
Abstract
This study builds on prior investigations into the influence of learners’ native language (L1) on morpheme acquisition, aiming to identify the factors that explain the varying effects of L1 across different morphemes. Specifically, it examines how the semantic characteristics of morphemes, combined with L1 influence, shape the development of morphological knowledge in English as a foreign language (EFL) compared to English as a second language (ESL) contexts. While earlier research suggests L1 plays a significant role in morpheme acquisition patterns, this study delves deeper into the critical role of morpheme interpretability. Findings reveal that interpretability, as a semantic attribute, significantly impacts the variability in morpheme acquisition beyond L1 influence alone. The study concludes by discussing the intricate interplay between L1 and the semantic features of English morphemes in the acquisition processes.
Keywords
I Introduction
Researchers in language acquisition/development have investigated the acquisition order of English grammatical morphemes among both first (L1) and second (L2) language learners since the 1970s (Brown, 1973; Dulay and Burt, 1973). Most early studies on morphemes (Freeman, 1975; Pica, 1983) aimed to demonstrate that English learners develop morphemes in an order consistent with Krashen’s (1977) universal natural order (Figure 1), previously observed among English-speaking children.
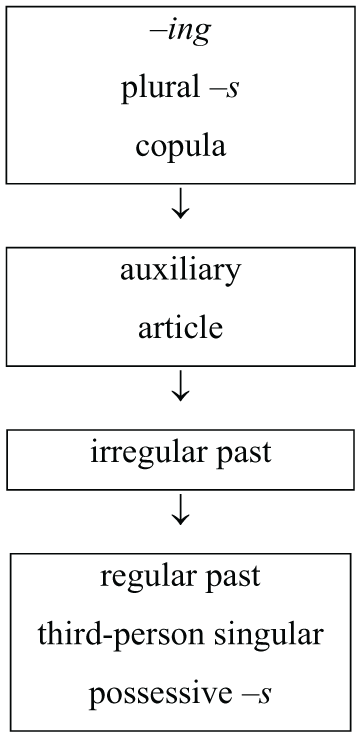
Natural order for second language (L2) acquisition (Krashen, 1977).
However, as subsequent studies began including English learners with diverse L1 backgrounds, the influence of L1 on L2 morpheme acquisition became increasingly evident. The absence of L1 effects in earlier studies was attributed to the fact that participants primarily consisted of Spanish learners of English. Later research revealed how the lack of equivalent morphemes in L1 accounts for L2 learners’ unconventional uses or omissions of English morphemes (Andersen, 1983; Lightbown, 1983; Pak, 1987; Shin and Milroy, 1999). For example, Pak’s (1987) study of Korean children and adults acquiring English as a second language in the United States found that articles and third-person singular -s are acquired relatively late, plural -s much later, and regular past tense and possessive -’s slightly earlier compared to the natural order. These patterns were attributed to the absence or presence of corresponding morphemes in Korean. Similar findings were reported by Shin and Milroy (1999), as summarized in Table 1.
Results of studies with Korean learners of English compared with the natural order.
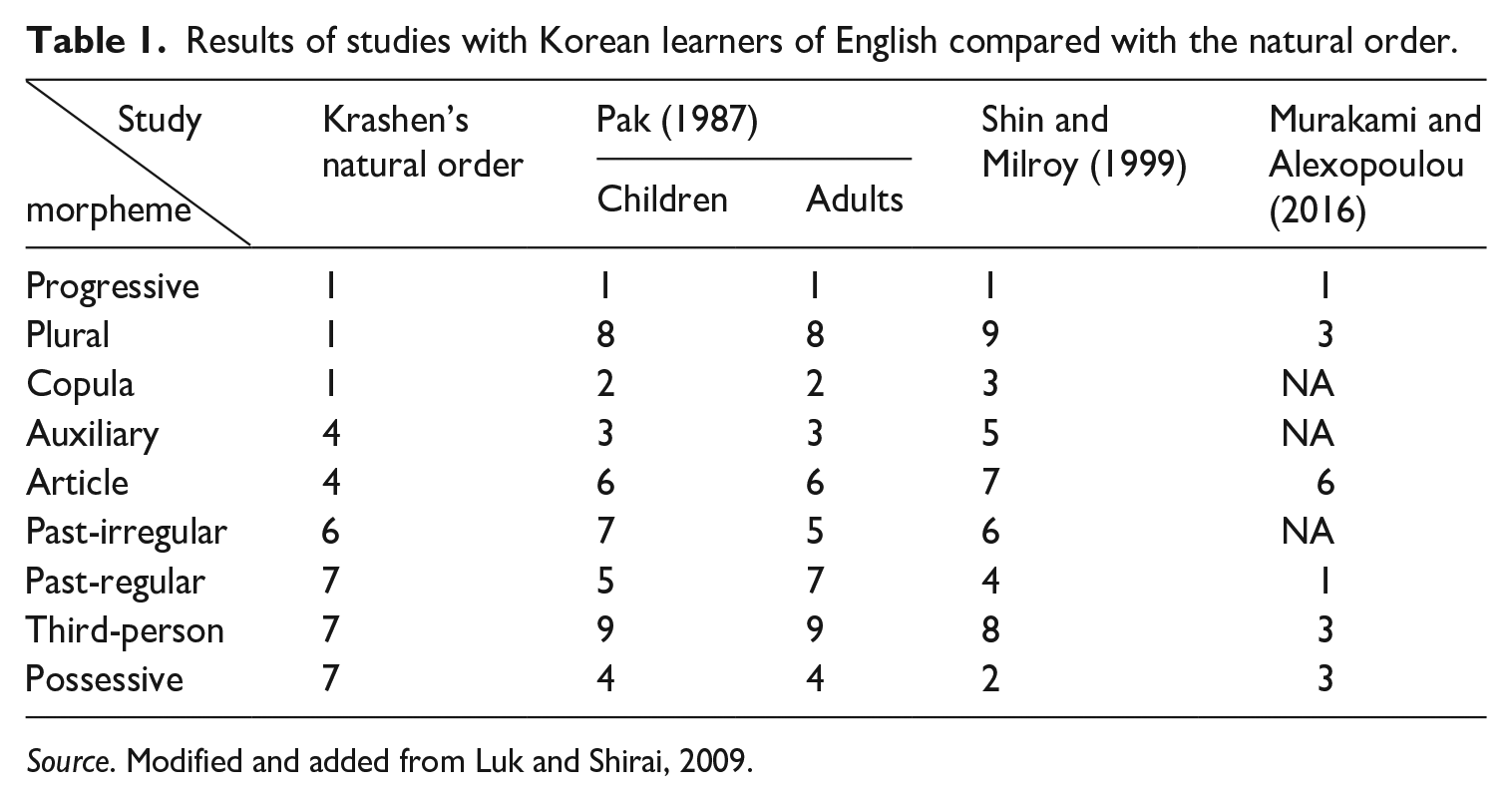
Source. Modified and added from Luk and Shirai, 2009.
Equivalents of plural -s, articles, and third-person singular -s are absent in Korean, while equivalents of regular past tense and possessive -’s are present. Researchers interpreted these results as evidence that the absence or presence of corresponding grammatical morphemes in L1 significantly affects the acquisition of English morphemes. Indeed, many relatively recent studies (Ionin and Montrul, 2010; Jarvis and Pavlenko, 2008) reported cases where the presence of the corresponding L1 morphemes seems to facilitate the pertinent English morphemes development while certain L2 morphemes are developed later than predicted by the natural order if those morphemes are absent in learners’ L1s. In their systematic review article, Luk and Shirai (2009) also advocated how the presence or absence of the equivalent category in L1 is influential in affecting English morpheme acquisition of native speakers of Japanese, Korean, and Chinese.
More recent studies, however, suggest that the L1 effect applies only to certain morphemes. Murakami and Alexopoulou (2016) found that L2 learners sometimes develop morphemes with ease and earlier, even when corresponding L1 morphemes are absent, while struggling with others despite their presence in L1. For instance, the plural morpheme -s, absent in Korean, was developed earlier than suggested by Pak (1987) and Shin and Milroy (1999) among Korean learners of English. This implies that the mere presence or absence of corresponding L1 morphemes does not solely determine acquisition order.
Furthermore, discrepancies have been observed between English as a second language (ESL) contexts and English as a foreign language (EFL) contexts (see Ghonchepour et al., 2020). Studies indicate delayed development of plural -s in ESL settings (Pak, 1987; Shin and Milroy, 1999), while EFL studies report earlier acquisition (Murakami and Alexopoulou, 2016; Schenck and Choi, 2013; Seog, 2015). These differences suggest that classifying L1 effects in binary terms (absent/present) is insufficient, even within the same L1 group (Akbaş and Ölçü-Dinçer, 2021), and thus it is necessary to conduct research focusing on the individual language. As Seog (2015) pointed out, this discrepancy between ESL and EFL contexts might be partially due to methodological differences methodologies adopted as ESL groups were mainly measured on oral data while the EFL groups were scored on written data. It is prevalently discussed that different types of data may reveal different findings in morpheme studies (Ellis, 1994; Krashen, 1977; Larsen-Freeman, 1975). In a similar vein, Goldschneider and DeKeyser (2005) also selectively/exclusively included studies with oral production data to make sure their meta-analysis study is based on comparable types. In this sense, it is crucial for morpheme acquisition studies to collect Korean learners’ oral data in the EFL setting to make a reasonable comparison with the ESL data. Another issue to tackle is, even though Pak (1987) and Shin and Milroy (1999) claimed how the presence or absence of the corresponding L1 morphemes can affect advancement or delay of relevant L2 morphemes, they did not address varying advancement or delay rates across morphemes. For example, the acquisition of plural -s is much more delayed (1 vs. 8 and 9) than that of articles (4 vs. 6 and 7), both of which are absent morphemes in Korean (L1), when compared with the natural order as a baseline (see Table 1). Murakami and Alexopoulou (2016) demonstrated that L1 effects are inconsistent across morphemes. Some morphemes appear more resistant to L1 influence, while others are significantly affected. For example, both plural -s and articles are absent in Korean, yet the delay in developing plural -s is shorter compared to articles, contradicting earlier findings by Pak (1987) and Shin and Milroy (1999).
These findings suggest that L1 influence is morpheme-specific and not a definitive factor uniformly determining delays or facilitations in L2 morpheme development. Murakami and Alexopoulou (2016) preliminarily attributed this variability to the Interpretability Hypothesis (Tsimpli and Dimitrakopoulou, 2007) and Slobin’s (1996) distinction between language-specific and language-universal concepts. Their study, based on English learners from seven L1 backgrounds, categorized morphemes into three groups according to their sensitivity to L1 influence, which aligns with Slobin’s accounts. For instance, third-person singular -s was found to be relatively immune to L1 effects, while plural -s was mildly affected.
However, this classification does not fully account for Korean learners’ case. For example, despite the absence of third-person singular -s and plural -s in Korean, the accuracy difference between these two morphemes is minimal compared to other L1 groups. Moreover, Murakami and Alexopoulou’s (2016) analysis tested these frameworks post hoc, without incorporating semantic features into statistical models. This calls for more systematic research focused on individual L1 groups, such as Korean, to better understand the factors beyond L1 that explain variability in morpheme acquisition.
This study explores the semantic aspects of morphemes as an explanatory factor. Just as all grammatical structures not only have form, but also meaning, and context-appropriate use (Larsen-Freeman, 2001), English morphemes are not merely grammatical forms but also carry semantic and pragmatic features (Lardiere, 2003). Previous research on L2 morpheme acquisition has considered predictors like semantic complexity: the number of meanings expressed by a morpheme (Goldschneider and DeKeyser, 2005). However, salience as a semantic construct has not been systematically addressed, and this study expects to provide an original insight.
Inspired by Brown’s (2000) study on L2 phonological acquisition, which sought to explain ‘partial influence’ of L1 through phonological representations and their components, this study hypothesizes that semantic elements could similarly complement L1 effects in explaining interlanguage patterns. For instance, Ionin et al. (2008) demonstrated how semantic universals, beyond L1 transfer, influence English article usage among learners with and without article systems in their L1. Such findings suggest that semantic features, along with L1 effects, may interact to shape L2 morpheme acquisition patterns. In a similar vein, the semantic features of morphemes in this study are expected to provide supplementary explanations on why the L1 effect appears to be morpheme-specific and how L1 and those semantic aspects of morphemes interact with each other in exerting their influence over L2 morpheme acquisition.
The next section introduces two conceptual frameworks that guide a meaning-oriented viewpoint and discusses their potential for explaining variability in L2 morpheme acquisition.
II Two theoretical frameworks to embrace semantic aspects
This study adopts the Interpretability Hypothesis and Levinson’s Mapping Problem Framework to investigate how morphemes’ underlying semantic features interact with L1 influence, shaping L2 morpheme acquisition patterns. These frameworks provide complementary perspectives: the Interpretability Hypothesis emphasizes semantic interpretability as a key factor in L2 learnability while Levinson’s framework introduces a layered view of learning difficulty based on mapping complexity.
1 The Interpretability Hypothesis
The Interpretability Hypothesis distinguishes between semantically interpretable features and semantically uninterpretable ones based on whether the morphosyntactic realization of morphemes is derived from semantic embodiment or pure syntactic operation. According to Tsimpli (2003) and Tsimpli and Dimitrakopoulou (2007), interpretable features are accessible at the Logical Form (LF) interface, while uninterpretable features are processed purely syntactically at the Phonetic Form (PF) level.
For example, the plural morpheme -s is considered LF-interpretable because it conveys semantic meaning (e.g. plural vs. singular) and is realized directly on the noun. In contrast, the third-person singular -s is LF-uninterpretable, as its presence is determined by syntactic rules (e.g. agreement with the subject) rather than inherent semantic content. 1 Similarly, articles are categorized as bearing uninterpretable features, as their use depends on syntactic operations like c(ategory)-selection, rather than semantic embodiment (Van Gelderen, 2007). According to Van Gelderen’s (2007) claim with a cognitive principle, Feature Economy, articles cannot occur without a corresponding noun (e.g. in English *I ate the) and this indicates that the article c-selects a nominal constituent. C-selection is a syntactic operation just as predicates select a proper syntactic category of complement arguments (e.g. noun phrase, verb phrase, adjective phrase, etc.), as opposed to s(emantic)-selection, where predicates select the semantic contents of the arguments. The configuration of articles and their nominal constituent is considered as the output of syntactic operation, which supports that articles bear uninterpretable features. Moreover, Van Gelderen (2007) presumed that ‘there is a probe (with uninterpretable phi-features, such as person and number) looking for phi-features on a nominal in its c-command domain and that these probes have to be heads. This set of grammatical features ensures that a noun can be interpreted in the discourse’ (p. 278). As can be seen in Figure 2 excerpted from Van Gelderen (2007), articles are obvious probes in D, with uninterpretable features checking with the phi-features of the noun, which can be inferred from the discourse context.
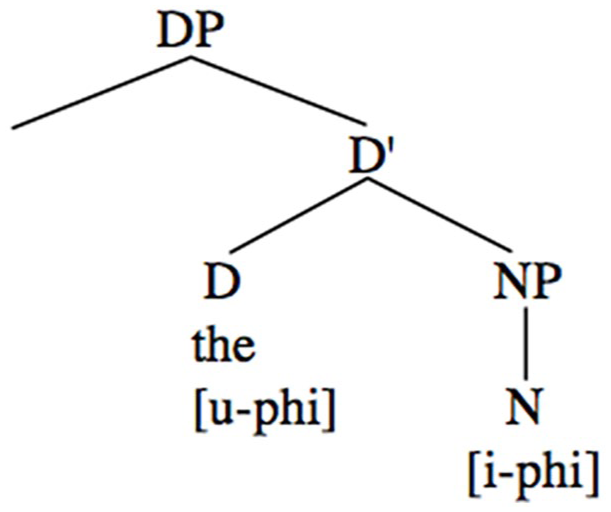
Head D as a probe within DP (Determiner Phrase).
This framework posits that interpretable features are more accessible to L2 learners, while uninterpretable features are more challenging due to their semantic opaqueness. For example, Tsimpli and Dimitrakopoulou (2007) found that Greek learners of English, despite lacking animacy distinctions in their L1, acquired animacy-related features in English (e.g. who vs. what and he, she vs. it) relatively easily. This highlights that semantic interpretability, rather than L1 transfer alone, influences L2 learnability. Also, this finding manifests how the L1 effect is not a panacea to predict learnability of certain features in L2 (to repeat, L1 effect refers to L2 acquisition being affected by the transfer of the learners’ knowledge of L1; see Ellis, 2006). While the Interpretability Hypothesis argues for L1 effects on L2 grammar, it believes this influence is performed not in a definitive way, but in a relative way. To be more specific, it claims that in spite of L1 transfer effects, uninterpretable features are more resistant to L2 acquisition while interpretable features are more easily accessible to L2 learners (Tsimpli and Dimitrakopoulou, 2007). This point aligns with the current study’s intention to explore how and why the L1 effect is not absolute in explaining L2 morpheme development variabilities. As LF is a semantic level that bridges linguistic and conceptual representations, examining the interpretability of morphemes in addition/relation to the L1 within the framework of the Interpretability Hypothesis would help investigating the L1 effect and its interactions with the meaning aspects of morphemes. The current study explores whether the interpretability of morphemes, in addition to L1 influence, can explain why L1 effects vary across morphemes. By examining the LF features of morphemes, this study anticipates uncovering how interpretability complements and interacts with L1 effects in shaping L2 morpheme development patterns.
2 Levinson’s Mapping Problem Framework
Although the Interpretability Hypothesis considers both the L1 effect and semantic interpretability, it does not systematically address the additive effects between these two factors. This study specifically examines how the interplay between L1 influence and semantic aspects impacts English morpheme development, focusing on the dimension of the ‘mapping problem’. Levinson (2001) describes the process by which children learn the meanings of words or morphemes, identifying three distinct degrees of ascending complexity in the mapping problem. This process involves mapping words or morphemes onto meanings and includes:
Degree 1.0 Mapping Problem: The simplest level, involving mapping known phonological entities to known semantic or conceptual entities.
Degree 2.0 Mapping Problem: A more complex level, where learners map known phonological entities to unknown semantic entities constructed from universal concepts.
Degree 3.0 Mapping Problem: The most complex level, involving mapping language-specific word forms to language-specific meanings, requiring learners to develop non-universal working concepts.
Levinson asserts that children’s early-stage words primarily fall under Degrees 1 and 2, with Degree 3 learning emerging later.
Applying Levinson’s framework – originally designed for first language acquisition – to L2 morpheme development, this study proposes three analogous degrees of mapping complexity that incorporate L1 influence and semantic interpretability. The simplest case (Degree 1) occurs when both L1 and L2 share morphosyntactic forms for a specific semantic feature. Degree 2 mapping applies when the L1 lacks the corresponding morpheme, but the L2 morpheme conveys interpretable features. Degree 3 mapping involves the most significant challenge, where the L2 morpheme carries uninterpretable features absent in L1.
As illustrated in Table 2, these three levels align with Levinson’s (2001) original mapping framework:
Degree 1 Problem: Involves correspondences between two levels: word forms and innate conceptual meanings (L1), or word forms in the target language and previously acquired semantic concepts (L2).
Degree 2 Problem: Involves universal semantic primes underlying word meanings (L1) and mapping target language word forms to interpretable semantic concepts (L2).
Degree 3 Problem: Entails universal conceptual primes underlying culture-specific semantic parameters (L1), corresponding to the involvement of uninterpretable semantic features in L2.
This study investigates which degree of mapping in L2 morpheme development is most vulnerable and whether learners can overcome these mapping challenges developmentally.
Three degrees of mapping complexity in second language (L2) morpheme development.

III The present study
1 Research questions and predictions
This study is the first to directly test interpretability as a factor predicting L2 morpheme development patterns. To investigate whether interpretability explains the variability in L1 influence, the study compares the effects of the L1 factor and the interpretability factor on the ease or difficulty of morpheme acquisition in L1 Korean-L2 English learners.
If the L1 factor is dominant, morphemes with corresponding forms in Korean will be easier to acquire. If interpretability is more robust, morphemes with uninterpretable features will be more challenging, regardless of L1 correspondence (see Table 3). The study also examines whether the combined effects of L1 and interpretability provide a more comprehensive understanding of L2 morpheme development. As shown in Table 4, plural -s serves as a crucial index in the current study to investigate whether interpretability contributes to variations in L1 influence.
Predicted ease or difficulty of second language (L2) morpheme acquisition based on first language (L1) and interpretability factor.

Predicted three degrees of difficulty based on complexity (additive effects of the L1 factor and the interpretability).
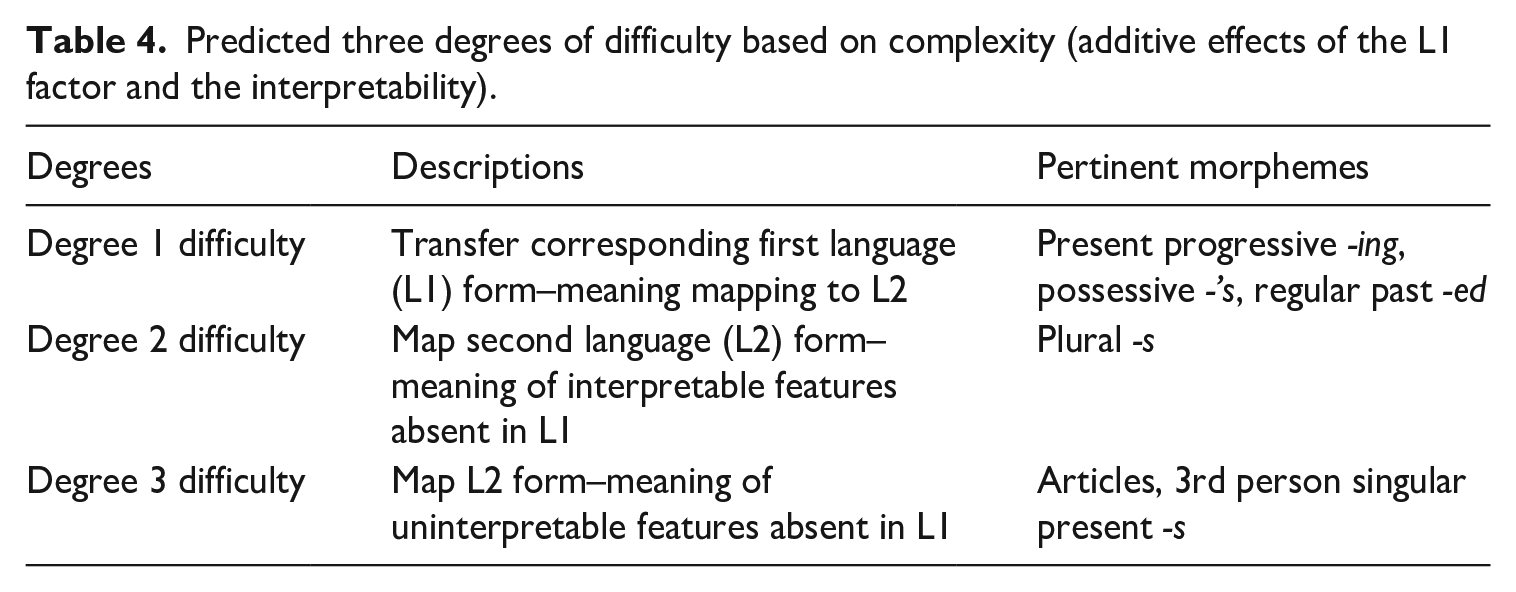
If additive effects exist between L1 and interpretability, three differentiated levels of difficulty in L1 Korean-L2 English morpheme acquisition are predicted. English morphemes with equivalent Korean morphemes would be the least challenging, while learning English morphemes without Korean equivalents would be more difficult, as those semantic components are not morphosyntactically encoded in Korean. Among those without corresponding L1 morphemes, those embodying uninterpretable features are expected to cause more developmental complications due to their relatively opaque semantic concepts at the LF level. Rather than solely depending on the presence or absence of matching L1 morphemes, this conceptual framework considers whether interpretability can complement L1 effects, previously shown to be morpheme specific.
To clarify why the L1 effect on the acquisition of English morphemes is specific to certain morphemes, the following research questions are posed:
Research question 1: How do Korean learners of English in EFL settings develop English grammatical morphemes? How are their developmental paths similar to or different from Krashen’s (1977) natural order? How do they compare to developmental paths in ESL settings?
Research question 2: Between L1 and semantic interpretability, which factor better accounts for the relative ease and difficulty of morphemes in L1 Korean-L2 English acquisition?
Research question 3: Previous studies showed that the L1 effect is morpheme specific, indicating that it is not definitive in explaining English morpheme development. Can the combined effects of L1 and semantic interpretability provide a better understanding of L2 morpheme development than either factor alone?
2 Participants
One hundred students in three grade groups (5th, 6th, and 7th grades: aged 10 to 13 years) participated in the experiment. Initially, the groups included 35, 33, and 32 students, respectively. To account for individual differences, information on factors such as private English education and study-abroad experience was collected. When examining interlanguage patterns in EFL settings especially such as South Korea, it is worthwhile to take into account the amount of instruction the learners receive in the private education sector. Although the vast majority of Korean students commonly attend the private education institutions after school, as the amount of time invested varies across individuals, this factor might contribute to varying degrees of proficiency among learners. Students with over six months of study or living-abroad experience were excluded, leaving 96 participants (34, 30, and 32 students in the respective grades). Of these, 47 were female and 49 male. Table 5 summarizes the participants’ background information.
Background information on participants.
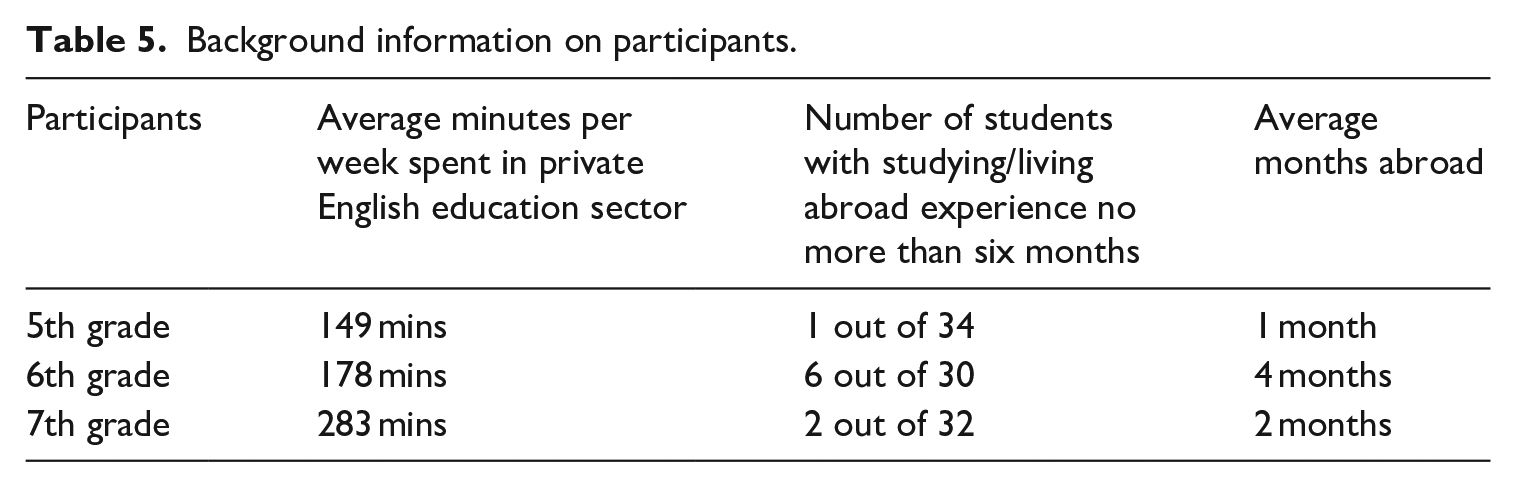
All participants were native Korean speakers, learning English as their L2 within the Korean education system. Students began learning English in 3rd grade, giving participants 2.5 to 4.5 years of English instruction. They were all attending public schools except for some among the 6th grade at a private school. However, it should be noted that both the participating public and private schools in the current study abided by the national curriculum and exclusively used textbooks authorized by the Ministry of Education. Recruitment occurred through researcher acquaintances within Seoul Metropolitan Area, South Korea.
3 Target test items
The current study focused on six English grammatical morphemes that are among the most frequently examined in the field: present progressive -ing, plural -s, possessive -’s articles, third-person singular present -s, and regular past -ed. These morphemes were selected based on their prominence in prior research, as highlighted in Goldschneider and DeKeyser’s (2005) meta-analysis. For plural forms, both regular -s and -es were included. In the case of articles, both indefinite (a, an) and definite (the) forms were considered. Progressive -ing was tallied in all instances of progressive use, regardless of tense and aspect, while gerundive or participial uses were excluded. Similarly, for past tense, irregular past forms and instances of -ed used in passives or participles were omitted, aligning with the conventions established in previous studies.
4 Experimental instruments
Given the potential limitations of relying solely on naturally elicited speech and spontaneous storytelling – which may lack focus on specific morphemes – the current study employed structured tasks. These tasks were designed to elicit target morphemes and to control the frequency of contexts requiring particular morphemes as much as possible. To ensure a sufficient number of obligatory contexts for morpheme use, two task types were implemented: narrative storytelling with picture prompts and storytelling in a dialog format. 2
These task types were chosen because storytelling and dialogues represent the most common forms of language activities and presentations in English textbooks authorized by the Ministry of Education. To make participants feel at ease during data collection, the materials used were intentionally familiar in format. Collectively, the tasks aimed to produce structured speech that necessitated the use of specific morphemes. Detailed descriptions of each task type are provided in the following sections.
a Narrative storytelling with picture prompts
In this task, participants were presented with four or six sequential pictures that formed a storyline. The interviewer described only the first picture in Korean, providing a prompt to initiate the task. Participants were then required to continue the story by describing the remaining pictures in English. The first picture was described in Korean to prevent learners from being exposed to target English morphemes prior to the task, which might otherwise act as a hint.
The picture sets were designed by the researcher, following the format of the General English Proficiency Test (GEPT) kids, as illustrated in Figure 3. This oral production task was selected because participants in the study had been learning English with a focus on speaking and listening, making them more comfortable with this format than written tasks.

Example picture prompts from General English Proficiency Test (GEPT) kids.
For example, one set of picture prompts depicted Tom’s daily routine, including waking up in the morning, eating apples and breakfast, studying English at school, and playing soccer with friends. The description for the first picture was provided in Korean, e.g. ‘Tom wakes up at 7 o’clock every day.’ Participants were then expected to describe the subsequent pictures, producing third-person singular -s, plural -s, and articles.
Three sets of picture prompts were included in the task. While each set aimed to elicit slightly different morphemes, they were carefully balanced to target all six morphemes under investigation in the study.
b Storytelling in a dialogue format
In this second task, participants engaged in a role-play dialogue with the interviewer, using various realia such as fruits, pictures, and a grocery list. The dialogue topics were designed to be familiar and relatable to the participants’ daily lives. The interviewer’s questions were crafted to prompt answers that required the use of the target morphemes. Before the dialogue began, the background context for the role-play was explained in Korean. For example, the interviewer might explain that both the participant and herself are friends of Sally, and they are planning a birthday gift for her next week. Figure 4 illustrates Sally’s room, and the dialogue continues based on observations from this picture. Sample question prompts include: ‘What do you like in Sally’s room?’, ‘What do you see in her room?’ and ‘What do you think Sally would like?’ These prompts aimed to elicit morphemes such as third-person singular -s, plural -s, possessive ‘s, and articles in the participants’ responses. Four sets of role-play scenarios were included in this task, each designed to target all six morphemes under investigation in the study. During data collection, the interviewer was required to adapt spontaneously, improvising to align with each participant’s responses and ensuring a natural flow of conversation.

Example realia used in the task (Sally’s room).
5 Research design and procedure
The study utilized three tasks: a narrative storytelling task, a dialogue task, and a background questionnaire. All data collection steps were conducted one-on-one in an empty classroom, involving only the researcher and one participant at a time. The process began with participants completing a background survey form. They were then informed that they would perform some tasks in English, and their performance would be audio-recorded for analysis. The narrative storytelling task was conducted first, followed by the dialogue task. The entire procedure took approximately 15 to 25 minutes per student. Since the participants were minors, informed consent was obtained from their parents beforehand. To ensure confidentiality, identification codes were assigned to each participant, anonymizing their identities in the dataset.
6 Scoring for the narrative storytelling task and the dialogue task
The current study utilizes Target Like Use (TLU) score to evaluate the accuracy of learners in producing required morphemes in obligatory contexts. The TLU score accounts for potential overgeneralizations in contexts where the morpheme is not required. This is reflected in the following formula:
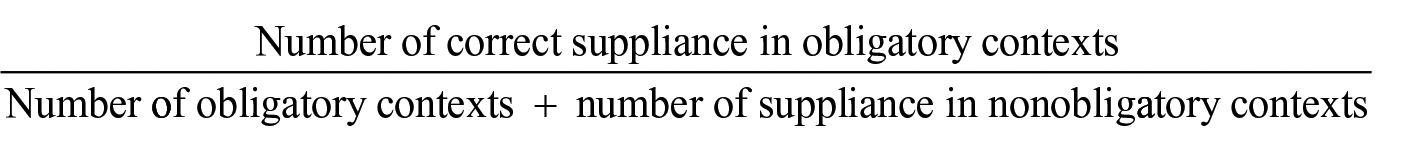
TLU scoring has been widely favored over SOC (Suppliance in Obligatory Context) scoring in previous studies, as it better captures interlanguage patterns and contextual uses by considering both overgeneralization (e.g. I
Using transcribed audio recordings, the TLU score is calculated as a proportional value ranging from 0 to 1. For each participant, the transcription is analysed to count obligatory contexts, suppliances in non-obligatory contexts, and correct suppliances in obligatory contexts. Six TLU scores are then calculated per participant, corresponding to the six target morphemes. Developmental orders are determined based on these TLU accuracy scores by ranking morphemes in descending order of mean scores.
Although some studies have applied thresholds such as 0.9 or 0.8 TLU scores to classify acquisition (Andersen, 1983; Hakuta, 1976; Nuibe, 1986; Shirahata, 1988), this binary approach creates a rigid distinction between acquisition and non-acquisition. To better represent the gradient and variable nature of second language development, the current study derives developmental orders without fixed criteria for acquisition, following prior research practices (Dulay and Burt, 1973, 1974; Izumi and Isahara, 2005; Murakami and Alexopoulou, 2016; Shin and Milroy, 1999).
IV Data analysis and results
This section summarizes all the statistical results obtained. All computations were done using R and SPSS. Descriptive statistics on the total TLU scores revealed the mean to be .6000 and standard deviation .2677. A Shapiro–Wilk test and a Kolmogorov–Smirnov test showed TLU scores followed a normal distribution. Kurtosis and skewness also verified that TLU scores are normally distributed. 3 Table 6 summarizes TLU scores each grade students received for each morpheme type. The total number of morpheme contexts was 4,471. The number of contexts for each morpheme for each grade is put within the parentheses.
Means of TLU scores for each morpheme.

1 Resemblances among developmental orders
Addressing research question 1, to find out which proposed model the Korean EFL learners’ morpheme developmental order is closest to, Spearman’s rank order correlation analysis was performed. Prior to this correlation analysis, morphemes with similar TLU scores were clustered together, following Murakami and Alexopoulou (2016) within each grade level. Morpheme order studies receive the criticism that ranking can potentially misrepresent the relative accuracy distance among the ranked morphemes to be the same, by not virtually distinguishing 1% and 50% differences (Murakami and Alexopoulou, 2016). Specifically, if the distances between ranks are substantially uneven (e.g. if ranks 1 and 2 are widely spaced and ranks 2 and 3 extremely close), then the ranks and the order may be meaningless, which would distort the analysis results. Due to the potential that small differences might lead to statistical exaggeration, rank order correlation analyses were conducted with clustered ranks. Also, another main purpose of clustering was to make the accuracy order obtained in the current study comparable to Krashen’s (1977) natural order and the hypothetical models based on L1 type, interpretability, and the degrees of complexity of mapping. As presented earlier in Figure 1, Krashen’s (1977) natural order shows how it is not always the case that only one morpheme is developed at each learning stage, but rather during one stage, there can be one or more morphemes simultaneously developed. In a similar vein, the hypotheses that morpheme development would be influenced by L1 type, interpretability, or complexity of mapping predict developmental orders where one or more particular morphemes are grouped within each stage. Accordingly, the morpheme developmental orders from the current study are attained based on clustered rankings.
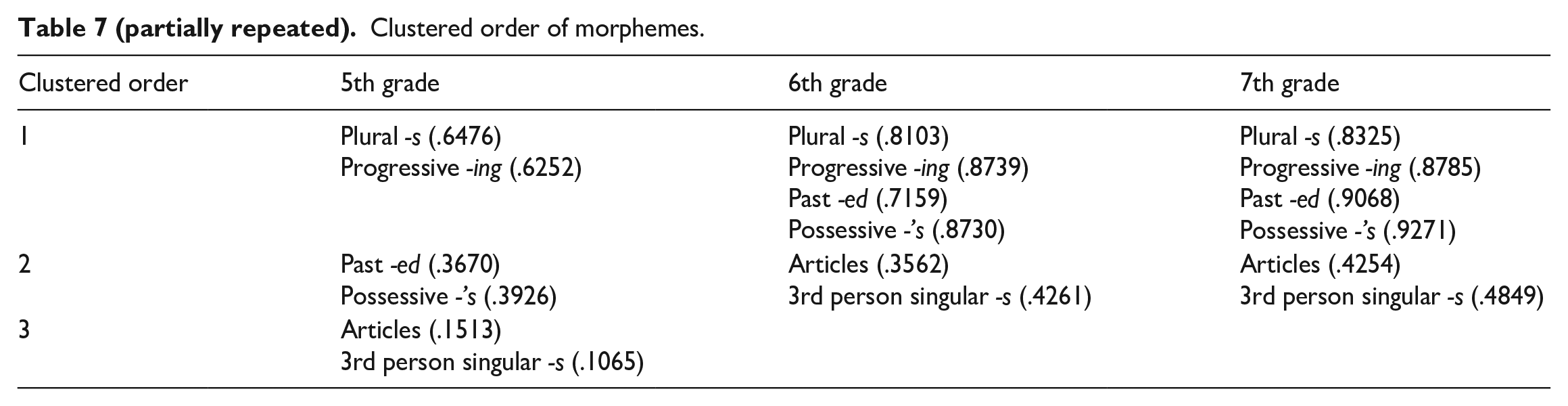
The clustering process was conducted by using post hoc multiple comparison tests with the One-way ANOVA (Analysis of Variance). According to Tukey’s post hoc test results, morphemes were clustered together in one rank if their TLU scores did not differ significantly from each other, while a rank boundary was drawn between the two morphemes if one morpheme’s TLU score reached a significant difference from another’s. Table 7 summarizes the clustered orders of each grade in morpheme development. The order was revealed to be consistent across the grade spectrum and there was no between-grade difference in terms of accuracy ranking. Eye-measuring the clustered order suggests L1 absent and uninterpretable morphemes (articles and third-person singular -s) are consistently challenging to these learners. Also, Degree 2 Complexity morpheme (plural -s) intriguingly exhibits higher accuracy than Degree 1 Complexity morphemes (progressive -ing, past -ed, and possessive -’s) among the 5th grade.
Clustered order of morphemes.

The Spearman’s correlation analysis was run by entering 6 ordinal variables: 5th grade order, 6th grade order (identical to 7th grade order), natural order, L1 type order (according to the presence/absence of the corresponding morphemes in L1), interpretability order (according to the inherent interpretability/uninterpretability of English morphemes), and complexity order (according to the degrees of complexity of mapping). 5th and 6th/7th grade orders were based on clustering as in Table 7, and Krashen’s (1977) natural order was entered, but limited to the target morphemes of the present study.
The results showed that the orders of acquisition in 6th/7th grades were significantly correlated with the interpretability order (r = 1.000, p < .01) while the correlation between the 5th grade order and the interpretability order was marginally insignificant (r = .866, p = .054) after correcting for multiple comparisons. 4 The 6th/7th acquisition orders were significantly correlated with the complexity order (r = .894, p < .05). None of the acquisition orders among the 5th, 6th, and 7th grades was found to be statistically correlated with the natural order nor L1 type order. All the significant Spearman’s correlation coefficient values implied a very strong, positive correlation between ordinal variables.
2 Different factors explaining TLU scores
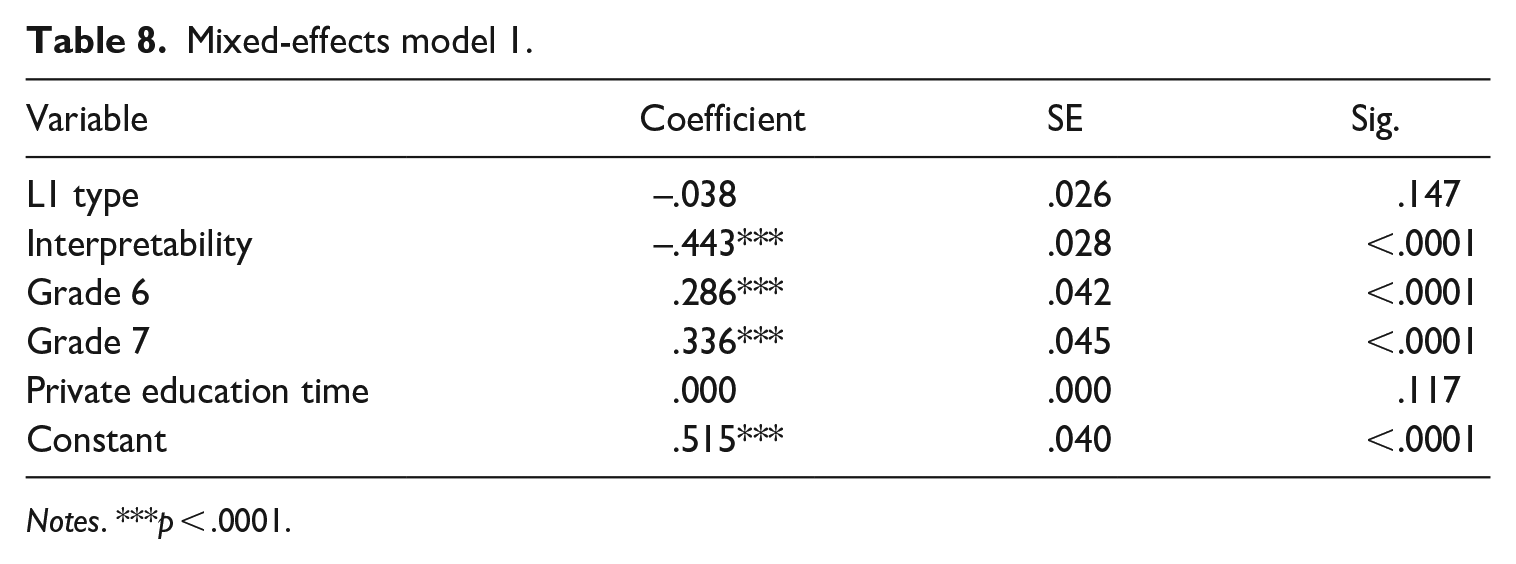
From the correlation analysis, both interpretability and complexity were found to be correlated with the Korean EFL learners’ morpheme development. However, as the correlation analysis was rather preliminary and exploratory, mixed-effects models were further conducted to examine which factors better account for TLU scores. Mixed-effects models were selected as the QQ plot from a regular regression showed that the ordinary least squares (OLS) model may be inappropriate. Furthermore, to address one anonymous reviewer’s concern with dependency in intra-individual observations, mixed-effects models were built with morpheme as the first level and student as the second level. In the original plan for formulating a model that can predict TLU scores efficiently, there were 4 categorical independent predictors: L1 type (two levels: Absent or Present), Interpretability (two levels: Interpretable or Uninterpretable), Complexity (three levels: Degree 1 complexity, Degree 2 complexity, or Degree 3 complexity), and Grade (three levels: 5th grade, 6th grade, or 7th grade). Additionally, there was a continuous independent variable which is the private English education time each participant received per week in minutes. This particular variable was treated as a covariate variable at the participant level. As Complexity is an additive construct of L1 type and Interpretability, entering these three variables simultaneously caused a collinearity issue. Correspondingly, in Model 1, L1 type, Interpretability, Grade, and private education time were entered as independent variables. L1 type and Interpretability were first selected as they are the two variables of interest in research question 2. By default, the reference level of Interpretability was the Interpretable group, L1 type was the L1-absent group, and that of Grade was the 5th grade. The result showed Interpretability and Grade were significant predictors as can be seen in Table 8.
Mixed-effects model 1.
Notes. ***p < .0001.
ICC (Intraclass Correlation Coefficient) from this mixed-effects model was .284, indicating that the mixed-effects model was more appropriate for the current study’s nested data. It is worth noting that the value direction indicates uninterpretability imposes a negative effect on TLU scores, after the effects of the other variables are considered. This implies that overall students received higher TLU scores in interpretable morphemes than in uninterpretable morphemes. Also, the result indicates that as the grade years go up, the mean of TLU scores also tends to increase. The coefficients for Grade 6 and Grade 7 are the average difference in TLU scores with 5th grade regarding L1-absent and interpretable morphemes only. Accordingly, to better grasp the overall TLU score differences between interpretable and uninterpretable morphemes across the grade levels, the visual representation of the patterns was examined in Figure 5. Furthermore, it could be inferred that Interpretability can outweigh grade differences in morpheme accuracy, after accounting for the influence of other variables as the sizes of their values indicate.
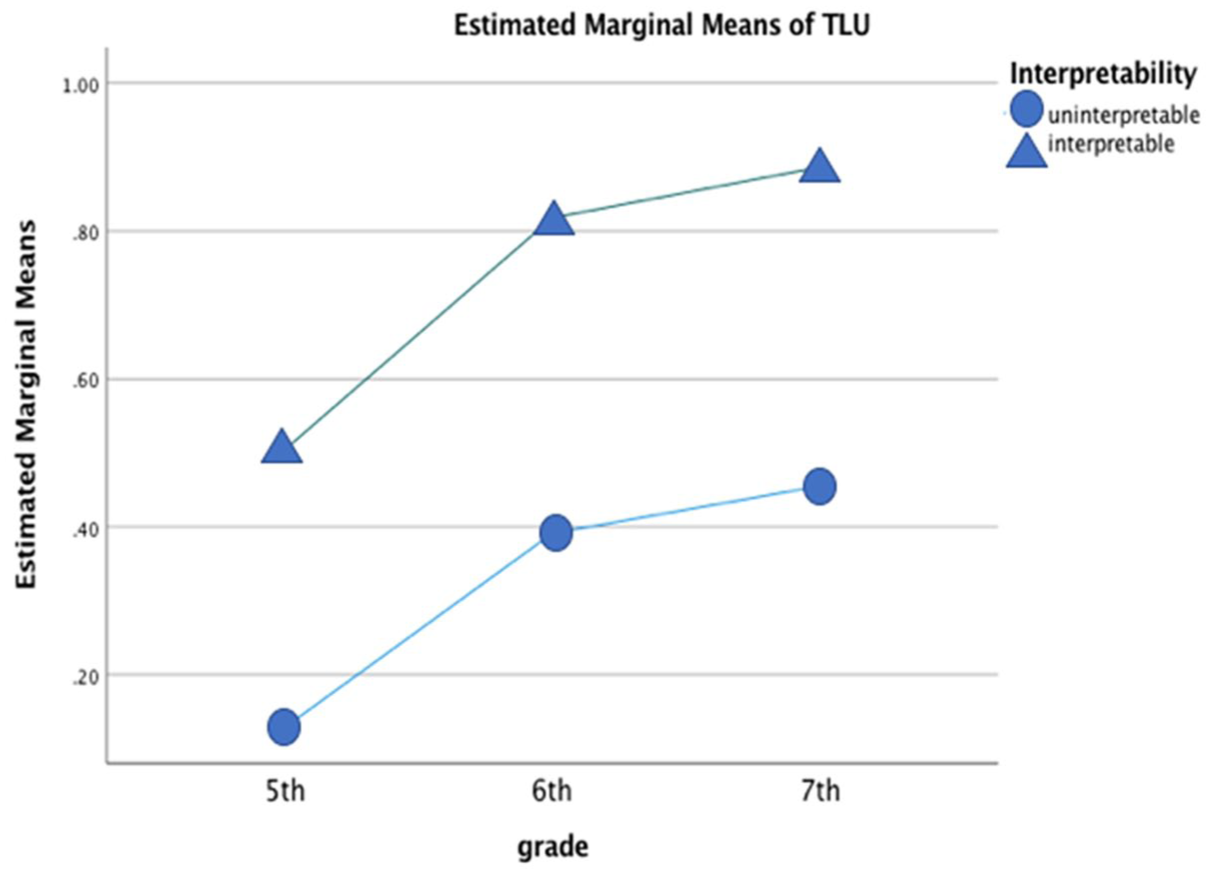
Mean scores in 5th, 6th, and 7th grade by interpretability.
As Interpretability turned out to have more explanatory effects than L1 type, in the sequent Mixed-effects model 2, Interpretability, Complexity, Grade, and private education time were entered as independent variables to address research question 3. This Model 2 revealed that Interpretability and Grade are significant factors (p < .0001 for both) while Complexity is not (p = .147). Effect directionality and effect sizes concerning Grade were identical to Model 1 and the effect size regarding Interpretability was −.404. In sum, among the independent variable candidates of interest, Interpretability was identified to have greater predictability on TLU scores than L1 type or Complexity did.
3 Between interpretability and complexity
Although mixed-effects models illustrated Interpretability is the most predictive factor, among L1 type, Interpretability, and Complexity, on morpheme accuracy, as Complexity was a newly proposed variable to be tested for its potential, the data were further examined from a descriptive statistic approach.
Figure 6 illustrates that the morphemes in Level 3 Complexity show the lowest accuracy across the grade years while the Level 2 morphemes are slightly less accurate than the Level 1 morphemes among the 6th and 7th graders. Although the pattern of Level 1 morphemes being the most accurate and Level 3 morphemes the least accurate is not consistent throughout the grade levels, the overall tendency is worth the attention.
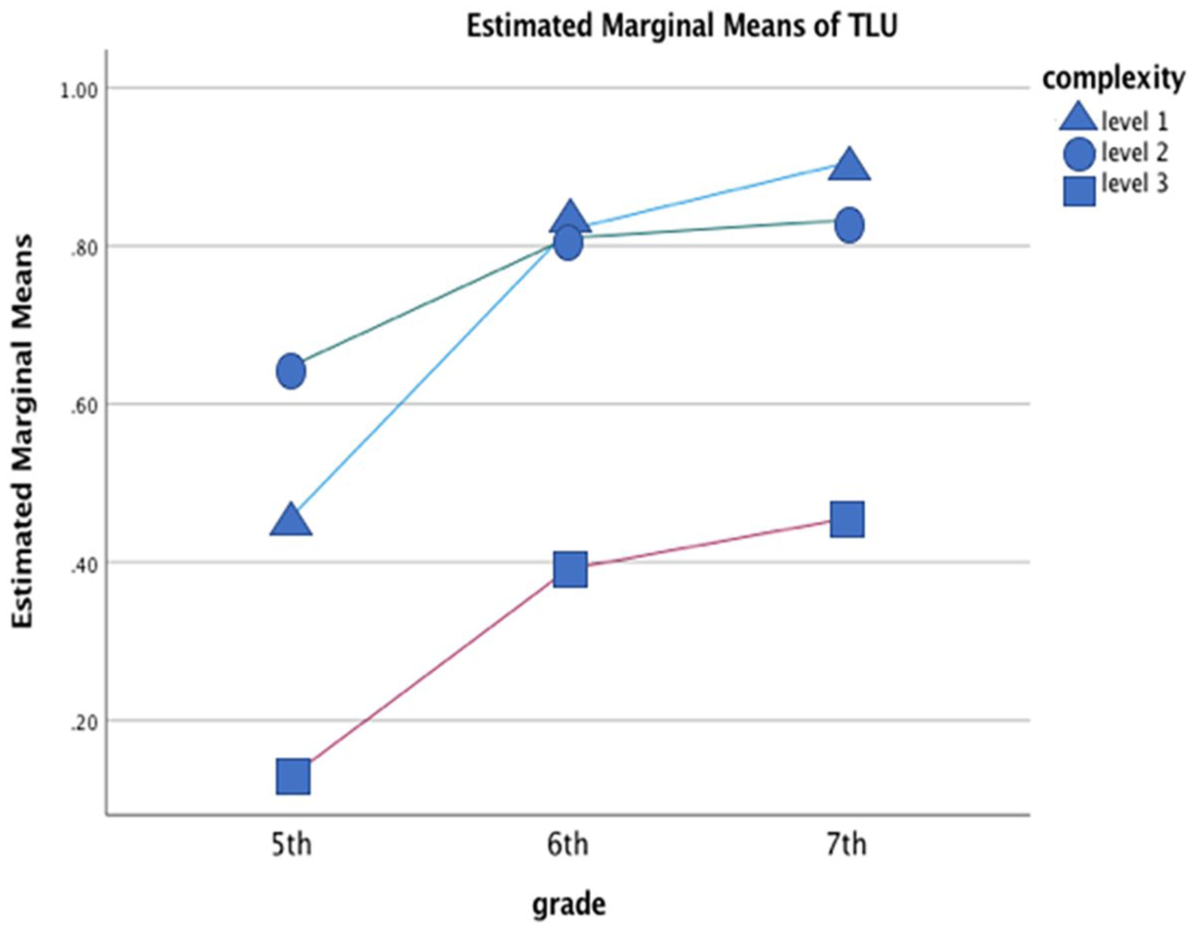
Mean scores in 5th, 6th, and 7th grade by complexity.
Pseudo-R squared measures (Shaw et al., 2023) of explained variance for multilevel models were calculated across the three mixed-effects models (see Table 9). These Rights and Sterba pseudo-R squared were estimated utilizing the ‘r2mlm’ package. The result indicates Complexity bears a higher level of explanatory power than L1 type in the model.
Rights and Sterba pseudo-R2 in mixed-effects models fitted to TLU scores.

When Complexity was additionally entered into the model with independent variables of Interpretability, Grade, and private education time, Rights and Sterba pseudo-R-squared value increased to .462 from .261. Although this minute increase in pseudo-R-squared with respect to the effect size does not propose the optimal fit, the potential of Complexity as a meaningful addition to explain L2 morpheme development may remain for further investigation in the field.
V Discussion
The key findings from the previous section include the consistent morpheme accuracy ranking across the grade levels, the correlations between interpretability and Korean EFL learners’ morpheme accuracy, the significant role of interpretability in predicting morpheme accuracy, and the unexpected finding regarding related to the complexity construct. This section discusses these results in the context of the research questions.
1 How do Korean learners of English in EFL settings develop English grammatical morphemes? How are their developmental paths similar to or different from Krashen’s natural order? How do they compare to developmental paths in ESL settings?
The study revealed that while TLU scores for all morpheme types varied across grades, they generally increased with grade levels, indicating progressive development in Korean EFL learners’ command of English morphemes. Despite this growth, the morpheme accuracy rankings remained consistent, suggesting that certain morphemes are inherently more or less challenging for these learners, regardless of overall proficiency improvements.
As shown in Table 7, articles and third-person singular -s were the most challenging morphemes across all grade levels, whereas plural -s was consistently among the easiest. Interestingly, 5th graders found possessive -’s and past -ed more difficult than plural -s and progressive -ing, but it was not the case that possessive -’s and past -ed marked lower accuracy ranks in 5th grade than in 6th and 7th grades; they were all within the fourth ranks across the grades. Moreover, all these four morphemes were clustered within the same accuracy level right off from the 6th grade. These findings support the view that the L1 effect alone is insufficient to predict the advanced or delayed acquisition of specific morphemes. While plural -s, articles, and third-person singular -s are all absent in Korean, only plural -s consistently ranked as one of the easiest morphemes, whereas articles and third-person -s remained challenging. This aligns with Murakami and Alexopoulou’s (2016) assertion that the L1 effect is morpheme-specific, as learners’ performance on individual morphemes is not uniformly influenced by the presence or absence of corresponding features in their L1.
Clustered order of morphemes.
In comparison to Krashen’s (1977) natural order, Korean EFL learners showed a delayed development of articles and earlier acquisition of possessive -’s. Spearman’s rank order correlation analysis confirmed that the natural order was not statistically correlated with any acquisition orders for 5th, 6th, and 7th graders. This result aligns with prior studies (Luk and Shirai, 2009; Pak, 1987; Shin and Milroy, 1999) that challenge the universality of Krashen’s natural order, emphasizing the influence of L1 on morpheme acquisition.
This study is noteworthy for using oral production data to examine Korean EFL learners’ morpheme accuracy. Previous research highlighted discrepancies between ESL and EFL contexts within the same L1 group, particularly concerning the plural -s (e.g. Ghonchepour et al., 2020; Murakami and Alexopoulou, 2016; Pak, 1987; Schenck and Choi, 2013; Seog, 2015; Shin and Milroy, 1999). The present study confirms that, even with oral data, Korean EFL learners develop the plural -s early despite its absence in their L1. In contrast, Korean ESL learners showed delayed development of the plural -s, suggesting that the L1 influence is more consistent in ESL settings. This study suggests that interpretability may override the L1 effect in EFL contexts, while the reverse may hold true in ESL settings. A plausible explanation is that in the absence of corresponding L1 features and limited L2 input typical of EFL contexts, learners rely on interpretability, a universal semantic construct, to compensate. This pattern resembles findings by Ionin et al. (2008), where Russian learners of English, lacking an article system in their L1, relied on semantic universals for article use until sufficient L2 input clarified the appropriate patterns. Similarly, Korean EFL learners may access interpretability to navigate the absence of plural -s in their L1.
2 Between L1 and semantic interpretability, which factor better accounts for the relative ease and difficulty of morpheme acquisition?
Spearman’s correlation analysis indicated that morpheme acquisition orders were not significantly correlated with L1 influence across grades. However, strong positive correlations were found between interpretability and the acquisition orders for 6th and 7th graders, with a marginally insignificant correlation for 5th graders. These results suggest that interpretability plays a more critical role in Korean learners’ morpheme development than the presence or absence of corresponding L1 morphemes.
Mixed-effects analyses further confirmed that interpretability was a stronger predictor of TLU scores than L1 type. This implies that the semantic interpretability of a morpheme significantly influences learners’ performance, surpassing the impact of L1 features. Notably, private education time did not significantly predict morpheme accuracy, emphasizing the predominant role of interpretability regardless of instructional time.
3 Can the combined effects of L1 and semantic interpretability provide a better understanding of L2 morpheme development than either factor alone?
The results showed that interpretability was the strongest predictor of TLU scores, even compared to complexity (a combined measure of L1 and interpretability effects). However, the analysis of global effect sizes through Rights and Sterba’s R-squared values suggested that complexity remains a relevant factor.
The developmental trends across grades (Figure 6) revealed that higher complexity levels were generally associated with greater difficulty, with accuracy improving over time. An exception was observed among 5th graders, who performed better on Degree 2 complexity morphemes than Degree 1 morphemes. This counterintuitive result may be explained by U-shaped learning behavior (Sharwood Smith and Kellerman, 1989), where learners initially display target-like accuracy, followed by a decline and eventual reestablishment of accurate forms. Sharwood Smith and Kellerman (1989) define this notion as ‘the appearance of correct, or nativelike, forms at an early stage of development, which then undergo a process of attrition, only to be re-established at a later stage’ (p. 220). Among the oft-cited examples of U-shaped learning patterns in language acquisition are the English morphemes -ing (Pica, 1985; Schmidt, 1983) and past tense -ed (for L1, see Clahsen, 2006; for L2, see Leung, 2006). Research indicates that English language learners often exhibit a tendency to oversupply -ing forms, as shown in examples (1) and (2), and to overgeneralize -ed to irregular verbs (e.g. comed instead of came and goed instead of went). The overgeneralization and oversuppliance of Degree 1 morphemes like -ing and -ed among 5th graders support this hypothesis, as these patterns align with previously documented U-shaped learning trajectories.
(1) so yesterday I didn’t painting (Schmidt, 1983: 147)
(2) I like to studying English (Pica, 1985: 143)
These instances of oversuppliance and overgeneralization are commonly observed during the middle stage of development, situated between the earlier and later phases when learners produce target-like forms. In other words, oversuppliance and overgeneralization often characterize the language patterns of learners navigating through a U-shaped learning curve.
If we assume that the 5th graders in the current study were in the middle stage of a U-shaped learning curve for Degree 1 complexity morphemes, the observed pattern in Figure 6 can be explained. The U-shaped learning model suggests that progress is not always linear or consistently marked by increasing accuracy.
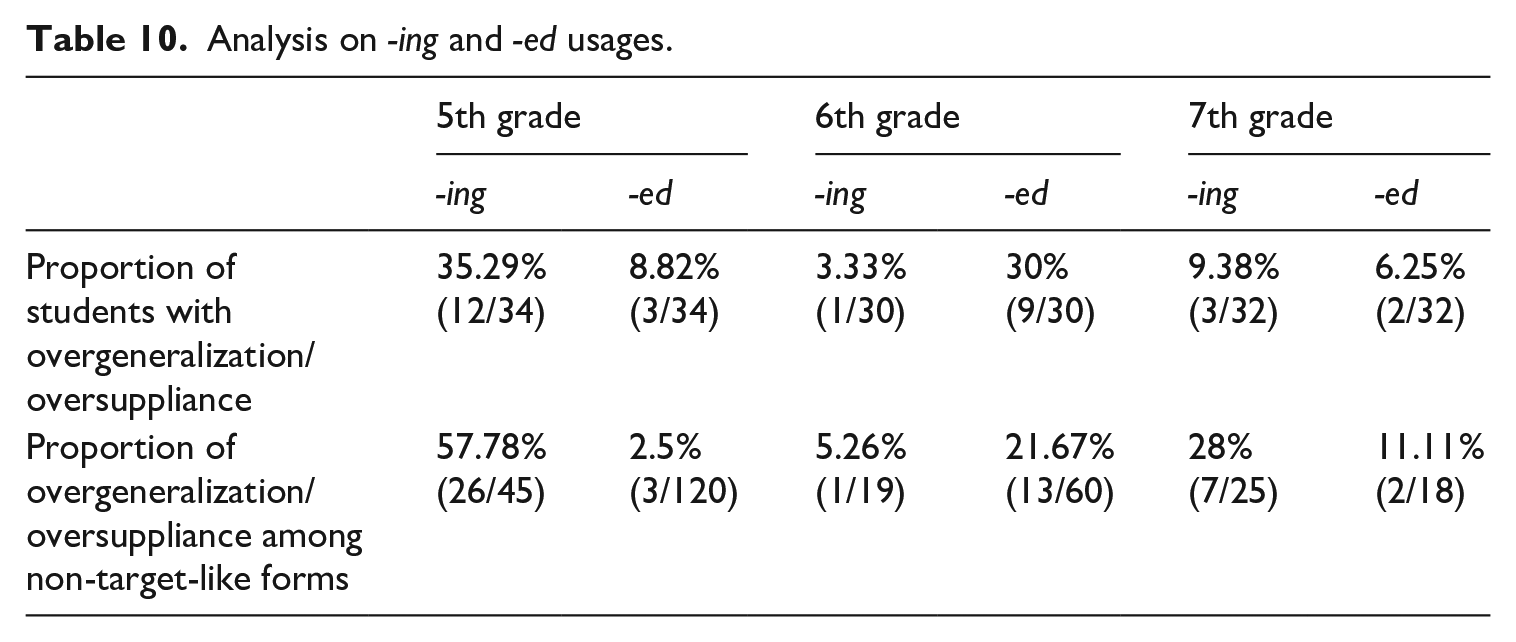
Notably, the inclusion of both English -ing and -ed in the Degree 1 complexity morpheme group makes this hypothesis more plausible. To explore this further, the usage of -ing and -ed by 5th graders, as well as by other grade levels, was analysed to determine how many students produced non-target-like morphemes due to overgeneralization or oversuppliance and to assess the proportion of such forms within the total non-target-like instances.
As shown in Table 10, for -ing, over 35% of the 5th graders demonstrated a tendency toward oversuppliance. Among all the non-target-like forms, more than 55% were categorized as oversuppliance. While very few students overgeneralized -ed, and overgeneralized -ed forms were rarely observed among the non-target-like instances, the oversuppliance pattern for -ing suggests that the 5th graders’ unexpectedly low scores for Degree 1 complexity morphemes might be attributed to the U-shaped learning pattern. Although the data for 6th grade -ed and 7th grade -ing show that 20–30% of the non-target-like forms were oversupplied, these proportions are less pronounced compared to the 5th graders’ results.
Analysis on -ing and -ed usages.
Additionally, an analysis was conducted to examine how many students exhibited fluctuations between omissions and appropriate suppliances simultaneously, as observed through intraindividual data. The findings are presented in Table 11.
Analysis on fluctuation patterns for -ing and -ed.
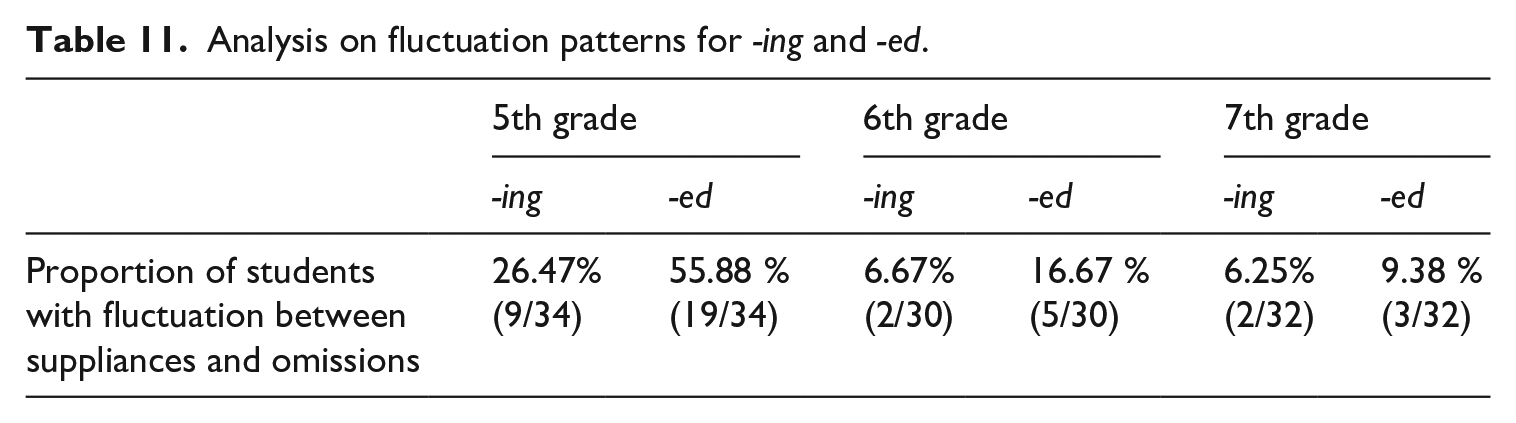
If a learner omits morphemes in some obligatory contexts but correctly supplies them in others, this conflicting behavior indicates restructuring, defined by Ortega (2009) as ‘the process of self-organization of grammar behavior representations’ (p. 117). Over half of the 5th graders displayed a restructuring pattern for -ed, suggesting they experienced a temporary decline in TLU scores, which subsequently served as a foundation for significant improvement. This pattern was less apparent among the 6th and 7th graders. Taken together, the evidence of overgeneralization and restructuring tentatively supports the hypothesis that students experienced U-shaped learning for Degree 1 morphemes during the 5th grade. However, this interpretation is presented with the caveat that further research involving participants younger than 5th grade is necessary, as the current study does not include such groups.
This study offers preliminary insights into whether the combined effects of L1 and semantic interpretability better explain the L2 morpheme developmental path compared to interpretability alone. While statistical analyses remain inconclusive, the observed variability in morpheme accuracy underscores the importance of complexity as a key factor. Although the L1 factor alone cannot fully account for why plural -s is acquired more readily than articles and third-person singular -s, despite all being absent in Korean, combining interpretability with L1 effects provides a more nuanced understanding. Specifically, the distinction between articles and third-person singular -s (Degree 3 complexity) and plural -s (Degree 2 complexity) lies not solely in interpretability but in its interaction with L1 influence.
VI Conclusions and suggestions for future research
This study aimed to enhance the understanding of variations in English morpheme development by examining the explanatory power of L1 influence and interpretability. The findings reveal that morpheme development is more critically determined by interpretability than by the influence of L1 alone. This suggests that the fundamental semantic characteristics of each morpheme play a more significant role in shaping the developmental trajectory than the mere presence or absence of analogous morphemes in a learner’s L1. Additionally, this explains why the L1 effect has appeared inconsistent across different morphemes in previous studies. Morphemes encompass not only surface forms but also underlying semantic features, and this study confirms that these semantic aspects are vital in accounting for variability in L2 morpheme development.
Furthermore, the study replicates prior findings that the L1 effect may manifest differently even within the same L1 group. For instance, previous research noted that the plural -s developed late among Korean ESL learners but emerged earlier among Korean EFL learners, attributing this disparity to differences in data types (oral vs. written). In addressing the scarcity of oral data on EFL learners in morpheme research, this study fills a critical gap. However, the oral tasks used in this study were not strictly controlled to ensure sufficient contexts for morpheme use. Future research should expand sample sizes and refine methodologies to address this limitation.
The study tentatively proposes that for linguistic items absent in learners’ L1, limited L2 input exposure in EFL settings motivates learners to rely on interpretability – a cognitive, semantic construct. This hypothesized dominance of interpretability over L1 influence in EFL contexts requires further investigation, particularly with diverse L1 groups exhibiting varying interlanguage patterns across ESL and EFL settings.
By integrating interpretability with direct L1 effects, this study provides a more comprehensive understanding of English learners’ morpheme development patterns. However, the findings would be more robust if additional L1 groups were included. Future research should include a broader range of L1 backgrounds to validate interpretability and complexity as explanatory factors for the morpheme-specific nature of L1 effects noted in earlier studies (Andersen, 1983; Lightbown, 1983; Luk and Shirai, 2009; Pak, 1987; Shin and Milroy, 1999). To substantiate the potential of complexity – defined as the combined effect of L1 and interpretability – as a meaningful construct in morpheme studies, future studies should also include participants across a wider range of grade levels. While U-shaped learning has been proposed as evidence of the role of complexity in morpheme development, this interpretation remains speculative and requires stronger empirical support. Expanding participant grade levels could provide more comprehensive insights into developmental trends and patterns.
The findings also have pedagogical implications. Korean learners, particularly, face challenges with English morphemes that are uninterpretable and lack counterparts in their L1. This difficulty persists even among higher-grade learners. English language instruction should prioritize addressing these challenges by focusing on the essential semantic and grammatical characteristics of English morphemes.
Footnotes
Acknowledgements
This research article is based on a portion of my doctoral dissertation completed at the University of Pennsylvania, USA. I extend my deepest gratitude to the editors and anonymous reviewers of Second Language Research for their insightful feedback and constructive suggestions, which have significantly improved the quality of this work. Their expertise and attention to detail have been invaluable throughout the revision process. I also thank my dissertation committee members, whose guidance and support have been instrumental in shaping this research.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.