
Abstract
This study examined the consistency between instructor ratings of learner-generated summaries and those estimated by a large language model (LLM) on summary content checklist items designed for undergraduate second language (L2) writing instruction in Japan. The effects of the LLM prompt design on the consistency between the two were also explored by comparing six types of prompts obtained by altering the amount of information included in the prompt and the direction concerning the order in which different parts of the LLM output (a checklist-based rating and its rationale) are generated. Ninety-seven summaries written by Japanese undergraduate students were analyzed by employing three checklist items on the use of topic sentences included in the source text. Satisfactory agreement between instructor and LLM ratings for low-stakes use was obtained for certain checklist item-by-prompt type combinations. When discrepancies between the two were observed, LLM ratings tended to be harsher than instructor ratings in general. Furthermore, the amount of information included in the LLM prompt affected the instructor-LLM rating agreement more than the order of generating a rating and its rationale in the output. The results offered initial empirical support for employing LLM-generated formative feedback on summary content in L2 writing classrooms.
Keywords
The central role that feedback plays in second language (L2) learning is well recognized in the current L2 assessment literature (Jang & Sinclair, 2021; Lam, 2021; Lee, 2015; Turner & Purpura, 2016). Ideally, engaging in feedback should allow learner to accurately grasp their current level and its distance from a learning goal in order for them to properly gauge what strategies would be required to close the gap (Hattie & Timperley, 2007; Sadler, 1989). However, doing so can be an arduous task for the learner, particularly when the target task itself is complex. One such example is written summarization, the multifaceted construct of which makes it a challenge for the learner to understand the task demands. As a text-responsible integrated writing task type (Leki & Carson, 1997), summary writing requires the writer to represent the source text content accurately. Thus, the construct of written summarization involves not only general writing ability (e.g., vocabulary, grammar, organization) but also the ability to comprehend the source text and reproduce its gist in writing. Furthermore, previous text processing research has shown that summary content reflects a range of gist formation operations required for a succinct representation of main ideas and important details as well as their interrelationships (Kintsch & Van Dijk, 1978; Van Dijk & Kintsch, 1983).
Yet, the appropriateness of summary content has been relatively underexplored in the L2 integrated writing literature, and the primary focus of relevant previous L2 research has been on the linguistic quality of writing (Plakans, 2015). Presumably reflecting this trend, feedback research in L2 writing has also focused attention on corrective feedback, that is, feedback concerning accuracy and appropriateness of grammar and vocabulary, over the appropriateness of content. Furthermore, this trend applies not only to traditional feedback studies in L2 writing (Biber et al., 2011; Bitchener & Ferris, 2012) but also to more recent studies on automated feedback on L2 learner writing samples conducted in the context of automated writing evaluation (AWE; Fu et al., 2024; Shi & Aryadoust, 2024). Thus, the extant literature offers little insight into how content feedback for source-based writing tasks such as summarization can be designed or implemented.
In sum, much work remains to make the construct of summarization accessible to learners through explicating assessment criteria and providing them with actionable feedback to better support learning. As a first step to do so, this study explored the possibility of automated content feedback based on a summary-content checklist. This study is novel in terms of two points: (1) directly addressing the literature gap by focusing on content feedback for source-based writing and (2) examining the accuracy of automated feedback for learning-oriented assessment LOA). First, informed by the formative assessment and LOA literature (Andrade, 2010; Carless, 2007; Keppell & Carless, 2006), our checklist is designed to offer individualized feedback at the level of gist formation operations for summarization. This approach enables the generation of more granular content feedback than that based on scoring rubrics for L2 summary writing (e.g., Kato, 2021; Li, 2014; Sawaki, 2020; Yamanishi et al., 2019; Yu, 2007), which yield analytic scores at larger grain sizes. As such, we aim to offer metacognitive support for learners to better understand various features underlying quality performance.
Second, by adopting an AWE approach, we focused on the accuracy of automated feedback, whose importance in classroom-based assessment is increasing with the rapid advancement of technology in recent years (Turner & Purpura, 2016; Voss, 2021). Indeed, Purpura’s (2025) update of Turner and Purpura’s (2016) original framework of LOA in language assessment signifies the central role that technology plays in enhancing learning through formative assessment. While immediacy is a notable strength of technology-mediated assessment (Alderson, 2005), its pedagogical value depends on whether it closely mirrors instructor judgment. If automated feedback adequately reflects instructor judgment, learners would treat the feedback as provisional guidance—especially useful when instructor feedback cannot be provided in a timely manner. Such timely and accurate automated feedback would be particularly advantageous for summary writing, where manual scoring and commentary are notoriously labor-intensive and challenging due to the complexity of the construct.
With the above as the background, this study addressed automated feedback accuracy for summary content from the perspective of the consistency between automated checklist-based rating and instructor rating. To generate the automated rating, we employed a large language model (LLM), a neural network model comprising a large number of parameters trained with vast corpora to predict tokens given the context. LLMs have quickly become prominent in the field over the last few years. Multiple scoping and systematic reviews (Law, 2024; Li et al., 2024; Yang & Li, 2024) report that LLMs are already in use to perform a range of assessment/feedback tasks in language education. Our aim was to examine (1) the degree to which checklist-based rating on summary content by LLM corresponds to writing instructor rating and (2) how the prompt design affects the LLM vs. instructor rating consistency. In so doing, we emulated a small-scale LLM application situation in the L2 writing classroom. We also employed realistic LLM use scenarios that L2 writing instructors without much knowledge of or experience with LLMs could implement for summary writing instruction in classroom settings.
This study was part of a larger project for designing and validating an online module for formative assessment of summary writing for use in undergraduate academic writing courses in Japan. This module, W-Writing, delivers summary writing exercises along with four different types of automated feedback on summary content as scaffolding for revisions. Initial empirical validation studies of this module examined the efficacy of the automated feedback from the perspective of the change in learner performance in summary writing (Sawaki, Ishii, Yamada, & Tokunaga, 2024) as well as learner revision behaviors and learners’ and instructors’ perceptions of the feedback (Sawaki, Ishii, & Oi, 2024). This study focuses specifically on the summary content checklist for self-assessment implemented as one of the four feedback types in the module. Currently, no automated rating results are delivered based on the checklist in the module. However, empirical evidence supporting the accuracy of LLM-based feedback would inform further enhancement of the checklist-based feedback design, such as the delivery of LLM feedback upon completion of the checklist for learners to verify their self-assessment results.
Literature review
Feedback provision on L2 performance plays a pivotal role in learning. In their seminal review of feedback research in education, Hattie and Timperley (2007) defined feedback as “information provided by an agent (e.g., teacher, peer, book, parent, self, experience) regarding aspects of one’s performance or understanding” (p. 81). They argued that good feedback should address three key questions posed by the learner: “Where am I going?” (the target level), “How am I going?” (the learner’s current level), and “Where to next?” (how to close the gap between the two). These questions adeptly summarize the current view in classroom-based assessment of the central role that feedback plays in learning (Black & Wiliam, 1998; Sadler, 1989). Various researchers (Carless, 2007; Keppell & Carless, 2006; Lam, 2021) have proposed the qualities required for effective feedback in the context of classroom-based assessment, including LOA. Among them, of particular relevance to this study are specificity and accuracy, which are both intricately related to Hattie and Timperley’s key questions above.
Feedback specificity: Can granular feedback on summary content be devised?
Various authors (Jang & Sinclair, 2021; Lam, 2021; Lee, 2015) have stressed the importance of delivering fine-grained feedback for facilitating learners’ understanding of their strengths and weaknesses as well as areas for further practice. In the context of L2 performance assessment, rubrics are often employed to specify target knowledge/skills/abilities to be assessed, their definitions, and descriptions of different levels for each. Elaboration of the target construct is considered to be facilitated further when analytic rating scales are employed. Previously proposed rubrics for L2 summary writing have indeed adopted this approach, where the multifaceted nature of the construct is represented by analytic rating scales corresponding to conceptually distinct aspects of the construct, such as language quality, content, and source text use (Kato, 2021; Li, 2014; Yu, 2007; see Sawaki, 2020; see Sawaki, Ishii, Yamada, & Tokunaga, 2024 for further details). Yet, this grain size may still be too large for the learner to adequately understand the nature of the construct, let alone their current level or the target level. For instance, summary content rating scales, even analytic, typically lump together gist formation operations (e.g., covering main ideas, omitting redundant and trivial details, connecting main ideas across paragraphs). Thus, resulting analytic scores do not yield feedback customized for individual learner needs at the level of such operations because they do not offer step-by-step guidance as to how the learner can revise summary content by paying attention to them.
The foregoing discussion suggests that other types of assessment instruments that allow further elaboration of the target construct may be worth considering. A viable option is checklists, which have been employed for formative assessment of L2 performance. Checklists typically decompose the target construct into finer grain sizes than rating scales. Thus, this approach is deemed particularly suitable for communicating to the learner what a complex construct such as summarization entails. The granular definition of the target construct also makes it accessible to the learner. As such, using checklists is expected to facilitate the learner’s understanding of the instructor’s concept of quality performance, which Sadler (1989) considers essential for learner improvement. Presumably for this reason, checklists are often employed for student-led assessment activities such as self- and peer-assessments, which aim to promote self-regulated learning (Andrade, 2010; Panadero et al., 2012, 2014). Previous research syntheses (Falchikov & Boud, 1989; Li & Zhang, 2020) have shown that self-assessment activities that incorporate clearly stated assessment criteria in forms such as rating scales and checklists tended to be more effective than those that employ none.
Studies that provide support for the use of checklists for formative purposes have already been reported in the field. For example, in the context of a large-scale speaking assessment preparation (the Cambridge English: First test), Nakatsuhara et al. (2018) devised a learning-oriented checklist for assessing interactional competence (IC) based on a thematic analysis of experienced examiners’ comments on candidates’ speaking performance. The short version of the checklist resulting from a trial with a small group of instructors comprised 13 items corresponding to four subareas of IC, which is often represented by a single rating scale. Another example is Babaii et al.’s (2016) self-assessment checklist designed for speaking practice for undergraduate students in Iran, consisting of 10 items on IELTS speaking assessment criteria identified by five experienced teachers of the IELTS test preparation. They found that employing the checklist for self-assessment contributed to better communication of teacher expectations to learners as well as better learner performance on subsequent tests.
Along the lines of the attempts by Nakatsuhara et al. (2018) and Babaii et al. (2016), one of the initial validation studies of the current formative assessment module for summary writing conducted in an undergraduate academic writing program (Sawaki, Ishii, & Oi, 2024) reported instructors’ and students’ positive perceptions of the feedback based on the self-assessment checklist, which is the focus of this study. When asked about their views of the 15-item checklist on summary content, two instructors commented on the merits of the checklist for explicating model performance by presenting rules for summarization that they need to eventually internalize (Instructor A) and by enabling the learner to “experience what an expert summarizer would be thinking [while summarizing]” (Instructor D; p. 60). Furthermore, in a survey of 81 Japanese undergraduate students conducted upon their completion of the module in the same study, 86.4% of them endorsed the usefulness of the checklist-based feedback for learning.
In the meantime, a drawback of checklist-based feedback would be that it may miscommunicate a complex, holistic construct as a collection of points to be checked-off (Nicol & Macfarlane-Dick, 2006). In other words, satisfying all criteria presented in the checklist does not necessarily represent expected performance. This suggests the need to alleviate such misunderstanding of the learning goal. When sufficient care is taken to avoid such a situation, however, checklists appear to be a viable tool for delivering fine-grained feedback in instructional settings.
Automating content feedback: Can accurate automated feedback be designed?
Even if a checklist that enables fine-grained feedback provision can be developed, the feedback would not inform learning if it comes too late in the learning process. Accordingly, technology can be a viable feedback agent that facilitates timely feedback provision (Keppell & Carless, 2006; Voss, 2021). Recent syntheses of previous studies on the rapidly growing literature on AWE (e.g., Fu et al., 2024; Shi & Aryadoust, 2024; Stevenson & Phakiti, 2014) have revealed the wide variety of automatically delivered feedback that supports L2 learning and assessment.
However, the extant literature does not offer much empirical evidence relevant to this study for two reasons. First, discussions of checklist-based AWE applications have been scant in the field. Second, the majority of previous works on this topic has focused on corrective feedback on grammar and vocabulary, while research on content feedback, particularly those concerning summary writing, is scarce. To the best of the authors’ knowledge, the only relevant AWE system reviewed in previous L2 studies is a component of WriteToLearn called Summary Street!. Designed specifically for summary writing practice, this component offers a variety of automated content feedback based on latent semantic analysis (LSA; Landauer & Dumais, 1997), including semantic similarity of a learner summary to the source text at the paragraph and sentence levels. Classroom trials of Summary Street! conducted in U.S. grade schools (Foltz et al., 2013; Wade-Stein & Kintsch, 2004) reported positive effects on learner task engagement and some aspects of learner summary writing performance. However, more recent studies on this AWE system or other summary writing systems are, as yet, unavailable. Thus, more research is certainly needed on this topic. In doing so, the flexibility of rapidly emerging LLM-based systems such as ChatGPT seems promising. The LLM could be employed not only for straightforward linguistic analyses of learner texts but also for scoring learner responses according to pre-defined assessment criteria such as rubrics and checklists. Furthermore, these operations are accessible to educational practitioners as LLMs accept natural language as input, thus they do not require advanced programming skills.
In terms of feedback accuracy, the fast accumulating literature on LLM use in education has shown that LLMs can predict human assessor judgment reasonably well for tasks such as scoring and error detection (Yan et al., 2024). Consistent with this view are the results of two recent studies conducted by Mizumoto and his colleagues. Mizumoto and Eguchi (2023) investigated the functioning of ChatGPT 3.5 for automated scoring of TOEFL iBT® essays, reporting substantial agreement between ChatGPT ratings with human ratings. They also found that adding linguistic variables to the ChatGPT scoring model contributed to enhancing scoring accuracy. In another study, Mizumoto et al. (2024) focused on linguistic accuracy error coding. They compared error tags generated by ChatGPT 4 and Grammarly against those produced by human coders on Cambridge First Certificate of English (FCE) essays written by Japanese, Korean, and Chinese test takers. The authors found closer alignment to human judgments for ChatGPT than Grammarly in terms of accuracy of error detection as well as prediction of overall writing ability.
While AWE is often intended for low-stakes assessment settings, the accuracy of LLM-produced feedback still matters because properly addressing Hattie and Timperley’s (2007) questions above hinges on the learner’s accurate understanding of their current level. Thus, the empirical results supporting LLM feedback accuracy above are encouraging. They are also impressive particularly because the required training of LLMs is minimal (Steiss et al., 2024) compared to traditional algorithms employed in other common AWE platforms. However, LLM research is still in its infancy, so it is not yet well understood what factors influence the accuracy of feedback generated by LLM.
While the effects of various issues concerning LLM functions and prompts used for an LLM run on the accuracy of LLM-generated feedback require close examination, a key issue that needs to be taken into account is prompt engineering (Liu et al., 2023). Given that ChatGPT is an interactive AI, analysis results vary depending on the prompt provided by the user. Thus, it is essential to explore prompt designs that enable the optimal modeling of quality language use task performance. A key concept is that of chain of thought (CoT), namely, “a series of intermediate natural language reasoning steps that lead to the final output” (Wei et al., 2022, p. 2). G. G. Lee et al.’s (2024) study suggested a degree of effectiveness of using CoT prompts and rubrics in combination to enhance scoring accuracy across different categories and levels. A related issue is the order in which a given prompt instructs an LLM to generate different parts of the output. In a scoring context, for instance, whether the score is generated first followed by its rationale (explanation), or vice versa, matters because the LLM output content is dependent on what has already been generated in the same output (Chiang & Lee, 2023). Another issue concerns training strategies: fine-tuning and in-context learning. Fine-tuning is conducted when the researcher aims to create a model reflecting knowledge of a particular field or to generate sentences in a particular style or tone. For instance, aligning ChatGPT with corpora unique to a given domain and fine-tuning on context can lead to equitable and domain-appropriate automated scoring. However, fine-tuning may fail on a small dataset because it requires a large dataset to update a large number of LLM parameters. In contrast, in-context learning does not update model parameters, making it more suitable for applications involving smaller datasets.
Two types of relevant experimental settings for in-context learning are few-shot, which employs examples of correct outputs in the prompts, and zero-shot, which provides no such example. In an analysis of two essay corpora to compare LLMs on automated scores generated by them against those assigned by human raters, S. Lee et al. (2024) proposed a zero-shot prompting framework called Multi-Trait Specialization (MTS), where the LLMs were prompted to analyze each learner essay on multiple traits reflective of the target writing ability before assigning the overall score. In their experiment, the MTS prompts tested by Lee et al. outperformed straight prompting without such an elaborate scoring scheme in agreement with human rater scores across all LLMs and datasets, suggesting that, when performed on well-designed prompts, zero-shot learning can yield satisfactory scoring results.
Although S. Lee et al.’s (2024) study did not involve few-shot learning, studies comparing the level of agreement with human judgments between zero-shot and few-shot learning are also available. For instance, Yancey et al. (2023) found that adding even a single example to a prompt containing only a minimal scoring rubric noticeably improved human-LLM agreement in their analysis of short L2 essays, although the level of agreement differed across L1 groups. Similarly, in the context of an academic genre analysis, Kim and Lu (2024) reported improvement in few-shot learning over zero-shot learning with regard to the agreement between automated versus manual annotation results of the moves and steps of 100 research articles in applied linguistics (although the improvement was modest compared to that observed for fine-tuning). These results suggest that it is worth exploring the accuracy of L2 writing analysis between zero-shot and few-shot approaches.
The present study
The present review of the extant literature suggests that checklist-based feedback for AWE seems a promising option for immediate delivery of fine-grained feedback that supports summary writing practice. Moreover, the flexibility of LLMs such as ChatGPT, which accommodates various types of natural language input (e.g., learner writing samples, scoring rubrics, checklists) and generates feedback on the scoring results, is particularly attractive in pursuing this direction. At the same time, however, the accuracy of LLM feedback in these types of prediction tasks requires further scrutiny while taking account of various issues such as training strategies and prompt design. With these points in mind, this study examined the consistency of the checklist-based ratings of summary content generated by the LLM and those assigned by writing instructors. We also compared different types of prompts by taking into account the training strategies and prompt design issues discussed above through the following research questions:
How consistent are checklist rating results on summary content generated by LLM with those generated by writing instructors?
How does the LLM prompt design affect the consistency between the LLM and instructor evaluations of summary content?
Method
Participants
A total of 97 first-language (L1) Japanese undergraduate students participated in this study. The sample represented three cohorts of first- and second-year students enrolled in required academic writing courses at two universities in Tokyo in 2020, 2021, and 2023. The 2020 and 2023 cohorts were English majors at University A (40 students and 25 students, respectively), while the 2021 cohort comprised engineering majors at University B (32 students). Inclusion of students from different majors and universities in the dataset was intentional. This is because the data were collected for the piloting of the aforementioned online module for formative assessment of summary writing designed in the larger project for introductory academic writing courses in Japan (Sawaki, Ishii, & Oi, 2024; Sawaki, Ishii, Yamada, & Tokunaga, 2024). All students completed the summary task, described below, as part of class activities and gave the research team permission to analyze their summaries for the purpose of the current study. With regard to English language ability, the sample roughly represented A2 through low B2 levels on the Common European Framework of Reference for Languages (CEFR; Council of Europe, 2001).
Instruments
Summary task
The summary task completed by all participants was based on a source text developed by the first author for summarization instruction in the larger research project (see Supplemental Appendix A; the same source text was employed by Sawaki, Ishii, Yamada, & Tokunaga, 2024, and Sawaki, Ishii, & Oi, 2024). It was an expository text comprising four paragraphs on a new environmental technology for water purification in a problem-solution rhetorical structure (391 words; Flesch-Kincaid Grade Level of 11.8, based on Text Inspector, https://textinspector.com/). This topic was chosen due to the frequent appearance of environmental issues in English textbooks and the uniqueness of the innovation made by a Japanese company that may interest university students. In a survey on the usability of the online module conducted upon completion of the summary writing exercises, 84.1% of the students in the three cohorts (n = 145; the 97 students whose data were analyzed in this study could not be individually identified) reported that they were able to understand the source text (60.0%) or understand it very well (24.1%), suggesting the appropriateness of the source text difficulty for the students. The task instructed learners to summarize key points of the source text in approximately 80 words in English.
Summary content checklist
The same 15-item checklist, written in Japanese, as the one developed by Sawaki, Ishii, Yamada, and Tokunaga (2024) and Sawaki, Ishii, and Oi (2024) was employed. We retained the original phrasing of the checklist items designed for self-assessment, hypothesizing a situation where a tutor or an LLM provides learners with feedback on the checklist items for comparison against their self-assessment results. Based on the previous literature on L2 summary writing assessment, the checklist was designed to elaborate on two key components of summary content covered in criterion-referenced analytic scoring rubrics for summary writing (Sawaki, 2020), developed as part of the larger project: appropriateness of source text gist representation and paraphrasing. Only 13 items corresponding to the former will be described below (see Supplemental Appendix B for the Japanese original and an English translation of the checklist items analyzed in this study). The remaining two items on paraphrasing were excluded from subsequent analyses because they were designed for automated analyses, not for instructor rating. With regard to the appropriateness of source text gist representation, previous empirical studies on L2 summary content in the field (Kato, 2021; Li, 2014; Sawaki, 2020; Yu, 2007) defined this subconstruct in terms of macrorules, a set of semantic mapping rules for gist formation proposed as part of the construction-integration model of text processing (Kintsch, 1998; Kintsch & Van Dijk, 1978; Van Dijk & Kintsch, 1983). Kintsch and van Dijk originally suggested three macrorules: deletion (omitting unnecessary details); generalization (collapsing lists and a series of events); and construction (substituting micro-level statements with a global one). While they have been operationalized in different ways in subsequent summarization studies, we adapted the definition presented in Hare and Borchardt’s (1984) rulesheet for their summarization training study, detailed below, due to its accessibility to learners. The 13 items were designed to tap into the following rules:
Rule 1: Collapse lists (1 item)
Rule 2: Omit unnecessary details (5 items)
Rule 3: Use topic sentences (4 items)
Rule 4: Collapse paragraphs (2 items)
Rule 5: Polish the summary (1 item)
It should be noted that the checklist content was customized for each source text, citing specific parts of it to which the five rules above could be applied. This approach was adopted to provide learners with fine-grained feedback specific to the task at hand.
As described in more detail below, the main analyses (consistency of instructor ratings and LLM ratings) focused only on those corresponding to Rule 3: Use topic sentences. This is because a previous study conducted as part of the larger project (Sawaki, 2018) identified Rule 3 as a distinct weakness of this learner population. Moreover, this study limited the subsequent LLM analyses to three items (Items 2, 3, and 5) that required the restatement of topic sentences of Paragraphs 1, 2, and 4 (henceforth, P1, P2, and P4, respectively), which were explicit in the source text. The remaining item under Rule 3 (Item 4) was excluded. This item concerned constructing a topic sentence for Paragraph 3, for which no explicit topic sentence was present. Thus, it required the consideration of a different set of issues for designing the LLM experiment.
Procedure
First, a brief instruction on summary writing strategies was conducted by the first author in Japanese (40 minutes in total). This lecture, delivered either on Zoom in class or as a video lecture that students watched either before or in class, presented the five rules of summarization described above with concrete examples. Also covered in this lecture were the criterion-referenced analytic scoring rubrics for summary content (Sawaki, 2020), on which the five rules were based. As the next step, the students completed the summary task within 40 minutes in class. All students word-processed their responses. Dictionary use was allowed.
Analyses
The initial drafts for the summary task above submitted by the 97 students were analyzed. Instructor ratings and LLM ratings were obtained on each checklist item for each student’s summary response on a 3-point scale (2 points = complete fulfillment; 1 point = partial fulfillment; 0 point = no fulfillment). While employing a simple 2-point scale (e.g., 1 point = fulfillment; 0 = no fulfillment), as done in the original self-assessment scale (Sawaki, Ishii, & Oi, 2024; Sawaki, Ishii, Yamada, & Tokunaga, 2024), was also a possibility. However, this study adopted the 3-point scale in order to provide students with more detailed feedback. Full credit (2 points) was awarded to responses that fully and accurately represented the target content, whereas partial credit (1 point) was awarded to those that involved minor distortion of meaning or partial omission of the target content. No credit (0 point) was awarded to responses including no information relevant to the target content and those involving major distortion of meaning.
Instructor rating
Two independent raters provided ratings based on the 13 checklist items. One was the first author, while the other was a writing instructor/academic English researcher involved in the larger research project. Both raters were native speakers of Japanese, with doctoral degrees in applied linguistics and extensive previous experience in teaching academic writing at the university level in Japan. They were also instructors of the academic writing courses where the data for this study were collected.
A random sample of 25 summaries out of the 97 student summaries analyzed in this study were used for rater training and were double-rated. It should be noted that this rating design, where only approximately 25% of the entire dataset was double-rated, was adopted because the data were originally obtained as codes for a qualitative description of summary content accompanying rubric-based scores in the larger study.
The raters first reviewed and discussed scoring rules for each checklist item and samples of rated summaries from a previous pilot study. They then rated five student summaries independently as Round 1. With some noticeable disagreements observed in the results (73.8% agreement), the scoring rules were scrutinized further. After that, the remaining 20 summaries were rated in two rounds of independent rating and discussion of 10 summaries in each, resulting in the rater agreement of 76.2% in Round 2, and 82.3% in Round 3. Most rater disagreements concerned the judgment of awarding full credit (2 points) or partial credit (1 point) across items. In other words, the raters somewhat differed in the degree of tolerance to omission, ambiguity, and inaccuracy of the representation of the required content. All rating discrepancies were resolved through discussion. Given that a satisfactory level of inter-rater agreement was achieved, the remaining 72 summaries were rated by the first author.
LLM analyses
We formulated the present rating task as an ordinal classification task with a student summary as the input, and the score and its reasons as the output. We designated the 25 summaries with double rating as the test set, and the remaining 72 summaries with single rating as the development set. We chose in-context learning (few-shot) over fine-tuning as the training strategy to optimize the LLM due to its suitability for small-scale classroom applications. This approach also accommodates potential variations in task design as well as scoring criteria and feedback methods across instructors, allowing their adjustment according to students’ needs. We used straightforward verbalizations of assessment steps, leveraging L2 writing instructors’ knowledge of assessment criteria and their elaborate comments on learner responses.
All prompts employed were written in English, while we manipulated two aspects of their design. First, we devised two types of prompts called “rate-explain” and “analyze-rate” (Chiang & Lee, 2023) by changing the order in which scores and their rationales were generated in the LLM output. The rate-explain prompt instructs an LLM to provide a score and then analyze the input text according to the given criteria, while the analyze-rate prompt gives instructions in reverse order (see Figure 1 for examples of each type; see the parts shaded in light gray and those in black in the figure to compare the rate-explain and analyze-rate prompts, respectively). The prompt begins by defining the role of an LLM and then describes the rule for the target checklist item. The remainder of the prompt provides a format definition for the expected output, starting at “Response to Rule_1” (note that the rule number here is arbitrary and thus does not correspond to Rules 1 through 5 associated with the 13 checklist items presented above). The special expression “{{text}}” plays the role of a placeholder, which the LLM should fill with a corresponding text from a student’s summary. The underlined strings beginning with a dollar sign ($) represent variables that are automatically filled with corresponding strings (Note that the underlines are not part of the LLM prompts). In the rate-explain prompt in Figure 1, for example, “$source_text_with_topicsentence_annotation” at the bottom was replaced with the source text with annotation on topic sentences of different paragraphs. The topic sentences are annotated with tripled square brackets “[[[” and “]]].” “$target_paragraph” was filled with a paragraph ID such as “P1” for Paragraph 1. In addition, we inserted elaborated instructor comments on the checklist items in “$elaborate_rule,” aiming to provide the LLM with more concrete guidelines for assessment. Figure 2 presents an example of an elaborated rule for Item 5. The first author wrote all such comments employed for the present LLM analyses.

Standard prompt (/ ).
).

Elaborated rule example (Item 5).
Second, we also manipulated the amount of information included in the prompt. Three settings were tested. The baseline setting was the standard prompt (Standard) depicted in Figure 1. Two variants of this standard output were also prepared. One was a simpler prompt (Simple), created by omitting the $elaborate_rule from the Standard prompt. The other (few-shot) was extended from the Standard prompt, to which three exemplars were added immediately after the Standard prompt. The Simple and the Standard prompts are zero-shot approaches that did not contain any exemplars. The Few-shot prompt was devised by adding three examples to the end of the Standard prompt. One exemplar for each score level (0, 1, 2) was included for each checklist item (Figure 3). The first author selected representative responses as exemplars. All the exemplars were from the test set. The development set was used to prepare all prompts.

Few-shot exemplar (Item 5, analyze-rate).
We conducted the LLM analyses on the three items for Rule 3 (Use topic sentences) for each of the three focal items on OpenAI GPT-4 turbo (ver. 2024-04-09) through Open AI API. The hyperparameters were set at temperature = 0 and max_tokens = 1024. We also fixed the seed to obtain the most reproducible output. Note that OpenAI API does not guarantee determinism. Accordingly, LLM can return different outputs against the same input even if we use these hyperparameters. All the other hyperparameters were default values. We tested six prompts in all possible combinations of the order in which scores and their rationales are generated in the output (rate-explain and analyze-rate) and the setting (Simple, Standard, and Few-shot) described above.
Statistical analyses
First, as a preliminary analysis, descriptive statistics were calculated for instructor ratings of learner-produced summaries on the 13 checklist items in order to gain an overall picture of relative strengths and weaknesses of the three cohorts across the five rules of summarization. Next, to address the main research questions, agreement between instructor ratings and LLM-estimated ratings was explored from two perspectives. First, we examined the overall level of agreement based on two agreement statistics, linear weighted kappa (Cohen, 1968) and Krippendorff’s (2019) alpha, following the recommendation by Sakai (2021) for examining agreement for ordinal classification. We calculated means for these two coefficients across five runs. We ran the analyses five times because variation was observed in the LLM output due to technical (software) limitations at the time of data analysis in April 2024, even though we fixed the temperature to zero to suppress output variability, as noted above. We kept the number of repetitions low given that the variation was expected to be minor. The means were obtained for each of the six prompt types tested. To interpret the values of linear weighted kappa and Krippendorff’s alpha, we used κ > 0.6 (substantial agreement, Landis & Koch, 1977, p. 165) and α > 0.667 (the minimum level for drawing tentative conclusions, Krippendorff, 2019, p. 356) as satisfactory levels of agreement for low-stakes purposes. Second, confusion matrices were devised to explore relative harshness and leniency of LLM ratings against instructor ratings. Frequencies in each cell were aggregated across the five runs in the matrices, again for the six prompt types. To examine the appropriateness of the LLM results, we also checked sampled outputs manually.
Results
Descriptive statistics
Figure 4 summarizes mean instructor ratings on the 13 summary content checklist items (n = 97), which showed a general pattern of strengths and weaknesses across the checklist items. More specifically, the summaries tended to collapse lists (Rule 1) and omit unnecessary details (Rule 2) properly, while they did not always use topic sentences effectively (Rule 3) and were not polished (Rule 5).
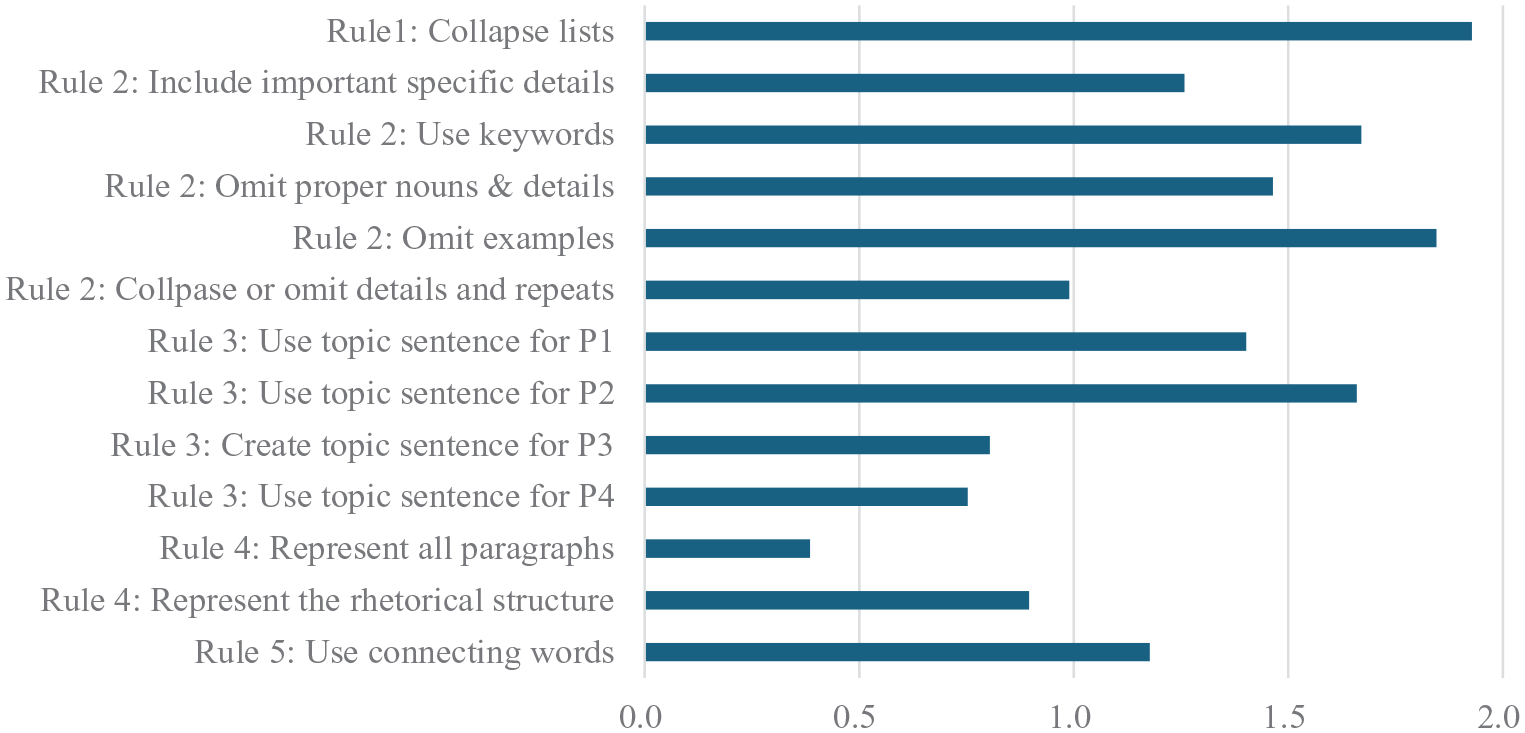
Mean instructor ratings on the summary content checklist items (n = 97).
As for the three focal items concerning Rule 3 (Use topic sentences; Items 2, 3, and 5) subjected to the main analyses (instructor ratings vs. LLM ratings comparison), two points are worth noting. First, students generally did well on Items 2 and 3, using the topic sentences explicitly stated in Paragraphs 1 and 2, respectively. In essence, the topic sentence for Paragraph 1 concerned the problem statement (lack of safe water for living) and the need to resolve this life-threatening issue, whereas Paragraph 2 centered on the presentation of a human-powered water purifier as a possible solution for the problem. These results suggest that, on average, student summaries reproduced the relationships among these three concepts (problem—need for a resolution—the product as a solution) in the source text relatively well. In contrast, the mean for Item 5, concerning the topic sentence for Paragraph 4, was considerably lower. This topic sentence stated the potential contributions of the product as the conclusion: helping people in need of safe water and improving public health in the affected areas. Two frequent reasons for earning no or partial credit on this item, identified through a closer inspection of student summaries, were (1) absence of relevant information from the paragraph and (2) overgeneralization of the topic sentence or partial reproduction of its key points. See Table 1 for detailed scoring rules and sample responses.
Elaboration of instructor scoring rules.

Consistency between instructor ratings and LLM-estimated ratings
Table 2 presents the mean linear weighted kappa and Krippendorff’s alpha values across five LLM analysis runs for the six types of prompts tested, along with the corresponding standard deviations in brackets. In general, no particular prompt type performed better than the others across the board; however, two distinct patterns observed in the table are notable. First, the types of prompts that resulted in relatively high agreement varied across the items. On one hand, concerning Items 2 and 3, the mean weighted kappa and Krippendorff’s alpha values were highest for the Few-shot prompts in the rate-explain structure. In contrast, the statistics for the Simple and Standard prompt types were generally low, without any clear pattern of preference between the rate-explain and analyze-rate structures. These results suggest that adding the exemplars to yield the Few-shot prompts noticeably contributed to the improvement of the mean agreement statistics for these two items. On the other hand, the results obtained for Item 5 were distinct: The Simple prompts, particularly the one in the analyze-rate structure, performed the best among all prompts tested. Thus, the addition of the elaborate rule explanation in the Standard prompt and exemplars in the Few-shot prompt negatively affected agreement of the LLM-estimated ratings with instructor ratings concerning this item. Second, the linear weighted kappa and Krippendorff’s alpha values obtained for the Few-shot prompts on Item 3 and for the Simple prompts on Item 5 are sufficiently high, in the range acceptable for low-stakes use of LLM-estimated ratings (κ > 0.6 and α > 0.667; see the Method section for further detail). However, the agreement rates for the other scenarios were generally low. In particular, no satisfactory results were obtained for Item 2.
Overall agreement statistics between instructor ratings and LLM ratings.
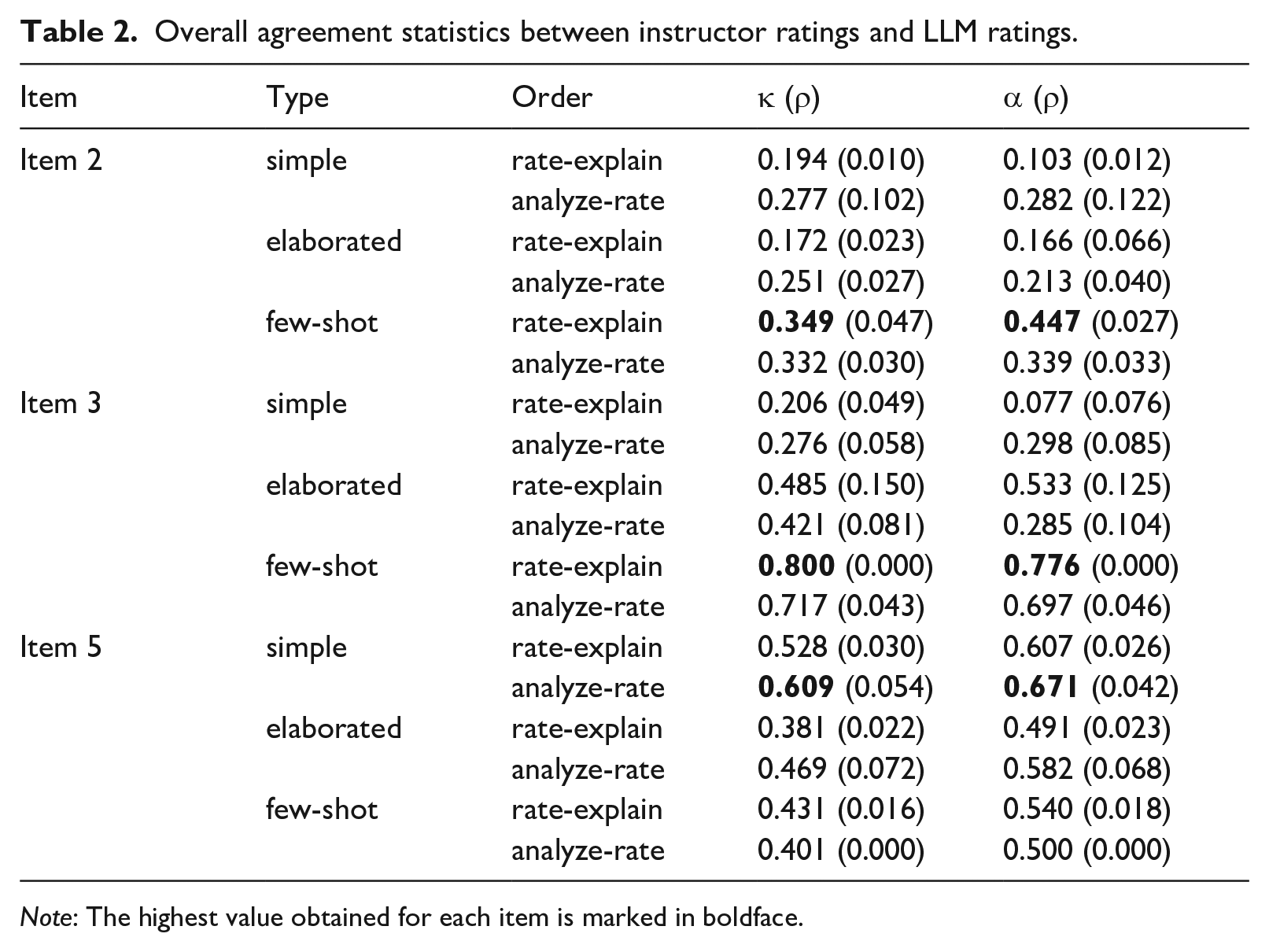
Note: The highest value obtained for each item is marked in boldface.
The patterns of agreement between instructor ratings and LLM-estimated ratings were explored further by inspecting confusion matrices. Figures 5 and 6 show the rate-explain and analyze-rate prompts, respectively. In each matrix, the rows present instructor ratings (true values), while the columns present the LLM-estimated ratings (predicted values). The cells in the diagonal represent cases of exact agreement between the true values (instructor ratings) and the LLM-expected ratings. The cells in the off-diagonals represent misclassified cases. Lower off-diagonals represent cases where LLM ratings were harsher than instructor ratings, while upper off-diagonals represent those where LLM ratings were more lenient than instructor ratings.
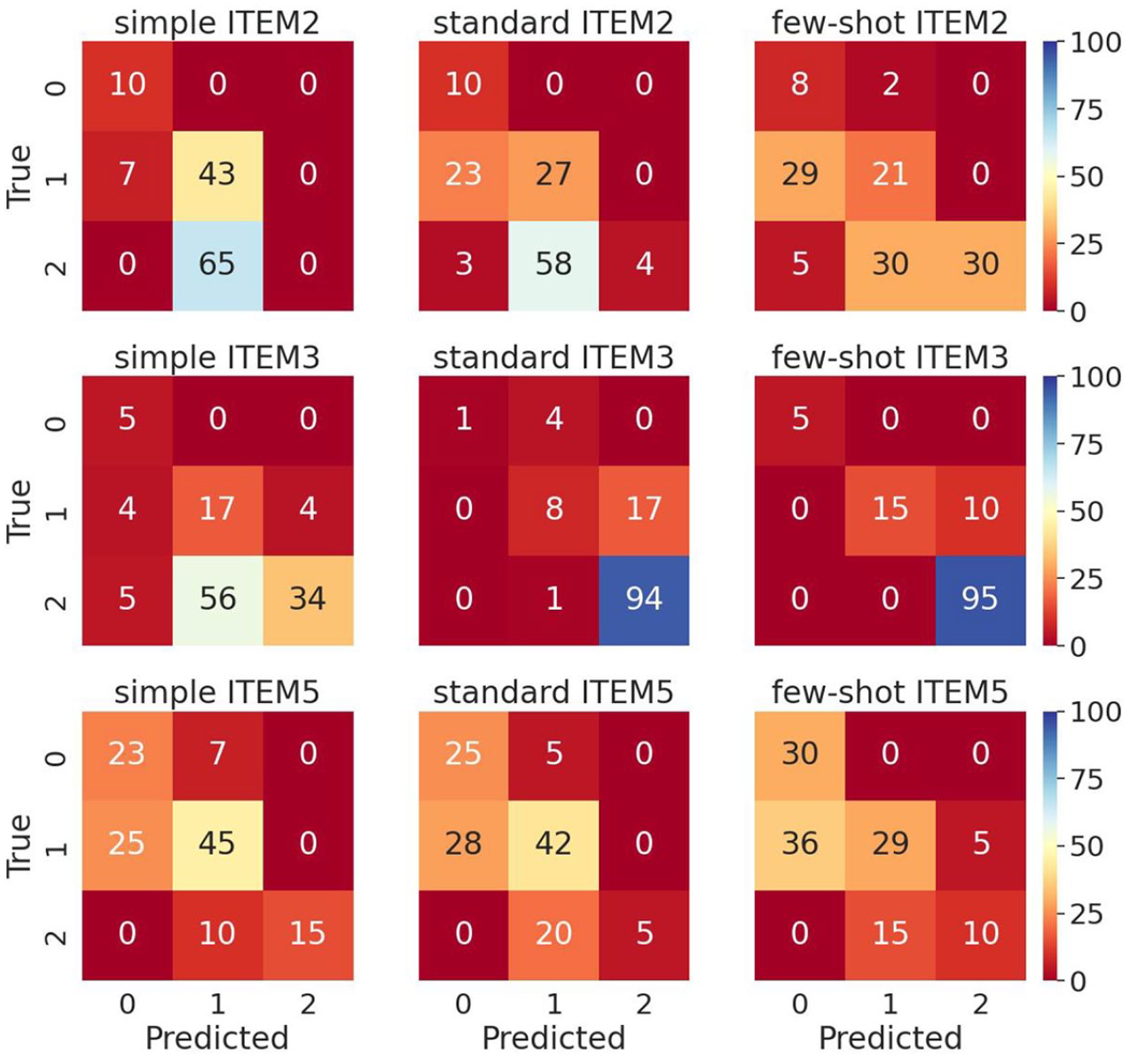
Confusion matrices for rate-explain prompts (five runs aggregated).
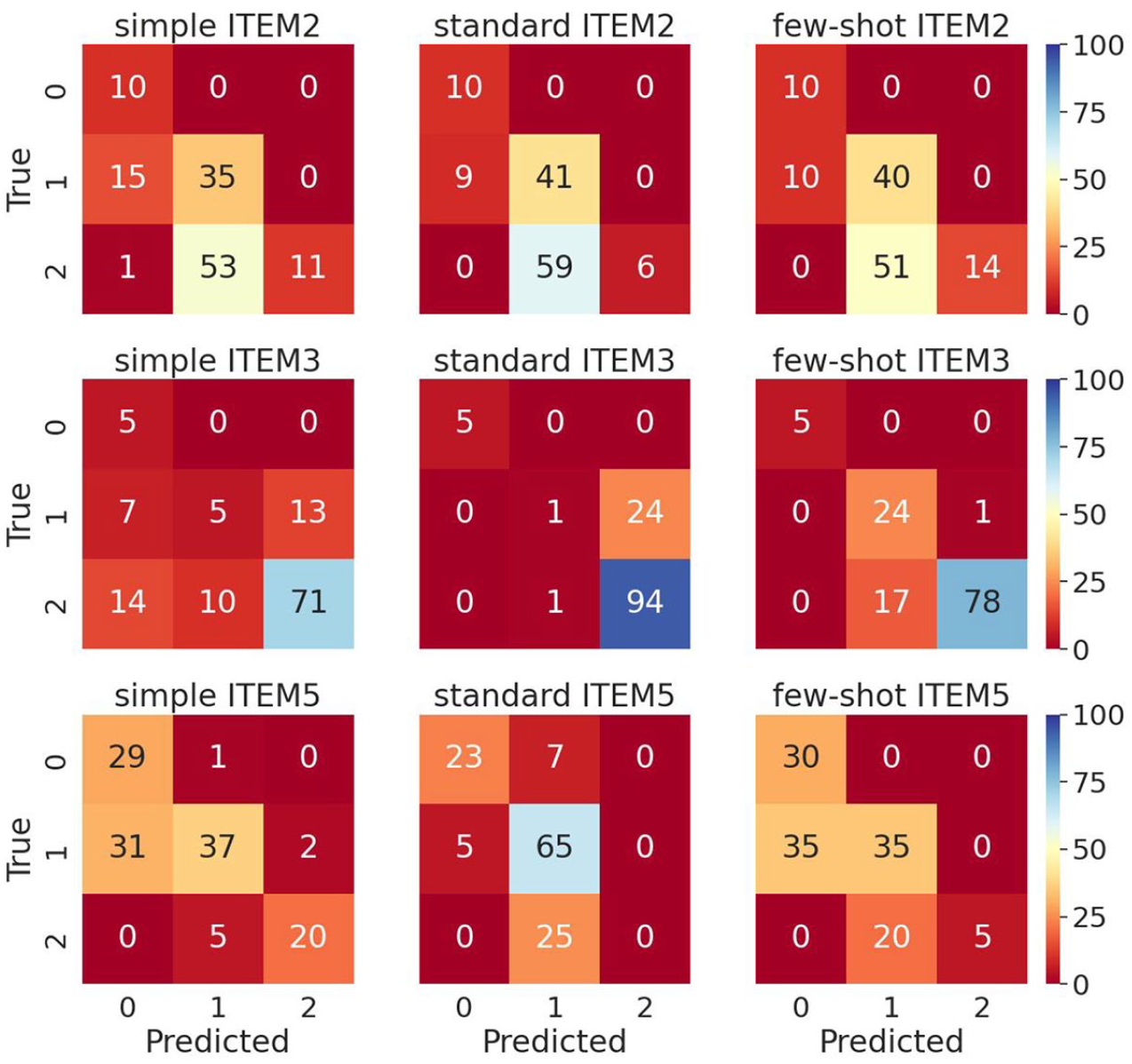
Confusion matrices for analyze-rate prompts (five runs aggregated).
A close inspection of these confusion matrices suggests two points. First, the misclassified cases concentrated in the cells in the lower off-diagonals. This suggests that, when misclassified, LLM ratings tended to be harsher than instructor ratings, in general. Meanwhile, exceptions were observed for Item 3, where some cases concentrated in the upper off-diagonals for the Standard and Few-shot prompts in the rate-explain structure (Figure 1) and in the Simple and Standard prompts in the analyze-rate structure (Figure 1). Second, most misclassifications were adjacent agreements, while there were considerably fewer cases of non-adjacent discrepancies (i.e., rating differences of two points), again for Item 3. (See the 14 cases placed in the cell in the bottom-left corner for the Simple prompt in the analyze-rate structure in Figure 6).
In order to explore reasons behind the instructor vs. LLM rating disagreements observed in the confusion matrices above, LLM-estimated ratings and their rationales generated in the LLM outputs were examined further for each item. For this purpose, the LLM output files for the prompt type associated with the highest instructor vs. LLM agreement were examined for the test set for each item (the Few-shot prompt in the rate-explain structure for Items 2 and 3, and the Simple prompt in the analyze-rate structure for Item 5). This analysis revealed some systematic patterns accounting for the instructor vs. LLM rating discrepancies.
For Item 2, where relatively large numbers of misclassifications were observed (Figure 5), a few issues explaining the relative harshness of the LLM were identified. One was the LLM’s rigidity in requiring explicit statements of both the problem and the mission to resolve it as opposed to the instructors’ higher tolerance to the implicitness of the mission when it did not obscure the overall problem-solution structure. A second, more problematic issue identified was the lack of distinction between the coverage of the main idea of Paragraph 1 and the omission of unnecessary details in LLM ratings for Item 2. For instance, the instructor assigned a rating of 2 to a student summary that included a sentence representing the main idea. In contrast, the LLM rating of this summary on this item was 0. The generated rationale explained that the LLM penalized for the inclusion of unnecessary details (many children’s deaths) in a different sentence in the summary, despite the fact that Item 2 was supposed to take account of the coverage of the main idea of Paragraph 1 only.
LLM rationale: “No credit was awarded to this response because it does not properly paraphrase the topic sentence of P1. The summary incorrectly focuses on the specific detail of child deaths due to diarrhea, which is explicitly mentioned as a detail that should not be included in the summary according to the rules. . . .“ (Summary 75)
Similarly to Item 2 above, the LLM ratings’ relative severity on Item 5 (main idea of Paragraph 4; Figure 6) was also explained by its strict adherence to the coverage of two points stated in Table 1: helping people who are in need of safe water for living and improving public health in affected areas. When a vague or incomplete statement was in a summary, LLM generated a rationale such as the following for the rating of 1:
LLM Rationale for Summary 32: “. . . the summary does not fully capture the specific context of hope and the potential impact of the product as described in the original topic sentence. Thus, the paraphrasing is somewhat aligned but lacks completeness and specificity.”
At the same time, however, there were multiple instances where the LLM’s rationale did not mention a statement in a student summary that the instructors had identified as an attempted paraphrase of the topic sentence of Paragraph 4, resulting in lower LLM ratings. This was particularly the case when the relevant parts were too vague or brief (“This activity is making the issue better.” [Summary 83]).
Finally, the pattern observed for Item 3 (main idea of Paragraph 2) was different from the other two: The LLM-estimated ratings on Item 3 tended to be more lenient than instructor ratings. This was explained by LLM’s awarding full credit to statements that did not explicitly mention the product’s role as a solution to the problem, whereas the instructors tended to require a clear statement of it. For instance, the instructor rating of 1 was assigned to a summary which stated (1) the need to bring water to people with no access to clean water and (2) a bicycle developed by a Japanese company that can be used to purify water, with no explicit statement of it being a solution. In contrast, LLM awarded the rating of 2 to it, presumably because the product’s role as a solution to the water problem could be inferred from the context.
LLM rationale for Summary 46: “The summary earns a full score because it clearly states that Cycloclean is developed as a response to the need for providing clean water in areas lacking access (direct quote of the relevant part of the student response). This directly addresses the relationship between the problem stated in P1 and Cycloclean as a solution. . . .”
In summary, based on two agreement statistics (linear weighted kappa and Krippendorff’s alpha), sufficient levels of agreement for low-stakes use were observed between instructor ratings and LLM-estimated ratings on certain prompt types for Items 3 and 5 (the Few-shot prompt in the rate-explain structure for the former, and the Simple prompt in the analyze-rate structure for the latter), while it was not the case for Item 2. Concerning harshness/leniency of the rating results, however, LLM-estimated ratings tended to be harsher than instructor ratings on Items 2 and 5 across the different prompt types tested, whereas some tendency for leniency in LLM ratings was observed for the Standard and Few-shot prompts in the rate-explain structure and the Simple and Standard prompts in the analyze-rate structure for Item 3. A close inspection of LLM outputs revealed some reasons behind the instructor vs. LLM rating disagreements. Notable ones included differences between instructors and the LLM in the level of tolerance to implicitness of required information in student summaries, confusion of scoring rules on the part of the LLM, and the LLM’s failure to recognize paraphrases that the instructors identified as relevant.
Discussion
This study explored the possibility of employing the LLM for rating based on a summary content checklist for formative assessment in undergraduate L2 writing courses in Japan. This study was novel in its focus on designing fine-grained content feedback to promote learners’ understanding of the summarization construct as well as the application of the LLM to automating the content feedback as an attempt to facilitate timely feedback provision to support learning. First, instructor ratings on the 13-item checklist, based on Hare and Borchardt’s (1984) five rules of summarization, identified areas of relative strengths and weaknesses among Japanese L1 undergraduates in this study, suggesting the potential usefulness of providing feedback on summary content at this level of specificity. Second, the consistency of instructor ratings and LLM ratings was examined with a focus on three checklist items concerning the use of topic sentences in the source text. In so doing, results were compared across six different types of LLM prompts developed by manipulating the amount of information included (Simple, Standard, and Few-shot) and the order in which scores and their rationales were generated in the output (the rate-explain and analyze-rate structures). Assuming small-scale classroom applications, we adopted a realistic scenario by implementing prompt designs that leverage L2 writing instructors’ expert knowledge on summary writing and by employing a small dataset (n = 25) designated as a test set for the LLM analyses.
Research Question 1 concerned the consistency of instructor ratings and LLM ratings. We examined agreement statistics (linear weighted kappa and Krippendorff’s alpha) as well as confusion matrices to address this research question. Among the three checklist items on the use of topic sentences analyzed in this study, satisfactory high agreement for low-stakes use was obtained for certain item-by-prompt type combinations. Further inspection of the patterns of agreement observed in the confusion matrices showed that, although there were some exceptions, most disagreements observed were adjacent discrepancies, with a tendency for LLM ratings to be lower than those of instructors.
The findings concerning Research Question 1 above suggest that LLM applications based on small samples can yield fairly reliable results under certain conditions. This is encouraging because, unlike the algorithms for the existing AWE programs described above, the LLM analysis did not require resource-intensive and large-scale training. This result is consistent with favorable findings of previous studies on the efficacy of LLM applications for scoring and feedback generation on writing data in learners’ L1 (Steiss et al., 2024) and L2 (Mizumoto & Eguchi, 2023; Mizumoto et al., 2024).
The LLM’s tendency to be more conservative in the ratings than instructors for this low-stakes context is acceptable, considering that the checklist-based feedback is designed to draw the learner’s attention to points of improvement based on the five rules of summarization. However, given the importance of feedback accuracy in learners’ understanding of their current level (Hattie & Timperley, 2007; Sadler, 1989), potential reasons for the discrepancies need to be sought carefully. Two points this study has suggested are worth noting. First, the variation observed in the level of LLM vs. instructor rating agreement across the three focal checklist items may be partly explained by the characteristics of the target responses required for these items. As noted in the Results section, the consistency was found to be the highest for Item 3, the target main idea of which was relatively straightforward, requiring only a brief text to represent the key point (the product = a solution to the problem). This might have made it easier for the LLM to identify the target features in learner summaries. In contrast, the other two items required somewhat longer text strings and were more open to variation in terms of the expressions employed. Second, a detailed analysis of the LLM-generated rationales shed light on a confusion between the main idea representation and the omission of unnecessary details in the evaluation of paragraph gist on the part of the LLM and differences in the degree of tolerance in ambiguities in the representation of target information in learner summaries between the LLM and human raters. Providing more precise instructions in the prompts may help address the former, while the present results do not offer sufficient information to explain how the latter could be minimized. Doing so calls for a more elaborate qualitative investigation into how LLM and human raters handle ambiguities introduced by L2 writers’ attempts to synthesize information.
Research Question 2 examined the effects of the prompt design on the consistency between LLM ratings and instructor ratings of summary content. Results of this study concerning this research question signified the importance of prompt design for in-context learning, supporting Brown et al. (2020). The considerable variation in the level of agreement observed across the prompt types suggested that how the prompt is crafted (the amount of information included and the order in which scores and their rationales are generated in the output) indeed matters. At the same time, however, the present results were mixed in that no specific type of prompt performed consistently better than others.
A point of interest is the relative similarity of the results between the rate-explain and analyze-rate structures as opposed to the greater differences observed across the Simple, Standard, and Few-shot prompts, suggesting the relative importance of the amount of information provided compared to the order of the generation of ratings and their rationales in the output. This is also in line with Yancey et al.’s (2023) finding, which suggested the critical role exemplars included in prompts play in ensuring LLM vs. human rating agreement. However, the pattern observed in this study was not systematic across the board: The Few-shot prompts performed the best on Items 2 and 3, whereas the Simple prompt performed the best on Item 5. The increase in agreement with the availability of full information for the former is reasonable, while the deterioration in agreement with the added information on Item 5 requires substantive explanations. Some points that should be scrutinized carefully include the degree of representation of instructor scoring rules in the elaborate explanation in the Standard prompts and the adequacy of the exemplars in the Few-shot prompts. Specifically, the variation in the reasons for earning no or partial credit (0 or 1 point) on Item 5 described in the Results section might suggest the need for incorporating more exemplars to adequately accommodate variation in lower-level responses.
Limitations and future directions
This study has offered some insights into how the LLM might perform in a small-scale application for classroom use. However, the results must be interpreted with caution due to limitations of the study design. First and foremost, the results presented above were based on a single task. The checklist items analyzed were also small in number and type, representing only one of the five rules of summarization implemented in the focal self-assessment checklist. Moreover, as noted in the Method section, the instructor ratings analyzed in this study were only partially double-rated, given their initial conceptualization as summary content codes supplementing rubric-based scores. Accordingly, it is advisable that future studies employ fully-crossed rating designs, where all learner responses to all checklist items are scored by multiple raters, to enable a full-scale analysis of rating consistency on a larger number of checklist items across tasks. Such future works should also dig deeper into the reasons behind the discrepancies between LLM vs. human ratings through systematic qualitative comparisons of rationales for the scoring results obtained both from LLM output and human raters.
Another point that merits further consideration is what prompt characteristics to manipulate. This study focused only on two prompt variables: (1) the amount of information (presence/absence of elaborate scoring rules) and the number of exemplars; and (2) the order of generation of information in the output. Yet, other features should also be explored in future investigations. One such characteristic is the temperature setting, which manipulates the degree of diversity in the language generated in the LLM output. A higher value means a higher degree of diversity allowed. Similarly to Steiss et al.’s (2004) automated feedback generation study, we adopted a low temperature setting. However, a higher temperature may be more reasonable for generating feedback where the same message can be phrased differently across runs, which might be motivating for learners as well. While the present analysis focused on the LLM rating results, with only a brief analysis of the corresponding LLM-generated rationales, this is an area for further research, given that other approaches are also possible (e.g., setting the temperature low while carefully specifying how the feedback should be phrased in the prompt).
Finally, while learner and instructor endorsement of this self-assessment checklist as implemented in the formative assessment module developed in the larger study (without the LLM-generated ratings) was obtained in a previous validation study described above (Sawaki, Ishii, & Oi, 2024), further investigations are required to explore how the provision of the LLM-generated feedback impacts stakeholders’ perceptions and feedback engagement. Such studies should examine how the LLM-generated feedback could be delivered alone or in combination with the self-assessment activity to facilitate instruction and learning from the perspectives of the key stakeholder groups.
Conclusion
This study yielded findings that contribute to the literature in some important ways. First, the checklist-based feedback for summary writing analyzed in this study informs the discussion of developing specific feedback that clarifies a complex construct to the learner in formative assessment and offers a concrete example of content feedback, which has enjoyed limited attention in previous AWE research. Second, sufficient agreement between LLM ratings and instructor ratings observed for certain item-by-prompt type combinations provides initial support for small-scale LLM applications to automated content feedback generation for low-stakes use in L2 writing classrooms. In terms of the prompt design, this study suggested the relative importance of elaborate scoring rule explanations and exemplars for few-shot learning as opposed to the order in which a rating and its rationale are generated in the output, in ensuring LLM-human rating agreement. At the same time, however, the results were mixed across the three main idea items analyzed, generating various issues for further consideration. Specifically, reasons behind the tendency of LLM ratings to be harsher than instructor ratings observed in this study should be scrutinized further by examining the relationship between LLM vs. human rating agreement and a range of checklist items and prompt design characteristics. Obviously, further research should continue to accumulate empirical evidence to examine the extent to which LLM-based content feedback use facilitates the instruction and learning of summary writing skills in the L2 classroom.
Supplemental Material
sj-pdf-1-ltj-10.1177_02655322251349217 – Supplemental material for Examining the consistency of instructor versus large language model ratings on summary content: Toward checklist-based feedback provision with second language writers
Supplemental material, sj-pdf-1-ltj-10.1177_02655322251349217 for Examining the consistency of instructor versus large language model ratings on summary content: Toward checklist-based feedback provision with second language writers by Yasuyo Sawaki, Yutaka Ishii, Hiroaki Yamada and Takenobu Tokunaga in Language Testing
Footnotes
Acknowledgements
The authors’ special thanks go to the students who made data available to this study. The authors are also grateful to Yumi Fujita and Ryuhei Mizoguchi for their assistance in materials preparation, and to Sayako Maswana for her contribution to data analysis.
Author contributions
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Yasuyo Sawaki is a guest co-editor of this special issue, “Advancing language assessment for teaching and learning in the era of the artificial intelligence (AI) revolution: Promises and challenges”.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was funded by the Japan Society for the Promotion of Science (JSPS) Grant-in-Aid for Scientific Research (B) (grant nos. 20H01292 and 24K00095).
Ethical approval and informed consent statements
Institutional review board (IRB) permissions were obtained for the data collection and analyses from Waseda University and Tokyo Institute of Technology.
Supplemental material
Open practice
Data availability statement
Learner summary responses analyzed in the current study are not available because permissions to share them with a third party were not obtained from all study participants.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.