
Abstract
A longstanding criticism of traditional high-stakes writing assessments is their use of static prompts in which test takers compose a single text in response to a prompt. These static prompts do not allow measurement of the writing process. This paper describes the development and validation of an innovative interactive writing task. After the test taker responds to an initial prompt, a large language model automatically analyzes their response to identify the prompt themes they discussed. The test taker then receives a customized follow-up prompt asking them to discuss one of the themes they did not address in their original response. Several experimental results support the task’s validity. Results showed that prompt phrasing is important to elicit responses most consistent with the task expectations and that test takers are able to produce responses that are relevant. Regarding issues of fairness in administration, we found that scores are not negatively affected by the type of follow-up task. We found that an accurate theme-detection model ensures test takers are not asked to write about something they addressed in their initial response, which could threaten test score validity claims. This design brings high-stakes writing tasks into closer alignment with writing models that frame writing as a process.
Keywords
Introduction
Measurement of academic writing ability has been a core component of language assessment for the last several decades (Cumming et al., 2021). Due to the scale and standardization of traditional high-stakes tests, writing tasks on many large-scale assessments have predominantly been static prompts to which test takers compose a single, unrevised response. Consequently, most large-scale writing assessments do not reflect real-world and classroom-based composing, where writers develop their ideas over multiple drafts. Given the importance of text development skills and strategies, innovations in large-scale writing test design should align with real-world and classroom-based composing practices. Recent advancements in artificial intelligence (AI) and machine learning (ML) show promise for enhancing the interactivity and responsiveness of such writing tasks. These advancements open up the possibility for automated feedback on all elements of a written text including more global elements, such as organization and development, which can be difficult for automated feedback systems. While AI holds much promise for authentic task design, it is crucial to carefully consider the potential for AI to generate inaccurate or invalid feedback to test takers, unintentionally degrading the writing process and potentially negatively affecting the test taker’s motivation and the validity of the task.
In this paper, we describe the development and validation of a multi-stage, interactive writing task. This task extends a previous static writing task on a large-scale English proficiency assessment that required test takers to respond to a single prompt. The new Interactive Writing task extends the static task by detecting themes in what test takers wrote, then prompting them for a follow-up response. The task is designed to better reflect real-world writing processes in which writers develop their ideas, revisit previous ideas, and consciously plan and monitor their steps (Council of Europe, 2020). By using real-time AI, powered by large language models (LLMs), the Interactive Writing task also models one of the ways in which writers are using AI technologies today in school, work, and everyday settings (Coman & Cardon, 2024).
This paper presents the results of a series of experiments and evaluations designed to refine the task and its item-generation processes, creating evidence for the validity of the task. We report on results from five experiments and evaluations designed to answer questions about the two-part (initial and follow-up) writing task: how the language of the follow-up prompts influences responses, how accurately LLMs detect themes in written responses, how theme-detection accuracy impacts scores on the follow-up task, how well test takers are able to write relevant responses to the follow-ups, and test-taker perceptions of the task.
Research context
The Interactive Writing task was developed for the Duolingo English Test (DET). The DET is a computer-adaptive, high-stakes English proficiency test, widely used to assess language proficiency in English-medium settings (Cardwell et al., 2024). Test scores are designed to assess test takers’ English language skills and are used in high-stakes decision-making contexts, including admissions decisions at the post-secondary level. The target language use (TLU) domain for the test encompasses a range of real-world English-medium scenarios including academic, professional, and everyday communication contexts. The writing subconstruct includes relevance and development of the response, text coherence, lexicogrammatical accuracy and range, and theme elaboration. A key theoretical underpinning and addition to the construct with Interactive Writing is that writers in these TLUs often must extend, or elaborate on, their content based on new information; thus, writing assessments that include elaboration can better prepare test takers for TLU-domain writing (Graham, 2018a; Shi et al., 2020).
Literature review
Changes in the writing construct
Contemporary theories of writing draw from sociocognitive perspectives on learning, emphasizing that learning to write, much like other skills, is deeply rooted in the social interactions and cultural contexts within which individuals are immersed (Corrigan & Slomp, 2021; Deane, 2018; Weir, 2005). This perspective argues that writing development is not just an individual cognitive change but a developmental transformation influenced by engagement with other readers and writers (Nishino & Atkinson, 2015) and that those social interactions shape writers’ ways of knowing and knowledge construction (Tan et al., 2022). Researchers using a sociocognitive framework have shown that while writers can be taught abstract skills and practices for composing and editing texts, the successful development of self-regulated writers requires pedagogical practices that include active interaction with others (Graham, 2018a, 2018b) Sociocognitive theories of writing have informed first- and second-language (L1 and L2) studies of the composing process and the teaching of writing (Bennett et al., 2020; Davoodifard, 2022; Hawkins & Razali, 2012; Sandmel & Graham, 2011). When combined with explicit teaching, individualized instruction, and criterion-based learning, sociocognitive approaches to teaching writing have been shown to be highly effective (Graham & Perin, 2007; Harris & Graham, 2009).
Writers’ capability to demonstrate these competencies is reflected in the Common European Framework of Reference for Languages (CEFR), which recognizes that both product and process elements contribute to writing proficiency. For example, the CEFR describes B1 (intermediate proficiency) writers as being capable of crafting “straightforward connected texts on a variety of familiar subjects within their field of interest, by seamlessly integrating a series of shorter discrete elements into a cohesive linear sequence” (Council of Europe, 2020, p. 66). This process also involves adopting an appropriate tone, style, or register for the envisioned audience. In addition, the CEFR emphasizes the importance of monitoring and repair, the deliberate process of reviewing and refining text to ensure its accuracy and suitability. These aspects demonstrate how written production is intertwined with sociolinguistic and pragmatic competencies, while also recognizing that cognitive and metacognitive processes are involved in producing elaboration in writing.
Sociocognitive approaches to writing instruction have yielded compelling evidence of their effectiveness (Graham et al., 2012), and frameworks such as the CEFR align with changes in the workplace that are reshaping writing tasks to be more process-oriented (Abdel Latif, 2021). Yet, despite the importance of interactivity, feedback, and collaboration in written production, these elements of the writing process have had little implementation on standardized large-scale high-stakes tests. With the exception of innovations in integrated writing tasks (e.g., Plakans & Gebril, 2013), writing tasks on large-scale assessments still use static prompts in which test takers compose a single, unrevised text in response. If large-scale language testing is to evolve in the face of calls for expanded construct representation, real-world applicability, and AI technological innovation, tasks like Interactive Writing are ideal sites for the applied advancement of theory.
Writing prompt innovations in large-scale assessment
Awareness of the need to diversify and improve the measurement of writing abilities and align measurement with the types of writing performance required in many schooling contexts has led to innovations in prompt design for large-scale assessment of writing. One recent innovation in integrated writing tasks is story continuation in which writers read the beginning of a story and then are prompted to finish it (Ye & Ren, 2019). In a recent study, Shi et al. (2020) experimented with four follow-up prompt variations on story completion tasks: bare prompt in which the test taker was instructed to make the story complete; framed prompt in which the test taker was instructed to continue the story based on the opening sentence of each paragraph provided; vocabulary prompt in which the test taker was instructed to continue the story using key words underlined in the given passage; and framed vocabulary prompt in which the test taker was instructed to continue the story “based on the opening sentence of each paragraph provided and using at least five key words underlined in the given passage” (p. 366). They found that bare prompts resulted in lower scores than the other types of follow-up prompts, suggesting that prompts with higher cognitive demands resulted in higher scores. Different types of prompts also resulted in different textual features, such as a higher degree of alignment between the source text and the follow-up text and lower syntactic variation but higher cohesion in the framed prompt conditions. The researchers concluded “that prompts that include both opening sentences for the paragraphs and required key words are likely to allow test takers to better demonstrate their full writing ability, compared to prompts that integrate none or one of these elements” (Shi et al., 2020, p. 383).
Research points to the potential in designing test prompts that provide test takers with scaffolded follow-up prompts (e.g., Shi et al., 2020). Yet, while integrated writing tasks incorporate multiple processes such as reading and writing, and continuation tasks include multi-step composing processes, neither offers real-time interventions between composing stages. With the advancement in AI technology, Interactive Writing using prompting that is specifically keyed to the content of an initial response offers greater opportunities for measuring test takers’ full writing abilities in an interactive writing process while avoiding the risks of negatively impacting test takers by providing direct, critical feedback on organizational or mechanical elements of their writing in a high-stakes setting. This focus on tailored prompting aligns with the interactive and contextual nature of writing, and advancements in AI now offer tools to implement these approaches at scale.
AI in assessment and learning
Automated writing evaluation (AWE) systems have been well-researched as a way to automate writing assessment or complement the work of human raters. The earliest AWE systems focused primarily on easily quantifiable surface-level statistical and linguistic features to do with length, sentence complexity, punctuation accuracy, and lexicogrammatical accuracy, range, and diversity (see, e.g., Page, 1966). Later, AWE systems for high-stakes testing utilized natural language processing (NLP; Attali & Burstein, 2006; Shermis & Burstein, 2003) to replicate human scoring patterns. More recent AWE systems implement deep neural algorithms that can automatically process and incorporate complex language features and world knowledge (Shin & Gierl, 2021).
In parallel, there has been a surge in automated written feedback (AWF) systems, especially in word-processing programs but also as standalone writing assistants (for reviews see Burstein & Attali, 2024). Research on AWF tools has focused on validity, user perceptions, impact, and influencing factors on its use, such as the accuracy and coverage of feedback types (Bai & Hu, 2017; Ranalli, 2018), and user perception and utilization (L. Jiang et al., 2020). AWE and AWF systems have drastically improved in their ability to read and respond to text with recent advances in LLMs like the Generative Pretrained Transformer (GPT; OpenAI, 2023, 2024). As these models have evolved and become more accessible, they have rapidly been integrated into writing instructional settings, highlighting their dual role not just as scoring tools (Naismith et al., 2023; Yancey et al., 2023) but also as pedagogical tools. In pedagogical applications, researchers have explored how LLMs can elicit metalinguistic feedback on writing (Beguš et al., 2023), detect stance in and support learning of argumentative writing (Eguchi & Kyle, 2023), and support student writing by identifying main points in a text and suggesting areas for elaboration (Zhang et al., 2024).
LLMs, such as GPT, bring a new set of possibilities to the design and evaluation of writing tasks. One of these possibilities is to use LLMs to create a task that is interactive and responsive to test-taker writing, which would move high-stakes writing assessment past the current approach of a static prompt. To that end, we leverage these new models to develop a new Interactive Writing task for large-scale assessment.
Overview of the interactive writing task
The Interactive Writing task is an extension of a traditional writing assessment in which a test taker responds to a narrative or argumentative writing prompt that asks them to describe an experience or their opinions on a topic. What distinguishes the Interactive Writing task from traditional tasks is that test takers have the opportunity to elaborate further on related themes with customized prompting (Figure 1).
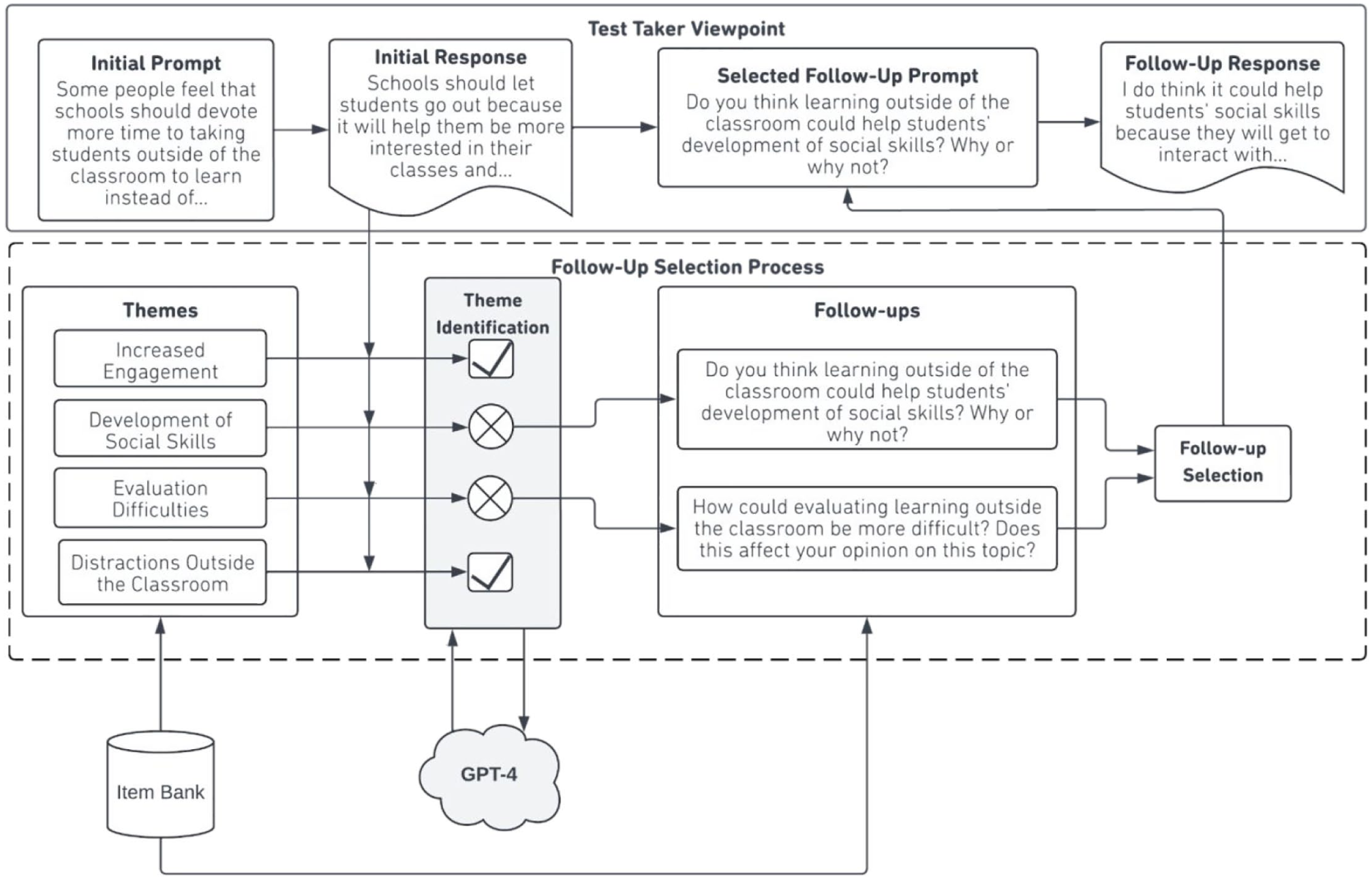
Interactive writing administration process.
The purpose of this research is to generate empirical evidence that supports the design and administration characteristics of the task. We answer the following research questions:
How does follow-up writing prompt phrasing impact test takers’ performance on and perception of the task?
How accurately do LLMs detect themes in test takers’ initial responses?
What impact does the accuracy of theme detection have on follow-up prompts and writing scores?
Does the interactive task structure support relevant follow-up responses?
How do test takers perceive the task?
Methods
Materials and participants
Data-collection platform
Data for these experiments were collected from a piloting platform integrated into the practice test (PT) version of the DET, which mirrors the full official test version and is freely available online, drawing over 10,000 test sessions each day. Test takers come from around the world and range in proficiency from CEFR A1 to C2 (in this study, we did not collect information on gender, age, or first language, nor on whether test takers responded in a language other than English). Test takers were able to opt into the pilot platform upon completing the PT and were informed that opting in or out would have no impact on their PT score. Test takers who opted in were asked to complete an Interactive Writing task. Figure 2 shows participants’ CEFR proficiencies as estimated by their PT score, while Table 1 shows the breakdown of participants by continent.
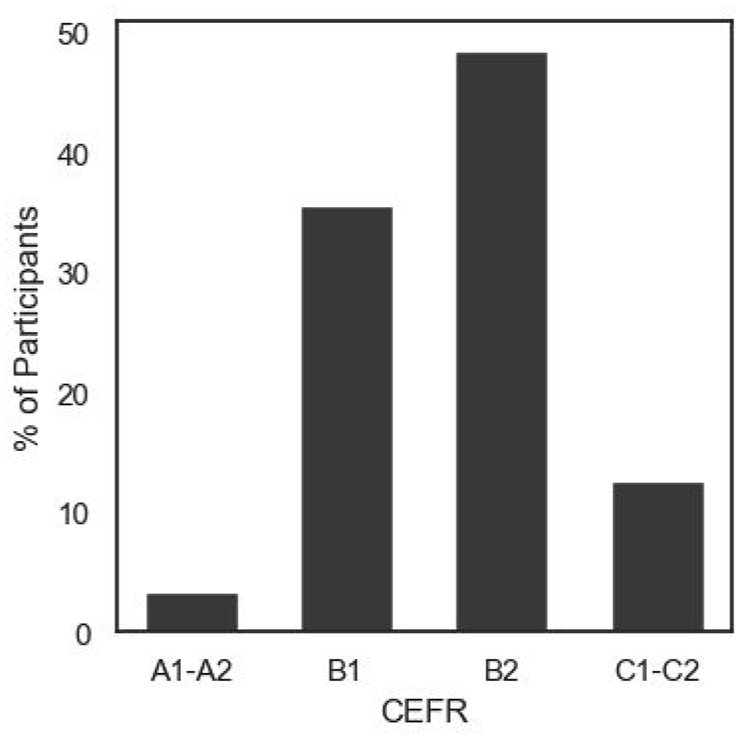
Number of participants by CEFR proficiency level.
Breakdown of participants by continent.

Writing scoring system
We used the DET automated writing scoring system to score both responses on the Interactive Writing task. It evaluates subconstructs of topic/theme relevance and development, discourse coherence, grammar, and lexis and produces scores roughly scaled with a mean of 0 and SD of 1.
Procedure
This section describes three sets of procedures. First, we discuss how the task administration works. Next, we present our approaches to using LLMs to automatically generate the required content for the Interactive Writing task. Finally, we describe the automated theme-detection procedures.
Task administration
Similar to traditional independent writing prompts, the Interactive Writing task begins with a prompt for which a test taker creates a written response. These prompts are designed to elicit either narrative writing, in which test takers describe an experience, person, event, or interest from their perspective, or argumentative writing, in which test takers choose and advocate for a stance on a topic. Each prompt is associated with a list of predefined themes that are brief descriptions of potential subtopics a test taker might address in their response. Each theme is paired with a secondary prompt that asks for a follow-up response discussing the theme in the context of a response to the initial prompt. After the test taker writes their response to the initial prompt, we use a fine-tuned LLM to evaluate their response and detect which of the predefined themes they wrote about in their initial response. Based on this evaluation, the system randomly selects one of the themes they did not discuss and presents the associated secondary prompt as a follow-up task to the test taker. In other words, the set of themes that were not identified in the test taker’s initial response determines the set of eligible follow-ups for a given administration. Test takers who address all themes in their initial response receive a randomly selected follow-up prompt from the available follow-ups. See Figure 1 for the process and Supplemental Appendix A for task screenshots.
Theme detection and follow-up selection are conducted immediately after the test taker submits the initial response, drawing from the existing human-reviewed pool of follow-up prompts. We chose to use pre-generated follow-up questions rather than live-generated follow-ups to prevent unpredictable LLM behavior.
Task generation
The initial prompts, themes, and follow-up prompts were all generated automatically using LLMs and reviewed by humans before being administered as part of the task. We defined topic and theme during item generation as follows:
A
A
Figure 3 illustrates the process for generating Interactive Writing tasks for an argumentative writing prompt (Column 1) with clearly defined stances (Column 2). For narrative prompts, the only input would be the initial prompt. We generate themes for the prompt and each stance (Column 3) and create a follow-up prompt (Column 4) for each theme that relates the theme to the initial prompt. While only four follow-up prompts are shown here, each initial prompt could have up to 20 follow-up prompts. Human experts review and edit the initial prompt, themes, and follow-up prompts to ensure they meet our quality standards.
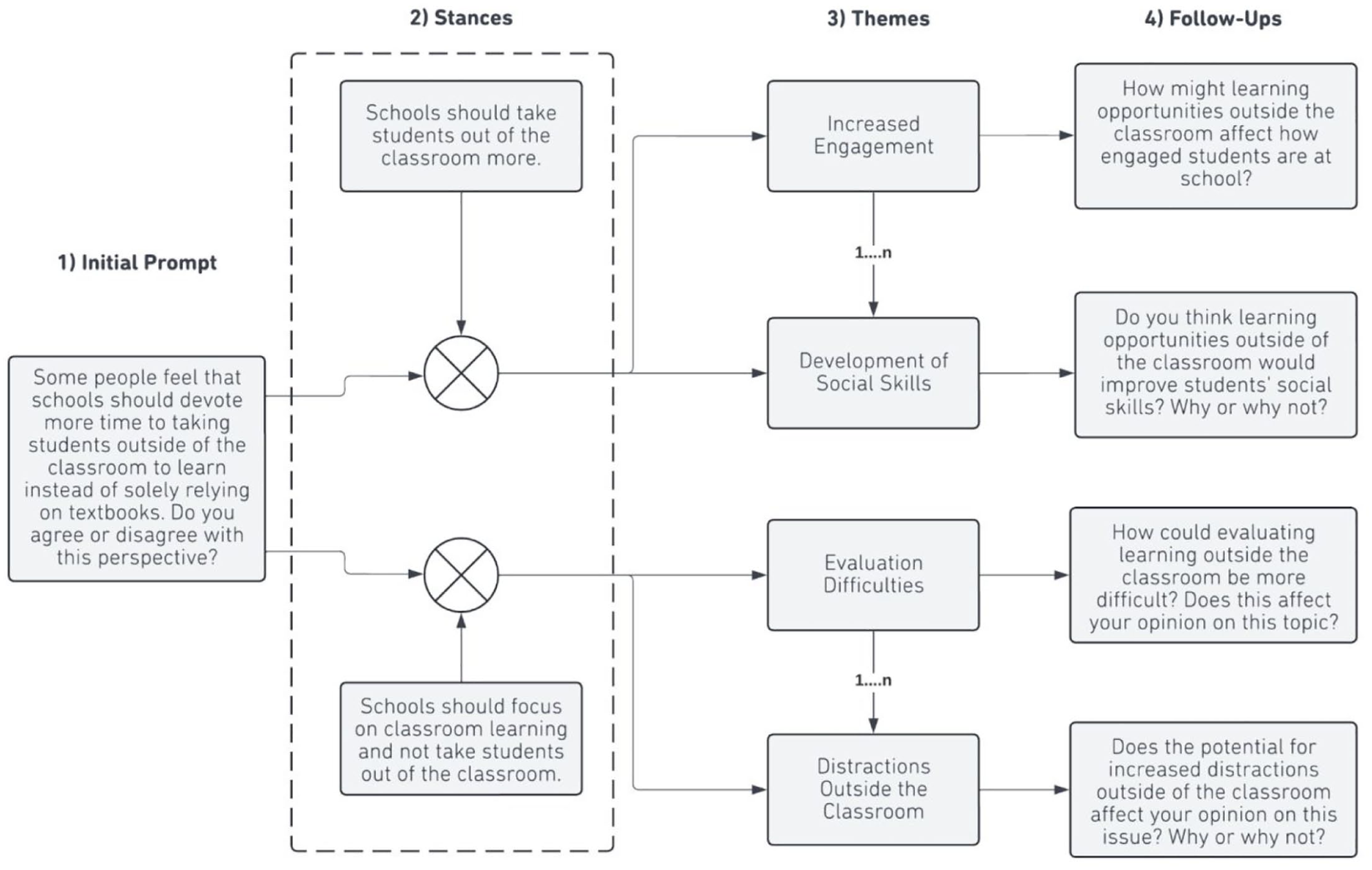
Interactive writing task-generation process.
Initial Prompt Generation
We generated initial prompts for the Interactive Writing task as follows. Expert test developers selected keywords and phrases that should be central to the topics of the generated prompts. To better control the task demands, each prompt’s topic targeted one of four CEFR domains of language use: personal, related to the writer’s own thoughts or experiences in their personal lives; public, relevant to society, culture, or public affairs; educational, related to learning and the writer’s educational background; and occupational, related to career and professional experiences and interests (Council of Europe, 2020).
We then generated prompts with GPT-4 1 (OpenAI, 2024) by providing the selected keywords/phrases, as well as example prompts, domain descriptions, and the type of writing to be elicited (narrative or argumentative). We automatically filtered out generated prompts longer than 50 words or four sentences. In addition, we used GPT-4 to identify and remove prompts that were unclear, ambiguous, or ungrammatical; asked non-substantive questions (e.g., “What is your favorite color and why?”); or contained highly technical or topic-specific vocabulary. We also removed prompts that discussed sensitive or controversial subjects, asked test takers to write about culturally bound or atypical experiences, or asked test takers to dwell on negative experiences (Zieky, 2016). These GPT-4-based filters supported quality, appropriateness, and fairness in prompt design.
Theme Generation
After generating and filtering the initial prompts, for each retained prompt, we used GPT-4 to generate a list of candidate themes representing different possible ideas that test takers could write about. We generated sets of ten themes at a time, along with a short description of how the theme relates to the prompt. When generating themes for argumentative prompts with clear stances, we included the stance in the input to GPT-4 and generated themes separately for each potential stance (see Figure 3) to ensure we represented the range of possible themes that could be included in test-taker responses.
We filtered out themes that were longer than seven words, that contained potentially offensive terms, or that contained extremely low-frequency words (<1 per million) based on corpus frequency counts from the Corpus of Contemporary American English (COCA; Davies, 2008). In addition, we de-duplicated the generated themes by using a neural language model 2 (Reimers & Gurevych, 2019) to embed the texts of the themes into a vector space and identified close semantic matches using cosine distance between these embeddings.
Follow-Up Prompt Generation
For the secondary task prompts, we used GPT-4 to generate follow-up prompts for each of the themes generated for each initial prompt. We provided the initial prompt, a short description of the topic of the initial prompt, and the text of the theme as the main input to the model. We also provided instructions and examples to GPT-4 to generate follow-up prompts that linked the selected theme back to the initial topic of the prompt to clearly establish the relationship between the theme and topic. In an early set of experiments (see the Follow-up prompt language experiment section), we compared four ways of phrasing the follow-ups to capture this relationship: Suggestion, Rigid, Flexible, and Free (examples in Supplemental Appendix B). For argumentative follow-up prompts, we also gave instructions to generate follow-ups that related the theme and topic using neutral language, rather than linking the theme to a particular stance. We did this to allow test takers more freedom in how they address the theme, rather than requiring agreement or disagreement with an assumed stance.
To elicit sustained discussion of the theme in relation to the original topic from test takers, we filtered out follow-up prompts that could be answered with a simple statement of agreement or disagreement. We filtered out generated follow-ups longer than 30 words or two sentences and imposed the same vocabulary frequency checks as we did on the themes. We used the same GPT-4-based filters for quality, appropriateness, and fairness as we used for the initial prompts. We generated multiple candidate follow-ups for each theme and randomly selected one that passed these filters as the associated follow-up for the theme.
Human Review
Initial prompts, themes, and follow-up prompts were edited and reviewed by experts with advanced degrees and experience in second language studies, applied linguistics, and English language education to ensure that the stimuli adhered to development specifications. The first group of reviewers included item quality reviewers who corrected grammar and vocabulary problems and ensured that follow-up prompts framed their topics neutrally. A second group of reviewers conducted sensitivity reviews. They reviewed each prompt and its follow-up prompts to ensure that test takers from a wide range of backgrounds would be able to address both the prompt and any potential follow-up prompts, labeling any fairness violations not flagged in the automatic filtering processes described earlier. These reviewers either proposed edits or rejected initial prompts and/or any follow-up prompts.
Automated theme detection
We framed the task of theme detection as a binary classification task where, given a writing prompt, a response to the prompt, and a list of themes, the goal was to label each of the themes as being present or absent in the response.
To train models to perform this task automatically, we first collected a dataset of responses from the test’s 5-minute, single-response writing task (see Cardwell et al., 2024, for a full description of the item). We selected 113 argumentative and 145 narrative prompts and sampled 30 responses for each from within a 3-month window. To ensure the representation of responses from test takers with a wide range of proficiency levels, we sampled 5–10 responses for each of the three proficiency bands based on writing section scores from the test. This resulted in a dataset of 7395 responses, which we used to develop the theme-detection models.
We used the methods described in the Theme Generation subsection to generate themes for each of the combined sets of prompts (n = 258) in the response dataset and developed a prompt for GPT-4 to automatically identify which themes were addressed in a given response. The prompt (see Supplemental Appendix C) included a few examples of the theme-detection task to help guide the model on how to correctly perform the task.
After iterating this GPT-4 prompt to achieve satisfactory results based on a manual review of the outputs, we used it to automatically label the full dataset of responses with their themes. Finally, we used this automatically labeled dataset to fine-tune two LLMs, GPT-3.5 (gpt-3.5-turbo-0613, OpenAI, 2023) and Mistral-7B (A. Q. Jiang et al., 2023), to specialize in the task of theme identification.
To evaluate the accuracy of our theme-detection models, we internally labeled a set of 305 responses (160 argumentative and 145 narrative) at three proficiency bands, which were sampled from 199 prompts created for a static writing task. Given a prompt, a list of themes, and a response, we identified which of the themes were addressed, even minimally, in the response. Annotation was carried out by two of the authors on independent sets of responses.
We describe how we evaluated and selected a model to use for the operational task (Supplemental Appendix A) in the Theme-detection evaluation subsection of the Results.
Evaluations
Follow-up response relevance rating
The automated writing scorer we used evaluates the relevance of a response to the prompt as one of its features. Because the follow-up prompts are extensions of the initial prompt that require test takers to write on a more specific aspect of the initial prompt, one of our research questions was to assess how well test takers were able to write relevant responses within this more complex context. To address this question, we conducted a small human labeling study focusing on the relationship between the two prompts (initial and follow-up) and the test taker’s response to the follow-up prompt. We used the human-rated data to develop and validate an automated approach that took both prompts into account when assessing the follow-up response’s relevance so that we could apply it to a larger sample of responses.
For the labeling study, we developed a 4-point rubric for assessing the relevance of the test taker’s response to the follow-up prompt in the context of the initial, with a 1 indicating that the test taker did not address the main topic of the follow-up prompt at all, and a 4 indicating that they addressed the topic clearly, directly, and in detail. Two of the authors labeled a sample of 50 test-taker responses and used them to refine the rubric and identify examples of responses for each rubric category. The final rubric and examples are provided in Supplemental Appendix D. We hired three raters with prior experience in English language teaching and assessing writing to each label a set of 300 responses using this rubric.
For our automated approach, we provided the same rubric to GPT-4 along with two examples at each score point in the rubric. Each example consisted of the initial prompt, the follow-up prompt, the test taker’s response to the follow-up prompt, and the authors’ assigned rating. We then trained GPT-4 to label the same set of 300 responses that we gave to the human raters.
Post-test survey
In addition to collecting responses to the Interactive Writing task, we administered a survey, asking participants to share their feedback about their experience with the task to assess test takers’ perceptions of the task. The survey instrument contained nine items: one open-ended question asking about how test takers approached the task, six 5-point Likert-scale survey items about their perceptions of the task and their ability to respond to it (1 = Strongly disagree; 3 = Neither agree nor disagree; 5 = Strongly agree), and two questions asking about any technical difficulties they had with the task. We used the data from this survey to inform and validate task design decisions throughout our experiments. The survey questions can be found in the tables in Supplemental Appendix F.
Data-collection procedure
Participants were recruited immediately after completing the DET PT via the opt-in platform, with a 41% opt-in rate. Participants who opted in were randomly assigned to a condition according to the experimental setup and asked to complete an Interactive Writing task. We collected 25,454 responses after filtering out empty or insubstantial responses across all our experiments.
We scored test-taker responses to three PT writing tasks, as well as both the initial and follow-up responses to the Interactive Writing tasks using the automated writing scoring system (Cardwell et al., 2024). We evaluated the relevance of the follow-up response to the prompts using the GPT-based relevance assessment described in the Evaluations section. We also collected responses to the post-test survey from each participant.
Results
This section presents results from our experiments conducted to address our research questions related to task design and validity. We first present results from an experiment testing how the framing of the follow-up prompts impacts test-taker responses. We next present an evaluation of our theme-detection models, followed by results from two experiments to determine the impact of theme detection and the resulting follow-up selection on test takers’ task performance. We evaluate the results of our automated response relevance models and provide summaries of results from applying them to collected test-taker responses. Finally, we show results from the post-test task perception survey.
Follow-up prompt language experiment
To answer our first research question about the impact of follow-up language on test-taker responses, we compared follow-ups generated using each of the four framings: suggestion, rigid, flexible, and free (see Follow-up prompt generation section). A one-way analysis of variance (ANOVA) on follow-up scores (Table 2) found a significant effect (
Descriptive results for prompt framing experiment.
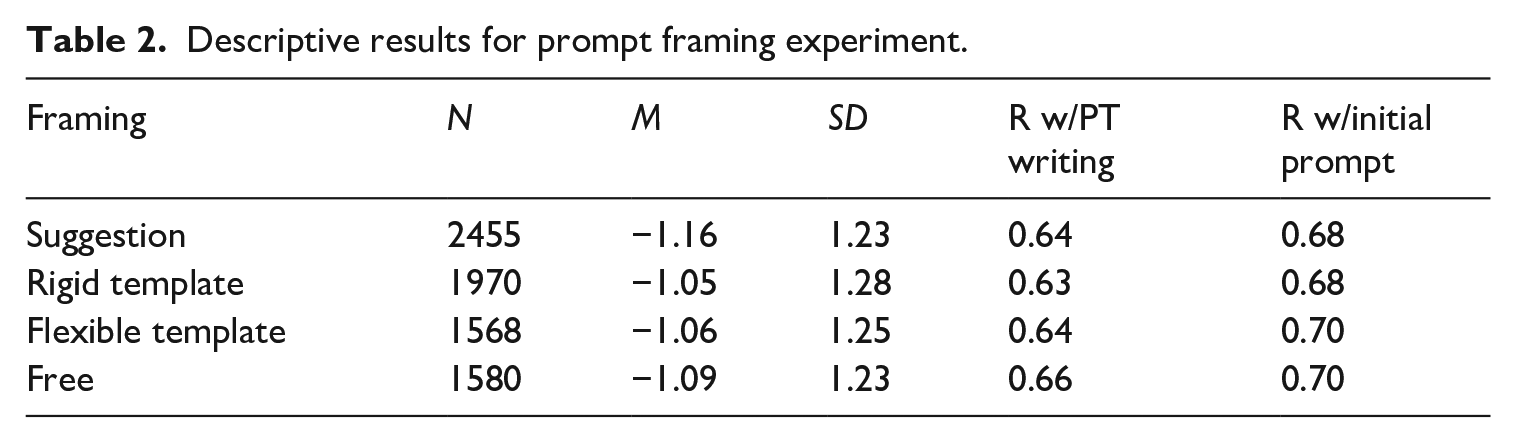
Our analysis of responses found that test takers sometimes used a more conversational tone in the Suggestion framing (e.g., “yes I can talk about . . .”). Our post-test survey of test takers also found a small but significant (1–5 scale,
Theme-detection evaluation
To assess how accurately language models can detect themes in written responses, we evaluated the performance of each of our fine-tuned models on our manually labeled theme-detection evaluation dataset. We additionally evaluated non-fine-tuned GPT-4 and GPT-3.5 models on this dataset for comparison. As inputs to these models, we used the same language model prompts that were used to label the training dataset for our fine-tuned models (Supplemental Appendix C). For each response, we computed the model’s precision, which is a measure of the rate of Type I errors on that response as the number of human-identified themes the model correctly predicted, divided by the total number of themes it predicted. We similarly computed per-response recall, a measure of the rate of Type II errors, as the number of human-identified themes the model correctly predicted, divided by the total number of human-identified themes for the response. We then averaged the per-response precision and recall values across the dataset. We report performance on the argumentative and narrative prompts separately, and also performance per proficiency band in Supplemental Table E1. We find that the off-the-shelf GPT-3.5 and GPT-4 models had higher precision but lower recall, i.e. made more Type II errors, across prompt types and proficiency bands. The fine-tuned models showed the opposite performance (more Type I errors), with the fine-tuned GPT-3.5 model performing better than Mistral on both precision and recall overall.
When deciding which model to select for the theme-detection task, we considered the implications of each type of error. Type I errors represent an incorrect prediction that a test taker wrote about a theme when they actually did not. Our task design means that the primary outcome of this error is that we would not ask them to write about the theme, and the error would thus be invisible to the test taker. However, a model with particularly poor precision might over-predict themes to the point that it frequently predicts that the test taker has covered every possible theme.
Type II errors, however, mean that a test taker could be asked to write about a theme they have already written about. This could be confusing or frustrating for a test taker, who might be led to believe that their initial response was unclear. Alternatively, this could give an advantage to these test takers, since they would be asked to write about something they are already familiar with. We explore this risk further in the following section.
Given the relative risks associated with these two errors, we computed the F-beta measure, a generalization of the F-1 model evaluation metric which measures the weighted harmonic mean of precision and recall (van Rijsbergen, 1979). We used a beta of 2 (i.e., F-2) to reflect the increased importance of recall over precision. Under this metric, the fine-tuned GPT-3.5 model performed best across all narrative subsets and comparably to the best model on three of four subsets for the argumentative task (full results in Supplemental Table E2). This improvement over GPT-4, which provided the labeled data used to train the GPT-3.5 model, may be due to the model seeing a wider range of prompts and response types in its training data, as opposed to the small number of fixed examples in the language model prompt provided to GPT-4. As a result, we selected the fine-tuned GPT-3.5 model for use in the operational task.
Effect of theme-detection model on writing scores
We next evaluated how the accuracy of the theme-detection model could impact scores on the follow-up task. As described in the previous section, inferior theme-detection models could result in a test taker being asked to write about a theme they had already written about in their initial response, potentially leading to confusion or frustration. This could also potentially give an advantage to some test takers who could simply repeat the content of their initial response. More critically, it would undermine the goal of having the test taker elaborate on their initial response with respect to the follow-up prompt.
In the previous section, we identified the best-performing theme-detection model for use in the operational task. However, it is important to estimate potential effects of using an inferior model from an operational perspective as well, since it is possible that, for technical reasons, the chosen model would not be available at times. As such, an inferior model might need to be used instead as a fallback to administer the task to test takers during periods of unavailability.
For this experiment, we compared our selected (fine-tuned GPT-3.5) theme-detection model with two potential candidates for fallback models: the base GPT-4 model (the same off-the-shelf GPT-4 model used in the previous experiments) and a weighted-sample-detection model. The latter model uses weighted random selection of the themes, based on their inverse likelihood of being discussed in the initial response to a prompt. Likelihoods were estimated from responses in prior experiments using the same prompts. We evaluated this model as an LLM-free solution to the follow-up prompt selection task. We collected a total of 8380 responses for initial and follow-up prompts of Interactive Writing tasks on our pilot platform, where each participant’s follow-up task was selected using one of these three models chosen randomly.
We focused on identifying test takers for whom one of the fallback theme-detection models would have exhibited a Type II error. To do this, we collected the initial responses from test takers whose follow-up was selected by one of the two potential fallback models and re-ran those responses through the fine-tuned GPT-3.5 theme-detection model. Based on the set of themes detected by this model, we then checked whether the theme of the follow-up selected by the fallback model was detected in the initial response by the fine-tuned model, indicating a test taker who received a follow-up about a theme they had likely written about in their response. We refer to these test takers as “theme repeaters.”
The percentages of theme repeaters were 14% and 21% for the base GPT-4 and weighted-sample fallback models, respectively. In general, theme repeaters wrote longer responses to the initial Interactive Writing task prompts (mean of 525 vs. 383 characters, with an effect size of
In other words, theme repeaters seem to have written better responses, as indicated by their PT writing scores, that addressed more of the available themes, which (at least partly) explains why they are more likely to have themes repeated under the less-reliable models. Therefore, in comparing follow-up scores of theme repeaters with non-theme repeaters, we needed to take into account test takers’ performance on the initial task. Figure 4 shows that the relation between initial and follow-up scores was stronger for theme repeaters (b = .12, p < .001). This means that for test takers with higher initial scores, theme repeaters tended to score higher on the follow-up task. However, for test takers with lower initial scores, theme repeaters tended to score lower on the follow-up task. The effect of theme repeating on follow-up scores for an average initial score of 0 was positive (b = .07, p = .02) but quite small.
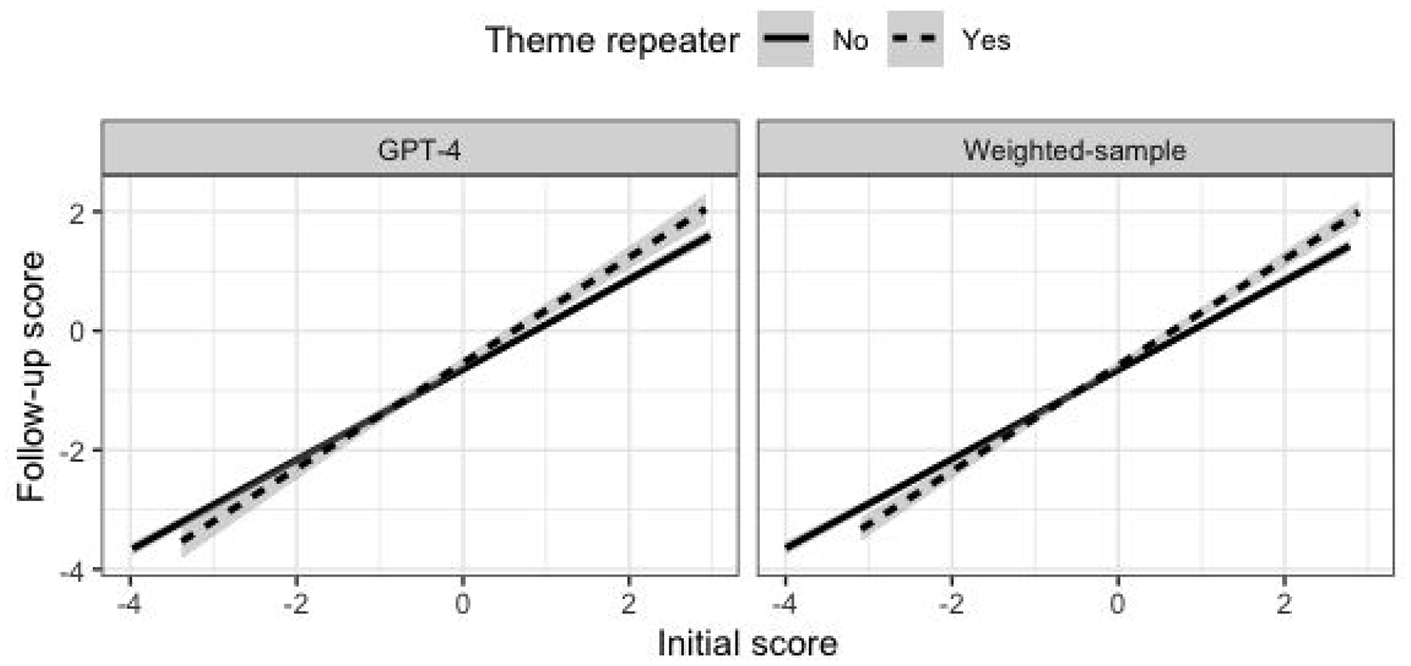
Follow-up score as a function of initial score.
Finally, we asked test takers in our post-task survey (discussed further in the Post-test survey section) whether the follow-up task asked them to write about something they had already written about in the initial response (1–5 scale, from Strongly disagree to Strongly agree, with Neutral as mid-point). Theme repeaters (
Follow-up scores as a function of selected theme
Some large-scale assessments of writing assign prompts randomly to test takers. A question that arises for every large-scale writing assessment is the degree to which scores depend on the particular prompts that a test taker was assigned to write about. For the Interactive Writing task, this question is of particular importance for the follow-up task since this task is not randomly assigned; it depends on the themes detected in the test taker’s initial response.
To evaluate the variability of follow-up scores across themes, we estimated a mixed-effects model of follow-up scores with prompt and theme (nested within prompt) as two random effects and initial score as a fixed effect. We used the data from the detection model experiment, including theme repeater cases (we found no difference if we excluded theme repeaters or the fallback models), which included nine prompts and 6–15 themes per prompt (with a median of nine themes). Results showed that scores varied very little across themes and prompts. The theme random effect accounted for just 0.6% of the total variance of follow-up scores (after accounting for initial scores), and the prompt effect accounted for a negligible 0.01%. In other words, follow-up scores are unlikely to be affected by the particular theme selected for the follow-up task.
Evaluation of response relevance
To address our question about how well test takers were able to write relevant responses in this new task framework, we evaluated the results of human and GPT-based relevance ratings. Table 3 shows average quadratic weighted kappas and correlations within our three human raters, as well as between our human raters and GPT.
Rater agreement and correlations between human and machine raters.

We found that our human raters achieved substantial interrater agreement (>.6; Landis & Koch, 1977) and that the GPT-based method of relevance rating performed comparably to our human raters. These results provide support for the use of our GPT-4-based relevance rater to answer our research question about how well test takers are able to write relevant responses to the follow-ups. We used the GPT-4 relevance measure to label 13,048 responses from test takers whose experimental conditions matched our final task design. We found that 58% of test takers scored 3-4 for relevance (Supplemental Table D2), indicating test takers could generally understand the follow-ups and their relation to the topic sufficiently to write relevant responses.
Post-test survey
Finally, we examined test-taker perceptions of the task based on our post-test survey results. We used only responses from test takers whose experience of the task matched our final design and filtered responses from test takers who either did not complete both portions of the task or who gave extremely low-effort responses to either of the prompts. This process resulted in a set of 13,048 survey responses for our analysis. Summaries of the results can be found in Supplemental Table F1 and full results in Supplemental Table F2.
Test takers generally responded favorably to the task as an assessment of their writing. No significant technical issues were noted. On average, test takers agreed that the follow-ups were clear extensions of the first task, and a slightly lower majority reported they were able to connect their two responses. While test takers were neutral about their familiarity with the topic of the follow-up, they generally reported that they understood what the follow-up was asking them to write about. We observed small but significant correlations between test takers’ performance on the two tasks and their responses to the survey questions, indicating test takers who performed better on the task had a better opinion of the task and their ability to respond to it.
Discussion
In this paper, we have presented an innovative, interactive writing assessment task that is integrated into a large-scale, high-stakes writing test. Compared to static prompting that has pervaded writing assessment for decades, the Interactive Writing task analyzes test-taker responses in real-time using LLMs to select a follow-up prompt that encourages further elaboration on the initial response.
The results of our evaluations provide evidence that the Interactive Writing task successfully meets its design goals. Follow-up prompts framed in more natural language (“free” phrasing) improved task performance and test taker perceptions of the task. The fine-tuned theme-detection model showed high recall, minimizing the risk of asking test takers to repeat content, and its performance was consistent across prompt types and proficiency bands. We also found that follow-up writing scores were largely unaffected by specific themes or prompts, indicating robust score consistency. These findings suggest that integrating real-time interactivity using LLMs can enhance construct representation in high-stakes writing assessments while maintaining fairness and usability.
Limitations
There are of course limitations to the current task. One notable limitation is our use of pre-generated follow-ups, which offer reduced personalization compared to approaches that more directly interact with test taker responses via overt correction, subjective feedback, or dynamically generated follow-ups. However, this limitation was by design: by limiting the interactivity to neutral, non-reactive prompts and avoiding direct feedback on the organizational or grammatical quality, we reduce potential stress and cultural bias in the high-stakes testing environment. While we could have introduced more interactive elements that are possible in today’s modern writing interfaces such as spelling or grammar correction or rhetorical suggestions, we elected not to draw test takers’ attention to any errors they had made or suggest stylistic changes. In addition, using an LLM to select from a set of expert-reviewed follow-ups to administer, rather than directly generating new content, reduces the risk of erroneous LLM output and limits the potential for jailbreaking (Li et al., 2023), in which a test taker could submit adversarial responses designed to cause the LLM to divulge information about its instructions or provide the test taker with unexpected assistance. While we recognize that this approach to follow-up prompting is different from dynamic feedback that offers areas for writers to improve with iterative revision processes, the task structure we implemented allows us to directly engage with test-taker responses and present an interactive experience without incurring the costs, risks, and scoring challenges of generating novel content as part of the task administration.
In evaluating task scores for our study, we found that the selected follow-up accounted for a small proportion of total variance in scores (0.6%). We additionally found that test takers who receive a follow-up for a theme they have already written about (i.e., theme repeaters) may receive higher scores on the follow-up task. The theme-detection model achieves strong, but not perfect, recall, presenting a risk for theme repeaters, and technical issues with the model provider may result in a weaker model being used to avoid disrupting the test session. Furthermore, responses that cover all themes for an initial prompt will inevitably get a repeated theme, making items with only a few follow-ups more susceptible to this issue. These risks can be mitigated through careful system design to ensure fallbacks during task administration, combined with monitoring and pruning of the item bank to remove tasks exhibiting these issues.
Conclusions and future directions
The Interactive Writing task marks an important advancement in large-scale writing assessment by drawing on sociocognitive theories of writing. By expanding the construct of writing to include elaboration, the Interactive Writing task models the kinds of process-based writing situations that test takers will encounter in college and workplace contexts and is theoretically consistent with a sociocognitive framework for the assessment of writing. Consistent with research on other multi-part writing prompts used in large-scale testing, such as story completion tasks (Shi et al., 2020), we found that task framing for the follow-up prompt is a critical element in generating high-quality responses from test takers. Importantly, however, scores were unlikely to be affected by the particular theme selected for the follow-up task, suggesting that assessments designed with follow-up prompting do satisfactorily measure writing proficiency.
The Interactive Writing task follows recent work in developing innovative complex assessments that are automatically generated and introduce interactive elements in large-scale assessments of reading (Attali et al., 2022) and listening (Runge et al., 2024). It represents an important step toward developing large-scale assessments of writing that focus on not just the final product but also the writing process. Our findings have broader implications for the future design of large-scale writing assessments and are consistent with advancements in integrated writing tasks and story continuation tasks. The capability of AI to adapt and respond to individual student outputs in near real-time opens new avenues for authentic assessment where students engage in a more meaningful process of writing, one that better reflects a process of constructing and communicating meaning. By utilizing LLMs to provide reactions to writing input, assessments can better reflect writing scenarios where the ability to construct compelling arguments and address a topic comprehensively is essential. This feedback mechanism is impossible to implement with human reviewers in the context of large-scale assessments. However, the judicious use of AI can also promote consistency and evidence-based feedback that contributes to fair and equitable assessments. By employing a real-time AI model as part of the task administration, the Interactive Writing task illustrates one way test developers can employ AI/ML while minimizing risk, a key element of responsible application of AI in assessment (e.g., Burstein, 2023). In addition, the use of AI can help to standardize the process of prompt creation, ensuring that each test taker is provided with prompts that are clear, fair, and aligned with the assessment objectives. This standardization ensures that evaluation is focused on test takers’ writing abilities and enhances the fairness and efficacy of writing assessments.
In conclusion, new AI tools have the potential to profoundly change assessment (Harding, 2025). AI is changing every aspect of test development, from automatic item generation to automatic evaluation. However, one of the most exciting developments is the creation of state-of-the-art tasks with the potential to more authentically assess complex constructs such as writing.
Supplemental Material
sj-pdf-1-ltj-10.1177_02655322251349908 – Supplemental material for A multi-stage interactive writing task for the assessment of English language writing proficiency
Supplemental material, sj-pdf-1-ltj-10.1177_02655322251349908 for A multi-stage interactive writing task for the assessment of English language writing proficiency by Andrew Runge, Sarah Goodwin, Yigal Attali, Mya Poe, Phoebe Mulcaire, Kai-Ling Lo and Geoffrey T. LaFlair in Language Testing
Footnotes
Acknowledgements
The authors would like to thank Jill Burstein and Alina von Davier for reviews of early paper drafts, Ruisong Li for engineering support, and Yukti Sharma for coordination of the project’s technical aspects.
Author contribution(s)
Declaration of conflicting interests
The authors disclose the following potential conflicts of interest related to the research, authorship, and/or publication of this article: The Duolingo English Test is owned by Duolingo, Inc. The authors AR, SG, YA, PM, KL, and GL are employed by Duolingo, Inc. and receive stock-based compensation as part of their remuneration package. The author MP is a consultant for Duolingo. The views shared represent our individual perspectives and experiences rather than Duolingo, Inc. as a whole.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.