
Abstract
Feature-based approaches to acquisition principally focus on second language (L2) learners’ ability to perceive non-native consonants when the features required are either contrastively present or entirely absent from the first language (L1) grammar. As features may function contrastively or allophonically in the consonant and/or vowel systems of a language, we expand the scope of this research to address whether features that function contrastively in the L1 vowel system can be recombined to yield new vowels in the L2; whether features that play a contrastive role in the L1 consonant system can be reassigned to build new vowels in the L2; and whether L1 allophonic features can be ‘elevated’ to contrastive status in the L2. We examine perception of the oral–nasal contrast in Brazilian Portuguese listeners from French, English, Caribbean Spanish, and non-Caribbean Spanish backgrounds, languages that differ in the status assigned to [nasal] in their vowel systems. An AXB discrimination task revealed that, although all language groups succeeded in perceiving the non-naïve contrast /e/–/ẽ/ due to their previous exposure to Québec French while living in Montréal, Canada, only French and Caribbean Spanish speakers succeeded in discriminating the naïve contrast /i/–/ĩ/. These findings suggest that feature redeployment at first exposure is only possible if the feature is contrastive in the L1 vowel system (French) or if the feature is allophonic but variably occurs in contrastive contexts in the L1 vowel system (Caribbean Spanish). With more exposure to a non-native contrast, however, feature redeployment from consonant to vowel systems was also supported, as was the possibility that allophonic features may be elevated to contrastive status in the L2.
Keywords
I Introduction
The segmental component of a second language (L2) is rarely acquired to native-like levels of proficiency by adult learners. In the perceptual domain, learners may experience difficulties discriminating and categorizing segments that do not contrast lexical items in their native language (L1) (e.g. Goto, 1971). These perceptual challenges, in turn, are manifested in non-target-like production (Flege, 1995). Although the L1 grammar has typically been held responsible for the perception and production challenges that learners face, an important question that has less often been addressed is how the structure of the L1 grammar may inhibit successful acquisition and, conversely, the conditions under which successful acquisition can be achieved.
In this article, we explore this question from the perspective of generative phonology. An important tenet of this theory of grammar is that features are the primitives from which segments are built (Chomsky and Halle, 1968; Jakobson et al., 1952). In the context of L2 acquisition, two things follow from this. One, the absence of a given segment from the L1 grammar does not necessarily predict acquisition failure. Two, the presence of a given feature in the L1 may not be enough to ensure successful acquisition of segments that employ this feature in the L2. This is because a feature may function contrastively, allophonically or phonetically in the segmental system of a language, which will impact both what features are present in stored forms and the nature of the formal mechanisms (rules and/or constraints) responsible for generating surface forms. It follows that the predictions of feature-based approaches to segment acquisition will differ depending on the role that a given feature plays in both the L1 and L2 grammars.
We refer to all approaches to segmental acquisition that are grounded in features as feature models, independent of other assumptions that individual researchers may make about feature accessibility. We explore the implications of feature accessibility as follows. First, we examine whether a feature [F] can be redeployed from the L1 grammar (Archibald, 2005), that is, combined with another L1 feature [G] to create a novel category, [F, G], in the L2. Second, we test the conditions under which redeployment can take place. Specifically, we vary the status of [F] in the L1 grammars under focus – contrastive, allophonic or phonetic – to determine whether there are differences in the ability to redeploy features depending on their formal status, which would follow from the generative perspective outlined here.
Our position contrasts with a significant body of research on the L2 development of perceptual contrasts that has been couched in frameworks that do not assign or are agnostic to a determining role for feature-based representations (e.g. Best and Tyler’s (2007) Perceptual Assimilation Model-L2 (see earlier Best, 1995); Flege’s (1995) Speech Learning Model; Escudero’s (2005) Second Language Perception Model). We will collectively refer to these approaches as phonetic models, since they focus principally on acoustic-phonetic differences between L1 and L2 sounds, rather than on phonological differences between L1 and L2 grammars.
Much research that adopts a feature-based approach to segmental acquisition has set out to test the predictions of Brown (1998, 2000) because it is a particularly restrictive view on the conditions under which it assumes that successful acquisition can be achieved. Brown proposes that reliable discrimination of non-native segments in the L2, a necessary precursor to the building of new phonemes, can only arise through a recombination of features that have contrastive status in the L1. Although some support has been attained for Brown’s proposal (see, for example, Jackson and Archibald, 2011; Kulikov, 2011; LaCharité and Prévost, 1999; Larson-Hall, 2004), this research has been somewhat narrow in scope, thereby leaving a number of questions unaddressed. For one, to our knowledge, all of the studies that have set out to test Brown’s assumptions have examined features that play a role in the consonant system. Although there is a significant body of research on the development of perceptual contrasts in vowels (e.g. Elvin and Escudero, 2014; Escudero and Vasiliev, 2011; Flege and MacKay, 2004; Levy and Strange, 2008; Tyler et al., 2014), this literature has been couched in phonetic models and so the questions it asks are different from those that are focal to feature models. For example, while phonetic models may ask how the formant structure of L1 vowel categories impacts the relative difficulty of perceiving new vowels, feature models instead ask how features in the L1 grammar, assigned based on contrast and phonological behaviour, may have an effect. In view of this, one question we strive to address is: Can features that serve a contrastive function in the vowel system of the L1 be recombined to yield new vowels in the L2?
Similarly, features that operate in both the consonant and vowel systems have not, to our knowledge, been investigated in studies testing Brown’s version of the feature model. In light of this, a second question we examine is: Can features that play a contrastive role in the L1 consonant system be reassigned to build new phonemes in the L2 vowel system?
Finally, Brown assumes that if a new segment requires features that either function allophonically in the L1 or are absent altogether from the L1, the new segment cannot be successfully built in the L2. Following Curtin et al. (1998), we question whether these two types of non-distinctive features should be treated as equally inaccessible. Indeed, given that allophonic features, like distinctive features, play a role in regulating the shape of the L1 grammar, the third question we address is: Can allophonic features in the L1 be ‘elevated’ to serve a contrastive function in the L2?
As these three questions underlie the research undertaken in this article, we focus on the feature [nasal], which can operate in both consonant and vowel systems and whose status can be contrastive or allophonic in the latter. Our main goal is to better understand how the L1 grammar constrains L2 perception at the onset of acquisition. Thus, we investigate the perception of the oral–nasal contrast in Brazilian Portuguese (BP) front vowels by speakers of varieties of French, English and Spanish, who have never before been exposed to BP. By examining the performance of each group of listeners, we strive to determine whether the feature [nasal] can be detected on the vowels /ẽ/ and /ĩ/. If so, this would mean that they can successfully redeploy the feature [nasal], that is, combine it with the L1 features [mid] and [high] to (eventually) create the novel categories /ẽ/ and /ĩ/, respectively.
We chose to test individuals who had been living in Montréal and had been exposed to Québec French, which possesses the mid front vowel /ẽ/, like BP, unlike the other language varieties under focus. This enabled us to directly compare performance on a naïve (/i/–/ĩ/) vs. non-naïve (/e/–/ẽ/) contrast. We thus first investigate whether redeployment of the feature [nasal] to create the novel category /ẽ/ has already taken place, on account of listeners’ earlier exposure to Québec French. Although we find that it has, we also find that this in no way impacts listeners’ behaviour on /ĩ/, which is instead seemingly mediated by the shape of the L1 grammar. Following from this, we probe the conditions under which redeployment of [nasal] for the eventual creation of the category /ĩ/ could be possible, namely when: (1) the feature functions contrastively in the L1 vowel system (hereafter redeployment within systems); (2) the feature functions contrastively in the L1 consonant system (redeployment across systems); or (3) the feature functions non-contrastively (specifically, allophonically) in the L1 vowel system (redeployment across levels).
Earlier literature has suggested that both contrastive and non-contrastive properties of the L1 can impact the perception of non-native sounds (see, for example, Best et al., 2003). In particular, previous studies investigating perception of the oral–nasal vowel contrast suggest that the redeployment possibilities we have discussed require some attention. Beddor and Strange (1982) examined the oral–nasal vowel distinction by English and Hindi native speakers, whose L1 grammars contain the feature [nasal] non-contrastively and contrastively for vowels, respectively. Both groups of speakers were able to discriminate the contrast, although Hindi speakers’ discrimination was categorical and English speakers’ discrimination was continuous. These results put into question the ability of English speakers to form two categories for naturally-produced stimuli and, in turn, suggest that redeployment across levels may only be possible in optimal learning situations (as in Curtin et al. (1998)).
Lahiri and Marslen-Wilson (1991) and Ohala and Ohala (1995) also examined the perception of oral, nasal and nasalized vowels by speakers of English and Bengali and of English and Hindi, respectively. In both studies, participants were exposed to gradually incrementing parts of each stimulus and had to guess the incomplete word being presented to them. As English speakers predicted that nasal consonants should follow nasalized vowels, they were able to distinguish the oral and nasal vowels from each other. In a production study, Carignan (2018) analysed the imitation of French nasal vowels by naïve English and native French speakers and observed that the difference in nasalance between oral and nasal vowel targets was more pronounced in native than in naïve productions, but that the difference in tongue height was greater in naïve than in native productions. In all three of these studies, we suggest that the differences observed between oral and nasal vowels may have arisen from misperception of an illusory nasal consonant (N) in the latter case, that is, where the nasal vowel (Ṽ) was misidentified as a VN sequence. It appears that this was not considered in the analyses undertaken by these researchers, but other studies have found evidence that L2 learners and bilinguals may perceive illusory segments in their L2 due to L1–L2 phonotactic mismatches (Cabrelli et al., 2019; Carlson et al., 2016; de Leeuw et al., 2019; Dupoux et al., 1999). In addition, Beddor’s (2009) study on the production of English VN sequences has shown that the duration of the nasalized portion of V and that of the coda N are inversely correlated, which leads English listeners to perceive nasality on the vowel and the consonant as equivalent. In turn, they have difficulties attending to the precise alignment of the velum lowering gesture relative to the oral articulators. In view of all of these findings, we include the contrast Ṽ-VN in the present study to determine whether English listeners incorrectly perceive nasal vowels as VN sequences or whether they can instead successfully redeploy the feature [nasal] across systems or across levels.
To examine the three options mentioned above for immediate feature redeployment, we test speakers from five different L1 backgrounds, none of which possess the phoneme /ĩ/ and which differ from the others in systematic ways concerning the status of the feature [nasal] in their consonant and vowel systems: France French, Québec French, Canadian English, Caribbean Spanish, and non-Caribbean Spanish.
After further detailing the characteristics of nasality in each of the languages under focus, the predictions of the three feature redeployment options introduced above will be outlined. We then turn to the methodology used to test the availability of a feature for immediate redeployment, an AXB discrimination task. The results obtained in the discrimination task will then be presented and discussed. As will be seen, our findings have various implications for feature-based models of L2 segment acquisition, given that we test this approach in ways that go beyond what can be gleaned from the available literature. Specifically, we show that our results are consistent with a feature-based approach in that varying the formal status assigned to [nasal] across languages impacts redeployment as early as on first exposure to the non-native segment we examine.
II Nasality
1 Phonemic, allophonic and phonetic nasality
Nasality can play a contrastive (typically phonemic) or non-contrastive (allophonic or phonetic) role in languages. In addition, as we propose in this article, allophonic nasality can give rise to another type of role, namely pseudo-contrastive, when interacting with variable processes of elision of the triggering nasal consonant.
When [nasal] functions contrastively, minimal pairs or contextual evidence for distinctive status can be found, exemplified for consonants by English [nɪp] ‘nip’ vs. [dɪp] ‘dip’ and for vowels by (Québec) French [me] ‘my, pl.’ vs. [mẽ] ‘hand’ and BP [si] ‘if’ vs. [sĩ] ‘yes’. 1 Nasal consonants are phonemic in over 95% of the languages examined in Maddieson’s (1984) survey and, for this reason, we are not able to include an L1 in our study that lacks nasals altogether. Nasal vowels, by contrast, are distinctive in only slightly more than 20% of the languages examined, which enables us to include L1s without phonemic nasal vowels.
Allophonic nasality is contextually-determined, arising from the nasal gesture (lowered velum) of a nasal consonant overlapping a preceding or following vowel. For instance, in the English word bin, the vowel assimilates to the lowered velum gesture of the following nasal, resulting in [bɪ̃n] from underlying /bɪn/. While allophonic nasality is non-contrastive in English, we observe a different type of allophony in languages such as Caribbean Spanish, in which elision of the nasal consonant is frequently observed while maintaining the vowel’s derived [nasal] feature. This results in CṼ syllables (e.g. /sin/ → |sĩŋ| → [sĩ] ‘without’), which superficially contrast with CV syllables (e.g. [si] ‘yes’). We refer to cases such as this, when the feature [nasal] functions allophonically while variably participating in an apparent but necessarily derived contrast, as pseudo-contrastive (for more details, see Section II.2.d).
We distinguish allophonic and phonetic nasality along the following lines. Although assimilatory processes between adjacent segments for both types of nasality involve overlapping gestures, important differences are observed between them. Studies on nasality suggest that allophonic, like phonemic, nasalization is intended and controlled by speakers, whereas phonetic nasalization is unintended and automatic, as it results from physiological constraints on coarticulation (Moraes, 1977; Solé, 1992). For instance, allophonic nasalization in English extends temporally quite far back into the vowel, but it is not categorical and it is variably produced, depending on prosodic factors, phonetic context and speech rate (e.g. Beddor, 2009; Cho et al., 2017; Clumeck, 1975; Rochet and Rochet, 1991; Solé, 1992). In contrast, the duration of nasalization in non-Caribbean Spanish is minimal and relatively constant, independent of speech rate (Solé, 1992, 1995); it is thus interpreted as mechanical or phonetic, rather than caused by a phonological rule. 2
In formal terms, we interpret this to mean that allophonic and phonemic nasalization employ the feature [nasal] as part of the phonological grammar of a given language and that this feature can thereby express contrasts (when phonemic) or be otherwise manipulated in phonological operations (when allophonic). We do not take a stand on exactly how phonetic assimilation is formally expressed but we assume that the output of phonetic assimilation, as purely mechanical, is not accessible to the phonological component of the grammar of a given language. Thus, in comparison with the preceding Caribbean Spanish example, the representation of the vowel in the word [sin] ‘without’ in non-Caribbean Spanish lacks the feature [nasal], although a very short portion of the vowel is nasalized due to coarticulation with the following nasal consonant.
Finally, even with phonemic and allophonic nasality, studies have observed variation across speakers in the onset and relative strength of a given physical correlate of nasality. For example, while Desmeules-Trudel and Brunelle (2018) find a higher degree of inter-speaker variability in nasal airflow in BP in comparison with Québec French, they conclude that ‘variability [in BP] does not compromise contrasts or lead listeners to confuse lexical items’ (Desmeules-Trudel and Brunelle, 2018: 54). Similarly, Beddor (2009) finds that ‘American English-speaking listeners accommodate the wide range of Ṽ and N variation that occurs in natural speech by attending . . . to relatively stable properties such as nasalization across the syllable rhyme’ (Beddor, 2009: 809–10). Consistent with this, we assume that variation in the phonetic implementation of a categorically represented feature like [nasal] is inevitable but this does not impede faithful perception of the segment or string. 3
2 Nasality in the languages under study
As we have alluded to, the grammars of the languages under consideration differ with respect to the role of nasality in each. In the following sections, the vowel system of each language will be detailed. The nasal consonant systems will not be discussed, except where their distribution impacts the realization of vowels, because the languages do not differ from each other in critical ways in this part of the grammar: [nasal] is contrastive for consonants in all four languages.
a Brazilian Portuguese (BP)
BP was selected as the target language because it contains the contrast /i/–/ĩ/, which is absent from the other languages under examination. BP also contains /e/–/ẽ/, which we included to provide a point of comparison with /i/–/ĩ/.
The vowel inventory of BP contains seven oral (/i, u, e, o, ɛ, ɔ, a/) and five nasal (/ĩ, ũ, ẽ, õ, ɐ̃/) monophthongs, as well as oral and nasal diphthongs, which we set aside (inventories adapted from Brito, 1975). Mid nasal monophthongs can variably be diphthongized (e.g. [ẽ]~[ẽj̃]), especially in stressed word-final position (Major, 1985: 266). Oral and nasal vowels contrast with each other in both open (e.g. [si] ‘if’ vs. [sĩ] ‘yes’; [ˈli.dɐ] ‘manage, 3sg.’ vs. [ˈlĩ.dɐ] ‘pretty, fem.’) and final closed syllables (e.g. [tres] ‘three’ vs. [trẽs] ‘trains’). In addition to contrastive vowel nasality, non-contrastive vowel nasalization processes may occur when an oral vowel precedes (V.N) or follows (NV) a nasal consonant (Fails, 2011).
Nasal consonants are only present in onset position in BP; they no longer occur in coda, as historically these were the source of phonemic nasal vowels (Teyssier and Cunha, 1982). However, nasal vowels are variably followed by a consonantal nasal appendix (or nasal murmur) (Shosted, 2006), which refers to a short consonant-like segment having a lower intensity than a full nasal consonant (Gigliotti de Sousa, 1994).
b French (FR)
FR, like BP, also contains contrastive nasal vowels. However, the nasal phonemes in the two languages differ: critically, FR lacks the high nasal vowels present in BP. The oral vowel inventories for both dialects of French under focus, France French (FFR) and Québec French (QFR), are the same, except that QFR has one additional low vowel, /ɑ/: /i, y, u, e, ø, o, ɛ, œ, ɔ, a, (ɑ)/. The nasal vowels differ in both number and quality: FFR: /ɛ̃, õ, ɑ̃/; QFR: /ẽ, œ̃, ɔ̃, ã/ (oral and nasal vowel inventories for both dialects based on Delvaux, 2012; Martin, 2002). 4 Differences in the quality of the mid front unrounded nasal vowel in the two dialects, /ɛ̃/ vs. /ẽ/, is of particular interest to us, given that we include the BP vowel /ẽ/ in our experiment. Note that since we focus on categorical differences between FFR and QFR, the symbols provided for the nasal vowels in both dialects reflect the traditional transcription of these vowels and generalize away from their phonetic and/or positional complexity (see Carignan, 2014; Delvaux, 2012: 84–85, 137–38). It is well documented, though, that FFR nasal vowels have undergone a counter-clockwise shift with respect to their traditional notation, while QFR vowels have undergone a clockwise shift (Fagyal et al., 2006). This has had the effect of reinforcing the perceptual difference between /ẽ/ and /ɛ̃/ in the two dialects (Nicholas et al., 2019). Another difference between the dialects is that nasal vowels are variably diphthongized in QFR (e.g. Côté, 2012). Nonetheless, non-diphthongized [ẽ] is heard alongside its diphthongized counterparts, providing QFR speakers with previous experience of the equivalent of BP [ẽ].
FR oral and nasal vowels can appear word-finally ([pe] ‘P’ vs. [pẽ] ‘bread’) or be followed by an oral onset ([a.fi.ˈle] ‘to sharpen’ vs. [ã.fi.ˈle] ‘to thread’) or word-final coda ([fos] ‘false fem.’ vs. [fõs] ‘rush’) (QFR pronunciations provided). We can conclude from this that, like in BP, the feature [nasal] is contrastive for vowels in FR, with the two languages differing most importantly in the presence or absence of nasal high vowel phonemes.
Turning to non-contrastive nasality in FR, oral vowels that precede a nasal consonant undergo phonetic nasalization. Although high vowels are more nasalized than non-high vowels (Delvaux et al., 2008; Rochet and Rochet, 1991), this seems to be due to their inherently shorter duration (Dow, 2020; Hajek and Maeda, 2000). We accept this view and thus conclude that [nasal] is absent from high vowels in the phonological grammar of FR.
c English (EN)
The inventory of vowels for Canadian EN does not contain nasal vowel phonemes: /i, u, ɪ, ʊ, e, o, ɛ, ʌ, æ, ɑ/ (adapted from Labov et al., 2005). Nasality operates non-contrastively in the vowel system as a consequence of regressive nasalization processes (e.g. Donegan and Stampe, 1978). Regressive nasalization results from an allophonic rule by which nasality is spread from a nasal consonant to a preceding oral vowel in closed syllables; for instance, underlying /bin/ ‘bean’ is realized as [bĩn] (e.g. Lahiri and Marslen-Wilson, 1991; Solé, 1992). Regressive nasalization is, however, often blocked or occurs to a lesser degree in open syllables followed by a nasal onset (e.g. [ˈkli.nər] ‘cleaner’), in which case it is due to phonetic coarticulation (e.g. Clumeck, 1975). Based on the distinction between allophonic and phonetic nasalization motivated by Solé (1992; see Section II.1), we consider regressive vowel nasalization only before coda nasals to be an allophonic process that operates in the phonological grammar of EN, supplying vowels with the feature [nasal], which has non-contrastive status.
d Spanish (SP)
SP, like EN, does not contain a phonemic oral–nasal contrast for vowels: /i, u, e, o, a/ (Alarcos Llorach, 1961). In both dialects under focus, NS (non-Caribbean Spanish such as Mexican, South American and most Peninsular varieties) and CS (varieties of Spanish spoken around the Caribbean sea as well as in Andalusia and Extremadura 5 ), oral vowels surface as oral before nasal onsets (e.g. [ˈte.ma] ‘theme’). This also holds before nasal codas in NS (e.g. [tan] ‘so’); nasal consonants in coda position are not weakened (e.g. Colantoni and Kochetov, 2012; Harris, 1969; Quilis, 1993) and vowel nasalization in VN strings is phonetic (Solé, 1992), as previously discussed, meaning that vowels are represented as oral phonologically.
In CS, however, nasal codas are typically weakened, i.e. velarized or elided, in word-medial and -final position and, as a result, the preceding vowel is nasalized (e.g. Cedergren and Sankoff, 1975; Colantoni and Kochetov, 2012; D’Introno and Sosa, 1988; Sampson, 1999; Terrell, 1975). Weakening of the nasal coda follows a continuum, where the segment can be produced as a velar nasal [ŋ] or nasalized glide [ɣ̃] (both likely a nasal appendix, as in BP nasal vowels), or it can be elided altogether. For example, the word tan ‘so’ can be realized as [tan], as in NS, or as [tãŋ], [tãɣ̃] or [tã].
Although the realization of coda nasals in CS has been extensively investigated from a sociolinguistic perspective, to our knowledge, nasalization of the preceding vowel has only been examined from a phonetic point of view by Lederer (2003). Her aerodynamic study reveals that vowels followed by a velarized nasal consonant in Cuban Spanish are categorically nasalized. Moreover, Cedergren and Sankoff (1975) report that, in Panamanian Spanish, high vowels favour elision and, when nasal codas are elided in such words (68% of the time), nasalization of the preceding vowel is obligatory.
Elision of the nasal coda is present in all CS varieties, although with different frequencies that also vary according to speech style (Colantoni and Kochetov, 2012; Terrell, 1975). Of interest to the present study, elision gives rise to CṼ syllables, so nasal vowels must be interpreted by CS speakers as distinct from their oral counterparts in CV syllables, as exemplified by the possible pronunciations of the following pairs of words: [sĩ] ‘without’ vs. [si] ‘yes’; [ˈmẽ.ta] ‘mint’ vs. [ˈme.ta] ‘goal’. Given that elision is variable, the CS grammar possesses the feature [nasal] for vowels that is allophonic, since it is derived from an underlying VN sequence; at the same time, the feature functions as contrastive on vowels when the nasal consonant that triggered vowel nasalization subsequently deletes. As mentioned earlier, we refer to this type of allophony as pseudo-contrastive. The variation currently observed in CS likely reflects a change in progress (Colantoni and Kochetov, 2012: 31) and, thus, this variety of SP can be seen as in transition from a grammar like that of EN, where [nasal] is strictly allophonic for vowels, to a grammar like that of FR and BP, where [nasal] is fully contrastive for vowels. 6
In sum, [nasal] is absent from vowels in the grammar of NS but operates allophonically (and, specifically, pseudo-contrastively) in the grammar of CS.
III Predictions
The stimuli in our experiment were divided into four contrast categories, as shown in Table 1. (In addition, there were fillers that involved different combinations of oral and nasal consonants and vowels; these will not be discussed further nor included in the analysis.) In this section, we provide our predictions for each contrast category for the four linguistic systems under consideration: FR, EN, CS and NS. C stands for the various (oral) onset consonants that were used in the stimuli; V and Ṽ collapse /i, e/ and /ĩ, ẽ/, respectively, when both high and mid vowels were examined within a single contrast category. Further details on the shapes of the stimuli and how they were constructed are provided in Section IV.
Contrasts.

1 Naïve perception
Recall from Section I that we identified three conditions under which a feature like [nasal] could potentially be redeployed in the L2:
Redeployment within systems: Redeployment of contrastive [nasal] within the vowel system itself;
Redeployment across systems: Redeployment of contrastive [nasal] from the consonant system to the vowel system;
Redeployment across levels: Elevation of [nasal] from allophonic to contrastive status within the vowel system.
We first discuss these three conditions assuming that the L1 grammar is the only system that learners can draw from for redeployment of the feature [nasal]. We then turn to address the possibility that exposure to the /e/–/ẽ/ contrast in Québec French provides learners with another option.
Under option (1), [nasal] would be redeployed from a native vowel on which it is contrastively specified to a native vowel on which it is not. If successful detection of the /i/–/ĩ/ contrast is only possible under option (1), then we predict that only the FR group will be successful, as FR is the sole language tested that contains nasal vowel phonemes. The expected results under option (1) are sketched in Table 2.
Detection of Ci–Cĩ under option (1): Redeployment within systems.

Notes. FR = French. EN = English. CS = varieties of Spanish spoken around the Caribbean sea as well as in Andalusia and Extremadura. NS = non-Caribbean Spanish such as Mexican, South American and most Peninsular varieties.
It is important to consider what ‘successful’ performance looks like in the context of naïve perception. Success does not necessarily mean that performance should be indistinguishable from that of native speakers of BP. After all, all non-native groups are hearing the Ci–Cĩ contrast for the first time. In the case of option (1), success for the FR listeners would mean that their performance is expected to be both above chance and significantly higher than that of the other non-native groups. This should optimally position listeners from this language group for success in real language learning of the /i/–/ĩ/ contrast and the eventual creation of the new category /ĩ/ in BP.
Under option (2), the feature [nasal] that operates contrastively in native language consonants would be redeployed to the vowel system to eventually create a new category of nasal high vowels. If redeployment of this sort is possible on first exposure to a second language, then all four non-native groups should be successful at detecting the /i/–/ĩ/ contrast, as all four L1s contain nasal consonant phonemes. The expected results under this option are shown in Table 3. Again, successful performance should be reflected in above chance behaviour for all non-native groups, even if this falls short of the performance exhibited by native speakers of BP.
Detection of Ci–Cĩ under option (2): Redeployment across systems.

Notes. FR = French. EN = English. CS = varieties of Spanish spoken around the Caribbean sea as well as in Andalusia and Extremadura. NS = non-Caribbean Spanish such as Mexican, South American and most Peninsular varieties.
Under option (3), we consider the possibility that the allophonic feature [nasal] that operates on vowels in languages like EN and CS could be accessible to and thus used by naïve listeners from these language backgrounds to perceive the BP /i/–/ĩ/ contrast. The results expected under this option are provided in Table 4. We have excluded FR since this language employs [nasal] contrastively in its vowel system. Nevertheless, listeners from this language background are also expected to be successful if option (3) holds; that is, it would be highly unusual for redeployment under option (3) to hold without redeployment under option (1).
Detection of Ci–Cĩ under option (3): Redeployment across levels.

Notes. EN = English. CS = varieties of Spanish spoken around the Caribbean sea as well as in Andalusia and Extremadura. NS = non-Caribbean Spanish such as Mexican, South American and most Peninsular varieties.
As is evident from a comparison of Tables 2–4, NS is the only non-native group with only one redeployment option available. Thus, if all groups of listeners succeed on Ci–Cĩ, this would appear to confirm that contrastive [nasal] was redeployed across systems (option (2)). There is, however, another option available, under which listeners’ prior exposure to Québec French leads to the feature [nasal] being contrastively specified for mid vowels in the grammars that all listeners have built for this language. If they can draw on this knowledge, then all non-native groups should successfully detect the /i/–/ĩ/ contrast. This option is shown in Table 5; as it involves redeployment within systems from the grammar of Québec French, we have labelled it option (1)’.
Detection of Ci–Cĩ under option (1)’: Redeployment within systems from Québec French.

Notes.FR = French. EN = English. CS = varieties of Spanish spoken around the Caribbean sea as well as in Andalusia and Extremadura. NS = non-Caribbean Spanish such as Mexican, South American and most Peninsular varieties.
An important question that we must address is how we can distinguish the two options in Tables 3 and 5: option (2): redeployment of [nasal] across systems (from the consonant system of the L1 to the vowel system of BP) and option (1)’: redeployment of [nasal] within systems (from the vowel system of Québec French to the vowel system of BP). We focus on non-native groups other than QFR. As mentioned, under both redeployment options, performance should be successful, that is, above chance. If listeners are successful under option (2) and, thus, do not draw on their knowledge of Québec French, there should be no statistical difference between their performance on the /i/–/ĩ/ and /e/–/ẽ/ contrasts: for both contrasts, they are building the necessary representation in the same fashion, from the [nasal] feature available in their L1 consonant systems. If, in contrast, listeners are successful under option (1)’ and thereby draw on their knowledge of Québec French, their performance on /e/–/ẽ/ should be statistically higher than their performance on /i/–/ĩ/, closely mirroring the behaviour of native speakers of Québec French. We turn more concretely to our predictions for /e/–/ẽ/ in the next section.
2 Non-naïve perception
The BP nasal vowel /ẽ/ was included to compare its non-naïve perception with the naïve perception of /ĩ/ and thereby better interpret the results obtained for the latter category. Recall from Section II that /e/–/ẽ/ is a native contrast for QFR listeners, and thus it serves as a control for QFR and BP. Concerning the other groups, all participants lived in Montréal at the time of testing and so EN, CS, NS as well as FFR speakers had been actively exposed to Québec French, in formal (classroom) and/or informal settings (see further Section IV.4). Therefore, the perception of this phoneme is not naïve for the participants in our study, which allows us to determine whether a feature that could not be redeployed at first exposure to a non-native segment may be redeployed with greater exposure.
3 Perceptual illusion
We refer to misidentification of Ṽ as VN as perceptual illusion, given that it reflects the erroneous detection of an ‘extra’ segment in the string due to mismatches between the grammars of BP and the listener’s L1. As mentioned earlier, we include the perceptual illusion contrast Ṽ-VN to help interpret our results on the naïve and non-naïve contrasts. Concerning the former, for example, should EN and CS speakers prove to be equally successful in discriminating /i/–/ĩ/ while NS speakers are not, this would appear to support option (3), redeployment across levels. Performance on the corresponding /ĩ/–/iN/ contrast, however, could confirm or refute this, as we detail in the following lines.
Although allophonic features are active in the phonological component of grammatical systems, they differ from contrastive features in that they are licensed in a limited range of contexts. For example, the feature [nasal] on allophonically-derived nasal vowels is obligatorily followed by a contrastively specified nasal consonant (i.e. a single feature [nasal] is shared between Ṽ and N, licensed by N, on which it is contrastive). In order for listeners to be successful under option (3), the feature [nasal] present on vowels must be completely dissociated from the nasal consonant that follows it, so that Ṽ is not misperceived as a VN sequence (i.e. so that Ṽ itself licenses the feature [nasal]). Indeed, previous studies have shown that English speakers tend to interpret nasal(ized) vowels as being followed by a nasal coda (Beddor, 2009; Beddor et al., 2013; Lahiri and Marslen-Wilson, 1991; Márquez Martínez, 2016; Ohala and Ohala, 1995). Thus, if listeners from EN and CS backgrounds are successful under option (3), we cannot necessarily conclude that this dissociation has taken place. It could instead be the case that an illusory nasal consonant following the vowel in CṼ has been perceived, and that the oral–nasal vowel contrast is distinguished by these listeners as CV vs. CVŋ rather than as CV vs. CṼ. In order to ensure that we can appropriately interpret our results – that is, that success on CV vs. CṼ truly reflects a contrast between two open syllables – we also included the contrast type CṼ–CVŋ in our experiment.
4 Control
Control stimuli were included to ensure that the experiment was appropriately designed and understood by participants. Accordingly, we predicted that these pairs would be successfully discriminated by all listeners, regardless of L1 background. The control stimuli were shaped CV–CVŋ and Ciŋ–Ceŋ. The first tested perception of the absence vs. presence of a coda while the second tested perception of high vs. mid vowels before a coda, that is, types of contrasts that exist in all of the languages under study. However, in order not to favour one language over another, the control stimuli were constructed so as not to correspond to native strings in any of the languages included. Specifically, in BP and CS, word-final [ŋ] is a consonantal nasal appendix, not a true consonant as it is here; EN does not permit [ŋ] to follow tense vowels, as it does here; and FR and NS lack word-final [ŋ], although they both permit word-final [n].
IV Methodology
As mentioned earlier, in order to test the perceptual abilities of non-native listeners, we employed an AXB discrimination task. We begin this section by providing details on how the stimuli for this task were constructed. We then turn to the task itself and, finally, provide information on the groups of individuals who participated in the experiment.
1 Stimuli
The experimental stimuli consisted of three types of monosyllables: open oral (CV), open nasal (CṼ) and closed (CVŋ). Onset consonants were voiceless obstruents: /p/, /k/, /f/, /s/. Nuclei were limited to /i/, /e/, /ĩ/ and /ẽ/. The nasal coda in closed syllables was /ŋ/ because it closely approximates the consonantal nasal appendix that often accompanies nasal vowels in BP. The stimuli were created from recorded syllables of five shapes: CV, CṼ, NṼ, CVɡ and CṼŋ. NṼ was included, where the nasal onset was /m/ (for labial-initial CṼ stimuli) or /n/ (for non-labial-initial CṼ stimuli), to ensure that the degree of nasality was sufficiently high and constant throughout the entire duration of nasal vowels. CVɡ was included to create CVŋ stimuli (i.e. with an oral vowel), which are not well-formed in BP. The consonantal nasal appendix, if present, was removed from CṼ stimuli and, in tokens where /ẽ/ was diphthongized, the glide [j] was also deleted.
One male and one female native speaker of BP recorded the syllables in a sound attenuated booth in the Multilingual Speech Laboratory at Concordia University, Montréal. Both speakers were linguists, with training in phonetics, and were given specific instructions on how to produce the stimuli (e.g. nasalizing throughout the entire nasal vowel, avoiding diphthongizing mid-front nasal vowels, etc.). Recordings were made in stereo using Praat (Boersma and Weenink, 2015), sampled at 44.1 kHz. A Glottal Enterprises nasometer (NAS-1 SEP Clinic), connected to an iMac computer outside the booth, was used to measure the nasal energy in the production of nasal vowels. The nasometer, which was held by the speakers, consisted of two equally spaced microphones separated by a plate, which was placed between the speaker’s nose and upper lip.
All syllables were recorded in a carrier phrase: Ele diz . . . três vezes (‘He says . . . three times’). The syllables were extracted from the carrier phrase and then analysed on various dimensions, as follows.
Nasality was quantified using the Differential Energy Ratio (DER) measurement, which models the proportion of the vowel at which energy is predominantly nasal (Dow, 2014, 2020). Ideally, the DER for nasal vowels should be close to 100%. For each speaker in our experiment, the two tokens with the greatest proportion of nasality per vowel were selected to create the CṼ and CṼŋ stimuli; each had a minimum DER of 90%, which indicates that the vowel was nasalized throughout most of its duration. This ensured that variability in the phonetic implementation of nasality in the BP stimuli was not a factor that could influence non-native discrimination of the oral–nasal contrast.
Based on analysis undertaken in Praat, the stimuli underwent further modification to ensure uniformity and maximize naturalness: (1) The length of the rhyme was set at 400 ms for both open and closed syllables, where in closed syllables, the vowel portion was 245 ms and the coda portion 155 ms. (2) The onset consonants were modified when necessary to ensure acoustic similarity across all stimuli beginning with the same consonant. (3) The pitch contour of all stimuli was made uniform (shallow rise, followed by level). (4) Intensity was normalized to 70 dB. (5) A fade-out effect was added to the end of each stimulus to avoid the percept of a final click. (6) For each stimulus, five tokens with slightly different fundamental frequencies (f0) were created to reflect natural phonetic variability on the pitch dimension; the factors used to synthesize different frequencies were 0.96, 0.98, 1.00, 1.02 and 1.04.
In sum, 2 tokens (token_1 and token_2) per speaker (n = 2) were created for each stimulus type. There were 32 different stimulus types: 4 monosyllabic shapes (CV, CṼ, CVŋ, CṼŋ) * 4 vowels (/i/, /e/, /ĩ/, /ẽ/) * 2 different onset types (labial /p, f/, non-labial /k, s/). Multiplying this by 5 different frequencies yielded a total of 640 tokens. Of these 640, 378 tokens were used to construct the experiment. These were randomly selected in a counterbalanced fashion for token number (half of the selected stimuli were instances of token_1 and the other half of token_2) and frequency multiplication factor (approximately 75 stimuli were selected from each of the five frequency factors).
2 Design
In the AXB discrimination task, designed and administered in Praat (Boersma and Weenink, 2015), participants heard 120 sequences of three stimuli and were asked to indicate if the second stimulus (X) was more similar to the first (A) or the third (B) (e.g. Gerrits, 2001; MacKain et al., 1981; van Hessen and Schouten, 1999). There were eight triads testing each contrast (including fillers). Triad types (X = A vs. X = B) and onset types (/p/ vs. /k/; /f/ vs. /s/) were counterbalanced using different randomization patterns. 7
For each triad, A and B were produced by one BP speaker, while X was produced by the other. Multi-speaker stimulus presentation ensures that listeners generalize away from indexical properties and focus on phonological rather than fine-grained acoustic information in making discrimination judgements (based on Flege et al., 1994; Gottfried, 1984; Levy and Strange, 2008). In a further attempt to obtain phonological judgements, the interstimulus interval (ISI) between items in a triad was set to 750 ms, as it has been shown that shorter ISIs lead to acoustic or phonetic processing instead (Werker and Logan, 1985).
These methodological decisions were made to approximate phonological (i.e. feature-based) processing, as this is the level at which we expect to find cross-language differences. If we do observe categorical differences across non-native groups using this methodology, on our view, this would be due to the role that the feature [nasal] plays in the L1 grammar. The L1 would thus serve as a launching point for L2 acquisition: the status of [nasal] in the L1 could position listeners from some language groups well for early success in real language learning of the /i/–/ĩ/ contrast in BP. If, on the contrary, the AXB task were to involve shorter ISIs and same-voice stimuli, thereby tapping lower level phonetic processing, we would expect to find some individual variation but we should not observe categorical differences across non-native groups. As will be seen, we find support for the former option and, thus, we contend that using AXB tasks with naïve listeners, who, unlike real language learners, cannot pair sound with meaning, can still inform us about phonological processing in this population.
3 Procedure
The experiment took place in sound attenuated booths in the Departments of Linguistics at McGill University, Université de Montréal and Concordia University. After providing written informed consent following the Research Ethics Board protocol for McGill University and Université de Montréal (approval numbers 21-0615 and 2014-15-056-D, respectively), participants completed a short training session in which they listened to six practice triads and had an opportunity to ask the researcher questions. Participants then completed one half of the discrimination task (60 triads), after which they had a short break and filled out a language background questionnaire. Finally, they completed the second half of the discrimination task (60 triads). The training session and the AXB task were run on a MacBook laptop computer, using AKG K 240 MK II Semi-open studio headphones. The entire experiment took approximately 30 minutes to complete. Participants were compensated for their time.
4 Participants
A total of 103 native speakers of BP, FFR, QFR, EN, CS, and NS took part in the experiment. However, the data from 20 participants were excluded from the analysis due to one or more of the following reasons (number of excluded participants in parentheses): chronic ear infections during childhood (5), exposure to more than one language from birth (4), exposure to an L2 with high nasal vowels (1), advanced proficiency in an L2 for non-BP speakers (8), technical problems with the experiment (2), or construction noise in close proximity to the testing site (3). Among the remaining 83 participants, there were 15 native speakers of BP, included as controls, 11 of FFR, 10 of QFR, 14 of EN, 15 of CS, and 18 of NS. All of the participants were between the ages of 18 and 35; 32 were men and 51 were women. They were recruited through postings in Montréal universities, community centres, language schools, and on the internet.
All participants were living in Montréal at the time of testing and, thus, all had been previously exposed to Québec French and, as a result, to the /e/–/ẽ/ contrast. Aside from QFR, the EN group had the greatest amount of exposure; these participants were exposed to Québec French starting in elementary or high school, although French was taught as a subject rather than being the medium of instruction. The mean exposure for this group is 92.93 months. The FFR group had the next highest amount of exposure, 21.73 months on average. The two Spanish-speaking groups had the least amount of exposure: NS, an average of 8.64 months, and CS, an average of 6.57 months. 8 Although there are large differences across groups in terms of amount of exposure to Québec French, we will see shortly that this does not, in fact, impact the results.
V Results and analysis
For each control contrast (Ci–Ciŋ, Ce–Ceŋ and Ciŋ–Ceŋ) in the AXB discrimination task, the average proportion of correct responses for all language groups was higher than 85%. We can thus be confident that lower performance on other contrasts can be interpreted as reflecting difficulties in perception and not difficulties performing the task itself. Recall that the control stimuli were selected so as not to correspond to native strings in any of the languages included in the study. For this reason, we did not exclude participants from the analysis based on their performance on the controls. Instead, participants’ reaction times for responses to all stimuli were measured in Praat (Boersma and Weenink, 2015) from the onset of each trial, and trials having a reaction time of two standard deviations higher than the mean for a given participant and contrast were removed from the analysis. 414 responses out of 9,711 (4.3%) were excluded, yielding a total of 9,297 responses. The maximum number of trials discarded for any participant was 9 (out of a total of 119 trials per participant 9 ). No single combination of contrast shape and vowel target was disproportionately affected by this process. Reaction times were not otherwise analysed.
The remaining data were modelled in R using hierarchical logistic regressions with crossed by-participant and by-item random intercepts, to account for the variation across participants within each language group and across test items (i.e. trials) within each contrast category (Table 1), respectively (R Development Core Team, 2017). The logistic regressions were run using the glmer() function of the lme4 package (Bates et al., 2015) with the BP group as the baseline to determine whether the non-native groups performed significantly differently from BP on each contrast. Additional logistic regressions were run using the glht() function of the multcomp package (Hothorn et al., 2008) to obtain comparisons across all non-native groups. Moreover, in order to compare the performance on the high vowel vs. the mid vowel, one logistic regression per language group and contrast with by-participant and by-item random intercepts was run using the glmer() function of the lme4 package. In addition to making comparisons across language groups and vowels, we also considered the performance of each group on each contrast relative to chance, which was established to be 50% (given that the task involves two choices). To do so, one intercept-only logistic regression per language group and contrast with by-participant and by-item random intercepts was run using the glmer() function of the lme4 package. All statistical comparisons were planned.
1 Non-naïve perception
We first consider performance on the non-naïve contrast, Ce–Cẽ. This contrast is not native for any non-native group, with the exception of QFR. Nevertheless, due to all participants having been exposed to Québec French prior to testing, the Ce–Cẽ contrast represents a case of non-naïve perception and, thus, redeployment of the feature [nasal] may already have taken place, which could result in better performance on this contrast for all non-native groups.
The results for the Ce–Cẽ contrast for all language groups are provided in Figure 1. They suggest that the BP and QFR groups’ performance is considerably higher than that of all other groups, reflecting the fact that Ce–Cẽ represents a native contrast for both. (The import of the asterisks in Figure 1 will be addressed shortly.)
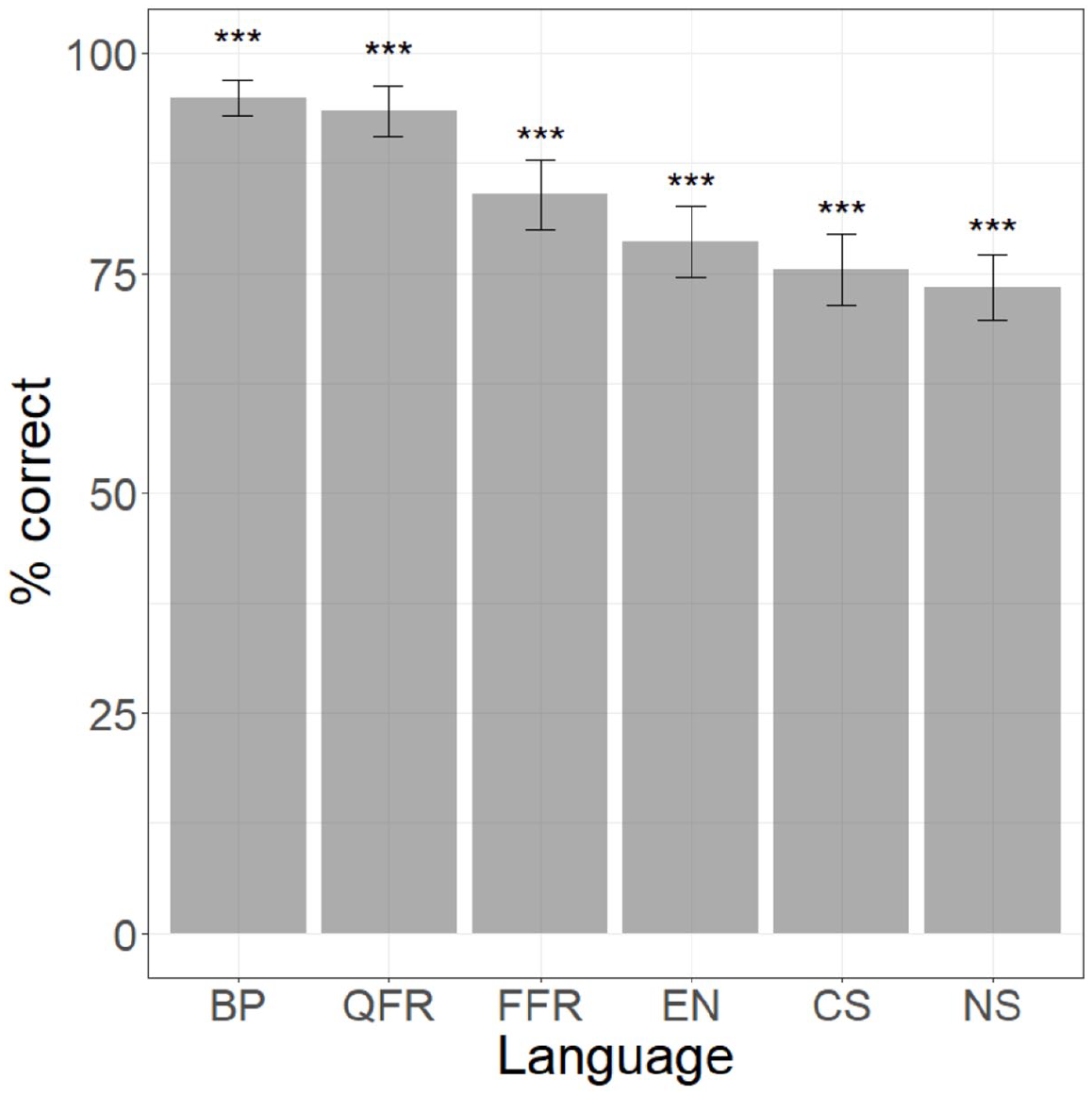
Performance on Ce–Cẽ contrast across language groups.
In order to determine whether the difference between BP and the other language groups is statistically supported, we initially ran a logistic regression for the Ce–Cẽ contrast, with BP as the baseline. Table 6 shows the estimates (
Model for Ce–Cẽ contrast.
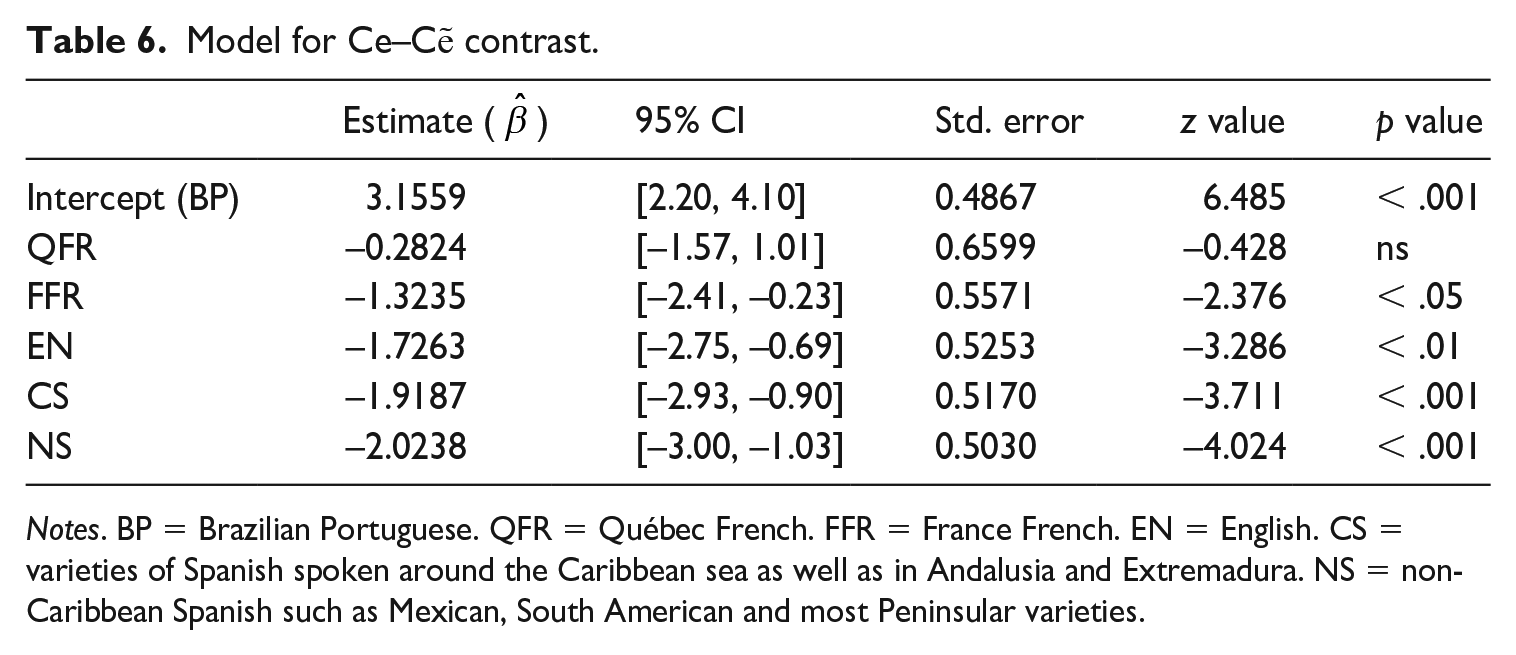
Notes. BP = Brazilian Portuguese. QFR = Québec French. FFR = France French. EN = English. CS = varieties of Spanish spoken around the Caribbean sea as well as in Andalusia and Extremadura. NS = non-Caribbean Spanish such as Mexican, South American and most Peninsular varieties.
Although the statistical results indicate that the non-native groups other than QFR are significantly lower than BP, Figure 1 suggests that this may not necessarily reflect poor performance. Indeed, a logistic regression examining performance relative to chance per language group revealed that all groups performed significantly above chance (for the full model, see Appendix 2). The level of statistical significance is represented by asterisks in Figure 1.
Taken together, these findings suggest that all non-native groups have successfully redeployed the feature [nasal] to create the novel category /ẽ/ in QFR, due to their earlier exposure to this language. However, this interpretation assumes that successful performance on Ce–Cẽ indicates that the nasal vowel is appropriately perceived (and represented) as a single segment, Ṽ, and not as a VN sequence. As we will see in the next section, the latter possibility is particularly important to consider for EN and CS, given the status of [nasal] in the L1 grammars of these languages.
2 Perceptual illusion: Mid vowels
Because the feature [nasal] operates allophonically in the vowel system of EN, earlier studies have found that native speakers of this language tend to perceive nasal vowels as followed by an illusory nasal consonant (see Sections I and III.3). When acquiring non-native nasal vowels, EN speakers are thus required to ‘detach’ [nasal] from this illusory consonant and reanalyse it as an inherent property of the vowel. This process might also be necessary for CS speakers, given that vowels are allophonically nasalized in their L1 when followed by a nasal consonant that is often weakened or elided. Because of this, we must determine whether success on the Ce–Cẽ contrast truly means that EN and CS speakers accurately perceive the oral–nasal contrast or whether they instead perceive Cẽ as CeN, which they then successfully discriminate from Ce.
The results for Cẽ–Ceŋ are plotted in Figure 2. A logistic regression model of performance relative to chance for this contrast per language group shows that all language groups, including EN and CS, perform above chance (for the full model, see Appendix 3). 10 The level of statistical significance is represented by asterisks in Figure 2. This finding indicates that the successful performance on the non-naïve contrast, Ce–Cẽ, by EN and CS groups was not biased by perceptual illusion.
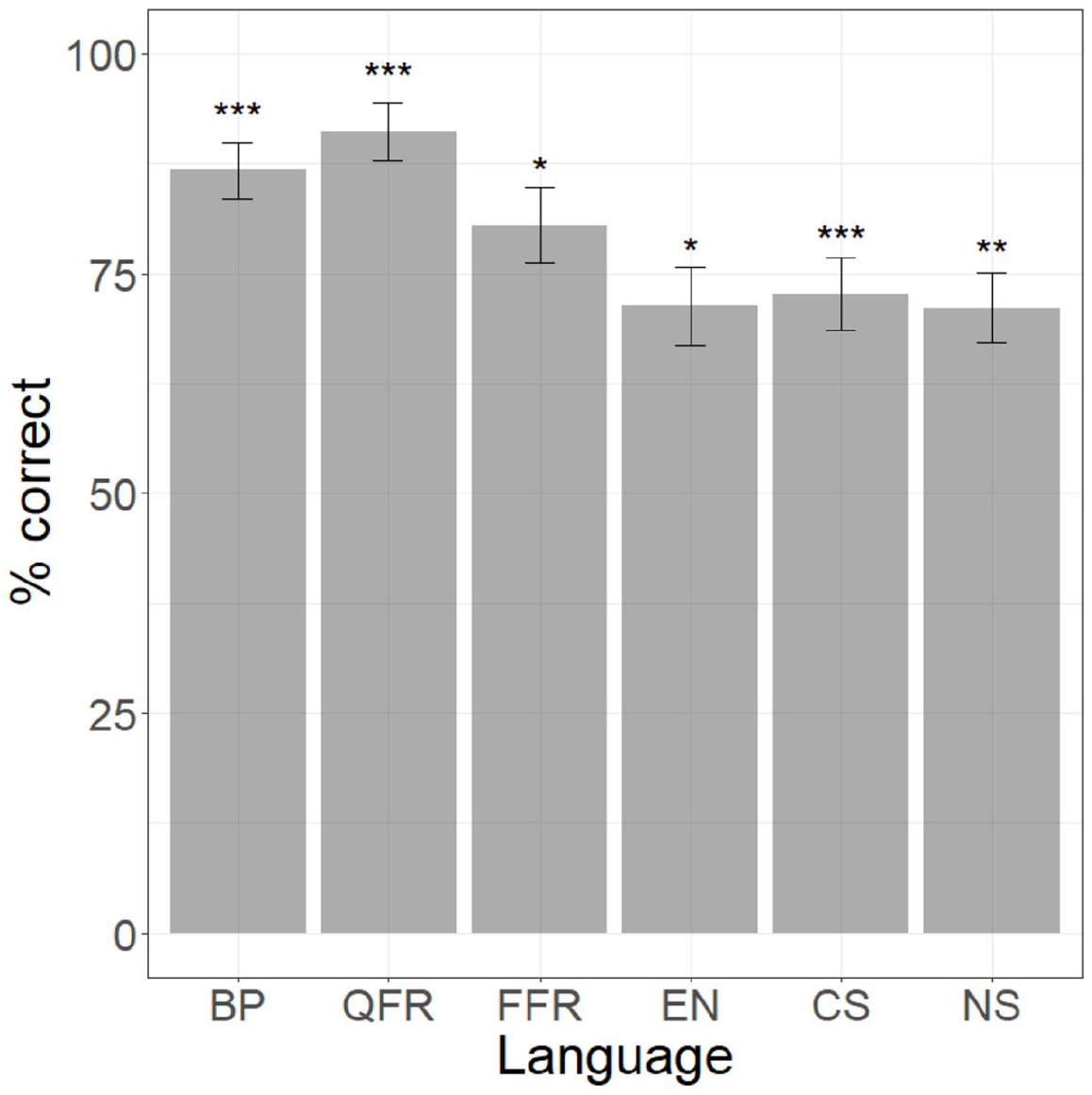
Performance on Cẽ–Ceŋ contrast across language groups.
The results presented in this section on Cẽ–Ceŋ, coupled with those from the previous section on Ce–Cẽ, suggest that all non-native groups had successfully redeployed the feature [nasal] and combined it with the feature [mid] to create the novel category /ẽ/, due to their earlier exposure to Québec French. We address what this tells us about feature redeployment after we examine the performance of each non-native group on the high vowel stimuli.
3 Naïve perception
We now consider the main contrast under focus, Ci–Cĩ. Recall that the goal of the present study is to examine the naïve perception of the BP oral–nasal contrast by speakers from various L1s, in order to probe into the different feature redeployment options proposed in Section III: (1) redeployment within systems, (2) redeployment across systems, and (3) redeployment across levels. Given that all non-native groups had been exposed to Québec French and, as we saw in Sections V.1 and V.2, they had successfully redeployed the feature [nasal] to create the novel category /ẽ/, another option to consider is (1)’ redeployment within systems from Québec French.
We begin with the BP group, whose performance on Ci–Cĩ serves as a control. This group obtained an average success rate of 86% for this contrast. As this result was surprisingly low, further examination of the data was warranted. Two problematic triads are identified, which one third of BP participants failed to discriminate. Closer inspection of these triads revealed that one stimulus within each was acoustically flawed and, thus, the triads were excluded from the analysis for all language groups. The BP group’s success rate after exclusion of these triads rose to 92%.
The results for the Ci–Cĩ contrast for all language groups are provided in Figure 3. They suggest that the BP group’s performance is considerably higher than that of all other language groups, reflecting the fact that Ci–Cĩ represents a native contrast for this group.
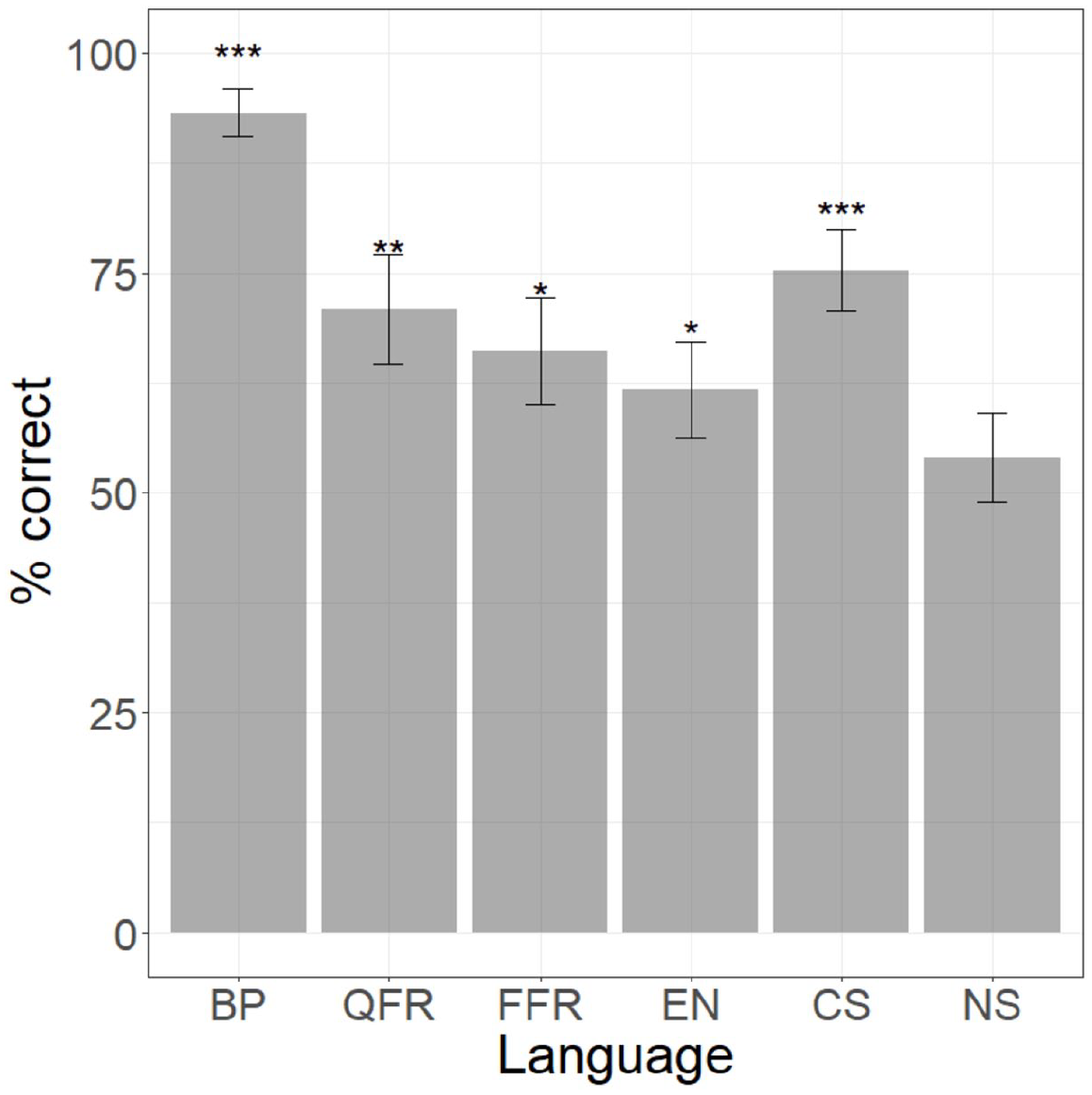
Performance on Ci–Cĩ contrast across language groups.
In order to determine whether the difference between BP and the other language groups is significant, we ran a logistic regression for the Ci–Cĩ contrast, with BP as the baseline. Table 7 shows the estimates (
Model for Ci–Cĩ contrast.
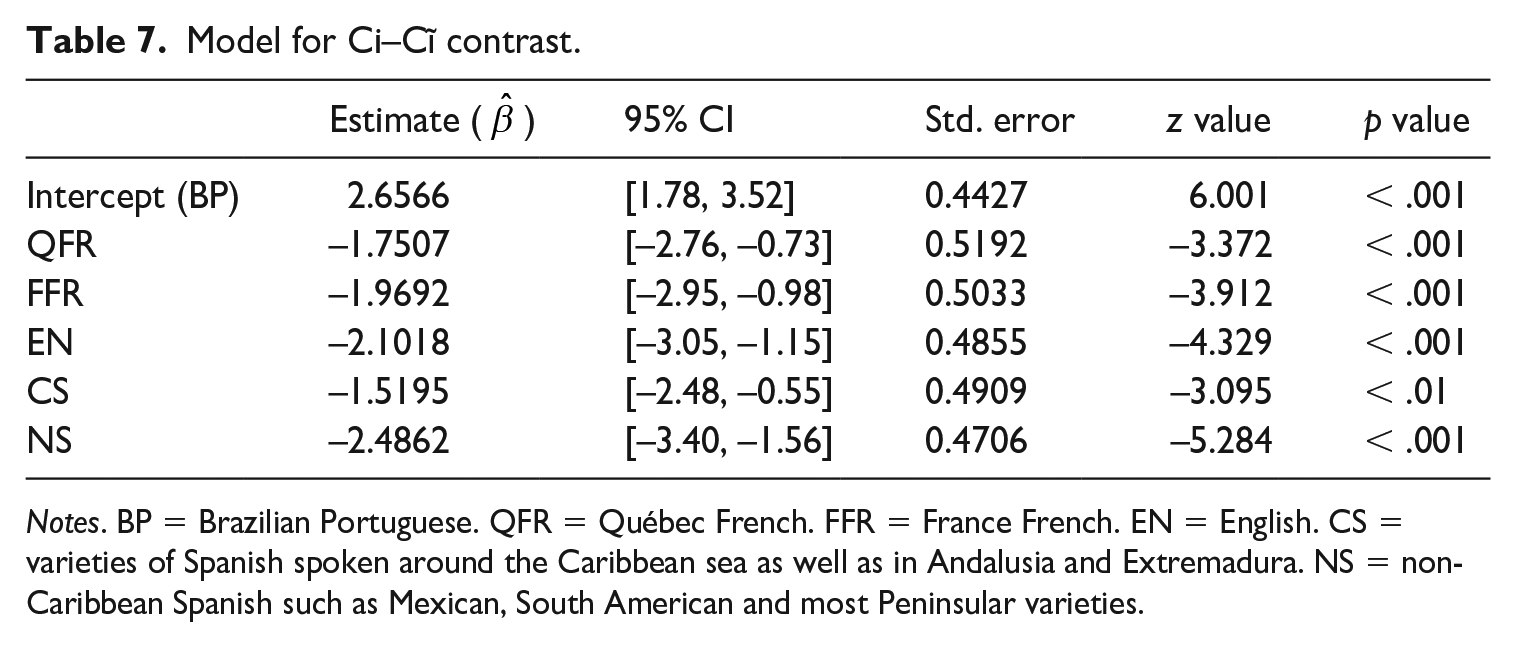
Notes. BP = Brazilian Portuguese. QFR = Québec French. FFR = France French. EN = English. CS = varieties of Spanish spoken around the Caribbean sea as well as in Andalusia and Extremadura. NS = non-Caribbean Spanish such as Mexican, South American and most Peninsular varieties.
We additionally ran a logistic regression model of performance relative to chance for the Ci–Cĩ contrast per language group. The model shows that NS is the only non-native group whose performance is not significantly above chance on this contrast (for the full model, see Appendix 4). The level of statistical significance is represented by asterisks in Figure 3.
A comparison of our findings for the non-naïve vs. naïve contrasts, Ce–Cẽ vs. Ci–Cĩ, indicates that: (i) the performance of all non-native groups (aside from QFR on Ce–Cẽ) was significantly lower than BP on both contrasts; (ii) all non-native groups performed above chance on Ce–Cẽ; and (iii) all non-native groups except for NS performed above chance on Ci–Cĩ. In addition, separate logistic regressions comparing the performance of each language group on the two contrasts, displayed in Table 8, reveal that the performance of all non-native groups, aside from CS, is significantly lower on the naïve contrast, Ci–Cĩ, than on the non-naïve contrast, Ce–Cẽ. We believe that this same pattern does not hold for CS because speakers of this language have experience with both [ĩ] and [ẽ] from their native language. Recall from Section II.2 that nasal codas are variably elided in CS, with concomitant nasalization of the preceding vowel. As a result, Ci–Cĩ and Ce–Cẽ should be equally difficult to perceive for this group. Finally, we point out that, as expected, the difference between the two contrasts for the BP speakers is not significant; for both contrasts, this group is at ceiling (Figures 1–3).
Models for Ci–Cĩ vs. Ce–Cẽ contrasts.
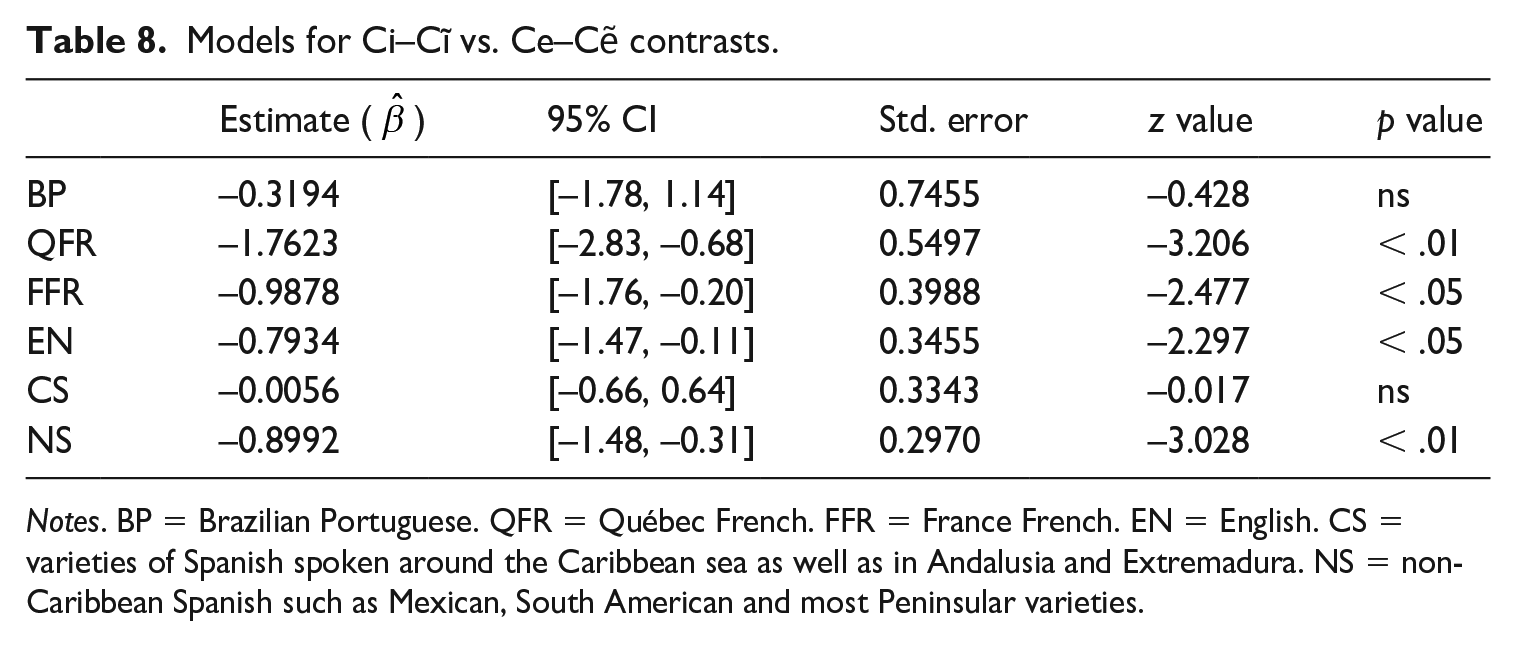
Notes. BP = Brazilian Portuguese. QFR = Québec French. FFR = France French. EN = English. CS = varieties of Spanish spoken around the Caribbean sea as well as in Andalusia and Extremadura. NS = non-Caribbean Spanish such as Mexican, South American and most Peninsular varieties.
The lower performance of all non-native groups on Ci–Cĩ vs. Ce–Cẽ, aside from CS, and the chance level performance of NS on Ci–Cĩ suggest that, although all non-native groups had already redeployed the feature [nasal] to create the novel category /ẽ/ in Québec French (Section V.1), redeployment from this grammar did not occur for any non-native groups on first exposure to Ci–Cĩ in BP. This eliminates option (1)’, redeployment within systems from Québec French, and indicates that only redeployment directly from the L1 grammar – options (1), (2) and (3) – should henceforth be considered as possibilities on first exposure to a new contrast.
Recall that NS was the only group that performed at chance level on Ci–Cĩ, while the other non-native groups performed significantly higher than chance. Although under options (1) and (3), redeployment within systems and across levels, respectively, it was expected that most non-native groups would approach the performance of BP – FR because [nasal] is contrastive in this language, and EN and CS because [nasal] is allophonic in these languages – the group that was expected to exhibit great difficulty with this contrast under both options was NS, which is the result that we find. This suggests that, on first exposure to the oral–nasal contrast in high vowels, the feature [nasal] can be redeployed – although with some difficulty – regardless of whether it is allophonic or contrastive in the vowel system of the L1. Returning to Brown (1998), only the latter is consistent with her proposal. Recall that she hypothesizes that reliable discrimination of non-native segments can only arise through a recombination of features that have contrastive status in the L1. If so, we would expect to see contrastive [nasal] in the FR vowel system providing some advantage for that group in statistical comparisons across non-native groups. Contra Brown, however, the logistic regressions comparing all non-native groups found that the FR listeners did not perform any better than the EN and CS listeners (for the full model, see Appendix 5), suggesting that redeployment under options (1) and (3) do not differ in their degree of difficulty.
This conclusion, however, must be accepted with caution, because we have thus far only provided tentative support for option (3). We must still consider the possibility that for the EN and CS groups, the nasal vowel was not perceived as a single segment Ṽ, but instead, as a VN sequence. We turn to this possibility in the following section.
4 Perceptual illusion: High vowels
We examine the high vowel perceptual illusion contrast, Cĩ–Ciŋ, to determine whether the successful performance on the naïve contrast, Ci–Cĩ, by the EN and CS groups was due to misperception of /ĩ/ as a VN string, /iŋ/. The results for Cĩ–Ciŋ are plotted in Figure 4. A logistic regression model of performance relative to chance for this contrast per language group shows that EN and QFR perform at chance level, while the other language groups perform above chance (for the full model, see Appendix 6). The level of statistical significance is represented by asterisks in Figure 4.
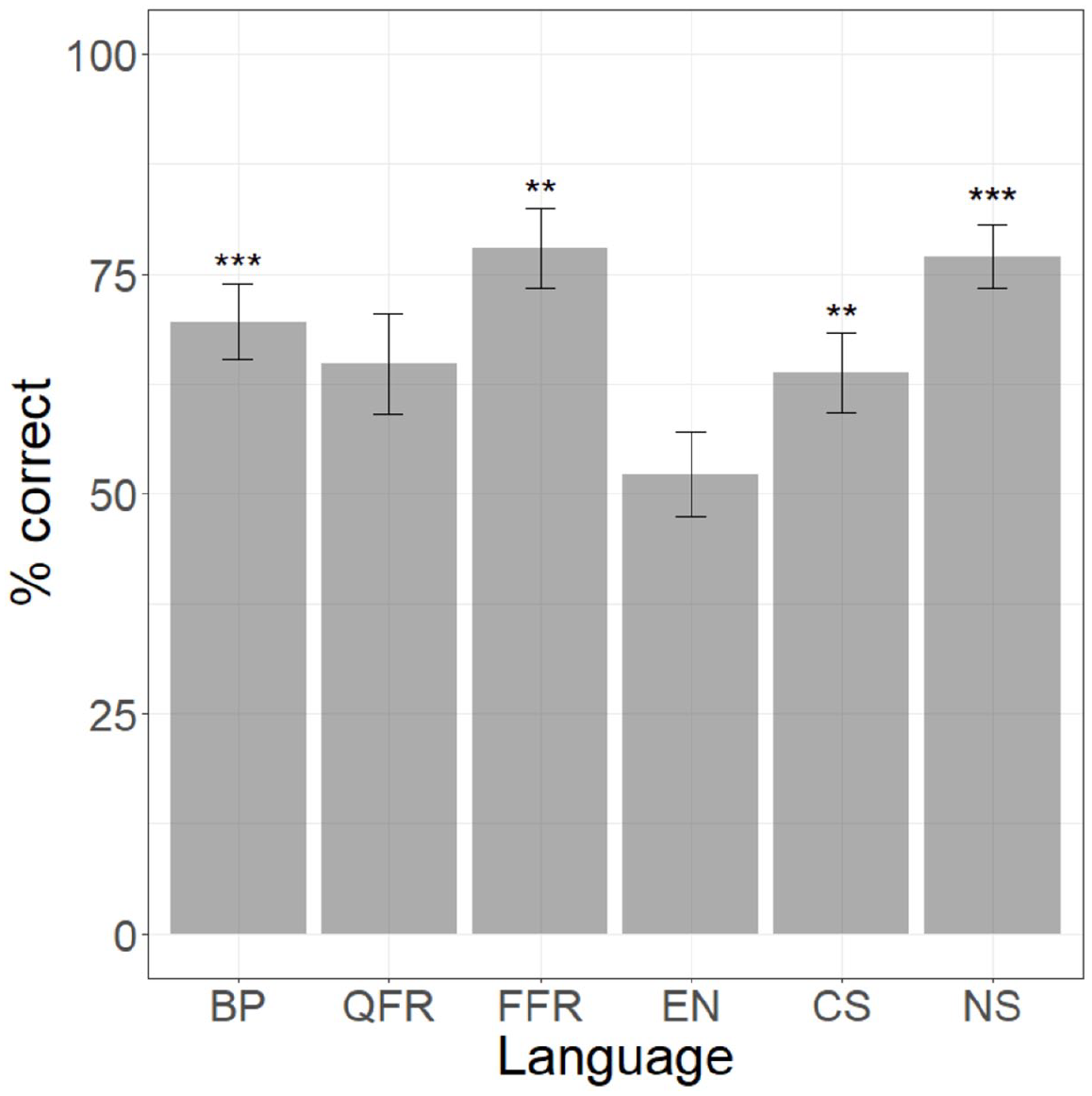
Performance on Cĩ–Ciŋ contrast across language groups.
Several observations emerge from these results. Most relevant to the question at hand, we see that: (i) EN listeners perform only at chance level on Cĩ–Ciŋ, in contrast to how they did on Ci–Cĩ; and (ii) CS listeners perform at a higher-than-chance level on Cĩ–Ciŋ. In addition, we see that: (iii) while FFR listeners perform above chance on Cĩ–Ciŋ, QFR listeners perform at chance level; and (iv) NS listeners’ above-chance performance on Cĩ–Ciŋ appears to well exceed their at-chance performance on Ci–Cĩ. We begin by comparing the results for the FR, CS, and EN groups on Cĩ–Ciŋ, and then turn to the results obtained for NS.
While the CS and FFR listeners are above chance, unexpectedly, the QFR listeners are not. A glance back at Figure 4 shows that the means for CS and QFR are virtually the same (64% and 65%, respectively). A closer look at the data, however, reveals more variation in the QFR group. Indeed, if we remove the random intercept for participants, the model returns a significant result for this language group (p = 0.04).
The results for EN on Cĩ–Ciŋ suggest that, even though listeners from this L1 background were able to discriminate Ci from Cĩ, they do not perceive the nasal high vowel as /ĩ/ but, instead, as /iŋ/. This does not appear to be the case for CS; their performance on Cĩ–Ciŋ is higher than chance. Recall from Section II that although we treated [nasal] in CS as allophonic, on par with English, elision of the coda nasal is variably observed in this variety of Spanish with concomitant nasalization of the preceding vowel, which means that CS speakers have had prior exposure to nasal vowels that are not followed by nasal consonants (i.e. [nasal] is pseudo-contrastive for vowels). This exposure, although variable, seems to facilitate redeployment from allophonic to contrastive status for this group, as opposed to the EN group.
Returning more concretely to Ci–Cĩ, the findings for EN and CS on this contrast had provided tentative support for redeployment across levels (option (3)) for naïve contrasts: elevation of [nasal] from allophonic to contrastive status within the vowel system. The results from Cĩ–Ciŋ force us to revisit this: the accurate perception of /ĩ/ by CS, but not by EN, supports redeployment across levels only when the feature that functions allophonically occurs in pseudo-contrastive contexts in the L1. One question that this finding raises, however, is whether the pseudo-contrastive status of [nasal] in the CS grammar should truly be analysed as allophonic; that is, whether the success of this group indicates that the feature is instead contrastive for vowels. The latter possibility would make option (3) not applicable for listeners from this language background, as we saw was the case for FR (see Table 4). This would effectively mean that no redeployment is necessary, that both [ĩ] and [ẽ] are phonemes in CS. If this were the case, the CS listeners should perform at ceiling on Ce–Cẽ, like the BP and QFR speakers, and at ceiling on Ci–Cĩ, like the BP speakers. A return to the results in Tables 6 and 7 and Appendix 1, however, shows that this is not the case: the CS listeners are significantly lower than both the BP and QFR listeners on Ce–Cẽ and are significantly lower than the BP listeners on Ci–Cĩ. This suggests that [nasal] still functions as allophonic in the vowel system of CS, even though the pseudo-contrastive status of this feature puts listeners from this language background at an advantage relative to the EN speakers.
Turning finally to NS, recall from our discussion of Ci–Cĩ that this language group was the only one that did not perform above chance on this contrast. Yet, NS performed well above chance on the Cĩ–Ciŋ contrast. We interpret these results as follows. As [nasal] is not present in the phonological system for vowels in this language, NS speakers misperceive the nasal vowel of Cĩ as oral, thereby leading to Ci–Cĩ pairs being perceived as identical, as Ci–Ci. At the same time, the absence of [nasal] on vowels leads to Cĩ–Ciŋ pairs being perceived as distinct, as Ci–Ciŋ, that is, as the absence or presence of a nasal consonant, which corresponds to well-formed strings found in the language (e.g. chico [ʧiko] ‘small’ vs. cinco [siŋko]/[θiŋko] ‘five’).
To summarize, the results from the naïve contrast, Ci–Cĩ, coupled with those from Cĩ–Ciŋ, support redeployment of contrastive [nasal] within the vowel system itself (option (1)). This ensures success for FR listeners on both contrasts but success for EN listeners only on the former. The results also support redeployment of allophonic [nasal] to contrastive status (option (3)), but only if [nasal] occurs in pseudo-contrastive contexts in the L1, thereby ensuring success for CS listeners.
VI General discussion and conclusions
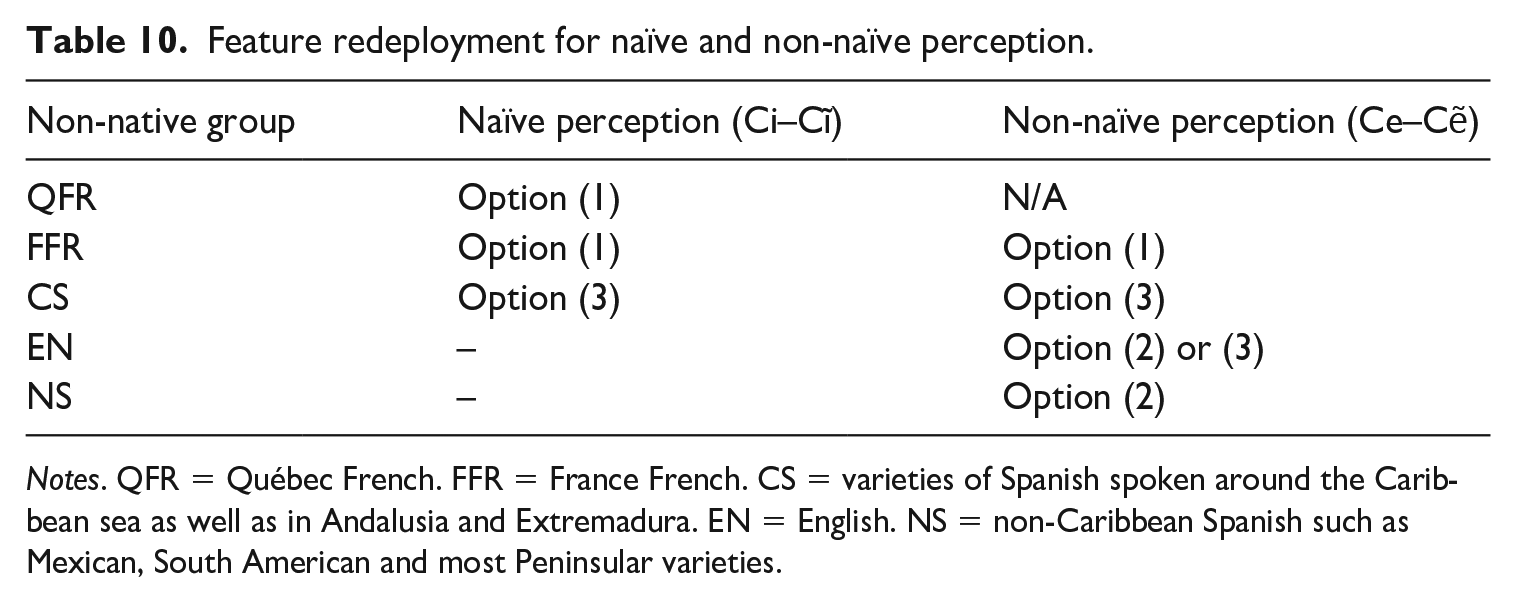
The goal of the present article was to test various redeployment possibilities for the feature [nasal] on first exposure to the non-native contrast /i–ĩ/ by speakers of QFR, FFR, EN, CS, and NS. As described in Section II.2, these languages differ with regard to the status of nasality in each: in QFR and FFR, [nasal] is contrastive in the vowel system; in EN and CS, [nasal] is allophonic in the vowel system (although pseudo-contrastive in CS); and in NS, [nasal] is contrastive in the consonant system only (i.e. it plays no role in the vowel system). These differences in the L1 grammars of naïve listeners allowed us to test whether, to eventually create the novel category /ĩ/, the feature [nasal] could be combined with the feature [high] through redeployment, either within the vowel system itself (option (1)); across systems, from consonants to vowels (option (2)); or across levels, from allophonic to contrastive within the vowel system (option (3)). In addition, given that all listener groups had previously been exposed to Québec French, the non-naïve contrast /e–ẽ/ was examined to determine whether the feature [nasal] had already been redeployed, that is, combined with the feature [mid], to create the non-native category /ẽ/. If so, another possibility for the creation of the category /ĩ/ could be the redeployment of [nasal] within systems from the Québec French grammar rather than from the L1 grammar (option (1)’). The results obtained in the AXB discrimination task are summarized in Table 9, where we see that: (i) FFR, QFR, and CS listeners accurately perceived Ci–Cĩ; (ii) EN listeners perceived Ci–Cĩ as Ci–Ciŋ; (iii) NS listeners perceived Ci–Cĩ as Ci–Ci; and (iv) all groups of listeners accurately perceived Ce–Cẽ.
Perception of Ci–Cĩ and Ce–Cẽ contrasts across language groups.
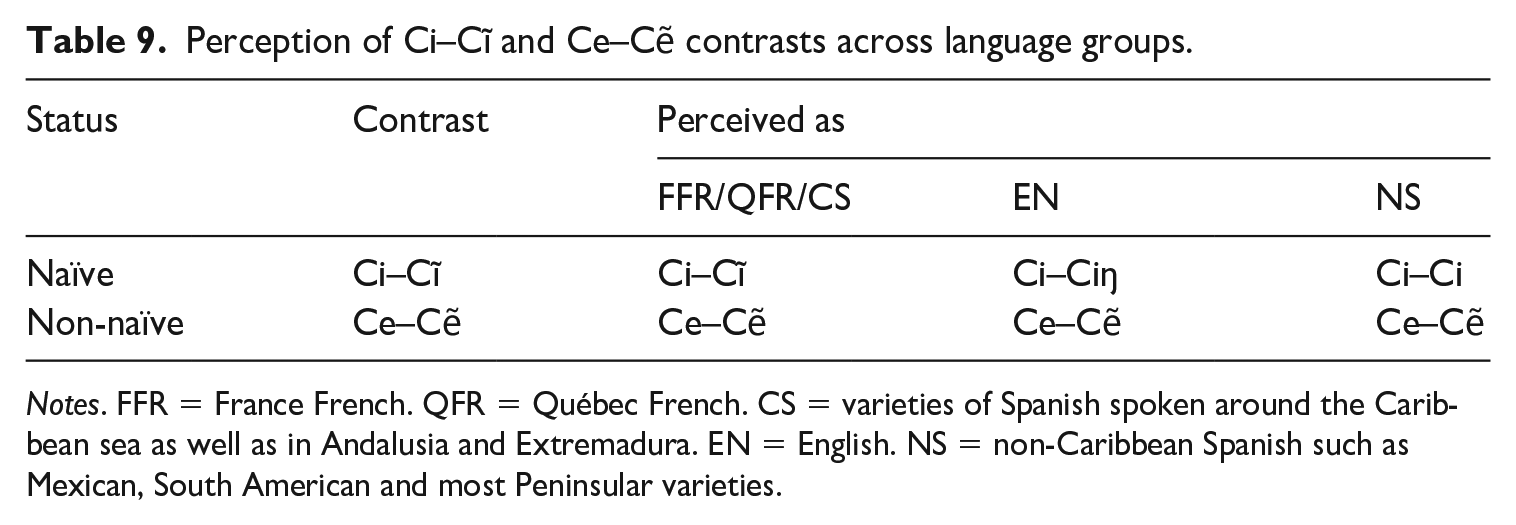
Notes. FFR = France French. QFR = Québec French. CS = varieties of Spanish spoken around the Caribbean sea as well as in Andalusia and Extremadura. EN = English. NS = non-Caribbean Spanish such as Mexican, South American and most Peninsular varieties.
We turn now to address the implications of these results for feature redeployment. Under option (1)’, the feature [nasal], which had already been redeployed from the L1 grammar to create the category /ẽ/ after exposure to Québec French, would be redeployed from the vowel system of Québec French, previously built by the participants, to yield the new category /ĩ/ in BP. If this redeployment option were possible, no robust differences would be observed across language groups on the perception of the naïve contrast, Ci–Cĩ. Although the results showed that all non-native groups succeeded in discriminating the non-naïve contrast, Ce–Cẽ, all groups (aside from CS) performed significantly worse on Ci–Cĩ than on Ce–Cẽ. Further, differences in performance across non-native groups were found for the naïve contrast, Ci–Cĩ, which indicates that the feature [nasal] could not have been redeployed within systems from Québec French on first exposure to the Ci–Cĩ contrast for any of the non-native groups. This rules out option (1)’, and suggests that only redeployment directly from the L1 grammar – options (1), (2) and (3) – should be considered for naïve contrasts.
Under option (1), redeployment within systems, the feature [nasal] operating contrastively in the L1 vowel system would be redeployed within this system itself to yield new nasal vowels in BP. Under this option, it was predicted that the feature [nasal] that is contrastive in the vowel system of FFR and QFR could be redeployed to allow for discrimination of the non-native contrast /i/–/ĩ/. The accurate discrimination of Ci–Cĩ by FR listeners suggests that redeployment within systems is possible at first exposure.
Under option (2), redeployment across systems, the feature [nasal] that is contrastive in the L1 consonant system of all languages under study would be redeployed to the vowel system to allow for discrimination of non-native oral–nasal contrasts in BP. Given that NS is the only language in which [nasal] does not function contrastively or allophonically within the vowel system, it was expected that NS listeners would accurately discriminate the non-native contrast /i/–/ĩ/ only if redeployment across systems was possible. NS listeners perceived the contrast Ci–Cĩ as Ci–Ci, which suggested that redeployment across systems was not possible at first exposure. However, NS did accurately discriminate the non-naïve contrast Ce–Cẽ, which was confirmed by their accurate performance on Cẽ–Ceŋ. As the feature [nasal] cannot come from the L1 vowel system for this group, this suggests that redeployment across systems, from the consonant to the vowel system (option (2)), is possible with greater exposure to the non-native contrast. This interpretation should be confirmed by comparing the performance of NS to that of a group of listeners whose L1 grammar does not possess the feature [nasal] altogether.
Under option (3), redeployment across levels, the feature [nasal] having allophonic status in the L1 vowel system would be redeployed to yield contrastive nasal vowels in the L2. As EN and CS possess allophonic nasality, it was predicted that, if redeployment across levels were possible, these language groups would discriminate the non-native oral–nasal contrast, whereas NS listeners would not. The results indicated that, indeed, NS listeners could not discriminate the non-native contrast at first exposure. However, divergent results were found for EN and CS. EN listeners performed above chance on Ci–Cĩ but not on Cĩ–Ciŋ, indicating that their performance on the naïve contrast, Ci–Cĩ, was biased by perceptual illusion in that they perceived /ĩ/ as /iŋ/. On the contrary, the CS group performed well on the naïve contrast, Ci–Cĩ, as well as on the perceptual illusion contrast, Cĩ–Ciŋ, suggesting that they accurately perceived /ĩ/.
We accounted for the unexpected difference between EN and CS by proposing that the occurrence of allophonic [nasal] in pseudo-contrastive contexts in CS favoured redeployment across levels for naïve contrasts. Recall that in CS, regressive nasalization can result in elision of the coda nasal, leading to the variable production of nasal vowels in open syllables, as reported in Section II. The similar distribution of CS nasal allophones and FR nasal phonemes – both can occur without a following nasal consonant – seems to have favoured redeployment of the allophonic feature to contrastive status in the case of CS, in contrast to EN.
Nonetheless, the performance of CS was significantly lower than that of QFR and BP on the non-naïve /e/–/ẽ/ contrast and than that of BP on the naïve /i/–/ĩ/ contrast, presumably because QFR and BP possess the nasal phoneme /ẽ/ and BP possesses /ĩ/, while CS listeners only have experience with allophonic [ẽ] and [ĩ] in pseudo-contrastive contexts from their L1. This suggests that allophones with pseudo-contrastive status are not analysed by CS speakers as phonemes and thus redeployment of the feature [nasal] across levels is still required. Although the performance of both QFR and CS was significantly lower than that of BP on the naïve contrast, Ci–Cĩ, the two groups did not significantly differ from each other, which suggests that redeployment either from phonemic or from pseudo-contrastive allophonic status to contrastive status in the L2 involves the same degree of difficulty.
In addition, even if a feature does not occur in pseudo-contrastive contexts in the L1, redeployment across levels might be possible with greater exposure to the non-native contrast, as suggested by the successful performance of EN on Ce–Cẽ and Cẽ–Ceŋ. Nonetheless, because NS performed above chance on these contrasts as well, the results do not allow us to conclude whether the feature [nasal] was redeployed across levels or across systems for EN. If NS had not succeeded in discriminating Ce–Cẽ, we would have been able to conclude with certainty that redeployment option (3) took place for the EN listeners. However, given the above-chance performance of NS, it is not possible to tease apart option (2), redeployment across systems, from option (3), redeployment across levels, to account for the performance of EN on the non-naïve contrast.
The various redeployment options observed in our study are summarized in Table 10. As we mentioned in Section III.1, successful perception of the oral–nasal contrast on first exposure to /i/–/ĩ/ does not necessarily mean that naïve listeners have already created a new phonological category for /ĩ/, but rather that they are optimally positioned for the successful creation of this category in real language learning of BP. Our findings indicate that redeployment of the feature [nasal] within systems (option (1)) is possible on first exposure, while redeployment across systems (option (2)) is only possible with greater exposure to the non-native contrast. Furthermore, redeployment across levels (option (3)) is only possible on first exposure if the feature with allophonic status can occur in pseudo-contrastive contexts in the L1. Although this type of redeployment seems to involve the same degree of difficulty as option (1), allophones occurring in pseudo-contrastive contexts are not analysed as phonemes, at least in this case, so the feature must still be redeployed across levels. Finally, future research should investigate whether a feature with allophonic status that does not occur in pseudo-contrastive contexts can be redeployed with greater exposure to the non-native sound, thereby enabling us to arbitrate between options (2) and (3).
Feature redeployment for naïve and non-naïve perception.
Notes. QFR = Québec French. FFR = France French. CS = varieties of Spanish spoken around the Caribbean sea as well as in Andalusia and Extremadura. EN = English. NS = non-Caribbean Spanish such as Mexican, South American and most Peninsular varieties.
We turn finally to address the implications of our results for feature-based models. In the present study, we strived to test the conditions under which phonological features present in the learners’ L1 grammar could be redeployed to build new categories in the L2. The most restrictive position on this question was taken by Brown (1998): she proposes that only features that are contrastive in the L1 may be recombined in the L2, a position which has found support in some studies examining the L2 acquisition of consonantal contrasts. Our goal was to extend examination of feature models to vowel contrasts and further investigate whether contrastive features operating in a different system (i.e. vowel vs. consonant) as well as features operating allophonically could be accessed to eventually create new L2 categories. The results discussed above have various implications for feature-based models.
First, contrastive features operating in the vowel system and those operating in the consonant system seem to behave differently: on first exposure to a non-native contrast, redeployment of contrastive features within the same system seems possible for vowels but not for consonants. Matthews (1997) probed the naïve and non-naïve perception of non-native consonant contrasts by Japanese speakers using an AX discrimination task and found that three contrasts involving non-native segments that could be built from existing (L1) contrastive features were accurately discriminated only 4–6 times out of 12 on first exposure. The success rate increased slightly, to 5–7 out of 12, after five weeks of training. By contrast, we found that FR listeners performed at a higher than chance level even on first exposure to a non-native vowel contrast. Whether this disparity truly reflects a difference between consonant and vowel contrasts or whether it can instead be reduced to methodological differences between the two studies remains unanswered.
Second, our study has enabled an examination of the accessibility for redeployment of contrastive features operating in the other (vowel or consonant) system. Although we observed that this option (i.e. redeployment across systems) only appears to be possible with more exposure to a non-native contrast, we believe that this is an important and understudied area of work on contrast acquisition. Considering that many features in the phonology of a language operate in both the consonant and vowel systems, this may lead to more options for feature redeployment for learners than have typically been considered.
Third, features that function allophonically seem to be accessible for redeployment. Curtin et al.’s (1998) examination of the acquisition of the three-way laryngeal contrast in Thai by English and French speakers had previously suggested that redeployment across levels was possible within the consonant system. The data obtained in the present study indicate that redeployment across levels is facilitated when the allophonic feature operates in pseudo-contrastive contexts in the L1 grammar. In fact, redeployment of the feature [nasal] both from pseudo-contrastive and from contrastive status seemed to present the same degree of difficulty, as shown by the similar performance of the CS and FR groups on first exposure to the non-native contrast. Nonetheless, from the results obtained, it is not possible to determine whether, with greater exposure to the non-native contrast, allophonic [nasal] can be redeployed across levels if it does not occur in pseudo-contrastive contexts in the listeners’ L1.
In conclusion, we have argued that our results support feature-based models, where the phonological status of a feature in the L1 grammar impacts whether listeners can successfully discriminate new contrasts on first exposure. As mentioned in the Introduction, however, a large body of work, which argues for phonetic-based models, is agnostic to the position that features and their formal status are required to explain perceptual outcomes in L2 acquisition. Since, in our view, the phonological status of a feature like [nasal] partly depends on how it is phonetically realized, there is some potential to find common ground between feature-based and phonetic-based models in explaining the findings of the current study. We leave exploration of this question to future work.
Footnotes
Appendix
Models for Cĩ–Ciŋ contrast: Performance relative to chance.
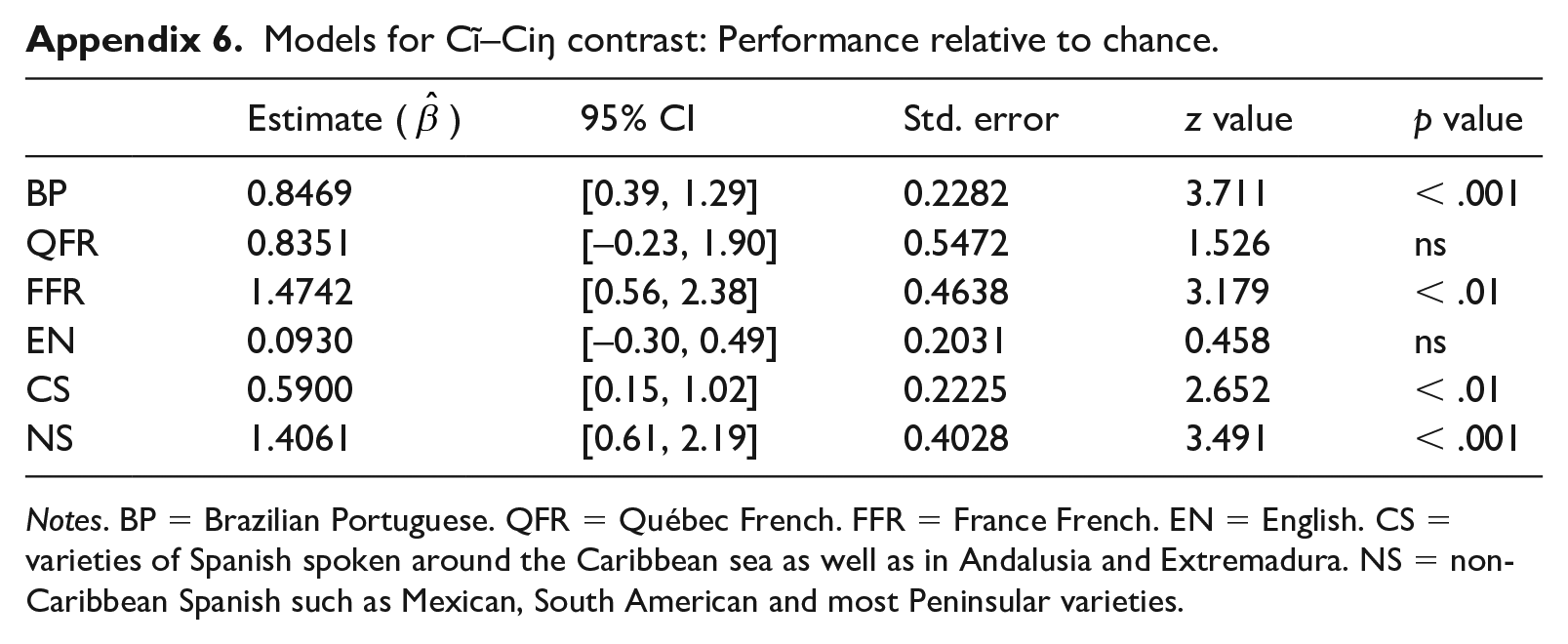
| Estimate ( |
95% CI | Std. error | z value | p value | |
|---|---|---|---|---|---|
| BP | 0.8469 | [0.39, 1.29] | 0.2282 | 3.711 | < 0.001 |
| QFR | 0.8351 | [–0.23, 1.90] | 0.5472 | 1.526 | ns |
| FFR | 1.4742 | [0.56, 2.38] | 0.4638 | 3.179 | < 0.01 |
| EN | 0.0930 | [–0.30, 0.49] | 0.2031 | 0.458 | ns |
| CS | 0.5900 | [0.15, 1.02] | 0.2225 | 2.652 | < 0.01 |
| NS | 1.4061 | [0.61, 2.19] | 0.4028 | 3.491 | < 0.001 |
Notes. BP = Brazilian Portuguese. QFR = Québec French. FFR = France French. EN = English. CS = varieties of Spanish spoken around the Caribbean sea as well as in Andalusia and Extremadura. NS = non-Caribbean Spanish such as Mexican, South American and most Peninsular varieties.
Acknowledgements
We would like to thank Daniel Valois, Mireille Tremblay, Anne Bertrand, Myriam Lapierre, and Alexei Kochetov for their feedback on this research project as well as Victor Boucher and Julien Plante-Hébert for their advice on modifying and normalizing the stimuli. We are grateful to Larissa Buss and Guilherme D Garcia for recording the stimuli, to Miriam Diaz for providing access to the Multilingual Speech Laboratory for testing, to Hugues Lacroix and Kate Shaw for recruiting and testing participants, and to Natália Brambatti Guzzo and Guilherme D Garcia for their extensive help with the statistical analyses. We would also like to thank the reviewers and Associate Editor Esther de Leeuw for their invaluable comments and suggestions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Social Sciences and Humanities Research Council of Canada (BESC-M fellowship and grant 435-2015-0490); the Fonds de recherche du Québec – Société et culture (fellowship 182204 and grant 2016-SE-188196); and the Faculty of Graduate and Postdoctoral Studies at the Université de Montréal.