
Abstract
This article proposes a novel account for the overuse of free morphemes and underuse of bound morphemes in English as a second language (L2) based on the framework of Distributed Morphology. It will be argued that an Economy Principle ‘Do everything in Narrow Syntax (DENS)’ operates in the L2 learner’s computational system. Consequently, derivation in Morphology becomes as limited as possible except when applying Vocabulary Items to syntactic objects (Vocabulary Insertion). This results in non-target-like use/acceptance of certain morphemes: Bound morphemes are often omitted in early L2 grammar, and alternative free morphemes may apparently be used instead. Two types of data, namely the overuse of be reported in previous research, and the preference of to-infinitives over -ing gerunds in early L2 grammar, will be presented in support of the proposal, and the plausibility of the operation of DENS will be discussed.
I Introduction
This article discusses non-target-like use of morphemes in second language (L2) and suggests that it can be accounted for by a Principle of Economy that operates in the derivation/computation in interlanguage grammar. Reviewing a number of morpheme studies, Zobl and Liceras (1994) concluded that L2 learners produce free morphemes earlier and use them with higher accuracy than bound morphemes regardless of their first language (L1). A number of accounts offered for why certain bound morphemes are (extremely) difficult, including the Missing Surface Inflection Hypothesis (MSIH: Haznedar and Schwartz, 1997; Prévost and White, 2000), the Failed Functional Features Hypothesis (FFFH: Hawkins and Chan, 1997), the Bottleneck Hypothesis (Slabakova, 2016), the Interpretability Hypothesis (Hawkins and Casillas, 2008; Tsimpli and Dimitrakopoulou, 2007) among others (for review, see Slabakova, 2016). Although MSIH and FFFH appear to have tended to seek one sole factor when they were originally proposed, multiple factors influence the use of any morpheme in L2, such as the types of features (Wakabayashi 1997, 2013; see also Jiang 2004, 2007; Lim and Christianson, 2014) and syntactic contexts (Hawkins and Casillas, 2008; Wakabayashi, 2013, and studies cited there). On the other hand, the overuse of free morphemes observed in L2 learners’ productions has been neither adequately discussed nor well explained. At the least, neither the MSIH nor FFFH appears to have explained such overuse straightforwardly.
Ionin and Wexler (2002, henceforth I&W) observe that missing English 3rd person singular -s (3p -s) and overuse of be are closely related in the speech of low proficiency L1 Russian learners, and they suggest that the difficulty in lowering of relevant features from T to V is the cause of such non-target-like use, assuming feature-lowering to be a ‘marked’ operation. The current study will extend this discussion adopting the theoretical framework of Distributed Morphology (Halle and Marantz, 1993, henceforth DM). It will be proposed that a Principle of Economy (‘Do everything in Narrow Syntax: DENS’) operates in derivation/computation in interlanguage. Several predictions of this proposal will be discussed and one of them, i.e. the asymmetry between to-infinitives and -ing gerunds, will be evaluated against data.
In the next section, we will illustrate computation in DM. This is necessary because the distinction between Narrow Syntax and Morphology in DM (Halle and Marantz, 1993) is crucial. In Section III we will review I&W. Then, in Section IV, we will present DENS and describe how it explains the findings in I&W. In Section V we present predictions based on DENS, and in Section VI we examine DENS with data concerning to-infinitives and -ing gerunds. In Section VII conclusions will be given.
II Derivation in Distributed Morphology
This study is based on DM, a theoretical approach to languages within the Minimalist Program (Chomsky, 1995). Many studies have shown that the same abstract constraints operate in second language (L2) grammar as in first languages (see, for example, White, 2003) although not everyone agrees on this point. In this article, we assume that the fundamental blueprint of interlanguages is the same as for first languages. The model of linguistic knowledge is depicted in Figure 1. 1
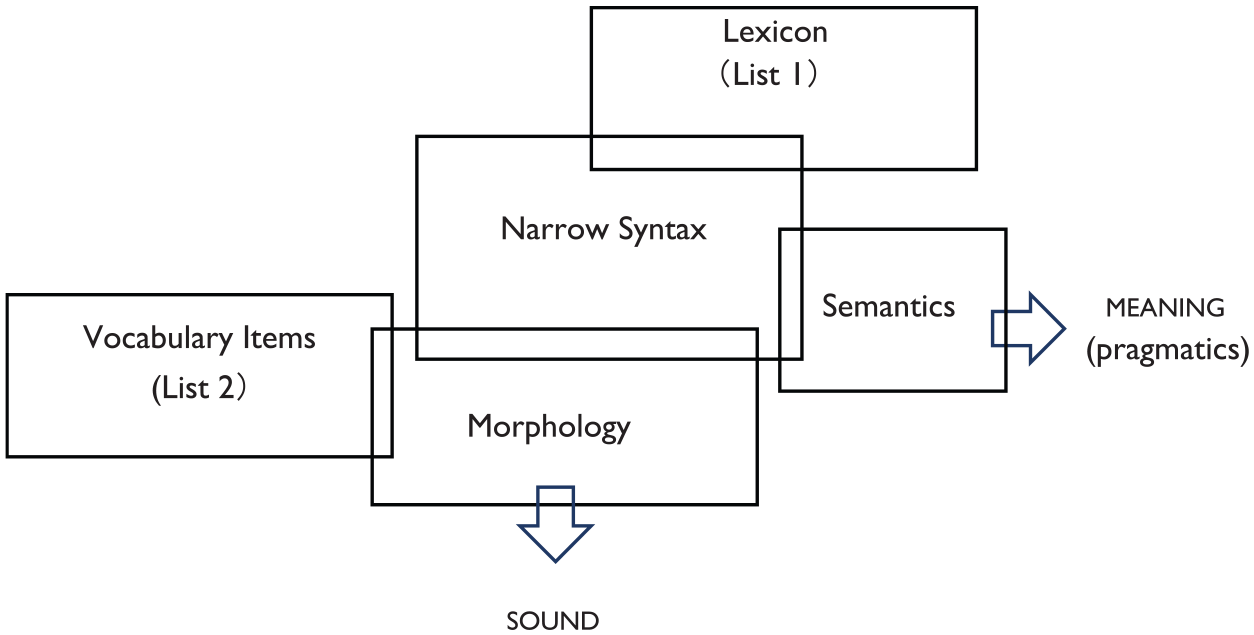
Linguistic knowledge for derivation/computation in Distributed Morphology.
This article is not, in fact, the first attempt to advance the position that DM can account for L2 morphological errors (see e.g. Prévost and White, 2000), but it differs from earlier proposals in: (1) providing a more detailed exposition of how DM might play out in L2; (2) trying to explain more than one phenomenon with a single underlying principle; and (3) looking at phenomena different from earlier studies. This article necessarily includes certain technical mechanics to discuss the proposal; refer to Embick and Noyer (2007) for a fuller description of DM.
In DM, grammar consists of Lexicon (List 1), Narrow Syntax, Morphology, and Vocabulary (List 2). Morphemes, in the traditional sense, are distributed across (at least) two modules, i.e. Lexicon (List 1), where formal features and categories (Lexical Items, LIs) are listed, and Vocabulary (List 2), where phonological properties of syntactic objects (Vocabulary Items) are listed.
Let us illustrate the computation/derivation with an example.
(1) Mike plays the violin.
At the beginning of the derivation, the relevant LIs 2 are taken from Lexicon and listed, and relevant features are assembled and associated with categories when necessary, e.g. T has [‒past] [uPers(on)] [uNum(ber)] [EPP], 3 as in (2). (Only a portion of the features and LIs are presented in the illustration.)
(2) {
This list is taken into Narrow Syntax, where LIs merge to create a larger syntactic object. At a point in the derivation, vP is structured while some items are still in the list, as in (3).
(3) {C, T[-past][uPers][uNum][EPP]}
[vP
When CP is structured, all and only necessary operations have already taken place, such as raising of the subject from Spec vP to Spec TP, and the list is exhausted, as illustrated in (4) (the solid arrow shows movement / internal Merge):
(4) The list of LIs: { }
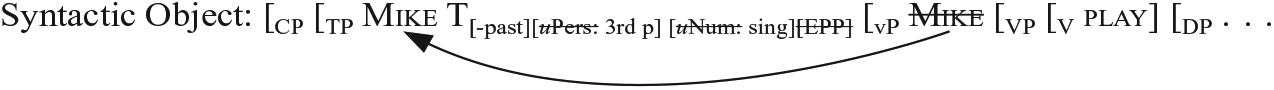
The syntactic object in (4) is taken into Morphology, where further operations take place. With this example, the feature bundle [‒past] [3rd p(erson)] [+sing(ular)] 4 is lowered from T to V as in (5) (the broken arrow shows feature-lowering):

All LIs, including features, are placed in positions where they are reflected by exponents (sounds) as Vocabulary Insertion takes place based on Vocabulary Items (List 2), which creates a pairing of a syntactic object and its exponent. In this example the Vocabulary Items in (6) are relevant:
(6) Mike ↔
play ↔
-s ↔ [-past] [3rd p] [+sing]
the ↔ D [+def]
violin ↔
These Vocabulary Items are applied to nodes in (5), resulting in (7).
(7) Mike plays the violin. (=1)
As shown here, the inflectional morphology (3p -s in this case) is processed in four stages:
(8) a. Feature assembly (e.g. assembling [-past][uPers][u Num] to T)
b. Operations in Narrow Syntax (e.g. valuing [uPers] and [uNum] with [3rd p] and [+sing])
c. Feature lowering in Morphology
d. Vocabulary Insertion in Morphology
In the next section, we will consider the acquisition of 3p -s and be.
III L2 acquisition and use of 3p -s and be: Ionin and Wexler (2002)
Although many studies have investigated L2 use of 3p -s, only a limited number have examined it in contrast with be. I&W is one such study. I&W discuss two types of data, one of which is spontaneous production data collected from twenty L1 Russian-speaking children. They included both omission errors and overuse errors, but the latter were limited. The numbers are given in Table 1. I&W regarded these kinds of non-target-like sentences as agreement errors. Examples are as follows.
(9) a. I likes costumes for Halloween for Batman (KI, sample 2, 6;10)
b. this three ducks is going (GU, 3;9)
c. this two kittens is big (MA, sample 2, 7;5) (I&W, 2002: (3))
Omission errors and inappropriate use errors in Ionin and Wexler (2002).
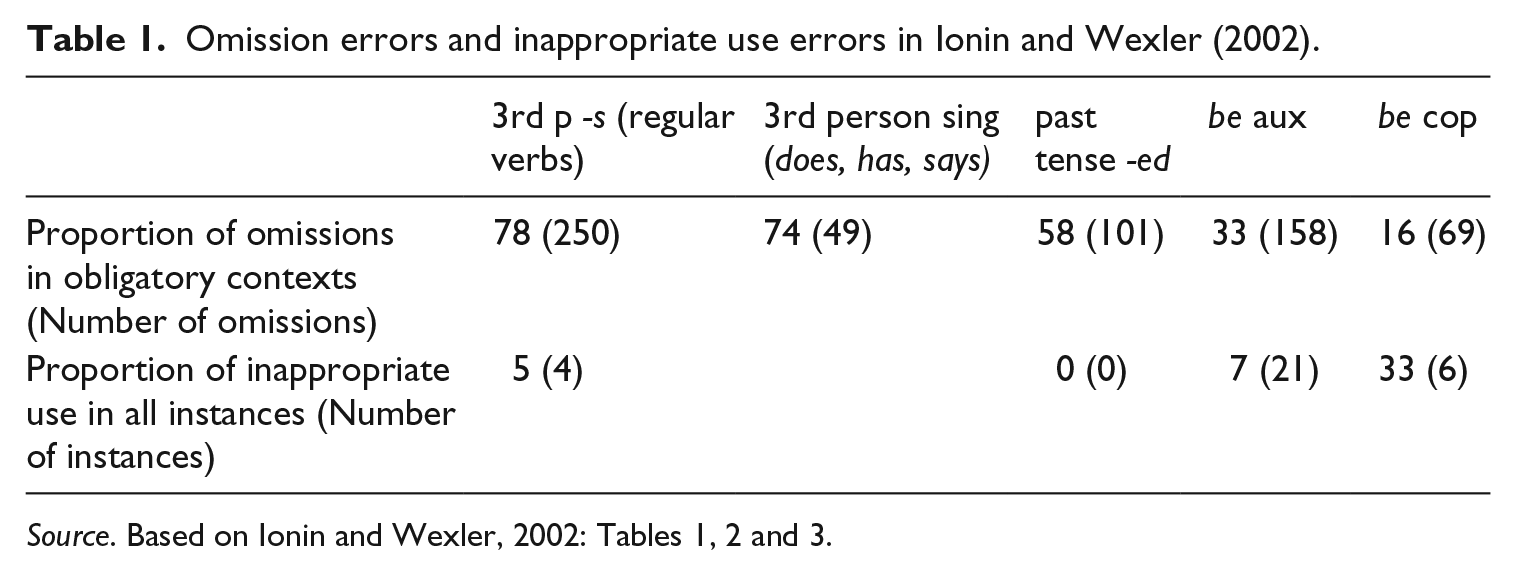
Source. Based on Ionin and Wexler, 2002: Tables 1, 2 and 3.
On the other hand, the overuse of forms of be (without agreement errors) was more pervasive as shown in Table 1. I&W grouped overuse errors as in Table 2. Examples are in (10), where I&W’s interpretation of tense/aspect are in square brackets:
(10) a. the cats are pull mouse’s tail (AN, 10; 1) [progress]
b. they are help people when people in trouble (DA, sample 1, 9;7) [generic]
c. he is want go up then (GU, 3;9) [stative]
d. he is run away and I stayed there (GU, 3;9) [past tense / irregular]
e. in one episode he is said to Bart, I’ll kill you (RO, 13;10) [past tense / regular]
f. I’m buy for my mother something (AY, sample 2, 10;4) [future]
(cited from I&W, 2002: (5))
Overgeneralization of be.
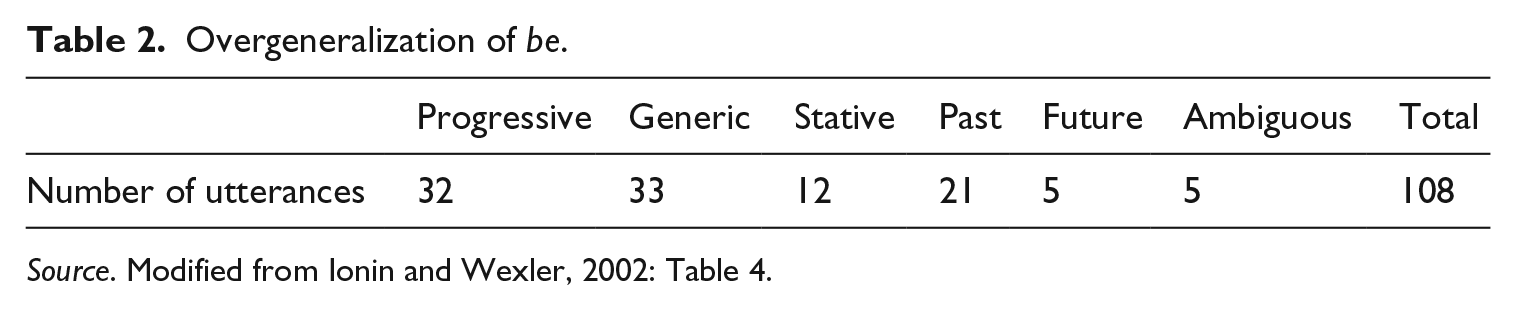
Source. Modified from Ionin and Wexler, 2002: Table 4.
Based on Table 2 and the examples in (10), I&W (2002: 111–12) observed that most errors were overuse of be although a few could be described as underuse of -ing, and hence many errors cannot be explained as a ‘missing’ inflection. 5 They also found that when be was overused, the main verb was not inflected; the learners correctly use do-support with negation (91%); and the negator and frequency adverbs are placed before the main verb but after be. These data led I&W to conclude that a fully specified functional category is present in the learner grammar, adopting Guasti and Rizzi’s (2001) analysis of child L1 data. With regard to the question of why L2 learners’ productions are not exactly like a native speaker’s, I&W suggest that morphological expression of features as inflection is a language specific property, being either outside the core system of UG (Guasti and Rizzi, 2001) or the setting of a parameter (Schütze, 2001, cited in I&W), that L2 learners take time to acquire. Citing White (1992: 280, based on Chomsky, 1989), I&W propose that tense and agreement features are reflected on be as a result of raising an auxiliary out of VP, which is more economical than 3p -s through affix-lowering. 6 This is plausible, but the current theoretical framework demands that Economy be defined, which we will do below.
IV Discussion: 3p -s, copula be , and overuse of is/am/are
Stauble (1984) points out the importance of looking at incorrect uses of morphemes beyond omissions to understand learner grammar (and see Hawkins, 2001: Chapter 2). This advisory is applicable to the data in I&W. I&W found that the suppliance of 3p -s on lexical verbs was more difficult than inflected be, and that overgeneralized be was produced. Hawkins and Casillas (2008) found the same in oral production data by Chinese and Spanish learners of English, although they did not discuss the overuse of be there. Moreover, García Mayo et al. (2005) reported the overuse of be in oral narratives by Basque/Spanish bilingual children learning English in the classroom. Yang and Huang (2004, cited in Hawkins and Casillas, 2008) found that be + bare V was used in the written narratives of Cantonese classroom learners of English in Hong Kong. In short, early L2 learners of English tend to omit 3p -s and overuse be, regardless of their age or L1.
As posited in the last section, a Principle of Economy may be the key to explain this tendency. If we assume that an explanation based on economy is correct, then the next question is how to understand verb raising as more economical than feature-lowering (and presumably overuse of be as more economical than feature lowering). This requires a comparison of the derivations that include 3p -s and of those that include is. We have already described the derivation of 3p -s above. Here let us consider the derivation of the sentence in (11).
(11) Mike is a boy.
At the beginning, relevant LIs consist of a list, where relevant features are assembled, e.g. T has [‒past] [uNum] [uPers] [EPP], as in (12).
(12) {
This list is taken into Narrow Syntax, and its derivation proceeds. At some point in derivation, VP is structured.
(13) {C, T[-past][uPers][uNum][EPP]}
[VP
T merges with VP, and then the subject
(14) { }
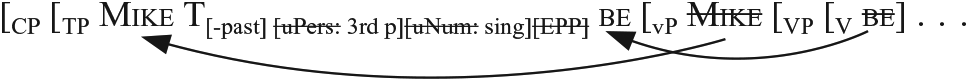
The resulting Syntactic Object is taken into Morphology. Without further operation, all LIs, including features, are set in a linear order, and Vocabulary Insertion takes place, based on Vocabulary Items in (15):
(15) Mike ↔
is ↔
a ↔ D [-def][+sing]
boy ↔
The resulting string is as follows.
(16) Mike is a boy. (=11)
Hence, this sentence is computed through three stages as in (17).
(17) a. Feature assembly (e.g. assembling [-past] [uPers][uNum] into T)
b. Operation in Narrow Syntax (e.g. valuing [uPers] and [uNum] of T at [3rd p] and [+sing], movement of
c. Vocabulary Insertion in Morphology
Comparing (17) with (8) shows a difference in the number of stages. In addition, the two derivations differ in three points. First, in Narrow Syntax, the lexical verb play does not move while the light verb (copula) be does, as in (18):
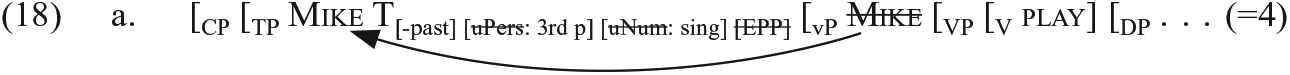

Second, feature lowering takes place in the derivation of Mike plays the violin as follows but not in that of Mike is a boy:
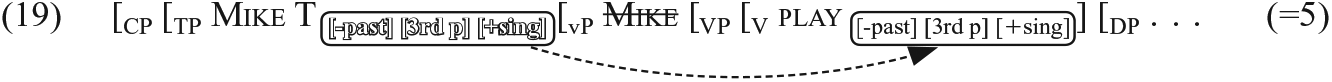
The third difference is in Vocabulary Insertion: plays consists of two Vocabulary Items while is consists of one item.
(20) a. play ↔
-s ↔ [-past] [3rd p] [+sing] (= part of (6))
b. is ↔
One may wonder why
Based on these contrasts between be and lexical verbs, let us consider why L2 learners produce non-target-like forms more often with 3p -s than with copula be. The numbers of movements in Narrow Syntax are different. As shown in (18), both derivations include raising of the subject from VP/vP Spec to TP Spec, while raising of the verb occurs only with
This account is compatible with those in the previous section. If this is the explanation, why does this difficulty appear in early L2 grammar? I suggest that there is a Principle of Economy at play in L2 grammar derivations:
(21) A Principle of Economy: DENS: Do Everything in Narrow Syntax (if possible).
Since DENS is new and central to the analysis in this article, in the next section 9 we will discuss:
(i) where it comes from;
(ii) why it is not operative in L1s;
(iii) how DENS works with real data; and
(iv) how it should be generalized and what prediction this account makes.
V DENS: Reasons and predictions
DENS come from the consideration of economy in the derivation of sentences in DM. The operations in Narrow Syntax are more straightforward than Morphology: The former has only one ‘input’, an array of LIs from Lexicon, and produces two pieces of output i.e. transfer to Morphology and that to semantics (see Figure 1) WITHOUT reference to requirements at the interfaces. The required inclusion of LIs in the array is determined by requirements of the
DENS is also based on the proposition that the involvement of more than one submodule for a morphosyntactic operation may cause difficulty. That is, operations in one submodule (i.e. Narrow Syntax) are more economical than sequential operations in two modules (i.e. Narrow Syntax and Morphology). 11 Narrow Syntax is the module where linguistic information for meaning and sound meet, and hence derivation at this module is inevitable. However, operations (e.g. feature lowering) in another module (i.e. in Morphology) could be avoided if an alternative (e.g. verb raising) is available in Narrow Syntax. In an informal way, we may envision linguistic knowledge as endeavoring to do all parts of its work in one workspace, rather than doing one type of work in one space and another type of work in another. Operations in two submodules involve mapping (transfer) of an object at the interface, as interfaces may generally cause problems in L2 acquisition (see Sorace, 2011).
The next question is why DENS is L2 specific: Native speakers and/or child L1 learners would not adopt it (i.e. Question (ii) above). I argue that the ‘size of workspace’ of Narrow Syntax is larger in L2 grammar than in child L1 grammar, and hence computing non-native-like syntactic objects in Narrow Syntax (e.g. the structure underlying overuse of be) is carried out there. On the other hand, the working space is not ‘large’ enough in child L1 grammar. Metaphorically speaking again, the size of the workspace in Narrow Syntax is small, derivation has to be kept minimal, 12 and hence operations in Morphology are required. As the capacity of sub-modules, including Narrow Syntax and Morphology, become large enough, the grammar computes morphosyntactic objects as in the adult L1 grammar. This is reflected in the observation that children come to use bound morphemes consistently at the same time as (or earlier than) free morphemes (Vainikka and Young-Scholten, 1996; Zobl and Liceras, 1994). Again, informally, we may envision linguistic knowledge as trying to do all parts of its work in a single workspace, but the space is limited, so one type of work has to be done in one space and another type of work in another. The space enlarges with maturation and/or with repeated computation, but there is no pressure to move the type of work performed in one space to another space, which results in all submodules becoming fixed in the manner observed in adult L1 grammar.
Now let us consider how DENS works with real data (Question (iii) above): Let us first examine how the overuse of be with a lexical verb can be attributed to DENS. Consider the derivation of sentence (22) from I&W’s data.
(22) the cats are pull mouse’s tail (AN, 10; 1) (= (10a), cited from I&W, 2002: (5))
At some point in derivation, (23) is structured.
(23) {C, T[-past][uPers][uNum][EPP]}
[vP
T merges with vP, the subject DP raises to Spec, TP, and then C merges with TP. The LIs in the list are exhausted and the full sentence is structured.

The syntactic object is taken to Morphology, [+plural] is lowered and attached to N. 13 However, unlike in the adult L1 grammar, the feature lowering of [-past][+plural] from T to V is difficult, so it remains at the head of T.

Vocabulary Insertion takes place, based on the Vocabulary Items in (26):
(26) the ↔
cat ↔
-s ↔ [+plural]
are ↔ [-past][+plural]
pull ↔
. . .
We assume that the fourth line in (26) is a Vocabulary Item in the learner’s grammar, although the target grammar has the following item instead.
(27) are ↔
As shown in (26), are is the exponent of the feature complex [-past][+plural] alone, while it is the exponent of
This is compatible with the Subset Principle in DM (Halle, 1997). 17
Subset Principle: The phonological exponent of a Vocabulary Item is inserted into a position if the item matches all or a subset of the features specified in that position. Insertion does not take place if the Vocabulary Item contains features not present in the morpheme. Where several Vocabulary Items meet the conditions for insertion, the item matching the greatest number of features specified in the terminal morpheme must be chosen.
Table 2 shows the overgeneralized be used with a number of tenses/aspects. This supports our proposal that the feature bundle paired with a form of be in Vocabulary Insertion in the L2 learner grammar may lack certain features obligatorily associated in the target grammar.
This reasoning gives us a clue to answer a learnability problem: How do learners cease overusing be? Our answer should be through acquisition of the semantic/functional features associated with
Now we have reached the following conclusion: be is overgeneralized because of DENS and the Subset Principle. L2 learners (may) overcome their overuse of be once they have acquired its semantic and distributional properties.
The next question is how DENS should be generalized and what prediction this account makes (Question (iv) above). Let us first generalize the explanation for the differences in omission errors in the use of 3p -s; overuse of be; and the lack of co-occurrence of these two morphemes. The structure for these two morphemes at the end of Narrow Syntax can be schematized as in (28) 18 :
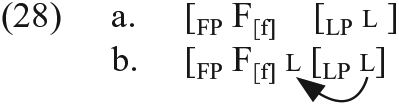
FP and LP are headed by F and L, and a feature (bundle) [f] is [+bound]. When L is heavy, it is not raised, as in (28a), while it is raised if it is light, as in (28b). In order to satisfy the [+bound] of [f] in (28a), [f] must be lowered in Morphology:
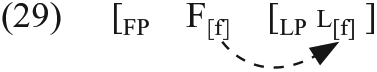
If [f] is lowered, then the target-like use of a bound morpheme appears, as long as other operations (i.e. Vocabulary Insertion) take place correctly. But this operation (feature lowering) is difficult. If [f] fails to be lowered, L will be spelled out as a default form following the Subset Principle (i.e. an omission error occurs). The exponent of F[f] would be realized as a free morpheme (as a form of be). 19
DENS predicts that operations outside Narrow Syntax are problematic, and hence the operation depicted in (29) is difficult because it takes place in Morphology. 20 It is impossible to provide an exhaustive list of phenomena that could be explored experimentally to test this prediction, but there are at least five phenomena to be mentioned here.
One type concerns the use of different morphemes that share a similar or identical grammatical function. One example is to infinitives and -ing gerunds. In both cases, a functional category is involved, for example, to make a verb phrase the argument of a verb: F[infinitive] is spelled out as to at the head of such functional category (28a), but F[gerund] needs to be lowered and merge with a verb within its c-commanding domain (29). We will discuss this further in the next section. Another example is the number marking in a noun phrase. In English, [plural] is expressed at Q (e.g. many), D (e.g. these), Num (e.g. two) and as plural -s (e.g. book-s). DENS predicts that those items spelled out at Q, D or Num are easier than plural marker -s. In the same way, some languages have definiteness marking on both D and N; DENS predicts that marking on D is less problematic than on N, all other factors being the same. Another example concerns comparative forms in English: Adjectives and adverbs take either more (e.g. more beautiful) or -er (e.g. easier). A functional category with a [comparative] feature c-commands its complement AP, and only when comparative -er is used, is feature lowering required; more is arguably the exponent of [comparative] at its head. Hence, it is predicted that L2 learners may omit -er and use bare adjective forms (e.g. *This is easy than that) – similar to the omission of 3p -s – and overuse of more (e.g. *This is more easy than that): similar to the overuse of be.
The second prediction concerns the lack of overuse among bound morphemes. With regard to comparative forms, DENS predicts that L2 learners will not produce errors such as *My explanation is preciser than yours, where -(e)r is attached to an adjective that should be used with more. No such errors should be observed because the non-target-form violates DENS. A similar prediction can be made for the overuse of 3p -s: 3p -s should not be overgeneralized, and hence sentences, such as, *The boy clever-s (compare The boy is clever), are not expected (Wakabayashi, 2019). 21
The third prediction concerns prepositions. English prepositions might be included as LIs or inserted in Morphology to mark Case on its complement. For example, the sentences in (30a, 30b) have structures (30c, 30d) in Narrow Syntax, respectively (only relevant LIs are included).
(30) a. The drawing of the flowers
b. The drawing with the flowers
c. [DP draw [DP flower]]
d. [DP draw [PP with [DP flower]]]
The derivation for (30b) does not violate DENS because with is merged in Narrow Syntax: PP with the flowers is an adjunct and with is interpreted in semantics. On the other hand, that for (30a) violates DENS because of is inserted in Morphology: DP the flower is the complement of drawing and has no role in semantics: ‘of-insertion’ takes places in Morphology (Harley, 2009), which violates DENS. Then, if DENS is correct, the derivation of the latter will be more problematic for L2 learners. Yusa et al. (2014) carried out two experiments with a sentence-integration task, where 116 Japanese undergraduate/graduate students produced sentences when given noun phrases such as (30a, 30b) as sentential subjects. Yusa et al. do not report whether the participants dropped of but they report that participants dropped 3p -s significantly more often when they produced (30a) type than (30b) type sentences. Yusa et al. suggest that this reflects the greater syntactic distance between the subject and the verb in a sentence containing (30a) than in one with (30b). Instead, I contend that a sentence containing (30a) requires the violation of DENS; and that its derivation is less economical than a sentence with (30b). The violation of DENS affected subject-verb agreement (i.e. drawing in (30a, 30b) and a verb) and consequently they produced errors in producing sentences including of in the subject noun phrases.
Fourthly, let us consider an account in which DENS does not operate in L2 grammar but, for some unknown reason, free morphemes are preferred to bound morphemes. That is, ‘(an item equivalent to) be + V’ is preferred to ‘V+inflection’ with no relation to feature lowering in Morphology. For example, it is generally assumed that ser and estar in Spanish are equivalent to be (and have), and hence ‘ser/estar + V’ might be used by L2 learners instead of ‘V+inflection’ if this were the case. In other words, the overuse of ser/estar might be expected among L2 learners of Spanish, a language where lexical verbs raise in Narrow Syntax. 22 A quick survey of studies on the acquisition of copulas in Spanish (e.g. Geeslin and Guijarro-Fuentes, 2005) shows that none reports the overuse of ser/estar to mark tense and agreement where adult grammar marks them with lexical verbs, although substitution errors are pervasive in the two copular forms (ser is overgeneralized and estar emerges later).
Lastly, I suggest that the same account is possible with the computation of ‘meaning’, for which Narrow Syntax and Semantics in Figure 1 are the relevant submodules. DENS predicts that computation in Semantics is more problematic than that in Narrow Syntax for essentially the same two reasons seen in our comparison of computation in Morphology vs. Narrow Syntax: (i) computation in Semantics must refer to requirements at the Interface to ‘pragmatics’; and (ii) computing in two submodules (i.e. Narrow Syntax and Semantics) is more difficult than computation in one submodule (i.e. Narrow Syntax). One relevant phenomenon is the interpretation of Quantifier Raising (May, 1985), 23 which takes place in Semantics (Heim and Kratzer, 1998). For example, (31a) is ambiguous.
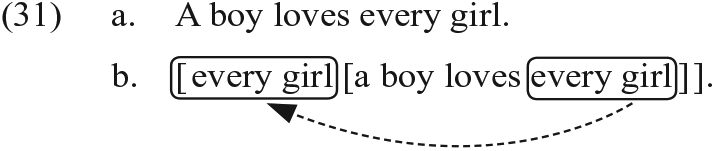
In (31a), one interpretation is that there is a boy, say, Tom, who loves every girl in the world of discourse, say, Jane, Sue, and Mary. This sentence is true when Tom loves Jane, Sue and Mary. The other interpretation is that for every girl, say, Jane, Sue, and Mary, a different boy loves each girl. In this case, the sentence is true when David loves Jane; Luke loves Sue; and George loves Mary. This distributive interpretation requires every girl to have scope over a boy; that is, every girl moves higher than a boy as in (31b). This movement, Quantifier Raising, has no effect on ‘sounds’ and is assumed to take place in Semantics (Heim and Kratzer, 1998). DENS predicts that L2 learners will have problems with Quantifier Raising, and this prediction is supported by empirical data (see Kimura, to appear). DENS predicts that operations in Semantics in Figure 1, like Quantifier Raising described above, are more problematic than those in Narrow Syntax.
Clearly, the five predictions of DENS presented in this section need to be examined empirically. We will examine one of them in the next section: how L2 learners use to-infinitive and -ing gerunds.
VI DENS in the use of to-infinitives and -ing gerunds
Verb complement selection is an area where early L2 learners have problems when there is more than one possible candidate. This is the case with regard to the choice between a to-infinitive and an -ing gerund, and we will discuss why L2 learners’ grammars prefer one form to the other. We describe the morphosyntax of these two forms, make predictions based on DENS, and examine the predictions against data from Shirahata (1991), Fujimoto (2008), and Haniu (2015). To foreshadow the conclusion here, a DENS account is supported by the data in all three studies.
Some verbs select a to-infinitive but not an -ing gerund; some select an -ing gerund but not a to-infinitive; and some allow both forms without much difference in meaning. This is illustrated with the examples in (32).
(32) a. Susan liked to play tennis.
b. Susan liked playing tennis.
c. Lucy wanted to play basketball.
d. *Lucy wanted playing basketball.
e. Gabby enjoyed playing hockey.
f. *Gabby enjoyed to play hockey.
The semantic and functional differences between to-infinitives and -ing gerunds have been discussed in descriptive linguistics (see, for example, Huddleston and Pullum, 2002). However, early L2 learners do not use either in a target-like way (see below). We will first consider their derivations, taking (32a, 32b) as examples.
Let us start with the to-infinitive in (32a). In Lexicon, a functional category F[infinitival],
24
the head of a to-infinitive phrase, and
(33) {C[root], T[+past], v,
[FP F[infinitival] [
Later, the syntactic object is taken into Morphology, where Vocabulary Items in (34) (among others) are applied.
(34) like ↔
to ↔ F[infinitival]
play ↔
. . .
Next, the exponents of these structures are set in a linear order, and the string Susan liked to play tennis is spelled out. The derivation of (32b) proceeds in a similar way. First, in Lexicon, a functional category F[gerundive],
25
the head of the -ing gerundival phrase, and
(35) {C[root], T[+past], v,
[FP F[gerundive] [
Later, the syntactic object is taken into Morphology. Here, unlike the derivation with to-infinitives, [gerundive] has to be lowered, as in (32).

Then, the Vocabulary Items in (37), among others, are applied.
(37) like ↔
play ↔
-ing ↔ F[gerundive]
. . .
The exponents are set linearly, and the string Susan liked playing tennis is spelled out.
The difference between the derivations for (32a) and (32b) lies in whether feature lowering takes place. There is no principled reason to expect a difference in difficulty among the Vocabulary Items in (34) and (37). With DENS, we expect (32a) to be preferred to (32b). More generally,
(38) L2 learners would: a. prefer to-infinitives to -ing gerunds when both are allowed;
b. underuse -ing gerunds; and
c. overuse to-infinitives.
(38c) is on a par with the overgeneralization of be examined in the previous section: In an early L2 grammar a non-target-like form may be used in order not to violate DENS. Let us examine these predictions with experimental data from Shirahata (1991), Fujimoto (2008) and Haniu (2015).
1 Shirahata (1991)
Shirahata (1991) collected data from 110 first-year university students in Japan (13 low, 67 intermediate, 30 advanced) using a sentence manipulation task with three types of verbs: verbs that take either a gerund or an infinitive as their complement: start, begin, like, love, continue (Type 1); verbs that take an infinitive but not a gerund as their complement: want, need, learn, allow, promise, hope (Type 2); and verbs that take a gerund but not an infinitive: enjoy, practice, postpone, finish, miss, mind (Type 3). Participants were asked to make a sentence by changing the form of the underlined part of each stimulus sentence, as in (39). The expected answer here was needs to study.
(39) Taro thinks he really
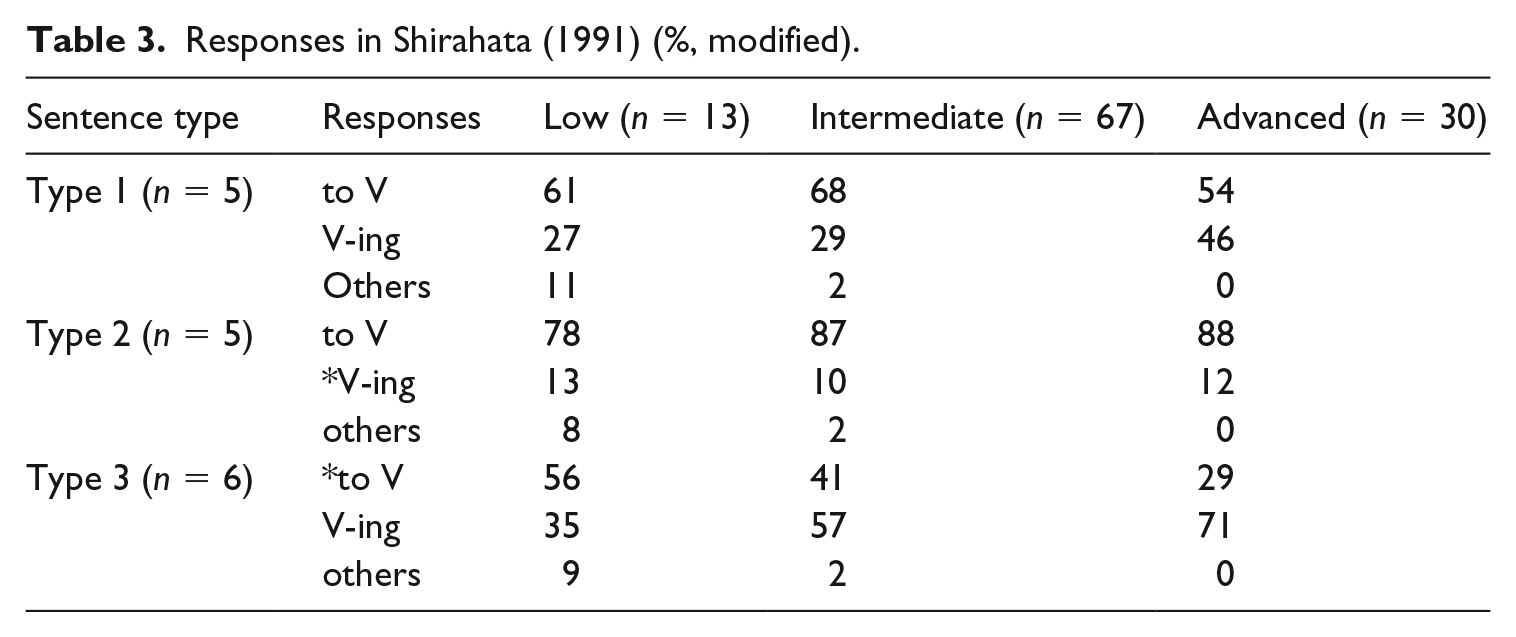
In the analysis, errors other than in the use of infinitives or gerunds (e.g. errors in tense or agreement) were ignored. The results in Table 3 show that early learners preferred infinitives (low learners 61% and intermediate learners 68%) to gerunds with Type 1 verbs, which allow both forms, while preferences among advanced learners is not so clear. Learners correctly used to-infinitives around 80% or better with Type 2 verbs. Even low learners made target-like selections here. On the other hand, participants did not use gerunds for Type 3: Low learners prefer infinitives (56%) to gerunds (35%), and their selection ratios improve as proficiency rises. Overall these data supported the predictions in (38).
Responses in Shirahata (1991) (%, modified).
2 Fujimoto (2008)
Shirahata’s (1991) task forced participants to use one form for each item, and hence it was impossible to determine whether participants were aware that some verbs do not permit gerunds or infinitives as their complements. In order to examine learners’ knowledge of such restrictions, Fujimoto (2008) carried out an experiment with an acceptability judgment task, using the same types of verbs as Shirahata (1991). Forty Japanese university students participated in the experiment. The verbs in Type 1 (to-infinitive / -ing gerunds) included start, begin, like, love, and continue; Type 2 (to-infinitive / *-ing gerunds) want, need, learn, hope, and offer; and Type 3 (*to-infinitive / -ing gerunds) enjoy, appreciate, postpone, finish, and mind. They were asked to judge the acceptability of a given sentence by choosing from three choices: 正しい ‘correct’, 誤っている ‘incorrect’, and 分からない ‘I don’t know.’ A sample is given in (40):
(40) He offers to drive her to school. (正しい・誤っている・分からない) (Fujimoto, 2008: 3)
The results are shown in Table 4. Participants accepted the sentences as correct, with either infinitives or gerunds as complements, around 60% for Type 1, although they exhibited a slight preference for infinitives over gerunds. With regard to Types 2 and 3, Japanese learners of English judged infinitive complements as correct and gerunds as incorrect, as expected, for Type 2 ((to-infinitive, -ing gerunds) × (correct, incorrect): 26 χ2(1) = 105.77, p < .001), and the opposite for Type 3 (χ2(1) = 43.19, p < .001). However, even though the responses to target forms in Types 2 and 3 (i.e. to-infinitive for Type 2; -ing gerunds for Type 3) are not significantly different ((correct, incorrect) × (to-infinitive) for Type 2, -ing gerunds for Type 3): χ2(1) = 1.63, p = .202), the responses to the non-target ones are (i.e. *-ing gerunds for Type 2; *to-infinitive for Type 3; (correct, incorrect) × (*-ing gerunds for Type 2; *to-infinitive for Type 3): χ2(1) = 7.40, p = .007). Participants correctly rejected gerunds in Type 2 sentences but were more likely to incorrectly accept infinitives in Type 3.
Number (%) of responses in Fujimoto (modified).
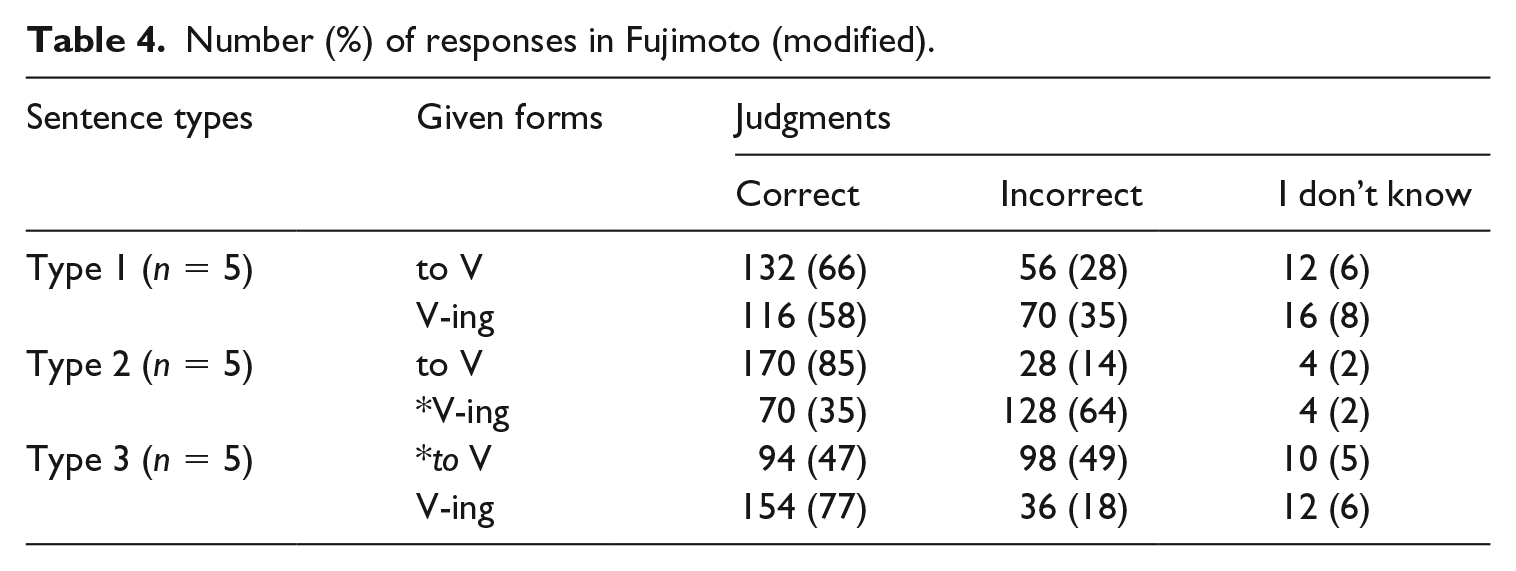
These results show that L2 learners tended to accept a to-infinitive even when an -ing gerund should have been used and that they rejected a gerund where an infinitive was the only option in the target grammar, as predicted in (38). In short, Fujimoto (2008) revealed that Japanese learners of English have difficulty in rejecting infinitives on an acceptability judgment task.
3 Haniu (2015)
Haniu (2015) carried out an experiment similar to Fujimoto (2008). Data were collected from 45 university students in Japan. In the current study, we analysed Haniu’s original data, excluding those whose first exposure was earlier than 10 years old and/or those who had spent more than a year abroad. This leaves 38 participants for analysis. Five native-speakers of English took part in the experiment as a control group. Like Shirahata (1991) and Fujimoto, three types of verbs were used: Type 1 verbs take both infinitives and gerunds as complements (begin, continue, like, start); Type 2 verbs only take infinitives (agree, decide, hope, want); and Type 3 verbs only gerunds (avoid, consider, enjoy, mind). A five-point Likert-scale acceptability judgment task was administered: Choices were −2 ‘incorrect’; −1 ‘if I am forced to judge, this is incorrect’; 0 ‘I cannot judge’; 1 ‘if I am forced to judge, this is correct’; and 2 ‘correct’. An example is given in (41):
(41) Mike likes to play tennis. (−2 −1 0 1 2) (Haniu, 2015: 30)
Table 5 shows that native-speakers accepted both infinitives and gerunds for Type 1, accepted infinitives but rejected gerunds for Type 2, and the reverse for Type 3. Japanese learners’ responses showed that they: (i) accepted to-infinitives (1.46) and -ing gerunds, though less so (0.56), for Type 1; (ii) accepted to-infinitives (1.43) and -ing gerunds, though less so (0.95), in Type 2 while they did not reject -ing gerunds much (–0.82); and they rejected to-infinitives to an even less extent (–0.49) in Type 3. The results of a two factor repeated measures ANOVA (Type × to-infinitive / -ing gerund) showed that the interaction between sentence type and verb form was significant (df = 2, F = 73.90, p < 0.01) and that the effect size was large (partial η2 = 0.6664, effect size f = 1.4132). Multiple comparisons with Bonferroni showed that participants judged to-infinitives significantly higher than -ing gerunds for Types 1 (df = 1, MS = 15.21 F = 16.66, p < .01) and 2 (df = 1, MS = 96.19, F = 169.98, p < .01) and the other way round for Type 3 (df = 1, MS = 39.44, F = 24.06, p < .01). They accepted to-infinitives for Types 1 and 2 more than for Type 3 (both p < .05) but no difference was observed between Types 1 and 2 (p > .05, ns). They accepted -ing gerunds significantly higher for Types 1 and 3 than for Type 2 (both p < .05), but no difference was observed between Types 1 and 3 (p > .05, ns). Hence, statistically speaking, to-infinitives were judged to be significantly more acceptable than -ing gerunds with Type 1 verbs, but no significant difference was found between to-infinitives for Type 2 (1.43) and -ing gerunds for Type 3 (0.95) or between -ing gerunds for Type 2 (–0.82) and to-infinitives for Type 3 (–0.49).
Averages of the responses (SD).
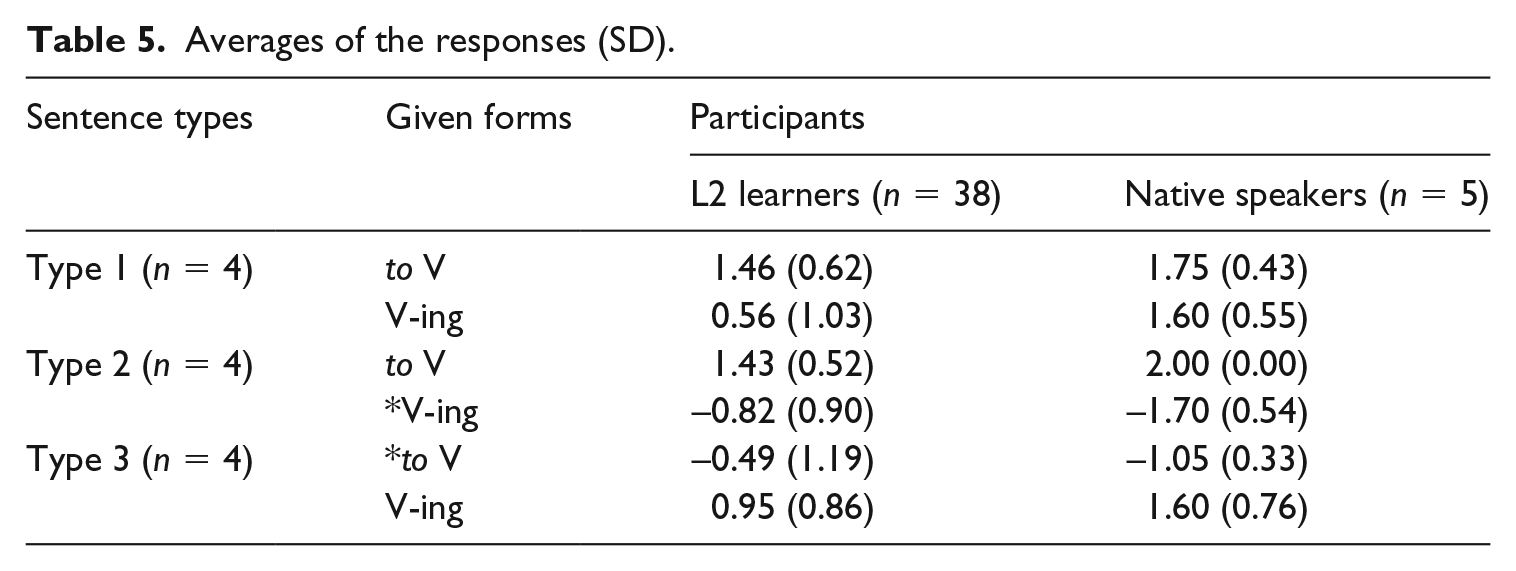
In addition to the main experiment, learners completed a cloze test (range: 12–28, mean = 20.29, sd = 3.56). Examination with Spearman’s rho showed a positive correlation between the cloze test and the acceptance rate for Type 1 -ing (rs(36) = .42, p < .01). That is, learners judged -ing forms as acceptable to a higher extent for Type 1 when they scored higher on the cloze test. A positive correlation was found between -ing for Type 1 and for Type 3 (rs(36) = .51, p < .001) and a negative correlation between to-infinitive and -ing for Type 3 (rs(36) = −.53, p < .001). These results show that learners accepted to-infinitives more often than -ing gerunds regardless of their proficiency for Types 1 and 2, and that they gradually come to accept -ing gerunds when both forms are possible as their proficiency improves. Since the acceptance of -ing gerunds for Type 1 verbs correlates with the acceptance rate of the same form for Type 3, learners probably learn when to accept -ing gerunds, and when they do so, they may cease using to-infinitives with Type 3 verbs (when a to-infinitive is not allowed). If both forms are allowed, they still prefer to-infinitives to -ing gerunds as the results of the ANOVA and Bonferroni showed for Type 1.
The three studies all showed that L2 learners do not use/accept infinitives and gerunds randomly. When both infinitives and gerunds were allowed (Type 1), all groups in Shirahata (1991) and low and intermediate groups in Haniu (2015) preferred infinitives to gerunds. Shirahata’s advanced learners did not use infinitives as much (54%) as learners in low and intermediate groups (61% and 68%, respectively). This between-group difference may be explained as follows: Shirahata’s task was a forced-choice task; low and intermediate learners may not have been confident in using gerunds and hence chose infinitives; but advanced learners were more confident in using the two forms, and their answers became more-or-less random (i.e. around 50%). In fact, in Haniu’s data, there was a significant difference between the two forms even among advanced learners. Although Shirahata’s advanced learners cannot be directly compared with Haniu’s advanced learners in terms their English proficiency, it is safe to conclude that Japanese learners accept infinitives regardless of their proficiency for Type 1 verbs. When verbs selected an infinitive but not a gerund (Type 2), learners correctly used/accepted infinitives regardless of proficiency. Shirahata’s participants used infinitives at 78% or more; Fujimoto’s (2008) participants accepted them at 85%; and Haniu’s participants rated them 1.43 (maximum: 2.0). Since all learners used/accepted infinitives as correct regardless of proficiency, no correlation between proficiency and target-like response was observed.
On the other hand, lower proficiency learners used/accepted gerunds to a limited extent while advanced learners did so to a greater extent when both gerunds and infinitives are allowed (Type 1). Haniu’s (2015) data supported this with a significant difference between the two forms. These data show that learners’ use/acceptance of gerunds increases along with a rise in proficiency. Shirahata’s (1991) data were similar to Haniu’s in that they showed a gradual increase in acceptance. Moreover, the correct use/acceptance rates of -ing gerunds in Shirahata and in Haniu were lower than those for to-infinitives by all proficiency groups (see Tables 3 and 5), although Haniu’s data did not show a statistically significant difference. The differences were also observed in Fujimoto’s (2008) data: learners judged gerunds as incorrect at a higher rate than infinitives (35% vs. 28%, p < .05).
With regard to Type 3 verbs, Shirahata’s (1991) data show that low, intermediate, and advanced learners incorrectly used infinitives at 56%, 41% and 29%, respectively. In Fujimoto’s (2008) data, 47% of responses were incorrect acceptance of ungrammatical infinitives. Haniu’s (2015) data also showed that L2 learners had problems rejecting infinitives with confidence.
Lastly, let us consider the cases where gerunds were not acceptable as complements of verbs, as in Type 2. Shirahata’s (1991) data show that participants used gerunds to a very limited degree (low: 13%; intermediate: 10%; and advanced: 12%). In Fujimoto (2008), participants judged gerunds as incorrect at 64%. Haniu’s (2015) data show the same tendency (–0.82). In short, L2 learners use/accept gerunds only when they are sure that they should use them and hesitate to extend their use to other cases.
One may wonder why low proficiency learners accept gerunds at all if their grammar is constrained by DENS. Our answer is that even low proficiency learners have had exposure to L2 input including gerunds with Type 1 and 3 verbs, so they violate DENS to accommodate such input into their L2 grammar despite being costly. DENS is a Principle of Economy, which can be violated under competing pressure. Regarding Type 2 verbs, the acceptance ratios in all three studies were low, and these acceptances were probably no more than false alarms in performing the task. In fact, the same description is applicable for L2 learners’ overgeneralization of 3p -s, involving the apparent violation of DENS. This happens albeit the number is very limited (for such data, see Table 3 in this study, and I&W: 106–07), which can be regarded as false alarms as well.
To summarize, the data from the three experiments showed that the predictions in (38) were all borne out: L2 learners prefer infinitives to gerunds when both forms are allowed; they overgeneralize the use of infinitives but not gerunds; L2 learners at an early stage use infinitives correctly with verbs that take them but not gerunds as their complements; and they use infinitives even when verbs in the target grammar allow gerunds but not infinitives as their complements.
There might be more than one factor making the gerund more difficult than the infinitive. One possibility is that L2 learners may ‘miss’ -ing after the derivation for some phonological reason or performance limitation. This is, however, not empirically supported: -ing for marking progressive aspect is acquired at an early stage of development (Bailey et al., 1974; Dulay and Burt, 1973, 1974; Shirahata, 1988). In addition, if they truly miss -ing, we would expect them to use/accept bare forms, but such use/acceptance was rare. Here, learners are likely to be aware of -ing gerunds in the L2 input, but because of the unclear distinction between -ing gerunds and to-infinitives in terms of their formal function/meaning, L2 learners favor to-infinitives under pressure from DENS.
Another potential source for L2 learners’ non-target-like behavior is their L1. Japanese has no distinction corresponding to what differentiates to-infinitives and -ing gerunds (Wakabayashi et al., 2017), and hence the L1 is unlikely to have an effect on the asymmetry reported here. L2 learners show the same asymmetry as described in (34) when their L1 fails to differentiate the two items, as in Inuktitut (Mazurkewich, 1988), Spanish (Schwartz and Causarano, 2007) and Thai (Keawchaum and Pongpairoj, 2017). 27 It is open to further research whether DENS overrides cross-linguistic influence when a learner’s L1 has a rule corresponding to the distinction between to-infinitive and -ing gerund.
Thus far we have assumed no semantic difference between infinitives and gerunds as complements of verbs. However, a difference in meaning does exist between the two forms (see, for example, Duffley, 2006), and the acquisition of the semantic properties of these two constructions may trigger the differentiation of the two forms. This is an empirical question and left open to further research. We do not discuss this issue further because the meaning differences appear to play little role in the L2 grammars under consideration.
VII Conclusions
In this article, we considered a modulated model of L2 grammar based on DM (Halle and Marantz, 1993). We focused on two areas of morphosyntactic phenomena in English. One was the derivation of 3p -s, which was described in Section II. We discussed I&W’s data and explanation for the asymmetry between two morphemes, be and 3ps -s. In Section III, we reframed I&W’s argument within DM. In Section IV, the derivation of a sentence with overgeneralized be was also analysed and DENS was proposed. Section V provided five predictions that follow from DENS. In Section VI, data concerning an asymmetry between to-infinitives and -ing gerunds were presented and discussed against these predictions. In short, this asymmetry also receives an explanation with DENS.
It should be emphasized that DENS is based on a conceptualization of a general model of linguistic knowledge. It is a Principle of Economy, and hence when necessary (i.e. internalized L2 input forces a learner’s grammar to carry out derivation in a target-like way), it is violated, although violation costs. Morphosyntactic and semantic phenomena that force DENS violations are difficult, or at least take time, to acquire. In order to avoid violation of DENS, an L2 grammar generates either spell-out of a form with relevant features in a non-target-like exponent, resulting in the overuse of be, for example, or a default form of a lexical verb, resulting in the omission of 3ps -s following the Subset Principle (Halle, 1997) in Morphology.
Although only a limited range of data was examined in this article, it is expected that DENS will explain L2 learner non-target-like behavior to a larger extent. It should be applicable to L2 acquisition of any language as the target language. For example, Yoshida and Shirahata (2013) found that an advanced learner of Japanese, who had lived for more than ten years in Japan, used a topic marker wa where a native speaker would have used a nominative case marker ga but not the other way around (and wa and ga never appeared at the same time in a noun phrase). This might be because the suppliance of wa does not violate DENS but that of ga does: When wa is used, a feature [topic]
28
is assembled with a lexical item L, which merges with a complement in Narrow Syntax, and Vocabulary Insertion (wa ↔
Footnotes
Acknowledgements
We are very grateful to the two anonymous reviewers for their constructive comments. The first version was written during the author’s visit to Churchill College, University of Cambridge and Language Institute, Thammasat University, supported by the Chuo University Overseas Research Program, to which I am grateful. Earlier versions of this study have been presented at the City University of Hong Kong, PacSLRF2016 at Chuo University, Chulalongkorn University, CLARK2018 at the University of Rijeka, LAVA at UiT, Tromsø. I would like to thank participants in these talks for valuable comments and feedback. Parts of earlier discussions are presented in ![]() and Wakabayashi et al. (2016). I also thank Tomohiro Hokari, Takayuki Akimoto, and Takayuki Kimura for their comments. I am grateful to John Matthews for his comments on the English as well as on his insightful comments. The remaining shortcomings are of course mine.
and Wakabayashi et al. (2016). I also thank Tomohiro Hokari, Takayuki Akimoto, and Takayuki Kimura for their comments. I am grateful to John Matthews for his comments on the English as well as on his insightful comments. The remaining shortcomings are of course mine.
Declaration of Conflicting Interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by JSPS KAKENHI Grant Numbers 26370707, 18H00696, and Chuo University Personal Research Grant.