
Abstract
The current study investigated the extent to which naive listeners could incidentally acquire non-native phonemic contrasts and the degree to which the frequency of exposure to the target phonemes affects their learning. A total of 100 English speakers were assigned to the following conditions: (1) 0-occurrence; (2) 2-occurrence; (3) 10-occurrence; (4) 20-occurrence; or (5) 30-occurrence. The participants watched a video that provided instruction on counting numbers in Korean while incidentally exposing them to various repetitions of the target phonemes. All participants completed a pretest, an immediate posttest, and a delayed posttest, each comprising an AX discrimination task. The effects of incidental exposure were found only in the 10-occurrence condition, in both the immediate posttest and the delayed posttest. While the current study demonstrates the overall efficacy of incidental exposure on the perception of non-native speech, it also highlights the important role that selective attention plays in language learning.
I Introduction
Incidental learning refers to the acquisition of a linguistic target without the conscious intention to learn the target, such as ‘picking up’ a new word or expression from linguistic input (Hulstijn, 2013). Evidence largely suggests that intentional learning is more beneficial for second language (L2) acquisition than incidental learning (e.g. Hamrick and Rebuschat, 2014; Ishikawa, 2019; Sonbul and Schmitt, 2010; Webb et al., 2023). However, due to the finite nature of learner attention and time available for L2 instruction, not only is it unrealistic to expect all linguistic targets to be acquired in an intentional manner, but learning additional targets incidentally as a by-product of intentional learning or of other activities would be in the best interests of learners. Researchers have thus investigated the effects of incidental learning on L2 acquisition to a great extent. While the overwhelming majority of previous research focuses on the acquisition of L2 vocabulary and morphosyntax (e.g. Ishikawa, 2019; Ruiz et al., 2018; Tao and Williams, 2018; Webb, 2007), the available research in the L2 speech domain indicates that non-native listeners can acquire linguistic targets in an incidental manner to some extent, with a few studies (e.g. Lim and Holt, 2011; Vlahou et al., 2012) even suggesting that incidental learning can be equal to or more effective than explicit, intentional learning. In addition, given the notion that frequency of input is an important component of language learning in general, a substantial number of studies in the vocabulary and morphosyntax domains have examined frequency as a variable. However, frequency of input has not been studied in incidental learning of L2 speech. The current study aims to fill this gap by investigating the role of input frequency in the extent to which naive listeners could acquire non-native phonemic contrasts in an incidental manner.
To pursue this research objective, an experimental study was conducted with 100 first language (L1) speakers of English targeting Korean lenis stops (/p/, /t/, and /k/) and fortis stops (/p*/, /t*/, and /k*/), which are difficult for L2 learners of Korean to acquire (e.g. Chang, 2010; Francis and Nusbaum, 2002; Holliday, 2015, 2019). The current study is expected to expand the literature regarding the effects of incidental exposure and its frequency on L2 acquisition, while offering pedagogical implications with respect to the role of incidental learning in L2 speech learning.
II Background
1 Incidental learning and frequency
In the field of L2 acquisition, learning can be categorized into two types: intentional and incidental. Intentional learning involves a conscious effort to learn or memorize new information (DeKeyser, 2003; Hulstijn, 2003, 2013), whereas incidental learning is widely defined as learning without a deliberate intent to learn (Hulstijn, 2003; Williams, 2009). Incidental learning stems from the view that aspects of an L2 can be ‘picked up’ while the learner’s attention is focused on a different target (Hulstijn, 2003). Hence, linguistic knowledge gained while one was focusing on something other than that language form or pattern can be said to have been learned incidentally. With respect to L2 acquisition, there is ample evidence suggesting that intentional learning results in more learning than incidental learning does (e.g. Hamrick and Rebuschat, 2014; Norris and Ortega, 2000; Sonbul and Schmitt, 2010), with higher rates of knowledge retention (Denhovska et al., 2016; Hulstijn, 2003; Ishikawa, 2019; Schmitt, 2008). However, some studies (e.g. Lim and Holt, 2011; Morgan-Short et al., 2010, 2012; Vlahou et al., 2012) have made a case for incidental learning, which has potential implications for optimal L2 learning conditions and warrants further examination. Furthermore, given common constraints, such as limited learner attention and time devoted to learning an L2, it is worthwhile to explore ‘what can be learned as mere result of exposure and without explicit instructional treatments’ (Rebuschat, 2013: 598). As noted by Leow and Zamora (2017), a deeper understanding of incidental learning is ‘of clear theoretical value to the field of SLA [second language acquisition]’ (p. 44), which may yield further insights on learning conditions that fully utilize learners’ cognitive processes.
A major variable often addressed in research on incidental learning, especially of vocabulary, is the frequency of exposure to the target input. In general, it is uncontroversial that ‘learning is sensitive to frequency: the more times a stimulus is encountered, the faster and more accurately it is processed’ (Ellis, 2006a: 5). At this point, it should be noted that frequency is just one of several interconnected components that contribute to L2 learning, such as attention and salience (Robinson et al., 2019). The distinction between input and intake is also important in considering the role of input frequency; frequency alone does not guarantee that the target input will be further processed by the learner, particularly in incidental learning. Nonetheless, frequency is a highly important factor that is relatively easy to control and manipulate in instructed L2 acquisition, making it the primary focus of the current study.
There is a wealth of research on the effects of incidental learning on L2 acquisition, with a notably heavy focus on vocabulary and morphosyntax. Following research that showed gains in vocabulary knowledge from meaning-focused activities, such as extensive reading (e.g. Horst et al., 1998; Waring and Takaki, 2003; Zahar et al., 2001), numerous studies have demonstrated that vocabulary can be learned incidentally while reading (Eckerth and Tavakoli, 2012; Ruiz et al., 2018; Teng, 2020; Webb, 2007), including an eye-tracking study (Mohamed, 2018), which found that even during comprehension-focused reading, L2 learners spent more time looking at novel words. Incidental learning of L2 vocabulary has also been shown to occur during activities other than reading, such as reading while listening (Malone, 2018; Webb and Chang, 2015; Webb et al., 2013), listening (Jin and Webb, 2020; Pavia et al., 2019; van Zeeland and Schmitt, 2013), watching videos (Nguyen and Boers, 2019; Peters and Webb, 2018), and speaking (Newton, 2013). A meta-analysis of 32 studies on incidental vocabulary learning (de Vos et al., 2018) substantiated the benefits of listening during meaning-focused activities. Another meta-analysis by Webb et al. (2023) found that, while likely less effective than learning intentionally, incidental learning of L2 vocabulary occurred during meaning-focused activities, at similar rates during reading, listening, or reading while listening.
Following a seminal study by Saragi et al. (1978), many researchers have reported a positive correlation between frequency and incidental vocabulary learning at varying degrees (Horst et al., 1998; Rott, 1999; Vidal, 2003, 2011; Waring and Takaki, 2003; Webb, 2007). Holding repetition as an important variable, recent studies have provided further support for input frequency as a predictor of incidental vocabulary learning (Hulme et al., 2019; Mohamed, 2018; Pavia et al., 2019; Peters and Webb, 2018; Teng, 2020). However, there is a lack of consensus on the exact number of encounters required (i.e. between two and over 20), and some studies (e.g. Jin and Webb, 2020; Webb and Chang, 2015) found no significant effects of frequency on vocabulary learning. Nonetheless, incidental learning has been reported as more sensitive to frequency than intentional learning is (Hamrick and Rebuschat, 2014), and a meta-analysis by Uchihara et al. (2019) found a medium effect (r = .34) of repetition on incidental vocabulary learning. Taken together, though frequency may not be the only nor most significant predictor of learning, it remains a necessary component of language processing and acquisition.
Morphosyntax is another domain in which incidental L2 learning has been extensively investigated. Research has provided evidence that novel grammar structures can be successfully acquired under incidental learning conditions, by employing semiartificial languages that combine target vocabulary with morphological or syntactic features of other languages, (e.g. Grey et al., 2014; Rebuschat and Williams, 2012; Rogers et al., 2016; Tao and Williams, 2018) as well as natural languages (e.g. Brooks and Kempe, 2013; Denhovska and Serratrice, 2017; Godfroid, 2016; Lee, 2002; Robinson, 2005; Shintani, 2015). However, it has been noted that while various aspects of grammar can be acquired incidentally, the amount of learning is usually not robust (Leow and Zamora, 2017). In many cases, morphosyntactic knowledge gained through incidental exposure was limited to receptive, but not productive, knowledge (Denhovska and Serratrice, 2017; Godfroid, 2016; Shintani, 2015) or not transferred to new items learners had not been exposed to (Robinson, 2005). Ruiz et al. (2018), which examined the simultaneous incidental learning of vocabulary and syntax, found significantly greater learning gains for vocabulary than for syntax.
In contrast to those on vocabulary, few studies on incidental learning of L2 morphosyntax have specifically examined frequency as a variable. They have provided divergent conclusions, either that higher frequency of exposure to target input increases learning to some extent (Aka, 2020; Lee, 2002; Robinson, 2005), or that ‘less is more’ (Denhovska et al., 2016: 178) for beginner learners, who are cognitively taxed while processing L2 input. While it seems probable that frequently occurring morphosyntactic features would be acquired more successfully than infrequent features, it remains open whether that is empirically the case.
There is relatively little research on incidental learning of L2 speech (see Hulstijn, 2003; Loewen, 2020), but the available evidence collectively indicates that sounds can be learned incidentally. Using a videogame task, Lim and Holt (2011) demonstrated that Japanese speakers could not only incidentally learn the English /r/–/l/ categories, but that their gains after a mere 2.5 hours of incidental exposure were comparable to learning gains found in previous studies that largely involved two to four weeks of explicit categorization training. Saito et al. (2022), a later study based on Lim and Holt (2011), produced limited but similar results, adding that incidental speech learning may be more effective for more learnable targets (i.e. the English /æ/–/ʌ/ contrast rather than /r/–/l/ for Japanese speakers). Targeting non-speech sounds, several studies employing the videogame paradigm also demonstrated that new sound categories or patterns could be reliably learned in an incidental manner (Gabay et al., 2018, 2023; Lim et al., 2019; Wade and Holt, 2005), be generalized to non-native natural speech (Liu and Holt, 2015), and even be consolidated into long-term memory (Gabay et al., 2023). Notably, fMRI scans in Lim et al. (2019) showed that the striatum, an area of the brain thought to be involved in explicit category learning, similarly contributed to the incidental learning of auditory categories.
Employing a simpler technique for incidental exposure to non-native speech, Vlahou et al. (2012) had Greek speakers listen to Hindi consonants but focus on the differences in volume between pairs of sounds, rather than on the consonants themselves. Results showed that the most robust learning occurred in the group that received this incidental exposure without any feedback on their volume discrimination, compared to the group that received feedback and to the group that received explicit training on identifying the target consonants. Luthra et al. (2019), utilizing the same learning paradigm and targets, provided weak but consistent findings with those of Vlahou et al. (2012), in that participants incidentally exposed to the Hindi consonants performed better on an identification task than control participants with no exposure. Hutchinson and Dmitrieva (2022) explored a more ecologically valid method of incidental exposure, in which naive-listener L1 speakers of English watched a French film while completing a vocabulary task. Though their focus was on production (as opposed to perception), Hutchinson and Dmitrieva’s (2022) findings indicate that incidental exposure through film viewing improved the participants’ pronunciation of the French /y/.
As discussed, the extant research provides evidence that novel sounds, both speech and non-speech, can be acquired incidentally, potentially even more effectively than in an intentional manner. Yet, although L2 environments and classrooms are full of novel speech sounds, pronunciation instruction is seldom prioritized in instructional settings (Darcy, 2018; Foote et al., 2016; Huensch, 2019), with time constraints cited as the primary reason. With this reality, neglecting to utilize incidental exposure for pedagogical benefit would be a missed opportunity in instructed L2 speech acquisition. A key factor to consider in the pursuit of leveraging incidental learning with limited time is the amount of incidental exposure necessary for learning. However, to the best of our knowledge, the role of input frequency in incidental L2 learning has not been investigated in the domain of speech perception as it has been in vocabulary and morphosyntax. Therefore, the current study attempts to fill this research gap by conducting an experimental study on the effects of various input frequencies on the incidental learning of non-native speech sounds; more specifically, Korean stop consonants.
2 The three-way laryngeal contrast of Korean stops
Stop consonants are differentiated by various acoustic dimensions, such as voicing, aspiration, and voice onset time (VOT). Korean, in particular, has a typologically unusual three-way stop contrast, comprising lenis (lax), fortis (tense), and aspirated stops from three places of articulation: bilabial (/p/, /p*/, /ph/), alveolar (/t/, /t*/, /th/), and velar (/k/, /k*/, /kh/). For instance, /tal/, /t*al/, and /thal/ denote ‘moon’, ‘daughter’, and ‘mask’, respectively. Phonetically, in the word-initial position, the three categories of Korean stops are all voiceless and – much like two- and three-way stop contrasts in many other languages – are differentiated by the VOT. It has historically been the case that fortis stops have the shortest VOT, lenis stops have intermediate VOT, and aspirated stops have the longest VOT. However, unlike many other languages, the Korean three-way stops are also differentiated by the fundamental frequency (F0) of the following vowel, with the highest F0 corresponding to aspirated stops, then fortis stops, and lenis stops with the lowest F0 (Cho et al., 2002; Francis and Nusbaum, 2002; Kim, 2004). Remarkably, researchers have noted a sound change in the contrasts in the past several decades, specifically in the convergence of VOTs of lenis and aspirated stops among speakers of Seoul (‘standard’) Korean (Bang et al., 2018; Kang, 2014; Kang and Guion, 2008; Silva, 2006). With the disappearance of the difference in VOT, which previously differentiated the two stops, the secondary cue F0 is now the primary contrast between lenis and aspirated stops. Lee et al. (2020) report that this ‘phonetic reorganization’ is spreading to all varieties of Korean.
Due to their unique three-way contrast, Korean stops have been a topic of much research not only with respect to their phonetic and phonological properties (see Kang et al., 2022), but also in their perception and acquisition by naive listeners and L2 learners of Korean, as introduced below. According to the Perceptual Assimilation Model (PAM) (Best, 1995), adults perceive novel non-native phones in terms of their articulatory similarities and differences to phonemes and contrasts in their L1s. Within this framework, novel non-native phones are assimilated, or mapped onto existing L1 sound categories based on their perceived similarity to the L1 category. Hence, when Korean stops are perceived by non-native listeners, they would be assimilated to the listeners’ L1 categories based on acoustic dimensions that differentiate stop consonants in their respective L1s. The PAM outlines six types of assimilation that can occur, depending on the perceived similarities among the non-native phonemes and corresponding L1 phonemes:
• two-category (TC);
• single-category (SC);
• category-goodness (CG);
• uncategorized–categorized (UC);
• uncategorized–uncategorized (UU); and
• non-assimilable (NA) (see Best, 1995).
This prediction has been explored in numerous previous studies for a variety of L1s. With naive-listener L1 speakers of Mandarin, which contrasts stops by VOT, Holliday (2014) demonstrated that the Mandarin speakers categorized the Korean stops primarily in terms of VOT, assimilating both lenis and aspirated stops to Mandarin aspirated voiceless stops, which have longer-lag VOTs (SC), and fortis stops to Mandarin unaspirated voiceless stops (with short VOTs). Though less categorical, similar effects were observed with naive-listener L1 speakers of Japanese (Holliday, 2019), a language that also mainly differentiates stops by VOT. The Japanese participants also assimilated the Korean lenis and aspirated stops to Japanese voiceless stops (SC) and the Korean fortis stops as Japanese voiced stops, solely based on VOT cues. Martínez-García and Holliday (2019) compared the perception of Korean three-way stops by Spanish naive listeners and Spanish L2 learners of Korean. With Spanish stops being either ‘unequivocally pre-voiced’ (p. 2585) or voiceless in the word-initial position, all the participants assimilated all three of the Korean stops, which are voiceless in the word-initial position, to a Spanish voiceless stop category (SC). Although a significant level of inter-listener variability was found, on the whole, the naive listeners and the L2 learners showed only minor differences in assimilating word-initial Korean stops. This pattern of perception that aligns with predictions based on the PAM has also been found in L1 speakers of Hindi and Paite (CG) (Ngaihte and Holliday, 2019), as well as Quebec French (Nam et al., 2021). Notably, in addition to an identification task, in which all Korean stops were assimilated to French voiceless stops as expected (SC for most contrasts; UC for a few exceptions), Nam et al. (2021) employed an AX discrimination task to measure the discrimination of Korean stops by naive-listener Quebec French speakers. Based on the participants’ relative difficulty discriminating between the lenis and aspirated stops, Nam et al. (2021) concluded that the stop contrasts with high assimilation overlap hindered the participants’ discrimination ability.
The current study focuses particularly on L1 English speakers’ ability to perceive Korean stops. Previous research indicates a pattern in line with speakers of the other L1s discussed above. English has a two-way stop contrast that is differentiated by voicing (i.e. voiced and voiceless stops) along the VOT continuum (Cho et al., 2019). Even with high degrees of variation among speakers, the variation is still highly structured, with mean VOT values correlated with linear relations between voiced and voiceless stops and between different places of articulation (Chodroff and Wilson, 2017). With VOT being the key cue for discriminating English stops, naive-listener L1 speakers of English also perceive both Korean lenis and aspirated stops as English voiceless stops and Korean fortis stops as English voiced stops (Schmidt, 2007), and they are unable to attend to the F0 cue that distinguishes lenis stops from aspirated and fortis stops. However, Francis and Nusbaum (2002) demonstrated that with explicit training on identification, L1 English speakers with no prior knowledge of Korean learned to use both VOT and F0. In a similar vein, Kong et al. (2022) found that for L1 English learners of Korean, VOT and F0 were the primary and secondary cues, respectively, in distinguishing Korean stops.
III Current study
The current study aims to advance our understanding of incidental learning of non-native speech and the role of the frequency of input. Considering the attention that frequency of exposure has received in other domains (e.g. Aka, 2020; Hamrick and Rebuschat, 2014; Lee, 2002; Robinson, 2005; Webb, 2007), the current study addresses the research gap that exists in the domain of L2 speech. This inquiry is particularly important in speech learning. It is well known that infants can detect all phonetic information in their early stages due to their ability to attend to fine-grained phonetic distinctions and then direct their attention only to information that is significant in their ambient languages (Munro, 2021). Though they weaken with age, there is evidence that the mechanisms underlying L1 speech learning are maintained and that L2 learners could access them when they are given optimal L2 input (Flege and Bohn, 2021). Regarding what constitutes optimal L2 input, Flege and Bohn (2021) further added that it is ‘unknown at present how much L2 input is needed to form phonetic categories in an L2 and optimally adapt them to everyday use’ (p. 15). By testing various quantities of repeated input, the current study aims to offer some insight into the elements of optimal input in L2 speech learning.
The current study focuses particularly on the perceptual discrimination of Korean lenis stops and fortis stops by naive L1 English speakers. Despite the three-way contrast of Korean stops, only the lenis and fortis stops were included for the following reasons: with the aforementioned convergence of VOTs of lenis and aspirated stops in modern Korean speech, the lenis-aspirated contrast may not be perceptible at all to naive L1 English speakers, who are likely to attend only to VOT. The results of Schmidt (2007) suggested that Korean aspirated stops would be the most difficult for L1 English speakers, especially in distinguishing them from lenis stops. The same was noted among L1 speakers of Spanish (Martínez-García and Holliday, 2019) and Dutch (Broersma, 2009; Choi, 2015). Furthermore, as demonstrated in Nam et al. (2021), discrimination by L1 speakers of French, which has two-way stops differentiated by voicing like English, was the least accurate for lenis-aspirated contrasts across all three places of articulation due to their high assimilation overlap. In Guion and Pederson (2007), out of five Hindi phonemic contrasts learned by L1 speakers of English, explicit directing of attention to their phonetic forms had an effect for only the most difficult contrast, with the authors concluding that explicit attention has a greater effect on learning for difficult contrasts that take longer to learn. Bearing that in mind, the lenis-aspirated contrasts are unlikely to be impacted by the incidental learning conditions of the current study. Conversely, evidence suggests that Korean fortis and aspirated stops are easily distinguished by speakers of L1s that have VOT-cued stop contrasts. If so, the participants in the current study may perform well in discriminating the fortis-aspirated contrast regardless of any incidental exposure, making it difficult to attribute any learning to the instructional treatment or creating a potential ceiling effect.
To pursue our research objectives, an experimental study was conducted to answer the following research questions:
• Research question 1: To what extent do naive L1 speakers of English increase their perception accuracy in discriminating between Korean lenis stops and fortis stops after incidental exposure to them?
• Research question 2: To what extent does the frequency of exposure to the Korean lenis and fortis stops (i.e. 0, 2, 10, 20, or 30 occurrences) affect the L1 English speakers’ incidental learning?
IV Method
1 Participants
A total of 100 English speakers (22 males; 78 females) participated in the current study. Their average age was 25.6 years (SD = 10.1); 89 participants were university students, and the remaining 11 participants were professionals. All participants learned English as their L1 from birth, from at least one parent. They had never learned Korean nor ever lived in Korea, and no participant spoke an L2 that contains phonemes similar to those targeted in the current study.
In addition, five speakers of Korean (2 males; 3 females) contributed to the current study. One female speaker served as an instructor in a language instruction video, and the remaining four speakers provided audio stimuli for testing sessions. Thirteen additional Korean speakers contributed by providing baseline data on the discrimination task. The average age of all the Korean-speaking contributors was 22.2 years (SD = 1.5). They all learned Korean as their L1 from birth from at least one parent. While all of them were university students from South Korea, they were residing in Canada (average length of residence = 3.1 months; SD = 1.5) for the purpose of learning English at the time of data collection.
2 Procedures
The overall design of the current study comprised a pretest, an incidental learning session, an immediate posttest, and a delayed posttest. The 100 participants were randomly assigned to one of the following five conditions (20 participants per condition): (1) 0-occurrence; (2) 2-occurrence; (3) 10-occurrence; (4) 20-occurrence; or (5) 30-occurrence. On their first day, the participants completed a pretest consisting of an AX discrimination task. All participants attended their second session an average of 4.5 days (SD = 19.4) later. Eighty-nine out of the 100 participants completed their second sessions within one to four days of their pretests, 10 participants attended between five to nine days later, and one outlier participant completed the second session 197 days later. Because the current study was interrupted by institutional closures due to a global pandemic, this participant had to return after data collection resumed approximately six months later. At the second session, all participants received language instruction consisting of two consecutive viewings of a video that explicitly taught the participants how to count numbers in Korean while incidentally exposing them to various repetitions of the target phonemes (i.e. Korean lenis and fortis stops), depending on their treatment condition. Immediately following the instructional treatment, all the participants completed the same AX discrimination task. The participants returned for a third session to complete their delayed posttests (i.e. the AX discrimination task) an average of 61.6 days (SD = 70.4) after their immediate posttests. Again, due to the pandemic interruption, while 76 participants had a delay of between 12 and 33 days (average = 22.2; SD = 3.6), 24 participants had a delay of between 174 and 218 days following their immediate posttests. It is crucial to note that for both the immediate and delayed posttests, the variation in the delays did not affect the data. Statistical analyses including and excluding the outlier participants showed no significant differences (p > .05).
a Instructional treatment
To operationalize incidental exposure as defined in the current study, the instructional treatment consisted of a video teaching participants how to count numbers in Korean (i.e. meaning-focused instruction) and a worksheet that assessed participants’ knowledge of Korean numbers, about which they were forewarned (i.e. directing their attention to the Korean numbers instead of the target phonemes). The goal of the instructional treatment was to direct the participants’ attention to comprehending and memorizing the Korean numbers while measuring their ability to ‘pick up’ the unfocused targets as a by-product of completing the main task. Each of the 100 participants watched a video providing explicit instruction on how to count from one to four in Korean. Before watching, the participants were told that they would learn how to count in Korean and complete a worksheet after watching the video twice. The video for each condition was narrated by a female instructor, one of the aforementioned Korean speakers. Given that none of the participants had learned Korean before, the medium of the instruction was English. In the video, the instructor explained how to count from one to four in Korean. She orally presented each number with an explicit translation (e.g. ‘one is hana in Korean’; ‘two is dul in Korean’). Pronouncing the numbers clearly, the instructor invited the participants to verbally repeat after her. The accompanying visual material in the video consisted of the words ‘How to count numbers in Korean’, the numerals 1, 2, 3, 4, and color drawings of six different fruits. The instructor then used the Korean numbers to count the six fruits, each of which was pseudo-labeled as each of the target phonemes paired with the vowel /a/ as follows: ‘apple’ as /pa/, ‘orange’ as /p*a/, ‘strawberry’ as /ta/, ‘lemon’ as /t*a/, ‘pear’ as /ka/, and ‘grapes’ as /k*a/. The instructor orally presented the pseudo-labels at different frequencies depending on the condition, but they were not explicitly taught nor emphasized in any way.
Regarding the different frequencies of exposure in the current study, as no previous research on the role of repetition in the incidental learning of L2 speech had been conducted, an exploratory approach was taken to cover a variety of numbers between 0 and a number high enough to provide input flooding in a relatively short video (watched twice). Hence, in addition to 0 as a control, a video including just one exposure was created, as well as with five exposures to align with the ‘count to four’ scheme. The block of five exposures was included twice to include 10 exposures, and three times to include 15 exposures in each video. To illustrate, for the 2-occurrence condition, the instructor said ‘This is called /pa/’ when a picture of an apple appeared on the screen, then counted hana, dul, set, net as additional apples appeared, exposing the viewer to the target syllable /pa/ just once, then she continued on in the same manner with the other objects and target phonemes. For the 10-occurrence condition, the instructor said ‘This is called /pa/’ when an apple appeared, then counted ‘/pa/ hana, /pa/ dul, /pa/ set, /pa/ net’ to expose the viewer to /pa/ a total of five times, and so on. For the 20- and 30-occurrence conditions, the instructor repeated the counting accordingly, and for the 0-occurrence condition, the instructor counted Korean numbers as the objects appeared without using their pseudo-labels, not exposing the viewer to the target phonemes at all (for a script of all the videos by condition, see Appendix A). Each participant watched the instructional video, which ranged in length from approximately 2.5 to 4 minutes depending on their condition, twice consecutively. In this manner, participants in the 2-occurrence, 10-occurrence, 20-occurrence, and 30-occurrence conditions were incidentally exposed to each target phoneme a total of twice, 10 times, 20 times, and 30 times respectively (i.e. once, five times, 10 times, and 15 times in the video, watched twice).
As informed in advance, after the second viewing of the instructional video, all the participants were asked to complete a worksheet comprising three simple multiple-choice questions, as shown in Figure 1. This worksheet activity was included to keep the participants’ focus on comprehending the message of the instructional video (i.e. counting numbers in Korean), rather than on the target phonemes (i.e. the ‘names’ of the fruits). Although the results of the worksheet were not further analysed in the current study, all participants showed nearly perfect scores, indicating that they successfully learned the numbers one to four in Korean.

Worksheet on Korean numbers.
b Testing sessions
The participants completed a pretest, an immediate posttest, and a delayed posttest, each of which consisted of an AX discrimination task designed and administered using Praat (Boersma and Weenink, 2021) and Test Invite on individual computers. To measure listeners’ perception of target sounds, two commonly implemented types of tasks are forced-choice identification tasks and categorical AX discrimination tasks (see Strange and Shafer, 2008). Given that the participants are completely naive listeners with no perceptual nor orthographic knowledge of the Korean stops, an identification task would be unsuitable for the current study. In contrast, an AX discrimination task merely requires listeners to decide whether two audio stimuli are the same or different from one another, making it a more accurate measure of whether the participants learned the phonemic contrasts (i.e. whether they can perceive the categorical differences, which exist in Korean). Hence, an AX discrimination task was employed to measure the extent to which the participants perceptually discriminated between the corresponding Korean lenis stops and fortis stops (i.e. /pa/ vs. /p*a/; /ta/ vs. /t*a/; /ka/ vs. /k*a/).
To record the audio stimuli for the task, two male (M1, M2) and two female (F1, F2) Korean speakers were asked to pronounce each target stimulus (see Table 1) in a carrier sentence, ‘The next word is [X].’ Each stimulus was then extracted from the carrier sentence using Praat (Boersma and Weenink, 2021). To ensure the validity of all stimuli, two separate analyses were conducted. First, the authors of this article, who are L1 speakers of Korean, listened to each stimulus in a random manner and orthographically transcribed it in Korean. The analysis confirmed that all the stimuli were correct. Second, the stimuli were acoustically analysed by Praat (Boersma and Weenink, 2021), measuring VOT and F0 values in particular. Based on previous studies (Chang, 2010; Francis and Nusbaum, 2002; Kim, 2004), VOT values were measured as the time, in milliseconds, from the beginning of the release burst to the onset of voicing (i.e. the first point of the glottal periods and a clear voicing bar in the spectrogram). F0 values were measured by calculating the average duration of the first three glottal pulses in the vowel /a/ following each target phoneme and then converting it to a frequency value (Chang, 2010).
Mean voice onset time (VOT) and F0 values (with standard deviations in parentheses) by stimulus and by gender.
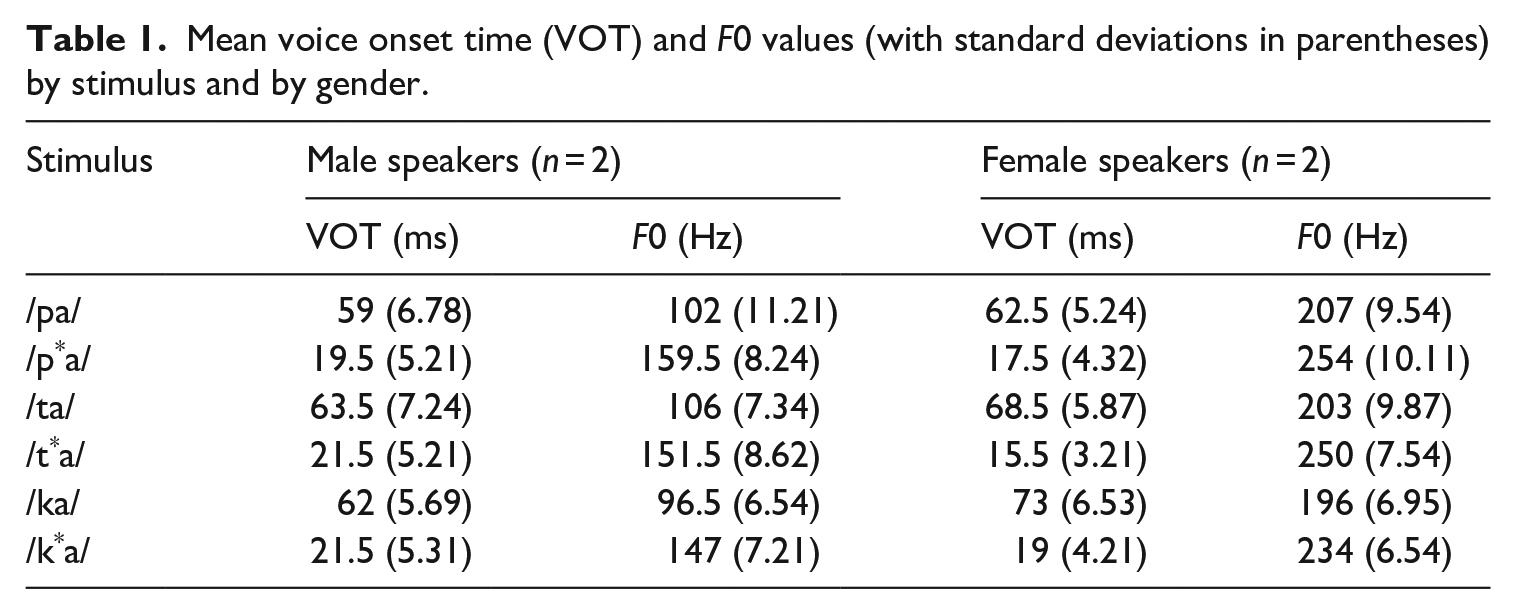
Table 1 summarizes the acoustic properties of the audio stimuli. The acoustic properties were compatible with those reported in previous studies (Francis and Nusbaum, 2002; Kang and Guion, 2008; Kim, 2004), showing that the lenis sounds (i.e. /pa/, /ta/, and /ka/) had longer VOT values and lower F0 values than the fortis sounds (i.e. /p*a/, /t*a/, and /k*a/).
During the task, the participants listened to a sequence of two sounds ‘A’ and ‘X’ and then were asked to indicate whether the second sound (i.e. ‘X’) was the same as or different from the first sound (i.e. ‘A’) by clicking either the ‘same’ or ‘different’ button on a computer screen. Each sequence of two sounds was played only once. There was no predetermined time interval between trials, and participants moved onto subsequent trials by clicking ‘next’ on the screen. To induce the participants to focus on the categorical differences between two sounds during the task, sound ‘A’ of each sequence was a recording of a male speaker, and sound ‘X’ was a recording of a female speaker in a 1,500-msec inter-stimulus interval condition (Werker and Logan, 1985). The four speakers were paired as follows: M1–F1 and M2–F2. A total of 24 same sound trials were prepared: 6 same pairs (/pa/–/pa/, /ta/–/ta/, /ka/–/ka/, /p*a/–/p*a/, /t*a/–/t*a/, and /k*a/–/k*a/) × 2 speaker pairs × 2 repetitions. Another 24 trials were prepared as different sound trials: 6 different pairs (/pa/–/p*a/, /ta/–/t*a/, /ka/–/k*a/, /p*a/–/pa/, /t*a/–/ta/, and /k*a/–/ka/) × 2 speaker pairs × 2 repetitions. Each participant thus completed a total of 48 randomized trials at each testing session, which took approximately 15–20 minutes. Further, baseline data was collected from 13 L1 speakers of Korean, which indeed confirmed that the acoustic variability among the four speakers did not interfere with the categorial distinctions between each pair of sounds.
3 Data preparation and analysis
To analyse data, the percentage accuracy of the same and different sound trials by condition at the time of each testing was prepared. In addition, signal detection theory was employed to effectively control for individual response biases in the AX discrimination task. Specifically, dʹ (sensitivity index) scores were calculated to measure sensitivity to each phonemic contrast (i.e. /pa/–/p*a/; /ta/–/t*a/; /ka/–/k*a/) with z scores of hit rates (H) and false-alarm rates (F) using the following formula (MacMillan and Creelman, 2005):

A hit rate resulted from the ratio of the number of times the ‘different’ button was selected to the total number of the different sound trials. A false-alarm rate was the ratio of the number of times the ‘different’ button was selected to the total number of the same sound trials. Based on Stanislaw and Todorov (1999), the computation of dʹ scores was adjusted when hit and false-alarm rates were 0 or 1. Therefore, a dʹ score for a perfect detection performance was 4.65 (the effective limit, using .99 and .01) in the current study. Following this procedure, a dʹ score per phonemic contrast was prepared for each participant for each testing.
The participants’ dʹ scores were statistically analysed using mixed effects models in R (R Core Team, 2023) using the lme4 package (version 1.1-34) and restricted maximum likelihood. For the statistical model, fixed effects included ‘condition’ (0-occurrence, 2-occurrence, 10-occurrence, 20-occurrence, and 30-occurrence), ‘time’ (pretest, immediate posttest, and delayed posttest), ‘phonemic contrast’ (/pa/–/p*a/, /ta/–/t*a/, and /ka/–/k*a/), their two-way interactions, and three-way interactions. Given the research questions, the factors ‘condition’, ‘time’, and ‘phonemic contrast’ were coded using treatment coding with the 0-occurrence condition, the pretest, and /pa/–/p*a/ as reference levels. Individual participants were treated as random effects in the model. All statistical outcomes were interpreted with alpha set at .05. Before conducting each analysis, statistical assumptions were verified (e.g. the explanatory variables were linearly related to the response; the errors had constant variance, which were independent and normally distributed).
V Results
Table 2 summarizes the descriptive statistics regarding mean percentage accuracy scores and their standard deviations (in parentheses) for the same and different sound trials by condition at the time of each testing. Overall, the participants had lower accuracy for different sound trials than for same sound trials, indicating that they had difficulty discriminating between the lenis stops and the fortis stops.
Mean percentage accuracy scores (with standard deviations in parentheses) for the same and different sound trials by condition at the time of each testing.
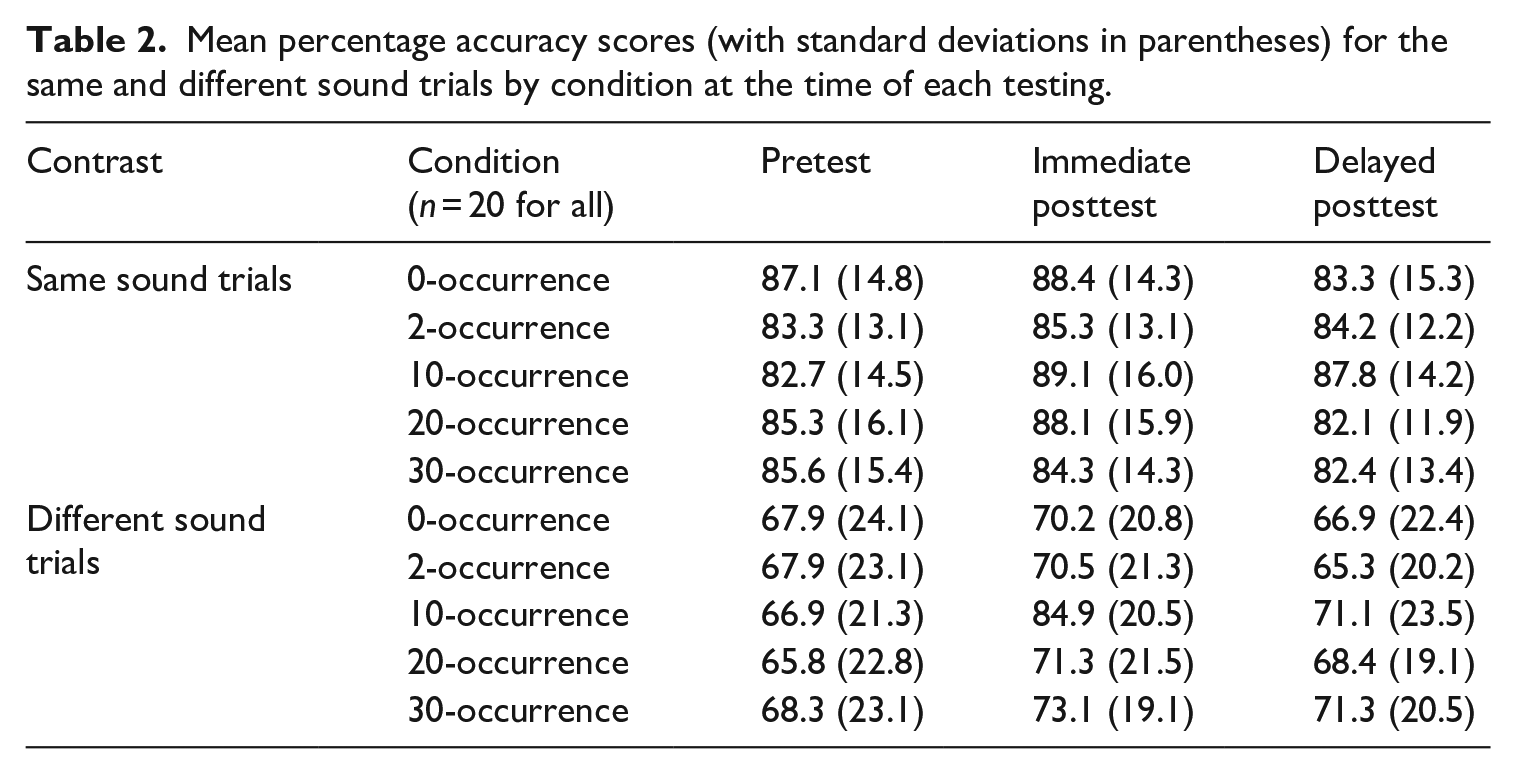
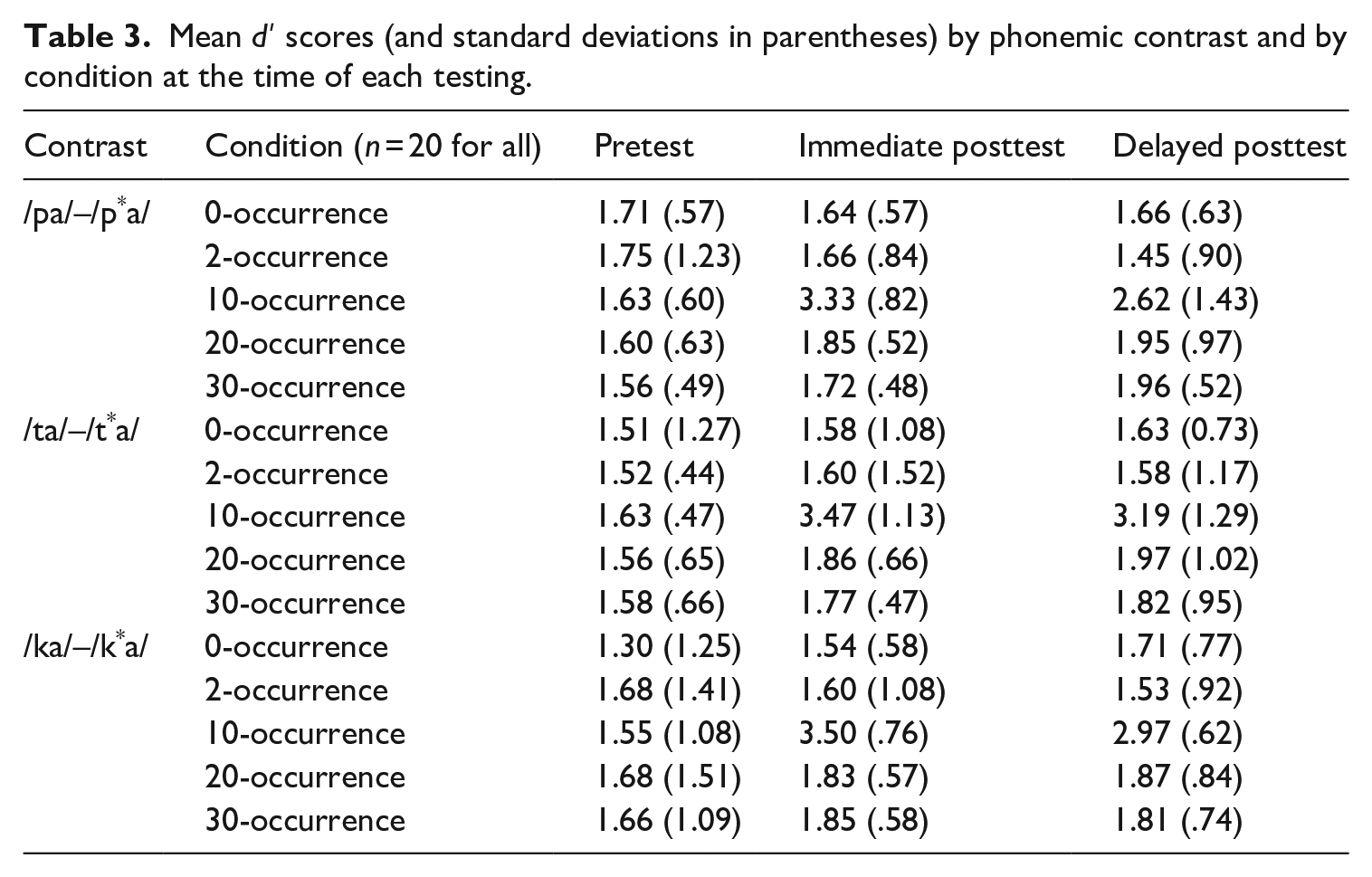
Table 3 shows the descriptive statistics including mean dʹ scores and their standard deviations (in parentheses) by phonemic contrast and by condition at the time of each testing. Figure 2 visualizes the mean dʹ scores of each phonemic contrast by condition at the time of each testing. As a pre-analysis, separate univariate analyses were conducted; there were no significant differences among the five conditions for all three phonemic contrasts at the time of pretesting (p > .05). As shown in the descriptive statistics, the pretest scores ranged from 1.30 to 1.75 out of 4.65.
Mean dʹ scores (and standard deviations in parentheses) by phonemic contrast and by condition at the time of each testing.
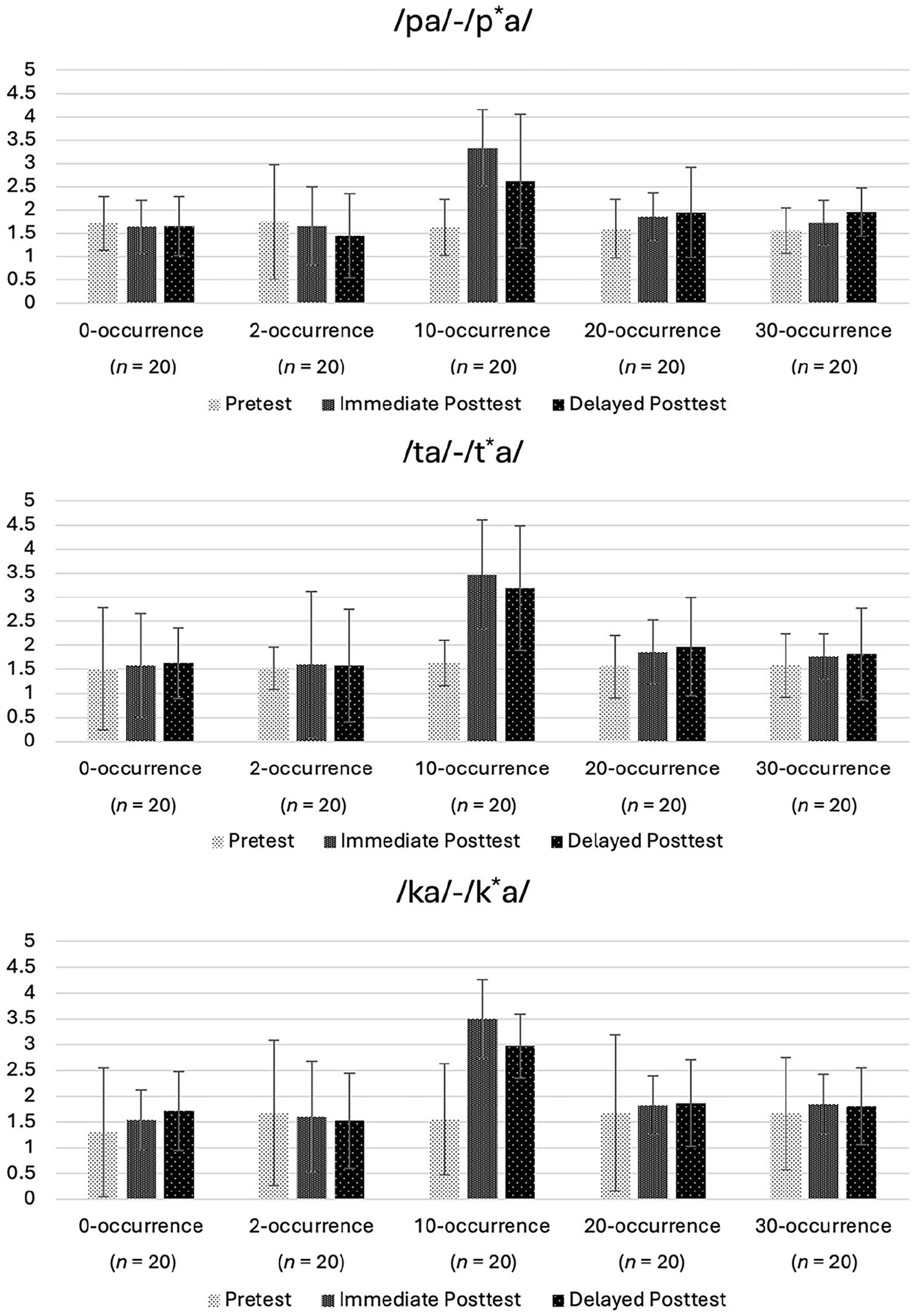
Mean dʹ scores by phonemic contrast and by condition at the time of each testing.
Table 4 shows the inferential statistics regarding the fixed effects in the model. The variance of the random effects was .16. Integrating the random effects improved the fit of the model: χ2 (1) = 76.65, p < .001. The marginal R2 of the model was .26, and the conditional R2 was .41, which indicates that the fixed effects accounted for 26% of the variance and that the fixed and random effects altogether accounted for 41% of the variance in the model. Based on Plonsky and Ghanbar (2018)’s effect size benchmarks (R2 ⩽ .20: Small; .20 < R2 < .50: Medium; .50 ⩽ R2: Large), the overall model was in the medium range.
Fixed-effects model.
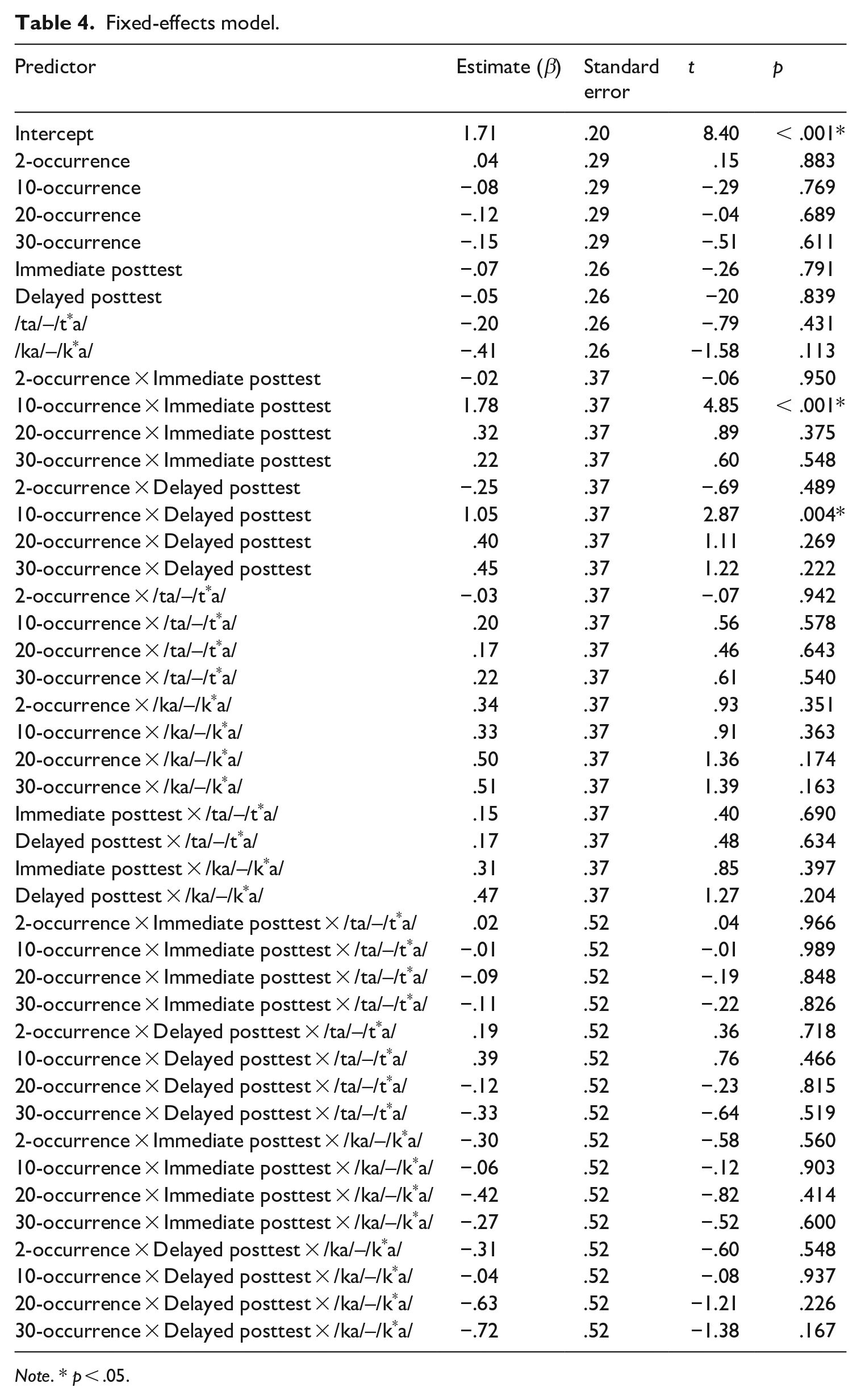
Note. * p < .05.
In the model, the only significant effects were found from the following two interactions: 10-occurrence condition × Immediate posttest (β = 1.78, SE = .37, t = 4.85, p < .001) and 10-occurrence condition × Delayed posttest (β = 1.05, SE = .37, t = 2.87, p = .004). That is, the participants in the 10-occurrence condition significantly outperformed those in the 0-occurrence condition at the time of both posttesting. According to the descriptive statistics in Table 3 and the nonsignificant three-way interaction effects, the effects of the 10-occurrence condition were observed across all three phonemic contrasts. There were no other significant findings from those in the other conditions.
VI Discussion
Based on the results, incidental learning of non-native phonemic contrasts clearly occurred for some of the participants in the current study. The pretest scores indicated that L1 English speakers had difficulty discriminating between Korean lenis stops and fortis stops, with dʹ scores ranging from 1.30 to 1.75 in the AX discrimination task. After watching the instructional video, participants who received 10 incidental exposures to each target phoneme significantly increased in their discrimination accuracy, indicating that an incidental learning condition can enable naive listeners to improve their perception of the Korean stops. While this outcome is consistent with previous research findings that non-native speech can be acquired incidentally, the finding that learning gains were observed only in the 10-occurrence condition, consistently across all the target contrasts in both the immediate posttest and the delayed posttest, was unanticipated and warrants further examination.
While there has been significant variation in the specific number of occurrences required in input for learning, the overwhelming majority of extant research in both vocabulary and morphosyntax learning has suggested a positive correlation between input frequency and learning gains, that is, the more frequently a target occurs in the input, the more likely that the target is to be learned. To the best of our knowledge, no other study investigating input frequency in incidental L2 learning has found results similar to those in the current study, in which learning occurred only at a specific input frequency then returned to baseline levels at higher frequencies. It is thus difficult to interpret or explain the results in terms of frequency as the key factor. However, given how pronounced the results are, it can only be deduced that they were affected by some specific determinant.
In the absence of frequency-related explanations, we turned to the characteristics of the learning conditions themselves. Before watching the instructional video, all the participants were told that they would learn to count in Korean and be asked to demonstrate that knowledge afterwards. As far as the participants were concerned, their main task was to learn and memorize novel vocabulary (i.e. Korean numbers). As they watched the video, all participants were presented with information necessary for that task. In addition, depending on their condition, some participants received various amounts of extra input (i.e. the target Korean stops). Based on the responses on the simple worksheet that was administered after the video, nearly all participants were successful in learning the Korean numbers, regardless of their treatment condition. This is unsurprising, given that there were only four simple mono- or bi-syllabic words to process, and the participants heard them a total of 44 times each. The key question at hand is how and why only those in the 10-occurrence condition were able to process the extra input that was irrelevant to their overt main task. The results from the 0-occurrence condition were as expected, with no change in discrimination ability. Similar results from the 2-occurrence condition were also expected, as learning completely novel phonemes after hearing each of them only twice in a span of roughly five and a half minutes is justifiably difficult. However, as the exposure increases to 10, 20, and 30 occurrences, an explanation seems to lie not in how often, but in the way in which the target phonemes were presented, along with the cognitive mechanisms involved in processing them.
In order to learn the novel Korean words, the participants likely employed their working memory (Baddeley, 1986), or more specifically, the phonological loop. The phonological loop comprises the short-term phonological store, which temporarily holds auditory information, and an articulatory rehearsal process. When novel information is presented auditorily, as in the current study, it has direct obligatory access to the phonological store (see Salamé and Baddeley, 1982). To retain any information held in the phonological store, the articulatory rehearsal process works to repeatedly refresh those new sounds to prevent them from fading away. While the participants in the current study were invited to verbally repeat after the instructor in the video, most of them did not and instead engaged in subvocal rehearsal, the typical method of articulatory rehearsal. The primary purpose of the phonological loop is to facilitate the learning of new words, as seen in both L1 by children and L2 by adults (see Baddeley et al., 1998), and likely in the current study.
When the Korean numbers are presented in a continuous pattern (i.e. hana–dul–set–net), it can be easily learned using the phonological loop. However, the counting pattern is disrupted when the target Korean syllables are embedded in between the numbers (i.e.
The explanation above provides a likely account of why the participants in the 20- and 30-occurrence conditions did not improve their discrimination of the target Korean phonemes, despite having received more exposures than those in the 10-occurrence condition. The main finding of the current study indeed suggests that 10 incidental exposures to a non-native sound are sufficient for learning, while 2 exposures are not. Based on the unexpected results and our interpretation of them, any further conclusions regarding the effect of various input frequencies on incidental learning of non-native speech would be speculative at best. However, there are significant pedagogical implications to derive from the current study.
The first pedagogical implication regards leveraging incidental exposures to novel sounds in L2 instruction. Based on our finding that 10 exposures to the target Korean phonemes resulted in durable perceptual learning, practitioners could utilize their regular instruction of other L2 domains as opportunities to incidentally expose learners to L2 speech. Preemptively embedding certain L2 phonemes that are difficult for learners to acquire into primarily meaning-focused activities could be a double-pronged pedagogical technique that maximizes learning when there is limited time and attention.
Second, the lack of learning in the 20- and 30-occurrence conditions underscores the importance of selective attention in L2 learning. Despite the high frequency of the target phonemes in the input, the participants failed (or neglected) to attend to them due to the cognitive demands of the main task. While the 10-occurrence condition demonstrated that it is possible for intentional and incidental learning to occur simultaneously in the domain of L2 speech, it seems possible only if learners are not overtaxed during instruction. Practitioners should thus be mindful of the attentional demands of specific tasks and ensure that simultaneous learning targets are paired appropriately. It is important to ensure that one learning target does not get acquired at the expense of the other by overshadowing and blocking it.
VII Limitations and directions for future research
The present study has several limitations, yielding suggestions for future studies in this line of research. The design of the learning conditions (i.e. instructional videos), though they yielded important unintended findings, did not reveal the effects of various frequencies of incidental exposure. With much more research needed in this area, it would be important to conduct studies that can more clearly attribute results to frequency only. Also, including an intentional learning condition would provide concrete, measurable comparisons between incidental and intentional L2 speech learning. Furthermore, incorporating more ecologically valid learning conditions, such as watching videos (Nguyen and Boers, 2019; Peters and Webb, 2018) and listening to songs (Baills et al., 2021; Pavia et al., 2019), would provide more realistic accounts of incidental learning, particularly in the domain of L2 speech.
The current study used an AX discrimination task to test participants’ ability to discriminate the phonemic contrasts. Though the task itself is an effective measure, given the current study’s focus on incidental learning, there is a possibility of participants becoming aware of the targets during the pretest and intentionally learning them during the instructional treatment. A way to mitigate this concern in future research is to include distractors in the AX discrimination task using non-target filler items.
For our participant sample, naive listeners with no prior knowledge of Korean and the target phonemes were deliberately selected to ensure that we could control their amount of exposure to the target phonemes. However, their level of motivation may be a concern, as their interest in the Korean language is likely lower than that of active L2 learners of Korean. It is possible that as non-learners, the participants did not care to learn or maintain any learning gains that may have occurred. A similar study with L2 learners of the target language may provide different results that are more in line with findings in L2 acquisition research.
Due to the timing of the data collection, we were met with unforeseen methodological issues, particularly the significant variation in the intervals among testing sessions and instructional treatment. While this fortunately did not impact the data in the current study, it goes without saying that better control of the data collection process should be a priority.
The current study specifically examined Korean lenis and fortis stops as linguistic targets. As the Korean three-way stops are a uniquely rich set of phonemes, including the aspirated stops in the set of targets would provide more complete insights to the acquisition of L2 speech. It would also be useful to target different phonemes and various languages to generalize the findings of the current study. In addition, the current study focused on the development of L2 speech perception. Keeping in mind that L2 speech learning pertains not only to perception but also to production, future studies need to be conducted to examine whether L2 learners can improve their production accuracy of target phonemes after incidental exposure to them. Previous studies (Denhovska and Serratrice, 2017; Godfroid, 2016; Shintani, 2015) found that L2 learners showed improvement in receptive tasks after incidental exposure but not in productive tasks. Therefore, taking a close look at L2 speech production would contribute significantly to what is currently known.
Finally, previous studies (e.g. Li and DeKeyser, 2017; Saito et al., 2020) indicated that L2 speech learning is highly influenced by L2 learners’ individual differences such as L1 background, L2 learning experience, age, awareness, motivation, attitudes, and musicality. Accordingly, it would be worthwhile to tease apart how incidental learning of L2 speech and individual differences may be related.
VIII Conclusions
The current study examined the extent to which naive listeners could acquire non-native phonemic contrasts (i.e. Korean lenis vs. fortis stops) in an incidental manner, as well as the degree to which the frequency of exposure to each target phoneme affects their incidental learning. A total of 100 L1 English speakers received one language instruction session that provided explicit instruction on how to count numbers in Korean. During the session, they were incidentally exposed to each of the target phonemes twice, 10 times, 20 times, 30 times, or not at all. According to the results of the AX discrimination tasks, only the participants in the 10-occurrence condition significantly improved their discrimination ability in both posttests for all target contrasts, indicating that 10 incidental exposures to non-native phonemes are indeed enough for perceptual learning. However, given the general premise that high frequency of input yields more learning, along with the lack of previous research in incidental learning that contradicts this notion, the results showing no learning in the 20- and 30-occurrence conditions were unexpected. This outcome is thus interpreted as demonstrating the role of selective attention in incidental learning of non-native speech, rather than a function of input frequency. Due to the way in which the target phonemes were embedded in the instructional content, the participants in the 20- and 30-occurrence conditions were subject to more attentional demands, which likely led them to block the target phonemes, the less salient input, in order to focus on the Korean numbers, the more salient input. It is hoped that the current study contributes valuable insights to this line of research and that future studies will build on its findings to continue exploring the effects of incidental exposures to non-native speech on perceptual learning.
Footnotes
Appendix A
Acknowledgements
We sincerely thank all participants and extend our gratitude to the following research assistants: Kelyn Rae Best and Caroline Duarte Ramos Avila.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Faculty of Social Sciences at Brock University and the Social Sciences and Humanities Research Council of Canada (SSHRC) (430-2021-00076).