
Abstract
While the automated assessment of oral reading fluency (ORF) using accuracy and speech rate has proliferated, expressiveness of speech, as measured by prosodic features, has been neglected due to its inherent complexity and lack of technological resources. Despite the potential benefits of burgeoning technology for assessing hard-to-measure constructs such as ORF, insensitivity to linguistic diversities threatens valid score interpretations and fair use for all learners. The present study investigated the potential benefits of developing an automated, prosody-inclusive ORF assessment in a post-secondary education setting involving many English language learners (ELLs). The analysis focused on three ways the inclusion of prosody may improve automated ORF assessments: by reducing bias against ELLs, improved prediction of reading comprehension, and improved diagnostic information. Data were analyzed by comparing two different scoring outcomes, the traditional ORF measure and a new prosody-inclusive outcome score, comparing these measures across language background. Results showed that the inclusion of prosody improves automated ORF assessment by reducing discrepancies between ELLs and English first language students caused by automated speech recognition inaccuracies, leads to better prediction of reading comprehension with ELLs, and provides meaningful diagnostic information. Detailed descriptions of the models, their relevance, and implications for the language testing community are discussed.
Keywords
Introduction
Artificial intelligence (AI) is transforming the fields of language education and assessment, offering unprecedented opportunities to redefine and enhance both how language is learned and how it is assessed (Chapelle & Chung, 2010; Nakatsuhara & Berry, 2021; Xi, 2023). Technological advances facilitate the assessment of complex language abilities like prosody in oral reading fluency (ORF) assessment, which has traditionally been underrepresented. This underrepresentation stems from multiple challenges, including the theoretical complexity of defining and operationalizing prosody as a construct that encompasses features of expression, psychometric challenges in reliably measuring it, and the practical difficulties associated with the resource-intensive nature of manual prosody assessment (Chaudhry & Kazim, 2022). While technological advancements address some of these long-standing challenges, they also bring new and complex concerns. As Nakatsuhara and Berry (2021) caution,
while these innovations have opened the door to types of speaking test tasks which were previously not possible . . . it should be kept in mind that each of the affordances offered by technology also raises a new set of issues to be tackled (p. 343).
For example, though AI-driven technologies such as automated speech recognition and natural language processing enable the analysis of speech features (e.g., rhythm, intonation, stress), they also raise concerns about transparency and fairness due to potential AI biases against accented speech (Hannah et al., 2022). Furthermore, the opacity of AI scoring processes can undermine trust as educators and students may find it difficult to understand how scores are generated or interpret what they represent. To address these challenges, the field of language assessment needs to balance the benefits of AI-driven assessments with mindful consideration of their potential pitfalls to ensure innovative and ethical practices.
The present study investigates the integration of prosody in automated ORF assessment, focusing on its potential to improve the construct representation and psychometric rigor. Prosody in oral reading is defined as the ability to read text “with appropriate expression or intonation coupled with phrasing that allows for the maintenance of meaning” (Kuhn et al., 2010, p. 235). While automated assessment of accuracy and speech rate in ORF has advanced significantly (Peng et al., 2022; White et al., 2021), the expressiveness of speech, as measured by prosodic features, is often neglected in both traditional and automated ORF assessment due to its complexity (Washburn, 2022). This is an oversight that has been a concern for over two decades (Kim et al., 2021; Kuhn & Schwanenflugel, 2019; Kuhn & Stahl, 2003; Schwanenflugel et al., 2004; Schwanenflugel & Kuhn, 2015).
Additionally, research in ORF assessment has predominantly focused on primary grade students (Grabe, 2010; Jiang, 2016; Jiang et al., 2012) reading in their first language (Chang, 2019; Khor et al., 2014; Prakash & Kurian, 2019) while there is limited research on ORF assessment in English language learning (ELL) contexts (Yang, 2021). This limitation is further complicated by a potential reduction in the accuracy of automated ORF assessment relying on speech-to-text technology for ELL students compared to English first language students (EL1s; Chen et al., 2018; Hannah et al., 2022; Mirzaei et al., 2015). The purpose of the present study was to examine the extent to which a new automated ORF scoring method, incorporating prosody, differs from the conventional scoring approach relying on accuracy and rate metrics. Specifically, the study was guided by two primary objectives: (1) to evaluate whether the inclusion of prosody in the scoring method reduces discrepancies in ORF scores between EL1 and ELL students and (2) to determine whether incorporating prosody enhances the predictive and diagnostic efficacy of ORF assessments.
Literature review
Automated oral reading fluency assessment
Oral reading fluency (ORF) is defined as the ability to read text aloud with accuracy, speed, and proper expression (Kennedy Shriver, 2010). It is a well-established, core skill that is highly predictive of later reading comprehension, especially among young children (Morrison & Wilcox, 2020). The National Assessment of Educational Progress (NAEP), a federally mandated US education progress monitoring organization, recognizes ORF assessment as a key tool for evaluating students’ progress toward meeting state reading standards (White et al., 2021). Accuracy refers to the ability to correctly decode and pronounce the words in a given text. It is foundational to fluency, as errors such as mispronunciations, skipped words, or substitutions can disrupt comprehension. In assessment, accuracy is typically measured as the percentage of words read correctly out of the total number of words (Hudson et al., 2020). Readers may struggle with accuracy or unfamiliar vocabulary (Samuels, 2006). Speed or reading rate reflects the rate at which a reader processes and verbalizes text. It demonstrates automaticity, the ability to recognize words effortlessly without pausing for conscious decoding. Fluent readers maintain a steady, appropriate pace that allows for efficient comprehension without sacrificing understanding. Reading speed is often quantified in words correct per minute (WCPM), with benchmarks tailored to specific proficiency levels or age groups (Hasbrouck & Tindal, 2017). Proper expression, largely corresponding to speech prosody, refers to reading with rhythm, intonation, pitch, and stress that align with the meaning and structure of the text (Kuhn et al., 2010). Prosody allows readers to convey emotions, tone, and intent, making the text engaging and meaningful for listeners.
Unlike accuracy and speed, prosody is more challenging to measure quantitatively, leading to its relative neglect in traditional ORF assessment (Kuhn & Stahl, 2003). Where prosody is often not overlooked is in assessments that target the construct of speaking (as opposed to the construct of reading). Table 1 presents some common assessments that include an oral reading task, with the scoring protocol, target construct, and prosody inclusion indicated. The table illustrates the divide between assessments in language learning contexts (with many age groups) measuring speaking ability and assessments in the K-12 context which measure reading ability, and prosody is only commonly included in the former. Despite the use of prosody in speaking assessment, there remains a dearth of automated reading assessments designed to measure the full breadth of the ORF construct, inclusive of prosody, especially in language learning contexts.
Assessments that include an oral reading task.
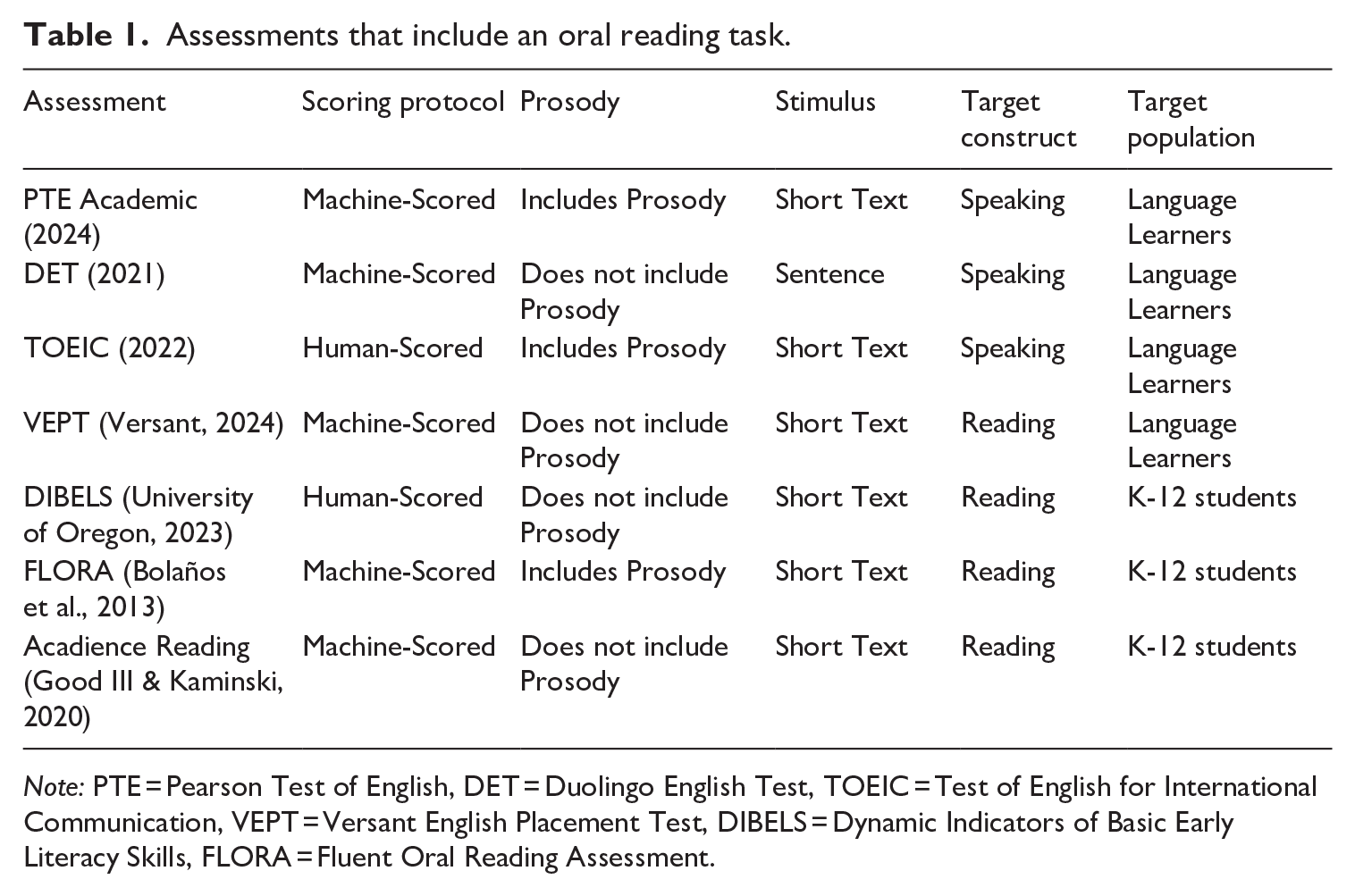
Note: PTE = Pearson Test of English, DET = Duolingo English Test, TOEIC = Test of English for International Communication, VEPT = Versant English Placement Test, DIBELS = Dynamic Indicators of Basic Early Literacy Skills, FLORA = Fluent Oral Reading Assessment.
In reading assessment contexts, where prosody is often not included, automaticity is measured using words correct per minute (WCPM), which calculates the average number of correctly spoken words in a 60-second reading interval. The correctness of the words is determined based on whether the spoken word matches the read word, as determined by the listener (either a human or machine, depending on the scoring protocol). WCPM grade norms have been established for grades 3–8 (Hasbrouck & Tindal, 2017) and post-secondary students (Jiang et al., 2012; Rasinski et al., 2022), making it the standard ORF outcome measure.
While WCPM is a robust predictor of comprehension across various developmental stages, including young students (Hudson et al., 2020), adolescents (Washburn, 2022), and post-secondary students (Jiang et al., 2012), researchers have raised concerns about its omission of prosody (Kuhn & Schwanenflugel, 2019; Kuhn & Stahl, 2003; Schwanenflugel et al., 2004; Schwanenflugel & Kuhn, 2015). It is argued that comprehension is enhanced when readers not only read but also incorporate the proper phrasal and syntactical structures intended by the author. This is because meaning is conveyed not solely through individual word forms but also through their arrangement and relationships within the broader text (Morrison & Wilcox, 2020).
Consequently, when ORF is assessed without considering prosody, the construct is not effectively represented, potentially weakening its relationship to comprehension (Kuhn & Stahl, 2003). From an assessment perspective, over-reliance on WCPM can also obscure distinct reader profiles (Schwanenflugel & Kuhn, 2015) and may inadvertently encourage instructional practices that prioritize reading speed over comprehension (Kuhn & Schwanenflugel, 2019). Additionally, although WCPM is intended to encompass both accuracy and rate, research by Valencia et al. (2010) indicates that it predominantly measures reading rate (r = .99) rather than accuracy (r = .43).
The automation of ORF assessment is rapidly becoming the standard (Peng et al., 2022; White et al., 2021). For instance, NAEP’s scoring approach uses a speech-to-text system that transcribes students’ oral reading, subsequently evaluating accuracy and rate, while prosody continues to be assessed by human assessors. This approach has been validated for both EL1 and Spanish L1 speakers, demonstrating sufficient human-machine reliability (Balogh et al., 2012) with that sample. Several research initiatives (Bailly et al., 2022; Bolaños et al., 2013; Molenaar et al., 2023; Proença et al., 2017) and industry efforts (Kelly et al., 2020; Peng et al., 2022) are also focused on developing automated ORF scoring models. These efforts have primarily focused on English L1 primary grade students and, in some cases, have included the automated scoring of prosody.
Automated prosody assessment
Recent advances have enriched our understanding of prosody’s role in language processing, particularly its communicative functions and relationships with other speech aspects (Kalathottukaren et al., 2015). However, challenges persist in precisely identifying prosodic features (Peppé, 2009) and developing tools to systematically assess prosodic skills across different age groups (Crystal, 2009). Theoretical frameworks explain prosody through phonetic (pitch, duration, stress), physical (fundamental frequency, syllable duration, intensity), and phonological (variations in pitch, length, loudness) correlates. These features extend the meaning of spoken language beyond mere words and grammatical structures (Kalathottukaren et al., 2015; Roach, 2000).
Prosodic impairments are notably evident in children with autism spectrum disorder (ASD), who exhibit distinctive differences in acoustic parameters (Diehl & Paul, 2013). Similarly, individuals with apraxia of speech exhibit pronounced inaccuracies in acoustic features, including inappropriate pitch assignments, uneven syllable timing, varied speech rates, and uniform loudness (Barry, 1995). These prosodic inaccuracies can significantly diminish speech intelligibility (Chin et al., 2012).
The communicative functions of prosody are categorized into grammatical, affective, and pragmatic roles. Grammatically, prosody helps delineate the boundaries of phrases, clauses, or sentences, and can differentiate between word classes in the case of homonyms. Affectively, it expresses the speaker’s emotions and attitudes, where emotions like happiness may be conveyed through a quick speech rate, rising pitch, high pitch variability, and rapid voice onsets. Pragmatically, prosody manages discourse, signaling to listeners when a speaker has concluded their thoughts or expects a particular response. Effective social interactions, therefore, rely on accurate perception and production of these varied communicative functions of prosody.
Despite the considerable attention that prosody has received in speech pathology and communication disorders, it remains underexplored in the field of language assessment, where both its teaching and assessment are quite challenging (Levis, 2023). In read-aloud tasks, prosody is typically rated by humans using rubrics or, more recently, by machines trained to predict human scores. Several prosody rubrics have been developed, including the NAEP scale (Daane et al., 2005), the multi-dimensional fluency scale (MDFS; Rasinski et al., 2009), and the comprehensive oral reading fluency scale (CORFS; Benjamin et al., 2013). Bolaños et al. (2013) pioneered automated expressive (i.e., prosody-inclusive) ORF assessment by building a machine learning model trained to predict a unidimensional, human-generated prosody score, using 19 lexical and prosodic features. Subsequent models developed in research contexts have been published by Proença et al. (2017) and Molenaar et al. (2023), who have continued to develop novel approaches, utilizing additional features and techniques. These prosody or expressive reading fluency models extract features from the sound input using speech processing software such as Praat (Boersma & van Heuven, 2001) and then train machine learning models to predict human scores which are based on one of the prosody rubrics described above.
ORF assessment with additional language learners
Some research has found that the relationship between ORF and reading comprehension extends to ELL students in both K-12 context (Marrs et al., 2022; Newell et al., 2020) and post-secondary contexts (Jiang et al., 2012; Yang, 2021). However, ELL students experience ORF assessments differently from EL1 students, leading to pronounced differences in score interpretations. For example, Marrs et al. (2022) found that ELLs are disproportionately placed in special education streams based partially on poor ORF performance, arguing that the ELL groups’ scores are primarily a language proficiency issue, not a reading ability issue. This suggests potential shortcomings for ORF assessments with ELL students, a point also concluded by a systematic review on ORF as a screening tool for ELLs (Newell et al., 2020), which suggests that the strength of validity evidence is weaker for ELLs. Lems (2012) further found that ELL students’ ORF scores were lower than those of EL1 students, even when their reading comprehension scores were equivalent, a gap that widened with increasing differences between students’ primary language orthography and English. Additionally, Aldhanhani and Abu-Ayyash (2020) found that ELL students are less inclined to practice reading aloud, which they linked to pronunciation-related social anxiety, further complicating ORF assessments for ELLs.
When ORF is machine-scored, automated speech recognition (ASR) models are used to convert the speech to text, and then scores are calculated by comparing the ASR transcript to the read text. Automated ORF assessments, when used with ELL students, bring forth a very important, bias-related issue. The issue is that ASR models consistently show lower accuracy for these groups, identified by comparing human transcripts to ASR transcripts (Derwing et al., 2000). For instance, research on the SpeechRater scoring engine (Zechner & Loukina, 2020) Chen et al.’s (2018) found that the error rates were 5%–15% higher for nonnative speech than for native speakers. Another study comparing ASR error rates across language backgrounds in both predictable (reading) and unpredictable speech (describing a picture) contexts, found averages of 19.5% for EL1s, 23.2% for students with other Indo-European language backgrounds, and 26.9% for those with non-Indo-European language backgrounds (Hannah et al., 2022). Mohyuddin & Kwak (2023) found similar results comparing groups with six different language backgrounds to an English language background group across six different ASR models. They found that the English language background group had the highest accuracy in all cases. We characterize the reduced ASR accuracy for L2 groups as bias because the accuracy of the transcription is directly related to the outcome scores for ORF assessments and not related to the target construct (reading fluency). Rather, the accuracy of ASR is determined largely by the language backgrounds present in ASR training data (Isaacs, 2017). Given that ASR accuracy is directly related to automated ORF scores, the differential accuracy with L2 populations presents serious threats to the validity and fairness of automated scoring. The present study seeks to investigate these threats and better understand how they may be mitigated by the inclusion of prosody as a core sub-construct within a traditional ORF assessment.
Present study
The present study investigated the extent to which a new ORF scoring method, which incorporates prosody (described below), differs from the traditional scoring method relying on accuracy and rate alone. Specifically, we focused on examining differences in these two automated scoring methods between EL1 and ELL students in post-secondary university settings. Two lines of inquiry guided the below research questions: (1) whether the inclusion of prosody can reduce scoring bias (first two research questions) and (2) whether the inclusion of prosody can improve the predictive and diagnostic efficacy of ORF assessment (last three research questions). The research questions are:
How do human and ASR transcription methods affect the difference between EL1 and ELL ORF scores, using the traditional scoring method?
How do the existing and new ORF scores differ between EL1 and ELL students?
How do the existing and new ORF scores predict reading comprehension differently across language backgrounds?
How do the existing and new ORF scores predict reading comprehension across language backgrounds, considering comprehension ability levels?
What are the characteristics of ORF diagnostic profiles based on the new ORF component scores?
Methods
Participants
Data were collected from APLUS (Academic Platform for Languages in University Settings), a digital learning-oriented language assessment platform at a large Canadian University. APLUS is designed to support the development of academic communication skills among first-year undergraduate and graduate students. Summer bridge programs and foundational core courses have adopted it by assigning 5% of the course grade for the completion of APLUS. When students complete the APLUS tasks, they receive a certificate which they submit to their instructors to indicate completion. The scores derived from APLUS are primarily used by the students to better understand their own language abilities in relation to the university’s expectations. A total of 807 students have used APLUS with varying degrees of task completion. Table 2 summarizes the sample characteristics of the study participants in terms of gender, educational degree, and language background (EL1s and ELLs).
Sample characteristics on gender, level, and language backgrounds.

Note: Other includes 16 other languages, each of which only one student indicated as their first language.
Tasks
The present study used the reading comprehension and read-aloud tasks included in APLUS. In the reading comprehension task, students read a short (1685 word) academic article (Murray, 2021) on popular science focusing on gender equity and innovation, and responded to 21 reading comprehension questions. Students were instructed to take notes focusing on the author’s key points and supporting details and were also asked to practice time management by setting a timer for their own reading. The reading comprehension test was designed to elicit three core comprehension skills, explicit, inferential, and global comprehension. The test had a Cronbach’s alpha of α = .86 and α = .83 for ELL and EL1 students, respectively (measured using the Kuder–Richardson reliability estimate).
The read-aloud task asked students to read a challenging 138-word excerpt from the Murray article (described above) and instructed to read “naturally and clearly.” The read-aloud task participants included 105 EL1 and 307 ELLs. Students complete APLUS tasks on their own time and so the study had no control over the acoustic environment or recording equipment used, nor was there any proctoring employed. Students’ speech inputs were automatically saved and processed using OpenAI’s open-source Whisper ASR model for automatic transcription (Radford et al., 2022). Whisper demonstrates robust transcription capabilities, achieving an average text-normalized word error rate (WER) of 12.8 across 15 standard datasets, which are among the best performance metrics of any ASR model to date (Radford et al., 2022). Comparing the results of Radford et al. (2022) to Ferraro et al. (2023), who benchmarked the performance of many paid and open-source ASR platforms, Whisper performs better than average and outperforms the three major paid platforms of Amazon, Google, and Microsoft. Importantly, Whisper’s training data includes 680,000 hours of audio, with 117,000 covering 96 languages besides English (Radford et al., 2022). However, there are indications that the Whisper model more accurately transcribes North American English dialects over others (Calbert & Roll, 2023).
Analysis
Scoring
Reading comprehension test scores were derived from a 2-parameter logistic (2PL) item-response theory (IRT) model using a maximum likelihood estimator (Bock & Aitkin, 1981; Lord, 1980). For the read-aloud task data, five different scores were estimated: speed, accuracy, existing ORF score (WCPM), prosody, and a new ORF score. Speed was calculated by subtracting each student’s reading time from the maximum time any reader took to read the Murray excerpt. Accuracy was calculated as the 1 − WER (word error rate), which is the percentage of words read incorrectly based on either a human or ASR-derived transcript. To calculate the percentage of words read incorrectly, the sum of miscues (insertions, substitutions, and deletions) was divided by the total words in the read text. An NLP algorithm was used to parse each transcript and compare it to the original reference text to identify each incorrect word from the transcript and return the number of incorrect words as a percentage of the total words read. The existing ORF score (WCPM) combines speed and accuracy. WCPM is calculated by dividing the raw number of correctly spoken words by the reading time and dividing the result by 60. Finally, the new ORF score was calculated for the purpose of this study, by combining speed, accuracy, and prosody. The new ORF score was calculated as
Descriptive statistics for ORF variables.
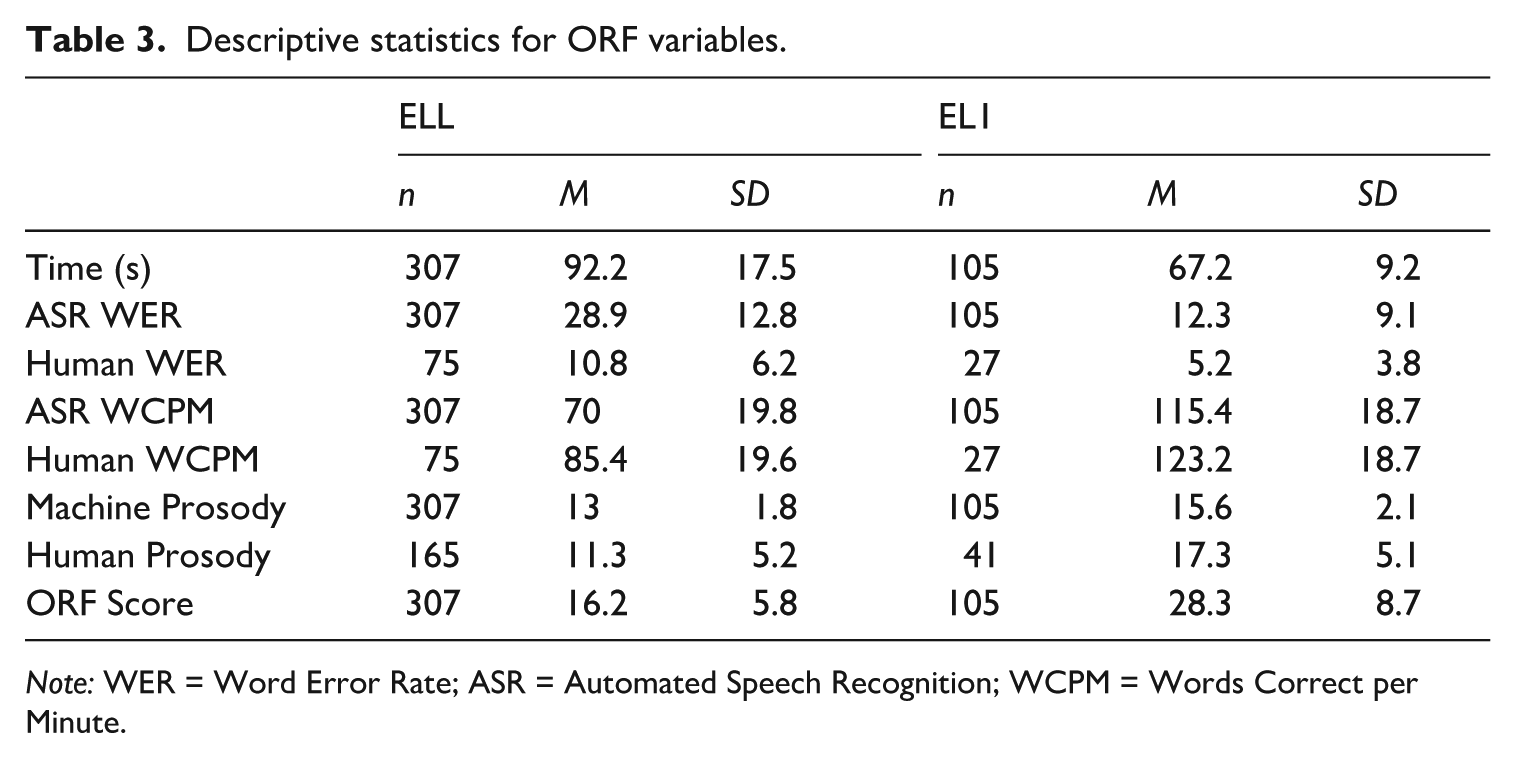
Note: WER = Word Error Rate; ASR = Automated Speech Recognition; WCPM = Words Correct per Minute.
Prosody ML model
Prosody scores were derived from a machine learning model trained to predict human scores. Seven human raters, trained using a rubric based on the multi-dimensional fluency scale (MDFS; Rasinski, 2004), assessed four dimensions of reading prosody: expression and volume, phrasing, smoothness, and pace. All raters were graduate students in education, three of whom were EL1s, and four were ELLs with Mandarin as their first language. Two rater training sessions were held where raters closely reviewed the rubric and independently scored a set of 15 speech samples, followed by discussions on challenges, confusion, and scoring discrepancies. The raters then scored 206 samples for model training, with each sample being scored by four randomly assigned raters. The final scores were summed into a single prosody score as the machine learning model was better able to predict a single, combined score than four trait scores. Inter-rater reliability was evaluated using the intra-class correlation coefficient (ICC), with high values ranging from .957 to .964. Expert raters resolved any score differences as long as they were not involved in the original scoring.
The prosody ML model was built using an initial set of 63 prosodic and lexical features derived from the acoustic properties of each student’s audio recording in combination with grammatical reference points in the ASR transcript. During model training, some features were not retained, resulting in a final model that included 47 features. The present study’s original 63 features were built upon previous research, incorporating many acoustic properties referenced in previous studies as well as new features explored here, such as the number and range of relative decibels and pitch peaks. Previous research into machine-derived prosodic features highlighted two main groupings: pitch- and pausing-related features (Benjamin et al., 2013; Kim et al., 2021). The present model added two additional groupings: speech rate and volume (containing 15 of the 63 total features). All retained features, their groupings, and descriptions are detailed in Table 4.
Prosodic features included in the prosody ML model.

Early work by Schwanenflugel et al. (2004) identified the core acoustic properties of prosodic reading used in this study, such as less variable intersentential pauses, more variable fundamental frequency (F0, also known as pitch), consistent demarcation of sentence boundaries, and a falling pitch at the end of sentences, all of which were associated with high-skill readers. Subsequent research expanded these early findings, introducing features like the ratio between the average pitch of lexically stressed syllables and unstressed syllables (Bolaños et al., 2013) and the number of vocalic nuclei per minute (Bailly et al., 2022).
To build the most optimal ML model, we tested four common ML regression algorithms: extreme gradient boosting (XGBOOST; Chen & Guestrin, 2016), random forest regression (Ho, 1995), ridge regression, and lasso regression (Hastie et al., 2009). Tree-based ML models (i.e., random forest) use a complex series of if-then-else decision trees based on the training data, comparing final decisions to the ground truth (human scores). Gradient boosting decision trees (i.e., XGBOOST) iteratively train an ensemble of shallow decision trees, multiplying the total number of trees compared to a traditional tree-based model. XGBOOST, a scalable tree-based regression model, performed the best and was retained.
All 63 features were normalized and included in all models initially. Features not contributing independent information to the model were removed, as described in Hastie et al. (2009). Models and feature combinations were tested using 10-fold cross-validation, aiming to minimize the mean absolute percentage error (MAPE) in the testing sample. The MAPE statistic is the average difference between the predicted score and the reference score as a percentage of the reference score. The best model (XGBOOST) and the best feature combination (indicated in Table 4) achieved a MAPE of 0.198. All features were extracted with Praat (Boersma & van Heuven, 2001), and models were built and run in Python (version 3.7) using the scikit-learn toolkit (version 2.22).
Analysis by research questions
RQ1 (asking how ASR accuracy affects EL1 and ELL ORF scores) was answered by comparing the existing ORF scores between EL1 and ELL students when derived from both the ASR and human transcripts. Using the human transcripts as the “ground truth,” RQ1 therefore identifies the amount of discrepancy added to ORF scores by the ASR system and compares the standardized difference (d) between the EL1 and ELL groups in both conditions. For RQ2 (asking how EL1 and ELL groups differ between the two ORF scores), an independent samples t-test was conducted to examine group differences in: (1) the existing WCPM-based method and (2) the new prosody-inclusive method. RQ3 (asking how the prediction of reading comprehension differs between the two ORF scores) compared the ability of existing and new ORF scores to predict reading comprehension between language groups using two regression models. Model 1 was a hierarchical regression model which included each of the independent components of ORF (speed, accuracy, and prosody), language background, and interactions between each ORF component and language background. This model aimed to assess the strength of the independent relationships between traditional ORF variables and reading comprehension and then examine the added predictive relationship of prosody, controlling for language background. Model 2 included the existing ORF score and the new ORF score as independent variables, along with language background and interaction terms. This model examined the relative strength of each ORF score after controlling for the other and for language background. Both models for RQ3 set ELLs as the reference group, as they were the larger sample and the primary group of interest for this study. Multicollinearity was assessed for each RQ3 model by examining the variable inflation factor (VIF), with a cutoff of 5 (James et al., 2013).
For RQ4, we tested Model 2 described from RQ3 using quantile regression analysis to determine if predictive relationships vary across different comprehension levels. Unlike ordinary least squares (OLS) regression, which estimates the mean of the dependent variable based on the independent predictor variables, quantile regression estimates the conditional median or other quantiles of the dependent variable (Koenker & Basset, 1978). This analytic approach is particularly useful for investigating the predictive relationship of independent variables across different score points in the distribution of the dependent variable. We analyzed the 10th, 25th, 50th, 75th, and 90th quantiles of the dependent reading comprehension variable.
For RQ5 (asking about the characteristics of ORF diagnostic profiles), we conducted latent profile analysis (LPA) to identify distinct reading fluency profiles based on three ORF variables: speed, accuracy, and prosody, which were each standardized to the same scale. LPA is an analytic technique that estimates a categorical latent variable identifying subpopulations based on each individual’s level on a set of continuous variables. The optimal number of latent profiles was determined based on Spurk et al. (2020), by using a combination of content-related considerations and statistical fit values: bootstrap likelihood ratio test (BLRT), Bayesian information criterion (BIC), Akaike information criterion (AIC), Kullback information criterion (KIC), and Entropy.
All analyses were conducted in R (version 3.6.1) using open-source packages: mirt for IRT models (Chalmers, 2012), psych for RQ1, RQ2, and RQ3 (Revelle, 2022), quantreg for RQ4 (Koenker et al., 2023), and tidyLPA for RQ5 (Rosenberg et al., 2019).
Results
Differences in ASR and human transcription accuracy between ELL and EL1 students
The mean difference between ELL and EL1 WCPM scores when using an ASR transcript was 45 points (d = 2.33, t = 20.59***) while the difference was 38 points when using a human transcript (d = 1.97, t = 8.69***). Both differences are large, but the human transcript difference is 7 points smaller, indicating that about 16% of the difference between ELL and EL1 scores can be attributed to reduced ASR accuracy with ELL students, in the current sample. Table 3 shows the means and standard deviations for WCPM scores using both human and ASR transcription on both ELL and EL1 groups.
Differences in existing and new ORF scores between ELL and EL1 students
Two ORF scoring methods were compared: the existing ORF scoring approach accounting for accuracy and speed and the new ORF scoring method adding prosody. As shown in Table 5, the standardized group difference between EL1 and ELL groups’ existing ORF scores is d = 2.33 (t = 20.59***) compared to a difference of d = 1.64 (t = 13.14***) with the new ORF score. Both group differences are large, which can be seen clearly in Figure 1, but the new ORF score difference between these groups is much smaller.
Comparison of ORF scores using different methods for ELL and EL1 students.
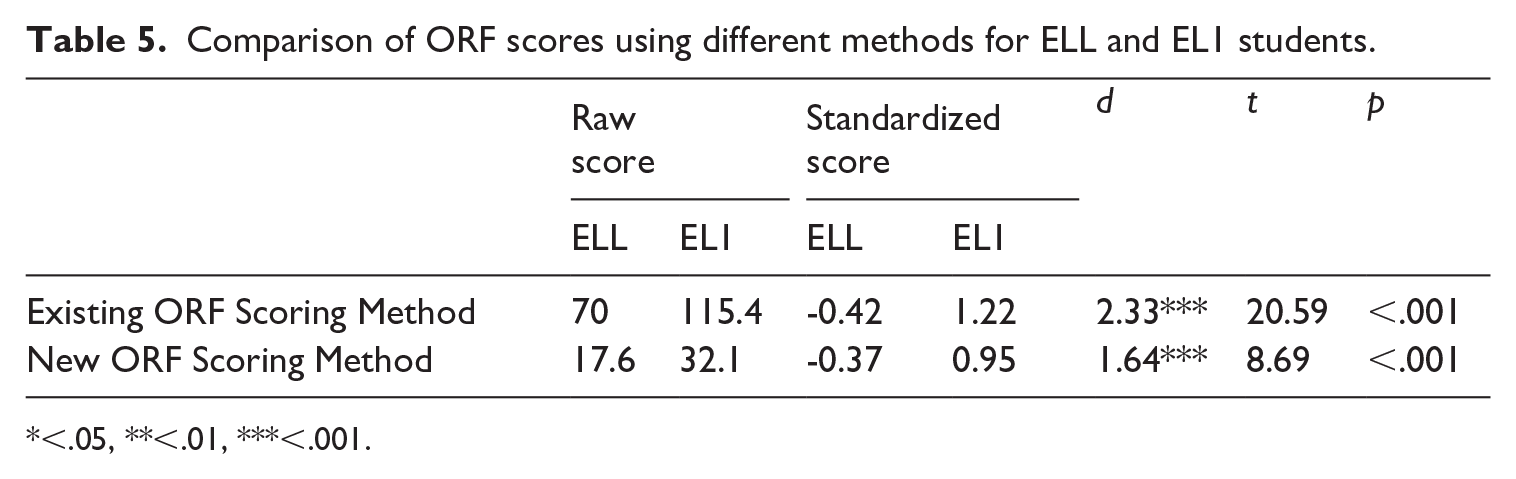
<.05, **<.01, ***<.001.
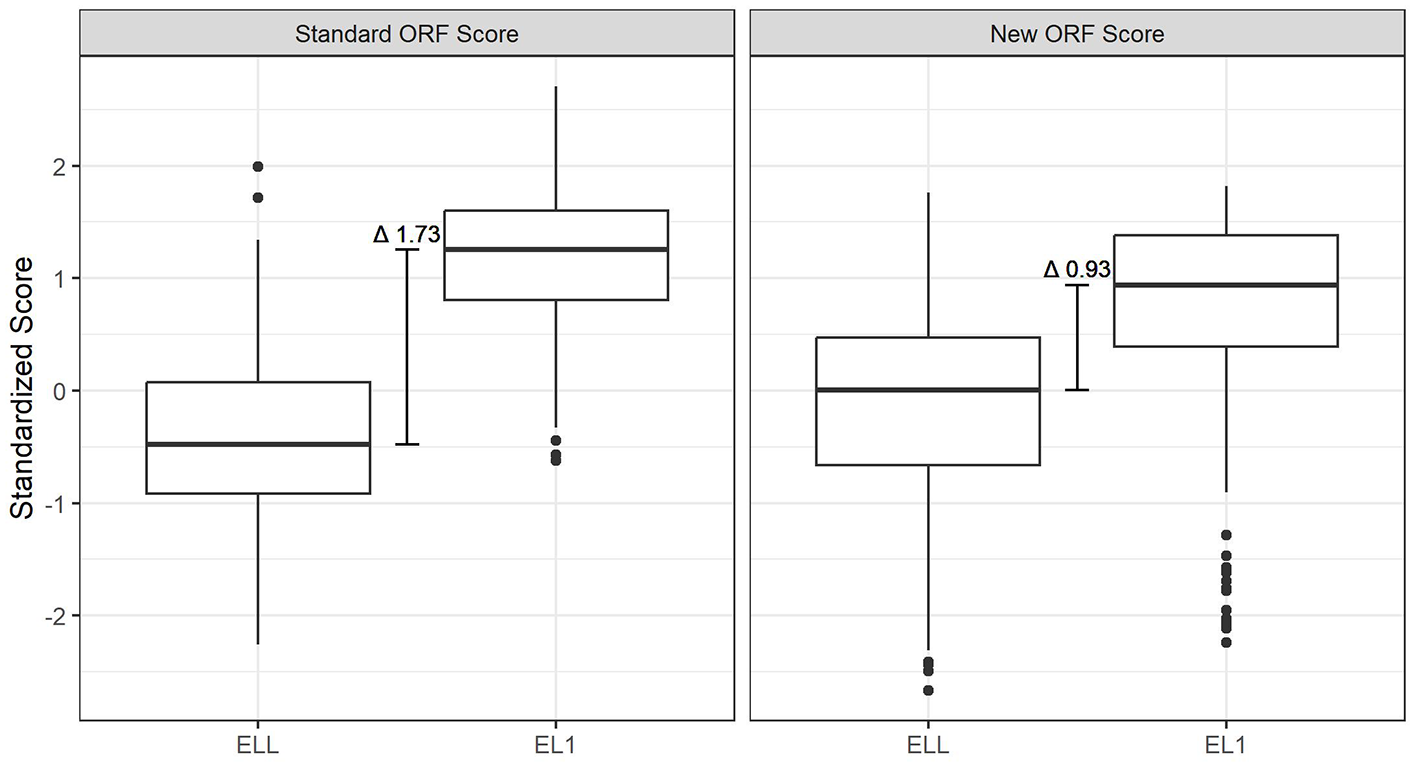
Boxplots comparing ORF scoring methods for language groups.
Difference in predictive relationships between ORF scoring methods and reading comprehension ability
The results from hierarchical multiple regression analyses are presented in Table 6. The result from Model 1 showed that without prosody, both speed and accuracy significantly predicted reading comprehension (β = 0.203** and 0.212**, respectively), and that there was no statistically significant group difference in reading ability (β = 0.101), though the EL1 group’s mean was higher (0.28 and −0.07 for EL1s and ELLs, respectively). When prosody was added, only accuracy and prosody remained significant (β = 0.194* and 0.295***, respectively). Additionally, no significant interaction effects were observed, indicating that the relationship between ORF variables and reading comprehension was not significantly different between ELL and EL1 students. The adjusted R2 increased from 9% to 17% of total variance explained when prosody was added.
Hierarchical multiple regression analysis results.
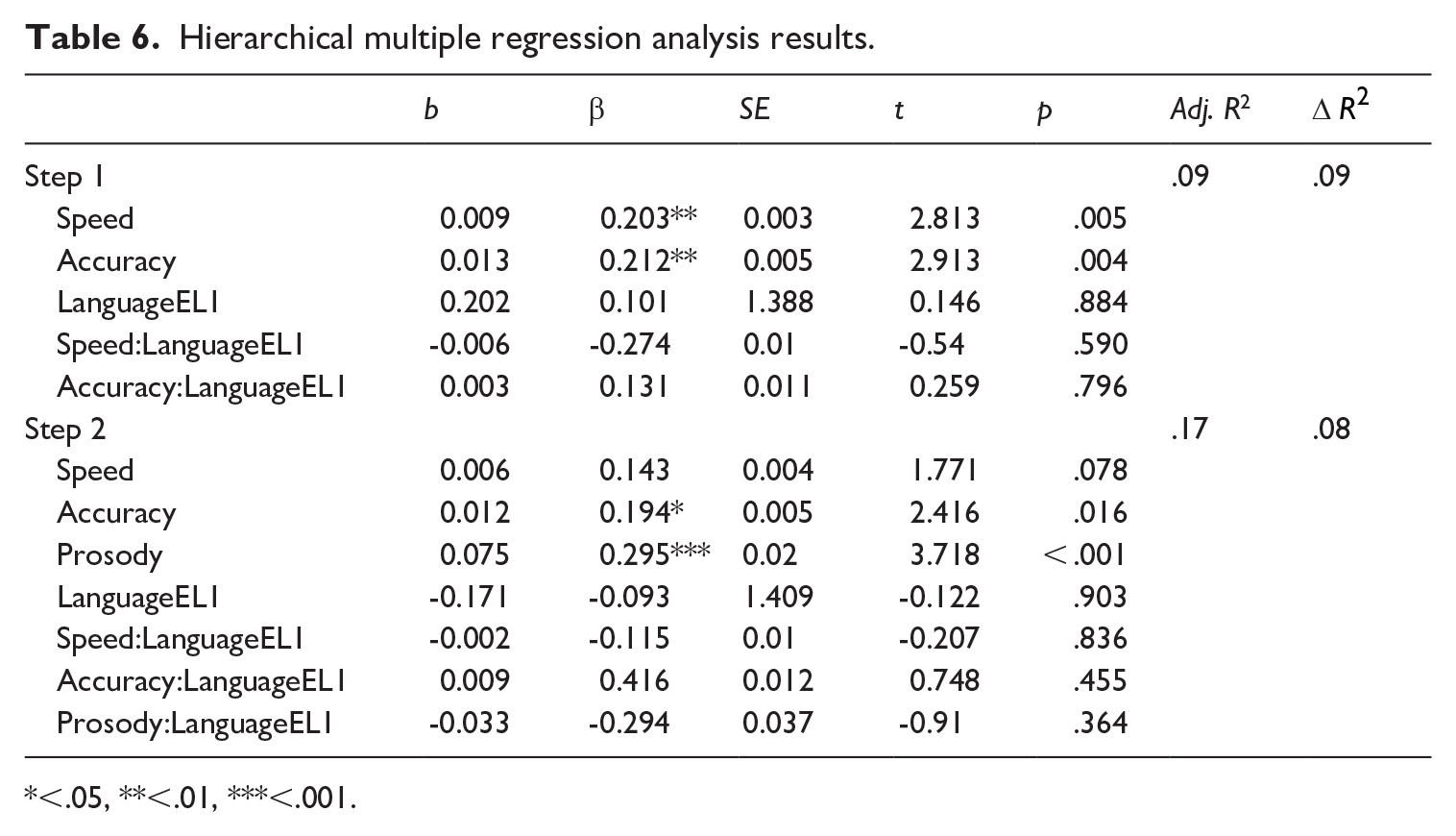
<.05, **<.01, ***<.001.
Model 2 examined the predictive relationship of existing and new ORF scores with reading comprehension. As shown in Table 7, both significantly predicted reading comprehension (β = 0.277* and 0.34**, respectively) after controlling for each other and language background. Similar to the results from Model 1, the standardized β coefficient for the new ORF score was higher than that of the existing ORF score, indicating improvement in the predictive power of the new method. None of the interaction terms was significant.
Regression results of predictive relationship between ORF scores and reading comprehension.
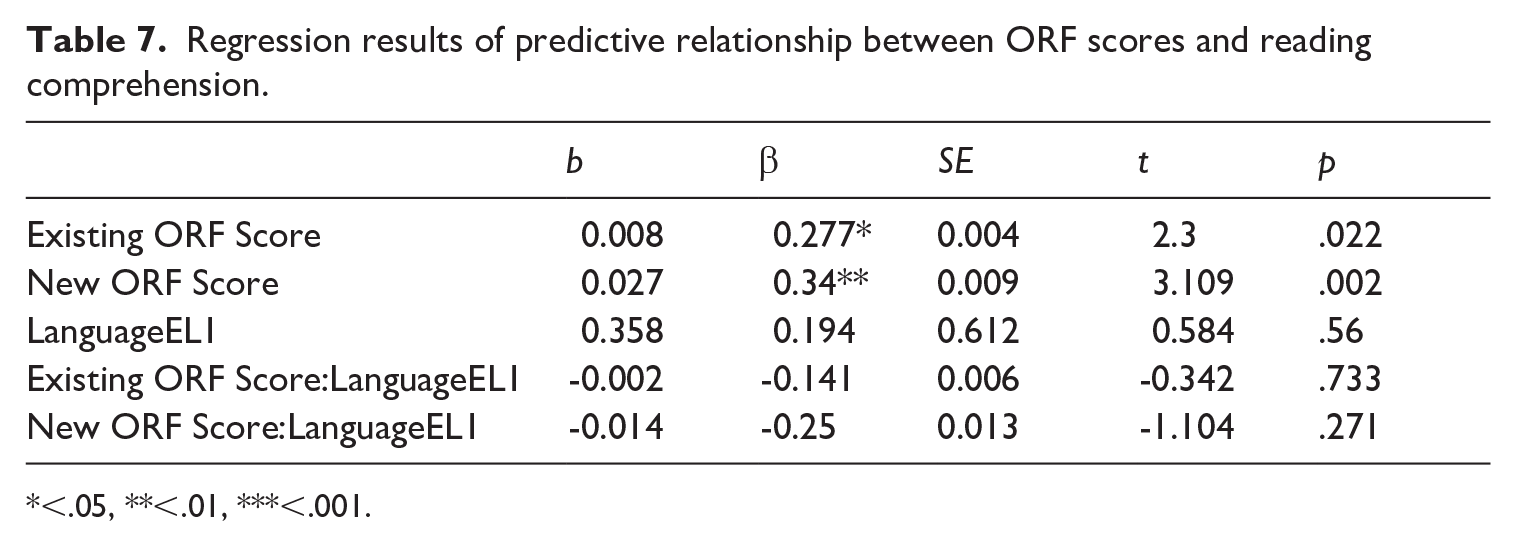
<.05, **<.01, ***<.001.
Results from quantile regression analysis
Table 8 presents the quantile regression results which indicate that both the existing ORF and the new ORF scores were significant predictors of reading comprehension across the distribution of reading comprehension scores. The main effect of each scoring method was significant for all of the quantiles measured except for the 90th. However, the estimated beta coefficients for the existing ORF score were strongest toward the upper end of the distribution, while the new ORF score coefficients were strongest toward the lower end. This suggests that the new ORF score may be slightly better at predicting reading comprehension in students with poorer reading comprehension skills.
Quantile regression results.
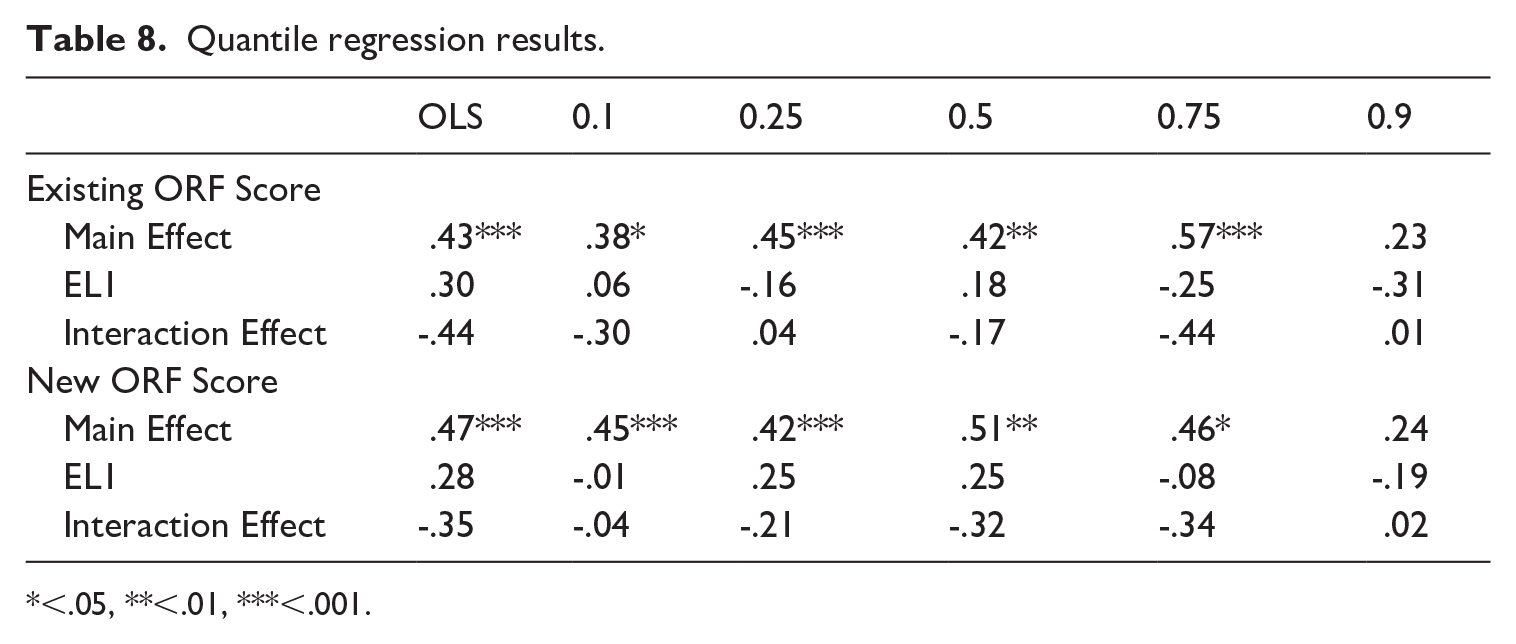
<.05, **<.01, ***<.001.
ORF latent profiles
Table 9 shows the model fit statistics for LPA models, ranging from 3 to 10 profiles. The six-profile model was determined to be the best-fitting model as it demonstrated the most favorable BIC, KIC, and entropy values, and it was the last model to exhibit a significant BLRT value compared to the preceding model. The six-profile model included two profiles (three and four) representing small percentages of the total sample, with sizes of n = 16 (5%) and n = 11 (3.4%), respectively. Although a profile with <25 individuals or <3% of the sample size is not recommended (Spurk et al., 2020), it is often justified if the profiles depict distinct groups worth identifying.
Fit statistics for LPA models with 3 to 10 profiles.
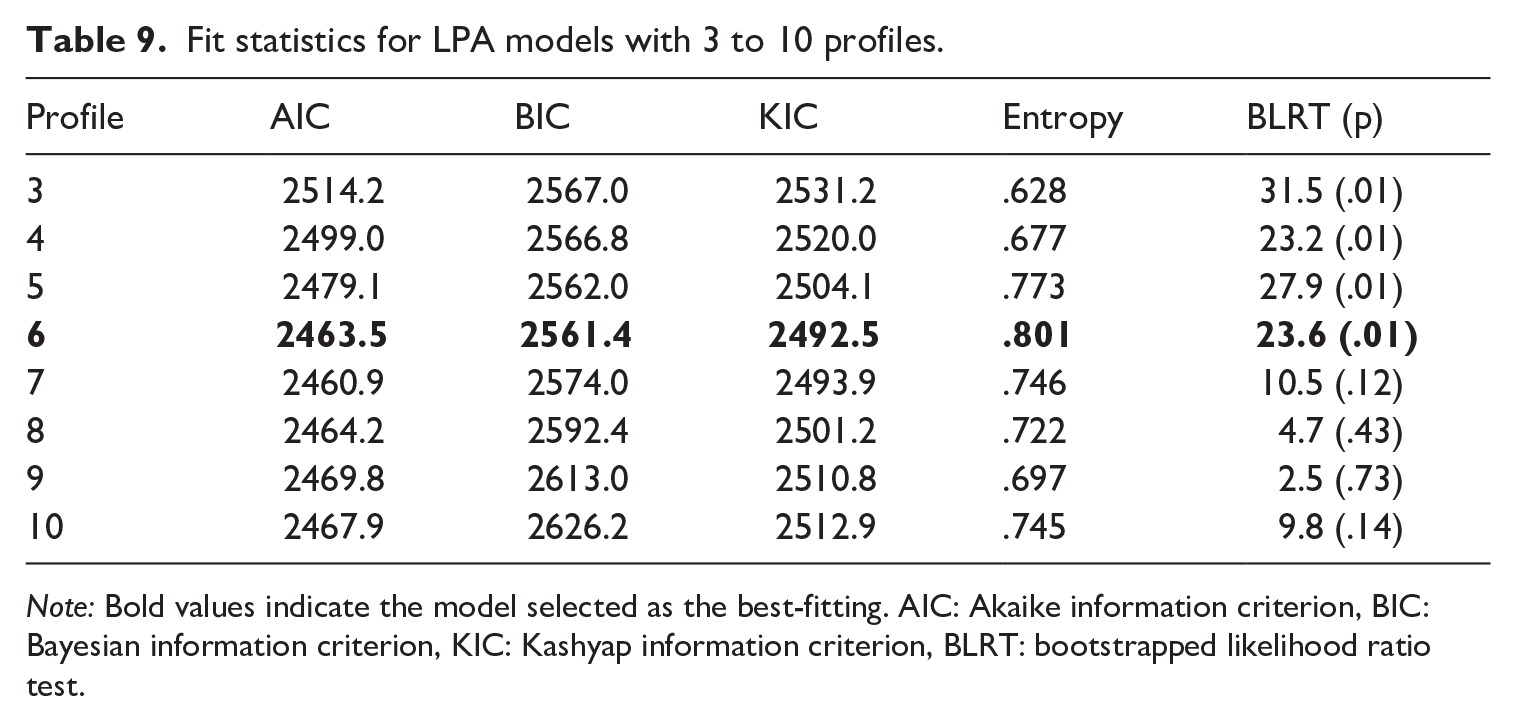
Note: Bold values indicate the model selected as the best-fitting. AIC: Akaike information criterion, BIC: Bayesian information criterion, KIC: Kashyap information criterion, BLRT: bootstrapped likelihood ratio test.
Figure 2 compares six latent profiles, with each differentiated by their estimated scores on the z-scale across three components of oral reading fluency: speed, accuracy, and prosody. Profile 1, comprising 13% of the sample, exhibited very low scores in speed and prosody and moderately low accuracy scores. Profile 2, representing 39%, showed low to moderate performance across all three components. Profile 3 (5%) exhibited very high speed and accuracy, but very low prosody. Profile 4 (3%) displayed high speed, very low accuracy, and high prosody. Profiles 5 (24%) and 6 (15%) exhibited high and very high scores in all three components, suggesting these profiles represented the fluent and extremely fluent readers.
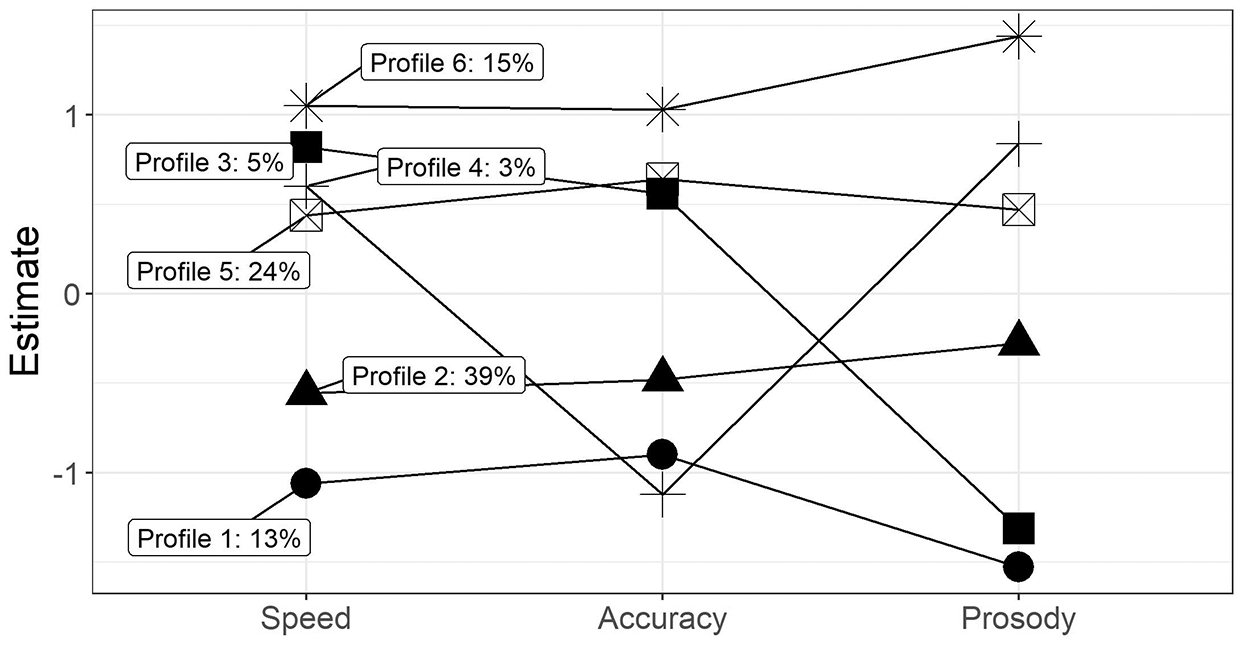
Latent profile analysis of three ORF sub-scores.
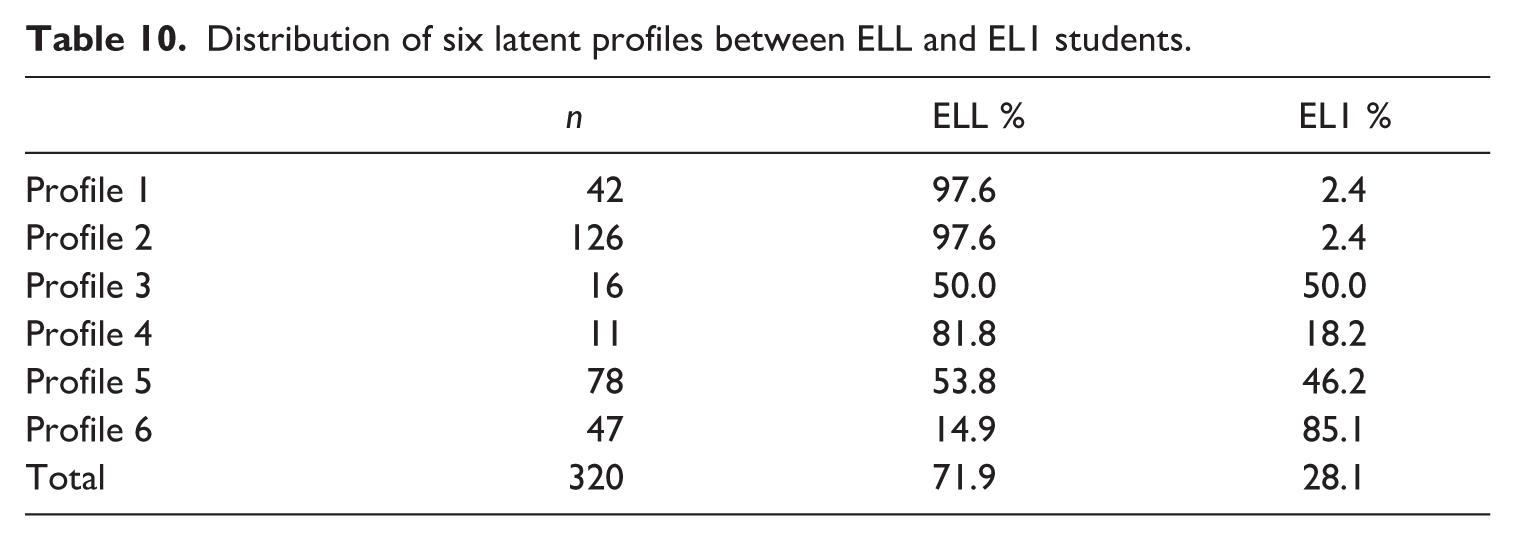
Table 10 shows the percentages of language groups across the different latent profiles. Students in Profile 1 were slow and inaccurate, with low prosody scores 1.5 standard deviations below the mean. Profile 1 (42 students) had a high predominance of ELL students at 97.6%, compared to only 2.4% of EL1 students, suggesting marked differences in the characteristics of ORF profiles by language background. Profile 3, which is balanced between ELLs and EL1s, included students who read with well above average speed and accuracy but were very poor at reading prosodically. Profile 4, consisting of 11 students, were fast and prosodic readers but read the least accurately of all profiles, evoking the profile of a reader who may skim content, incorrectly reading many words along the way but doing so fairly effectively. About 18% of Profile 4 students were EL1, which is close to the percentage of EL1 students in the sample overall. Profile 6 predominantly consisted of EL1 students, suggesting that these students were the most fluent readers, as they exhibited high scores in all three ORF components.
Distribution of six latent profiles between ELL and EL1 students.
Discussion
The present study evaluated the potential of incorporating prosody into automated ORF assessment and the ways this may reduce language background bias and provide greater construct coverage and diagnostically useful information about student reading profiles. Recognizing the construct underrepresentation of traditional ORF assessment based on accuracy and rate alone, the present study further questioned whether its reliance on ASR speech-to-text transcription models would present a potential bias against ELL students due to ASR inaccuracy, as well documented in previous research (L. Chen et al., 2018; Hannah et al., 2022; Mirzaei et al., 2015). RQ1 replicated these previous findings and quantified the impact on traditional ORF scores by comparing the difference between ELL and EL1 students’ WCPM when using human and ASR transcription. The difference between these two groups’ WCPM scores was smaller (7 points on average) when human transcription was used, indicating that differential ASR accuracy is systematically driving ELL students’ automated ORF scores down. This issue poses a significant threat to the validity of automated ORF assessments, as reduced ASR accuracy embedded within the system can result in unfair disadvantages for specific groups of test takers, such as ELLs. Building on the results showing language group differences in ORF scores between human transcription and ASR models, RQ2 then questioned whether a new, prosody-inclusive ORF score would reduce or amplify those differences. The findings indicated that the new ORF score did reduce the gap between these two groups, dropping from d = 2.33 to d = 1.64. The difference between ELL and EL1 scores in both cases was greater in the present study than has been found in previous studies. For example, White et al. (2021) found a difference of d = 0.61, and Jimerson et al. (2013) found d = 0.81. However, both those studies focused on primary grade students, in those cases the English language skills of the students were likely far more developed than in the present study where international students likely had much less exposure to English. No previous studies could be found that disaggregated ORF scores by language background in a post-secondary, English language learning context.
RQ3 and RQ4 then sought to evaluate the relationship between the new ORF score and reading comprehension when the new ORF score encompasses all three components (accounting for speed, accuracy, and prosody). The findings showed that prosody was a crucial predictor within the studied sample, being the strongest predictor and nearly doubling the variance explained in the initial model. Consequently, the new ORF score outperformed the existing ORF score in predicting reading comprehension but was not further differentiated across the distribution of the reading comprehension scores. These study results somewhat align with previous studies with similar samples (post-secondary ELLs), though it should be noted that no previous research has predicted reading comprehension using automated ORF scores. Jiang (2016) found that, compared to WCPM, prosody was a stronger predictor of reading comprehension for Japanese L1 speakers, less strong for Arabic L1 speakers, and comparable for Chinese L1 speakers. Tunskul and Piamsai (2016) identified accuracy as the most significant predictor of reading comprehension, followed by prosody, and then reading rate. The results of the present study align more closely with research conducted in EL1 contexts, which consistently indicates that prosody predicts comprehension beyond the contributions of accuracy and rate (Kuhn & Schwanenflugel, 2019; Schwanenflugel & Benjamin, 2017; Schwanenflugel & Kuhn, 2015). Unlike many previous studies which focus on young learners, the present study found prosody to be an important predictor of reading comprehension with older students. This point adds evidence to the notion that while gains in accuracy and rate tend to plateau as children develop, prosody continues to be an important predictor into adolescence, becoming a stronger predictor of more complex comprehension tasks in later years (Schwanenflugel & Kuhn, 2015).
Finally, RQ5 sought to consider a diagnostic approach to ORF assessment by examining the characteristics of ORF latent profiles between language groups. The study results clearly indicate different associations between the ORF latent profiles and language backgrounds. Further research may explore implications for reading instruction that would benefit readers who struggle with only one or two of speed, accuracy, or prosody, rather than thinking about them as struggling readers generally. Instructional practices targeting students with struggling prosody were identified as a research gap in a recent review of reading interventions (Hudson et al., 2020), and the importance of considering ORF components separately has been stressed by researchers (Samuels, 2006; Valencia et al., 2010). Valencia et al. (2010) for example found that a model including rate, accuracy, and prosody outperformed a model that combined the three sub-components into a single score, which is consistent with the present study. The same authors further argued that assessment results which separate these three sub-constructs would “add specificity and diagnostic information that are necessary for effective instructional interventions” (Valencia et al., 2010, p. 286).
The present study has several limitations that future studies could address. First, although the sample size was substantial, the balance between language background groups and the overall diversity of ELL language backgrounds could be improved to ensure more representative results. In addition, further research should explore methods to enhance the automated prosody model. Language background-specific training could potentially yield better results for the various language backgrounds represented in the study participants. Moreover, employing more advanced ML approaches, such as large language models and word embedding models, shows promise and could significantly improve the automated scoring of prosody and ORF. Future studies should also investigate the utility and impact of incorporating prosody into ORF assessments. This could be achieved by evaluating the experiences and reading-related outcomes of both teachers and students who utilize prosody-inclusive ORF assessments compared to those relying on accuracy and rate alone.
Conclusion
The present study showed that the inclusion of prosody within automated ORF assessment can mitigate bias against ELL students caused by differential ASR accuracy, improves the predictive power for reading comprehension with both ELL and EL1 post-secondary students, and improves the diagnostic capacity of the assessment. These findings underscore the transformative potential of technology in addressing the long-standing issues of construct under-representation in ORF assessments. Additionally, the distinct profiles of reading fluency identified in this research highlight the importance of a nuanced approach to both assessment and instruction. By providing score reports that identify levels across the different components of ORF—speed, accuracy, and prosody—educators can develop tailored instructional strategies that better meet the unique needs of individual students. This diagnostic specificity in assessment and intervention could hold promise for improving language outcomes for students (in formative assessment contexts), especially those who may be marginalized by traditional, less sensitive assessment methods.
The broader implications of this research extend beyond immediate educational contexts, suggesting a paradigm shift in how we understand and measure language competence. As we continue to harness the capabilities of AI and related technologies, there is a critical need to ensure these tools are developed and implemented with an eye toward ethical considerations, particularly concerning fairness and accessibility for all test takers. Ongoing research and dialogue among educators, technologists, policymakers, and assessment practitioners are essential to navigate these challenges, aiming for a future where technology-rich assessments enable all students to demonstrate their true potential without bias.
Footnotes
Acknowledgements
The authors express their sincere gratitude to the editors of Language Testing and especially to the special issue editors, Yasuyo Sawaki and Eunice Eunhee Jang, for their thoughtful reviews and insights.
Author contributions
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: E.E.J. is a co-editor of this special issue, “Advancing language assessment for teaching and learning in the era of the artificial intelligence (AI) revolution: Promises and challenges.”
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the University of Toronto International Student Experience Fund (ISEF).
Ethical approval and informed consent
This research has been approved by the Social Sciences, Humanities & Education Research Ethics Board of the University of Toronto, RIS Protocol Number: 39783. Informed written consent was obtained from each participant included in the study.
Data availability statement
Unfortunately, the data cannot be made available at this time.