
Abstract
This study problematizes the second language (L2) / third language (L3) initial state, questioning who the real initial state-learners are and whether it is the initial state that has been explored in some previous L3 studies that claim to do so. We will discuss the notion of initial stages in relation to the initial state. We argue that, depending on prior language knowledge, learners can – thanks to intercomprehension – advance rapidly from the initial state into the initial stages of interlanguage. We base these suggestions on data from a small-scale study in which 20 native speakers of Swedish assessed whether some Dutch, Finnish and Norwegian sentences were grammatical or not. The results from this study led us to a discussion of whether the leap from the initial state to the initial stages can be overcome more quickly, due to the clues from typological similarity on the lexical level that the learners are given .
I Introduction
Many studies on third language (L3) acquisition or learning 1 have concentrated on the initial state (IS) of the L3 and the research conducted has come to various results concerning the source language for transfer mainly drawing on data gathered through judgement tasks. However, there is no common definition of the IS. The aims of the present study are to problematize the notion of the IS in non-native language learning and to evaluate whether judgement tasks are always the most appropriate data collection method in studies concerned with the IS.
We will start by reviewing some operationalizations of the IS and discuss what they mean for the interpretation of different results. Thereafter we bring up the notion and the role of intercomprehension, arguing that the real IS-learner is hard to identify if the involved languages are very similar. For example, we suggest that the leap from the IS to the initial stages is much greater when learning a language that is very remote to one or more of the learner’s background languages compared to when the target language is closely related to them. We also question what judgement tasks (JT) can tell us about language knowledge in the early stages of non-native language learning. In order to develop the understanding of the role of intercomprehension and of the knowledge that results from judgement tests really represent, we conducted a study of native speakers of Swedish who were given grammaticality judgment tasks in three languages: Dutch, Finnish and Norwegian. The typological proximity to Swedish of these three languages differs distinctly, which makes them a suitable set of languages in our test case. As opposed to theories that claim the importance of typological proximity in L3 acquisition (e.g. Rothman, 2011) we do not take for granted that learning or acquisition has taken place in the IS, or in the initial stages, based only on results from JTs. Instead, we suggest that what is going on is intercomprehension.
1 The initial state and what follows
Several studies on L3 syntax that have emerged during the last decades claim to say something about the role that prior language knowledge plays in the L3 IS. But as observed by Leung (2005): [t]he term ‘initial state’ loosely refers to the grammar at the outset of language acquisition. There is no precise definition or objective criterion to determine, for instance, its duration. However, what is considered more important and more interesting is its characterization – when a learner first starts learning a language L, what does this particular system L look like? (Leung, 2005: 40)
As suggested by Leung, it is not always clearly defined what is meant with the term ‘initial state’. Not only does it remain unclear how long it lasts, but also whether it is thought of as a period, in the first place. This problem is not exclusively related to the L3 literature. The imprecise reference to the concept of an initial state was pointed out already by Schwartz and Sprouse (1996) apropos the starting point of the second language (L2) grammar: ‘One of the more neglected topics in L2 acquisition research is the precise characterization of the L2 initial state, where “L2 initial state” refers to the starting point of non-native grammatical knowledge’ (p. 1, our emphasis). As explained by White (2012 [2003]: 58), ‘the term initial state is variously used to mean the kind of unconscious linguistic knowledge that the L2 learner starts out with in advance of the L2 input and/or to refer to characteristics of the earliest grammar’ (our emphasis). Of relevance to the current study is the notion of a ‘starting point’, and the definition of IS as ‘a kind of knowledge’, that is, the state from which the non-native language learning process begins, since we are interested in the very first encounter with unknown languages.
Up to now, several L3 studies on what has been called the IS have been carried out. Both what different authors mean with ‘initial state’ and what kind of data they rely on when investigating it definitely varies. This is summarized in Table 1. As can be seen in the table, there is big variation, when it comes the length of study of the language in question when referring to the initial state. Furthermore, the data collections have sometimes been carried out in countries where the language is spoken which means that the amount of input is likely to be very high. According to us, all these studies do not capture the initial state, but rather different initial stages of interlanguage development. For example, Hermas (2010) investigated learners who had studied the language for four years.
Third language studies on the initial state (IS).
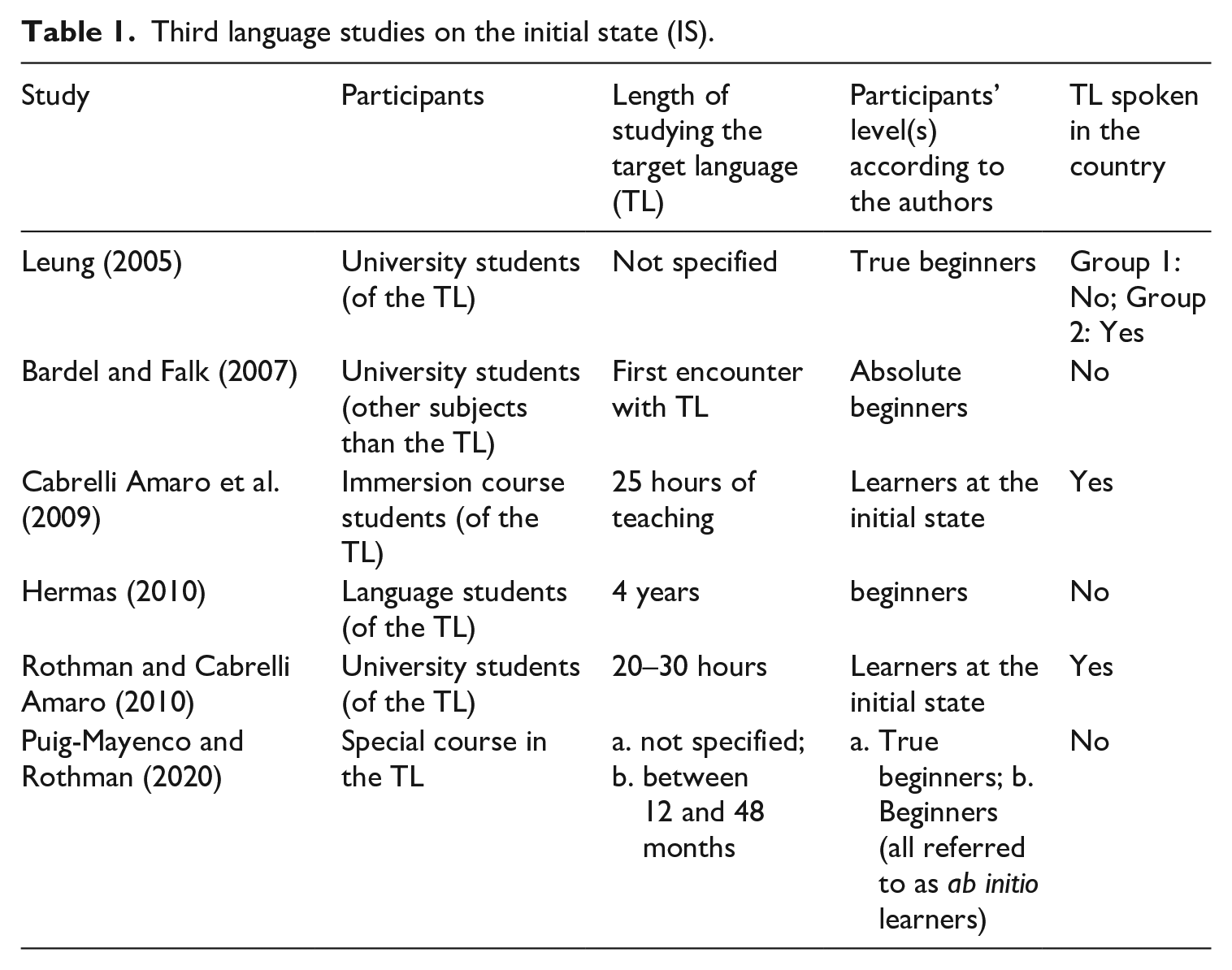
Regardless of operationalizations of the IS, it is interesting to note what Westergard et al. (2017: 669), point out; according to them ‘transfer cannot occur in the initial state, before any exposure to the L3’ and ‘the learner needs to have some basic experience with the L3 before the parser can make the decision’. As Westergard et al. (2017) also point out, it is not clear how much exposure the initial stages comprise. Considering this, how can then the IS be tested, if it only exists in advance of L2 input (White, 2012 [2003])? As soon as the learner is confronted with the test input he or she is theoretically not in the IS any longer. However, this applies only if the test input is processable (thanks to typological similarity). If the test items of the tested language do not supply any clue, for example cognates, we suggest that the learner will not leave the IS only through the input from the test.
2 Intercomprehension
The term intercomprehension is defined as ‘a form of communication in which each person uses his or her own language and understands that of the other’ (Doyé, 2005: 7). Gooskens and van Heuven (2020) argue that when learning a closely related language ‘only a short language course . . . makes speakers conscious of the most important differences and similarities between their native language, and the language of the speaker can improve receptive proficiency considerably’ (p. 374).
One study that explores the role of intercomprehension in L3 learning is that of Marx (2011). German native speakers (with English as L2) were given written texts in Danish, Dutch, Icelandic, Norwegian or Swedish, all languages that they did not know. They read the texts and were given questions about them covering both content and structure in the texts. The participants scored higher for Dutch than for the other languages on global understanding of the content of the text as well as of specific content words, function words and syntax. Questions about syntax were correctly answered for Dutch in about 50% of the cases.
Intercomprehension between the background languages – first languages (L1s) and second languages (L2s) – and the target language is likely to have an impact on how quickly the learner leaves the IS and advances through the initial stages. If there are many lexical items that are transparent to the learner, comprehension of the syntax in the initial state might quite naturally be influenced in a positive way. Lexical similarity can give the learner information about which lexical item corresponds to a specific clause element; compare with the notion of lexical inferencing, which will however not be adopted here (Haastrup, 1991; Wesche and Paribakht, 2009). But if the L1/L2s have very few lexical similarities with the target language, the learner will hardly recognize nouns or verbs and then the syntax of the IS has no lexical information to fall back upon.
3 Judgment tasks
In this section we turn to the judgment task (JT) as data collection method. JTs are frequently and increasingly used in SLA research generally (Plonsky et al., 2020) and have been adopted in the last decades’ L3 research, especially the branch that investigates L3 syntax within the generativist paradigm. Spinner and Gass (2019: 1) call individuals’ judgments of what is acceptable and not in a given language a ‘prominent way of determining what is part of one’s knowledge of language’. Still, the judgement methodology is characterized by variation and enfolded by controversy (Plonsky et al., 2020; Spinner and Gass, 2019).
In their study, Plonsky et al. (2020) cite some concerns regarding the validity, reliability, and suitability of the JT for eliciting learner language data. They raise questions about what kind of knowledge JTs really measure, what the results can say about learning vs. acquisition (and related concepts), and whether learners can be trusted to take the task seriously, or if there is a risk that boredom or fatigue might jeopardize the reliability of the data. Other methodological problems related to their administration (the effect of task conditions, e.g. timed/untimed tests; oral/written input) are pointed out. In their meta-study of 302 studies using JTs, Plonsky et al. found that scores on untimed JTs tended to be substantially higher than on timed JTs.
The aim of JTs is to elicit test-takers’ intuitions about the well-formedness of sentences. Linguistic intuitions are held to reflect the competence underlying performance. As explained by Spinner and Gass (2019: 2), Chomsky, who proposed judgments as a method to define a natural language, argued for the importance of introspective reports to capture the linguistic intuition of the native speaker, or the linguist who had ‘learned the language’ (p. 18). The question then arises whether true beginner learners of a non-native language can be held to have intuition of the new language. If given a JT, they will build their conjectures on intra-linguistic clues from either their target language, i.e. the sentence, or inter-linguistic clues from the background language(s).
Another issue is how to interpret the results from JTs. There are several things in a sentence (such as other syntactic or morphological traits than the ones intended, vocabulary, spelling, pragmatics) that learners might react to, according to their perception of the target language, based on the hypothesis they make, according to their interlanguage. Experimental stimuli should therefore be carefully designed to control for such confounding variables, matching lexical complexity, sentence length, etc. The problem can also to some extent be prevented by encouraging participants to concentrate on the structure of the sentences and discouraging them from focusing on spelling or punctuation issues, to try to prevent them from searching for minor errors or typos (Bley-Vroman et al., 1988: 32). But it cannot be taken for granted that all participants understand such instructions and, for instance, what is meant by ‘structure’. 2 Test-takers can be trained as part of the experiment. However, such training is likely to enhance metalinguistic awareness, and thereby steer the test-takers away from underlying competence.
II A study on the impact of intercomprehension in the initial stages
As said, the aims of this study are to problematize the notion of the IS in L2/L3 learning and to try to understand whether judgement tasks are an appropriate data collection method in studies concerned with the IS.
1 Method
We constructed a grammaticality judgement test with 12 sentences in Dutch, Finnish and Norwegian respectively with a basic vocabulary (for all target sentences in all languages, see Appendix A). These sentences were first created in Swedish and then translated by native speakers into the target languages – any lexical similarities between the tested languages and Swedish were in other words not considered when choosing the sentences in Swedish.
Some rules of thumb according to Spinner and Gass (2019: 61–64) were applied in the current study:
Higher numbers of sentences per targeted grammatical element will lead to greater confidence in the results.
It is generally wise to avoid making the grammatical target obvious. This can be done easily when multiple structures are being investigated.
Some sort of randomization is desirable.
There were six grammatical and six ungrammatical sentences in each of the three target languages. Here follows an example of a grammatical sentence in Norwegian: (1) Karin drikker mineralvann ettersom hun er avholdsmenneske. ‘Karin drinks mineral water, because she is sober.’
For an ungrammatical sentence see (2).
(2) * Peter tomater spiser, ettersom han er vegetarianer. ‘Peter tomatoes eats, because he is vegetarian.’
For an illustration of the similarity between target language Norwegian and the L1 of the participants (Swedish), see (3) and (4).
(3) Karin (4) * Peter
The ungrammatical sentences had the same basic sentence structure as the grammatical ones, but one word order structure was incorrect. The lexical items also differed slightly (see Appendix A) within each pair; see examples (1) to (4). Target structures were adjective placement in relation to the noun, placement of sentence adverb in relation to the verb, and verb placement in sub- and main clauses.
The test was administered online. The participants could choose between three answers: ‘Correct’, ‘Incorrect’ or ‘I don’t know’. The choice of incorporating the ‘I don’t know’ option was made because we did not want the test-takers to provide wild guesses if they were forced to judge the syntax in most of the Finnish sentences and, moreover, we wanted to see clearer results from correct–incorrect judgements (see Tremblay, 2005: 140). It was not possible to skip a sentence – responses were compulsory. Moreover, no fillers were included due to the fact that there were various syntactic aspects in the items and fillers would not have given any further information to the results (see Spinner and Gass, 2019: 70).
The sentences in the grammaticality judgment test used in this study came in the following order: 6 sentences in Dutch; 6 sentences in Finnish; 6 sentences in Norwegian; 6 sentences in Finnish; 6 sentences in Norwegian; 6 sentences in Dutch (this was in another randomized order in a second and third version of the test). Eight participants were given the first version, 9 participants the second version and 3 the third version; this distribution was based on when participants agreed to participate in the study. The instructions before the test were as follows (but in Swedish): You will see 36 sentences in three different languages (Dutch, Finnish and Norwegian). We want you to answer whether each sentence is correct or incorrect or if you don’t know. If you think that the sentence is correct, choose ‘Correct’, if not, choose ‘Incorrect’. If you are not sure, please choose ‘I don’t know’. Concentrate on grammatical aspects of the sentence, i.e. not spelling, interpunctuation, etc. (see the instructions suggested by Bley-Vroman et al., 1988; Spada et al., 2015)
The sentences were presented one at a time to make sure that it was not possible to compare the different sentences. The participants could not go back to previous items in the survey. The task was untimed since we were interested in the participants’ interpretation of the sentences and not their immediate reaction (see Schütze, 1996).
2 Participants
In total, 20 adult native speakers of Swedish with no prior knowledge of neither Dutch, nor Finnish or Norwegian, reached by convenience sampling, conducted the test. All informants were of working age. They were not linguists. Before agreeing to participate, the participants were informed that the test was voluntary and that they were guaranteed anonymity.
III Results
Below the overall results of the grammatical judgement task are rendered. As can be seen there is great variation in correctness rate between the three languages. There were 12 sentences per language and 20 participants, which gave us a total of 240 answers per language (with a total of 720 answers across languages).
As seen in Figure 1, the participants chose the option ‘I don’t know’ in more than 86% of the Finnish sentences. Moreover, they were able to judge the Norwegian sentences correctly in 90% of the cases, and their answers to the Dutch sentences were somewhere in between as for degree of correctness and the option ‘I don’t know’ (see Table 2).
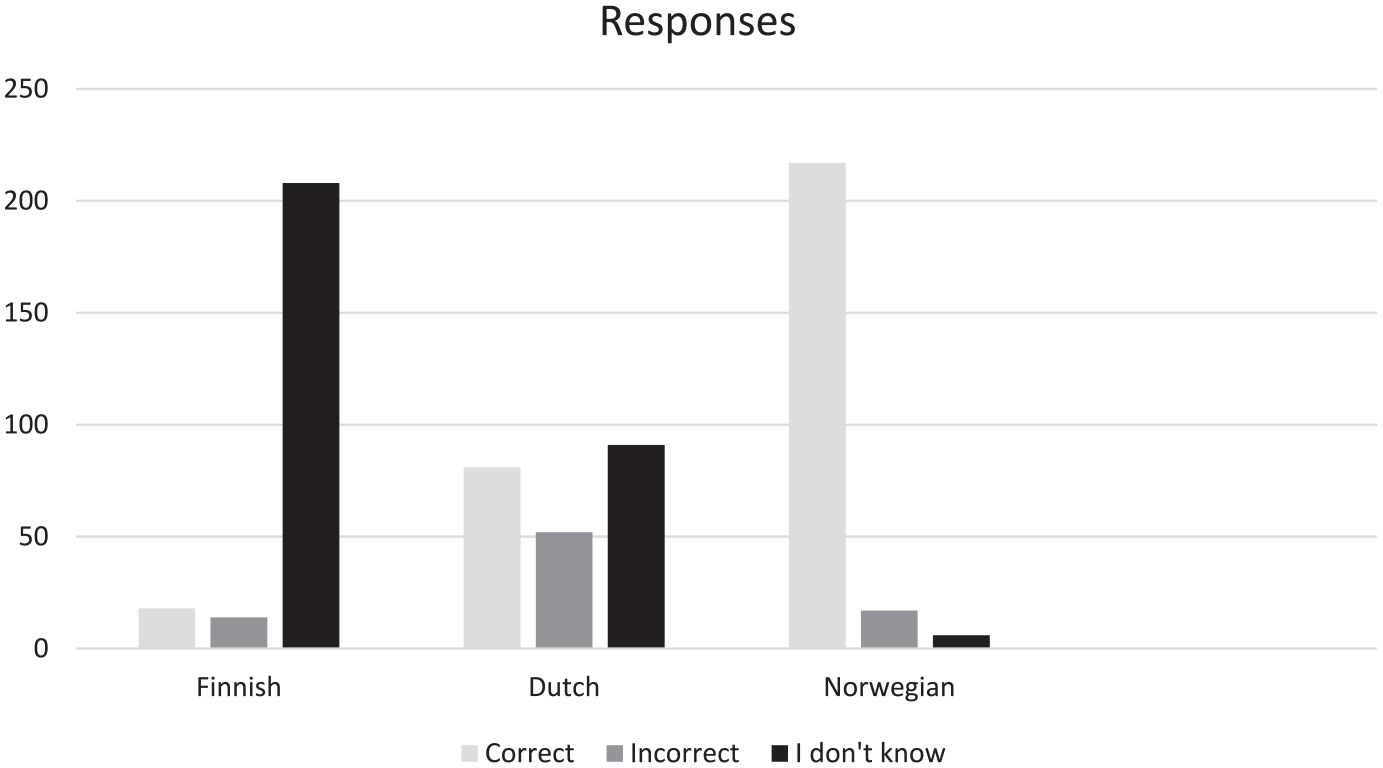
Distribution of answers to the grammatical judgements.
We now turn to the impact of lexical similarity on the results. Starting with the Norwegian sentences, which gave mainly correct answers, the participants had no major problem deciding whether the sentences were grammatical or ungrammatical. However, there are two sentences where the participants’ judgements stand out because the correctness rate was relatively low: 60% and 75%, respectively. These two sentences contained a verb which is not lexically transparent for Swedish native speakers. In (5a) the grammatical version from the test is presented, and in (5b) the Swedish version is given: (5) a. NO
3
: Om bussen kommer i tide, b. SW: Om bussen kommer i tid, ‘If the bus is on time, have-time-to Anna buy socks for the children.’
It is plausible that the Norwegian verb rekker (SW hinner ‘have-time-to’) causes the uncertainty in the participants’ judgements and therefore this sentence (as well as its ungrammatical counterpart) was judged with uncertainty. These two sentences with this verb are the only cases where the option ‘I don’t know’ is used (by six participants), when judging the Norwegian sentences. Based on our own L1 intuition we claim that for Swedish native speakers the Norwegian word rekker is not necessarily recognized as a verb, but could as well be interpreted as a noun in plural.
Turning to the Dutch sentences we find the correctness rate of the grammaticality judgements quite varied. Dutch and Swedish have some lexical similarities, but Dutch also has lexical items that are not transparent at all for a native speaker of Swedish. Examples (6a) and (6b) illustrate the lexical transparency: (6) a. DU: De mann, dat ik niet mag, drinkt altijd coffie in een café. b. SW: Mannen, som jag inte like, dricker alltid kaffe på ett kafé. ‘The man, that I not like, drinks always coffee in a café.’
The judgements of the Dutch sentence in (6a) rendered 13 correct answers (out of 20), probably due to the lexical similarity, which makes it possible to recognize the different parts of speech. There were also Dutch sentences containing very few or no transparent lexical items, such as the following: (7) a. DU: * De vrouw nooit leest morgens de krant. b. SW: *Kvinnan inte läser tidningen på morgonen. ‘The woman reads never the paper in the morning.’
This sentence was judged correctly in five cases, and the answer ‘I don’t know’ was chosen by 14 participants (and one participant judged the sentence as incorrect).
Finally, we turn to the Finnish sentences, which in most cases rendered ‘I don’t know’. There are however two sentences that are judged in a deviant manner from the other 10. These two sentences contained lexical items that are highly likely to be transparent to Swedish native speakers: (8) a. FI: * Peter b. SW: * Peter ‘Peter tomatoes eats, because he is vegetarian.’ (9) a. FI: Karin juo b. SW: Karin dricker ‘Karin drinks mineral water, because she is non-drinker.’
For sentences (8a) and (9a) the level of ‘I don’t know’ answers was 60% and 65% as compared with the overall results of the Finnish sentences, which in 86.7% of the answers yielded an ‘I don’t know’ answer (see Table 2). It seems probable that the lexical similarities make the participants a bit more tempted to try to make a judgement of the sentences.
Correctness rate, grammaticality judgement test (percentages in parentheses).
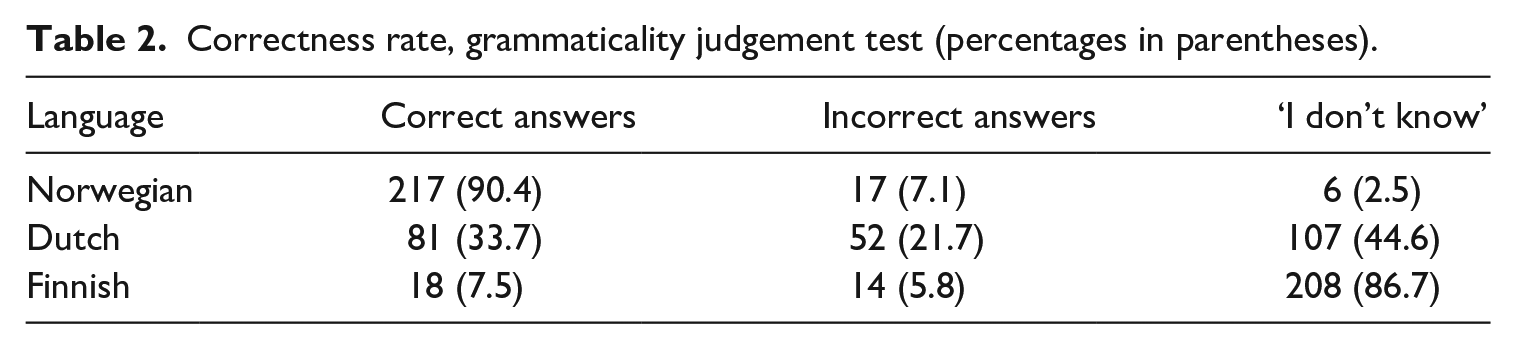
When looking at the results of the judgement test, we see that there is a huge difference between correctness rate across the three languages; see Table 2. We interpret the high correctness rate from the Norwegian sentences as a result of intercomprehension, which boosted the receptive skill. If the task had been a production task where the participants were asked to translate Swedish sentences into Norwegian, or have a conversation in that language, it is not plausible that this would have rendered a result with 90% grammatical correctness, since this production would require word knowledge, knowledge of morphology and word order. In the few cases where the syntax differs between Norwegian and Swedish, we would expect L1 speakers of Swedish to make errors in Norwegian like * Min hund er glad (the correct form is Hunden min er glad, i.e. ‘My dog is happy’).
Turning to the Dutch and Finnish results, we see that a third of the Dutch sentences are judged correctly and only 7.5% of the Finnish sentences are judged correctly. What this JT shows us is that lexical similarities between background languages and target language exerts an impact on judging grammaticality, especially when languages are very, very similar and the participants even can identify which words are nouns, verbs and so on. According to us the JTs used here do not reflect learning, but rather, when being judged correctly, reflect intercomprehension based on lexical similarity.
IV Discussion
Considering previous research and our results, we are not convinced that researchers always denote the same thing with the term IS (see Table 1). Also, we argue that typological lexical similarities between background languages and target languages exert a huge impact on the duration of the IS. From the present study it is obvious that the degree of lexical similarity between the tested languages and the participants’ L1 Swedish (and other learnt L2s) has an impact on the results. The differences between the correctness rates in the different target languages indicate that the leap from the IS to the initial stages is much greater when learning a language (Finnish in this case) that is very remote to one or more of the background languages, compared to when the target language (Norwegian in this case) is closely related to them. Furthermore, we do not know whether the tested structures are learnt; we only know which structures the test-takers were able to judge correctly. In other words it is reasonable to question whether it is really learning that can be observed with JTs in the IS. Our results show that there is a very strong impact on the results stemming from intercomprehension; see Gooskens and Heuven (2020) and Marx (2011), who claim that learning a closely related language is a different learning process than when learning an unrelated language). The lexical similarity between Swedish and Norwegian makes it possible to judge grammaticality, whereas in most of the Finnish JTs there were hardly any lexical clues – with two exceptions; see examples (5) and (6) above – and it is therefore impossible to judge whether or not a sentence was grammatical.
As our results showed, the Norwegian JTs were correctly judged in 90% of the cases; according to us this does not mean that the participants have learnt Norwegian. Nor do our results of the Dutch JTs (correctly judged in almost 34% of the cases) mean that the participants have learnt ‘some’ Dutch. We argue that these results do not reflect learning of a new language at all; the participants were just successful in judging grammaticality when they could make use of lexical inferencing (see the results from Marx, 2011).
There are some strong advantages indeed with the JT method and they are pointed out by Plonsky et al., 2020). JTs can be used to test a variety of complex morphological and syntactic patterns that may be impossible to find (especially to any convincing extent) in spontaneous oral production and they are easy to develop and administer. JTs typically test a few specific grammatical traits, and it is easy for researchers to produce a number of complex sentences containing the specific structure they are interested in. But do researchers interested in the L2/L3 initial state need data of the kind, for example declarative sentences with embedded questions and wh-questions that violated Subjacency (Murphy, 1997, quoted in Plonsky et al., 2020: 586)? And how can JTs help L3 researchers to get the whole picture of how learning a new grammar takes place at the initial state and the immediately following initial stages?
Plonsky et al. (2020) conclude from the samples found in studies employing JTs that the learners in question were likely to be labeled as advanced (p. 603): Somewhat unique to this body of research is the distribution of proficiency levels found in our sample. Whereas L2 research as a whole has focused more often on relatively equal amounts of samples described as beginner/novice or intermediate (Plonsky et al., 2020), the samples found in studies employing JTs were much more likely to be labeled as advanced. One reason for this may be that there has tended to be interest in advanced stages of the learning process in generative research, and 50% of our JTs were situated within a generative framework (for example, generative-inspired research that focused on whether L2ers can attain native-like levels of sensitivity to grammatical constraints). (Plonsky et al., 2020: 603)
This leads us to suspect that earlier L3 research where JTs (without a correction task) have been adopted has been too strongly influenced by previous L2 research methods, applying a type of instrument devised for advanced L2 learners and aimed at answering questions about initial stages of the L3. This can be illustrated with our results of the Norwegian (and to some extent the Dutch) sentences. The participants do not know any explicit grammatical rules of Norwegian or Dutch, but they are able to judge grammaticality thanks to lexical similarity between the languages, and we assume that this makes it possible for the participants to judge syntactic grammaticality and ungrammaticality.
The results from our study clearly show that there is not one IS. As Leung (2005: 40) stated, it is hard to define the IS, but it is of interest to pose the question: ‘when a learner first starts learning a language L – what does this particular system L look like?’ We suggest that the particular system L is different based on, among other factors, the typological similarities between the background languages of the learner and the target language. Consequently, we claim that when a learner can already make use of intercomprehension at the IS, the learning process is different compared to when learning a remote language. And, furthermore, that results from judgement tests on syntax are not appropriate to show whether some aspects in the area of syntax are learnt when lexical similarity is present. We base this suggestion on the differences in correctness rate found in our test.
V Conclusions and a look ahead
In this study we have problematized the various definitions of the initial state that are used in research of mainly third language acquisition, but also second language acquisition. Some researchers have suggested that if claiming to study the initial state, data must be collected from the very first encounter with the language (e.g. Bardel and Falk, 2007; Falk et al., 2015; White, 2012 [2003]), while others have a different understanding of what constitutes the initial state, letting data gathered after weeks or months of instruction of a new language serve as initial state data (e.g. Puig-Mayenco and Rothman, 2020; Rothman and Cabrelli Amaro, 2010). We do not argue that one is correct and the other not, but it is of importance to reach a common understanding of what counts as data from the initial state. In connection to the discussion about the initial state we problematized what bearings very closely related languages have on the processing of sentences in the L3 initial state, and whether the initial state is the same for a Swedish L1 speaker encountering Finnish as an L3 and for a Swedish L1 speaker encountering Norwegian as an L3. In some cases where the background language and the L3 are very similar to each other it might be that intercomprehension, rather than language learning, is at hand. We conducted a test in order to evaluate how Swedish native speakers judge three unlearnt languages’ grammaticality. We came to the conclusion that lexical similarity between the languages and the L1 had a huge impact on the ability to decide whether a sentence is grammatically correct or not.
A fundamental epistemological problem with JTs is that they do not reflect natural L2 or L3 speech, and speech can well be claimed to be the most reliable source to human linguistic competence (see discussion in Plonsky et al., 2020: 585). In order to capture a holistic view on the L3 initial state we suggest additional L3 research based on oral production from the transition from the initial state to the initial stages to be conducted in the future.
This small-scale study would clearly benefit from a bigger format replication. However, the results from our 20 participants are crystal clear. Lexical clues have a huge effect when judging whether a sentence is grammatical or not. Grammatical transfer is likely to be a consequence of lexical similarity between the tested language and the background languages of the test-taker. Therefore, we suggest that guessing based on lexical recognition (i.e. intercomprehension) is the key to understanding the results.
Footnotes
Appendix
Target sentences for Dutch (DU), Finnish (FI) and Norwegian (NO) with corresponding Swedish (SW) sentences.

| Adjective placement in relation to noun: Correct: | |
| SW | Den bruna hunden sover djupt, men katten är vaken. |
| NO | Den brune hunden sover dypt, men katten er våken. |
| DU | De bruine hond slaapt diep, maar de kat is wakker. |
| FI | Ruskea koira nukkuu sitkeästi, mutta kissa on hereillä. |
| ‘The brown dog sleeps deeply, but the cat is awake.’ | |
| Adjective placement in relation to noun: Incorrect: | |
| SW | * Den katten svarta hoppar högt, men Christian ser det inte. |
| NO | * Den katten svarte hopper høyt, men Christian ser det ikke. |
| DU | * De kat zwart springt hoog, maar Christian ziet het niet. |
| FI | * Kissa musta hyppii korkealle kun Christian ei huomaa. |
| ‘The black cat jumps high, but Christian does not see it.’ | |
| Adjective placement in relation to noun: Correct: | |
| SW | Jag vet att grannen har en gammal bil. |
| NO | Jeg vet at naboen har en gammel bil. |
| DU | Ik weet dat de buurman en oud auto bezit. |
| FI | Tiedän että naapurilla on vanha auto. |
| ‘I know that the neighbor has an old car.’ | |
| Adjective placement in relation to noun: Incorrect: | |
| SW | * Felicia tror att jag har en cykel ny |
| NO | * Felicia tror at jeg har en sykkel ny. |
| DU | * Feline denkt dat ik een fiets nieuwe heb. |
| FI | * Felicia luulee että minulla on pyörä uusi. |
| ‘Felicia thinks that I have a new bike.’ | |
| Negation placement (subclause): Correct: | |
| SW | Mannen, som jag inte gillar, dricker alltid kaffe på ett café. |
| NO | Mannen, som jeg ikke liker, drikker alltid kaffe på en kafé. |
| DU | De man, dat ik niet mak, drinkt altijd koffie in een café. |
| FI | Mies jota en tunne, juo aina kahvia kahvilassa. |
| ‘The man that I do not like, always drinks coffee in a café.’ | |
| Negation placement (subclause): Incorrect: | |
| SW | * Flickan, som han känner inte äter ofta hamburgare på restaurang. |
| NO | * Jenta, som han kjenner ikke spiser ofte hamburger på restaurant. |
| DU | * Het meisje, dat hij kent niet, eet vaak hamburgers in restaurants. |
| FI | * Tyttö, jota hän tunne ei, usein syö hampurilaisia ravintolassa. |
| ‘The girl that he does not know often eats hamburgers in restaurants.’ | |
| Negation placement (main clause): Incorrect: | |
| SW | * Kvinnan aldrig läser tidningen på morgonen. |
| NO | * Kvinnen aldri leser avisen om morgenen. |
| DU | * De vrouw nooit leest morgens de krant. |
| FI | * Nainen koskaan ei lue lehtiä aamulla. |
| ‘The woman never reads the newspaper in the morning.’ | |
| Negation placement (main clause): Correct: | |
| SW | Pojken köper aldrig böcker på nätet. |
| NO | Gutten kjøper aldri bøker på nettet. |
| DU | De jonge koopt nooit boeken online. |
| FI | Poika ei koskaan osta kirjoja netistä. |
| ‘The boy never buys books on the internet.’ | |
| Verb placement (main clause): Correct: | |
| Om bussen kommer i tid, hinner Anna handla strumpor till barnen. |
|
| Om bussen kommer i tide, rekker Anna å handle strømper til barna. |
|
| Als de bus op tijd is zal Anna kousen voor de kinderen te kopen. |
|
| Jos linjaauto tulee ajoissa, ehtii Anna ostamaan sukkia lapsille. |
|
| ‘If the bus comes in time, Anna will have time to buy socks for the children.’ | |
| Verb placement (main clause): Incorrect: | |
| * Om taxin kommer snart, Anne hinner köpa blommor till pappa. |
|
| * Om taxien kommer snart, Anne rekker å kjøpe blomster til pappa. |
|
| * Als de taxi gauw komt, Anne zal bloemen voor haar vader, kopen. |
|
| * Jos taksi tulee ajoissa, Anne ehtii ostamaan kukkia isälle. |
|
| ‘If the taxi comes soon, Anne will have time to buy flowers for her father.’ | |
| Verb placement (main clause): Incorrect: | |
| * Peter tomater äter, eftersom han är vegetarian. |
|
| * Peter tomater spiser, ettersom han er vegetarianer. |
|
| * Peter tomaten eet omdat hij vegetariër is. |
|
| * Peter tomaatteja syö, koska hän on vegetariaani. |
|
| ‘Peter eats tomatoes because he is a vegetarian.’ | |
| Verb placement (main clause): Correct: | |
| Karin dricker mineralvatten eftersom hon är nykterist. |
|
| Karin drikker mineralvann ettersom hun er avholdsmenneske. |
|
| Karin drinkt spuitwater omdat ze geheelonthouder is. |
|
| Karin juo mineraalivettä, koska hän on absolutisti. |
|
| ‘Karin drinks mineral water because she is abstainer.’ |
Notes. Sentence within ‘xxx’ – idiomatic translation to English. * Ungrammatical stimuli.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was carried out with funding from the faculty program for leading research at Stockholm University ‘Bilingualism and second language acquisition’.
1.
Both terms are used in second and third language research and in this study; we make no distinction between them.
2.
A way to control for learners answering haphazardly – or in relation to something else than the grammar error that the researcher is interested in – is to use grammatical and ungrammatical counterparts (like the example given by Spinner and Gass, 2019: 61: Yesterday we saw an eagle vs. We saw yesterday an eagle) when interested in learners’ acquisition of adverb placement. Another solution is to use error correction tasks (Spinner and Gass, 2019: 104–105), where the participant is not only asked to mark if the sentence is acceptable or not, but also, in case of negative answers, to correct the sentence (see Falk and Bardel, 2011: 69).
3.
DU = Dutch. FI = Finnish. NO = Norwegian. SW = Swedish.