
Abstract
Vocabulary knowledge strongly predicts second language reading, listening, writing, and speaking. Yet, few tests have been developed to assess vocabulary knowledge in French. The primary aim of this pilot study was to design and initially validate the Context-Aligned Two Thousand Test (CA-TTT), following open research practices. The CA-TTT is a test of written form–meaning recognition of high-frequency vocabulary aimed at beginner-to-low intermediate learners of French at the end of their fifth year of secondary education. Using an argument-based validation framework, we drew on classical test theory and Rasch modeling, together with correlations with another vocabulary size test and proficiency measures, to assess the CA-TTT’s internal and external validity. Overall, the CA-TTT showed high internal and external validity. Our study highlighted the decisive role of the curriculum in determining vocabulary knowledge in instructed, low-exposure contexts. We discuss how this might contribute to under- or over-estimations of vocabulary size, depending on the relations between the test and curriculum content. Further research using the tool is openly invited, particularly with lower proficiency learners in this context. Following further validation, the test could serve as a tool for assessing high-frequency vocabulary knowledge at beginner-to-low intermediate levels, with due attention paid to alignment with curriculum content.
Introduction
Vocabulary knowledge strongly predicts second language (L2) proficiency in listening (In’nami et al., 2022), reading (Jeon & Yamashita, 2022), writing (Kojima et al., 2022), and speaking (Jeon et al., 2022). This is not surprising given that learners need to know at least 95% of the words in any given written or spoken text in English to fully understand it (H.-C. Hu & Nation, 2000; Laufer & Ravenhorst-Kalovski, 2010; Schmitt et al., 2011). Knowledge of high-frequency words can thus help learners to reach this level of coverage. For instance, the first 2,000 most frequent words in English have been found to cover at least 82% of written language and 89% of spoken language (Dang & Webb, 2014; Webb & Nation, 2017; Webb & Rodgers, 2009). As such, there is a need for learners to know and be tested on their knowledge of high-frequency words (Webb et al., 2017). Indeed, many education systems prioritize high-frequency words in their curricula. Highly relevant to the current study are the Department for Education’s (2022) recently announced reforms to the General Certificate in Secondary Education (GCSE; a national high-stakes external examination taken almost exclusively by 16-year-olds in schools) curriculum for French, German, and Spanish in England. The revised curriculum stipulates that the words used in each exam must be sampled from a compulsory wordlist where at least 85% of the items are high-frequency (defined as being in the most frequent 2,000 words). For further information about GCSEs, curriculum reforms, and other jurisdictions where frequency has informed vocabulary selection (see Supplemental Appendix S1).
Although many vocabulary tests are available in English (Meara & Milton, 2003; Nation, 1990; Nation & Beglar, 2007; Schmitt et al., 2001), very few exist for languages other than English. This is problematic for several reasons. First, it makes it difficult to know whether the reported relations between English vocabulary knowledge and L2 proficiency similarly hold for learners of languages other than English. Second, teachers and materials and test developers currently do not have a reliable understanding of vocabulary knowledge among these learners that could help when selecting or creating appropriate materials (Nation & Beglar, 2007; Schmitt et al., 2001; Stoeckel & Bennett, 2015). Although some such tests do exist (for French, see Batista & Horst, 2016; Milton, 2006; Peters et al., 2019), they provide limited coverage of the first 2,000 most frequent words and/or are not designed specifically with beginner-to-low intermediate adolescent learners in instructed contexts in mind. This gap is of particular concern given that current test development and validation theory advocates against a one-size-fits-all approach (Chapelle, 2012; Kane, 2006; Read, 2000). Likewise, there have been calls for more rigorous validation of existing and new tests of vocabulary knowledge and, in particular, a better specification of tests’ purpose(s) and the type of learners and educational contexts that tests have been developed for (Schmitt et al., 2020).
To address these gaps, we piloted a new written test of form–meaning recognition of high-frequency vocabulary for beginner-to-low intermediate learners of French: the Context-Aligned Two Thousand Test (CA-TTT). This article describes the rationale and process behind the CA-TTT’s development and presents results from a pilot study designed to initially validate this test with 222 16-year-old English-speaking learners of French. Using an argument-based validation framework, we drew on classical test theory and Rasch modeling, together with correlations with another vocabulary size test and proficiency measures, to assess preliminary evidence for the CA-TTT’s internal and external validity.
Literature
This section reviews the existing measures of form–meaning knowledge in English and French that motivated the CA-TTT’s development and then outlines the argument-based validation framework used in this study.
Tests of vocabulary knowledge in English
When developing measures of vocabulary knowledge, most researchers have adopted a frequency-driven approach to item selection. Perhaps the most well-known tests of form(–meaning) recognition in English are the X-Lex (Meara & Milton, 2003), Y-Lex (Meara & Miralpeix, 2006), Vocabulary Levels Test (VLT; Nation, 1990; Schmitt et al., 2001), and Vocabulary Size Test (VST; Nation & Beglar, 2007).
X-Lex (Meara & Milton, 2003) is a yes–no (self-report) test of form recognition knowledge. In each of the three versions, participants are presented with 120 words: 20 words from the first five 1,000-word frequency bands and 20 pseudowords. Participants are told that not all words are real and must tick the words they know or can use. For every real word ticked, 50 points are awarded and for every pseudoword ticked, 250 points are deducted to account for false alarms. X-Lex suits low proficiency learners due to its low cognitive demands. X-Lex, however, tests form recognition, not form–meaning recognition, and can thus only give a partial indication of vocabulary knowledge. Y-Lex (Meara & Miralpeix, 2006) adopts an identical format, but where X-Lex focuses on the 5,000 most frequent words, Y-Lex tests vocabulary in the 6,000–10,000 word frequency range and may therefore be better suited to more advanced learners.
The original VLT estimates learners’ written receptive knowledge of the form–meaning links of words in four frequency bands (2,000, 3,000, 5,000, and 10,000) and an academic vocabulary level, whereas the updated VLT (Webb et al., 2017) focuses on the first five bands (1,000, 2,000, 3,000, 4,000, and 5,000). In both versions, each band includes 30 items consisting of five 6-noun clusters, three 6-verb clusters, and two 6-adjective clusters. Within each cluster, learners must select which of the six words matches one of three definitions. The VST (Nation & Beglar, 2007), on the other hand, estimates learners’ written receptive vocabulary size and contains 140 items sampled from the 14,000 most frequently occurring words in English with 10 items per frequency band. The VST has since been expanded to include the 20,000 most frequently occurring words with five items per frequency band (Coxhead et al., 2015). Within each band, participants must select which of the four definitions matches the target word presented within a sentence. The form–meaning recognition format, however, has been criticized for several reasons, including its potential to over-estimate vocabulary knowledge and lower internal reliability relative to more open-ended formats such as meaning recall (McLean et al., 2020; Stewart et al., 2023).
Most of this test development research has focused on English, with few measures of form(–meaning) recognition being available for learners of other languages, including French. Further research is thus needed in languages other than English.
Tests of vocabulary knowledge in French
The available measures for French include X-Lex (Meara & Milton, 2003; Milton, 2009), the Test de la Taille du Vocabulaire (TTV; Batista & Horst, 2016), and the VocabLab test (Peters et al., 2019).
The French X-Lex (Meara & Milton, 2003; Milton, 2009) is similar to the English version. The three versions (forms) test knowledge of the 5,000 most frequent words in French sampled from Baudot’s (1992) frequency list. Several studies (David, 2008; Milton, 2006, 2015) have used X-Lex to estimate vocabulary size among GCSE French learners. Milton (2006) found that these learners (n = 49) knew approximately 852 words (standard deviation [SD] = 440, range: 0–1,800). In a follow-up study, Milton (2015) reported similar findings: 775 words (n = 18, SD = 341, range: 350–1,250). David (2008) found even lower sizes: 564 (n = 26, SD = 352, range: 0–1,650), although the discrepancy is likely due to learners being tested at the beginning of the school year in David’s study and at the end in Milton’s.
The VocabLab test (Peters et al., 2019), of which one version (form) exists, assesses form–meaning recognition among Dutch-speaking learners of French. The test samples 30 words from each of the four frequency bands (2,000, 3,000, 4,000, and 5,000) based on the Lonsdale and Le Bras (2009) frequency list. The 2,000 band is broader than the others and includes words from both the 1,000 and the 2,000 bands. In this test, participants select a word’s meaning from four options, but unlike the original VLT, words are presented in isolation (rather than a sentence) and an ‘I don’t know’ option is included to reduce guessing. The use of an ‘I don’t know’ option is not without criticism due to individual differences in how likely participants are to select it (X. Zhang, 2013). Nevertheless, weaker correlations between proficiency and vocabulary knowledge have been reported when the option is included relative to when it is not (Stoeckel et al., 2016). The VocabLab test, however, is not a measure of vocabulary size as it does not contain a dedicated 1,000 band. As such, accuracy rates per frequency band, not estimated vocabulary sizes, are reported.
The TTV (Batista & Horst, 2016), of which one version (form) exists, adopts a similar format to the VLT and tests 120 words, with 30 words from each of four frequency bands (2,000, 3,000, 5,000, and 10,000) based on Lonsdale and Le Bras’ (2009) frequency list. The items in the 10,000 band, however, are from the Baudot (1992) frequency list, as the Lonsdale and Le Bras list only contains the 5,000 most frequent words. Unlike the VocabLab test, the TTV does not include any items from the 1,000 band.
Limitations of existing tests
The VocabLab test, the TTV, and X-Lex are not without their limitations. Although the former two include more items from each frequency band (i.e., 30 instead of 20 in the latter), following recent recommendations (Gyllstad et al., 2021; Schmitt et al., 2020), these items were randomly sampled from each band without consideration for the vocabulary learners might encounter in the classroom. This design feature may be inherent to the very purpose of a size test. However, it can cause problems if these tests are administered in specific populations. For instance, although X-Lex has been used to test GCSE learners’ vocabulary knowledge, only 27% of the 100 test items appeared in at least one or more of the vocabulary lists created for these learners (Assessment and Qualifications Alliance [AQA], 2016; Edexcel, 2018).
Critically, by the time 16-year-olds in England take their GCSE exams, they will have received approximately 400 to 450 hours of classroom exposure to French, with very little (if any) exposure outside of the classroom. These learners’ lexicons are thus largely restricted to the classroom input, which is typically composed of the vocabulary featured in the GCSE curriculum lists, the textbooks written using those lists, and the GCSE exam papers. Moreover, much of this vocabulary is likely to be mid-to-low frequency: Marsden et al. (2023), for instance, reported that of the 1,322 flemmas on AQA’s (the leading awarding organization in England) current GCSE French wordlist, only 48% were high-frequency. Thus, any test of vocabulary knowledge that randomly samples 20 or even 30 words from each band is unlikely to provide a valid or useful measure of these students’ vocabulary knowledge.
Such an argument echoes recent calls to examine the role of factors beyond frequency alone in predicting word difficulty (Hashimoto, 2021). For instance, He and Godfroid (2019) gathered usefulness and difficulty ratings from 76 experienced teachers of L2 English and found that frequency correlated only moderately with perceived usefulness and difficulty. Likewise, Robles-García et al. (2023) observed that 29 teachers’ judgments of what words their students were most likely to know had a stronger relationship with students’ vocabulary test scores than frequency. These findings point to the influence of classroom instruction on students’ vocabulary knowledge.
Another limitation of existing tests is that they “lack the needed precision to estimate the number of words that a learner knows [and] to determine mastery of specific word bands” (Stoeckel et al., 2021, p. 198). One way to address these limitations in light of the above discussion, at least with classroom learners with limited L2 exposure, may be to develop measures that factor in word frequency and the language featured in the curriculum.
A commonly cited advantage of vocabulary size tests is that they can assess the knowledge of learners from a wide range of proficiencies. However, their design often means that they provide more useful information about the vocabulary knowledge of intermediate-to-advanced learners and/or learners who have ample exposure to the language outside the classroom than for the beginner-to-low intermediate proficiency level and limited exposure that characterize GCSE learners.
First, the tests provide limited coverage of the 2,000 most frequent words, despite their high importance for comprehension. For instance, neither the VocabLab test nor the TTV has a dedicated 1,000 band: The 2,000 band in the VocabLab test sampled 30 words from the 0-2,000 range (i.e., approximately 15 words in each 1,000 band), and the 2,000 band in the TTV only sampled 30 items from the 1,000 to the 2,000 band. There is thus a need to develop a test that focuses solely on assessing high-frequency vocabulary knowledge, particularly in instructed contexts such as ours where a compulsory list of high-frequency vocabulary has recently been introduced for those starting to study GCSE French in 2024.
Second, both the VocabLab and the TTV tests provide definitions of the target words in the L2. Thus, each item tests knowledge of the target word and the words in the multiple-choice options (i.e., definitions). As Elgort (2013) argues, vocabulary size estimates using bilingual tests
Finally, there are no data about how the TTV performs with a population comparable to GCSE learners. Although the TTV reliably distinguished between proficiency levels, it was only validated with adult learners (Batista & Horst, 2016). In contrast, the VocabLab test was validated with different age groups, including secondary school students. These groups generally had lower scores and displayed more variability than other groups. Given the low proficiency characterizing their secondary school group, Peters et al. (2019) argued that it may be worthwhile to develop a test that focuses specifically on the 1,000 most frequent words. This has also been suggested by other researchers, including Webb and Sasao (2013).
Considering these issues, we developed the Context-Aligned Two Thousand Test (CA-TTT) to assess knowledge of curriculum-relevant words from the 2,000 most frequent French words among beginner-to-low intermediate adolescent learners. In our preliminary validation of the CA-TTT, we chose to focus on learners who had recently completed their GCSE French exams. In doing so, we acknowledge that further research will be needed to validate the test with more diverse sets of beginner-to-low intermediate learners.
GCSEs are high-stakes national exams taken by approximately 600,000 16-year-olds in at least one (academic) subject every year. For most students, these subjects include Maths, English, and Science, together with five optional subjects. Approximately 20% of each annual cohort choose to study French as an optional subject. These numbers, however, have decreased dramatically in the past two decades from 331,089 in 2003 to 130,901 in 2023 (Joint Council for Qualifications, 2003, 2023). Concerns have thus been raised about a shortage of language skills in the United Kingdom and its impact on the country’s ability to compete internationally (Ayres-Bennett et al., 2022). With this in mind, we focused predominately on testing high-achieving learners (i.e., those obtaining Level 7 or above in GCSE French) in the current study, as these individuals are the most likely to pursue further language study and, in turn, help to address the current shortage in language skills.
Given the size of this population, our limited understanding of these learners’ vocabulary knowledge, and their impact on the UK’s language skills shortage, the CA-TTT’s intended uses were to provide: (a) a test instrument for researchers to explore the extent to which high-frequency, curriculum-relevant vocabulary knowledge correlates with existing measures of vocabulary knowledge and L2 proficiency, (b) a valuable datapoint to inform policy-makers’ decisions regarding language learning, teaching, and testing, and, eventually following further validation work, (c) an achievement test for teachers to identify gaps in students’ curriculum-specific knowledge as they approach their high-stakes exams.
Argument-based validation
The process of validation involves collating evidence to support and explain the interpretation of a test’s scores for its intended purpose (Purpura et al., 2015). A unitary view of test validation, as proposed by Messick (1989) and Kane (2006, 2013), has become highly influential in language testing. Kane’s (2006, 2013) argument-based framework is based upon an interpretive validity argument whereby test designers must explicitly state their claims about test score interpretation and use and then provide a series of inferences about the test—that is, justifications supported by logical and/or empirical evidence. Adaptations of this framework have been successfully applied in many domains of L2 research, including Bokander and Bylund’s (2020) validation of the LLAMA language aptitude test. In a similar vein, our study adopts a logical framework of argument-based validation that is described in Table 1.
Proposed framework for the validation of the CA-TTT.
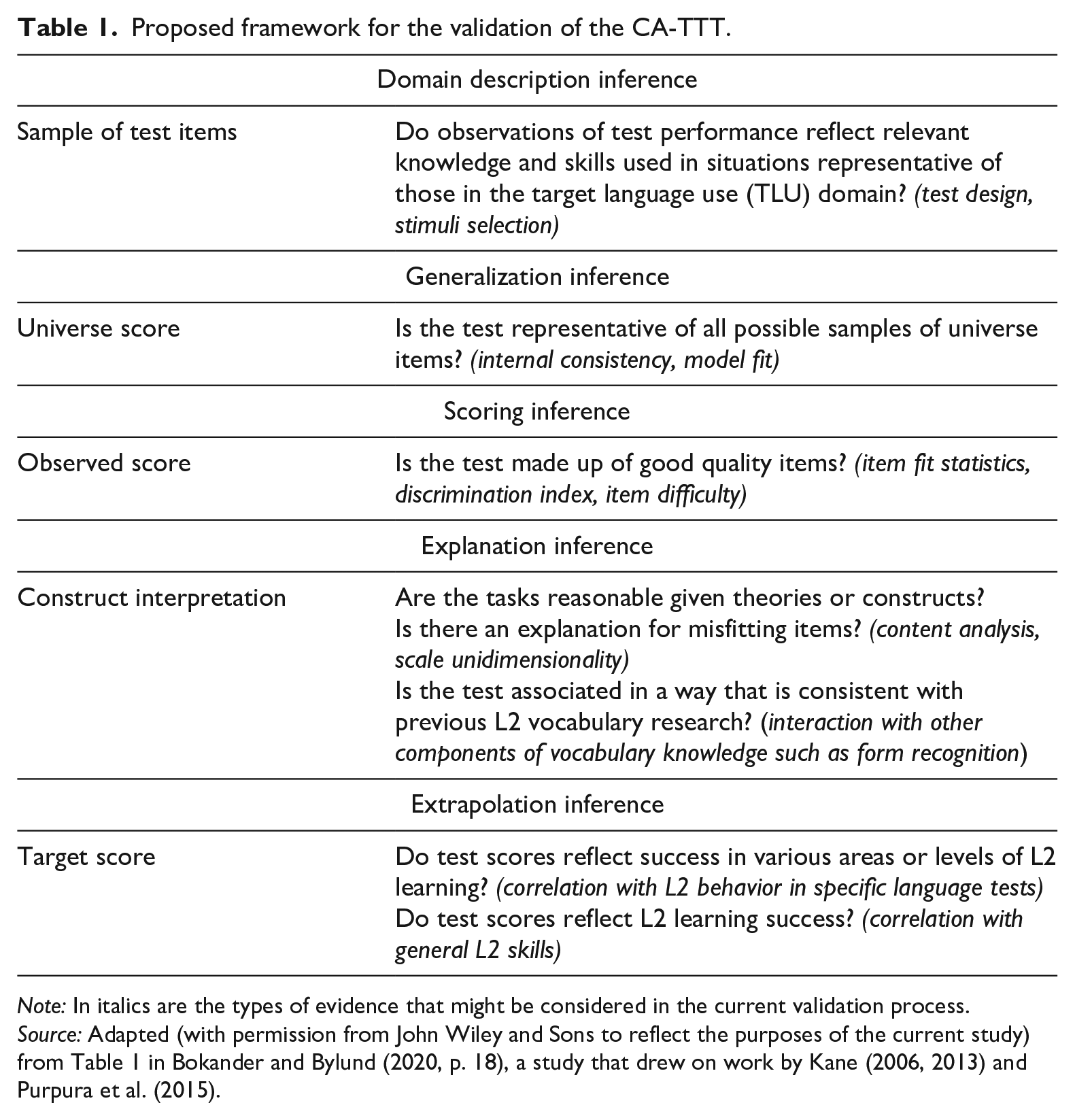
Note: In italics are the types of evidence that might be considered in the current validation process.
Source: Adapted (with permission from John Wiley and Sons to reflect the purposes of the current study) from Table 1 in Bokander and Bylund (2020, p. 18), a study that drew on work by Kane (2006, 12013) and Purpura et al. (2015).
The current study
The purpose of the current pilot study was to design and initially validate a test of context-aligned high-frequency vocabulary knowledge for beginner-to-low intermediate school-aged learners of French. In doing so, we also sought to explore the extent to which different approaches to sampling of test items can affect vocabulary size estimates in instructed, low-exposure contexts.
To achieve this, we set out to assess four test-internal links (domain description, generalization, scoring, and explanation) and one test-external (higher-order) link (extrapolation) in the chain of inferences, using the validation framework presented in Table 1. Specifically, at the level of domain description inference, we compared the level of overlap between the test items and the vocabulary used in the target language use (TLU) domain (i.e., the curriculum followed by the participants in this study) to determine whether observations of test performance revealed relevant knowledge in situations representative of those in the TLU domain. Second, we examined the generalization inference, using internal consistency measures, and the scoring inference, using Rasch modeling to assess whether the test was made up of items of appropriate difficulty. Then, at the level of explanation inference, we conducted item content analyses to explain any misfitting items and correlated CA-TTT performance with X-Lex estimates, a measure of form recognition. Finally, we investigated the extrapolation inference by examining the extent to which CA-TTT estimates correlated with performance in high-stakes and standardized testing. Our research questions (RQs), generated from the validation framework proposed in Table 1, were as follows:
In the past decade, open research practices have been gaining traction in the language sciences (Liu et al., 2023; Marsden & Morgan-Short, 2023), with an increasing number of materials, data, and analysis codes being made Findable, Accessible, Interoperable, and Reusable (FAIR; GO FAIR, n.d.). Exemplifying these FAIR principles, this article shares the materials, data, and analysis code used to initially validate the CA-TTT via our Open Science Framework (OSF) repository project page (Dudley et al., 2024) and on Instruments and Data for Research in Language Studies (IRIS, n.d.). Data cleaning and analysis were conducted using the freely available statistical software, R, to ensure that the analysis pipeline is reusable.
Method
Participants
Participants included two cohorts of 16-year-old learners of French (113 in 2022 and 109 in 2023) who had recently (within the previous 1 to 6 weeks) finished their GCSE exams, after approximately 400 to 450 hours of instruction in French and very little (if any) exposure outside the classroom. For more information about learners’ language background and minimal out-of-school exposure (see Supplemental Appendix S2). On average, participants reported learning French from 9.68 years of age (95% CI [9.31, 10.06], SD = 2.83, range: 1–15). All participants (of which 26% reported English as an additional language) had completed their secondary education in English and were from 89 state-funded secondary schools across England. Participants were recruited via their school and told that participation was optional and that they would receive £25 or £35 in Amazon vouchers for completing two or three sessions, respectively. Ethics approval for the study was obtained from the University of York.
Instruments and procedures
The CA-TTT
Test items
Given the low proficiency of our target population and the importance of high-frequency words for comprehension, the CA-TTT focuses solely on the 2,000 most frequently occurring lemmas from the Lonsdale and Le Bras (2009) frequency list. The lemma includes the base form (e.g., dance) and its inflections (e.g., dances, dancing, danced). Acknowledging the ongoing debate surrounding lexical units (Kremmel, 2021; Webb, 2021), the lemma was selected as many learners do not possess the relevant knowledge to comprehend the derivational forms of known headwords (Brown et al., 2022).
We removed the 3,000 to 10,000 bands from Batista and Horst’s (2016) TTV and created a new 1,000 band while still sampling from the same frequency list (Lonsdale & Le Bras, 2009) as the original TTV. Thus, the CA-TTT contains two bands: 1–1,000 and 1,001–2,000. Each band in the CA-TTT is twice as large as each band in the TTV, with 60 target items per band split across 20 clusters and 120 items in total. (We supplemented the 30 target items in the existing 2,000 band with an additional 30 items.) The number of items per 1,000-word frequency band was based on Gyllstad et al.’s (2021) recommendation that researchers use at least 30 items because test score inferences become more representative of actual knowledge as the number of items increase. The CA-TTT maintains a 3:5:2 ratio between verbs, nouns, and adjectives across clusters, respectively, broadly mirroring the part of speech distributions of the Lonsdale and Le Bras’ (2009) word frequency list. When sampling new items, we included as many words as possible from the awarding organizations’ (AQA, 2016; Edexcel, 2018) GCSE vocabulary lists (of 1,058 and 1,811 lemmas, respectively) to approximate the vocabulary used in the classroom. (For more information about how these lists were developed; see Supplemental Appendix S1, Finlayson et al., 2024; Marsden et al., 2023). To make the test more sensitive to partial knowledge and less demanding for beginner-to-low intermediate learners, word definitions were presented in English (Elgort, 2013).
Test format
English definitions were presented in clusters of three alongside a drop-down menu from which participants could choose one of six French words from the same part of speech (Figure 1). Participants were told to “choose the French word closest to the word or phrase on the right.” The words in the drop-down menu were identical for each definition in the cluster, but their order was randomized across definitions within each cluster.
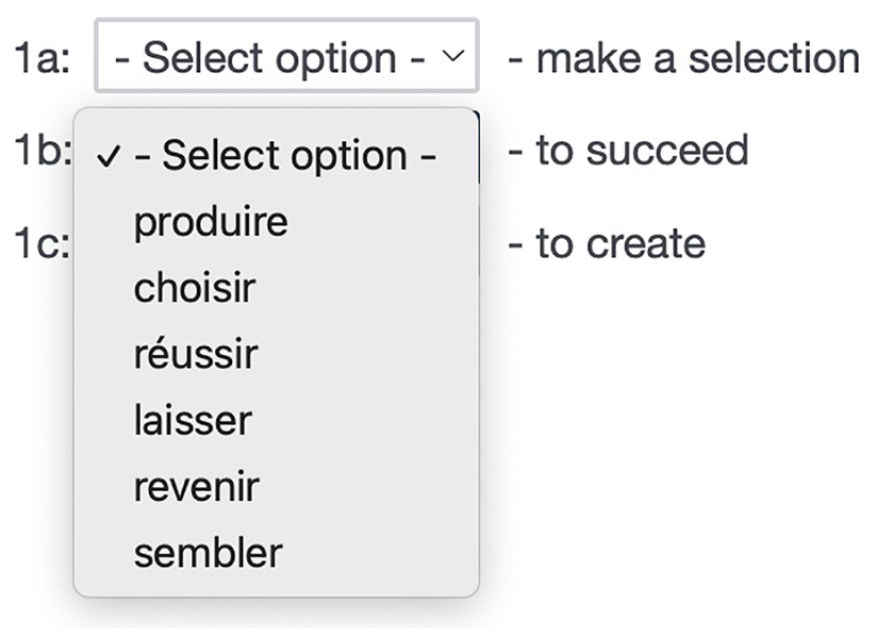
Sample CA-TTT items from one cluster.
Answers were scored on a binary scale (1 for correct word–definition matches; 0 for incorrect matches). Estimates of high-frequency vocabulary size were inferred by multiplying the decimal percentage of correctly answered items from each frequency band by the number of words (1,000) in each band (Batista & Horst, 2016).
A form–meaning recognition format was selected over recall primarily due to the ease and simplicity with which it could be administered and scored. However, in selecting a test of form–meaning recognition as opposed to recall, we acknowledge its limitations, including the reportedly lower internal reliability of this format relative to more open-ended formats (McLean et al., 2020) and its potential to over-estimate vocabulary size (Gyllstad et al., 2021; Stoeckel et al., 2021). At the same time, we note that these findings almost exclusively pertain to research conducted among adult highly-educated L2 learners of English. Until further research is undertaken, we argue that form–meaning recognition remains a valid and thus appropriate measure of vocabulary knowledge.
X-Lex test
We also administered the French X-Lex Vocabulary Test (the first version [“Test 1”] as reported by Milton, 2009; available via FLLOC, n.d.). (Examples of test items are presented in Figure 2.) This test had a very low overlap with the CA-TTT: Of the 40 items from the 0 to 2,000 range in X-Lex—the range relevant to the CA-TTT—none were used as target words in the CA-TTT and only two (ville “town” and peser “to weigh”) were used as distractors.

Sample X-Lex items. Pseudowords are italicized for illustration purposes only.
In the 2022 iteration of the current study, the test consisted of 100 real words and 20 pseudowords randomized across participants. In the 2023 iteration, we included an additional 20 pseudowords to align with recommendations in the field (Pellicer-Sánchez & Schmitt, 2012). These additional pseudowords, however, did not appear to influence vocabulary size estimates (see Supplemental Appendix S3 for the full analyses). Participants saw the following instructions: “Please look at these words. Some of these words are real French words and some are invented but are made to look like real words. Please tick the words that you know or can use.” Although the presence of “or” may result in ambiguity, the original instructions were maintained.
X-Lex was scored following the procedure described by Milton (2006, 2015). The number of “Yes” responses to real words was multiplied by 50 to give a maximum raw size estimate of 5,000. The number of “Yes” responses to pseudowords was then multiplied by 250 for the 2022 dataset (and 125 for the 2023 dataset; given the higher number of pseudowords, this maintained parity with the calculation across iterations) and subtracted from the raw score to account for false alarms. Unlike previous studies (David, 2008; Milton, 2006, 2015), participants were not excluded if they ticked five or more pseudowords given the potential for such data trimming to over-estimate vocabulary size.
DELF proficiency test
Participants completed the listening and reading sections of the Common European Framework of Reference for Languages A2 Junior version of the Diplôme d’études en langue française (DELF; France Éducation International, n.d.), a French proficiency test that participants were not familiar with. In this test, participants read and listened to short passages and answered multiple-choice comprehension questions. The DELF was selected due to it meeting all 17 of the Association of Language Testers in Europe’s quality standards as well as the ease with which it can be administered and scored. We were specifically interested in the listening and reading components given our focus on the receptive form–meaning link and its strong relationship with listening and reading (S. Zhang & Zhang, 2022).
Procedure
The tests were administered online through the survey platform, Qualtrics (n.d.), between June and August in 2022 and 2023 as part of a larger study on the components of French language proficiency among GCSE students. This larger study consisted of two 90-minute sessions and one further optional session. The CA-TTT and X-Lex were completed in the first session, and the DELF sub-tests in the second. In August, we asked participants to self-report their GCSE results, including their overall and skill-specific (listening, reading, writing, speaking) levels (graded as 1–9), by providing a photo of their official results statement.
When designing the study, we were faced with the challenge of testing this population at the height of their knowledge—that is, in the summer holidays following their GCSE exams. Although participants were not monitored when completing the tasks, to mitigate the risk of cheating, participants were told at the beginning of each session that they would not receive compensation for their involvement in the study if they consulted external sources (e.g., the Internet, friends, or family). Additional measures, including disabling the copy-and-paste function within Qualtrics and forcing the browser into full-screen mode, were implemented.
Results
Score overview
Tables 2 and 3 present raw accuracy scores and estimated vocabulary sizes, respectively. Shapiro-Wilk tests revealed significant deviations from normality both in the 1,000 (W = .829, p < .001) and 2,000 band (W = .865, p < .001). Inspection of histograms (Figure 3) and skewness coefficients further showed that scores in both frequency bands were negatively skewed, thus suggesting that the test was easy for most participants.
CA-TTT raw and percentage accuracy scores (n = 222).
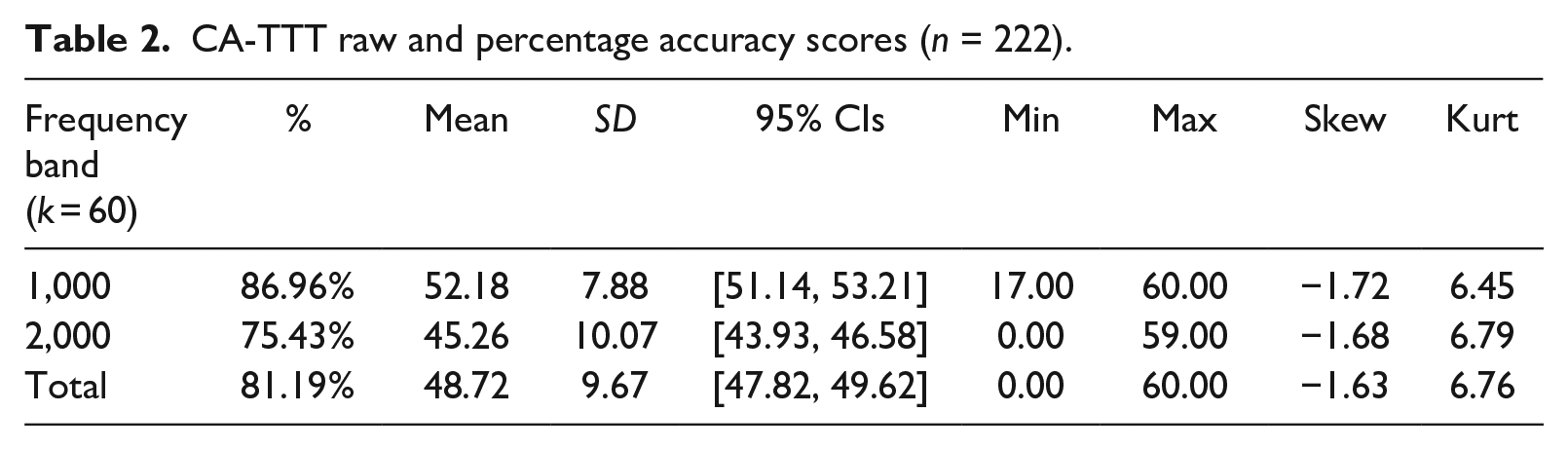
CA-TTT estimated vocabulary size (n = 222).
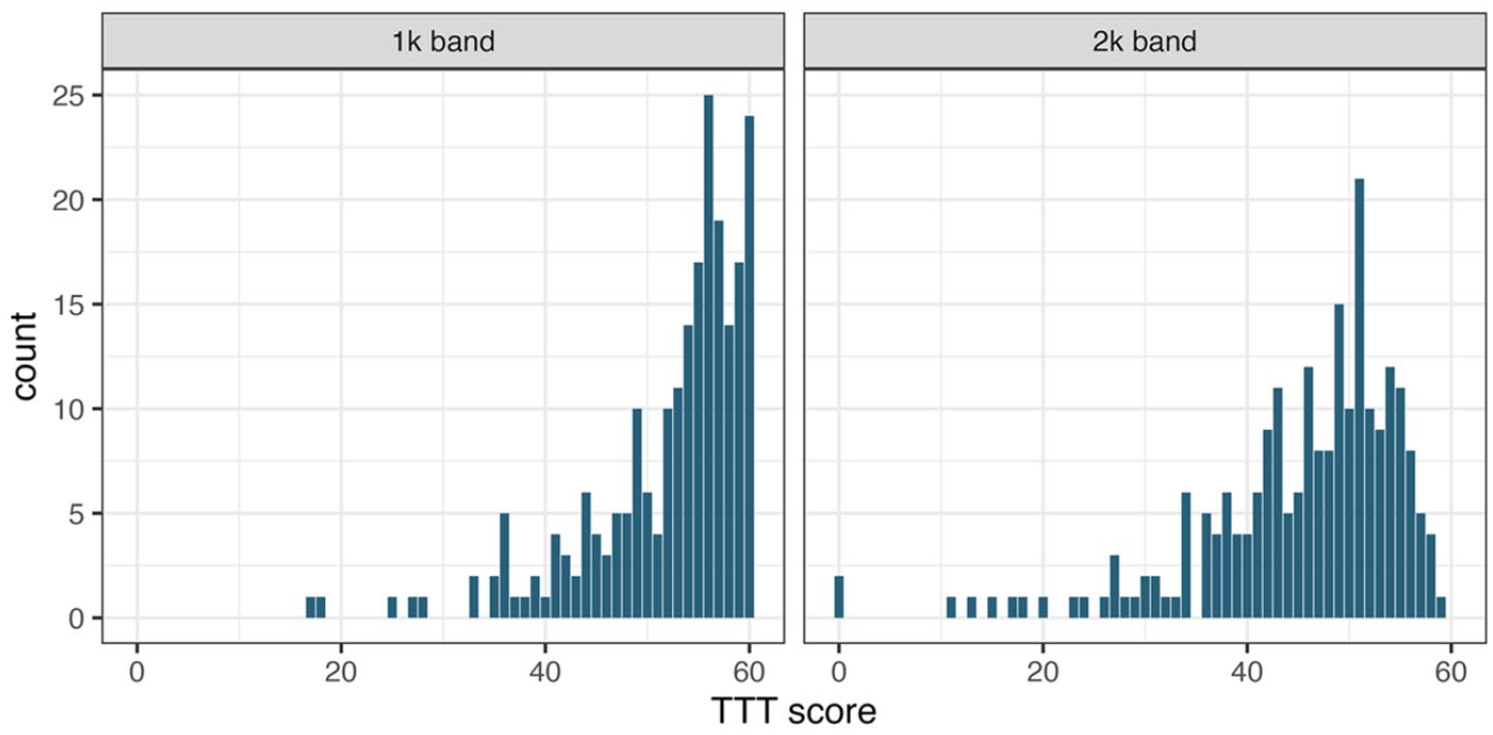
Distribution of CA-TTT raw scores.
Domain description inference
To investigate whether CA-TTT test items were representative of the vocabulary used in the TLU domain (RQ1), we calculated the level of overlap between CA-TTT items and vocabulary on the GCSE curriculum list. As expected, given our approach to sampling, the level of overlap was very high: On average, 79.42% (SD = 2.61%, 95% CI [79.07%, 79.77%]) of CA-TTT items also appeared on the curriculum list specific to the participant, their awarding organization (AQA or Edexcel), and entry tier (foundation or higher).
We then explored the extent to which this overlap determined CA-TTT performance. Non-overlapping confidence intervals (Table 4) suggested that mean accuracy scores were consistently higher for words that were on the relevant list than those that were not.
Accuracy scores for words on and off the relevant curriculum list (n = 220).
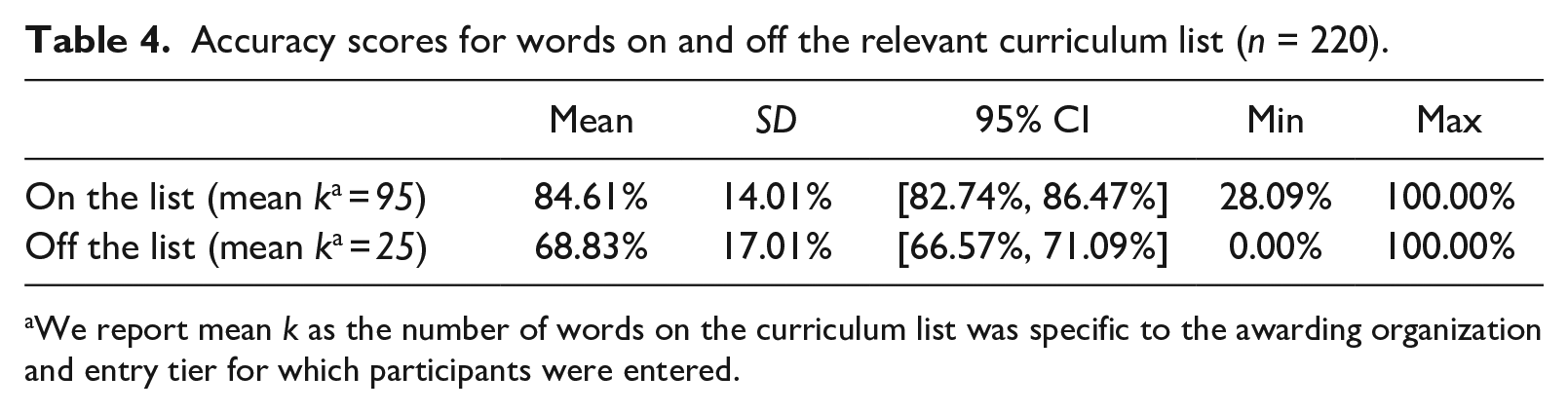
We report mean k as the number of words on the curriculum list was specific to the awarding organization and entry tier for which participants were entered.
To further examine the predictive role of the curriculum, we then adjusted the initial CA-TTT vocabulary size estimates by multiplying (a) the mean accuracy decimal percentage for words on the list in the CA-TTT by the number of high-frequency words on the relevant curriculum list and (b) the mean accuracy decimal percentage for words off the list in the CA-TTT by the number of high-frequency words off the curriculum list, and then adding the two estimates together (see Table 5 for raw and adjusted estimates). For example, if a participant scored 80% for the words on the curriculum list and 50% for the words off the curriculum list, the corresponding decimal percentages would be multiplied by the number of high-frequency words (out of the total 2,000) on (649) and off (1,351) the curriculum list, respectively: (0.80×649) + (0.50×1,351) = 1,194.70. This process accounted for words being more likely to be known if they were on the curriculum list to provide a more objective measure of known high-frequency words. These calculations resulted in a significant decrease in vocabulary size estimates, as demonstrated by non-overlapping confidence intervals (Table 5).
Raw and adjusted vocabulary size estimates from the CA-TTT (n = 220).

Generalization inference
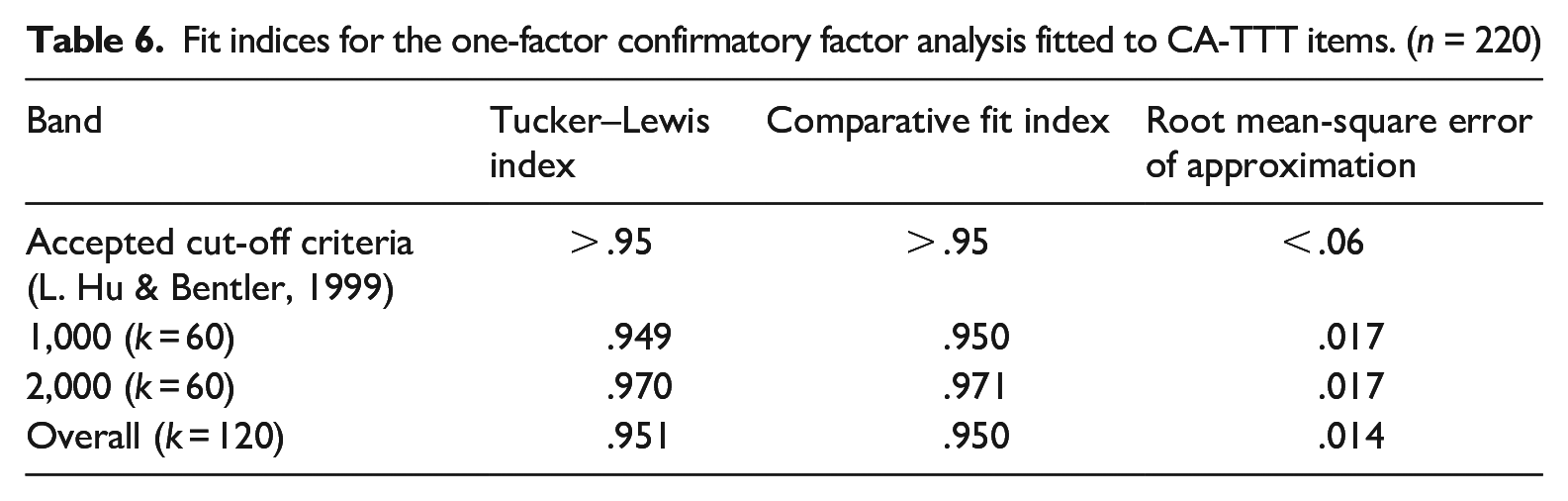
To explore the question of generalization and, in particular, the internal consistency of the test, we computed categorical omega for the overall test and each frequency band in two steps, following Flora (2020). 1 We first fitted a one-factor confirmatory factor analysis using the lavaan package (Rosseel, 2012) to test the unidimensionality assumption for omega and Rasch models (i.e., to see whether all items loaded onto a single factor). A one-factor model (Table 6) was a good fit for the overall test and both frequency bands, suggesting that the items measured the same construct and thus met the unidimensionality assumption. We then obtained omega estimates using the reliability() function from the semTools package (Jorgensen et al., 2022). These estimates indicated good reliability (Nunnally & Bernstein, 1994): .92 for the 1,000 band, .94 for the 2,000 band, and .96 for the two bands combined.
Fit indices for the one-factor confirmatory factor analysis fitted to CA-TTT items. (n = 220)
Since 26% of our sample reported having a first language (L1) other than English, we explored the effect of language background on CA-TTT performance. Overlapping confidence intervals around mean accuracy percentages for learners with L1 English and an L1 other than English suggested no significant difference (see Supplemental Appendix S4).
Scoring inference
To address whether the CA-TTT is made up of items of appropriate difficulty (RQ3; the scoring inference), we compared Rasch model estimates from two packages: eRm (Mair et al., 2021), a conditional maximum likelihood estimation package, and TAM (Robitzsch et al., 2022), a joint maximum likelihood estimation package, following recent guidance to conduct both (Linacre, 2021; Nicklin & Vitta, 2022). Given the largely negligible differences in estimates, we present the eRm models here and the corresponding TAM models in Supplemental Appendix S5.
To test the local independence assumption (Baghaei, 2008), a pre-requisite for Rasch modeling, we inspected correlations between test item residuals. Residuals were not significantly correlated (overall test: mean p = .48 [SD = .29]; 1,000 band: mean p = .50 [SD = .29]; 2,000 band: mean p = .48 [SD = .29]), suggesting that our data met the local independence assumption.
To visualize how difficult specific items were for individual participants, person and item values were plotted together on the same logit scale in individual Wright maps for each frequency band (see Figures 4 and 5). Items were plotted on the y-axis and the latent dimension (item difficulty/person ability) on the x-axis. The histogram at the top shows the distribution of person abilities. A participant placed at the same point on the scale as an item has a 50% probability of getting that item right. If a participant is placed higher on the scale than the item is, then the chance of the participant getting the item right is above 50%. In contrast, if a participant is placed lower on the scale than the item is, their chance of getting the item right is below 50%. For the item and person parameters, see Supplemental Appendix S6.

Wright map for items in the 1,000 band.
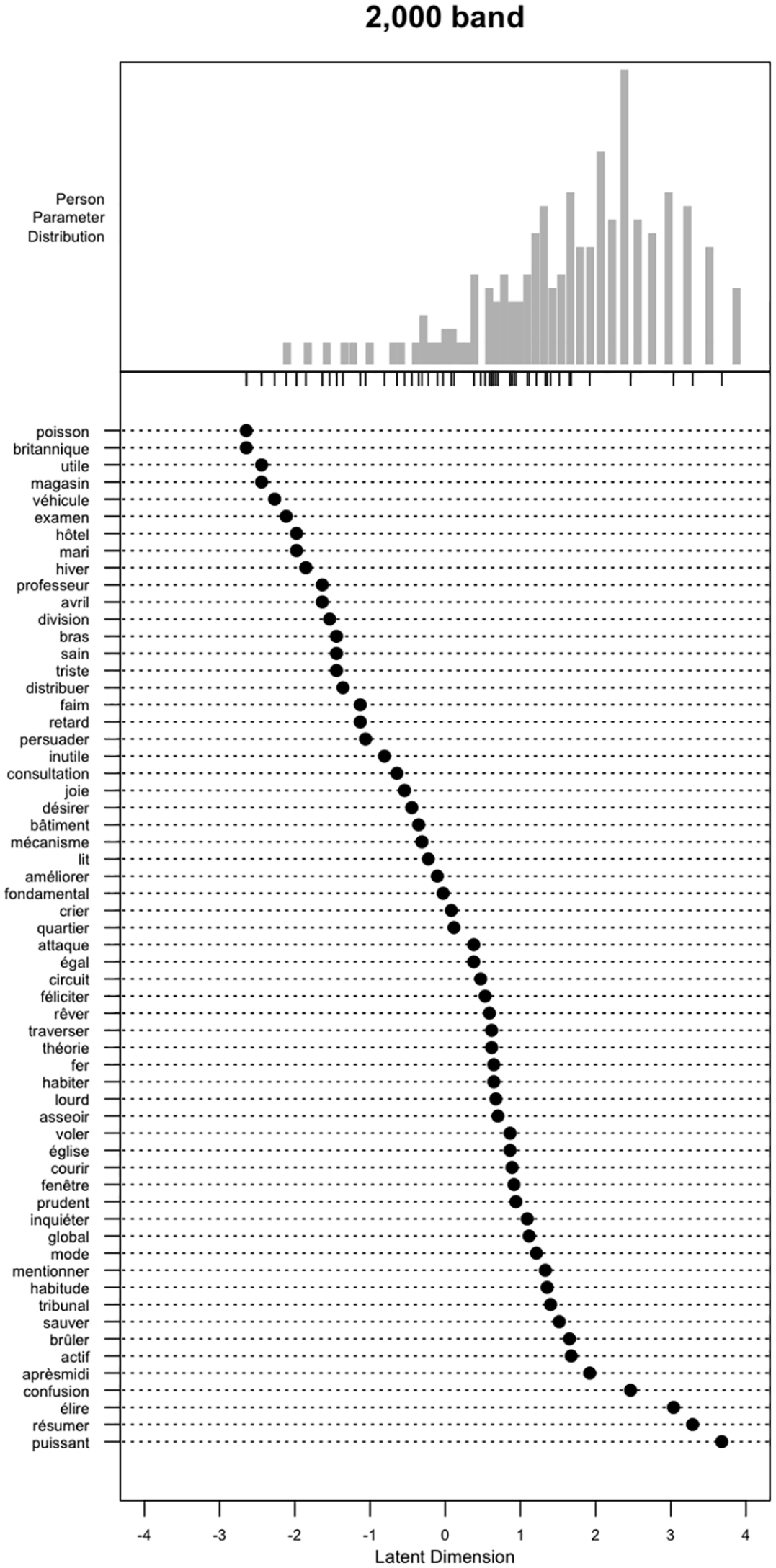
Wright map for items in the 2,000 band.
Although item difficulties were evenly distributed, the test appeared to be very easy for the vast majority of the sample: In most cases, the item means (i.e., 0 on the x-axis) were below many of the participants’ chances of getting that item right. Both in the band-specific and overall Rasch models, mean person ability was higher than maximum item difficulty, especially in the 1,000 bands. As expected, the 2,000 band was more challenging than the 1,000 band, with a greater overlap between item difficulty and person ability distributions (i.e., a smaller distance between mean item difficulty and mean person ability relative to the 1,000 band) due to a higher proportion of challenging items.
To examine how reliably the test could distinguish between different abilities, we calculated person separation reliability. The value for both the 2,000 band (.88) and the overall test (.93) indicated two or more separate levels of performance in the data. In contrast, the value for the 1,000 band (.80) was on the threshold between low and acceptable separation reliability (Aryadoust et al., 2021), indicating a lack of discrimination between high- and low-ability participants due to the relative ease of the frequency band.
Explanation inference
To examine the explanation inference (RQ4), we conducted content analyses to identify any potentially misfitting items and then explored whether the test was associated in a manner consistent with previous L2 vocabulary research, by examining correlations between CA-TTT and X-Lex scores.
Content analysis: Facility and discriminations indices
Infit mean-square values (see Supplemental Appendix S6) for CA-TTT items were all within the optimal range (i.e., between 0.5 and 1.5; Linacre, 2002; Wright & Linacre, 1994) both in the frequency-band models and the overall test model. There was, however, greater variation in outfit mean-square values with both underfitting and overfitting items. According to Wright and Linacre (1994), values below 0.5 (underfitting) and between 1.5 and 2 (overfitting) are unproductive (but not degrading) for the construction of measurement.
The overall Rasch model identified three items with outfit mean-square statistics above 2: éducation “education” (with the correct response being “learning”), femme “woman” (“adult female”), and puissant “powerful” (“which has great power”). Both éducation and femme were easy items, with facility indices of .98 and .99 and estimated logit (difficulty) values of −1.79 and −2.83, respectively. Participants who answered incorrectly (n = 5 for éducation and n = 3 for femme) included those who were within the bottom 10th percentile of performers or who scored 90% or more. In contrast, puissant was a difficult item, with a facility index of .17 and an estimated logit value of 4.19. The band-specific Rasch models revealed a similar pattern of results. Although femme was not identified as a misfitting item, semaine “week” (“seven days”) was. Semaine was an easy item, with a facility index of .97 and an estimated logit value of −1.59. Again, the five participants who answered incorrectly included those who were within the bottom 10th percentile of performers or who scored 90% or more. Since outfit mean-square statistics are sensitive to mistakes by more-proficient learners (i.e., outlier gaps between item difficulty and person ability; Linacre, 2002), this may explain the poor fit exhibited by these four items.
Correlation with another vocabulary test: X-Lex
To further address the explanation inference, we analyzed correlations between (unadjusted) CA-TTT (Table 3) and X-Lex estimates (Table 7) for each frequency band. (For full X-Lex scores, see Supplemental Appendix S7). Given that X-Lex and the CA-TTT sampled from different frequency bands (X-Lex: 1,000 to 5,000; CA-TTT: 1,000 and 2,000), we only compared performance on the 1,000 and 2,000 bands, not overall scores from the two tests. To obtain comparable estimates, we divided the overall pseudoword penalty by five (the number of bands in X-Lex) to get a “by-band” pseudoword penalty estimate and subtracted this value from raw scores for the 1,000 and 2,000 bands to calculate adjusted X-Lex scores (henceforth, vocabulary size estimates).
X-Lex vocabulary size estimates (penalty-adjusted scores, n = 222).
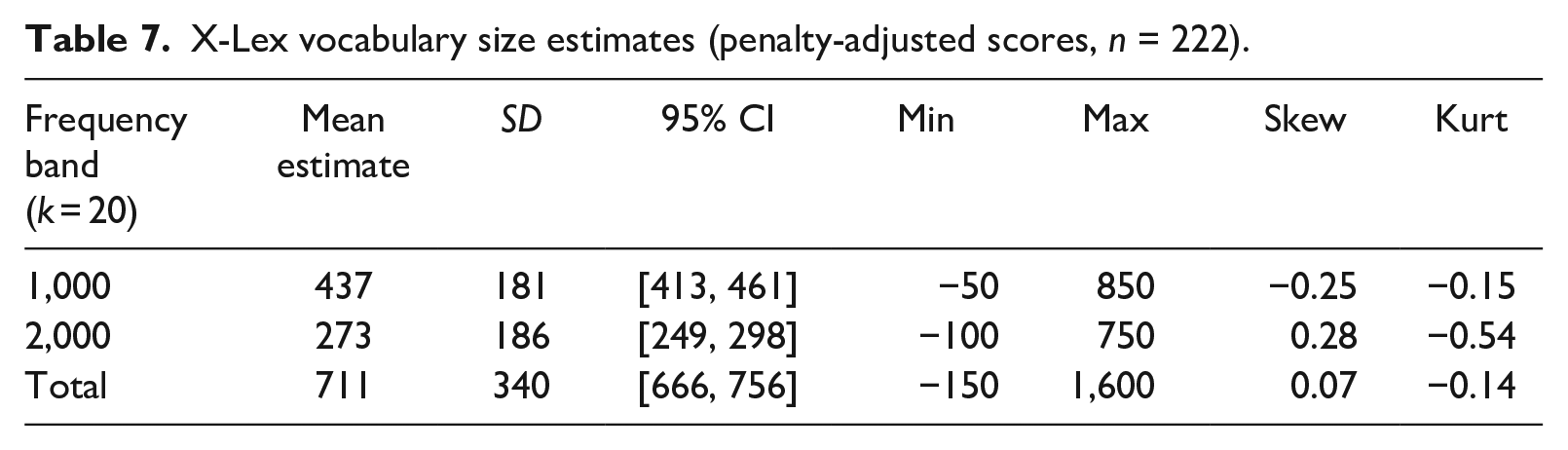
The Wilcoxon test for paired samples showed that mean vocabulary size estimates significantly differed between the CA-TTT and X-Lex (V = 24,753, p < .001). However, strong positive correlations (Figure 6) were found between the CA-TTT and X-Lex for the 1,000 band (rho = .67, 95% CI [.59, .74], p < .001) and the 2,000 band (rho = .69, 95% CI [.61, .75], p < .001). (Spearman’s rho was used due to both estimates being non-normally distributed.)
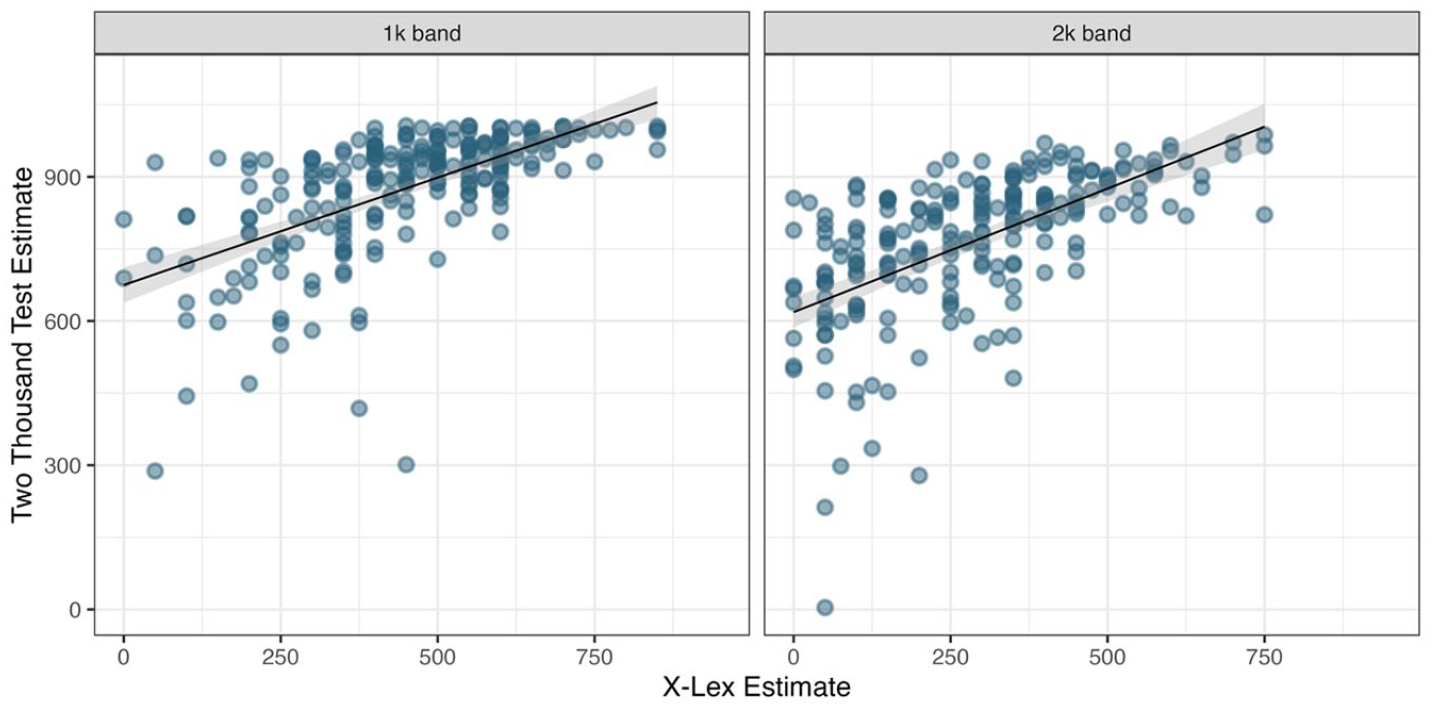
Scatterplots showing associations between the CA-TTT and the X-Lex scores. Darker dots represent a higher number of observations.
Differences in mean estimates between the two measures were very likely due to differences in test items. On average, of the 40 X-Lex items in the 1,000 and 2,000 frequency bands, only 25.81% (SD = 2.91%, 95% CI [25.42%, 26.20%]) appeared on the GCSE curriculum list, a level of overlap significantly lower than that observed for the CA-TTT (M = 79.42%, SD = 2.61%, 95% CI [79.07%, 79.77%]). To explore the role of the curriculum further, we compared mean accuracy percentages for words on and off the list. Non-overlapping confidence intervals around the mean suggested that participants were more likely to know a word in X-Lex if it appeared on (M = 53.57%, SD = 22.14%, 95% CI [50.63%, 56.52%]) than off (M = 46.63%, SD = 20.00%, 95% CI [43.97%, 49.29%]) the curriculum list.
Extrapolation inference
To examine the extrapolation inference (RQ5), we analyzed the relationships between (unadjusted) CA-TTT estimates and proficiency measures from both high-stakes (GCSE scores) and standardized testing (DELF scores) given that vocabulary knowledge strongly predicts L2 proficiency (see Introduction).
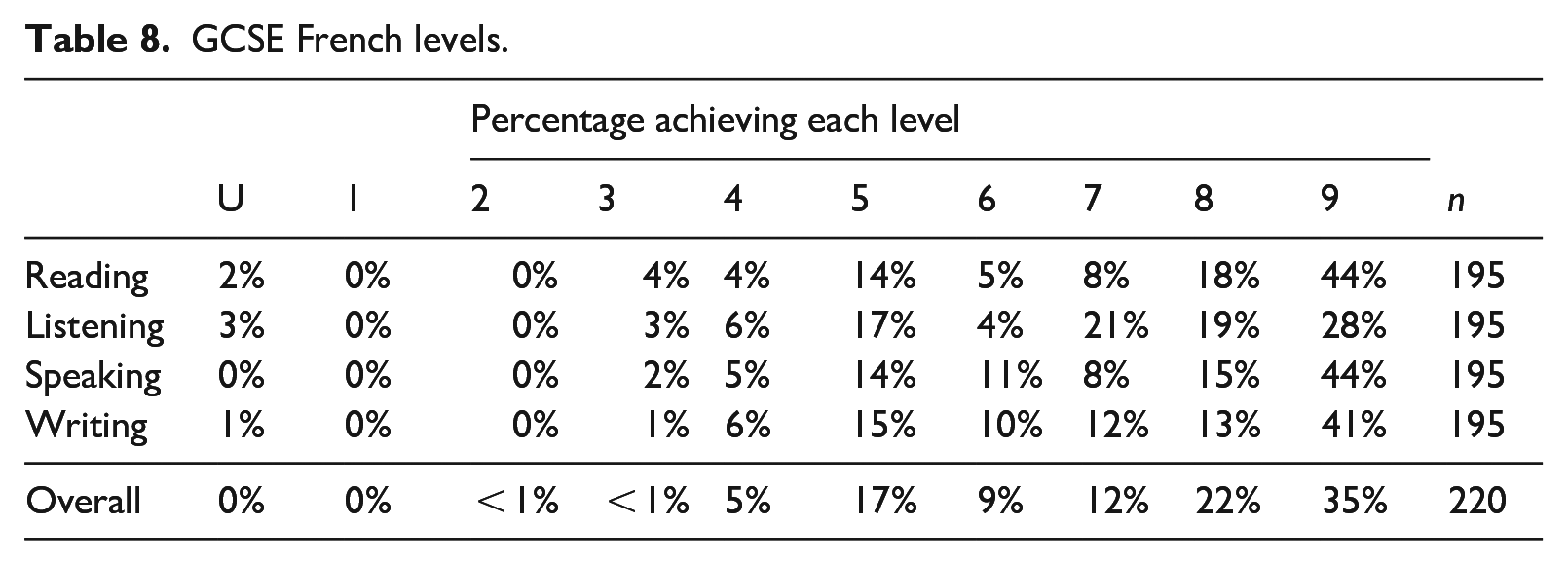
GCSE levels
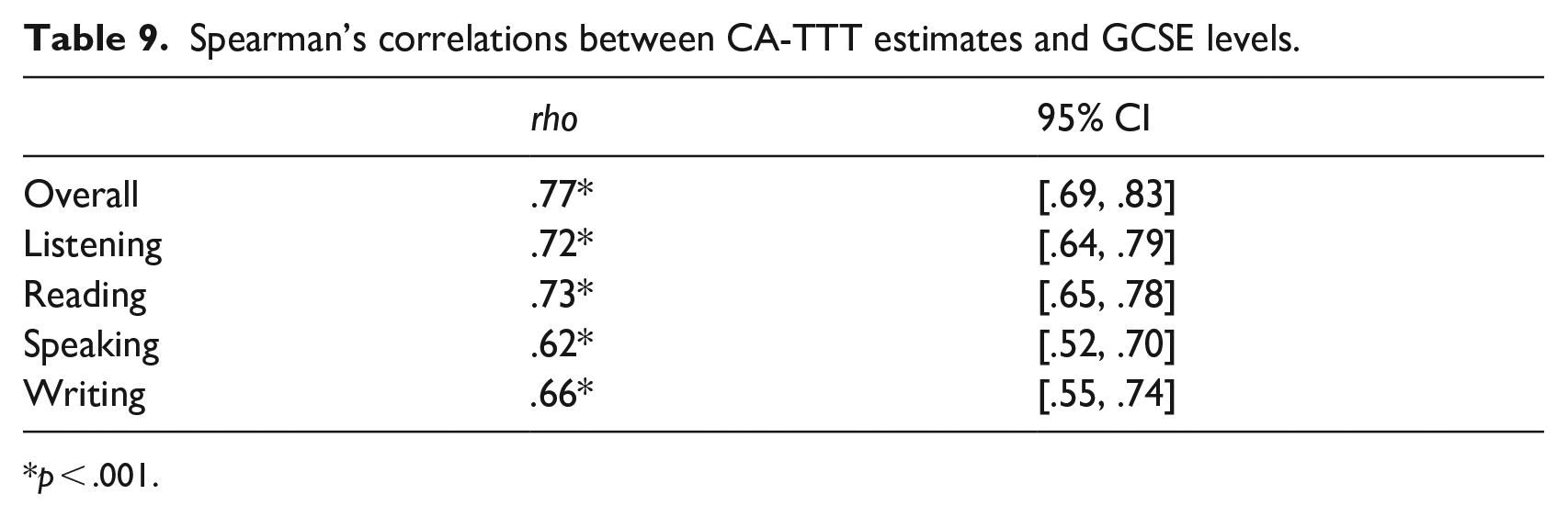
Of the 222 participants, 220 (99%) self-reported their overall level and 195 (88%) reported a skill breakdown (Table 8). Because GCSE data were ordinal and CA-TTT data non-normally distributed, Spearman’s correlations were calculated, using the cor.ci() function from the psych package (Revelle, 2024). CA-TTT estimates had strong positive correlations (> .60; Plonsky, 2015) with overall and skill-specific level (Table 9). That is, students with larger CA-TTT estimates were more likely to obtain higher GCSE grades in each skill than those with smaller CA-TTT estimates.
GCSE French levels.
Spearman’s correlations between CA-TTT estimates and GCSE levels.
p < .001.
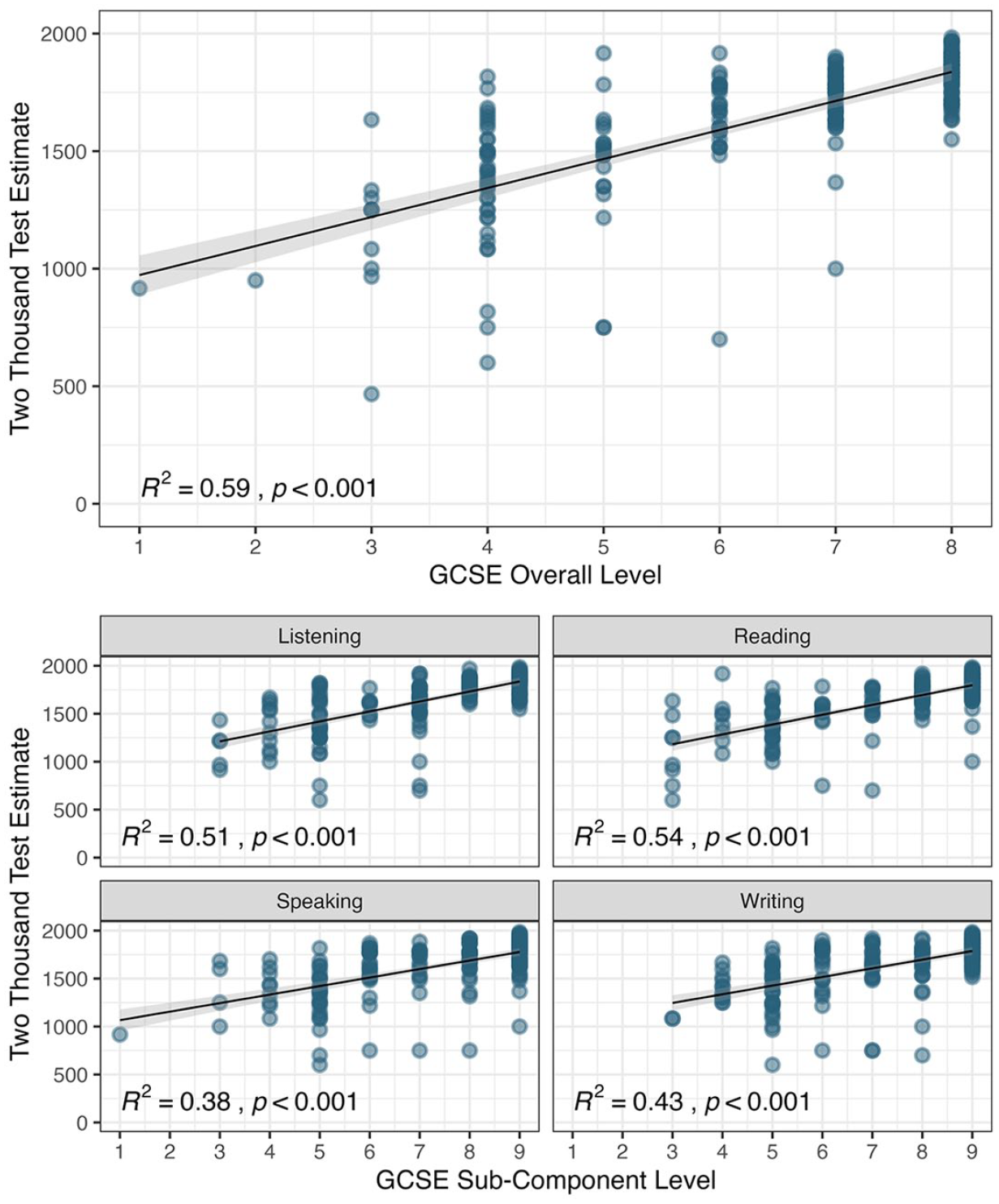
Scatterplots showing associations between CA-TTT estimates and GCSE French performance.
DELF scores
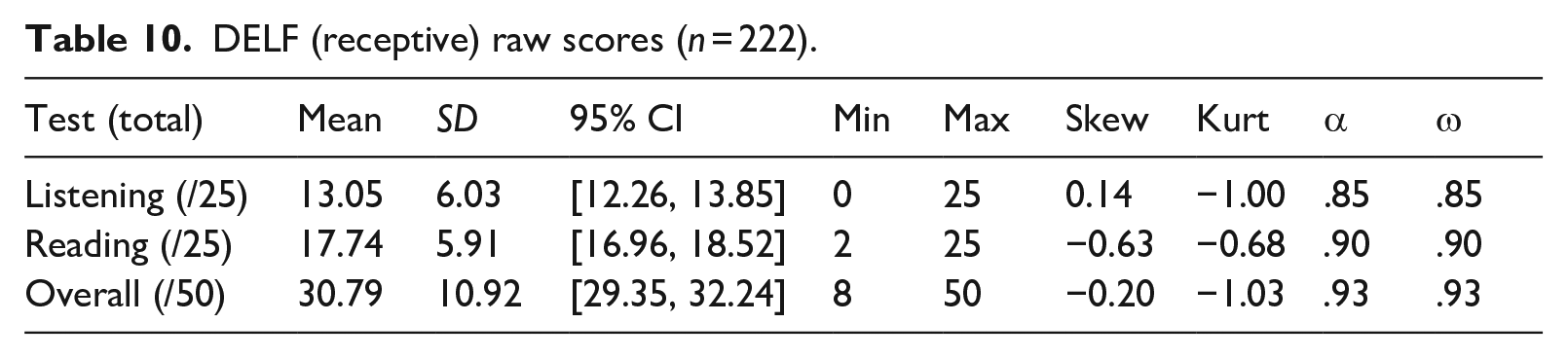
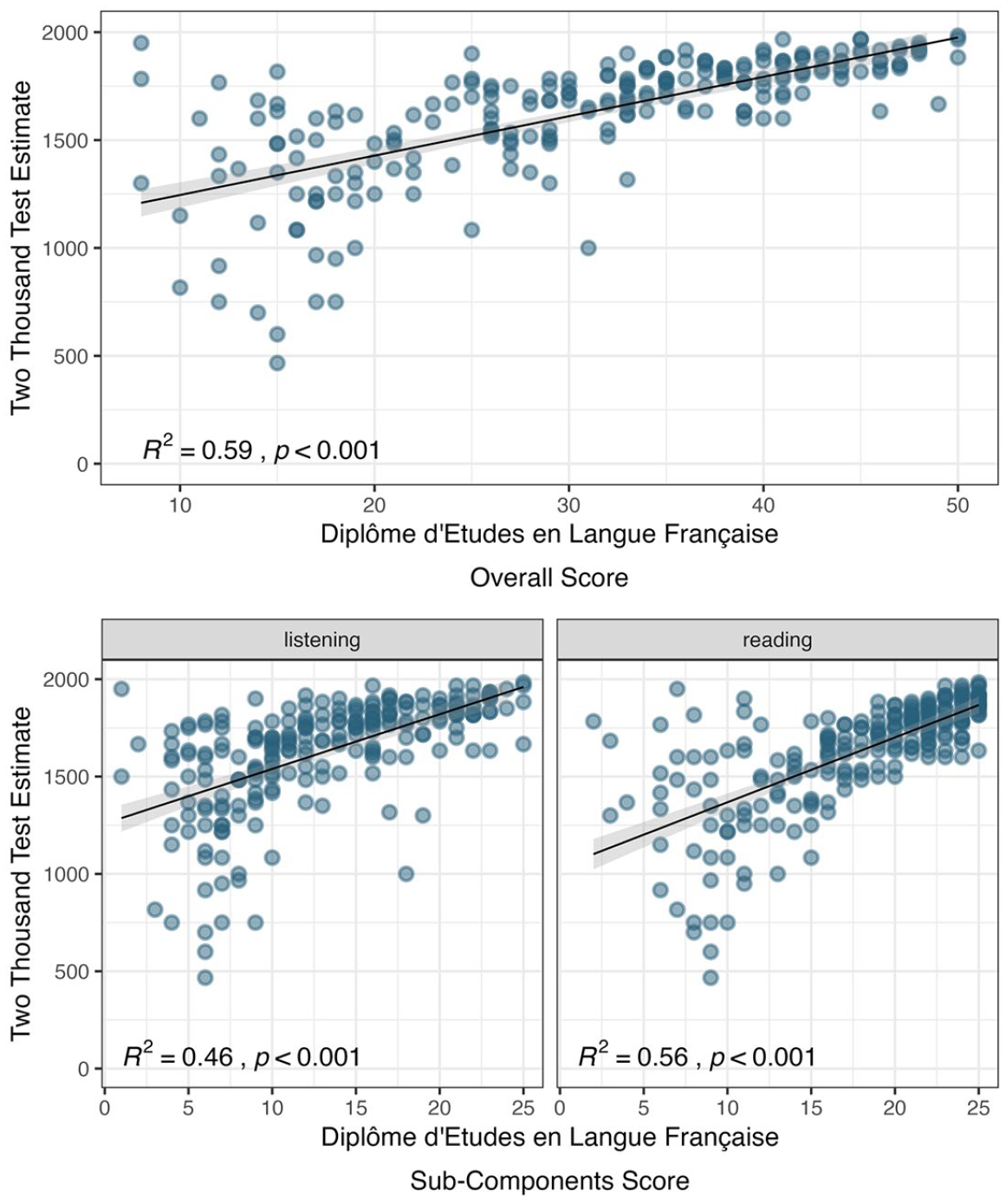
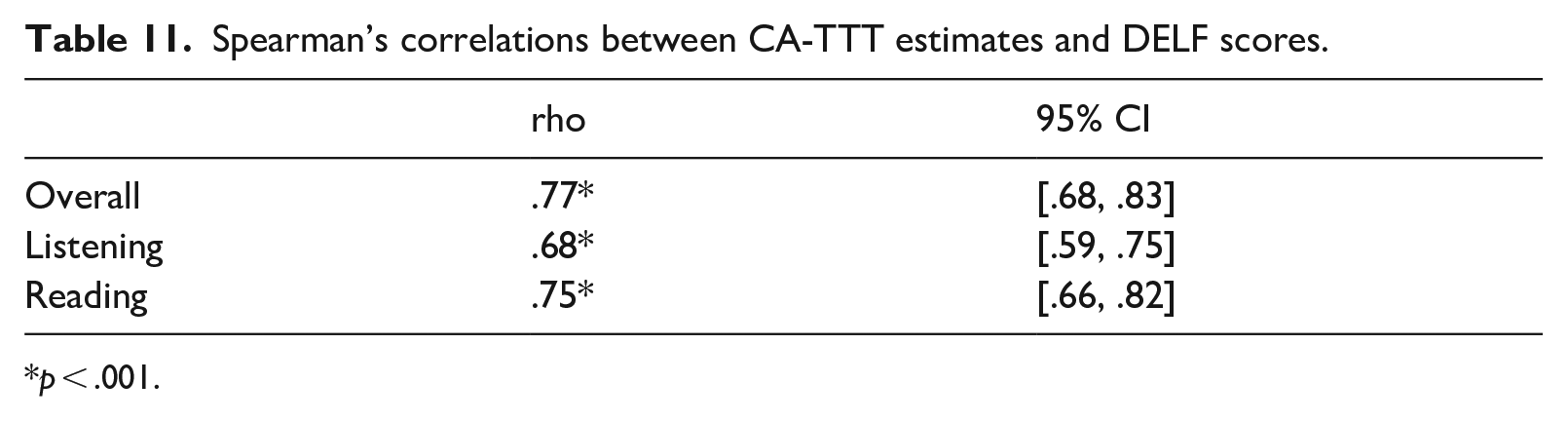
Finally, we explored the relations between DELF scores (Table 10) and CA-TTT estimates (Figure 8). Because CA-TTT estimates were non-normally distributed, Spearman’s correlations were computed, using the cor.ci() function from the psych package (Revelle, 2024). CA-TTT estimates demonstrated a strong positive correlation (> .60; Plonsky, 2015) with overall DELF scores and skill-specific scores (Table 11). That is, students who scored highly on the CA-TTT also scored highly on the DELF measures.
DELF (receptive) raw scores (n = 222).
Scatterplots showing associations between CA-TTT size estimates and DELF performance.
Spearman’s correlations between CA-TTT estimates and DELF scores.
p < .001.
Discussion
In response to calls for more rigorous test validation and better specification of each test’s purpose, including the type of learners and educational contexts for which the test has been developed (Schmitt et al., 2020), the current study sought to pilot a written receptive test of high-frequency vocabulary for adolescent beginner-to-low intermediate learners of French in instructed contexts in England. In doing so, we provided a snapshot of vocabulary knowledge among mostly high-achieving GCSE French learners and its role in accounting for proficiency. We now discuss our findings in the context of an argument-based validation framework.
Domain description
When addressing the domain description inference, we observed that learners were more likely to know a word in the CA-TTT (but also X-Lex) if it had appeared in the TLU domain. In this study, the TLU domain was the GCSE curriculum, given learners’ very limited exposure to the language outside the classroom. When adjusted to reflect the same proportion of words in the 2,000 most frequent words that were on and off the curriculum list, CA-TTT estimates were significantly lower than the unadjusted estimates (adjusted: n = 220 M = 1,480, 95% CI [1,439, 1,521]; unadjusted: n = 220, M = 1,627, 95% CI [1,589, 1,664]. In other words, exposure from instruction (classroom, textbooks, homework, etc.) strongly determined vocabulary knowledge. This finding potentially aligns with a recent study (Robles-García et al., 2023) showing that subjective exposure—such as teacher judgments about what words students are most likely to know—can moderate vocabulary tests scores as much as—if not more than—the frequency of words in the (arguably more natural and representative) general language as a whole.
Our study, although designed to assess knowledge of context-aligned, high-frequency vocabulary, has broader implications for future vocabulary test development. That is, any vocabulary test that randomly samples 20 or even 30 words from each frequency band will inevitably under- or over-estimate vocabulary knowledge depending on which words are selected. Future development of vocabulary knowledge measures could seek a better balance between words that learners could be expected to know (due to their inclusion in the curriculum, for instance) and words that reflect a wider breadth (size) of knowledge (if it is of interest to gauge impacts of any out-of-school exposure). However, ascertaining such a balance constitutes a serious challenge: How can we extract meaningful data about “size” from a relatively small set of words in contexts where exposure to the language is, for many learners, limited to instructed experience? The steps we adopted in the current study may go some way to addressing this challenge, such as adjusting for on- and off-curriculum words. Nevertheless, caution is needed when interpreting vocabulary size estimates in highly instructed, low-exposure contexts.
Generalization and scoring inference
When addressing the generalization and scoring inference, we found that the CA-TTT measured a unidimensional (i.e., a single underlying) construct, which, we assume, is the construct of form–meaning recognition of vocabulary. Moreover, omega reliability coefficients were high. Perhaps unsurprisingly, given the predictive role of the curriculum and the CA-TTT’s high overlap with the curriculum, scores were very high and negatively skewed in both frequency bands. This skew resulted from ceiling effects: Logit estimates for items and persons showed that most items were easy for most participants, with mean person ability above maximum item difficulty. Accordingly, Rasch person separation reliability for the 1,000 band was on the threshold between low and acceptable discrimination, although reliability for the 2,000 band was above the threshold. This suggests that items in the 1,000 band were not as effective at discriminating between different abilities as items in the 2,000 band, at least among our participants.
Item fit was generally satisfactory. Of the 120 items included in the CA-TTT, we identified four items (éducation, femme, semaine, and puissant) with poor fit in the eRm model estimations. Normally, poorly fitting items would be candidates for substitution during the validation process. However, there are reasons—in addition to their high relevance in the TLU domain—for retaining them. First, fit values obtained for the same items (with the exception of puissant) using a different method (TAM) were within the optimal range. Second, a closer inspection of these items suggested that poor fit may have resulted from ceiling effects: Three of the four items (éducation, femme, and semaine) had very low difficulty values, making their outfit mean-square statistics particularly sensitive to mistakes by more proficient learners who represented a significant proportion of our sample (see below). Administering the CA-TTT with a different sample (e.g., of a lower proficiency) from the same population could give different results.
Explanation inference
To assess the explanation inference, we correlated CA-TTT scores with an existing measure of vocabulary size (X-Lex). Although the CA-TTT assesses form–meaning recognition and X-Lex form recognition, we observed a strong and significant positive correlation between CA-TTT and X-Lex scores. This suggests that (a) they are tapping into similar underlying constructs (i.e., form[–meaning] recognition) and (b) the kind of knowledge elicited by one test tends to improve with the kind of knowledge elicited by the other.
However, vocabulary knowledge estimates were different across the tests: CA-TTT estimates (n = 222, M = 1,624, 95% CI [1,586, 1,662]) were often two or three times larger than the corresponding X-Lex estimates (n = 222, M = 711, 95% CI [666, 756]). This indicates systematic differences between the two tests. It could be argued that X-Lex measures a different construct (form recognition) from the CA-TTT (form–meaning recognition) and as such, we should not expect to see similar scores. Nevertheless, we should expect higher scores on the “easier” test (X-Lex) than the “harder” one (CA-TTT). Instead, we see the opposite.
We suggest that these differences can largely be attributed to the number and type of words in the two tests. First, and perhaps most importantly, the CA-TTT contained a far greater proportion of words sampled from the GCSE curriculum list than X-Lex. This, together with the predictive role of the curriculum, is very likely to strongly—or perhaps even entirely—explain differences in the scores obtained by the two tests.
Second, the CA-TTT included 60 items in each frequency band, whereas X-Lex only included 20 items. Stoeckel et al. (2021, p. 198) highlight that “the scale of uncertainty” associated with vocabulary size and levels tests (such as X-Lex) is “simply too large for test users to have confidence in such determinations.” One way to partially address this “scale of uncertainty” and improve the accuracy of these tests, as suggested by Gyllstad et al. (2021), is to increase the number of target items to at least 30 in each frequency band, as we have done for the CA-TTT.
Finally, test items in the X-Lex and the CA-TTT were sampled from two different frequency lists. X-Lex used an older frequency list (Baudot, 1992) based exclusively on written corpora, whereas the CA-TTT sampled from a more recent list (Lonsdale & Le Bras, 2009) of written and spoken materials. Strikingly, frequency values were quite different between the two lists: Of the 40 high-frequency (< 2,000) items in X-Lex, only 27 fell within the same frequency band across both the Lonsdale and Le Bras (2009) and the Baudot (1992) lists.
Extrapolation inference
When addressing the extrapolation inference, we found strong associations between (unadjusted) CA-TTT vocabulary size estimates and performance in both high-stakes (GCSE) and standardized (DELF) proficiency tests. Despite a skew toward higher GCSE grades in our sample (see below for potential reasons), CA-TTT scores correlated strongly with overall and skill-specific (reading, listening, writing, and speaking) GCSE levels. Likewise, CA-TTT scores correlated with DELF listening and reading performance
Limitations of the study and future directions
Differences between X-Lex vocabulary size estimates obtained in our study and previous research are noteworthy. The mean estimate in this study was 1,167 (95% CI [1,076, 1,259]), an estimate considerably larger than those previously reported: 852 (Milton, 2006 at the end of Year 11), 775 (Milton, 2015 at the end of Year 11), and 564 (David, 2008 at the beginning of Year 11).
Overall, the percentage achieving Level 7 or higher at GCSE in our study (68%) was much higher than the corresponding percentage for the population (31% in 2022 and 26% in 2023; Ofqual, 2023). One reason for the high GCSE performance of our sample (and thus low discrimination indices) could be self-selection: In our study, teachers told students about the study, but individuals chose to participate. An additional reason could be that although our learners were in the equivalent school year as those in David’s and Milton’s studies, they were tested immediately after their GCSE exams when their knowledge was likely to be strongest.
Interestingly, David (2008) observed a mean estimate of 1,577—only about 500 more words than our study—for students who had received an additional 190 hours of instruction (i.e., in Year 12). David’s participants—like many (68%) of ours—had also performed highly at GCSE, with 95% obtaining an A or A* (equivalent now to Level 7 or above). Despite these sampling differences, the fact that our X-Lex scores fell roughly in between the scores observed by David (2008) for Year 11 and Year 12 (564 and 1,577 respectively) suggests that our findings are broadly compatible with those from previous research. Nevertheless, future research should examine the CA-TTT’s (preliminary) internal and external validity with participants from a wider (including lower) range of knowledge and proficiency to reduce any effects resulting from self-selection bias. Future research could also go a step further in the validation process by ascertaining if the test correlates with entirely different measures, such as grammatical knowledge or phonological awareness, as suggested by Bachman (2004).
An indicator of a skew in our sample was that the percentage of correct answers in the 2,000 band of the CA-TTT (75%) was higher than the performance reported in Batista and Horst’s (2016) TTV validation study for the same frequency band (69%). This is noteworthy, given that Batista and Horst’s sample included adult learners spanning a range of proficiency levels: beginner, low intermediate, high intermediate, and advanced. One explanation for these differences might be that the CA-TTT contained twice the number of items in the 2,000 band than the TTV. Another explanation might be the use of English (rather than French) definitions in the CA-TTT. Size estimates based on bilingual tests have been shown to be larger and more accurate relative to monolingual tests because they are more sensitive to partial knowledge, especially among beginner-to-low intermediate learners (Elgort, 2013; Nation, 2013). Future research could compare results between the CA-TTT and TTV directly among the same population of learners.
A noteworthy finding from our initial validation was that the test items could be argued to be too “easy” for our specific sample of learners. As we have argued, this was in large part due to a combination of intentional design features, including the high proportion of words from the curriculum (relative to previous tests used in this context) and the high proportion of high-performing learners. It was critical to test these high-performing learners—given our aims of informing policy and practice about vocabulary knowledge at the end of the GCSE course—but we strongly encourage further validation work with low(er)-proficiency participants at the same stage of education (school year). Such work would build on our assessment of the test’s ability to discriminate between individuals, which would be especially important if (a revised version of) the CA-TTT were ever to be used as an achievement test to ascertain students’ knowledge as they approach their high-stakes exams.
One intuitive step to address the relative “ease” of the test, as suggested by an anonymous reviewer, could be to remove words overlapping in difficulty and replace them with low(er)-frequency words, based on an assumption that low(er)-frequency vocabulary is (usually) more difficult than high(er)-frequency vocabulary. However, we argue that, for our highly instructed context, such an approach would most likely be effective in making the test “more difficult” if these low(er)-frequency words were intentionally not from the curriculum list, given the strength of association between the curriculum and vocabulary knowledge observed in our study. We also reiterate that sampling words from low(er)-frequency bands would have run counter to the initial aim of the current study: to test knowledge of, specifically, high-frequency words. To preserve this aim, a more appropriate solution would be to test a greater number of high-frequency words on and off the curriculum list in a more balanced manner or possibly even every word via a bootstrapping methodology, whereby “cases, once sampled, are returned to the population before sampling occurs again” (McLean et al., 2020, p. 395). It could be that the words we selected were among the easiest of the high-frequency words. Therefore, testing the whole set would allow researchers to determine whether certain high-frequency words are more difficult than others due to factors (beyond frequency alone), such as “semantic neutrality, length, part of speech, polysemy, morphological regularity, cognateness, [and] orthographic transparency” (Hashimoto, 2021, p. 182).
Conclusion
The current study extends researchers’ and teachers’ toolkits by providing information about the internal and external validity of a new, freely available instrument (the CA-TTT) to test context-aligned, high-frequency French vocabulary size for beginner-to-low intermediate proficiency levels in instructed contexts. Preliminary results are promising: The CA-TTT showed high internal and external validity, with scores strongly and positively correlating with another measure of vocabulary size and both standardized and high-stakes proficiency measures. The CA-TTT, once piloted with lower-proficiency learners at the same stage of education and revised as appropriate, could potentially serve as a tool for assessing high-frequency L2 French vocabulary knowledge for students about to take GCSEs and even as a potential (albeit crude) proxy for proficiency at beginner-to-low intermediate levels at this stage of education.
We do, however, advocate caution when interpreting estimates from vocabulary size tests, including our own, and especially in instructed contexts. In our study, we found that the curriculum played a decisive role in predicting vocabulary knowledge and may have contributed to under-estimations (in the case of X-Lex) or over-estimations (in the case of the CA-TTT) of vocabulary size. Thus, without careful consideration of the curriculum context, such tests could inevitably under- or over-estimate vocabulary knowledge as a function of the relationship between the lexicons of the curriculum and the test. Our study has demonstrated that when designing such size tests and when calculating and interpreting the estimates, it is important to consider the tests’ intended purpose(s) and acknowledge an inevitable conflation of vocabulary size tests and achievement tests in highly instructed populations of L2 learners.
Finally, the open accessibility of the tool can, we hope, widen the scope of research producers and consumers (Marsden & Morgan-Short, 2023), adding to the numerous options already available in English. We hope that the CA-TTT inspires the development of equivalent tests for other languages and proficiency levels thus far underrepresented in the literature.
Supplemental Material
sj-pdf-1-ltj-10.1177_02655322241261415 – Supplemental material for A Context-Aligned Two Thousand Test: Toward estimating high-frequency French vocabulary knowledge for beginner-to-low intermediate proficiency adolescent learners in England
Supplemental material, sj-pdf-1-ltj-10.1177_02655322241261415 for A Context-Aligned Two Thousand Test: Toward estimating high-frequency French vocabulary knowledge for beginner-to-low intermediate proficiency adolescent learners in England by Amber Dudley, Emma Marsden and Giulia Bovolenta in Language Testing
Footnotes
Acknowledgements
We are grateful to the Language Testing reviewers and Dr. Benjamin Kremmel, the Guest Co-Editor handling this article in the Special Issue, for their valuable feedback on earlier versions of this article. Any remaining errors are our own.
Author contributions
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by funding from: the Department for Education for England (December 2018 – June 2024); Research England; the Higher Education Innovation Funding; an Economic and Social Research Council Impact Acceleration Account; and the University of York.
Open practice
Supplemental material
The materials, data, and analysis code used to initially validate the CA-TTT are available on both the OSF repository project page (Dudley et al., 2024; https://osf.io/k4y7p/), and on Instruments and Data for Research in Language Studies (IRIS, n.d.). In addition, supplemental material (supplemental appendices) for this article are available online at the following link: ![]() .
.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.