 2019) was used to report estimated marginal means for significant effects and interactions and to test post-hoc comparisons.
In addition to word acceptance scores, we also analysed participants’ d’ scores to capture their sensitivity to the presence of items in the sentence (Hautus et al., 2021). These pre-registered analyses can be found in the supplementary material E. We choose to report only analyses of word acceptance scores in this manuscript because they allow us to account for variability across items, whereas d’ scores are aggregated across items.
a General segmentation ability and the role of phonological awareness
The first set of preregistered analyses investigated general FL segmentation ability (research question 1) and whether this is influenced by individual variation in phonological awareness (research question 2). 4 For word acceptance as the dependent variable, a model was built including an interaction between the predictive, fixed effect of word status (target, lure; deviation coding scheme: 0.5, −0.5) and the phonological awareness score (continuous, onset-rhyme task). Additional control fixed effects, mean-centered, were entered as main effects: German semantic fluency score, summed digit span score, Raven’s Progressive Matrices 2 score, and crosslinguistic nonword repetition task score. The maximum random effects structure was initially set with slopes for segmentation task trial number (1–120) and word status (target, lure) on the participant and item (sentence) intercepts.
b Use of L1 phonotactics in foreign language segmentation and the influence of L1 language knowledge
The second set of preregistered analyses investigated the influence of L1 phonotactic cues on FL segmentation performance (research question 3), and whether this is affected by individual variation in majority language knowledge (research question 4). 5 This model included an interaction between the predictive, fixed effects of word candidate length (long, short; deviation coding scheme: 0.5, −0.5) and boundary type (clear, ambiguous; deviation coding scheme: 0.5, −0.5), and the German semantic fluency score (continuous). Model specification was otherwise the same as the previous model, except that the random slope of word status was replaced with random slopes for word candidate length (long, short) and boundary type (clear, ambiguous).
c Exploratory: The role of English language knowledge
We also conducted an exploratory analysis to assess the role of participants’ receptive English knowledge on their general FL segmentation ability and on the influence of L1 phonotactic cues on FL segmentation ability (research question 5). This exploratory analysis was motivated by finding that the participants had better English receptive vocabularies than we had anticipated, as measured by the English comprehension LITMUS-CLT task. A model was built including an interaction between the predictive, fixed effects of word status (target, lure), boundary type (clear, ambiguous), and the English comprehension LITMUS-CLT score (continuous). Otherwise, the specification and approach to this exploratory model was the same as the analogous models described above.
IV Results
Only significant main effects or interactions (p < .05) with the predictor variables are interpreted. Effects of the participants’ scores in the additional tasks are given in the respective supplementary material F table.
1 General segmentation ability and the role of phonological awareness
For research questions 1 and 2, the initial model did not converge with all of the additional tasks included as main effects. The model resulting from backward stepwise elimination of predictors included the fixed effects of participants’ German semantic fluency scores and an interaction between word status and participants’ score in the onset-rhyme task and had a maximum random effects structure of random intercepts for subjects and items, with random slopes of word status for both subjects and items. The main effects of word status (β = 1.98, SE = 0.13, z = 15.50, p < .001) and onset-rhyme score were significant (β = −0.06, SE = 0.02, z = −2.63, p < .01), as was the interaction between word status and onset-rhyme score (β = 0.09, SE = 0.03, z = 2.85, p < .01). Word acceptance was greater for target (EMM = 0.23, SE = 0.08) compared with lure words (EMM = −1.76, SE = 0.14) and overall word acceptance scores decreased with increasing onset-rhyme score. Critically, as onset-rhyme score increased, the difference in word acceptance between target and lure words increased. Figure 1 plots word acceptance scores for target and lure words and the relationship with onset-rhyme task scores. For full model details, see supplementary material F1. The results of this analysis suggest that pre-EFL learners are able to recognize individual words in continuous English speech, and that this ability is modulated by their phonological awareness skills.
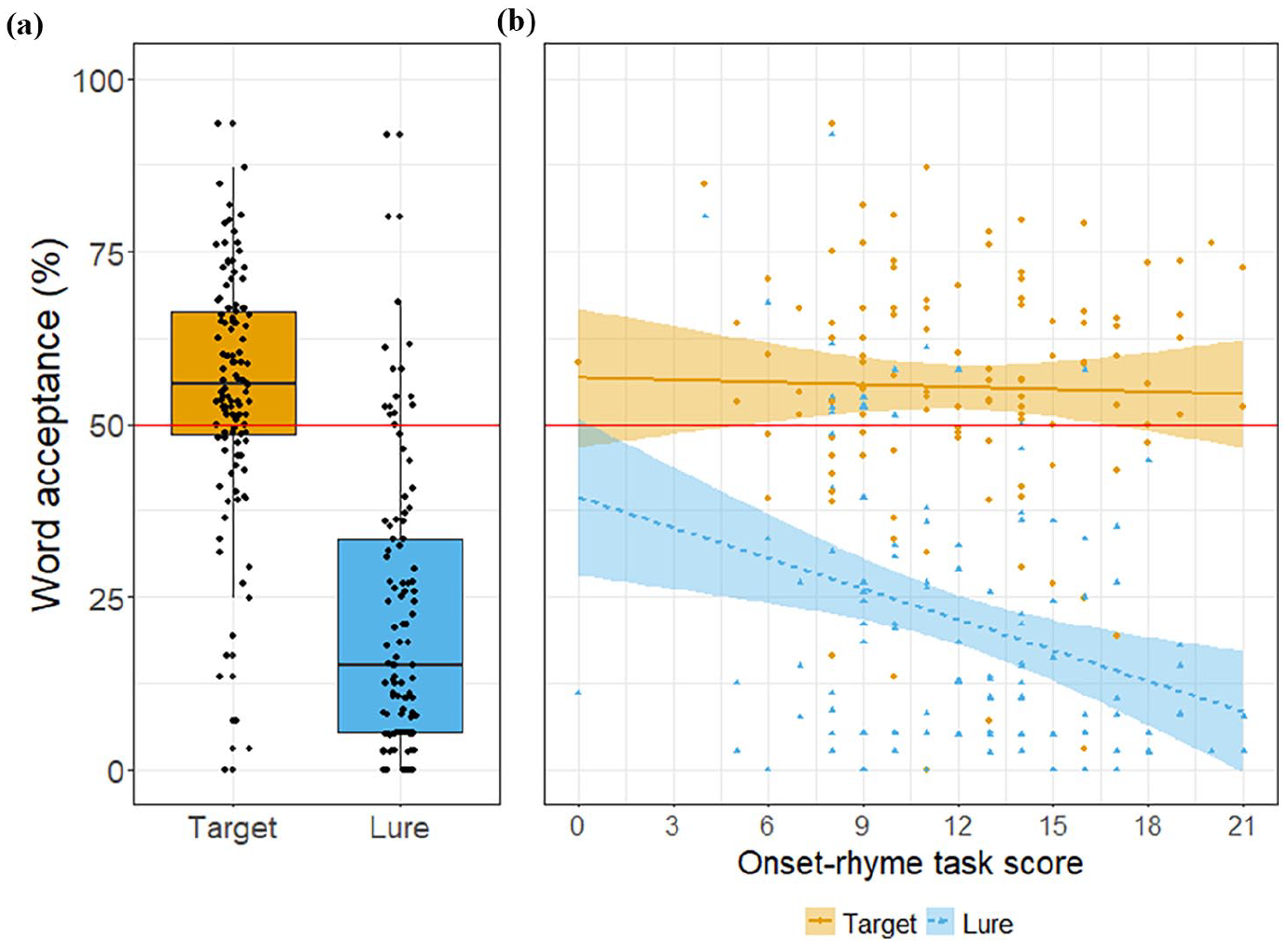
Overall results examining children’s general segmentation ability for both (a) word acceptance for target and lure words, as well as (b) the relationship between word acceptance for target and lure words and children’s onset-rhyme scores, where the red line at 50% indicates the chance level. Individual points represent participants’ average scores in response to target or lure words.
2 Use of L1 phonotactics in foreign language segmentation and the role of L1 language knowledge
For research questions 3 and 4, the best fitting model had a maximum random effects structure of random intercepts for subjects and items and random slopes of word candidate length for subjects and of word candidate length and boundary type for items. The main effects of word candidate length (β = −0.6, SE = 0.07, z = −9.08, p < .001) and German semantic fluency score (β = 0.03, SE = 0.01, z = 2.16, p = .03) were significant, as was the interaction between word candidate length and German semantic fluency score (β = −0.02, SE = 0.01, z = −2.33, p = .02). Word acceptance of short target words (EMM = 0.55, SE = 0.1) was greater than that of long target words (EMM = −0.05, SE = 0.09), and overall word acceptance scores decreased with increasing German semantic fluency score. As German semantic fluency scores increased, the difference in word acceptance between short and long target words increased. Critically, neither the main effect of boundary type nor any of the interactions with boundary type were significant. Figure 2 plots word acceptance scores for short and long target words in clear and ambiguous boundary contexts as well as the relationship with German semantic fluency scores. For full model details, see supplementary material F2. The absence of effects of boundary type suggests that pre-EFL learners’ initial segmentation of English speech is not influenced by whether that speech contains L1 phonotactic cues to word boundaries, neither for students with high L1 skills nor for students with lower L1 skills.
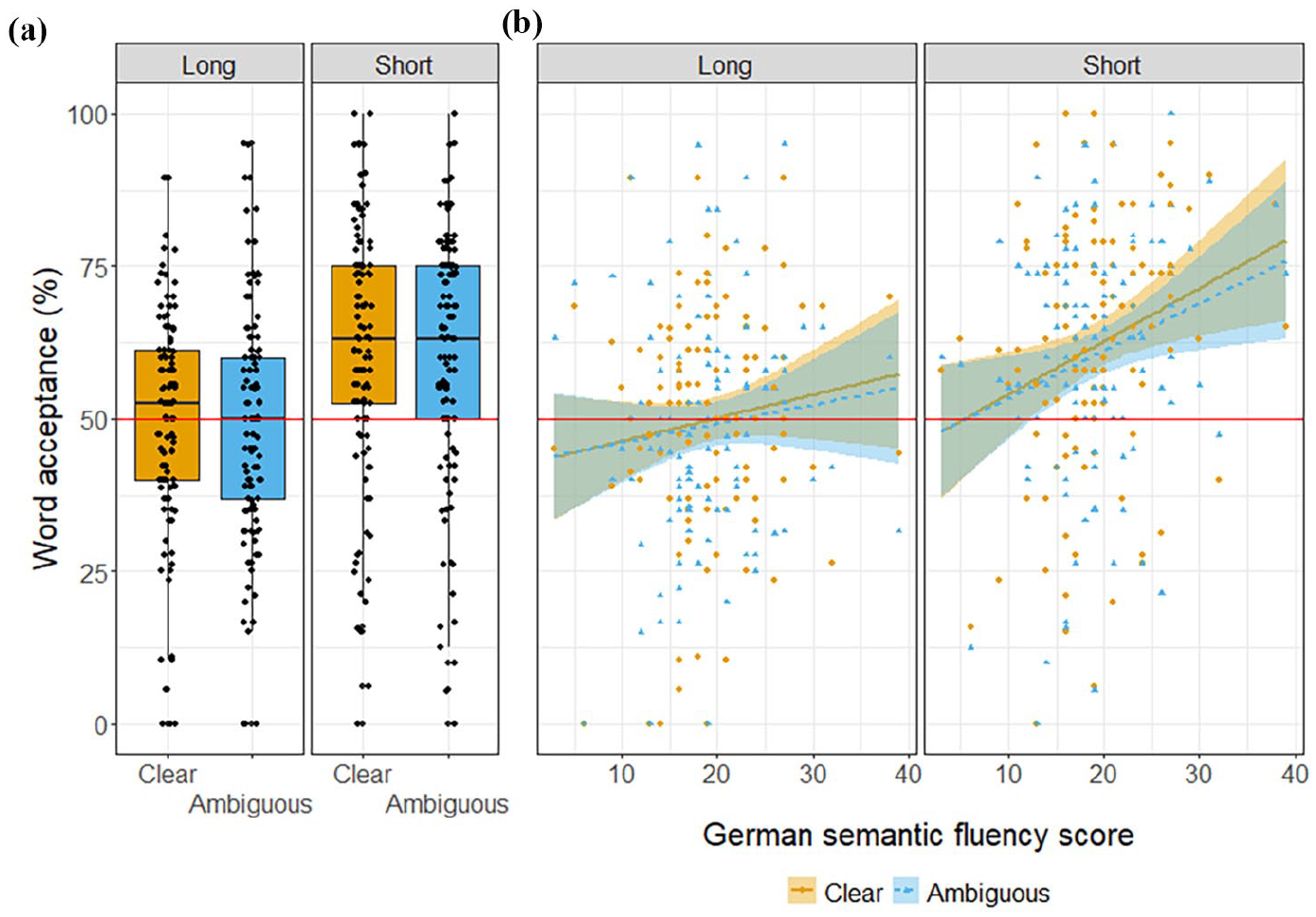
The relationship between word candidate length (long, short) and boundary type (clear, ambiguous) on children’s word acceptance scores (a) overall and (b) in relation to children’s German semantic fluency scores. The red line at 50% indicates the chance level. Individual points represent participants’ average scores in response to target words in clear or ambiguous boundary contexts.
3 Exploratory: The role of English receptive vocabulary
Considering the participants’ relatively high scores on the English comprehension LITMUS-CLT task, we examined whether English receptive vocabulary knowledge influenced their general segmentation ability in response to probe pseudowords presented in a clear or ambiguous boundary context (research question 5). Figure 3 plots word acceptance scores for target and lure words in clear and ambiguous boundary contexts as well as the relationship with English comprehension LITMUS-CLT scores. The best fitting model had a maximum random effects structure that included random intercepts for subjects and items and a random slope of word status for subjects. The main effect of word status was again significant (β = 2.29, SE = 0.14, z = 16.33, p < .001). Likewise, the interactions between English comprehension LITMUS-CLT score and word status (β = 0.15, SE = 0.04, z = 4.1, p < .001) as well as between English comprehension LITMUS-CLT score, word status, and boundary type (β = −0.06, SE = 0.03, Z value = −2.03, p = .04) were significant. As English comprehension LITMUS-CLT score increased, the difference in word acceptance between target and lure words increased. We used the ‘cov.reduce = range’ argument of the emmeans function to compare the estimated means of target and lure words in each boundary condition when English comprehension LITMUS-CLT scores were lower and higher. As can be seen in Figure 3, at lower English comprehension LITMUS-CLT scores, the difference in word acceptance between target and lure words was significant in the clear boundary (EMM = 1.16, SE = 0.40, p < .01), but not in the ambiguous boundary condition (EMM = 0.59, SE = 0.40, p = 0.14). At higher English comprehension LITMUS-CLT scores, the difference in word acceptance between target and lure words was significant in both the clear (EMM = 3.31, SE = 0.37, p < .001) and the ambiguous boundary conditions (EMM = 3.81, SE = 0.37, p < .001). Neither the main effect of boundary type nor any of the other interactions with boundary type were significant. For full model details, see supplementary material F3. The difference in word acceptance according to boundary type at low English comprehension suggests that pre-EFL learners may initially use L1 phonotactic cues to word boundaries to segment English speech, but rely less on them once their receptive English vocabulary has grown.
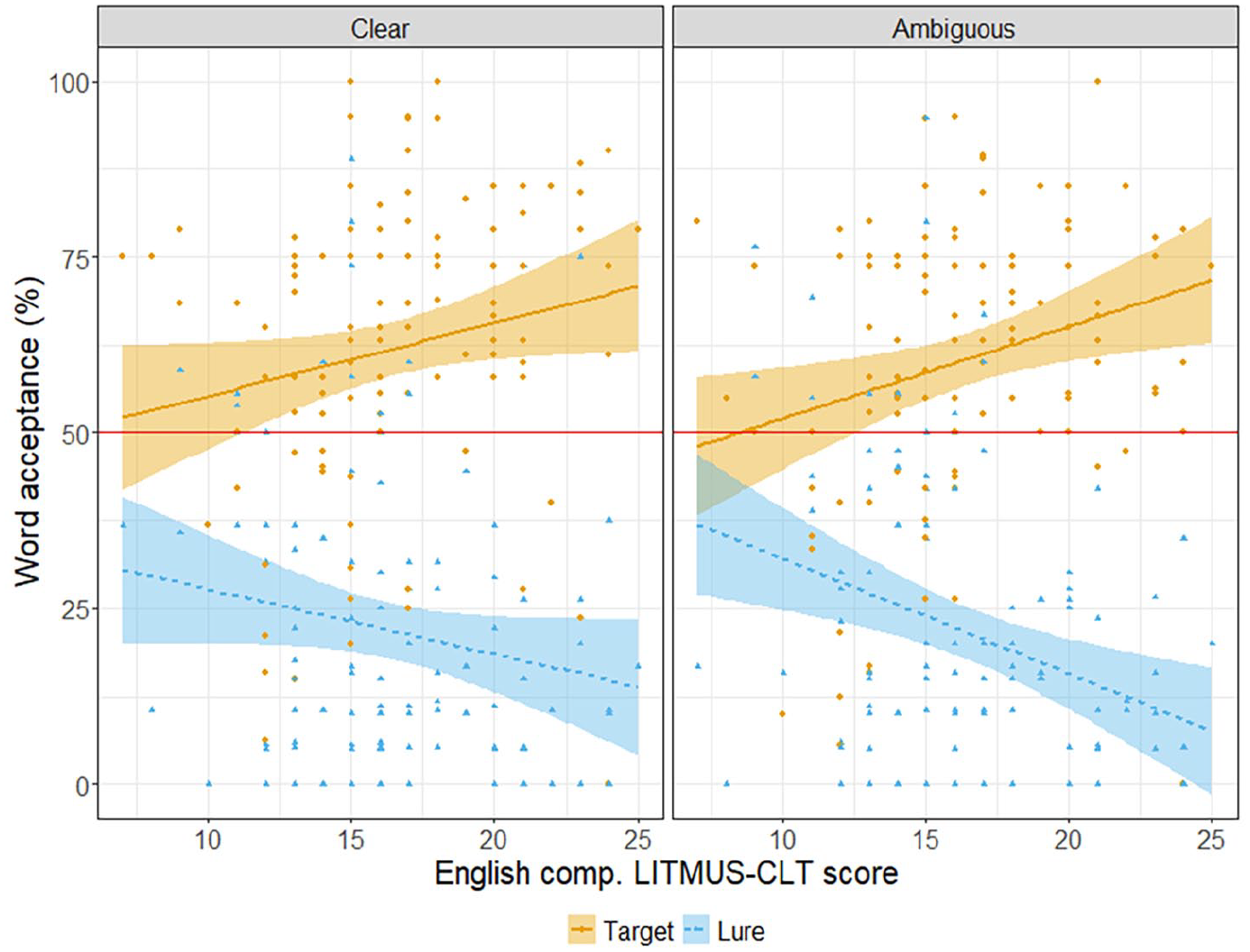
The relationship between children’s English receptive vocabulary, as measured in the English comprehension LITMUS-CLT task, and children’s word acceptance responses to target and lure words in the clear and ambiguous boundary type conditions. The red line at 50% indicates the chance level. Individual points represent participants’ average scores in response to target or lure words.
V Discussion
The current study investigated the ability of German 6- to 9-year-olds to segment and recognize words from English speech before they receive formal instruction in English. Furthermore, we examined whether this ability is influenced by individual differences in phonological awareness abilities, the alignment of the input structure with L1 phonotactic cues to word boundaries, as well as individual differences in children’s general L1 knowledge and receptive English vocabulary. Overall, the participants recognized words, demonstrating an acceptance of target words and rejecting lure words, and this recognition increased with their increasing phonological awareness skills. Against our predictions, we found no evidence that L1 German phonotactic cues to word boundaries led to increased recognition at the group level, nor that this was related to students’ L1 German skills. Yet, an exploratory analysis found that students who had low English receptive vocabulary scores were more likely to be influenced by L1 phonotactic cues than those with higher scores, suggesting that effects of L1 phonotactics may be short-lived in early EFL learning.
Previous studies have found evidence of segmentation in adult beginning learners at first exposure in a similar task to the current study (Shoemaker and Rast, 2013) as well as a task with a more extended familiarization phase (Gullberg et al., 2012). Despite differences between our young participants and those adults studied previously in their cognitive, metalinguistic, and linguistic skills, we also found evidence of initial segmentation and recognition in pre-EFL learners (research question 1). Our results suggest that, even before classroom instruction begins, German school-aged children are able to segment and recognize words from the continuous speech they will encounter in their EFL classroom (Feder et al., 2018; Große-Brauckmann and Heidelberg, 2018), demonstrating an ability to process and learn from this speech from the first day of instruction.
In our second research question (research question 2), we asked whether phonological awareness would support initial FL segmentation. Our prediction was borne out in the results: as participants’ scores on our measure of phonological awareness, the onset-rhyme task, increased, they were also more likely to accept target and reject lure words as having appeared in the previous sentence. Pre-EFL learners lack language-specific knowledge about how words are formed in English, making it unlikely that they directly located word boundaries in the sentences. Instead, participants likely encoded the incoming speech signal from the sentence into chunks of information and then compared these chunks with the probe pseudoword. This process requires not only that they hold information in their memory, but also that they manipulate and separate the sound segments in the chunks from one another during the comparison process. Learners with higher phonological awareness skills can more successfully compare and match this phonological information when they encounter it in multiple instances. Reliance on such processes supported by phonological awareness may therefore be a successful approach to speech segmentation and FL learning before any specific knowledge of the FL is acquired.
We also investigated whether participants applied their language-specific phonotactic knowledge about German word structure and boundaries to English (research question 3). When phonotactic cues differ between the L1 and the target language, adult listeners have been found to be misguided by the phonotactic cues from their L1, both at the onset of learning a new language (Finn and Hudson Kam, 2008) and at advanced proficiency levels (Hanulíková et al., 2011; Weber and Cutler, 2006). Unlike adult learners, however, our participants were not more likely to segment and recognize words in a FL when the word boundaries were signaled by L1 phonotactic cues than when they were not. Results from our pre-registered analysis suggest that, at the group level, word acceptance did not differ between the clear and ambiguous boundary conditions, regardless of whether the participants were responding to short or long target words. It therefore appears that, at the group level, unlike adults, children do not exploit L1 phonotactic cues to find word boundaries in a new language.
This may be due to differences between adults and younger learners in their application of L1 phonotactic cues, due to differences in their overall experience with their L1 (research question 4). Pierrehumbert (2003) describes the calculation of phonotactic probability as being shaped by experience with the language and generalized over entries in the mental lexicon. More frequently encountered combinations are more likely to constrain the phonological system. As children develop and learn more words, especially when they begin school, their knowledge of the phonotactic constraints of their L1 is becoming more adult-like but may still be weaker or more flexible (Edwards et al., 2004; Smalle et al., 2017). Young learners may therefore be less likely to apply L1 phonotactic constraints than adults because they have less cumulative experience with the L1 and their processing is less constrained by phonotactic probabilities. Evidence from infants shows that, as vocabulary in their first language increases, they are less likely to acquire phonotactically illicit words (Graf Estes et al., 2011, 2016), suggesting that individual differences in L1 skills may play a role in learners’ flexibility in the application of L1 phonotactic constraints. Contrary to this prediction, however, we found no evidence that individual differences in participants’ general L1 skills have an influence on the application of L1 phonotactic constraints in early FL segmentation.
Alternatively, young learners’ L1 phonotactic knowledge may actually be similar to that of adults, but they differ in their ability to apply this knowledge to information stored in memory. We have argued above that the participants in the current task may have first encoded the speech signal from the sentence and then compared the sound segments with the probe pseudoword. If so, then L1 phonotactic cues may come to guide listeners only during the comparison process, namely when they manipulate and separate the sound segments in memory. Combinations of sound segments that signal a boundary according to L1 phonotactics could then be easier to separate than combinations with no obligatory boundary. Considering we found no evidence of the application of L1 phonotactic cues at the group level in our study, it could be that our young participants did not yet have sufficient cognitive resources to apply these cues during the comparison process. Conversely, the word acceptance decision may have been made easier for participants due to the dissimilarity between target and lure probe pseudowords. Evidence from preschool-aged children suggests that lexical representations for newly learned words are initially not specified with full phonological detail but more holistic in nature (Creel and Frye, 2024). In our study, lure and target probe pseudowords were paired to be maximally different from one another. Future research could test older learners or employ different tasks, such as lure probes that are more phonologically similar to target probe words, to assess these potential effects on the application of L1 phonotactics.
In addition to manipulating the boundary condition in which target words were embedded, we also elicited participants’ responses to probe pseudowords that either spanned the onset boundary (long target words) or did not (short target words). Unexpectedly, we found that word acceptance scores for long target words (49.5%) were lower than those of short target words (61.6%), although these scores were still higher than that of lure words (21.2%). The higher word acceptance scores for long target words compared with lure words suggest that participants were sensitive to the fact that the sound sequences of long target words did appear in the sentence. But this does not explain why scores were lower for long compared with short target words, as the sound sequences for both of these items appeared in the sentence. Instead, this pattern of results may be due to our approach to preparing our materials. Long target words stretched across the onset word boundary in the sentences given to our speaker to read (e.g. /hiːs_lɔɪk/ in ‘I’m glad to see the heece loik peek up’). While reading the sentences, our speaker may have introduced subtle acoustic cues to the word boundaries, to which the participants in our study may have been sensitive. L2 listeners have been found to attend more to acoustic detail in general than L1 listeners (Song et al., 2020) and to specifically attend to such subtle acoustic cues to word boundaries (Weber and Cutler, 2006). To determine whether this is the case, future studies could explicitly manipulate acoustic cues to word boundaries or use stimuli produced by multiple speakers, so as to minimize individual speaker idiosyncrasies.
In order to best capture our participants’ initial FL processing capabilities, our target population in the current study were young learners who had not yet begun to receive classroom instruction in English. We included several measures to ensure that they had not acquired proficiency in English otherwise, for instance, a low percentage of exposure to English and when participants indicated knowing English, that they had a low English productive vocabulary. We also included the English comprehension LITMUS-CLT task (Haman et al., 2017) to assess that they did not have an active receptive vocabulary, as defined in our pre-registered exclusion criteria. Almost two-thirds of our sample would have been excluded based on this criterion. These participants likely gained this receptive vocabulary through extramural exposure to English, which has been found to influence English proficiency before instruction has taken place (De Wilde et al., 2020; Kuppens, 2010). As a result, we decided to disregard this criterion for exclusion and instead explore how incidental knowledge of English influenced children’s performance in the current study (research question 5).
In our exploratory analysis, we found an influence of receptive English vocabulary on both general segmentation ability and on the application of L1 phonotactic cues. As children’s receptive English vocabulary increased, so did their segmentation and recognition of words from English speech. Interestingly, this also had an impact on the application of L1 phonotactic cues to segment English speech: Participants who had the lowest receptive English vocabulary were more likely to use L1 phonotactic cues to segment and recognize words from English speech. This suggests that young learners may exploit L1 phonotactic cues at the onset of their FL learning journey, but this is quickly disregarded once more appropriate, target-like procedures begin to be acquired through incidental exposure.
Our evidence that exposure and experience with a FL influences young learners’ use of L1 phonotactic cues to segment speech may provide further support that adult learners and young learners differ in their approach to FL segmentation. In a study of artificial grammar learning, Finn and Hudson Kam (2008) tested adult participants on their ability to track statistical regularities, finding that they were more likely to extract words from the speech stream that are phonotactically licit in their L1, even if these words were not supported by the statistical regularities present in the input. This did not change, even when participants were given substantially increased exposure to the artificial language. These findings stand in contrast to the results of the current study, which suggest that after some English knowledge is acquired, children do not continue to rely on phonotactic cues from their L1. As argued above, this may partially be the result of the weaker status of L1 phonotactics in children. In terms of language development, adult learners are more entrenched in their L1, which may make them less likely to disregard phonotactic cues from their L1 (Siegelman et al., 2018), whereas the children in the current study may have been more likely to disregard L1 phonotactic cues when faced with speech produced in a FL.
Future studies may therefore wish to further explore the relationship between individual differences in participants’ L1 skills and the application of L1 phonotactic cues by using a different measurement of L1 skills or testing different groups of participants. Performance on the semantic fluency task, our measure of L1 skills, improves during the primary school years (Jacobsen et al., 2017) although the more automatic lexical-semantic processes that undergird the majority of fast and initial responses in this task may plateau by age 9 or 10 years (Hurks et al., 2010). Although we included participants of different ages and experience with German, there may have not been enough variation to capture a relationship between scores in the German semantic fluency task and the use of L1 phonotactic cues. We chose a semantic fluency task specifically because it was not directly related to phonotactic or phonological processing; rather, we wanted to have an independent assessment of how general L1 knowledge may impact the application of phonotactics. However, variation in more specific L1 phonological knowledge may be more directly linked to the application of L1 phonotactic cues to segment foreign speech, and future studies should administer tasks measuring L1 phonological knowledge. Nonetheless, a measure specifically designed to capture such knowledge, such as phonemic verbal fluency which asks participants to produce words that begin with a specific sound, would have likely correlated with our current measure (Jacobsen et al., 2017). Instead, testing learners across a wider age range, e.g. from preschool-aged children to adults, may better capture differences in L1 skills than the comparably narrow range of 6- to 9-year-olds tested in the current study. This would have been difficult to realize in the current study, as students currently begin to receive English instruction by at least third grade in Germany, which restricts the inclusion of older participants. Yet, adaptations of our task to other foreign languages that are not regularly taught in schools may be able to capture these effects and clarify the relationship between mastery of the L1 and the transfer of its features when beginning to learn a new language.
VI Conclusions
Even before receiving classroom instruction in English, German school-aged children are able to recognize individual words in continuous English speech. This successful recognition is supported by metalinguistic abilities at the phonological level. In contrast, L1 phonotactic cues do not seem to support pre-EFL learners in their detection of word boundaries, especially once they have acquired some limited receptive knowledge of English. In this respect, young learners appear to approach foreign language learning differently from adult learners, who rely more strongly on cues from their L1.
Supplemental Material
sj-pdf-1-slr-10.1177_02676583251348941 – Supplemental material for Speech segmentation in pre-foreign language learners: An investigation of meta-linguistic and linguistic knowledge
Supplemental material, sj-pdf-1-slr-10.1177_02676583251348941 for Speech segmentation in pre-foreign language learners: An investigation of meta-linguistic and linguistic knowledge by Katie Von Holzen, Sophia Wulfert, Marie Schnieders and Holger Hopp in Second Language Research
Footnotes
Acknowledgements
We would like to thank Amelie Schatull, Naomi Kailasam, Jacob-Johann Hinrichs, and Lisa Kümmel for their valuable assistance in testing participants and data processing. We would also like to thank Theres Grüter and Heather Goad for their helpful comments during the preparation of this manuscript as well as the school administrators, teachers, and afternoon care coordinators for their cooperation.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research reported here was funded by a German Research Foundation grant (project number: 465308402) awarded to Katie Von Holzen and Holger Hopp.
Open Badges Statement
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.