
Abstract
Children are known to be fast learners due to their neural plasticity. Learning a non-native language (L2) requires the mastering of new production patterns. In classroom settings, learners are not only exposed to the acoustic input, but also to the unfamiliar grapheme–phoneme correspondences of the L2 orthography. We tested how 9–10-year-old children, with Finnish as a native language (L1), respond to a two-day listen-and-repeat training paradigm, where they simultaneously hear acoustic stimuli and see orthographic cues. In the procedure, non-words containing the L2 vowel /ʉ/ were presented simultaneously with an orthographic cue showing <u>, guiding pronunciation towards the L1 vowel /u/ according to Finnish grapheme–phoneme correspondences. Earlier studies showed that Finnish adults rely on the orthographic cue over the acoustic one, leading them to produce /u/ instead of /ʉ/ when presented with the incongruent L1–L2 grapheme–phoneme correspondence (<u> – L1: /u/, L2: /ʉ/). Also, an earlier result from age-matched children receiving only acoustic input showed relatively fast pronunciation changes towards the target vowel. Our present results indicate clear and fast production learning of the non-native sound, and the misleading orthographic cue did not draw attention away from the target acoustic form. With orthographic cues, the participants learned to produce novel sounds faster than without them.
I Introduction
Models of non-native speech sound learning have proposed that the role of the native language is of crucial importance in how the non-native categories are perceived and thus produced. Several studies have proposed that perception precedes production in second language (L2) speech learning, meaning that accurate production of L2 sounds requires accurate L2 perception (Flege, 1995, 1999; Flege et al., 1999b), whereas more recent research suggests that L2 perception and production co-evolve (Flege and Bohn, 2021). In the framework of the Speech Learning Model (SLM; Flege, 1987) and its revised version – the SLM-r (Flege and Bohn, 2021) – the most difficult items are termed similar. This refers to a situation where the non-native sound bears a close resemblance to a native sound category, but is still distinct from it. In addition, the SLM-r (Flege and Bohn, 2021) predicts that the formation of a new phonetic category for a non-native sound is affected by the quantity and quality of phonetic input as well as the precision of existing first language (L1) categories. In contrast, the L2 Linguistic Perception (L2LP) model states that the most problematic items are the new items (Escudero, 2005). However, the term new in the L2LP model actually refers to the same situation as the term similar in the SLM: the L2 sound contains both non-native and native characteristics, thus making the target sound resemble a native sound. In terms of the Perceptual Assimilation Model (PAM-L2; Best and Tyler, 2007), the problems in non-native perception and production are most severe when two L2 categories are assimilated equally to one L1 category (single-category assimilation). In all of these models, the common factor is that a close resemblance of an L2 sound with an L1 sound category constitutes the most fundamentally difficult learning setting in L2 perception and production.
Earlier research has shown that L2 speech acquisition may depend on factors such as learning environment or age. Some of these studies have focused on the learning of perception (e.g. Flege and MacKay, 2004), whereas some others have focused on production (e.g. Immonen and Peltola MS, 2018). Immigration (Winkler et al., 1999) and language immersion education (Immonen and Peltola MS, 2018; Peltola MS et al., 2005) seem to be L2 learning environments that result in the formation of native-like perception and production patterns for the target language sounds. Non-native vowel contrasts elicit identical memory trace activation in immigrants and native speakers when pre-attentive perception is measured with mismatch negativity (MMN; Winkler et al., 1999). In contrast, classroom learning might not result in similar learning effects, since even proficient students show no neural memory traces for target language phoneme contrasts (Peltola MS et al., 2003). The imitation of a naturalistic learning setting seems to be conducive to learning L2 sounds, since it has been found that in early immersion settings children are able to discriminate non-native vowels through the formation of new memory traces (Cheour et al., 2002; Peltola MS et al., 2005). In contrast, another study by Peltola MS and Aaltonen (2005) showed results suggesting that the language context during testing may be the key for the activation of neural representations of non-native vowels in young adults. However, a study by Immonen and Peltola MS (2018) showed that school-aged children in a language immersion class learn to produce non-native vowels more accurately than their peers in a non-immersion class.
Several studies have indicated that learning proceeds faster at an early age and that child learners may achieve more accurate performance than adults (pronunciation, sound discrimination and identification) in L2 phonetic learning (Flege et al., 1999a; Giannakopoulou et al., 2013; Taimi et al., 2014). Age effects may be seen in a study by Giannakopoulou et al. (2013) showing that perceptual training effects are more pronounced in children than adults. The study showed that child learners, when compared to adults, seem to benefit more from high-variability training in L2 sound identification and discrimination. In a more recent study, however, Giannakopoulou et al. (2017) showed contrary results, i.e. a detriment of HVPT (high-variability phonetic training). Older learners (aged 62–73 years) also showed rapid L2 production learning (Jähi et al., 2015). The participants completed a simple two-day listen-and-repeat training protocol and gained significant changes in L2 vowel articulation. In addition, factors such as continued use of the L1 (Flege et al., 1997; Flege and MacKay, 2004) have been shown to result in less accurate L2 perception and production patterns.
Training type also seems to affect learning. For instance, Iverson et al. (2012) used the high-variability phonetic vowel training method and showed that both experienced and inexperienced L2 learners benefit from this type of training. This was shown in vowel identification and discrimination, and to a lesser degree in vowel production tests. Along similar lines, Tamminen and Peltola MS (2015) indicated that even highly proficient students of an L2 can enhance their voice onset time memory traces with a simple listen-and-repeat training paradigm. The same type of training was found to be effective in vowel production with adult learners, and surprisingly, even mere passive auditory training resulted in production changes (Peltola KU et al., 2017). Altogether, it seems that training results may depend either on the age of the participants, and/or the type of training provided.
L2 training studies have found that the role of orthography may be significant in phonetic learning. For example, Escudero et al. (2008) investigated the phonetic and lexical mappings of auditorily confusable L2 non-words. The participants learned the non-words by matching the auditory stimuli to either the orthographic form or a picture. The results indicated that the orthographic forms may help learners to form separate representations of L2 non-words that contain L2 sounds that are similar to each other. When studying literate learners, the role of orthography in non-native language learning has been found to be important. For example, Hayes-Harb et al. (2010) have shown that the phonological analysis of new words can be affected by orthography in adult learners. They tested three groups of learners who heard the same auditory stimuli paired either with no orthographic input or with written forms. The written forms were either congruent (<kamad>, /kɑmǝd/) or incongruent (<kamand>, /kɑmǝd/) with their L1 spelling conventions. The group who saw the incongruent written forms of the auditory stimuli showed interference from the orthographic forms in an auditory word-picture matching test. Furthermore, Rastle et al. (2011) showed that language processing involves rapid and automatic interaction between orthographic and phonological representations (when tested with picture naming, shadowing, forced-choice spelling, picture spelling and auditory lexical decision). They introduced L2 learners to spelling-sound consistent and spelling-sound inconsistent orthographic forms of novel spoken words. Underlining the importance of orthography in L2 learning, the results showed significant orthographic effects on speech perception (not on shadowing but on auditory lexical decision) and production (immediate and persistent effects on picture naming after the introduction of word spellings). In addition, when studying the learning of length production in experienced Italian L2 English learners, Bassetti (2017) found that the L1 grapheme–phoneme correspondences influenced L2 production. This effect was present even when the participants did not see the orthographic form. The results suggested that the interaction between L2 orthographic forms and L1 grapheme–phoneme correspondences can lead learners to produce L1 contrasts in L2 speech and that the role of orthographic conventions may extend far.
On the other hand, some training studies have found orthography to have no effect on L2 sound acquisition (Simon et al., 2010). In addition, the role of orthography in L2 sound learning may depend upon the manner in which the grapheme–phoneme correspondence functions in a particular language (Escudero and Wanrooij, 2010). A study by Peltola KU et al. (2015) demonstrated how L1 orthography affects L2 production learning when the spelling system is transparent and phonological. In that study, literate Finnish adult learners were presented with auditory cues (/ty
Based on earlier research, it is clear that learning to perceive and produce speech in a non-native language is a complex task. Learning may depend on several factors, such as age, training type and learning environment. The aim of this study is to see whether literate children, similarly to adults (Peltola KU et al., 2015), rely on the orthographic form over the acoustic one when making decisions about the phonological forms of words. Another aim is to see whether the audio-visual training results in the current study are different from those obtained with mere auditory training in an earlier study, where age-matched children learned to produce the exact same non-native vowel contrast after three training sessions (Taimi et al., 2014). The hypothesis is that after L1 grapheme–phoneme correspondences have been formed, they affect the learning and production of L2 sounds in literate children in a similar manner as in adults. Thus, children receiving audio-visual training, where the target L2 sound is paired with a grapheme that is incongruent with the L1 grapheme–phoneme correspondences and corresponds to a novel L2 phoneme, will not benefit from the training as much as age-matched children learning L2 sounds through mere auditory training.
II Methods
1 Participants
Twelve 9–10-year-old monolingual Finnish children participated in the study (mean age 9.5 years, range 9–10 years, 6 females). The children were in the third grade in a Finnish elementary school. They had started to study only English basics during the academic year and they only had a minor exposure to spoken English, none to written English and more importantly, none of them had any previous experience with Swedish and none had studied any other languages. All had resided in Finland for their whole childhood. All children had normal hearing and none had been diagnosed with language deficits of any kind. According to the teacher’s report, none of the participants deviated from the normal reading skills in relation to the age group. All participants reported to be in normal health on the day of testing and none showed any signs of fatigue. The group thus represented typical Finnish monolingual children who have learned to read their native language. All participants gave informed consent prior to participating, and a written approval was also obtained from their parents. The test procedures were approved by the Ethics Committee of the University of Turku, Finland.
2 Stimuli
The auditory stimuli were semi-synthetic pseudo-words /ty
The participants were also presented with the visual cues showing orthographic forms of the stimulus words during training. These visual cues derive from the Finnish writing system with the non-target vowel /y/ cued with <tyyti> and the target vowel /ʉ/ with <tuuti>. The visual cue followed Finnish grapheme–phoneme correspondences, which are transparent and according to which the grapheme <y> corresponds to the vowel /y/ and the grapheme <u> corresponds in all situations to the rounded back vowel /u/. Therefore, the target visual cue was misleading, since the symbol <u> corresponds to /u/ instead of /ʉ/ according to Finnish grapheme–phoneme correspondences.
In conclusion, the target vowel /ʉ/ is perceptually difficult to categorize according to second language learning models such as the SLM, the PAM-L2 and L2LP. More importantly for this study, the acoustic stimulus /tʉ
3 Procedure
The experiment was conducted on two consecutive days in a quiet room in an elementary school in Southern Finland using a portable laboratory consisting of an HP laptop with a Beyerdynamic MMX300 headset and an Asus Xonar U3 sound card. During recording sessions, Sanako Study Recorder software (version 8.22.0.0) was used to present the auditory stimuli and record the participants’ productions. During training sessions, the auditory stimuli and the orthographic cues were presented as a PowerPoint slideshow where the acoustic and visual cues were played simultaneously. The interstimulus interval (ISI) was 3 seconds both in training and recording sessions and the stimuli were presented automatically in an alternating order so that every other word was the target /tʉ
The first day of the experiment started with a short familiarization block, where the participants heard both stimuli three times but did not see the orthographic presentations. The purpose of the familiarization phase was to give the children the opportunity to adjust the volume to a comfortable level and get accustomed to the pace of the experiment. The participants were then instructed to listen and repeat after the model in the following recording and training sessions. After familiarization and instruction, the first day continued with the first recording (baseline) followed by the first training, then a second recording and a second training.
The second day began with a third training session followed by a third recording, a fourth training and then concluded with the fourth and final recording. For a more detailed description of the procedure see Figure 1. Altogether, the children participated in four training (4 minutes each) and four recording (2 minutes each) sessions and the experiment lasted about 15 minutes per day. The recording sessions included 10 repetitions of each stimulus. In other words, 40 repetitions of each word were recorded from each participant during the experiment. The training sessions included 30 repetitions of each stimulus presented in auditory and orthographic forms simultaneously. In short, the participants repeated each word 120 times in the four training sessions and they were not given any feedback during or after training or recording. All in all, the participants repeated each of the two words 160 times during the entire experiment. We did not want the visual cues to have an effect on the actual pronunciation testing. Therefore, the participants were not presented with any orthographic cues during testing. That is to say, we wanted to investigate how the orthographic information presented during the training phase affects the development of the mental representation of the non-native sound and its production.
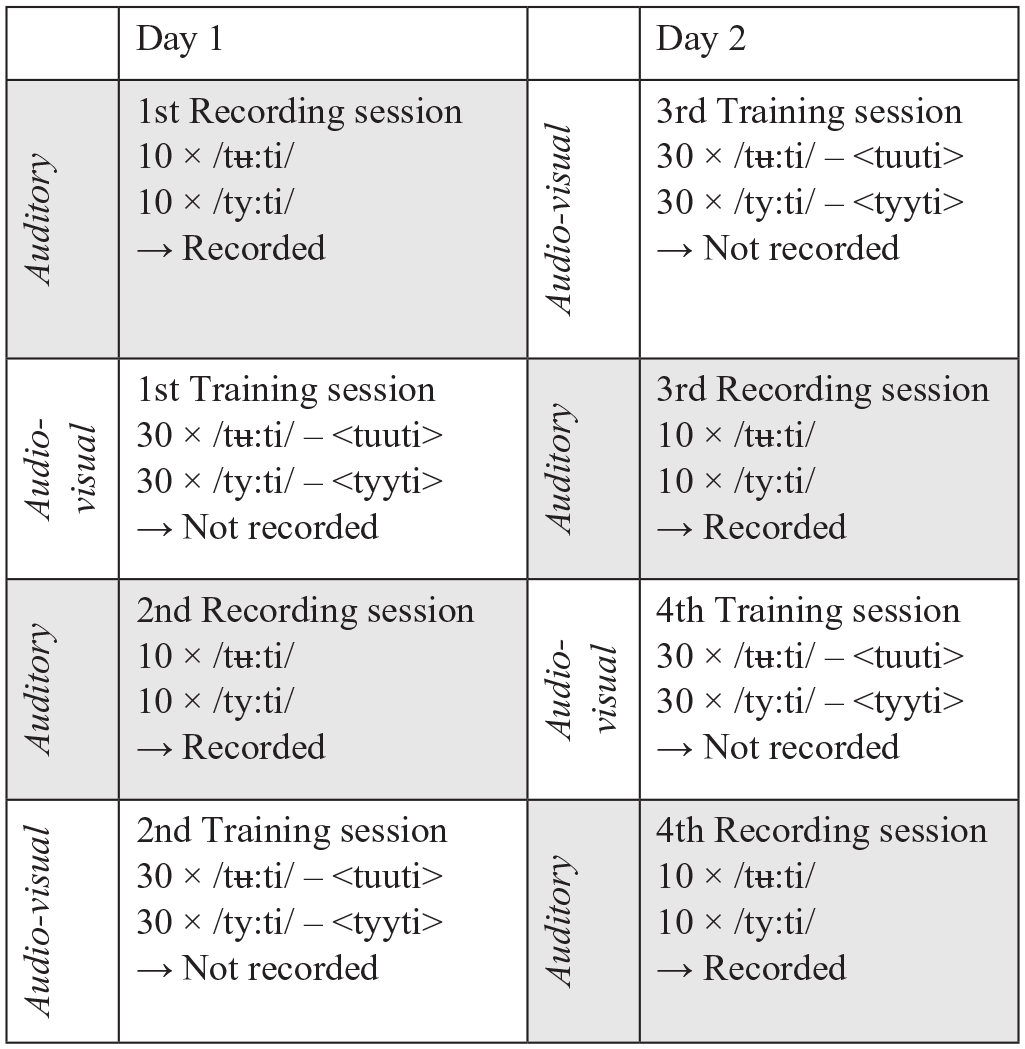
The experimental procedure.
4 Analysis
The acoustic recording data were analysed by a phonetician using Praat, version 5.3.01 (Boersma, 2001). A total of 80 tokens (10 productions of each word per recording session) were analysed from each speaker. We extracted the two lowest formant frequency values F1 and F2 (as well as F0) from the steady-state locations of the first syllable vowels using the Linear Predictive Coding (LPC) Burg algorithm. The values for F1 and F2 were then subjected to a repeated measures analysis of variance, and more importantly, they were analysed separately in more detail (ANOVA, IBM SPSS, version 22). In addition, we calculated each speaker’s average standard deviation values of the formant values for both words from all ten productions in each of the four sessions. These data were statistically analysed using the same ANOVA models as in the initial analysis of the F1 and F2 values. The more detailed analysis was performed so that we extracted one variable at a time from the data set and analysed the remaining data with the same ANOVA model.
III Results
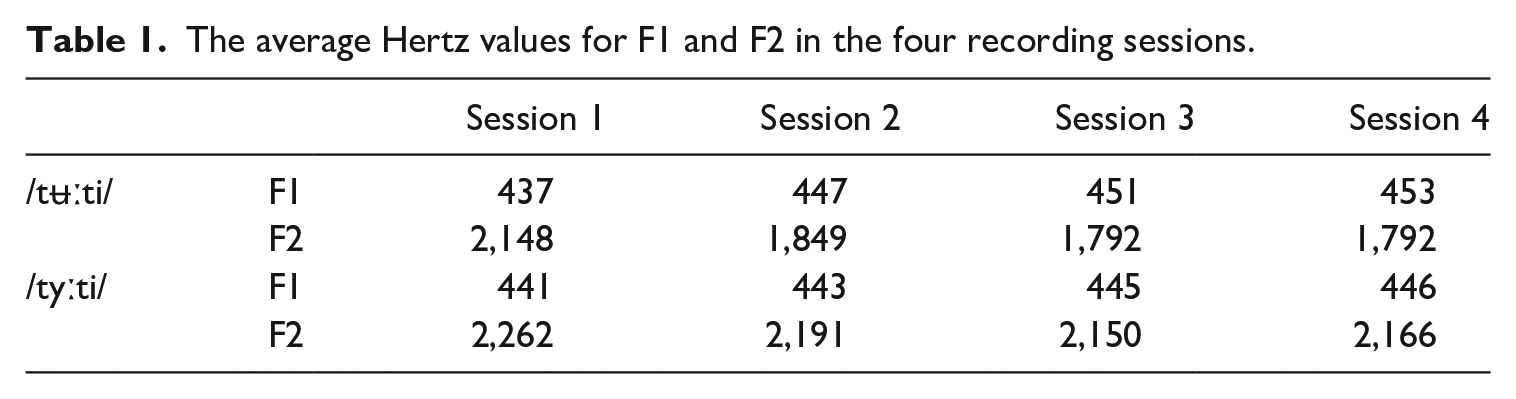
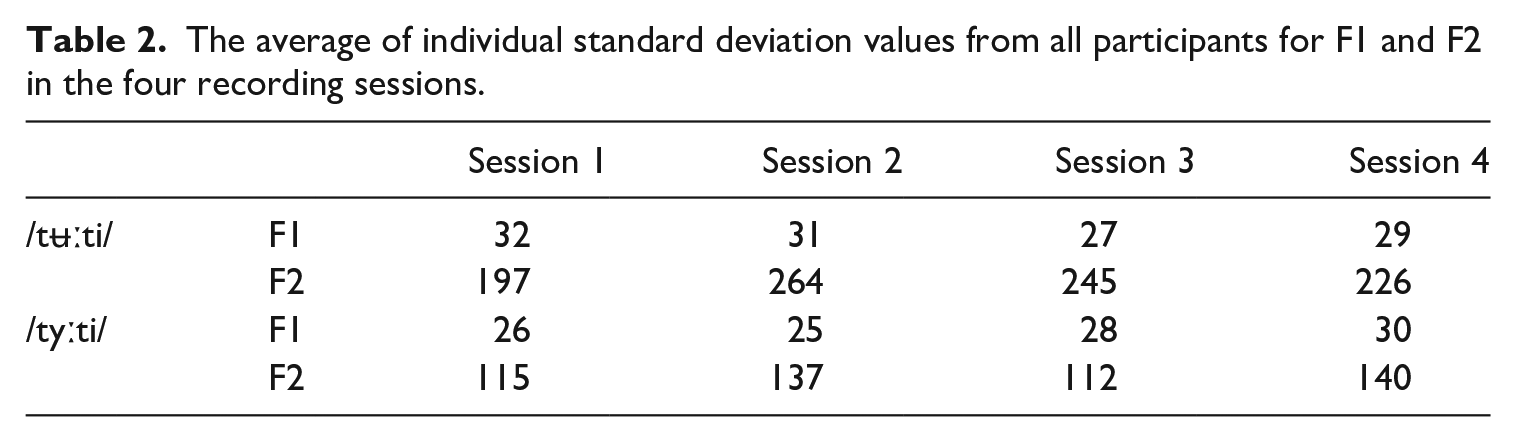
The average Hertz values and the average standard deviations for both the target and the non-target vowels are shown in Tables 1 and 2.
The average Hertz values for F1 and F2 in the four recording sessions.
The average of individual standard deviation values from all participants for F1 and F2 in the four recording sessions.
We began the analysis by subjecting the average F1 and F2 values (Table 1) separately to omnibus ANOVAs with the factors of Session (first, second, third, fourth) and Stimulus (/ty
In order to clarify the role of the Stimulus in the analysis, we performed separate ANOVAs for the non-target and target vowel F2 values (Session: first, second, third, fourth). No significant effects were found in the F2 values of the non-target vowel and thus we continued the analysis only on the target vowel. A similar analysis on the target word F2 values revealed a main effect of Session (F(3,9) = 4.630, p = 0.032, ηp2 = 0.607), showing a significant change over time. These findings showed that while the F1 and F2 values for the non-target vowel remained unchanged, the F2 values of the non-native target vowel changed from /y/-like values towards /ʉ/ as a function of training. The effect of Session was investigated further for the target vowel /ʉ/ F2 values with a series of comparisons between sessions via ANOVA. These comparisons revealed a significant difference between sessions 1 and 2 (F(1,11) = 9.559, p = 0.010, ηp2 = 0.465), sessions 1 and 3 (F(1,11) = 16.759, p = 0.002, ηp2 = 0.604) and sessions 1 and 4 (F(1,11) = 14.865, p = 0.003, ηp2 = 0.575). This showed that the training effects were relatively quick (evident starting in session 2) and that they remained constant throughout the rest of the experimental procedure. We analysed all session pairs, but no significant differences between sessions 2 and 3, 2 and 4, and 3 and 4 were observed.
In order to study whether the larger standard deviations (SD) of the target vowel F1 and F2 were significant, we performed separate omnibus ANOVAs for the speakers’ average F1 and F2 SD data with the factors of Session (first, second, third, fourth) and Stimulus (/ty
Altogether, the statistical analyses showed that, despite the misleading orthographic input, the production of the target vowel /ʉ/ changed quickly towards /ʉ/. Moreover, it became evident that the changes were concentrated in the F2 values relevant for distinguishing between the categories /y/ and /ʉ/. In addition, the formant values in Table 1 show that the F2 values produced for the target vowel /ʉ/ remained considerably higher than the average F2 values for the Finnish vowel /u/ (adult norms F1 = 332 Hz, F2 = 690 Hz; Iivonen, 2012), which is linked with a more back articulation for Finnish /u/. Also, we were able to show that the native vowel did not undergo change as a result of the training and that despite the changes in the formant values, the standard deviations for the target vowel F2 remained larger than for the native vowel.
IV Discussion
The acquisition of speech sounds is a significant part of the development of a language. In addition, reading skills play a role in how new languages are learned, since L1 grapheme–phoneme correspondences have an effect on how we perceive phoneme categories. Both adults and children encounter problems with the learning of a non-native language, but compared with adults, children benefit from neural plasticity. However, since neural commitment to L1 sounds happens already in early childhood, children are not immune to difficulties in the learning of new languages. For example, a study by Kuhl et al. (2008) found that infants’ L1 and L2 phonetic perception abilities at 7.5 months of age predict their later language skills. This not only reveals the significance of phonological processing in L1 learning, but it also has important implications for L2 learning: the ability to distinguish L2 sounds is impaired in conjunction with the increasing dominance of the L1 sound categories. In fact, several studies have shown that the L1 dominance results in L2 perception and production difficulties irrespective of the age of acquisition or the learning setting (Peltola MS et al., 2003, 2007; Winkler et al., 1999).
Earlier studies have important implications for our main finding that children learn to produce new vowels quickly with only a short training paradigm containing both auditory and orthographic exposure. Firstly, it becomes evident that children are fast learners in comparison with adult (Peltola KU et al., 2015) and senior (Jähi et al., 2015) learners. The finding that child participants changed their production of /ʉ/ according to the acoustic input after only one training session suggests not only high plasticity, but also accurate analysis of the acoustic dimensions to be altered. The rather small difference in the acoustic values of the stimuli was clearly substantial enough to be perceived by child learners. The formant values for /ʉ/ produced by the children remained higher than the exact values of the stimuli, but this was to be expected, as the stimuli were based on the voice of an adult male. Moreover, the acoustic data shows that instead of producing the Finnish vowel /u/ (F1 = 332 Hz, F2 = 690 Hz; Iivonen, 2012) as shown in the misleading visual cue, the children produced the vowel /ʉ/ according to the acoustic model. The /u/ F1 and F2 values described in Iivonen (2012) are from adult Finnish speakers. However, even considering the higher average formant values typical for child speakers, the F2 values produced by the participants of this study (Table 1) did not become /u/-like. Although the participants were exposed to the acoustic forms during familiarization before seeing the orthographic forms, the minimal auditory exposure (3 repetitions) is unlikely to affect the results. Secondly, the expected finding that the non-target vowel did not react to training implies that the stability of the native system was not affected by the non-native elements. This is contrary to an earlier finding, where child learners have shown changes also in the native categories as a function of exposure to a new language, but in that case the exposure took place in immersion education and the input was thus much more versatile (Peltola MS et al., 2007). Thirdly, despite clear production learning towards the acoustic stimulus, the fact that the standard deviations remained large for the target vowel indicates that variability in production persisted throughout the training. This probably suggests that the learning process is by no means finished by the end of this short exposure and/or that individual differences may play a role. To explore this effect in more detail, further research is needed.
The fourth conclusion is linked with the overall surprise that, contrary to our hypothesis, the misleading orthographic cues did not hinder production learning. On the basis of earlier adult data (Peltola KU et al., 2015), we assumed that the transparent Finnish orthography would result in problems in L2 sound contrast production in the audio-visual training paradigm, since the participants were already rather highly literate. However, this was clearly not the case, which suggests at least three alternative explanations: First, it may be that the grapheme–phoneme correspondence is not yet as strongly established at this stage of literacy development. Second, it could be that children are so attuned to auditory input that the changes take place irrespective of the visual cues. Most probably, however, the visual orthographic cues actually helped in directing attention to the non-native item. The third explanation seems plausible when combined with the observation that the participants in the present study changed their production faster than children in an earlier study where the same training paradigm with exactly the same amount of acoustic exposure was conducted with auditory stimuli only (Taimi et al., 2014). In Taimi et al. (2014) a listen-and-repeat protocol with no orthographic cues and the exact same acoustic ones changed the age-matched children’s production by the third recording. In contrast, in the present study the changes took place already by the second recording. Altogether, it may be that the L1 grapheme–phoneme correspondences are not hard-wired at this literacy level and that the visual cue helps the child learners to focus on the differences in the auditory cues during training. It may also be that, in addition to the natural age-related aptitude, child learners may be more driven towards the acoustic cues when a task is not demanding as in the case of this study; adults, on the other hand, may be able to tolerate more difficult learning tasks to a better extent. But the interrelation between these factors cannot be teased apart in this experiment and further tests are needed. In addition, it should be noted that the training paradigm in this study was not cognitively demanding and no acoustic variation inherent to normal speech was introduced, nor did we measure any potential long-term effects. Thus, new sets of data with longer exposures, more demanding trials and a longitudinal approach would address the complex task of learning in a more comprehensive manner.
V Conclusions
In conclusion, our results show that children can learn to produce an extremely difficult non-native vowel contrast very rapidly with a training method that utilizes an audio-orthographic training paradigm. Surprisingly, the ability to read in the native language (and thus the potential to be misled by the native orthography) does not appear to hinder L2 production learning in an undemanding training task even though the orthographic cues provide misleading information according to L1 grapheme–phoneme correspondences. In this respect the child learners seem to be different from adults, who were extremely sensitive to the visual orthographic cues in this relatively easy task. In addition, it seems that the orthographically misleading visual cue does not hinder the learning process of a non-native sound. In comparison with age-matched children training with only acoustic stimuli, the participants of the current study actually changed their pronunciation with less training. The non-native target sound /ʉ/ is acoustically situated around the border of the native sound categories /y/ and /u/, which makes it difficult to learn according to the L2 learning models mentioned in this article. The findings of the present study suggest that orthographic cues may help to attract attention to non-native sounds. This enabled the participants to better focus on the demands of the learning task.
Footnotes
Acknowledgements
We wish to thank MA Elina Lehtilä for her help in this study and Sanako Corp. for sponsoring the software used in data collection.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.