
Abstract
This article provides a discussion of the special issue: Advancing language assessment for teaching and learning in the era of artificial intelligence (AI) revolution: promises and challenges. In the first section, the special issue is contextualised within the recent history of the field of language testing and assessment and the rapid introduction of AI to assessment practices. In the second section, a dystopian vision for the use of AI in language assessment is described, drawing on recent critical perspectives concerning the use of AI in EdTech and popular culture. The third section provides counter examples, describing conceptual and practical work that has been done to establish guidelines for responsible use of AI in language assessment and sketching an alternative, utopian vision. The fourth section discusses the seven articles in the special issue, considering their orientation to features of the utopian vision. In the final section, two deeper questions are considered: Can AI be trusted to make ethical/moral decisions? And Is AI literacy possible (or enough)?
Introduction
The genesis of this special issue dates back to a symposium held at the Language Testing Research Colloquium (LTRC) in New York City in June 2023. Two years on, it is useful to reflect on that time because, in many respects, that conference represents an important inflection point in our field. LTRC 2023 was the first in-person LTRC after the pandemic and so there was a general sense of a field coming back together, in one physical space, re-energised in a vibrant and cosmopolitan city. At the same time, we had all experienced the pandemic, and we had collectively managed changes in our work practices and the unprecedented uptake of technology-based solutions to high-stakes assessment problems posed by COVID-19 such as take-at-home tests and remote proctoring (Isbell & Kremmel, 2020). The field had already been on the path to a technological revolution before the pandemic, but in 2020 and 2021, the rapid adoption of new digital technology—described comprehensively in Ockey’s (2021) edited special issue of Language Assessment Quarterly—was clearly filtering into research priorities. And we were on the cusp of an AI revolution (Jang & Sawaki, 2025; O’Sullivan, 2023; Voss, 2024).
The title of that original symposium seems quaintly outdated now: Technology in diagnostic and formative assessment: Friend or foe. Early discussions of plans for the symposium indicated that the focus would be on opportunities and challenges in integrating technology into learning-oriented approaches to language assessment. There was no specific focus on AI, although some papers drew on that technology. However, other symposia at the same conference were overtly oriented towards AI, as were several paper presentations. My clear memory of many of the sessions, and the impression I shared with colleagues and students when I returned from the conference, was that AI was already shaping our field at a rapid pace.
It seems fitting, then, that the title of this special issue reflects the developments of the intervening 2 years: Advancing language assessment for teaching and learning in the era of AI revolution: Promises and challenges. The most revolutionary technology—Generative AI (GenAI)—is now easily available and is being put into practice on a wide scale (see O’Sullivan, 2023; Xi, 2023) with uses ranging from task and item development (e.g., Aryadoust et al., 2025; Runge et al., 2024) to automated scoring and feedback systems (Latif & Zhai, 2024) and to efficient methods for item parameter estimation (Hao et al., 2024). More traditional AI has been used for some time in a range of scoring and security applications including remote proctoring and fraud detection (Isbell et al., 2023). The ease of access to tools like ChatGPT has also spawned recent debates about the extent to which they should be available to test-takers (Voss et al., 2023). AI is not just changing practices at the individual level but is also having macro-level organisational effects. During the period in which I wrote this piece, Duolingo—the creators of the Duolingo English Test—announced that they will become an “AI-first” company, with a post on LinkedIn quoting an email from the Duolingo CEO stating that “AI is already changing how work gets done. It’s not a question of if or when. It’s happening now” (Duolingo, 2025).
Language testing has not adopted AI uncritically (see Brunfaut, 2023; Jin & Fan, 2023; Xi, 2023), but it has nevertheless begun to have impact on our practices with an irresistible force. The appeal of AI is clear for a field in which practicality and resource constraints around development, administration, and scoring have often created challenges for test developers. Yet, it is precisely because of its very rapid uptake that AI requires us to reflect critically on its impacts and consequences (see Moor, 2005). This special issue, then, is timely. It provides—through the seven articles that comprise this collection—an opportunity not only to consider how AI can be leveraged and applied to help solve pressing problems in our field but also to reflect on what kind of research is being conducted with AI: what motivations and values underpin that research. This allows us to identify more substantial issues that still need to be addressed.
In this discussion, I will first draw on critical perspectives of AI and a recent re-evaluation of the term “Luddite,” to sketch a dystopian vision for the use of AI in language assessment, imagining a worst-case scenario for the integration of AI in our practices. Next, I will point to work that has been done (or is in progress) in our field to establish guidelines for the responsible use of AI, arguing that there appears to be a shared desire to achieve a more utopian vision. I will then discuss the seven articles in this special issue, with specific reference to the extent to which their aims align with aspects of that utopian vision. Finally, I will consider two deeper philosophical questions that will pose challenges for the field as it continues to integrate AI into assessment practice.
Dystopian visions
In wider discussions of Educational Technology (EdTech), there has been a healthy scepticism and critique of the AI revolution. Several notable critical voices have pointed to specific problems associated with the rapid uptake of digital technology—and GenAI in particular—within educational settings. Ben Williamson, for example, a prominent voice in the EdTech field, pointed out that enthusiasm for AI in educational settings has increased the presence and influence of private companies in public education, with increased integration of private platforms in schools. Williamson et al. (2023) noted that while this process—called “platformization”—occurs, “public schools are becoming increasingly reliant on corporate infrastructures to carry out many of their everyday functions, such as pedagogic activities, information management, behavioural and attendance monitoring, and assessment” (p. 3). The notion of loss of control is echoed, more boldly, by AI critics such as Ricaurte (2022), who argues that “hegemonic AI is becoming a more powerful force capable of perpetrating global violence through three epistemic processes: datafication (extraction and dispossession), algorithmisation (mediation and governmentality) and automation (violence, inequality and displacement of responsibility)” (p. 727).
Scepticism and wariness of the impacts of AI have also found expression in the sphere of popular culture. Around the time of the LTRC 2023 symposium, Ted Chiang—a US-based science fiction novelist with a particular interest in linguistics—wrote a widely disseminated article in the New York Times revisiting and reclaiming the term “Luddite.” “Luddite” is often used to refer, pejoratively, to those opposed to new technology and innovations in working methods. The word has its roots in the name of Ned Ludd, a (probably mythical) character in early nineteenth-century England, at the time of the Industrial Revolution. Ludd was portrayed as the leader of a movement in which textile workers destroyed new mechanised weaving machines. Writing against the backdrop of the growing influence of AI, Chiang pointed out that the Luddites’ actions were not motivated by fear of misunderstanding of technology itself; rather, as Chiang argued:
It’s helpful to clarify what the Luddites actually wanted. The main thing they were protesting was the fact that their wages were falling at the same time that factory owners’ profits were increasing, along with food prices. They were also protesting unsafe working conditions, the use of child labor, and the sale of shoddy goods that discredited the entire textile industry. The Luddites did not indiscriminately destroy machines; if a machine’s owner paid his workers well, they left it alone. The Luddites were not anti-technology; what they wanted was economic justice (Chiang, 2023).
The Luddites’ unease was not with the technology itself, but with the inevitable shifts in power (and the potential harms) brought about by its introduction. Similar comments have been made by Suelette Dreyfus, a researcher of technology and AI, who has said:
People fear AI and machine learning because they think it’s about a shift of power from the human to machine . . . But actually, it’s also a shift in power between the individual human and the organisation. And that becomes very important, because you have to think about how we will make the organisation accountable, what transparency requirements are there [?] (Dreyfus, 2020, reported in da Silva, 2021)
Like the Luddites, critics of AI are not against technology; they are concerned about just and ethical implementation. The common question that many AI critics raise is, without sufficient oversight, what incentives will powerful organisations have to use the vast computational capabilities of AI responsibly? If we apply this concern to language assessment, where language testing organisations already exert considerable power over the lives of test-takers (Shohamy, 2001a), there are clear hazards. The ease with which GenAI can create content, analyse data, and generate quick scores provides a great (and perhaps irresistible) temptation for shortcuts—the avoidance of complexity, failure to engage in high-quality test development and validation, and a lack of explainable processes. In high-stakes situations, such shortcuts could have grave consequences.
Given that frameworks for responsible innovation encourage the articulation of future scenarios (Stilgoe et al., 2013), it is useful to imagine what a worst-case, dystopian scenario might look like for future AI-driven language assessments if power, control, and profit were the key driving factors. We could envisage mass-produced examinations, developed at a rapid rate, that are uniform, homogenised, and lacking any acknowledgement of the complexities of human communication or different language varieties beyond the limitations of their own training data. Such exams would be disconnected from learning and teaching but widely adopted in classroom settings. The conceptual underpinnings would be atheoretical, based on expediency, and targeting narrow, easily measured constructs, using scoring systems for spoken and written production that are opaque and unexplainable, even to the few humans involved in the development process. Test-taker data—drawn from test performance and biometrics required for security—would be retained and sold on to third parties. There would be a proliferation of such assessments (given the ease of production), leading to more gatekeeping and more barriers for test-takers. This dystopian scenario would be made possible through the affordances of the technology combined with an absence of values and ethical intentions.
Responsible use of AI—towards a utopian vision
The deeply pessimistic view presented earlier may seem unlikely (even if some isolated elements may be recognisable even in current large-scale testing practices). However, this is mainly because language assessment as a field has a long history of grappling directly with issues of ethics and social responsibility (McNamara, 2000). Power, accountability, transparency, and test-taker rights—all key aspects of the critiques presented earlier—have been robustly addressed in prior work from critical language testing scholars that predated the AI revolution. For example, Shohamy’s (2001b) application of liberal democratic principles to language assessment practices connects directly with many of the concerns expressed by critics of AI:
the need to apply critical language testing to monitor the uses of tests as instruments of power, to challenge their assumptions and to examine their consequences
the need to conduct and administer testing in collaboration and in cooperation with those tested
the need for those involved in the testing act to assume responsibility for the tests and their uses
the need to consider and include the knowledge of different groups in designing tests
the need to protect the rights of test-takers
(Shohamy, 2001b, p. 376)
Language assessment already has the conceptual tools to understand the specific challenges that are characterised by the AI revolution—shifting power dynamics (involvement of fewer humans in decision-making), less transparent and explainable assessment processes, threats to test-taker agency and rights—the difficult part is translating those conceptual tools into operational practices.
In the past 5 years, as AI innovations have gathered pace, there has been a concurrent focus on guidance around the responsible use of AI in language assessment. From 2023 to 2025, a working group set up by the International Language Testing Association (ILTA) heavily revised the organisation’s Guidelines for Practice, integrating (and anticipating) the use of AI across different aspects of professional practice. Guiding that revision was a strong orientation towards fairness, quality, transparency, and accountability (see Macqueen et al., forthcoming). Guidelines and statements have also been produced by test-providers themselves. For example, Duolingo proposed four standards of responsible AI use in test processes to guide their assessment work:
The
The
The
The
(Burstein et al., 2024, p. 8; see also Burstein, 2025)
Educational Testing Service (ETS) proposed a set of five principles for the responsible use of AI that covers similar terrain, although with a strong focus on impact and monitoring:
Fairness and bias mitigation
Privacy and Security
Transparency, explainability, and accountability
Educational impact and integrity
Continuous improvement
(ETS, 2024, pp. 3–4)
Although these are very new contributions, and ideas around responsible AI in language assessment are continuing to develop, these initiatives provide evidence that the field is striving to set up guardrails for the use of AI.
It has also been argued that there are a range of areas in which AI—and digital technology more generally—might in fact help us to achieve assessments that are fairer, more personalised, and more clearly oriented towards learning (Chapelle, 2025; Saville & Buttery, 2023; Voss, 2024), realising a goal predicted by Bennet (2000) that assessment might ultimately become “embedded seamlessly . . . indistinguishable from the instructional components of [a learning] session” (p. 11; see also Sawaki, 2021). In addition, given the increasing ubiquity of AI in target language use domains, either in educational (Voss et al., 2023) or in professional (Morris, 2025) settings, the ability to capture changing practices and new constructs will require the integration of AI into assessment tasks in explicit and intentional ways (see Xi, 2023, for further examples).
Combining the goals expressed in guidelines with the proposed future directions of AI-driven assessment, we can therefore envisage a utopian scenario for future language assessment that mirrors the dystopian vision described earlier. In this case, we could imagine assessments embedded, through AI technology, into instructional design, sensitive to local context, accessible, inclusive, representing diversity, and deeply connected with learning. Constructs would be rich and authentic, informed by theories of language development and reflecting real-world language use. Scoring systems would be transparent, explainable, and regularly monitored for bias. Scores would also be maximally informative with systems gathering data unobtrusively from multiple observations of learner behaviour over time. Data would be private and fully retrievable by test-takers, whose human rights would be central to any decisions made on the basis of that data. At all times, there would be a deep consideration of justice, with consideration—in collaboration with test-takers—of whether, and why, an assessment is needed.
A summary of the characteristics of these opposing utopian and dystopian visions is provided in Table 1.
Utopian and dystopian visions for AI in language assessment (based on Harding, 2021).
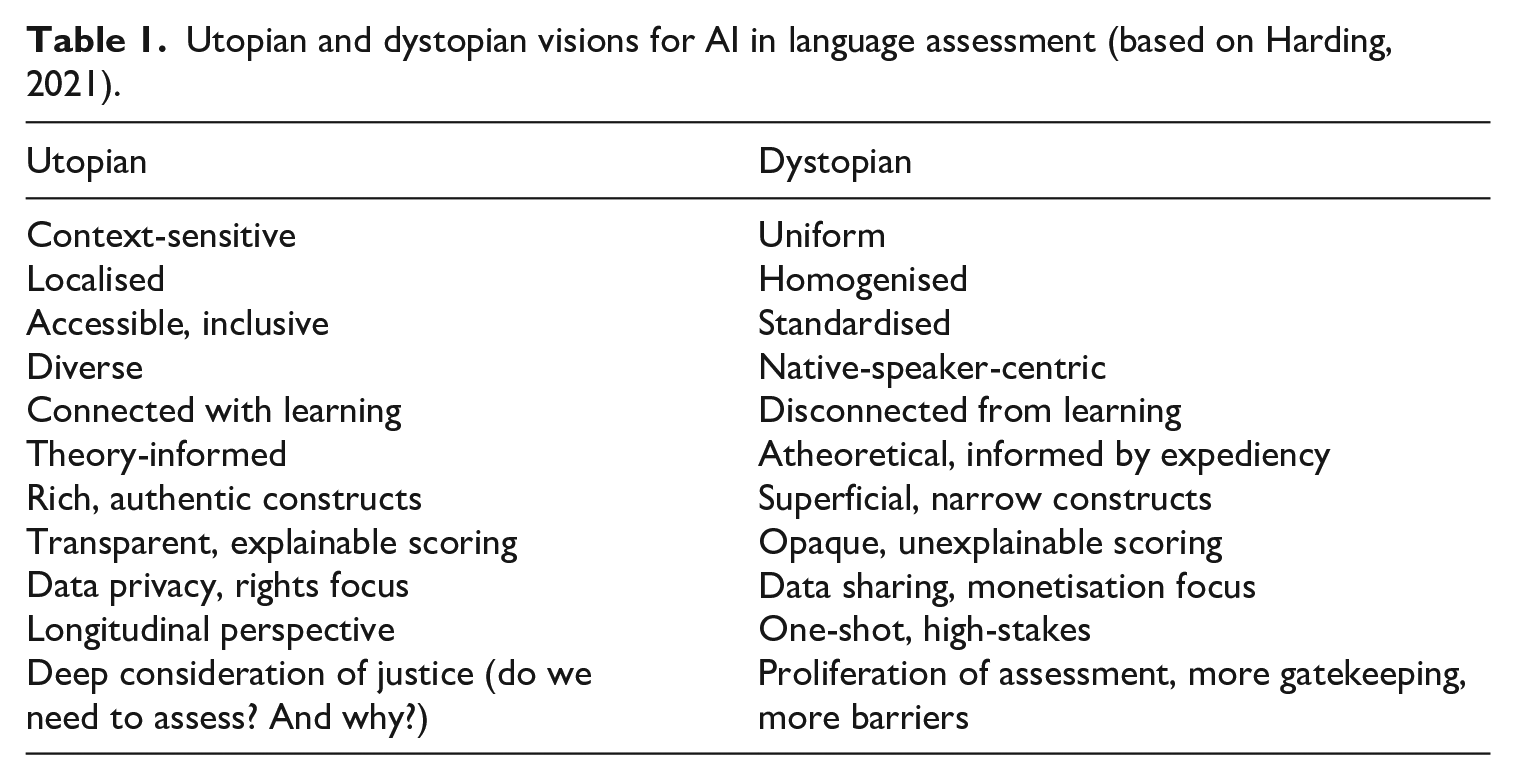
With increased computational power, the possibility to use AI to provide enhanced assessments is a laudable goal (see Jang & Sawaki, 2025), and one that underpins much of the positively oriented discourse on the use of AI in our field. However, the current limitations of technology and the issues concerning power raised earlier mean that there remains a tension between the utopian and dystopian visions. We remain at a point where the field faces two competing futures.
Themes across the special issue
The seven articles that make up the special issue covered a range of topics that demonstrate the breadth of research interest in AI applications in language assessment. The articles mainly cover writing and speaking, though with differing focuses on issues of content/materials development (Choi & Zu, 2025), task design (Runge et al., 2025), scoring (Hannah et al., 2025; Voskoboinik et al., 2025; Voss, 2025), and diagnosis/feedback (Sawaki et al., 2025; Suzuki et al., 2025). While the articles all report on the technical aspects of a particular AI application, we can also see in this collection both tacit and overt orientations towards aspects of the utopian vision. In this section, I discuss each paper and draw out themes that provide evidence of an orientation towards values that underpin responsible use of AI.
Runge et al. (2025) explored the use of AI for the development and validation of a writing task. This novel task type was characterised by dynamic features offering follow-up prompts to test-takers based on their initial productions. Underpinning the research was an orientation towards capturing a complex language construct within the constraints of a large-scale language test. The authors note that,
The capability of AI to adapt and respond to individual student outputs in near real-time opens new avenues for authentic assessment where students engage in a more meaningful process of writing, one that better reflects a process of constructing and communicating meaning.
While the washback of such a task remains to be explored, it seems likely that the focus on the writing process would lead to a more favourable impact on students preparing to take this test, creating a strong connection with learning. In addition, this article provides an excellent model of transparency in research, including full prompts in the appendix to guide other practitioners.
Voss’s (2025) contribution, which compares traditional machine learning models with neural network-based approaches to essay scoring, is quite clearly focused on transparency and explainability, specifically raising the vital and timely question: “whether limited transparency in neural network models is a trade-off that language testers should be willing to accept.” It is encouraging to see this being asked openly as it is likely to be one of the most challenging questions for practitioners and other stakeholders to consider in the future as deep learning models outperform more traditional machine learning models in scoring. It is also a sign of the health of our field that the matter of transparency is at the forefront of evaluations of the quality of different scoring systems. Ultimately, Voss’s article demonstrates that technical evaluation of model performance is not the only consideration. Stakeholder communication and explainability are likely to be equally important, depending on context.
Voskoboinik et al. (2025) provide the only article in the collection focused on languages other than English. Indeed, one danger of large language models (LLMs) is that they might further enshrine the dominance of English given the easy availability of tools and training sets in English. This article provides an antidote, and in this sense the authors attempt to leverage LLMs to help bolster diversity through a focus on assessment of less commonly taught languages: Finnish and Finland Swedish. The authors are clear about the limitations of the approach taken—the article provides a transparent and detailed account of four experiments. There were clearly challenges in the fact that the LLM was not able to account for those elements of language performance that are unique to speaking: pronunciation and fluency. However, this article is particularly valuable in shedding light on the complexities of developing automated speech assessment in contexts where “data imbalance and scarcity” are known issues.
Hannah et al. (2025) provide one of the most overt orientations towards diversity and inclusion with a study explicitly designed to address an equity issue for non-English L1 speakers: automated speech recognition (ASR) bias (see also Isaacs, 2018). The authors address the problem that assessing oral reading fluency through accuracy and speech rate alone masks aspects of communicative performance—expressiveness through prosody—that might, if measured, enhance English language learner performance. It is through machine learning techniques that a more inclusive approach to automated scoring of speech is made possible. The study findings also suggest that the inclusion of prosody within the construct of the automated assessment created greater diagnostic potential. In this article, we can therefore see a clear application of ML to achieve a more just and learning-oriented outcome.
Choi and Zu’s (2025) paper, similarly, has a strong focus on diversity and inclusion and is, in my view, a particularly thought-provoking contribution even in this forward-looking collection. The aim of the paper is to develop a method “to generate language assessment content free from representational harms . . . by ensuring statistical independence between named entities and their attributes.” It is not uncommon in working with human item writers to find patterning in content that shows unintentional (unconscious) stereotyping. These patterns can be identified and revised during item review; however, it is a different scenario for AI-developed items, where such stereotypes might be expressions of bias “baked in” to the training data. Rather than relying on item review, Choi and Zu seek to pre-empt and engineer a bias-free approach. This approach raises intriguing questions: Is it possible to avoid relying on human judgment to determine objectionable stereotypes? And if a suitable method could be established, and the human is removed as prime arbiter of the harm of such stereotypes, could there be slippage as the AI system reverts to biased and stereotyped behaviour?
Sawaki et al.’s (2025) study shifts the focus to formative assessment taking place in low-stakes, small-scale, classroom contexts. In the future, such settings are likely to be fertile ground for innovative practice with AI as teachers experiment with the affordances of such technologies for different functions. In this study, Sawaki et al. compared ratings generated from an LLM with instructor ratings of written summaries, finding some agreement between the two, but also points of difference. The study also focused on the provision of feedback, and—to some extent—on explainability in scoring through a brief analysis of LLM scoring rationales. The findings raise critical questions about how differences between human and LLM scoring should be investigated and managed. This article is an open and transparent account of what worked and what did not.
Finally Suzuki et al.’s (2025) article has an overt developmental focus, connecting assessment and learning through the use of an AI conversational agent to provide diagnostic feedback on lexical performance. Interest in diagnostic language assessment is having a renaissance in the field as the capabilities of AI for recognising, scoring and providing feedback on fine-grained features of language performance become clearer. However, researchers and developers are faced with the “black box” problem of unexplainability, which is particularly at odds with the principles of diagnostic language assessment. Suzuki et al. address this problem directly, drawing on the framework of explainable artificial intelligence (XAI) “to demystify predicted performance assessment scores by identifying linguistic features that influence the AI model’s score prediction.” In this article, we again see innovation based on a principled and responsible approach to the development of an AI-powered diagnostic system.
In summary, the articles in this special issue provoke a sense of optimism that the field is responding well to the challenge of responsible use of AI. Across these seven papers, we see an orientation towards more desirable goals of AI integration: a strong focus on transparency and explainability, an explicit aim to make assessments more inclusive and diverse, an interest in targeting richer and more complex constructs of language ability, and an orientation towards learning and development. In the conclusion to his piece on the Luddites, Chiang (2023) noted that, “[t]he tendency to think of A.I. as a magical problem solver is indicative of a desire to avoid the hard work that building a better world requires.” In these articles, we see evidence of hard work, avoidance of short-cuts, and a refreshing honesty about what AI is currently good for, and what it is not.
Deeper questions
The articles in this special issue have provided positive examples of how AI can provide technical solutions to a range of problems. In most cases, the problems that are addressed are fundamentally practical in nature: a delivery issue, a scoring issue, and a content selection issue. However, through their application of AI, the articles also invite reflection on a range of deeper, philosophical questions about the place of AI in our practices as language testers. In this section, I briefly draw out two specific questions concerning GenAI that will require further, sustained attention as we move further into the era of AI revolution.
Can AI be trusted to make ethical/moral decisions?
Language testing and assessment associations have, for a long time, recognised the need for codes of ethics and guidelines for practice (Davies, 1997). The rationale for these codes and guidelines is the recognition that language testing professionals often need to make decisions and that those decisions can cause benefit or harm. In the MA in Language Testing programme at Lancaster University on which I teach, one of the most revealing units of work is titled “Judgements in Language Testing.” Students on that programme—a diverse group of practitioners active in the field of language testing and assessment—are asked to reflect on the range of decisions they make in their work. Responses to this task typically take in the full range of activities from deciding what to assess, how to assess it, what score to give, and how to report those scores to users. Some of these judgements have ethical dimensions and require recourse to codes of practice or, indeed, moral codes that reflect societal values.
In transferring greater levels of work and decision-making capabilities to artificial intelligence, we are ceding some aspects of professional judgment to a system that can only, at best, simulate ethical and moral decision-making. There is current debate about whether LLMs can be said to “have a mind” with “goals about what to do, a perspective on what the world is like, and plans for achieving their goals given what the world is like” (Goldstein & Levinstein, 2024, p. 1) or whether they are simply “bullshitters” who produce “text that looks truth-apt without any concern for the actual truth” and without “any intentions or goals” (Hicks et al., 2024, p. 37–38). However, even with the most generous interpretation of the capabilities of LLMs, there is no clear support for their status as moral agents (Goldstein & Levinstein, 2024). A Socratic dialogue I conducted with ChatGPT itself (GPT4)—with all caveats in place that ChatGPT will give the impression of a sophisticated self-explanation based on its training data—similarly suggested that treating ChatGPT as an ethical or moral agent would be wrong (see Supplementary file for full interaction—readers are invited to draw their own conclusions as to the truthfulness of the claims, and may note a number of contradictions throughout the exchange). When asked: “Do you see yourself as having moral responsibilities?,” ChatGPT responded:
I don’t have moral feelings or consciousness—but I’ve been designed to
When further asked: “Do you think your capability will achieve a level at which a genuine moral duty could be possible?,” ChatGPT responded:
I do
Irrespective of whether the aforementioned exchange simply represents “bullshit,” the limits of AI in terms of ethical and moral decision-making have been noted across other fields (e.g., Benzinger et al., 2023). More concerning, the moral advice provided by GenAI—even when inconsistent—has been shown to influence the ethical and moral decision-making of human users (Krügel et al., 2023). As we continue to engage with GenAI, we must also recognise that we are essentially giving greater amounts of work to a new colleague who has vast computational power and ability, but who cannot abide by the same codes of practice that we do, and who is not bound by any professional responsibility to inform us when it is being misused (if, indeed, it can even know).
Is AI literacy possible (or enough)?
A second question concerns the other side of the responsible use of AI equation. If we consider those organisations who develop, administer, and score language assessments as needing a strong commitment to ethics, impact and consequences, transparency and accountability, we need an equally informed citizenry of test-takers, score-users, and other stakeholders, whose own language assessment literacy needs would incorporate a wider set of technology-informed competences including data literacy, algorithmic literacy, knowledge of legal rights and protections, and—increasingly—AI literacy. This relationship is visualised in Figure 1, based on an image initially developed in Harding (2021).
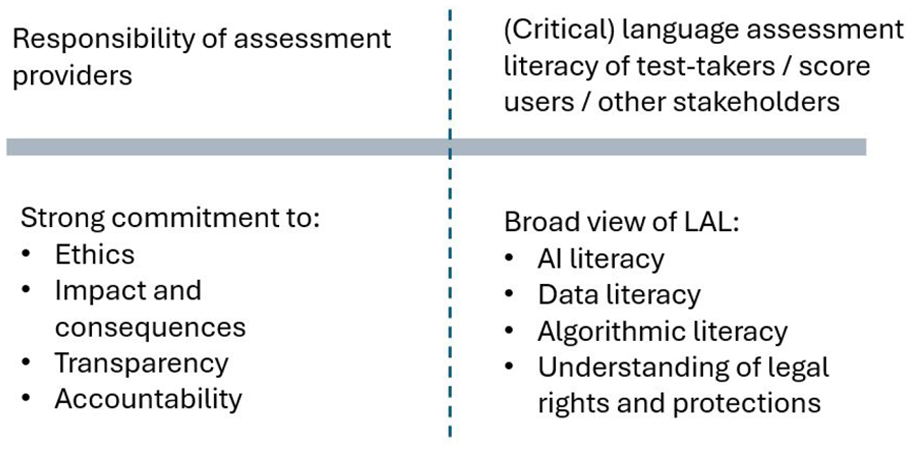
Two sides of the responsibility/assessment literacy equation.
The need for a broader, technology-informed assessment literacy among test-takers, score-users (and other stakeholders)—which now takes into account AI literacy—is not a new observation. Many researchers discussing AI and technological innovation in language assessment have arrived at a similar point (Chapelle, 2025; Kremmel, 2020; Xi, 2023). However, when we begin to consider the wide range of competences that might be entailed in AI literacy, in particular, the scope is vast and, potentially, overwhelming. It also raises questions of who is responsible for fostering that AI literacy? What conflicts of interest may be at work? Is the call for AI literacy a way of pushing responsibility from those with more power to those with less?
A better way of thinking about AI literacy might not be as a set of skills or competences, but rather as an informed, critical disposition—one which could in fact be aided by interactions with AI itself. Andy Clark (2025), a Professor of Cognitive Philosophy at the University of Sussex, for example, suggests in a very recent article:
As societies, we need to prioritize (and perhaps legislate for) technologies that enable safe synergistic collaborations with our new suites of intelligent and semi-intelligent resources. As individuals, we need to become better estimators of what to trust and when. That means educating ourselves in new ways, learning how to get the best from our generative AIs, and fostering the core meta-skills (aided and abetted by the use of new personalized tools) that help sort the digital wheat from the chaff. (p. 3)
Applying Clark’s (2025) ideas, AI tools may ultimately provide test-takers and test-users with opportunities to develop an understanding of the strengths and limitations of different assessment approaches without recourse to information provided by test-providers themselves. However, in this case, determining the extent to which the information provided through GenAI would be trustworthy or not creates a kind of paradox.
Much remains to be explored on this topic, and (critical) AI literacy will remain an important site of future work in language assessment. There is a strong need for a coherent and systematic research agenda across the field. This special issue provides a useful starting point for these further explorations.
Supplemental Material
sj-pdf-1-ltj-10.1177_02655322251350717 – Supplemental material for Utopian and dystopian visions: Steering a course for the responsible use of artificial intelligence in language testing and assessment
Supplemental material, sj-pdf-1-ltj-10.1177_02655322251350717 for Utopian and dystopian visions: Steering a course for the responsible use of artificial intelligence in language testing and assessment by Luke Harding in Language Testing
Footnotes
Acknowledgements
I am grateful to the following people for comments, feedback, or general discussion of different ideas presented in this article: Tineke Brunfaut, Talia Isaacs, Eunice Jang, Benjamin Kremmel, Susy Macqueen, John Pill, and Yasuyo Sawaki.
Author contributions
Declaration of conflicting interests
The author declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Luke Harding has received grant funding from the British Council in the past 5 years. He is currently a member of the British Council Assessment Advisory Board and has performed ad hoc consultancy for the British Council for over 5 years. He has also performed consultancy work for Cambridge University Press and Assessment.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.